論文翻訳: MultiPaxos Made Complete
Zhiying Liang
The Pennsylvania State University
zvl5490@psu.edu
Vahab Jabrayilov*
Columbia University
vj2267@columbia.edu
Aleksey Charapko
University of New Hampshire
Aleksey.Charapko@unh.edu
Abutalib Aghayev
The Pennsylvania State University
agayev@psu.edu
 Abstract
Abstract
MultiPaxos は基本的な Replicated State Machine アルゴリズムだが、完全で正しい実装を実現するための包括的なガイドラインが不足しているという問題を抱えている。この欠陥は MultiPaxos の実用性と採用を妨げ、MultiPaxos の能力に関する誤った主張をもたらす結果となっている。我々の論文では 1 年以上にわたる綿密で詳細な設計プロセスを通じて MultiPaxos の複雑さと実際の実装のギャップを埋めることを目的としており、MultiPaxos の各フェーズを慎重に分析し、リーダー選出、障害検出器、コミットフェーズを含むすべてのコンポーネントについて詳細なステップバイステップのコードを ─ 完全なオープンソース実装に加えて ─ 提供する。
また我々の完全な設計の実装は、素朴な MultiPaxos バージョンよりも優れた性能の安定性、リソース使用量、ネットワーク分断耐性も提供する。我々の仕様にはスナップショットの繰り返し取得を回避する軽量のログ圧縮アプローチが含まれており、リソースの使用量と性能の安定性を大幅に改善している。アルゴリズムのコミットフェーズに統合された我々の障害検出器 (failure detector) は、可変かつ適応的なハートビート間隔を使用して、部分的な接続やネットワーク分断の状況下でより適切なリーダーを決定し、そのような状況下での Liveness を向上させる。
Table of Contents
1 導入
ステートマシンレプリケーション (SMR; state machine replication) はクラスタの管理や構成、データベースやその他のデータ集約型システムなど、最新のフォールトトレラント分散コンピューティングサービスの要である。レプリケーション戦略を利用することで、SMR はすべてのピアが同じコマンドを同じ順序でステートマシンに適用することを保証し、それによって障害発生時でもピア間で一貫したコマンドの実行を保証する。多くの SMR プロトコルが存在するが、MultiPaxos コンセンサスプロトコルは Chubby [6]、Google Spanner [13]、Azure ストレージ [8]、Amazon DynamoDB [14] などの主要な大規模プロダクションシステムの間で依然として人気のある選択肢であり続けている。
20 年以上にわたる広範な議論と最適化にもかかわらず、その複雑なアルゴリズムを実用的、効率的、かつスケーラブルな実装に変換することは依然として困難な作業である。これまでの研究は実装経験に関する洞察を提供してきたが、これらの取り組みは正確で完全な MultiPaxos ベースのアプリケーションのための包括的で再現可能な青写真を提供するには至っていないことが多い [9, 35, 45]。2014 年に登場した Raft は明確に定義された仕様で知られており、業界の好みは MultiPaxos から大きくシフトした [39]。このシフトは、特に線形化可能な一貫性 (linearizable consistency) の達成を目指す分散システムが増加するにつれて、コンセンサスプロトコルの明確さとシンプルさに対する本質的な需要を浮き彫りにしている [3, 20, 33]。しかし Raft は選出時間のばらつきが大きくなる可能性があり [23]、連続したログを必要とするためいくつかの部分的なネットワーク分断ではデッドロックが発生する [37]。
MultiPaxos の最適化に関する現在進行中の研究は主に性能と可用性の向上に焦点を当てている [10, 17, 30, 34, 36, 38, 40, 44]。しかし、標準化された正確で詳細な実装がないため MultiPaxos の動作が誤解されるリスクがある。このギャップにより、ログトリミングのような重要な機能が欠落したり、本来の MultiPaxos が効率的に処理できる問題に不必要な複雑さが加わったりする可能性がある。
この論文では、理論上のアルゴリズムと実用上の実装の間に存在するギャップを埋めるために、我々は付録 A と付録 B で提供される詳細な擬似コードと共に、MultiPaxos の徹底的な設計を提示する。我々の研究は、準備フェーズとコミットフェーズ、障害検出器など、先行研究 [9, 35, 45] で明確に実装仕様が欠如している重要な領域に対処し、改善する。我々はまたこれらの複雑なコンポーネントを効率的に調整 (coordinate) するという課題にも取り組む。我々の設計では、ログトリミングやリカバリなどの重要なシステム機能を単に組み込むだけでなく、メッセージの複雑さを最小限に抑えながら可読性と明瞭性を確保するより合理的なアプローチを提案している。
MultiPaxos の中核的な側面に加えて、我々の論文ではログ圧縮のさらなる最適化についても掘り下げている。従来のスナップショット手法 [4, 5, 15, 16, 20, 21] はログ圧縮では一般的だが、性能に顕著な欠点が生じることが多く実装が困難である。我々の調査ではスナップショットなしでログ圧縮を実現できる代替パスがあることを示唆している。具体的には、あるコマンドがピアによってステートマシンに適用されると、そのコマンドは他のピアのステータスに関係なく、そのピア上で安全に削除することができる。このコマンドはほとんどのピアのステートマシンまたはログにすでに保存されている。ただしこれには大きな潜在的コストがかかる。通常のレプリケーション中に、一部のピアが 1 つ以上のコマンドを見逃す可能性がある。コマンドの削除が早すぎると、1 つのコマンドを回復するためにステートマシン全体をコピーする必要がある。そこで、スナップショットを回避しステートマシン全体を複製する必要性を減らす、適応型で軽量な新しいログ圧縮アプローチを提案する。このアプローチでは、リーダーがブロードキャストを行い、コミットフェーズを通じてすべてのピア間でログの最後に実行されたインスタンスの最小インデックスを収集する。新しいグローバルな最小インデックスを繰り返し計算することにより、ピアは実行されたログエントリの削除を自律的かつ効率的に管理する。
さらに我々は部分的なネットワーク分断がもたらす課題にも取り組む。特に 2 種類のネットワーク分断に焦点を当てる。1 つはすべてのサーバが相互に切断されるが同一のサーバへの接続が 1 つだけ維持されるシナリオで、もう 1 つは互いに到達不可能な 2 つのサーバが第 3 のサーバによって接続されるシナリオである。この状況は 2020 年の Cloudflare インシデント [32] で顕著に観察された。この分断により継続的なリーダー選出が引き起こされ、安定したリーダーシップの不在によって進行を阻害する。この問題に対処するために我々は障害検出器に変更を加えて適応型タイムアウト機構を導入する。このメカニズムは、特定の時間枠内でリーダー選出に過度に参加したピアのタイムアウトを増加させ、その後の選出を送らせる。最終的には、安定した接続を持つピアがそのタイムアウトの短さでリーダーとなる。重要なのは、我々のメカニズムにより MultiPaxos の基本設計原則を変更することなく性能が向上することである。
我々の主な貢献は以下の通り:
包括的かつ完全で理解しやすい MultiPaxos の設計と実装を詳細な擬似コードと共に示す。
MultiPaxos の準備フェーズとコミットフェーズの調整について説明し、リーダー選出、コミットメッセージ、障害検出器におけるそれらの拡張された役割を概説する。また、準備フェーズで複数のインスタンスのログ回復に対する詳細なアプローチも提供する。
継続的なスナップショットの必要性を排除するように設計された MultiPaxos 用の軽量かつ効果的なログ圧縮メカニズムを紹介する。
特に部分的なネットワーク分断を含むシナリオで、MultiPaxos の回復性 (resilience) を強化する適応型タイムアウト機構を提案する。
2 バックグラウンド
2.1 単一決定 Paxos と MultiPaxos
分散コンセンサスを解決するための基本的なアルゴリズムである単一決定 (single-decree) Paxos [26, 27] はピアのグループが集合的に何らかの重要な単一値に合意することで成り立っている。このアルゴリズムは準備 (Prepare) と受理 (Accept) という 2 つの異なるフェーズで動作する。準備フェーズでは、ピアはこれまでに遭遇したどの値よりも大きい一意の投票番号 (ballot number)でリーダーになる準備をする。ピアの過半数から約束 (promise) を受け取った後、リーダー候補は過半数が自分の投票番号より高い投票番号を見たことがないと結論付けた場合にリーダーとなる。その後、リーダーは受け取った約束の中で最も高い投票番号を持つ値を選択するか、約束の中に値が見つからなければ新しい値を選択する。次にリーダーは受理フェーズに進み、ピアは提案された値を受理する。リーダーが過半数の確認 (acknowledgment) を受け取るとコンセンサスに達する。この時点でコミットメッセージを送信して、すべてのピアに合意値を知らせることができる。
単一決定 Paxos は仕様が明確で実装も簡単だが、各値に対して複数のメッセージ往復が必要なため実用的なシステムではあまり使われていない。MultiPaxos はよく知られた最適化であり不要なメッセージを削減する。Figure 1 に示すように、MultiPaxos ではいったんリーダーが選出されると受理フェーズ中に無制限の数のインスタンスに対して値を直接提案できるようになるため、準備フェーズを繰り返す必要がなくなる。準備フェーズはリーダーがクラッシュした場合にのみ登場する。
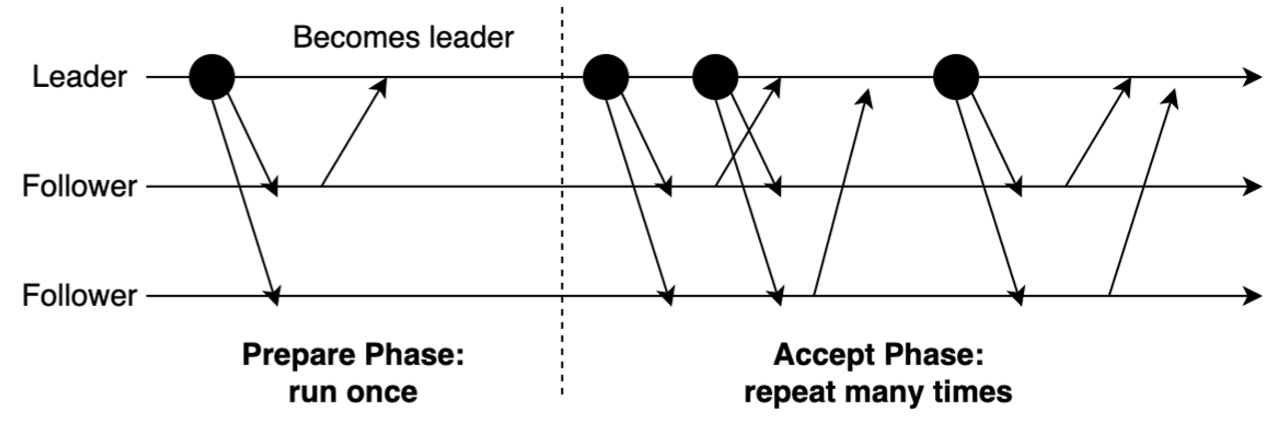
