論文翻訳: BzTree: A High-Performance Latch-free Range Index for Non-Volatile Memory
 概要
概要
データベース全体 (行とインデックス) を不揮発性メモリ (NVM; non-volatile memory) に保存することで潜在的に高性能と高速復旧の両方が有効になる。最新の CPU での並列処理を十分に活用するために、最新のメインメモリデータベースはラッチフリー (ロックフリー) のインデックス構造、例えば Bw-Tree やスキップリストを使用する。高性能を実現するには NVM に常駐するインデックスもラッチフリーである必要がある。この論文では NVM 向けに設計されたラッチフリーの B-Tree インデックスである BzTree の設計について説明する。BzTree は PMwCAS (persistent multi-word compare-and-swap) をコア・ビルディング・ブロックとして使用しており、Bw-Tree といった競合するインデックス構造と比較していくつかの重要な利点を持つインデックス設計を可能にしている。第一に、BzTree はラッチフリーでありながら実装が簡単である。第二に、我々の実験で BzTree は高速で Bw-Tree と比較して最大 2 倍のスループットを示した。第三に、BzTree は特別な復旧実装を必要とせず、障害発生時に実行されていた PMwCAS オペレーションをロールバック (またはロールフォーワード) するだけでほぼ瞬時に復旧する。BzTree のエンド・ツー・エンドの復旧実験では平均復旧時間は 145μs だった。さらに、同一の BzTree の実装が揮発性 RAM と NVM の両方でシームレスに動作することから実装のメンテナンスコストが大幅に削減されている。
- 1Carnegie Mellon University, jarulraj@cs.cmu.edu
- 2Microsoft Research, justin.levandoski@microsoft.com
- 3Microsoft Research, ufminhas@microsoft.com
- 4University of Waterloo, plarson@uwaterloo.ca
- *Microsoft Research で行われた研究。
Table of Contents
- 概要
- 1 導入
- 2 背景と概要
- 3 BzTree アーキテクチャと設計
- 4 BzTree ノード
- 5 Structure Modifications
- 6 BzTree Durability and Recovery
- 7 Evaluation
- 8 Related Work
- 9 Conclusion
- Acknowledgements
- 10 References
- 翻訳抄
1 導入
マルチスレッド化された並行処理はメインメモリデータベースの高いパソーマンスを引き出すための鍵の一つである。最新の CPU で並行実行を実現するため、研究および商用のいくつかのシステムではラッチ (ロック) プロトコルに内在するボトルネックを回避するためにラッチフリーのインデックス構造を実装している。例えば MemSQL はラッチフリースキップリスト [30] を使用しており、Microsoft の Hekaton メインメモリ OLTP エンジンはラッチフリー B-Tree である Bw-Tree [6] を使用している。
ラッチフリーインデックス設計はしばしば複雑である。これらのアルゴリズムはアトミックなインデックス状態を更新するために compare-and-swap (CAS) などのアトミックな CPU ハードウェアプリミティブに依存している。これらのアトミック命令は単一ワードに限定されているが、ラッチフリー B+Tree のような非自明 (non-trivial) なデータ構造では通常はノードの分割や結合のような操作を行うために複数ワードの更新が必要となる。これらの操作は複数のステップに分割する必要があるため他のスレッドに中間状態が漏洩してしまう。その結果、アルゴリズムは中間状態が漏洩するときに起きる可能性のある微妙な競合状態 (subtle race conditions) に対処しなければならない。またラッチフリーを実現するためにパフォーマンスを犠牲にした設計もある。一つの例はマッピングテーブルを使用して論理ページ識別子を物理ポインタにマッピングする Bw-Tree [22] である。Bw-Tree 内のノードは論理ポインタを格納しておりインデックスの走査中にノードにアクセスするたびにマッピングテーブルを参照しなければならない。このような間接参照は最近の CPU ではパフォーマンスを低下させる。
メインメモリデータベースをバイトアドレス方式の不揮発性メモリ (NVM) に格納することはラッチフリーインデックスの実装をさらに複雑化する。NVM デバイスは VNDIMM [27, 35], Intel 3D XPoint [5], STT-MRAM [14] の形で利用可能になりつつある。NVM は DRAM に近い性能を持ち通常の load や store 命令でアクセスすることができる。レコードとインデックスの両方を NVM に格納することでほぼ瞬時に復旧することができ、データベースがオンラインでアクティブとなるまでに僅かな作業しか必要としない。いくつかのシステムはこのアプローチをとっており [3, 29, 34, 38]、この論文で想定しているアーキテクチャでもある。
NVM でラッチフリーインデックスを実装する際に複雑さが増す主な理由は CAS やその他のアトミックなハードウェア命令が更新内容を自動的かつアトミックに NVM へ永続化しないためである。更新はプロセッサーキャッシュ上のターゲットワードを書き換えるだけで NVM のターゲットワードを自動的に更新することはない。電源障害が発生した場合、揮発性キャッシュの内容は喪失し、NVM 内のデータは不整合な状態のままとなる可能性がある。したがってシステムクラッシュ後にインデックスやその他のデータ構造を正しく回復することを保証するための永続化プロトコルが必要となる。
この論文では、下記のような利点を持つ、メインメモリデータベース用の高性能ラッチフリー B+Tree である BzTree を提案する。
