論文翻訳: Consensus: Bridging Theory and Practice
哲学博士の学位取得に必要な条件の一部を満たすためにスタンフォード大学計算機科学科および卒業研究委員会に提出した学位論文
Diego Ongaro
August 2014
 This work is licensed under the Creative Commons Attribution 4.0 International License. http://creativecommons.org/licenses/by/4.0/
This work is licensed under the Creative Commons Attribution 4.0 International License. http://creativecommons.org/licenses/by/4.0/
この論文は Diego Ongaro と John Ousterhout によって書かれた論文 "In Search of an Understandable Consensus Algorithm" [89] を発展させたものである。元の論文の内容のほとんどは何らかの形でこの論文に含まれている。本論文では John Ousterhout の許可を得て Creative Commons Attribution license の下で複製・ライセンスされている。
 Abstract
Abstract
分散コンセンサスはフォールトトレラントなシステムを構築するために不可欠である。これにより、一部のメンバーに障害が発生しても複数のマシンが動作を継続できる、一貫性のあるグループとして動作することが可能となる。しかし残念ながら最も一般的なコンセンサスアルゴリズムである Paxos は正しく理解し実装することが難しいと広く認識されている。
この論文では、理解しやすさを重視して設計された Raft と呼ばれる新しいコンセンサスアルゴリズムを紹介する。Raft はまずサーバをリーダーとして選出し、次にすべての意思決定をリーダーに集中させる。この 2 つの基本ステップは比較的独立しており、コンポーネントの分離が難しい Paxos よりも優れた構造を形成している。Raft は投票とランダムなタイムアウトを用いてリーダーを選出する。この選挙により、リーダーが必要なすべての情報を既に保存していることが保証されるため、データはリーダーから他のサーバへのみ流れる。他のリーダーベースのアルゴリズムと比較して、これによりメカニズムを減らし動作を簡素化する。選出されたリーダーは複製されたログを管理する。Raft は、ログの成長方法に関する単純な不変条件を利用することでアルゴリズムの状態空間を縮小し、最小限のメカニズムでこのタスクを達成する。
Raft は従来のアルゴリズムよりも実環境への実装に適している。また実用的なデプロイメントに十分なパフォーマンスを発揮し、クライアントとのやりとりを管理する方法、クラスタメンバーシップを変更する方法、ログが大きくなりすぎた場合にコンパクトにする方法など、完全なシステムを構築するためあらゆる側面に対応している。クラスタメンバーシップの変更において、Raft では一度に 1 つのサーバを追加または削除することができ (これらの基本的な手順から複雑な変更を構成できる)、クラスタは変更中もリクエストへの応答を継続する。
我々は、教育目的と実装の基礎の両面において Raft は Paxos やその他のコンセンサスアルゴリズムよりも優れていると考えている。ユーザ調査の結果、Raft は Paxos よりも学生にとって学習しやすいことを示している。このアルゴリズムは正式に仕様化され証明されており、そのリーダー選出アルゴリズムは様々な環境で適切に動作し、その性能は Multi-Paxos と同等である。現在、Raft の多くの実装が提供されており、いくつかの企業が Raft を導入している。
Table of Contents
- Abstract
- 序文
- Acknowledgements
- Chapter 1 - はじめに
- Chapter 2 - 動機
- Chapter 3 - 基本 Raft アルゴリズム
- Chapter 4 - クラスタメンバーシップ変更
- Chapter 5 - ログ圧縮
- Chapter 6 - クライアントとの相互作用
- Chapter 7 - Raft ユーザ調査
- Chapter 8 - 正しさ
- Chapter 9 - リーダー選出評価
- Chapter 10 - 実装と性能
- Chapter 11 - 関連研究
- Chapter 12 - 結論
- Appendix A - ユーザ調査資料
- Appendix B - Safety の証明と形式仕様
- Bibliography
- 翻訳抄
序文
読者は Raft に関するビデオや Raft のインタラクティブな可視化について Raft のウェブサイト [92] を参照することをおすすめする。
Acknowledgements
Acknowledgements
Thanks to my family and friends for supporting me throughout the ups and downs of grad school. Mom,thanks for continuously pushing me to do well academically, even when I didn’t see the point. I still don’t know how you got me out of bed at 6 a.m. all those mornings. Dad, thanks for helping us earn these six (seven?) degrees, and I hope we’ve made you proud. Zeide, I wish I could give you a copy of this small book for your collection. Ernesto, thanks for sparking my interest in computers; I still think they’re pretty cool. Laura, I’ll let you know if and when I discover a RAMCloud. Thanks for listening to hours of my drama, even when you didn’t understand the nouns. Jenny, thanks for helping me get through the drudgery of writing this dissertation and for making me smile the whole way through. You’re crazy for having wanted to read this, and you’re weird for having enjoyed it.
I learned a ton from my many labmates, both in RAMCloud and in SCS. Deian, I don’t know why you always cared about my work; I never understood your passion for that IFC nonsense, but keep simplifying it until us mortals can use it. Ankita, you’ve single-handedly increased the lab’s average self-esteem and optimism by at least 20%. I’ve watched you learn so much already; keep absorbing it all, and I hope you’re able to see how far you’ve come. Good luck with your role as the new Senior Student. Thanks especially to Ryan and Steve, with whom I formed the first generation of RAMCloud students. Ryan, believe it or not, your optimism helped. You were always excited about wacky ideas, and I always looked forward to swapping CSBs (“cool story, bro”) with you. You’ll make a great advisor. Steve, I miss your intolerance for bullshit, and I strive to match your standards for your own engineering work. You continuously shocked the rest of us with those silent bursts of productivity, where you’d get quarter-long projects done over a single weekend. You guys also figured out all the program requirements before I did and told me all the tricks. I continue to follow your lead even after you’ve moved on. (Ryan, you incorrectly used the British spelling “acknowledgements” rather than the American “acknowledgments”. Steve, you did too, but you’re just Canadian, not wrong.)
Thanks to the many professors who have advised me along the way. John Ousterhout, my Ph.D. advisor, should be a coauthor on this dissertation (but I don’t think they would give me a degree that way). I have never learned as much professionally from any other person. John teaches by setting a great example of how to code, to evaluate, to design, to think, and to write well. I have never quite been on David Mazières’s same wavelength; he’s usually 10–30 minutes ahead in conversation. As soon as I could almost keep up with him regarding consensus, he moved on to harder Byzantine consensus problems. Nevertheless, David has looked out for me throughout my years in grad school, and I’ve picked up some of his passion for building useful systems and, more importantly, having fun doing so. Mendel Rosenblum carries intimate knowledge of low level details like x86 instruction set, yet also manages to keep track of the big picture. He’s helped me with both over the years, surprising mewith how quickly he can solve my technical problems and how clear my predicaments are when put into his own words. Thanks to Christos Kozyrakis and Stephen Weitzman for serving on my defense committee, and thanks to Alan Cox and Scott Rixner for introducing me to research during my undergraduate studies at Rice.
Many people contributed directly to this dissertation work. A special thanks goes to David Mazières and Ezra Hoch for each finding a bug in earlier versions of Raft. David emailed us one night at 2:45 a.m. as he was reading through the Raft lecture slides for the user study. He wrote that he found “one thing quite hard to follow in the slides,” which turned out to be a major issue in Raft’s safety. Ezra found a liveness bug in membership changes. He posted to the Raft mailing list, “What if the following happens?” [35], and described an unfortunate series of events that could leave a cluster unable to elect a leader. Thanks also to Hugues Evrard for finding a small omission in the formal specification.
The user study would not have been possible without the support of Ali Ghodsi, David Mazières, and the students of CS 294-91 at Berkeley and CS 240 at Stanford. Scott Klemmer helped us design the user study, and Nelson Ray advised us on statistical analysis. The Paxos slides for the user study borrowed heavily from a slide deck originally created by Lorenzo Alvisi.
Many people provided feedback on other content in this dissertation. In addition to my reading committee, Jennifer Wolochow provided helpful comments on the entire dissertation. Blake Mizerany, Xiang Li, and Yicheng Qin at CoreOS pushed me to simplify the membership change algorithm towards single-server changes. Anirban Rahut from Splunk pointed out that membership changes may be needlessly slow when a server joins with an empty log. Laura Ongaro offered helpful feedback on the user study chapter. Asaf Cidon helped direct me in finding the probability of split votes during elections. Eddie Kohler helped clarify the trade-offs in Raft’s commitment rule, and Maciej Smoleński pointed out that because of it, if a leader were to restart an unbounded number of times before it could mark entries committed, its log could grow without bound (see Chapter 11). Alexander Shraer helped clarify how membership changes work in Zab.
Many people provided helpful feedback on the Raft paper and user study materials, including Ed Bugnion, Michael Chan, Hugues Evrard, Daniel Giffin, Arjun Gopalan, Jon Howell, Vimalkumar Jeyakumar, Ankita Kejriwal, Aleksandar Kracun, Amit Levy, Joel Martin, Satoshi Matsushita, Oleg Pesok, David Ramos, Robbert van Renesse, Mendel Rosenblum, Nicolas Schiper, Deian Stefan, Andrew Stone, Ryan Stutsman, David Terei, Stephen Yang, Matei Zaharia, 24 anonymous conference reviewers (with duplicates), and especially Eddie Kohler for shepherding the Raft paper.
Werner Vogels tweeted a link to an early draft of the Raft paper, which gave Raft significant exposure. Ben Johnson and Patrick Van Stee both gave early talks on Raft at major industry conferences.
This work was supported by the Gigascale Systems Research Center and the Multiscale Systems Center, two of six research centers funded under the Focus Center Research Program, a Semiconductor Research Corporation program, by STARnet, a Semiconductor Research Corporation program sponsored by MARCO and DARPA, by the National Science Foundation under Grant No. 0963859, and by grants from Facebook, Google, Mellanox, NEC, NetApp, SAP, and Samsung. Diego Ongaro was supported by The Junglee Corporation Stanford Graduate Fellowship. James Myers at Intel donated several SSDs used in benchmarking.
Chapter 1 - はじめに
今日のデータセンターシステムとアプリケーションは非常に動的な環境で稼働している。これらは追加サーバのリソースを活用してスケールアウトし、需要に応じて拡大・縮小する。サーバやネットワーク障害も日常的である。例えば毎年ディスクドライブの約 2-4% が故障し [103]、サーバもほぼ同じ頻度でクラッシュし [22]、現在のデータセンターでは毎日数十のネットワークリンクが故障している [31]。
その結果、システムは通常運用中にサーバの増減に対応しなければならない。システムは変化に反応し、数秒以内に自動的に適応する必要があり、人間が気づくような停止は通常許容されない。これは今日のシステムにとって大きな課題である。このような動的な環境では、障害処理、協調、サービスディスカバリー、構成管理のすべてが困難である。
幸いなことに、分散コンセンサスはこれらの課題を解決するのに役立つ。コンセンサスにより、機械の集合は、一部のメンバーの故障に耐えることができる一貫したグループとして機能することができる。コンセンサスグループ内では、障害は原則に基づいて実証済みの方法で処理される。コンセンサスグループは高い可用性と信頼性を持つため、他のシステムコンポーネントはコンセンサスグループを自身の耐障害性の基盤として使用することができる。したがって、コンセンサスは信頼性の高い大規模ソフトウェアシステムを構築する上で重要な役割を果たす。
我々がこの研究を始めたとき、コンセンサスの必要性は明らかになりつつあったが、多くのシステムは依然としてコンセンサスが解決できる問題に苦しんでいた。一部の大規模システムは単一障害点となる単一の協調サーバによって依然として制約を受けていた (例: HDFS [81, 2])。その他多くのシステムには安全でない方法で障害を処理するアドホックなレプリケーションアルゴリズムを採用していた (例: MongoDB および Redis [44])。新しいシステムはすぐに利用できるコンセンサス実装の選択肢がほとんどなく (ZooKeeper [38] が最も人気であった)、システム構築者は特定のコンセンサス実装に従うか、独自の実装を構築せざるを得なかった。
コンセンサスを独自に実装することを選択した人々は、通常、Paxos [48, 49] に目を向けた。Paxos は過去 20 年間にわたりコンセンサスアルゴリズムの議論を支配してきた。ほとんどのコンセンサス実装は Paxos に基づいて構築されているか、それから影響を受けており、Paxos は学生にコンセンサスを教えるための主要な手段となっていた。
残念ながら、より理解しようとするための数多くの試みにもかかわらず、Paxos は非常に難解である。さらに、そのアーキテクチャは実用的なシステムをサポートするために複雑な変更を必要とし、Paxos に基づいた完全なシステムを構築するには、詳細が公開されていない、あるいは合意されていない複数の拡張機能を開発する必要がある。結果として、システム開発者と学生の両方が Paxos に苦戦する。
他の 2 つのよく知られたコンセンサスアルゴリズムは Viewstamped Replication [83, 82, 66] と ZooKeeper で使用されている Zab [42] である。これらのアルゴリズムはどちらも、偶然にもシステム構築において Paxos よりも構造的に優れていると我々は考えているが、どちらもこの主張を明示的に行っていない。それらはシンプルさや理解しやすさを主要な目的として設計されたものではなかった。これらのアルゴリズムを理解し、実装する負担は依然として高すぎる。
これらのコンセンサスの選択肢はそれぞれ理解が難しく実装するのも難しかった。残念ながら、実証済みのアルゴリズムでコンセンサスを実装するコストが高すぎると、システム構築者は厳しい決断を迫られた。彼らはコンセンサスを完全に避けてシステムの障害耐性や一貫性を犠牲にするか、独自のアドホックなアルゴリズムを開発し、しばしば安全でない挙動につながるかのどちらかであった。さらに、コンセンサスを説明するコストが高すぎると、すべての講師がそれを教えようとせず、すべての学生がそれを習得できるわけではなかった。コンセンサスは 2-フェーズコミットと同じくらい基本的であり、(コンセンサスは根本的により難しいとはいえ) 理想的にはより多くの学生が習得すべきである。
我々自身が Paxos に苦戦した後、システム構築と教育のためによりよい基盤を提供できる新しいコンセンサスアルゴリズムを見つけることを目指した。我々のアプローチは、その主要な目標が理解しやすさ (understandability) であるという点で異例であった。すなわち、実用的なシステムのためのコンセンサスアルゴリズムを定義し、Paxos よりも著しく学習しやすい方法でそれを記述できるか、と言うことであった。さらに、アルゴリズムがシステム構築者にとって不可欠な直感を促進することを望んだ。アルゴリズムが機能するだけではなく、なぜ機能するのかが明白であることが重要であった。
このアルゴリズムは、実用的なシステムを構築するすべての側面に対処するのに十分完全である必要があり、また、実用的な展開のために十分な機能を発揮する必要があった。コアアルゴリズムは、メッセージの受信による効果を指定するだけでなく、何がいつ起こるべきかを記述すべきであり、これらはシステム構築者にとって同様に重要である。同様に、一貫性を保証する必要があり、また、可能な限り可用性も提供する必要があった。さらに、コンセンサスの達成を超えたシステムにおける多くの側面、例えばコンセンサスグループのメンバー変更にも対処する必要があった。これらは実際には不可欠であり、この負担をシステム構築者に任せることはアドホックで最適とは言えず、あるいは誤った解決策を招く危険性があった。
この研究の成果が Raft と呼ばれるコンセンサスアルゴリズムである。Raft の設計において我々は理解しやすさを向上させるための特定の手法を適用した。これには分解 (Raft はリーダー選出、ログレプリケーション、Safety を分離する) と状態空間の削減 (Raft は非決定論の度合いとサーバが互いに不整合になる方法を減らす) が含まれる。我々はまた、完全なコンセンサスベースのシステムを構築するために必要なすべての問題に対処した。各設計の選択は、我々の実装のためだけでなく、我々が実現を望む多くの他の実装のためにも慎重に検討された。
我々は Raft が教育目的および実装の基盤として Paxos や他のコンセンサスアルゴリズムより優れていると信じている。これは他のアルゴリズムよりもシンプルで理解しやすく、実用的なシステムのニーズを満たすのに十分完全に記述されている。いくつかのオープンソース実装があり、いくつかの企業で使用されている。Safety 特性は正式に仕様化され証明されており、効率性は他のアルゴリズムに匹敵する。
この論文の主な貢献は以下の通りである:
Raft コンセンサスアルゴリズムの設計、実装、評価。Raft は既存のコンセンサスアルゴリズム (特に Oki と Liskov の Viewstamped Replication [83, 66]) と多くの点で類似しているが、理解しやすさを目指して設計されている。これがいくつかの斬新な特徴につながった。例えば、Raft は他のコンセンサスアルゴリズムよりも強力な形式のリーダーシップを使用する。これにより、レプリケーションされたログの管理が簡素化され、Raft の理解が容易になる。
Raft の理解しやすさの評価。2 つの大学の 43 人の学生を対象としたユーザ調査は、Raft が Paxos よりも著しく理解しやすいことを示している。両方のアルゴリズムを学んだ後、これらの学生のうち 33 人は Paxos に関する質問よりも Raft に関する質問により正確に回答することができた。これは、教育と学習に基づいてコンセンサスアルゴリズムを評価する最初の科学的研究であると我々は考えている。
Raft のリーダー選出メカニズムの設計、実装、評価。多くのコンセンサスアルゴリズムは特定のリーダー選出アルゴリズムを規定しないが、Raft はランダム化されたタイマーを含む独自のアルゴリズムを採用している。これは、既存のコンセンサスアルゴリズムで既に必要なハートビートにわずかなメカニズムを追加するだけであり、同時に競合をシンプルかつ迅速に解決する。リーダー選出の評価はその挙動と性能を調査し、このシンプルなアプローチが多種多様な実用的な環境で十分であることを結論づけている。通常、Raft はクラスタの片方向ネットワーク遅延 (one-way network latency) の 20 倍未満でリーダーを選出する。
Raft のクラスタメンバーシップ変更メカニズムの設計と実装。Raft は一度に 1 台のサーバを追加または削除できる。これらの操作は、変更中に少なくとも 1 つのサーバが任意の過半数と重複するため Safety をシンプルに確保する。より複雑なメンバーシップ変更は単一サーバの変更を繰り返すことで実装される。Raft は変更中でもクラスタが正常に動作し続けることを可能にし、メンバーシップ変更は基本的なコンセンサスアルゴリズムへのいくつかの拡張だけで実現できる。
クライアントとの相互作用やログ圧縮など、完全なコンセンサスベースのシステムに不可欠な他のコンポーネントについて、徹底的な議論と実装。これらの Raft の側面が特に斬新であるとは考えていないが、完全な記述は理解しやすさ、そして他の人々が実際のシステムを構築できるようにするために重要である。我々は、関連するすべての設計上の決定を探求し対処するために完全なコンセンサスベースのサービスを実装した。
Raft アルゴリズムの Safety の証明と形式仕様。形式仕様の精度レベルは、アルゴリズムについて慎重に推論し、アルゴリズムの非形式的な説明の詳細を明確にするのに役立つ。Safety の証明は Raft の正しさへの信頼を構築するのに役立つ。また、Raft を拡張しようとする他の人々に対しても、拡張の Safety への影響を明確にすることで役立つ。
我々はこの論文の多くの設計を Raft のオープンソース実装である LogCabin [86] で実装した。LogCabin は Raft における新しいアイディアのテストプラットフォームとして、また、完全で実用的なシステムを構築する際の問題を理解していることを検証する手段として機能した。実装についてはセクション 10 でさらに詳しく説明する。
この論文の残りの部分では、複製ステートマシンの問題を紹介し Paxos の長所と短所を議論し (セクション 2)、Raft コンセンサスアルゴリズム、クラスタメンバーシップ変更とログ圧縮のための拡張、およびクライアントが Raft とどのように相互作用するかを提示し (セクション 3 ~セクション 6)、理解しやすさ、Safety、Liveness、リーダー選出、およびログ複製の性能に関して Raft を評価し (セクション 7 ~セクション 10)、関連する研究を議論する (セクション 11)。
Chapter 2 - 動機
コンセンサスは障害耐性システムにおける根本的な問題である。すなわち、サーバが故障に直面してもいかにして共有された状態について合意に達することができるのか。この問題は高レベルの可用性を提供する必要があり、一貫性を損なうことができない多種多様なシステムで発生する。そのため、コンセンサスは実質的に一貫性のあるすべての大規模ストレージシステムで利用されている。セクション 2.1 ではコンセンサスが障害耐性システムの汎用的な構成要素である複製ステートマシンを作成するために一般にどのように使われるかを説明する。セクション 2.2 では大規模システムにおける複製ステートマシンの様々な使用方法について議論する。セクション 2.3 では Raft が解決を目指す Paxos コンセンサスプロトコルの問題点について議論する。
2.1 複製ステートマシンによる障害耐性の達成
コンセンサスアルゴリズムは、通常、複製ステートマシン (replicated state machine) [102] の文脈で出現する。このアプローチでは、複数のサーバ上のステートマシンが同一のコピーの同じ状態を計算し、一部のサーバがダウンしても動作し続けることができる。複製ステートマシンは、セクション 2.2 で説明されているように、分散システムにおける様々な障害耐性問題を解決するために使用されている。複製ステートマシンの例には Chubby [11] と ZooKeeper [38] があり、どちらも少量の構成データのために階層的な key-Value ストアを提供している。get や put といった基本的な操作に加えて、それらは compare-and-swap のような同期プリミティブも提供し、並行クライアントが安全に連携することを可能にする。
典型的には複製ステートマシンは Figure 2.1 に示すように複製ログを使用して実装される。各サーバは一連のコマンドを含むログを保存し、そのステートマシンはそれらを順番に実行する。各ログは同じコマンドを同じ順序で含んでいるため、各ステートマシンは同じコマンドシーケンスを処理する。ステートマシンは決定論的であるため、各ステートマシンは同じ状態と同じ出力シーケンスを算出する。
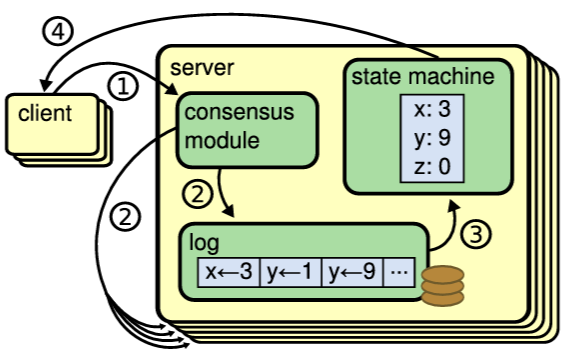
複製ログを一貫した状態に保つことがコンセンサスアルゴリズムの役割である。サーバ上のコンセンサスモジュールはクライアントからのコマンドを受信し、それらを自身のログに追加する。他のサーバ上のコンセンサスモジュールと通信することで、一部のサーバが故障してもすべてのログが最終的に同じリクエストを同じ順序で含むことを保証する。コマンドが適切に複製されるとコミットされた (committed) と見なされる。各サーバのステートマシンはログ順でコミットされたコマンドを処理し、その出力をクライアントに返す。結果としてサーバ群は非常に信頼性の高い単一のステートマシンを形成しているように見える。
実用的なシステムのコンセンサスアルゴリズムは、通常、以下の特徴を備えている:
ネットワーク遅延、パーティション、パケット損失、重複、順序逆転など、非ビザンチン条件の下で Safety (誤った結果を決して返さないこと) を保証する。
サーバの任意の過半数が稼働しており、相互に、そしてクライアントと通信できる限り、完全に機能 (Available) する。したがって、典型的な 5 台のサーバからなるクラスタは、任意の 2 台のサーバ故障に耐えることができる。サーバは停止することで故障すると想定され、その後、安定したストレージ上から回復してクラスタに再参加することができる。
ログの一貫性を保証するためにタイミングに依存しない。クロックの故障や極端なメッセージの遅延は、最悪の場合、可用性の問題を引き起こすだけである。つまり、メッセージとプロセッサが任意の速度で進行する非同期モデル [71] の下で Safety を維持する。
一般的なケースでは、コマンドはクラスタの過半数が 1 ラウンドのリモートプロシジャコールに応答するとすぐに完了することができる。少数の遅いサーバがシステム全体の性能に影響を与える必要はない。
2.2 複製ステートマシンの一般的なユースケース
複製ステートマシンはシステムに障害耐性を与えるための汎用的な構成要素である。それらは様々な用途があり、このセクションではいくつかの典型的な使用パターンについて説明する。
コンセンサスの最も一般的な手に開くでは、3 台または 3 台のサーバが 1 つの複製ステートマシンを形成する。他のサーバは Figure 2.2(a) に示すように、このステートマシンを使用して各自の活動を調整することができる。これらのシステムでは、グループメンバーシップ、構成管理、またはロック [38] を提供するためにしばしば複製ステートマシンを使用する。より具体的な例としては、複製ステートマシンが障害耐性のあるワークキューを提供し、他のサーバが複製ステートマシンを使用して自身に作業を割り当てることで連携する、といったことが挙げられる。
この使用法の一般的な簡略化が Figure 2.2(b) に示されている。このパターンでは 1 台のサーバがリーダーとして機能して他のサーバを管理する。リーダーは自身の重要なデータをコンセンサスシステムに保存する。リーダーが故障した場合、他のスタンバイサーバがリーサーの座を争い、成功すればコンセンサスシステム内のデータを使用して操作を継続する。GFS [30]、HDFS [105]、RAMCloud [90] のような単一のクラスタリーダーを持つ多くの大規模ストレージシステムがこのアプローチを使用している。
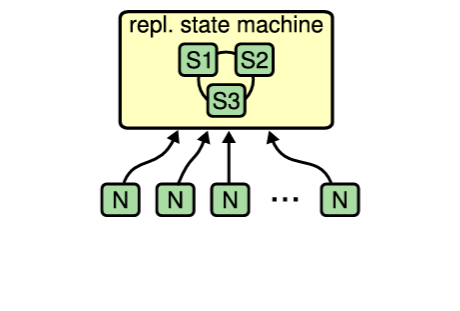
(a) クラスタ内のノードは、複製ステートマシンからの読み書きによって互いに活動を調整する。
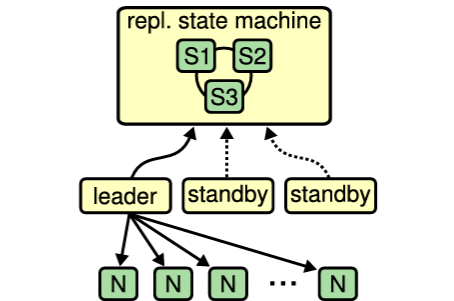
(b) 1 台のリーダーがクラスタ内のノードを積極的に管理し、その状態を複製ステートマシンを使用して記録する。他のスタンバイサーバはリーダーが故障するまでパッシブである。
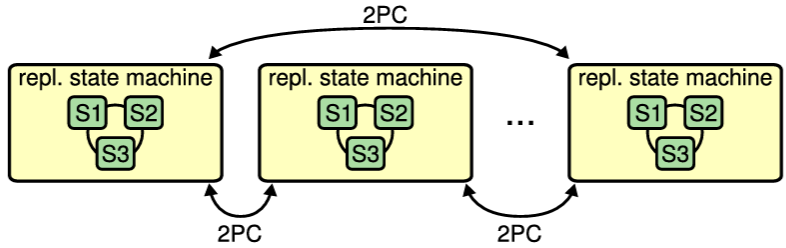
Figure 2.3 に示すように、コンセンサスは非常に大量のデータを複製するためにも使用されることがある。Megastore [5]、Spanner [20]、Scatter [32] のような大規模ストレージシステムは単一のサーバグループに収まらないほど大量のデータを保存する。それらはデータを多くの複製ステートマシンに分割し、複数のパーティションにまたがる操作は一貫性を維持するために 2-フェーズコミットプロトコル (2PC) を使用する。
