
論文翻訳: Don't Thrash: How to Cache your Hash on Flash
Michael A. Bender∗§ Martin Farach-Colton†§ Rob Johnson∗ Bradley C. Kuszmaul‡§ Dzejla Medjedovic∗ Pablo Montes∗ Pradeep Shetty∗ Richard P. Spillane∗ Erez Zadok∗
 Abstract
Abstract
多くの大規模ストレージシステムでは、処理する大量のデータを扱うために近似メンバーシップクエリー (AMQ; approximate-membership-query) データ構造を使用している。AMQ データ構造は、メンバーシップクエリーの偽陽性率と空間をトレードオフする辞書である。これは小型で高速なストレージに適合するように設計されており、低速なストレージでの I/O を回避するために使用される。Bloom フィルターは AMQ データ構造のよく知られた例である。ただし Bloom フィルターはメインメモリの外ではスケーリングできない。
この論文では、メインメモリを超えてスケーリングが可能な AMQ データ構造である Cascade フィルターについて説明する。Cascade フィルターは市販のフラッシュベース SSD で 1 秒あたり 50 万件以上の挿入/削除、および 1 秒あたり 500 件以上の検索をサポートする。
Table of Contents
- ∗Stony Brook University.
- †Rutgers University.
- ‡MIT.
- §Tokutek.
1 導入
多くの大規模ストレージシステムでは、近似メンバーシップクエリー (AMQ) に高速に応答するデータ構造を採用している。Bloom フィルター [2] は AMQ のよく知られた例である。
AMQ データ構造は、一連のキーに対して挿入、検索、およびオプションとして削除の辞書操作をサポートする。セット内のキーに対して検索を行うと「存在」という結果が返され、セット内に無いキーに対して検索を行うと少なくとも \(1-\epsilon\) の確率で「非存在」という結果が返される。ここで \(\epsilon\) は調整可能な偽陽性率である。\(\epsilon\) と空間消費量の間にはトレードオフがある。
Bloom フィルターのような AMQ データ構造がどのように使用されるかを理解するために webtable [6] を考えてみる。これはウェブサイトのドメイン名とそのウェブサイトの属性を関連付けるデータベーステーブルである。ユーザが自身でクエリーを実行する一方で、自動 Web クローラーはテーブルに新しいエントリを挿入する。このシステムではデータベーステーブルをより小さなサブテーブルに分割することで挿入率を高く最適化する。
ユーザが検索を行うと、この検索はすべてサブテーブルに複製される。高速な検索を実現するために、システムは各サブテーブルに Bloom フィルターを割り当てる。ほとんどのサブテーブルにはクエリー対象の要素が含まれていないため、システムはそれらのサブテーブルでの I/O を回避することができる。そのため、検索は通常、1 回または 0 回の I/O で完了する。