複雑さの軽減. BzTree 実装は PMwCAS を使用している。PMwCAS は高性能なマルチワード compare-and-swap 操作であり、NVM 上で使用するときには永続化も保証されている [37]。PMwCAS 操作はソフトウェアで実装されており CAS (またはそれと同等の) 命令以外の特別なハードウェアサポートを必要としない。PMwCAS はそれ自体がラッチフリーであり、すべての新しい値をアトミックにインストールするか、中間状態を漏洩することなく操作を失敗させるかのどちらかを取る。ラッチフリーのインデックスを構築するために PMwCAS を使用することは 2 つの大きな利点がある。まず PMwCAS ではすべてのマルチワード更新がアトミックとなることを保証しているため、マルチワード操作中に中間状態が漏洩することで生じる複雑な競合状態に対処する必要がない。次に PMwCAS は Bw-Tree [22] で使用しているような論理から物理への間接参照を回避することができる。BzTree はインデックスノードと葉ノードの両方に直接メモリポインタを格納する。
高いパフォーマンス. 我々は揮発性 RAM 上で YCSB ワークロードを使用して BzTree が Bw-Tree より優れていることを示す。これは BzTree が DRAM ベースのシステム向けに設計された最先端のインデックスよりも優れていることを示している。BzTree の移植性により、我々はまた NVM 上で実験的に BzTree を実行した場合のペナルティが低く、現実的なワークロードでの永続化のオーバーヘッドが平均 8% であることも示す。また PMwCAS を使用することで大規模なマルチワード処理でも無視できる程度の競合であることを示している。YCSB のアクセスパターンが非常に偏っている場合でも、複数の BzTree ノードでマルチワードを更新する際の失敗率は平均 0.2% しかない。
NVM へのシームレスな移植. 同一の BzTree 実装でコードのどこも変更することなく揮発性 DRAM と VNM の両方で動作させることができる。PMwCAS は更新が成功した (ここでは B+Tree ノードへの更新) 時に、その操作が NVM 上で永続化され障害が発生しても持続することを保証する。驚くべきことに、復旧は BzTree 固有の復旧コードを使用せず PMwCAS ライブラリによって完全に処理される。
この論文の残りの部分は以下のように構成されている。セクション 2 と 3 では BzTree のアーキテクチャの概要とともに BzTree に必要な背景を説明する。セクション 4 では BzTree のノードレイアウトと単一ノードの更新について、セクション 5 では構造上の変更について説明する。NVM 上での永続化と復旧性はセクション 6 で説明する。セクション 7 では実験的な評価を行い、セクション 8 では関連する研究について説明する。最後にセクション 9 で本論文を締めくくる。
2 背景と概要
2.1 システムモデルと NVM
ここでは NVM がメモリバスに直接接続されているシングルレベルストアのシステムモデルを想定する。このモデルは最近のいくつかの NVM ベースのシステムでも採用されている [3, 28, 34, 36, 38]。我々はインデックスとベースデータが NVM に存在すると想定する。システムには作業用ストレージとして使用される DRAM も含まれている。
NVDIMM 製品 [35, 27] のような NVM デバイスは DRAM と同じように動作するが、これらのデバイス上に格納されるデータは永続的であり電源故障があっても存続する。ハードディスクドライブ (HDD) やソリッドステートドライブ (SSD) とは異なり、NVM のデータは通常の load と store 命令でアクセスすることができる。NVDIMM は電源故障時にデータ内容をフラッシュストレージに保存する DRAM であるため、その性能特性は DRAM と同等である。この論文を書いている時点では Intel 3D XPoint DIMM はまだ販売されていないが、DRAM DIMM より容量が大きく読み込みレイテンシーがやや高く、帯域幅が低いと予想されている [10, 5]。STT-MRAM 技術に基づく NVDIMM は既に販売されており [7] 性能な DRAM と同等だが容量は非常に小さい。
アプリケーションが NVM 上の場所に store を発行すると書き込みは揮発性 CPU キャッシュに格納される。書き込みの永続性を確かなものにするためには、Intel プロセッサ上で Cache Line Write Back (CLWB) または Cache Line FLUSH (CLFLUSH) 命令を使って書き込みを CPU キャッシュからフラッシュしなければならない。どちらの命令も対象のキャッシュラインをメモリにフラッシュするが、CLFLUSH はキャッシュラインの退避も行う。
2.2 ラッチフリーのメモリ安全性
ラッチフリーのデータ構造実装はメモリの有効期限とガーベッジコレクションを管理するメカニズムが必要である。メモリの割り当て解除を保護するロックがないため、システムはメモリブロックが解放される前にどのスレッドもそのメモリブロックを逆参照できないように保証しなければならない。BzTree は高性能なエポックベースのリサイクルスキーム [23] を使用する。スレッドはアクセスするメモリを再利用から保護するためにインデックスに対して実行する各操作の前に現在のエポックに参加 (join) する。スレッドは操作を終えるとエポックを抜ける。エポック \(\epsilon\) に参加したすべてのスレッドが完了して終了すると、ガーベッジコレクタは \(\epsilon\) で解放されたディスクリプタが占有しているメモリを回収する。これによりメモリが回収された後どのスレッドもポインタを逆参照できないことが保証される。
2.3 永続的マルチワード CAS
BzTree はラッチフリーで永続的な方法で状態を更新するするために PMwCAS と呼ばれる効率的で永続的なマルチワードの compare-and-swap 操作に依存している。個の設計は Harris ら [11] による揮発性バージョンに基づいており、我々はそれを NVM 上で永続性を保証するように拡張している (詳細は [37])。このアプローチは操作に対するメタデータを追跡するディスクリプタを使用する (詳細は後述)。これらのディスクリプタはプールされ最終的に再利用される。PMwCAS の API は以下の通り:
AllocateDescriptor(callback = default): PMwCAS 操作で使用するディスクリプタを割り当てる。ユーザは PMwCAS 操作でワードが指すメモリをリサイクルするためのカスタムコールバック関数を提供することができる。Descriptor::AddWord(address, expected, desired): 書き換えるワードを指定する。呼び出し側はワード、期待する値、要望する値のアドレスを提供する。Descriptor::ReserveEntry(addr, expected, policy): 新しい値を指定しない点を除いてAddWordと似ている (new_valueフィールドへのポインタを返すので後から埋めることができる)。old_value/new_valueから参照されるメモリは指定されたポリシーに従ってリサイクルされる。Descriptor::RemoveWord(address): PMwCAS の一部として以前に指定されたワードを削除する。PMwCAS(descriptor): PMwCAS を実行し成功した場合は true を返す。Discard(descriptor): PMwCAS をキャンセルする (PMwCASを呼び出す前にのみ有効)。指定されたワードは書き換えられていることはない。
API は揮発性と永続性の両方の MWCAS で同一である。PMwCAS はアプリケーションのアクション追加なしに永続性に必要なすべての保証を提供する。
PMwCAS を使用するためにアプリケーションはまずディスクリプターを確保し、書き換えられる各ワードに対して一度 AddWord または ReserveEntry を実行する。また直前に指定したワードを削除するために必要に応じて RemoveWord を使用することができる。AddWord と ReserveEntry はターゲットアドレスがユニークであることを確認しそうでない場合はエラーとする。PMwCAS を呼び出すと操作が実行され Discard は操作を中断する。PMwCAS が失敗した場合はすべてのターゲットワードは変更されないままになるだろう。この挙動は NVM 上での操作で電源障害が発生しても保証される。
2.3.1 耐久性
NVM 上で動作するとき PMwCAS はキャッシュラインを選択的にフラッシュまたはライトバックする命令、例えば Intel プロセッサ上の cache line write-back (CLWB) や cache line flush (write-back なしの CLFLUSH) 命令 [16] を使って耐久性を保証する。これらの命令は線形化可能な書き込みを保証するとともに、クラッシュや電源障害が発生した場合の正しい復旧を保証するために慎重に配置されている。これは PMwCAS の間に他のスレッドが観測可能なすべての書き換えワードに単一のダーティビットを使用することで実現している。例えばあるディスクリプタアドレス (またはターゲット値) をインストールする各変更は、値が揮発性であることを示すダーティビットが設定され、読み手はその値をフラッシュしてビットを無効化 (unset) してから次の処理を行わなければならない。このプロトコルにより、依存性する書き込みは読み取られた値が電源障害に耐えられること保証されることを確かなものにする。
2.3.2 実行
| PMWCAS STATE | UNDECIDEC |
|---|---|
| PMWCAS SIZE | 3 SUB-OPERATIONS |
| TARGET WORD'S ADDRESS | EXPECTED OLD VALUE | NEW VALUE | DIRTY BIT | MEMORY RECYCLING POLICY |
|---|---|---|---|---|
| ADDRESS-1 | VALUE O | VALUE N | 0 | NONE |
| ADDRESS-2 | VALUE X | VALUE Y | 1 | FREE ONE |
| ADDRESS-3 | VALUE Q | VALUE R | 1 | FREE ONE |
内部的に PMwCAS は操作を完了するために必要なすべての情報を格納したディスクリプタを使用している。Figure 1 は 3 つのターゲットワードに対するディスクリプタの例である。ディスクリプタにはターゲットワードごとに (1) ターゲットワードのアドレス、(2) 比較する期待される値、(3) 新しい値、(4) ダーティビット、(5) メモリリサイクルポリシーが格納されている。ポリシーフィールドは新旧の値がメモリオブジェクトへのポインタであるかどうか、もしそうなら操作の成功 (または失敗) 時にそのオブジェクトは解放されるべきものかを示している。ディスクリプタはまた操作の進捗を追跡する状態ワードも含んでいる。PMwCAS 操作自体はラッチフリーである。ディスクリプタにはどのスレッドも操作を完了 (またはロールバック) させるのに十分な情報が含まれている。操作は 2 つのフェーズで構成されている。
フェーズ 1. このフェーズでは double-compare single-swap (RDCSS) 操作 [11] を用いてそれぞれのターゲットアドレスにディスクリプタへのポインタのインストールを試みる。RDCSS は (書き換えられるワードを含む) 2 つのワード値が期待している値と一致する場合のみターゲットワードに変更を適用する。つまり、RDCSS は通常の CAS と違って比較する (変更はしない) ための追加の "期待する" 値を必要とする。RDCSS は微妙な競合状態を防ぎ同一ワード上の一連の操作の線形性を維持するために必要である。具体的には、我々は完了した PMwCAS(\(p_1\)) に対するディスクリプタが別の PMwCAS(\(p_2\)) の結果を誤って上書きすることを防止しなければならない。ここで \(p_2\) は \(p_1\) の後に起きるものとする (詳細は [37])。
ワード内のディスクリプタポインターは PMwCAS が進行中であることを示している。ディスクリプタポインターに遭遇したスレッドは自分の作業を進める前に操作を完了させることで PMwCAS を協調的に行うことができる (ラッチフリー操作の典型的な例)。我々は PMwCAS で (ダーティビットに加えて) ターゲットワードの上位 1 ビットを使用してそれがディスクリプタであるか通常の値であるかを示している。ディスクリプタポインターのインストールは、同時にオーバーラップする可能性のある 2 つの競合する PMwCAS 操作間のデッドロックを避けるためにターゲットアドレスの順に進行する。