2.2 仕様ギャップの特定
MultiPaxos は Lamport の Paxos 論文やその後の最適化で広く論議されてきた [9, 22, 30, 34, 35, 36, 44]。しかし単一決定 Paxos とは対照的に MultiPaxos のアルゴリズム記述と実際の実装には依然として大きなギャップが存在する。以下に列挙するこれらのギャップは MultiPaxos アルゴリズム全体に及ぶ。
リーダー選出. 準備フェーズは MultiPaxos の重要なフェーズだが、リーダーシップの記録と追跡方法、投票番号の更新タイミング、ログ回復の処理方法など、アルゴリズムでは多くの詳細が不明瞭なままである。リーダーシップを追跡するために別のフィールドを使用し、独立したログ回復フェーズを持つことは一般的なアプローチではあるが、実装の複雑さを著しく増大させる [18, 30, 37]。
コミットフェーズ. このフェーズではコミットされたメッセージをブロードキャストしてフォロワーがリーダーの進行状況と同期をできるようにする。概念的には単純だが、実用的なアプリケーションのオーバーヘッドは些細なことではない。ログインスタンスごとに個別のコミットメッセージを使用するとクラスタ内のメッセージトラフィックが 2 倍になる可能性がある [1, 36, 44, 46]。一方、バッチコミットではコミット速度とメッセージのサイズを管理するための適切に設計された方法が必要である。
障害検出器. リーダーが選出されるとリーダーはそのリーダーシップをブロードキャストする必要があり、フォロワーはリーダーの状態を監視するために障害検出器を頼りにする。しかし MultiPaxos を障害検出器とシームレスに統合するための詳細なガイドラインはない。ほとんどの実装ではタイムアウト機構が採用されている。Raft の場合と異なり、MultiPaxos のハートビートメッセージに追加情報が含まれていない場合、単にメリットのないネットワークトラフィックの増加を引き起こすだけである。
ログ圧縮. ログの圧縮はログの無制限な増加を防ぐために不可欠である。定期的なスナップショットは広く使用されているが、ステートマシンを排他的にコピーする必要があるため定期的にパフォーマンスが低下する。さらに、ディスク I/O やスナップショットファイルの管理を含む複雑な設計が必要である。
部分的なネットワーク分断. 部分的な分断は MultiPaxos アルゴリズムの Safety を侵害しないが、実際には MultiPaxos の可用性を大幅に低下させる可能性がある。MultiPaxos がどのような分断シナリオに対応できるか、またどのような状況でライブロックが発生するかを把握することが重要である。このような状況下で回復性を強化することは実際のデプロイにとって非常に重要である。
3 仕様ギャップの解消
ここで MultiPaxos モジュール1の設計を紹介し、MultiPaxos の仕様ギャップを埋めるために行った決定について説明する。
MultiPaxos 実装の実用性とシンプルさの両方を向上させるために、我々は MultiPaxos の範囲を超えた補足コンポーネントを導入し、MultiPaxos ベースの線形化可能な分散 Key-Value ストアへと拡張する。このアプリケーションでは MultiPaxos モジュールが中心的な役割を果たし、MultiPaxos プロトコルとピア間通信を担当する。これはスレッドセーフな無制限 (unbounded) プロデューサ/コンシューマキューを提供するログモジュールと共に実行される。ログモジュールはステートマシンに適用されるコマンドの順序を維持する。すべてのモジュールは高度に分離されており、MultiPaxos モジュールは上位アプリケーション層のインターフェースも提供する。
このセクションでは MultiPaxos 設計が特定のギャップにどのように対処しているかに焦点を当てる。まずリーダー選出の不明瞭な仕様と、MultiPaxos アルゴリズムのコアシーケンスを形成する受理フェーズとコミットフェーズを明確にする。そして障害検出器を統合する方法、ログ圧縮を実行する方法、部分的なネットワーク分断に対する耐性を強化する方法について説明する。
3.1 リーダー選出
単一決定 Paxos と我々の MultiPaxos 実装の決定的な違いはリーダーシップモデルにある。MultiPaxos では特定のピアが長期的なリーダーとして指定されるため、多数の冗長な準備リクエストを省略している。リーダーが選出されると準備フェーズをバイパスして受理リクエストを直接発行できる。このセクションでは、リーダー選出プロセスの実装仕様を詳細に説明することで、リーダー選出プロセスのギャップを埋めることを目指す。
リーダー選出モジュールを実装するには、各ピアにリーダーまたはフォロワーのいずれかの役割を割り当てる。ピアはアクティブ投票番号 (Active Ballot Number) (ABN) を使用してリーダーシップを追跡する。さらに、我々は長時間実行スレッド (long-running thread) である準備スレッド (Prepare Thread) を採用する。Algorithm 1 は、準備スレッドは主に新しいリーダーをいつ初期化するかを決定し (2-4 行目)、リーダー選出を実行する (5-17 行目)。最初、各ピアはフォロワーとして実行され、準備スレッドは開始時にすぐにアクティブ化される。フォロワーの役割では、準備スレッドはランダムな期間断続的にスリープし、その後に障害検知器の状態を評価してリーダー選出を開始するかどうかを決定する。
リーダー選出が開始されると準備スレッドは ABN より高い投票、つまり準備投票番号 (Prepare Ballot Number) (PBN) を作成する。各ピアは peer_id + round * max_num_peers で示される利用可能な投票オプションの明確な範囲を持ち、それぞれの投票での一意性を保証する。単一決定 Paxos と同様に準備スレッドは投票番号と共に準備リクエストをディスパッチして定足数に達するまで応答を待つ。応答には OK と REJECT の 2 種類がある。OK 応答のみが定足数に寄与する。REJECT 応答を受信している間、ピアは ABN を更新することで新しいリーダーを学習する。これは Algorithm 1 (8-14 行目) に示されている。我々はこのアプローチを MultiPaxos 設計のすべてのタイプの応答に採用している。その後、準備スレッドはピアがリーダーシップを獲得すると条件変数でスリープ状態に入り、ピアがリーダーシップを放棄したときにのみ起動する。
先行研究 [1, 45] と異なる注目すべき決定は、選挙の投票を PBN にキャッシュしてリーダー選挙が正常に完了するまで ABN への更新を延期することである。我々は、実際のリーダーシップが変更された場合、つまりリーダーになるか新しいリーダーに遭遇した場合のみ ABN が更新されるようにする。リーダー選挙の開始時に ABN を更新する場合、ピアが現在の投票番号と実際のリーダーシップを区別できるように追加のリーダーシップフラグが必要である。そうしないとピアがリーダーになる前に ABN が更新されるため、誤って受理フェーズに進む可能性がある。このような 2 リーダーシップフラグのアプローチは先行研究 [45] で見つけることができる。実際の実装では、通常、両方のフィールドを同時に更新するために明示的なロックが必要である。しかし我々のアプローチではリーダー選挙の終了時にリーダーシップステータスを二重チェックするなど、投票番号のロックと冗長な比較が不要になり、したがってアトミック操作に関連するオーバーヘッドが軽減される。
MultiPaxos ではリーダー選出の実施に加えてログの回復も不可欠である。MultiPaxos と Raft の大きな違いの 1 つは、MultiPaxos ではピアがリーダーになるための前提条件として連続した指針のログは必要ではないことである。そのため、新しいリーダは完全なログを持っていない可能性があり、リーダーのログにギャップがあると進行が滞る可能性がある。この問題に対処するために、我々は準備フェーズ中のログ回復を効率的にオーケストレーションする。Algorithm 1 に示すように、準備リクエストハンドラでは、ピアが準備リクエストを約束すると OK 応答だけではなくそのログ内のすべての既存インスタンスも返す。Algorithm 1 の 9 行目は、準備スレッドが票を受け取ると、応答からすべてのインスタンスをマージし、それらを一時ログにキャッシュすることを示している。この一時ログ内の各インスタンスは、実行済み (Executed) (ステートマシンに適用)、コミット済み (Committed) (定足数に到達済み)、進行中 (In-progress) (初期の安全出ない状態) の 3 状態のいずれかとなる。

例えば、Figure 2 に示すように新しいリーダーは特定のログインスタンス (インデックス 3 と 5) を認識していない。プロミス応答の過半数を収集することで新しいリーダーは他のピアから既存のインスタンスをすべて学習する。これはすべてのコミット済みインスタンスが過半数のピアに保存されているためである。インデックス 3 のような競合が発生するインスタンスでは、リーダーはより投票番号の大きいインスタンスを選択する。これらの応答からすべての依存のインスタンスをマージした後、そのピアは正式にリーダーシップを引き継ぎ、マージされたログのレプリケーション (受理フェーズ) を再実行する (つまりリプレイ)。これにより、フォロワーは欠落しているインスタンスを個別に回復できるようになる。
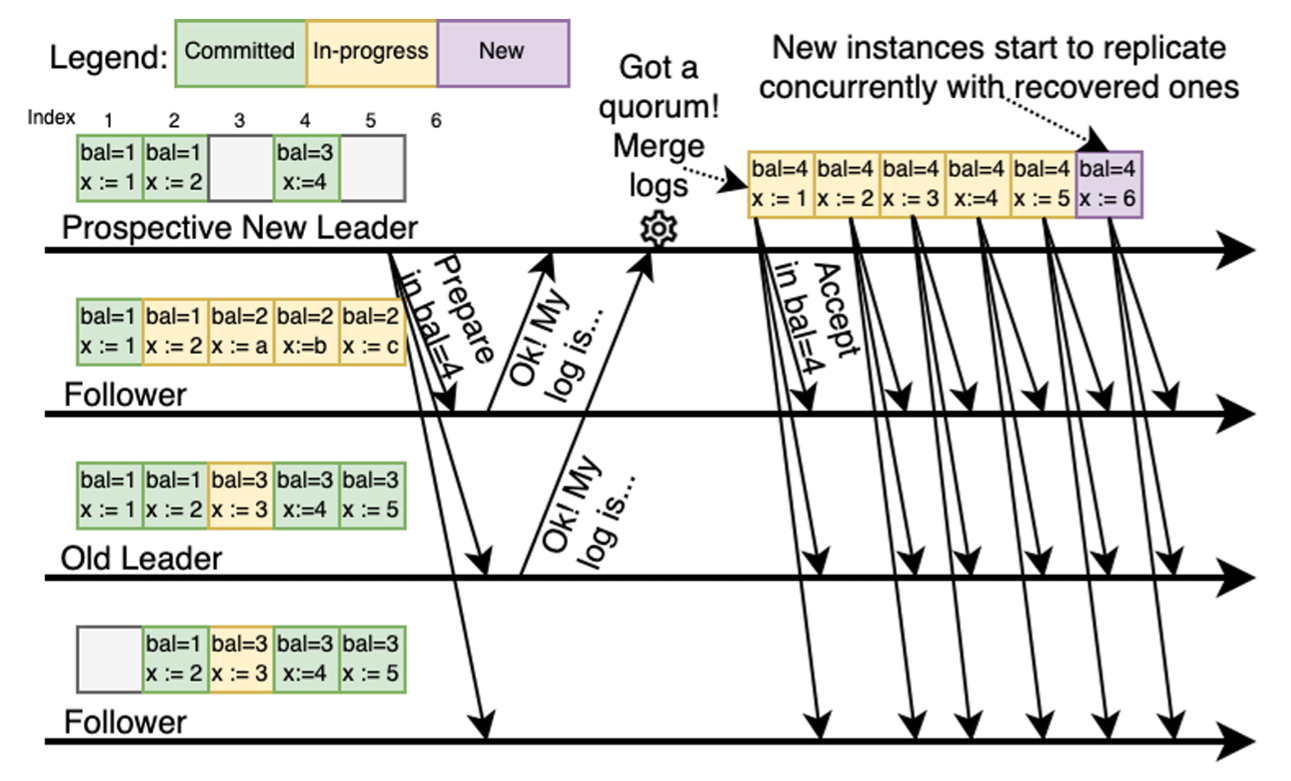
3.2 受理フェーズ
リーダーシップが確立されると、リーダーはクライアントのリクエストを受信してレプリケーションのフェーズ、特に受理フェーズを開始する準備が整う。Algorithm 2 のリーダー部分の 2-9 行目にその仕組みが示されている。リーダーはクライアントコマンドごとにインスタンスを生成し、それを自身のログに追加してから、現在の ABN を添えてすべてのフォロワーにインスタンスをブロードキャストする。フォロワーが受理リクエストを受信すると、Algorithm 2 のフォロワーハンドラに示されているように、単に投票番号を比較してそのインスタンスをログに追加するかをどうか決定する。これは単一決定 Paxos のアプローチに似ているが、我々は可用性と並列性を向上するために以下に説明するいくつかの最適化を実装した。
