
\(t\) 検定
 概要
概要
\(t\) 検定 (t-test; スチューデントの t) は正規分布に従う母集団から無作為に抽出した 2 つの標本が互いに異なるかを計測する仮説検定である。母集団の標準偏差が不明な場合は Z 検定の代わりに t 検定を使用する
Table of Contents
このページに例示している Python コードは Jupyter Notebook または Google Colaboratory で実行可能である。
t 検定計算機
想定する母集団の平均 \(\mu\) と実際に観測された標本 \(\vector{x}\) を入力すると帰無仮説 \(H_0\) に対する対立仮説 \(H_a\) ごとの \(p\) 値を計算する。\(H_0\) rejected の表示されたセルはその有効水準 \(\alpha\) で帰無仮説 \(H_0\) が棄却され対立仮説 \(H_a\) を採用できる。CI は \(1-\alpha\) 信頼区間を示している。
t 分布
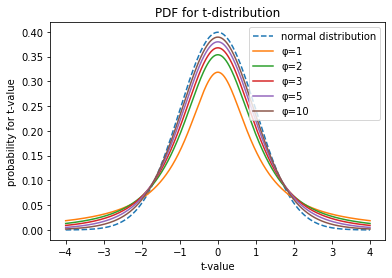
t 分布は正規分布に似た釣鐘状の連続分布である。Fig 1 に示すように正規分布より中心が低く裾野が太い特徴を持つ (つまり平均から離れた値を許容する傾向を持つ)。t 分布の形状は自由度 (degree of freedom) と呼ばれるパラメータ \(\phi\) によって決まり、自由度が大きくなるに連れて平均 0、分散 1 の標準正規分布に近似する。
統計量と確率関数
母平均 \(\mu\)、母標準偏差 \(\sigma\) の正規分布に従う母集団 \(X\) から抽出した \(n\) 個の標本 \(\vector{x}=\{x_1,\ldots,x_n\}\) について、その標本平均 \(\bar{x}\) が母平均 \(\mu\) からどれだけ乖離するかを考える。直感的には、標本抽出のランダム性により標本 \(\vector{x}\) の標本平均 \(\bar{x}\) は母平均 \(\mu\) と完全に一致することはまれだが、ある程度の確率で近しい値をとりやすいことが想像できる。
もし母集団の標準偏差 \(\sigma\) が既知であるならば、標本平均 \(\bar{x}\) と母平均 \(\mu\) の差異の発生確率は式 (\(\ref{z_value}\)) で表される統計量 \(z\) を変数とする標準正規分布で表すことができる (あるいは \(\bar{x}-\mu\) は \(\mathcal{N}(\mu, \sigma^2/n)\) の正規分布に従うと言える)。\[ \begin{equation} z = \frac{\bar{x} - \mu}{\sigma/\sqrt{n}} \label{z_value} \end{equation} \] この統計量 \(z\) と標準正規分布を使った検定は Z 検定として知られている。しかし現実には母標準偏差 \(\sigma\) が分かっているケースは稀である。そこで、標本 \(\vector{x}\) から式 (\(\ref{sample_standard_deviation}\)) のように導出できる、母標準偏差の推定値である不偏標準偏差 (unbiased standard deviation) \(s\) を使用する。\[ \begin{equation} s = \sqrt{\frac{1}{n-1} \sum_{i=1}^n (x_i - \bar{x})^2} \label{sample_standard_deviation} \end{equation} \] 式 (\(\ref{z_value}\)) における母標準偏差 \(\sigma\) をより現実的な不偏標準偏差 \(s\) で代用すると、差異の発生確率は統計量 \(t\) を変数とした自由度 \(\phi=n-1\) の確率密度関数である t 分布に従う。\[ \begin{equation} t = \frac{\bar{x}-\mu}{s/\sqrt{n}} \label{t} \end{equation} \] t 分布は、正規分布に従うある母集団と、その母集団から得られた標本との差異を表す統計量 \(t\) を変数として、そのような差異が実際に観測される確率分布を表している。
