論文翻訳: Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency
Computer Science Department
Stanford University
 Abstract
Abstract
キャッシュは一貫性を確保するためにオーバーヘッドと複雑さをはらんでおり、そのパフォーマンス上の利点を一部損なっている。分散システムにおいては、キャッシュは通信やホストの障害といった追加の複雑さにも対処する必要がある。
分散システムにおいてリース (lease) はキャッシュされたデータへの効率的で一貫性のあるアクセスを提供する時間ベースのメカニズムとして提案されている。非ビザンチン障害は正確性ではなくパフォーマンスに影響を与えるが、短いリース期間によりその影響は最小化される。V システムにおけるファイルアクセスの解析モデルと評価結果から、リース期間が短いほど良好なパフォーマンスが得られることが示されている。リースがパフォーマンスに与える影響は、システム規模が大きくなりプロセッサ性能が向上するにつれてさらに顕著になる。
Table of Contents
- Abstract
- 1 導入
- 2 リースとキャッシュの一貫性
- 3 リース期間の選択
- 4 リース管理の選択肢
- 5 障害耐性
- 6 関連研究
- 7 結論
- Acknowledgements
- References
- 翻訳抄
1 導入
キャッシュには、キャッシュされたデータとその主要な保存場所との間の一貫性を確保するという課題がある。ここで言う一貫性 (consistent) とは、キャッシュのパフォーマンス上の利点を除けば、データの (キャッシュされていない) コピーが 1 つしか存在しないのと同等の動作を意味する。大規模なキャッシュでは、一貫性を維持するために必要なトラフィックがキャッシュ性能の支配的な要因となることがある。
キャッシュ一貫性プロトコルは、共有メモリ型マルチプロセッサアーキテクチャの研究において広く研究されてきた。この研究はシステムバスによって提供される信頼性の高い同期ブロードバンド通信に依存している。しかし分散システムでは、ホストがクラッシュしたりメッセージが失われたり、部分的な障害が発生する可能性がある。ファイルキャッシュの一貫性に対する既存のアプローチは、信頼性の高いブロードキャストを前提としているため、通信障害を許容しないものと、読み出しのたびに一貫性チェックを必要とするため良好な性能を提供できないものの 2 つに分類される。
この論文では物理クロックを用いてホストと通信の障害を処理する一貫性プロトコルとしてリース (lease) を提案する。V システムのファイルアクセス特性を用いた解析モデルと評価により、障害耐性を考慮した上であっても、短期リースが大規模なシステムにおいてほぼ最適な効率性を実現することが示された。我々は、ネットワーク遅延に対するプロセッサ速度の比率が高く、総合的な故障率も高い将来の大規模分散システムにおいては、リースのメリットがさらに高まると主張する。
次のセクションではリースについて説明し、それがキャッシュ一貫性を実現するためにどのように用いられるかについて述べる。セクション 3 ではリース期間を選択するためのシンプルな解析モデルを導出し、V 分散システム [4] のデータを用いてその適用を検討する。セクション 4 では、リース管理におけるいくつかの最適化について述べる。セクション 5 ではリースの障害耐性を検証する。セクション 6 ではリースを分散キャッシュの一貫性および関連問題に関する他の研究と比較する。結論のセクションでは、我々の研究結果を要約し、リースのさらなる応用と今後の研究の方向性について考察する。
2 リースとキャッシュの一貫性
リースとは、その所有者に一定期間財産に関する特定の権利を付与する契約である。キャッシュの文脈におけるリースは、リース期間 (term) 中、対象となるデータへの書き込み制御権を所有者に与える。そのため、サーバはデータへの書き込みを行う前にリースの所有者の承認を得る必要がある。リース所有者が書き込みを承認すると、そのデータのローカルコピーは無効化される。
リースを使用するキャッシュは、読み取り要求に応答してデータを返す前や、書き込み要求に応答してデータを変更する前に、データに対する有効なリース (データを保持することに加えて) を必要とする。サーバ (データのプライマリストレージ場所) からデータがフェッチされると、サーバはリースも返却する。このリースは、リース期間中、サーバがリース保有者の承認を得ない限りどのクライアントからもデータへの書き込みが行われないことを保証する。リース期間内にデータが再度読み取られた場合 (かつデータがまだキャッシュ内にある場合)、きゃっシューはサーバと通信することなくデータへの即時アクセスを提供する。リースの有効期限が切れた後にデータを読み込むには、まずキャッシュがデータのリースを延長し、リース期間満了後にデータが変更されている場合はキャッシュを更新する必要がある。クライアントがデータを書き込む場合、サーバは各リース所有者が承認するか、リース期間が満了するまで要求を延長する必要がある。
ここではライトスルーキャッシュ (write-through cache) に限定して説明する。ライトスルーではないキャッシュをサポートするためにこのメカニズムを拡張することは簡単である。ライトスルーは明確な障害セマンティクスを提供する。つまり、どのクライアントからも可視化された書き込みが失われることはない。そうでないならアプリケーションは書き込み喪失から回復できるように準備しておく必要がある。ファイルキャッシュのライトスルーコストは法外であると考える人もいるが [18]、書き込みの大部分がテンポラリファイルに集中するため、テンポラリファイルに特別な処理を施すことでそのコストを大幅に削減できる [9, 14]。
