

論文翻訳: Concise Server-Wide Causality Management for Eventually Consistent Data Stores
Carlos Baquero, and Victor Fonte
HASLab, INESC Tec and Universidade do Minho
Portugal, Braga
{tome,psa,cbm,vff}@di.uminho.pt
 概要
概要
大規模な分散データストアはスケーリングとネットワーク分断時の高可用性を維持するために楽観的レプリケーションに依存している。調整なしでデータを管理することは同時データ更新が可能な結果整合性データストアを実現する。このようなシステムはしばしば (Merkle Tree のような) アンチエントロピー機構を使用してノード間のデータバージョンの乖離を検出し修復している。しかしながら、現実には大量のデータに対してハッシュに基づいたデータ構造は高コストであり、また誤った競合も多く発生する。
結果整合性のもう一つの局面は書き込みの競合を検出することである。論理クロックはしばしばデータの因果関係 (causality) を追跡するために使われ、同じキー上で因果関係のある並行した書き込みを検出するために必要とされる。しかし、キーごとに無視できないメタデータのオーバーヘッドがあり、これはノードの離脱率 (churn rate; クラッシュストップのように離脱して二度と復帰しないノードの割合) に比例して時間とともに増加する。もう一つの課題は因果関係を遵守しながらキーを削除することである: 値は削除できたとしてもメタデータは調整なしには永久に削除することができない。
我々は結果整合性データストアに対する新しい因果管理フレームワークを導入する。これはノードの論理クロック (Bitmapped Version Vectors) と新しいキーの論理クロック (Dotted Causal Container) により複数の面で利点を提供する: 1) 効率的で軽量な新しいアンチエントロピー機構; 2) キーごとの因果関係メタデータサイズの大幅な削減; 3) 恒久的なメタデータを持たない正確なキー削除。
Keywords: Distributed System, Key-Value Store, Eventual Consistency, Causality, Logical Clocks, Anti-Entropy
Table of Contents
- 概要
- 1 導入
- 2 アーキテクチャ概要とシステムモデル
- 3 因果管理フレームワーク
- 4 サーバサイド分散アルゴリズム
- 5 評価
- 6 関連研究
- Acknowledgements
- References
- 翻訳抄
1 導入
最近の分散データストアでは地理的複製環境での高可用性と低遅延が重視されている [2, 9, 7]。そのようなシステムの特性は強い整合性 [3] とは相反したもので異なるノード間で同時に書き込むことができる。これは全体の書き込み順序をグローバルに調整する必要性を回避するがデータの乖離を発生させる。並行する書き込みによって生成された同じキーに対する競合したバージョンに対処するために、(例えば壁掛け時計のタイムスタンプに従うような) "最後の" バージョンのみを保持し他のバージョンを喪失する last-writer-wins ルール [5] を使用するか、あるいは同時書き込みを検出するために特定のキーに対するすべての書き込みの部分順序を追跡する論理クロック [10] を使用して各キーの因果関係の履歴を適切に追跡することができる。
Dynamo で使用されている論理クロック Version Vecotors [13] は因果関係の履歴をコンパクトに表現できる確立された技術である [14]。しかしながら Version Vector は同じノードで複数のユーザが同時に更新するようなケースではユーザごとに一つのエントリを必要とするためうまくスケールしない。この問題を解決するために、Dynamo にインスパイアされた商用データベースである Riak は Dotted Version Vectors [1] と呼ばれる新しい機構を使って、ノード間の並行性に加えて同じノード上での並行バージョンを処理している。これらの開発によりスケーラビリティの問題は解決したが、多数の小さなデータ項目の更新を追跡するケースでは論理クロックのメタデータは依然として重大な負荷となる。
この論文では、それぞれのキーに対して将来のバージョンで上書きされるまで複数並行バージョン (multiple concurrent version) が維持され、任意に更新が取り消されることがないの一般的なケースを取り上げる。我々はキーごとの因果関係を追跡するために必要なメタデータのサイズを明示的に改善する解決策を追加するとともに、ノード同期に対してアンチエントロピー機構にどのような利点があるかも示し、正確な分散削除のサポートを追加する。投稿の簡単なまとめ:
因果関係メタデータの高い節約効果. 我々は Concise Version Vectors [11] と Dotted Version Vectors [1] に基づいて、ノードごとに新しい論理クロックを用いてどのキーバージョンが現在ローカルに保存されているか、あるいは過去に保存されていたかを要約する新しい因果管理フレームワークを提案する。ノードクロックでは、ノードクロックがすでに取得している情報を因数分解することでキーのメタデータのストレージフットプリントを大幅に削減することができる。フットプリントが小さくなることでメタデータのコスト全体が last-write-wins ソリューションに近づき、整数のような小さな値を保存するキーのメタデータ対ペイロード比が改善される。
分散キー削除. 結果整合性システムにおいて、従来の Version Vector に基づく機構を使用して因果関係を尊重しながらのキーの削除は自明ではない。追加のメタデータも含めてキーを完全に削除する場合、ある複製ノードが (メッセージの紛失やネットワーク分断によって) 削除操作を受信せずに古いバージョンがまだ残っていれば (オフラインで保存されているバックアップ複製の適用も同様)、そのキーは再び出現する。さらに悪いことに、もしキーの削除と再出現が発生すると、高い Version Vector を持つ旧バージョンによって暗黙のうちに上書きされる危険性がある (新しい Version Vector はゼロから始まるため)。この問題は、ノードの論理クロックを使用してキーの論理クロックに対して単調に増加するカウンターを生成することで回避することができる。
アンチエントロピー. 結果整合性データストアはアンチエントロピー機構によってノード間のキースペースをまたいだ乖離バージョンを修復する。アンチエントロピー機構は並行バージョンを検出し、新しいバージョンをすべての複製ノードに到達させることができる。Dynamo [2], Riak [7] や Cassandra [9] はアンチエントロピー機構に Markle-Tree [12] を使用している。これはハッシュツリーを頻繁に更新する必要があるため空間的にも時間的にも高コストな機構であり、ハッシュツリーのサイズと false positive のリスクでトレードオフが存在する。我々はビットマップと二値論理を使って非常にコンパクトで効率的なノードクロックを実装することで Markle ツリーを使用しなくてもアンチエントロピーをサポートできることを示す。
2 アーキテクチャ概要とシステムモデル
(たとえば数百台程度の) 物理ノードにマッピングされた多数の (たとえば数百万程度の) 仮想ノード (または単にノード) として構成されている Dynamo-like [2] な分散 KVS について考える。それぞれのキーは、例えば consistent hashing [6] のように、そのキーに対して決定論的に決まる複製ノード (replica node) と呼ばれるサブセットに複製される。共通の鍵を複製するノードはピア (peer) と呼ばれる。我々はクライアントとサーバノードの間に相性を仮定しない。また、ノードどうしは定期的にアンチエントロピープロトコルを実行してデータの同期と修復を行っているものとする。
2.1 クライアント API
システム API は高レベルでは 3 つの操作を公開している: 1) \({\sf read}:{\sf key} \to \mathcal{P}({\sf value}) \times {\sf context}\); 2) \({\sf write}:{\sf key} \times {\sf context} \times {\sf value} \to ()\); 3) \({\sf delete}:{\sf key} \times {\sf context} \to ()\).