Webtable と同様のワークロードで高速な挿入と独立した検索を必要とするものは重要性が増している [7, 11, 15]。Bloom フィルターは重複排除 [24]、分散情報検索 [20]、ネットワークコンピューティング [4]、ストリームコンピューティング [23]、バイオインフォマティクス [8, 18]、データベースクエリー [19]、確率的検証 [12] にも使用されている。Bloom フィルターの包括的なレビューについては Broder と Mitzenmacher の調査 [4] を参照のこと。
Bloom フィルターはメインメモリに収まるサイズであれば上手く機能する。Bloom フィルターは保存するデータ項目ごとに約 1 バイトを必要とする。挿入と削除をサポートする Counting Bloom フィルター [10] では 4 倍の空間が必要となる [3]。
Bloom フィルターが大きくなりすぎてメインメモリに収まらなくなった場合に何が問題になるだろうか? 回転するプラッターと可動ヘッドを備えたディスクでは Bloom フィルターは機能しなくなる。回転ディスクは 1 秒あたり 100〜200 回の (ランダムな) I/O しか実行できず、また Bloom フィルターの操作には複数の I/O が必要である。フラッシュベースのソリッドステートドライブでも Bloom フィルターの操作は 1 秒あたり数百回にとどまるが、メインメモリでは 1 秒あたり 100 万回の操作が実行される。
フラッシュメモリにおける Bloom フィルターへの挿入を改善する方法の一つにバッファリング手法 [5] を導入することができる。この考え方は、同じフラッシュページ宛の書き込みをメモリバッファに集め、複数の書き込みを 1 回の I/O で実行するというものである。バッファリングはある程度の改善効果をもたらし [5]、単純な Bloom フィルターと比較して 2 倍以上の改善効果がある。より大きなバッファとデータセットを使用した場合、バッファリングによって 80 倍の改善が得られることが測定されている。
ただし、Bloom フィルターのサイズが大きくなるにつれてメモリ内バッファサイズと比較してバッファリングのスケーリングがうまく行かなくなるため、フラッシュページあたりのバッファリング更新は平均してわずか数回にとどまる。
本論文では AMQ データ構造がメインメモリよりはるかに大きなデータセットに対して効率的でスケーラブル、柔軟かつコスト効果に優れていることを示す。また RAM からフラッシュにスケールアウトするように設計された Cascade フィルターと呼ばれる新しいデータ構造についても説明する。
我々の実験では Cascade フィルターを使用した Intel X25-M 160GB SATA II SSD は 85.9 億以上の要素を含むデータセットにおいて 1 秒あたり 67 万回の挿入と 530 回の検索を実行することができた。Cascade フィルターはバッファリング機能付きの Bloom フィルターの 40 倍、従来の Bloom フィルターの 3,200 倍の速度で挿入をサポートする。検索スループットは Bloom フィルターの 3 分の 1 の速度であり、フラッシュメモリのランダム読み取りの 6 倍程度のコストに相当する。
これらの数値を比較するために Intel X25-M では、1 秒あたり 5,603 回のランダム 4k ブロック書き込み (21.8MB/秒) と、1 秒あたり 3,218 回のランダムな 4k ブロック読み取り (12.5MB/秒) を計測した。ランダムなビット読み取り/書き込みも同等の速度である。シーケンシャル書き込みはおよそ 110MB/秒で実行される。
