
仕様翻訳: The RISC-V Instruction Set Manual
Volume I: Unprivileged ISA
Document Version 20191213
Editors: Andrew Waterman1, Krste Asanović1,2
1SiFive Inc.,
2CS Division, EECS Department, University of California, Berkeley
andrew@sifive.com, krste@berkeley.edu
December 13, 2019
本仕様書全バージョンの寄稿者 (アルファベット順): Arvind, Krste Asanović, Rimas Avižienis, Jacob Bachmeyer, Christopher F. Batten, Allen J. Baum, Alex Bradbury, Scott Beamer, Preston Briggs, Christopher Celio, Chuanhua Chang, David Chisnall, Paul Clayton, Palmer Dabbelt, Ken Dockser, Roger Espasa, Shaked Flur, Stefan Freudenberger, Marc Gauthier, Andy Glew, Jan Gray, Michael Hamburg, John Hauser, David Horner, Bruce Hoult, Bill Huffman, Alexandre Joannou, Olof Johansson, Ben Keller, David Kruckemyer, Yunsup Lee, Paul Loewenstein, Daniel Lustig, Yatin Manerkar, Luc Maranget, Margaret Martonosi, Joseph Myers, Vijayanand Nagarajan, Rishiyur Nikhil, Jonas Oberhauser, Stefan O’Rear, Albert Ou, John Ousterhout, David Patterson, Christopher Pulte, Jose Renau, Josh Scheid, Colin Schmidt, Peter Sewell, Susmit Sarkar, Michael Taylor, Wesley Terpstra, Matt Thomas, Tommy Thorn, Caroline Trippel, Ray VanDeWalker, Muralidaran Vijayaraghavan, Megan Wachs, Andrew Waterman, Robert Watson, Derek Williams, Andrew Wright, Reinoud Zandijk, and Sizhuo Zhang.
この文書は Creative Commons Attribution 4.0 International License の下で公開されている。
この文書は次のライセンスの下でリリースされた "The RISC-V Instruction Set Manual, Volumne I: User-Level ISA Version 2.1" から派生したものである: © 2010–2017 Andrew Waterman, Yunsup Lee, David Patterson, Krste Asanović. Creative Commons Attribution 4.0 International License.
Table of Contents
- 導入
- RV32I 基本整数命令セット, Version 2.1
- "Zifencei" 命令フェッチ・フェンス, Version 2.0
- RV32E 基本整数命令セット, Version 1.9
- RV64I Base Integer Instruction Set, Version 2.1
- RV128I Base Integer Instruction Set, Version 1.7
- 整数乗除算 "M" 標準拡張, Version 2.0
- "A" Standard Extension for Atomic Instructions, Version 2.1
- "Zicsr", 制御および状態レジスタ (CSR) 命令, Version 2.0
- Counters
- "F" Standard Extension for Single-Precision Floating-Point, Version 2.2
- 11.1 F Register State
- 11.2 Floating-Point Control and Status Register
- 11.3 NaN Generation and Propagation
- 11.4 Subnormal Arithmetic
- 11.5 Single-Precision Load and Store Instructions
- 11.6 Single-Precision Floating-Point Computational Instructions
- 11.7 Single-Precision Floating-Point Conversion and Move Instructions
- 11.8 Single-Precision Floating-Point Compare Instructions
- 11.9 Single-Precision Floating-Point Classify Instruction
- "D" Standard Extension for Double-Precision Floating-Point, Version 2.2
- "Q" Standard Extension for Quad-Precision Floating-Point, Version 2.2
- RVWMO Memory Consistency Model, Version 0.1
- "L" Standard Extension for Decimal Floating-Point, Version 0.0
- 圧縮命令 "C" 標準拡張, Version 2.0
- ビット操作 "B" 標準拡張, Version 2.0
- 動的変換言語 "J" 標準拡張, Version 0.0
- トランザクショナルメモリー "T" 標準拡張, Version 0.0
- パック化 SIMD 命令 "P" 標準拡張, Version 0.2
- ベクトル操作 "V" 標準拡張, Version 0.7
- "Zam" Standard Extension for Misaligned Atomics, Version 0.1
- "Ztso" Standard Extension for Total Store Ordering, Version 0.1
- RV32/64G Instruction Set Listings
- RISC-V Assembly Programmer's Handbook
- Extending RISC-V
- ISA Extension Naming Conventions
- 27.1 Case Sensitive
- 27.2 Base Integer ISA
- 27.3 Instruction-Set Extension Names
- 27.4 Version Numbers
- 27.5 Underscores
- 27.6 Additional Standard Extension Names
- 27.7 Supervisor-level Instruction-Set Extensions
- 27.8 Hypervisor-level Instruction-Set Extensions
- 27.9 Machine-level Instruction-Set Extensions
- 27.10 Non-Standard Extension Names
- 27.11 Subset Naming Convention
- History and Acknowledgements
- RVWMO Explanatory Material, Version 0.1
- A.1 Why RVWMO?
- A.2 Litnus Tests
- A.3 Explaining the RVWMO Rules
- A.3.1 Preserved Program Order and Global Memory Order
- A.3.2 Load Value Axiom
- A.3.3 Atomicity Axiom
- A.3.4 Progress Axiom
- A.3.5 Overlapping-Address Orderings (Rules 1-3)
- A.3.6 Fences (Rule 4)
- A.3.7 Explicit Synchronization (Rules 5-8)
- A.3.8 Syntactic Dependencies (Rules 9-11)
- A.3.9 Pipeline Dependencies (Rules 12-13)
- A.4 Beyond Main Memory
- A.5 Code Porting and Mapping Guidelines
- A.6 Implementation Guidelines
- Known Issues
- Formal Memory Model Specifications, Version 0.1
- Bibliography
- 翻訳抄
 導入
導入
RISC-V ("リスク ファイブ" と発音) は新しい命令セットアーキテクチャ (ISA; instruction-set architecture) であり、元はコンピュータアーキテクチャの研究と教育をサポートするために設計されていたが、現在では産業実装のための標準的でフリーなオープンアーキテクチャとなることを望んでいる。RISC-V の定義における我々の目標は次の通りである:
アカデミアや産業界が自由に利用できる完全にオープンな ISA。
シミュレーションやバイナリ変換だけではなく、ネイティブハードウェアの直接実装に適した本物の ISA。
特定のマイクロアーキテクチャ形式 (例えばマイクロコード化、in-order、デカップリング、out-of-order など) や実装技術 (フルカスタム、ASIC、FPGA など) に対する "over-architecture" を回避しつつ、これらのいずれにおいても効率的な実装を可能にする ISA。
カスタマイズされたアクセラレータや教育目的の根本としてそれ自体で利用可能な小規模な基本整数 ISA (base integer ISA) と、汎用ソフトウェア開発をサポートするためのオプショナル標準拡張に分離された ISA。
2008 年に改訂された IEEE-754 浮動小数点規格 [7] のサポート。
広範囲な ISA 拡張と特殊なバリアントをサポートする ISA。
アプリケーション、オペレーティングシステム、システムカーネル、ハードウェア実装のための 32 ビットおよび 64 ビットの両方のアドレス空間の多様性。
ヘテロジニアスマルチプロセッサを含む、高度に並列化されたマルチコアまたはメニーコアのジッスをサポートする ISA。
オプションの可変長命令により利用可能な命令符号化空間を拡大し、性能、静的コードサイズ、エネルギー効率を向上させるオプションの高密度命令エンコードのサポート。
ハイパーバイザ開発を容易にする、完全に仮想化可能な ISA。
新しい特権アーキテクチャ設計の実験を簡素化する ISA。
設計上の決定に関する解説はこの段落のような書式になっている。読者が仕様自体にしか興味が無いのであればこの非規範的な文章は読み飛ばしても良い。
RISC-V という名前は UC バークレイ校による 5 番目の主要な RISC-ISA 設計を表すために選ばれた (RISC-I [15], RISC-II [8], SOAR [21], SPUR [11] が先行する 4 つ)。また多様なデータ並列アクセラレータを含むさまざまなアーキテクチャ研究のサポートが ISA 設計の明確な目標であることから、"variations" や "vectors" を意味するローマ数字の "V" を使用することにした。
RISC-V の ISA は実装の詳細をなるべく避けて定義されており (ただし実装に依存する決定については解説が付け加えられている)、特定のハードウェア設計というよりは様々な実装に対するソフトウェアから見えるインターフェースとして読まれるべきである。RISC-V のマニュアルは二巻構成となっている。本書はオプションの非特権 ISA 拡張を含む基本的な非特権 (unprivileged) 命令の設計をカバーしている。非特権命令とは、特権モードや特権アーキテクチャによって動作が異なるかも知れないが、一般的にすべての特権アーキテクチャのすべての特権モードで利用可能な命令である。第二巻は最初の ("古典的な") 特権アーキテクチャの設計を提供する。マニュアルは IEC 80000-13:2008 の既約を使用しており 1 バイトは 8 ビットである。
非特権 ISA 設計ではキャッシュラインサイズのような特定のマイクロアーキテクチャの特徴や、ページ変換のような特権アーキテクチャの詳細への依存を取り除こうとした。これは、シンプルにするためと、代替マイクロアーキテクチャや代替特権アーキテクチャに対して最大限の柔軟性を持たせるためである。
1.1 RISC-V ハードウェアプラットフォーム用語
RISC-V ハードウェアプラットフォームは、1 つまたは複数の RISC-V 互換プロセッシングコアと、他の RISC-V 非互換コア、固定機能アクセラレータ、さまざまな物理メモリー構造、I/O デバイス、およびコンポーネントが通信するための相互接続構造を含むだろう。
独立した命令フェッチユニットを含むコンポーネントはコア (core) と呼ばれる。RISC-V 互換コアは、マルチスレッドによって複数の RISC-V 互換ハードウェアスレッド、ハーツ (harts) をサポートすることができる。
RISC-V コアには特殊な命令セット拡張やコプロセッサ (coprocessor) が追加されている場合がある。コプロセッサという用語は、RISC-V コアに接続され RISC-V 命令ストリームによってほとんどシーケンスされるが、追加のアーキテクチャステートと命令セットを含み、場合によってはプライマリ RISC-V 命令ストリームに対して制限された自律性を持つユニットを指す。
アクセラレータ (accelerator) という用語はプログラム不可能な固定機能ユニット、または自律的に動作できるが特定のタスクに特化したコアのいずれかを指すために使用する。RISC-V システムでは、多くのプログラマブルアクセラレータが、特殊な命令セット拡張機能やカスタマイズされたコプロセッサを備えた RISC-V ベースのコアとなることが予想される。RISC-V アクセラレータの重要なクラスは I/O アクセラレータであり、メインのアプリケーションコアから I/O 処理タスクをオフロードする。
RISC-V ハードウェアプラットフォームのシステムレベルの構成はシングルコアのマイクロコントローラからメニーコアサーバノードの数千ノードの共有メモリークラスタまで多岐にわたる。小規模なシステムオンチップであっても開発工数をモジュール化したり、サブシステム間の安全な分離を実現するために、マルチコンピュータやマルチプロセッサの階層構造になっているケースがある。
1.2 RISC-V ソフトウェア実行環境とハーツ
RISC-V プログラムの挙動はそれが実行される環境に依存する。RISC-V 実行環境のインターフェース (EEI; execution environment interface) はプログラムの初期状態、ハーツによってサポートされる特権モードを含む環境のハーツの数と種類、メモリーと I/O 領域のアクセシビリティと属性、各ハートで実行されるすべての正規命令の挙動 (つまり ISA は EEI の 1 つのコンポーネント)、環境呼び出しを含む実行中に発生する割り込みや例外の処理を定義する。EEI の例には Linux アプリケーションバイナリインターフェース (ABI; application binary interface) や RISC-V スーパーバイザーバイナリインターフェース (SBI; supervisor binary interface) などがある。RISC-V 実行環境の実装は、純粋なハードウェア、純粋なソフトウェア、またはハードウェアとソフトウェアの組み合わせのいずれも可能である。例えばオペコードトラップやソフトウェアエミュレーションを使用することでハードウェアでは提供されない機能を実装することができる。実行環境の例としては以下が挙げられる:
"ベアメタル" ハードウェアプラットフォームではハーツが物理プロセッサのスレッドによって直接実行され、命令は物理アドレス空間にフルアクセスできる。ハードウェアプラットフォームは電源オン・リセットから開始する実行環境を定義する。
RISC-V OS は、ユーザレベルのハートを利用可能な物理プロセッサのスレッドに多重化し、仮想メモリーを介してメモリーへのアクセスを制御することによって複数のユーザレベル実行環境を提供する。
RISC-V ハイパーバイザはゲスト OS に複数のスーパーバイザレベルの実行環境を提供する。
Spike, QEMU または rv8 のような RISC-V は、基盤となる x86 システム上で RISC-V ハートをエミュレートし、ユーザレベルまたはスーパーバイザレベルの実行環境を提供する。
ベアハードウェアプラットフォームは EEI を定義すると考えることができ、アクセス可能なハードウェア、メモリー、その他のデバイスが環境を構成し、初期状態はパワーオンリセット時の状態である。一般的にほとんどのソフトウェアはハードウェアに対してより抽象的なインターフェースを使用するように設計されている。これは、より抽象的な EEI を使用することで異なるハードウェアプラットフォーム間での移植性が高まるためである。多くの場合、EEI は互いにレイヤーがあり、ある上位の EEI が別の下位の EEI を使用する。
ある実行環境で動作するソフトウェアから見ると、ハートはその実行環境内で RISC-V 命令を自律的にフェッチして実行するリソースである。この点でハートは、実行環境によって実ハードウェア上に時間多重化されたとしても、ハードウェアスレッドリソースのように振る舞う。一部の EEI は新しいハートをフォークする環境呼び出しなどによって追加のハートの作成と破棄をサポートしている。
実行環境は各ハートの最終的な進行を保証する責務がある。特定のハートに対しての責務は、本書仕様書の第二巻で定義されている wait-for-interrupt 命令のようにハートがイベントを明示的に待機するメカニズムを行使している間は中断され、ハートが終了するとその責務も終了する。以下のイベントは進行を構成する:
- 命令のリタイヤ。
- セクション 1.6 に定義されているトラップ。
- 前方への進行を構成するために拡張機能によって定義されたその他のイベント。
ソフトウェアのスレッドプログラミングの抽象化とは対照的に、hart という用語は抽象的な実行リソースを表す用語を提供するために Lithe [13, 14] の研究で導入された。
ハードウェアスレッド (hart) とソフトウェアスレッドコンテキストの重要な違いは、実行環境内部で動作するソフトウェアは各ハートの進行を引き起こす責務を負わないということである。つまり、実行環境内部のソフトウェアから見れば環境のハートはハードウェアスレッドのように動作する。
実行環境の実装はそれ自身の実行環境が提供する少ないホストハートにゲストハートのセットを時間多重化するかもしれないが、ゲストハートが独立したハードウェアスレッドのように動作する方法で行わなければならない。特にゲストハートがホストハートより多い場合、実行環境はゲストハートを先制 (preempt) できなければならず、ゲストハート上のゲストソフトウェアが制御を "譲る" (yield) のをいつまでも待っていてはならない。
1.3 RISC-V ISA の概要
RISC-V ISA は、どのような実装にも存在しなければならない基本整数 ISA と、基本 ISA に対するオプションの拡張とで定義される。分岐遅延スロットがないことと、オプションで可変長命令エンコーディングをサポートすることを除けば、基本整数 ISA は初期の RISC プロセッサと非常によく似ている。基本はコンパイラ、アセンブラ、リンカー、オペレーティングシステム (特権演算の追加あり) の合理的なターゲットを提供するのに十分な最小限の命令セットとなるように注意深く厳選されているため、よりカスタマイズされたプロセッサ ISA を構築できる便利な ISA とソフトウェアツールチェーンの "スケルトン" を提供する。
The RISC-V ISA といえると便利だが、実際には RISC-V は関連する ISA ファミリーであり現在は 4 つの基本 ISA がある。各基本整数命令セットは整数レジスタの幅とそれに対応するアドレス空間のサイズおよび整数レジスタの数によって特徴付けられる。第 2 章と 5 章で説明する RV32I と RV64I の 2 種類の基本整数があり、それぞれ 32 ビットと 64 ビットのアドレス空間を提供する。XLEN と言う用語は整数レジスタのビット幅 (32 または 64) を意味する。第 4 章では小型マイクロコントローラをサポートするために追加された、RV32I 基本命令セットのバリアントである整数レジスタ数が半分の RV32E バリエーションについて説明する。第 6 章ではフラット 128 ビットアドレス空間 (XLEN=128) をサポートする基本整数命令セットの将来の RV128I バリアントを概説している。基本整数命令セットは符号付き整数値に対して 2 の補数表現を使用する。
より大規模なシステムには 64 ビットアドレスが必要だが、今後数十年間は多くの組み込み機器やクライアント機器にとって 32 ビットアドレス空間が適切であり続け、メモリートラフィックとエネルギー消費を低減するために望ましいと考えている。また教育目的であれば 32 ビットアドレス空間でも十分である。より大きなフラット 128 ビットアドレス空間がいずれ必要になる可能性があるため RISC-V ISA フレームワーク内で対応できるようにした。
RISC-V の 4 つの基本 ISA はそれぞれ異なる基本 ISA として扱われている。よくある質問はこれらがなぜ単一の ISA でないのか、特に RV32I はなぜ RV64I の厳密なサブセットではないのかと言うものである。初期の ISA 設計のいくつか (SPARC, MIPS) は新しい 64 ビットハードウェア上で既存の 32 ビットバイナリを実行するためにアドレス空間サイズを増やす際に厳密なスーパーセットポリシーを採用していた。
基本 ISA を明確に分離する利点は、他の基本 ISA に必要な演算のすべてをサポートする必要が無く、各基本 ISA のニーズに合わせて最適化できることである。例えば RV64I は RV32I の狭いレジスタに対応するためだけに必要な命令や CSR を省略することができるし、RV32I バリアントはより広いアドレス空間を必要とする命令用に確保された符号化空間を使用することができる。
設計を単一の ISA として扱わないことの主な欠点は、ある基本 ISA を別の基本 ISA でエミュレートするために必要なハードウェア構成が複雑になることである (RV32I を RV64I でエミュレートするなど)。しかし、完全スーパーセット命令エンコーディングであってもアドレッシングや不正命令トラップの違いからハードウェアで何らかのモード切替が必要になるのが一般的であり、異なる RISC-V 基本 ISA は十分に類似しているため複数バージョンをサポートすることは比較的低コストで済む。厳密なスーパーセット設計によりレガシー 32 ビットライブラリを 64 ビットコードとリンクできるようにすることを提案する人もいるが、ソフトウェアの呼び出し既約やシステムコールインターフェースが異なるため、互換性のあるエンコーディングであっても実際には非現実的である。
RISC-V 特権アーキテクチャは、同じハードウェア上で異なる基本 ISA のエミュレートをサポートするために、各レベルで非特権 ISA を制御するためのフィールドを misa に提供している。新しい SPARC と MIPS の ISA リビジョンは 64 ビットシステム上で 32 ビットコードを無変更で実行するサポートを終了している。
RV32I の 32 ビット加算 (ADD) と RV64I の 64 ビット加算 (ADDW) でエンコードが異なるのはなぜだろうか? RV32I の 32 ビット加算と RV64I の 64 ビット加算に同じオペコード ADD を使用する既存の設計に代わって、ADDW オペコードは RV32I の 32 ビット加算に利用でき、ADDD は RV64I の 64 ビット加算に使用できる。これは RV32I と RV64I の両方で 32 ビットのロードに同じ LW オペコードを使用することとも整合性がとれている。RISC-V ISA の最初のバージョンではこの代替設計のバリエーションを持っていたが、RISC-V 設計は 2011 年 1 月に現在の選択に変更された。我々が重視したのは 32 ビット ISA との互換性ではなく 64 ビット ISA で 32 ビット整数をサポートすることであり、その同期は RV32I のすべてのオペコードに *W 接尾辞が付かないことから生じる非対称性を取り除くことだった (例えば ADDW は ANDW ではなく AND)。今にして思えばこれは正統な理由ではなく、ISA の設計を同時に行った結果であり、後から ISA を追加するのとは対照的であった。また ISA の仕様にプラットフォーム要求を盛り込む必要があり、RV32I の命令はすべて RV64I でも必要であったと言うことになる。今更エンコーディングを変更するには遅すぎるが、これも上記の理由から実用上はほとんど意味が無い。
RV64I と将来の RV32I バリアントに共通のエンコーディングを提供するために RV32I システムの拡張として *W バリアントを有効にすることができるという指摘がある。
RISC-V は広範なカスタマイズと特殊化をサポートするように設計されている。各基本整数 ISA は 1 つまたは複数のオプション命令セット拡張で拡張することができ、各 RISC-V 命令セットの符号化空間 (および CSR などの関連する符号化空間) を標準 (standard)、予約 (reserved)、カスタム (custom) の 3 つのカテゴリに分割する。標準エンコーディングは財団によって定義され、同じ基本 ISA の他の標準拡張と衝突してはならない。予約エンコーディングは現在定義されていないが将来の標準拡張のために保存されている。我々は財団によって定義されていない拡張を記述するために非標準 (non-standard) という用語を使用する。カスタムエンコーディングは決して標準拡張に使用してはならない。非準拠 (non-conforming) という用語は標準エンコーディングまたは予約エンコーディングのいずれかを使用する非標準拡張を表すために使用する (すはなちカスタム拡張は非準拠ではない)。命令セット拡張は一般に共有されるが、基本 ISA に応じて若干異なる機能を提供することがある。第 26 章では RISC-V ISA を拡張するさまざまな方法について説明する。また第 27 章では RISC-V 基本命令と命令セット拡張の命名規則を策定している。
より一般的なソフトウェア開発をサポートするため、整数乗除算、アトミック演算、単精度および倍精度浮動小数点演算を提供する標準拡張機能のセットが定義されている。基本となる整数 ISA は "I" で示され (整数レジスタ幅に応じて RV32 または RV64 が先頭に付く)、整数演算命令、整数ロード、整数ストア、制御フロー命令を含んでいる。標準整数上除算拡張は "M" で示され、整数レジスタに保持された値を乗除算する命令が追加されている。標準アトミック命令拡張は "A" で示され、プロセッサ間の同期のためにアトミックにメモリーを読み書きする命令が追加されている。"F" で示される標準単精度浮動小数点拡張は、浮動小数点レジスタ、単精度演算命令、および単精度のロードとストアを追加している。"D" で示される標準倍精度浮動小数点拡張は、浮動小数点レジスタを拡張し、倍精度演算命令、単精度のロード、ストアを追加している。標準 "C" 圧縮命令拡張は一般的な命令を 16 ビットに狭めた形式を提供している。
基本整数 ISA と標準 GC 拡張を超えるような新しい命令がすべてのアプリケーションに大きな利点をもたらすことはまれであると我々は信じている。エネルギー効率への懸念がより大きな特殊化を余技なくしているため、我々は ISA 使用の必要な部分を簡素化することが重要だと考えている。通常、他のアーキテクチャ名 ISA を単一のエンティティとして扱い、時間の経過と共に命令が追加されると新しいバージョンに変更されるのに対して、RISC-V は基本と各標準拡張を時間の経過と共に一定に保ち、その代わりに新しい命令をさらなるオプション拡張としてレイヤー化するよう努める。例えば基本整数 ISA は、その拡張に関係なく完全にサポートされるスタンドアロン ISA として継続される。
1.4 メモリー
RISC-V ハートはすべてのメモリーアクセスに対して \(2^{\rm XLEN}\) バイトの単一バイト指定可能アドレス空間を持つ。メモリーのワード (word) は 32 ビット (4 バイト) と定義される。これに対応してハーフワード (halfword) は 16 ビット (2 バイト)、ダブルワード (doubleword) は 64 ビット (8 バイト)、クアッドワード (quadword) は 128 ビット (16 バイト) となる。メモリーアドレス空間は循環しており、アドレス \(2^{\rm XLEN}-1\) のバイトはアドレス 0 のバイトに隣接している。したがってハードウェアが行うメモリーアドレス演算はオーバーフローを無視し代わりに \(2^{\rm XLEN}\) 剰余で折り返す。
実行環境はハードウェアリソースに対するハートのアドレス空間のマッピングを決定する。ハートのアドレス空間とは異なる範囲は (1) 秋アドレス、(2) メインメモリー (main memory)、(3) 1 つ以上の I/O デバイス (I/O device) があるだろう。I/O デバイスへの読み書きには目に見える副作用があるかも知れないが、メインメモリーへのアクセスには副作用はない。実行環境はハートのアドレス空間のすべての I/O デバイスと呼ぶことは可能だが、通常はある部分がメインメモリーとして指定されるだろう。
RISC-V プラットフォームが複数のハートを持つ場合、2 つのハートのアドレス空間は完全に同じである場合もあれば完全に異なる場合もある。あるいは一部は異なるがリソースのサブセットを共有して同じアドレス範囲または異なるアドレス範囲にマッピングされる場合もある。
純粋な "ベアメタル" 環境ではすべてのハートが物理アドレスでアクセスされる同一のアドレス空間を参照することができる。しかし実行環境にアドレス変換を採用した OS が含まれていれば、各ハートには大部分または全体的に独自の稼働アドレス空間が与えられるのが一般的である。
RISC-V マシンの各命令を実行するには暗黙的 (implicit) と明示的 (explicit) アクセスに分けられる 1 回以上のメモリーアクセスが必要である。実行される各命令に対して暗黙的メモリー読み出し (命令フェッチ) が行われ、符号化された実行命令が取得される。多くの RISC-V 命令では命令フェッチ以上のメモリーアクセスは行われない。特定のロード命令とストア命令は、命令によって決定されたアドレスで明示的にメモリーの読み取りまたは書き込みを実行する。実行環境によっては命令の実行時に非特権 ISA で文書化されている以外の暗黙的メモリーアクセス (アドレス変換の実装など) が行われることがある。
実行環境は各種メモリーアクセスに対して空ではないアドレス空間のどの部分がアクセス可能かを決定する。例えば、命令フェッチのために暗黙的に読み出すことのできる位置のセットは、ロード命令によって明示的に読み出すことができる位置のセットと重複する場合もあれば重複しない場合もある。またストア命令によって明示的に書き込むことができる位置のセットは読み出すことができる位置のサブセットのみである場合もある。通常、ある命令がアクセスできないアドレスのメモリーにアクセスしようとするとその命令に対して例外が発生する。アドレス空間の空いている部分には決してアクセスできない。
別段の指定がない限り、例外を発生させない副作用の無い暗黙的読み出しは、マシンがその読み出しを必要とする前の早い段階で予測的に行われる可能性がある。例えば、最初にメインメモリーをすべて読み出し、後の命令フェッチのためにフェッチ可能な (実行可能な) バイトをできるだけ多くキャッシュして命令フェッチのメインメモリー読みだしを 2 回以上行わないようにする実装は有効である。特定の暗黙的読み出しが同じメモリー位置への書き込みの後にのみ行われるようにするには、ソフトウェアはその目的のために定義された特定のフェンス命令またはキャッシュ制御命令 (第 3 章で定義される FENCE.I 命令など) を実行する必要がある。
ハートが行った (暗黙的または明示的) メモリーアクセスは、同じメモリーにアクセスできる別のハートや他のエージェントが認識すると異なる順序で行われているように見える可能性がある。しかしこのように認識されるメモリーアクセスの順序は、適用されるメモリー一貫性モデルによって常に制約される。RISC-V のデフォルトのメモリー一貫性モデルは第 14 章および付録で定義されている RISC-V Weak Memory Ordering (RVWMO) である。実装はオプションとして第 23 章で定義されている Total Store Ordering というより強力なモデルを採用することができる。実行環境はメモリーアクセスで認識される並び替えをさらに制限する制約を追加することもできる。RVWMO モデルはどの RISC-V 実装でも許容されるもっとも弱いモデルであるため、このモデル向けに書かれたソフトウェアはすべての RISC-V 実装の実際のメモリー一貫性規則と互換性がある。暗黙的読み出しと同様に、想定されるメモリー一貫性モデルと実行環境の要件を超えたメモリーアクセスの特定の順序を保証するために、ソフトウェアはフェンス命令やキャッシュ制御命令を実行しなければならない。
1.5 基本命令長エンコーディング
基本となる RISC-V ISA は 32 ビット固定長命令であり 32 ビット境界に自然に配置されなければならない。しかし標準 RISC-V エンコーディング方式は可変長命令による ISA 拡張をサポートするように設計されており、各命令は任意数の 16 ビット命令パーセル (parcel) の長さにすることができ、このときパーセルは 16 ビット境界に自然に配置される。第 16 章で説明する標準圧縮 ISA 拡張は、圧縮された 16 ビット命令を提供することでコードサイズを縮小し、アラインメント制約を緩和してすべての命令 (16 ビットと 32 ビット) を任意の 16 ビット境界に配置できるようにしてコード密度を向上させている。
実装が強制する命令アドレスアラインメント制約を指すために IALIGN (ビット単位) という用語を使用する。IALIGN は基本 ISA では 32 ビットだが圧縮 ISA 拡張を含むいくつかの ISA 拡張では IALIGN を 16 ビットに緩和している。IALIGN は 16 または 32 以外の値を取ることはできない。
ILEN (ビット単位) という用語は実装によってサポートされている最大命令長を指すために使用され、これは常に IALIGN の倍数である。基本命令セットのみをサポートする実装では ILEN は 32 ビットである。より長い命令をサポートする実装では ILEN はより大きな値となる。
Figure 1.1 は標準 RISC-V 命令長の符号化規則を示している。基本 ISA のすべての 32 ビット命令はその下位 2 ビットが 11 に設定されている。オプションの圧縮 16 ビット命令セット拡張はその下位 2 ビットが 00, 01 または 10 に設定されている。
拡張命令長エンコーディング
32 ビット命令符号空間の一部は暫定的に 32 ビットより長い命令用に割り当てられている。この空間の全体は現時点では予約されており、32 ビットより長い命令をエンコードするための以下の提案は凍結されたとは見なされていない。
32 ビット以上でエンコードされた標準的な命令セット拡張は Figure 1.1 に示す 48 ビットと 64 ビット長の規約に従って追加の下位ビットが 1 に設定される。80 ビットから 176 ビットの命令長は、最初の 5✕16 ビットワードに加えて 16 ビットワードの数を与える [14:12] の 3 ビットフィールドを使用して符号化される。ビット [14:12] を 111 に設定したエンコーディングは将来におけるより長い命令エンコーディングのために予約されている。