この API はクライアントがデータの因果関係を保つために使用する read-modify-write パターンが動機となっている。つまり、まずクライアントはキーを読み込み、値を更新してからキーを書き戻す。複数のクライアントが同じキーを並行して更新できるため、読み込み操作はそれを解決するための複数の並行値をクライアントに返すことができる。読み取りのコンテキストを後続の書き込みに渡すことで、すべての書き込み要求はクライアントによって更新された値のコンテキストを提供する。このコンテキストは、クライアントがすでに参照したキーのバージョンを削除するためにシステムによって使用される。存在しないキーへの書き込みは空のコンテキストを持つ。削除操作は通常の書き込みと全く同じように動作するが、値は空になる。
2.2 サーバ側ワークフロー
データストアは、クライアント要求に応じるときやアンチエントロピー同期の定期実行のときにノード間でいくつかのプロトコルを使用する。
Serving Reads. 読み取り要求を受け取った任意のノードは、ローカルキーバージョンに対応する複製ノードに問い合わせることで読み取り要求を調整することができる。十分な応答があると、コーディネーターは古くなったバージョンを破棄し、因果関係のある最も最新の (並行) バージョンをクライアントに送信する。またその値の因果関係のコンテキストも送信する。コーディネーターは古いデータを持っている複製ノードに結果を送り返すこともできる (Read Repair と呼ばれる過程)。
Serving Writes/Deletes. 書き込んでいるキーに対する複製ノードのみが書き込み要求を調整でき、複製ノードでないノードは要求を複製ノードに転送する。コーディネーターノードは (1) この書き込みに対して論理クロックの新しい識別子を生成し; (2) 書き込みのコンテキストに関する古いバージョンを破棄し; (3) 新しい値を、ローカルに残っている並行バージョンのセットに追加し; (4) その結果を他の複製ノードに伝搬し; (5) クライアントに応答する前に、設定可能な数の ack を待機する。削除は全く同じだが新しい値が存在しないのでステップ 3 を省略する。
Anti-Entropy. メッセージを喪失したり、複製ノードがしばらくダウンしたり、帯域幅を節約するために書き込みがすべての複製ノードに送信されなかったりといったようなことから、書き込み時の複製を補完し整合性を収束させるためにノードは定期的にアンチエントロピープロトコルを実行する。このプロトコルはどのノードで何のバージョンが失われているか (あるいは削除しなければならないか)を把握し、それを適切に伝搬させることを目的としている。
2.3 システムモデル
すべてのやり取りは非同期メッセージパッシングによって行われる。グローバルクロックは存在せず、メッセージが到達するまでの時間や相対的な処理速度に制限はない。ノードは永続的なストレージにアクセスでき、クラッシュすることはあるものの最終的にはクラッシュ時点の永続的なストレージ内容で回復する。永続的な状態は状態遷移のたびにアトミックに書き込まれる。ノード \(i\) からノード \(j\) へのメッセージ送信はノード \(i\) の状態遷移時に \({\sf send}_{i,j}\) と表され、遷移後、つまり次の状態が永続的に書き込まれた後に行われるようにスケジュールされる。このような送信はノード \(j\) の将来のある時点で \({\sf receive}_{i,j}\) アクションを引き起こすだろう。それぞれのノードはグローバルに一意な識別子を持っている。
2.4 表記法
我々は主に集合と写像に関する標準的な表記を使用している。写像は \((k,v)\) ペアの集合であり、それぞれの \(k\) は単一の \(v\) に関連付けられている。写像 \(m\) が与えられたとき、\(m(k)\) はキー \(k\) に関連付けられた値を返し、\(m\{k \mapsto v\}\) は \(k\) 以外の射を等しく保ち \(k\) の射を \(v\) となるように \(m\) を更新する。写像 \(m\) の定義域と範囲はそれぞれ \({\sf dom}(m)\) と \({\sf ran}(m)\) で表す。\({\sf fst}(t)\) と \({\sf snd}(t)\) はそれぞれタプル \(t\) の第一成分と第二成分を表す。\(\{f(x) \mid x \in S\}\) または \(\{x \in S \mid {\it Pred}(x)\}\) 形式の集合内包を使用する。定義域減算に対して ⩤ を使用する。\(S ⩤ M\) は \(M\) から \(k \in S\) となるようなすべてのペア \((k,v)\) を削除して得られる写像である。\(\mathbb{K}\) をストア内で取りうるキーの集合、\(\mathbb{V}\) を値の集合、そして \(\mathbb{I}\) をノード識別子の集合とする。
3 因果管理フレームワーク
我々の因果管理フレームワークには2つの論理クロックがある。一つはノードごとに使用するもので、もう一つは各複製ノードのキーごとに使用する。
- ノード論理クロック
-
各ノード \(i\) は、ノード \(i\) が複製するキーに対する既知の全ローカル書き込みを表す論理クロックを持つ。これには他の複製ノードによって調整されたキーへの書き込みも含まれており、複製やアンチエントロピー機構を経由してノード \(i\) に到着する。
- キー論理クロック
-
複製ノードが保存している各キーには対応する論理クロックがある。この論理クロックは、この複製ノードでこのキーが (直接または経由して) 知ったすべての現在または過去のバージョンを表している。さらに我々は、このキー論理クロックに現在の並行値とその個々の因果関係の情報を添付している。
このデュアル論理クロックフレームワークは Concise Version Vector (CVV) [11] の研究を参考にしているが、CVV が分散ファイルシステム (DFS) を対象にしているのに対して我々は分散 Key-Value ストア (KVS) を対象としている。この違いにより CVV を単純に再利用できないいくつかの課題がある:
- 並行性の唯一の源がそれぞれのノード自身である DFS とは対照的に、KVS では外部のクライアントが並行してリクエストを行う。これは、単一のノードのみが関与している場合であっても同じキーに対する複数の並行バージョンが生成されることを意味している。そのため KVS のキー論理クロックは因果関係を維持した上で複数の並行値を管理する必要がある。
- 複製ノードの集合にキーセットを完全に複製することを考慮する DFS とは対照的に、KVS では 2 つのピアノードが 2 つの同一ではないキーセットの複製ノードになることができる。例えばキー \(k_1\) は複製ノード \(\{a,b\}\)、キー \(k_2\) は \(\{b,c\}\)、キー \(k_3\) は \(\{c,a\}\) となるとき、\(a\), \(b\), \(c\) はピア (共通のキーの複製ノード) だが全く同じキーセットを複製しているわけではない。結果として、ピアにまだ複製されていない書き込みの因果関係履歴のギャップに加えて、このノードが複製ノードではないキーに対する書き込みについて他にも多くのノード論理クロックのギャップを持つことになる。このため、ノード論理クロックをコンパクトに表現する必要性が高まっている。
3.1 ノード論理クロック
ノード論理クロックは、そのノードが複製ノードとなっているキーへの既知の書き込みのセットを表している。各書き込みは一つのノードによってのみ調整され、後に別の複製ノードに複製される。従ってノード \(a\) によって調整された \(n\) 番目の書き込みはペア \((a,n)\) と表すことができる。以後、このペアをドット (dot) と呼ぶ。基本的に、ドットは分散システム全体での各書き込みに対するグローバルに一意な識別子である。