リースを用いたファイルキャッシュの動作を説明するために、文書作成に使用されているディスクレスワークステーションを例に挙げる。ワークステーションが初めて latex を実行すると、latex を含むバイナリファイルのリースを (例えば) 10 秒間取得する。5 秒後に同じファイルにアクセスすると、ファイルサーバへの確認なしに、このファイルのキャッシュされたバージョンを使用できる。10 秒の期限が切れたあとにこのファイルにアクセスすると、キャッシュはサーバに確認する必要がある。latex の新しいバージョンがインストールされると、すべてのリース保持者が書き込みを承認するまで書き込みは遅延される。このファイルのリースを保持しているホストにアクセスできない場合はそのリースの有効期限が切れるまで遅延は続く。
上記の例では、関連する読み取りと書き込みはファイルの内容に対する操作に限定されない。繰り返しのオープンをサポートするために、キャッシュはファイル名とファイルの関連付けと権限情報も保持する必要があり、これらの情報を用いてオープンを実行するためにはこれらの情報に対するリースが必要である。同様に、ファイル名の変更など、この情報の変更も書き込みと見なされる。
短いリース期間にはいくつかの利点がある。1 つはクライアントとサーバの障害 (およびパーティションの通信障害) に起因する遅延を最小限に抑えることである。クライアントがサーバと通信できない場合、サーバは、障害が発生したクライアントがリースを保持しているファイルへの書き込みを、そのリースの有効期限が切れるまで遅らせる必要がある1。サーバがクラッシュ後に回復する場合、クラッシュする前に付与したリースを尊重する必要がある。これは、サーバが付与したリースの最大期間を記憶しており、その期間中のファイル書き込みのすべてを遅延させることで、実質的に最大期間分だけ完全回復までの時間を遅延することで最も簡単に実行できる。別の方法としてサーバが永続ストレージ上にリースのより詳細な記録を保持することもできるが、リースの期間が復旧までの時間よりはるかに長くない限り、追加の I/O トラフィックを正当化することは難しいだろう。
短いリース期間はまた偽書き込み共有の発生を最小限に抑える。偽共有 (false sharing) とは、ファイルアクセスに実際の競合が存在しないにもかかわらずリース競合が発生することを指す。具体的には、あるクライアントが保持しているリースでカバーされているファイルに他のクライアントが書き込みを行い、そのクライアントが現在そのファイルにアクセスしていないとき、偽共有が発生する。偽共有は、リースがなければ競合が発生しない状況において、リース所有者へのコールバックのオーバーヘッド (それによる要求元のクライアントの遅延と、リース所有者とサーバの負荷増加) をもたらす。極端に言えば、別のクライアントがファイルを更新する前にクライアントがファイルにアクセスするつもりがなければ、リース期間はゼロに設定されるべきである。
最後に、リース期間を短くすることで期限切れのリースの記録を再利用できるため、サーバのストレージ強健を減らすことができる。しかし、サーバが付与したリースを追跡するためのストレージオーバーヘッドはわずかである。サーバは、各リース所有者の ID と、所有するリースのリストの記録である。各リースに必要なポインタはわずか 2、3 個のポインタのみである。約 100 件のリースを保持するクライアントの場合、合計で 1 クライアントあたり約 1 キロバイト程度である。仮にこれが問題になったとしても、リースをより大きい粒度で記録することで各クライアントが保持するリースの数を減らすことができる。ただし競合が多少増加するという代償がある。広く共有されている最も一般的なファイルクラスについて、クライアントごとの記録をどのように削減できるかを後で示す。
繰り返しアクセスされ、書き込み共有が比較的少ないファイルでは、長期リースはクライアントとサーバの両方にとって大幅に効率的である。これは Andrew ファイルシステムプロジェクト [10] で観察された。このプロトタイプではゼロのリース期間を使用していたが、改訂版では実質的にリース期間を無限大に設定した2。次のセクションでは、リースパフォーマンスの分析モデルを示し、V 分散システムのデータに基づくパラメータを用いて適切なリース期間を決定する。
- 1書き込みの飢餓状態を避けるため、サーバーは書き込みが承認待ちのときやリースの有効期限が切れたときにファイルに新しいリースを付与しない。
- 2その代償として通信障害後の一貫性を保証できなくなる。
3 リース期間の選択
リース期間の選択は、リース延長のオーバーヘッドの最小化と、偽共有の最小化のトレードオフに基づいている。このトレードオフはサーバ負荷とクライアント応答の両方の最小化に適用される。リース空間のオーバーヘッドはそれほど重要ではないため要因としては無視される。さらに、特に短期リースの場合、故障率は平均応答時間に大きな影響を与えない程度に低いと仮定する。最後に、ここでは定期的な延長やセクション 4 で説明する他のオプションではなく、オンデマンドのリース延長のみを検討する。
3.1 シンプルな分析モデル
Table 1 に示す性能パラメータを持つ単一サーバからなるシステムを考える。サーバには 1 つのファイルがあり、そのファイルに対して \(N\) 個のクライアントが存在する。各クライアントの読み取りと書き込みは、それぞれ割合 \(R\) と \(W\) のポアソン分布に従う。ファイルは、書き込まれるたびに \(S\) 個のキャッシュで共有される。ファイルにはクライアントごとに最大 1 つのリースが存在する。
| 記号 | 説明 |
|---|---|
| \(N\) | クライアント (キャッシュ) 数 |
| \(R\) | 各クライアントの読み取り割合 |
| \(W\) | 各クライアントの書き込み割合 |
| \(S\) | ファイルが共有されているキャッシュの数 |