Cascade フィルターは費用対効果の高い方法で実装できる。例えば 512 バイトのキーを 1PB 保持するデータセンターを想定した場合、市販グレードのフラッシュディスク 10TB を使用すれば偽陽性率が 0.04% 未満の Cascade フィルターを構築できることが結果から分かる。この Cascade フィルターは比較的安価で、データセンターのコストに比べればわずかな額である 35,000 ドル未満で構築できる。
我々の 3 つの貢献は以下の通りである。(1) 挿入と削除、および 2 つの QF のマージやリサイズをサポートする Quotient フィルター (商フィルター) (QF) を導入する。QF は Bloom フィルターと機能的に類似したメモリ内 AMQ データ構造だが、検索時にキャッシュミスが 1 回発生する (Bloom フィルターでは少なくとも 2 回発生する)。QF は Bloom フィルターより 20% 大きいが、Counting Bloom フィルターが 4 倍に膨れ上がることに比べて遜色はない。(2) フラッシュ向けに設計された AMQ データ構造である Cascade フィルター (CF) を導入する。CF は Cache-Oblivious Lookahead Array (COLA) [1] に着想を得たデータ構造に編成された QF の集合体である。(3) CF の性能を理論的に分析し、実験的に検証する。CF は Cassandra [17]、TokuDB [21]、その他の書き込み最適化インデックスシステム、さらに挿入バッファを使用する Vertica [22] や InnoDB [13] などのシステムと同等に、挿入と削除を十分に高速に実行できる。
本論文の残りの部分は以下の構成となっている。セクション 2 では QF と CF のデータ構造について説明し理論的な分析結果を示す。セクション 3 では我々の実験結果を示す。セクション 4 では結論を述べる。
2 設計と実装
このセクションでは CF データ構造を導入し、その性能についての簡単な論理的分析を行う。CF は Cache-Oblivious Lookahead Array (COLA) [1] に似たデータ構造に編成された Quotient フィルターのコレクションで構成されている。COLA に似た CF は I/O 効率の良い方法で QF をマージしてディスクに書き込むことで高速な挿入性能を実現している。このセクションでは QF について説明し、QF を CF に結合する方法を示す。
QF は要素の \(p\)-bit フィンガープリントを格納する。QF は Cleary [9] によって説明されたものに似たコンパクトなハッシュテーブルである。このハッシュテーブルは Knuth [16, セクション 6.4, 演習 13] によって提案された手法である商計算 (quotienting) を採用しており、フィンガープリントは \(q\) 個の最上ビット (商) と \(r\) 個の最下位ビット (剰余) に分割される。剰余は、商によってインデックス付けされたバケットに格納される。Figure 1 は Quotient フィルターを示している。
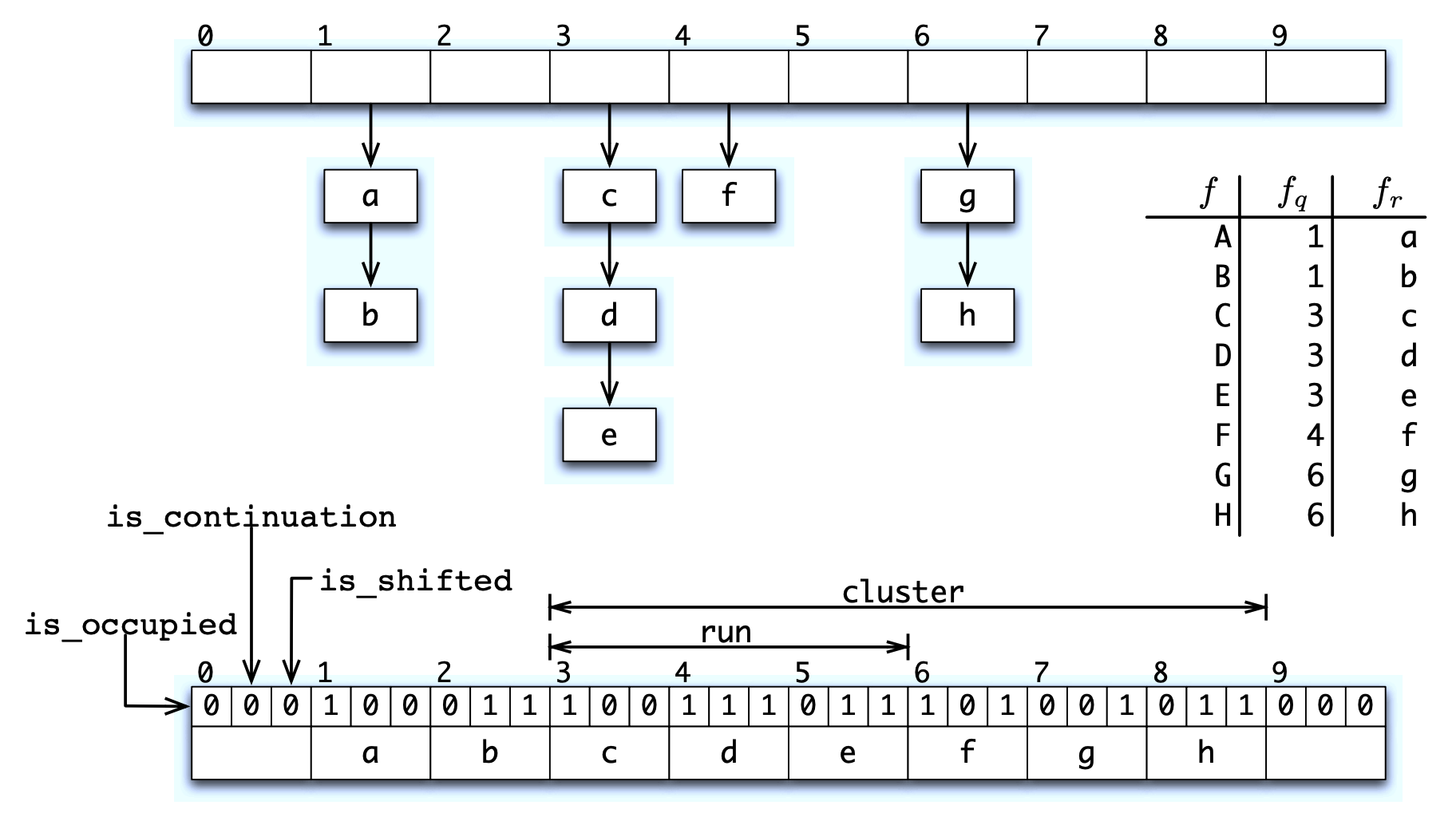
2 つの格納済みフィンガープリントの商が等しい場合、ソフト衝突 (soft collision) が発生したと言う。QF は衝突解決戦略として線形プローブ法を採用しており、剰余をソート順に格納する。そのため、剰余は前方にシフトされ、後続のスロットに保存される可能性がある。衝突が発生しなかった場合にフィンガープリントの剰余が格納されるスロットは正規スロット (canonical slot) と呼ばれる。同じ商を持つすべての剰余は連続して格納され連続部分 (run) と呼ばれる。
