
論文翻訳: Detection of Mutual Inconsistency in Distributed Systems
D. STOTT PARKER, JR., GERALD J. POPEK, GERARD RUDISIN, ALLEN STOUGHTON,
BRUCE J. WALKER, EVELYN WALTON, JOHANNA M. CHOW,
DAVID EDWARDS, STEPHEN KISER, AND CHARLES KLINE
 Abstract
Abstract
現在、数多くの分散システムが開発されており、ユーザはある種の通信ネットワークを介して簡単にデータにアクセスできるようになっている。多くの場合はネットワーク障害によってシステムが分断されてもシステムの機能を持続することが望まれている。ここで深刻な問題となるのが、信頼性のためにファイルなどのリソースの冗長コピーをサポートしながら、同時にそれらの整合性 (複数のコピーの同等性) をどのように監視するかということである。これはネットワークの障害により不整合を引き起こし、整合性を維持する試みを中断させる可能性があるため困難である。実際、整合性のないコピーの検出でさえ難しい問題である。従来の方法では 1) 複数のコピーを完全に比較するか、2) いくつかの整合性コピーに対して整合性の有無を診断する簡単なテストを行うかのいずれかであった。ここではバージョンベクトル (version vectors) と起点 (origin points) を含む新しいアプローチを提示し、単一ファイル、複数コピーの相互不整合 (mutual inconsistency) を効果的に検出することを示す。このアプローチは UCLA のローカルネットワーク OS である LOCUS の設計に使用されている。
Index Terms - Availability, distributed systems, mutual consistency, network failures, network partitioning, replicated data.
Table of Contents
I. 導入
近年、ユーザファイルをネットワーク上でほぼ無制限に分散させることができるオペレーティングシステムが数多く開発されている。これらのシステムは RSEXEC, NSW, ELAN [17], DCS [4] などのネットワークオペレーティングシステム (NOS) から SDD-1 [5], [13], INGRES [15] などの分散データベース管理システム (DDBMS) まで多岐にわたる。これらのシステムは複数のファイルシステムの統合的なインターフェースを重視している。ファイルはアクセッサやファイル位置に関係なくネットワーク全体からアクセスできるようになっている。
残念ながら、ネットワークの障害やファイルを保存している場所のクラッシュによってファイルにアクセスできなくなることがあり、ユーザはネットワーク状態のランダムなビューを把握することになる。この問題を解決するために多くのシステムでは信頼性のメカニズムとしてファイルの複製を保持することが提案されている。しかしこの解決方法には別の問題がある。ファイルのコピーが複数存在すると同時に、システムはこれらのコピーの相互整合性 (mutual consistency) を確保しなければならない。ファイルの 1 つのコピーが変更されると、それに応じて独立したアクセスが行われる前にすべてのコピーが変更されなければならない。
分散システムにおける整合性の維持の問題については内部整合性法 (internal consistency methods; あるリソースに同時にアクセスしようとしている複数のプロセスに対して単一のコピーを一貫して見えるようにする方法) から、相互整合性を確保する様々な独創的更新アルゴリズムまで [1], [2], [6], [8], [16] など多くの記述が見られる。ここではネットワーク分断 (network partitioning) に直面したときの相互整合性、すなはち、ネットワーク障害やサイトのクラッシュによりネットワーク内の様々なサイトがある程度の時間互いに通信できなくなる状況について考察する。これはほとんどのネットワークに置いて非常に現実的な問題である。例えば Ethernet [10] でもゲートウェイが普段接続している Ether セグメントは正常に動作しているのに、ゲートウェイがかなりの時間動作していないことがある。
最悪の場合、ネットワーク分断は相互整合性を完全に破壊する。この事実についてどのように処理すべきかについて、過去の議論ではある種の制限や曖昧さ、さらには神経質さが見られたが、環境によってはネットワークが分断されていてもユーザがファイルなどのリソースを変更し続けられることが望ましいし、またそうあるべきである。例えばネットワークオペレーティングシステム (NOS) などがその例である。このような環境では相互不整合は対処しなければならない事実となる。この論文では、このような場合にバージョンベクトルと起点と呼ばれるものを用いることで相互不整合を効率的に検出できることを示す。一旦不整合が検出されるといつくかの調整ステップが必要となる。関係する操作のセマンティクスが単純な場合には自動的な再調整が可能である。
