eBPF
 概要
概要
eBPF (extended Berkeley packet filter) はカーネルの再構築なしにカーネル空間でプログラムを実行することのできる仮想マシン技術。eBPF のバイトコードは実行時に JIT コンパイラによって検証とネイティブコード変換が行われ、カーネル内の保護された空間 (サンドボックス) で安全かつ効率的に実行することができる。
Table of Contents
導入
BPF は tcpdump(8) を高速化するためにカーネル内で動作する仮想マシンとして 1992 年に BSD Unix に導入された。これは事前定義された命令セットを実行するインタープリタとして機能するもので、アプリケーションの受信するパケットを負荷の低いカーネル空間でフィルタリングすることを目的としていた。BPF は継続的な開発によってカーネル空間で安全に実行できる JIT コンパイラをもつ汎用的な仮想マシン技術と進化し、Linux カーネル 3.18 での大幅な改定以降は eBPF と呼ばれている。現在では cBPF (classic BPF) とも呼ばる旧 BPF の機能はほとんど廃止されている。以下、この文書では BPF は eBPF を意味しているものとする。
Unix ライクな OS の処理はカーネルモードとユーザモードに分かれている。カーネルモードは主にデバイス操作や割り込みのような特権的な処理を行うことができる。ユーザモードで動作する処理はシステムコール (system call) と呼ばれる API を利用してカーネルモードの機能を使うことができる。
カーネル空間は I/O レイテンシーのようなシステムプロファイリングを行うのに最適な場所であるにも関わらず、バージョンごとに非常に神経質な改変が行われることから、あらゆるバージョンで動作するようなドメイン要件の計測からパッチを作成して導入することは難しい。パッチではなくカーネル標準として組み込むとしても、よしんば開発コミュニティを説得できたとしてもリリースまでに数年待たなければならない。BPF はそのような厳格なカーネルを修正することなく、将来のバージョンにわたって利用可能であることが保証されたプログラムをカーネルに追加できる機構といえる。
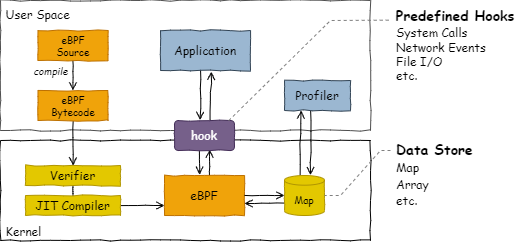
バイトコード
現在の BPF は 11 個の 64-bit レジスタと 512B のスタックフレームを備えた RISC レジスタマシンである。レジスタはプログラムカウンタと読み取り専用のスタックポインタを含んでおり、残りの 9 個を BPF プログラムで使用することができる。
BPF バイトコードの実体は C 言語から LLVM などのバックエンドを介してコンパイルされた命令セットである (したがってユーザ空間でも動作することができる)。カーネルにロードされた BPF バイトコードはシステムを再起動することなくアトミックに更新され、Verifier によって実行安全性の検証を受けてから JIT コンパイラでネイティブコードに変換される。
バイトコードあたりのインストラクション数は 100 万 (カーネル 5.2 より前は 4096) に制限されている。Verifier は BPF バイトコードの実行が一定の時間で終了することを保証するために有界ループが最大インタラクション数を超えないかの検査を行っている (カーネル 5.3 より前はループ命令そのものが禁止されているため for 文はコンパイラレベルで展開やジャンプに置き換えられていた)。
BPF プログラムは末尾呼び出し (tail call) を使って別の BPF プログラムを実行することができる。ただし、これは関数呼び出しのように呼び出し元に制御が戻ることはない。呼び出し元の使用していたスタックフレームを再利用した longjump の動作を行う。
BPF CO-RE (compile once run everywhere) は BPF バイトコードをビルドしたカーネルとは異なるバージョンの環境で実行できるようにする仕組みである。例えばバージョンによって異なるカーネルソース内の構造体フィールド定義を実行時に認識してオフセットを書き換えてるようなことを行っている。ただしこの BPF CO-RE はカーネル 5.13 (Ubuntu 21.10 相当) で導入されたため、現時点で比較的新しいディストリビューションしか利用できない。
フック
BPF はシステムで何かが起きたときに呼び出されるイベント駆動型のプログラムである。BPF プログラムを設置できるポイントをフック (hook) と呼ぶ。システムで利用可能な規定のフック (トレースポイント) は /sys/kernel/debug/tracing/events から参照することができる。
torao@beryl:~$ sudo ls /sys/kernel/debug/tracing/events
alarmtimer devlink hda_controller irq mdio page_isolation rseq timer
asoc dma_fence hda_intel irq_matrix mei pagemap rtc tlb
avc drm header_event irq_vectors migrate page_pool sched tls
block enable header_page iwlwifi mmap percpu scsi udp
bpf_test_run error_report huge_memory iwlwifi_data mmap_lock power signal vmscan
bpf_trace exceptions hwmon iwlwifi_io mmc printk skb vsyscall
bridge ext4 hyperv iwlwifi_msg module pwm smbus wbt
btrfs fib i2c iwlwifi_ucode mptcp qdisc sock workqueue
