Write-Ahead Log
 概要
概要
Write-Ahead Log (WAL) またはログ先行書き込みは、データベースや分散システムの更新処理で障害耐性やデータ一貫性を確保するための基本的な手法である。多くのデータベースやファイルシステムで使用されており、ファイルシステムではジャーナル (journal) と呼ばれることが多い。
WAL を使用した障害回復では、実際のデータベースを更新する前にまず変更操作をログ (WAL) に記録し、その後にログの内容に従ってデータベースを更新する。システムが障害から回復したとき、残っているログをリプレイ (replay) またはロールフォーワード (roll-forward) することでデータベースを一貫性のある正常な状態へリカバリすることができる。このとき、リプレイを通じて未完了トランザクションの再実行や整合性チェックを実装してシステム全体の信頼性を向上させている。また分散データベースではしばしばデータベース間で WAL を複製する方法をデータレプリケーションの基盤としている。
Table of Contents
- 概要
- どのように機能するか
- 参考文献
どのように機能するか
WAL はコンピュータ上での非アトミックな操作に対して障害耐性をもたらす。例えば、複数のファイルに渡る操作はアトミックに行うことができないことから、ファイル \(A\) に保存されている \(x\) の値から、ファイル \(B\) に保存されている \(y\) の値へ、量 100 を移動する操作について考えてみよう。ファイルはノードに置き換えても良い。
この操作を単純に実装するなら、ファイル \(A\) を読み込んで \(x\) から 100 を減算した値で更新した後に、ファイル \(B\) を読み込んで \(y\) に 100 を加算した値で更新することができるだろう (Figure 1)。
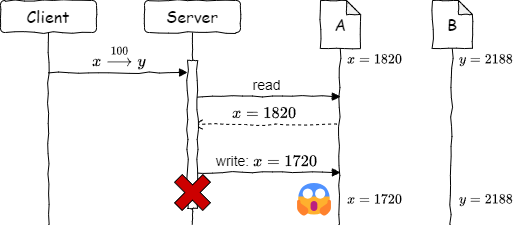
しかしこの方法ではシステム故障時に整合性が保証できない。ファイル \(A\) を更新した直後にシステムがクラッシュすると、システムが回復しても減算された 100 は元に戻ることはないためである (Figure 2)。
このような不整合が起きることを防ぐために WAL を使うことができる。プロセスはまず操作を WAL に書き込む (これは単一書き込みなのでアトミックに実装できる)。WAL への書き込みが完了すると Replayer プロセスがそれを読み込んで実行する。このとき、更新中にシステムがクラッシュしてもデータを一貫した状態に復元するのに十分な情報をログに記録しておく。例えば Figure 3 では \(x\) と \(y\) の値をログに記録しておくことで、Replayer が \(x\) を書き込んだ直後にシステムがクラッシュしても、システムの再起動後にログを読み込んで各トランザクションの進捗状況を確認して処理途中の操作を完了することができる。
このように、WAL はシステム障害があっても原子性 (atomicity) や一貫性 (consistency) を保証し、データの不整合が発生することを防ぐことができる。
参考文献
- Unmesh Joshi. Patterns of Distributed Systems. Addison-Wesley Professional (2023)