自由度 \(\phi\) の t 分布の確率密度関数 (PDF) \(f_\phi(t)\) と累積密度関数 (CDF) \(F_\phi(t)\) はそれぞれ式 (\(\ref{t_pdf}\)), (\(\ref{t_cdf}\)) のように表される。\[ \begin{eqnarray} f_\phi(t) & = & \frac{\Gamma(\frac{\phi+1}{2})}{\sqrt{\phi\ \pi} \ \Gamma(\frac{\phi}{2})} \ \left(1 + \frac{t^2}{\phi} \right)^{-\frac{\phi+1}{2}} \label{t_pdf} \\ F_\phi(t) & = & \int_{-\infty}^t f_{\phi}(u) du \label{t_cdf} \end{eqnarray} \]
一標本 t 検定
一標本 t 検定 (one-sample t-test; 一群 t 検定) は観測した標本 \(\vector{x}\) から想定されるの真の母集団の平均がある値 \(\mu\) と同じとみなせるかを統計的な数量を使って判断する。
t 分布の確率密度関数 (\(\ref{t_pdf}\)) および累積密度関数 (\(\ref{t_cdf}\)) により、観測した標本が想定する母集団から得られたものかを判断するための統計的な確率値を得ることができる。
正規分布に従う母集団からランダムに得た標本で、母集団と標本に統計量 \(t=\tau\) となる差異が発生する確率は \(f_\phi(\tau)\) である。
多くのケースでは統計量 \(t\) は点ではなく範囲で考えるため累積分布 (\(\ref{t_cdf}\)) を使用する。統計量 \(t\) は母平均 \(\mu\) に対する標本平均 \(\bar{x}\) の大小関係を \(t \gt 0 \Leftrightarrow \bar{x} \gt \mu\) のように維持することから、t 分布の片側のみを使用すれば母平均に対して標本平均が大小どちらの方向へ乖離しているかの確率を得ることができる。
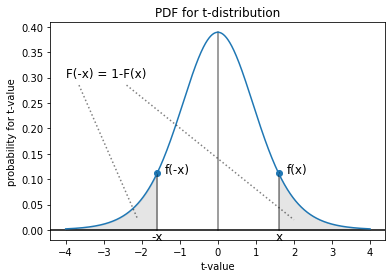
Fig 2 に示すように t 分布が左右対称であることを考慮し、ある量 \(\tau \ge 0\) より外側の片方の確率 (面積) を \(\rho(\tau)\) = \(F_\phi(-\tau)\) = \(1-F_\phi(\tau)\) で表すと、人に説明する言葉では:
- 両側: 標本平均 \(\bar{x}\) と母平均 \(\mu\) の差異が統計量 \(|t|=\tau\) より乖離する確率は \(p=2\rho(\tau)\) である。
- 片側: 標本平均 \(\bar{x}\) が母平均 \(\mu\) より大きく、かつ統計量 \(t=\tau\) より乖離する確率は \(p=\rho(\tau)\) である。
- 片側: 標本平均 \(\bar{x}\) が母平均 \(\mu\) より小さく、かつ統計量 \(t=-\tau\) より乖離する確率は \(p=\rho(\tau)\) である。
と表現することができる。ここで両側検定 (two-side) か片側検定 (one-side) かによって確率 \(p\) の計算方法が変わることに注意する必要がある。
検定の有効水準 \(\alpha\) を定めることで統計ライブラリの近似計算を使用して標本の \(p\) を計算し \(p \lt \alpha\) であれば帰無仮説 \(H_0\) は棄却される。あるいは、t 分布表から \(p \lt \alpha\) となるしきい値 \(\tau\) を参照して標本から導出される \(t\) 値の棄却域 (critical region) を予め定めておくこともできる。
- \(H_0\): 標本の真の母集団の平均はある値 \(\mu\) と等しい
→ \(\rho(\tau)=\frac{1}{2}\alpha\) となるしきい値 \(\tau\) に対して棄却域は \(|t| > \tau\) である。- \(H_0\): 標本の真の母集団の平均はある値 \(\mu\) より大きい
→ \(\rho(\tau)=\alpha\) となるしきい値 \(\tau\) に対して棄却域は \(t \lt -\tau\) である。- \(H_0\): 標本の真の母集団の平均はある値 \(\mu\) より小さい
→ \(\rho(\tau)=\alpha\) となるしきい値 \(\tau\) に対して棄却域は \(t \gt \tau\) である。