冗長コピーを維持する価値について少し考える。冗長性は信頼性と可用性を向上し、ほとんどの場合アクセス時間を改善するが、ネットワーク分断が発生したときに相互整合性の問題を引き起こす。ファイルを冗長化して保存するかを検討するときには、可用性が向上する利点と相互不整合が発生する可能性、および不整合が発生した場合の影響を考慮しなければならない。多くの NOS 環境ではファイルの更新頻度は中程度であり "衝突" はまれにしか起きない。しかしトランザクション指向の DDBMS では更新頻度が高く、操作のセマンティクスが複雑で整合性が極めて重要な場合がある。
それでもこの論文の結果はネットワーク分断に起因すると想定される相互不整合を許容するシステムであれば有用であろう。我々のアプリケーション (LOCUS [12], [14], [18]) はファイルに関してのものであることから今後は一般的なリソースではなくファイルの相互整合性に限定して論議する。ただしここでのすべての結果はより一般的なコンテキストに適用できることは明らかである。
この論文の構成は次の通り。セクション II ではパーティション分断問題に関する先行研究を簡単に紹介する。セクション III では不整合の検出に関する正式な基礎を構築し、相互不整合を検出するための正確で簡単に実装できる技術を開発している。セクション IV では不整合コピーの再調整で何をしなければならないかを簡単に指摘する。いくつかのケースではこれらの競合の調整をユーザに任せなければならないが、ある種のファイル (メールボックス、ディレクトリ) についてはシステムが自動的に調整を行うことができることも実証されている。最後にセクション V で結論を述べる。
II. パーティション分断の先行研究
ネットワーク分断とは、サイトやリンクの障害によりネットワークが論理的に個別のコンポーネントに分割されることである。分散ファイルシステムの設計では分断に関連した数多くの問題に対処しなければならない。ファイルの相互整合性よりも可用性が重要であったり、ファイルがアクセスできなくなったり古くなったりした場合の対応など、分散ファイルシステムの設計にはパーティション分断に関する問題が数多く存在する。
しかし、我々の知る限りではパーティション分断についてそれほど徹底的に検討されていない。分散ファイルシステムでファイルを更新するためのいくつかの方法が提案されているが、その中で分断についても言及されている。もっとも典型的な対応策は 1 つのパーティション内でのみファイルにアクセスできるようにすることで整合性を確保することである。残念ながら、このポリシーを効率的に実装するとファイルにアクセス可能なパーティションがゼロとなることがよく起きる。以下に既存の提案を紹介する。
Voting: Thomas [16] や Menasce ら [9] によって提案されたような投票ベースのシステムでは可用性を犠牲にして相互整合性を保証する。ファイルを変更したいユーザは投票で過半数の同意を得てファイルをロックする必要がある。サイトの過半数を含むパーティションは最大で 1 つであるため、どのファイルも最大で 1 つのパーティションでアクセス可能となる。しかし残念ながらサイトの過半数を含むパーティションが存在しない可能性もあり、その場合はどのパーティションも更新を行えないことになる。
Tokens: ここでは各ファイルにトークンが関連付けられていると仮定する。トークンを持っている者がそのファイルを変更することができる。トークンの取得は別の問題で多かれ少なかれロックに還元される。このモデルではトークンを含むパーティション内のサイトのみがファイルの更新を許可されるため、トークンの使用は投票を使用するよりも制限が少ない。しかし、紛失したトークンを再作成する問題は自明ではない。さらに、分断が発生したときにトークンがたまたまネットワークのほとんど利用されていない領域に常駐している可能性があり、事実上リソースが利用できなくなることがある。
Primary Site: このアプローチは Alsberg と Day [1] によって議論されたもので、1 つのサイトがファイルのアクティビティに責任を持つことを提案している。パーティション分断 (プライマリサイトのクラッシュを含む) が発生した場合、1) バックアップサイトが新しいプライマリサイトとして選択され整合性が犠牲になる (提案されたアプローチ)、2) プライマリサイトのパーティション以外ではアクセス不能になる、のどちらかとなる。
Reliable Networks and Optimism: SDD-1 システムの通信は "信頼性の高いネットワーク" [5] の使用に基づいている。このネットワークは分断が発生した場合でもすべてのメッセージを最終的な配信を保証する。この配信は通信中断中に送信メッセージを保存する "spooler" に依存している。プライマリサイトのモデルと同様に、後から一貫したデータを仮定することはうまく行かない可能性があるという意味で "楽観的" [6] だが、異なるパーティションで行われた作業が何らかの方法で不整合であることを検出し、ユーザが元に戻すか、何らかの方法で統合しなければならない可能性はかなり高いだろう。
Disk Toting: Xerox Parc など、非常にインテリジェントな端末がネットワークで結ばれている施設で利用されているこのアプローチは、ファイルは冗長的に保存されるのではなくリムーバブルストレージメディアに保存され、長時間の分断の間に持ち歩くことができる。このように可用性と一貫性は同時に達成されるが自動的に達成されるわけではない。このアプローチは、各サイトが互換性のあるポータブルストレージメディアを備え、発生する遅延や不便さを許容できるローカルネットワークのみで有効であることは明らかである。