| \(m_{\rm prop}\) | メッセージの伝達遅延 |
| \(m_{\rm proc}\) | メッセージ処理時間 (送信または受信) |
| \(\epsilon\) | クロックの誤差に対する許容値 |
| \(t_S\) | (サーバでの) リース期間 |
送信側と受信側のメッセージ処理時間3 \(m_{\rm proc}\) とメッセージの伝播時間 \(m_{\rm prop}\) はすべてのホストで同じであると仮定する。したがってメッセージは送信後 \(m_{\rm prop} + 2m_{\rm proc}\) に受信され、ユニキャストの要求と応答には \(2m_{\rm prop}+4m_{\rm proc}\) がかかる。マルチキャストメッセージは一度送信され、マルチキャスト機能 [5, 6] を使用して受信者に高い確率で受信される。マルチキャストメッセージの送信と \(n\) 個の応答の受信には \(2m_{\rm prop}+(n+3)m_{\rm proc}\) の時間がかかる4。
リース期間 \(t_S\) の場合、キャッシュに対する有効なリース期間は \[ t_C = \max\left(0, t_S-(m_{\rm prop}+2m_{\rm proc})-\epsilon\right) \] となる。これは、キャッシュがリース \(m_{\rm prop}+2m_{\rm proc}\) を受信するまでの時間と、クロックスキューの許容値 \(\epsilon\) によって \(t_C\) が短縮されるためである。したがって、クライアント間の伝播遅延が大きく、クロックスキューも大きいシステムにおいて、クライアントでのリース期間を実質的にゼロより大きくするためには、サーバはリース期間 \(t_S\) を比例的に長く設定する必要がある。
キャッシュがリースの期間中、リース要求につながる読み取りを含めずに、予想される \(R_{t_C}\) 回の読み取りを処理する場合、リース要求のコストは \(1+R_{t_C}\) 回の読み取りに渡って償却されるため、サーバが処理する拡張関連メッセージの割合は \[ \frac{2NR}{1+R_{t_C}} \] となり、各読み取り要求に \[ \frac{2(m_{\rm prop} + 2m_{\rm proc})}{1 + R_{t_C}} \] の平均遅延が追加される。
サーバは書き込みを受信するとすべてのリース所有者に承認要求をマルチキャストし応答を処理する。書き込み側がリース所有者の 1 人であると仮定すると、書き込み要求に要求元キャッシュの暗黙的な承認が含まれている場合、承認メッセージを 1 つ節約できる5。したがって、承認を得るには 1 つのマルチキャスト要求メッセージと \(S-1\) 個の承認、合計 \(S\) 個のメッセージが必要である6。承認を得るのにかかる時間 \(t_a\) は、\(S \gt 1\) の場合 \[ t_a = 2 m_{\rm prop}+(S+2)m_{\rm proc} \] であり、したがって遅延は最大 \(t_a\)、不可は最大 \(N S W\) である。
ファイルキャッシュ環境では、リース期間は秒単位、メッセージ時間 (\(t_a\) を含む) はミリ秒単位を想定している。したがって、\(t_a\) が \(t_S\) のかなりの割合を占めるようなケースは考慮しない。例外は \(t_S=0\) である。\(t_S\) が 0 以外で \(t_C\) が 0 の場合、書き込みはペナルティを受けるが、読み取りはメリットがないことから、リース時間が 0 の場合、非常に短いリース期間よりも優れていることを認識することが重要である。
リース期間がゼロ、または共有がない場合、付加と遅延はリースの延長によるものに限定される。ただし、\(S \gt 1\) および \(t_S \gt 0\) の場合、サーバは短時間あたり \[ \begin{equation} \frac{2NR}{1+R_{t_C}} + NSW \label{eq1} \end{equation} \] の一貫性関連メッセージを送受信し、\[ \begin{equation} \frac{1}{R+W}\left( \frac{2R(m_{\rm prop}+2m_{\rm proc})}{1+R_{t_C}} + Wt_a \right) \label{eq2} \end{equation} \] の平均遅延が各読み取りまたは書き込みに加算される。
リース期間がゼロの場合の付加は \(2NR\) であり、期間が \(t\) より長い場合は \[ 2NR \gt \frac{2NR}{1+R_{t_C}} + NSW \] であれば負荷はより低くなる。リース利益係数 (lease benefit factor) を \[ \alpha = \frac{2R}{SW} \] と定義すると、\(\alpha \gt 1\) かつ \[ t_C \gt \frac{1}{R(\alpha-1)} \] の場合に前述の条件が成立する。十分に長いリース期間は、\(\alpha\) が 1 より大きければサーバの負荷を軽減する。\(\alpha\) と \(R\) の値が大きいほど短いリース期間のパフォーマンスが向上する7。直感的には、\(\alpha\) は読み取りと書き込みの比率を表し、共有によって発生する追加のオーバーヘッドによってスケールされる。
この分析を複数のファイル処理に拡張すると、複数のリースによる負荷が直接合計されることに注意。キャッシュは拡張要求をバッチ処理することで、単一の要求で複数のファイルをカバーできる。\(R\) と \(W\) はカバーされているすべてのファイルの合計レートに対応するため値はより高くなる。読み取りの絶対レートが高いほど \(\alpha\) が増加するためメリットは大きくなる。一般的に、キャッシュは保持しているすべてのファイルに対してすべてのリースをまとめて拡張する必要がある。