2.3 Paxos の何が問題なのか?
過去 10 年で Leslie Lamport の Paxos プロトコル [48] はコンセンサスとほぼ同義となった。これは授業でも最も一般的に教えられているプロトコルであり、ほとんどのコンセンサス実装がその出発点としている。Paxos はまず、単一複製ログエントリのような単一の決定について合意に達することができるプロトコルを定義する。我々はこのサブセットを単一決定 Paxos (single-decree Paxos) と呼ぶ。次に、Paxos はログなどの一連の決定を促進するためにこのプロトコルの複数のインスタンスを結合する (Multi-Paxos)。単一決定 Paxos は Figure 2.4 に、Multi-Paxos は Figure A.2 にまとめられている。Paxos は Safety と Liveness を保証し (適切な故障検出器がプロポーザーのライブロックを回避するために使用されると仮定すれば、最終的にはコンセンサスに達する)、その正しさは証明されている。Multi-Paxos は通常の場合に効率的であり、Paxos はクラスタメンバーシップの変更をサポートしている [69]。
残念ながら Paxos には 2 つの重大な欠点がある。1 つ目の欠点は Paxos が並外れて理解しにくいことである。完全な説明 [48] は非常に難解で理解できる人はほとんどおらず、それも多大な努力を要する。その結果、Paxos をより簡単な言葉で説明しようとする試みが数多くなされてきた [49, 60, 61]。これらの説明は単一決定サブセットに焦点を当てているが、それでもなお難解である。NSDI 2012 の参加者を対象とした非公式な調査では、ベテランの研究者でさえ、Paxos に慣れている人はほとんどいないことがわかった。我々自身も Paxos の理解に苦戦し、いくつかの説明を読み、独自の代替プロトコルを設計するまで、完全なプロトコルを理解することができなかった。このプロセスにはほぼ 1 年を要した。
我々は、Paxos の不透明さはその基盤に単一決定サブセットを選択したことにある仮説を立てている。単一決定 Paxos は複雑で繊細である。これは 2 つの段階に分かれており、それぞれに直感的な説明を持たず、独立して理解することができない。このため、単一決定プロトコルがなぜ機能するのかについて直感を得ることが難しい。Multi-Paxos の合成ルールはさらに重大な複雑さと繊細さを加えている。複数の決定 (すなわち、単一のエントリではなくログ) についてコンセンサスに達するという全体的な問題は、より直感的で明白な他の方法で分解できると我々は信じている。
Paxos の 2 つ目の問題は、実用的な実装を構築するための良い基盤を提供しないことである。その理由の一つは Multi-Paxos について広く合意されたアルゴリズムが存在しないことである。Lamport の説明はほとんどが単一決定 Paxos に関するものである。彼は Multi-Paxos へのアプローチの可能性を概説しているが、多くの詳細が欠けている。例えば [77]、[108]、[46] など、Paxos を具体化し最適化しようとするいくつもの試みが成されてきたが、これらは互いに異なり、Lamport の概説とも異なる。Chubby [15] のようなシステムは Paxos に似たアルゴリズムを実装しているが、ほとんどの場合、その詳細は公開されていない。
さらに、Paxos のアーキテクチャは実用的なシステムを構築するのには貧弱である。これも単一決定分解のもう一つの結果である。例えば、ログエントリのコレクションを独立して選択し、それから順次ログにマージすることにはほとんど利点がない。これは単に複雑さを増すだけである。新しいエントリが制約された順序で順次追加されるログを中心にシステムを設計する方がよりシンプルで効率的である。もう一つの問題は、Paxos がそのコアで対称的なピアツーピアアプローチを使用していることである (ただし、性能最適化として弱い形式のリーダーシップも示唆している)。これは 1 つの決定のみが行われる単純化された世界では理にかなっているが、このアプローチを使用する実用的なシステムは少ない。一連の決定を行う必要がある場合、最初にリーダーを選出し、次にリーダーに決定を調整させる方がよりシンプルで高速である。(第 11 章では、リーダーを使用しないが状況によってはリーダーベースのアルゴリズムよりも効率的な Paxos の最近の変種である Egalitarian Paxos を議論する。ただし、このアルゴリズムはリーダーベースのアルゴリズムよりもはるかに複雑である。)
結果として、実用的なシステムは Paxos との類似性がほとんどない。各実装は Paxos から始まり、実装の困難さを発見し、その後、大きく異なるアーキテクチャを開発する。これは時間がかかり、エラーを起こしやすく、Paxos の理解の困難さが問題を悪化させる。Paxos の定式化は、その正しさに関する定理を証明するのには適しているかもしれないが、実際の実装は Paxos と大きく異なるため、証明にはほとんど価値がない。Chubby 実装者からの以下のコメントは典型的である。
There are significant gaps between the description of the Paxos algorithm and the needs of a real-world system.... the final system will be based on an unproven protocol [15].
Paxos アルゴリズムの記述と現実世界のシステムのニーズの間には大きなギャップがある.... 最終的なシステムは未検証のプロトコルに基づくことになるだろう [15]。
これらの問題のため、我々は Paxos がシステム構築にも教育にも適した基盤を提供しないと結論づけた。大規模ソフトウェアシステムにおけるコンセンサスの重要性を鑑み、我々は Paxos よりも優れた特性を持つ代替コンセンサスアルゴリズムを設計できるかどうかを検討することにした。Raft はその実験の結果である。
新しい提案番号 (proposal number) を選択する。一意性を保持するためにサーバ ID を含める。
Acceptor に Prepare リクエストを送信する。
Acceptor の過半数が応答した場合、同じ提案番号で Accept リクエストを Acceptor に送信する。
Acceptor の過半数が応答した場合、Accept リクエストの値がコミットされる。
Proposer からの Prepare および Accept リクエストを処理する。
| proposal | 提案番号 |
|---|
| acceptedProposal | この Acceptor がこれまでに Accept した最も高い提案番号 (存在する場合) |
|---|---|
| acceptedValue | この Acceptor がこれまでに Accept した最も高い提案の値 |
proposal が以前の Prepare または Accept リクエストにおけるどの番号よりも高い場合、その提案を保存して応答する。そうでない場合は応答しない。
| proposal | 提案番号 |
|---|---|
| value | Proposer が Accept 応答で何らかの acceptedValues を受信した場合、その値は最も高い acceptedProposal に対応するものでなければならない。そうでない場合、Proposer は任意の値を選択して良い。 |
proposal が以前の Prepare または Accept リクエストにおけるどの番号よりも高い場合、その提案と値を保存して応答する。そうでない場合は応答しない。
Chapter 3 - 基本 Raft アルゴリズム
この章では Raft アルゴリズムについて説明する。我々は Raft を可能な限り理解しやすいように設計した。最初のセクションでは理解可能性を考慮した設計への我々のアプローチを記述する。続くセクションではアルゴリズム自体を記述し、理解可能性のために我々が行った選択の例を示す。
3.1 理解可能性の設計
Raft の設計において、我々にはいくつかの目標があった。システム構築のための完全かつ実用的な基盤を提供し、開発者が必要とする設計作業量を大幅に削減すること。あらゆる条件下で Safety であり、典型的な運用条件下で可用性があること。そして、一般的な操作において効率的であることである。しかし、我々の最も重要な目標、そして最も困難な課題は理解可能性 (understandability) であった。幅広い読者がアルゴリズムを快適に理解できる必要がある。さらに、システム構築者が現実世界の実装で避けられない拡張を行えるように、アルゴリズムについての直感的な理解を得られるようにする必要がある。
Raft の設計には複数のアプローチから選択しなければならない局面が数多く存在した。これらの状況において我々は理解可能性に基づいて代替案を評価した。すなわち、それぞれの代替案を説明するのがどれほど難しいか (例えば、その状態空間の複雑さや、微妙な意味を持つのかなど)、そして読者がそのアプローチとその影響を完全に理解するのがどれほど容易か、と言う点である。
このような分析にかなりの主観性が含まれることは認識しているが、それでも我々は一般的に適用可能な 2 つの手法を用いた。1 つ目の手法はよく知られている問題分析のアプローチである。可能な限り、問題を比較的独立して解決、説明、理解できる個別の部分に分割した。例えば、Raft ではリーダー選出、ログ複製、Safety を分離した。
2 つ目の手法は、考慮すべき状態の数を減らすことで状態空間を単純化し、システムをより一貫性のあるものにし、可能な限り非決定性を排除することであった。具体的には、Raft はログに穴を許容せず、ログが互いに矛盾する可能性を制限する。ほとんどのケースで我々は非決定性を排除しようと試みたが、非決定性がむしろ理解可能性を向上させる状況もいくつか存在する。特に、ランダム化手法は非決定性をもたらすが、すべての可能な選択肢を同様に処理する (「どれを選んでも問題ない」) ことは状態空間を削減する傾向にある。我々は Raft のリーダー選出アルゴリズムを簡素化する目的でランダム化を使用した。
3.2 Raft の概要
Raft はセクション 2.1 で説明した形式の複製ログを管理するためのアルゴリズムである。Figure 3.1 は参照のためにアルゴリズムを要約したもので、 Figure 3.2 はアルゴリズムの主要な特性を列挙している。これらの図の要素は本章の残りの部分で個別に説明する。
Raft はまず、サーバをリーダー (leader) として選出し、そしてリーダーに複製ログの管理に関する完全な責任を与えることでコンセンサスを実装する。リーダーはクライアントからのログエントリを受け入れ、他のサーバにそれらを複製し、それらのステートマシンにログエントリを適用しても安全なタイミングをサーバに伝える。リーダーの存在により複製ログの管理が簡素化される。例えば、リーダーは他のサーバと相談することなく新しいエントリをログ内で配置する場所を決定でき、データはリーダーから他のサーバへ単純な方法で流れる。リーダーは、故障したり、他のサーバから切断される可能性があり、その場合、新しいリーダーが選出される。
リーダーアプリーチに基づき、Raft はコンセンサス問題を 3 つの比較的独立した部分問題に分解する。これらの部分問題は以下のサブセクションで議論される。
リーダー選出: クラスタの起動時および既存のリーダーが故障したときに、新しいリーダーを選出する必要がある (セクション 3.4)。
ログ複製: リーダーはクライアントからのログエントリを受け入れ、それらをクラスタ全体に複製することで、他のログを自身のログと一致させることを強制する必要がある (セクション 3.5)。
Safety: Raft の重要な Safety 特性は Figure 3.2 に示す State Machine Safety 特性である。つまり、あるサーバが特定のログエントリを自身のステートマシンに適用した場合、他のいかなるサーバも同じログインデックスに対して異なるコマンドを適用してはならない。セクション 3.6 は Raft がこの特性をどのように保証するかを記述する。この解決策は、セクション 3.4 で説明する選出メカニズムに対して追加の制約を伴う。
この章ではコンセンサスアルゴリズムを紹介した後、可用性の問題とシステムにおけるタイミングの役割 (セクション 3.9)、およびサーバ間でリーダーシップを転送するためのオプションの拡張 (セクション 3.10) について議論する。
| currentTerm | サーバが認識した最新のターム (初回起動時に 0 に初期化され単調増加する) |
|---|---|
| votedFor | 現在のタームで票を投じた候補者の candidateId (投票がない場合は null) |
| log[] | ログエントリ; 各エントリには、ステートマシンへのコマンドと、リーダーがエントリを受信した時点のタームを含む (最初のインデックスは 1) |
| commitIndex | コミット済みと認識されている最大のログエントリのインデックス (0 で初期化され単純増加する) |
|---|---|
| lastApplied | ステートマシンに適用された最大のログエントリのインデックス (0 で初期化され単調増加する) |
| nextIndex[] | 各サーバに対し、そのサーバに送信する次のログエントリのインデックス (リーダーの最後のログインデックス + 1 に初期化される) |
|---|---|
| matchIndex[] | 各サーバに対し、サーバで複製済みとして認識されている最大のログエントリのインデックス (0 に初期化され単調増加する) |
ログエントリを複製するためにリーダーによって呼び出される (§3.5)。ハートビートとしても使用される (§3.4)。
| term | リーダーのターム |
|---|---|
| leaderId | フォロワーがクライアントをリダイレクトできるようにするため |
| prevLogIndex | 新しいエントリの直前のログエントリのインデックス |
| prevLogTerm | prevLogIndex エントリのターム |
| entries[] | 保存するエントリ (ハートビートの場合は空; 効率化のため複数送信可能) |
| leaderCommit | リーダーの commitIndex |
| term | currentTerm (リーダーが自身を更新するため) |
|---|---|
| success | フォロワーが prevLogIndex と prevLogTerm に一致するエントリを含んでいた場合 true |
- commitIndex > lastApplied の場合: lastApplied をインクリメントし、log[lastApplied] をステートマシンに適用 (§3.5)
- RPC リクエスト/レスポンスがターム T > currentTerm を含む場合: currentTerm = T を設定しフォロワーに転身
- 候補者およびリーダーからの RPC に応答
- 現在のリーダーから AppendEntries RPC を受信せず、または候補者に投票することなく選挙タイムアウトが経過した場合: 候補者に転身
- 候補者に転身したら選挙を開始する:
- currentTerm をインクリメント
- 自身に投票
- 選挙タイマーをリセット
- 他のすべてのサーバに RequestVote RPC を送信
- 過半数のサーバから投票を受け取った場合: リーダーに転身
- 新しいリーダーから AppendEntries RPC を受信した場合: フォロワーに転身
- 選挙タイムアウトが経過した場合: 新しい選挙を開始
- 選出後: 最初に各サーバに空の AppendEntries RPC (ハートビート) 送信; 選挙タイムアウトを防ぐためにアイドル期間中も繰り返す (§3.4)
- クライアントからコマンドを受信した場合: ローカルログにエントリを追記し、エントリがステートマシンに適用された後に応答 (§3.5)
- フォロワーの最後のログインデックスが nextIndex より大きい場合: nextIndex から始まるログエントリを含む AppendEntries RPC を送信
- N > commitIndex であり、過半数のサーバが matchIndex[i] ≧ N であり、log[N}.term == currentTerm であるような N が存在する場合: commitIndex = N に設定 (§3.5, §3.6)
- Election Safety
-
特定のタームでは最大で 1 つのリーダーのみが選出される。§3.4
- Leader Append-Only
-
リーダーは自身のログ内のエントリを上書きや削除することはなく、新しいエントリを追記するのみである。§3.5
- Log Matching
-
もし 2 つのログが同じインデックスとタームのエントリを持つならば、そのインデックスまでのすべてのエントリにおいて、ログの内容は同一である。§3.5
- Leader Completeness
-
もし特定のタームであるログエントリがコミットされたならば、そのエントリは、それより番号の大きいタームのすべてのリーダーのログに存在する。§3.6
- State Machine Safety
-
もしあるサーバが特定のインデックスのログエントリを自身のステートマシンに適用したならば、他のサーバは同じインデックスに対して異なるログエントリを適用することはない。§3.6
3.3 Raft の基本
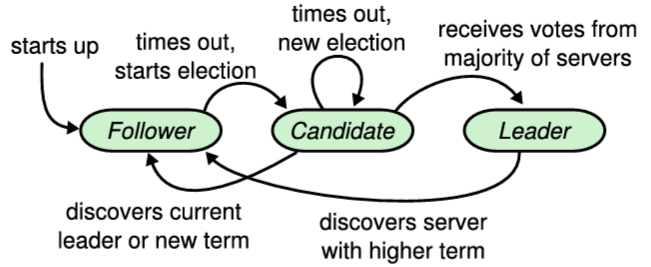
Raft クラスタは複数のサーバで構成される。通常は 5 台が典型的な数であり、これによりシステムは 2 台の故障に耐えることができる。任意の時点において、各サーバはリーダー (leader)、フォロワー (follower)、候補者 (candidate) の 3 つの状態のいずれかにある。通常の動作では、厳密に 1 台のリーダーが存在し、他のすべてのサーバがフォロワーである。フォロワーは受動的であり、自らはリクエストを発行せず、単にリーダーと候補者からのリクエストに応答するのみである。リーダーはすべてのクライアントリクエストを処理する (もしクライアントがフォロワーに接続した場合、フォロワーはそれをリーダーにリダイレクトする)。3 つ目の状態である候補者は、セクション 3.4 で記述されているように、新しいリーダーを選出するために使用される。Figure 3.3 は状態とその遷移を示しており、遷移については後述する。
Raft は Figure 3.4 に示すように時間を任意の長さのターム (term) に分割する。タームには連続した整数が番号付けされる。各タームは選挙 (election) から始まり、セクション 3.4 で記述されているように、選挙では 1 つ以上の候補者がリーダーになろうと試みる。ある候補者が選挙に勝利すれば、その候補者はタームの残りの期間のリーダーを務める。状況によっては分割投票 (split vote) となる場合がある。この場合、タームはリーダー不在で終了し、すぐに新しいターム (新しい選挙) が始まる。Raft は、特定のタームにおいてリーダーが最大 1 つしか存在しないことを保証する。
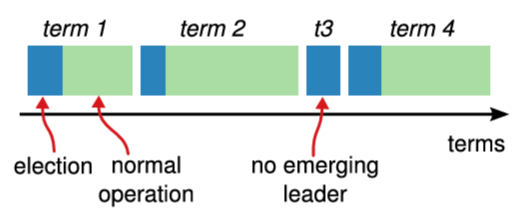
異なるサーバは異なるタイミングでターム間の遷移を観測する可能性があり、状況によってはサーバが選挙やターム全体を観測しないことさえある。タームは Raft において論理クロック [47] とし機能し、古いリーダーなどの期限の切れた情報をサーバが検出できるようにする。各サーバは時間の経過と共に単調増加する現在のターム (current term) を保存している。現在のタームはサーバが通信するたびに交換される。あるサーバの現在のタームが、他の一方のサーバの現在のタームより小さい場合、そのサーバは自身の現在のタームを大きい方の値に更新する。もし候補者やリーダーが自身のタームが期限切れであると気づくと、直ちにフォロワー状態に戻る。サーバが期限切れのターム番号を持つリクエストを受信した場合、そのリクエストを拒否する。
Raft サーバはリモートプロシジャコール (RPC) を使用して通信し、基本的なコンセンサスアルゴリズムにおいてはサーバ間で 2 種類の RPC のみを必要とする。RequestVote RPC は選挙中に候補者によって開始される (セクション 3.4)。AppendEntries RPC はリーダーによって開始され、ログエントリを複製し、一種のハートビートの役割を提供する (セクション 3.5)。リーダーシップ転送 (セクション 3.10) およびそれ以降の章で記述されるメカニズムは、コアコンセンサスアルゴリズムの 2 種類に加えて追加の RPC を導入する。
我々は通信パターンを簡素化するために Raft での通信を RPC として構築することを選択した。各リクエストタイプには対応するレスポンスタイプがあり、レスポンスタイプはリクエストの確認応答としても機能する。Raft は RPC リクエストとレスポンスがネットワーク内で失われる可能性があることを想定している。リクエスト側が適切なタイミングでレスポンスを受信しない場合、RPC を再試行するのはリクエスト側の責任である。サーバは性能を最大化するために RPC を並列に発行するが、Raft はネットワークが RPC 間の順序を維持することを想定していない。
3.4 リーダー選出
Raft はリーダー選出をトリガーするためにハートビートメカニズムを使用する。サーバは起動時にフォロワーとして開始する。サーバは、リーダーまたは候補者から有効な RPC を受信している限りフォロワー状態を維持する。リーダーは権限を維持するために定期的にハートビート (ログエントリを含まない AppendEntries RPC) をすべてのフォロワーに送信する。もしフォロワーが選挙タイムアウト (election timeout) と呼ばれる期間内に通信を受信しない場合、有効なリーダーが存在しないとみなし、新しいリーダーを選出するための選挙を開始する。
選挙を開始するには、フォロワーは現在のタームをインクリメントし、候補者状態に遷移する。その後、フォロワーは自身に投票し、並行してクラスタ内の他の各サーバに RequestVote RPC を発行する。候補サーバは次の 3 つの条件のいずれかが発生するまでこの状態を維持する: (a) 選挙に勝利する、(b) 別のサーバがリーダーとして確率する、(c) 勝者が決まらないまま再度選挙タイムアウトが発生する。これらの結果については以下の段落で個別に議論する。
候補者は、同じタームにおいてクラスタ全体のサーバの過半数から票を獲得すると選挙に勝利する。各サーバは、与えられたタームにおいて、先着順で最大 1 つの候補者に投票する (注: セクション 3.6 は投票に関する追加の制約を追加する)。過半数ルールによって特定のタームにおいて最大 1 つの候補者のみが選挙に勝利することを保証する (Figure 3.2 の Election Safety 特性)。候補者が選挙に勝利するとリーダーとなる。その後、他のすべてのサーバにハートビートメッセージを送信し、権限を確立して新たな選挙を防止する。
候補者が投票を待っている間、自身がリーダーであると主張する別のサーバから AppendEntries RPC を受信するケースがある。もしそのリーダーのターム (RPC に含まれている) が候補者の現在のタームと少なくと同じか大きい場合、候補者はそのリーダーを正当なものとして認識し、フォロワー状態に戻る。RPC 中のタームが候補者の現在のタームより小さい場合、候補者はその RPC を拒否し、候補者状態を継続する。
3 つ目の可能性は、候補者が選挙に勝つことも負けることもない場合である。多くのフォロワーが同時に候補者になった場合、票が分散し、どの候補者も過半数の票を獲得できない可能性がある。このような場合、各候補者はタイムアウトし、自身のタームをインクリメントして RequestVote RPC の次のラウンドを開始することで新しい選挙を開始する。しかし、追加の対策がなければ分割投票は無限に繰り返される可能性がある。
Raft は分割投票の発生頻度を低くし迅速に解決することを保証するために、ランダム化された選挙タイムアウトを使用する。つまり、分割投票を防ぐために、選挙タイムアウトは固定間隔 (例: 150~300 ミリ秒) からランダムに選択される。これによりサーバが分散され、ほとんどの場合、タイムアウトするのは単一のサーバのみになる。そのサーバは選挙に勝利し、他のどのサーバがタイムアウトする前にハートビートを送信する。同じメカニズムが分割投票にも使用される。各候補者は、選挙の開始時にランダム化された選挙タイムアウトを再開し、次の選挙を開始する前にそのタイムアウトが経過するのを待つ。これにより、新しい選挙でさらなる分割投票が起きる可能性が低くなる。第 9 章では、このアプローチによってリーダーが迅速に選出されることを示している。
選挙は、理解可能性が設計上の選択肢の間で我々の選択にどのように影響したかを示す一例である。当初、我々はランキングシステムを使用することを計画していた。各候補者には一位のランクが割り当てられ、このランクに基づいて競合する候補者が選出された。もし候補者がより高いランクの別の候補を発見した場合、フォロワー状態に戻り、より高いランクの候補者が次の選挙で勝利しやすくなる。我々はこのアプローチが可用性に関して微妙な (subtle) 問題を生じさせることを発見した (高ランクサーバに障害が発生した場合、低ランクサーバはタイムアウトして再び候補者になる必要があるかもしれないが、それがあまりに早すぎると、リーダー選出のための進捗をリセットしてしまう可能性がある)。我々はアルゴリズムに何度か調整を加えたが、調整のたびに新たなコーナーケースが発生した。最終的に、ランダム化された再試行アプローチがより明確で理解しやすいという結論に至った。
3.5 ログ複製