クラスタ (cluster) は占有されたスロットの最大シーケンスであり、その最初の要素はクラスタ唯一の要素として正規スロットに格納される。クラスタには一つ以上の連続部分を含むことができる。
クラスタの最初の要素は、各スロットの 3 つの追加ビットと合わせて、クラスタに格納された各剰余の完全なフィンガープリントを復元するためのアンカーとして機能する。
各スロットの 3 つの追加ビットは次の通り:
is_occupied は、スロットがフィルターに格納された値の正規スロットであるかどうかを指定する。
is_continuation は、スロットが連続部分 (ただし最初ではない) の一部である剰余を保持しているかどうかを指定する。
is_shifted は、スロットが正規スロットにない剰余を保持しているかどうかを指定する。
フィンガープリントを挿入するたびに、その商によってインデックス付けされたスロットを占有済みとしてマークし、必要に応じて剰余を前方にシフトして、それに応じてビットを更新する。
3 ビットではなく 2 ビットのインジケータビットを使用する設計もあり、ダミーデータを逆ソート順で格納することで空バケットを識別する。しかしこの方式の実装は CPU 負荷が高いため、実験では代わりに 3 ビット方式を採用した。
偽陽性は 2 つの要素が同じフィンガープリントにマッピングされた場合にのみ発生する。良好なハッシュ関数ではハッシュテーブルの負荷係数 (load factor) を \(\alpha=n/m\) とする。ここで \(n\) は要素数、\(m=2^q\) はスロット数である。この場合、このようなハード衝突 (hard collision) が発生する確率はおよそ \(1 - e^{-\alpha/2^r} \le 2^{-r}\) となる。
QF に必要な空間はパラメータの選択次第で Bloom フィルターとほぼ同程度である。同じ要素数を格納でき、同じ偽陽性率を持つ QF と Bloom フィルターでは、\(\alpha=3/4\) の QF は、ハッシュ関数が 10 個の Bloom フィルターの 1.2 倍の空間を必要とする。
QF はいくつかの便利な操作を効率的にサポートしている。フィンガープリントが昇順で格納されるため、2 つのソート済み配列のマージと同じ方法で 2 つの QF を効率的に 1 つの QF にマージすることができる。また、フィンガープリントは商と剰余から完全に復元できるため、フィンガープリントを再ハッシュすることなく QF のサイズを 2 倍または半分にすることもできる。
Quotient フィルターにおける検索、挿入、削除はすべてクラスタ全体のデコードを必要とするため、クラスタは小さいと主張する必要がある。ハッシュ関数 \(h\) が一様に分散する独立な出力を生成すると仮定すると、チェルノフ境界 (Chernoff bounds) を用いた分析により、高い確率で \(m\) スロットの Quotient フィルターはすべて長さ \(O(\log m)\) の連続部分を持つことが示される。ほとんどの連続部分の長さは \(O(1)\) である。
QF から CF へ
メインメモリに収まる QF の更新は高速である。QF が収まらない場合は更新時にランダム書き込みが発生する可能性がある。同じ偽陽性率と最大挿入数を持つ従来の Bloom フィルターと比較すると、I/O パフォーマンスは優れているが、CF を構築するために複数の QF を使用することでさらに改善できる。