これらのアプローチはいずれも 1) どのようにしてファイルの競合バージョンを検出するか、2) 複数のパーティションのマージ時にこれらの競合するファイルが検出された場合に何をすべきか、を明らかにしていないことに注意。ファイルの可用性を制限することで競合の可能性を排除するか、または競合していると思われるファイルを競合していない最新の状態まで "ロールバック" する必要がある。次のセクションでは、可用性を制限することなく、不可避的にファイルの競合バージョンが検出された場合を除き、すべての場合で更新の正しい伝播を保証する方法を示す。
III. 相互不整合の検出
パーティション分断問題が難しい理由の一つは、最終的にネットワーク全体が接続されるより前に各パーティションがサブパーティションに分割されたり他のパーティションとマージされたりする可能性が何度もあることである。ネットワークが完全に接続されることは実際には起きないかもしれない。しかし、送信されたすべてのメッセージは動的に変化するパーティションを介して最終的に配信されるかもしれない。この喜ばしくない事態に陥った中で、セクション II のようにファイルの可用性を制限することなくファイルの相互整合性を保証するにはどうすればよいだろうか? ここではファイルシステムの不整合または "競合" を簡単かつ正確に検出できる方法を示す。これにより問題の大部分が解決する。次のセクションではこれらの不整合をどのように再調整するかについて説明する。
パーティション分断後に発生するファイルの "競合" の意味を形式化し、分断が引き起こす可能性のある不整合の種類を特定する必要がある。前述のように、これは分断化の対象となるシステムで多くの基本的なシステム原理が無効になるため重要な点である。まず分断化されたシステムでは名前変更、削除、さらには冗長に保存されたファイルやリソースの生成セマンティクスが非常に不明確である。第二に、さらに悪いことにシステム内のエンティティのユーザに見える名前がエンティティ自体を一意に特定したり、正しく特定することさえできないとみなされる可能性がある。パーティション分断後に同じ名前の 2 つのファイルが独立して作成されていたり、同じファイルに対して 2 つの独立した更新が行われていたりすることがある。一般に、あるパーティションの名前は別のパーティションのエンティティとは関係がない。これがファイルの名前変更と削除のセマンティクスを定義するのが難しい主な理由である。パーティション分断に影響を受けない何らかの形のシステムエンティティ識別方法が必要である。以下では "起点" と "バージョンベクトル" を使用してこれを実現する。
A. ファイル競合の種類と起点
(ネットワーク) パーティションとは、あるファイルのセットについて共通の同期されたビューを共有するサイトのセットである。
ファイル \(f\) の起点 \(OP(f)\) は \(f\) が作成されたときに生成されるシステム全体で一意の識別子である。これは \(f\) の不変的な属性だが \(f\) の名前はそうではない (実際 \(f\) は複数のシステムワイドな名前を持つことがある)。したがって更新や名前の変更を何度行っても \(OP(f)\) は変わらない。
ファイルの起点は (作成日時, 作成サイト) ペアのようなものかもしれない。現在、名前でファイルを一意に特定できないのと同様に起点も一意に特定できないが重要な情報を提供する。起点は 2 つのファイルが共通のファイルをベースにしていることを示すが、両方が独立して変更された可能性があるため 2 つのファイルが同一であるかどうかは示さない。
検討したい競合には名前の競合とバージョンの競合の 2 種類がある。起点が異なる 2 つのファイルのシステムワイド名が同じである場合に名前の競合が発生する。対照的に、同じファイル (同じ起点) の 2 つのバージョンが "互換性なく" 変更された場合にバージョンの競合が発生する。前置きが長くなったがバージョンの競合は以下でより正確に定義される。
ファイル \(f\) に関連付けられたあるバージョンの変更 ID (modification ID) は、あるパーティションにおいてそのパーティションに関連するある時点に \(f\) が変更されたことを示すシステム全体で一意の識別子である。ファイル \(f\) のバージョンの変更履歴 (modification history) とは、\(f\) に発生したバージョン変更に対応する変更 ID の集合である。2 つの修正履歴はそれらが同一であるか一方が他方の初期履歴 (initial history) である場合に互換性があり (compatible)、そうでない場合には互換性がない (incompatible)。
同じファイル \(f\) (同じ起点) の 2 つのバージョンが互換性のない変更履歴を持っている場合、バージョンの競合が発生すると定義する。
あるファイルの 2 つのバージョンが同一の内容ではない場合、それらの変更履歴は常に異なることに注意。しかし、あるファイルの 2 つのバージョンが同一の内容であっても互換性のない履歴を持つ可能性がある。例えば銀行口座の残高を記録したファイルがあると仮定する。残高は最初 2,000 万ドルで、両方のパーティションがそれを 0 ドルに減額した場合、パーティションのマージ時には両方のバージョンが 0 ドルになっているが競合が発生している。また "減額" のセマンティクスが "引出" を意味する場合、直感的に競合が発生するはずである。