cfg80211 fib6 i915 jbd2 msr random spi writeback
cgroup filelock initcall kmem napi ras swiotlb x86_fpu
clk filemap intel_iommu kvm neigh raw_syscalls sync_trace xdp
compaction fs_dax interconnect kvmmmu net rcu syscalls xen
cpuhp ftrace iocost libata netlink regmap task xhci-hcd
cros_ec gpio iomap mac80211 nmi regulator tcp
dev gvt iommu mac80211_msg nvme resctrl thermal
devfreq hda io_uring mce oom rpm thermal_power_allocator
torao@beryl:~$ sudo ls /sys/kernel/debug/tracing/events/syscalls
enable sys_enter_msgrcv sys_enter_writev sys_exit_msgsnd
filter sys_enter_msgsnd sys_exit_accept sys_exit_msync
sys_enter_accept sys_enter_msync sys_exit_accept4 sys_exit_munlock
sys_enter_accept4 sys_enter_munlock sys_exit_access sys_exit_munlockall
sys_enter_access sys_enter_munlockall sys_exit_acct sys_exit_munmap
sys_enter_acct sys_enter_munmap sys_exit_add_key sys_exit_name_to_handle_at
sys_enter_add_key sys_enter_name_to_handle_at sys_exit_adjtimex sys_exit_nanosleep
sys_enter_adjtimex sys_enter_nanosleep sys_exit_alarm sys_exit_newfstat
sys_enter_alarm sys_enter_newfstat sys_exit_arch_prctl sys_exit_newfstatat
sys_enter_arch_prctl sys_enter_newfstatat sys_exit_bind sys_exit_newlstat
sys_enter_bind sys_enter_newlstat sys_exit_bpf sys_exit_newstat
sys_enter_bpf sys_enter_newstat sys_exit_brk sys_exit_newuname
...
sys_enter_mq_unlink sys_enter_vmsplice sys_exit_mremap sys_exit_wait4
sys_enter_mremap sys_enter_wait4 sys_exit_msgctl sys_exit_waitid
sys_enter_msgctl sys_enter_waitid sys_exit_msgget sys_exit_write
sys_enter_msgget sys_enter_write sys_exit_msgrcv sys_exit_writevsyscalls/* を見るとかなり多くの (すべての?) システムコール前後をトレースポイントとして使用できることが分かる。例えば syscalls/sys_enter_write というトレースポイントは、システムコール write() が呼び出されたときに起動するフックを意味している (write() の汎用性を考えれば出力に関するかなりの部分がこのトレースポイントでカバーできることが分かるだろう)。
事前定義されていないポイントに対しては、kprobe, uprobe というカーネル処理やユーザ空間のアプリケーションに処理を差し込むための仕組みを使って BPF プログラムを設置することもできる。
ネットワーク向けのフックでは、NIC デバイス上で BPF プログラムを実行できるようなオフロードインターフェースが用意されている。また BPF を使ってカーネルで TLS をサポートする拡張が提案されているように、透過的にデータを加工する用途に使用することもできる。
マップ
BPF プログラムはファイル入出力を含むシステムコールを利用できない代わりにマップ (map) と呼ばれるカーネル空間の key-value ストアを利用することができる。マップは複数の BPF プログラムおよびユーザ空間のプログラムで共有されているため、それらの間でデータ交換のために利用することができる。1 つの BPF プログラムで利用できるマップの上限は現在 64 である。
セキュリティ
BPF をカーネルにロードするには特権モード (root 権限) が必要。これはオプトアウト可能だが、特権モードでない場合は利用できる機能に制限がある。
BPF はカーネルのクラッシュや悪意的な攻撃を防ぐために硬化 (hardening) と呼ばれるメモリ保護機能を持つ。これはカーネルにロードされた BPF プログラムのメモリ領域を読み取り専用としてロックする。また JIT splaying attack を防ぐために (完全な防止策でないものの) JIT コンパイラが有効になっているときはすべての JIT 定数領域がブラインド化される。
libbpf-bootstrap サンプル
libbpf/libbpf-bootstrap は libbpf を使ったサンプル集である。これに含まれているいくつかの BPF プログラムを実際に動かしてみよう。これらは Ubuntu 22.02 環境で以下のようにビルドすることができる。
