論文翻訳: Large-scale Incremental Processing Using Distributed Transactions and Notifications
dpeng@google.com, fdabek@google.com
Google, Inc.
 Abstract
Abstract
文書がクロールされるときに Web のインデックスを更新するには、新しい文書が到着するたびに既存の文書の大規模なリポジトリを継続的に変換する必要がある。このタスクは、小規模で独立した変更によって大規模なデータリポジトリを変換するデータ処理タスクの一例である。これらのタスクは既存のインフラストラクタの能力とのギャップにある。データベースはこれらのタスクのストレージ要件またはスループット要件を満たしていない。Google のインデックス作成システムは、数十ペタバイトのデータを保存し、数千台のマシンで 1 日に数十億の更新を処理している。MapReduce やその他のバッチ処理システムは効率性のために大規模なバッチを作成する必要があるため小さな更新を個別に処理することができない。
我々は大規模なデータセットに対する更新を増分処理するシステムである Percolator を構築し、Google の Web 検索インデックスを作成するために導入した。バッチベースのインデックス作成システムを Percolator を使用した増分処理に基づくインデックス作成に置き換えることで、1 日あたりの文書処理数は同じでありながら Google の検索結果に表示される文書の平均年齢を 50% 下げる事に成功した。
Table of Contents
1 導入
検索クエリーに答えるために使用できる Web のインデックスを構築するタスクについて考える。インデックス作成システムは Web 上のすべてのページをクロールし、インデックスの不変量セット (set of invariants) を維持しながら処理することから始まる。たとえば、同じコンテンツが複数の URL でクロールされた場合、PageRank [28] が最も高い URL のみがインデックスに表示される。リンクの反転は重複を超えて機能しなければならず、ページの重複へのリンクは必要に応じて最も PageRank の高い重複に転送されなければならない。
これは一連の MapReduce [13] 操作として表現できる一括処理タスクであり、一つは重複のクラスタリング用、もう一つはリンク反転などである。MapReduce は計算の並列処理を制限するため、不変量を維持するのは簡単で、すべての文書は次の処理を始める前に一つの処理ステップを終了する。たとえば、インデックス作成システムが現在の最高 PageRank の URL に反転リンクを書き込んでいるとき、その PageRank が同時に変換することを心配する必要はなく、前の MapReduce ステップで既に PageRank が決定されている。
さて、Web のごく一部を再クロールした後にそのインデックスを更新する方法を考えてみよう。新しいページと Web の残りの部分の間にはリンクがあるため、新しいページだけに対して MapReduce を実行するだけでは不十分である。MapReduce はリポジトリ全体、つまり新しいページと古いページの両方で再度実行する必要がある。十分なコンピューティングリソースがあれば MapReduce のスケーラビリティによってこのアプローチは実現可能であり、実際、Google の Web 検索インデックスはここで説明する研究の前にこの方法で作成されていた。しかし Web 全体を再処理すると以前の実行で行われた作業は破棄され、レイテンシは更新サイズではなくリポジトリのサイズに比例する。
インデックス作成システムはリポジトリを DBMS に保存しトランザクションを使用して不変量を維持しながら個々の文書を更新できる。しかし既存の DBMS は膨大な量のデータを処理できず、Google のインデックスシステムは数千台のマシンに数十ペタバイトのデータを保存している [30]。Bigtable [9] のような分散ストレージシステムはリポジトリのサイズに合わせて拡張できるが、プログラマが同時更新に直面してもデータの不変量を維持するのに役立つツールは提供していない。
Web 検索インデックスを維持するタスクに最適なデータ処理システムは増分処理 (incremental processing) に最適化されている。つまり、非常に大きな文書のリポジトリを維持し、新しい文書がクロールされるたびに効率的に更新できる。システムが多数の小さな更新を同時に処理することを考えると、理想的なシステムでは同時更新にもかかわらず不変量を維持し、どの更新が処理されたかを追跡するメカニズムも提供するだろう。
このホワイトペーパーの残りの部分では特定の増分処理システムである Percolator について説明する。Percolator はマルチ-PB リポジトリへのランダムアクセスをユーザに提供する。ランダムアクセスにより文書を個別に処理できるため MapReduce に必要なリポジトリのグローバルスキャンを回避できる。高いスループットを実現するには、多くのマシン上の多くのスレッドが同時にリポジトリを変換する必要があるため、Percolator は ACID 準拠のトランザクションを提供し、プログラマがリポジトリの状態について推論しやすくしている。現在、スナップショット分離セマンティクス [5] を実装している。
同時実行に関する推論に加えて、増分システムのプログラマは増分計算の状態を追跡する必要がある。このタスクを支援するため Percolator はオブザーバを提供する。オブザーバとはユーザが指定した絡むが更新されるたびにシステムによって呼び出されるコードの一部である。Percolator アプリケーションは一連のオブザーバとして構成される。各オブザーバはタスクを完了してテーブルに書き込むことで「下流」のオブザーバの作業をさらに作成する。外部プロセスはテーブルに初期データを書き込むことでチェーンの最初のオブザーバをトリガーする。
Percolator は増分処理に特化して構築されており、ほとんどのデータ処理タスクの既存のソリューションに取って代わることは意図していない。結果を小さな更新に分割できない計算 (たとえばファイルのソートなど) は MapReduce で処理する方が適している。また計算には強い一貫性が要求され、そうでないなら Bigtable で十分である。最後に、計算はある次元 (データの総サイズ、変換に必要な CPU など) で非常に大きくなければならない。MapReduce や Bigtable に適さない小規模な計算は従来の DBMS で処理できる。
Google での Percolator の主な用途はライブの Web 検索インデックスに含めるために Web ページを準備することである。インデックス作成システムを増分システムに変換することでクロールされるたびに個々の文書を処理できる。これにより、文書処理の平均待ち時間が 100 分の 1 に短縮され、検索結果に表示される文書の平均年齢は 50% 近く短縮された (検索結果の年齢は文書が更新されてからクロールされるまでの時間など、インデックス作成以外の遅延も含まれる)。このシステムはページを画像にレンダリングするためにも使われている。Percolator は Web ページとそれが依存するリソースの関係を追跡するため、依存するリソースが変更されたときにページを再処理できる。
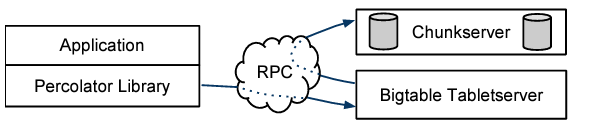
2 設計
Percolator は大規模な増分処理を実行するために主に 2 つの抽象化、ランダムアクセスリポジトリを介した ACID トランザクションと、増分計算を編成する方法であるオブザーバを提供する。
Percolator システムはクラスタ内のすべてのマシンで実行される、Percolator ワーカー、Bigtable [9] タブレットサーバ、GFS [20] チャンクサーバの 3 つのバイナリで構成される。すべてのオブザーバは Percolator ワーカーにリンクされており、Percolator ワーカーは Bigtable をスキャンして変更されたカラム ("通知") を探し、対応するオブザーバをワーカープロセスの関数コールとして呼び出す。オブザーバは Bigtable タブレットサーバに読み取り/書き込み RPC を送信することでトランザクションを実行し、Bigtable タブレットサーバは GFS チャンクサーバに読み取り/書き込み RPC を送信する。このシステムはタイムスタンプオラクル (timestamp oracle) と軽量ロックサービス (lightweight lock service) という 2 つの小さなサービスにも依存している。タイムスタンプオラクルは厳密に増加するタイムスタンプを提供する。この特性はスナップショット分離プロトコルを正しく動作させるために必要である。ワーカーはダーティ通知の検索を寄り効率的に行うために軽量ロックサービスを使用する。
プログラマの視点から見ると Percolator のリポジトリは少数のテーブルで構成されている。各テーブルは行と列でインデックス付けされた "セル" の集まりである。各セルには未解釈のバイト配列として値が格納されている (内部的にはスナップショット分離をサポートするために各セルをタイムスタンプでインデックス付けされた一連の値として表現している)。
Percolator の設計は、大規模なスケールで実行するという要件と、非常に低いレイテンシの要件がないということから影響を受けている。レイテンシ要件が緩和されたことで、例えば故障したマシンで実行されているトランザクションによって残されたロックをクリーンアップするための遅延アプローチを取ることができるようになった。この遅延があり実装が簡単なアプローチによりトランザクションのコミットが潜在的に数十秒遅れる可能性がある。この遅延は OLTP タスクを実行する DBMS では許容されないだろうが Web のインデックスを構築する増分処理システムでは許容できる。Percolator にはトランザクションを管理するために中央となる場所が存在せず、特にグローバルデッドロック検出器がない。このため、競合するトランザクションのレイテンシは長くなるが、システムは数千台のマシンにスケールすることができる。
2.1 Bigtable の概要
Percolator は Bigtable 分散ストレージシステムの上に構築されている。Bigtable は多次元のソートされたマップをユーザに提供する。そのキーは (row, column, timestamp) のタプルである。Bigtable は各行に対する検索と更新操作を提供し、Bigtable 行トランザクションは個々の行に対するアトミックな読み取り、更新、書き込み操作を可能にする。Bigtable はペタバイト単位のデータを処理し、多数の (信頼性の低い) マシン上で確実に動作する。