リーダーが選出されると、リーダーはクライアントからのリクエスト処理を開始する。各クライアントリクエストには、複製ステートマシンによって実行されるコマンドが含まれている。リーダーはコマンドを新しいエントリとしてログに追記し、その後、エントリを複製するために他の各サーバに並行して AppendEntries RPC を発行する。エントリが完全に複製されると (後述)、リーダーはそのエントリを自身のステートマシンに適用し、その実行結果をクライアントに返す。もしフォロワーがクラッシュしたり、動作が遅くなったり、ネットワークパケットが失われた場合でも、リーダーはすべてのフォロワーがすべてのログエントリを最終的に格納するまで AppendEntries RPC を (クライアントへの応答後であっても) 無期限に再試行する。
ログは Figure 3.5 に示すように構成される。各ログエントリには、リーダーがエントリを受信した時点のターム番号と、ステートマシンのコマンドが格納される。ログエントリ内のターム番号はログ間の不整合を検出し、Figure 3.2 にいくつかの特性を保証するために使用される。各ログエントリにはログ内の位置を示す整数インデックスも付与される。
リーダーは、ログエントリをステートマシンに適用しても安全な時期を決定する。そのようなエントリはコミット済み (committed) と呼ばれる。Raft は、コミット済みエントリが永続的であり、最終的には利用可能なすべてのステートマシンによって実行されることを保証する。ログエントリは、そのエントリを作成したリーダーがそれを過半数のサーバに複製した時点でコミットされる (例えば Figure 3.5 の Entry 7)。これにより、リーダーのログ内でそれより前に存在するすべてのエントリ (以前のリーダーによって作成されたエントリを含む) もコミットされる。セクション 3.6 ではリーダー交代後にこのルールを適用する際の微妙な点について議論し、またこのコミットの定義が Safety であることも示す。リーダーは、コミット済みであると認識している最も高いインデックスを追跡し、そのインデックスを将来の AppendEntries RPC (ハートビートを含む) に含めることで、他のサーバが最終的にそのインデックスを知ることを可能にする。フォロワーはログエントリがコミット済みであることを知ると、そのエントリを (ログの順序で) ローカルのステートマシンに適用する。
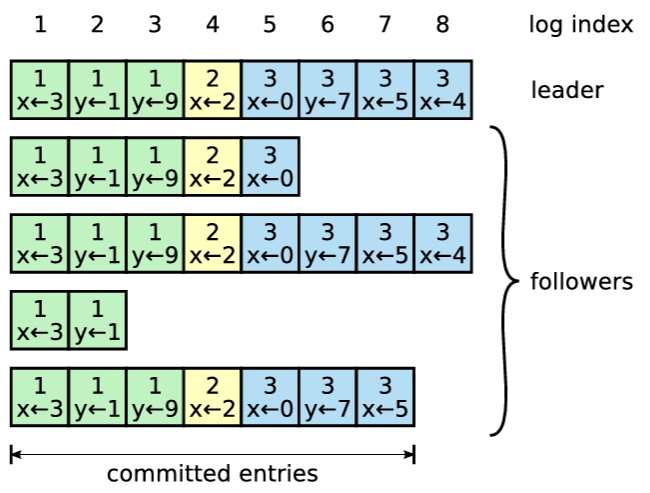
我々は、異なるサーバ上のログ間で高度な一貫性を維持するように Raft のログメカニズムを設計した。これはシステムの動作を簡素化し、予測可能性を高めるだけでなく、Safety を保証するための重要な要素でもある。Raft は以下の特性を維持しており、これは Figure 3.2 の Log Matching 特性を構成する。
異なるログ内の 2 つのエントリが同じインデックスとタームを持つ場合、それらは同じコマンドを格納する。
異なるログ内の 2 つのエントリが同じインデックスとタームを持つ場合、そのログは与えられたインデックスまでの先行するエントリすべてにおいて同一である。
一つ目の特性は、リーダーが特定のタームにおいて特定のログインデックスを持つエントリを最大で 1 つしか作成せず、ログエントリがログ内の位置を変更することがないという事実から導かれる。二つ目の特性は AppendEntries によって実行される一貫性チェックによって保証される。AppendEntries RPC を送信する際、リーダーは新しいエントリの直前に位置する自身のエントリインデックスとタームを含める。もしフォロワーが自身のログ内で同じインデックスとタームを持つエントリを見つけられない場合、新しいエントリを拒否する。この一貫性チェックは帰納ステップとして機能する。ログの初期状態は空で Log Matching 特性を見たており、一貫性チェックはログが拡張されるたびに Log Matching 特性を維持する。結果として、AppendEntries が成功して返るたびに、リーダーはフォロワーのログが新しいエントリまで自身のログと同一であることを認識する。
通常の動作中は、リーダーとフォロワーのログは一貫性が保たれているため AppendEntries の一貫性チェックが失敗することはない。しかしリーダーがクラッシュするとログに不整合が生じる可能性がある (古いリーダーが自身のロブ内のすべてのエントリを完全に複製できなかった可能性がある)。これらの不整合はリーダーとフォロワーが何度もクラッシュすることで複合して悪化する可能性がある。Figure 3.6 はフォロワーのログが新しいリーダーのログとどのように異なるかを示している。フォロワーではリーダーに存在するエントリが欠落しているかもしれないし、リーダーには存在していない余分なエントリを持っているかもしれないし、またその両方かもしれない。ログの欠落エントリと余分なエントリは複数のタームにまたがる可能性がある。
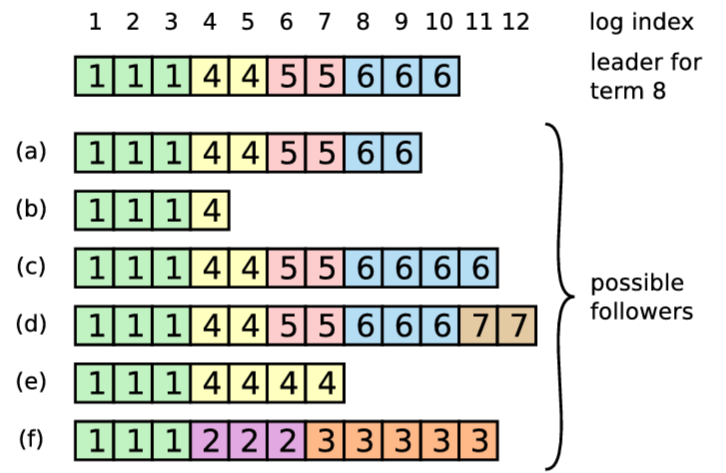
Raft では、リーダーはフォロワーのログを自身のログと同じように鳴るように強制することで不整合を処理する。これは、フォロワーのログに存在する競合するエントリがリーダーのログからのエントリで上書きされることを意味する。セクション 3.6 では、選挙における制約と組み合わせることでこれが安全であることを示す。
リーダーは、フォロワーのログを自身のログと整合させるために、2 つのログが一致する最新のエントリを見つけ、その時点以降のフォロワーのログエントリをすべて削除し、その時点以降のリーダーのエントリをすべてフォルワーに送信する必要がある。これらのアクションはすべて AppendEntries RPC によって実行される一貫性チェックに応答して発生する。リーダーは各フォロワーに対して nextIndex を保持する。これは、リーダーがそのフォロワーに送信する次のエントリのインデックスである。リーダーが最初に権限を得たとき、すべての nextIndex を自身のログの最後のインデックスの次 (Figure 3.6 では 11) に初期化する。もしフォロワーのログがリーダーのログと整合しない場合、次の AppendEntries RPC で AppendEntries 一貫性チェックが失敗する。拒否後、リーダーはフォロワーの nextIndex をデクリメントし、AppendEntries RPC を再試行する。最終的に nextIndex はリーダーとフォロワーのログが一致する点に到達する。この状況が発生すると AppendEntries は成功し、フォロワーのログから競合するエントリを削除し、(もしあれば) リーダーのログからエントリを追加する。AppendEntries が成功すると、フォロワーのログはリーダーのログと一貫し、その状態はタームの残りの期間を通して維持される。
リーダーは、自身とフォロワーのログが一致する箇所を見つけるまで、帯域幅を節約するためにエントリを含まない AppendEntries を (ハートビートのように) 送信できる。その後、matchIndex が nextIndex の直前に達すると、リーダーは実際のエントリの送信を開始する必要がある。
必要に応じて、プロトコルを最適化して拒否される AppendEntries RPC の数を減らすことができる。例えばフォロワーが AppendEntries リクエストを拒否する際に、競合するエントリのタームと、そのタームに格納されている最初のインデックスを含めることができる。この情報を使ってリーダーは nextIndex をデクリメントし、そのターム内のすべての競合エントリを迂回できる。これによってエントリごとに 1 つの RPC を実行するのではなく、エントリが競合する各タームで 1 つの AppendEntries RPC が必要となる。あるいは、リーダーはフォロワーのログが自身のログと異なる最初のエントリを見つけるために二分探索アプローチを使用することもできる。これは最悪ケースの動作がより優れている。しかし、実際には故障は頻繁に発生せず、不整合なエントリが多数発生する可能性は低いため、我々はこれらの最適化が必要であるとは考えていない。
このメカニズムにより、リーダーは権限を得たときにログの一貫性を回避服するための特別な行動を取る必要がない。通常動作を開始するだけで AppendEntries 一貫性チェックの失敗に応じてログは自動的に収束する。リーダーは自身のログ内のエントリを上書きしたり削除することはない (Figure 3.2 の Leader Append-Only 特性)。
このログ複製メカニズムはセクション 2.1 で説明した望ましいコンセンサス特性を備えている。Raft は、サーバの過半数が稼働している限り、新しいログエントリを受け入れ、複製し、適用することができる。通常の場合、新しいログエントリはクラスタの過半数へ 1 回の RPC ラウンドで複製できる。また、1 つの低速のフォロワーが性能に影響を与えることはない。他のコンセンサスアルゴリズムの中には、ログ全体をネットワーク経由で送信して実用的な実装のために必要な最適化の負担を実装者に課すものもあるが、このログ複製アルゴリズムは、AppendEntries リクエストが管理しやすいサイズなため (リーダーは処理を進めるために 1 回の AppendEntries リクエストで複数のエントリを送信する必要はない)、実装も実用的である。
3.6 Safety
前のセクションでは、Raft がどのようにリーダーを選出し、ログエントリを複製するかについて説明した。しかし、これまでに説明したメカニズムだけでは、各ステートマシンが同じコマンドを厳密に同じ順序で実行することを保証するに十分ではない。例えば、リーダーがいくつかのログエントリをコミットしている間にフォロワーが利用できなくなると、そのフォロワーがリーダーに選出され、これらのエントリを新しいエントリで上書きする可能性がある。結果として、異なるステートマシンが異なるコマンドシーケンスを実行する可能性がある。
このセクションでは、どのサーバがリーダーに選出されるかを制限することで Raft アルゴリズムを完成させる。この制限により、任意のタームのリーダーが、前のタームでコミットされたすべてのエントリを含むことが保証される (Figure 3.2 の Leader Completeness 特性)。この選出制限を考慮した上で、我々のコミットのルールをより厳密にする。最後に、Leader Completeness 特性の証明スケッチを提示し、それが複製ステートマシンの正しい動作にどのようにつながるかを示す。
3.6.1 選出制約
リーダーベースのコンセンサスアルゴリズムでは、リーダーは最終的にコミットされたログエントリをすべて保存する必要がある。Viewstamped Replication [66] のような一部のコンセンサスアルゴリズムでは、リーダーはコミットされたエントリを最初からすべて保持していなくても選出されることが可能である。これらのアルゴリズムには、選挙プロセス中またはその直後に、欠落しているエントリを特定し、新しいリーダーにそれらを送信するための追加のメカニズムが含まれている。残念ながら、これはかなりの追加メカニズムと複雑さをもたらす。Raft はより単純なアプローチを採用しており、新しいリーダーが選出された瞬間からそのリーダー上に以前のタームでコミットされたすべてのエントリが存在することを保証する。これらのエントリをリーダーに転送する必要はない。これは、ログがリーダーからフォロワーへの一方向にのみ流れ、リーダーがログ内の既存のエントリを上書きしないことを意味する。
Raft は、候補者のログにすべてのコミット済みエントリが含まれていない限り、その候補者が選挙に勝つことができない選挙プロセスを使用する。候補者が選挙に勝つためにはクラスタの過半数とコンタクトを取る必要がある。つまり、その中の少なくとも 1 つのサーバには、コミットされたすべてのエントリが存在するはずである。もし候補者のログがその過半数に属する他のログと同等かそれ以上に最新である場合 (「最新である (up-to-date)」は以下で正確に定義される)、候補者はコミットされたすべてのエントリを保持していることになる。RequestVote RPC はこの制限を実装いている。RPC は候補者のログに関する情報を含み、もし投票者のログが候補者のログよりも新しければ、投票者は投票を拒否する。
Raft では、2 つのログのどちらがより最新であるかを、ログ内の最後のエントリのインデックスとタームを比較することで判断する。2 つのログの最後のエントリのタームが異なる場合、より後のタームを持つログの方がより新しい。もしログが同じタームで終わる場合、より長いログの方がより最新である。
3.6.2 以前のタームからのエントリコミット
セクション 3.5 で記述したように、リーダーは自身の現在のタームでのエントリが過半数のサーバに保存された時点で、そのエントリがコミット済みであることと認識する。リーダーがエントリをコミットする前にクラッシュした場合、将来のリーダーはそのエントリの複製を完了させようと試みる。しかし、リーダーは、前のタームのエントリがサーバの過半数に保存されたからと言って、そのエントリが直ちにコミット済みであると結論付けることはできない。Figure 3.7 は古いログエントリが過半数のサーバに保存されているにもかかわらず、将来のリーダーによって上書きされる可能性がある状況を示している。
Figure 3.7 のような問題を排除するために、Raft はレプリカを数えることによって以前のタームからのログエントリをコミットすることはない。リーダーの現在のタームでのエントリのみがレプリカを数えることでコミットされる。現在のタームでのエントリがこの方法でコミットされると、Log Matching 特性によってそれ以前のすべてのエントリが間接的にコミットされる。リーダーは古いログエントリがコミット済みであると安全に結論づけられる状況もいくつか存在するが (例えばそのエントリがすべてのサーバに保存されている場合など)、Raft は簡潔さのためにより保守的なアプローチを採用している。
Raft では、リーダーが以前のタームでのエントリを複製する際に、ログエントリが元のターム番号を保持するために、コミットルールにこのような追加の複雑さが生じる。他のコンセンサスアルゴリズムでは、新しいリーダーが以前の「ターム」でのエントリを再複製する場合、新しい「ターム番号」で複製しなければならない。Raft のアプローチでは、ログエントリは時間の経過とログの経過にかかわらず同じターム番号を維持するため、ログエントリについての推論を容易にする。さらに、他のアルゴリズムではコミット前にエントリの番号を付け直すため冗長なログエントリの送信を行う必要があるが、Raft の新しいリーダーは以前のタームでのログエントリの送信は他のアルゴリズムよりも少ない。しかし、リーダーの変更はまれであるはずなので、これは実際ににはそれほど重要ではないかもしれない。
3.6.3 Safety 論証
完全な Raft アルゴリズムが与えられたので、ここで Leader Completeness 特性が成立することをより正確に議論できる (この論証は Safety の証明に基づいている; 第 8 章を参照)。我々は Leader Completeness 特性が成り立たないと仮定し、矛盾を証明する。ターム \(T\) のリーダー (\({\rm leader}_T\)) が自身のタームでのログエントリをコミットしたが、そのログエントリは将来のタームのリーダーに保存されていなかったと仮定する。\(U \gt T\) となる最小のタームを持つ、そのエントリを保存していないリーダー (\({\rm leader}_U\)) について考える。
コミットされたエントリは、\({\rm leader}_U\) が選出された時点で \({\rm leader}_U\) のログに存在してはならない (リーダーはエントリを削除または上書きしないため)。
\({\rm leader}_T\) はクラスタの過半数にエントリを複製し、\({\rm leader}_U\) はクラスタの過半数から票を得た。したがって、Figure 3.8 に示すように、少なくとも 1 つのサーバ (以下「投票者」と呼ぶ) が \({\rm leader}_T\) からエントリを受け入れ、\({\rm leader}_U\) に投票した。この投票者が矛盾に到達するための鍵である。
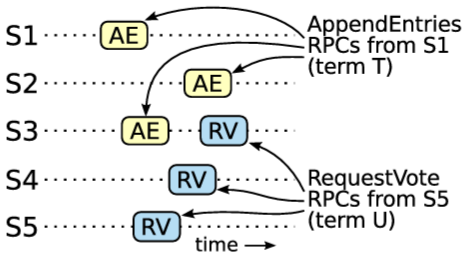
Figure 3.8: S1 (ターム T のリーダー) が自身のタームから新しいログエントリをコミットし、S5 がより後のターム U のリーダーに選出された場合、そのログエントリを受け入れ、かつ S5 に投票した少なくとも 1 つのサーバ (S3) が存在しなければならない。 投票者は \({\rm leader}_U\) に投票する前に \({\rm leader}_T\) がコミットしたエントリを受け入れていなければならない。そうでなければ \({\rm leader}_T\) からの AppendEntries リクエストを (その現在のタームが \(T\) より大きかったため) 拒否していたであろう。
投票者は \({\rm leader}_U\) に投票したときもエントリを保存していた。これは、介入するすべてのリーダーがエントリを含んでおり (仮定により)、リーダーはエントリを削除することはなく、フォロワーはリーダーと競合する場合にのみエントリを削除するためである。
投票者は \({\rm leader}_U\) に投票を許可したため、\({\rm leader}_U\) のログは投票者のログと同程度に最新のはずである。これは 2 つの矛盾のうちの 1 つにつながる。
まず、投票者と \({\rm leader}_U\) が同じログタームを共有していた場合、\({\rm leader}_U\) のログは少なくとも投票者のログと同じ長さだったはずで、したがって \({\rm leader}_U\) のログは投票者のログ内のすべてのエントリを含んでいるはずである。これは矛盾である。なぜなら、投票者はコミットされたエントリを含んでいたにもかかわらず、\({\rm leader}_U\) は含んでいないと仮定されたためである。
そうでなければ、\({\rm leader}_U\) の最後のログタームは投票者の最後のログタームよりも大きくなっていたはずである。さらに、投票者の最後のログエントリは少なくとも \(T\) であったため (ターム \(T\) のコミット済みエントリを含むため)、\({\rm leader}_U\) の最後のログタームは \(T\) よりも大きかった。\({\rm leader}_U\) の最後のログエントリを作成した以前のリーダーは、そのログにコミット済みのログを必ず含んでいる (仮定より)。その場合、Log Matching 特性により、\({\rm leader}_U\) のログもコミット済みエントリを含んでいるはずである。これは矛盾である。
これで矛盾によって完了する。したがって、\(T\) より大きいタームのリーダーは、ターム \(T\) でコミットされたターム \(T\) でのすべてのエントリを必ず含んでいる。
Log Matching 特性により、将来のリーダーも Figure 3.7(d2) のインデックス 2 のような間接的にコミットされたエントリを含むことを保証する。
Leader Completeness 特性が与えられると、Figure 3.2 の State Machine Safety 特性をより正確に証明できる。これは、あるサーバが特定のインデックスのログエントリを自身のステートマシンに適用した場合、他のいかなるサーバも同じインデックスに対して異なるログエントリを適用することはないことを述べている。サーバがログエントリを自身のステートマシンに適用した時点で、炉のログはそのエントリまでのリーダーのログと同一であり、そのエントリはコミット済みでなければならない。ここで、いずれかのサーバが特定のログインデックスを適用する最も小さいタームを考える。Leader Completeness 特性は、それより高いタームのすべてのリーダーが同じログエントリを保存していることを保証するため、後続のタームでそのインデックスを適用するサーバは同じ値を適用することになる。したがって State Machine Safety 特性は成立する。
最後に、Raft はサーバがログインデックスの順序でエントリを適用することを要求する。State Machine Safety 特性と組み合わせることで、すべてのサーバが厳密に同じログエントリのセットを同じ順序でステートマシンに適用することを意味する。
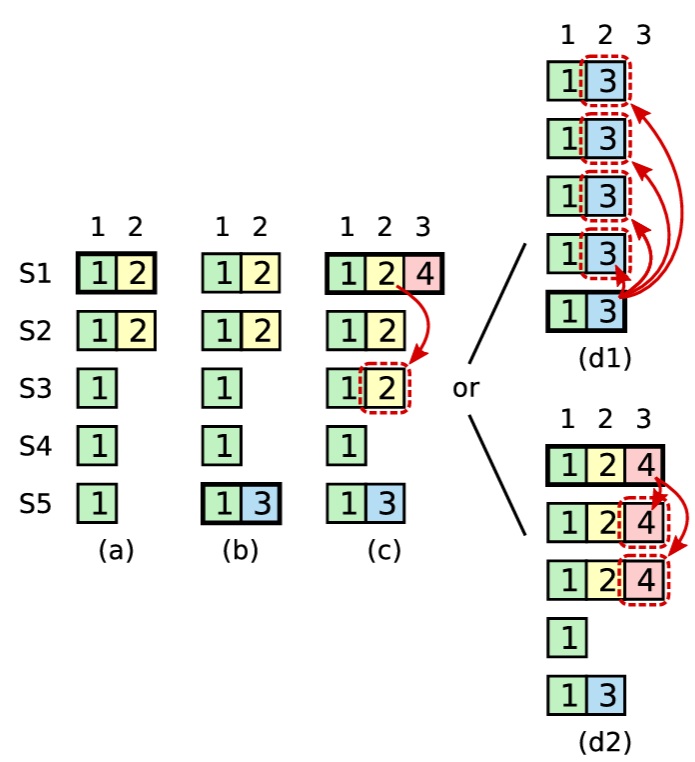
3.7 フォロワーおよび候補者のクラッシュ
ここまで、我々はリーダーの故障に焦点を当ててきた。フォロワーおよび候補者のクラッシュは、リーダーのクラッシュよりもはるかに処理が簡単であり、どちらも同じ方法で処理される。フォロワーまたは候補者がクラッシュした場合 (または、それらとリーダー間のネットワークリンクに障害が発生した場合)、それ以降に送信される RequestVote および AppendEntries RPC は失敗する。Raft はこれらの失敗を無制限に再試行することで処理する。クラッシュしたサーバが再起動すれば RPC は正常に完了する。サーバが RPC を完了した直後、応答する前にクラッシュした場合、再起動後に同じ RPC を再度受信することになる。Raft の RPC は繰り返されても同じ効果を持つため、これによる問題は発生しない。例えば、もしフォロワーが自身のログに既に存在するログエントリを含む AppendEntries リクエストを受信した場合、新しいリクエスト内のそれらのエントリを無視する。
3.8 永続状態とサーバの再起動
Raft サーバは、サーバの再起動を安全に乗り切るために十分な情報を安定したストレージに永続化しなければならない。特に、各サーバは自身の現在のタームと投票を永続化する。これは、サーバが同じタームで二度投票すること、また退任したリーダーのログエントリで新しいリーダーのログエントリを置き換えることを防ぐために必要である。各サーバはまた、新しいログエントリがコミット対象としてカウントされる前にそれらを永続化する。これにより、サーバの再起動時にコミットされたエントリが失われたり、「未コミット」となることを防ぐ。
それ以外の状態変数はすべて再作成可能であるため、再起動時に失われても安全である。最も興味深い例はコミットインデックスである。これは再起動時に安全にゼロに再初期化できる。たとえすべてのサーバが同時に再起動したとしても、コミットインデックスは一時的に実際の値から遅れるに過ぎない。リーダーが選出され、新しいエントリをコミットできるようになると、そのリーダーのコミットインデックスは進み、コミットインデックスはすぐにフォロワーに伝播される。
ステートマシンは揮発的でも永続的でもあり得る。揮発性ステートマシンは、再起動後に (最新のスナップショットを適用した後; 第 5 章参照) ログエントリを再適用することによって回復されなければならない。一方、永続性ステートマシンは再起動後にはほとんどのエントリを既に適用している。それらを再適用するのを避けるためには、その最後に適用済み (last applied) インデックスも永続化されていなければならない。
サーバが永続的な状態の一部を失った場合、以前の識別情報でクラスタに安全に再参加することはできない。そのようなサーバは通常、クラスタメンバーシップ変更を呼び出すことによって新しい識別情報で再びクラスタに参加できる (第 4 章参照)。ただし、もしクラスタの過半数がその永続状態を失った場合、ログエントリが失われ、クラスタメンバーシップ変更を進めることは不可能となる。続行するためには、システム管理者はデータ損失の可能性を認識しなければならないだろう。
3.9 タイミングと可用性
Raft に対する我々の要件の一つは Safety がタイミングに依存してはならないということである。つまり、あるイベントが予想よりも早くまたは遅く発生したという理由だけでシステムが誤った結果を生成してはならない。しかし、可用性 (システムがクライアントにタイムリーに応答する能力) は必然的にタイミングに依存する。例えば、サーバのクラッシュ間隔よりもメッセージの交換の方が時間がかかる場合、候補者は選挙に勝つまで十分に長く稼働し続けることができない。安定したリーダーがいなければ Raft は進捗できない。
リーダー選出は Raft においてタイミングが最も重要となる部分である。システムが以下のタイミング要件 (timing requirements) を満たしている場合、Raft は安定してリーダーを選出し維持することができる: \[ broadcastTime \ll electionTimeout \ll MTBF \] この不等式における \(broadcastTime\) は、サーバがクラスタ内のすべてのサーバに並行して RPC を送信し、それらの応答を受信するのにかかる平均時間である。\(electionTimeout\) はセクション 3.4 で説明した選挙タイムアウトである。\(MTBF\) は単一のサーバの故障間隔の平均時間である。\(broadcastTime\) は \(electionTimeout\) よりも一桁小さくする必要がある。これにより、リーダーはフォロワーが選挙を開始するのを防ぐためのハートビートメッセージを確実に送信できる。選挙タイムアウトにはランダム化アプローチが使用されるため、この不等式は分割投票も起こりにくくする。選挙タイムアウトは MTBF よりも数桁小さくする必要がある。リーダーがクラッシュした場合、システムは選挙タイムアウトとおよそ同じ時間で利用不能となる。我々はこの期間が全体の時間のほんのわずかな割合にとどめたいと考えている。
ブロードキャスト時間と MTBF は基盤となるシステムの特性だが、選挙タイムアウトはユーザが選択しなければならない。Raft の RPC は通常、受信者が情報を安定ストレージに永続化することを必要とするため、ブロードキャスト時間はストレージ技術に応じて 0.05~20 ミリ秒の範囲となる。結果として選挙タイムアウトは 10~500 ミリ秒の範囲になる可能性が高い。典型的なサーバの MTBF は数ヶ月以上でありタイミング要件を容易に満たす。第 9 章では選挙タイムアウトの設定方法と、それが可用性とリーダー選出の性能に与える影響についてより詳細に説明する。
3.10 リーダーシップ転送の拡張
このセクションでは、あるサーバが別のサーバにリーダーシップを転送できるようにする Raft のオプション拡張について記述する。リーダーシップ転送は次の 2 つの状況で役に立つ:
時々、リーダーは退任 (step down) しなければならない場合がある。例えばメンテナンスのために再起動する必要があるかもしれないし、クラスタから削除されるかもしれない (第 4 章参照)。リーダーが退任すると、クラスタは別のサーバがタイムアウトして選挙に勝利するまでの選挙タイムアウトの間アイドル状態となるだろう。この短期間の利用不能期間はリーダーが退任する前に自身のリーダーシップを別のサーバに転送することで回避できる。
場合によっては、1 つ以上のサーバが他のサーバよりもクラスタのリーダーとして適していることがある。例えば、高負荷のサーバは良いリーダーにはならないだろうし、WAN 環境ではクライアントとリーダー間の片方向ネットワーク遅延を最小限に抑えるためにプライマリデータセンター内のサーバが優先されるかもしれない。他のコンセンサスアルゴリズムでは、リーダー選出時にこれらの優先順位を考慮できるかもしれないが、Raft ではリーダーになるために十分に最新のログを持つサーバが必要であり、そのサーバが必ずしも最優先のサーバとは限らない。代わりに、Raft のリーダーは定期的に利用可能なフォロワーのいずれかがより適しているかを確認し、適任であればそのサーバに自身のリーダーシップを転送することができる (人間のリーダーもこのように優雅であれば良いのですが)。
Raft でリーダーシップを転送するには、先行リーダーは自身のログエントリをターゲットサーバに送信し、ターゲットサーバは選挙タイムアウトの経過を待たずに選挙を実行する。これにより、先行リーダーはターム開始時にターゲットサーバがすべてのコミットエントリを持っていることを保証する。通常の選挙と同様に、過半数投票は Safety 特性 (Leader Completeness 特性など) が維持されることを保証する。以下のステップはこのプロセスをより詳細に説明する:
先行リーダーは新しいクライアントリクエストの受け入れを停止する。
先行リーダーは、セクション 3.5 で説明した通常のログ複製メカニズムを使用して、ターゲットサーバのログを自身のログと一致するように完全に更新する。
先行リーダーはターゲットサーバに TimeoutNow リクエストを送信する。このリクエストはターゲットサーバの選挙タイマーの起動と同じ効果を持つ。つまり、ターゲットサーバは新しい選挙を開始する (自身のタームをインクリメントして候補者となる)。
ターゲットサーバが TimeoutNow リクエストを受信すると、他のどのサーバよりも早く選挙を開始し、次のタームでリーダーになる可能性が非常に高い。ターゲットサーバから先行リーダーへの次のメッセージにはその新しいターム番号が含まれ、以前のリーダーは退任する。この時点でリーダーシップ転送は完了である。
ターゲットサーバに障害が発生する可能性もある。この場合、クラスタはクライアント操作を再開する必要がある。もしリーダーシップ転送が選挙タイムアウトのおおむね 1 回分の時間経過後に完了しない場合、以前のリーダーは交替を中止し、クライアントリクエストの受け入れを再開する。もし以前のリーダーの判断が誤りでターゲットサーバが実際に稼働している場合でも、最悪の場合、この誤りによって余分な選挙が発生するだけであり、その後のクライアント操作は回復するだろう。
このアプローチは Raft クラスタの通常の遷移の範疇で動作することで Safety を維持する。例えば Raft はクロックが任意の速度で動作する場合でも Safety を保証している。ターゲットサーバが TimeoutNow リクエストを受信したとき、それはターゲットサーバのクロックが急速に前方へジャンプするのと同等であり、これは安全である。ただし、我々は現在、このリーダーシップ転送アプローチを実装も評価もしていない。
3.11 結論
この章ではコンセンサスに基づくシステムにおけるすべての中核的な問題について説明した。Raft は単一決定 Paxos のように単一の値でコンセンサスに達するというものには留まらない。これは複製ステートマシンを構築するために必要な、増大するコマンドログに対する合意形成を行う。また、合意に達した時点で情報を伝播させるため、他のサーバがコミットされたログエントリを知ることができる。Raft はクラスタリーダーを選出して一方的に決定を下し、新しいリーダーが就任したら必要なログエントリのみを送信することで、実用的かつ効率的な方法でコンセンサスを達成する。我々は複製ステートマシンである LogCabin (第 10 章で説明) に Raft のアイディアを実装した。
Raft は完全なコンセンサス問題に対処するためにわずかなメカニズムしか持たない。例えば 2 つの RPC (RequestVote と AppendEntries) のみを使用する。意外かもしれないが、コンパクトなアルゴリズムや実装を開発することは Raft の明示的な目標ではなかった。むしろ、それは理解可能性のための我々の設計の結果であり、そこではあらゆるメカニズムが完全に動機付けられ、説明されなければならない。我々は冗長なメカニズムや回りくどいメカニズムは動機付けが難しく、そのため設計プロセスで自然に排除されることを発見した。
特定の解決策が Raft のデプロイメントの大部分に影響を与えると確信できない限り、我々はそれを Raft で扱わなかった。その結果、Raft の一部は素朴に見えるかもしれない。例えば Raft のサーバは選挙タイムアウトを持つことで分割投票を検出する。原理的には、各候補者に与えられた票数を数えることで分割投票をより早く検出し、さらには解決することも可能であろう。我々はこの最適化を Raft のために開発しないことを選択した。なぜならそれは複雑さを増すだけで実用的な利益はほとんどもたらさないであろう。適切に設定されたデプロイメントでは分割投票はまれである。Raft の他の部分は過度に保守的に見えるかもしれない。例えばリーダーは現在のタームでのエントリのみを直接コミットする。たとえ特別な状況で以前のタームでのエントリを安全にコミットできたとしてもである。より複雑なコミットルールを適用することは理解可能性を損なうだけで、性能に大きな影響を与えることはない。現在のルールではコミットが短時間遅延するだけである。Raft について他者と議論する中で、多くの人々がそのような最適化を考え、それを提案せずにはいられないことに気づいたが、目標が理解可能性である場合は、時期尚早な最適化 (premature optimizations) は省かれるべきである。
必然的に、この章では実用上で役に立つ機能や最適化の一部が省略されている可能性がある。実装者が Raft に関する経験を積むに連れて、特定の追加機能がいつ、なぜ有用であるかを理解し、実際のデプロイメント時にはそれらのいくつかを実装する必要が生じる可能性がある。この章全体を通じて、現時点では不要であると考えているが、必要に応じて実装者を導くのに役立つかもしれないいくつかのオプション拡張を概説した。理解可能性に焦点を当てることで、我々は実装者が自身の経験に応じて Raft を調整するための確固たる基盤を提供できたことを願う。Raft は我々のテスト環境で動作するため、これらは根本的な変更ではなく、単純な拡張になると考えている。
Chapter 4 - クラスタメンバーシップ変更
これまではクラスタ構成 (configuration) (コンセンサスアルゴリズムに参加するサーバのセット) は固定されていると想定してきた。実際には、サーバの故障時の交換や、レプリケーション度の変更のために構成を変更する必要が時々生じるだろう。これは以下の 2 つのアプローチのいずれかを用いて手動で行うことができる:
構成変更は、クラスタ全体をオフラインにし、構成ファイルを更新し、その後にクラスタを再起動することで行うことができる。ただし、この方法では切り替え中にクラスタは利用できなくなる。
あるいは、新しいサーバが既存のクラスタメンバーのネットワークアドレスを取得することで、そのサーバを置き換えることもできる。ただし、管理者は置き換えられたサーバが二度と稼働しないことを保証しなければならない。そうしないと、システムは Safety 特性を失うことになる (例えば余分な投票が発生するなど)。
これらのメンバーシップ変更アプローチはどちらも重大な欠点があり、手動による手順はオペレータのミスが発生するリスクがある。
これらの問題を回避するために、我々は構成変更を自動化して Raft コンセンサスアルゴリズムに組み込むことを決定した。Raft は変更中もクラスタが正常に動作し続けることを可能にし、メンバーシップ変更は基本的なコンセンサスアルゴリズムにいくつかの拡張を加えるだけで実装できる。Figure 4.1 はクラスタメンバーシップ変更で使用される RPC を要約している。各要素については本章の残りの部分で説明する。
管理者によってクラスタ構成にサーバを追加するために呼び出される。
| newServer | 構成に追加するサーバのアドレス |
|---|
| status | サーバ正常に追加された場合 OK |
|---|---|
| leaderHint | 既知の場合、最新のリーダーのアドレス |
管理者によってクラスタ構成からサーバを削除するために呼び出される。
| oldServer | 構成から削除するサーバのアドレス |
|---|
| status | サーバが正常に削除された場合 OK |
|---|---|
| leaderHint | 既知の場合、最新のリーダーのアドレス |
4.1 Safety
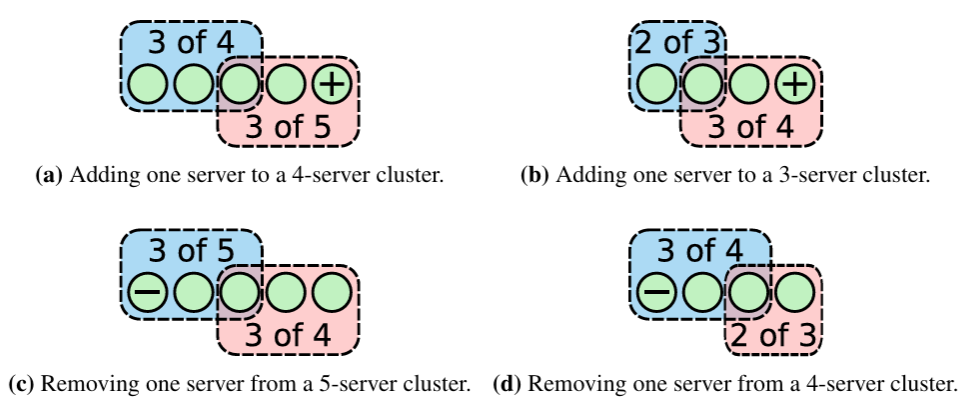
Safety の維持は構成変更における最初の課題である。メカニズムが安全であるためには、移行中に 2 つのリーダーが同じタームで選出される可能性があってはならない。1 回の構成変更で多数のサーバが追加または削除される場合、クラスタを古い構成から新しい構成に直接切り替えることは安全ではない。すべてのサーバを一度にアトミックに切り替えることは不可能であるため、移行中にクラスタが独立した 2 つの過半数に分裂する可能性がある (Figure 4.2 参照)。
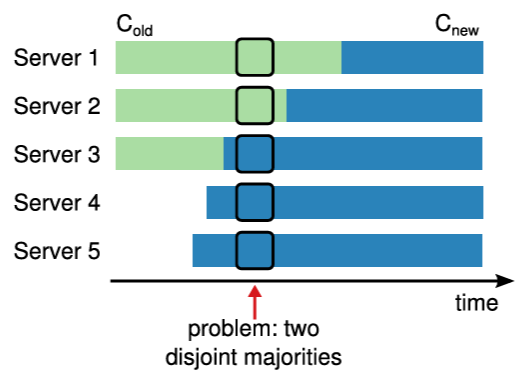
ほとんどのメンバーシップ変更アルゴリズムは、このような問題に対処するために追加のメカニズムを導入している。我々は当初 Raft でもこれを行ったが、その後、互いに排他的な過半数をもたらす可能性のあるメンバーシップ変更を禁止するというより単純なアプローチを発見した。このため Raft は許可される変更の種類を制限する。つまり、一度にクラスタに追加または削除できるサーバは 1 台のみである。より複雑なメンバーシップ変更は、単一サーバ変更の連続として実装される。この章のほとんどは、我々の元々のアプローチよりも理解しやすい単一サーバアプローチについて記述する。完全性を保つため、セクション 4.3 では任意の構成変更を処理するために追加の複雑さを伴う元のアプローチについて説明する。LogCabin では、より単純な単一サーバ変更アプローチを発見する前だったため、より複雑なアプローチを実装し、本稿執筆時点でも依然としてより複雑なアプローチを使用している。
クラスタに単一サーバを追加する場合、またはクラスタから単一のサーバを削除する場合、古いクラスタの任意の過半数は新しいクラスタの任意の過半数と重なり合う (Figure 4.3 参照)。この重複はクラスタが独立した過半数に分割されることを防ぐ。セクション 3.6.3 の Safety 論証の観点で言えば「投票者」の存在が保証される。したがって、単一のサーバを追加または削除するだけであれば新しい構成に直接切り替えても安全である。Raft はこの特性を利用して、追加のメカニズムをほとんど必要とせずにクラスタのメンバーシップを安全に変更する。
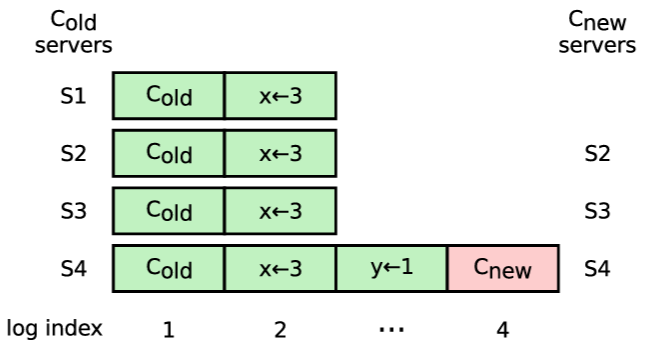
クラスタ構成は複製ログ内の特殊なエントリを使用して保存し伝達される。これにより、Raft の既存のメカニズムを使用して構成情報を複製して永続化する。また、構成変更とクライアントリクエスト間に順序付けを強制することで、構成変更の進行中にクラスタがクライアントリクエストを処理し続けることも可能にする (両者をパイプラインまたはバッチで同時に複製することも可能)。
リーダーは現在の構成 (\(C_{\rm old}\)) から現在のサーバを追加または削除するリクエストを受信すると、新しい構成 (\(C_{\rm new}\)) をログエントリとして追加し、通常の Raft メカニズムを使用してそのエントリを複製する。新しい構成は、各サーバのログに保存されるとすぐに有効になる。\(C_{\rm new}\) エントリは \(C_{\rm new}\) のサーバに複製され、新しい構成の過半数が \(C_{\rm new}\) エントリのコミットを決定するために使用される。つまり、サーバは構成エントリがコミットされるのを待たずに、各サーバが常に自身のログに記録されている最新の構成を使用することを意味する。
\(C_{\rm new}\) エントリがコミットされると構成変更は完了する。この時点で、リーダーは \(C_{\rm new}\) の過半数のサーバが \(C_{\rm new}\) を採用したことを認識する。また、\(C_{\rm new}\) に移行していないサーバはクラスタの過半数を構成できなくなり、\(C_{\rm new}\) を持たないサーバはリーダーに選出されないことも認識する。\(C_{\rm new}\) のコミットにより以下の 3 つのことが継続できる:
リーダーは構成変更が正常に完了したことを確認できる。
構成変更によってサーバが削除された場合、そのサーバをシャットダウンできる。
さらなる構成変更を開始できる。この時点より前に構成変更が重複すると Figure 4.2 のような安全ではない状況に陥る可能性がある。
前述の通り、サーバは構成エントリがコミットされているかどうかにかかわらず、常にログ内の最新の構成を使用する。これにより、リーダーは以前の変更のエントリがコミットされるまで新しい変更の開始を待つことで構成変更の重複を容易に回避できる (上記の 3 番目の項目)。古いクラスタの過半数が \(C_{\rm new}\) のルールに基づいて動作するようになった後でなければ、別のメンバーシップ変更を開始するのは安全ではない。もしサーバが \(C_{\rm new}\) がコミットされたことを認識してから \(C_{\rm new}\) を採用すると、Raft リーダーは古いクラスタの過半数がいつ \(C_{\rm new}\) を採用したかを知るのが困難になるだろう。これは、リーダーがエントリのコミットをどのサーバが認識しているかを追跡する必要があり、サーバはそのコミットインデックスをディスクに永続化する必要がある。これらのメカニズムはどちらも Raft では必要ない。代わりに、各サーバはログに \(C_{\rm new}\) エントリが存在するとすぐに \(C_{\rm new}\) を採用し、リーダーは \(C_{\rm new}\) エントリがコミットされるとすぐにさらなる構成変更を許可しても安全であると認識する。残念ながら、この決定は (リーダーが変更された場合に) 構成変更のログエントリが削除される可能性があることを意味する。この場合、サーバはログ内の以前の構成にフォールバックする準備ができていなければならない。
Raft では投票とログ複製の両方で、コンセンサスに使用されるのは呼び出し元の構成である:
サーバは、自身の最新の構成に含まれていないリーダーからの AppendEntries リクエストを受け入れる。そうしない場合、新しいサーバをクラスタに追加することはできないだろう (サーバを追加する構成エントリより前のログエントリは受け入れない)。
また、サーバは自身の最新の構成に含まれていない候補者にも票を与える (候補者が十分に最新のログと現在のタームを持っている場合)。この投票はクラスタの可用性を維持するために必要となる場合が時々ある。例えば、3 台のサーバクラスタに 4 台目のサーバを追加することを考える。1 台のサーバに障害が発生した場合、過半数を形成しリーダーを選出するために新しいサーバの票が必要となるだろう。
したがって、サーバは自身の現在の構成を参照することなく、受信した RPC リクエストを処理する。
4.2 可用性
クラスタメンバーシップの変更は、クラスタの可用性を維持する上でいくつかの問題を引き起こす。セクション 4.2.1 では、新しいサーバがクラスタに追加される前にそれらを追いつかせ (catch up)、新しいログエントリのコミットを妨げないようにすることについて議論する。セクション 4.2.2 では、既存のリーダーがクラスタから削除された場合に、そのリーダーを段階的に停止する方法について説明する。セクション 4.2.3 では、削除されたサーバが新しいクラスタのリーダーを妨害することを防ぐ方法を記述する。最後に、セクション 4.2.4 では、結果としてられるメンバーシップ変更アルゴリズムがあらゆるメンバーシップ変更中に可用性を維持するのに十分であるという議論で締めくくる。
4.2.1 新しいサーバのキャッチアップ
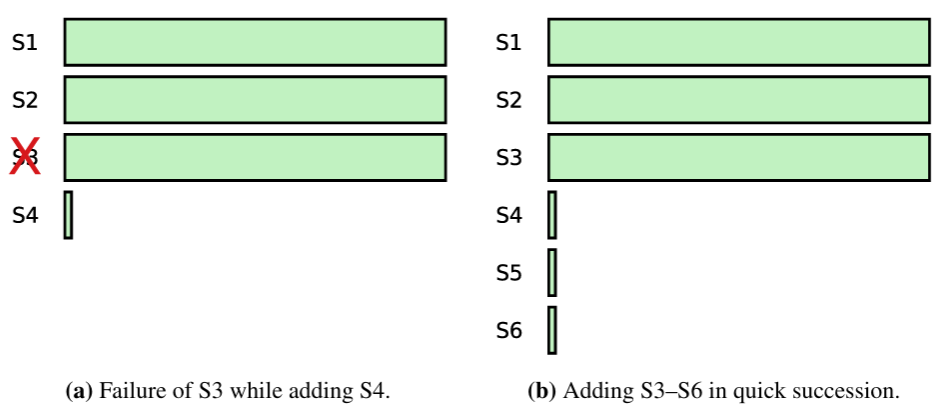
通常、サーバがクラスタに追加されるとき、ログエントリは何も保存していない。この状態でクラスタに追加されると、そのログがリーダーに追いつくまでにかなりの時間がかかり、この間、クラスタは可用性低下によってより脆弱になる。例えば 3 台で構成されるサーバクラスタは、通常、1 台の故障までであれば可用性を損なうことなく許容できる。しかし、ログが空の 4 台目のサーバが同じクラスタに追加され、元の 3 台のうち 1 台が故障した場合、クラスタは一時的に新しいエントリをコミットできなくなる (Figure 4.4(a) 参照)。また、多数の新しいサーバが立て続けにクラスタに追加され、それらの新しいサーバがクラスタの過半数を形成するために必要となる場合 (Figure 4.4(b) 参照) にも、可用性に関する別の問題が発生する可能性がある。どちらの場合も、新しいサーバのログがリーダーに追いつくまでクラスタは利用不能になるだろう。
可用性のギャップを避けるために、Raft は構成変更前に追加のフェーズを導入する。このフェーズでは、新しいサーバは非投票メンバーとしてクラスタに参加する。リーダーはログエントリをそのサーバに複製するが、それはまだ投票やコミットの目的での過半数にはカウントされない。新しいサーバがクラスタの他のサーバに追いつくと、上記のように再構成を進めることができる。(非投票サーバをサポートするメカニズムは他の文脈でも有用である。例えば、緩い一貫性で読み取り専用リクエストを処理できる多数のサーバに状態を複製するために使用できる。)
リーダーは構成変更を続行するために新しいサーバが十分に追いついたかを判断する必要がある。これには可用性を維持するためにいくつかの注意が必要である。もしサーバがあまりにも早く追加されると、前述のようにクラスタの可用性が危険にさらされる可能性がある。我々の目標は、一時的な利用不能期間を選挙タイムアウトより短く抑えることであった。なぜなら、クライアントは既にその規模の一時的な利用不能期間 (リーダー故障の場合など) を許容できる必要があるからである。さらに、可能であれば、新しいサーバのログをリーダーのログにさらに近づけることで、利用不能期間をさらに最小限に抑えたいと考えている。
リーダーはまた、新しいサーバが利用不能であるか、あるいは追いつくのがあまりにも遅すぎて決して追いつけないような場合には、変更を中止すべきである。このチェックは重要である。Lamport の古い Paxon 政府はこれを考慮しなかったために崩壊した。彼らは誤って溺死した船員のみでメンバーシップを構成するように変更してしまい、それ以上進捗できなくなったのである [48]。利用不能または低速のサーバを追加しようと試みることは多くの場合間違いである。実際、我々の最初の構成変更リクエストにはネットワークポート番号のタイプミスが含まれていたため、システムは正しく変更を中止してエラーを返した。
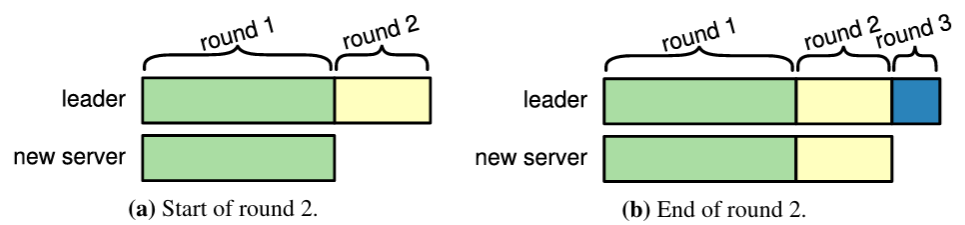
新しいサーバをクラスタに追加するのに十分な程度に追いついたと判断する以下のアルゴリズムを提案する。Figure 4.5 に示すように、新しいサーバへのエントリの複製はラウンドに分割される。各ラウンドでは、ラウンドの開始時点でリーダーのログに存在するすべてのログエントリが新しいサーバのログに複製される。ここで現在のラウンドのエントリを複製している間にリーダーに新しいエントリが到着する可能性があるが、これらは次のラウンドで複製される。進捗が進むにつれて、ラウンドの継続時間は短縮される。このアルゴリズムは、所定のラウンド数 (例えば 10 回) 待機する。もし最後のラウンドが選挙タイムアウトより短かった場合、リーダーは、実質的な可用性ギャップが生じるほど未複製エントリは残っていないという仮定のもと、新しいサーバをクラスタに追加する。そうでない場合、リーダーはエラーを返して構成変更を中止する。呼び出し元は常に再試行できる (新しいサーバのログは既に部分的に追いついているため、次回は成功する可能性が高くなる)。
新しいサーバが追いつくための最初のステップとして、リーダーは新しいサーバのログが空であることを発見しなければならない。新しいサーバの場合、AppendEntries の一貫性チェックはリーダーの nextIndex が最終的に 1 になるまで繰り返し失敗するだろう。この往復が、新しいサーバをクラスタに追加する性能を左右する要因となる可能性がある (このフェーズの後は、バッチ処理を使用することでログエントリをより少ない RPC でフォロワーに転送できる)。nextIndex をより早く正しい値に収束させるには、第 3 章で説明した方法を含め様々な方法がある。しかし、新しいサーバを追加するというこの特定の問題を解決する最も簡単なアプローチは、フォロワーが AppendEntries のレスポンスでログの長さを返すことである。これにより、リーダーはフォロワーの nextIndex を適切に制限できる。
4.2.2 現在のリーダーの削除
現存のリーダーがクラスタから自身を削除するよう求められた場合、ある時点で退任する必要がある。一つの直接的なアプローチは第 3 章で説明したリーダーシップ転送の拡張を使用することである。自身を削除するよう求められたリーダーは、そのリーダーシップを別のサーバに転送し、その後そのサーバが通常通りメンバーシップ変更を実行する。
我々は当初、Raft のために異なるアプローチを開発した。それは、既存のリーダーが自身を削除するメンバーシップの変更を実行し、その後に退任するというものである。これにより、リーダーが一時的に自身がメンバーではない構成を管理する期間があり、Raft はややぎこちない動作モードになる。我々は当初、任意の構成変更 (セクション 4.3 参照) のためにこのアプローチが必要であった。そこでは、古い構成と新しい構成がリーダーシップを転送できる共通のサーバを全く持たない可能性があったからである。同じアプローチは、リーダーシップ転送を実装していないシステムでも実行可能である。
このアプローチでは、構成から削除されたリーダーは \(C_{\rm new}\) エントリがコミットされると退任する。もしリーダーがこの時点より前に退任した場合、再びタイムアウトしてリーダーとなり、進捗を遅らせる可能性がある。2 台のサーバクラスタからリーダーを削除するという極端なケースでは、クラスタの処理を進めるためにサーバが再びリーダーにならざるを得ないことさえある (Figure 4.6 参照)。このためリーダーは \(C_{\rm new}\) がコミットされるまで退任を待機する。これは、新しい構成が、退任したリーダーの参加なしに確実に動作できる最初の時点である。\(C_{\rm new}\) のメンバーは常に自分たちの中から新しいリーダーを選出することが可能となる。削除されたリーダーが退任した後、\(C_{\rm new}\) のサーバがタイムアウトして選挙に勝利するだろう。同様の可用性ギャップはリーダーが故障したときにも発生するため、この小さな可用性ギャップは許容できるはずである。
このアプローチは、意思決定に関して特に有害ではないものの、意外な結果をもたらす意味合いのある 2 つの影響をもたらす。一つ目は、リーダーが (\(C_{\rm new}\) をコミットしている間) 自身を含まないクラスタを管理できる機関が存在することになる。つまり、リーダーはログエントリを複製するが過半数には自身をカウントしない。二つ目は、自身の最新の構成の一部ではないサーバも \(C_{\rm new}\) エントリがコミットされるまで (Figure 4.6 のように) 必要とされる可能性があるため、新しい選挙を開始すべきであるということである。自身の最新構成に含まれていないサーバは選挙において自身の投票をカウントしない。
4.2.3 妨害的なサーバ
追加のメカニズムなしでは \(C_{\rm new}\) に含まれていないサーバがクラスタを妨害 (disrupt) する可能性がある。クラスタリーダーが \(C_{\rm new}\) エントリを作成すると、\(C_{\rm new}\) に含まれていないサーバはハートビートを受信しなくなるため、タイムアウトして新しい選挙を開始する。さらに、\(C_{\rm new}\) エントリを受信できずそのコミットも認識できないため、自身がクラスタから削除されたことを知ることはできない。このサーバは新しいターム番号を持つ RequestVote RPC を送信し、これによって現在のリーダーはフォロワー状態に戻される。最終的に \(C_{\rm new}\) の中から新しいリーダーが選出されるが、妨害的なサーバは再びタイムアウトし、このプロセスが繰り返されるため結果的に可用性が低下する。複数のサーバがクラスタから削除された場合、状況はさらに悪化する可能性がある。
妨害を排除するための我々の最初のアイディアは、サーバが選挙を開始する前に、それが全員の時間を無駄にしないか、つまり、選挙に勝つチャンスがあることを確認するというものであった。これにより選挙に Pre-Vote フェーズと呼ばれる新しいフェーズが導入された。候補者はまず他のサーバに、自身のログが投票するのに十分なほど最新であるかを尋ねる。候補者がクラスタの過半数から投票を得られると判断した場合のみ、自身のタームをインクリメントして通常の選挙を開始する。