我々の設計の重要な特徴は、リーダーが ABN を設定した直後に受理フェーズを開始し、準備フェーズからマージされたログの再生と並行してそれを実行することである。ログの回復は準備フェーズの不可欠な部分だが、我々の調査では準備フェーズと受理フェーズの間に競合は発生しないことが示唆されている。我々の並行性アプローチにより、リーダーは既存のインスタンスを効率的に再ディスパッチしながら、同時に新しいクライアントリクエストを処理することができる。Figure 2 はリーダーがインデックス 1-5 の受理フェーズを再実行し、新しいインスタンス ('new' と表記) を複製していることを示している。このような並列処理はクラスタの可用性を維持するために極めて重要であり、特に多数のインスタンスを再生する場合に受理フェーズの遅延を確実に防止する。
さらに我々の設計のもう一つの特徴は、リーダーが複数のレプリケーションを同時に処理できることである。例えば 64 個の未処理のクローズドループクライアント (outstanding closed-loop clients) がある場合、リーダーは 64 個のハンドラーを使用して同時にレプリケーション処理を操作する。対照的に、多くの実装ではクライアントリクエストを格納するためにバッファを採用し、リーダーは一度に一つのリクエストを複製する [1, 18, 36, 41]。これはしばしばレイテンシの大幅な増加につながる。我々のアプローチはシステム内の並列性を効果的に活用しながら低レイテンシを維持する。

3.3 ハートビートを使用したコミットフェーズ
受理フェーズの後、フォロワーが決定済みインスタンスをそれぞれのステートマシンにコミットして適用できるようにするためには、コミットメッセージが必要である。コミット済みインスタンスごとに個別のコミットメッセージを持つことは単純明快なオプションに思えるが、リクエストの流入とネットワークトラフィックの増加を招く可能性がある。一つの潜在的な最適化は、コミットメッセージを次の受理リクエストに乗せることである [11]。ただしこの方法は受理リクエストの頻度に依存しており、これは不安定でクライアントリクエストの数と密接に結びついている。受理リクエストがまばらなシナリオでは、リーダーはまだ追加のコミットメッセージを送信する必要があるかもしれない。
この問題に対処するために、我々はバッチコミットの情報を含む定期的なリクエスト、つまりコミットリクエストを送信して、複数の個別のコミットメッセージの必要性を排除することを提案する。コミットリクエストはバッチコミットの情報を伝えるが、リーダー側のコミット済みインデックスをすべて網羅するわけではない。代わりに、Algorithm 3 のリーダー部分の 5 行目に示されているように、リーダーの最後に実行されたインスタンス (last_executed) のインデックスという 1 つの値だけを含む。この設計はリクエストサイズを最小化し、リクエストサイズを一貫して小さく制限された状態に保つ。Algorithm 3 のフォロワー部分の 1 行目は、フォロワーがコミットリクエストを受信すると、リーダーから提供された last_executed のインデックスに到達するか、または不在のインスタンスに到達するまで、連続したインスタンスをコミットすることを示している。
Figure 3 は我々の設計におけるコミットフェーズの動作を示している。リーダーがコミットリクエストを送信すると、その last_executed としてインデックス 104 が含まれる。フォロワーがリーダーからリーダーからリクエストを受信すると、インデックス 104 までのインスタンスをコミットする。Follower 2 のように、リーダーが送信した last_executed より前のインスタンスが欠落している場合、フォロワーは単にコミット処理を一次停止する。ギャップと last_executed の間にある既存のインスタンスはすべてコミットしても安全と見なされるが (この場合インスタンス 104 など)、それらの状態にかかわらず、ステートマシンに適用することはできない。したがって、我々はこれらのインスタンスは未コミットのままにしておく。
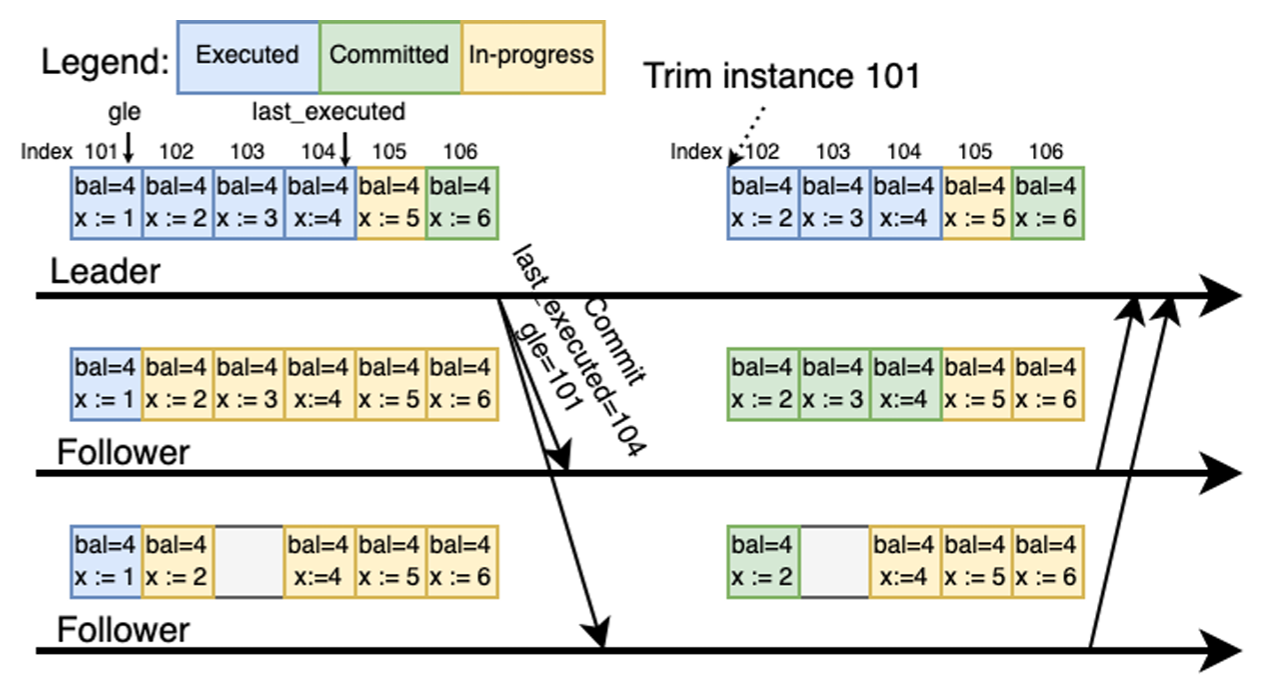
Paxos では、ログに連続したインスタンスは必要ないことに注意することが重要である。last_executed ではなく、最後にコミットされたインスタンスのインデックスを送信すると、これら 2 つのインデックスの間にあるインスタンスの一部が進行中状態のままになるため、曖昧さが生じる可能性がある。具体的には、インデックス 105 がまだ進行中状態である場合、フォロワーはどのインスタンスがコミットしても安全かを判断するのに十分な情報を持っていない。その結果、インスタンス 105 はリーダーよりも先にフォロワー側で誤ってコミットされる可能性がある。このようなシナリオを回避するために、我々はこのコミット要求には last_executed インデックスを使用する。この方法では、コミット処理の簡素化と、last_executed を使用することによるフォロワーのコミット速度との間でトレードオフが行われる。
この解決策の潜在的な欠点は、commit_interval (CI) と呼ばれるコミット要求間の間隔が大きい場合にフォロワーで実行遅延が発生することである。ただしリーダーは定足数に達すると即座にコミットし、フォロワーの実行を待たずに迅速にクライアントに応答するため、フォロワーの進行のわずかな遅れはクライアントが認識するレイテンシに影響しない。

3.4 障害検出器
次に、既存の文献 [9, 27] で簡単に説明されている別のギャップを解決しながら MultiPaxos に障害検出器を統合する方法を説明する。障害検出器は、リーダーシップの安定性を維持することと、必要に応じてリーダー選挙を開始することの 2 つの主な責任を負っている。第一に、リーダーシップの維持は不必要なリーダー選挙の頻繁な発生でシステムの性能が乱されることを防ぐために不可欠である。第二に、セクション 3.1 で述べたように、障害検出器はこのリーダー選挙をいつ開始するかを決定する上で極めて重要な役割も担っている。リーダーが機能しなくなると、障害検出器はフォロワーにリーダー選挙を開始して古いリーダーを置き換えるように信号を送りシステムの可用性を確保する。
リーダーはすでにコミット要求を定期的に送信しているため、我々はコミット要求をハートビートメッセージとして利用し、選挙をトリガーするためにタイムアウトメカニズムを採用している。このアプローチによってリーダーが送信するメッセージの数を減らすことができる。具体的には、リーダーは commit_interval 期間ごとにハートビートをディスパッチし、フォロワーは時間ごとにハートビートの到着を監視し、時間内にハートビートを受信できなかった場合はリーダー選挙を開始する。
準備フェーズと同様に、我々はリーダーシップを維持する役割を担う長時間実行されるスレッド、つまりコミットスレッドを持っている。準備スレッドとは対照的に、コミットスレッドはピアがフォロワーとして実行されているときは条件変数でスリープしている。これはリーダーの役割を引き受けたときのみアクティブになり、Algorithm 3 のリーダーの 1-5 行目に示されているように、定期的コミット要求をディスパッチし始める。
フォロワー側においては、フォロワーは準備スレッドのランダムタイマーに関連付けられた最後に受信したハートビートの状態、つまりアトミックなブーリアン値 (commit_received) を監視する。Algorithm 3 のフォロワー部分の 1 行目は、フォロワーがリーダーからコミット要求を受け取るたびに commit_received を 'true' に設定することを示している。ランダムタイマーによってタイムアウトが発生すると、Algorithm 1 の準備スレッドの 2-4 行目に示されているように、まず commit_received の状態をチェックし、次にそれを 'false' にリセットする。'true' 状態はフォロワーがリーダーからハートビートを正常に受信したことを示し、'false' 状態はハートビートの受信に失敗したことを示すため、フォロワーはリーダー選出プロセスを開始する。複数のリーダー選出が同時に開始されることを避けるため、タイマーを特定の範囲 (通常は commit_interval の 2~2.5 倍) に調整する [39]。
3.5 適応型ログ圧縮
ログに蓄積される実行済みインスタンスの数が増えるにつれて、無制限の増加を防ぐためにログ圧縮が不可欠になる。学術的な研究ではログの圧縮を省略するか非現実的なアプローチを提案することがよくあるが [1, 18, 30, 36]、多くの産業的な実装では単にスナップショットに依存している [4, 15, 21, 42]。しかし、定期的なスナップショットはステートマシンへの排他的なアクセスを要求するため、特にステートマシンのサイズが大きい場合は圧縮中の可用性が低下する。したがって、我々はほとんどの場合にスナップショットを回避する適応的で軽量なログ圧縮アプローチを提案する。さらに重要なことは、我々の調査によりスナップショットはログ圧縮の絶対的な前提条件ではないことが明らかになったことである。この点は過去の研究でしばしば見逃されてきた。
理想的なシナリオでは、MultiPaxos でインスタンスが定足数にコミットされている場合、Safety を侵害することなく、各ピアのステートマシンにインスタンスを適用した直後にログから削除することができる (すなはち定足数トリム (quorum-trim)) [1, 45]。ピアによってインスタンスが適用されると、そのインスタンスはピアにとって冗長になる。遅れているピアが他のピアによって削除されたインスタンスを回復しようとする場合、他のピアにステートマシン全体のコピーを要求することで進捗に追いつくことができる。ピアの過半数が機能している限り、コミットされた状態が失われるリスクはない。