torao@lazurite:~/git$ sudo apt install -y build-essential clang libelf-dev zlib1g
torao@lazurite:~/git$ git clone https://github.com/libbpf/libbpf-bootstrap.git --recurse-submodules
torao@lazurite:~/git$ cd libbpf-bootstrap/examples/c
torao@lazurite:~/git/libbpf-bootstrap/examples/c$ make
make 時に llvm-strip が見つからないエラーが発生する場合は /usr/bin/llvm-strip-XX のシンボリックリンクを作成する。
torao@lazurite:/usr/bin$ sudo ln -s /usr/bin/llvm-strip-14 /usr/bin/llvm-stripサンプル: bootstrap (C)
libbfp-bootstrap に含まれている bootstrap コマンドはシステム上で起動するすべてのプロセスの開始から終了までの時間をトレースする BPF プログラムである。
上記の例は bootstrap を起動した状態で bash, python3, および libbpf-boostrap 自体の make を実行している。bootstrap 起動画面にそれらの実行で起動したプロセスのプロセス ID や終了コード、実行時間が表示されていることがわかる。
サンプル: xdp の実行 (Rust)
xdp は XDP (express data path) と libbpf-rs (Rust) を使用したサンプルである。cargo が利用可能な環境で以下のようにビルド/実行することができる。
torao@beryl:~/git/libbpf-bootstrap$ cargo install libbpf-cargo
torao@beryl:~/git/libbpf-bootstrap$ cd examples/rust$
torao@beryl:~/git/libbpf-bootstrap/examples/rust$ cargo build --release
torao@beryl:~/git/libbpf-bootstrap/examples/rust$ sudo ./target/release/xdp 1
このサンプルはシステムで発生するネットワークパケットのプロファイリングを行っている。xdp を起動した状態で /sys/kernel/debug/tracing/trace_pipe ファイルを cat すると、各ネットワークデバイスの入力に接続してパケットサイズをログ出力する。
サンプル: minimal の分析
libbpf-bootstrap に含まれている minimal は BPF を動作できる (ほぼ) 最小セットの実装サンプルである。これは BPF CO-RE の代わりにシステムのカーネルヘッダを直接参照するため古いカーネルでも動作する。これはバイトコードがビルド環境のカーネルに強く依存する汎用性のない方法だが、ローカルで実行するだけであればこれでも十分だろう。
minimal コマンドは 1 秒に 1 回 /sys/kernel/debug/tracing/trace_pipe にメッセージを出力する。その動作原理は 1) ユーザ空間側のプロセス \(P_u\) が 1 秒に 1 回 . を出力し、2) カーネル側の BPF プログラム \(P_k\) は \(P_u\) で write() システムコールが呼び出されるたびに起動され trace_pipe にメッセージを出力する。
torao@beryl:~/git/libbpf-bootstrap/examples/c$ sudo ./minimal
[sudo] password for torao:
libbpf: loading object 'minimal_bpf' from buffer
libbpf: elf: section(3) tp/syscalls/sys_enter_write, size 104, link 0, flags 6, type=1
...
libbpf: prog 'handle_tp': found data map 1 (minimal_.rodata, sec 7, off 0) for insn 6
libbpf: map 'minimal_.bss': created successfully, fd=4
libbpf: map 'minimal_.rodata': created successfully, fd=5
Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` to see output of the BPF programs.
...................xdp と同様に、minimal コマンドを実行しながら /sys/kernel/debug/tracing/trace_pipe を経由してメッセージを参照することができる (tail ではなく cat であることに注意)。
torao@beryl:~$ sudo cat /sys/kernel/debug/tracing/trace_pipe
minimal-13986 [003] d...1 13587.843103: bpf_trace_printk: BPF triggered from PID 13986.
minimal-13986 [003] d...1 13588.843427: bpf_trace_printk: BPF triggered from PID 13986.
minimal-13986 [003] d...1 13589.843740: bpf_trace_printk: BPF triggered from PID 13986.