CF の全体的な構造は大まかに COLA [1] と呼ばれるデータ構造に基づいており Figure 2 に示されている。CF は QF0 と呼ばれるインメモリ QF で構成される。さらにサイズ \(M\) の RAM の場合、CF は指数関数的に増加するサイズの \(\ell=\log_2 (n/M)+O(1)\) 個のインフラッシュ QF1, QF2, …, QF\(\ell\) に連続して格納される。簡単のためここでは挿入の場合について説明する (削除は 4 ビット目の墓石ビットを犠牲にして墓石で処理できる)。挿入のみの場合、インフラッシュ QF は空であるかまたは最大負荷率に達している。挿入は QF0 に対して行われる。QF0 が最大負荷係数に達すると、最も小さい空の QF である QF\(i\) を見つけ、QF0 … QF\(i-1\) を QF\(i\) にマージする。CF の検索を行うには空でないすべての QF を調べ、各 QF から 1 ページずつ取得する。
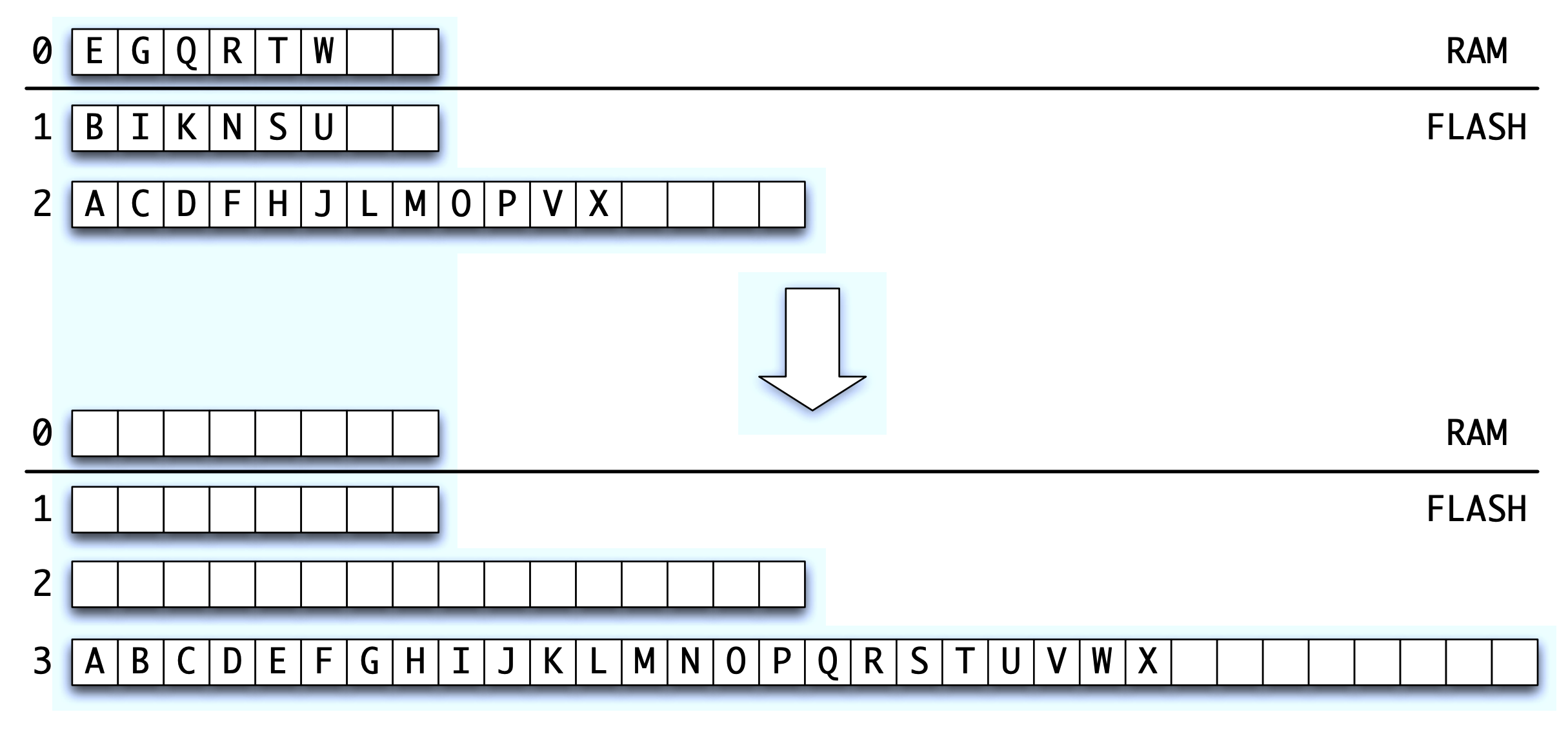
CF のパフォーマンスに関する理論的分析は COLA から導かれる。検索にはレベルごとに 1 ブロックの読み取りが必要であり、合計で \(O(\log(n/M))\) ブロックの読み取りが必要となる。挿入には \(O((\log(n/M))/B)\) の平均ブロック書き込み/消去のみが必要であり、ここで \(B\) はフラッシュの自然なブロックサイズである。通常 \(B \gg \log(n/M)\) であるため挿入や削除のコストは要素 1 つあたりのブロック書き込みよりもはるかに少ない。
CF も COLA と同様に最悪ケースの境界をより良くするために償却解除 (deamortized) することができる [1]。この償却解除により大きな QF をマージすることによって発生する遅延が取り除かれる。
CF の偽陽性率はその構成要素である QF の偽陽性率に類似している。CF は、それぞれ幅が \(p\) ビットの整数の多重集合である。最大レベルが \(\alpha 2^{q-1}\) 個の要素を格納するように構成されている場合、CF 全体では \(\alpha 2^q\) 個の要素を格納できる。構成要素である QF の場合と同じ論法により偽陽性の期待値は \(1-e^{-\alpha/2^r} \le 2^{-r}\) となる。
3 評価
このセクションでは QF と CF の挿入と検索のスループットを評価する。QF を従来の Bloom フィルター (BF) と RAM 上で比較し、CF をフラッシュ上の従来の BF とエレベータ BF と比較する。
実験は、8MB のキャッシュと 24GB の RAM を搭載したクアッドコア 2.4GHz Xeon E5530 上で Linux (CentOS 5.4) を実行して行った。RAM 0.994GB でマシンを起動し、RAM 外のパフォーマンスをテストした。159.4GB の Intel X-25 SSD (第二世代) を使用した。コールドキャッシュとディスク上の同等のブロックレイアウトを確実に確保するため、関連するベンチマークの反復処理は、まず /bin/dd を使用してゼロクリアした新規フォーマットのファイルをシステム上で実行した。スワッピングが発生していないことを確認した。パーティションサイズは 90GB、すなはちドライブ容量の 58% に固定し、これは SSD にとってほぼ最適な値である [14]。CF は 256MB の RAM を使用するように構成した。