しかしこの定足数トリムアプローチは、ピアが遅れている限り複数のスナップショットが生成される可能性があるため、実世界のデプロイには実用的ではない。例えばあるピアがネットワークの変動鬼よりリーダーからのインスタンスのレプリケーションを逃した場合、このインスタンスは過半数によってコミットされ安全に削除されるため、他のピアのログから直接この欠落したインスタンスを回復する方法はない。このような状況は、ピアが 1 つのインスタンスしか見逃していないにもかかわらず、最終的にステートマシン全体をコピーすることになる。
したがって、我々はログ圧縮の効率を最大化することと、スナップショット作成の可能性を最小化することの間でバランスを取る。具体的には、我々の設計では各フォロワーはリーダーのコミットメッセージにローカルの last_executed 値で応答する。すべてのピアから応答を受信すると、リーダーはすべての last_executed 値の最小値である global_last_executed (gle) を計算し、Algorithm 3 に示すようにそれを後続のコミットメッセージに含める。これにより、すべてのピアはこの gle 値まで安全にログをトリミングできる。例えば Figure 3 に示すように、リーダーはピア全体の last_executed 値に基づいて gle 101 を計算する。フォロワーが gle 101 のコミットメッセージを受信すると、そのフォロワーはインデックス 101 までのインスタンスをすべてトリミングする。global_last_executed により、ログからトリミングされたすべてのインスタンスがすべてのピアのステートマシンに適用されていることが保証される。別のピアがリーダーになったとしても global_last_executed より前のインスタンスは必要ない。これによりインスタンスのトリミングの効率が最大化されスナップショットを転送する必要がなくなる。
さらに、実行時に動的に圧縮率を調整する我々のログ圧縮アプローチは、圧縮のために事前に設定された頻度を必要とする他の方法とは対照的である。コミットメッセージの各ラウンドにおいて、リーダーはすべてのフォロワーのコミット応答から圧縮率を自律的に計算する。すべてのピアが同じような速度で操作するシナリオでは、我々のアプローチはログに保持されるエントリが少なくなる。逆に、特定のピアに地縁がはあ制した場合、どのピアで遅延が発生しているかに関する情報がリーダーに提供される。この動的なメカニズムにより手動で構成を微調整する必要がある。
Table 1 は、すべてのピアが機能し応答している場合 (正常系)、新しいピアがクラスタに参加する場合、ピアが切断後に再接続する場合という、さまざまなシナリオの下で 3 つのログ圧縮アプローチがどのように動作するかを比較している。我々の圧縮アプローチでは、ほとんどのケースでスナップショットを作成する必要性を最小限に抑えるため、圧縮時のパフォーマンスへの影響を軽減する。逆に、定期的なスナップショットはすべてのシナリオでスナップショットを作成するが、定足数トリムでも新しいピアの追加やピアの再接続の際にスナップショットを要求する。
我々のアプローチの唯一の欠点は、いずれかのピア、たとえば \(P\) が一時的に切断され、そのログにコマンドが記録されていない場合に発生する (Table 1 参照)。\(P\) の last_executed と global_last_executed は欠落したコマンドが回復して適用されるまでギャップ以降のコマンドを実行できないため進行を停止する。このため、欠落したコマンドが回復するまですべてのピアでログが増大する。この問題、および貧弱なネットワーク接続によって発生するその他の問題に対する現実的な解決策は、Chubby [6] で行われているように、既存のリーダーに定期的に完全な準備フェーズを実行させて、一時的に切断されたピアのログのギャップを埋め、圧縮を再開することである。
| 正常系 | 新しいピアの追加 | ピアの再接続 | |
|---|---|---|---|
| 我々の適応型ログトリム | 性能劣化なし | 必要に応じてスナップショットが必要 | 切断時に圧縮が一時停止; スナップショット不要 |
| 定期スナップショット | スナップショットは役に立たない; ディスク I/O 増加を起しながら進行を止めてゆく |
最新のスナップショットを使用; 追加のオーバーヘッドなし |
最新のスナップショットを使用; 追加のオーバーヘッドなし |
| 定足数トリム | 性能劣化なし | 必要に応じて少なくとも 1 つのスナップショットが必要 | 必要に応じて少なくとも 1 つのスナップショットが必要 |
3.6 部分的なネットワーク分断
正常なネットワーク状態から異常なネットワーク状態に話を移し、次に我々は部分的なネットワーク分断のシナリオで MultiPaxos と我々の拡張の回復性を実証する。部分的なネットワーク分断とは、少なくとも 1 つのピアが一部のピアとの接続を失ったにもかかわらず、両方のピアが第 3 のピアによって接続されたままになるシナリオとして定義される [2]。この状況は MultiPaxos や Raft を含む SMR システムにライブロック (live lock) のリスクをもたらす。顕著な例として Cloudflare での停止障害 [32] がある。過去の研究ではいくつかの種類の部分分断シナリオを要約して分析している [37]。このような状況で MultiPaxos は限定的な回復性になるという以前の主張 [37] とは対照的に、我々の重要な観察は、適切な障害検出器の設計により追加のオーバーヘッドなしで回復性を十分に保証できることを示唆している。この主張を検証するために 2 種類の代表的な部分分断を検証する。
3.6.1 Leader-Losing-Quorum 分断
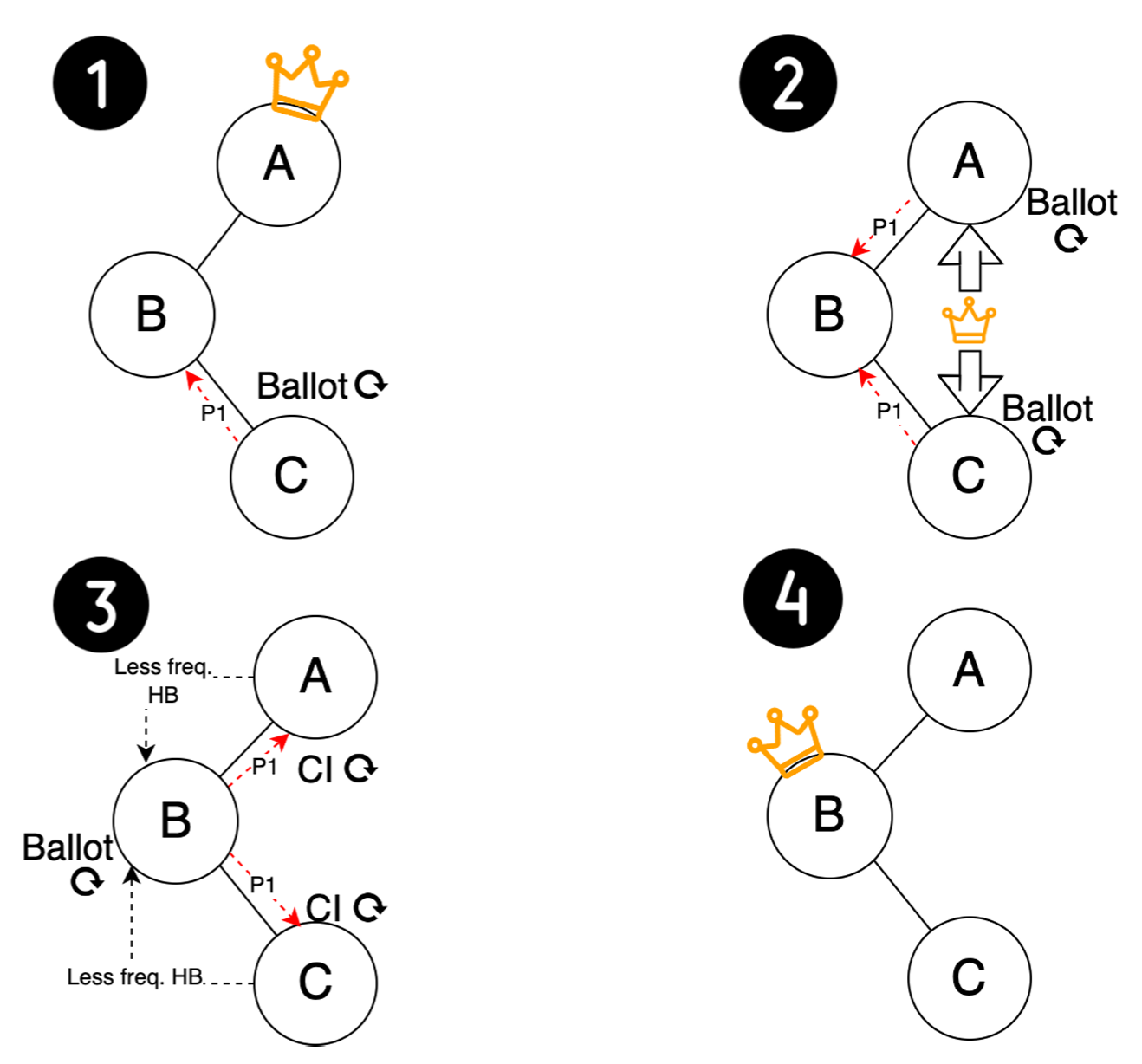
Figure 4 は 5 台のサーバが完全に接続されたクラスタを示しており、ピア B が元のリーダーである。このシナリオでは、ピア E を除くすべてのピアが相互接続を失うと分断が発生する。その結果、ピア E は定足数の接続を持つ唯一のピアとなり、ピア B は定足数を失って機能しなくなる。その後、ピア A, C, D はリーダー選出を開始するが、新しいリーダーになるための十分な投票を確保できない。先行研究では、この分断ではピア E がピア B のハートビートに応答し続け、リーダー選出を開始しないため、この分断では MultiPaxos が失敗すると示唆されている [37]。しかしこの主張は無効であり、MultiPaxos 誤った障害検出器の実装 [46] に起因している。
MultiPaxos の設計では、適切に実装されたハートビート検出器がこのようなシナリオで新しい安定したリーダー選出を促進できることを実証している。ピア A, C, D がより高い投票でリーダー選出をトリガーし、ピア E に準備リクエストを送信すると、ピア E は投票番号を更新する。この更新により、ピア E は古いリーダーであるピア B からのハートビートへの応答を停止する。その間、どのピアも新しいリーダーになることに成功せず、ピア E は新しいリーダー候補からハートビートを受信しないためタイムアウトが発生する。これにより、ピア E によって開始された別のリーダー選出がトリガーされる。最終的に、ピア E が新しいリーダーとして登場し、正常な動作が回復し、システムが進行を再開できるようになる。

3.6.2 リーダー交替と適用型タイムアウト設定
MultiPaxos は一般的に回復性を発揮するが、すべてのネットワーク分断シナリオに対応できるわけではない。Figure 5 は元々ピア A が主導していた 3 台のサーバが完全に接続されたクラスタにおけるこのようなケースを示している。ピア A と C が互いに到達不能になって部分的な分断が発生すると、ピア C がリーダー選出を開始し、成功裏に新しいリーダーとなる。しかしピア A がピア B を通じて C の新しいリーダーシップについて知ると、C からのハートビートを受信しないため別の選出をトリガーし、クラスタ内でライブロック状況を引き起こすリーダーシップ変更の周期的なパターンを発生させる。
この問題は多くの注目を集めているが [25, 37]、驚くべきことに我々は MultiPaxos アルゴリズムに変更を加えることなく障害検出器に簡単な変更を加えるだけでこの問題を効率的に解決できることを発見した。当初、我々の障害検出器は commit_interval の 2~2.5 倍に設定されていたランダムタイマーを使用していた。我々はこのアプローチを強化するために適応型ランダムタイマーメカニズムを導入した。ピア A やピア C のようなピアは、ある時間枠内で自分自身によって開始されたリーダー選出が多すぎると、その commit_interval を長くする。この変更により、別のリーダー選挙を開始するまでのスリープ期間が延長され、これらの選挙の頻度が減少する。
さらに重要なことは、commit_interval が延長されたことで一時的なリーダーがハートビートを送信する頻度が減り、ピア B のようなより案適したピアが新しいリーダーとして選出される可能性が高くなることである。ピア B の commit_interval が変更されていないため、ピア A や C よりもタイムアウトが早くなり、リーダー選出の開始が促される。ピア B は他のすべてのピアとの接続を維持しているため、一度選出されて安定したリーダーになると、リーダーシップの入れ替わり (leadership churning) を効率的に終わらせることができる。クラスタはすぐに通常の可用性に戻ることができる。さらに、分断のバリアが解消されたとき、つまりピア A と C が接続を再確立したときに、ピア B の現在のリーダーシップが中断されることはないため、システム全体の可用性が維持される。
4 評価
MultiPaxos 実装の評価では次の重要な質問に答えることを目標としている: (1) MultiPaxos は他のコンセンサスプロトコル実装と比較してどのように機能するか? (2) 我々のログトリミングアプローチは、さまざまなシナリオにおいてスナップショットや定足数トリムと比較してどのように機能するか? (3) さまざまな部分的ネットワーク分断シナリオの下で MultiPaxos はスループットの点でどの程度の回復性を発揮するか?