我々はファイル内容のセマンティクスについて何も知らされていなければバージョンの競合に関するこの定義は合理的なものであることを主張する。
名前の競合を検出するのは簡単だがバージョンの競合を効率的に検出するのはより困難である。後者の問題は次のセクションで取り上げる: 様々なコピーの変更、削除、名前の変更。
B. バージョン競合検出の問題
単純なタイムスタンプ方式を使えばファイル間で起き得るバージョンの競合を検出できると考える人もいるかも知れない。ファイルがパーティション内で更新されるたびに更新時刻と前回の更新時刻をマークする。パーティションのマージ時にファイルのコピーのタイムスタンプが全て同一であるか (ファイルの更新が発生していない)、またはファイルの 1 のコピーがほかのコピーと 1 つの更新によって異なっているかを確認する。このように更新が 1 回しか行われていない場合には競合は発生しないがより複雑な状況ではバージョンの競合状態が発生する。一部の非競合状態が競合として処理されるためこのアプローチは一般的に不十分である。
バージョン競合の問題を次のように説明する。あるファイルのパーティションとは、ファイルのすべてのコピーが相互に一貫性を持って維持されるネットワーク上のサイトの部分集合と考える。この定義はネットワーク障害の物理的な詳細に厳密に関連付けられていないことに注意。そうではなく、ここではファイルと一貫性という上位概念に基づいてパーティションを定義している。あるファイル \(f\) の異なるバージョンを持つ 2 つのサイトがしばらくの間通信していたとしても、2 つのバージョンの違いが解消されない限りそのサイトは \(f\) に対して共通のパーティションにあるとはみなされない。
定義: 任意のファイル \(f\) のパーティショングラフ \(G(f)\) は次のようにラベル付けされた有向非巡回グラフ (dag) である。そのソースノード (および、もし存在するならシンクノード (sink node)) にはファイル \(f\) のコピーを持つネットワーク上のすべてのサイトの名前がラベル付けされ、他のすべてのノードにはこの名前集合の部分集合がラベル付けされる。各ノードはグラフ上の祖先ノードに現れるサイト名でのみラベル付けされ、逆にノード上のすべてのサイト名はその子孫ノードの 1 つに正確に現れなければならない。さらに、対応するパーティション内で 1 回以上更新された場合、および/またはバージョンの競合を再調整しなければならない場合にはノードに "+" がマークされる。
この後者の状況を再帰的に次のように定義する。\(P\) を \(G(f)\) のノードとする。\(P\) から \(G(f)\) 上の別のノード \(P1\) と \(P2\) への後方経路が存在し、以下の場合に \(P\) でバージョン競合を再調整しなければならない。
- \(P1\) と \(P2\) の両方で \(f\) の更新および/または \(f\) のバージョン競合の再調整が行われた。
- \(P\) の祖先ノードで、\(P1\) と \(P2\) の両方に 2 つの後方経路を持つものが存在しない。
したがって \(G(f)\) の各ノードは \(f\) のパーティションに対応しており、ラベル付けされたサイトが \(f\) に関する情報を "同期" して維持する期間である。ノードラベルに表示されるすべてのサイトは \(f\) のコピー間に存在する可能性のあるすべての差異を解決する。\(G(f)\) のノード間のすべての接続は、パーティションまたはマージの下でネットワークの遷移を示している。
競合と再調整の定義は以下の理由でセクション III-A の概念をモデル化している。第一に、再調整するバージョン競合は 2 つの先行するパーティション \(P1\) と \(P2\) によって生成されたものでなければならず、互換性のない修正セットを与える。第二に、逆に、ある種のファイル変更 (更新または更新の再調整) が 2 つのパーティション \(P1\) と \(P2\) で独立して発生した場合、これらのパーティションのサイトが \(f\) を検査するたびに、バージョン競合が後に発生しなければならない。条件 2) はパーティション \(P\) が相互整合性が再び確立される最初のポイントであることを保証する。
パーティショングラフの例を Fig 1 に示す。ここでは \(f\) をサポートする \(A\), \(B\), \(C\) および \(D\) の 4 つのサイトがある。最初はつながっていたこれらのサイトに複数のパーティションが発生し、最初は \(A\) と \(B\) は通信可能だが、\(C\) と \(D\) からは分離されている。最終的には 4 つのサイトすべてがグラフの一番下のノードで再接続される。ファイル \(f\) はまず \(\{A,B\}\) パーティションで変更され、続いて \(\{A\}\) と \(\{B,C\}\) の両方のパーティションで変更される。\(BC\) または \(BCD\) パーティションでは、サイト \(B\) が常に \(f\) の最新バージョンを持っているため、この一連の変更によってバージョン競合が発生しないことに注意。競合検出のインテリジェントな実装ではこの事実を認識し、サイト \(C\) または \(D\) に \(f\) のバージョンが現在のものと競合していることを通知しないようにする必要がある。しかし、最終的な \(ABCD\) パーティションでは、\(f\) の両方のバージョンが互換性のない修正セットを持っているため競合が再調整される (されるべきである)。