フェーズ 1 が終了するとスレッドはダーティビットの設定されたターゲットワードを永続化する。正しいリカバリを行うためにはディスクリプタの status フィールドを更新してフェーズ 2 に進む前にこの操作を行う必要がある。フェーズ 1 が成功したかどうかに応じて CAS を使用してステータスを Succeeded または Failed のいずれかに (ダーティビットの設定とともに) 更新する。そして status フィールドを永続化しそのダーティビットをクリアする。status フィールドを永続化することでオペレーションを "コミット" し、電源障害があってもその効力が持続するようにする。
フェーズ 2. フェーズ 1 が成功した場合、障害が発生しても PMwCAS の成功が保証されディスクリプタに記録された新しい値で復旧が行われる。フェーズ 2 では最終的な値を (ダーティビットの設定とともに) ターゲットワードにインストールし、ディスクリプタへのポインターを置き換える。最終的な値は 1 つずつインストールされるため、フェーズ 2 の途中でクラッシュした場合はあるターゲットフィールドには新しい値が残り、ほかのフィールドはディスクリプタを指している可能性がある。別のスレッドは新しくインストールされた値の一部を観測し、読み取った値に基づいて依存するアクション (例えば自身の PMwCAS を実行するなど) を行ったかもしれない。このような場合にロールバックを行うとデータの不整合が発生する可能性がある。そのためフェーズ 2 に入る前にステータスを永続化させることが重要である。(次で説明する) 復旧ルーチンはディスクリプタの status フィールドを頼りにロールフォーワードすべきかバックワードすべきかを決定する。もしフェーズ 1 で PMwCAS が失敗した場合、フェーズ 2 ではディスクリプタポインターを含むすべてのターゲットワードに古い値を (ダーティビットの設定とともに) インストールすることでロールバック手順となる。
復旧. PMwCAS は 2 フェーズで実行されるためターゲットアドレスはクラッシュ後にディスクリプタポインターまたは正常な値を含んでいる可能性がある。正しく回復するためにはフェーズ 1 に入る前のディスクリプタを保持しておく必要がある。status フィールドのダーティビットがクリアされているのは呼び出し側がターゲットフィールドにディスクリプタポインターのインストールを開始していないためである。この時点までに発生した障害は復旧時のデータの一貫性に影響を与えていない。
PMwCAS ディスクリプタは復旧のためにメモリ上の既知の場所にプールされている。クラッシュの回復はディスクリプタプールをスキャンしてゆく。ディスクリプタの status フィールドが成功を示している場合、ディスクリプタのターゲット値を適用して操作がロールフォーワードされる。ステータスが失敗を示している場合は古い値を適用してロールバックされる。初期化されていないディスクリプタは単に無視される。したがって、復旧時間はクラッシュ時に実行中だった PMwCAS 操作の数によって決まる。これは通常、スレッド数のオーダーであり、非常に速い復旧を意味する。実際、BzTree のエンド・ツー・エンドの復旧実験では、48 スレッドで書き込み過多ワークロードを実行したときの平均復旧時間は 145μs となった。
メモリ管理. PMwCAS がラッチフリーであることから、ディスクリプタのメモリ寿命はセクション 2.2 で述べたエポックベースのリサイクルスキームによって管理されている。これにより、他の PMwCAS によってメモリがさk利用された後、度のスレッドもディスクリプタポインターを参照できないようになっている。8 バイトの期待する値やターゲット値がより大きなメモリオブジェクトへのポインターである場合、これらのオブジェクトも同じメモリ再利用スキームで管理することができる。ディスクリプタの各ワードには、操作の完了時に開放するかどうか、どのメモリを開放するかを示すメモリリサイクルポリシーが記されている。例えば PMwCAS が成功した場合、ユーザはディスクリプタをリサイクルしても安全であると判断した時点で期待する (古い) 値の背後にあるメモリを解放したいと思うかもしれない。セクション 6 では PMwCAS とメモリの再利用の詳細について説明する。
3 BzTree アーキテクチャと設計
3.1 アーキテクチャ
BzTree は高性能なメインメモリ型 B+Tree である。内部ノードは検索キーと子ノードへのポインターを格納している。葉ノードはキーとレコードへのポインタまたは実際のペイロード値を格納している。キーは可変長または固定長である。我々の実験では (メインメモリデータベースでは一般的なように 6]) 葉ノードが 8 バイトのペイロードとしてレコードポインタを格納することを想定しているが、完全な可変長ペイロードを扱う場合についても説明する。BzTree は標準的なアトミック key-value 操作 (挿入、読み込み、更新、削除、レンジスキャン) をサポートするレンジアクセス方式である。ほとんどのアクセス方式と同様に、スタンドアロンの key-value ストアとして展開することもできるし、データベースエンジンに組み込んで ACID トランザクションをサポートすることもできる。この場合、ほとんどのシステムで一般的に行われているように、アクセス方式の外部 (例えばロックマネージャのような) で同時実行制御が行われる [12, 23]。
永続化モード. BzTree の顕著な特徴は、その設計が揮発性環境と永続性環境の両方に対応していることである。揮発性モードでは、BzTree ノードは揮発性 DRAM に格納され、システムが故障すると内容は失われる。このモードは、インデックスを回復するための復旧インフラをあらかじめ備えているため既存のメインメモリシステム設計 (Microsoft Hekaton [6] など) での使用に適している。耐久モード (durable mode) では内部のノードと葉ノードの両方が NVM に保存される。BzTree はすべての更新が永続的に行われることを保証し、障害発生後にインデックスが正しい状態に迅速に復旧できるようにしている。災害復旧 (disaster recovery) やメディア障害では、BzTree はデータベースレプリケーションのような一般的なソリューションに頼らなければならない。
メタデータ. ノードの他に BzTree が使用する 64 ビット値は 2 つだけである:
- ルートポインター. これはインデックスのルートノードへの 64 ビットポインターである。永続化モードで動作している場合、この値は再起動時にインデックスを見つけるために既知の場所に永続化される。
- グローバルインデックスエポック. 永続化モードで動作しているとき、BzTree はインデックスエポック番号に関連付けられている。この値はグローバルカウンター (インデックスごとに一つ) から引き出されている。新しいインデックスではこのカウンターは初期値ゼロで、クラッシュ後に BzTree が再起動したときにのみインクリメントされる。この値は既知の場所に永続化されており、クラッシュ時の回復目的や in-flight 操作 (ノード内の空間割り当てなど) を検出するために使用される。この値の使用についてはセクション 4 と 6 で詳しく説明する。
3.2 複雑性と性能
BzTree の設計は最先端のラッチフリーレンジインデックスの実装上の複雑性と性能上の欠点を解決している。
実装の複雑性. 最先端のレンジインデックスの設計では通常アトミックなプリミティブを使用して状態を更新する。これは単一ワードの更新では比較的簡単である。例えば Bw-Tree [22] は単一ワード CAS を用いてノードを更新し、マッピングテール内の差分レコードへのポインターをインストールする。同様に MassTree [25] のような設計ではステータスワード上の CAS を使用してノードの更新を仲裁する。インデックスを成長 (または縮小) するノード分割や結合のような複数位置の更新を扱う場合の実装はより複雑となる。Bw-Tree では複数ノード操作を単一のアトミック CAS でインストール可能なステップに分割している。同様のアプローチは他の高性能インデックスでもノード間のラッチングを制限するためにとられている。これらのマルチステップ操作はインデックスを同時にアクセスするスレッドに中間状態を漏洩する。つまり、スレッドが (a) 不完全なインデックスにアクセスしていることを認識し (例えば進行中の分割やノード削除を見て)、(b) 進行中の操作を完了させるために協力的な行動をとることができるように、実装には特別なロジックが必要となる。このロジックはコードの肥大化やデバッグ困難な微妙な競合状態を引き起こす [24]。
これから説明するように、BzTree は PMwCAS プリミティブを使用してインデックス状態を更新する。我々はこのアプローチが複数のノードをアトミックに更新する場合でも良好なパフォーマンスを発揮することを示す。BzTree はより複雑な複数ノード操作の微妙な競合状態を回避する。実際、我々は循環的複雑度分析1 (cyclomatic complexity analysis) を用いて BzTree の設計が最先端のインデックス設計である Bw-Tree と MassTree [25] の 2 つと比較して少なくとも半分の複雑度であることを示す。
パフォーマンス考察. Bw-Tree のようなラッチフリー設計は更新 (およびノードの再編成) を一つの場所に分離するためにマッピングテーブルを介した間接参照に依存している。Bw-Tree ノードは、物理ノードへのポインタを格納するマッピングテーブルへのインデックスである論理ノードポインターを格納している。このアプローチにはトレードオフがある。この方法では親ノードなどへのポインタ変更がインデックスを伝播することはないが、各ノードにアクセスする際にポインターの余計な逆参照が必要となる。これによりインデックス探索時のポインター参照の量が実質的に 2 倍となり、我々の実験評価 (セクション 7) で示すようにパフォーマンスの低下につながる。
BzTree ではラッチフリーを達成するために間接参照に依存していない。内部のインデックスノードは子ノードへの直接ポインタを格納しており、走査中に余計なポインターの逆産業が発生しないようになっている。後述のセクション 7 で示すように、ラッチフリーインデックス設計の最新技術と比較したときにこれは高い性能と解釈できる。
- 1循環的複雑度はソースコードを通る線形独立経路数の定量的尺度である。
4 BzTree ノード
このセクションではまず BzTree のノード構成について説明し、次に BzTree がどのようにノード上でラッチフリーの読み取りと更新をサポートするかについて説明する。そしてノードの整理統合 (consolidation) について説明する。整理統合とはデッドスペースを確保して検索を高速化するためにノード内を再構成する操作である。分割や結合などのマルチノードの操作についてはセクション 5 まで延期する。
4.1 ノードレイアウト
BzTree のノード表現は、固定サイズのメタデータがノードの "下方向" に、可変長のストレージ (キーとデータ) が "上方向" に伸びてゆく、典型的なスロットページ (slotted-page) レイアウトを採用している。具体的にはノードは次のように構成されている: (1) 固定サイズのヘッダ、(2) 固定サイズのレコードメタデータエントリの配列、(3) ノードへの更新をバッファリングする空き領域、(4) 可変長のキーとペイロードを保存するレコードストレージブロック。すべての固定サイズメタデータは、PMwCAS のラッチフリー手法での更新を容易にするために 64-bit に配したワードにまとめられている。
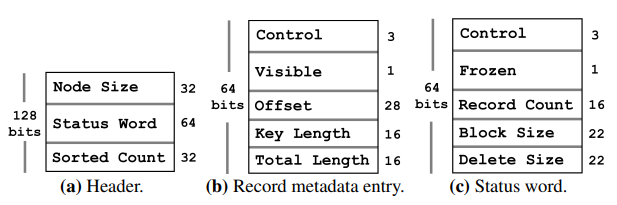
ヘッダー. ヘッダーはノードの先頭に配置され Figure 2 に示すように 3 つのフィールドで構成されている: (1) node size フィールド (32-bit) はノード全体のサイズを保存する、(2) status word フィールド (64-bit) はノードの更新を調整するメタデータ (内容はこのセクションの後半で述べる) を格納する、(3) sorted count フィールド (32-bit) はソート済みレコードメタデータ配列の最後のインデックスである (ここから先のエントリはソートされておらず、ノードに追加された新しいレコードを表している可能性がある)。