設計仕様に従って擬似コードを 4 つの異なる言語に移植した。他のオープンソースの MultiPaxos や Raft プロジェクトと比較するために、このようなプロジェクトの大部分が Go で実装されていることを考慮して、簡単のため Go 実装を選択した。我々はピア間の MultiPaxos 通信には gRPC [19] を使用し、クライアントとサーバ間の通信には非同期 TCP を採用している。
すべての実験は 8 vCPU と 32 GiB RAM を備えた AWS m5.2xlarge インスタンスを使用して 3 ノードと 5 ノードのクラスタで実施した。両方の構成でさまざまな実験設定に渡って同様の傾向が見られるため 3 ノードクラスタの結果を分析する。実験設定には Zipfian 要求分布が含まれており、キーと値のサイズはそれぞれ 23 B と 500 B に設定されている [47]。実験に先立ち、データベースに 100 万個の Key-Value ペアを投入し、20 秒間のウォームアップフェーズを開始する。64 クライアントスレッドを使用する独立した m5.2xlarge インスタンスで YCSB ワークロード A (読み取り 50%、書き込み 50%) [7, 12] を実行する。報告された結果は、5 回の独立した実行から得られた 1 つのサンプルを表している。
4.1 スループット vs レイテンシ
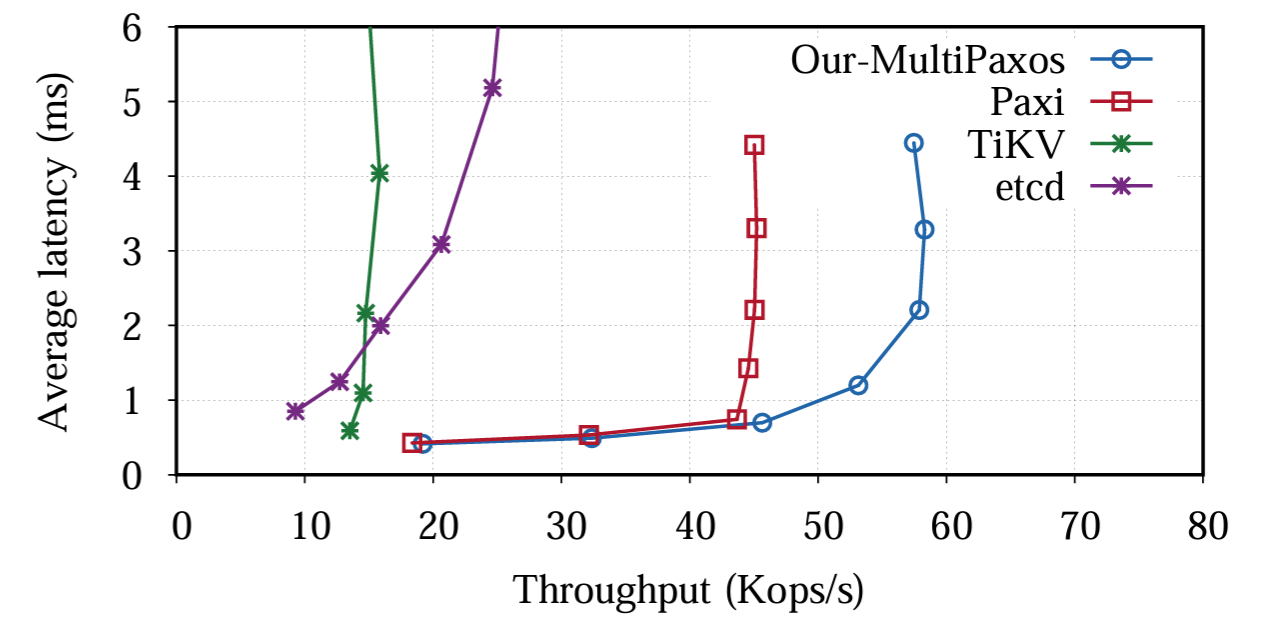
まず我々は共通的なシナリオにおける我々の MutiPaxos 実装の一般的なパフォーマンスを検証する。この実験では YCSB ワークロード A を 3 分間実行し、MultiPaxos の性能を学術プロジェクトの Paxi や実駆動対応システムの etcd や TiKV などを含むいくつかの確立された SMR 実装と比較する。この論文の焦点は性能の向上ではなく、この評価の主な目的はこれらの確立されたシステムと比較して MultiPaxos 実装が妥当で競争力のあるパフォーマンスを提供することを示すことである。公平な比較を確実にするために、デフォルトですべての操作エントリをログに保存する etcd と TiKV を、この実験では RAM ディスクを使用するように構成する。
Figure 6 に示されている結果から 8 から 256 までのさまざまなクローズドループクライアント数の範囲でスループットと平均レイテンシのメトリクスが明らかになる。etcd と TiKV は 10-25 Kop/s の間で同程度の性能を示したのに対して、MultiPaxos は 60 Kop/s 近い性能を達成する。このパフォーマンスの違いは、etcd と TiKV の両方の実駆動対応システムにはスループットに影響を与える可能性がある追加機能が組み込まれているためと予想される。Paxi と比較すると MultiPaxos はクライアント数が 32 以下の場合に同程度のスループットと平均レイテンシを示す。ただしクライアント数が増加すると MultiPaxos は同程度の平均レイテンシを維持しながら最大スループットはほぼ 1.5 倍に達する。この結果は MultiPaxos が最小限の遅延で迅速に操作を処理し、幅広いスループットレベルで一貫して低いレイテンシを維持していることを示している。MultiPaxos のレイテンシは、スループットが 45 Kop/s を超えた後にのみ大幅に増加し始め、これはシステムでリソース競合や処理のボトルネックが発生し始めるしきい値を示唆している。
4.2 ログ圧縮のオーバーヘッド
次に我々は、正常系 (common path)、一時的なノード切断、新しいノードの導入という 3 つの異なるシナリオを対象としてログ圧縮が性能とリソース使用率に与える影響を評価する。特に、ノードが長期間切断された場合に観測される影響は、新しいノードが参加した場合と似ている (ログエントリを再生するのではなくてスナップショットを送信する必要がある)。したがって我々は新しいノードを追加するシナリオのみを評価および分析する。
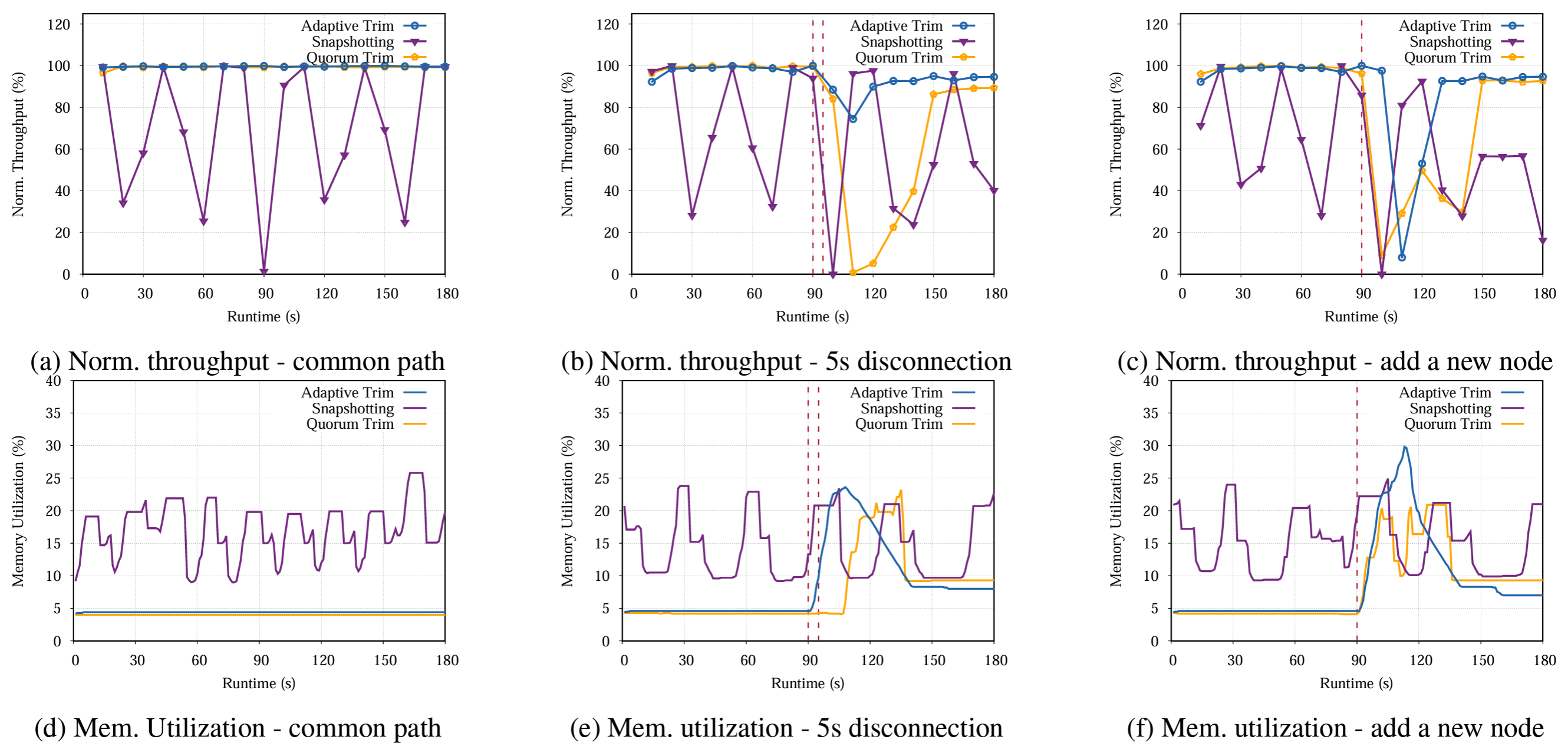
オープンソースプロジェクトで広く使用されているスナップショットベースのアプローチとして、我々は etcd の Raft モジュールを選択する。公平な比較のために MultiPaxos モジュールを公式のサンプルガイドライン [16] に従ってコンセンサスモジュールに置き換える。主な違いは定期的なスナップショットを取得するかどうかの決定にある。これにより性能の違いが他のモジュールによって発生していないことが保証される。スナップショット感覚については、ログの 500K エントリごとに取得するように設定する。定足数トリムアプローチではすべてのインスタンスは実行後にトリムされ、スナップショットはオンデマンドで実行される。
Figure 7 は実行時間全体のリアルタイムスループットとメモリ使用率を示している。各実装には異なるスループット限界があるため、すべてのスループット値をそれぞれの最大スループットで正規化し、スナップショットがスループットの変動に与える影響を強調している。メモリ使用率はすべてのノードで一貫しているため、スペースを節約するためにリーダーのメモリ使用率のみを示す。我々が新しいノードを追加したり一時的な切断をトリガーしたりするときは、これらのイベントを 90 秒目に実行する (図では赤い縦線で示されている)。各ピアの切断は 5 秒間続く。
Figure 7a は我々の適応型トリムと定足数トリムアプローチが正常系の実行時間全体にわたって非常に安定したパフォーマンスを示し、一貫して最大のスループットを達成していることを示している。対照的にスナップショットベースのアプローチのスループットは最大スループットの 20% 未満から 80% を超える範囲で急激なピークとダウンを伴う非常に不安定なパターンを示している。この変動性はスナップショットに関連するかなりの性能コストを強調している。さらに Figure 7d に示すように、我々のアプローチではメモリ使用率が低く安定していることも示している。使用率はすべてのログエントリを即座に削除する定足数トリムと同じレベルである。この結果は、我々の方法でメモリ内のログエントリをトリミングするペースが一定であることに起因している。逆に、スナップショットではメモリ使用率が高くなるだけではなく、顕著な変動が見られる。これらのメモリ使用量のピークはスナップショット生成時に発生している。スナップショット生成時には大量のメモリが一時的に割り当てられ、その後ディスクに永続化されて最終的に収集される。
ただし、Figure 7b と Figure 7c に示すように、スナップショットは切断シナリオと新しいノードシナリオの両方で一貫したパフォーマンスを示している。スナップショットのコストは実行時間を通じて償却されるため、これは我々の予想と一致している。ただし、スナップショットの送信はネットワーク帯域幅を消費し、時折リーダー選出のラウンドが複数回発生することがあり、リーダーがすぐに選出されない場合はスナップショットの送信後にもパフォーマンスの低下が続く可能性がある (Figure 7c の 90 秒目から 180 秒目まで)。
対照的に、このようなイベントが発生すると我々のログ圧縮メカニズムも影響を受けるが、どのような劣化も一過性であり、切断の場合はノードが参加した場合よりも低下が大幅に少なくなっている。Figure 7e に示すように、切断の状況ではログ圧縮の一時停止によりメモリ使用率が急上昇して 5% から 25% 近くに跳ね上がり、この増加は 5 秒以上 (切断の継続時間) 持続する。これは再接続されたフォロワーが進行状況に追いついてバッチコミットを完了するために数ラウンドのコミットメッセージを必要とするためである。その後、リーダーは global_last_execute を更新しログのトリミングを開始する。
新しいノードの追加に関しては、現在のステートマシンのスナップショットを取ることが適用型トリム方式の唯一のオプションである。そのコストはスナップショット作成と同程度で、スナップショットの作成と転送に必要な時間に加え、メモリ内のスナップショットのサイズが大きいため定足数のメモリ割り当ても含まれる。重要な点として、定足数トリムもスナップショット作成に依存しているが、Figure 7c に示されているように、パフォーマンスを回復するのにかかる時間は適応型トリムアプローチのほぼ 2 倍になる。ピアが以前のスナップショットから復元されると、リーダーが新しいエントリを追加し続け実行後すぐに削除するため、新しい別のスナップショットが必要になる。したがって状態を復元するためのスナップショットが複数になる。スナップショット複製が多すぎると、リーダーがスナップショット作成に長い時間を費やすため、リーダー選出が繰り返される可能性がある。特に、すべてのアプローチは両方のイベント後に最大スループットに回復しないことがあり、これは fail-slow フォロワー [48] に関連している。要約すると、導入または再接続のシナリオ下でも我々のログ圧縮メカニズムによるスループットの低下はほとんどの場合 10% 未満だが、定期的なスナップショットベースの方法では実行時に 40-60% の低下が発生する可能性がある。また我々のログ圧縮方法はメモリ使用率でも優れている。
4.3 部分的な分断での回復性
次に我々は部分的なネットワーク分断を伴うシナリオでパフォーマンスを分析する。具体的には Leader-Losing-Quorum シナリオと Chained-Leader-Churning シナリオの 2 種類の分断を検証する。どちらの場合も YCSB ワークロードを 3 分間実行し、80 秒目にネットワーク分断を開始し、100 秒目にクラスタを復元して 20 秒間実行する。すべてのクラスタが 20 秒以内に可用性を回復するか無期限に利用不可のままになるためこの期間は実行に関係なく十分である。
前の実験と同様に、この分析でも主に MultiPaxos 設計と etcd 統合バージョンを比較する。さらに、ネットワーク分断中の障害検出器のパフォーマンスへの影響を調べるために CheckQuorum オプションが有効になっている etcd (つまり etcd-cq) や、適応型タイムアウト最適化のない MultiPaxos (Classic MultiPaxos と表記) などのバリアントを比較に含めた。CheckQuorum オプションは、リーダーが過半数のピア接続を失ったときにリーダーを退き、リーダー選出を許可することを示している。なお etcd の実装では、これはフォロワーがリーダーからメッセージを受信したときに投票に応答するを阻止するようにもなっていることに注意。ここでも、公平な比較を保証するために、スループットを各実装のそれぞれの最大値に正規化する。