実行中の Bigtable はタブレットサーバの集合体から構成され、各タブレットサーバは複数のタブレット (キースペースの連続領域) にサービスを提供する責任がある。マスターは、例えばタブレットのロードやアンロードを指示することによりタブレットサーバの動作を調整する。タブレットは Google SSTable 形式の読み取り専用ファイルのコレクションとして格納される。SSTable は GFS に保存され、Bigtable はディスク損失が発生した場合にデータを保持するために GFS に依存している。Bigtable では一連のカラムをローカリティグループにグループ化することでテーブルの性能特性を制御することができる。各ローカリティグループのカラムは独自の SSTable セットに格納されるため、他のカラムのデータをスキャンする必要がないためスキャンにかかるコストが軽減される。
Bigtable 上に構築するという決定により Percolator の全体的な形状が定義された。Percolator は Bigtable のインターフェースの要点を維持しており、データは Bigtable の行と列に整理され、Percolator のメタデータは特別な列に格納される (Figure 5 参照)。Percolator の API は Bigtable の API によく似ている。Percolator ライブラリは主に Percolator 固有の計算でラップした Bigtable 操作で構成されている。したがって Percolator を実装する歳の課題は Bigtable にはない多行トランザクションとオブザーバフレームワークの機能を提供することである。
2.2 トランザクション
Percolator は ACID スナップショット分離セマンティクスを備えた、行間、テーブル間のトランザクションを提供する。Percolator ユーザはトランザクションコードを命令型言語 (現在は C++) で記述し、コードに Percolator API への呼び出し混在させる。Figure 2 はコンテンツのハッシュによる文書クラスタリングの簡略版を示している。この例では Commit() が false を返した場合、トランザクションは競合しており (この場合は同じコンテンツハッシュを持つ 2 つの URL が同時に処理されたため)、バックオフの後に再試行する必要がある。Get() と Commit() の呼び出しはブロッキングであり、並列処理はスレッドプールで多数のトランザクションを同時に実行することによって実現される。

強力なトランザクションの恩恵を受けずにデータを増分的に処理することは可能だが、トランザクションを使用することでユーザがシステムの状態について推論しやすくなり、長寿命のリポジトリにエラーが混入することを防ぐことができる。例えばトランザクションによる Web インデックスシステムでは、プログラマは、文書のコンテンツハッシュは重複をインデックスするテーブルと常に一致するという仮定を立てることができる。トランザクションがなければ、タイミングの悪いクラッシュによって永続的なエラーが発生する可能性がある。つまり文書テーブル内のエントリが重複テーブル内の URL に対応していないというエラーである。トランザクションはまた、常に最新で一貫性のあるインデックステーブルを簡単に構築できる。これらの例はいずれも Bigtable が既に提供している単一行のトランザクションではなく、行にまたがるトランザクションを必要とすることに注意。
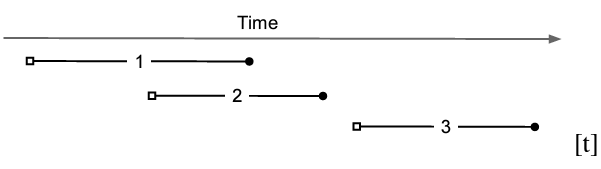
Percolator は Bigtable のタイムスタンプ次元を使用して各データ項目の複数のバージョンを格納する。複数のバージョンはスナップショット分離 [5] を実現するために必要であり、これにより各トランザクションはあるタイムスタンプの安定したスナップショットから読み取っているように見える。書き込みは別の後のタイムスタンプで表示される。砂婦ショット分離は書き込みと書き込みの競合を防ぎ、同時に実行されているトランザクション A と B が同じセルに書き込みを行った場合、コミットされるのは最大でも 1 つだけである。スナップショット分離では直列化可能性を提供しない。特に、スナップショット分離下で実行されるトランザクションは書き込みスキュー [5] の影響を受ける。直列化可能なプロトコルに対するスナップショット分離の主な利点は読み取りの効率性である。どのタイムスタンプも一貫性のあるスナップショットを表しているため、セルの読み取りには指定されたタイムスタンプの Bigtable 検索を実行するだけで済み、ロックを取得する必要はない。Figure 3 はスナップショット分離の下でのトランザクション間の関係を示している。
Percolator はストレージ自体へのアクセスを制御するのではなく、Bigtable にアクセスするクライアントライブラリとして構築されているため、従来の RDMS (原文は PDMS) とは異なる一連の分散トランザクション実装の課題に直面する。他の並列データベースではディスクへのアクセスを管理するシステムコンポーネントにロックが統合されている。各ノードは既にディスク上のデータへのアクセスを仲介しているため、リクエストにロックを付与し、ロック要件に違反するアクセスを拒否することができる。
対照的に、Percolator のどのノードも Bigtable の状態を直接変更するリクエストを発行できる (実際に発行している)。トラフィックをインターセプトしてロックを割り当てる便利な場所はない。その結果、ロックはマシンが故障しても維持しなければならず、Percolator はロックを明示的に維持する必要がある。もしロックがコミットの 2 つのフェーズの間に消えてしまうと、システムは競合するはずの 2 つのトランザクションを誤ってコミットする可能性がある。数千のマシンが同時にロックを要求することになるため、ロックサービスは高いスループットを提供しなければならない。各 Get() 操作はデータに加えてロックの読み取りを必要とするため、このレイテンシは最小限に抑えることが望ましく、ロックサービスは低レイテンシである必要がある。これらの要件を考慮すると、ロックサーバは (障害に耐えるため) 複製され、(負荷に対処するために) 分散されてバランス去れ、永続的なデータストアに書き込まれる必要がある。Bigtable 自体はすべての要件を満たしているため、Percolator はデータを格納するのと同じ Bigtable の特別なインメモリカラムにロックを格納し、その行のデータにアクセスするときに Bigtable の行トランザクションでロックを読み取りまたは更新する。
ここでトランザクションプロトコルを寄り詳細に検討する。Figure 6 は Percolator トランザクションの擬似コードを示し、Figure 4 はトランザクション実行中の Percolator データとメタデータのレイアウトを示している。システムで使用されるこれらのさまざまなメタデータ列については Figure 5 で説明する。トランザクションのコンストラクタは、タイムスタンプオラクルに開始タイムスタンプを要求し (6行目)、これにより Get() が参照する一貫性のあるスナップショットが決定される。Set() への呼び出しはコミット島でバッファリングされる (7行目)。バッファリングされた書き込みをコミットするルための基本的なアプローチは、クライアントによって調整される 2 フェーズコミットである。異なるマシン上のトランザクションは Bigtable タブレットサーバ上のカラムトランザクションを介して相互作用する。

1. 初期状態: Joe の口座には 2 ドル、Bob の口座には 10 ドル。

2. 転送トランザクションは lock カラムを書き込んで Bob の口座残高をロックすることから始まる。このロックがトランザクションのプライマリである。またトランザクションは開始タイムスタンプ 7 でデータを書き込む。

3. このトランザクションは Joe のアカウントをロックして Joe の新しい残高を書き込む (ここでも開始タイムスタンプで)。このロックはトランザクションのセカンダリであり、(行 "Bob", 列 "bal" に格納されている) プライマリロックへの参照を含んでいる。クラッシュによりこのロックが取り残された場合、ロックをクリーンアップしたいトランザクションは、クリーンアップを同期させるためにプライマリの場所を必要とする。

4. トランザクションはコミットポイントに到達した。これはプライマリロックを消去し、(コミットタイムスタンプと呼ばれる) 新しいタイムスタンプ 8 の書き込みレコードに置き換える。書き込みレコードにはデータが格納されているタイムスタンプへのポインタが含まれている。今後 "Bob" 行の "bal" 列を読む人は 3 ドルという値を見ることになる。

5. トランザクションは書き込みレコードを追加し、セカンダリセルのロックを削除することで完了する。この場合 Joe に一つのセカンダリがあるだけである。


コミットの最初のフェーズ ("事前書き込み") では書き込み中のすべてのセルをロックしようとする (クライアントの障害を処理するために 1 つのロックを任意にプライマリとして指定する; このメカニズムについては後述)。トランザクションはメタデータを読み取り、書き込まれる各セルの競合をチェックする。競合するメタデータには 2 種類ある。トランザクションがその開始タイムスタンプの後に別の書き込みレコードを検出するとトランザクションは中止する (32行目)。これはスナップショット分離が防御する write-write 競合である。トランザクションが任意のタイムスタンプで別のロックを検出した場合もトランザクションを中止する (34行目)。他のトランザクションが我々の開始タイムスタンプより前にコミットした後にロック解放が遅れているだけの可能性もあるが、我々はその可能性は低いと考えて中止する。競合がなければ、開始タイムスタンプの各セルにロックとデータを書き込む (36-38行目)。
セルが競合しなければトランザクションはコミットして第 2 フェーズに進行する。第 2 フェーズの最初にクライアントはタイムスタンプオラクルからコミットタイムスタンプを取得する (48行目)。その後、(プライマリから開始する) 各セルでクライアントはロックを解放し、ロックを書き込みレコードに置き換えることでその書き込みを読み手 (reader) から見えるようにする。書き込みレコードはコミットされたデータがこのセルに存在することを読み手に示すものであり、読み手がスキャンして実際のデータを見つける開始タイムスタンプへのポインタを含んでいる。プライマリの書き込みが可視化されると (58行目)、書き込みが読み手に表示されるためそのトランザクションはコミットしなければならない。