圧縮フォーマットのコードサイズと省エネルギー性を考慮すると、後付けで追加するのではなく ISA エンコーディング方式に圧縮フォーマットのサポートを組み込みたかったが、よりシンプルな実装を可能にするために圧縮フォーマットを必須にはしたくなかった。また、実験やより大規模な命令セットの拡張をサポートするためにオプションでより長い命令を許容したいと考えていた。我々のエンコーディング既約では、コア RISC-V ISA をより厳密に符号化する必要があったが、これにはいくつかの有用な効果がある。
標準 IMAFD ISA の実装では命令キャッシュの最上位 30 ビットのみを保持すれば良い (6.25% の節約)。命令キャッシュのリフィルの際、いずれかの下位ビットがクリアされため入れは不正命令例外の動作を保持するためにキャッシュに格納する前に不正な 30 ビット命令に再符号化されるべきである。
さらに重要なことは、基本 ISA を 32 ビット命令語のサブセットに凝縮することで非標準やカスタム拡張のための空間をより多く確保できることである。特に基本 RISC-V ISA は 32 ビット命令語の符号化空間の 1/8 未満しか使用していない。第 26 章で説明するように、標準の圧縮命令拡張のサポートを必要としない実装は標準の 32 ビット以上の命令セット拡張のサポートを維持したままさらに 3 つの非準拠な 30 ビット命令空間を 32 ビット固定幅フォーマットにマップすることができる。加えて 32 ビットを超える長さの命令を必要としない実装であれば、さらに 4 つの主要なオペコードを非準拠拡張用にリカバリすることができる。
ビット [15:0] がすべてゼロのエンコーディングは不正命令として定義される。これらの命令は 16 ビットの命令セット拡張が存在する場合は 16 ビット、そうでない場合は 32 ビットの最小長であると見なされる。ビット [ILEN-1:0] がすべて 1 のエンコーディングも不正であり、この命令は ILEN ビット長であると見なされる。
これはゼロのメモリー領域への誤ったジャンプを素早くトラップするため、すべてのゼロビットを含む命令の長さは合法ではないという特徴であると考えている。同様に、プログラムされていない不揮発性メモリーデバイス、切断されたメモリーバス、または破損したメモリーデバイスで観察される他の典型的なパターンを補足するために、すべて 1 を含む命令エンコーディングも不正な命令であるとしている。
ソフトウェアは、すべての RISC-V 実装上で不正命令として機能するようなゼロを含む自然に配置された 32 ビットワードに依存することができ、不正命令が明示的に必要なソフトウェアで使用される。すべて 1 に対応する既知の不正値を定義することは可変長コーディングのためより困難である。ソフトウェアは最終的なターゲットマシンの ILEN を知らない可能性があるため (例えばソフトウェアが多くの異なるマシンで使用されている標準バイナリライブラリにコンパイルされている場合)、一般的にソフトウェアはすべて 1 の ILEN ビットの不正値を使用することはできない。すべてのマシンが 32 ビットの命令サイズをサポートする必要があるため、すべて 1 の 32 ビットワードを不正なものとして定義することも検討されたが、これには ILEN>32 を持つマシンの命令フェッチユニットがアクセスフォールトではなく不正命令例外を報告する必要がある。このような命令が保護境界に接すると可変長命令のフェッチとデコードが複雑になる。
RISC-V の基本 ISA にはリトルエンディアンまたはビッグエンディアンのメモリーシステムがあり、特権アーキテクチャはさらにバイエンディアン (bi-endian) 動作を定義している。命令は、メモリーシステムのエンディアンに関係なく 16 ビットのリトルエンディアンパーセルのシーケンスとしてメモリー上に格納される。1 つの命令を形成するパーセルはハーフワードアドレスが増加するように格納され、最下位アドレスのパーセルが命令仕様の最下位ビットを保持する。
我々は当初、RISC-V メモリーシステムに対してリトルエンディアン・バイト順序を選択した。これは現在リトルエンディアン・システムが商業的に主流であるためである (すべての x86 システム; iOS、Android、および ARM 用 Windows)。些細なことだがハードウェア設計者にとってもリトルエンディアン・メモリーシステムがより自然であることが分かった。ただし IP ネットワーキングのような特定のアプリケーション領域はビッグエンディアンデータ構造で動作し、特定のレガシーコードベースはビッグエンディアン・プロセッサを想定して構築されているため、RISC-V ではビッグエンディアンとバイエンディアンのバリアントを定義した。
メモリーシステムのエンディアンに関係なく、命令パーセルがメモリーに格納される順序を固定し、長さをエンコードするビットが常にハーフワードアドレスの順序で最初に現われるようにしなければならない。これにより、命令フェッチユニットが最初の 16 ビット命令パーセルの最初の数ビットだけを調べることで可変長命令の長さを迅速に決定できるようになる。
さらに、命令のエンディアンをメモリーシステムのエンディアンから完全に切り離すために、命令パーセル自体をリトルエンディアンとする。この設計はソフトウェアツールとバイエンディアンハードウェアの両方にメリットがある。そうでないと、例えば RISC-V アセンブラや逆アセンブラはバイエンディアンシステムではエンディアンモードが実行中に動的に変換する可能性があるため、常に意図されたアクティブなエンディアンを知る必要がある。対照的に命令を固定エンディアンとすることによって、位置に依存しないコードと同様に、注意深く書かれたソフトウェアがバイナリ形式であってもエンディアンに依存しないことが可能である。
しかし命令をリトルエンディアンのみにするという選択はマシン命令wをエンコードまたはデコードする RISC-V ソフトウェアに影響を及ぼす。例えばビッグエンディアン JIT コンパイラは命令メモリーに格納する前にバイト順序を入れ替えなければならない。
リトルエンディアンの命令エンコーディングを採用することに決まれば、オペコードのフィールドの分断を避けるために当然ながら長さ符号ビットを命令フォーマットの LSB 位置に配置することになる。
1.6 例外・トラップ・割り込み
例外 (exception) という用語は現在の RISC-V ハートの命令に関連して実行時に発生する異常な状態を指す。割り込み (interrupt) という用語は RISC-V ハートに予期しない制御の移行を引き起こすことのできる外部非同期イベントを指す。トラップ (trap) という用語は、例外または割り込みによって挽きオこなれるトラップハンドラへの制御の移行を意味する。
次章の命令説明では、実行中に例外が発生する条件について説明する。ほとんどの RISC-V EEI の一般的な動作は、命令で例外が通知されたときに一部のハンドラへのトラップが発生するというものである (浮動小数点例外を除く; 標準の浮動小数点拡張ではトラップが発生しない)。割り込みがどのように発生し、ハートにルーティングされ、ハートによって有効になるかは EEI によって異なる。
"例外" と "トラップ" の用途は IEEE-754 浮動小数点規格のものと互換性がある。
トラップがどのように処理され、ハート上で実行されているソフトウェアから参照できるようになるかはそれを取り囲む実行環境に依存する。実行環境内で実行されるソフトウェアの観点から見ると、実行時にハートが遭遇するトラップは次の 4 つの影響をもたらす可能性がある:
- Contained トラップ
-
トラップは実行環境内で実行されているソフトウェアから認識され処理される。例えばハートにスーパーバイザーモードとユーザモードの両方を提供する EEI では、一般にユーザモードのハートが ECALL を実行すると同じハート上で実行されているスーパーバイザーモードへ制御が移行する。同様に同じ環境でハートが割り込まれるとそのハートのスーパーバイザーモードで割り込みハンドラが実行される。
- Requested トラップ
-
トラップは同期例外であり、実行環境内のソフトウェアに代わってアクションを要求するための実行環境に対する明示的な呼び出しである。例としてシステムコールがある。この場合、要求されたアクションが実行環境によって実行された後、ハートの実行が再開される場合もあれば再開されない場合もある。例えばシステムコールによってハートが削除されたり実行環境全体が正常に終了したりする可能性がある。
- Invisible トラップ
-
トラップは実行環境によって透過的に処理され、トラップの処理後に実行が通常通り再開される。例としては欠落命令のエミュレート、デマンドページ型仮想メモリシステムでの非常駐ページフォールトの処理、マルチプログラムマシンでの別の上のデバイス割り込み処理などが挙げられる。このような場合、実行環境内で実行されているソフトウェアはトラップを意識しない (これらの定義ではタイミングの影響を無視している)。
- Fatal トラップ
-
トラップは致命的な失敗を表し、実行環境の実行を終了させる。例としては仮想メモリのページ保護チェックの失敗は監視タイマーの期限切れなどがある。各 EEI は、実行がどのように終了したかを外部環境に報告する方法を定義する必要がある。
以下の表はそれぞれのトラップの特徴を表している:
| Contained | Requested | Invisible | Fatal | |
|---|---|---|---|---|
| 実行終了? | N | N1 | N | Y |
| ソフトウェアが認識しない? | N | N | Y | Y2 |
| 環境によって処理される? | N | Y | Y | Y |
EEI は各トラップが正確に処理されるかどうかを定義しているが、可能なカアギリ正確さを維持することを推奨している。Contained および Requested トラップは実行環境内のソフトウェアによって不正確に観測される可能性がある。Invisible トラップは定義上、実行環境内で実行されているソフトウェアからは性格であるか不正確であるかを観測することはできない。Fatal トラップは、既知のエラー命令が即時終了を引き起こさない場合、実行環境内で実行されているソフトウェアによって不正確であることが観測される可能性がある。
この文書では非特権命令について説明しているためトラップについてはほとんど言及していない。リッチな EEI をサポートするための他の機能とともに、Contained トラップを処理するアーキテクチャ上の手段が特権アーキテクチャマニュアルで定義されている。Requested トラップを引き起こすためだけに定義された非特権命令はここに文書化されている。Invisible トラップはその性質上この文書の対象外である。ここで定義されておらず、他の何らかの方法でも定義されていない命令エンコーディングは Fatal トラップを引き起こす可能性がある。
1.7 未指定の挙動と値
アーキテクチャは、実装が何をしなければならないか、また実装が何をできるかについての制約を完全に記述している。アーキテクチャが意図的に実装を制約しない場合には明示的に "未指定" (unspecified) という用語が使われている。
"未指定" というお用語は意図的に制約されていない動作や値を指す。これらの動作または値の定義は、拡張、プラットフォーム標準、または実装に対応している。拡張、プラットフォーム標準、または実装ドキュメントは基本アーキテクチャが未指定として定義するケースをさらに制限するために規範的なコンテンツを提供することがある。基本アーキテクチャと同様に拡張も許容される動作と値を完全に記述し、意図的に制約されていないケースには未指定という用語を使用する必要がある。これらのケースは、他の拡張、プラットフォーム標準、または実装によって制約または定義される場合がある。
RV32I 基本整数命令セット, Version 2.1
この章では RV32I 基本整数命令セット (Base Integer Instruction Set) バージョン 2.0 (訳注: 2.1 の誤記?) について説明する。
RV32I はコンパイラターゲットを形成し最新のオペレーティングシステム環境をサポートするのに十分となるように設計されている。また ISA は最小限の実装で必要なハードウェアを削減するようにも設計されている。RV32I には 40 個の固有命令が含まれているが、単純な実装では ECALL/EBREAK 命令を常にトラップする単一の SYSTEM ハードウェア命令でカバーし、FENCE 命令を NOP として実装して基本命令数を合計 38 に減らすことができるかも知れない。RV32I は他のほぼすべての ISA 拡張をエミュレートすることができる (アトミック性のための追加のハードウェア支援が必要な A 拡張を除く)。
実際にはマシンモード特権アーキテクチャを含むハードウェア実装にも 6 個の CSR 命令が必要になる。
基本整数 ISA のサブセットは教育目的には有用かも知れないが、この基本はミスアラインメントメモリアクセスのサポートを省略し、すべての SYSTEM 命令を 1 つのトラップとして扱う以上に、実際のハードウェア実装ではサブセット化する動機付けはほとんどないように定義されている。
RV32I に関する説明のほとんどは基本 RV64I にも適用される。
2.1 基本整数 ISA のプログラマモデル
Figure 2.1 は基本整数 ISA の非特権状態を示している。RV32I では 32 本の x レジスタはそれぞれ 32 ビット幅、すなはち XLEN=32 である。レジスタ x0 はすべてのビットが 0 と等しくなるように配線されている。汎用レジスタ x1~x31 は各種命令がブール値のコレクション、または 2 の歩数の符号付き 2 進整数、または符号なし 2 整数として解釈する値を保持する。
追加の非特権レジスタが一つある: プログラムカウンタ pc は現在の命令のアドレスを保持する。