一貫性に起因するサーバ負荷は、サーバが処理 (送信または受信) するメッセージ数にほぼ比例する。リース期間がゼロの場合の一貫性に起因するサーバ負荷の割合がわかれば、(相対的な) 一貫性負荷から (相対的な) 総負荷を計算できる。同様に、アプリケーションレベルの応答時間には、一貫性を確保するために必要な時間に加えてその他の処理も含まれる。
我々が導き出した数式は、次のセクションで示すように、適切なパラメータが与えられれば特定のシステムにおけるパフォーマンスを予測するために使用できる。
- 3処理時間にはパケットの送信後または受信前の処理は含まず、クリティカル遅延パス上の処理のみが対象となる。輻輳によるキューイング遅延や、応答時間のリクエストレートへの二次的な影響は無視される。
- 4伝播時間と処理時間 (\(m_{\rm prop}\) \(m_{\rm proc}\)) の平均には、通常の再送回数が含まれているため、少数の受信者へのマルチキャストに対して我々の推定値は合理的なものである。受信者数 (および応答数) が増加すると再送信が必要になる可能性が高まるため、遅延と処理のオーバーヘッドが増加する。
- 5この最適化は、共有されていないファイルの一般的なケースをクライアントからサーバへの単一のユニキャスト要求-応答で処理できるようにするために特に重要である。つまり、期間を長くすることで、共有されていないファイルに対するサーバ負荷が常に軽減されることを意味する。
- 6マルチキャストがなければ \(2(S-1)\) 個のメッセージが必要となる。
- 7ユニキャストを使用して承認を要求する場合、対応する定義は \(\alpha=R/(S-1)W\) である。
3.2 V における期待性能
V ファイルシステムキャッシングメカニズム [9] を使用したリースの期待性能は、上記で開発した分析モデルと測定から収集されたシステム性能パラメータを使用して決定され Table 2 に示されている。測定値は、イーサネットで接続された MicroVAX II ワークステーション上でファイルサービスとクライアントプログラムを実行し、V ファイルサーバを再コンパイルすることによって生成されたファイルアクセストラフィックのトレースから決定されている。メッセージ時間は V プロセス間通信の個別のタイミングに基づいている。トレースには 1 つのクライアントしか含まれていないため、共有ファイルへの書き込みはありません。妥当な範囲での影響を示すために共有の程度に応じて推定値を計算した。
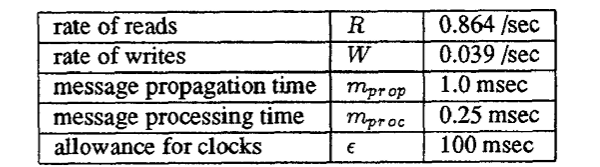
Figure 1 はセクション 3.1 の式 \(\ref{eq1}\) を使用して計算された、期間の関数としての一貫性の相対的なサーバ負荷を示している。Trace とラベル付けされた曲線はキャッシュとサーバのトレースの駆動型シミュレーションを使用して決定された。この曲線は我々の解析モデルから導出された非共有 (\(S=1\)) 曲線に近接しているため、このケースのモデルが検証される。Trace 曲線の屈曲部はより急峻で、より短い期間にあることに注意。この (好ましい) 不一致は予想通りである。このバースト性は、短期的には我々の推定値よりもさらに良いパフォーマンスを示すはずであることを示唆している。
Figure 1 から、リース期間をゼロ以外にすることで得られるメリットのほとんどはわずか数秒の期間で得られる。例えば \(S=1\) の場合、10 秒の期間は一貫性トラフィックがゼロ期間の 10% に削減される。一貫性の負荷はサーバの合計に影響するため考慮する必要がある。リース期間がゼロの場合、トレース内のサーバトラフィックの 30% が一貫性によって占められるため、実際の利点はサーバトラフィック合計の 27% 削減となり、無限期間の場合よりもわずか 4.5% 高いレベルである。\(S=10\) の場合、サーバの総トラフィックはゼロ期間の場合より 20% 減少し、無限期間の場合よりも 4.1% 増加する。リース期間を長くしてもサーバの負荷削減効果はほとんど追加されないが、その一方で、より長いリース期間がもたらすすべてのデメリットが生じる。したがって、これらのファイルアクセス特性に対しては、先に述べた短いリース期間の利点と、長いリース期間によるサーバ負荷の軽微な削減効果を考慮すると、(たとえば) 10 秒のような短いリース期間が最適な選択肢であるように思われる。
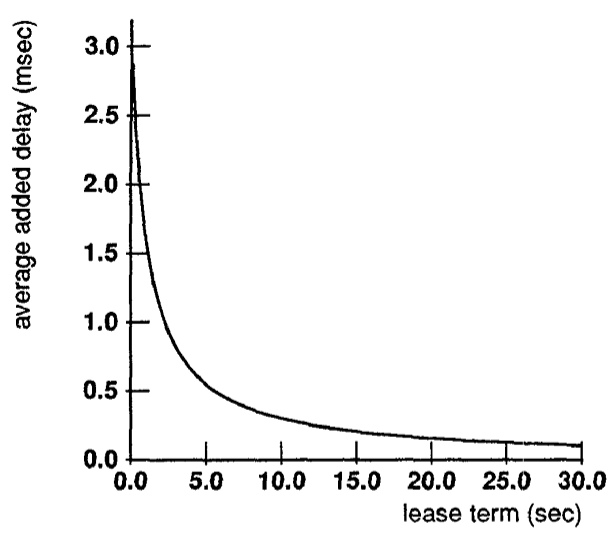
Figure 2 は一貫性によって各読み込みまたは書き込みに追加される平均遅延をリース期間の関数として示している。書き込みは全操作に占める割合が極小さいため、共有書き込みに追加される遅延は平均遅延にほとんど影響せず、\(S=1\) から \(S=40\) までの曲線は図に示されているグラフでは区別できない。繰り返しになるが、リースの利点の多くは 10 秒程度のリース期間で得られる。多くのプログラムはファイルアクセスの間にかなりの計算時間があるため、より長いリース期間による応答時間の改善は極わずかである。
我々は、我々のアクセスレートの測定値が Unix システムでの長期的なトレースで報告されてている [8, 17] とは異なるものの、同様の結果が Unix ライクなシステムにも当てはまると考えている。たとえば我々の読み込みと書き込みの比率は他で報告されているものよりほぼ一桁高い。この違いにはいくつかの要因がある。第一に、(書き込みの大部分を占める) テンポラリファイルに対する操作は、テンポラリファイルをあたかもローカルディスクとして使用するのと同じように扱われるため、測定値には現われない。第二に、他のほとんどのトレースとは異なり、我々の測定にはプログラムのロードやファイルに関する情報へのアクセス (ディレクトリ検索など) が含まれており、これらはいずれも主に読み込み操作である。最後に、読み込みと書き込みの測定は、ブロックが読み書きされるたびではなく、ファイルが読み込みのために開かれたとき、または書き込みで閉じられた (コミットされた) ときに対応している。したがって、ディレクトリ操作は (論理的な) 読み書きより大きな割合を占める。
