
Bloom Filter
 概要
概要
Bloom Filter (ブルームフィルタ) は大規模データセットに対する近似メンバーシップクエリー (approximately membership query)、つまり特定の要素が含まれているかを効率的にテストするための確率的データ構造。false positive (偽陽性; 含まれていないのに true となること) を許容するが false negative (偽陰性; 含まれているのに false となること) は発生しないという特徴を持つ。言い換えると、Bloom Filter の結果は、集合に要素が確実に含まれていないか、含まれている可能性があるかのどちらかを示す。
単純な Boom Filter は追加された要素を削除することはできないが、Counting Filter のような派生アルゴリズムでは (一定の制約はあるものの) 要素の削除を行うことができる。
Bloom Filter は優れたメモリ空間特性を持っており、集合内のメンバーシップ検査が高コストな状況において非常に効率的に機能する。またクエリーのコストはデータサイズによらず \(O(1)\) と効率的である。巨大な集合を保管している分散システムに問い合わせを行う前にそのデータが存在するかを判定するために MapReduce, HBase, Cassandra, Oracle Database, PostgreSQL, Bitcoin (BIP0037) といった分散データベースなどで使用されている。また汎用的なアルゴリズムであるため分散システム以外にも応用が可能である (Wikipedia 参照)。
Table of Contents
アルゴリズム
Bloom Filter は状態変数である長さ \(m\) のビット列 \(z\) と、要素 \(x\) に対して 0 から \(m-1\) までのハッシュ値を生成する \(k\) 個のハッシュ関数 \(h_i(x)\) で実装することができる。
- 設定
-
式 (\(\ref{z}\)) のような \(m\) 個のビット列で表される値 \(z\) について考える。\(z\) は初期状態ですべてのビット \(b_i\) が 0 に設定されていると仮定する。\[ \begin{equation} z = (b_1, \ldots, b_m) \label{z} \end{equation} \]
ある要素 \(x\) から \(k\) 個の独立したハッシュ値を生成する関数を (\(\ref{concat_hash}\)) のように表す。このとき、それぞれのハッシュ関数 \(h_i(x)\) は範囲 \([0, \ldots, m-1]\) の値を生成すると仮定する。例えば \({\sf SHA1}\) を使用するのであれば \(h_i(x) = {\sf SHA1}(x \ || \ i) \bmod{m}\) のように容易に \(k\) 個のハッシュ関数を構築できるだろう。\[ \begin{equation} H(x) = \{h_1(x), \ldots, h_k(x)\} \label{concat_hash} \end{equation} \] ハッシュの計算は \(O(k)\) に漸近するが、ほとんどの場合 \(k \le 12\) であることから定数時間 \(O(1)\) と見なすことができる [5]。
- 要素の追加
-
集合に値 \(x\) を追加するとき、\(z\) の \(h_i(x)\) ビット目をすべて 1 に更新する。
- 要素の検査
-
集合に値 \(x\) が含まれているかを検査するとき、\(z\) の \(h_i(x)\) ビット目がすべて 1 であるかを検証する。すべて 1 であれば集合の中に要素 \(x\) が含まれている可能性がある。すべてでなければ集合に \(x\) は含まれていない。
\(H\) の生成するハッシュ値は独立しており均一に分散している必要がある。また暗号論的な強度を保つ必要がない代わりに、高速に動作することが好ましい。Bloom Filter によく使われているハッシュ関数には murmur、NFV Hash、HashMix などがある。
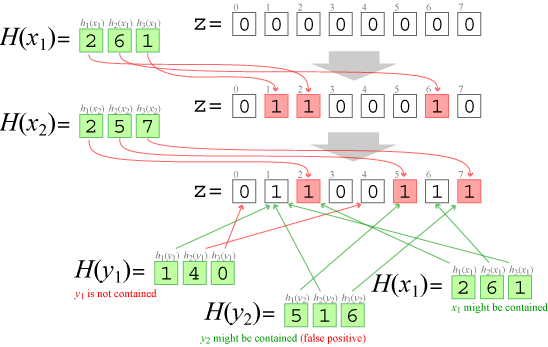
例1: 具体的な状態遷移
\(k=3\), \(m=8\) の設定を仮定する。初期状態の \(z\) は状態 (\(\ref{z0}\)) が示すようにすべてのビットが 0 である。\[ \begin{equation} z := (0,0,0,0,0,0,0,0) \label{z0} \end{equation} \] 最初に \(H(x_1)=\{2, 6, 1\}\) となるような値 \(x_1\) の追加を行うと状態 (\(\ref{z1}\)) のように \(z\) 上の 1, 2, 6 ビット目が 1 に設定される。\[ \begin{equation} z := (0,1,1,0,0,0,1,0) \label{z1} \end{equation} \] 続いて \(H(x_2)=\{2,5,7\}\) となるような値 \(x_2\) を追加すると \(z\) は状態 (\(\ref{z2}\)) のように更新される。\[ \begin{equation} z := (0,1,1,0,0,1,1,1) \label{z2} \end{equation} \]
ここで集合に \(H(x_1)=\{2, 6, 1\}\) となるような値 \(x_1\) が含まれているかを検査する。状態 (\(\ref{z2}\)) における 1, 2, 6 ビット目はすべて 1 であるため集合には \(x_1\) が含まれている可能性があると言える。
次に \(H(y_1)=\{1,4,0\}\) となるような \(y_1\) が集合に含まれているかを考えると、状態 (\(\ref{z2}\)) の 0 ビット目が 1 ではないことから集合に \(y_1\) が含まれていないことがわかる。
さらに false positive となるケースとして \(H(y_2)=\{5,1,6\}\) となるような \(y_2\) が集合に含まれているかを考えると、状態 (\(\ref{z2}\)) における 1, 5, 6 ビット目はすべて 1 であるため (実際には含まれていないが) 集合に \(y_1\) が含まれている可能性があるという判断となる。