このためノード論理クロックは単純にドットのセットとなる。しかし、このセットは束縛されておらず書き込みによって線形に成長する。より簡潔な実装では各ピアノード ID に対する最初の書き込みから連続したドットのセットを表す Version Vector を持ち、残りのドットは別のセットして保持する。例えば、ノード論理クロック \(\{(a,1)\), \((a,2)\), \((a,3)\), \((a,5)\), \((a,6)\), \((b,1)\), \((b,2)\}\) は \(([(a,3)\), \((b,2)]\), \(\{(a,5)\), \((a,6)\})\) というペアによって表すことができる。ここで最初の要素は Version Vector であり、2 つ目は残りのドットのセットである。さらに、最大連続ドットと非連続ドット集合のペアとピア ID を直接マップすることができる。この例では \(\{a \mapsto (3, \{5,6\})\), \(b \mapsto (2, \{\})\}\) というマップがある。
ノード論理クロックを効率的かつコンパクトに表現するためにはドット間のギャップをできるだけ少なくする必要がある。例えば、ローカルノードからのノード論理クロックのドットは常にギャップがなく連続している。これは、ローカルノード ID へのマップに関しては最大値のドットカウンターのみが必要であることを意味しており、一方で非連続ドットは空である。
[11] の著者は外因性集合 (extrinsic set) の概念を定義しているが、我々はそれを改良して以下のように一般化している (イベントは特定のキーに行われた書き込みとみなすことができることに注意)。
定義 1 (外因性). あるイベント集合 \(E_1\) は、別のイベント集合 \(E_2\) のイベントにも関与するキーを含む \(E_1\) イベントの部分集合が \(E_2\) と等しい場合、\(E_2\) に外因すると言う。
この定義は、結果として得られるドットの集合が元の集合に外因するものであれば、ノード論理クロックを伸長してコンパクトにしやすくなることを意味している。言い換えると、ローカルノードが複製ノードを担当していないキーのドットに対応するノード論理クロックのギャップを埋めることができる。
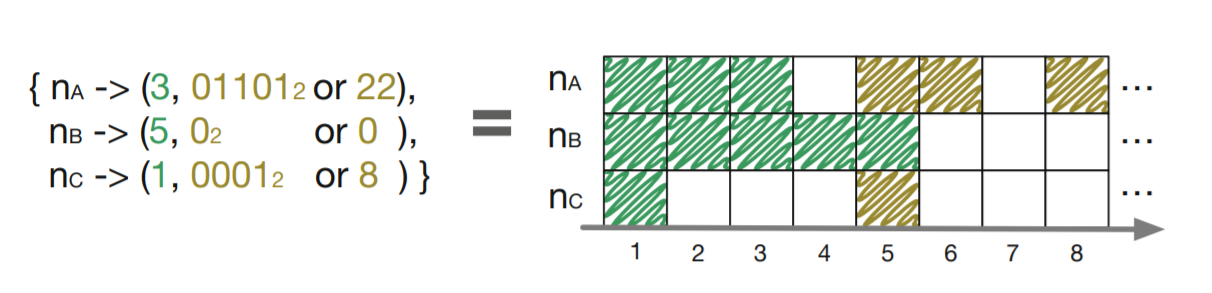
この点を考慮して、我々が実際に行っているノード論理クロックの実装は Bitmapped Version Vector (BVV) と呼ばれるもので、従来のように非連続のドットを整数の集合で表現する代わりにビットマップを用いており、ペアの最初の要素のドットの直後のドットが最下位ビットを表している。0 はそのドットが欠落していることを意味し、1 はその逆である。BVV の実際の構造はビットマップに対応する整数を使用してドットの大きな集合や疎な集合を効率的に表現している。Fig 1 は簡単な BVV の例とその視覚的表現を示している。
ノード論理クロックに関する関数. ここではノード論理クロックを含む、この論文の残りの部分で必要となる関数について簡単に説明する (スペース制限のため実際の定義は省略する)。
- \({\sf norm}({\it base},{\it bitmap})\) はペア \(({\it base},{\it bitmap})\) を正規化する。言い換えると、非連続の集合のドットがベースと連続していればそれらを除去し、除去した数だけベースをインクリメントする。例えば: \({\sf norm}(2,3) = (4,0)\);
- \({\sf values}({\it base},{\it bitmap})\) はペア \(({\it base},{\it bitmap})\) で表されるすべてのドットのカウンター値を返す。例えば: \({\sf values}(2,2) = \{1,2,4\}\);
- \({\sf add}(({\it base},{\it bitmap}),m)\) はペア \(({\it base},{\it bitmap})\) にカウンター \(m\) のドットを追加する。例えば: \({\sf add}((2,2),3) = (4,0)\);
- \({\sf base}({\it clock})\) は \({\it clock}\) から連続したドットのみを持つような、ビットマップがゼロに設定されている新しいノード論理クロックを返す。例えば: \({\sf base}(\{a \mapsto (2,2),\ldots\}) = \{a \mapsto (2,0),\ldots\}\);
- \({\sf event}(c,i)\) はノード \(i\) の論理クロック \({\it clock}\) とそのノード ID \(i\) を取り、このノード \(i\) に新たに書き込まれた場合のカウンターと、もとの論理クロック \(c\) に新たなカウンターをドットして付加したペアを返す。例えば: \({\sf event}(\{a \mapsto (4,0),\ldots\},a) = (5,\{a \mapsto (5,0),\ldots\})\);
3.2 キー論理クロック
クライアントの数が事実上制限されていないことから、構築している種類の KVS ではクライアント ID を使用したキー論理クロックは現実的ではない。またノード ID を用いた単純な Version Vector を使用しても、1 つのノードが 1 つのキーに対して複数の並行バージョンを保存している場合には因果関係を正確に捉えることができない [1]。一つの解決策は (並行バージョン間で共有されている) 因果関係情報のすべてを記述した Version Vector を持ち、さらに各並行バージョンにそれぞれのドットを関連付けることである。これにより、各並行バージョンの因果関係を独立して推論することができ、誤った並行性を削減することができる。このアプローチの実装は Dotted Version Vector Sets (DVVS) [1] に見られる。
しかし、DVVS のような論理クロックはキーごとの情報に基づいている。つまり、書き込みをタグ付けするために生成された各ドットは、書き込まれるキーのコンテキスト内でのみ一意となる。しかし我々のフレームワークでは、書き込みのために生成された各ドットはシステム全体で一意となる。我々のフレームワークの主なアイディアの一つは、このグローバルに一意なドットを格納するノード論理クロックを持っていることを可能な限り利用してキー論理クロックから冗長な因果関係の情報を取り除くことである。
Version Vector や DVVS はキーごとにカウンターを使用するためコンパクトな表現が可能な連続したドット範囲を持っているが、グローバルに一意なドットを使用することは DCC とその操作を定義する上でいくつかの課題がある。キーごとに 1 つのバージョンしか持たなかったとしても、カウンター 1 から始まるドットの連続した集合を持つとは限らない。そのためキー論理クロックをコンパクトかつ正確に実装することが課題となる。また、ノードごとに 1 つの BVV を使用することはできるが、キーごとに使用することは現実的ではなく、ノードと同じ大きさの低密度ビットマップが多くできてしまうことから、BVV のような構造を使用することもできない。ノードごとに何百万ものキーが存在する可能性があるため、キーの論理クロックサイズは非常に小さくなければならない。
解決策は、外因集合の概念を使用して、クロックのギャップを他のキーに関連するドットで満たすことで、誤った因果関係情報を導入しないようにすることである。ここで重要なことは、元の集合のすべてのギャップが他のキーに属するドットによるものであるため、すべてのキー論理クロックはドットの連続した集合にインフレーションさせることができるということである1。