Get() 操作ではまずトランザクションのスナップショットで見えるタイムスタンプ範囲 [0, start_timestamp] 内にロックがあるかどうかをチェックする (12行目)。ロックが存在する場合、別のトランザクションが同時にこのセルに書き込んでいるため、読み取りトランザクションはロックが解除されるまで待機する必要がある。競合するロックが見つからなければ、Get() はそのタイムスタンプ範囲内の最新の書き込みレコードを読み取り (19行目)、その書き込みレコードに対応するデータ項目を返す (22行目)。
トランザクション処理はクライアント障害の可能性によって複雑になる (Bigtable がタブレットサーバの障害をまたいで書き込みロックを維持することを保証しているため、タブレットサーバの障害はシステムに影響しない)。トランザクションのコミット中にクライアントに障害が発生するとロックが残される。Percolator はこれらのロックをクリーンアップする必要がある。さもなくば将来のトランザクションが無期限にハングすることになるだろう。Percolator はクリーンアップに対して遅延アプローチを採用している。つまり、トランザクション A がトランザクション B によって残された競合するロックに遭遇した場合、A は B が失敗したと判断しそのロックを消去する。
A が B が故障したという判断に完全な自信を持つことは非常に困難である。その結果、A が B のトランザクションをクリーンアップすることと、実際には故障していない B が同じトランザクションをコミットすることとの間の競合を回避する必要がある。Percolator はすべてのトランザクションで 1 つのセルを、コミッターのクリーンアップ操作の同期ポイントとして指定することでこれを処理する。このセルのロックはプライマリロックと呼ばれる。A と B の両方はどちらのロックがプライマリであるかに合意する (プライマリの場合は他のすべてのセルのロックに書き込まれる)。クリーンアップ操作またはコミット操作のどちらかを実行するにはプライマリロックを変更する必要がある。この変更は Bigtable 行トランザクションの下で実行されるため、クリーンアップ操作またはコミット操作のいずれか 1 つだけが成功する。具体的には、B がコミットする前にプライマリロックがまだ保持されていることを確認し、書き込みレコードに置き換える必要がある。A が B のロックを消去する前に、A はプライマリロックをチェックして B がコミットしていないことを確認しなければならない。プライマリロックがまだ存在する場合はロックを安全に消去できる。
コミットの第 2 フェーズ中にクライアントがクラッシュすると、トランザクションはコミットポイントを過ぎているが (少なくとも 1 つの書き込みレコードが書き込まれている)、ロックはまだ未処理のままである。これらのトランザクションに対してロールフォーワードを実行しなければならない。ロックに遭遇したトランザクションはプライマリロックを調べることで 2 つのケースを区別できる。プライマリロックが書き込みレコードによって置き換えられた場合、ロックを書き込んだトランザクションはコミットされている必要があり、ロックはロールフォーワードしなければならない。そうでなければロールバックしなければならない (プライマリを常に最初にコミットするため、プライマリがコミットされていなければロールバックしても安全であることを確証できる)。ロールフォーワードするには、クリーンアップを実行するトランザクションが、元のトランザクションが実行したように、取り残されたロックを書き込みレコードに置き換える。
クリーンアップはプライマリロック状で同期されるため、ライブクライアントが保持すっろっくをクリーンアップしても安全である。ただし、ロールバックによってトランザクションが強制的に中止されるため性能上のペナルティをもたらす。したがって、トランザクションはロックがデッドまたはスタックしたワーカーに属していると疑わない限りロックをクリーンアップすることはない。Percolator は別のトランザクションの生存性を判断するために簡単なメカニズムを使用する。実行中のワーカーは、自分がシステムに属していることを示すために Chubby lockserver [8] にトークンを書き込む。他のワーカーはこのトークンの存在をワーカーが生きていることをサインとして使うことができる (トークンはプロセスが終了すると自動的に削除される)。生きているが動作していないワーカーを処理するためにさらにロックにウォールタイム (wall time) を書き込む。ワーカーの生存性トークンが有効であっても古すぎるウォールタイムを含むロックはクリーンアップされる。長時間実行されるコミット操作を処理するためにワーカーはコミット中にこのウォールタイムを定期的に更新する。
2.3 タイムスタンプ
タイムスタンプオラクルは厳密な昇順のタイムスタンプを配布するサーバである。すべてのトランザクションでタイムスタンプオラクルに 2 回アクセスする必要があるため、このサービスは適切にスケールしなければならない。オラクルは定期的にタイムスタンプの範囲を割り当て、最も高い割り当てタイムスタンプを安定したストレージに書き込む。割り当てられたタイムスタンプの範囲が与えられると、オラクルは将来の要求をメモリのみで満たすことができる。オラクルが再起動したとき、タイムスタンプは割り当てられた最大タイムスタンプまでジャンプする (ただし後戻りすることはない)。RPC のオーバーヘッドを節約するために (トランザクションのレイテンシが増加するという代償を払って) 各 Percolator ワーカーはオラクルへの保留中の RPC を一つだけ維持することでトランザクション間でタイムスタンプ要求をバッチ処理する。オラクルの負荷が増加するとバッチ処理が自然に増加して埋め合わせする。バッチ処理によりオラクルのスケーラビリティが増加するがタイムスタンプの保証には影響しない。我々のオラクルは 1 台のマシンから毎秒約 200 万のタイムスタンプを提供する。
トランザクションプロトコルは厳密に増加するタイムスタンプを使用して、Get() がトランザクションの開始タイムスタンプより前にコミットされたすべての書き込みを返すことを保証する。この保証がどのように提供されるかを確認するために、タイムスタンプ \(T_R\) で読み取りを行うトランザクション \(R\) と、タイムスタンプ \(T_W \lt T_R\) でコミットされたトランザクション \(W\) について考え、\(R\) が \(W\) の書き込みを見ることができることを示す。\(T_W \lt T_R\) なのでタイムスタンプオラクルは \(T_W\) を \(T_R\) より前、または同じバッチで発行したことがわかる。したがって \(W\) は \(R\) が \(T_R\) を受信する前に \(T_W\) を要求した。\(R\) は開始タイムスタンプ \(T_R\) を受信する前に読み取りを行うことはできず、\(W\) はコミットタイムスタンプ \(T_W\) を要求する前にロックを書き込んだことがわかる。したがって、上記の性質は \(R\) が読み取りを実行する前に \(W\) が少なくともすべてのロックを書き込んでいる必要があることが保証される。\(R\) の Get() は完全にコミットされた書き込みレコードまたはロックのどちらかを参照する。後者の場合、\(W\) はロックが解放されるまでブロックする。いずれにせよ \(W\) の書き込みは \(R\) の Get() から参照できる。
2.4 通知
ユーザはトランザクションによって不変性を維持しながらテーブルを更新することができるが、ユーザはトランザクションをトリガーして実行する手段も必要である。Percolator では、ユーザはテーブルの変更によってトリガーされるコード ("オブザーバ") を記述し、システム内の各タブレットサーバと一緒に実行されるバイナリにすべてのオブザーバをリンクする。各オブザーバは関数とカラムのセットを Percolator に登録し、Percolator は任意の行のいずれかのカラムにデータが書き込まれた後に関数を呼び出す。
Percolator アプリケーションは一連のオブザーバとして構成される。各オブザーバはタスクを完了してテーブルに書き込むことで "下流" (downstream) のオブザーバにさらなる作業を発生させる。我々のインデックス作成システムでは MapReduce がローダートランザクション (loader transaction) を実行することでクロールされた文書を Percolator にロードする。このローダートランザクションは文書処理トランザクションをトリガーして文書のインデックスを作成する (解析やリンクの抽出など)。文書処理トランザクションはクラスタリングのようなさらなるトランザクションをトリガーする。クラスタリングトランザクションは、変更された文書クラスタをサービスシステムにエクスポートするトランザクションをトリガーする。
通知 (notification) はデータベースのトリガーやアクティブデータベース [29] のイベントに似ているが、データベーストリガーとは異なりデータベースの不変性を維持するために使用することはできない。特に、トリガーされたオブザーバはトリガーされた書き込みとは別のトランザクションで実行されるため、トリガーされた書き込みとトリガーされたオブザーバの書き込みはアトミックではない。通知はデータの整合性を維持するためではなく増分計算の構造化を支援することを目的としている。
このセマンティクスと意図の違いにより、オブザーバの動作はオーバーラップしたトリガーや複雑なセマンティクスよりもはるかに理解しやすくなる。Percolator アプリケーションは非常に少数のオブザーバで構成されており、Google のインデックス作成システムにはおよそ 10 のオブザーバがある。各オブザーバはワーカーバイナリの main() の中で明示的に構築されるため、どのオブザーバがアクティブであるかは明らかである。複数のオブザーバが同じカラムを監視することも可能だが、特定のカラムが書き込まれたときにどのオブザーバが実行されるかを明確にするためにこの機能は避けている。Percolator は通知の無限サイクルを防ぐための対策は何も講じていないため、ユーザが注意する必要がある。ユーザは通常、無限サイクルを回避するために一連のオブザーバを構築する。
Percolator は、監視対象のカラムが変更されるたびにコミットされるオブザーバのトランザクションは最大でも 1 つだけであるという保証を提供する。ただし逆は当てはまらない。監視対象のカラムに複数の書き込みが行われると、対応するオブザーバが 1 回だけ呼び出される場合がある。この機能は、多くの通知に対応するコストを償却することで計算を回避するのに役立つため、メッセージ折りたたみ (message collapsing) と呼ばれている。例えば http://google.com では新しいリンクが見つかるたびに再処理するのではなく、定期的に再処理するだけで十分である。