近年は表計算を始め scipy.stats など多くの統計ライブラリで \(f_\phi(t)\) や \(F_\phi(t)\), \(p\), \(\tau\) の近似値を直接得ることができる (算出される値が両側か片側かに十分注意する必要がある)。手計算でガンマ関数や積分を算出するのが難しいことから歴史的に t 分布表がよく利用されてきたが、現在でも受理/棄却の 2 値判断のみが必要なケースであれば t 分布表を用いて \(t\) の棄却域を定める方が計算量もはるかに少ない利点もある。
信頼区間
t 検定に基づいて標本 \(\vector{x}\) と有効水準 \(\alpha\) から \(1-\alpha\) 以上の確率をとる \(\mu\) の信頼区間 (confidence interval; CI) を算出することができる。\(\tau\) を \(\rho(\tau)=\frac{1}{2}\alpha\) とすると、\(t\) の取りうる範囲は \(|t| \le \tau\) であることから \[ \begin{eqnarray} -\tau \le & \frac{\bar{x} - \mu}{s/\sqrt{n}} & \le \tau \nonumber \\ \bar{x} - \frac{s}{\sqrt{n}} \tau \le & \mu & \le \bar{x} + \frac{s}{\sqrt{n}} \tau \end{eqnarray} \] つまり \(\bar{x} \pm \frac{s}{\sqrt{n}} \tau\) が t 検定に基づく \(1-\alpha\) 有効水準の信頼区間と言える。
\(1-\alpha=0.95\) となる信頼区間は観測値に対して真の値が 95% 以上の確率で含まれる範囲を示すための誤差範囲 (エラーバー) としてしばしばグラフに描画される。
仮説検定では \(p\) や \(t\) が信頼区間に含まれるとしても帰無仮説が正しいと判断することはできないことに注意。t 検定で標本 \(\vector{x}\) の精度が悪いケース (標本数が少なすぎる、分散が大きすぎる等) を想定すると、不偏標準偏差 \(s\) 項が大きくなり \(t \simeq 0\) を取りやすくなる。\(t\) 値がゼロに近くなると棄却域に該当しない可能性が高くなる。そして結果的にどのような仮説や有効水準に対しても「間違っているとは言えない」という意味のない結果をもたらす。標本 \(\vector{x}\) が正規分布に従っているか疑わしい場合はアンダーソン-ダーリング検定 (Anderson-Darling test) などを使用して検証する必要があるかもしれない。
Z 検定との比較
式 (\(\ref{z_value}\)) で表される統計量 \(z\) を使用する Z 検定は、母集団の標準偏差 \(\sigma\) が分かっているか、標本標準偏差が十分に母標準偏差と近似している状況で有効に機能する。例えばコンピュータシミュレーションのように大量の標本が容易に収集できるケースでは、母標準偏差がわからなくても Z 検定でも十分な正確さで仮説検定を行うことができるだろう。これは Fig 1 に示すように自由度 \(\phi\) が高くなるにつれて (つまり標本数 \(n\) が多くなるにつれて) t 分布が正規分布に、同時に標本平均 \(\bar{x}\) は真の母集団の平均 \(\mu\) に近似する性質を持つためである。
母標準偏差 \(\sigma\) が不明なときに Z 検定が適用可能であるかは、慣例的に標本数が 50 以上、少なくとも 30 以上であると言われている (Z 検定が適用可能な標本数を大標本、そうでない標本を小標本とも呼ぶ)。いずれにしても Z 検定は手計算で統計量を求めていた時代の手法と考えてよく、コンピュータによって容易に \(t\) 値や \(p\) 値の計算が可能な今日では t 検定を使用すべきである。
例1: 期待値と観測値の比較
一標本 t 検定がよく適用されるケースの一つは、ある現象の観測値が特定の期待値 (理論値) を反映した結果であるかを評価する場合である。例えば、あるメーカー公称値に対して製品がその仕様を満たしているか、ある理論値に対して実験的に得られた観測値は妥当か (実験方法か、もしくは理論のどちらかが間違っているか) の評価である。
問. 280g と表記のある特大ステーキをランダムに 8 枚選んで重さを測定してみたところ \(\vector{x}=\{278.8,\) \(278.2,\) \(281.4,\) \(276.1,\) \(272.6,\) \(282.2,\) \(276.1,\) \(274.8\}\), 標本平均は \(\bar{x}=277.525\) だった。このステーキが少なくとも 280g の量があることを期待して良いだろうか?