Dotted Causal Container. 我々のキー論理クロック実装は Dotted Causal Container (DCC) と呼ばれている。DCC は DVVS の理念を引き継いだコンテナ型データ構造で、与えられたキーの並行バージョンと因果関係の情報を格納し、ノード論理クロック (例えば BVV) と一緒に使用する。外因性のドット集合はバージョンベクトルとして表現され、並行バージョンはグループ化されてそれぞれのドットでタグ付けされる。
定義 2 . Dotted Causal Container (略して DCC) は \((\mathbb{I} \times \mathbb{N} \hookrightarrow \mathbb{V}) \times (\mathbb{I} \hookrightarrow \mathbb{N})\) のペアである。ここで第一成分はドット (識別子-整数ペア) から値へのマップでバージョンの集合を表し、第二成分は第一成分のバージョン集合の集合的因果関係過去 (the collective causal past) に外因する集合を表す Version Vector ([複製ノード]識別子から整数へのマップ) を表している。
キー論理クロック上の関数. Fig 2 はこの論文の残りの部分で必要となる (ノード論理クロック (BVV) も含む) キー論理クロック (DCC) 上の関数定義を表している。関数 \({\sf values}\) は DCC の並列バージョンの値を返す。\({\sf add}(c,(d,v))\) は、BVV 上で定義されている \({\sf add}\) 関数を持つ標準の \({\sf fold}\) 高階関数を使用して、DCC \((d,v)\) 内のすべてのドットを BVV \(c\) に追加する。\({\sf sync}\) 関数は 2 つの DCC をマージする。一方の DCC の因果関係履歴によって古くなったもう一方のバージョンは破棄されるが、Version Vector は pointwise maximum を実行する (最大値を得る) ことでマージされる。\({\sf context}\) 関数は単純に DCC の Version Vector を返す。これはその DCC の因果関係履歴全体を表している (並行バージョンのドットも Vection Vector の要素に含まれていることに注意)。\({\sf discard}((d,v),c)\) 関数は DCC \((d,v)\) の中から VV \(c\) によって古くなったバージョンを破棄し \(c\) を \(v\) にマージする。\({\sf add}((d,v),(i,n),x)\) 関数はドット \((i,n)\) から値 \(x\) へのマッピングをバージョン \(d\) に追加し、VV \(v\) の \(i\) 成分を \(n\) に進める。
\[ \begin{eqnarray*} {\sf values}((d,v)) & = & \{x \mid (\_,x) \in d\} \\ {\sf context}((d,v)) & = & v \\ {\sf add}(c, d,v)) & = & {\sf fold}({\sf add},c,{\sf dom}(d)) \\ {\sf sync}((d_1,v_1),(d_2,v_2)) & = & ((d_1 \cap d_2) \cup \{((i,n),x) \in d_1 \cup d_2 \mid n \gt \min(v_1(i),v_2(i))\}, {\sf join}(v_1,v_2)) \\ {\sf discard}((d,v),v') & = & (\{((i,n),x) \in d |mid n \gt v'(i)\}, {\sf join}(v,v')) \\ {\sf add}((d,v),(i,n),x) & = & (d\{(i,n) \mapsto x\}, v\{i \mapsto n\}) \\ {\sf strip}((d,v),c) & = & (d, \{(i,n) \in v \mid n \gt {\sf fst}(c(i))\}) \\ {\sf fill}((d,v),c) & = & (d, \{i \mapsto \max(v(i), {\sf fst}(c(i)) \mid i \in {\sf dom}(c)\}) \end{eqnarray*} \]
最後に、\({\sf strip}\) と \({\sf fill}\) 関数は我々のフレームワークに不可欠である。\({\sf strip}((d,v),c)\) 関数は DCC 中の VV \(v\) から、対応する BVV \(c\) の基本成分によってカバーされるすべてのエントリを破棄し、より大きなシーケンス番号を持つエントリのみが保持されるようにする。これは、ノード論理クロックにすでに存在する因果関係情報を取り除いた後の DCC のみを保存するという考えに基づく。\({\sf fill}\) 関数は \({\sf strip}\) された DCC にドットを戻してから関数を実行する。
BVV の基本成分は、ある DCC の 2 回連続した \({\sf strip} \mapsto {\sf fill}\) 操作の間に増加している可能性があるが、DCC に追加される余分な (連続した) ドットは必然的に他のキーである (そうでなければ DCC はもっと速く埋められ更新されていたはずである)。従って埋めた DCC は、DCC 内の現在の並行バージョンの因果関係履歴に対する外因的な集合を依然として表している。また、ノードがキーを交換する場合、単一の DCC は送信前に埋められているが、複数の DCC を送信する場合は、送信者から BVV (場合によっては null ビットマップも含む) とともに、よりコンパクトに除去された形式で送信され、後で受信側で埋められてから使用される。このような因果関係除去によって大規模なキー集合を転送する際にストレージが節約できることに加えてネットワークトラフィックを大幅に削減することができる。
- 1ギャップは常に他のキーからのものである。なぜなら、ドット \((i,n)\) を生成するあるキー \(k\) への書き込みを調整しているノード \(i\) は、ドット \((i,m)\) を持つ \(k\) の他のすべてのバージョンをローカルに調整していることが保証されるからである。ここで \(m \lt n\) だが、これはローカル書き込みが逐次処理され新しいドットが単調に増加するカウンターを持つためである。
4 サーバサイド分散アルゴリズム
ここではセクション 2.2 で説明したサーバサイドのワークフローに対応する分散アルゴリズムを定義する。我々はノードの状態、更新 (書き込みと削除) の提供方法、読み込みの提供方法、およびアンチエントロピーの実行方法を定義する。Algorithm 3 では、メッセージ構造上のパターンマッチによって定義された (基本的には \({\sf receive}\) の) アクションによる状態遷移に関連する節 (on -) を用いて定義している。またアンチエントロピーに対して、定期的に発生するアクションを特定するための \({\sf periodically}\) もある。余白の関係また副次的な問題であることから読み込みリペアについては扱わない。
すでに紹介した BVV と DCC に対する操作に加えて以下を利用している: \({\sf node}(k)\) はキー \(k\) に対する複製ノードを返す。\({\sf peers}(i)\) 関数はノード \(i\) のペアであるノード集合を返す。\({\sf random}(s)\) 関数は集合 \(s\) からランダムな要素を返す。