通知にこれらのセマンティクスを提供するために、各監視対象カラムには各オブザーバの "acknowledgement" カラムが付随しており、このカラムにはオブザーバが実行された最新の開始タイムスタンプが含まれている。監視対象カラムに書き込まれると、Percolator は通知を処理するためのトランザクションを開始する。このトランザクションは監視対象カラムとそれに対応する acknowledgement カラムを読み込む。監視対象カラムがその最後の acknowledgment の後に書き込まれた場合、Percolator はオブザーバを実行し、acknowledgement カラムを介した有無スタンプに設定する。そうでなければ、オブザーバは既に実行されているので再度実行することはない。Percolator が特定の通知に対して誤って 2 つのトランザクションを同時に開始した場合、両方のトランザクションがダーティ通知を認識してオブザーバを実行するが、acknowledgement カラムで競合するため 1 つは中止されることに注意。Percolator は通知ごとに最大 1 つのオブザーバがコミットすることを約束する。
通知を実装するに、Percolator は実行する必要のあるオブザーバを持つダーティセルを効率的に見つける必要がある。この検索は通知が稀であるという事実によって複雑になる。Percolator のテーブルには数兆個のセルが存在するが、適用された負荷にシステムが対応していれば数百万の通知しかない。さらに、オブザーバコードはマシンの集合体に分散された多数のクライアントプロセスで実行される。つまりダーティセルの検索は分散されなければならない。
Percolator はダーティセルを識別するために、ダーティセルごとにエントリを含む特別な "notify" Bigtable 列を維持する。トランザクションが監視対象セルに書き込むと対応する notify セルも設定される。ワーカーは notify カラムに対して分散スキャンを実行してダーティセルを見つける。オブザーバがトリガーされ、トランザクションがコミットされると、Percolator は notify セルを削除する。notify カラムは Percolator 列ではなく単なる Bigtable カラムであるため、トランザクション特性はなく、スキャナが acknowledgement カラムをチェックしてオブザーバを実行する必要があるかを判断するためのヒントとしてのみ機能する。
Percolator はこのスキャンを効率的に行うために notify カラムを別の Bigtable ローカリティグループに保存する。これによりカラムをスキャンするときに合計数兆のデータセルではなく数百万のダーティセルのみを読み取るだけで済むようにしている。各 Percolator ワーカーはスキャンに複数のスレッドを割り当てる。各スレッドでは、ワーカーはまずランダムな Bigtable タブレットを選択肢、次にタブレット内のランダムなキーを選び、最後にその位置からテーブルをスキャンすることでスキャンするテーブルの部分を選択する。各ワーカーはテーブルのランダムな領域をスキャンするため、2 つのワーカーが同じ行で同時にオブザーバーを実行することが心配になる。この動作は、通知のトランザクションの性質上、正確性 (correctness) の問題を引き起こすことはないが非効率的である。これを回避するために、各ワーカーは行をスキャンする前に軽量ロックサービスからロックを取得する。このロックサーバはアドバイザリであるため状態を保持する必要がなく、非常にスケーラブルである。
ランダムスキャンのアプローチにはもう 1 つの工夫が必要である。このアプローチを最初に導入したとき、スキャンスレッドがテーブルのいくつかの領域に密集する傾向があり、スキャンの並列性が実質的に低下することがわかった。この現象は公共交通機関でよく見られるもので、”プレーティング" (platooning) または "バスクランピング" (bus clumping) と呼ばれ、バスが (おそらく交通渋滞や乗車の遅れにより) 減速したときに発生する。各停留所の乗客数は時間と共に増加するため、乗車の遅れはさらに悪化し、バスの速度はさらに低下する。同時に、遅いバスの後ろにいるバスは各停留所で乗車する乗客が少なくなるため速度が上がる。その結果、停留所に同時に到着するバスの塊が発生する [19]。我々のスキャンスレッドも同様に動作した。オブザーバを実行していたスレッドが減速する一方で、その "後ろ" のスレッドはクリーンになったばかりの行を素早くスキップして先頭のスレッドと塊となり、スレッドの密集によってタブレットサーバが過負荷になったため先頭のスレッドを通過できなかった。この問題を解決するため、我々は公共交通機関ではできない方法でシステムを改良した。スキャンスレッドは、別のスレッドと同じ行をスキャンしていることを検出すると、テーブル内の新しいランダムな場所を選択してスキャンする。交通機関のたとえをさらに進めるなら、しないのバス (スキャナースレッド) は前方のバスに近づきすぎるとランダムな停留所 (テーブル内の場所) にテレポートして密集を回避する。
最後に、通知に関する経験から、より軽量だが意味的に弱い通知メカニズムを導入するに至った。同じページの多くの重複が同時に処理されると、各トランザクションは同じ重複クラスタの再処理をトリガーしようとして衝突することがわかった。このことからトランザクションの衝突の可能性なしにセルに通知する方法を考案することになった。この弱い通知 (weak notification) は Bigtable の "notify" カラムにのみ書き込むことで実装する。Percolator の残りの部分のトランザクションセマンティクスを維持するために、これらの弱い通知を、書き込みはできず通知のみが行われる特殊なタイプのカラムに制限する。セマンティクスが弱いということは、1 つの弱い通知の結果として複数のオブザーバが実行されてコミットされる可能性があるということでもある (ただしシステムはこの発生を最小限に抑えようとする)。これは競合を管理する上で重要な機能となっている。あるオブザーバがホットスポットで頻繁に競合する場合は、ホットスポットの非トランザクション通知によって接続された 2 つのオブザーバに分離すると役に立つことがよくある。
2.5 議論
MapReduce ベースのシステムに対する Percolator の非効率な点の 1 つは、ワークユニットごとに送信される RPC の数である。MapReduce は GFS への大規模な単一の読み取りで数十または数弱の Web ページのデータをすべて取得するが、Percolator は 1 つの文書を処理するために約 50 の個別の Bigtable 操作を実行する。
追加の RPC の原因の一つはコミット中に発生する。ロックの書き込み時には 2 つの Bigtable RPC を必要とする read-modify-write 操作を行う必要がある。1 つは競合するロックまたは書き込みの読み取り用で、もう 1 つは新しいロックの書き込み用である。このオーバーヘッドを削減するために Bigtable API に条件付き変異 (conditional mutation) を追加して read-modify-write のステップを 1 つの RPC で実装するように変更した。また同じタブレットサーバに宛てられる多くの条件付き変異を 1 つの RPC にまとめてバッチ処理し、送信する RPC の総数をさらに削減することもできる。ロック操作を数秒遅らせてバッチにまとめることでバッチを作成する。ロックは並列に取得されるため、各トランザクションのレイテンシはわずか数秒しか追加されない。追加のレイテンシは並列性を高めることで補う。バッチ料理により、競合が発生酢可能性のある時間ウィンドウも増加するが、競合の少ない我々の環境ではこれは問題にならなかった。
またテーブルから読み取る時にも同じバッチ処理を実行する。すべての読み取り操作は、同じタブレットサーバへの他の読み取りとバッチを形成する機会を与えるために遅延される。これにより各読み取りが遅延し、トランザクションのレイテンシが大幅に増加する可能性がある。しかし最終的な最適化、プリフェッチによってこの影響は軽減される。プリフェッチは、同じ行で 2 つ以上の値を読み取ることは、1 つの値を読み取ることと本質的に同じコストであるという事実を利用する。どちらの場合も Bigtable はファイルシステムから SSTable ブロック全体を読み取って解凍する必要がある。Percolator は、カラムが読み込まれるたびにその行の他のカラムがトランザクションの後半でどのように読み込まれるかを予想しようとする。この予想は過去の挙動に基づいて行われる。プリフェッチ、既に読み取られた項目のキャッシュを組み合わせることで、システムが通常行う Bigtable の読み取り回数を 10 分の 1 に減らすことができる。
Percolator の実装の初期段階ですべての API コールをブロック化し、マシンごとに数千のスレッドを実行して十分な並列処理を実現し、良好な CPU 使用率を維持することにした。我々がこのリクエストごとのスレッドモデル (thread-per-request model) を選択したのは、主にイベント駆動型モデルと比較してアプリケーションコードの記述を容易にするためである。テーブルからデータ項目を (何度も) フェッチするたびにユーザに状態をまとめるように強制すれば、アプリケーション開発はもっと難しくなっているだろう。リクエストごとのスレッドに関する我々の経験は全体として肯定的なものであった。アプリケションコードがシンプルになり、メニーコアマシンで良好な使用率を達成し、意味のある完全なスタックトレースによってクラッシュのデバッグが簡素化された。アプリケーションコードで発生するレースコンディションは懸念していたよりも少なかった。このアプローチの最大の欠点は、スレッド数が多いことに関連する Linux カーネルと Google インスラのスケーラビリティの問題だった。我々のカーネル開発チームは、カーネルの問題に対処するために修正プログラムを配備することができた。
3 評価
Percolator は MapReduce と DBMS の間のパフォーマンス領域のどこかに位置する。例えば Percolator は分散システムであるため一定量のデータを処理するためには従来の DBMS よりはるかに多くのリソースを使う。これはスケーラビリティの代償である。MapReduce と比較すると Percolator ははるかに低いレイテンシでデータを処理できるが、やはりランダムルックアップをサポートするために追加のリソースが必要になる。これらは工学的トレードオフであり定量化するのは難しい。単にマシンを買い足すだけで容量を無限に追加できる能力に対してどの程度の効率損失を支払うのが妥当なのか? あるいは、階層化システムによって実現される開発時間の短縮と、それに対応する効率の低下とをどのようにトレードオフすれば良いのだろうか?