レコードメタデータ配列. Figure 2 はレコードメタデータ配列のエントリを示しており、次のように構成されている: (1) フラグビット (4-bit) は PMwCAS の内部メタデータとして使用される PMwCAS control bits2 (3-bit) (例えばフラッシュが必要なダーティワードを示すなど) と、レコードが可視かを示す visible (1-bit) に分割される、(2) offset 値 (28-bit) は key-value ストレージブロック内の完全なレコードエントリを指す、(3) key length フィールド (16-bit) は可変長キーサイズを保存する、(4) total length フィールド (16-bit) はレコードブロックの全長が格納されている (この値から key length を引くとレコードのペイロードサイズになる)。
空き領域. 空き領域はレコードの挿入などのノードの変更を吸収するために使用される。この空き領域は固定サイズのレコードメタデータ配列とレコードストレージブロックの間に配置されている。レコードメタデータ配列はこの領域を "下方向" に、データストレージブロックは "上方向" に伸びてゆく。ただし内部インデックスノードには空き領域がない。後述するように、これらのノードは検索に最適化されているため更新をバッファリングしない。
レコードストレージブロック. このブロックのエントリは key-payload ペアの連続で構成されている。キーは可変長バイト列である。BzTree 内部ノードのペイロードは固定長 (8-byte) の子ノードのポインタである。この論文では葉ノードに格納されたペイロードが (メインメモリデータベースで一般的な [8]) 8-byte のレコードポインタであると仮定する。ただし、BzTree でもリーフノード内に完全な可変長ペイロードを格納することもサポートしている。我々はこのセクションの後半で両方のタイプのペイロードを更新する方法を説明する。
ステータスワード. Figure 2 に示すステータスワードは更新中に変更するノードメタデータを保存する 64-bit 値である。葉ノードではこのワードに次のフィールドが含まれている: (1) PMwCAS control bits (3-bit) はワードをアトミックに更新するために使用される、(2) frozen フラグ (1-bit) はノードが不変であることを告知する、(3) record count フィールド (16-bit) はレコードメタデータ配列のエントリ総数を格納する、(4) block size フィールド (22-bit) はノード末端のレコードストレージブロックが占めるバイト数を保存する、(5) delete size フィールド (22-bit) は、ノードをマージや再編成するタイミングを決めるのに有用なノード内の論理削除領域の量を格納する。内部ノードのステータスワードには 2 つのフィールドしか含まれていない。これは内部ノード上ではシングルトン更新を実行しないためほかのフィールドが不要なためである。検索パフォーマンスの理由から我々は (例えばレコードの追加や更新時に) 内部ノードを大規模 (wholesale) に置き換えることを選択している。
内部ノードと葉ノードの違い. ステータスワードの形式に加えて、内部ノードと葉ノードの違いは、内部ノードが一度作成されてから不変であることに対して葉ノードはそうではないという点である。内部ノードは (高速な二分検索のために) キーでソートされた順序でレコードを保存するだけであり空き領域は含まれていない。一方、葉ノードには挿入 (および葉ノードがフルレコードのペイロードを格納している場合は更新) をバッファリングするための空き領域を持つ。つまり葉ノードはソートされたレコード (ノードが作成されたときに存在したノード) とソートされていないレコードを (ページに加算的に追加されたレコード) の両方で構成されている。我々は、B-Tree の更新の大部分は葉レベルで行われることから、葉ノードがレコードの更新を "その場で" 素早く吸収することが重要であるという理由でこのアプローチを選択した。一方で、内部インデックスノードはほとんどが読み込みであり変更頻度が低いことから、例えばノードの分割の結果として新しいキーを追加する場合などで、大規模な置き換えを許容することができる。我々の経験では内部インデックスノードを検索最適化しておくことで、ソートされたキー空間とソートされていないキー空間との両方で内部ノードを編成するアプローチの方法 [22] よりも良いパフォーマンスとなる。
- 2PMwCAS はこれらのビットを使用してプロパティを機能させる。紙面の理由によりこれらのビットについては詳しく説明しない。詳細は [37] 参照。
4.2 葉ノード操作
このセクションでは BzTree 葉ノードに対するラッチフリーの読み出しと更新について説明する。書き込みについての基本的なアイディアは、スペースの確保 (可変長データをページにコピーする場合) とページにアクセスする並行実行スレッドからの更新を "見える" ようにするために、PMwCAS を使用してラッチフリーでページとメタデータをアトミックに操作することである。読み込みは書き込みにブロックされることなくページにアクセスすることができる。Table 1 はすべてのツリー操作に関連する PMwCAS 操作をまとめたものである。
4.2.1 挿入
新しいレコードはノードで有効な空き領域に追加される。新しいレコード \(r\) を挿入するためにスレッドはまず frozen ビットを読み込む。もし設定されているなら、(例えば並行するノード削除によって) ページは不変であり既にインデックスの一部ではないかもしれない。この場合、スレッドはインデックスを再走査して "ライブ" 葉ノードの新たな実体を見つけなければならない。そうでなければ、スレッドはレコードメタデータ配列とレコードストレージブロックの両方で \(r\) に対するスペースを確保する。これは次のフィールド上での 2-word PMwCAS を実行することで行われる: (1) ノードの status ワードでは record count フィールドをアトミックに 1 つ増やし block size 値に \(r\) のサイズを追加する、(2) レコードメタデータ配列のエントリは、offset フィールドの上位ビットを反転させ、残りのビットをグローバルインデックスエポック3と等しく設定する。この PMwCAS が成功すれば割り当ては成功である。このフェーズの間に割り当てのインデックスエポックを記録するために offset フィールドが上書きされる。我々はこの値を allocation epoch として参照し復旧の目的で使用する (後述)。我々は上位ビットを使用して、値が割り当てエポックであるか (設定) 実際のレコードオフセットであるか (未設定) であるかを告知する。