Fig 1 はこの例の一連の手順を図にしたものである。
例2: 実装例
以下はサンプルコード部分を実行した結果である。
import scala.collection.mutable.BitSet
import scala.util.hashing.MurmurHash3
val m = 10
val k = 3
val z = new BitSet()
def H(x:String):Seq[Int] = (0 until k).map(i => math.abs(MurmurHash3.stringHash(x + i)) % m)
def add(z:BitSet, x:String):Unit = H(x).foreach(i => z += i)
def exists(z:BitSet, x:String):Boolean = H(x).forall(i => z(i))
add(z, "0")
add(z, "1")
add(z, "2")
exists(z, "1") // true
exists(z, "A") // false
exists(z, "Z") // true (false positive)例3: Guava の Bloom Filter 機能
Java 実装では Google Guava の BloomFilter クラスを使用することができる。このクラスは最初に \(n\) と false positive 生起確率 (デフォルトは 0.03) を指定することで適切な内部構造を取る。
$ cat Main.javaimport java.util.HashSet; import java.util.Set; import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnel; import com.google.common.hash.PrimitiveSink; public class Main { public static void main(String[] args) { final int n = 500; final Funnel<Integer> funnel = (Integer x, PrimitiveSink into) -> into.putInt(x); final BloomFilter<Integer> filter = BloomFilter.create(funnel, n); // 0 から 998 までの偶数を Bloom Filter に追加 for (int i = 0; i < n * 2; i += 2) { filter.put(i); } // すべての偶数が positive であることを確認 for (int i = 0; i < n * 2; i += 2) { if (!filter.mightContain(i)) { System.out.printf("%d should be contained!\n", i); } } // 1 から 999 までの奇数で false positive となる値を抽出 final Set<Integer> falsePositives = new HashSet<>(); for (int i = 1; i < n * 2; i += 2) { if (filter.mightContain(i)) { falsePositives.add(i); } } System.out.printf("expected false positive probability is %f\n", filter.expectedFpp()); System.out.printf("actual false positive probability is %f\n", (double) falsePositives.size() / n); System.out.printf("%d false-positives appeared: %s\n", falsePositives.size(), falsePositives); } }
実行結果から false negative は発生しておらず 2.2% の確率で false positive が発生していることがわかる。
expected false positive probability is 0.026961
actual false positive probability is 0.022000
11 false-positives appeared: [609, 131, 197, 405, 951, 41, 169, 649, 877, 175, 255]確率の数式化
\(z\) が集合の要素数に依存しない固定長であることは Boom Filter の大きな利点である。しかし要素を追加してゆくに連れて 1 となるビットが増え、しだいに false positive となる判断が増加して効率が低下することが予想される。最終的にすべてのビットが 1 となれば 100% の確率で false positive が発生するだろう。ここで false positive の生起確率とビット幅 \(m\) と要素数 \(n\) に対する最も効率の良い設定を求める。
false positive の生起確率