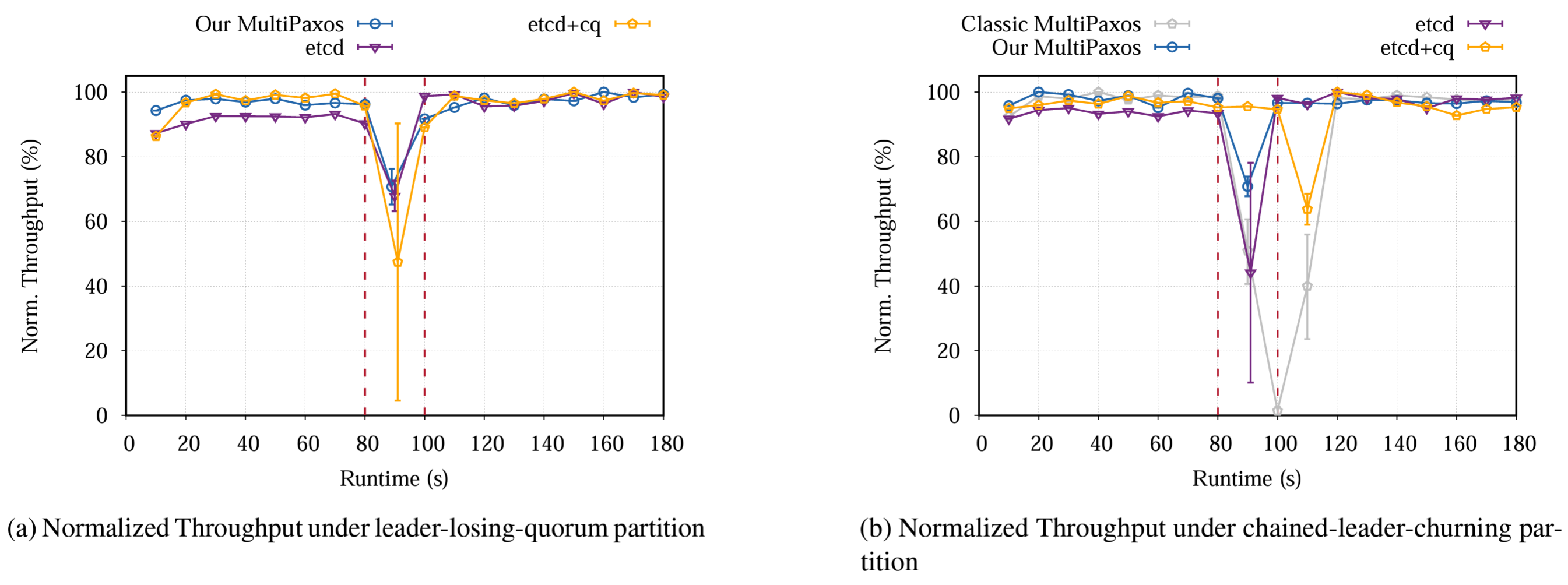
Figure 8a は Leader-Losing-Quorum 分断シナリオ中に MultiPaxos のパフォーマンス低下が最大 65%~75% の範囲に留まっていることを示している。この低下は主に、分断中に旧リーダーが定足数を失い、分断中の進行を停止したためである。分断が開始されると、他のすべてのピアと接続している唯一のピアである "安定したピア" はハートビートが失われた後にのみリーダー選出を開始する。これは通常、少なくとも 2 ラウンドの選出が必要である (1 つは他のフォロワーが選出を開始するため、もう 1 つは安定したピアが選出を開始するため)。安定したリーダーが選出されるとスループットは通常レベルに回復し 95% を超える。分断が解消された後でも、新しいリーダーがすべてのフォロワーとの安定した接続を維持するため、スループットはネットワーク状況の変化による影響を受けない。Classic MultiPaxos も同様の回復性を示すためそのデータは図から省略している。
(CheckQuorum が有効になっていない) etcd は MultiPaxos と同等のパフォーマンスを発揮する。分断の開始時に安定したピアはターム番号を更新し、旧リーダーからのハートビートを無視する。これは、安定したピアが最終的に選出を開始してリーダーシップを引き継ぐまで、どのピアもリーダーにならない MultiPaxos で見られる動作を反映している。その結果、etcd での利用不能期間とパフォーマンス低下は MultiPaxos と同等で 65% から 70% の範囲に収まる。
ただし CheckQuorum オプションを有効にすると性能のばらつきが大幅に拡大する。このばらつきはリーダー選出が複数ラウンド発生する可能性があることに起因する。安定ノードは選挙タイムアウトをトリガーしていない場合、すべての投票要求を無視する。一部の実行では、安定ピアが他のピアと同様にリーダー選出を開始し、1 ラウンドでリーダーシップを確保して 90% の上限を達成する。一方、安定リーダーは選挙を遅らせ、そのターム数が他の候補者より遅れる場合がある。そのため最高ターム数に追いつくために複数の選出ラウンドが発生し、下限は 10% 未満となる。
Figure 8b は Chained-Leader-Churning 分断中の正規化された実行時スループットを示す。前述のように、Classic Paxos は予想通りの挙動を示し、クラスタはほぼ完全に利用できなくなる。スループットは 99% 近く急落し、分断が解消されてから徐々に回復を始める。対照的に、最適化した適応型タイムアウト設定の我々の MultiPaxos ははるかに優れた回復性を発揮する。クラスタはリーダーシップ交替中に部分的に使用できなくなる。分断が解消される前であっても安定したリーダーが選出されるとパフォーマンスは即座に再開する。4 つの実装の中で、我々の最適化された MultiPaxos は最大スループットが 30% しか低下せず、最高のパフォーマンスを示している。
興味深いことに、どちらの etcd バージョンも以前の分断シナリオとは異なるパフォーマンスを示す。etcd のパフォーマンス低下の範囲は 20% から 90% と大きく差がある。この変化はリーダー選出の頻度が異なることに起因する。フォロワーがリーダーとの接続を失うと、徐々に高いターム番号でリーダー選手を繰り返し開始する。安定したピアは投票を許可しないが、選挙が繰り返されることでターム番号が上昇し続け、旧リーダーからのハートビートを無視するようになる。その結果、旧リーダーも繰り返しリーダー選挙を繰り返すサイクルに入る。パフォーマンスが再開されるのは安定したピアが選出を開始する機会を得た時だけであり、その結果さまざまな度合いでパフォーマンス低下が発生する。
ただし etcd+cq は異なる挙動を示す。安定したピアは切断されたフォロワーからの投票をすべて無視し、定足数を維持するため、分断中もスループットは影響を受けない。しかし分断が終了すると切断されたフォロワーはより高いターム番号を持つようになり、リーダー選挙を開始し、選挙とスナップショット転送が数ラウンド発生する。これによりパフォーマンスが約 30%~40% 低下する。まとめると、etcd+cq は分断が終わるまでコストを先送りするが、我々の MultiPaxos 設計では分断中に新しい安定したリーダーを選出してフォロワーが遅れるケースを回避する。
5 関連研究
元の MultiPaxos 論文は Lamport が発表したその変種とともにアルゴリズムの最適化に重点が置かれていたが、実用的な実装の詳細は省略されていたため実世界の導入には課題があった [22, 27, 28, 29, 36]。その後の研究努力はこのギャップを埋めようとしたが、主な重点は再現のための包括的な青写真を提供するのではなく特定の実装の考慮事項や選択に置かれていた [9, 35]。数多くの学術研究プロジェクトがオープンソース実装を生み出してきたが、効果的なログ圧縮など実用的なアプリケーションに不可欠な機能が欠けていることが多い [1, 18, 30, 36, 41, 46]。さらに、これらのプロジェクトではレプリケーションプロセスのさまざまなフェーズの調整が考慮されていない。
対照的に、産業界ではコンセンサスモジュールの構築には MultiPaxos より主に Raft コンセンサスアルゴリズムを採用している [4, 5, 15, 21, 42, 43, 49]。しかしそれらは言語に制限があることが多く、統合のための詳細なチュートリアルが必ずしも利用できるとは限らない。さらに、ほとんどの産業用オープンソースフレームワークはログトリミングのためにスナップショットに大きく依存している。特に TiKV と etcd V3 は定期的なスナップショットを回避するために代替オプションである MVCC を使用している。
部分的なネットワーク分断に関する研究は行われているが、それらは解決策ではなく分析を重視している [2, 25, 31]。それ以外に OmniPaxos は部分的な分断に対する MultiPaxos の回復性を強化することを目的としているが、全体的な設計に複雑さをもたらし、特定のタイプの分断では最適なソリューションを提供しない可能性がある [37]。エッジシナリオ向けに etcd を変更すると一貫性が低下するという代償が伴う [24]。Nifty は部分的な分断を処理するためにオーバーレイネットワークを使用する [2]。
6 考察
この論文で我々は MultiPaxos の見逃されてきたアルゴリズムの詳細と実際の実装との間の重大なギャップを埋めている。我々はログ選出、ログ回復、コミットフェーズ、障害検出器など、すべての重要なコンポーネントにステップバイステップの擬似コードを使用して MultiPaxos の包括的で詳細な設計を提供している。これらのコンポーネントは実装に不可欠であるにもかかわらずアルゴリズムの説明では見落とされている。我々のパフォーマンス評価では MultiPaxos 実装が既存のシステムと比較して競争力のあるスループットとレイテンシを示していることが示されている。さらに、我々はスナップショットの必要性の排除する革新的で軽量なログ圧縮アプローチを紹介する。我々の結果は、性能コストが低く、メモリ使用率が低いことを強調し、ほとんどの場合でスナップショットより優れている。さらに、我々は部分的なネットワーク分断の下での MultiPaxos の回復性を実証し、リーダー交替シナリオで MultiPaxos の可用性を高めるための適応型タイムアウトメカニズムを提案する。我々の取り組みは MultiPaxos の実装におけるギャップを解消するだけでなく、実行時のコストを削減し、より優れた回復性を実現するための実用的なヒントも提供する。
References
- Ailidani Ailijiang, Aleksey Charapko, and Murat Demirbas. Dissecting the performance of strongly-consistent replication protocols. In Proceedings of the 2019 International Conference on Management of Data, SIGMOD ’19, pages 1696–1710, New York, NY, USA, 2019. Association for Computing Machinery.
- MohammedAlfatafta, Basil Alkhatib, Ahmed Alquraan, and Samer Al-Kiswany. Toward a generic fault tolerance technique for partial network partitioning. In 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), pages 351–368, 2020.
- Meta Authors. Building and deploying MySQL Raft at Meta. https://engineering.fb.com/2023/05/16/data-infrastructure/mysql-raft-meta/, 2023.
- TiKV Authors. Tikv is a highly scalable, low latency, and easy to use key-value database. https://tikv.org, 2023.
- braft Authors. An industrial-grade C++ implementation of RAFT consensus algorithm based on brpc, widely used inside Baidu to build highly-available distributed systems. https://github.com/baidu/braft, 2023.