基本整数 ISA には専用のスタックポインタやサブルーチンリターンリンクレジスタはない。命令エンコーディングにより任意の x レジスタをこれらの目的に使用できる。ただし標準のソフトウェア呼び出し既約ではレジスタ x1 を使用して呼び出しの戻りアドレスを保持し、レジスタ x5 を代替リンクレジスタとして使用する。標準の呼び出し既約ではレジスタ x2 をスタックポインタとして使用する。
ハードウェアは x1 または x5 を使用する関数呼び出しと戻りを高速化することを選択するかも知れない。JAL 命令と JALR 命令の説明を参照。
オプションの圧縮 16 ビット命令フォーマットは x1 がリターンアドレスレジスタ、x2 がスタックポインタという前提で設計されている。他の既約を使用するソフトウェアも正しく動作するがコードサイズが大きくなる可能性がある。
利用可能なアーキテクチャレジスタの数はコードサイズ、性能、エネルギー消費に大きな影響を与える可能性がある。コンパイル済みのコードを実行する整数 ISA ではおそらく 16 レジスタで十分だが、16 レジスタを持つ完全な ISA を 3 アドレス形式を使用して 16 ビット命令でエンコードすることは不可能である。2 アドレス形式は可能だが命令数が増え効率が低下する。基本ハードウェア実装を簡素化するために (Xtensa の 24 ビット命令のような) 中間的な命令サイズは避けたいと考えていた。32 ビット命令サイズが採用されると 32 個の整数レジスタをサポートするのは簡単になった。整数レジスタの数が多いとループアンローリング、ソフトウェアパイプライン、キャッシュタイリングが広範囲に使用される高性能コードでの性能も向上する。
これらの理由から基本 ISA には従来のサイズの 32 整数レジスタを選択した。動的レジスタの仕様は頻繁にアクセスされる少数のレジスタに支配される傾向があり、regfile の実装を最適化して頻繁にアクセスされるレジスタのアクセスエネルギーを削減するように最適化することができる [20]。オプションの圧縮 16 ビット命令フォーマットはほとんどが 8 レジスタのみにアクセスするだけであるため高密度の命令エンコーディングを提供することができる。また追加の命令セット拡張により必要に応じてより大きなレジスタ空間 (フラットまたは階層) をサポートすることもできる。
リソースに制約のある組み込みアプリケーションのために 16 個のレジスタのみを持つ RV32E サブセットを定義した (第 4 章)。
2.2 基本命令フォーマット
Figure 2.2 に示すように基本 RV32I ISA には 4 つのコア命令フォーマット (R/I/S/U) がある。すべて 32 ビット固定長でメモリ上の 4 バイト境界に配置されていなければならない。ターゲットアドレスが 4 バイト境界にアラインメントされていない場合、分岐または無条件ジャンプの実行に instruction-address-misaligned 例外が発生する。この例外はターゲット命令ではなく分岐またはジャンプ命令で報告される。条件分岐が成立しなかった場合 instruction-address-misaligned 例外は発生しない。
基本 ISA 命令のアラインメント制約は、16 ビット長または 16 ビット長の奇数倍の命令拡張が追加されると (つまり IALIGN=16) 2 バイト境界まで緩和される。
デバッグを支援し IALIGN=32 のシステムのハードウェア設計を簡素化するために instruction-address-misaligned 例外はミス配置が起き得る分岐またはジャンプで報告される。
予約された命令をデコードする際の動作は未指定である。
プラットフォームによっては標準仕様のために予約されているオペコードが illegal-instruction 例外を発生させることを要求する場合がある。他のプラットフォームでは予約されたオペコード領域を非準拠の拡張に使用できる場合がある。
RISC-V ISA はデコードを簡略化するためにすべてのフォーマットでソースレジスタ (rs1 および rs2) と宛先レジスタ (rd) を同じ位置に保持している。CSR 命令 (第 9 章) で使用される 5 ビットの即値 (immediate) を除き、即値は常に符号拡張 (sign-extended) され、通常は命令内で使用可能なビットの左端に向かってパックされ、ハードウェアの複雑さを軽減するために割り当てられる。特に符号拡張回路を高速化するためにすべての即値命令の符号ビットは常に命令のビット 31 にある。
通常、レジスタ指定子のデコードは実装のクリティカルパス上にあるため、フォーマット間で即値ビットを移動すること犠牲にして、すべてのレジスタ指定子をすべてのフォーマットで同じ位置に保つような命令フォーマットが選択された (RISC-IV、別名 SPUR [11] と共有される特性)。
実際にはほとんどの即値命令は小さいか、すべての XLEN ビットを必要とする。通常の命令で使用できるオペコード空間を増やすために、我々は非対称の即値分割 (通常の命令の 12 ビットと、20 ビットの特別な load-upper-immediate 命令) を選択した。MIPS ISA のように一部の即値にゼロ拡張を使用するメリットがなく ISA をできるだけシンプルに保ちたかったため即値は符号拡張している。

2.3 即値エンコーディングバリアント
Figure 2.3 に示すように即値の処理に基づく命令フォーマット (B/J) はさらに 2 つのバリエーションがある。

S フォーマットと B フォーマットの唯一の違いは、B フォーマットでは分岐オフセットを 2 の倍数でエンコードするために 12 ビットの即値フィールドが使用されることである。従来のように命令エンコードされた即値のすべてのビットをハードウェアで 1 つ左にシフトする代わりに、中間ビット (imm[10:1]) と符号ビットは固定位置に留まり、S フォーマットの最下位ビット (inst[7]) は B フォーマットの上位ビットをエンコードする。
同様に U フォーマットと J フォーマットの唯一の違いは、20 ビットの即値が 12 ビット左にシフトされて U 即値が形成され、1 ビットだけ左にシフトして J 即値を形成する点である。U および J フォーマットの即値内の命令ビットの位置は他のフォーマットとの重複が最大となるように選択されている。
Figure 2.4 に各基本命令フォーマットで生成される即値を示し、どの命令ビット (inst[\(y\)]) で即値の各ビットが生成されるかをラベル付けしている。

符号拡張は即値に対する最も重要な演算の一つであり (特に XLEN>31)、命令のデコードと並行して符号拡張を実行できるように RISC-V ではすべての即値ビットが常に命令のビット 31 に保持されている。
より複雑な実装では、分岐計算とジャンプ計算に個別の加算機を使用するため、命令の種類によって即値ビットの位置を一定に保つメリットは得られないが、もっとも単純な実装のハードウェアコストを削減したいと考えた。動的ハードウェアマルチプレクサ (dynamic hardware mux) を使用して即値を 2 倍にする代わりに、B 即値と J 即値の命令エンコーディングでビットを回転することにより、命令信号のファンアウト (fanout) と即値マルチプレクサ (immediate mux) のコストを約 2 分の 1 に削減する。スクランブルされた即値エンコードは静的コンパイルや事前コンパイル (ahead-of-time compilation) にはほとんど時間を追加しない。命令を動的に生成する場合は若干のオーバーヘッドが追加されるが、もっとも一般的な短い順方向分岐では即値エンコーディングは単純である。
2.4 整数演算命令
ほとんどの整数演算命令は整数レジスタファイルに保存されている値の XLEN ビットで動作する。整数演算命令は、I 型フォーマットを使用して register-intermediate 操作として、または R 型フォーマットを使用して register-register 操作としてエンコードされる。register-intermediate 命令と register-register 命令の両方の宛先は rd レジスタである。整数演算命令で算術例外が発生することはない。
多くのオーバーフローチェックは RISC-V 分岐を使用し安価に実装できるため、基本命令セットには整数演算のオーバーフローチェックに対する特別な命令セットを含めなかった。符号なし加算のオーバーフローチェックは加算後に 1 つの分岐命令を追加するだけで良い: add t0, t1, t2; bltu t0, t1, overflow
符号付き加算の場合、一方のオペランドの符号が分かっていればオーバーフローチェックでは加算後に 1 つの分岐命令が必要なだけである: addi t0, t1, +imm; blt t0, t1, overflow. これは即値オペランドによる加算の一般的なケースをカバーしている。
一般的な符号付き加算の場合、もう一方のオペランドが負の場合に限り合計が一方のオペランドより小さくなるはずであるという観測を利用して、加算語に 3 つの追加命令が必要である。
add t0, t1, t2
slti t3, t2, 0
slt t4, t0, t1
bne t3, t4, overflowRV64I ではオペランドの ADD と ADDW の結果を比較することで 32 ビットの符号付き加算のチェックをさらに最適化できる。
整数 Register-Immediate 命令

ADDI は符号拡張された 12 ビット即値をレジスタ rs1 に加算する。算術オーバーフローは無理され、結果は単純に結果の下位 XLEN ビットとなる。ADD rd, r1, 0 は MV rd, rs1 アセンブラ疑似命令の実装に使用される。
SLTI (set less than immediate) は、レジスタ rs1 と符号拡張された即値が符号付き整数として扱われるとき、レジスタ rs2 が即値より小さい場合にレジスタ rd の値 1 を置き、そうでない場合は rd に 0 を書き込む。SLTIU も同様だが値を符号なし整数として比較する (つまり即値はまず XLEN ビットに符号拡張され、次に符号なし整数として扱われる)。SLTIU rd, rs1, 1 は rs1 がゼロの時に rd に 1 を設定し、そうでなければ rd に 0 を設定することに注意 (アセンブラ疑似命令の SEQZ rd, rs)。
ANDI, ORI, XORI はレジスタ rs1 と符号拡張された 12 ビット即値に対してビット単位の AND, OR, XOR を実行し結果を rd に置く論理演算である。XORI rd, rs1, -1 はレジスタ rs1 のビット単位の論理反転を行う (アセンブラ疑似命令の NOT rd, rs)。

定数によるシフトは I 型フォーマットの特殊化として符号化される。シフトされるオペランドは rs1 にあり、シフト量は I-immediate フィールドの下位 5 ビットに符号化される。右シフト型はビット 30 でエンコードされる。SLLI は論理左シフト (logical left shift) (下位ビットに 0 がシフトされる)、SRLI は論理右シフト (logical right shift) (上位ビットに 0 がシフトされる)、SRAI は算術右シフト (arithmetic right shift) (元の符号ビットが空いた上位ビットにコピーされる) である。

LUI (load upper immediate) は 32 ビット定数の構築に使用され U 型フォーマットを使用する。LUI は U-immediate の値を宛先レジスタ rd の上位 20 ビットに配置し、下位 12 ビットをゼロで埋める。
AUIPC (add upper immediate to pc) は pc-相対アドレスの構築に使用され U 型フォーマットを使用する。AUIPC は 20 ビットの U-immediate 値から 32 ビットのオフセットを形成し、下位 12 ビットをゼロで埋め、このオフセットを AUIPC 命令のアドレスに加算し、その結果をレジスタ rd に置く。
AUIPC 命令は制御フロー転送とデータアクセスの両方で PC から任意のオフセットにアクセスするための 2 命令シーケンスを支援する。AUIPC と JALR の 12 ビット即値を組み合わせれば任意の 32 ビット PC 相対アドレスに制御を移すことができ、AUIPC と通常のロード命令やストア命令の 12 ビット即値オフセットを組み合わせれば 32 ビットの相対データアドレスにアクセスできる。
現在の PC 値は U-immediate を 0 に設定することで取得できる。JAL +4 命令でも (JAL に続く命令の) ローカル PC 値を取得できるが、単純なマイクロアーキテクチャでパイプライを中断したり、複雑なマイクロアーキテクチャで BTB 構造を汚染する可能性がある。
整数 Register-Register 操作
RV32I はいくつかの R 型算術演算を定義している。すべての演算は rs1 と rs2 レジスタをソースオペランドとして読み込み、結果をレジスタ rd に書き込む。funct7 と funct3 フィールドは演算のタイプを選択する。

ADD は rs1 と rs2 の加算を行う。SUB は rs1 から rs2 の減算を行う。オーバーフローは無視され、結果の下位 XLEN ビットが宛先の rd に書き込まれる。SLT と SLTU はそれぞれ符号付きと符号なしの比較を行い、rs1<rs2 であれば rd に 1 を書き込み、そうでなければ 0 を書き込む。なお、SLTU rd, x0, rs2 は rs2 がゼロでない場合に rd に 1 を設定し、そうでなければ rd に 0 を設定する (アセンブラ疑似命令の SNEZ rd, rs)。AND, OR, XOR はビットごとの論理演算を行う。
SLL, SRL, SRA はレジスタ rs2 の下位 5 ビットに保持されているシフト量だけ、レジスタ rs1 の値を論理左、論理右、算術右シフトする。
NOP 命令

NOP 命令は pc を進め該当するパフォーマンスカウンターをインクリメントする以外にアーキテクチャ的に目に見える状態変更を行わない。NOP は ADDI x0, x0, 0 とエンコードされる。
NOP はコードセグメントをマイクロアーキテクチャ上の重要なアドレス境界に配置したり、インラインコード用の空間を残したりするために利用できる。NOP をエンコードする方法は数多くあるが、マイクロアーキテクチャの最適化を可能にし、より読みやすい逆アセンブル出力を実現するために標準的な NOP エンコーディングを定義する。他の NOP エンコーディングは HINT 命令で利用可能である (セクション 2.9)。
NOP エンコーディングに ADDI を選んだのは (デコードで最適化されていない場合に) さまざまなシステムで最も少ないリソースで実行できる可能性が高いためである。特にこの命令は 1 つのレジスタのみを読み取るだけである。また、加算がもっとも一般的な操作であるため ADDI 機能ユニットはスーパースカラー設計で利用できる可能性が高い。特にアドレス生成機能ユニットはベースオフセットアドレス計算に必要なハードウェアと同じハードウェアを使用して ADDI を実行できるが、register-register ADD または論理操作、シフト操作には追加のハードウェアが必要となる。
2.5 制御転送命令
RV32I には無条件ジャンプ (unconditional jump) と条件分岐 (conditional branch) という 2 種類の制御転送命令 (control transfer instruction) がある。
無条件ジャンプ
ジャンプ・リンク命令 (JAL; jump and link) は J 型フォーマットを使用し、J 即値は 2 バイトの倍数で符号付きオフセットをエンコードする。オフセットは符号拡張され、ジャンプ命令のアドレスに加算されてジャンプターゲットアドレスとなる。したがってジャンプは ±1MiB の範囲をターゲットにすることができる。JAL はジャンプ後の命令のアドレス (pc+4) をレジスタ rd に格納する。標準的なソフトウェア呼び出し規約では x1 をリターンアドレスレジスタ、x5 を代替リンクレジスタ (alternate link register)として使用する。
代替リンクレジスタは、通常のリターンアドレスレジスタを保持したままミリコードルーチンの呼び出し (例えば圧縮コードでレジスタを保存及び復元するルーチン) をサポートする。レジスタ x5 は標準の呼び出し規約で一時レジスタにマップされ、通常のリンクレジスタと 1 ビットだけ異なるエンコードを持つため、代替リンクレジスタとして選択された。
単純な無条件ジャンプ (アセンブラ疑似コード J) は rd=x0 を使用した JAL としてエンコードされる。
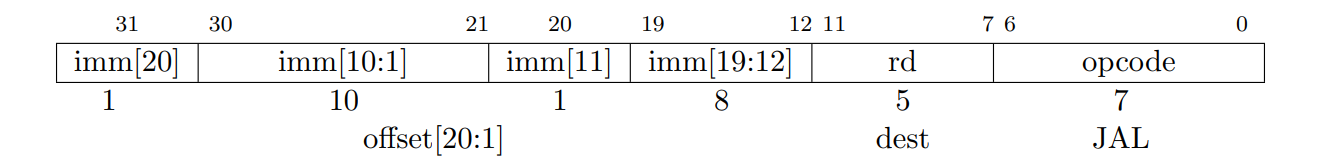
間接ジャンプ命令 JALR (jump and link register) は I 型エンコードを使用する。ターゲットアドレスは符号拡張された 12 ビット I 即値をレジスタ rs1 に加算し、結果の最下位ビットを 0 に設定することで得られる。ジャンプ後の命令のアドレス (pc+4) はレジスタ rd に書き込まれる。結果が必要ない場合はレジスタ x0 を宛先として使用することができる。