残念ながら、Pre-Vote フェーズは妨害的なサーバの問題を解決することはできない。妨害的なサーバのログが十分に最新であるにもかかわらず、選挙を開始すると依然として妨害的になる状況がある。おそらく驚くべきことだが、このような状況は構成変更が完了する前でさえ発生し得る。例えば Figure 4.7 はクラスタから削除されるサーバを示している。リーダーが \(C_{\rm new}\) ログエントリを作成すると、削除されるサーバが妨害的になる可能性がある。この場合、削除されるサーバはどちらのクラスタの過半数よりも最新のログを持っているため、Pre-Vote チェックは役に立たない。(ただし、Pre-Vote フェーズは妨害的なサーバの問題を解決しないもの、一般的にリーダー選出の堅牢性を向上させるのに有用なアイディアであることが判明した。第 9 章参照。)
このシナリオのため、我々は現在、ログの比較のみに基づく解決策 (Pre-Vote チェックなど) では、選挙が妨害的になるかどうかを判断するのに十分ではないと考えている。Raft は常に障害を許容できなければならないため、サーバが選挙を開始する前に \(C_{\rm new}\) のすべてのサーバのログをチェックすることを要求することはできない。また、リーダーが Figure 4.7 に示すシナリオを迅速に乗り越えるのに十分な速さでエントリを確実に複製することを仮定したくなかった。これは実際には機能するかもしれないが、ログの分岐箇所を見つけるパフォーマンスやログエントリを複製するパフォーマンスに関して、我々が避けたいより強い仮定に依存している。
Raft の解決策は、有効なリーダーが存在するかどうかを判断するためにハートビートを使用する。Raft では、リーダーはフォロワーへのハートビートを維持できる場合にアクティブであると見なされる (そうでない場合は別のサーバが選挙を開始する)。したがって、クラスタがハートビートを受信しているリーダーをサーバが妨害できるべきではない。我々はこの目的を達成するために RequestVote RPC を変更する。サーバが現在のリーダーからの通信を受けてから最小選挙タイムアウト以内に RequestVote リクエストを受信した場合、自身のタームを更新したり、票を与えたりしない。サーバはリクエストを破棄するか、投票拒否で応答するか、リクエストを遅延させるかを選択できる。結果は基本的に同じである。これは通常の選挙には影響しない。通常の選挙では、各サーバは選挙を開始する前に少なくとも最低限の選挙タイムアウトを待機する。しかし、\(C_{\rm new}\) に参加していないサーバによる中断を回避するのに役立つ。リーダーは自身のクラスタにハートビートを届けられる限り、より大きなターム番号によって退任させられることはない。
この変更は第 3 章で説明したリーダーシップ転送メカニズムと衝突する。リーダーシップ転送メカニズムでは、サーバは選挙タイムアウトを待たずに正当に選挙を開始する。その場合、他のサーバは現在のクラスタリーダーが存在すると認識していても RequestVote メッセージを処理すべきである。これらの RequestVote リクエストにはこの動作を示す特別なフラグ (「リーダーを中断する許可を得た ── リーダーがそう指示した!」) を含めることができる。
4.2.4 可用性の議論
このセクションでは、上記の解決策がメンバーシップ変更時の可用性維持に十分であることを議論する。Raft のメンバーシップ変更はリーダーベースであるため、このアルゴリズムはメンバーシップ変更中にリーダーを維持し、交代させることができ、またリーダーはクライアントの要求に応答し、かつ構成変更を完了させられることを示す。とりわけ我々は、古い構成の過半数が利用可能であること (少なくとも \(C_{\rm new}\) がコミットされるまで)、および新しい構成の過半数が利用可能であることを前提とする。
リーダーは構成変更のすべてのステップで選出されうる。
新しいクラスタ内で最新のログを持つ利用可能なサーバが \(C_{\rm new}\) エントリを持っている場合、そのサーバは \(C_{\rm new}\) の過半数から票を集めてリーダーになることができる。
そうでない場合、\(C_{\rm new}\) エントリはまだコミットされていないはずである。新旧両方のクラスタの中で最も最新のログを持つ利用可能なサーバは、\(C_{\rm old}\) の過半数と \(C_{\rm new}\) の過半数から票を集めることができるため、どの構成を利用していてもリーダーになることができる。
リーダーは一度選出されると、ハートビートが構成に届く限り維持される。ただし、\(C_{\rm new}\) に含まれていないが \(C_{\rm new}\) をコミットしてから意図的に退任する場合を除く。
リーダーが、自身の構成に確実にハートビートを送信できる場合、リーダーもそのフォロワーもより高いタームを採用することはない。彼らは新しい選挙を開始するためにタイムアウトすることはなく、他のサーバからのより高いタームを持つ RequestVote メッセージを無視する。したがって、リーダーは強制的に退任されることはない。
\(C_{\rm new}\) に含まれていないサーバが \(C_{\rm new}\) エントリをコミットして退任した場合、Raft は新しいリーダーを選出する。この新しいリーダーは \(C_{\rm new}\) の一部である可能性が高いため、構成変更が完了するだろう。ただし、退任したサーバが再びリーダーになるリスクも (わずかに) ある。もし再び選出された場合、そのサーバは \(C_{\rm new}\) エントリのコミットを確認し、すぐに退任するため、次回は \(C_{\rm new}\) のサーバが成句する可能性が高いだろう。
リーダーは構成変更全体を通してクライアントリクエストを処理する。
リーダーは変更全体を通してクライアントリクエストをログに追加し続けることができる。
新しいリーダーはクラスタに追加される前に追いつく必要があるため、リーダーはコミットインデックスを進めてクライアントにタイムリーに応答できる。
リーダーは \(C_{\rm new}\) をコミットすることで構成変更を進めて完了させる。必要に応じて、\(C_{\rm new}\) のサーバがリーダーになることを可能にするために退任する。
したがって、上記の仮定の下では、このセクションで述べられているメカニズムはあらゆるメンバーシップ変更中の可用性を維持するのに十分である。
4.3 ジョイントコンセンサスを用いた任意の構成変更
このセクションではクラスタメンバーシップの変更に対するより複雑なアプローチを紹介する。これは構成に関する任意の変更を一度に処理する、例えば、2 台のサーバを一度にクラスタに追加したり、5 台のサーバクラスタ内のすべてのサーバを一度に置き換えたりすることが可能である。これは我々が考案したメンバーシップ変更の最初のアプローチであり、ここでは完全性のためにのみ説明する。より単純な単一サーバアプローチを知った今となっては、任意の変更を扱うには余分な複雑さが必要となるため、代わりにそちらを推奨する。文献では、メンバーシップ変更は一般的に任意の変更によって行われると想定されているが、実際のシステムでは単一サーバの変更を繰り返すことでクラスタメンバーシップを任意の構成に変更できるため、この柔軟性は必要ないと考えている。
任意の構成変更について Safety を確保するために、クラスタはまず我々がジョイントコンセンサス (joint consensus) と呼ぶ過渡的な構成に切り替わる。ジョイントコンセンサスがコミットされるとシステムは新しい構成に移行する。ジョイントコンセンサスは古い構成と新しい構成の両方を組み合わせたものである。
ログエントリは両方の構成のすべてのサーバに複製される。
どちらの構成のサーバでもリーダーになることができる。
(選挙およびエントリのコミットに関する) 合意には、古い構成と新しい構成の両方からの個別の過半数が必要である。例えば、3 台のサーバからなるクラスタから 9 台のサーバからなる別のクラスタに変更する場合、合意には古い構成の 3 台のサーバのうちの 2 台と、新しい構成の 9 台のサーバのうちの 5 台の両方が必要である。
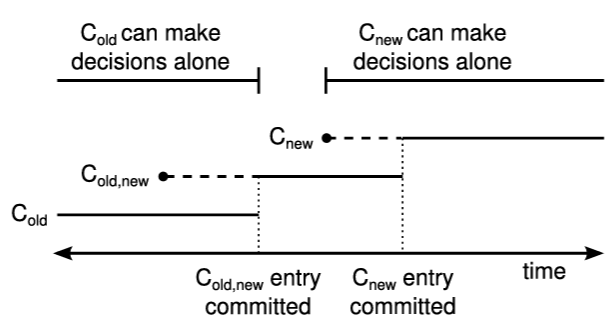
ジョイントコンセンサスにより、個々のサーバは Safety を損なうことなく、異なるタイミングで構成間を移行できる。さらに、ジョイントコンセンサスにより、クラスタは構成変更中もクライアントからのリクエストに引き続き対応できる。
このアプローチは、単一サーバのメンバーシップ変更アルゴリズムを、ジョイント構成の中間ログエントリによって拡張する。Figure 4.8 にそのプロセスを示している。リーダーが \(C_{\rm old}\) から \(C_{\rm new}\) への構成変更リクエストを受信すると、ジョイントコンセンサス用の構成 (図中の \(C_{\rm old,new}\)) をログエントリとして保存し、通常の Raft メカニズムを使用してそのエントリを複製する。単一サーバ構成変更アルゴリズムと同様に、各サーバはログに構成を保存するとすぐに新しい構成の使用を開始する。これは、リーダーが \(C_{\rm old,new}\) のログがいつコミットされるかを判断するために \(C_{\rm old,new}\) のルールを使用することを意味する。リーダーがクラッシュした場合、\(C_{\rm old,new}\) を受信した候補が勝利したかどうかに応じて、\(C_{\rm old}\) または \(C_{\rm old,new}\) のいずれかの元で新しいリーダーが選出される可能性がある。いずれにせよ、この期間中は \(C_{\rm new}\) が一方的な決定を下すことはできない。
一度 \(C_{\rm old,new}\) がコミットされると、\(C_{\rm old}\) も \(C_{\rm new}\) も他方の承認なしに決定を下すことはできなくなる。また Leader Completeness 特性により \(C_{\rm old,new}\) ログエントリを持つサーバのみがリーダーとして選出されることが保証される。ここでリーダーが \(C_{\rm new}\) を記述するログエントリを作成して安全にクラスタに複製することができる。繰り返しになるが、この構成は各サーバで観測されるとすぐに有効になる。\(C_{\rm new}\) ログエントリが \(C_{\rm new}\) のルールに基づいてコミットされると、古い構成は無関係になり、新しい構成に含まれないサーバはシャットダウンできる。Figure 4.8 に示すように \(C_{\rm old}\) と \(C_{\rm new}\) の両方が一方的な決定を下す時間は存在せず、これにより Safety が保証される。
ジョイントコンセンサスは、以前の構成変更がまだ進行中であっても構成変更を開始できるように一般化できる。しかし、これを行うことで得られる実用的な利点はあまりないだろう。代わりに、リーダーは構成変更が既に進行中の場合 (その最新の構成がコミットされていないか、または単純な過半数ではない場合)、追加の構成変更を拒否する。このように拒否された変更は、単に待機して後で再試行できる。
このジョイントコンセンサスアプローチは中間構成への移行とそこからの移行が必要となるため単一サーバ変更よりも複雑である。ジョイント構成はまたすべての投票およびコミットメントの決定方法に変更を必要とする。リーダーは単にサーバを数えるだけではなく、サーバが古いクラスタの過半数を形成し、かつ新しいクラスタの過半数を形成するかどうかをチェックしなければならない。これを実装するには、我々の Raft 実装 [86] において約 6 箇所の比較を見つけて変更する必要があった。
4.4 システム統合
Raft の実装は、本章で述べたクラスタメンバーシップ変更メカニズムを異なる方法で公開する場合がある。例えば Figure 4.1 の AddServer および RemoveServer RPC は、管理者によって直接呼び出されることもあれば、一連の単一サーバステップを使用して任意の方法で構成を変更するスクリプトによって呼び出されることもある。
サーバ障害のようなイベントに応じてメンバーシップ変更を自動的に呼び出すことが望ましい場合もあるだろう。ただし、これは合理的なポリシーに従ってのみ行うべきである。例えば、故障したサーバをクラスタが自動的に削除することが危険な場合がある。その結果として、意図された耐久性および障害耐性要件を満たすのに十分なレプリカ数が不足してしまう可能性がある。妥当なアプローチの一つは、システム管理者が希望するクラスタサイズを設定し、その制約内で故障したサーバを利用可能なサーバで自動的に置き換えるようにすることである。
複数の単一サーバステップを必要とするクラスタメンバーシップ変更を行う場合は、サーバを削除する前にサーバを追加することが望ましい。例えば 3 台のサーバで構成されるクラスタでサーバを交換する場合、まず 1 台のサーバを追加し、次に別のサーバを削除することで、プロセス全体を通して常に 1 台のサーバの故障をシステムが処理できる。しかし、もし 1 台のサーバを削除してからもう 1 台のサーバを追加した場合、システムは一時的にいかなる故障も隠蔽できなくなるだろう (2 台のサーバで構成されるクラスタでは両方のサーバが両可能である必要があるため)。
メンバーシップ変更はクラスタのブートストラップに異なるアプローチを必要とする。動的なメンバーシップがない場合、各サーバは構成をリストした静的ファイルを持つことになる。動的なメンバーシップ変更の場合、システムは Raft ログで構成を管理するため、静的な構成ファイルはもはや必要ない。また、静的構成ファイルは潜在的にエラーが発生しやすい可能性がある (例えば新しいサーバはどの構成で初期化されるべきか? など)。代わりに、クラスタを初めて作成する際には、1 台のサーバのログの最初のエントリとして構成エントリで初期化することを推奨する。この初期構成にはその 1 台のみがリストされており、それ単独で過半数を形成するため、この構成をコミット済みと見なすことができる。それ以降、他のサーバは空のログで初期化され、クラスタに追加され、メンバーシップ変更メカニズムを通じて現在の構成を知る。
メンバーシップ変更はまた、クライアントがクラスタを見つけるための動的なアプローチも必要とする。これについては第 6 章で議論する。
4.5 結論
本章ではクラスタメンバーシップ変更を自動的に処理するための Raft の拡張機能について記述した。障害耐性要件は時間の経過と共に変化し、故障したサーバはいずれ交換する必要があるため、これは完全なコンセンサスベースのシステムの重要な部分である。
新しい構成は「過半数」の意味に影響を与えるため、コンセンサスアルゴリズムは構成変更全体にわたる Safety を維持するために根本的に関与する必要がある。本章では、一度に 1 台のサーバを追加または削除する単純なアプローチを提示した。これらの操作は、変更中に少なくとも 1 台のサーバが任意の過半数と重なり合うため Safety を単純に維持する。複数の単一サーバ変更を組み合わせることでクラスタを大幅に更新できる。Raft ではメンバーシップ変更中にクラスタが正常に動作し続けることを可能にする。
構成変更中に可用性を維持するにはいくつかの重要な問題に対処する必要がある。特に、新しい構成に含まれていないサーバが有効なクラスタリーダーを妨害するという問題は驚くほど微妙であった。ログの比較に基づくいくつかの不十分な解決策に苦労した後、ハートビートに基づく実用的なソリューションに落ち着いた。
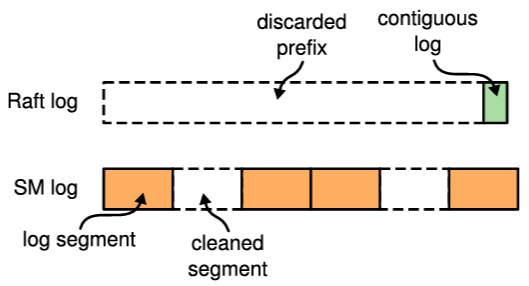
Chapter 5 - ログ圧縮
Raft のログは、通常運用中に取り込んだクライアントリクエストが増えるにつれて増大する。ログが大きくなるとより多くのスペースを占有し、リプレイに時間がかかるようになる。ログを圧縮する方法がなければ、サーバはスペースを使い果たすか、起動時に時間がかかりすぎるかで、最終的には可用性の問題を引き起こすだろう。そのため、実用的なシステムでは何らかのログ圧縮が必要である。
ログ圧縮の一般的な考え方は、ログ内の情報の多くが時間の経過と共に陳腐化し、破棄できるというものである。例えば \(x\) を 2 に設定する操作は、その後の操作で \(x\) を 3 に設定すると陳腐化する。ログエントリがコミットされてステートマシンに適用されると、現在の状態に到達するために使用された中間状態や操作はもはや必要なくなり、圧縮によって削除できる。
Raft のコアアルゴリズムやメンバーシップの変更とは異なり、ログ圧縮に関してはシステムごとに異なるニーズがある。いくつかの理由からログ圧縮には万能な解決策はない。第一に、システムごとに単純性と性能のトレードオフの程度が異なる。第二に、ステートマシンはログ圧縮に密接に関与する必要があり、ステートマシンは、そのサイズや、ディスクベースか揮発性メモリベースかによって大きく異なる。
本章の目的はログ圧縮に関する様々なアプローチを議論することである。いずれのアプローチにおいても、ログ圧縮の責務のほとんどはステートマシンにあり、ステートマシンが状態をディスクに書き込み、状態を圧縮する役割を担う。ステートマシンはこれを様々な方法で実現でき、それは本章全体を通して説明され Figure 5.1 にまとめられている。
メモリベースのステートマシンにおけるスナップショットは概念的に最も単純なアプローチである。スナップショットでは、現在のシステム状態全体が安定したストレージ上のスナップショット (snapshot) に書き込まれ、その時点までのログ全体が破棄される。スナップショットは Chubby [11, 15] や ZooKeeper [38] で使用されており、我々は LogCabin でも実装した。スナップショットは本章で最も詳細に説明されているアプローチでありセクション 5.1 で詳しく説明している。
ディスクベースのステートマシンでは、システム状態の最新のコピーが通常動作の一環としてディスク上に保持される。そのためステートマシンがディスクへの書き込みを反映するとすぐに Raft ログは破棄でき、スナップショットは一貫性のあるディスクイメージを他のサーバに送信する場合にのみ使用される (セクション 5.2)。
ログクリーニングやログ構造マージツリー (log-structured merge tree) のような、ログ圧縮に対する増分アプローチについてはセクション 5.3 で説明する。これらのアプローチはディスクへの書き込みを効率的に行い、時間の経過と共にリソースを均等に利用する。
最後に、セクション 5.4 では、スナップショットを直接ログに保存することで必要なメカニズムを最小限に抑えるログ圧縮のアプローチについて説明する。実装は容易であるが、このアプローチは非常に小規模なステートマシンにのみ適している。
現在、LogCabin はメモリベースのスナップショットアプローチのみを実装している (メモリベースのステートマシンを組み込んでいるため)。
これらの様々な圧縮アプローチにはいくつかの共通するコアコンセプトがある。第一に、圧縮の決定をリーダーに集中させるのではなく、各サーバがログのコミット済みプレフィクスを独立して圧縮する。これにより、既にログにデータを持つフォロワーにリーダーはデータを送信する必要がなくなる。またモジュール性も向上する。ログ圧縮の複雑性のほとんどはステートマシン内に収まっており、Raft 自体とはあまりやりとりをしない。これはシステム全体の複雑さを最小限に抑えるのに役立つ。Raft の複雑さはログ圧縮の複雑さと「乗算」されるのではなく「加算」される。圧縮の責任をリーダーに集中させる代替アプローチについてはセクション 5.4 で詳しく説明する (そして非常に小さなステートマシンにとっては、リーダーベースのアプローチの方が優れている場合がある)。
第二に、ステートマシンと Raft の間の基本的な相互作用は、ログのプレフィクスに対する責任を Raft からステートマシンに委譲することを含んでいる。エントリを適用した後、遅かれ早かれステートマシンは現在のシステム状態を回復できる方法でそれらのエントリをディスクに反映する。それが完了すると、ステートマシンは Raft に対して対応するログプレフィクスを破棄するように指示する。Raft がロブプレフィクスに対する責任を放棄する前に、ログプレフィクスを記述する自身の状態の一部を保存しなければならない。具体的には、Raft は破棄した最後のエントリのインデックスとタームを保持する。これにより、ログの残りの部分がステートマシンの状態の後に固定され、AppendEntries の一貫性チェックが機能し続けることを可能にする (ログの最初のエントリに先行するエントリのインデックスとタームが必要である)。Raft はまたクラスタメンバーシップ変更をサポートするために、破棄されたログプレフィクスから最新の構成も保持する。
第三に、Raft がログのプレフィクスを破棄するとステートマシンは 2 つの新たな役割を担うことになる。サーバが再起動したとき、ステートマシンは Raft のログからエントリを適用する前に、破棄されたログエントリに対応する状態をディスクからロードする必要がある。さらに、ステートマシンは遅いフォロワー (リーダーのログより大幅に遅れているフォロワー) に送信できるように、一貫性のある状態イメージを生成する必要があるかもしれない。少数の遅いフォロワーがクラスタの完全な可用性を妨げてはならず、またクラスタはいつでも新しいサーバが追加される可能性があるため、ログエントリがクラスタ内のすべてのメンバーに「完全に複製」されるまで圧縮を遅らせることは現実的ではない。したがって、遅いフォロワーや新しいサーバは、時折、ネットワーク経由で初期状態を受信する必要があるだろう。この場合、ステートマシンは一貫性のある状態イメージを提供し、リーダーはそれをフォロワーに送信する必要がある。
インメモリデータ構造を変更
インメモリデータ構造で結果を検索
ログサイズが以前のスナップショットサイズの 4 倍に達した場合:
- ステートマシンのメモリをフォーク
- 親プロセスはリクエスト処理を継続
- 子プロセスはインメモリデータ構造をディスク上の新しいスナップショットファイルにシリアライズ
- 以前のスナップショットファイルをディスク上から破棄
- 子プロセスの最終適用インデックスまで Raft ログを破棄
最新のスナップショットファイル (不変)
- インメモリのヘッドセグメントにエントリを追記
- キーの場所でインデックスを更新
- インデックスでキーの場所を検索
- インデックス上のセグメントから値を読み取り
インメモリのヘッドセグメントが 2MB に達した場合:
- インメモリセグメントを新しいヘッドセグメントとしてディスクに書き込み
- インメモリセグメントをリセット
- 最後に適用したインデックスまでの Raft ログを破棄
空きスペースが 5% を下回った場合:
- 以下の値が最大となる 10 個のセグメントを選択してクリーンアップ: \[ \frac{benefit}{cost} = \frac{1-u}{1+u}\times segmentAge \] ここで \(u\) はセグメント内のライブバイトの割合
- ライブエントリを新しいセグメントにコピー
- エントリがライブかどうかを判断するためにインデックスのキーで検索
- キーの新しい場所でインデックスを更新
- 元のセグメントを破棄
ディスク上のすべてのセグメント (不変)
ログエントリを破棄する前に保持される。また、状態を転送する際にリーダーから遅いフォロワーに送信される。
| prevIndex | 最後に破棄されたエントリのインデックス (初回起動時に 0 に初期化) |
|---|---|
| prevTerm | 最後に破棄されたエントリのターム (初回起動時に 0 に初期化) |
| prevConfig | prevIndex までの最新のクラスタメンバーシップ構成 |
- ディスク上のデータ構造を更新
- 最後に適用されたインデックスまでの Raft ログを破棄
ディスク上のデータ構造で結果を検索
ディスク上のデータ構造のコピーオンライトスナップショット
インメモリツリーにエントリを追加
- インメモリツリーでキーを検索
- すべてのレベル 0 ランを検索 (いずれもキーを含む可能性)
- 1 から順にカウントアップする各レベルについて、キーを含む可能性のある単一のランを検索
インメモリツリーが 1MB に達した場合:
- インメモリツリーをディスク上の新しいソートされたレベル 0 ランに直列化
- インメモリツリーをリセット
- 最後に適用したインデックスまで Raft ログを破棄
レベル 0 に 4 つのランがある場合:
- すべてのレベル 0 ランをすべてのレベル 1 ランにマージし、2MB 境界で分割された新しい重複しないレベル 1 ランを生成
- マージされたランを破棄
レベル \(L\) のすべてのランの合計サイズが \(10^L\) MB を超えた場合:
- 1 つのレベル \(L\) ラン (ラウンドロビンで選択) を、重複するすべてのレベル \(L+1\) ランとマージし、2MB 境界で分割された新しい重複しない \(L+1\) ランを生成
- マージされたランを破棄
ディスク上のすべてのラン (イミュータブル)
インメモリデータ構造を変更
インメモリデータ構造で結果を検索
Raft ログがバイト単位で 1MB に達した場合:
- クライアントリクエストの受け入れを停止
- 最後に適用したインデックスがログの末尾に達するまで待機
- データ構造を直列化し、新しいスナップショットエントリをログに追記
- クライアントリクエストの処理を再開
- 各サーバのスナップショットエントリがコミットされたことを確認すると、そのエントリまでの Raft ログエントリを破棄
Raft ログ (追加の情報なし)
5.1 メモリベースのステートマシンのスナップショット
スナップショットの最初のアプローチは、ステートマシンのデータ構造がメモリ内に保持されている場合に適用される。これは、数ギガバイトまたは数十ギガバイトのデータセットを持つステートマシンにとって妥当な選択である。データはディスクから読み取る必要がないため操作は迅速に完了できる。また、豊富なデータ構造を利用でき、すべての操作を (I/O によるブロックなしで) 完了まで実行できるため、プログラミングも容易である。