エレベータ BF は 256MB 分のキーを RAM で使用するように構成したが、メモリの断片化によりこのアルゴリズムでは 512MB 近くを使用した。残りの RAM はファイルシステムのキャッシュに使用された。従来の BF では RAM のすべてがバッファキャッシュに使用されていた。すべてのフィルターの偽陽性率は 0.04% で同じだった。従来の BF とエレベータ BF では 11 個のハッシュ関数を使用するように設定されており、CF では最下位レベルで 11 個の \(r\) ビットを使用して構成された。
QF 挿入スループット. 同じ要素数と偽陽性率で最適なハッシュ関数の数を用いた QF と BF の RAM 内パフォーマンスを比較した。挿入の場合、BF と QF の累積スループットはそれぞれ 1 秒あたり 690,000 件と 2,400,000 件であった。要素数が増加するにつれ QF のパフォーマンスは低下したが BF よりも常に大幅に優れていた。検索についてはベンチマークを通して BF と QF の両方の動作は安定していた。BF は平均で 1 秒あたり 1,900,000 回の検索を実行し、QF は 2,000,000 回の検索を実行した。
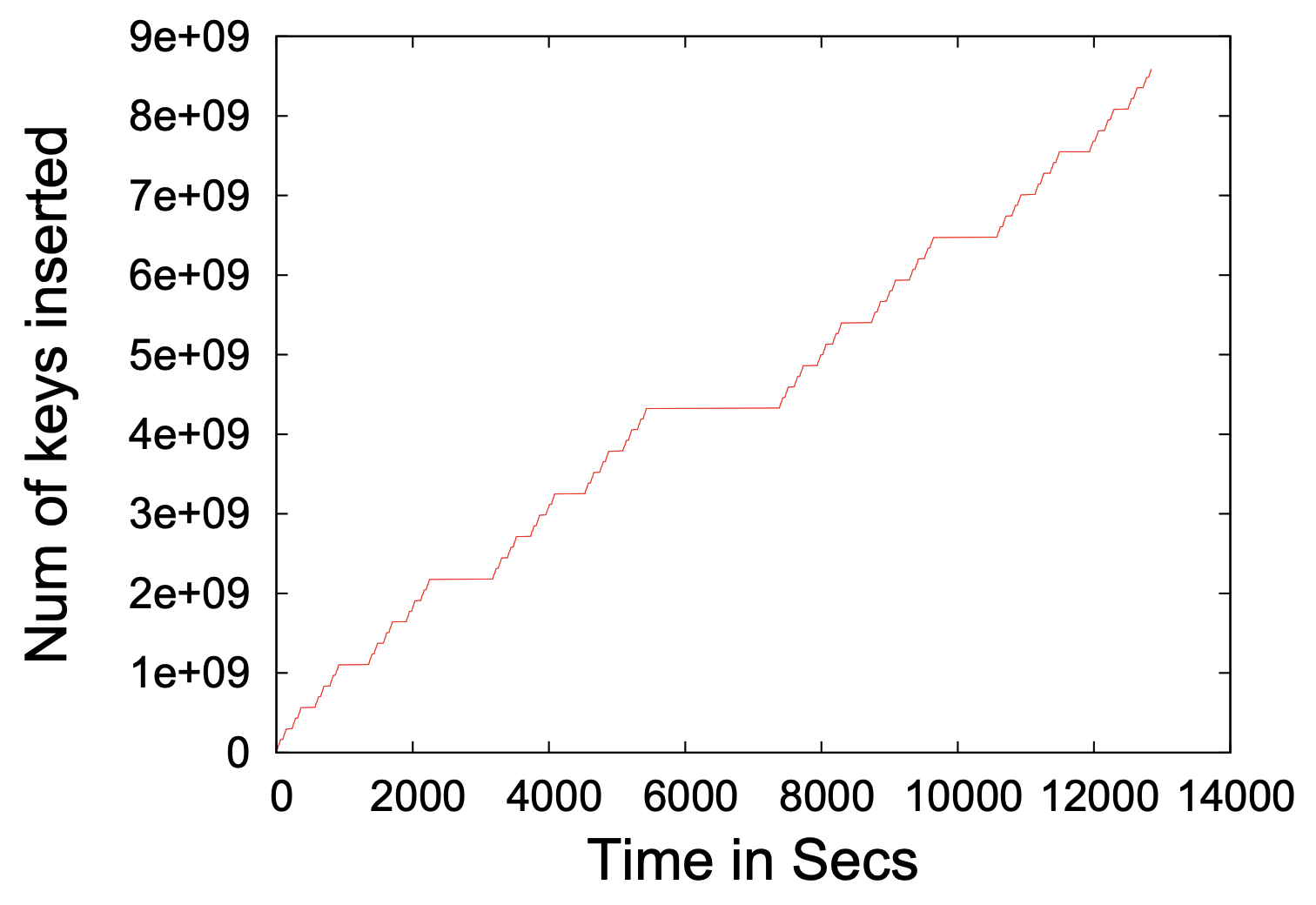
CF 挿入スループット. 85.9 億個の 64 ビットキーを CF に挿入した。Figure 3 は長いマージ処理で挿入が中断した時間を考慮しても、CF は 1 秒あたり平均 67 万回の挿入を維持したことを示している。最大の停滞は中央で発生し、1 つを除くすべての QF が CF の最大の QF にマージされた。我々は実施しなかったが、長い停止を回避する償却解除手法もある [1]。最大のマージは 8.4MB/秒で実行されたが、これはフラッシュのシリアル書き込みスループット (110MB/秒) を遙かに下回っている。システムは CPU に制限されており、QF 内のビットパッキング操作に時間を費やしていることが分かった。実際、CPU 依存が大きかったため、挿入速度が高い場合でもディスクサブシステムは容量のわずか数パーセントでしか実行されなかった。
比較のために (1) 従来の BF と (2) 大きなエレベータ BF の 2 つのデータ構造を評価した。従来の BF はターゲットディスクをストレージとして使用し、キーをハッシュ化してストレージに保存する。書き込みはファイルキャッシュを使用できる。エレベータ BF には次のような最適化がある。最近書き込んだ場所の大きなバッファーを維持し、このバッファがいっぱいになるとオフセット順に各ビットをストレージにフラッシュする。
従来の BF は 1 秒あたり 200 回の挿入を達成したが、エレベータ BF は 1 秒あたり 17,000 回の挿入処理を達成した。これはかなりの改善だが CF のスループットには遠く及ばない。両アルゴリズムのパフォーマンスはフラッシュのランダム書き込みスループットによって制限されるため、データ構造がいっぱいになるにつれて一定となった。
検索スループット. 従来の BF と CF の検索スループットを相互に比較し、そのパフォーマンスの理論的な予測と比較する。