これらの要因を考慮すると、この短いトレースの構成は Unix システムの長期的なトレースとかなり一致している。最後の要因だけが Unix ファイルシステムのより一般的なセマンティクスからの逸脱を表している。他の 2 つの要因は V のキャッシュ設計の結果であり、Unix システムで有益に採用されるかも知れない。読み書きがブロックレベルの操作に対応する Unix セマンティクスをサポートすると、読み込みの絶対レートは高くなるが、読み書きの比率は (ファイルブロックの読み書きの比率は他のファイルシステムデータよりも低いため) やや低くなる。このようなシステムにおけるリースの性能は質的に類似しているだろう。読み込みレートが高いほどカーブの屈曲率は急峻になり、かなり短い期間が有利になる一方で、書き込み頻度が高くなると共有に対して敏感になる。
3.3 将来の分散システムへの適用性
将来の分散システムの特性を予想するいくつかの傾向がある。システムは広域ネットワークに拡張されつつあり、通信の遅延が増加している。プロセッサの速度も増大し続けている。最後に、クライアントとサーバの両方を含む多数のホストが単一システム内に結合されつつある。
クライアントとサーバ間の伝達遅延が大きくなると、リースの延長および無効化が応答時間に与える影響が大きくなることを意味する。figure 3 はラウンドトリップタイムが 100 ミリ秒のネットワークで他のすべてのパラメータが以前の分析と同様の場合の追加遅延を示している。この場合、10 秒の期間では無限期間を使用する場合と比べて応答が 10.1% 悪化し、30 秒の期間では 3.6% 悪化する。このように、伝播遅延が大幅に増加するとリース期間を若干長くすることが適切であるかもしれないが、10-30 秒範囲の期間は依然として適切であるように思われる。
クライアントプロセッサが高速化すると、読み書き要求間の計算時間が短縮されるため、期間内に発生する操作の数が増加する。レートが高くなるほど負荷曲線の屈曲部が低くなる。アプリケーションレベルの応答時間への影響は、より遅いネットワークの場合とほぼ同じである。つまり、通信遅延に費やされる時間の割合が大きくなるため、一貫性の重要性は大きくなる。
クライアントとサーバの数が増加しても書き込み共有のレベルが増加しない限り大きな影響はない。実際、Montgomery [15] が 12 年以上前に Multics で測定した非常に控えめなレベルから書き込み共有のレベルが増加したという証拠はない。リースには、(一貫性のオーバーヘッドを削減することによって) クライアントとサーバの比率を高め、それによって大規模システムのコストを削減する (または性能を向上させる) という利点がある。
4 リース管理の選択肢
サーバのリース管理には性能を向上させるために利用できるいくつかの選択肢がある。サーバは付与するリースの期間を制御する。また、書き込みの承認を求める代わりにリースの期限切れまで待つことも自由にできる。クライアントは、リースの延長をいつ要求するか、リースをいつ破棄するか、いつ書き込みを承認するかを自由に決定できる。これらの選択肢の組み合わせは負荷と応答時間の間に異なるトレードオフをもたらす。
例えば、クライアントはリースの期限切れを予想し、対象ファイルにアクセスする前に延長を要求するかもしれない。そうすることで読み込みの遅延がなくなり応答時間を改善するが、それはサーバの負荷増加という代償を伴う。特に、アイドル状態のクライアントは、ファイルにアクセスしていない場合でも延長を要求し続け、キャッシュはリースを保持し続けるために偽共有による競合のレベルが上昇する可能性がある。
サーバはこれらの選択肢を利用して、共有アクセスにおいてかなりの割合を占めるインストール済みファイル (installed file) の処理を最適化できる。インストール済みファイルとは、標準的なシステムサポートの一部であるコマンド、ヘッダーファイル、ライブラリなどのファイルである。これらのファイルは広く共有され頻繁に読み込まれるが書き込みはめったに行われない。V システムからのトレースでは、これらのファイルは全読み込みのほぼ半分を占めるが書き込みはゼロであった。インストール済みファイルの処理は、これらのファイルをカバーするためにより少ない数のリースを使用し8 (主要ディレクトリごとに 1 つなど)、インストール済みファイルのリースをカバーする延長要求をすべてのクライアントに定期的にマルチキャストすることで最適化される。これにより、クライアントがこれらのリースの延長を要求する必要がなくなる。加えて、リースによってカバーされているファイルを変更する場合、サーバはマルチキャスト延長から単にそのリースを除外するだけで済む。これにより書き込み操作はリースが期限切れになるとすぐ実行される。このアプローチは、インストール済みファイルが更新されたときに、サーバが多数のクライアントに接続する必要がなくなり、その結果として生じる応答の集中を回避する。多数のクライアントマシンの 1 つが到達不能なためにサーバがリース切れを待機しなければならない可能性が圃場に高いことを考慮すると、この最適化の結果として、インストール済みファイルへの書き込み操作で必ずしも遅延が大きくなるわけではない。この最適化はまたサーバがインストール済みファイルのリース所有者を追跡する必要も排除する。最後に、インストール済みファイルへの書き込みがない場合、これらのリースは期限切れにならないため、クライアントのキャッシュにおけるインストール済みファイルの読み込みに対する追加遅延を排除する。