Figure 5.2 はステートマシンがメモリ内に保持されている場合の Raft におけるスナップショットの基本的な考え方を示している。各サーバは独立してスナップショットを作成し、そのログ内のコミット済みエントリのみをカバーする。スナップショットの作業のほとんどはステートマシンの現在の状態を直列化することであり、これは特定のステートマシン実装に固有のものである。例えば LogCabin のステートマシンはツリーを主要なデータ構造としており、このツリーを先行順深さ優先探索 (pre-order depth-first traversal) を使用して直列化される (これにより、スナップショットを適用すると親ノードが子ノードより先に作成される)。ステートマシンはまた、クライアントへの線形化可能性を提供するために保持する情報も直列化する必要がある (第 6 章参照)。
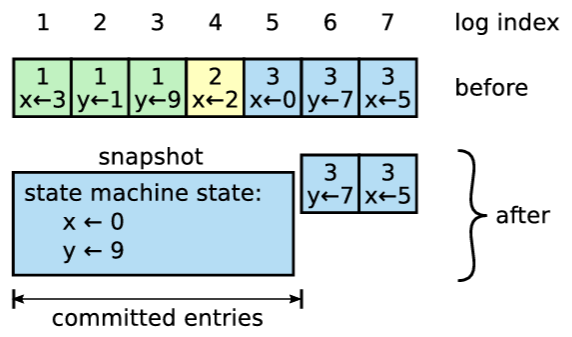
ステートマシンがスナップショットの書き込みを完了するとログを切り詰めることができる。Raft はまず再起動のために必要な状態、すなわち、スナップショットに含まれる最後のエントリのインデックスとターム、およびそのインデックス時点での最新の構成を保存する。その後、そのインデックスまでのログのプレフィクスを破棄する。以前のスナップショットも不要になるため破棄することができる。
前述のように、リーダーはときどき自身の状態を、遅いフォロワーや、クラスタに参加する新しいサーバに送信する必要があるかもしれない。スナップショット作成においてこの状態は最新のスナップショットであり、リーダーはこれを Figure 5.3 に示すように InstallSnapshot と呼ばれる新しい RPC を使用して転送する。フォロワーはこの RPC でスナップショットを受信すると、既存のログエントリをどのように処理するかを決めなければならない。通常、スナップショットにはフォロワーのログにまだ含まれていない新しい情報が含まれているだろう。この場合は、フォロワーはログ全体を破棄する。スナップショットと衝突する未コミットのエントリが含まれている可能性もあるため、これはすべてスナップショットによって置き換えられる。もし、代わりにフォロワーが (再送信または誤りによって) 自身のログのプレフィクスを記述するスナップショットを受信した場合、スナップショットによってカバーされているログエントリは削除されるが、スナップショットに続くエントリは依然として有効であるため保持する必要がある。
リーダーによってフォロワーにスナップショットのチャンクを送信するために呼び出される。リーダーは常にチャンクを順番通りに送信する。
| term | リーダーのターム |
|---|---|
| leaderId | フォロワーがクライアントをリダイレクトできるようにするため |
| lastIndex | スナップショットがこのインデックスまでのすべてのエントリを置き換える (このインデックスを含む) |
| lastTerm | lastIndex のターム |
| lastConfig | lastIndex 時点での最新のクラスタ構成 (最初のチャンクでのみ送信) |
| offset | スナップショットファイル内でのチャンクが配置されるバイトオフセット |
| data[] | オフセットから始まるスナップショットチャンクの生バイト列 |
| done | これが最後のチャンクの場合 true |
| term | リーダーが自身を更新するための currentTerm |
|---|
- term < currentTerm の場合、直ちに返信
- 最初のチャンク (offset が 0) の場合、新しいスナップショットファイルを作成
- 指定されたオフセットでスナップショットファイルにデータを書き込む
- done が false の場合、返信してさらなるデータチャンクを待機
- lastIndex が最新のスナップショットのインデックスより大きい場合、スナップショットファイルと Raft の状態 (lastIndex, lastTerm, lastConfig) を保存。既存の、または不完全なスナップショットは破棄。
- 既存のログエントリが lastIndex および lastTerm と同じインデックスおよびタームを持つ場合、lastIndex までのログを破棄し (ただし後続のエントリは保持)、返信
- ログ全体を破棄
- スナップショットの内容を使用してステートマシンをリセット (そして lastConfig をクラスタ構成としてロード)
本セクションの残りの部分では、メモリベースのステートマシンのスナップショットに関する二次的な問題について議論する:
セクション 5.1.1 では、スナップショットのクライアントへの影響を最小限に抑えるため、通常の操作と並行してスナップショットを生成する方法について議論する。
セクション 5.1.2 では、スペース使用量とスナップショットのオーバーヘッドのバランスを取りながら、いつスナップショットを作成するかについて議論する。
セクション 5.1.3 では、スナップショットの実装で発生する問題について議論する。
5.1.1 スナップショットの並行性
スナップショットの作成には、状態の直列化とディスクへの書き込みの両方で長い時間がかかることがある。例えば今日のサーバでは 10GB のメモリをコピーするのに約 1 秒かかり、それを直列化するには通常さらに時間がかかる。ソリッドステートディスクでさえ 1 秒あたり約 500MB しか書き込めない。したがって、可用性ギャップを回避するためにスナップショットの直列化と書き込みの両方を通常の操作と並行して行う必要がある。
幸いなことに、コピーオンライト (copy-on-write) 技術により書き込み中のスナップショットに影響を与えることなく新しい更新を適用できる。これには 2 つのアプローチがある:
ステートマシンは、これをサポートするために不変 (関数型) データ構造で構築することもできる。ステートマシンのコマンドが状態をその場で更新しないため、スナップショットタスクは以前の状態への参照を保持し、それを一貫してスナップショットに書き込むことができる。
あるいはオペレーティングシステムのコピーオンライトのサポートを利用することもできる (プログラミング環境がこれを許容する場合)。例えば Linux では、インメモリのステートマシンは fork を使用してサーバのアドレス空間全体をコピーできる。その後、子プロセスはステートマシンの状態を書き出して終了し、その間も親プロセスはリクエストの処理を継続する。LogCabin の実装は現在このアプローチを使用している。
サーバはスナップショットを並行して実行するために追加のメモリを必要とする。これは計画的に管理されている必要がある。ステートマシンはスナップショットファイルへのストリーミングインターフェースを持つことが不可欠である。これにより、スナップショットの作成時にスナップショット全体をメモリに一時的に保持する必要がなくなる。それでも、コピーオンライトは、スナップショット処理中にステートマシンの状態が変更される割合に比例して追加のメモリを必要とする。さらに、オペレーティングシステムによるコピーオンライトに依存すると、偽共有 (false sharing) (例えば、無関係な 2 つのデータ項目がたまたま同じメモリページ上にある場合、1 つ目の項目のみが更新されているにもかかわらず 2 つ目の項目も重複して複製される) により、通常さらに多くのメモリを使用する。スナップショット作成中にメモリ容量が枯渇するという不幸な事態が発生した場合、サーバはスナップショットが完了するまで新しいログエントリの受け入れを停止する必要がある。これは一時的にそのサーバの可用性を犠牲にするかもしれないが (クラスタは引き続き利用可能かもしれない)、少なくともサーバが回復することを可能にする。スナップショットを中止して後で再試行することは、次回の試行でも同じ問題が発生する可能性があるため避けるべきである。(LogCabin ではディスクへのストリーミングインターフェースを使用するが、現時点ではメモリ枯渇を適切に処理できない。)
5.1.2 スナップショットのタイミング
サーバはいつスナップショットを作成するかを決定しなければならない。サーバが頻繁にスナップショットを作成しすぎると、ディスク帯域幅やその他のリソースが無駄になる。一方でスナップショットの頻度が低すぎると、ストレージ容量を枯渇させるリスクがあり、再起動時のログのリプレイに必要な時間が増加する。
一つの単純な戦略は、ログがバイト単位で固定サイズに達したときにスナップショットを作成することである。このサイズがスナップショットの予想サイズよりも大幅に大きく設定されていれば、スナップショット取得に伴うディスク帯域幅のオーバーヘッドは小さくなるだろう。しかし、これにより小さなステートマシンではログが不必要に大きくなる可能性がある。
よりよいアプローチはスナップショットのサイズとログのサイズを比較することである。スナップショットがログよりも何倍も小さい場合、スナップショットを作成する価値があるだろう。しかし、スナップショットを作成する前にそのサイズを計算することは困難で負担が大きく、ステートマシンにかなりの記録管理の負荷を課したり、サイズを動的に算出するために実際にスナップショットを作成するのとほぼ同じ量の作業を必要としたりする可能性がある。スナップショットファイルを圧縮することもスペースと帯域幅の節約につながるが、圧縮後の出力サイズを予測することは難しい。
幸いなことに、次のスナップショットのサイズではなく以前のスナップショットのサイズを使用することで妥当な振る舞いが得られる。サーバは、以前のスナップショットのサイズに設定可能な拡張係数 (extension factor) を乗じた値をログのサイズが超えたときにスナップショットを作成する。拡張係数はディスク帯域幅とスペース利用率のトレードオフを行う。例えば拡張係数が 4 の場合、ディスク帯域幅の約 20% がスナップショットの作成に費やされ (スナップショット 1 バイトごとに 4 バイトのログエントリが書き込まれる)、1 つの状態コピー (古いスナップショット、その 4 倍の大きさのログ、そして書き込まれる新しいスナップショット) を保存するのに必要なディスク容量の約 6 倍のディスク容量が必要となる。
スナップショットの作成は依然として CPU およびディスク帯域幅のバーストを発生させ、クライアントの性能に影響を与える可能性がある。これはハードウェアを追加することで緩和できる。例えば 2 台目のディスクドライブを使用して追加のディスク帯域幅を提供できる。
また、スナップショット作成中のサーバでクライアントリクエストが待機することがないように、スナップショットをスケジューリングすることも可能かもしれない。このアプローチでは、サーバがクラスタ内で調整して、少数派のサーバだけが一度にスナップショットを作成する (可能であれば)。Raft ではログエントリをコミットするために過半数のサーバのみを必要とするため、少数派のサーバがスナップショットを作成しても通常はクライアントに悪影響を与えないだろう。リーダーがスナップショットを作成したい場合、まずそのサーバが退任し、その間は別のサーバにクラスタを管理させる。このアプローチが十分に信頼できるものであれば、スナップショットを並行して作成する必要性も排除できるだろう。つまり、サーバはスナップショットを取得している間、単に利用不能になるだけで良い (ただしこれはクラスタの故障を隠蔽する能力に影響する)。これはシステム全体の性能を向上させ、メカニズムを削減する可能性があるため、今後の研究にとって非常に興味深い機会である。
5.1.3 実装上の考慮事項
このセクションでは、スナップショットの実装に必要とされる主要なコンポーネントを概観し、それらの実装上の困難について議論する:
スナップショットの保存と読み込み: スナップショットの保存は、ステートマシンの状態を直列化し、そのデータをファイルに書き出す処理である。読み込みはその逆のプロセスである。様々な種類のデータオブジェクトをネイティブ表現から直列化するのはやや面倒であったが、我々はこれが比較的単純な作業であることに気づいた。ステートマシンからディスク上のファイルへのストリーミングインターフェースは、ステートマシンの状態全体をメモリにバッファリングするのを避けるのに役立つ。また、ストリームを圧縮してチェックサムを適用することも効果的かもしれない。LogCabin は、各スナップショットをまず一時ファイルに書き込み、書き込みが完了しディスクにフラッシュされた後にファイル名を変更する。これにより、サーバ起動時に部分的に書き込まれたスナップショットをロードすることがないことを保証する。
スナップショットの転送: スナップショットの転送には InstallSnapshot RPC のリーダー側とフォロワー側の実装が必要である。これは比較的単純であり、スナップショットのディスクへの書き込みと読み込みのコードと一部共有できる可能性がある。この転送の性能は通常それほど重要ではない (この状態を必要とするフォロワーはエントリのコミットに参加していないため、すぐに必要とされる可能性は低い; 一方で、クラスタが追加のの障害に見舞われた場合、可用性を回復するためにフォロワーを追いつかせる必要があるかもしれない)。
安全でないログアクセスとログエントリ破棄の排除: 我々は当初、ログ圧縮を考慮せずに LogCabin を設計したため、エントリ \(i\) がログに存在する場合、エントリ 1 から \(i-1\) も存在すると仮定していた。しかしログ圧縮ではこれはもはや真ではない。例えば AppendEntries RPC で前のエントリのタームを決定する際に、そのエントリが破棄されている可能性がある。コード全体からこの仮定を排除するには慎重な推論とテストが必要であった。より強力な型システムであれば、コンパイラがログへのすべてのアクセスにおいてインデックスが範囲外の場合も処理するように強制できれば、これはより容易になったであろう。すべてのログアクセスを安全にしてからは、ログのプレフィクスを破棄することは簡単になった。これまでは、スナップショットの保存、読み込み、転送を個別でしかテストできなかったが、ログエントリが安全に破棄できるようになったことで、これらすべてのシステム全体のテストを実行できるようになる。
コピーオンライトによるスナップショットの並行処理: スナップショットを並行して作成するには、ステートマシンの再設計やオペレーティングシステムの fork 操作の利用が必要になるかもしれない。LogCabin は現在 fork を使用しているが、これはスレッドや C++ のデストラクタと相性が悪く、これを正しく機能させるにはいくらかの困難があった。しかしコード量は少なく、ステートマシンのデータ構造を変更する必要性を完全に排除するため、我々はそれが正しいアプローチであったと考えている。
スナップショットのタイミングの決定: 開発中はすべてのログエントリを適用した後にスナップショットを作成することを推奨する。これはバグを迅速に発見するのに役立つだろう。実装が完了したら、スナップショットのタイミングに関するより有用なポリシーを追加すべきである (例えば Raft ログのサイズと最後のスナップショットのサイズに関する統計情報を使用するなど)。
我々は、スナップショットの段階的な開発とテストが困難であることを見出した。これらのコンポーネントのほとんどは、ログエントリを破棄できるようになる前に実装する必要があるが、その新しいコードパスの多くが実行されるのはシステム全体のテストより後になる。したがって、実装者はこれらのコンポーネントの実装とテストの順序を慎重に検討すべきである。
5.2 ディスクベースのステートマシンのスナップショット
このセクションでは、ディスクを主要な記録場所として使用する大規模なステートマシン (数十~数百ギガバイト規模) のスナップショット作成方法について議論する。これらのステートマシンは、クラッシュに備えて常にディスク上に状態のコピーを保持するという点で他のステートマシンとは異なる挙動を示す。Raft ログの各エントリを適用すると、ディスク上の状態が変更され、実質的に新しいスナップショットが作成される。したがって、エントリが適用されると Raft ログから削除できる。(ステートマシンはディスク効率を向上させるために書き込みをメモリにバッファリングすることもできる; それらがディスクに書き込まれると対応するエントリは Raft ログから削除できる。)
ディスクベースのステートマシンの主な問題は、ディスク上の状態の変更がパフォーマンスの低下につながる可能性があることである。書き込みバッファリングがない場合、適用されるコマンドごとに 1 つ以上のランダムなディスク書き込みが必要となり、これがシステム全体の書き込みスループットを制限する可能性がある (そして書き込みバッファリングはあまり効果がないかもしれない)。セクション 5.3 では、大規模なシーケンシャル書き込みによってディスクへ効率的に書き込むログ圧縮の増分アプローチについて議論する。
ディスクベースのステートマシンは、遅いフォロワーにディスクの一貫したスナップショットを提供できる必要がある。ディスク上には常にスナップショットが存在するが、それを継続的に更新している。したがって、一貫性のあるスナップショットを十分な期間保持して転送するために、依然としてコピーオンライト技術が必要である。幸いなことに、ディスクフォーマットはほぼ常に論理ブロックに分割されているため、ステートマシンにコピーオンライトを実装するのは容易である。ディスクベースのステートマシンは、スナップショットのためにオペレーティングシステムのサポートに頼ることもできる。例えば Linux の LVM (論理ボリューム管理) はディスクパーティション全体のスナップショットを作成するために使用できる [70]。また、最近のファイルシステムの中には個々のディレクトリのスナップショットを作成できるものもある [19]。
ディスクイメージのスナップショットのコピーには長い時間がかかり、ディスクへの変更が蓄積されるにつれてスナップショットを維持するために必要な追加のディスク使用量も増加する。我々はディスクベースのスナップショットは実装していないが、ディスクベースのステートマシンでは以下のアルゴリズムでディスクの内容を転送することで、こうしたオーバーヘッドの大部分を回避できると推測している:
各ディスクブロックについて、最終更新時刻を追跡する。
通常の操作を継続しながら、ディスクの内容全体をブロックごとフォロワーに転送する。この処理中、リーダー側では余分なディスク領域は使用されない。ブロックは並行して変更されているため、フォロワー上では不整合なディスクイメージになる可能性がある。リーダーから各ブロックが転送される際、その最終更新時刻を記録する。
ディスクの内容のコピーオンライトスナップショットを作成する。このスナップショットが作成されると、リーダーはディスクの内容の一貫したコピーを保持するが、クライアントによる継続的な操作によってディスクへの変更が発生するにつれ追加のディスク領域が使用される。
ステップ 2 で最初に送信されてからステップ 3 でスナップショットが作成されるまでの間に変更されたディスクブロックのみを再送する。
うまくゆけば、一貫したスナップショットのブロックのほとんどはステップ 3 でスナップショットが作成されるまでに既に転送されているだろう。もしそうならステップ 4 での転送は迅速に進行する。ステップ 4 でリーダーノード上にスナップショットを保持するために追加されるディスク容量は少なく、変更されたブロックを再送するためにステップ 4 で使用される追加のネットワーク帯域幅も少ないだろう。
5.3 増分クリーニングのアプローチ
ログクリーニング [97, 98] やログ構造マージツリー [84, 17] (LSM tree) といった圧縮に対する増分アプローチも可能である。これらはスナップショットよりも複雑だが、増分アプローチにはいくつかの望ましい特徴がある:
これらのアプローチは一度にデータの一部のみを処理するため、圧縮の負荷が時間の経過と共に均等に分散される。
これらは通常動作時と圧縮中の両方でディスクへの書き込みを効率的に行う。いずれの場合も大規模なシーケンシャル書き込みが行われる。増分アプローチはまた、最も再利用しやすい領域を持つディスクの一部を選択的に圧縮するため、(スナップショットごとにディスク全体を書き換える) メモリベースのステートマシンのスナップショットよりもディスクへの書き込みデータ量が少ない。
増分アプローチはディスク領域をその場で変更しないため、一貫性のある状態スナップショットを比較的容易に転送できる。
セクション 5.3.1 とセクション 5.3.2 では、まずログクリーニングと LSM ツリーの一般的な基礎について説明する。その後、セクション 5.3.3 でこれらを Raft に適用する方法について説明する。
5.3.1 ログクリーニングの基礎
ログクリーニングはログ構造化ファイルシステム [97] の文脈で導入され、最近では RAMCloud [98] などのインメモリストレージシステムにも提案されている。原則として、ログクリーニングはあらゆる種類のデータ構造に使用できるが、効率的に実装するのが他の構造より難しいものもある。
ログクリーニングはログをシステムの状態を記録する場所として維持する。レイアウトはシーケンシャル書き込みに最適化されており、読み取り操作は実質的にランダムアクセスとなる。したがって、データを読み取るためにインデックス構造が必要となる。
ログクリーニングでは、ログはセグメントと呼ばれる連続した領域に分割される。ログクリーナーの各パスは 3 段階のアルゴリズムを使用してログを圧縮する。
まず、不要となったエントリが大量に蓄積されているセグメントをクリーニング対象として選択する。
次に、それらのセグメントからライブエントリ (現在のシステム状態に影響を与えるエントリ) をログの先頭にコピーする。
最後に、セグメント用のストレージスペースを解放し、そのスペースを新しいセグメントに利用できるようにする。
通常の操作への影響を最小限に抑えるため、このプロセスは並行実行できる [89]。
ライブエントリをログの先頭にコピーした結果、エントリはリプレイ時に順序がずれることになる。ログを適用する際に正しい順序を再構築するために、エントリには追加情報 (バージョン番号など) を含む場合がある。
どのセグメントをクリーニング対象として選択するかというポリシーは性能に大きな影響を与える。先行研究では、ライブエントリによって使用されるスペースの量だけではなく、それらのエントリがどれくらいの期間ライブ状態のままかという要素も考慮した費用対効果の高いポリシーが提案されている [97, 98]。
エントリがライブであるかを判断するのはステートマシンの責任である。例えばキーバリューストアでは、キーを特定の値に設定するログエントリは、そのキーが存在し、現在その値に設定されている場合にライブである。キーを削除するログエントリがライブであるかを判断するのはより微妙である。そのキーを設定する以前のエントリがログに存在し続ける限り有効である。RAMCloud は必要に応じて (墓石 (tombstone) と呼ばれる) 削除コマンドを保存するが [98]、別の方法として、現在の状態にあるキーの要約を定期的に書き出し、その後、リストにはないキーに関するすべてのログエントリはライブでないと見なす方法がある。キーバリューストアはかなり単純な例である。他のステートマシンも可能ではあるが、残念ながらライブ状態の判断はそれぞれ異なる。
5.3.2 ログ構造マージツリーの基礎
ログ構造マージツリー (LSM ツリー) は O'Neil [84] によって初めて記述され、後に BigTable [17] によって分散システムで普及した。これらは Apache Cassandra [1] や HyperDex [27] などのシステムで使用されており、LevelDB [62] やそのフォーク (RocksDB [96] や HyperLevelDB [39]) のようなライブラリとしても利用可能である。
LSM ツリーは、順序付けられたキーと値のペアを格納するツリー状のデータ構造である。大まかに言えばこれらはログクリーニングのアプローチと同様にディスクを使用する。すなわち、大きなシーケンシャルストライドで書き込みを行い、ディスク上のデータをインプレースで変更しない。ただし、LSM ツリーはすべての状態をログに保存する代わりに、状態を再編成することでランダムアクセスを向上させる。
典型的な LSM ツリーは、最近書き込まれたキーをディスク上の小さなログに保存する。ログが一定サイズに達すると、キーでソートされ、ソートされた順序でラン (run) と呼ばれるファイルに書き込まれる。ランはインプレースで変更されることはないが、圧縮プロセスが定期的に複数のランをマージし、新しいランを生成して古いものを破棄する。このマージはマージソートを想起させる。キーが複数の入力ランに依存する場合、最新バージョンのみが保持されるため、生成されるランはよりコンパクトになる。LevelDB で使用される圧縮戦略は Figure 5.1 にまとめられている。これは効率性を高めるためにランを世代別に分離する (ログクリーニングに似ている)。
通常の操作中、ステートマシンはこのデータを直接操作できる。キーを読み取るには、まずそのキーがログ内で最近変更されたかを確認し、次に各ランをチェックする。検索のたびにすべてのランでキーをチェックするのを避けるために、一部のシステムでは各ランに対してブルームフィルタを作成する (これは、特定のケースでキーがランに存在しないことを確実に判断できるコンパクトなデータ構造だが、キーが存在しない場合でもランを検索する必要がある場合がある)。
5.3.3 Raft におけるログクリーニングとログ構造マージツリー
我々は Raft においてログクリーニングや LSM ツリーを実装しようとはしなかったが、どちらも上手く機能するのではないかと推測している。LSM ツリーを Raft に適用するのは比較的簡単である。Raft ログは既に最近のエントリをディスクに永続的に保存しているため、LSM ツリーは最近のデータをより便利なツリー形式でメモリ上に保持できる。これは検索処理を高速化し、Raft のログが一定サイズに達した時点でツリーは既にソートされた順序でディスクに新しいランとして書き込まれる準備が整っているだろう。リーダーから遅いフォロワーに状態を転送するには、すべてのランをフォロワーに転送する必要がある (ただしインメモリのツリーは送信しない)。幸いにもランは不変であるため、転送中にランが変更される心配はない。