挿入は、\(r\) の内容をストレージブロックにコピーし、対応するレコードメタデータエントリのフィールドを更新し、visible フラグを 0 (不可視) に初期化することで行われる。コピーが完了すると、インデックスの永続性を確保する必要があればスレッドは (CLWB や CLFLUSH を使用して) \(r\) をフラッシュする。そしてステータスワード値 \(s\) を読み込んで frozen ビットを再度チェックし、(並行で構造が変化したなどで) ページが凍結した場合は中断して再試行する。そうでなければ、次の 2 ワードの PMwCAS を実行してレコードを可視化する: (1) 64-bit のレコードメタデータエントリに対して 2 ワードの PMwCAS を実行し visible ビットを設定し、offset フィールドに実際のレコードブロックオフセットを (上位ビットを unset して) 設定し、(2) ステータスワードに \(s\) (最初に読み込んだ値と同じ値) を設定し、frozen ビットを設定しようとしている並行スレッドとの衝突を検出する。PMwCAS が成功した場合、挿入は成功する。そうでなければスレッドは (frozen ビットが unset されていることを確認しながら) ステータスワードを読み直して PMwCAS を再実行する。
並行性の問題. BzTree では、例えばユニークキー制約を達成するために同じキーの同時挿入を検出できなければならない。我々は同時のキー操作を検出する楽観的プロトコルを次のように実装している。挿入操作が最初にノードにアクセスするとき、ソート済みキー空間からそのキーを検索し、もしキーが存在していれば中断する。
| Tree 操作 | PMwCAS サイズ |
|---|---|
| ノード操作 | |
| 挿入 [割り当て, 完了] | 2, 2 |
| 削除 | 2 |
| 更新 [レコードポインタ, インラインペイロード] | 3, 2 |
| ノード整理統合 | 2 |
| SMOs | |
| ノード分割 [準備, インストール] | 1, 3 |
| ノードマージ | 2, 3 |
- 3領域割り当てが成功した場合にのみ成功するため、割り当てとともにアトミックにこのフィールドを設定することは安全であることに注意。
4.2.2 Delete
4.2.3 Update
4.2.4 Upsert
4.2.5 Reads
4.2.6 Range Scans
4.3 Leaf Node Consideration
4.4 Internal Node Operations
5 Structure Modifications
5.1 Prioritizing Structure Modifications
5.2 Node Split
5.3 Node Merge
5.4 Interplay Between Algorithms
6 BzTree Durability and Recovery
6.1 Persistent Memory Allocation
6.2 Durabiliy
6.3 Recovery
7 Evaluation
7.1 Experimental Setup
7.1.1 Environment
7.1.2 Evaluation Workloads
7.2 Design Complexity
7.3 Runtime Performance
7.4 Durability
7.5 Scan Performance
7.6 PMWCAS Statistics
7.7 Sensitivity Analysis
7.8 Memory Footprint
7.9 Execution Time Breakdown
8 Related Work
9 Conclusion
Acknowledgements
We would like to thank Donald Kossmann, Phil Bernstein, and David Lomet for their feedback that helped improve this work.
10 References
- J. H. Anderson, S. Ramamurthy, and R. Jain. Implementing wait-free objects on priority-based systems. PODC, pages 229–238, 1997.
- S. Chen, P. B. Gibbons, and S. Nath. Rethinking database algorithms for phase change memory. In CIDR, pages 21–31, 2011.
- S. Chen and Q. Jin. Persistent b+-trees in non-volatile main memory. PVLDB, 8(7):786–797, 2015.
- B. F. Cooper, A. Silberstein, E. Tam, R. Ramakrishnan, and R. Sears. Benchmarking cloud serving systems with YCSB. In SoCC, pages 143–154, 2010.
- R. Crooke and M. Durcan. A revolutionary breakthrough in memory technology. Intel 3D XPoint launch keynote, 2015.
- C. Diaconu, C. Freedman, E. Ismert, P.-A. Larson, P. Mittal, R. Stonecipher, N. Verma, and M. Zwilling. Hekaton: SQL Server’s Memory-optimized OLTP Engine. In SIGMOD, pages 1243–1254, 2013.
- Everspin. DDR3 DRAM compatible MRAM: Spin torque technology. https://www.everspin.com/ddr3-dram-compatible-mram-spin-torque-technology-0, 2017.
- K. Fraser. Practical lock-freedom. PhD thesis, University of Cambridge, 2004.