無条件ジャンプ命令はすべて PC 相対アドレスを使用し位置に依存しないコードをサポートする。JALR 命令は、2 つの命令シーケンスが 32 ビットの絶対アドレス範囲内の任意の位置にジャンプできるように定義された。LUI 命令はまずターゲットアドレスの上位 20 ビットを rs1 にロードし、次に JALR で斎戒ビットを追加することができる。同様に AUIPC 命令と JALR は 32 ビットの pc 相対アドレス範囲内のどこにでもジャンプすることができる。
条件分岐命令とは異なり JALR 命令は 12 ビットの即値を 2 バイトの倍数として扱わないことに注意。これによりハードウェアでの即時フォーマットが 1 つ増えるのを回避している。実際には JALR のほとんどの用途では、ゼロ即値が使われるか、LUI または AUIPC と組み合わせで使うため、わずかな範囲の現象は重要ではない。
JALR ターゲットアドレスを計算するときに最下位ビットをクリアすると、ハードウェアが若干簡素化され、関数ポインタの下位ビットを補助情報の格納に利用できるようになる。この場合、エラーチェックがわずかに失われる可能性があるが、実際には不正な命令アドレスに対するジャンプは通常すぐに例外を発生させる。
基本 rs1=x0 とともに使用する場合、アドレス空間の任意の位置から最低 2KiB または最高 2KiB アドレス領域への単一命令サブルーチン呼び出しを実装するために JALR を使用すること可能で、これを利用して小規模なランタイムライブラリの高速な呼び出しを実装することができる。あるいは、ABI はアドレス空間の他の位置にあるライブラリを指すために汎用レジスタを専用化することもできる。
JAL 命令と JALR 命令は、ターゲットアドレスが 4 バイト境界に配置されていない場合に instruction-address-misaligned 例外を発生する。
圧縮命令セット拡張 C のような 16 ビット配置命令の拡張をサポートするマシンでは instruction-address-misaligned 例外は発生しない。
リターンアドレス予測スタックは高性能な命令フェッチユニットの一般的な機能だが、有効に機能させるにはプロシジャコールやリターンに使用される命令を正確に検出する必要がある。RISC-V では、命令の使用に関するヒントは使用されるレジスタ番号によって暗黙的にエンコードされる。JAL 命令は rd=x1/x5 の場合にのみリターンアドレススタック (RAS; return-address stack) にプッシュする必要がある。JALR 命令については Table 2.1 に示すように RAS をプッシュ/ポップする。
他の一部の ISA ではリターンアドレススタック操作をガイドするために間接ジャンプ命令に明示的なヒントを追加しているものもある。我々はレジスタ番号と呼び出し規約に関連付けられた暗黙的なヒントを使用して、これらのヒントに使用されるエンコーディング空間を削減している。
2 つの異なるリンクレジスタ (x1 と x5) が rs1 と rd として与えられた場合、RAS はコルーチンをサポートするためにポップとプッシュの両方が行われる。rs1 と rd が同じリンクレジスタ (x1 または x5) である場合、RAS は次のシーケンスのマクロ演算の融合を有効にするためにのみプッシュされる: lui ra, imm20; jalr ra, imm12(ra) および auipc ra, imm20; jalr ra, imm12(ra)
| rd | rs1 | rs1=rd | RAS 動作 |
|---|---|---|---|
| ! link | ! link | - | none |
| ! link | link | - | pop |
| link | ! link | - | push |
| link | link | 0 | pop, then pusl |
| link | link | 1 | push |
条件分岐
すべての分岐命令は B 型の命令フォーマットを使用する。12 ビット B 即値は 2 バイトの倍数の符号付きオフセットをエンコードする。オフセットは符号拡張され、分岐命令のアドレスに加算されてターゲットアドレスが得られる。条件分岐の範囲は ±4KiB である。

分岐命令は 2 つのレジスタを比較する。BEQ と BNE はそれぞれレジスタ r1 と r2 が等しいか等しくないかの場合に分岐する。BLT と BLTU はそれぞれ符号付き比較と符号なし比較として r1 が r2 より小さい場合に分岐する。BGE と BGEU はそれぞれ符号付き比較と符号なし比較として rs1 が rs2 以上の場合に分岐を行う。なお BGT, BGTU, BLE, BLEU はそれぞれオペランドを BLT, BLTU, BGT, BGEU と逆にすることで合成することができる。
どのような負のインデックスも非負の境界より大きく比較されるため、符号付き配列の境界は 1 つの BLTU 命令でチェックできる。
ソフトウェアは逐次コードパスが最も一般的な経路であり、それより使用頻度の低いコードパスはライン外に配置されるように最適化されるべきである。またソフトウェアは、少なくとも最初に分岐に遭遇したときは、後方の分岐が実行され前方の分岐は実行されれないと予測されることを想定すべきである。動的予測器は予測可能な分岐を素早く学習する必要がある。
他の一部のアーキテクチャと異なり RISC-V ジャンプ命令 (rd=x0 での JAL) は always-true 条件分岐命令の代わりの無条件分岐として常に使われるべきである。また RISC-V ジャンプは PC 相対であり、分岐よりはるかに広いオフセット範囲をサポートしているため、分岐予測テーブルを汚染することはない。
条件分岐は、条件コードを使用したり (x86, ARM, SPARC, PowerPC)、1 つのレジスタをゼロと比較したり (Alpha, MIPS)、また単に 2 つのレジスタを比較する (MIPS) のではなく、(PA-RISC, Xtensa, MIPS R6 でも行われているように) 2 つのレジスタ間の算術比較演算を含むように設計されている。この設計の動機は compare-and-branch 命令が通常のパイプラインに収まり、追加の条件コード状態や一時レジスタの仕様を回避し、静的コードサイズと動的命令フェッチトラフィックを削減するという観察にある。もう一つの点は、ゼロとの比較には無視できない回路遅延が必要であるため (特に高度なプロセスで静的ロジックに移行した後)、算術絶対値の比較とほぼ同じ程度のコストがかかることである。融合された compare-and-branch 命令のもう一つの利点は、命令がフロントエンド命令ストリームの早い段階で観測されるため、より早い段階で予測できることである。同じ条件コードに基づいて複数の分岐を取ることができる場合、条件コードを使用した設計のほうが有利かもしれないが、そのようなケースは比較的まれであると考えている。
我々は静的な分岐ヒントを命令エンコードに含めることも検討したが今回は見送った。これらは動的予測器への負担を軽減することができるが、最良の結果を得るにはより多くの命令エンコード領域とソフトウェアプロファイリングが必要であり、本番実行がプロファイリング実行と一致しない場合にパフォーマンスが低下する可能性がある。
我々は予測不可能な短い前方分岐を効果的に置き換えることができるような条件付き移動命令や述語化命令 (predicted instruction) を検討したが含めなかった。条件付き移動はこの 2 つのなかでもっとも簡単だが、例外 (メモリアクセスや浮動小数点) を引き起こす可能性のある条件付きコードと共に使用するのは困難である。述語化はシステムにフラグ状態を追加し、フラグの設定とクリアの命令が追加され、すべての命令にエンコードのオーバーヘッドを追加する。条件付き移動命令も述語化命令も述語が false の場合に宛先アーキテクチャレジスタの元の値を名前変更された宛先物理レジスタにコピーする必要があるため、暗黙の第 3 のソースオペランドを追加して out-of-order マイクロアーキテクチャに複雑性を加える。また分岐の代わりに述語を使用するという静的なコンパイル時の決定によりコンパイラの学習セットに含まれていない入力に対する性能が低下する可能性がある。特に、予測不可能な分岐はまれであり、分岐予測技術が向上するにつれてまれになることを考慮するとそのような傾向は顕著である。
予測不可能な前方武器を内部で述語化されたコードに動的に変換し、分岐予測ミスによるパイプラインのフラッシュコストを回避するためのさまざまなマイクロアーキテクチャ技術が存在し [6, 10, 9]、商用プロセッサに実装されている [17]。もっとも単純な技術はフェッチパイプライン全体ではなく分岐シャドウ内の命令のみをフラッシュするか、ワイド命令フェッチやアイドル命令フェッチスロットを使用して両側から命令をフェッチすることによって予測ミスの短い前方分岐から回復するペナルティを軽減するだけである。out-of-order コアのより複雑な技術では、分岐シャドウ内の命令に内部述語を追加し、内部述語の値を分岐命令によって書き込むことで分岐命令とそれに続く命令を投機的かつ他のコードに対して out-of-order で実行できるようにする [17]。
条件付き分岐命令では、ターゲットアドレスが 4 バイト境界に配置されておらず、分岐条件が true を評価された場合 instruction-address-misaligned 例外が発生する。分岐条件が false と評価された場合、instruction-address-misaligned 例外は発生しない。
instruction-address-misaligned 例外は圧縮命令セット拡張 C などの 16 ビット配置命令の拡張をサポートするマシンでは発生しない。
2.6 ロード命令とストア命令
RV32I はロード-ストアアーキテクチャである。ロード命令とストア命令のみがメモリにアクセスし、演算命令は CPU レジスタに対してのみ動作する。RV32I はバイトアドレス指定される 32 ビットアドレス空間を提供する。EEI はアドレス空間がどの部分にどの命令でアクセスできるかを定義する (例えば一部のアドレスは読み取り専用であったり、ワードアクセスのみをサポートする場合がある)。x0 を宛先とするロードでは、ロード値が破棄されたとしても、任意の例外を発生させ任意の副作用を引き起こさなければならない。
EEI はメモリシステムがリトルエンディアンであるかビッグエンディアンであるかを定義する。RISC-V ではエンディアンネスはバイトアドレス不変である。
エンディアンネスがバイトアドレス不変のシステムでは次の性質が当てはまる: 単一バイト値があるエンディアンのあるアドレスのメモリに格納されている場合、そのアドレスから任意のエンディアンでバイトサイズのロードを行うと、格納されている値が返される。
リトルエンディアン構成では、マルチバイト値のストアは最下位のメモリバイトアドレスに最下位のレジスタバイトを書き込み、その後に位の昇順でほかのレジスタバイトを書き込む。ロードも同様に下位のメモリバイトアドレスの内容を下位のレジスタバイトに転送する。
ビッグエンディアン構成では、マルチバイト値のストアは最下位のメモリバイトアドレスに最上位のレジスタバイトを書き込み、その後に位の降順でほかのレジスタバイトを書き込む。ロードも同様に上位のメモリバイトアドレスの内容を下位のレジスタバイトに転送する。
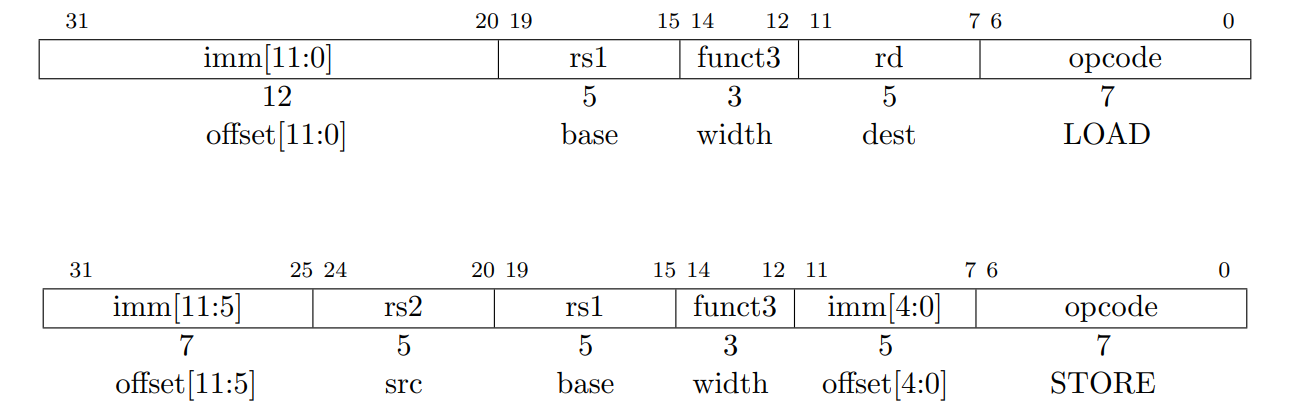
ロード命令とストア命令はレジスタとメモリー間で値を転送する。ロードは I 型フォーマット、ストアは S 型フォーマットでエンコードされる。実効アドレスはレジスタ rs1 を符号拡張された 12 ビットのオフセットを加算することによって得られる。ロードはメモリからレジスタ rd に値をコピーする。ストアはレジスタ rs2 の値をメモリにコピーする。
LW 命令はメモリから 32 ビット値を rd にロードする。LH はメモリから 16 ビット値をロードし、符号を 32 ビットに拡張してから rd に格納する。LHU はメモリから 16 ビット値をロードして 32 ビットにゼロ拡張してから rd に格納する。LB と LBU は 8 ビット値に対して同様に定義される。SW, SH, SB 命令はレジスタ rs2 の下位ビットから 32 ビット、16 ビット、8 ビットの値をメモリに格納する。
EEI に関係なく、実効アドレスが自然にアラインメントされているロードとストアは address-misaligned 例外を発生しない。実効アドレスが参照データ型に対して自然に (つまり 32 ビットアクセスの場合は 4 バイト、16 ビットアクセスの場合は 2 バイト) アラインメントされていないロードとストアの動作は EEI に依存する。
EEI は misaligned ロードとストアを完全なサポートを保証していることがあり、実効環境内で実行されているソフトウェアが包含トラップ (contained trap) や致命的な address-misaligned トラップを経験することは決してない。この場合、misaligned ロードとストアはハードウェアで処理するか、実効環境の実装で不可視トラップ (invisible trap) を介して処理するか、またはアドレスによってはハードウェアと不可視トラップの組み合わせで処理することができる。
EEI は misaligned ロードとストアが不可視に処理されることを保証していないことがある。この場合、自然に配置されていないロードとストアは実行が完全に成功するか、例外が発生するかのどちらかだろう。発生する例外は address-misaligned 例外か access-fault 例外のいずれかである。misaligned アクセスをエミュレートすべきではない場合、例えばメモリ領域へのアクセスが副作用を持つ場合、misaligned を除けば完了できるメモリーアクセスについては address-misaligned 例外の代わりに access 例外を発生させることができる。EEI が misaligned ロードとストアが不可視で処理されることを保証しない場合、EEI は、アドレスのミスアラインメントによって発生した例外は包含トラップ (実効環境内で実行されているソフトウェアがトラップを処理できるようにする) になるか、致命的なトラップ (実行を修了する) になるかのどちらかを定義しなければならない。
レガシーコードを移植するときに misaligned アクセスが必要になることがあり、これは任意の形式のパック化 SIMD 拡張を使用するときや、外部的にパックされたデータ構造を処理するときにアプリケーションのパフォーマンスに役に立つ。EEI が通常のロード命令とストア命令による misaligned アクセスをサポートするできるようにする根拠は misaligned ハードウェアサポートの追加を簡素化するためである。1 つのオプションは基本 ISA で misaligned アクセスを禁止し、ソフトウェアによる misaligned アクセスの処理を支援する特別な命令か、または misaligned アクセスに対する新しいハードウェアアドレッシングモードのどちらかで misaligned アクセスに対する別の ISA サポートを提供することだった。特別な命令は扱いが難しく、ISA を複雑にし、多くの場合、新しいプロセッサ状態を追加したり (例えば SPARC VIS アラインメントアドレスオフセットレジスタなど)、既存のプロセッサ状態へのアクセスを複雑にする (例えば MIPS LWL/LWR 部分レジスタ書き込み)。さらにループ指向のパック化 SIMD コードの場合、オペランドの位置がずれているときの余計なオーバーヘッドのため、ソフトウェアはオペランドのアラインメントによって複数の形式のループを提供することとなり、コード生成が複雑になり、ループ起動のオーバーヘッドが増加する。新しい misaligned ハードウェアアドレッシングモードは、命令エンコーディングでかなりのスペースを必要とするが、非常に単純化されたアドレッシングモード (例えばレジスタ間接のみ) を必要とする。
misaligned ロードとストアが正常に終了した場合でも実装によってはこれらのアクセスが非常に遅くなる可能性がある (例えば不可視トラップを介して実装されている場合)。さらに自然に配置されたロードとストアはアトミックに実行されることが保証されるが、misaligned ロードとストアはそうではない可能性があるため、アトミック性を保証するためにさらなる同期が必要となる。
我々は misaligned アクセスに対するアトミック性を義務付けていないため、実行環境の実装では不可視マシントラップとソフトウェアハンドラを使用して misaligned アクセスの一部またはすべてを処理することができる。ハードウェアの misaligned サポートが提供されている場合、ソフトウェアは通常のロード及びストア命令を使用するだけでこれらを利用することができる。ハードウェアは実行時アドレスがアラインメントされているかどうかに応じて自動的にアクセスを最適化することができる。
2.7 メモリ順序命令

FENCE 命令は他の RISC-V ハートおよび外部デバイスまたはコプロセッサから見たデバイス I/O およびメモリアクセスを順序付けるために使用される。デバイス入力 (I)、デバイス出力 (O)、メモリ読み出し (R)、メモリ書き込み (W) の任意の組み合わせに関して順序付けることができる。非公式には、他の RISC-V ハートはまたは外部デバイスは FENCE に先行する先行セット内のどの操作よりも前に FENCE に続く後続セット内のどの操作も観測することはできない。第 14 章では RISC-V メモリ一貫性モデルについて正確に説明している。
| fm フィールド | ニーモニック | 意味 |
|---|---|---|
| 0000 | none | 通常 fence |
| 1000 | TSO | FENCE RW, RW あり: write-to-read 順序を除外する それ以外: 将来のために予約 |
| other | 将来のために予約 | |
fence モードのフィールド fm は FENCE のセマンティクスを定義する。fm=0000 の FENCE は先行セット内のすべてのメモリ操作を後行セット内のすべてのメモリ操作の前に順序付ける。
オプションの FENCE.TSO 命令は、fm=1000, predecessor=RW, successor=RW.FENCE.TSO の FENCE 命令としてエンコードされ、先行セット内のすべてのロード操作を後行セット内のすべてのメモリ操作および先行セット内のすべてのストア操作よりも前に順序付ける。これにより、FENCE.TSO の先行セット内の non-AMO ストア操作は後続セット内の non-AMO ロード操作とともに順序付けられないままとなる。
FENCE.TSO エンコーディングはオリジナルの基本 FENCE 命令エンコーディングのオプション拡張として追加された。基本定義では、実装は設定されたビットを無視し、FENCE をグローバルとして扱う必要があるため、これは後方互換性のある拡張である。
FENCE 命令の未使用フィールド ─ rs1 と rd ─ は将来の拡張でより細かい fence 用に予約されている。前方互換性のために、基本実装はこれらのフィールドを無視しなければならず、標準ソフトウェアはこれらのフィールドをゼロにする必要がある。同様に Table 2.2 の多くの fm および先行/後行セット設定も小りゃいの仕様のために予約されている。基本実装はこのような予約された設定をすべて fm=0000 の通常 fence として扱い、標準ソフトウェアは予約されていない設定のみを使用しなければならない。
我々は、シンプルなマシン実装や将来のコプロセッサまたはアクセラレータの拡張による高いパフォーマンスを実現するために緩和されたメモリモデル (relaxed memory model) を選択した。デバイスドライバのハート内での不要な直列化を回避し、追加されたコプロセッサまたは I/O デバイスを制御するための代替の非メモリー経路をサポートするために、メモリーの R/W 順序から I/O 順序を分離した。単純な亜実装ではさらに先行フィールドと後行フィールドを無視し、すべての操作に対して常に保守的な fence を実行することができる。
2.8 環境コールとブレイクポイント
SYSTEM 命令は特権アクセスを必要とするシステム機能にアクセスするために使用され I 型命令フォーマットを使用してエンコードされる。これらは、アトミックに read-modify-write を行う制御状態レジスタ (CSR; control and status register) と、それ以外の潜在的な特権を持つ命令の 2 つに大別できる。CSR 命令については第 9 章で説明し、基本的な非特権命令については次のセクションで説明する。
SYSTEM 命令は、単純な実装では常に 1 つのソフトウェアトラップハンドラにトラップできるように定義されている。より洗練された実装ではハードウェアで各システム命令を実行する必要がある。