ログクリーニングを Raft に適用するのはそれほど簡単ではない。我々はまず Raft ログをセグメントに分割してクリーニングするアプローチを検討した (Figure 5.4(a) 参照)。残念ながら、クリーニングを行うとセグメントが解放されたログに多くの穴を開けることになり、ログレプリケーションのアプローチを修正する必要がある。このアプローチは機能させることができると考えるが、Raft とステートマシンとの相互作用に大きな複雑性を加えることになる。さらに、Raft ログに追記できるのはリーダーのみであるため、クリーニングはリーダーベースである必要があり、リーダーのネットワーク帯域幅を消費することになるだろう (これについてはセクション 5.4 で詳しく説明する)。
よりよいアプローチはログクリーニングを LSM ツリーと同様に扱うことである。Raft は最近の変更に対して連続したログを保持し、ステートマシンは自身の状態をログとして保持するが、これらのログは論理的に区別されるだろう (Figure 5.4 参照)。Raft ログが一定サイズに達すると、新しいエントリはステートマシンのログに新しいセグメントとして書き込まれ、対応する Raft ログのプレフィクスは破棄される。ステートマシン内のセグメントは各サーバで独立してクリーニングされるため、Raft ログはこれによる影響を受けないだろう。ログクリーニングの複雑性はステートマシン内に完全にカプセル化されており (ステートマシンと Raft 間のインターフェースはシンプルなまま)、サーバは独立してクリーニングできるため、Raft ログを直接クリーニングするよりもこのアプローチを推奨する。
前述のように、このアプローチではステートマシンが Raft のすべてのログエントリを独自のログに書き込む必要がある (ただし大規模なバッチ処理も可能である)。この追加のコピーは、ログエントリからなるファイルを Raft のログから直接移動し、そのファイルをステートマシンのデータ構造に組み込むとで最適化できるかもしれない。これは性能が重視されるシステムにおいて有用な最適化となる可能性があるが、残念ながら、ステートマシンが Raft ログのディスク上の表現を理解する必要があるため、ステートマシンと Raft モジュールの結合度がより高くなるだろう。
(a) Raft ログを直接クリーンアップすると多くの穴が発生し、Raft とステートマシンとのやりとりが大幅に複雑になる。
(b) ステートマシンは代わりに自身のデータをログとして構造化し、Raft を介さずにそのログを独立してクリーンアップできる。
5.4 代替案: リーダーベースのアプローチ
本章で提示したログ圧縮アプローチはサーバがリーダーの知識なしに自身のログを圧縮するため、Raft の強力なリーダー原則から逸脱している。しかし我々はこの逸脱は正当化されると考える。リーダーの存在はコンセンサスに達する際の矛盾する決定を避けるのに役立つが、スナップショット作成時には既にコンセンサスが達成されているため矛盾した決定は発生しない。データは依然としてリーダーからフォロワーにのみ流れるが、フォロワーは独自にデータを再編成できるようになる。
我々はリーダーベースのログ圧縮アプローチも検討したが、通常は性能上の考慮事項の方がその利点を上回っている。リーダーがログを圧縮し、その結果をフォロワーに送信することは無駄が多く、フォロワーがそれぞれ独立してログを圧縮する方が効率的である。各フォロワーに冗長な状態を送信すると、ネットワーク帯域幅が浪費され、圧縮プロセスが遅くなる。各フォロワーは既に自身の状態を圧縮するために必要な情報を持っており、リーダーの送信ネットワーク帯域幅は通常、Raft の最も貴重な (ボトルネックとなる) リソースである。メモリベースのスナップショットの場合、サーバがローカル状態からスナップショットを作成する方が、ネットワーク経由でスナップショットを送受信するよりもはるかに安価である。増分圧縮アプローチの場合、これはハードウェア構成に依存するが、我々は独立した圧縮の方が安価であると予想する。
5.4.1 スナップショットのログへの保存
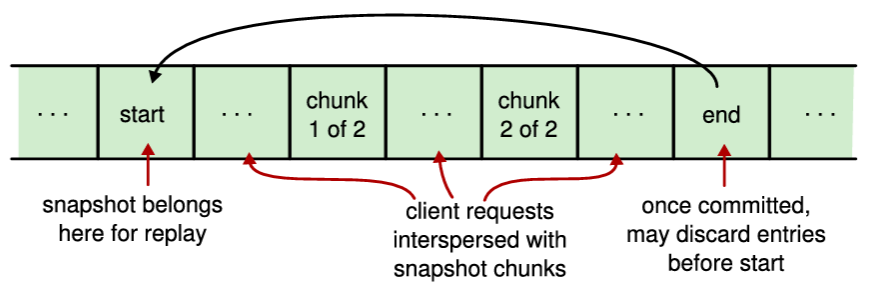
リーダーベースのアプローチで考えられる利点の一つは、もしシステム状態のすべてをログに保存できれば、状態を複製および永続化するための新しいメカニズムが不要になることである。したがって、Figure 5.5 に示すように、リーダーがスナップショットを作成してそのスナップショットを Raft ログ内のエントリとして保存するリーダーベースのスナップショットアプローチを検討した。リーダーは次に AppendEntries RPC を使用してこのスナップショットを各フォロワーに送信するだろう。通常の操作への支障を最小限に抑えるため、各スナップショットは複数のエントリに分割され、ログ内の通常のクライアントコマンドとインターリーブされるだろう。
この方法は、サーバがスナップショットを転送したり永続化するための個別のメカニズムを必要としない (スナップショットは他のログエントリと同様に複製され永続化される) ことから、スナップショットをログの外に保存するよりもメカニズムの経済性を高めるだろう。しかし、自身でスナップショットを生成できるフォロワーに対してネットワーク帯域を無駄にするだけでなく、別の深刻な問題がある。リーダーがスナップショット作成中に障害を起こすと、サーバのログに不完全なスナップショットが残される。原理的には、この現象が繰り返し発生して多数のスナップショット作成失敗が蓄積し、ゴミデータによってサーバのストレージ容量を枯渇させる可能性がある。したがって、このメカニズムは実際には実行可能ではないと考えている。
5.4.2 非常に小さなステートマシン向けのリーダーベースのアプローチ
非常に小さなステートマシンの場合、スナップショットをログに保存することは実行可能なだけではなく大幅な簡素化にもつながる。スナップショットが十分に小さい場合 (最大約 1MB)、通常の操作を長時間中断することなく、単一のログエントリに十分収まるだろう。このようにサーバのログを圧縮するためにリーダーは次のことを行う:
新しいクライアントリクエストの受け入れを停止する。
ログ内のすべてのエントリがコミットされ、ステートマシンがログ内のすべてのエントリを適用するまで待機する。
スナップショットを (同期的に) 作成する。
スナップショットをログの末尾に単一のログエントリとして追加する。
新しいクライアントリクエストの受け入れを再開する。
各サーバは、スナップショットエントリがコミットされたことを確認すると、ログ内のスナップショットより前のすべてのエントリを破棄できる。このアプローチは、クライアントリクエストが停止され、スナップショットエントリが転送されている間にわずかな可用性ギャップを引き起こすが、非常に小さなステートマシンにとってその影響は限定的だろう。
このようなよりシンプルなアプローチは、スナップショットをログの外部に永続化し、新しい RPC を使用して転送し、並行してスナップショットを取得する実装の労力を省く。しかし、成功したシステムは当初の設計者が想定した以上に利用される傾向があり、そのためこのアプローチは大規模なステートマシンではうまく機能しない可能性がある。
5.5 結論
本章では Raft におけるログ圧縮のいくつかのアプローチについて議論した。これは Figure 5.1 にまとめられている。ステートマシンのサイズ、要求される性能レベル、そして許容される複雑さの程度に応じて、システムごとに適切なアプローチは異なる。Raft は、共通の概念的フレームワークを共有する幅広いアプローチをサポートしている。
各サーバは、コミット済みのログのプレフィクスを独立して圧縮する。
ステートマシンと Raft の間の基本的なやりとりは、ログのプレフィクスに対する責任を Raft からステートマシンに委譲することを含む。ステートマシンがコマンドをディスクに適用すると、対応するログのプレフィクスを破棄するよう Raft に指示する。Raft は、破棄した最後のエントリのインデックスとターム、およびそのインデックス時点での最新の構成を保持する。
Raft がログのプレフィクスを破棄すると、ステートマシンは、再起動時に状態をロードすることと、遅いフォロワーに転送するために一貫性のあるイメージを提供するという 2 つの新しい責任を負う。
メモリベースのステートマシン向けのスナップショットは Chubby や ZooKeeper などいくつかの本番システムで成功裏に利用されており、我々はこのアプローチを LogCabin に実装した。インメモリデータ構造上での操作はほとんどの操作で高速だが、スナップショット作成プロセス中の性能は大きく影響を受ける可能性がある。スナップショットを並行して作成することでリソースの使用を隠蔽でき、将来的にはクラスタ全体のサーバを異なる時間にスナップショットを作成するようにスケジュールすることで、スナップショット作成がクライアントに全く影響を与えないようにできる可能性がある。
状態をディスク上でインプレースに変更するディスクベースのステートマシンは概念的には単純である。一貫性のあるディスクイメージを他のサーバに転送するためには依然としてコピーオンライトが必要だが、自然にブロックに分割されるディスクでは小さな負担かもしれない。しかし、通常の操作中のランダムなディスク書き込みは遅い傾向があるため、このアプローチはシステムの書き込みスループットを制限するだろう。
最終的に、増分アプローチが最も効率的な圧縮形式となり得る。一度に小さな状態の断片を操作することで、リソース使用のバーストを制限できる (そして並行して圧縮することもできる)。また、同じデータをディスクに繰り返し書き出すことを避けることもできる。安定したデータは、あまり頻繁に圧縮されないディスクの領域に配置する必要がある。増分圧縮の実装は複雑になるかもしれないが、この複雑さは LevelDB のようなライブラリにオフロードできる。さらに、データ構造をメモリに保持し、ディスクのより多くを部分をメモリにキャッシュすることで、増分圧縮によるクライアント操作の性能はメモリベースのステートマシンに近づく可能性がある。
Chapter 6 - クライアントとの相互作用
この章では、クライアントが Raft ベースの複製ステートマシンとどのように相互作用するかに関するいくつかの問題について説明する:
セクション 6.1 ではクラスタのメンバーが時間と共に変化する場合でも、クライアントがクラスタを見つける方法について説明する;
セクション 6.2 ではクライアントのリクエストが処理のためにクラスタリーダーにルーティングされる方法について説明する;
セクション 6.4 では Raft が読み取り専用リクエストをより効率的に処理する方法について説明する。
Figure 6.1 はクライアントが複製ステートマシンと対話するために使用する RPC を示している。これらの問題は、すべてのコンセンサスベースのシステムに当てはまり、Raft の解決策は他のシステムと同様である。
この章では Raft ベースの複製ステートマシンがネットワークサービスとしてクライアントに直接公開されていることを想定する。また Raft をクライアントアプリケーションに直接統合することもできる。この場合、クライアントとの対話におけるいくつかの問題は、組み込みアプリケーションのネットワーククラインとにまで持ち越される可能性がある。例えば、組み込みアプリケーションのネットワーククライアントは、Raft ネットワークサービスのクライアントが Raft クラスタを見つけるときに遭遇する問題と同様の問題を抱えることになる。
複製された状態を変更するためにクライアントによって呼び出される。
| clientId | リクエストを呼び出しているクライアント (§6.3) |
|---|---|
| sequenceNum | 重複排除のため (§6.4) |
| command | ステートマシンへの要求, 状態に影響を与える可能性がある |
| state | ステートマシンがコマンドを適用するとき OK |
|---|---|
| response | 成功の場合、ステートマシンの出力 |
| leaderHint | 既知の場合、最近のリーダーのアドレス (§6.2) |
- リーダーでない場合は NOT_LEADER を応答し、既知のリーダーのヒントがあれば提供 (§6.2)
- コマンドをログに追加し、複製してコミット
- clientId の記録がない場合、またはクライアントの sequenceNum に対する応答がすでに破棄されている場合は SESSION_EXPIRED を応答 (§6.3)
- sequenceNum が既にクライアントから処理されている場合、保存されている応答と共に OK を応答 (§6.3)
- ログの順序に従ってコマンドを適用
- クライアントの sequenceNum を含むステートマシン出力を保存し、クライアントの以前の応答を破棄 (§6.3)
- ステートマシン出力と共に OK を応答
新しいセッションをオープンするために新しいクライアントによって呼び出され、重複したリクエストを排除するために使用される。§6.3
| state | ステートマシンがクライアントを登録したとき OK |
|---|---|
| clientId | クライアントセッションの一意な識別子 |
| leaderHint | 既知の場合、最近のリーダーのアドレス |
- リーダーでない場合は NOT_LEADER を応答し、ヒントがある場合はそれを提供 (§6.2)
- register コマンドをログに追加し、複製してコミット
- ログの順序に従ってコマンドを適用し、新しいクライアントにセッションを割り当て
- 一意のクライアント識別子 (この register コマンドのログインデックスを使用可能) で OK を応答
複製された状態を紹介するためにクライアントによって呼び出される。§6.4
| query | ステートマシンに対するリクエスト、読み取り施用 |
|---|
| state | ステートマシンがクエリーを実行したとき OK |
|---|---|
| response | 成功の場合、ステートマシンの出力 |
| leaderHint | 既知の場合、最近のリーダーのアドレス |
- リーダーでない場合は NOT_LEADER を応答し、ヒントがある場合はそれを提供 (§6.2)
- 最後にコミットされたエントリがこのリーダーのタームのものになるまで待機
- commitIndex をローカル変数 readIndex に保存 (下記参照)
- 新しいハートビートを送信し、過半数のサーバからの応答を待機
- ステートマシンが少なくとも readIndex ログエントリまで進むまで待機
- クエリーを処理
- ステートマシンの出力で OK を応答
- リーダーになるとログに no-op エントリを追加する
- 選挙タイムアウトが経過しても過半数のサーバへのハートビート送信が成功しない場合はフォロワーに切り替わる
6.1 クラスタの検出
Raft がネットワークサービスを公開している場合、クライアントは複製ステートマシンとやりとりするためにクラスタの場所を特定する必要がある。メンバーシップが固定のクラスタの場合は簡単で、例えばサーバのネットワークアドレスは設定ファイルに静的に格納できる。しかし、(第 4 章で説明するように) サーバセットが時間の経過と共に変化する可能性がある場合、クラスタの検出はより困難である。一般的には 2 つのアプローチがある:
クライアントは、ネットワークブロードキャストまたはマルチキャストを使用してすべてのクラスタサーバを検出できる。ただし、これはこれらの機能をサポートする特定の環境でのみ機能する。
クライアントは、既知の場所からアクセス可能な DNS などの外部ディレクトリサービスを介してクラスタサーバを検出できる。この外部システム内のサーバリストは一貫している必要はないが、包括的である必要がある。クライアントは常にすべてのクラスタサーバを検出できる必要があるが、現在クラスタのメンバーではない追加のサーバをいくつか含めていても問題はない。したがって、クラスタメンバーシップが変更された場合、メンバーシップの変更前にクラスタに追加されるサーバが含まれるようにサーバの外部ディレクトリを更新し、メンバーシップ変更が完了した後にクラスタの一部でなくなったサーバが削除されるように再度更新する必要がある。
LogCabin クライアントは現在 DNS を使用してクラスタを検索する。LogCabin は現在メンバーシップ変更の前後で DNS レコードを自動的に更新しない (これは管理スクリプトによって実行される)。
6.2 リーダーへのリクエストのルーティング
Raft のクライアントリクエストはリーダーを介して処理されるため、クライアントはリーダーを見つける手段が必要である。クライアントが最初に起動するとランダムに選択されたサーバに接続する。クライアントが最初に選んだサーバがリーダーではない場合、そのサーバはリクエストを拒否する。このとき、非常に単純なアプローチは、クライアントはリーダーが見つかるまでランダムに選択された別のサーバで再試行することである。クライアントがサーバを無作為に選択する場合、この単純なアプローチは \(n\)-サーバクラスタのリーダーを期待値 \(\frac{n+1}{2}\) 回の試行で見つける。これは小規模なクラスタであれば十分な速度である。
リーダーへのリクエストルーティングも単純な最適化で高速化できる。AppendEntries リクエストにはリーダーの ID が含まれているため、通常、サーバは現在のクラスタリーダーのアドレスを知っている。リーダーでないサーバがクライアントからのリクエストを受け取ると、次の 2 のどちらかを実行する:
1 つ目の方法は、サーバがリクエストを拒否し、既知であればリーダーのアドレスをクライアントに返すというものである。これは我々が推奨し LogCabin でも実装している。これにより、クライアントはリーダーに直接再接続できるようになり、以降のリクエストはフルスピードで進められるようになる。また既に、リーダーが故障した場合にクライアントは別のサーバに再接続する必要があるため、実装に必要な追加コードはほとんどない。
別の方法として、サーバがクライアントのリクエストをリーダーにプロキシすることができる。これは場合によってはシンプルな選択肢である。例えば、クライアントが読み取りリクエストのために任意のサーバに接続する場合 (セクション 6.4 参照)、クライアントの書き込みリクエストをプロキシすることで、クライアントは書き込みのためだけに使用されるリーダーへの個別の接続を管理する必要がなくなる。
Raft は、古くなったリーダーシップ情報がクライアントのリクエストをいつまでも延期されることを防ぐ必要もある。リーダーシップ情報は、リーダー、フォロワー、クライアントなど、システム全体で古くなる可能性がある:
リーダー: サーバはリーダー状態にあるかも知れないが、それが現在のリーダーではない場合、クライアントのリクエストを無駄に送らせている可能性がある。例えば、あるリーダーがクラスタの他のサーバから分離されているものの、特定のクライアントとは通信できているとする。追加のメカニズムがなければ、そのクライアントからのリクエストを永久に遅延させ、ログエントリを他のサーバに複製できない可能性がある。一方、クラスタの過半数と通信でき、クライアントのリクエストをコミットできる、より新しいタームの別のリーダーがいるかも知れない。このように、Raft のリーダーはクライアントの過半数へのハートビート送信が成功しないまま選挙タイムアウトが経過すると降格する。これにより、クライアントは別のサーバにリクエストを再試行できる。
フォロワー: フォロワーはクライアントをリダイレクトまたはプロキシができるようにリーダーの ID を追跡しておく。フォロワーは、新たな選挙を開始するときやタームが変更されるときにこれらの情報を破棄する必要がある。さもないとクライアントを不必要に遅延させるかもしれない (例えば 2 つのサーバが互いにリダイレクトし合い、クライアントが無限ループに陥る可能性がある)。
クライアント: クライアントがリーダー (または特定のサーバ) との接続を失ったとき、単にランダムなサーバで再試行すべきである。最後に接続したリーダーへの接続を要求し続けると、そのサーバに障害が発生したときに不必要な遅延が発生する。
6.3 線形可能なセマンティクスの実装
これまで説明したように Raft はクライアントに対して at-least-one セマンティクスを提供する。複製ステートマシンはコマンドを複数回適用するかもしれない。例えば、クライアントがリーダーにコマンドを送信し、リーダーがそのコマンドをログに追加し、ログエントリをコミットしたが、クライアントに応答する前にクラッシュしたとする。クライアントは確認応答を受信していないため、コマンドを新しいリーダーに再送し、リーダーはそのコマンドを新しいエントリとしてログに追加し、この新しいコマンドをコミットする。クライアントはコマンドを 1 回だけ実行するつもりだったが 2 回実行された。また、ネットワークがクライアントのリクエストを重複させる可能性がある場合、クライアントが関与していなくてもコマンドが複数回適用される可能性がある。
この問題は Raft 固有のものではなく、ほとんどのステートフル分散システムで発生する。しかし、このような at-least-once セマンティクスは、特にクライアントが通常より強力な保証を必要とするコンセンサスベースのシステムには適していない。コマンドの重複による問題は、クライアントが回復するのが困難な微妙な形で現われることがある。この問題は、誤った結果、誤った状態、またはその両方を引き起こす。Figure 6.2 は誤った結果の例を示している。ステートマシンはロックを提供しているが、クライアントは (確認応答を受け取っていない) 元のリクエストが既にロックを獲得しているため、ロックを取得できない。誤った状態の例としてはインクリメント操作が挙げられる。クライアントは値を 1 ずつ増やすつもりだが、実際には 2 以上増えてしまう可能性がある。ネットワークレベルの並べ換えや並行クライアントはさらに驚く結果をもたらす可能性がある。
Raft における我々の目標は、これらの問題を回避する線形化可能なセマンティクス [34] を実装することである。線形化可能性 (linearizability) とは、各操作が呼び出しから応答までのある時点で、瞬時に、正確に一度だけ (exactly once) 実行されているように見えることを意味する。これは、クライアントが推論しやすい強力な一貫性であり、コマンドが複数回処理されることを禁止する。
Raft で線形可能性を実現するにはサーバが重複リクエストをフィルタリングする必要がある。基本的な考え方は、サーバがクライアントの操作結果を保存し、それを使って同じリクエストを複数回実行しないようにすることである。これを実装するために、各クライアントには一意な識別子が付与され、クライアントはすべてのコマンドに一意のシリアル番号を割り当てる。各サーバのステートマシンは各クライアントのセッションを維持する。セッションは、クライアントに対して処理された最新のシリアル番号と、それに対応する応答を追跡する。サーバは、既に実行されたシリアル番号のコマンドを受信した場合、リクエストを再実行せずに即座に応答する。
このように重複リクエストをフィルタリングすることで Raft は線形可能性を提供する。Raft のログはすべてのサーバでコマンドが適用される順序を提供する。コマンドは、Raft ログに最初に現われた順序に、瞬時に、かつ正確に一度だけ有効になる。これは前述のようにステートマシンによって後続の出現がフィルタリングされるためである。
このアプローチはまた、一つのクライアントからの並行リクエストを許可するように一般化できる。クライアントのセッションは、クライアントの最新のシーケンス番号と応答だけを追跡するのではなく、シーケンス番号とレスポンスのペアのセットも追跡する。クライアントは各リクエストにまだ応答を受け取っていない最小のシーケンス番号を組み込む。ステートマシンはそれより低いシーケンス番号の応答をすべて破棄する。
残念ながら、スペースが限られているためセッションを永久に保持することはできない。サーバは最終的にクライアントのセッションを終了することを決定しなければならないが、このことは 2 つの問題を生み出す。1 つは、サーバがクライアントのセッションを期限切れにするタイミングをどのように合意するか、もう 1 つは、セッションが期限切れになるのが早すぎたアクティブなクライアントをどのように処理するかである。
サーバはクライアントのセッションを期限切れにするタイミングについて合意する必要がある。そうでなければ、サーバのステートマシンが互いに乖離する可能性がある。例えば、あるサーバが特定のクライアントのセッションを期限切れにし、そのクライアントの重複したコマンドをいくつも再適用したとする。一方、他のサーバはセッションを維持して重複したコマンドを適用しなかったとする。複製ステートマシンは一貫性を失うことになる。このような問題を回避するには、通常のステートマシンの操作と同様に、セッションの終了も決定論的でなければならない。1 つの解決策は、セッション数に上限を設定し、LRU (Least Recently Used) ポリシーを使用してエントリを削除することである。もう 1 つの選択肢は、合意された時間ソースに基づいてセッションを期限切れにすることである。LogCabin では、リーダーは Raft ログに追加する各コマンドに現在時刻を追加する。サーバはログエントリをコミットするときにこの時刻について合意し、その後、ステートマシンはこの時間入力を決定論的に使用して非アクティブなセッションを期限切れにする。ライブクライアントはセッションを維持するために非アクティブな期間中に keep-alive リクエストを発行する。このリクエストもリーダーのタイムスタンプが追加され、Raft ログにコミットされる。これによりセッションは維持される。