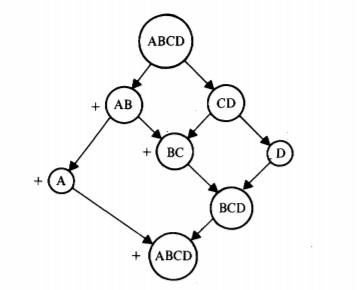
さて、前述のようにすべての可能なバージョン競合を検出する何らかのメカニズムを提供するのは簡単である。しかし、より難しいのはバージョン競合が実際に起きたときのみ検出するメカニズムを見つけることである。例えば Fig 1 では最初の更新がサイト \(A\) によって開始されたとしても、この情報はサイト \(B\) によってサイト \(C\) と \(D\) に競合することなく伝達される。
C. バージョン競合とバージョンベクトル
バージョン競合を正確に検出するという問題を解決するために多くのアプローチが存在している。より精巧なタイムスタンプ方式も考えられるし、"更新ログファイル" ("ジャーナリング" と呼ばれることもある) に基づく方法も数多く存在する。残念ながらこれらのアプローチには 1) ある種のグローバルなネットワーク時間を維持する必要があること (それ自体は自明ではない [7]) と、2) パーティショングラフ全体 (またはそれに相当するもの) を後でアクセスできる場所に保存する必要があること、のいずれかまたは両方がある。パーティショングラフは任意に大きくなる可能性があるため後者の要件は望ましくない。そこで、履歴グラフの必要な特性だけを符号化したバージョン番号方式に基づいてこの問題の簡単な解決策を提示する。
各ファイルのコピーごとにベクトルを管理する。これらのベクトルはそれぞれのパーティション (相互整合性の単位) 内でファイルの更新履歴を維持する。パーティションが統合されると、不一致の可能性があるファイルのこれらのベクトルが比較される。ベクトルが "非互換" の場合のみバージョンの競合が通知されることがわかる。これを次のように形式化する。
定義: ファイル \(f\) のバージョンベクトル (version vector) は \(n\) 個のペアの列である。\(n\) は \(f\) が保存されているサイトの数である。\(i\) 番目のペア \(S_i:v_i\) はサイト \(S_i\) で作成された \(f\) の最新のバージョンのインデックスを示す。言い換えると、\(i\) 番目のベクトルエントリはサイト \(S_i\) で行われた \(f\) の更新の数 \(v_i\) をカウントしている。ここではサイト名に文字 \(A\), \(B\), \(C\), \(\ldots\) を使用し、ベクトルは \(\langle A:9\), \(B:7\), \(C:22\), \(D:3 \rangle\) のように記述する。
定義: バージョンベクトルの集合は、あるベクトルが他のベクトルに対して、それぞれのエントリの全てのサイトの成分において少なくとも大きいときに互換性がある。ベクトルの集合はそれらが互換性を持たない場合に競合する。
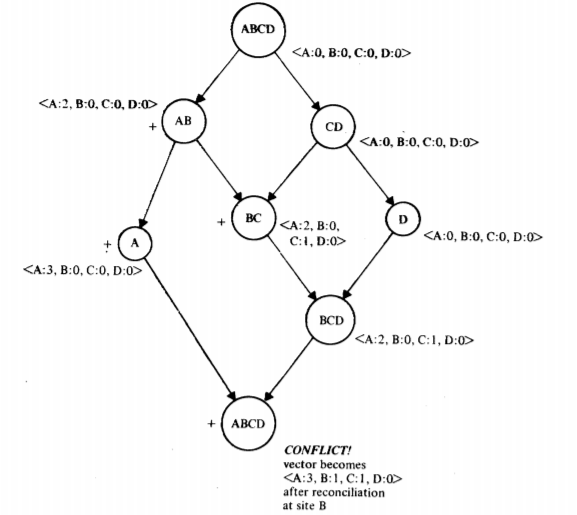
例えば、バージョンベクトル \(\langle A:1,\) \(B:2,\) \(C:4,\) \(D:3\rangle\) は \(\langle A:0,\) \(B:2,\) \(C:2,\) \(D:3\rangle\) を支配しているためこの 2 つは互換性がある。また、\(\langle A:1,\) \(B:2,\) \(C:4,\) \(D:3\rangle\) と \(\langle A:1,\) \(B:2,\) \(C:3,\) \(D:4\rangle\) は競合するが、\(\langle A:1,\) \(B:2,\) \(C:4,\) \(D:3\rangle\)、\(\langle A:1,\) \(B:2,\) \(C:3,\) \(D:4\rangle\)、\(\langle A:1,\) \(B:2,\) \(C:4,\) \(D:4\rangle\) は 3 番目のベクトルが他の 2 つのベクトルを支配しているので競合しない。Fig 2 では、Fig 1 のすべてのパーティションにおいて \(f\) のバージョンベクトルが与えられている。\(BCD\) と書かれたノードに関連付けられたベクトル \(\langle A:2,\) \(B:0,\) \(C:1,\) \(D:0\rangle\) は、\(f\) がサイト \(A\) で 2 回、サイト \(C\) で 1 回修正され、それ以外の場所では変更されていないことを示している。特に \(\{A,B\}\) パーティションではファイルはサイト \(A\) で 2 回変更されていることに注意。最終的なマージで競合が発生する。
ここではバージョンベクトルの使い方を以下のようにする。
- サイト \(S_i\) で \(f\) の更新が発生するたびに \(f\) のバージョンベクトルの \(S_i\) 番目のコンポーネントを 1 つ増やす。このベクトルは更新されたファイルとともにコミットされる。
- ファイルの削除と名前の変更はファイルの更新として扱われる。例えば、削除を行うとファイルの長さがゼロのバージョンとなる。ファイルのすべてのバージョンが長さゼロとなるとそのファイルに関する情報がシステムから削除される可能性がある。