...BPF バイトコードの本体は minimal の実行バイナリに定数としてハードコードされている。そして main() 内で load, attach することでカーネルに BPF プログラムがロードされ write() システムコールにアタッチされる。これは minimal プロセスが終了するとアンロードされる。

minimal サンプルの構造。syscalls/sys_enter_write はすべてのプロセスの write() システムコールに反応してしまうため、実際の BPF プログラムでは PID を比較して自身をロードした minimal プロセスからの write() 呼び出しでのみ処理を行う設計になっている。
以下、minimal のコードを読み解きながら libbpf を使ったプログラム構造について説明する。
BPF プログラム
以下は minimal.bpf.c の内容。
// SPDX-License-Identifier: GPL-2.0 OR BSD-3-Clause
/* Copyright (c) 2020 Facebook */
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
char LICENSE[] SEC("license") = "Dual BSD/GPL";
int my_pid = 0;
SEC("tp/syscalls/sys_enter_write")
int handle_tp(void *ctx)
{
int pid = bpf_get_current_pid_tgid() >> 32;
if (pid != my_pid)
return 0;
bpf_printk("BPF triggered from PID %d.\n", pid);
return 0;
}
6 行目: BPF プログラムのライセンス表明は必須であり、この例ではセクション指定 SEC("license") を使って LICENSE 変数にライセンスを表示している。ライセンスの明示は GPL 非互換の BPF プログラムで一部の機能を使用できないようにするために参照される。
8 行目: libbpf を使った BPF プログラムのグローバル変数は、ユーザ空間のプロセスとカーネルで動作している BPF プログラムで共有することができる。この例の my_pid は後述するようにユーザ空間側のコードから skel->bss->my_pid で参照できる (ビルド時にそのような構造体が自動生成される)。ユーザ空間側のプロセスとの状態共有手段として見るとグローバル変数を使う方法はマップよりも効率が良い。
10-21 行目: SEC("tp/syscalls/sys_enter_write") に続く関数はカーネルにロードされる BPF プログラムの本体である。
SEC() で指定するセクション名は libbpf が作成すべき BPF プログラムの種類と、それをどこのフックにアタッチするか示している。tp/[event] または tracepoint/[event] はトラップポイント (規定のフック) を使用することを示している。syscalls/sys_enter_write は前述の通り /sys/kernel/debug/tracing/events/syscall/sys_enter_write で定義されている名前に相当する。トラップポイント以外では、例えば kprobe を使用する場合は kprove/[function] のようになる。
この例では、任意のユーザ空間プロセスから write() システムコールが呼び出されるたびに起動され、そして write() システムコールを行ったのがユーザ空間側で動作する minimal プロセスであった場合にのみ (つまり PID が一致した場合にのみ) bpf_printk() 経由でメッセージを出力している。
bpf_printk() は /sys/kernel/debug/tracing/trace_pipe にメッセージを出力するためのヘルパー機能である。その他に使用できるヘルパー関数は bpf-helpers(7) — Linux manual page 参照。
ユーザ空間プロセス
以下は minimal.c の内容。
// SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause)
/* Copyright (c) 2020 Facebook */
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "minimal.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
struct minimal_bpf *skel;
int err;
/* Set up libbpf errors and debug info callback */
libbpf_set_print(libbpf_print_fn);
/* Open BPF application */
skel = minimal_bpf__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
/* ensure BPF program only handles write() syscalls from our process */
skel->bss->my_pid = getpid();
/* Load & verify BPF programs */
err = minimal_bpf__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
/* Attach tracepoint handler */
err = minimal_bpf__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
for (;;) {
/* trigger our BPF program */
fprintf(stderr, ".");
sleep(1);
}
cleanup:
minimal_bpf__destroy(skel);
return -err;
}
minimal.skel.h ヘッダファイルは bpftool によって自動生成され、minimal_bpf 構造体と minimal_bpf__xxx() 関数の定義、それにハードコードされた ELF バイナリが含まれている。詳細は make 後に残されている .output/minimal.skel.h を参照。
ユーザ空間で動作する minimal プロセスは、minimal BPF プログラムをオープンし、minimal 以外の write() に反応しないように前述のグローバル変数に PID を設定し、バイトコードをカーネルにロードし、規定のフックにアタッチしたあと、1 秒おきに . を出力して (write() システムコールを呼び出して) BPF プログラムを起動している。
実行環境
この章でのサンプル実行環境は以下の通り。なお Windows 11 の WSL2 + Ubuntu 22.04 や Docker コンテナ上ではビルドは成功するもののいくつかのコマンドはうまく起動ができなかったため、最初は仮想化されていない最新カーネルの Linux 環境で試すことをおすすめする。
torao@beryl:~$ uname -a
Linux beryl 5.15.0-30-generic #31-Ubuntu SMP Thu May 5 10:00:34 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
torao@beryl:~$ cat /etc/lsb-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=22.04
DISTRIB_CODENAME=jammy
DISTRIB_DESCRIPTION="Ubuntu 22.04 LTS"BPF 開発
bpftool のインストール
bpftool は BPF のためのユーティリティである。bpftool を使うことでマップを参照したり更新することができる。
torao@beryl:~$ sudo apt install -y linux-tools-common linux-tools-generic linux-cloud-tools-genericまたは Linux カーネルのリポジトリを取得してソースビルドを行う。
TBC..