このセクションでは、まず MapReduce ベースのインデックス作成パイプラインを Percolator に変換した経験に基づいて Percolator とバッチ処理システムを比較し、これらの質問のいくつかに答えることを試みる。またよく知られた TPC-E ベンチマーク [1] に基づくマイクロベンチマークと合成ワークロード (synthetic workload) で Percolator を評価する。このテストにより Bigtable や DBMS に対する Percolator のスケーラビリティと効率性を評価する機会が得られる。
このセクションのすべての実験は Google データセンター内のサーバのサブセットで実行されている。サーバは x86 プロセッサ状で Linux オペレーティングシステムを実行している。各マシンは複数の汎用 SATA ドライブに接続されている。
3.1 MapReduce からの変換
我々は、以前は MapReduce で実行されていたタスクである Google の大規模な "ベース" インデックスを作成するために Percolator を構築した。我々の以前のシステムでは毎日数十億の文書をクロールし、既存の文書のリポジトリと共に 100 回の MapReduce をフィードしていた。その結果、ユーザのクエリーに答えるインデックスができた。すべての文書のクリティカルパスに 100 個の MapReduce がすべて含まれていたわけではないが、システムが一連の MapReduce として構成されていたため、各文書が検索結果として返されるまで 2~3 日を費やしていた。
Percolator ベースのインデックス作成システム (Caffeine [25] として知られている) は同じ数の文書をクロールするが、各文書はクロールするたびに Percolator にフィードされる。Caffeine の直接的な利点と主な設計目的はレイテンシの短縮である。中央値となるドキュメントは以前のシステムよりも 100 倍以上速く Caffeine を通過する。このレイテンシの改善はシステムが複雑になるにつれて大きくなる。Percolator ベースのシステムに新しいクラスタリングフェーズを追加すると、リポジトリの追加スキャンではなく、各文書の追加検索が必要になる。追加のクラスタリングフェーズも別の MapReduce ではなく同じトランザクションで実装できる。この単純化は Caffeine のオブザーバの数 (10) が以前のシステムの MapReduce の数 (100) よりはるかに少ない理由の一つである。この構成によりリポジトリ全体を再スキャンすることなくリポジトリのサブセットのみに対して追加処理を実行することも可能である。
増分システムでは追加のクラスタリングフェーズを追加することは無料ではない。システムが入力に追いつくようにするにはより多くのリソースが必要になるが、これはいくらリソースを増やしてもリポジトリの追加パスではぐれもの (stragglers) によって生じる遅延を克服できないバッチ処理システムよりはまだ改善されている。Caffeine は、処理の大部分がいくつかの非常に遅い操作によって遅れることがないため、バッチベースのインデックス作成システムで深刻な問題であったはぐれものの影響を本質的に免れることができる。また、新システムのレイテンシが根本的に低くなったことで、更新の遅い大きなインデックスと、更新が速い小さなインデックスの厳密な区別をなくすこともできる。Percolator を使用すると文書をインデックスするたびにリポジトリを大きくすることもできる。Caffeine の文書収集は現在、以前のシステムの 3 倍の大きさで、利用可能なディスクスペースによってのみ制限されている。
Caffeine は置き換えたシステムと比較すると同じくロールレートを処理するのにおよそ 2 倍のリソースを使用している。しかし Caffeine は余分なリソースを有効に活用している。もし旧インデックス作成システムを 2 倍のリソースで実行するとしたら、インデックスサイズを大きくするか、レイテンシをせいぜい 2 分の 1 に減らすことができるだろう (ただし両方を行うことはできない)。一方、Caffeine を半分のリソースで駆動させた場合、1 日あたりの文書処理数は旧システムほど多くはないだろう (しかし生成される文書のレイテンシは大幅に低くなる)。
新しいシステムは操作も簡単である。Caffeine は可動部分がはるかに少なく、タブレットサーバ、Percolator ワーカー、チャンクサーバが稼働している。旧システムでは 100 個の異なる MapReduce をそれぞれ個別に構成する必要があり、独立して故障する可能性もあった。また MapReduce ワークロードの "ピーキー" (peaky) な性質によって、Percolator のはるかスムーズなリソース使用と比較して、データセンターのリソースを完全に活用することが困難だった。
直線的なコードを書くシンプルさとリポジトリへのランダムなルックパップ機能により Percolator の新機能の開発が容易になる。MapReduce ではランダム検索は扱いにくくコストがかかる。一方、Caffeine の開発射は MapReduce パラダイムには存在しなかった並行性を推論する必要がある。トランザクションはこの並行性を処理するのに役立つが、追加された複雑さを完全に排除することはできない。
MapReduce から Percolator に移行するメリットを定量化するために、Google のインデックス作成パイプラインの動作とほぼ同じ方法で、新たにクロールされた文書を 10 億文書のリポジトリに対してクラスタリングして重複を削除する合成ベンチマークを作成した。文書は 3 つのクラスタリングキーによってクラスタリングされる。実際のシステムでは、クラスタリングキーはリダイレクトターゲットやコンテンツハッシュのような文書プロパティになるが、この実験では 750M の可能なキーのコレクションから一様にランダムに選択した。合成リポジトリ内の平均クラスタには 3.3 個の文書が含まれており、93% の文書が比シングルトンクラスタに属している。このようなキーの分散によりクラスタリングロジックが実行されるが、実際に確認した少数の非常に大きなクラスタには影響しない。これらのクラスはレイテンシのテールにのみ影響しここで示す結果には影響しない。Percolator クラスタリング実装では、クロールされた各文書はリポジトリに直ちにリポジトリに書き込まれオブザーバによってクラスタリングされる。オブザーバは各クラスタリングキーのインデックステーブルを保持し、文書を各インデックスと比較して重複しているかどうかを判断する (Figure 2 の詳細)。MapReduce は 3 つのクラスタリング MapReduce (クラスタリングキーごとに 1 つ) のシーケンスを繰り返し実行することで、継続的に到着する文書のクラスタリングを実装する。3 つの MapReduce シーケンスは、リポジトリ全体と、前の 3 つの MapReduce が実行されている間に蓄積されたクロールされた文書を処理する。
この実験では均一な速度でクロールされた文書をクラスタリングすることをシミュレートしている。この指標で MapReduce と Percolator のどちらが優れたパフォーマンスを示すかは、文書がクロールされる頻度 (クロールレート) とリポジトリのサイズによって決まる。我々はリポジトリのサイズを固定し、新し文書が到着するレート (1 時間当たりにクロールされるリポジトリの割合として表される) を変化させることでこの領域を調査する。実際のシステムでは 1 時間あたりにクロールされるリポジトリの割合は極わずかである。Web 上には 1 兆を超える Web ページがあり (理想的にはインデックス作成システムのリポジトリにも)、1 日で妥当な割合をクロールするには多すぎる。新しい入力がリポジトリのごく一部である場合 (クロールレートが低い)、MapReduce は (大きな) リポジトリをマッピングして (小さな) 新しい文書のバッチをクラスタリングする必要があるのに対し、Percolator は新しく到着した文書の小さなバッチに比例した作業 (文書ごとに最大 3 つのインデックステーブルの検索) のみを行うため、Percolator の方が MapReduce よりパフォーマンスが優れていると予想される。新しくクロールされる文書の数がリポジトリのサイズに近づくような非常に大きなクロールレートでは、MapReduce のパフォーマンスは Percolator よりも優れている。このクロスオーバーは、ディスクからデータをストリーミングする方が、ランダム検索するよりもバイトあたりのコストがはるかに安いために発生する。クロスオーバーの時点では、Percolator で新しい文書をクラスタ化するために必要な検索の総コストは、MapReduce で文書とリポジトリをストリーミングするコストと等しくなる。クロールレートがこれよりも高い場合は MapReduce 使用する方が適している。
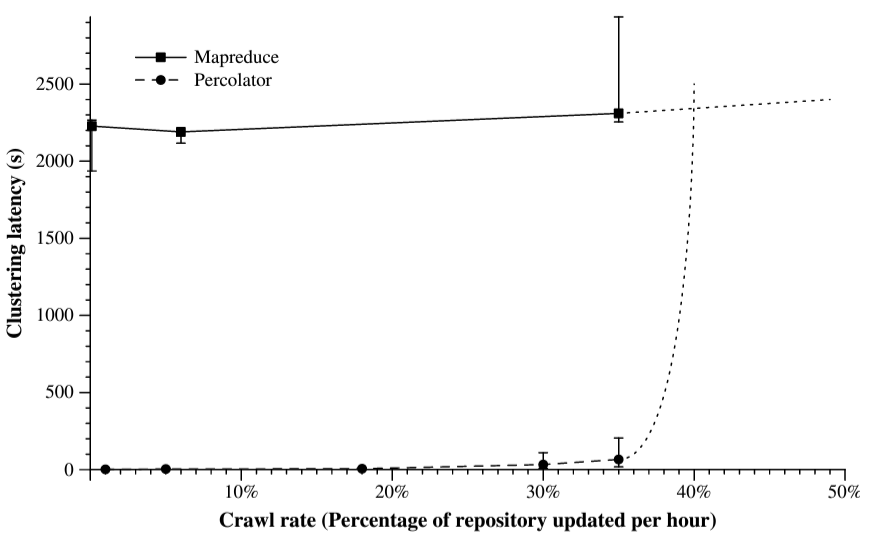
このベンチマークを 240 台のマシンで実行し、文書がクロールされてからクラスタリングされるまでの遅延の中央値を測定した。Figure 7 は両方の実装における文書処理の平均レイテンシをクロールレートの関数としてプロットしたものである。クロールレートが低い場合、Percolator は予想通り MapReduce よりも速く文書をクラスタリングする。このシナリオは 1 時間あたり 1 パーセントの文書をクロールすることに対応する左端の 2 つのポイントで示されている。MapReduce ではリポジトリを 3 つの MapReduce で処理するだけで 20 分かかるため、文書をクラスタリングするのに 20 分かかる (新しくクロールされた少数の文書が実行時間に与える影響は無視できる)。この結果、文書のクロールとクラスタリングの間の平均遅延は約 30 分となる。これは、ランダムな文書がクロールされてから前の MapReduce が終了するまで 10 分待ち、その後 3 つの MapReduce によって処理されるのに 20 分を費やしている。一方 Percolator は新しくロードされた文書を見つけて平均 2 秒で処理する。これが MapReduce の約 1000 倍の速度である。この 2 秒にはダーティ通知を見つけてクラスタリングを実行するトランザクションを実行する時間が含まれている。この 1000 倍のレイテンシ改善はリポジトリのサイズを増やすことで任意に大きくできることに注意。