答. 帰無仮説 \(H_0\)「ステーキの真の平均は \(\mu=280\)g 以上」、対立仮説 \(H_a\)「ステーキは 280g 未満」として有意水準 \(\alpha=0.05\) の片側検定を行う。
t 分布表を用いた方法では、標本の自由度 \(\phi=7\) において \(\rho(\tau)=0.05\) となるようなしきい値は \(\tau=1.864579\) であるため、このケースでの棄却域は \(t \lt -1.864579\) の範囲であることが分かる。そして標本から算出される t 値は -2.143 であることから、帰無仮説は棄却され、このステーキは 280g に満たない (280g 以上あるとは考えにくい) と主張できる。
また近似計算の結果からも帰無仮説 \(H_0: \bar{x}\ge\mu\) は \(p=0.0347 \lt 0.05\) であることから帰無仮説は棄却され対立仮説 \(H_a\) が採用される。したがって観測した標本からその母集団の重さが 280g 以上であることは考えにくいと主張できる。
例2: 偶発的なできごとの影響
一標本 t 検定は、再現不可能な状況や事故的な状況の下で得た唯一の標本が、通常時の標本と比較して何かしらの影響を受けているかの判断に使用することができる。このようなケースでは唯一の標本を \(\mu\)、つまり母平均と想定し、そのような母集団から通常時の標本が得られる確率を検証する。
問. ある大手コンビニエンスストアで 4 日間の客単価を調査したところ \(\vector{x}=\{586, 502, 556, 544\}\) 円、平均 \(\bar{x}=547\) 円だった。ところが 5 日目になって店舗で取り扱っている食品メーカーの不祥事がニュースになった。そしてこの日の客単価は 596 円だった。悪いニュースであっても社名が呼ばれることで商品が想起され売上が伸びることもあるだろう。ではこのニュースは客単価に影響したと言えるだろうか?
答. まず帰無仮説 \(H_0\)「ニュースのなかった日の客単価はニュースのあった日の客単価 596 円に等しい」、対立仮説 \(H_a\)「…の客単価は 596 円と異なる」として有意水準 \(\alpha=0.05\) の両側検定を行ってみよう。標本の自由度 \(\phi=3\) において \(\rho(\tau)=0.025\) となるしきい値は \(\tau=3.182446\)、つまり棄却域は \(|t| \gt 3.182446\) である。標本から算出される t 値は -2.815 であることから帰無仮説は棄却できず「596 円に等しくないとは言えない」と言うにとどまる。
次に仮説を \(H_0\)「客単価は下がった」\(H_a\)「客単価は上がった」として有意水準 \(\alpha=0.05\) で片側検定を行ってみよう。t 分布表において \(\rho(\tau)=0.05\) となるしきい値は \(\tau=-2.353363\)、つまり棄却域 \(t \gt \tau\) に対して \(t=-2.815) より帰無仮説は棄却され、このニュースによって単価が下がったとは言えない、つまり客単価は上がったか少なくとも同等であると主張することができる。
また近似計算の結果からも帰無仮説 \(H_0: \bar{x}\ge\mu\) は \(p=0.0335 \lt 0.05\) であることから帰無仮説は棄却され対立仮説 \(H_a\) が採用される。したがってニュースのあった日の客単価は通常の日より低いとは言えないと主張できる。
例3: 簡易な正規乱数の検定
以下のような方法で一様乱数から簡易的に正規分布乱数を生成することができる (より正確で効率的な方法は Box-Muller 法などを参照)。
値域 \(0 \le x \lt 1\) をとる理想的な一様乱数から \(m\) 個の乱数 \(r_i\) を無作為に抽出したとき、その標本平均 \(\bar{r}=\frac{\sum_i r_i}{m}\) は平均 \(\mu=\frac{1}{2}\)、分散 \(\sigma=\frac{1}{12m}\) の正規分布に従う。言い換えると \(\bar{r}\) は正規分布に従う乱数とみなすことができる。
擬似乱数生成器 \(\mathcal{R}\) を使用して、この性質のうち「\(\bar{r}\) の平均は \(\mu=\frac{1}{2}\) である」が妥当であるかを判断しよう (t 検定では母集団の分散は考慮しない)。
- 帰無仮説 \(H_0\): 擬似乱数生成器 \(\mathcal{R}\) の生成する乱数の平均は \(\mu=0.5\) である。
- 対立仮説 \(H_a\): 擬似乱数生成器 \(\mathcal{R}\) の生成する乱数の平均は \(\mu=0.5\) ではない。