これらの 2 つの命令はサポートする実行環境に正確な要求トラップを引き起こす。
ECALL 命令は、実行環境に対してサービス要求を行うために使用される。サービス要求のパラメータがどのように渡されるかは EEI によって定義されるが、通常は整数レジスタファイル内の定義された場所に配置される。
EBREAK 命令は制御をデバッグ環境に戻すために使用する。
ECALL と EBREAK は、以前は SCALL と SBREAK という名前だった。これらの命令は同じ機能とエンコーディングを持つが、スーパーバイザレベルのオペレーティングシステムやデバッガを読みだすためではなく、より一般的に使用できることを反映するために名前が変更された。
EBREAK は主にデバッガが実行を停止してデバッガにフォールバックするために使用するように設計されている。EBREAK は標準の gcc コンパイラでも実行すべきでないコードパスをマークするために使用されている。
EBREAK のもう一つの用途は、EBREAK 命令を中心に構築された代替システムコールインターフェースを介してサービスを提供できるデバッガを実行環境に含む "セミホスティング" (semihosting) をサポートすることである。RISC-V のベース ISA は複数の EBREAK 命令を提供しないため、RISC-V セミホスティングは特別な命令シーケンスを使用してセミホスティング BREAK とデバッガ挿入 EBREAK を区別する。
slli x0, x0, 0x1f # Entry NOP ebreak # Break to debugger srai x0, x0, 7 # NOP encoding the semihosting call number 7これらの 3 つの命令は 32 ビット幅の命令でなければならないことに注意。つまり第 16 章で説明される圧縮 16 ビット命令であってはならない。
シフト NOP 命令は引き続き HINT として使用できるとみなされる。
セミホスティングはサービスコールの一形態であり、既存の ABI を使用して ECALL としてエンコードするのがより自然だが、これにはデバッガが ECALL をインターセプトできるようにする必要がある。これはデバッガデバッグ標準に新たに追加されたものである。我々は標準 ABI で ECALL を使用する方向に移行する予定である。この場合、セミホスティングは既存の標準とサービス ABI を共有することができる。
ARM プロセッサでも新しい設計ではセミホスティング呼び出しに BKPT ではなく SVC を使用するようになっていることに注意。
2.9 HINT 命令
RV32I は、マイクロアーキテクチャに性能のヒントを伝えるために通常で使用される HINT 命令用に大きなエンコードスペースを確保している。HINT は rd=x0 の整数演算命令としてエンコードされる。したがって、NOP 命令と同様に、HINT は pc と適用可能なパフォーマンスカウンタを進めること以外にはアーキテクチャ的に見える状態を変更しない。実装では常にエンコードされたヒントを無視することが許されている。
この HINT エンコーディングは、単純な実装が HINT を完全に無視し、代わりに HINT をアーキテクチャ状態を変更させない通常の計算命令として実行できるように選択されている。例えば ADD は宛先レジスタが x0 であれば HINT であり、5 ビットの rs1 および rs2 フィールドは HINT の引数をエンコードしている。しかし単純な実装では x0 を書き込む rs1 と rs2 の ADD として HINT を実行するだけでアーキテクチャ的に目に見える効果はない。
Table 2.3 にすべての RV32I HINT コードポイント示す。HINT 空間の 91% は標準 HINT 用に予約されているが、現在定義されているものは何もない。残りの HINT 領域はカスタム HINT 用に予約されていて標準 HINT が定義されることはない。
現在、標準的なヒントは定義されていない。標準ヒントには、メモリシステムの空間的および時間的局所性ヒント、分岐予測ヒント、スレッドスケジューリングヒント、セキュリティタグ、シミュレーション/エミューレーションのインスツルメンテーションフラグなどが含まれると予想される。
| 命令 | 制約 | コードポイント | 目的 |
|---|---|---|---|
| LUI | rd=x0 | \(2^{20}\) | 将来の標準使用のため予約 |
| AUIPC | rd=x0 | \(2^{20}\) | |
| ADDI | rd=x0, かつ rs1≠x0 または imm≠0 | \(2^{17}-1\) | |
| ANDI | rd=x0 | \(2^{17}\) | |
| ORI | rd=x0 | \(2^{17}\) | |
| XORI | rd=x0 | \(2^{17}\) | |
| ADD | rd=x0 | \(2^{10}\) | |
| SUB | rd=x0 | \(2^{10}\) | |
| AND | rd=x0 | \(2^{10}\) | |
| OR | rd=x0 | \(2^{10}\) | |
| XOR | rd=x0 | \(2^{10}\) | |
| SLL | rd=x0 | \(2^{10}\) | |
| SRL | rd=x0 | \(2^{10}\) | |
| SRA | rd=x0 | \(2^{10}\) | |
| FENCE | pred=0 または succ=0 | \(2^5-1\) | |
| SLTI | rd=x0 | \(2^{17}\) | カスタム使用のため予約 |
| SLTIU | rd=x0 | \(2^{17}\) | |
| SLLI | rd=x0 | \(2^{10}\) | |
| SRLI | rd=x0 | \(2^{10}\) | |
| SRAI | rd=x0 | \(2^{10}\) | |
| SLT | rd=x0 | \(2^{10}\) | |
| SLTU | rd=x0 | \(2^{10}\) |
"Zifencei" 命令フェッチ・フェンス, Version 2.0
この章では "Zifencei" 拡張を定義する。この拡張には同じハート上での命令メモリへの書き込みと命令フェッチとの間での明示的な同期を提供する FENCE.I 命令が含まれる。現在、この命令はハートに見えるストアがその命令フェッチにも見えることを保証する唯一の標準メカニズムである。
我々は (MAJC [19] のような) "ストア命令ワード" 命令を検討したが含めなかった。JIT コンパイラは 1 つの FENCE.I の前に大量の命令トレースを生成し、I キャッシュに存在しないことがわかっているメモリ領域に変換された命令を書き込むことで、命令キャッシュの監視 (snooping) / 無効化のオーバーヘッドを償却できる。
FENCE.I 命令は様々な実装をサポートするように設計されている。単純な実装では FENCE.I 命令の実行時にローカル命令キャッシュと命令パイプラインをフラッシュすることができる。より複雑な実装では、データ (命令) キャッシュミスのたびに命令 (データ) キャッシュを監視したり、ローカルストア命令によって書き込まれるときに包括的な統合プライベート L2 キャッシュを使用してプライマリ命令キャッシュからのラインを無効化するかもしれない。このように命令キャッシュとデータキャッシュの一貫性 (coherent) が保たれている場合、またはメモリシステムがキャッシュされていない RAM のみで構成されている場合は FENCE.I でフェッチパイプラインだけをフラッシュする必要がある。
以前は、FENCE.I 命令は基本 I 命令セットの一部だった。2 つの主な問題により個の命令を必須ベースから外すことになったが、本稿執筆時点では FENCE.I はまだ命令フェッチの一貫性を維持するために唯一の標準的な方法である。
第一に、一部のシステムでは FENCE.I の実装にコストがかかることが確認されており、メモリモデルタスクグループでは代替メカニズム検討されている。特に、非一貫命令キャッシュと非一貫データキャッシュを備えた設計や、命令キャッシュのリフィルが一環データキャッシュを監視しない設計の場合、FENCE.I 命令が発生したときに両方のキャッシュを完全にフラッシュしなければならない。この問題は統合キャッシュまたは外部メモリーシステムの前に複数のレベルの I および D キャッシュがある場合に悪化する。
第二に、この命令は Unix ライクなオペレーティングシステム環境でユーザレベルで利用できるほど強力ではない。FENCE.I はローカルハートを同期するだけであり、OS は FENCE.I の後にユーザハートを別の物理ハートに再スケジュールできる。これには OS がすべてのコンテキスト移行の一部として追加の FENCE.I を実行する必要がある。これにより OS は現在のシステムで必要とされる FENCE.I の実行回数を最小限に抑え、将来改良される命令フェッチ一貫性メカニズムとの互換性を提供することができる。
現在議論されている命令フェッチ一貫性に関する将来のアプローチには、rs1 で指定された特定のアドレスのみをターゲットとする FENCE.I を提供すること、および/または、マシンモードキャッシュメンテナンス操作に依存する ABI をソフトウェアが使用できるようにすることが含まれる。

FENCE.I 命令は命令とデータストリームを同期させるために使用される。RISC-V は、RISC-V ハートが FENCE.I 命令を実行するまで命令メモリーへのストアが RISC-V ハート上の命令フェッチから見えるようになることを保証しない。FENCE.I 命令は RISC-V ハート上の後続の命令フェッチで同じ RISC-V ハートから既に見えるようになっている以前のデータストアを確実に参照できることを保証する。FENCE.I は、マルチプロセッサシステムにおいて他の RISC-V ハートの命令フェッチがローカルハートのストアを参照することを保証するものではない。命令メモリへのストアをすべて RISC-V ハートが認識できるようにするには、すべてのリモート RISC-V ハートに FENCE.I の実行を要求する前に、書き込みハートがデータ FENCE を実行する必要がある。
FENCE.I 命令の未使用フィールドである imm[11:0]、rs1、rd は将来の拡張におけるより細かいフェンス用に予約されている。前方互換性のため基本実装はこれらのフィールドを無視し、標準ソフトウェアはこれらのフィールドをゼロにしなければならない。
FENCE.I はハート独自の命令フェッチを使用してストアを順序付けるだけであるため、アプリケーションスレッドが別のハートに移行されない場合にのみアプリケーションコードは FENCE.I に依存すべきである。EEI は効率的なマルチプロセッサ命令ストリーム同期のためのメカニズムを提供できる。
RV32E 基本整数命令セット, Version 1.9
この章では組み込みシステム用に設計された RV32I の縮小版である RV32E 基本整数命令セットのドラフト案を説明する。唯一の変更点は整数レジスタの数を 16 に減らしたことである。この章では RV32E と RE32I の相違点のみを説明するため、第 2 章の後に読む必要がある。
RV32E は組み込みマイコン用にさらに小さなベースコアを提供するように設計された。この文書のバージョン 2.0 でこの可能性について言及していたが、当初は神津佐ブセットを定義することに抵抗があった。ただし、可能な限り最小の 32 ビットマイクロコントローラの需要を考慮し、またこの分野での断片化を防ぐという観点から RV32I、RV64I、RV128I に加えて RV32E を 4 番目の標準ベース ISA として定義した。高度にスレッド化された 64 ビットプロセッサのコンテキスト状態削減する RV64E の定義にも関心が集まっている。
4.1 RV32E プログラミングモデル
RV32E は整数レジスタの数を 16 個の汎用レジスタ (x0-x15) に削減する。ここで x0 は専用のゼロレジスタである。
小規模な RV32I コア設計では上位 16 個のレジスタがメモリーを除くコア総面積の約 4 分の 1 を占有しているため、これを削減することでコア面積を約 25% 節約し、それに伴ってコア消費電力も削減できることが分った。
この変更には異なる呼び出し既約と ABI が必要である。特に RV32E はソフトフロート呼び出し既約でのみ使用される。RV32E と RV32I で動作する新しい組み込み ABI を検討している。
4.2 RV32E 命令セット
RV32E はレジスタ x0-x15 のみが提供されることを除いて RV32I と同じ命令セットエンコーディングを使用する。将来の標準拡張ではレジスタ指定フィールドの削減によって開放されたいかなる命令ビットも使用されず、そのためカスタム拡張で使用できる。
RV32E は現在のすべての標準拡張と組み合わせることができる。F, D, Q 拡張を RV32E と組み合わせた場合、16 エントリの浮動小数点レジスタを持つものとして定義することを検討したが却下された。浮動小数点レジスタの状態を減らすシステムをサポートするために、浮動小数点演算で整数レジスタを使用し、浮動小数点のロード、ストア、および浮動小数点レジスタと整数レジスタの間の移動を削除する "Zfinx" 拡張を定義することを予定している。
RV64I Base Integer Instruction Set, Version 2.1
RV128I Base Integer Instruction Set, Version 1.7
整数乗除算 "M" 標準拡張, Version 2.0
この章では "M" と名付けられた標準整数乗除算命令拡張について説明し、2 つの整数レジスタに保持された値を乗算または除算する命令が含まれている。
ローエンドの実装を簡素化するため、または整数の乗除算操作が頻繁に行われなかったりアタッチされたアクセラレータでより適切に処理できるアプリケーション向けに、整数の乗算と除算を基本から分離している。
7.1 乗算操作

MUL は rs1 と rs2 の XLEN ビット ✕ XLEN ビットの乗算を実行し、下位 XLEN ビットを宛先レジスタに置く。MULH, MULHU, MULHSU は同様の乗算を実行するが、それぞれ符号付き✕符号付き、符号なし✕符号なし、符号付き rs1✕符号なし rs2 乗算に対して完全な 2✕XLEN ビット積の上位 XLEN ビットを返す。同じ積の上位ビット都会ビットの両方が必要な場合、推奨されるコードシーケンスは次の通り: MULH[[S]U] rdh, rs1, rs2; MUL rdl, rs1, rs2 (ソースレジスタ識別子は同じ順序でなければならず、rdh は rs1 または rs2 と同じであってはならない)。マイクロアーキテクチャは 2 つの乗算を別々に実行する代わりにこれらを 1 つの乗算演算に融合することができる。
MULHSU はマルチワード符号付き乗算で使用され、被乗数 (multiplicand) の最上位ワード (符号ビットを含む) と乗数 (multiplier) の下位ワード (符号なし) を乗算する。
MULW はソースレジスタの下位 32 ビットを乗算し、結果の下位 32 ビットの符号拡張を宛先アドレスに配置する RV64 命令である。
RV64 では MUL を使用して 64 ビット積の上位 32 ビットを取得できるが、符号付き引数は適切な 32 ビット符号付き値でなければならず、一方で符号なし引数は上位 32 ビットがクリアされている必要がある。引数が符号拡張かゼロ拡張か不明な場合は、両方の引数を 32 ビット左にシフトしてから MULH[[S]U] を使用する方法もある。
7.2 除算操作

DIV および DIVU は XLEN ビット ✕ XLEN ビットの符号付きおよび符号なし整数除算を rs1✕rs2 で実行しゼロに向かって丸める。REM および REMU は対応する除算の余りを提供する。REM の場合、結果の符号は被除数の符号と等しくなる。
符号付き除算と符号なし除算の両方で、被除数 = 除数 ✕ 商の剰余が成立する。
同じ除算で商と余りの両方が必要な場合、推奨されるコードシーケンスは次の通り: DIV[U] rdq, rs1, rs2; REM[U] rdr, rs1, rs2 (ここで rdq は rs1 または rs2 と同じにはできない)。マイクロアーキテクチャでは 2 つの個別の除算を実行する代わりにこれらを 1 つの除算操作に融合できる。
DIVW と DIVWU は rs1 の下位 32 ビットを rs2 の下位 32 ビットで除算し、それぞれを符号付き整数と符号なし整数として扱い、32 ビットの商を rd に置いて 64 ビットに符号拡張する RV64 命令である。REMW および REMUW は対応する符号付きおよび符号なし剰余演算をそれぞれ提供する RM64 命令である。REMW と REMUW の両方はゼロ除算も含めて常に 32 ビットの結果を 64 ビットに符号拡張する。
ゼロ除算と除算オーバーフローのセマンティクスを Table 7.1 にまとめる。ゼロ除算の商にはすべてのビットが設定されており、ゼロ除算の余りは被除数に等しくなる。符号付き除算のオーバーフローは、最も負の整数 (most-negative integer)が -1 で除算される場合にのみ発生する。オーバーフローを伴う符号付き除算の商は被除数に等しく剰余はゼロである。符号なし除算のオーバーフローは発生しない。
| 条件 | 被除数 | 除数 | DIVU[W] | REMU[W] | DIV[W] | REM[W] |
|---|---|---|---|---|---|---|
| ゼロ除算 | \(x\) | \(0\) | \(2^L-1\) | \(x\) | \(-1\) | \(x\) |
| オーバーフロー (符号付きのみ) | \(-2^{L-1}\) | \(-1\) | - | - | \(-2^{L-1}\) | \(0\) |
我々は整数のゼロ除算で例外を発生させることを検討したが、これらの例外はほとんどの実行環境でトラップを引き起こす。しかしこれは標準 ISA の唯一の算術トラップであり (浮動小数点例外はフラグと設定しデフォルト値を書き込むがトラップは引き起こさない)、この場合、言語実装射が実行環境のトラップハンドラと対話する必要がある。さらに、言語標準では、divide-by-zero 例外は直ちに制御フローを変更しなければならないと義務化されているが、各除算命令に追加する必要があるのは分岐命令 1 つだけで、この分岐命令は除算の後に挿入できる。通常は実行時のオーバーヘッドがほとんど追加されないため実行されることはほとんど無い。
除算回路を簡素化するために、符号なしと符号付きのゼロ除算の両方に対して、すべてのビットがセットされた値が返される。すべて 1 の値は符号なし除算で返される自然な値であり、符号なしの最大数を表し、また単純な符号なし除算の実装のための自然な結果でもある。符号付き除算は多くの場合、符号なし除算回路を使用して実装され、同じオーバーフロー結果を指定することでハードウェアを簡素化することができる。
"A" Standard Extension for Atomic Instructions, Version 2.1
8.1 Specifying-ordering-of-atomic-instructions
8.2 Load-Reserved/Store-Conditional Instructions
8.3 Eventual Success of Store-Conditional Instructions
8.4 Atomic Memory Operations
"Zicsr", 制御および状態レジスタ (CSR) 命令, Version 2.0
RISC-V は各ハートに関連する 4096 個の制御レジスタと状態レジスタからなる独立したアドレス空間を定義している。この章ではこれらの CSR を操作する CSR 命令の完全なセットを定義する。
CSR は主に特権アーキテクチャで使用されるが、カウンターやタイマー、浮動小数点ステータスなど非特権コードでもいくつかの用途がある。
カウンターとタイマーは標準基本 ISA の必須部分とは見なされなくなったため、それらにアクセスするために必要な CSR 命令は基本 ISA の章からこの章に移された。
9.1 CSR 命令
すべての CSR 命令は単一の CSR をアトミックに読み取り、変更、書き込みを行い、その CSR 記述子はビット 31~20 に保持される命令の 12 ビット csr フィールドにエンコードされる。即値形式は rs1 フィールドにエンコードされた 5 ビットのゼロ拡張即値を使用する。