- パーティション内でバージョン競合が再調整された場合、調整されたファイルのバージョンベクトルの \(S_i\) 番目のエントリは、それに先行するすべての \(S_i\) 番目エントリの最大値に設定され、さらに再調整を開始するサイトはそのエントリをインクリメントする。これによりネットワーク上に残っている古いバージョンのファイルとの将来の互換性が確保される。
- ファイルのコピーが後に新しいサイトに保存される場合、バージョンベクトルは新しいサイトの情報を含むように拡張される。この場合でも上記の互換性の定義が適用される。
ポイント 4 ではベクトルは固定長である必要はなく、関連するサイト情報が維持されている限り拡張しても良い (実際には縮小しても良い) ことを示している。あるパーティション分断の間にサイト \(E\) に \(f\) のコピーが追加された場合、コピーが取得されたパーティション内のベクトルは \(E\) のコピーの存在を反映して単純に拡張される。その後、このパーティションに合流するサイトは、それに応じてベクトルを拡張する必要がある。また、バージョンカウントは可変長である必要があるためスペースが不足しても問題ないことに注意。
基本的にバージョンベクトルはパーティショングラフによって定義された部分的な順序を符号化するのに役立つ。グラフ内のあるノードが他のノードに "先行" している場合、つまりグラフソースから前者を経由して後者に至るケースがある場合、2 つのノードのバージョンベクトルは競合しない。この観察結果から、バージョンの競合を検出するためには基本的にバージョンベクトルだけが必要であるという結果が得られる。
定理: バージョンの競合は \(G(f)\) 上のあるノードにおいて \(f\) のバージョンベクトルが競合している場合に限り再調整しなければならない。
証明: \(G(f)\) 上のノード \(P\) で競合の再調整がある場合、バージョンベクトルは \(P\) で競合することは明らかである (バージョンベクトルは単純なタイムスタンプアルゴリズムと同様に現実の競合を検出する: 示さなければならないのは実際の競合のみを検出することである)。逆に \(f\) のバージョンベクトルがノード \(P\) で競合したとすると、2 つのベクトルが競合し、3 つめのベクトルに支配されていてはならない。この 2 つのベクトルは \(P\) への経路を持つ 2 つの先行するパーティション \(P1\) と \(P2\) で生成されたもので、\(f\) は独立して変更されたものである。\(P\) の祖先 \(P'\) には \(P1\) と \(P2\) への逆方向の経路が存在しないことを示せば良い (\(P'\) は \(P1\) または \(P2\) のいずれかである可能性があることに注意)。\(P'\) が存在すると仮定すると、\(P1\) と \(P2\) のバージョン競合は \(P'\) で再調整され、\(P1\) と \(P2\) のベクトル成分の最大値を持つバージョンベクトルが得られることがわかっている。しかし、このベクトルは \(P\) で \(P1\) と \(P2\) の両方のベクトルを支配し、それらの競合を解消する。これは我々の元の仮定と矛盾する。したがって \(P'\) は存在しないためパーティショングラフの条件は満たされ \(P\) で競合の再調整が行われる。
D. ファイル競合検出の結論
上記の定理はバージョン競合を検出しユーザに競合の再調整を要求するためにバージョンベクトルが使用できることを示している。バージョンベクトルは "実際の" 競合、つまりファイルのバージョンが別々のパーティションで個別に変更された状況のみを検出する。したがって、多くの人々は競合が存在するための十分条件を検出するメカニズム (例えばタイムスタンプなど) を開発してきたが、我々の研究は競合が存在するための必要十分条件を検出するメカニズムを提供することに努めてきたという点でこれまでの研究とは異なっている。
注意すべき点は、2 つの異なるパーティションで同一の更新が行われた場合、ファイルの競合がないにもかかわらずバージョンベクトルはファイルの競合を示すことである。いくつかのアプリケーションでは、いくつかのコピーが相反するベクトルを持っていることがわかったときに、実際にファイルの差分をチェックすることが望ましい場合がある。実際、ユーザがファイルの競合を解決するためには、このコピーのクロスチェックを最終的に実行する必要があるかもしれない。
また、ここで示している内容は単一のファイルを処理する場合にのみ適用可能であることを認識することも重要である。以下の (Mark Brown の) 例では 2 つの "トランザクション" \(T1\) と \(T2\) が異なるネットワークパーティションで実行される場合を考える。\[ \begin{eqnarray*} {\rm readset}(T1) & = & {\rm readset}(T2) = \{f,g\} \\ {\rm writeset}(T1) & = & \{f\} \\ {\rm writeset}(T2) & = & \{g\} \end{eqnarray*} \] とし \(T1\) と \(T2\) の両方がネットワークの再接続前に完了したと仮定する。すると、再接続後に競合 (直列化エラー) が発生するはずだが、この場合、バージョンベクトルは何も間違いを検出しないことが容易に分かる。すぐに多くの適切な拡張が提案されその一つが [11] に示されている。興味深いことにセクション II で述べた相互整合性を提供するための "ソリューション" の多くはこの問題を解決していない。特にトークン方式やプライマリサイト方式ではすべての更新が単一のパーティション内で行われるように制約されていない限りこのような衝突が起きる可能性がある。