クロールレートが増加すると MapReduce の処理時間もそれに応じて増加する。理想的には、リポジトリと、クロールレートと共に増加する入力を合わせたサイズに比例するだろう。実際にはこのような小さな MapReduce の実行時間ははぐれものによって制限されるため、処理時間の増加 (ひいてはクラスタリングのレイテンシ) は、低いクロールレートではクロールレートとほとんど相関しない。例えば 6% のクロールレートでは 1 TB のデータセットに 150 GB しか追加されず、150 GB を処理するための余分な時間はノイズである。クロールレートが増加しても Percolator のレイテンシは比較的変化しないが、クロールレートが 1 時間あたり 40% になるとレイテンシは突然実質的に無限に増加する。この時点で Percolator はテストクラスタのリソースを飽和させ、クロールレートに対応できなくなり、未処理の文書の無制限のキューを構築し始める。40% の点線の漸近線はこの限界点を超えた Percolator のパフォーマンスの外挿である。MapReduce も同じ影響を受ける。最終的に、クロールされた文書は MapReduce がそれらをクラスタリングできる速度よりも速く蓄積され、その後の実行でバッチサイズが際限なく増加する。しかし、この特定の構成では MapReduce は 100% を超えるクロールレートを維持することができる (点線はパフォーマンスを外挿したものである)。
これらの結果は、実際のシステムが動作する事が予想される状況 (1 桁のクロールレート) では Percolator が MapReduce よりも桁違いに優れたレイテンシで文書を処理できることを示している。
3.2 マイクロベンチマーク
このセクションでは Percolator が提供するトランザクションセマンティクスのコストを決定する。この実験では Percolator を "生の" (raw) Bigtable と比較する。Bigtable の性能が向上すればそのまま Percolator の性能向上にもつながるため、我々は Bigtable と Percolator の相対的なパフォーマンスにのみ関心がある。Figure 8 は Percolator と生の Bigtable を 1 台のタブレットサーバに対して実行したときの性能を示している。実験中、すべてのデータはタブレットサーバのキャッシュにあり、Percolator のバッチ処理最適化は無効になっていた。

Percolator は予想通り Bigtable に比べてオーバーヘッドをもたらす。まず 2 つのシステムが実行できるランダム書き込みの数を測定する。Percolator の場合、単一のセルを書き込んでからコミットするトランザクションを実行する。これは Percolator のオーバーヘッドの最悪ケースを表している。書き込みを行うとき、Percolator はこのベンチマークでは約 4 倍のオーバーヘッドが発生する。これは、Bigtable が発行する単一の書き込み以外に Percolator がコミットに必要とする追加の操作、つまりロックをチェックするための読み取り、ロックを追加するための書き込み、およびロックレコードを削除するための 2 回目の書き込みの結果である。特に読み取りは書き込みよりもコストが高くオーバーヘッドの大部分を占める。このテストではタブレットサーバのパフォーマンスが制限要因であったため、タイムスタンプのフェッチによる追加のオーバーヘッドは測定していない。Percolator は読み取りごとに 1 回の Bigtable 操作を実行するがその読み取り操作は生の Bigtable 操作よりもやや複雑であるため (Percolator の読み取りはデータからムに壊れてメタデータからムも参照する) ランダム読み取りもテストした。
3.3 合成ワークロード
より現実的なワークロードで Percolator を評価するために TPC-E [1] に基づく合成ベンチマークを実装した。TPC-E は OLTP システム向けに設計されており、Percolator のトレードオフの多くは OLTP システムの望ましい特性 (競合するトランザクションのレイテンシなど) に影響を与えるため、これは Percolator にとって理想的なベンチマークではない。しかし TPC-E は広く認知され理解されているベンチマークでアリ、より伝統的なデータベースに対する我々のシステムのコストを理解することができる。
TPC-E は取引、市場検索、口座照会を行う顧客を持つ証券会社をシミュレートしている。証券会社は取引注文を市場取引所に提出し、市場取引所は取引を執行し、ブローカーと顧客の状態を更新する。このベンチマークは実行された取引の数を測定する。各顧客は平均して 500 秒に 1 回取引を行うため、ベンチマークは顧客と関連データを追加することでスケールする。
従来、TPC-E には顧客エミュレータ、市場エミュレータ、ストアド SQL プロシジャを実行する DBMS の 3 つのコンポーネントで構成されていた。Percolator は Bigtable に対して実行されるクライアントライブラリであるため、我々の実装は Bigtable に対して操作を実行する Percolator ライブラリを呼び出す、顧客/市場エミュレータを組み合わせたものである。Percolator は高レベルの SQL インターフェースではなく、低レベルの Get/Set/iterator API を提供するため、我々はインデックスを作成し、すべての "クエリー計画" を手作業で行った。
Percolator は OLTP システムではなく増分処理システムであるため TPC-E のレイテンシ目標を満たすことは試みていない。我々の平均トランザクションレイテンシは 2~5 秒だが外れ値には数分かかる場合がある。外れ値、たとえば競合時の指数バックオフや Bigtable タブレットが使用できない場合などに発生する。最後に TPC-E トランザクションに若干の変更を加えた。TPC-E では取引結果が出るたびにブローカーの手数料が増加し取引回数が増加する。各ブローカーは 100 人の顧客にサービスを提供するため、平均的なブローカーは 5 秒に 1 回更新する必要があり、Percolator では書き込み競合が繰り返される。Percolator では、増分をサイドデープルに書き込み、各ブローカーの増分を定期的に集計することでこの機能を実装する。ベンチマークではこの書き込みを単純に省略することにした。
Figure 9 は需要が増加するにつれて Percolator のリソース使用料がどのように増加するかを示している。CPU コアのリソース使用量は実験環境で制限されるリソースであるため我々はこれを測定する。テスト用に少数のマシンを調達できたが、テスト用の Bigtable セルははるかに大規模な本番クラスタのディスクリソースを共有している。その結果、ディスク帯域幅はシステムの性能には影響しない。この実験では顧客数を増やしてベンチマークを構成して達成されたパフォーマンスと、Bigtable コンパクションなどのバックグラウンドメンテナンスに使用されるコアを含むシステムのすべての部分で使用されるコア数の両方を測定した。パフォーマンスとリソース使用料の関係は 11 コアから 15,000 コアまで数桁にわたって本質的に線形である。
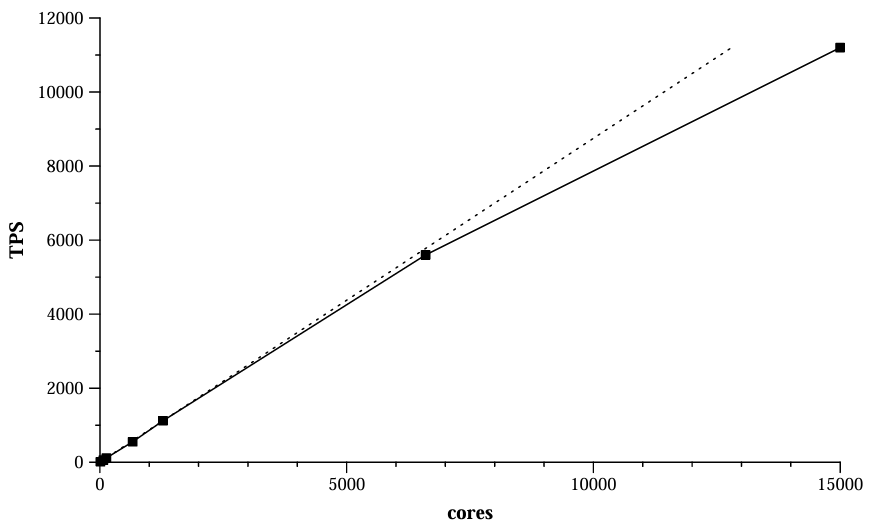
この実験は DBMS に対する Percolator のオーバーヘッドを測定する機会にもなる。現在最速の商用 TPC-E システムは 64 個の Intel Nehalem コアと、コアあたり 2 つのハイパースレッドを持つ 1 台の大容量共有メモリマシンを使用して 3,183 tpsE を実行する [3]。TPC-E に基づく我々の合成ベンチマークは 15,000 個のコアを使用して 11,200 tps を実行する。この比較は非常に大雑把なものである。比較マシンの Nehalem コアは我々のテストセルのコアよりもかなり高速である (Nehalem プロセッサでの小規模テストではテストクラスタのコアと比較してスレッドあたり 20~30% 高速であることが示されている)。ただし、Percolator はベンチマークシステムよりもトランザクションあたり約 30 倍の CPU を使用すると推定される。トランザクションあたりのコストで見ると、リファレンスマシンのエンタープライズクラスのハードウェアに比べ、我々のテストクラスタはより安価なコモディティハードウェアを使用しているため、その差は 30 倍よりはるかに小さいと思われる。
データベースの実装に関する従来の考え方は "鉄に近づける" (get close to the iron) こと、そしてハードウェアをできるだけ直接使用することである。これは、ディスクキャッシュやスケジューラなどのオペレーティングシステム構造でさえ、効率的なデータベースの実装を困難にするためである [32]。Percolator ではデータベースとハードウェアの間にオペレーティングシステムを介在させただけではなく、複数のソフトウェア層とネットワークリンクも介在させた。従来の考え方は正しく、この配置にはコストがかかる。リクエストを準備してネットワークに送信し、リモートマシンで処理するにはかなりのオーバーヘッドがある。Percolator でこれらのオーバーヘッドを説明するためにデータベースを変更する行為を考えてみよう。DBMS ではデータをメモリに保存するための関数呼び出しと、ハードウェア制御の RAID アレイにログを強制するためのシステム呼び出しが発生する。Percolator では、トランザクションコミットを実行するクライアントが Bigtable に複数の RPC を送信し、Bigtable は変更を 3 つのチャンクサーバに記録してコミットし、チャンクサーバは実際にデータをディスクにフラッシュするためシステム呼び出しを実行する。その後、同じデータがマイナー SSTable とメジャー SSTable に圧縮され、それぞれが再び複数のチャンクサーバに複製される。
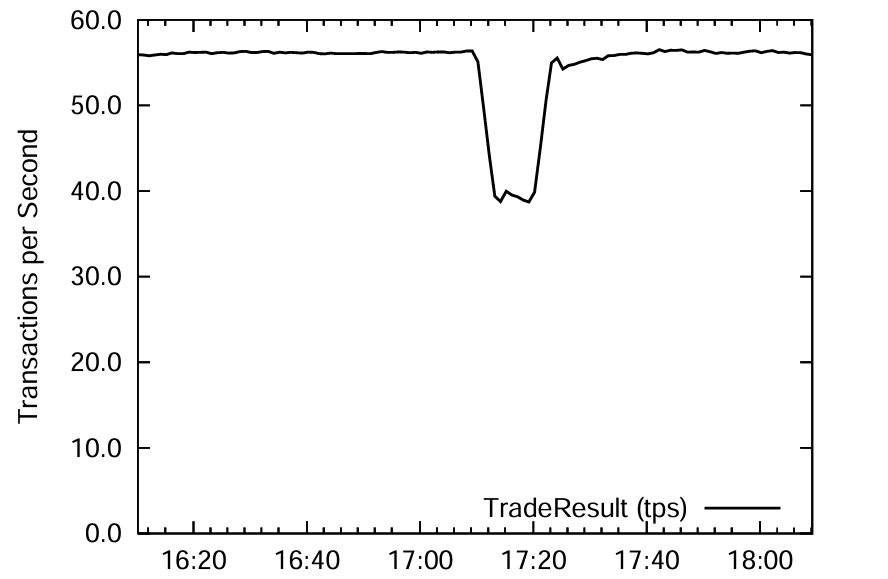
CPU のインフレ要因はレイヤーリングのコストである。その代わり、スケーラビリティ (TPC-E と直接比較sることはできないが、我々の最速の結果は現在の公式記録 [33] の 3 倍以上) が得られ、障害に対する回復力など、我々が構築したシステムの有用な機能を継承することができる。後者を実証するために 15 台のタブレットサーバでベンチマークを実行し性能が安定するまで待った。Figure 10 はシステムのパフォーマンスの経時変化を示している。17:09 の性能低下は障害イベントに対応しており、我々はタブレットサーバの 1/3 を停止した。障害イベントの直後にパフォーマンスが低下するが、タブレットが他のタブレットサーバによって再ロードされると回復する。停止したタブレットサーバを再起動できるようにしたため、パフォーマンスは最終的に元のレベルに戻った。
4 関連する研究