CSRRW (Atomic Read/Write CSR) 命令は CSR と整数レジスタの値をアトミックに交換する。CSRRW は CSR の古い値を読み取り、その値を XLEN ビットにゼロ拡張してからそれを整数レジスタ rd に書き込む。rs1 の初期値が CSR に書き込まれる。rd=x0 であれば命令は CSR を読み取らず、CSR 読み取りで発生する可能性のある副作用を引き起こしてはならない。
CSRRS (Atomic Read and Set Bits in CSR) 命令は CSR の値を読み取り、その値を XLEN ビットにゼロ拡張して整数レジスタ rd に書き込む。整数レジスタ rs1 の初期値は CSR に設定されるビット位置を指定するビットマスクとして扱われる。CSR ビットが書き込み可能であれば rs1 のどのビットが high でも対応するビットが CSR に設定される。CSR 内の他のビットは影響を受けない (ただし CSR が書き込まれると服作業が生じる可能性がある)。
CSRRC (Atomic Read and Clear Bits in CSR) 命令は CSR の値を読み取り、その値を XLEN ビットにゼロ拡張して整数レジスタ rd に書き込む。整数レジスタ rs1 の初期値は CSR のクリアすべきビット位置を指定するビットマスクとして扱われる。CSR のビットが書き込み可能であれば rs1 のどのビットが high でも対応するビットが CSR でクリアされる。CSR 内の他のビットは影響を受けない。
CSRRS と CSRRC の両方について、rs1=x0 のとき命令は CSR に全く書き込まれないため、読み取り専用 CSR へのアクセスで不正な命令例外が発生するといったような CSR 書き込みで発生する可能性のある副作用を引き起こしてはならない。CSRRS と CSRRC は rs1 フィールドと rs2 フィールドに関係なく読み出しの副作用を発生させる。rs1 が x0 以外のゼロ値を保持するレジスタを指定した場合でも、命令は未変更の値を CSR に書き戻そうとしてそれに伴う副作用が発生することに注意。rs1=x0 の CSRRW は宛先 CSR にゼロ値を書き込もうとする。
CSRRWI, CSRRSI, CSRRCI のバリアントは、それぞれ CSRRW, CSRRS, CSRRC と似ているが、整数レジスタの値ではなく rs1 フィールドにエンコードされた 5 ビットの符号なし即値 (uimm[4:0]) フィールドをゼロ拡張して得られる XLEN ビット値を使用して CSR を更新する。CSRRSI と CSRRCI で uimm[4:0] フィールドが 0 であれば、これらの命令は CSR に書き込みを行わず、CSR 書き込み時に発生する可能性のある副作用を引き起こしてはならない。CSRRSI と CSRRCI はどちらも rd フィールドと rs1 フィールドに関係なく、常に CSR を読み出し、読み取りの副作用を引き起こす。
Table 9.1 は CSR を読み込むか書き込むかに関する CSR 命令の動作をまとめたものである。

これまでに定義された CSR は許可されていないアクセスで不正な命令例外を発生させるだけで、と看取りに対するアーキテクチャ上の副作用はない。カスタム拡張では読み取り時に副作用を伴う CSR が追加される可能性がある。
instructions-retired カウンター instret のようないくつかの CSR は命令実行の副作用として変更される可能性がある。このような場合、CSR アクセス命令で CSR を読み出すと命令の実行前にその値が読み出される。CSR アクセス命令がこのような CSR を書き込む場合、インクリメントの代わりに書き込みが行われる。特に、ある命令で instret に書き込まれた値は次の命令で読み取られる値となる。
CSR を読み出すアセンブラ疑似命令 CSRR rd, csr は CSRRS rd, csr, x0 としてエンコードされる。CSR を書き込むアセンブラ疑似命令 CSRW csr, rs1 は CSRRW x0, csr, rs1 としてエンコードされ、CSRWI csr, uimm は CSRRWI x0, csr, uimm としてエンコードされる。
さらに、古い値が不要な場合の CSR のビットを設定およびクリアするためのアセンブラ疑似命令 CSRS/CSRC csr, rs1; CSRSI/CSRCI csr, uimm が定義されている。
CSR アクセス順序
特定のハートでは、アクセスされた CSR の状態によって実行動作が影響を受ける命令に関して、明示的および暗黙的な CSR アクセスがプログラム順序で実行される。特に CSR アクセスは、その動作が変更されるプログラム順序の先行命令の実行後に実行されるか、CSR の状態によって変更されその動作が変更されるプログラム順序内の後続の命令の実行前に実行されるか、または CSR 状態によって変更される。さらに CSR 読み込みアクセス命令は命令の実行前にアクセスされた CSR 状態を返し、CSR 書き込みアクセス命令は命令の実行後にアクセスされた CSR 状態を更新する。
上記のプログラム順序が成立しない場合、CSR アクセスは弱く順序づけされ、ローカルハートまたは他のハートはプログラム順序とは異なる順序で CSR アクセスを観測する可能性がある。さらに、CSR アクセスによって明示的にメモリアクセスを実行する命令の実行動作が変更される場合や、CSR アクセスと明示的メモリアクセスがメモリモデルによって定義された構文依存関係またはこのマニュアルの第二巻のメモリ順序付け PMA セクションによって定義された順序付け要件によって順序付けられている場合を除き、CSR アクセスは明示的なメモリアクセスに応じて順序付けされない。それ以外のすべてのケースで順序づけを強制するには、ソフトウェアは関連するアクセス間で FENCE 命令を実行する必要がある。FENCE 命令の目的上、CSR 読み取りアクセスはデバイス入力 (I) に分類され、CSR 書き込みアクセスはデバイス出力 (O) に分類される。
非公式には、CSR 空間はこのマニュアルの第二巻メモリ順序 PMA セクションで定義されているように弱く順序づけされたメモリマップド I/O 領域として機能する。この結果、他のすべてのアクセスに対する CSR アクセスの順序は、そのような領域へのメモリマップド I/O アクセスの順序を制約するのと同じメカニズムによって制約される。
これらの CSR 順序制約は主に time CSR の読み取りに関してメインメモリとメモリマップド I/O アクセスの順序付けをサポートするために課される。time, cycle, mcycle CSR をのぞき、この使用の第一巻および第二巻でこれまでに定義された CSR は、他のハードウェアやデバイスから直接アクセスできず、他のハートまたはデバイスに見られる副作用も引き起こさない。したがって上記 3 つ以外の CSR へのアクセスはこの使用に違反することなく FENCE 命令に対して自由に順序を変更することができる。
副作用を引き起こす CSR アクセスについては、上記の順序付け制約はそれらの副作用の開始順序には適用されるが、それらの副作用の完了順序には必ずしも適用されない。
ハードウェアプラットフォームは、このマニュアルの第二巻のメモリ順序付け PMA セクションで定義されているように、特定の CSR へのアクセスが強く順序付けされると定義できる。強く順序づけされた CSR へのアクセスには、弱く順序付けされた CSR へのアクセスやメモリマップド I/O 領域へのアクセスに対して、より強い順序付け制約を持つ。
Counters
10.1 Base Counters and Timers
10.2 Hardware Performance Counters
"F" Standard Extension for Single-Precision Floating-Point, Version 2.2
11.1 F Register State
11.2 Floating-Point Control and Status Register
11.3 NaN Generation and Propagation
11.4 Subnormal Arithmetic
11.5 Single-Precision Load and Store Instructions
11.6 Single-Precision Floating-Point Computational Instructions
11.7 Single-Precision Floating-Point Conversion and Move Instructions
11.8 Single-Precision Floating-Point Compare Instructions
11.9 Single-Precision Floating-Point Classify Instruction
"D" Standard Extension for Double-Precision Floating-Point, Version 2.2
12.1 D Register State
12.2 NaN Boxing of Narrower Values
12.3 Double-Precision Load and Store Instructions
12.4 Double-Precision Floating-Point Computational Instructions
12.6 Double-Precision Floating-Point Conversion and Move Instructions
12.7 Double-Precision Floating-Point Classify Instruction
"Q" Standard Extension for Quad-Precision Floating-Point, Version 2.2
13.1 Quad-Precision Load nad Store Instructions
13.2 Quad-Precision Computational Instructions
13.3 Quad-Precision Convert and Move Instructions
13.4 Quad-Precision Floating-Point Compare Instructions
13.5 QUad Precision Floating-Point Classify Instruction
RVWMO Memory Consistency Model, Version 0.1
14.1 Definition of the RVWMO Memory Model
Memory Model Primitives
Syntactic Dependencies
Preserved Program Order
Memory Mode Axioms
14.2 CSR Dependency Tracking Granularity
14.3 Source and Destination Register Listings
"L" Standard Extension for Decimal Floating-Point, Version 0.0
15.1 Decimal Floating-Point Registers
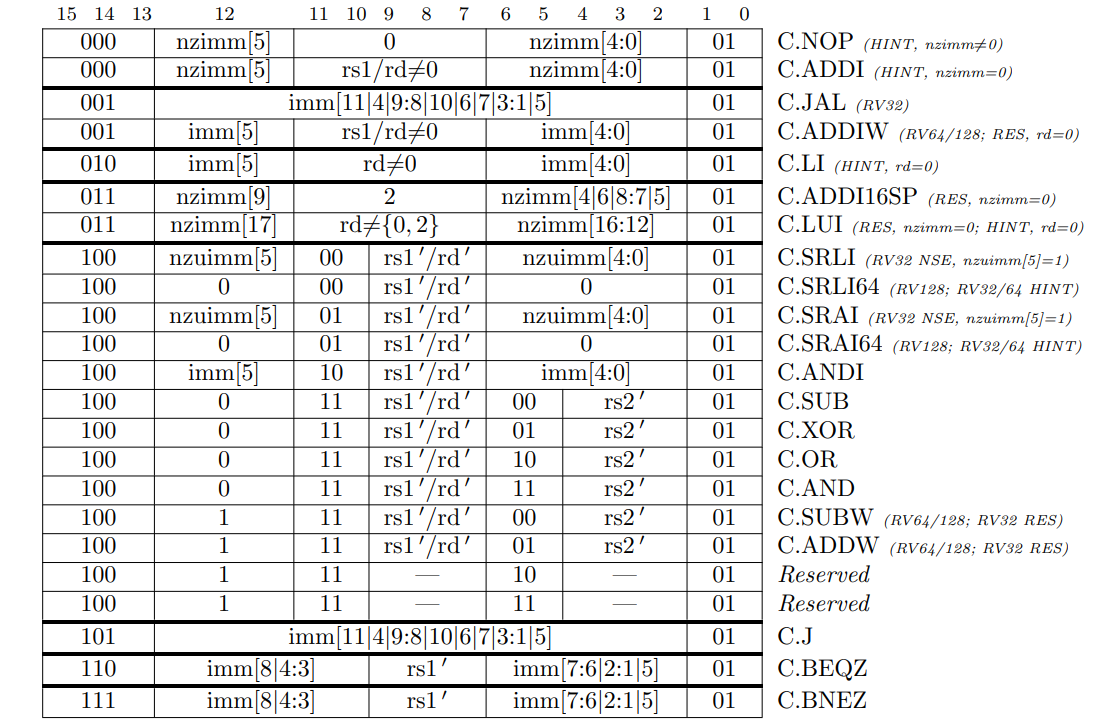
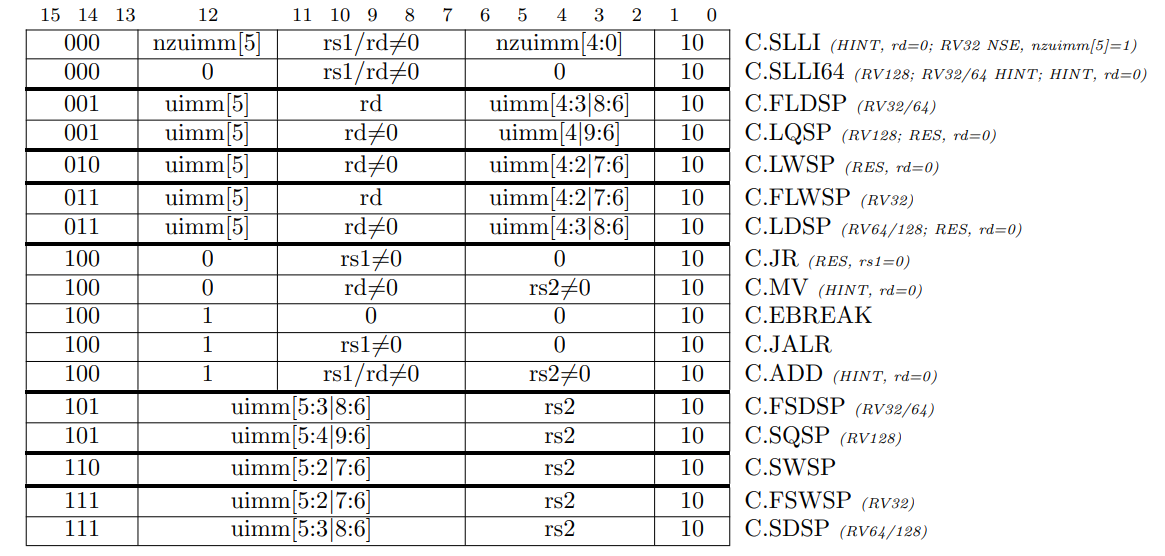
圧縮命令 "C" 標準拡張, Version 2.0
この章では "C" という名前の RISC-V 標準圧縮命令セット拡張の現在の提案について説明する。この拡張は一般的な操作に 16 ビットの短い命令エンコーディングを追加することで静的および動的なコードサイズを削減する。C 拡張は基本 ISA (RV32, RV64, RV128) のいずれにも追加でき、これらのいずれにも対応できるように一般的な用語 "RVC" という総称を使用する。通常、プログラム内の RISC-V 命令の 50%-60% を RVC 命令に置き換えることができ、その結果コードサイズを 25%-30% 削減できる。
16.1 概要
RVC は次のような場合に一般的な 32 ビット RISC-V 命令の短い 16 ビットバージョンを提供する単純な圧縮スキームを使用する:
- 即値またはアドレスオフセットが小さい
- レジスタの一つがゼロレジスタ (x0)、ABI リンクレジスタ (x1)、または ABI スタックポインタ (x2)
- 宛先レジスタと最初のソースレジスタが同一
- 使用されるレジスタが最も一般的な 8 個
C 拡張は他のすべての標準命令拡張と互換性がある。C 拡張により 16 ビット命令を 32 ビット命令と自由に混在させることができるようになり、後者は任意の 16 ビット境界、すなはち IALIGN=16 から開始できるようになった。C 拡張の追加により、どの命令も instruction-address-misaligned 例外を発生させることができなくなった。
元の 32 ビット命令の 32 ビットアラインメント制約を削除するとコード密度が大幅に向上する。
圧縮命令エンコーディングは RV32C, RV64C, RV128C でほぼ共通だが、Table 16.4 に示すように基本 ISA 幅によって異なる目的で使用されるオペコードがいくつかある。例えばより広いアドレス空間の RV64C および RV128C バリアントでは、64 ビット整数値のロードとストアを圧縮するために追加のオペコードが必要だが、RV32C では単精度浮動小数点値のロードとストアを圧縮するために同じオペコードを使用する。同様に、RV128C は 128 ビット整数値のロードとストアを取り込むために追加のオペコードを必要とするが、RV32C と RV64C では倍精度浮動小数点のロードとストアに同じオペコードが使用される。C 拡張が実装されている場合、関連する浮動小数点拡張 (F または D) も実装されている場合は常に、適切な浮動小数点ロードおよびストア命令を提供する必要がある。さらに RV32C には短距離サブルーチン呼び出し (short-range subroutine call) を圧縮するための圧縮ジャンプおよびリンク命令が含まれており、同じオペコードを使用して RV64C と RV128C の ADDIW を圧縮する。
倍精度のロードとストアは静的命令と動的命令のかなりの割合を占めているため、RV32C と RV64C のエンコーディングに倍精度ロードとストアを含めることにした。
現在サポートされている ABI 用にコンパイルされたベンチマークの静的または動的圧縮では、単精度ロードとストアは重要な要因ではないが、ハードウェア単精度浮動小数点ユニットのみを提供し、単精度浮動小数点のみをサポートする ABI を備えたマイクロコントローラでは、単精度ロードとストアは少なくとも測定ベンチマークで倍精度ロードおよびストアと同じ頻度で使用される。したがって RV32C でこれらの圧縮サポートを提供する動機になる。
短距離サブルーチンの呼び出しは、マイクロコントローラ用の小さなバイナリでより頻繁に使用される可能性が高いためこれらを RV32C に含める動機となる。
異なる基本レジスタ幅に対して異なる目的でオペコードを再利用することは、ドキュメンテーションを多少煩雑にするが、複数の基本 ISA レジスタ幅をサポートする設計であっても実装の複雑さに与える影響はわずかである。圧縮浮動小数点のロードとストアのバリアントはより広い整数のロードとストアを同じレジスタ指定しを持つ同じ命令フォーマットを使用する。
RVC は、各 RVC 命令が基本 ISA (RV32I/E, RV64I, RV128I) または F および D 標準拡張 (存在する場合) のいずれかの 32 ビット命令に拡張されるという制約の下で設計された。この制約を採用すると次の 2 つの主な利点がある:
ハードウェア設計ではデコード時に単純に RVC 命令を拡張でき、既存のマイクロアーキテクチャへの検証が簡素化され変更が最小限に抑えられる。
コンパイラは RVC 拡張を意識せずコードの圧縮をアセンブラとリンカに任せることができるが、圧縮を意識したコンパイラの方が一般的に良い結果が得られる。
我々は、C 命令と基本 IDF 命令の単純な 1 対 1 のマッピングによる複数の複雑さの軽減は、C 拡張のみでサポートされる命令を追加したり、1 つの C 命令で複数の IFD 命令をエンコードできるような、わずかに高い密度のエンコードによる潜在的な利益を遙かに上回っていると考えた。
C 拡張は独立した ISA として設計されているわけではなく、基本 ISA と並行して使用することを目的としていることに注意することがで重要である。
可変長命令セットはコード密度を向上させるために長い間使用されてきた。たとえば 1950 年代後半に開発された IBM Stretch [4] は 32 ビット命令と 64 ビット命令を備えた ISA を持ち、32 ビット命令の一部は完全な 64 ビット命令の圧縮バージョンであった。Stretch はまたインデックスレジスタの 1 つだけを参照できる短い分岐命令を使用して、一部の短い命令フォーマットでアドレス指定可能なレジスタのセットを制限するという概念も採用していた。後の IBM 360 アーキテクチャ [3] では 16 ビットと 32 ビット、または 48 ビットの命令フォーマットによる単純な可変長命令エンコーディングをサポートしていた。
1963 年、CDC は RISC アーキテクチャの先駆けである Cray 設計の CDC 6600 [18] を発表した。これは 15 ビットと 30 ビットの 2 つの長さの命令を備えたレジスタリッチなロードストアアーキテクチャを導入した。後の Cray-1 設計は 16 ビットと 32 ビットの命令長で非常によく似た命令フォーマットを使用していた。
1980 年代初期の RISC ISA はいずれもコードサイズより性能を重視していた。これはワークステーション環境では合理的だったが組み込み環境には適していなかった。そのため ARM と MIPS の両社はその後、標準の 32 ビット幅の命令の代わりに代替の 16 ビット幅の命令セットを提供することで、よりコードサイズを小さくしたバージョンの ISA を作成した。圧縮 RISC ISA は開始時点に比べてコードサイズが約 25%~30% 削減され、生成されるコードは 80x86 より大幅に小さくなった。可変長 CISC ISA は 16 ビットおよび 32 ビット形式のみを提供する RISC ISA よりも小さくなるはずだと直感していたため、この結果は一部の人を驚かせた。
元の RISC ISA にはこれらの計画外の圧縮命令を含めるための十分なオペコード空間が残されていなかったため、代わりにそれらは完全な新しい ISA として開発された。これはコンパイラが個別の圧縮 ISA に対して異なるコードジェネレータを必要としたことを意味する。最初の圧縮 RISC ISA 拡張 (ARM Thumb や MIPS16 など) は固定の 16 ビット命令サイズのみを使用していたため、静的なコードサイズは大幅に削減できたが、動的な命令数が増加し、元のバージョンと比較して性能が低下した。これにより 16 ビットと 32 ビットの命令長が混在する第 2 世代の圧縮 RISC ISA 設計 (ARM Thumb2, microMIPS, PowerPC VLE など) の開発が行われ、純粋な 32 ビット命令と同等の性能でありながらコードサイズを大幅に削減できるようになった。残念ながらこれらの異なる世代の圧縮 ISA は相互に互換性がなく、元の非圧縮 ISA とも互換性がないため、書籍、実装、ソフトウェアツールのサポートが大幅に複雑になっている。
一般的に使用されている 64 ビット ISA のうち、現在圧縮命令フォーマットをサポートしているのは PowerPC と microMIPS だけである。静的コードサイズと動的命令フェッチ帯域幅が重要な指標であることを考えると、モバイルプラットフォームで最も普及している 64 ビット ISA (ARM v8) に圧縮命令フォーマットが含まれていないことは驚きである。大規模なシステムでは静的コードサイズは大きな問題ではないが、命令フェッチ帯域は大規模な命令ワーキングセットを持つことが多い商用ワークロードを実行するサーバでは大きなボトルネックになる可能性がある。
RISC-V は 25 年間の振り返りの恩恵を受け最初から圧縮命令をサポートするように設計されており、基本 ISA 上に (他の多くの拡張機能とともに) 単純な拡張機能として RVC を追加できる十分なオペコード領域が残されている。RVC の理念は、組み込みアプリケーションのコードサイズを削減し、命令キャッシュのミスを減らすことですべてのアプリケーションの性能とエネルギー効率を向上させることである。Waterman は、RVC がフェッチする命令ビットが 25%~30% 減少し、これにより命令キャッシュのミスが 20%~25% 減少すること、つまり命令キャッシュのサイズを 2 倍にした場合とほぼ同じ性能効果があることを示している [20]。
16.2 圧縮命令フォーマット
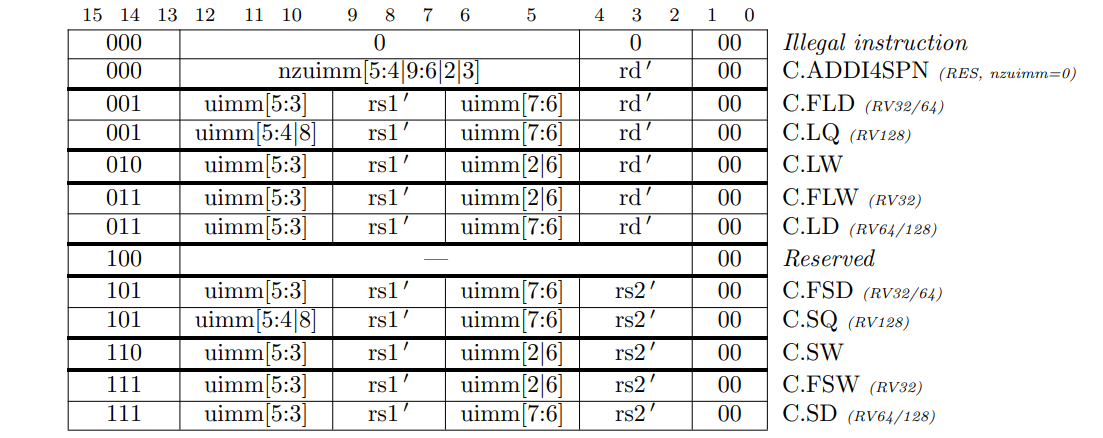
Table 16.1 に 9 個の圧縮命令フォーマットを示す。CR, CI, CSS は 32 個の RVI レジスタのいずれかを使用できるが、CIW, CL, CS, CA, CB は 8 個だけに制限されている。Table 16.2 にレジスタ x8 から x15 に対応するこれらの一般的なレジスタを示す。スタックへの保存とスタックからの復元が非常に普及しているため、ベースアドレスレジスタとして使用するロード命令とストア命令には別のバージョンがあり、これらの命令では 32 個のデータレジスタすべてにアクセスできるように CI と CSS フォーマットを使用していることに注意。CIW は ADDI4SPN 命令に 8 ビット即値を提供する。
RISC-V ABI は使用頻度の高いレジスタをレジスタ x8-x15 にマップするように変更された。これにより自然に整列された連続したレジスタ番号が得られるため、伸張デコーダが簡素化され 16 個の整数レジスタしか持たない RV32E 基本 ISA とも互換性がある。
圧縮レジスタベースの浮動小数点ロードとストアもそれぞれ CL と CS フォーマットを使用し、8 つのレジスタが f8~f15 にマッピングされる。
標準的な RISC-V の呼び出し既約では、最も頻繁に使用される浮動小数点レジスタはレジスタ f8 から f15 にマッピングされる。これにより整数レジスタ番号の場合と同様の伸張デコードが可能となる。
このフォーマットは 2 つのレジスタソース記述子のビットをすべての命令で同じ場所に保つように設計されているが、宛先レジスタフィールドは移動することができる。完全な 5 ビット宛先レジスタ記述子が存在する場合、それは 32 ビット RISC-V エンコーディングと同じ場所にある。即値フィールドが符号拡張されている場合、符号拡張は常にビット 12 から行われる。基本仕様と同様に即値フィールドはスクランブルされ、必要な即値マルチプレクサの数が削減されている。
可能な限り多くのビットがすべての命令で同じ位置に配置されるように、即値フィールドは順次ではなく命令フォーマットでスクランブルされ、それにより実装が簡素化される。例えば即値ビット 17~10 は常に同じ命令ビットの位置から供給される。他の 5 つの即値ビット (5, 4, 3, 1, 0) には 2 つのソース命令ビットがあるだけだが、4 つ (9, 7, 6, 2) には 3 つのソースがあり、1 つ (8) には 4 つのソースがある。
多くの RVC 命令ではゼロ値の即値は浸漬されており、x0 は有効な 5 ビットレジスタ記述子ではない。これらの制限により、より少ないオペランドビットを必要とする他の命令のためのエンコード空間が確保される。