- M. Greenwald. Two-handed emulation: How to build non-blocking implementations of complex data-structures using DCAS. PODC, pages 260–269, 2002.
- J. Handy. Understanding the Intel/Micron 3D XPoint memory. http://www.snia.org/sites/default/files/SDC15_presentations/persistant_mem/JimHandy_Understanding_the-Intel.pdf, 2015. Storage Developer Conference.
- T. L. Harris, K. Fraser, and I. A. Pratt. A practical multi-word compare-and-swap operation. DISC, pages 265–279, 2002.
- J. M. Hellerstein, M. Stonebraker, and J. R. Hamilton. Architecture of a Database System. Foundations and Trends in Databases, 1(2):141–259, 2007.
- M. Herlihy. A methodology for implementing highly concurrent data objects. ACM TOPLAS, 15(5):745–770, Nov. 1993.
- M. Hosomi et al. A novel nonvolatile memory with spin torque transfer magnetization switching: spin-ram. IEEE International Electron Devices Meeting (IEDM), pages 459–462, 2005.
- Intel. Intel Architecture Instruction Set Extensions Programming Reference. https://software.intel.com/sites/default/files/managed/0d/53/319433-022.pdf, 2017.
- Intel Corporation. Intel®64 and IA-32 architectures software developer’s manuals. 2016.
- Intel Corporation. NVM library. http://www.pmem.io, 2016.
- A. Israeli and L. Rappoport. Disjoint-access-parallel implementations of strong shared memory primitives. PODC, pages 151–160, 1994.
- C. Jacobi, T. Slegel, and D. Greiner. Transactional memory architecture and implementation for IBM System Z. MICRO, pages 25–36, 2012.
- V. Leis, A. Kemper, and T. Neumann. The adaptive radix tree: ARTful indexing for main-memory databases. ICDE, pages 38–49, 2013.
- V. Leis, F. Scheibner, A. Kemper, and T. Neumann. The ART of practical synchronization. DaMoN, pages 3:1–3:8, 2016.
- J. Levandoski, D. Lomet, and S. Sengupta. The Bw-Tree: A B-tree for new hardware platforms. ICDE, pages 302–313, 2013.
- J. Levandoski, D. B. Lomet, S. Sengupta, R. Stutsman, and R. Wang. High performance transactions in deuteronomy. In CIDR, 2015.
- D. Makreshanski, J. Levandoski, and R. Stutsman. To lock, swap, or elide: On the interplay of hardware transactional memory and lock-free indexing. PVLDB, 8(11):1298–1309, 2015.
- Y. Mao, E. Kohler, and R. T. Morris. Cache craftiness for fast multicore key-value storage. EuroSys, pages 183–196, 2012.
- Microsoft. Profiling Tools. https://docs.microsoft.com/en-us/visualstudio/profiling/profiling-feature-tour.
- Netlist. Netlist storage class memory: http://www.netlist.com/products/Storage-Class-Memory/HybriDIMM/default.aspx, 2017.
- I. Oukid, J. Lasperas, A. Nica, T. Willhalm, and W. Lehner. FPTree: A hybrid SCM-DRAM persistent and concurrent B-tree for storage class memory. SIGMOD, pages 371–386, 2016.
- I. Oukid, W. Lehner, T. Kissinger, T. Willhalm, and P. Bumbulis. Instant recovery for main memory databases. In CIDR, 2015.
- A. Prout. The Story Behind MemSQL’s Skiplist Indexes. http://blog.memsql.com/the-story-behind-memsqls-skiplist-indexes/, 2014.
- D. Schwalb, T. Berning, M. Faust, M. Dreseler, and H. Plattner. nvm malloc: Memory allocation for NVRAM. In ADMS, pages 61–72, 2015.
- N. Shavit and D. Touitou. Software transactional memory. PODC, pages 204–213, 1995.
- H. Sundell and P. Tsigas. Lock-free deques and doubly linked lists. JPDC, 68(7):1008–1020, July 2008.
- S. Venkataraman, N. Tolia, P. Ranganathan, and R. H. Campbell. Consistent and durable data structures for non-volatile byte-addressable memory. In FAST, pages 61–75, 2011.
- Viking. Viking technology memory and storage: http://www.vikingtechnology.com/uploads/embedded_overview.pdf, 2017.
- H. Volos, A. J. Tack, and M. M. Swift. Mnemosyne: lightweight persistent memory. In R. Gupta and T. C. Mowry, editors, ASPLOS, pages 91–104. ACM, 2011.
- T. Wang, J. Levandoski, and P. A. Larson. Easy lock-free indexing in non-volatile memory. Technical report, Microsoft Research, 2017.
- J. Yang, Q. Wei, C. Chen, C. Wang, K. L. Yong, and B. He. NV-Tree: Reducing consistency cost for NVM-based single level systems. FAST, pages 167–181, 2015.
- R. M. Yoo, C. J. Hughes, K. Lai, and R. Rajwar. Performance evaluation of Intel® transactional synchronization extensions for high-performance computing. SC, pages 19:1–19:11, 2013.
翻訳抄
NVM (不揮発性メモリ) 向けデータ構造 BzTree に関する 2018 年の論文。Microsoft US #10599485 特許。
- J. Arulraj, J. Levandoski, U. F. Minhas, and P.-A. Larson. BzTree: A High-Performance Latch-free Range Index for Non-Volatile Memory. PVLDB, 11(5):553--565, 2018.
- [US Patent] Microsoft (2018) Index structure using atomic multiword update operations