User × Kernel パフォーマンス比較
一般にユーザ空間よりカーネル空間で動作するほうが速いと言われるが、実際に BPF での処理はどうなるだろうか。BPF の複雑性検査が失敗しない範囲で右のような簡素な素数判定機を作成した。
以下のコードの左が BPF のトレースポイントをトリガーに起動される関数、右が main() から呼び出される関数である。どちらも 0 から 100 の範囲に含まれる素数の個数を数えている。
typedef unsigned long long u64;
bool is_prime(u64 x) {
if (x < 2) {
return false;
}
for (u64 i = 2; i * i <= x; ++i) {
if (x % i == 0) {
return false;
}
}
return true;
}
// clang -g -O2 -target bpf -D__TARGET_ARCH_x86 ... -c cnt_prime.bpf.c -o .output/cnt_prime.bpf.o
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
char LICENSE[] SEC("license") = "Dual BSD/GPL";
int my_pid = 0;
SEC("tp/syscalls/sys_enter_write")
int cnt_prime(void *ctx) {
int pid = bpf_get_current_pid_tgid() >> 32;
if (pid != my_pid) {
return 0;
}
int count = 0;
u64 t0 = bpf_ktime_get_ns();
for (int i = 0; i <= 100; ++i) {
if (is_prime(i)) {
++count;
}
}
u64 t1 = bpf_ktime_get_ns();
bpf_printk("[%d] %d, %d[nsec]\n", pid, count, t1 - t0);
return 0;
}
// clang -g -O2 -o cnt_prime cnt_prime.c
void cnt_prime() {
struct timespec t0;
struct timespec t1;
int count = 0;
clock_gettime(CLOCK_MONOTONIC, &t0);
for (int i = 0; i <= 100; ++i) {
if (is_prime(i)) {
++count;
}
}
clock_gettime(CLOCK_MONOTONIC, &t1);
u64 elapsed = 1000 * 1000 * 1000 * (t1.tv_sec - t0.tv_sec);
elapsed += t1.tv_nsec - t0.tv_nsec;
printf("%d, %lld[nsec]\n", count, elapsed);
}
Table 1 は上記の cnt_prime() をそれぞれ 15 回呼び出し、最初の 5 回を破棄して 10 回分の計測の平均と標準偏差を出したものである。ユーザ空間での実行よりもカーネルで動作する BPF ほうが 15 倍以上遅いという結果となった。
JIT を有効化している状態でここまで差が出る理由は分からないが、少なくともカーネル空間だから BPF のほうが速いという盲目的な先入観は疑う余地がある。なお -g オプションは (多分グローバル変数名を取得するような目的で) bpftool がシンボルを参照するために必要らしい。
| BPF | ユーザ空間 | |
|---|---|---|
| 平均 | 14,879.1 | 984.0 |
| 標準偏差 | 1,190.0 | 46.2 |
Intel Core i3-10110U CPU @ 2.10GHz + Ubuntu 22.04 (Kernel 5.15.0)
$ sudo cat /proc/sys/net/core/bpf_jit_enable => 1
参照
- Brendan Gregg (2020) Systems Performance, Pearson
- eBPF - Introduction, Tutorials & Community Resources
- BPF and SDP Reference Guide ─ Cilium 1.11.5 documentation