以下は実際に JavaScript の Math.random() 関数を使用して一様乱数を生成し一標本 t 検定を行うデモである。
ここで仮説検定では帰無仮説を棄却できなければ有用な情報はないことを思い出そう。今回の試行は母集団が帰無仮説 \(H_0\) と一致するため \(H_0\) は棄却できない (したがって特に意味のある結論を出すことができない)。しかし、有意水準 \(\alpha=0.05\) としていることから、繰り返しサンプリングを行っていると 5% の観測結果で帰無仮説を棄却する様子を見ることができる。
例4: COVID-19 期間中の東京都の超過死亡
東京都人口推計の死亡数から東京都で2019型コロナウイルス![]() COVID-19 期間中に有意な超過死亡が発生しているかを t 検定で調べてみよう。基本的に東京都は人口増加傾向にあり死者数だけ見れば毎年増加しているため、超過死亡を判断するには人口比に対する死者数を考慮する必要がある。
COVID-19 期間中に有意な超過死亡が発生しているかを t 検定で調べてみよう。基本的に東京都は人口増加傾向にあり死者数だけ見れば毎年増加しているため、超過死亡を判断するには人口比に対する死者数を考慮する必要がある。
期間中の人口比死亡数を母集団の真の平均 \(\mu\) とし、それより前の年の人口比死亡数を正規分布に従う標本 \(x_i\) と考えれば、それらが同一の母集団に由来するかどうか (統計的な差異があるかどうか) を検定することができるだろう。したがって仮説を以下のように設定する。
- 帰無仮説 \(H_0\): COVID-19 の影響がない年の月々の死亡数 \(x_i\) は COVID-19 期間中の人口比死亡数 \(\mu\) と同じかそれより多い。
- 対立仮説 \(H_a\): COVID-19 の影響がない年の月々の死亡数 \(x_i\) は COVID-19 期間中の人口比死亡数 \(\mu\) より低い (超過死亡が発生している)。
Table 1 は COVID-19 期間と過去 4 年の東京都の 10 万人あたりの死者数を表している。\(t\) 値は過去 4 年の数値を正規分布に従う標本 \(\vector{x}\)、COVID-19 期間の数値を \(\mu\) としたものである。\(p\) 値は帰無仮説 \(H_0: {\bar{x}\ge\mu}\) に対する数量を示している。
| 9月 | 10月 | 11月 | 12月 | 1月 | 2月 | 3月 | 4月 | 5月 | 6月 | 7月 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2015年 | 63.13 | 70.34 | 67.70 | 69.66 | |||||||
| 2016年 | 65.40 | 69.59 | 73.57 | 72.30 | 80.99 | 76.21 | 75.70 | 64.52 | 69.82 | 64.32 | 59.82 |
| 2017年 | 64.70 | 71.67 | 72.40 | 72.76 | 90.98 | 74.78 | 75.99 | 66.47 | 71.38 | 64.56 | 62.58 |
| 2018年 | 61.76 | 75.91 | 72.92 | 71.11 | 92.29 | 79.69 | 76.43 | 64.33 | 73.24 | 62.81 | 68.32 |
| 2019年 | 67.12 | 74.63 | 70.85 | 73.05 | 93.77 | 78.83 | 73.94 | 67.65 | 77.18 | 59.53 | 69.19 |
| 2020年 | 90.99 | 69.63 | 76.48 | 72.18 | 66.54 | 66.07 | 67.32 | ||||
| \(t\) | |||||||||||
| \(p\) |
COVID-19 は 11 月に中国武漢で最初に確認、1 月に国内初の感染者確認、2 月にダイヤモンド・プリンセス号入港、4 月に緊急事態宣言、5月に宣言解除と推移した。詳しい時系列は NHK 特設サイト新型コロナウイルスなどを参照。2019年9月の増加は沖縄でインフルエンザが大流行した影響かもしれない。
集計結果から、COVID-19 期間中の 11 月から 3 月までは有意水準 \(\alpha=0.05\) で有意に増加したとは言えないことが分かる。特に 2 月はうるう年で 1 日多いにもかかわらず例年より有意に少ない死者数であった。これは民間レベルの対策強化により例年のインフルエンザや肺炎などによる要因が減ったものと考えられる。
しかし 4 月の死者数は有意水準 \(\alpha=0.01\) すらも下回ることから帰無仮説 \(H_0\) は棄却され、母集団となる死亡数は例年より多い (超過死亡が発生している) と主張することができる (計算の詳細は近似計算参照)。仮に死者数比が 67.62 人であれば \(p=0.05\) となり有意水準を上回ることから、10万人あたり少なくとも 72.18-67.62 = 4.56 人、14,002,973÷100,000×4.56 = 639 人程度は例年にはない要因で死亡している可能性を示唆している。