4.1 ノード状態
各ノードの状態には 5 つの構成要素がある。\(g_i\) はノード論理クロックである BVV。\(m_i\) はキーをそれぞれの論理クロック (DCC) にマッピングする適切なデータストア。\(l_i\) はドットカウンターからキーへのマップで、どのキーがローカルに書き込まれたかを保持するログとしての役割を果たす。\(v_i\) は他のピアがローカルに生成されたドットを観測したかを追跡するための Version Vector。我々はピアによって観測されたドットの連続集合のみを考慮することから、すべてのピアによって観測された古いセグメントを容易に \(l_i\) から削除するために BVV ではなく VV を使用する。\(r_i\) は、読み取り要求でのクライアント返信前に、他のノードからの着信応答を追跡するための補助的なマップである。\(r_i\) は揮発性の状態で保持されている唯一の構成要素であり、ノードの故障によって失われる可能性がある。それ以外の 4 つの構成要素はすべて耐久性のある状態で保持されている (従って状態遷移のたびに原子的に書き込まれたように振る舞わなければならない)。
| 1. | \( {\bf durable \ state}: \) | |
| 2. | \( \hspace{12pt}g_i: {\rm BVV} \) | // ノード論理クロック; 初期状態 \(g_i = \{j \mapsto (0,0) \mid j \in {\sf peers}(i)\}\) |
| 3. | \( \hspace{12pt}m_i: \mathbb{K} \hookrightarrow {\rm DCC} \) | // キーからその論理クロックへのマッピング; 初期状態 \(m_i=\{\}\) |
| 4. | \( \hspace{12pt}l_i: \mathbb{N} \hookrightarrow \mathbb{K} \) | // ローカルで更新されたキーのログ; 初期状態 \(l_i=\{\}\) |
| 5. | \( \hspace{12pt}v_i: {\rm VV} \) | // 他のピアの知識; 初期状態 \(v_i=\{j \mapsto 0 \mid j \in {\sf peers}(i)\}\) |
| 6. | \( {\bf volatile \ state}: \) | |
| 7. | \( \hspace{12pt}r_i: (\mathbb{I} \times \mathbb{K}) \hookrightarrow ({\rm DCC} \times \mathbb{N}) \) | // 要求マップ; 初期状態 \(r_i=\{\}\) |
| 8. | \( {\bf on} \ {\sf receive}_{j,i}({\sf write}, k: \mathbb{K}, v:\mathbb{V}, c:{\rm VV}): \) | |
| 9. | \( \hspace{12pt}{\bf if} \ i \not\in {\sf nodes}(k) \ {\bf then} \) | |
| 10. | \( \hspace{24pt}u = {\sf random}({\sf nodes}(k)) \) | // \(k\) のランダムな複製ノードを選択 |
| 11. | \( \hspace{24pt}{\sf send}_{i,j}({\sf write},k,v,c) \) | // ノード \(u\) に要求を転送 |
| 12. | \( \hspace{12pt}{\bf else} \) | |
| 13. | \( \hspace{24pt}d = {\sf discard}({\sf fill}(m_i(k),g_i),c) \) | // \(k\) の DCC 内の古くなったバージョンを破棄 |
| 14. | \( \hspace{24pt}(n,g'_i) = {\sf event}(g_i,i) \) | // ローカル BVV から新しい最大のドットを取得し加算 |
| 15. | \( \hspace{24pt}d' = {\sf if} \ v \ne {\sf nil} \ {\bf then} \ {\sf add}(d,(i,n),v) \ {\bf else} \ d \) | // 書き込みならバージョンを加算 |
| 16. | \( \hspace{24pt}m'_i = m_i \{k \mapsto {\sf strip}(d',g'_i)\} \) | // \(k\) に対する DCC エントリを更新 |
| 17. | \( \hspace{24pt}l'_i = l_i \{ n \mapsto k \} \) | // ログにキーを追加 |
| 18. | \( \hspace{24pt}{\bf for} \ u \in {\sf nodes}(k) \ \backslash \ \{i\} \ {\bf do} \) | |
| 19. | \( \hspace{36pt}{\sf send}_{i,u}({\sf replicate},k,d') \) | // 他の複製ノードへ新しい DCC を複製 |
| 20. | \( {\bf on} \ {\sf receive}_{j,i}({\sf replicate},K:\mathbb{K},d:{\rm DCC}): \) | |
| 21. | \( \hspace{12pt}g'_i = {\sf add}(g_i,d) \) | // DCC コンテキストを無視して、バージョンドットをノードクロック \(g_i\) に追加 |
| 22. | \( \hspace{12pt}m'_i = m_i \{k \mapsto {\sf strip}({\sf sync}(d,{\sf fill}(m_i(k),g_i)),g'_i)\} \) | // ローカルと同期して取り除く |
| 23. | \( {\bf on} \ {\sf receive}_{j,i}({\sf read},K:\mathbb{K}, d:{\rm DCC}): \) | |
| 24. | \( \hspace{12pt}r'_i = r_i\{(j,k) \mapsto (\{\},n)\} \) | // 読み込み要求のメタデータを初期化 |
| 25. | \( \hspace{12pt}{\bf for} \ u \in {\sf nodes}(k) \ {\bf do} \) | |
| 26. | \( \hspace{24pt}{\sf send}_{i,u}({\sf read\_request},j,k) \) | // 複製ノードから \(k\) 個のバージョンを要求 |
| 27. | \( {\bf on} \ {\sf receive}_{j,i}({\sf read\_request},u:\mathbb{I}, k:\mathbb{K}): \) | |
| 28. | \( \hspace{12pt}{\sf send}_{i,j}({\sf read\_response},u,k,{\sf fill}(m_i(k),g_i)) \) | // \(k\) のローカルバージョンを返す |
| 29. | \( {\bf on} \ {\sf receive}_{j,i}({\sf read\_response},u:\mathbb{I},k:\mathbb{K},d:{\rm DCC}): \) | |
| 30. | \( \hspace{12pt}{\sf if} \ (u,k) \in {\sf dom}(r_i) \ {\bf then} \) | |
| 31. | \( \hspace{24pt}(d',n) = r_i((u,k)) \) | // \(d'\) は現在のマージされた DCC |