このセクションではファイルの競合が名前の衝突であれバージョンベクトルの衝突であれ、各ファイル \(f\) が:
- 起点
- バージョンベクトル
の 2 つの情報を保持するだけで正確に検出できることを示した。次のセクションでは検出の問題が明らかになったことを受けてファイルの競合をどのように解決するかという問題を取り上げる。
IV. 相互不整合の解消
競合検出メカニズムには価値があるが、競合を自動的に再調整する方法もあれば効果が高まるだろう。この方法は、ファイルのいくつかの競合バージョンからそれのバージョンに行われた操作を保存しながら、それらのバージョンを支配する後続のバージョンを生成する必要がある。たしかにこれは一般的には不可能だが、自動調整が可能なケースはたくさん存在する。
競合の再調整では、競合しているデータオブジェクトに対して行われた操作のセマンティクスを考慮に入れなければならないことは明らかである。これは多くの研究者によって指摘されている (例えば [1,p.568], [5,.p.65], [13,p.57])。セマンティクスの性質が十分に制約されている場合には分かりやすい調整アルゴリズムが与えられる。例えば LOCUS における 2 つの重要なタイプのファイル、ディレクトリとユーザメールボックスについて考える。この 2 つのケースではどちらの場合も使用できる操作は 2 つだけである。
- アイテムの挿入 (例: ファイルの作成、メッセージの受信)
- アイテムの削除 (例: ファイルの削除、メッセージの処理)
このようなファイルでは各ファイルのエントリを結合し削除されたエントリを削除するだけでバージョンの競合を再調整できるという特徴がある。これらのファイルタイプの再調整は LOCUS では自動的に処理される1。
自動再調整はシステムレベルよりもっと広範囲な文脈で適用される。有用な例は電子送金である。セクション III-A で示したような当座預金口座を考える。クレジットとデビットは口座の様々なコピーに対して行うことができる。\(i\) 番目のコピーが \[ x + \delta_i(x) \] と表されている限り解決は簡単である。ここで \(x\) はパーティション分断前の元の口座残高で、\(\delta_i(x)\) はそのパーティションでの変更点である。そして新しい残高は \[ x + \sum_i \delta_i(x) \] となる。残高をプラスに保つ必要がある場合、このアプローチは不適切かもしれない。しかしその問題に対処する方法はたくさんある。\(x\) が大企業の残高であればおそらくその問題は起きないだろう。より一般的には顧客が信用できない場合には引出しを制限したり各パーティション内の引出しにクォータのような制限を課すことによって、システムが分断されたときにより制約のある方法でシステムを運用することができる。
既存のアプリケーションの中にはパーティション分断中の堅牢な操作を可能にしつつ自動化された再調整を可能にするものが数多くある。銀行や航空会社の予約システムなどの事例がよく研究されている [3]。これらのシステムは完全ではないもののパーティション分断された状態での広範囲な操作が可能である。
システム操作セマンティクスや縮小されたパーティションセマンティクスの望ましい特性は、あるデータ項目の再調整が他の多くのデータ項目の変更を必要としないことである。例えばデータベースの自動調整コストを低く抑えるためにはパーティション内で実行されているほとんどのトランザクションが調整中に読み取りセットが変更されても元に戻したりやり直したりする必要がないようにする必要がある。これは今日の銀行システムの一部である現金自動預払機などに当てはまる。
一般に操作のセマンティクスをクラスに分けてクラスごとに再調整アルゴリズムを構成できるルールを指定できる場合が多い。単純なセマンティッククラスであれば履歴をあまり残さずに簡単な方法で再調整が可能である。セマンティクスが複雑になればなるほどより多くの履歴と作業が必要となる。
もちろん操作のセマンティクスが明確であっても自動調整は非常に難しくコストもかかり、場合によっては不可能なこともある。システムのアクティビティの一環としてもとに戻すことも補償することもできない外部アクションが行われた場合、再調整は実行できない。このようなケースは一般的なデータ管理の復旧が不可能なケースと同じである。
多くのシステムでは大部分のデータ項目に対して自動調整が実行可能であると思われる。しかし人間の介入が必要なケースも残る。
自動調整の程度とは関係なく以下の質問に対して一貫したシステムポリシーを定義する必要がある。
- データの競合はいつ、どのようにして検出されるのか?
- データ項目へのアクセス権限はその項目が競合しているという事実によって変更されるか? 権限を変更しないと、どのバージョンを使用可能にするという問題が発生し、不適切な値が伝播する可能性が出てくる。
- ユーザはどのように競合について通知されるか?
- システムはユーザが競合を再調整するためにどのようなサポートを提供するか?