16.3 ロード命令とストア命令
16 ビット命令の到達範囲を高めるために、データ転送命令ではバイト単位でデータサイズをスケーリングしたゼロ拡張即値を使用する (ワードの場合は ✕4、ダブルワードの場合は ✕8、クアッドワードの場合は ✕16)。
RVC ではロードとストアに 2 種類の方法がある。1 つは ABI スタックポインタ x2 ベースアドレスとして使用し、任意のデータレジスタをターゲットとすることができる。もう一つは、8 個のベースアドレスレジスタのうち 1 つと、8 個のデータレジスタのうち 1 を参照できるものである。
スタックポインタに基づくロードとストア

これらの命令は CI フォーマットを使用する。
C.LWSP は 32 ビット値をメモリーからレジスタ rd にロードする。これはスタックポインタ x2 に 4 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。lw rd, offset[7:2](x2) と展開される。C.LWSP は rd≠x0 の場合にのみ有効で、rd=x0 のコードポイントは予約されている。
C.LDSP は 64 ビット値をメモリーからレジスタ rd にロードする RV64C/RV128C 専用の命令である。スタックポインタ x2 に 8 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。ld rd, offset[8:3](x2) に展開される。C.LDSP は rd≠x0 の場合にのみ有効で、rd=x0 のコードポイントは予約されている。
C.LQSP は 128 ビット値をメモリーからレジスタ rd にロードする RV128C 専用の命令である。スタックポインタ x2 に 16 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。lq rd, offset[9:4](x2) に展開される。C.LQSP は rd≠x0 の場合にのみ有効で、rd=x0 のコードポイントは予約されている。
C.FLWSP は単精度浮動小数点値をメモリーからレジスタ rd にロードする RV32FC 専用の命令である。スタックポインタ x2 に 4 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。flw rd, offset[7:2](x2) に展開される。
C.FLDSP は倍精度浮動小数点値をメモリーからレジスタ rd にロードする RV32DC/RV64DC 専用の命令である。スタックポインタ x2 に 8 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。fld rd, offset[8:2](x2) と展開される。

これらの命令は CSS フォーマットを使用する。
C.SQSP はレジスタ rs2 の 32 ビット値をメモリーにストアする。スタックポインタ x2 に 4 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。これは sw rs2, offset[7:2](x2) に展開される。
C.SDSP はレジスタ rs2 の 64 ビット値をメモリーにストアする RV64C/RV128C 専用の命令である。スタックポインタ x2 に 8 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。これは sd rs2, offset[8:3](x2) に展開される。
C.SQSP はレジスタ rs2 の 128 ビット値をメモリーにストアする RV128C 専用の命令である。スタックポインタ x2 に 16 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。これは sq rs2, offset[9:4](x2) に展開される。
C.FSWSP は浮動小数点レジスタ rs2 の単精度浮動小数点値をメモリーにストアする RV32FC 専用の命令である。スタックポインタ x2 に 4 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。これは fsw rs2, offset[7:2](x2) に展開される。
C.FSDSP は浮動小数点レジスタ rs2 の倍精度浮動小数点値をメモリーにストアする RV32DC/RV64DC 専用の命令である。スタックポインタ x2 に 8 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。これは fsd rs2, offset[8:3](x2) に展開される。
関数の入口/出口におけるレジスタの保存/復元コードは静的コードサイズのかなりの部分を占めている。RVC のスタックポインタに基づく圧縮ロードと圧縮ストアは、動的命令帯域幅を削減することで性能を向上させる一方で、静的コードサイズを 2 分の 1 に削減するのに効果的である。
保存/復元のコードサイズをさらに削減するために他の ISA で使用されている一般的なメカニズムは、ロードマルチプル命令とストアマルチプル命令 (load-multiple and store-multiple instruction) である。これらを RISC-V に採用することも検討したが、これらの命令には次のような欠点があることに気づいた:
これらの命令はプロセッサの実装を複雑にする。
仮想メモリシステムの場合、データアクセスの一部が物理メモリに常駐し一部が常駐しない可能性があるため、部分的に実行された命令に対する新しい再起動メカニズムが必要となる。
他の RVC 命令と異なり Load Multipe と Store Multipe に相当する IFD が存在しない。
他の RVC 命令と異なりこれらの命令は順番に保存および復元されるため、コンパイラはこれらの命令を認識して命令を生成し、命令が保存およびストアされる可能性を最大化するためにレジスタを割り当てる必要がある。
単純なマイクロアーキテクチャの実装では複数のロードとストアの命令の周辺に他の命令をスケジューリングする方法が制限され、潜在的な性能低下に繋がる可能性がある。
逐次レジスタ割り当ての要望は CIW, CL, CS, CA, CB フォーマット用に選択された機能レジスタと矛盾する可能性がある。
さらに、[23] のセクション 5.6 で説明されている手法により、プロローグとエピローグのコードを共通のプロローグとエピローグのコードのサブルーチン呼び出しに置き換えることによって、リア気の多くはソフトウェアで実現することができる。
合理的なアーキテクトは異なる結論を出すかも知れないが、我々はロードとストアの多重化を省略し、代わりに保存/復元ミリコードルーチンを呼び出すようなソフトウェアのみのアプローチを使用することでコードサイズの削減を最大限にすることにした。
レジスタに基づくロードとストア

これらの命令は CL フォーマットを使用する。
C.LW は 32 ビット値をメモリーからレジスタ rd' にロードする。これはレジスタ rs1' に 4 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。lw rd', offset[6:2](rs1') に展開される。
C.LD は 64 ビット値をメモリーからレジスタ rd' にロードする RV64C/RV128C 専用の命令である。レジスタ rs1' に 8 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。ld rd', offset[7:3](rs1') に展開される
C.LS は 128 ビット値をメモリーからレジスタ rd' にロードする RV128C 専用の命令である。レジスタ rs1' に 16 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。lq rd', offset[8:4](rs1') に展開される
C.FLW は単精度浮動小数点値をメモリーからレジスタ rd' にロードする RV32FC 専用の命令である。レジスタ rs1' に 4 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。flw rd', offset[6:2](rs1') に展開される。
C.FLD は倍精度浮動小数点値をメモリーからレジスタ rd' にロードする RV32DC/RV64DC 専用の命令である。レジスタ rd' に 8 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。fld rd', offset[7:3](rs1') に展開される。

これらの命令は CS フォーマットを使用する。
C.SW はレジスタ rs2' の 32 ビット値をメモリーにストアする。レジスタ rs1' に 4 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。これは sw rs2', offset[6:2](rs1') に展開される。
C.SD はレジスタ rs2’ の 64 ビット値をメモリーにストアする RV64C/RV128C 専用の命令である。レジスタ rs1' に 8 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。これは sd rs2', offset[7:3](rs1' に展開される。
C.SQ はレジスタ rs2’ の 128 ビット値をメモリーにストアする RV128C 専用の命令である。レジスタ rs1' に 16 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。これは sq rs2', offset[8:4](rs1') に展開される。
C.FSW は浮動小数点レジスタ rs2' の単精度浮動小数点値をメモリーにストアする RV32FC 専用の命令である。レジスタ rs1' に 4 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。これは fsw rs2', offset[6:2](rs1') に展開される。
C.FSW は浮動小数点レジスタ rs2' の倍精度浮動小数点値をメモリーにストアする RV32DC/RV64DC 専用の命令である。レジスタ rs1' に 8 倍にスケールされたゼロ拡張オフセットを加算することで実効アドレスを計算する。これは fsd rs2', offset[7:3](rs1') に展開される。
16.4 制御転送命令
RVC には無条件ジャンプ命令と条件分岐命令がある。基本 RVI 命令と同様にすべての RVC 制御転送命令のオフセットは 2 バイトの倍数である。

これらの命令は CJ フォーマットを使用する。
C.J は無条件に制御転送を行う。オフセットは符号拡張され、pc に加算されてジャンプターゲットアドレスとなる。したがって C.J は ±2KiB 範囲をターゲットとすることができる。C.J は jal x0, offset[11:1] に展開される。
C.JAL は C.J と同じ動作を行うが、ジャンプ (pc+2) に続く命令のアドレスをリンクレジスタ x1 に書き込む RV32C 専用の命令である。C.JAL は jal x1, offset[11:1] に展開される。

これらの命令は CR フォーマットを使用する。
C.JR (jump register) はレジスタ rs1 のアドレスへの無条件転送を実行する。C.JR は jalr x0, 0(rs1) と展開される。C.JR は rs1≠x0 の場合にのみ有効で、rs1=x0 のコードポイントは予約されている。
C.JALR (jump and link register) は C.JR と同じ動作を行うが、ジャンプ (pc+2) に続く命令のアドレスをリンクレジスタ x1 に書き込む。C.JALR は jalr x1, 0(rs1) に展開される。C.JALR は rs1≠x0 の場合にのみ有効で、rs1=x0 のコードポイントは C.EBREAK 命令に対応する。
厳密に言えば C.JALR は、リンクアドレスを形成するために PC に追加される値が基本 ISA の 4 ではなく 2 であるため、基本 RVI 命令を正確に拡張していないが、2 バイトと 4 バイトの両方のオフセットをサポートするのは基本マイクロアーキテクチャに対する非常に小さな変更に過ぎない。

これらの命令は CB フォーマットを使用する。
C.BEQZ は条件付き制御転送を実行する。オフセットは符号拡張され pc に加算されて分岐先アドレスが形成される。したがって ±256B 範囲をターゲットとすることができる。C.BEQZ はレジスタ rs1' の値がゼロの場合に分岐を行う。これは beq rs1', x0, offset[8:1] に展開される。
C.BNEZ も同様に定義されるが、rs1' に非ゼロ値が含まれている場合に分岐する。これは bne rs1', x0, offset[8:1] と展開される。
16.5 整数演算命令
RVC は整数演算と定数生成のためのいくつかの命令を提供する。
整数定数生成命令
2 つの定数生成命令はどちらも CI 命令フォーマットを使用して任意の整数レジスタをターゲットとすることができる。

C.LI は符号拡張された 6 ビット即値 imm をレジスタ rd にロードする。C.LI は addi rd, x0, imm[5:0] に展開される。C.LI は rd≠x0 の場合にのみ有効で、rd=x0 のコードポイントは HINT を符号化する。
C.LUI は非ゼロの 6 ビット即値フィールドを宛先アドレスのビット 17~12 にロードし、下位 12 ビットをクリアし、ビット 17 を宛先のすべての上位ビットに符号拡張する。C.LUI は lui rd, nzimm[17:12] に展開される。C.LI は rd≠{x0,x2} かつ即値が 0 でない場合にのみ有効で、nzimm=0 のコードポイントは予約されており、残りの rd=x0 のコードポイントは HINT、rd=x2 のコードポイントは C.ADDI16SP 命令に対応する。
整数レジスタ-即値操作
これらの整数レジスタ-即値操作は CI フォーマットでエンコードされ、整数レジスタおよび 6 ビット即値で操作を実行する。

C.ADDI はレジスタ rd の値に非ゼロの符号拡張 6 ビット即値を加算し、結果を rd に書き込む。C.ADDI は addi rd, rd, nzimm[5:0] に展開される。CADDI は rd≠x0, nzimm≠0 の場合にのみ有効で、rd=x0 のコードポイントは C.NOP をエンコードし、nzimm=0 のコードポイントは HINT を符号化する。
C.ADDIW は RV64C/RV128C 専用の命令で、同じ計算を行うが 32 ビットの結果を生成し、その結果を 64 ビットに符号拡張する。C.ADDIW は addiw rd, rd, imm[5:0] に展開される。C.ADDIW では即値を 0 にすることができ、これは sext.w rd に相当する。C.ADDIW は rd≠x0 の場合にのみ有効で、rd=x0 のコードポイントは予約されている。
C.ADDI16SP は C.LUI とオペコードを共有するが宛先フィールドは x2 である。C.ADDI16SP はスタックポインタ (sp=x2) の値に非ゼロの符号拡張 6 ビット即値を加算する。ここで即値は範囲 (-512, 496) の 16 の倍数を表すようにスケーリングされる。C.ADDI16SP はプロシージャのプロローグとエピローグでスタックポインタを調整するために使用される。これは addi x2, x2, nzimm[9:4] に展開される。C.ADDI16SP は nzimm≠0 の場合にのみ有効で、nzimm=0 のコードポイントは予約されている。
標準的な RISC-V の呼び出し既約では、スタックポインタ sp は常に 16 バイトアラインメントである。

C.ADDI4SPN はスタックポインタ x2 に 4 倍にゼロ拡張された非ゼロ即値を追加し、結果を rd' に書き込む CIW フォーマットの命令である。この命令はスタックに割り当てられた変数へのポインタを生成するために使用され、addi rd', x2, nzuimm[9:2] に展開される。C.ADDI4SPN は nzuimm≠0 の場合にのみ有効で、nzuimm=0 のコードポイントは予約されている。

C.SLLI はレジスタ rd の値を論理左シフトし、その結果を rd に書き込む CI フォーマットの命令である。RV128C の場合、64 シフトをエンコードするためにシフト量 0 が使用される。C.SLLI は slli rd, rd, shamt[5:0] に展開されるが、RV128C の場合は slli rd, rd, 64 に展開される。
RV32C の場合、shamt[5] は 0 でなければならない。shamt[5]=1 のコードポイントはカスタム拡張用に予約されている。RV32C と RV64C の場合、シフト量は 0 以外でなければならない。shamt=0 のコードポイントは HINT である。すべての基本 ISA では RV32C の shamt[5]=1 を除いて rd=x0 のコードポイントは HINT である。

C.SRLI はレジスタ rd' の値を論理右シフトし、その結果を rd' に書き込む CB フォーマットの命令である。シフト量は shamt フィールドにエンコードされている。RV128C の場合、64 シフトをエンコードするためにシフト量 0 が使用される。さらに、RV128C ではシフト量は符号拡張されるため、有効なシフト量は 1~31、64、96~127 となる。C.SRLI は srli rd', rd', shamt[5:0] と展開されるが、RV128C の場合は shamt=0 を除いて srli rd', rd', 64 に展開される。
RV32C の場合、shamt[5] は 0 でなければならない。shamt[5]=1 のコードポイントはカスタム拡張用に予約されている。RV32C と RV64C の場合、シフト量は 0 以外でなければならず、shamt=0 のコードポイントは HINT である。
C.SRAI は C.SRLI と同様に定義されるが、代わりに算術右シフトを実行する。CSRAI は srai rd', rd', shamt[5:0] に展開される。
左シフトはアドレス値のスケーリングに頻繁に使用されるため、通常は右シフトより左シフトの方が使用頻度が高い。したがって、右シフトにはより少ないエンコード空間が与えられ、他のすべての即値が符号拡張されるエンコード象限 (quadrant) に配置される。RV128 では 6 ビットのシフト量の即値も符号拡張することにした。デコードの複雑さを軽減する以外にも、128 ビットアドレスポインタの上位部分に位置するタグを抽出できるようにするためには 64~95 より 96~127 の右シフト量の方が有用であると考えている。128 ビットアドレス空間コードの一般的な使用法を評価できるように RV128C は RV64C と同じ時点で凍結しないことに注意。