| 32. | \( \hspace{24pt}d'' = {\sf sync}(d,d') \) | // 受信したものを現在の DCC と同期 |
| 33. | \( \hspace{24pt}{\bf if} \ n=1 \ {\bf then} \) | |
| 34. | \( \hspace{36pt}r'_i = \{(u,k)\} ⩤ r_i \) | // 要求マップから \((u,k)\) エントリを削除 |
| 35. | \( \hspace{36pt}{\sf send}_{i,j}(k,{\sf values}(d''),{\sf context}(d'')) \) | // クライアント \(u\) に応答 |
| 36. | \( \hspace{24pt}{\bf else} \) | |
| 37. | \( \hspace{36pt}r'_i = r_i\{(u,k) \mapsto (d'',n-1)\} \) | // 要求マップを更新 |
| 38. | \( {\bf periodically}: \) | |
| 39. | \( \hspace{12pt}j = {\sf random}({\sf peers}(i)) \) | |
| 40. | \( \hspace{12pt}{\sf send}_{i,j}({\sf sync\_request},g_i(j)) \) | |
| 41. | \( {\bf on} \ {\sf receive}_{j,i}({\sf sync\_request},(n,b):(\mathbb{N}\times\mathbb{N})): \) | |
| 42. | \( \hspace{12pt}e = {\sf values}(g_i(i)) \ \backslash {\sf values}((n,b)) \) | // \(j\) から欠落しているドットを \(i\) から取得 |
| 43. | \( \hspace{12pt}K = \{l_i(m) \mid m \in e \land j \in {\sf nodes}(l_i(m))\} \) | // \(j\) が複製ではないキーを削除 |
| 44. | \( \hspace{12pt}s = \{k \mapsto {\sf strip}(m_i(k),g_i) \mid k \in K\} \) | // DCC を取得しローカル BVV で取り除く |
| 45. | \( \hspace{12pt}{\sf send}_{i,j}({\sf sync\_response},{\sf base}(g_i),s) \) | |
| 46. | \( \hspace{12pt}v'_i = v_i\{ j \mapsto n\} \) | // \(u_i\) を \(i\) 上の \(j\) の情報で更新 |
| 47. | \( \hspace{12pt}M = \{m \in {\sf dom}(l_i) \mid m \lt \min({\sf ran}(v'_i)\} \) | // 全ピアから観測されたドット \(i\) を取得 |
| 48. | \( \hspace{12pt}l'_i = M ⩤ l_i \) | // ログからこれらのドットを削除 |
| 49. | \( \hspace{12pt}m'i = m_i\{k \mapsto {\sf strip}(m_i(k),g_i) \mid m \in M, k \in l_i(m)\} \) | // ロクから削除されたキーを取り除く |
| 50. | \( {\bf on} \ {\sf receive}_{j,i}({\sf sync\_response},g:{\rm BVV},s:\mathbb{K} \hookrightarrow {\rm DCC}): \) | |
| 51. | \( \hspace{12pt}g'_i = g_i\{j \mapsto g(j)\} \) | // \(j\) のエントリでノード論理クロックを更新 |
| 52. | \( \hspace{12pt}m'_i = m_i\{k \mapsto {\sf strip}({\sf sync}({\sf fill}(m_i(k),g_i),{\sf fill}(d,g)),g'_i) \mid (k,d) \in s\} \) | |
4.2 更新
我々は書き込みと削除の両方を統一されたフレームワークで統合することができた。\({\sf delete}(k,c)\) 操作はクライアントサイドでは \({\sf write}(k,{\sf nil},c)\) 操作と解釈され、値として特別な \({\sf nil}\) を渡している。
クライアントから \(({\sf write},k,v,c)\) メッセージ (アルゴリズムの最初の "on" 節) としてノード \(i\) に到着した更新を提供しているとき、\(i\) はキー \(k\) の複製ノードであるかそうでないかのいずれかである。もしそうでなければ \(i\) は \(k\) のランダムな複製ノードに要求を転送する。そうであれば (1) コンテキスト \(c\) に従って古くなったバージョンを破棄し、(2) 新しいドットを作成してそのカウンターをノード論理クロックに追加し、(3) 操作が削除でなければ (\(v \ne {\sf nil}\)) 新しいバージョンを作成して \(k\) の DCC に追加し、(4) 不要な因果関係情報を取り除いた後に新しい DCC を保存し、(5) ローカルに更新されたキーのログに \(k\) を追加し、(6) \(k\) の他の複製ノードに新しい DCC を含む複製メッセージを送信する。複製メッセージを受信したノードは DCC 内の並行バージョンの (Version Vector ではなく) ドットをノード論理クロックに追加し、ローカルキーの DCC と同期する。その結果は保存する前にストリップされる。
削除. 表記の都合上、\(k\) がマップにないときに \(m_i(k)\) を実行すると空の DCC \((\{\},\{\})\) をもたらす。またマップの更新 \(m\{k \mapsto (\{\},\{\})\}\) はキー \(k\) のエントリが削除される。これは、削除がどのようにして特定のキーに対するすべての内容をストレージから削除することになるかを説明している: (1) DCC 内に現在のバージョンが存在しない場合や、(2) 因果関係コンテキストがノード論理クロックより古くりストリップ後の DCC が空になった場合である。削除が最初に要求されたときにこれらの条件が満たされていない場合、キーには関連する因果関係のメタデータが残っているが、この削除がすべてのピアで知るところとなれば、アンチエントロピー機構がこのキーをキーログ \(l_i\) から削除し、DCC に残っている因果関係の履歴をストリップして、自動的かつ完全なキーとメタデータの削除が行われる2。
従来の論理クロックでは、ノードは削除されたキーのコンテキストを永久に保存するか、または削除されたキーが再び現れたり削除後に作成された新しいキー値を喪失するリスクを許容する必要があった。我々のノード論理クロックを用いるアルゴリズムではこの 2 つのケースを同時に解決する。削除されたあとに新しい書き込みを喪失することについては、更新は常にカウンターが増加する新しいドットを持つため、以前に削除された更新の過去とは因果関係がないとみなされる。古いノードや遅延メッセージを持つアンチエントロピーから再び削除が現れた場合、ノードは、鍵ごとの特定のメタデータを保存することなく、その削除のドットを自分の BVV で既に観測したかどうかを確認することができる。
- 2その間に別のクライアントがこのキーを挿入し直した場合、またはこのキーを同時に更新した場合、キーが完全に削除されないことがある。これは削除後の同時書き込みまたは新規挿入を処理するときに予期される動作である。このような場合を除いて、最終的には削除要求を受け取ったすべてのキーが削除される。