MapReduce [13, 22, 24] のようなバッチ処理システムはコーパス全体を効率的に変換または分析するのに適している。これらのシステムは膨大な量のデータを迅速に処理するために同時に多数のマシンを使用することができる。このようなスケーラビリティにもかかわらず、小さな更新バッチごとに MapReduce パイプラインを再実行すると許容できないレイテンシと無駄な作業が発生する。隣接するステージをオーバーラップさせたりパイプラインス化することでレイテンシを削減できる [10] が、それでもはぐれシャードによってパイプラインを完了するための最小時間が設定される。基本的に Percolator は文書をクラスタリングするために使用するキーにインデックスを作成することで繰り返しスキャンのコストを回避する。Stonebraker と DeWitt の最初の批評 [16] で指摘した批判の 1 つは MapReduce がそのようなインデックスをサポートしていないというものだった。
MapReduce に対するいくつかの修正案 [18, 26, 35] は、ワーカーがベースリポジトリをランダムに読み取りながら新しく到着した作業のみをマッピングできるようにすることでリポジトリへの変更の処理コストを削減する。これらのシステムでクラスタリングを実装するには、クラスタリングフェーズごとにリポジトリを維持することになるだろう。リポジトリ全体を再マッピングする必要がなくなるため、バッチを小さくしてレイテンシを削減できる。DryadInc [31] は以前の実行からの計算の同一部分を再利用し、ユーザが新しい入力と以前の反復の出力を組み合わせるマージ関数を指定できるようにすることで同じ問題に対処している。これらのシステムは MapReduce を使用してリポジトリ全体をマッピングすることと、Percolator を使用して一度に 1 つの文書を処理することの中間を表している。
データベースは増分システムの要件の多くを満たしている。RDBMS は大規模なコーパスに対して多くの独立した同時変更を行うことができ、計算を表現するための柔軟な言語 (SQL) を提供する。実際 Percolator はユーザに、トランザクション、イテレータ、セカンダリインデックスのサポートといった、データベースのようなインターフェースを提供する。Percolator は分散トランザクションを提供するが本格的な DBMS ではない。たとえばクエリ言語や結合 (join) などの完全なリレーショナル操作はない。Percolator は既存の並列データベースよりもはるかに大きな規模で動作し、故障したマシンの上手く対処するように設計されている。Percolator とは異なり、データベースシステムでは人間がデータベースクエリーの結果を待つことが多いため、スループットよりもレイテンシを重視する傾向がある。
Percolator のデータ構成はシェアードナッシング (shared-nothing) パラレルデータベース [7, 15, 4] と同じである。データはシェアードナッシング方式で多数のコモディティマシンに分散され、マシンは明示的な RPC を介してのみ通信し、共有メモリや共有ディスクは使用されない。Percolator によって格納されたデータは Bigtable によって連続行のタブレットに分割されマシン間で分散される。これは並列データベースによって実行されるクラスタリング解除 (declustering) と同じである。
Percolator のトランザクション管理はデータベースシステムの分散トランザクションに関する長年の研究成果に基づいている。Percolator は 2-フェーズコミットを使用して分散システム全体にマルチバージョンタイム順序付け (multi-version timestamp ordering) [6] を拡張することでスナップショット分離 (snapshot isolation) [5] を実装する。
システムを増分的に "クリーン" な状態に移行させる Percolator のオブザーバの役割と、従来のデータベースにおけるマテリアライズドビューの段階的メンテナンスとの間には類似点がある (この分野の調査については Gupta と Mumick [21] を参照)。実際には、文書をコンテンツ別にクラスタリングするような一部のインデックス作成タスクは段階的ビューメンテナンスに適した形式で表現できるが、生の文書からインデックス付き文書に変換することをそのような形式で表現することは難しいだろう。
並列データベース、ひいては Percolator のようなシステムの有用性はこれまで何度も疑問視されてきた [17]。ハードウェアのトレンドは過去に並列データベースに不利に作用してきた。CPU はディスクよりもはるかに高速なったため、共有メモリマシン内の数個の CPU で、分散トランザクションの複雑さを伴わずに必要な負荷を処理するのに十分なディスクヘッドを駆動できるようになった。現在、最高の TPC-E ベンチマーク結果は SAN に接続された大規模な共有メモリマシンで達成されている。しかし Percolator が処理することを意図しているような膨大なデータセットは、単一の共有メモリマシンでは処理できないほど大きくなり、この傾向は逆転し始めている。このようなデータセットには 1000 台規模のマシンに拡張できる分散ソリューションが必要だが、既存の並列データベースは数百台のマシンしか利用できない [30]。Percolator は並列データベースの柔軟性と低レイテンシを一部 (すべてではない) 犠牲することで、インターネット規模のデータセットに十分対応できる拡張性を備えたシステムを提供する。
Bigtable のような分散ストレージシステムは MapReduce のようなスケーラビリティと障害耐性の特徴を備えているが、リポジトリを保存するためのより自然な抽象化を提供する。分散ストレージシステムを使用することで、システムはリポジトリを書き換えるのではなく変更 (mutating) することで状態を変更できるため、低レイテンシの更新が可能になる。しかし Percolator はデータを変換するために計算を構造化する方法を提供するデータ変換システムであり、単なるデータストレージシステムではない。これとは対照的に Dynamo [14]、Bigtable、PNUTS [11] などのシステムは変換の付随メカニズムなしで可用性の高いデータストレージを提供する。これらのシステムはまた NoSQL データベース (MongoDB [27] など) とグループ化することもできる。どちらも従来のデータベースより高いパフォーマンスと拡張性を提供するが、セマンティクスは弱くなる。
Percolator は Bigtable を複数行の分散トランザクションで拡張し、変更されたデータの通知を中心にアプリケーションを構成できるようにするオブザーバインターフェースを提供する。新しいインデックス作成システムを Bigtable 上に直接構築することも検討したが、強力な一貫性の助けを借りずに同時並行的な状態変更について推論する複雑さは大変なものだった。Percolator は Bigtable のすべての機能を継承しているわけではない。例えばデータセンター間でのテーブルのレプリケーションのサポートは限定的である。Bigtable のデータセンター間のレプリケーション戦略はタブレットごとにのみ一貫性があるため、レプリケーションによって分散トランザクションの書き込み間で不変性が破壊される可能性がある。ユーザへの応答を提供する Dynamo や PNUTS とは異なり、Percolator はより厳密な一貫性と引き換えに単一のデータセンターの低い可用性を受け入れることをいとわない。
Percolator のようないくつかの研究システムは分散ストレージシステムを拡張して強い一貫性を組み込んでいる。Sinfonia [3] は分散リポジトリへのトランザクションインターフェースを提供する。Sinfonia の初期の公開バージョン [2] は Percolator のオブザーバモデルに似た通知メカニズムを提供していた。Sinfonia と Percolator は使用目的が異なる。Sinfonia は分散インフラストラクチャの構築を目的として設計されているが、Percolator はアプリケーションで直接使用することを目的としている (Sinfonia の作者が通知メカニズムを廃止した理由はおそらくここにある)。さらに Sinfonia のミニトランザクションは RDBMS や Percolator が提供するトランザクションと比較してセマンティクスが限定されており、ユーザはトランザクションを発行する前に、比較、読み込み、書き込みを行う項目のリストを指定する必要がある。ミニトランザクションは多様なインフラストラクチャを構築するのには十分だが、アプリケーションビルダーにとっては制限となる可能性がある。
CloudTPS [34] は Percolator と同様に分散ストレージシステム (HBase [23] または Bigtable) 上に ACID 準拠のデータストアを構築する。ただし Percolator と CloudTPS システムは設計が異なり、CloudTPS のトランザクション管理層はローカルトランザクションマネージャと呼ばれるサーバの中間層によって処理される。対照的に Percolator は Bigtable と直接通信するクライアントを使用してトランザクション管理を調整する。システムの焦点も異なり、CloudTPS は Web サイトのバックエンドとなることを想定しており、そのため Percolator よりもレイテンシとパーティション耐性に重点を置いている。
トランザクションデータストアである ElasTraS [12] はアーキテクチャ的に Percolator とにしてる。ErasTraS の所有トランザクションマネージャは基本的にタブレットサーバである。Percolator とは異なり ElasTranS はデータセットを動的に分割するときに限定されたトランザクションセマンティクス (Sinfonia のようなミニトランザクション) を提供し、計算を構造化するためのサポートはない。
5 考察と将来の作業
我々は Percolator を構築して導入し、2010 年 4 月から Google の Web 検索インデックスの作成に使用している。このシステムは以前のインデックス作成システムと比較して許容可能なリソースの使用量を増加させながら 1 文書あたりのインデックス作成のレイテンシを削減するという目標を達成した。
TPC-E の結果は今後の調査の有望な方向性を示唆している。我々はコモディティマシン上で何桁も線形にスケーリングするアーキテクチャを選択したが、この場合、従来のデータベースアーキテクチャと比較してオーバーヘッドが 30 倍も大きくかかることがわかった。我々はこのトレードオフを探り、このオーバーヘッドの性質を特徴付けることに非常に興味を持っている。分散ストレージシステムにとって基本的な要素はどの程度で、どの程度最適化できるだろうか?