最後に、サーバは、要求されたファイルのファイルアクセス特性とクライアントへの伝播遅延に基づいてリース期間を設定できる。特に、書き込み共有の多いファイルにはリース期間を 0 に設定することができる。遠方のクライアントに付与されたリースは、伝播遅延によってリース期間が短縮される分と、クライアントがリースを延長することによって発生した追加遅延を補うために増加させることができる。一般に、サーバは、必要な性能パラメータがサーバによって監視されていると仮定して、分析モデルを使用して、ファイルごと、クライアントごとのキャッシュに動的にリース期間を選択できる。
- 81 つのリースで複数のファイルをカバーすることも偽共有を引き起こす可能性がある。インストール済みファイルについては更新頻度が非常に低いためこの影響は無視している。
5 障害耐性
リースは、ホストとネットワークがクロック故障などの特定のビザンチン障害に見舞われない限り一貫性を保証する。具体的には、メッセージ損失 (パーティション化を含む) やクライアントまたはサーバの障害 (クラッシュしても書き込みはサーバ上で永続的であると仮定) にも関わらず一貫性は維持される。さらに、到達不能なクライアントが他のクライアントからの書き込みアクセスをせいぜい短期化送らせるだけなので、キャッシュによって可用性が低下することはない。
リースは適切に動作するクロックに依存する。特に、サーバクロックの進みが速すぎると、クライアントが保持している以前のリース期間がそのクライアントで切れる前に書き込みを許可してしまう可能性があるため、エラーが発生する可能性がある。同様に、クライアントクロックの進みが遅すぎるために故障した場合、サーバが期限切れと見なしているリースを使い続ける可能性がある。反対に、サーバクロックが遅い場合やクライアントクロックが速いというエラーでは不整合は発生しないが、余分なトラフィックを発生させる。このような故障はクラッシュは通信故障よりもはるかに稀である。それらは同期プロトコル、またはリース関連メッセージに明示的なタイムスタンプを含めることによって迅速に検出できる。
また、分散システムのノードのクロックは、数秒のリース期間と比較して小さい \(\epsilon\) 範囲内で同期しているという仮定は合理的であると考える。Unix の make 機能で使用されるファイル変更時刻など、同期された時刻はファイルアクセスの他の側面でも必要である。リースが正しく機能するには、最低限、クロックに基地の制限付きドリフトがあることだけが必要であり、その場合、リース期間はその持続時間 \(t\) として通信できる。
6 関連研究
これまで一貫性を保証してきたキャッシュファイルシステムのほとんどは、リース期間としてゼロまたは無限の期間のいずれかを使用していた。Sprite [16], RFS [1] および Andrew ファイルシステムのプロトタイプ [18] はファイルオープンの粒度でゼロ期間リースを使用していた。Sprite と RFS はファイルがオープンされている間は無限の期間を使用する。Andrew プロトタイプでは、システム構成がスケールアップするに連れて、一貫性チェックによる過度のサーバ負荷が発生した [10]。非ゼロ期間リースはこれら 3 つのシステムすべてに適用可能で、特にプロセッサの高速化とネットワークの遅延の増大により、現在の設計と比較して大幅な性能改善をもたらす。
後発の Andrew ファイルシステム [10, 11] は基本的に無限の期間を使用し、キャッシュされたデータが変更されたときにサーバがクライアントに通知することに依存している。クライアントとの通信が (トランスポート層で) 失敗した場合、サーバは更新を許可し、クライアントは古いデータで操作を続ける可能性がある。クライアントは次にサーバと通信しようとするまでエラーを認識しない。不整合なデータが使用される期間を制限するために 10 分間間隔でポーリングが使用される。Andrew は、通常のメカニズムでのファイル更新コストを回避するために、インストール済みファイルに別の不変ボリュームを使用している。我々の研究は、無限期間のリースとは対照的に短い期間のリースが Andrew にとって適切であり、クライアント故障時に不整合を回避するのに十分な期間、更新を延長できることを示唆している。短いリースのその他の利点も同様に利用可能であり、我々が記述した最適化を使用して、インストール済みファイルを同じフレームワーク内で適切に処理する機能も含まれる。
Burrows の MFS [2] と Mann らによる Echo ファイルシステム [13] は両方ともトークン (token) を使用しており、これらは期限付きリースと見なすことができるが、非ライトスルーキャッシュをサポートしている。拡張すれば、我々の性能分析はこれらのシステムに有益に適用できるだろう。
他のシステムは、NFS [21] のように一貫性を保証しないか、Cedar ファイルシステム CFS [19] のように書き込み共有を禁止することで一貫性の問題を回避してきた。我々は、リースが持つ単純さと効率性、そして一貫性と書き込み共有の重要性を考慮すると、これらの解決策は将来的に魅力が低下するだろうと考えている。特に、リースに必要なソフト状態 (soft state) は、NFS で使用されているいわゆるステートレス (stateless) インターフェースと互換性があることに注目する。
Xerox DFS [20] はタイムアウト付きの破壊可能ロックを使用しており、表面上はリースに似ている。しかし、タイムアウトはトランザクション中止率の過度な増加を避けるために、ロックが破壊されるまでの最小時間を指定している。しかし、クライアントはロックのタイムアウト値を使用せず、ロックが破壊されたときに確実に通知されないため、この方式は期間がゼロのリースに縮退する。