なお、実際に超過死亡が COVID-19 の影響かを判断するには高齢化比や様々な外的要因の影響を排除しなければならないため、ここでは COVID-19 との関連までは言及しない。
対応のある t 検定
対応のある t 検定 (paired t-test) は対をなす 2 つの標本に有意な差異が存在するかを計測する。これは効果測定 (ベンチマーク) のように、同一の対象に対して異なる条件で得た 2 つの標本を評価して、条件による有意な差異や効果があったかを評価するために用いられる。
\(x_i\) と \(y_i\) が対をなす 2 つの標本 \(\vector{x}=\{x_1,\ldots,x_n\}\), \(\vector{y}=\{y_1,\ldots,y_n\}\) について考える。それぞれのペアの差 \(d_i=y_i-x_i\) が正規分布に従うとすると、式 (\(\ref{paired_t}\)) で算出される統計量 \(t\) は t 分布に従う。\[ \begin{equation} t = \frac{\bar{d} - \mu_d}{s_d / \sqrt{n}} \label{paired_t} \end{equation} \] ここで \(\bar{d}\) は \(d\) の標本平均、\(s_d\) は \(d\) の不偏標準偏差、\(\mu_d\) は検定が差異に期待する母平均である。ただし、多くの場合は \(\vector{x}\) と \(\vector{y}\) に差があるかのみに注目するため \(\mu_d=0\) とする。この統計量 \(t\) を使用することで一標本 t 検定と同様に有意水準を設定した帰無仮説の受理/棄却や信頼区間を得ることができる。
対応のある t 検定は、差分 \(d_i\) が対象 \(i\) やその属性に依存するようなケースでは \(d_i\) が正規分布に従わないため有効に機能しないことに注意。例えば女性の方が効きやすい薬の効果を試すのに母集団が男女混合では、差分の分布は正規分布ではなく 2 つのピークを持つことが予想される。
例1: 手段の前後での効果の比較
対応のある標本の t 検定の代表的な適用例は、同一の対象に対してある手段に対する何らかの結果に有意な差異があるかを検証することである。
問. コーヒーを飲むと集中力が高まる効果があるだろうか。
答. 同一の被験者に対してコーヒーを飲んで 30 分後と、飲まなかった日とで集中力を測るテストを行ったところ Table 2 のような結果が得られた。
帰無仮説「コーヒーを飲んだ後と飲まなかったときの集中力テストの結果は同じ」、対立仮説「飲んだ後は飲まなかったときより高い」としてペア t 検定を行うと、\(p=0.0375 \lt 0.05\) という結果が得られ、帰無仮説は棄却され対立仮説 \(H_a: \bar{d} \gt 0\)、つまりコーヒーを飲んだあとの方が飲んでいないときよりも集中力テストの点数が有意に高いと主張することができる。実際の計算結果も参照。
| 被験者 | 飲まなかった | 飲んだ | 差 \(d_i\) |
|---|---|---|---|
| 1 | 63 | -2 | |
| 2 | 48 | 10 | |
| 3 | 29 | 19 | |
| 4 | 66 | -4 | |
| 5 | 56 | 6 | |
| 6 | 55 | 17 | |
| 7 | 53 | -2 | |
| 8 | 63 | -3 | |
| 9 | 30 | 12 | |
| 10 | 35 | -10 | |
| 11 | 62 | -7 | |
| 12 | 43 | -8 | |
| 13 | 45 | -10 | |
| 14 | 12 | 19 | |
| 15 | 65 | 7 | |
| 16 | 41 | 21 | |
| 17 | 10 | -3 | |
| 18 | 50 | -1 | |
| 19 | 58 | 23 | |
| 20 | 36 | 9 |
例2: 異なる手段の効果の比較
対応のある標本の t 検定の適用例の一つは、同一の対象 (人やデータセットなど) に対して 2 つの手段を使って得た結果に有意な差異があるかを検証することである。
問. ある競泳用水着メーカーが従来の水着 A に代わる新しい水着 B を開発した。被験者として 20 人の競泳選手を集め、A と着たときと B を着たときとで 100m 自由形のタイムを計測したところ Table 3 のような結果が得られた。差の平均は \(\bar{d}=-0.677\) だが、タイムは有意に短くなったと言って良いだろうか?