我々の設定では CF はフラッシュ上に最大 6 レベルを保つ。CF では、CF にないキーを検索するときに各レベルで 1 回の読み取りを実行する (6 I/O)。我々のドライブのランダムリードスループットは 1 秒あたり 3,218 の 4kB ページであるため、CF の読み取りスループットは 1 秒あたり約 530 回の検索になるはずである。偽陽性率が同等の 0.04% の BF には 11 のハッシュ関数と 16GB の容量が必要である。その検索スループットを予測するには、最適に構成された BF では各ビットが 1/2 の確率で 1 に設定されていることに注意。BF の検索では 0 が見つかるまでハッシュ関数を次々と使用する。つまり、ネガティブ検索 1 回あたりの I/O の期待値は 2 である。従って検索スループットの期待値はフラッシュドライブのランダム読み取りスループットの半分となり、このケースでは 1 秒あたり 1600 件となる。
計測すると、実際の BF の検索パフォーマンスは 1 秒あたり 1609 回であり、これはモデルの予想値と一致する。ネガティブ CF の検索は 1 秒あたり 530 回であり、これはモデルの予測値 (検索 1 回あたり 6 回の読み取り) と一致する。
墓石ビット付き CF. 削除処理のオーバーヘッドを測定するために、要素あたり 3 ビットではなく 4 ビットを使用した点を除いて同一の実験設定で CF スループット実験を再実行した。その結果、挿入スループットは 1 秒あたり 670,000 挿入に低下していることが分かった。検索スループットは変化しなかった。
評価のまとめ. CF は、ランダム書き込みのキューイングにバッファをすべて使用するように最適化された BF と比較して、挿入スループットを 40 倍高速化する代わりにフラッシュでの検索スループットを 3 分の 1 に低下させる。従来の BF とは異なり CF は CPU に制限され I/O には制限されない。
4 結論と今後の研究
我々は最新のフラッシュドライブの優れた機能を活用するために 2 つの効率的なデータ構造である Quotient フィルター (QF) および Cascade フィルター (CF) を設計した。挿入、クエリー、削除の処理能力が高くなるように設計した。我々の分析結果と評価を組み合わせると、従来の Bloom フィルターの最適化実装を 2 桁以上上回る優れたパフォーマンスが示される。
CPU 操作と比較した I/O の相対コストは過去数十年間に桁違いに増加しており、マルチコアの出現により今後もこの傾向は続くと考えられる。ほとんどのストレージシステムでは I/O を待っている間、CPU が十分に活用されていない。これに対し我々のデータ構造では I/O が効率的に活用され挿入操作は CPU に制限される。マージ操作は並列化が可能でありさらなるパフォーマンスの向上が期待できる。
今後の研究. データセンターや大規模ネットワークにおけるトラフィックルーティング、重複排除、レプリケーション、書き込みオフロード、負荷分散、セキュリティへの応用を検討する。Cascade フィルターは現在 CPU に制限されている。並列実装によりドライブが 400MB/秒のシリアル書き込みを行う場合、1 秒あたり 5,000 万以上の挿入と更新を実行できる可能性がある。効率的な実装は、並列 GPU プログラミングを利用することで非常にコスト効率の高いものになる可能性がある。Cascade フィルターはさまざまな読み取り/書き込み最適化構成が可能であり、実行時にそれらの間で動的に切り替えることができる。Cascade フィルターを書き込み最適化インデックス作成に適用することを検討する。
5 Acknowledgements
Thanks to Guy Blelloch for helpful discussions and especially for suggesting that we use quotient filters.