Mirage [7] は無限期間リースを使用して一貫性のある分散共有メモリを提供している。Mirage は、(リースフレームワークの観点から) クライアントがリースを取得してからリースを放棄するまでの最小時間を指定するタイマーと追加してこの機能を補強している。DFS のロックタイムアウトによって中断されるトランザクションを減らすのと同様に、この時間を増やすとスラッシングの量を減らすことができる。
リースに似た時間ベースの手法は少なくとも 2 つの分散ネーミングシステムでも使用されている。Lampson のグローバルディレクトリサービス [12] にはサーバが指定した時間にエントリを破棄するクライアントキャッシュがある。サーバは、エントリが期限切れになる前にエントリを変更することを禁止されている。この条件は、インストール済みファイルに対する我々のリースのポリシーと同等である。ただし、書き込みの承認を要求したり、期間を延長したりする規定はない。
ネームサービスでは、一貫性を保証する必要の無い「ヒント」としてキャッシュデータを使用することが一般的である。例えば、インターネットドメインネームサービス [14] では、ネームサーバが返すデータに time-to-live を指定し、クライアントはその期間データをキャッシュする。ただしデータはその期間内に変更される可能性がある。結果として生じるいかなる不具合も、他の手段で検出して修正する必要がある。Terry [22, 23] は、名前解釈のためのヒントのキャッシュについて、キャッシュの制度を望ましいレベルに維持するためのオプションとして、使用時チェックと定期チェックの使用を含め、より詳細に議論している。
最後に、共有メモリシステムのキャッシュに関する一貫性の研究では、今日まで通信とキャッシュ障害の問題を無視してきた。しかし、リースは大規模な多層共有メモリマルチプロセッサ向けの一貫性プロトコルへの有用な拡張となる可能性がある [3]。
7 結論
リースは、分散システムにおいてファイルキャッシュの一貫性を維持するための、効率的で障害耐性に優れたアプローチである。この論文ではその性能を分析し、実際のシステムの文脈で性能を評価し、その耐障害特性を検証し、他の分散システム、特に将来の大規模・高性能システムへの適用性を検討した。
我々の単純な分析モデルは、リース期間、読み書き比率、共有の程度、メッセージ時間関数として、サーバの一貫政府かと一貫性によって誘発されるキャッシュ要求の遅延を推定する。このモデルは、観察されたファイルアクセス特性に基づいてファイルサーバがリース条件を動的に設定するための基礎を提供する。特に、高い書き込み共有のレベルがファイルキャッシュを非効率にすることを考慮して、非ゼロ期間のリースがいつサーバ負荷を軽減するかを示す。V システムからのデータを使用したトレース駆動シミュレーションは分析モデルの (部分的な) 検証を提供する。
ファイルアクセスの大部分がソフトウェア開発や文章作成である Unix ライクなシステムで期待されるファイルアクセス特性においては、比較的短いリース期間がほぼ最適である。特に、V システムからのパラメータ値とこのモデルを使用すると、10 秒のリース期間は無限期限で達成可能なサーバ負荷の 5% 以内に収まる。我々は V システムのファイルアクセス特性がさまざまな Unix ライクシステムで観察されるものと類似していると主張した。短期間のリースは、クライアントのクラッシュによる書き込み遅延の低減、サーバのクラッシュからの回復遅延の低減、偽共有の削減など、長期のリースに比べて多くの重要な利点がある。
リースは大規模な分散システムに適していると思われる。リースが提供する応答時間の改善は、高速なプロセッサや遅延の大きいネットワークにおいてより顕著である。このような状況では、クライアントまでの往復時間が大きなコストと形、リース期間の選択に影響を与える可能性がある。多数のクライアントを処理するリースのオーバーヘッドは、アクセス特性に基づいて異なる種類のファイルを区別することで削減できる。特に、インストール済みファイル (共有度が高く読み込みアクセスが多いが書き込みは少ないファイル) は、サーバからのマルチキャスト延長を使用してこれらのファイルのディレクトリに対するリースを延長し、明示的なリース無効化のオーバーヘッドを避けるために更新を遅延させることで効率的に処理できる。
Acknowledgements
Acknowledgments. These ideas have benefited from discussions with many members of the Distributed Systems Group, of whom Joe Pallas has been especially helpful. The comments of the SOSP referees, and especially the more detailed reviews by Marvin Theimer and Doug Terry, have helped to improve the quality of this paper. The name “lease” was suggested by Marry Katz.
References
- BACH, M. J., LUJPPI, M. W., MELAMED, A. S., AND YUEH, K. A remote-file cache for RFS. In Proceedings of the Summer 1987 Usenix Conference (June 1987), Usenix Association, pp. 273–279.
- BURROWS, M. Efficient data sharing. Tech. Rep. No. 153, Computer Laboratory, University of Cambridge, Dec. 1988. The author’s PhD thesis.