- Mike Burrows. The chubby lock service for loosely-coupled distributed systems. In Proceedings of the 7th Symposium on Operating Systems Design and Implementation, OSDI ’06, pages 335–350, USA, 2006. USENIX Association.
- Sean Busbey. Core Workloads. https://github.com/brianfrankcooper/YCSB/wiki/Core-Workloads, 2015.
- Brad Calder, Ju Wang, Aaron Ogus, Niranjan Nilakantan, Arild Skjolsvold, Sam McKelvie, Yikang Xu,Shashwat Srivastav, Jiesheng Wu, Huseyin Simitci, et al. Windows azure storage: a highly available cloud storage service with strong consistency. In Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles, pages 143–157, 2011.
- Tushar D. Chandra, Robert Griesemer, and Joshua Redstone. Paxos made live: An engineering perspective. In
Proceedings of the Twenty-Sixth Annual ACM Symposium on Principles of Distributed Computing
, PODC ’07, pages 398–407, New York, NY, USA, 2007. Association for Computing Machinery. - Aleksey Charapko, Ailidani Ailijiang, and Murat Demirbas. Linearizable quorum reads in paxos. In 11th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 19), 2019.
- Aleksey Charapko, Ailidani Ailijiang, and Murat Demirbas. Pigpaxos: Devouring the communication bottlenecks in distributed consensus. In Proceedings of the 2021 International Conference on Management of Data, pages 235–247, 2021.
- Brian F. Cooper, Adam Silberstein, Erwin Tam, Raghu Ramakrishnan, and Russell Sears. Benchmarking cloud serving systems with ycsb. In Proceedings of the 1st ACM Symposium on Cloud Computing, SoCC’10,pages 143–154, New York, NY, USA, 2010. Association for Computing Machinery.
- James C. Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, JJ Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, Wilson Hsieh, Sebastian Kanthak, Eugene Kogan, Hongyi Li, Alexander Lloyd, Sergey Melnik, David Mwaura,David Nagle,Sean Quinlan,Rajesh Rao, Lindsay Rolig, Dale Woodford, Yasushi Saito, Christopher Taylor, Michal Szymaniak, and Ruth Wang. Spanner: Google’s globally-distributed database. In OSDI, 2012.
- Mostafa Elhemali, Niall Gallagher, Nick Gordon, Joseph Idziorek, Richard Krog, Colin Lazier, Erben Mo, Akhilesh Mritunjai, Somasundaram Perianayagam, Tim Rath, Swami Sivasubramanian, James Christopher Sorenson III, Sroaj Sosothikul, Doug Terry, and Akshat Vig. Amazon DynamoDB: A scalable, predictably performant, and fully managed NoSQL database service. In 2022 USENIX Annual Technical Conference (USENIX ATC 22), pages 1037–1048, Carlsbad, CA, July 2022. USENIX Association.
- etcd Authors. etcd: A distributed, reliable key-value store for the most critical data of a distributed system. https://etcd.io/, 2023.
- etcd-raft-example Authors. raftexample is an example usage of etcd’s raft library. https://github.com/etcd-io/etcd/tree/main/contrib/raftexample, 2023.
- Pedro Fouto, Nuno Preguiça, and João Leitão. High throughput replication with integrated membership management. In 2022 USENIX Annual Technical Conference (USENIX ATC 22), pages 575–592, 2022.
- Aishwarya Ganesan, Ramnatthan Alagappan, Anthony Rebello, Andrea C Arpaci-Dusseau, and Remzi H Arpaci-Dusseau. Exploiting nil-external interfaces for fast replicated storage. ACM Transactions on Storage (TOS), 18(3):1–35, 2022.
- Google. gRPC: A high performance, open source universal RPC framework. https://grpc.io/, 2023.
- Yossi Gottlieb. Introducing RedisRaft, a New Strong-Consistency Deployment Option. https://redis.com/blog/redisraft-new-strong-consistency-deployment-option/, 2020.
- haishicorp Authors. Golang implementation of the Raft consensus protocol. https://github.com/hashicorp/raft, 2023.
- Heidi Howard, Dahlia Malkhi, and Alexander Spiegelman. Flexible paxos: Quorum intersection revisited. arXiv preprint arXiv:1608.06696, 2016.
- Heidi Howard and Richard Mortier. Paxos vs raft: Have we reached consensus on distributed consensus? In Proceedings of the 7th Workshop on Principles and Practice of Consistency for Distributed Data, pages 1–9, 2020.
- Andrew Jeffery, Heidi Howard, and Richard Mortier. Mutating etcd towards edge suitability. arXiv preprint arXiv:2311.09929, 2023.
- Chris Jensen, Heidi Howard, and Richard Mortier. Examining raft’s behaviour during partial network failures. In Proceedings of the 1st Workshop on High Availability and Observability of Cloud Systems, pages 11–17, 2021.
- Leslie Lamport. The part-time parliament. ACM Trans. Comput. Syst., 16(2):133–169, may 1998.
- Leslie Lamport. Paxos made simple. ACM SIGACT News (Distributed Computing Column) 32, 4 (Whole Number 121, December 2001), pages 51–58, December 2001.
- Leslie Lamport. Generalized consensus and paxos. 2005.