集合に \(n\) 個の要素が追加された後に特定のビットが 0 である確率は式 (\(\ref{prob_bit0}\)) のように表される。ここで近似の右辺は \(\lim_{x \to \infty} (1-1/x)^{-x} = e\) から得られる。\[ \begin{equation} \left( 1 - \frac{1}{m} \right)^{kn} \approx e^{-\frac{kn}{m}} \label{prob_bit0} \end{equation} \] したがって特定のビットが 1 である確率は式 (\(\ref{prob_bit1}\)) となる。\[ \begin{equation} 1 - \left( 1 - \frac{1}{m} \right)^{kn} \approx 1 - e^{-\frac{kn}{m}} \label{prob_bit1} \end{equation} \] ある要素 \(x\) に対するすべてのハッシュ値 \(\{h_1,\ldots,h_k\}\) の位置のビットが 1 となるとき false positive となることから、その生起確率の近似値 \(P\) は式 (\(\ref{prob_fp}\)) で表すことができる。\[ \begin{equation} \left( 1 - \left( 1 - \frac{1}{m} \right)^{kn} \right)^k \approx \left( 1 - e^{-\frac{kn}{m}} \right)^k = P \label{prob_fp} \end{equation} \]
false positive を最小化する \(k\) の算出
あるビット幅 \(m\) と要素数 \(n\) に対して false positive の生起確率 \(P\) を最小化する \(k\) について考える。\(p=e^{-\frac{kn}{m}}\) と置くと: \[ \begin{eqnarray*} P & = & \left( 1 - e^{- \frac{kn}{m}} \right)^k \\ & = & (1 - p)^k \\ & = & e^{k \log (1 - p)} \end{eqnarray*} \] であることから \(g = k \log (1 - p)\) を最小化する \(k\) で false positive の生起確率が最小となる。\(\log p = -\frac{kn}{m}\)、つまり \(k = -\frac{m}{n} \log p\) より: \[ \begin{eqnarray} g & = & k \log (1 - p) \nonumber \\ & = & -\frac{m}{n} \log (p) \log (1-p) \nonumber \\ \frac{dg}{dp} & = & \frac{m}{n} \frac{(p-1) \log (1-p) + p \log p}{(1-p)p} \label{dg} \end{eqnarray} \] 式 (\(\ref{dg}\)) において \(p=e^{-\frac{kn}{m}}=\frac{1}{2}\) のときに \(\frac{dg}{dp}=0\) となることから false positive の生起確率 \(P\) が最小となる \(k_{\rm min}\) は式 (\(\ref{prob_min_k}\)) のように表される。\[ \begin{equation} k_{\rm min} = \frac{m}{n} \log 2 \label{prob_min_k} \end{equation} \] したがって \(p=\frac{1}{2}\) となるところの false positive の最小生起確率 \(P_{\rm min}\) は式 (\(\ref{p_min}\)) のように表される。\[ \begin{eqnarray} P_{\rm min} & = & ( 1 - p )^k & = & \left( \frac{1}{2} \right)^{\frac{m}{n} \log 2} \nonumber \\ & = & \left( 2^{-\log 2} \right)^{\frac{m}{n}} & \simeq & 0.618503^{\frac{m}{n}} \label{p_min} \end{eqnarray} \] \(p = e^{-\frac{kn}{m}}\) は特定のビットが 0 である確率を表していることから、\(p=\frac{1}{2}\) は \(z\) のビット列の 1/2 が埋め尽くされている状態であることを意味する。
\(\frac{m}{n} = -2.08 \times \log P\) より、直感的には false positive の生起確率を \(P_{\rm min} = 0.5\) 程度としたいなら \(m=1.5n\)、同様に \(P_{\rm min}=0.05\) 程度としたいなら \(m=6.2n\) 程度と見積もれば良い。
最適値の計算
以下は式 (\(\ref{prob_min_k}\)) と式 (\(\ref{prob_fp}\)) を使用して、想定要素数 \(n\) とハッシュ値/フィルターのビット数 \(m\) の入力から最も false positive 生起確率の低い \(k_{\rm min}\) と \(P_{\rm min}\) を求める。
MapReduce での Bloom Filter
互いに膨大な数の要素を含んでいる 2 つのデータセット \(A\) と \(B\) の間での内部結合 (join) について考える。単純にすべてのデータの組み合わせを考えると最悪ケースでは \(|A| \times |B|\) 回の検査を行う可能性がある。これは非常に非効率で長い時間を要するだろう。
MapReduce はデータセットのうちサイズの小さい方に対して Bloom Filter を作成し、それを使用してもう片方のデータセットの値をフィルタしてから内部結合を行うことでシステム全体の負荷を軽減している。
参照
- Jacob Honoroff (2006) An Examination of Bloom Filters and their Applications
- E. Spafford. OPUS: Preventing Weak Password Choices. Computer and Security, 1991
- A. Snoeren et al. Hash-Based IP Traceback, SIGCOMM, 2001
- Bloom Filters by Example
- Dzejla Medjedovic, Emin Tahirovic, Ines Dedovic. 大規模データセットのためのアルゴリズムとデータ構造. マイナビ出版 (2024)