答. \(t = -2.6465\) より、\(p_{\bar{d}\lt 0}=0.992\)、\(p_{\bar{d} \gt 0}=0.008\)、\(p_{\bar{d}=0}=0.016\) を導くことから、有意水準 \(\alpha=0.05\) で「B のタイムは A より有意に短い」と主張することができる。実際の計算結果も参照。
| 選手 | A | B | 差 \(d_i\) |
|---|---|---|---|
| 1 | 51.88 | 51.40 | -0.48 |
| 2 | 50.93 | 50.58 | -0.35 |
| 3 | 54.03 | 55.27 | 1.24 |
| 4 | 49.71 | 49.53 | -0.18 |
| 5 | 51.37 | 50.67 | -0.70 |
| 6 | 50.73 | 52.39 | 1.66 |
| 7 | 57.00 | 54.38 | -2.62 |
| 8 | 54.01 | 52.80 | -1.21 |
| 9 | 50.45 | 49.37 | -1.08 |
| 10 | 54.25 | 55.38 | 1.13 |
| 11 | 53.08 | 52.20 | -0.88 |
| 12 | 54.99 | 53.16 | -1.83 |
| 13 | 50.96 | 50.11 | -0.85 |
| 14 | 49.57 | 47.70 | -1.87 |
| 15 | 55.46 | 54.45 | -1.01 |
| 16 | 54.52 | 52.30 | -2.22 |
| 17 | 60.85 | 60.95 | 0.10 |
| 18 | 54.13 | 52.33 | -1.80 |
| 19 | 58.95 | 58.22 | -0.73 |
| 20 | 58.15 | 58.29 | 0.14 |
二標本 t 検定
二標本 t 検定 (two sample t-test; 独立二標本 t 検定) は正規分布に従う (対応のない) 2 つの独立した母集団から無作為に抽出した 2 つの標本の母平均が互いに異なるかを計測する。母集団 \(X\) と \(Y\) が互いに独立であれば、\(\bar{x}-\bar{y}\) に対する式 (\(\ref{two_sample_z_value}\)) で表される変数は標準正規分布に従う (あるいは \(\bar{x}-\bar{y}\) は \(\mathcal{N}(\mu_x-\mu_y, \sigma_x^2/n_x + \sigma_y^2/n_y)\) の正規分布に従うとも言う)。\[ \begin{equation} z = \frac{(\bar{x}-\bar{y}) - (\mu_x-\mu_y)}{\sqrt{\frac{\sigma_x^2}{n_x} + \frac{\sigma_y^2}{n_y}}} \label{two_sample_z_value} \end{equation} \]
一標本 t 検定では式 (\(\ref{z_value}\)) の母標準偏差 \(\sigma\) を不偏標準偏差 \(s\) に置き換えたが、二標本 t 検定でも同様に式 (\(\ref{two_sample_z_value}\)) の母標準偏差 \(\sigma_x\), \(\sigma_y\) をそれぞれの不偏標準偏差 \(s_x\), \(s_y\) に置き換えることで自由度 \(\phi=n_x+n_y-2\) の t 分布に従う変数 \(t\) を得ることができる。\[ \begin{equation} t = \frac{(\bar{x} - \bar{y}) - (\mu_x - \mu_y)}{\sqrt{\frac{s_x^2}{n_x} + \frac{s_y^2}{n_y}}} \label{two_sample_t_value} \end{equation} \]
ここで \(X\) と \(Y\) の母標準偏差が等しいと仮定できるのであれば (母平均は異なっていて構わない)、それぞれの母標準偏差 \(\sigma_x\), \(\sigma_y\) に対して式 (\(\ref{pooled_sd}\)) で表されるプールされた標準偏差 (pooled standard deviation) \(s_p\) を適用するほうが個別の不偏標準偏差を適用するよりもより正確な結果が得られる。