これらの質問は多くのアーキテクチャ上の問題を提起しそのいくつかは [12], [14], [18] で取り上げられている。
- 1ほとんどのディレクトリシステムおよび一部のメールシステムでは追加の操作を許可している。したがって、これらのファイルタイプに対する LOCUS の自動回復ソフトウェアはここに示しているよりも複雑である。
V. 結論
我々は分散システムにおける相互不整合を検出するための効率的な方法を開発した。ここでの不整合とは、複数のユーザが共通のファイルの異なるコピーを相互に排他することなく変更することで発生すると想定している。このような状況は、例えばネットワークの障害によりこれらのユーザがネットワークの異なるパーティションに隔離された場合に発生する。この技術は、例えば接続されたネットワーク内のステーションが 1 日の様々な時間にバッチ処理や通信速度の低下を利用して送信を遅らせるなど、人為的なパーティション分断を導入したときにも適用される。この方法は新たに導入された 2 つの構成要素、バージョンベクトルと起点のみに依存したシンプルなものである。この方法は、特にファイルシステムの文脈で議論されたが、可用性のために時折の相互不整合が許容される、あるいは許容される操作のセマンティクスが自動回復を可能にするようなリソースのクラスにも同様に適用できる。
リソースのコピーの相互不整合が検出された場合、それをどのように解決するかという一般的な問題は複雑である。この問題には多くの設計上の問題があり、リソースの使用に関するセマンティクスが明確にわかっている場合にのみ完全な答えを出すことができることからここでは要約的な扱いのみを示した。しかしいくつかのリソースについては自動調整の実装が容易であることに注意。
References
- P. A. Alsberg and J. D. Day, "A principle for resilient sharing of distributed resources," in Proc. 2nd Int. Conf Software Eng., Oct. 1976.
- C. A. Ellis, "A robust algorithm for updating duplicate databases," in Proc. 2nd Berkeley Workshop Distributed Data Management and Comput. Networks, 1977, pp. 1146-158.
- S. Faissol, "Operation of distributed database systems under network partitions," Ph.D. dissertation, Dep. Comput. Sci., UCLA, 1981.
- D. J. Farber and F. R. Heinrich, "The structure of a distributed computer system-The distributed file system," in Proc. ICCC, 1972.
- M. Hammer, and D. Shipman, "An overview of reliability mechanisms for a distributed data base system," in Proc. Spring Compcon, San Francisco, CA, Feb. 28-Mar. 3, 1978.
- H. T. Kung and J. R. Robinson, "On optimistic methods for concurrency control," ACM TODS, vol. 6, pp. 213-226, June 1981.
- L. Lamport, "Time, clocks, and the ordering of events in a distributed system," Commun. Ass. Comput. Mach., vol. 21, pp. 558-565, July 1978.
- B. Lampson and H. Sturgis, "Crash recovery in a distributed data storage system," Tech. Rep., Xerox PARC, 1976.
- D. A. Menasce, G. J. Popek, and R. R. Muntz, "A locking protocol for resource coordination in distributed systems."
- R. M. Metcalfe and D. R. Boggs, "Ethernet: Distributed packet switching for local computer networks," Commun. Ass. Comput. Mach., vol. 19, pp. 395-404, July 1976.
- D. S. Parker and R. Ramos, "A distributed file system architecture supporting high availability," in Proc. 6th Berkeley Conf Distributed Data Management & Comput. Networks, Asilomar, CA, Feb. 1982.
- G. Popek, B. Walker, J. Chow, D. Edwards, C. Kline, G. Rudisin, and G. Thiel, "LOCUS: A network-transparent, high reliability distributed system," in Proc. 8th Symp. Oper. Syst. Principles, Asilomar, CA, Dec. 1981.
- J. B. Rothnie and N. Goodman, "A survey of research and development in distributed database management," in Proc. 3rd VLDB, Tokyo, Oct. 1977.
- G. J. Rudisin, "Architectural issues in a reliable distributed file system," M. S. thesis, Dep. Comput. Sci., UCLA, Rep. UCLAENG-8014 SDPS-80-001, Apr. 1980.
- M. Stonebraker, "Concurrency control and consistency of multiple copies of data in distributed INGRES," IEEE Trans. Software Eng., vol. SE-5, pp. 188-194, May 1979.
- R. F. Thomas, "A solution to the concurrency control problem for multiple copy data bases," in Proc. Spring COMPCON, Feb. 28-Mar. 3, 1978.
- R. F. Thomas, R. H. Schantz, and H. C. Forsdick, "Network operating systems," Rome Air Develop. Cen., Tech. Rep. RADCTR-78-117, May 1978.
- B. J. Walker, "Issues of network transparency and file replication in distributed systems: LOCUS," UCLA Tech. Rep., June 1981.
翻訳抄
バージョンベクトル (version vector) と起点 (origin point) を使用して、特定ファイルの複数のコピーに対して独立して行った操作による相互不整合 (mutual inconsistency) を検出する方法についての 1983 年の論文。
- D.S. Parker, G.J. Popek, G. Rudisin, A. Stoughton, B.J. Walker, E. Walton, J.M. Chow, D. Edwards, S. Kiser, C. Kline. Detection of Mutual Inconsistency in Distributed Systems. In Journal of Parallel and Distributed Computing Volume 6, Issue 3, June 1989, Pages 498-514