4.3 読み込み
読み込み要求 (3 つ目の "on" 節) を提供するために、ノードはそのキーのすべての複製ノードに対応する DCC を要求する。柔軟性をもたせるために、(例えばノードの定足数または一定の応答が必要な場合) クライアントは調整者が待機すべき返信の数を追加の引数として指定する。すべての応答は同期され、古くなったバージョンは破棄されてから、(並行) バージョン (複数可) と DCC 内の因果関係コンテキストをクライアントに返信する。状態の構成要素 \(r_i\) は、クライアントのキーのペアごとに、これまでに受信したバージョンの同期を維持する DCC と、あと何回の返信が必要かを維持する。
4.4 アンチエントロピー
ノード論理クロックには、ローカルに保存されている現在及び過去のバージョンに関するノードの知識が既に反映されているため、これらのクロックを比較することで 2 つのピアノード間で欠落している更新を正確に知ることができる。しかし、かけているドットを知るだけでは十分ではなく、ドットがどのキーを指しているかを知る必要がある。これが状態の構成要素 \(l_i\) の目的で、ローカルで調整された更新のキーを格納し、連続した一連のカウンターによってインデックス付された動的配列とみなすことができる。
ノード \(i\) はそのピアの一つである \(j\) と定期的に同期プロトコルを開始する。それは \(i\) のノード論理クロックの \(j\) のエントリを \(j\) に送信することから始まる。ノード \(j\) はそのエントリを受信して自身のローカルエントリと比較し、ノード \(i\) が認識していないローカルドットを検出する。ノード \(j\) は次に、自身の BVV のエントリ (ビットマップ部分は関係なく) と、\(i\) が複製ノードでもある欠落キーバージョン (DCC) を送り返す。おそらく大量の DCC を送信することになるため、帯域幅を節約するために送信前に不要な因果関係コンテキストを除去する (保存時に除去されているが、ノードのクロックがそれよりも進んでいる可能性があるため、さらに節約するために再度コンテキストをストリップする)。
ノード \(i\) は受信すると自身の BVV 内の \(j\) のエントリを更新し、\(j\) が調整したすべての更新が \(j\) の受信論理クロックに反映されたことを \(i\) が確認したことを反映する。またノード \(i\) は受信した DCC をローカルのものと同期する。それぞれのキーに対して受信した DCC を \(j\) の論理クロックで埋め、同等のローカル DCC を読み込んで \(i\) 自身の論理クロックで埋め、各ペアを単一の DCC に同期させ、最後に \(i\) の論理クロックで再度ストリップした結果をローカルに保存する。
さらに、ノード \(j\) も (1) \(v_j\) の \(i\) のエントリを、\(i\) が知っている \(j\) が生成した連続する最大のドットで更新し、(2) 新しいキーがすべてのピアに認識されている場合 (すなはち \(v_j\) の最小カウンターが増加した場合)、対応するキーをキーログ \(l_i\) から削除する。これは、これらのキーについてローカルに保存された DCC を再検討する良い機会でもあり、ノード論理クロックの情報が常に増加していることから、因果関係情報をさらに取り除くことができるかどうかをチェックする。削除の場合と同様に、キーログのドットが表している後にキーへの新たな更新がなかった場合、DCC はその因果関係の履歴全体が取り除かれる。つまり、保存された DCC では並行バージョンごとに 1 つのドットがあれば良いことになる。
5 評価
我々のフレームワークに基づいたプロトタイプデータストアと、Merkle Tree およびキーごとの論理クロックに基づく従来のデータストアとを比較する小規模なベンチマークを行った。システムには 40000 個のキーが登録されており、各キーは 3 つのブロックに複製されている。10000回の書き込みを行い、複製ノードへ書き込みを複製するメッセージを 10% 失う状態でいくつかの指標を測定した。評価はアンチエントロピーに関連するメッセージのメタデータのサイズと、データストアの因果関係に関連するメタデータのサイズを比較することを目的としている。また 4 種類の Merkle Tree のサイズを比較し、Merkle Tree の "resolution"、つまり葉あたりのキーの比率が結果にどのような影響を与えるかを示す。
| Key/Leaf率 | ヒット率 | メタデータ | リペアごとのメタデータ | |
|---|---|---|---|---|
| Merkle Tree | 1 | 60.214% | 449.65kB | 4.30kB |
| 10 | 9.730% | 293.39kB | 2.84kB | |
| 100 | 1.061% | 878.40kB | 7.98kB | |
| 1000 | 0.126% | 6440.96kB | 63.15kB | |
| BVV & DCC | - | 100% | 3.04kB | 0.019kB |
| キー論理クロックごとの 平均エントリ数 |
|
|---|---|
| VV or DVV |
3 |
| DCC | 0.231 |
ベンチマークの結果を Table 1 に示す。Merkle Tree には常に大きなオーバーヘッドがあり、葉あたりのキーの比率が大きくなるほど誤検出が多くなる。比率が小さいとしても、交換されたハッシュよりも関連するハッシュの「ヒット率」が高いところでは木構造自体が大きいためかなりのメタデータが転送されることになる。一般的に、我々のスキームでアンチエントロピーを実行するためのメタデータのオーバーヘッドは、どの Merkle Tree の構成よりも桁違いに小さい。
因果関係に関連するメタデータのサイズについては、ノード全体のメタデータのコストを大規模なデータベースで償却しても無視できる程度絵あり、因果関係はほとんどの場合、ノード全体の論理クロックによって完全に凝縮されるため、キーごとの論理クロックのメタデータの平均オーバーヘッドも我々の方式では大幅に小さくなる。従来のキーごとの論理クロックでは、エントリの数は一般的に複製の程度であり、リタイアしたノードのエントリが永遠にクロックに残るため、より大きくなる可能性があるが、その問題もこの方式で解決されている。
6 関連研究
この論文のメカニズムとアーキテクチャは [11, 1] に特化した因果関係機構を拡張して結果整合性をもつデータストア上に適用している。既に述べた Concise Version Vectors [11] との違いに加えて、PVE とは違い我々のキー論理クロックサイズは実際にアクティブな複製ノードの数に制限されている (CVV キー論理クロックは制限されていない)。
また我々の研究はログベースのシステム [15, 8, 4] やデータ/ファイルの同期 [13] に見られる弱い整合性の複製の概念に基づいている。各更新イベントにローカルな一意の識別子を割り当てることは [15] ですでに存在しているが、各ノードがローカルなイベントを完全に順序付けるのに対して、我々は同じノードへの並列クライアントを考慮する。あるイベントが他のすべての複製ノードで認識している場合 (ログの刈り込み条件) の検出は前述のログベースのシステムと共通である。しかし、我々のログ構造 (キーログ) は分岐したデータ複製を追跡する転置インデックスでしかないため、楽観的複製ファイルシステムに近いものとなる。我々の設計は、共通の因果関係フレームワークを使用しながら、フォアグラウンドのユーザアクティビティ (書き込み、削除および読み取りリペア) の結果として、また、周期的なバックグラウンドのアンチエントロピーによって発散を削減することができる。