References
- M. A. Bender, M. Farach-Colton, J. T. Fineman, Y. R. Fogel, B. C. Kuszmaul, and J. Nelson. Cache-oblivious streaming B-trees. In SPAA, 2007.
- B. H. Bloom. Space/time trade-offs in hash coding with allowable errors. Commun. ACM, 13(7):422–426, 1970.
- F. Bonomi, M. Mitzenmacher, R. Panigrahy, S. Singh, and G. Varghese. An improved construction for counting Bloom filters. In ECA, 2006.
- A. Broder and M. Mitzenmacher. Network applications of Bloom filters: A survey. In Internet Mathematics, 2002.
- M. Canim, G. A. Mihaila, B. Bhattacharhee, C. A. Lang, and K. A. Ross. Buffered Bloom filters on solid state storage. In ADMS, 2010.
- F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, and R. E. Gruber. Bigtable: a distributed storage system for structured data. In OSDI ’06: Proceedings of the 7th USENIX Symposium on Operating Systems Design and Implementation, pages 15–15, Berkeley, CA, USA, 2006. USENIX Association.
- F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, and R. E. Gruber. Bigtable: A distributed storage system for structured data. In OSDI, pages 205–218, 2006.
- Y. Chen, B. Schmidt, and D. L. Maskell. A reconfigurable Bloom filter architecture for BLASTN. In ARCS, pages 40–49, 2009.
- J. G. Cleary. Compact hash tables using bidirectional linear probing. IEEE T. Comput., 33(9):828–834, 1984.
- L. Fan, P. Cao, J. Almeida, and A. Z. Broder. Summary cache: a scalable wide-area web cache sharing protocol. IEEE/ACM T. Netw., 8:281–293, June 2000.
- Larry Freeman. How netapp deduplication works - a primer, April 2010. http://blogs.netapp.com/drdedupe/2010/04/how-netapp-deduplication-works.html.
- G. J. Holzmann. Design and validation of computer protocols. Prentice-Hall, Inc., 1991.
- Innobase Oy. Innodb. www.innodb.com, 2011.
- Intel. Over-provisioning an Intel SSD, October 2010. cache-www.intel.com/cd/00/00/45/95/459555_459555.pdf.
- Kimberly Keeton, Charles B. Morrey, III, Craig A.N. Soules, and Alistair Veitch. Lazybase: freshness vs. performance in information management. SIGOPS Oper. Syst. Rev., 44:15–19, March 2010.
- D. E. Knuth. The Art of Computer Programming: Sorting and Searching, volume 3. Addison Wesley, 1973.
- A. Lakshman and P. Malik. Cassandra - a decentralized structured storage system. OS Rev., 44(2):35–40, 2010.
- K. Malde and B. O’Sullivan. Using Bloom filters for large scale gene sequence analysis in Haskell. In PADL, 2009.
- J.K. Mullin. Optimal semijoins for distributed database systems. IEEE T. Software Eng., 16(5):558–560, May 1990.
- A. Singh, M. Srivatsa, L. Liu, and T. Miller. Apoidea: A decentralized peer-to-peer architecture for crawling the world wide web. In SIGIR Workshop Distr. Info. Retr., pages 126–142, 2003.
- Tokutek, Inc. TokuDB for MySQL Storage Engine, 2009. http://tokutek.com.
- Vertica. The Vertica Analytic Database. http://vertica.com, March 2010.
- Z. Yuan, J. Miao, Y. Jia, and L. Wang. Counting data stream based on improved counting Bloom filter. In WAIM, pages 512–519, July 2008.
- B. Zhu, K. Li, and H. Patterson. Avoiding the disk bottleneck in the data domain deduplication file system. In FAST, 2008.
翻訳抄
Quotient フィルターをカスケード上に配置してフラッシュデバイスへ対応した、近似メンバーシップクエリーのための確率的データ構造である Cascade フィルターに関する 2012 年の論文。
- Michael A Bender, Martin Farach-Colton, Rob Johnson, Russell Kraner, Bradley C Kuszmaul, Dzejla Medjedovic, Pablo Montes, Pradeep Shetty, Richard P Spillane, and Erez Zadok. Don’t thrash: How to cache your hash on flash. Proceedings of the VLDB Endowment, 5(11), 2012.
- Don’t Thrash: How to Cache Your Hash on Flash