\[ \begin{eqnarray} t & = & \frac{(\bar{x} - \bar{y}) - (\mu_x - \mu_y)}{s_p \sqrt{\frac{1}{n_x} + \frac{1}{n_y}}} \label{two_sample_t_with_same_sd} \\ s_p & = & \frac{(n_x - 1) \times s_x^2 + (n_y - 1) \times s_y^2}{n_x + n_y - 2} \nonumber \\ & = & \frac{1}{n_x + n_y - 2} \left\{ \sum_{i=1}^{n_x} (x_i - \bar{x})^2 + \sum_{j=1}^{n_y} (y_j - \bar{y})^2 \right\} \label{pooled_sd} \end{eqnarray} \] ここで \(n_x\), \(n_y\) は標本数、\(\bar{x}\), \(\bar{y}\) は標本平均、\(s_x\), \(s_y\) は式 (\(\ref{sample_standard_deviation}\)) で表される不偏標準偏差である。
仮説検定では帰無仮説 \(H_0: \mu_x=\mu_y\) と設定するため式 (\(\ref{two_sample_t_value}\)), (\(\ref{two_sample_t_with_same_sd}\)) は \(\mu_x-\mu_y=0\) となるように設計する。もし \(\mu_x - \mu_y = \delta\) のように期待する差分が存在するのであれば標本を \(y_i' = y_i + \delta\) のように置き換えれば良い。
例1: アヤメの花弁の長さの差異
統計の例としてよく利用されているフィッシャーの iris データセットに対して二標本 t 検定を適用し、Iris setosa![]() と Iris versicolor の花弁の長さ (petal length) の差異が有意であるかを調べてみよう。 scikit-learn の標準として用意されているこのデータセットを使用して以下の仮説を検定する。
と Iris versicolor の花弁の長さ (petal length) の差異が有意であるかを調べてみよう。 scikit-learn の標準として用意されているこのデータセットを使用して以下の仮説を検定する。
- 帰無仮説 \(H_0:\mu_x=\mu_y\) - Iris setosa と Iris versicolor の花弁の長さは等しい。
- 対立仮説 \(H_a:\mu_x\ne\mu_y\) - Iris setosa と Iris versicolor の花弁の長さは異なる。
独立二標本 t 検定の \(t\) 値と \(p\) 値 (両側検定, \(\sigma_x=\sigma_y\) 想定) は scipy の scipy.stats.ttest_ind() 関数を使用して算出することができる。
from sklearn import datasets
import scipy
import numpy as np
iris = datasets.load_iris()
petals = [features[2] for features in iris.data]
x = [petal for (petal, target) in zip(petals, iris.target) if target == 0]
y = [petal for (petal, target) in zip(petals, iris.target) if target == 1]
t, p = scipy.stats.ttest_ind(x, y)
print("n(x)=%d, avr(x)=%f, s(x)=%f" % (len(x), np.mean(x), np.std(x, ddof=1))) # n(x)=50, avr(x)=1.462000, s(x)=0.173664
print("n(y)=%d, avr(y)=%f, s(y)=%f" % (len(y), np.mean(y), np.std(y, ddof=1))) # n(y)=50, avr(y)=4.260000, s(y)=0.469911
print("t=%f, p=%e" % (t, p)) # t=-39.492719, p=5.404911e-62得られた両側検定の \(p=5.405\times 10^{-62} \lt 0.05\) より帰無仮説 \(H_0:\mu_x=\mu_y\) は棄却され、Iris setosaと Iris versicolor の花弁の長さには優位な差があると主張することができる。
参考文献
- 久保川達也, 国友直人. 統計学, 東京大学出版 (2016)
- Graham Upton, Ian Cook. 統計学辞典, 共立出版 (2010)
- Are the data consistent with the assumed process mean?
- Two-Sample t-Test for Equal Means
- このページで使用した Jupyter Notebook 用 t-test.ipynb