- CHERITON, D., GOOSEN, H., AND BOYLE, P. Multi-level shared caching techniques for scalability in VMP-MC. In Proc. 16th Int. Symp. on Computer Architecture (May 1989).
- CHERITON, D. R. The V distributed system. Commun. ACM 31, 3 (Mar. 1988), 314–333.
- CHERITON, D. R., AND DEERING, S. E. Host groups: A multicast extension for datagram internetworks. In 5th Data Communications Symposium (Sept. 1985), ACM/IEEE, pp. 172–179.
- CHERITON, D. R., AND ZWAENEPOEL, W. Distributed process groups in the V kernel. ACM Trans. Comput. Syst. 3, 2 (May 1985), 77–107.
- FLEISCH, B. D., AND POPEK, G. J. Mirage: A coherent distributed shared memory design. In Proceedings of the Twelfth ACM Symposium on Operating Systems Principles (Dec. 1989), ACM.
- FLOYD, R. Short-term file reference patterns in a UNIX environment. Tech. Rep. TR 177, University of Rochester, Department of Computer Science, Mar. 1986.
- GRAY, C. G. Performance and Fault-Tolerance in a Cache for Distributed File Service. PhD thesis, Stanford University, Department of Computer Science, 1989. In preparation.
- HOWARD, J. H., KAZAR, M. L., MENEES, S. G., NICHOLS, D. A., SATYANARAYANAN, M., SIDEBOTHAM, R. N., AND WEST, M. J. Scale and performance in a distributed file system. ACM Trans. Comput. Syst. 6, 1 (Feb. 1988), 51–81.
- KAZAR, M. L. Synchronization and caching issues in the Andrew file system. Tech. Rep. CMU-ITC-058, Information Technology Center, Carnegie Mellon University, June 1987.
- LAMPSON, B. W. Designing a global name service. In Proceedings of the Fifth Annual ACM Symposium on the Principles of Distributed Computing (Aug. 1986), ACM, pp. 1–10.
- MANN, T., HISGEN, A., AND SWART, G. An algorithm for data replication. Research Report 46, DEC Systems Research Center, 1989.
- MOCKAPETRIS, P. Domain names — concepts and facilities. Request for Comments 1034, Network Information Center, SRI International, Menlo Park, CA, Nov. 1987.
- MONTGOMERY, W. Measurements of sharing in MULTICS. In Proc. of Sixth ACM Symposium on Operating Systems Principles (1977), ACM, pp. 85–90.
- NELSON, M. N., WELCH, B. B., AND OUSTERHOUT, J. K. Caching in the Sprite network file system. ACM Trans. Comput. Syst. 6, 1 (Feb. 1988), 134–154.
- OUSTERHOUT, J. K., COSTA, H. D., HARRISON, D., KUNZE, J. A., KUPFER, M., AND THOMPSON, J. G. A trace-driven analysis of the UNIX 4.2BSD file system. In Proceedings of the Tenth ACM Symposium on Operating Systems Principles (Dec. 1985), ACM, pp. 15–24. Published as Operating Systems Review 19, 5.
- SATYANARAYANAN, M., HOWARD, J. H., NICHOLS, D. A., SIDEBOTHAM, R. N., SPECTOR, A. Z., AND WEST, M. J. The ITC distributed file system: Principles and design. In Proceedings of the Tenth ACM Symposium on Operating Systems Principles (Dec. 1985), ACM, pp. 35–50. Published as Operating Systems Review 19, 5.
- SCHROEDER, M. D., GIFFORD, D. K., AND NEEDHAM, R. M. A caching file system for a programmer’s workstation. In Proceedings of the Tenth ACM Symposium on Operating Systems Principles (Dec. 1985), ACM, pp. 25–34. Published as Operating Systems Review 19, 5.
- STUGIS, H., MITCHELL, J., AND ISRAEL, J. Issues in the design and use of a distributed file system. Operating Systems Review 14, 3 (July 1980), 55–69.
- SUN MICROSYSTEMS, INC. SunOS Reference Manual, 1988.
- TERRY, D. B. Distributed name servers: Naming and caching in large distributed computing environments. Tech. Rep. UCB/CSD 85/228, Computer Science Division (EECS), University of California, Mar. 1985. The author’s PhD thesis.
- TERRY, D. B. Caching hints in distributed systems. IEEE Trans. Softw. Eng. SE-13, 1 (Jan. 1987), 48–54.
- THOMPSON, J. G. Efficient analysis of caching systems. Tech. Rep. UCB/CSD 87/374, Computer Science Division (EECS), University of California, Oct. 1987. The author’s PhD thesis.
翻訳抄
分散ファイルキャッシュの整合性を効率的かつ耐障害性を持って維持するための「リース」という時間ベースのメカニズムを提案する 1989 年の論文。
インストール済みファイル: 当時の Unix ライクな環境では、多くのクライアントマシンがネットワークを通じて共有ファイルサーバに接続し、/usr をマウントして /usr/bin, /usr/lib, /usr/include などのシステム共通のリソースにアクセスする構成がしばしば行われていた。論文ではその時代背景を反映しており、こうした特性を持つファイルをインストール済みファイルとしてリースメカニズムの適用可能性を論じている。
スラッシング (thrashing): 仮想メモリやキャッシュにおいて頻繁にキャッシュのデータが入れ替わり、実際の処理よりそのオーバーヘッドが支配的になってしまう現象。
- GRAY, C., AND CHERITON, D. Leases: An efficient fault-tolerant mechanism for distributed file cache consistency. In Proceedings of the 12th ACM Symposium on Operating Systems Principles (1989), pp. 202–210.