- Leslie Lamport. Fast paxos. Distributed Computing, 19:79–103, 2006.
- Jialin Li, Ellis Michael, Naveen Kr Sharma, Adriana Szekeres, and Dan RK Ports. Just say no to paxos overhead: Replacing consensus with network ordering. In OSDI, pages 467–483, 2016.
- Yuetai Li, Yixuan Fan, Lei Zhang, and Jon Crowcroft. Raft consensus reliability in wireless networks: Probabilistic analysis. IEEE Internet of Things Journal, 2023.
- Tom Lianza and Chris Snook. A byzantine failure in the real world. https://blog.cloudflare.com/a-byzantine-failure-in-thereal-world/, 2021.
- Tzach Livyatan. 5.2: ScyllaDB Open Source With Raft-Based Schema Management. https://www.scylladb.com/2023/05/04/scylladb-open-source-5-2-with-raft-based-schema-management/, 2023.
- Yanhua Mao, Flavio P. Junqueira, and Keith Marzullo. Mencius: Building efficient replicated state machines for wans. In Proceedings of the 8th USENIX Conference on Operating Systems Design and Implementation, OSDI’08, pages 369–384, USA, 2008. USENIX Association.
- David Mazieres. Paxos made practical, 2007.
- Iulian Moraru, David G. Andersen, and Michael Kaminsky. There is more consensus in egalitarian parliaments. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles, SOSP ’13, pages 358372, New York, NY, USA, 2013. Association for Computing Machinery.
- Harald Ng, Seif Haridi, and Paris Carbone. Omni-paxos: Breaking the barriers of partial connectivity. In Proceedings of the Eighteenth European Conference on Computer Systems, pages 314–330, 2023.
- Brian M Oki and Barbara H Liskov. Viewstamped replication: A new primary copy method to support highly-available distributed systems. In Proceedings of the seventh annual ACM Symposium on Principles of distributed computing, pages 8–17, 1988.
- Diego Ongaro and John Ousterhout. In search of an understandable consensus algorithm. In 2014 USENIX Annual Technical Conference (USENIX ATC 14), pages 305–319, Philadelphia, PA, June 2014. USENIX Association.
- Haochen Pan, Jesse Tuglu, Neo Zhou, Tianshu Wang, Yicheng Shen, Xiong Zheng, Joseph Tassarotti, Lewis Tseng, and Roberto Palmieri. Rabia: Simplifying state-machine replication through randomization. In Proceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles, pages 472–487, 2021.
- Marco Primi and Daniele Sciascia. Libpaxos. https://libpaxos.sourceforge.net/, 2013.
- redis-raft Authors. A Redis Module that make it possible to create a consistent Raft cluster from multiple Redis instances. https://github.com/RedisLabs/redisraft, 2023.
- rethinkdb Authors. The open-source database for the realtime web. https://github.com/rethinkdb/rethinkdb, 2023.
- Sarah Tollman, Seo Jin Park, and John Ousterhout. {EPaxos} revisited. In 18th USENIX Symposium on Networked Systems Design and Implementation (NSDI 21), pages 613–632, 2021.
- Robbert Van Renesse and Deniz Altinbuken. Paxos made moderately complex. ACM Comput. Surv., 47(3), feb 2015.
- Michael Whittaker. Frankenpaxos. https://github.com/mwhittaker/frankenpaxos, 2021.
- Juncheng Yang, Yao Yue, and K. V. Rashmi. A large scale analysis of hundreds of in-memory cache clusters at twitter. In 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), pages 191–208. USENIX Association, November 2020.
- Andrew Yoo,Yuanli Wang,Ritesh Sinha, Shuai Mu, and Tianyin Xu. Fail-slow fault tolerance needs programming support. In Proceedings of the Workshop on Hot Topics in Operating Systems, pages 228–235, 2021.
- Jianjun Zheng, Qian Lin, Jiatao Xu, Cheng Wei, Chuwei Zeng, Pingan Yang, and Yunfan Zhang. Paxosstore: High-availability storage made practical in wechat. Proc. VLDBEndow., 10(12):1730–1741, aug 2017.
A MultiPaxos 設計仕様
このセクションでは MultiPaxos モジュールの擬似コードを紹介する。MultiPaxos モジュールはピア間の通信に gRPC を採用しているため、まずコミットフェーズ、準備フェーズ、受理フェーズのそれぞれで使用される gRPC メッセージと、これらのメッセージで使用される protobuf の仕様を示す。我々は gRPC 版の仕様を提供するが設計は gRPC には制限されない。したがってメッセージのフィールドが同じであれば protobuf をバイト値や JSON などの他の型に置き換えることができる。
− types / protobufs
− commit_request protobuf
− ballot_ : コミット RPC を送信するリーダーの ballot (投票)
− last_executed_ : コミット RPC を送信するリーダーの last_executed_
− global_last_executed_ : コミット RPC を送信するリーダーの global_last_executed
− sender : 送信者の id
− commit_response protobuf
− type_ : enum {ok, reject}
− ballot_ : ピアの投票 (type_ == reject の場合のみ有効)
− last_executed_ : コミット RPC に応答するフォロワーの last_executed_
− prepare_request protobuf
− ballot_ : 送信者の ballot
− sender : 送信者の id
− prepare_response protobuf
− type_ : enum {ok, reject}
− ballot_ : ピアの投票 (type_ == reject の場合のみ有効)
- instances_ : global_last_executed_ 以降のピアのインスタンス ( type_ == ok の場合のみ有効)
− accept_request protobuf
− instance_ : リーダーから送信されたインスタンス
− sender_ : 送信者の id
− accept_response protobuf
− type_ : enum {ok, reject}
− ballot_ : ピアの投票 (type_ == reject の場合のみ有効)
− command protobuf
− type_ : enum {get , put , del}
− key_: string
− value_ : string
− instance protobuf
− ballot_ : インスタンスの投票
− index_ : ログのインスタンスのインデックス
− client_id_ : コマンドを発行したクライアントの id
− command_: コマンド protobuf
− result
− type_ : enum {ok, retry , someone_else_leader}
− leader_ : optional int
MultiPaxos のフェーズを実行する場合、複数のピアにリクエストを送信し、それから応答を受信する。各フェーズでは受信した応答の数など特定の変数を追跡する必要がある。ピアへのリクエストごとに個別のスレッドを起動するため、これらのスレッドはこれらの変数を共有し、応答に基づいて更新する必要がある。理論上、これらのスレッドは MultiPaxos オブジェクトよりも長く存続する可能性があるため、これらの変数をクラスメンバーにすることはできない (threadsanitizer が文句を言う)。したがって、各フェーズでは、追跡する必要のある変数をすべて 1 つの構造体に収集し、参照カウントポインタを使用して割り当て、各スレッドに構造体への参照カウントポインタを渡す。これらの構造体はロックによって保護されており、各スレッドは構造体を更新する前にまずロックを獲得する。最後に終了したスレッドが構造体の割り当てを解放する。
− prepare_state
− num_rpc_: 受信した RPC 応答数
− num_oks_: 肯定的な準備応答数
− leader_ : 現在のリーダー
− last_index_ : 受信したインスタンスで観測された最高インデックス
− log_ : 肯定的応答の統合ログ
− mu_: この構造体を保護する mutex
− cv_: 各スレッドが完了時にシグナルを送る条件変数 (run_prepare_phase() はこれでスリープし、スレッドがシグナルを送ると起動して定足数に
達したかを確認する)
− accept_state
− num_rpc_: 受信した RPC 応答数
− num_oks_: 肯定的な準備応答数
− leader_ : 現在のリーダー
− mu_: この構造体を保護する mutex
− cv_: 各スレッドが完了時にシグナルを送る条件変数 (run_accept_phase() はこれでスリープし、スレッドがシグナルを送ると起動して定足数に
達したかを確認する)
− commit_state
− num_rpc_: 受信した RPC 応答数
− num_oks_: 肯定的な準備応答数
− leader_ : 現在のリーダー
− min_last_executed : the smallest last_executed of positive responses
− mu_: この構造体を保護する mutex
− cv_: 各スレッドが完了時にシグナルを送る条件変数 (run_commit_phase() はこれでスリープし、スレッドがシグナルを送ると起動してすべての
ピアが応答したかを確認する)MultiPaxos オブジェクトの仕様は、メンバー、定数、非メンバー関数、メソッドを含めて次のようにリストされている。すべての変数とメソッドにはその動作についての詳細な説明が含まれている。
− MultiPaxos
− members
− ballot_ : int64_t ; current ballot number known to the peer ; initialized | max_num_peers_ | , which indicates
that there is no current leader, since valid leader ids are in [0, max_num_peers_). it is a 64−bit integer, the
lower 8 bits of which is always equal to | id_ | of the peer that chose | ballot_ |, and the higher bits represent
the round number. we preserve 8 bits for | id_ | but limit | id_ | to 4 bits to avoid an overflow when identifying
a leader. initialized to | id_ |. at any moment, we can l ook at the lower 8 bits of | ballot_ | to determine
current leader.
− log_ : non−owning pointer to Log instance.
− id_ : int64 ; identifier of this peer . initialized from the configuration file. currently, we limit the number of
peers to 16; therefore , id_ is a value in [0 , 16).
(省略...)B ログ設計仕様
同様に、ログオブジェクトの仕様はメンバー、定数、非メンバー関数、メソッドを含めて以下のようにリストされている。すべての麺数とメソッドには詳細な紹介が含まれている。
Log は制限のない producer-consumer キュート考えることができる。この観点から以下の execute メソッドはキューの consume メソッドとして機能し、以下の commit メソッドはキューの producer メソッドとして機能する。技術的には、インスタンスは append メソッドを介してキューに挿入されるが、インスタンスに対して commit を呼び出してコミットされるまで実行可能にはならない。wake-up は 1 つの方法だけで発生する。コミットするスレッドは execute メソッドを呼び出してインスタンスを実行する executor スレッドを wake-up する。
executor スレッドは log の execute メソッドの呼び出しでブロックする可能性があるため、システムをクリーンにシャットダウンする場合は executor を wake-up する必要がある。このためログには実行中フラグと stop メソッドがあり、実行中フラグを false に設定し、実行スレッドがスリープ状態にある (execute メソッドの呼び出しによる) 条件変数を通知する。execute メソッドはログが停止された後に nullopt を返し、実行メソッドは nullopt を受け取ると終了できる。
仕様にアサーションを追加して不変条件が成立するかどうかを検証していることに注意。(1) ログ内のインスタンスは順番に実行されなければならない、(2) last_executed は最後に実行されたインスタンスのインデックスである、(3) global_last_executed はすべてのピアで最後に実行されたインスタンスのインデックスである。これらを個苦慮するとログには次の不変条件がある。
(i1) global_last_executed <= last_executed である。
(i2) [global_last_executed, last_executed] 内のすべてのインスタンスは実行されている。
(i3) last_executed より後のインスタンスで実行されているものは存在しない。
(i4) global_last_executed より小さいインデックスにインスタンスは存在しない。
- Log
(省略...)翻訳抄
リーダー選出、障害検出器、コミットフェーズなど、MultiPaxos を構成する各コンポーネントの詳細な分析とステップバイステップのコードを含むオープンソースによって正確な実装を提供することを目的とした 2024 年の論文。
- Liang, Z., Jabrayilov, V., Charapko, A., & Aghayev, A. (2024). MultiPaxos Made Complete. arXiv preprint arXiv:2405.11183.