C.ANDI はレジスタ rd' の値と符号拡張された 6 ビットの即値とのビットごとの AND を計算し、その結果を rd' に書き込む CB フォーマットの命令である。C.ANDI は andi rd', rd', imm[5:0] に展開される。
整数レジスタ-レジスタ操作

これらの命令は CR フォーマットを使用する。
C.MV はレジスタ r2 の値を rd にコピーする。C.MV は add rd, x0, rs2 に展開される。C.MV は rs2≠0 の場合にのみ有効で、rd=x0 のコードポイントは HINT である。
C.MV は標準的な MV 疑似命令とは異なる命令に展開され、代わりに ADDI を使用する。MV を特別に扱う実装、例えば register-renaming ハードウェアを使用する実装では、ハードウェアの追加コストがわずかに発生するが C.MV を ADD ではなく MV に展開する方が便利な場合がある。
C.ADD はレジスタ rd と rs2 の値を加算し、結果をレジスタ rd に書き込む。C.ADD は add rd, rd, rs2 と展開される。C.ADD は rs2≠0 の場合にのみ有効で、rs2=x0 のコードポイントは C.JALR 命令と C.EBREAK 命令に対応する。rs2≠x0 と rd=x0 のコードポイントは HINT である。

これらの命令は CA フォーマットを使用する。
C.AND はレジスタ rd' と rs2' の値のビット単位の AND を計算し、その結果をレジスタ rd' に書き込む。C.AND は and rd', rd', rs2' に展開される。
C.OR はレジスタ rd' と rs2' の値のビット単位の OR を計算し、その結果をレジスタ rd' に書き込む。C.OR は or rd', rd', rs2' に展開される。
C.XOR はレジスタ rd' と rs2' の値のビット単位の XOR を計算し、その結果をレジスタ rd' に書き込む。C.XOR は xor rd', rd', rs2' に展開される。
C.SUB はレジスタ rd' から rs2' の値を減算し、その結果をレジスタ rd' に書き込む。C.SUB は sub rd', rd', rs2' に展開される。
C.ADDW はレジスタ rd' と rs2' の値を加算し、その結果をレジスタ rd' に書き込む前に合計の下位 32 ビットを符号拡張する RV64C/RV128C 専用の命令である。C.ADDW は addw rd', rd', rs2' に展開される。
C.SUBW はレジスタ rd' から rs2' の値を減算し、その結果をレジスタ rd' に書き込む前に差の下位 32 ビットを符号拡張する RV64C/RV128C 専用の命令である。C.SUBW は subw rd', rd', rs2' に展開される。
この 6 個の命令グループは個々には大きな節約にはならないが、エンコード空間を余り占有せず、実装が簡単であり、グループとして静的圧縮と動的圧縮に価値のある改善をもたらす。
定義済み違反命令

すべてのビットが 0 の 16 ビット命令は違反命令として永久に予約されている。
すべて 0 の命令は、メモリー空間のゼロ化されたポインタまたは存在しないポインタを実行する試みをトラップするために違反命令として予約されている。すべて 0 の値は非標準の拡張で再定義すべきではない。同様に、すべてのビットが 1 に設定された命令 (RISC-V 可変長エンコード方式における非常に長い命令に相当) も存在しないメモリ領域でよく見られる別のよくある値を補足するために不正な命令として予約する。
NOP 命令

C.NOP は pc を進め該当するパフォーマンスカウンターをイン栗夫婦する以外にユーザから見える状態を変更しない CI フォーマットの命令である。C.NOP は nop に展開される。C.NOP は imm=0 の場合にのみ有効で、imm≠0 のコードポイントは HINT をエンコードする。
ブレイクポイント命令

デバッガは ebreak に展開される C.EBREAK 命令を使用して制御をデバッグ環境に戻すことができる。C.EBREAK は C.ADD 命令とオペコードを共有するが、rd と rs2 は両方とも 0 であるたえ CR フォーマットも使用できる。
16.6 LR/CS シーケンスにおける C 命令の使用法
C 拡張をサポートする実装ではセクション 8.3 で説明されているように制約付き LR/SC シーケンス内で許可されている I 命令の圧縮形式も制約付き LR/SC シーケンス内で許可されている。
つまり A 拡張と C 拡張の両方をサポートすると主張する実装は、有効な C 命令を含む LR/SC シーケンスが最終的に完了することを保証しなければならない。
16.7 HINT 命令
RVC エンコード空間の一部はマイクロアーキテクチャ HINT 用に予約されている。RV32I 基本 ISA の HINT (セクション 2.9 参照) と同様に、これらの命令は pc および該当するパフォーマンスカウンターを進める以外にアーキテクチャの状態を変更しない。HINT を無視する実装では HINT は no-ops として実行される。
RVC HINT は、rd=x0 (例えば C.ADD x0, t0) または rd がそれ自身のコピーで上書きされる (例えば C.ADDI t0, 0) ため、アーキテクチャの状態を変更しない計算命令としてエンコードされる。
この HINT エンコーディングは単純な実装で HINT を完全に無視し、代わりにアーキテクチャの状態を変更しない通常の計算命令として HINT を実行できるように選択されている。
RVC HINT は必ずしも RVI HINT に展開されるわけではない。例えば C.ADD x0, t0 は ADD x0, x0, t0 と同じ HINT をエンコードしないかもしれない。
RVC HINT を RVI HINT に展開する必要がない主な理由は、HINT が基礎となる計算命令を同じ方法で圧縮できる可能性が低いためである。また RVC と RVI の HINT マッピングを切り離すことで希少な RVC HINT 空間を最も一般的な HINT、特にマクロ操作の融合に適した HINT に割り当てることができる。
Table 16.3 にすべての RVC HINT コードポイントを示す。RV32C では HINT 空間の 78% が標準 HINT 用に確保されているが現在は何も定義されていない。残りの HINT 空間はカスタム HINT のために予約されている。このサブ空間で標準 HINT が定義されることはない。
| 命令 | 制約 | コードポイント | 目的 |
|---|---|---|---|
| C.NOP | nzimm≠0 | 63 | 将来の標準利用のため予約 |
| C.ADDI | rd≠x0, nzimm=0 | 31 | |
| C.LI | rd=x0 | 64 | |
| C.LUI | rd=x0, nzimm≠0 | 63 | |
| C.MV | rd=x0, rs2≠x0 | 31 | |
| C.ADD | rd=x0, nzimm≠x0 | 31 | |
| C.SLLI | rd=x0, nzimm≠0 | 31 (RV32) 63 (RV64/128) |
カスタム利用のため予約 |
| C.SLLI64 | rd=x0 | 1 | |
| C.SLLI64 | rd≠x0, RV32 と RV64 のみ | 31 | |
| C.SRLI64 | RV32 と RV64 のみ | 8 | |
| C.SRAI64 | RV32 と RV64 のみ | 8 |
16.8 RVC 命令セットリスト
Table 16.4 は RVC の主要なオペコードのマップを示している。表の各行はエンコード空間の1つの象限に対応している。最下位ビットが 2 つ設定されている最後の象限は、基本 ISA 内の命令を含む 16 ビットより広い命令に対応する。いくつかの命令は特定のオペランドに対してのみ有効であり、無効な場合、そのオペコードが将来の標準拡張のために予約されていることを示す RES、そのコードがカスタム拡張のために予約されていることを示す NSE、またはそのオペコードがマイクロアーキテクチャのヒント (セクション 16.7 参照) のために予約されていることを示す HINT のいずれかでマークされている。
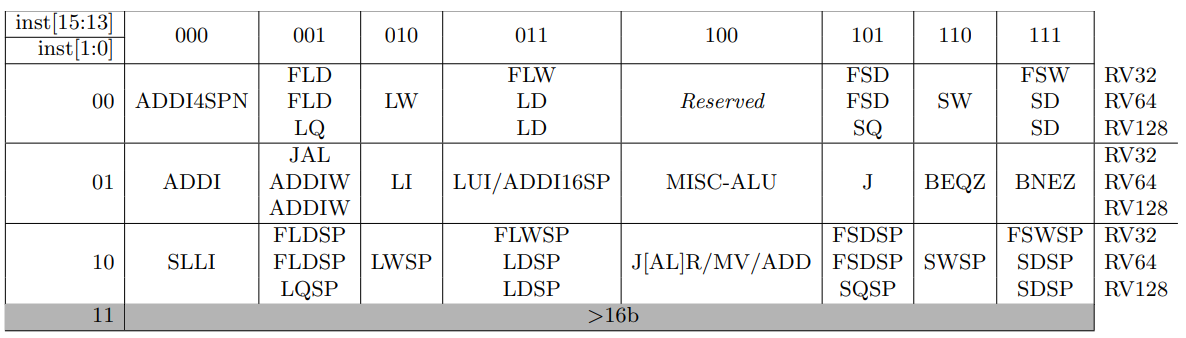
Table 16.5~16.7 は RVC 命令のリストである。
ビット操作 "B" 標準拡張, Version 2.0
この章は、ビットフィールドの挿入、抽出、検査滅入れやローテーション、ファンネルシフト、ビットとバイトの置換といったビット操作命令を提供するための将来の標準拡張のプレースホルダである。
ビット操作命令は一部の亜アプリケーション領域、特に外部でパックされたデータ構造を扱う場合に非常に効果的だが、すべての領域で役立つわけではなく、必要なすべてのオペランドを提供するために複雑性や命令フォーマットが追加される可能性があるため基本 ISA から除外した。
我々は B 拡張が基本 30 ビット命令空間のブラウンフィールドエンコーディングになると予想している。
動的変換言語 "J" 標準拡張, Version 0.0
この章は動的に変換される言語をサポートするための将来の標準拡張のプレースホルダである。
Java や Javascript などの一般的な言語の多くは、通常、動的な変換によって実装されている。これらの言語は動的チェックとガーベッジコレクションに対する追加の ISA 支援をの恩恵を受けることができる。
トランザクショナルメモリー "T" 標準拡張, Version 0.0
この章はトランザクショナルメモリー操作を提供するための将来の標準拡張のプレースホルダである。
過去 20 年にわたる多くの研究と初期の商用実装にもかかわらず、複数のアドレスが関与するアトミックな操作をサポートする最良の方法については依然として多くの議論がある。我々の現在の考えは当初のトランザクショナルメモリーの提案に沿って、小さな容量制限のあるトランザクショナルメモリーバッファを含めることである。
パック化 SIMD 命令 "P" 標準拡張, Version 0.2
第 5 回 RISC-V ワークショップでの議論では、大規模な浮動小数点 SIMD 演算を V 拡張で標準化することが望まれ、浮動小数点レジスタに対するこのパック化 SIMD 提案を取り下げたいという要望が示された。しかし小規模な RISC-V 実装の整数レジスタで使用されるパック化 SIMD 固定小数点演算には関心があった。タスクグループは新しい P 拡張の定義に取り組んでいる。
ベクトル操作 "V" 標準拡張, Version 0.7
現在のワーキンググループのドラフトは https://github.com/riscv/riscv-v-spec でホストされている。
基本ベクトル拡張は 32 ビット命令エンコーディング空間内でのデータ並列実行の一般的なサポートを提供することを意図しており、その後のベクトル拡張では特定のドメイン向けにより豊富な機能をサポートする。
"Zam" Standard Extension for Misaligned Atomics, Version 0.1
"Ztso" Standard Extension for Total Store Ordering, Version 0.1
RV32/64G Instruction Set Listings
RISC-V Assembly Programmer's Handbook
Extending RISC-V
26.1 Extension Terminology
Standard versus Non-Standard Extension
Instruction Encoding Space and Prefixes
Greenfield versus Brownfield Extensions
Standard-Compatible Global Encodings
Guaranteed Non-Standard Encoding Space
26.2 RISC-V Extension Design Philosophy
26.3 Extensions within flexed-width 32bit instruction format
Available 30-bit instruction encoding spaces
Available 25-bit instruction encoding spaces
Available 22-bit instruction encoding spaces
Other spaces
26.4 Adding aligned 64-bit instruction extensions
26.5 Supporting VLIW encodings
Flexed-size instruction group
Encoded-Length Groups
Flexed-Size Instruction Bounds
End-of-Group bits in Prefix
ISA Extension Naming Conventions
27.1 Case Sensitive
27.2 Base Integer ISA
27.3 Instruction-Set Extension Names
27.4 Version Numbers
27.5 Underscores
27.6 Additional Standard Extension Names
27.7 Supervisor-level Instruction-Set Extensions
27.8 Hypervisor-level Instruction-Set Extensions
27.9 Machine-level Instruction-Set Extensions
27.10 Non-Standard Extension Names
27.11 Subset Naming Convention
History and Acknowledgements
28.1 "Why Develop a new ISA?" Rational from Berkeley Group
28.2 History from Revision 1.0 of ISA manual
28.3 History from Revision 2.0 of ISA manual
Acknowledgements
28.4 History from Revision 2.1
Acknowledgements
28.5 History from Revision 2.2
Acknowledgements
28.6 History from Revision 2.3
Acknowledgements
RVWMO Explanatory Material, Version 0.1
A.1 Why RVWMO?
A.2 Litnus Tests
A.3 Explaining the RVWMO Rules
A.3.1 Preserved Program Order and Global Memory Order
A.3.2 Load Value Axiom
A.3.3 Atomicity Axiom
A.3.4 Progress Axiom
A.3.5 Overlapping-Address Orderings (Rules 1-3)
A.3.6 Fences (Rule 4)
A.3.7 Explicit Synchronization (Rules 5-8)
A.3.8 Syntactic Dependencies (Rules 9-11)
A.3.9 Pipeline Dependencies (Rules 12-13)
A.4 Beyond Main Memory
A.4.1 Coherence and Cacheability
A.4.2 I/O Ordering
A.5 Code Porting and Mapping Guidelines
A.6 Implementation Guidelines
A.6.1 Possible Future Extensions
Known Issues
A.7.1 Mixed-size RSW
Formal Memory Model Specifications, Version 0.1
B.1 Formal Axiomatic Specification in Alloy
B.2 Formal Axiomatic Specification in Herd
B.3 An Operational Memory Model
B.3.1 Intra-instruction Pseudocode Execution
B.3.2 Instruction Instance State
B.3.3 Hart State
B.3.4 Shared Memory State
B.3.5 Transitions
B.3.6 Limitations
Bibliography
- RISC-V ELF psABI Specification. https://github.com/riscv/riscv-elf-psabi-doc/.
- IEEE standard for a 32-bit microprocessor. IEEE Std. 1754-1994, 1994.
- G. M. Amdahl, G. A. Blaauw, and Jr. F. P. Brooks. Architecture of the IBM System/360. IBM Journal of R. & D., 8(2), 1964.
- Werner Buchholz, editor. Planning a computer system: Project Stretch. McGraw-Hill Book Company, 1962.
- Kourosh Gharachorloo, Daniel Lenoski, James Laudon, Phillip Gibbons, Anoop Gupta, and John Hennessy. Memory consistency and event ordering in scalable shared-memory multiprocessors. In In Proceedings of the 17th Annual International Symposium on Computer Architecture, pages 15–26, 1990.
- Timothy H. Heil and James E. Smith. Selective dual path execution. Technical report, University of Wisconsin - Madison, November 1996.
- ANSI/IEEE Std 754-2008, IEEE standard for floating-point arithmetic, 2008.
- Manolis G.H. Katevenis, Robert W. Sherburne, Jr., David A. Patterson, and Carlo H. Séquin. The RISC II micro-architecture. In Proceedings VLSI 83 Conference, August 1983.
- Hyesoon Kim, Onur Mutlu, Jared Stark, and Yale N. Patt. Wish branches: Combining conditional branching and predication for adaptive predicated execution. In Proceedings of the 38th annual IEEE/ACM International Symposium on Microarchitecture, MICRO 38, pages 43–54, 2005.
- A. Klauser, T. Austin, D. Grunwald, and B. Calder. Dynamic hammock predication for non-predicated instruction set architectures. In Proceedings of the 1998 International Conference on Parallel Architectures and Compilation Techniques, PACT ’98, Washington, DC, USA, 1998.
- David D. Lee, Shing I. Kong, Mark D. Hill, George S. Taylor, David A. Hodges, Randy H. Katz, and David A. Patterson. A VLSI chip set for a multiprocessor workstation–Part I: An RISC microprocessor with coprocessor interface and support for symbolic processing. IEEE JSSC, 24(6):1688–1698, December 1989.
- OpenCores. OpenRISC 1000 architecture manual, architecture version 1.0, December 2012.
- Heidi Pan, Benjamin Hindman, and Krste Asanović. Lithe: Enabling efficient composition of parallel libraries. In Proceedings of the 1st USENIX Workshop on Hot Topics in Parallelism (HotPar ’09), Berkeley, CA, March 2009.
- Heidi Pan, Benjamin Hindman, and Krste Asanović. Composing parallel software efficiently with Lithe. In 31st Conference on Programming Language Design and Implementation, Toronto, Canada, June 2010.
- David A. Patterson and Carlo H. Séquin. RISC I: A reduced instruction set VLSI computer. In ISCA, pages 443–458, 1981.
- Ravi Rajwar and James R. Goodman. Speculative lock elision: enabling highly concurrent multithreaded execution. In Proceedings of the 34th annual ACM/IEEE International Symposium on Microarchitecture, MICRO 34, pages 294–305. IEEE Computer Society, 2001.
- Balaram Sinharoy, R. Kalla, W. J. Starke, H. Q. Le, R. Cargnoni, J. A. Van Norstrand, B. J. Ronchetti, J. Stuecheli, J. Leenstra, G. L. Guthrie, D. Q. Nguyen, B. Blaner, C. F. Marino, E. Retter, and P. Williams. IBM POWER7 multicore server processor. IBM Journal of Research and Development, 55(3):1–1, 2011.
- James E. Thornton. Parallel operation in the Control Data 6600. In Proceedings of the October 27-29, 1964, Fall Joint Computer Conference, Part II: Very High Speed Computer Systems, AFIPS ’64 (Fall, part II), pages 33–40, 1965.
- Marc Tremblay, Jeffrey Chan, Shailender Chaudhry, Andrew W. Conigliaro, and Shing Sheung Tse. The MAJC architecture: A synthesis of parallelism and scalability. IEEE Micro, 20(6):12– 25, 2000.
- J. Tseng and K. Asanovi´c. Energy-efficient register access. In Proc. of the 13th Symposium on Integrated Circuits and Systems Design, pages 377–384, Manaus, Brazil, September 2000.
- David Ungar, Ricki Blau, Peter Foley, Dain Samples, and David Patterson. Architecture of SOAR: Smalltalk on a RISC. In ISCA, pages 188–197, Ann Arbor, MI, 1984.
- Andrew Waterman. Improving Energy Efficiency and Reducing Code Size with RISC-V Compressed. Master’s thesis, University of California, Berkeley, 2011.
- Andrew Waterman. Design of the RISC-V Instruction Set Architecture. PhD thesis, University of California, Berkeley, 2016.
- Andrew Waterman, Yunsup Lee, David A. Patterson, and Krste Asanović. The RISC-V instruction set manual, Volume I: Base user-level ISA. Technical Report UCB/EECS-2011-62, EECS Department, University of California, Berkeley, May 2011.
- Andrew Waterman, Yunsup Lee, David A. Patterson, and Krste Asanović. The RISC-V instruction set manual, Volume I: Base user-level ISA version 2.0. Technical Report UCB/EECS2014-54, EECS Department, University of California, Berkeley, May 2014.
翻訳抄
RISC-V 非特権 ISA に関する 2019 年の仕様書。
- “The RISC-V Instruction Set Manual, Volume I: User-Level ISA, Document Version 20191213”, Editors Andrew Waterman and Krste Asanović, RISC-V Foundation, December 2019