Acknowledgements
Percolator could not have been built without the assistance of many individuals and teams. We are especially grateful to the members of the indexing team, our primary users, and the developers of the many pieces of infrastructure who never failed to improve their services to meet our increasingly large demands.
References
- TPC benchmark E standard specification version 1.9.0. Tech. rep., Transaction Processing Performance Council, September 2009.
- AGUILERA, M. K., KARAMANOLIS, C., MERCHANT, A., SHAH, M., AND VEITCH, A. Building distributed applications using Sinfonia. Tech. rep., Hewlett-Packard Labs, 2006.
- AGUILERA, M. K., MERCHANT, A., SHAH, M., VEITCH, A., AND KARAMANOLIS, C. Sinfonia: a new paradigm for building scalable distributed systems. In SOSP ’07 (2007), ACM, pp. 159174.
- BARU, C., FECTEAU, G., GOYAL, A., HSIAO, H.-I., JHINGRAN, A., PADMANABHAN, S., WILSON, W., AND I HSIAO, A. G. H. DB2parallel edition, 1995.
- BERENSON, H., BERNSTEIN, P., GRAY, J., MELTON, J., O’NEIL, E., AND O’NEIL, P. A critique of ANSI SQL isolation levels. In SIGMOD (New York, NY, USA, 1995), ACM, pp. 1–10.
- BERNSTEIN, P. A., AND GOODMAN, N. Concurrency control in distributed database systems. ACM Computer Surveys 13, 2 (1981), 185–221.
- BORAL, H., ALEXANDER, W., CLAY, L., COPELAND, G., DANFORTH, S., FRANKLIN, M., HART, B., SMITH, M., AND VALDURIEZ, P. Prototyping Bubba, a highly parallel database system. IEEE Transactions on Knowledge and Data Engineering 2, 1 (1990), 4–24.
- BURROWS, M. The Chubby lock service for loosely-coupled distributed systems. In 7th OSDI (Nov. 2006).
- CHANG, F., DEAN, J., GHEMAWAT, S., HSIEH, W. C., WALLACH, D. A., BURROWS, M., CHANDRA, T., FIKES, A., AND GRUBER, R. E. Bigtable: A distributed storage system for structured data. In 7th OSDI (Nov. 2006), pp. 205–218.
- CONDIE, T., CONWAY, N., ALVARO, P., AND HELLERSTIEN, J. M. MapReduce online. In 7th NSDI (2010).
- COOPER, B. F., RAMAKRISHNAN, R., SRIVASTAVA, U., SILBERSTEIN, A., BOHANNON, P., JACOBSEN, H.-A., PUZ, N., WEAVER, D., AND YERNENI, R. PNUTS:Yahoo!’s hosted data serving platform. In Proceedings of VLDB (2008).
- DAS, S., AGRAWAL, D., AND ABBADI, A. E. ElasTraS: An elastic transactional data store in the cloud. In USENIX HotCloud (June 2009).
- DEAN, J., AND GHEMAWAT, S. MapReduce: Simplified data processing on large clusters. In 6th OSDI (Dec. 2004), pp. 137150.
- DECANDIA, G., HASTORUN, D., JAMPANI, M., KAKULAPATI, G., LAKSHMAN, A., PILCHIN, A., SIVASUBRAMANIAN, S., VOSSHALL, P., AND VOGELS, W. Dynamo: Amazon’s highly available key-value store. In SOSP ’07 (2007), pp. 205–220.
- DEWITT, D., GHANDEHARIZADEH, S., SCHNEIDER, D., BRICKER, A., HSIAO, H.-I., AND RASMUSSEN, R. Thegamma database machine project. IEEE Transactions on Knowledge and Data Engineering 2 (1990), 44–62.
- DEWITT, D., AND STONEBRAKER, M. MapReduce: A major step backwards. http://databasecolumn.vertica.com/database-innovation/mapreduce-a-major-step-backwards/.
- DEWITT, D. J., AND GRAY, J. Parallel database systems: the future of database processing or a passing fad? SIGMOD Rec. 19, 4 (1990), 104–112.
- EKANAYAKE, J., LI, H., ZHANG, B., GUNARATHNE, T., BAE, S.-H., QIU, J., AND FOX, G. Twister: A runtime for iterative MapReduce. In The First International Workshop on MapReduce and its Applications (2010).
- GERSHENSON, C., AND PINEDA, L. A. Why does public transport not arrive on time? The pervasiveness of equal headway instability. PLoS ONE 4, 10 (10 2009).
- GHEMAWAT, S., GOBIOFF, H., AND LEUNG, S.-T. The Google f ile system. vol. 37, pp. 29–43.
- GUPTA, A., AND MUMICK, I. S. Maintenance of materialized views: Problems, techniques, and applications, 1995.
- Hadoop. http://hadoop.apache.org/.
- HBase. http://hbase.apache.org/.
- ISARD, M., BUDIU, M., YU, Y., BIRRELL, A., AND FETTERLY, D. Dryad: Distributed data-parallel programs from sequential building blocks. In EuroSys ’07 (New York, NY, USA, 2007), ACM, pp. 59–72.
- IYER, S., AND CUTTS, M. Help test some next-generation infrstructure. http://googlewebmastercentral.blogspot.com/2009/08/help-test-some-next-generation.html, August 2009.
- LOGOTHETIS, D., OLSTON, C., REED, B., WEBB, K. C., AND YOCUM, K. Stateful bulk processing for incremental analytics. In SoCC ’10: Proceedings of the 1st ACM symposium on cloud computing (2010), pp. 51–62.
- MongoDB. http://mongodb.org/.
- PAGE, L., BRIN, S., MOTWANI, R., AND WINOGRAD, T. The PageRank citation ranking: Bringing order to the web. Tech. rep., Stanford Digital Library Technologies Project, 1998.
- PATON, N. W., AND D´ IAZ, O. Active database systems. ACM Computing Surveys 31, 1 (1999), 63–103.
- PAVLO, A., PAULSON, E., RASIN, A., ABADI, D. J., DEWITT, D. J., MADDEN, S., AND STONEBRAKER, M. Acomparison of approaches to large-scale data analysis. In SIGMOD ’09 (June 2009), ACM.
- POPA, L., BUDIU, M., YU, Y., AND ISARD, M. DryadInc: Reusing work in large-scale computations. In USENIX workshop on Hot Topics in Cloud Computing (2009).
- STONEBRAKER, M. Operatingsystemsupportfordatabase management. Communications of the ACM 24, 7 (1981), 412–418.
- NECExpress5800/A1080a-E TPC-E results. http://www.tpc.org/tpce/results/tpce_result?detail.asp?id=110033001, Mar. 2010.
- WEI, Z., PIERRE, G., AND CHI, C.-H. CloudTPS: Scalable transactions for Web applications in the cloud. Tech. Rep. IR-CS-053, Vrije Universiteit, Amsterdam, The Netherlands, Feb. 2010. http://www.globule.org/publi/CSTWAC_ircs53.html.
- ZAHARIA, M., CHOWDHURY, M., FRANKLIN, M., SHENKER, S., AND STOICA, I. Spark: Cluster computing with working sets. In 2nd USENIX workshop on Hot Topics in Cloud Computing (2010).
翻訳抄
小規模なデータ変更を効率的に反映しながら、分散トランザクションと通知メカニズムを追加してリアルタイムに近い更新を可能にした、従来の MapReduce によるバッチ処理システムの代替として設計された Google Percolator に関する 2010 年の論文。Percolator は Google の KVS である Bigtable 上で複数行/複数タブレットにまたがる ACID トランザクションを実装することを目的としており、この設計は TiDB のベースとなっている。
- Daniel Peng, Frank Dabek. Large-scale Incremental Processing Using Distributed Transactions and Notifications. In 9th USENIX Symposium on Operating Systems Design and Implementation (OSDI 10). 2010.