Acknowledgements
Acknowledgments. This work is financed by the FCT – Fundação para a Ciência e a Tecnologia (Portuguese Foundation for Science and Technology) within project UID/EEA/50014/2013 and scholarship SFRH/BD/86735/2012; also by the North Portugal Regional Operational Programme (ON.2, O Novo Norte), under the National Strategic Reference Framework (NSRF), through the European Regional Development Fund (ERDF), within project NORTE-07-0124-FEDER-000058; and by EU FP7 SyncFree project (609551).
References
- Almeida, P.S., Baquero, C., Gonçalves, R., Preguiça, N., Fonte, V.: Scalable and accurate causality tracking for eventually consistent stores. In: Magoutis, K., Pietzuch, P. (eds.) DAIS 2014. LNCS, vol. 8460, pp. 67–81. Springer, Heidelberg (2014)
- DeCandia, G., Hastorun, D., Jampani, M., Kakulapati, G., Lakshman, A., Pilchin, A., Vosshall, P., Vogels, W.: Dynamo: amazon’s highly available key-value store. In: ACM SIGOPS Operating Systems Review, vol. 41, pp. 205–220 (2007)
- Gilbert, S., Lynch, N.: Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services. ACM SIGACT News 33(2), 51–59 (2002)
- Golding, R.A.: Weak-consistency group communication and membership. Ph.D. thesis, University of California Santa Cruz (1992)
- Johnson, P.R., Thomas, R.H.: The maintenance of duplicate databases. Internet Request for Comments RFC 677, Information Sciences Institute (1976)
- Karger, D., Lehman, E., Leighton, T., Panigrahy, R., Levine, M., Lewin, D.: Consistent hashing and random trees. In: Proceedings of the Twenty-Ninth Annual ACM Symposium on Theory of Computing, pp. 654–663. ACM (1997)
- Klophaus, R.: Riak core: building distributed applications without shared state. In: ACM SIGPLAN Commercial Users of Functional Programming. ACM (2010)
- Ladin, R., Liskov, B., Shrira, L., Ghemawat, S.: Providing high availability using lazy replication. ACM Trans. Comput. Syst. 10(4), 360–391 (1992)
- Lakshman, A., Malik, P.: Cassandra: a decentralized structured storage system. ACM SIGOPS Operating Systems Review 44(2), 35–40 (2010)
- Lamport, L.: Time, clocks, and the ordering of events in a distributed system. Communications of the ACM 21(7), 558–565 (1978)
- Malkhi, D., Terry, D.: Concise version vectors in winFS. In: Fraigniaud, P. (ed.) DISC 2005. LNCS, vol. 3724, pp. 339–353. Springer, Heidelberg (2005)
- Merkle, R.C.: A certified digital signature. In: Brassard, G. (ed.) Advances in Cryptology - CRYPTO 1989. LNCS, vol. 435, pp. 218–238. Springer, Heidelberg (1990), http://dl.acm.org/citation.cfm?id=118209.118230
- Parker Jr., D.S., Popek, G., Rudisin, G., Stoughton, A., Walker, B., Walton, E., Chow, J., Edwards, D.: Detection of mutual inconsistency in distributed systems. IEEE Transactions on Software Engineering, 240–247 (1983)
- Schwarz, R., Mattern, F.: Detecting causal relationships in distributed computations: In search of the holy grail. Distributed Computing 7(3), 149–174 (1994)
- Wuu, G., Bernstein, A.: Efficient solutions to the replicated log and dictionary problems. In: Symp. on Principles of Dist. Comp. (PODC), pp. 233–242 (1984)
翻訳抄
ノード論理クロックとキー論理クロックを使用して分散システムにおけるデータ更新の因果関係を追跡するための 2015 年の論文。
- Ricardo Gonçalves, Paulo Sérgio Almeida, Carlos Baquero, and Victor Fonte. 2015. "Concise Server-Wide Causality Management for Eventually Consistent Data Stores." In Distributed Application and Interoperable Systems, 66-79. Berlin: Springer.