2 つ目の問題は、セッションが終了した後も操作を続けるクライアントにどう対処するかである。これは例外的な状況だと想定しているが、一般にクライアントがいつ終了したかを知る方法がないため、常に何らかのリスクが存在する。一つの選択肢は、クライアントの記録がないときはいつでも新しいセッションを割り当てることであるが、この方法では、クライアントの以前のセッションの有効期限が切れる前に実行されたコマンドが重複して実行されるリスクがある。より厳密な保証を提供するためには、サーバは新しいクライアントとセッションの有効期限が切れたクライアントを区別する必要がある。クライアントが最初に起動すると、RegisterClient RPC を使用してクラスタに自身を登録できる。これにより、新しいクライアントのセッションが割り当てられ、クライアントに識別子が返される。クライアントは後続するすべてのコマンドにこの識別子を含める。ステートマシンがセッションの記録がないコマンドに遭遇した場合、そのコマンドは処理されず、代わりにクライアントにエラーを返す。LogCabin は現在、この場合クライアントをクラッシュさせる (ほとんどのクライアントはセッション有効期限エラーを適切に正しく処理できない可能性があるが、システムは通常、クライアントのクラッシュを既に処理しているはずである)。
6.4 読み取り専用クエリーのより効率的な処理
読み取り専用のクライアントコマンドは、複製ステートマシンへのクエリーのみを実行して更新は行わない。したがって、サーバのステートマシンが同じ順序で複製することを目的とした Raft ログをこのようなクエリーがバイパスできるかという疑問は当然生じる。ログをバイパスすることは性能上の魅力的な利点を提供する。読み取り専用クエリーは多くのアプリケーションで一般的であり、ログにエントリを追加するために必要な同期ディスク書き込みは時間がかかる。
しかし、追加の予防措置をしなければ、ログをバイパスすることで読み取り専用クエリーの結果が古く (stale) なる可能性がある。例えば、リーダーがクラスタの他の部分から分断され、クラスタの残りの部分が新しいリーダーを選出し、新しいエントリを Raft ログにコミットしている可能性がある。分断されたリーダーが他のサーバに問い合わせをせずに読み取り専用クエリーに応答した場合、古い結果を返すことになり線形化可能ではなくなる。線形化可能性を実現するには、読み取り結果が読み取り開始後のシステム状態を反映する必要がある。つまり、各読み取りは少なくとも最後にコミットされた書き込みの結果を返す必要がある。(ステールリード (stale read) を許可するシステムは、一貫性のより弱い形態である直列化可能性 (serializability) しか提供しない。) ステールリードによる問題はすでに 2 つのサードパーティ Raft 実装 [45] で発見されているため、この問題には注意が必要である。
幸いなことに、読み取り専用クエリーでは Raft ログをバイパスして線形化可能性を維持することが可能である。これを行うために、リーダーは次のステップを実行する:
リーダーが現在のタームのエントリをまだコミット済みとしてマークしていなければマークするまで待機する。Leader Completeness Property はリーダーがすべてのコミット済みエントリを持っていることを保証するが、タームの開始時にはどのエントリがコミット済みであるか分らない可能性がある。これを確認するには、そのタームからエントリをコミットする必要がある。Raft は各リーダーがタームの開始時に空の no-op エントリをログにコミットすることでこれを処理する。この no-op エントリがコミットされるとすぐに、リーダーのコミットインデックスは少なくともそのターム中の他のサーバのコミットインデックスを同じ大きさになる。
リーダーは現在のコミットインデックスをローカル変数 readIndex に保存する。これは、クエリーが操作する状態のバージョンの下限として使用される。
リーダーは自分が知らないうちに新しいリーダーに取って代わられていないことを確認する必要がある。新しいハートビートのラウンドを発行してクラスタの過半数からの確認応答を待つ。これらの確認応答を受信すると、リーダーはハートビートを送信した時点でそれ以上のタームのリーダーが存在しなかったことを認識する。したがって readIndex は、その時点でクラスタ内のどのサーバでも確認された最大のコミットインデックスとなる。
リーダーは自身のステートマシンが少なくとも readIndex まで進むのを待つ。これは線形化可能性を満たすのに十分な最新な状態である。
最後に、リーダーは自身のステートマシンに対してクエリーを発行し、結果をクライアントに応答する。
このアプローチは同期ディスク書き込みを回避できるため、ログの新しいエントリとして読み取り専用クエリーをコミットするより効率的である。効率をさらに向上させるために、リーダーはリーダーシップの確認にかかるコストを償却できる。つまり、蓄積した読み取り専用リクエストの数に関係なく 1 回のハートビート送信で済む。
フォロワーは読み取り専用クエリーの処理負荷を軽減することもできる。これにより、システムの読み取りスループットが向上するだけでなく、リーダーの負荷を軽減できるため、リーダーはより多くの読み取りと書き込みリクエストを処理できるようになる。しかし、追加の予防装置を講じないとこのような読み取りによって古いデータが返されるリスクもある。例えば、分断されたフォロワーは、長期にわたってリーダーから新しいログエントリを受信しないかもしれない。また、フォロワーがリーダーからハートビートを受信しても、そのリーダー自身が退位していて、まだそれを知らない可能性がある。安全に読み取りを処理するために、フォロワーはリーダーに対して現在の readIndex を要求するリクエストを発行できる (リーダーは上記のステップ 1~3 を実行する)。フォロワーは蓄積された読み取り専用クエリーの数に応じて、自身のステートマシン上でステップ 4 と 5 を実行できる。
LogCabin は上記のアルゴリズムをリーダーノードに実装し、高負荷時に複数の読み取り専用クエリー間でハートビートのコストを分散させる。現在、LogCabin のフォロワーは読み取り専用リクエストに対応していない。
6.4.1 クロックを使用した読み取り専用クエリーのメッセージング削除
これまで提案されてきた読み取り専用クエリーのアプローチは、非同期モデル (クロック、プロセッサ、メッセージがすべて任意の速度で動作できるモデル) における線形化可能性を提供してきた。このレベルの安全性を実現するには通信が必要である。つまり、読み取り専用クエリーのバッチごとにクラスタの半分にハートビートのラウンドを送信する必要であり、クエリーのレイテンシが増加する。このセクションの残りの部分では、クロックを使用することで読み取り専用クエリーがメッセージ送信を完全に回避する代替案を探る。LogCabin は現在この選択肢を実装しておらず、性能要件を満たす必要がある場合を除いて使用は推奨しない。
読み取り専用クエリーにメッセージの代わりにクロックを使用するには、通常のハートビートメカニズムで一種のリース (lease) [33] を提供する。リーダーのハートビートがクラスタの過半数から確認応答を受けると、リーダーは選挙タイムアウトまでの間、他のサーバがリーダーにならないと想定し、それに応じてリースを延長することができる (Figure 6.3 参照)。その期間中、リーダーは追加の通信を行わずに読み取り専用クエリーに応答する。(第 3 章で示したリーダー交替メカニズムではリーダーを早期に交替できる。リーダーはリーダーシップを後退する前にリースを期限切れにする必要がある。)
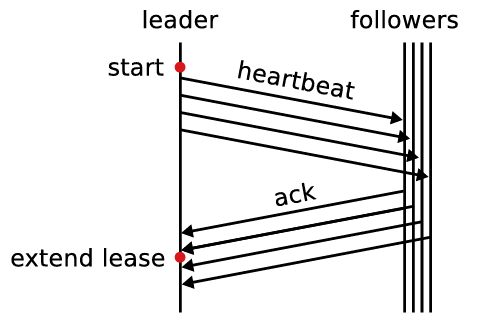
リース方式では、サーバ間のクロックドリフトに上限が設定されていることを前提とする (ある期間中、どのサーバのクロックもこの上限値と他のサーバのクロック値の積を超えて増加することはない)。この上限を発見し維持することは運用上の課題となる可能性がある (例えばスケジューリングやガーベッジコレクションによる一時停止、仮想マシンのマイグレーション、時刻同期のためのクロックレート調整など)。この前提が破られると、システムは恣意的に古い情報を返す可能性がある。
幸いなことに、単純な拡張によってクライアントに提供される保証を改善できるため、非同期の想定下でも (クロックが誤動作しても) 各クライアントは複製ステートマシンの単調な進行 (逐次一貫性) を見ることができる。例えば、クライアントはログインデックス \(n\) の状態を見ることができず、その後、別のサーバに変更するとログインデックス \(n-1\) の状態だけを見るといった単調増加を見ることができる。この保証を実装するには、サーバはクライアントへの各応答にステートマシンの状態に対応するインデックスを含める。クライアントは自分が見た結果に対応する最新のインデックスを追跡し、リクエストごとにこの情報をサーバに提供する。サーバが最後に適用したログインデックスよりも大きなインデックスを見たクライアントの要求を受け取った場合、サーバはそのリクエストを (まだ) 処理しない。
6.5 結論
この章ではクライアントと Raft の相互作用におけるいくつかの問題について説明した。線形化可能性の提供と読み取り専用クエリーの最適化の問題は、特に正確性という観点から微妙な問題である。残念ながら、コンセンサスに関する文献はクラスタサーバ間の通信のみを対象としているため、これらの重要な問題が見落とされている。我々はこれが間違いであると考えている。完全なシステムはクライアントと正しくやりとりしなければならない。そうでなければ、コアとなるコンセンサスアルゴリズムによって提供される一貫性のレベルは無駄になってしまう。実際の Raft ベースのシステムで既に見てきたように、クライアントとのやりとりはバグの大きな原因になり得るが、これらの問題をより深く理解することで将来の問題を未然に防ぐことができると期待している。
Chapter 7 - Raft ユーザ調査
これは Raft の各側面を評価する 4 つの章の最初である。
本章では Raft の理解しやすさを評価する。
第 8 章では Raft の正しさを議論する。
第 9 章では Raft のリーダー選出アルゴリズムを評価する。
第 10 章では Raft の実装を議論し、その性能を評価する。
我々は著者間と経験的証拠に基づいて Raft が理解しやすいように設計したが、その理解しやすさをより客観的に評価したいと考えた。理解しやすさを測定することは本質的に困難であるものの、これは我々にとって 2 つの理由から重要であった。1 つは、評価がなければ Raft が理解しやすいという我々の中心的な主張を正当化することは難しいだろう。2 つ目に、我々の目的の 1 つはコンピュータシステムにおける理解しやすさを第一の機能として提供することであったため、その評価方法を提案する負担も担っていた。
Raft の理解しやすさを評価するために、我々は実験的な研究を実施した。この研究では、学生が各アルゴリズムを学習した後に Raft と Paxos に関するクイズに解答する能力を比較した。参加者はスタンフォード大学とカリフォルニア大学バークレー校の上級学生部と大学院生であった。我々は Raft のビデオ講義と Paxos のビデオ講義を録画し、対応するクイズを作成した。Raft の講義は Raft の基本アルゴリズム (第 3 章) を扱い、任意のメンバーシップ変更のためジョイントコンセンサスアプローチ (セクション 4.3) を簡単に扱った。Paxos の講義は、単一決定 Paxos、Multi-Paxos、クラスタメンバーシップ変更、および現実で必要となるいくつかの最適化 (リーダー選出など) を含む、同等の複製ステートマシンを構築するのに十分な内容を扱った。講義ビデオとスライドはオンラインで入手可能である [88]。クイズはアルゴリズムの基本的な理解度をテストし、学生にコーナーケースについて推論することも求めた。各学生は 1 つのビデオを視聴し、対応するクイズを受け、2 番目のビデオを視聴し、2 番目のクイズを受けた。参加者の約半分は Paxos の部分を、残りの半分は Raft の部分を最初に実施し、個人差によるパフォーマンスの違いと、研究の前半から得られる経験の両方を考慮に入れた。我々は参加者の 2 つのクイズのスコアを比較し、参加者が Paxos よりも Raft をよりよく理解しているかどうかを判断した。
平均して、参加者は Raft クイズの方が Paxos クイズよりも 22.6% の高いスコアを獲得した (60 点満点中、Raft の平均スコアは 25.7 点、Paxos の平均スコアは 21.0 点であった)。人々が Paxos と Raft のどちらを最初に学ぶかを考慮すると、線形回帰モデルは、Paxos を初めて学習する学生の場合、Paxos クイズよりも Raft クイズで 12.5 点高いスコアを予測する。セクション 7.4.1 ではクイズの結果を詳細に分析する。
我々はまた、クイズ後に参加者にアンケートを実施し、どちらのアルゴリズムの実装または説明が容易だと感じたかを尋ねた。参加者の圧倒的多数 (各質問に対して 41 人中 33 人) が Raft の方が実装も説明も容易であると回答した。しかし、これらの自己申告による感覚は、参加者のクイズのスコアよりも信頼性が低い可能性がある。セクション 7.4.2 ではアンケートの結果を詳細に分析する。
我々の研究はシステム研究としては異例であり、その設計と実施を通して多くの教訓を得た。例えば、ユーザ調査では結果を見る前にほぼすべての作業を完了する必要があり、誤りが許される余地はほとんどない。2 つのセクションで我々が学んだ教訓を議論する。セクション 7.2 では我々の手法と資料の開発において検討した数多くの設計上の決定について考察する。セクション 7.5 では実験がいかに Raft の理解しやすさについて他者を効果的に納得させたか、そしてそれが費やした時間と労力に見合うものであったかを考察する。
7.1 調査の課題と仮説
本研究における我々の主要な目標は Raft の理解しやすさを示すことであった。開発者は不必要な時間と労力の負担なしに正しい実装を作成できるほど Raft アルゴリズムを十分に習得できるべきである。残念ながら、Raft の理解しやすさを直接測定することは困難である。理解しやすさの確立された尺度はなく、Raft が最も理解しやすいアルゴリズムであるかどうかを知る方法もない。
実験を行うには測定可能な指標とテスト可能な仮説を策定する必要があった。まず、誰かの理解しやすさを測定するための代理指標が必要だった。我々は参加者にクイズを受けさせ、そのクイズスコアを測定することを選択した (セクション 7.2.3 では参加者にアルゴリズムを実装して貰う代替案について説明する)。次に、Raft と他のコンセンサスアルゴリズムにおける参加者のクイズスコアを比較する必要があった。我々は Raft を、現在最も広く使用されているコンセンサスアルゴリズムである Paxos と比較することを選択した。
我々の研究では以下の問いを探求することを目指した:
- Raft は Paxos よりも理解しやすいか?
我々は学生が Paxos クイズよりも Raft クイズで高いスコアを出すと予測した。
- Raft のどの側面が最も理解しにくいか?
この問いは Raft の理解度をさらに改善するのに役に立つ可能性があるため我々の関心を寄せた。学生が Raft におけるコミットメントとメンバーシップ変更に最も苦労する可能性が高いと考えた。これらは Raft の説明において最も複雑で困難な側面であると感じたため、学生がこれらを理解するのに最も苦労する可能性が高いと我々は考えた (これは Raft のよりシンプルな単一サーバのメンバーシップ変更アルゴリズムよりも古いものである)。また、Paxos ベースのメンバーシップアプローチは説明がよりシンプルであると感じた (ただし、未解決のまま残る二次的な問題は重大である)。
- Paxos を知っていることが Raft の学習にどう影響するか、またその逆はどうか?
我々は学生が一般的に 2 回目のクイズでより高いスコアを出すだろうと予測した。これには 2 つの理由があった。第一に、コンセンサスアルゴリズムは基本的な概念を共有しており、学生は同じ概念を 2 度目に見たとき、より容易に把握できるはずである。第二に、講義とクイズが同じ形式であったため、学生は最初の講義とクイズの間に有用な経験を得ると考えた。
- 人々は他の選択肢よりも Raft を好むだろうか?
我々は Raft の理解しやすさから Raft を実装し説明することを好むだろうと予測した。
7.2 手法に関する議論
コンピュータシステム分野の文献においてこの種の実験の前例がほとんどなかったため、我々は多くの実験設計の決定を第一原理から推論した。このプロセスにおいて Scott Klemmer の貴重な支援に特に感謝する。このセクションでは、我々が書く決定について検討した代替案を記述することにより、なぜこの手法に至ったかを説明する。具体的には以下の点についてである。
- 参加者の選択と、参加意欲の向上方法 (セクション 7.2.1)
- 参加者にアルゴリズムを教える方法 (セクション 7.2.2)
- 理解度をテストする方法 (セクション 7.2.3)
- 彼らの成績を評価する方法 (セクション 7.2.4)
- アンケート調査でどのような質問をするか (セクション 7.2.5)
- 研究開始前に問題を発見し修正する方法 (セクション 7.2.6)
我々が最終的に採用を決定した手法については、後のセクション 7.3 でより正式な APA (アメリカ心理学会) 形式で提示する。
我々が適用した共通の原則の一つは、アルゴリズムの学習曲線の初期段階で参加者をテストすることであった。我々は、参加者が知識ゼロの状態から中程度の理解度へとどれだけ容易に移行できるかを知りたかった。参加者が少なくとも両方のアルゴリズムについて基本的な理解を得ることを望んだが、過度に準備させることは望まなかった。無限の時間があればほとんどの参加者は最終的にどのようなコンセンサスアルゴリズムでも理解するだろう。したがって、アルゴリズム間の違いを測定するには、学習曲線の初期段階で参加者をテストする必要があった。例えば、これは次のサブセクションで述べるように、参加者の動機付けにおいて葛藤が生じたことを意味した。参加者にはアルゴリズムを試して貰いたい一方で、アルゴリズムを広範囲にわたって学習させることは望まなかった。
7.2.1 参加者
我々はスタンフォード大学とバークレー大学の両方の学生に研究の参加を依頼した。これはサンプルサイズを増やして結果の一般性を広げることにつながった。良好で同じ資料と手順を使用することを選択したのは、学校間での参加者の成績を比較できるようにするためであった。
我々は、学生の研究参加を促すために、コースの成績を利用する様々な方法を検討した。学生が各アルゴリズムの学習に均等な努力を払い、外部情報を使用したり過度に学習したりせず、講義を視聴して予習するだけで済むようにしたいと考えた。しかし、学生の参加を促すために検討したそれぞれの方法には大きな懸念があった:
もし、学生の参加がコースの成績に影響し、不正解の回答であっても単位が得られる場合、学生が講義に注意を払わないのではないかと懸念した。例えば、講義をスキップしてクイズに適当な回答を記入した学生でも、コースの成績には全単位が付与されることになるだろう。
もし、クイズのスコアがコースの成績に影響する場合、学生がクイズの準備に過度に時間を費やしたり、同じ成績を得るために理解の難しいアルゴリズムに一層努力したりするのではないかと懸念した。我々は学習曲線の初期段階で参加者をテストすることを望んでおり、学生がアルゴリズムをあまりにも深く理解しすぎて、質問によってアルゴリズム間の理解度の差がまったく測定できない状況にはしたくなかった。また、各アルゴリズムに同等の努力を費やして貰いたかった。
- もし参加やクイズの高得点に対して学生に追加のコース単位を付与すると、成績の悪い学生やストレスを感じやすい学生が参加者に過剰に代表される可能性を懸念した。
我々が検討したもう一つのアイディアは、どちらかのクイズで少なくとも 50% のスコアを獲得した学生にコースの全単位を与えるというものであった。このアプローチでは、クイズの特典についてあまりにも多くの解釈の余地を残してしまうことが懸念された。例えば、学生は最初のアルゴリズムで十分な成績を収めたと確信した後、そこで学習を止めてしまうだろうか? 学生は Raft で良い成績を収めることを目差し、Paxos クイズについては気にしない (またはその逆) であろうか?
スタンフォードの学生については、最終的に研究への妥当な参加に対してコースの全単位 (総コース成績の 5%) を与えることを決定した。我々はこの定義を意図的に曖昧にしたが、学生が研究に何らかの努力を払ったと見なされた場合、コースの全単位を付与した。また学生にはこの資料がコースの期末試験に再び出題される可能性があることも伝えた。スタンフォード大学のクラスではほぼ全員が授業に参加した (Table 7.1 参照)。
しかし、バークレー大学の参加者に対する唯一のインセンティブは、資料を学習する機会であった。バークレーのクラスの担当教員は、研究への参加をコースの成績に含めないことを選択し、そのクラスには試験が実施されなかった。追加のインセンティブがなくても、バークレー大学のクラスの学生の少なくとも 3 分の 1 が参加した (Table 7.1 参照)。
| 大学 | 総数 | 1 回以上のクイズ | 両方のクイズ | 完全な学習 | インセンティブ |
|---|---|---|---|---|---|
| スタンフォード | 34 | 33 | 31 | 31 | 5% の卒業単位, 最終試験 |
| バークレー | 46 | 16 | 12 | 11 | なし |
| 合計 | 80 | 49 | 43 | 42 | - |
7.2.2 指導
参加者にアルゴリズムを指導する方法には多くの選択肢があった。一般的な指導方法が多数存在するだけではなく、特に Paxos の指導には様ザなアプローチがある。この研究の目標は、アルゴリズム自体を比較することであり、その伝え方を比較することではない。したがって、指導方法とスタイルの一貫性を保つことが重要であった。我々はアルゴリズムを同様の方法で伝え、同等の内容を網羅することを望んだ。また、参加者が各アルゴリズムに費やす時間を数時間以内に収めることも望んだ。これは参加者にとって無理のない要求であり、その上で各アルゴリズムの学習曲線の初期段階で彼らをテストできると考えた。
我々は参加者への指導に論文を使用することも検討したが、これには 2 つの問題があった。第一に、適切な Paxos 論文が見つからなかった。この論文は以下を満たす必要があった。
比較的理解しやすい Paxos の変種を網羅していること (Paxos アルゴリズムには統一されたアルゴリズムはないが、中には理解しやすいものもある)。
複製ステートマシンを構築するのに十分なほど完全に記述されていること。
そのトピックに関する背景知識を有さない学生でも、関連研究を事前に理解することなく理解しやすいこと。
Raft 論文と同等の品質、スタイル、長さであること。
このような論文を我々が書くこともできたが、それには数ヶ月かかるであろう。第二の問題は、論文を読むには多くの時間がかかり、参加者にはより短い時間でアルゴリズムを学習できることを望んだ。
代わりに、我々は講義形式で参加者に教えることを決定した。各アルゴリズムについて 1 時間の講義で十分な内容をカバーできると見積もった。これは参加者に過度な負荷をかけない程度に短く、かつ十分な量の内容を快適なペースでカバーできる程度に長かった。また、アルゴリズムの学習曲線の初期段階で参加者にクイズを行うことができる程度に短かった。
Paxos については別の講師を起用するのではなく、John Ousterhout に両方のアルゴリズムの講義を担当して貰うことを選択した。アルゴリズム間の一貫性を最大限に高めるために、我々は以下の要素を考慮して決定した:
専門知識: それぞれのアルゴリズムについて同等の専門知識レベルを望んでおり、研究開始前は自分たちを Paxos の専門家であるとは考えていなかった。Paxos の専門家を招いて Paxos の講義をして貰うこともできたであろう。しかし、Ousterhout は専門家のスライドを基に自身のスライドを作成し、Paxos の講義の準備をする中で、自信を十分な知識があると見なせるほど Paxos を十分に学んだと我々は信じている。
指導スタイルと能力: Ousterhout は 2 つの講義を通してこれを非常に一貫して保つことができた。一方、もし別の講師が Paxos の講義を行った場合、異なる指導スタイルや能力に苦労したかもしれない。
講義の質: Ousterhout が両方の講義を行ったことで、彼が同等に質の高い Paxos の講義を行う努力をしなかったのではないかという疑念を生じさせる。しかし、彼は同等の講義を作成しようと務めており、これは彼が Paxos のスライドを専門家のスライドに基づいて作成したことで軽減されている。(また、Raft の講義には研究中に既知の欠陥があった。我々は、時間があればもっと明確にできたはずのバグを修正するために、講義の土壇場でいくつかの変更を加えた。さらに、このときの Raft はより単純な単一サーバ変更アルゴリズムよりも前の話であるため、より複雑な形式のメンバーシップ変更を提示した。) 2 人目の講師が研究にそれほど熱心ではない可能性があるため、別の Paxos 講師であれば講義の質のバランスを取るのがより困難だったかもしれない。
我々は Paxos の基礎に忠実でありながら、比較的理解しやすく完全な Paxos の変種を教えることを望んだ。残念ながら Paxos の変種については合意された見解がなく、どの変種を教えるべきかについて講師間で意見が一致しなかった。我々は最終的に、効率的であるだけでなく比較的理解しやすい David Mazières [78] の変種を採用した。しかし、再構成には Mazières のアプローチではなく Leslie Lamport のアプローチ [49] を使用した。Lamport のアプローチには、通常動作中に Paxos の並列性を制限するという望ましくない特性があるが、我々 (Mazières を含む) はその基本的なアイディアが Mazières や他のアプローチよりも理解しやすいと考えている。
John Ousterhout には直接講義をして貰うのではなく、両方の講義をビデオ録画することを選択した。これにはいくつかの利点があった:
我々は、間違いを犯した際にセグメントを再録画できたため、同じ時間内でより多くの内容を盛り込むことができた。
我々は、各アルゴリズムについて実施した 2 回のパイロットスタディ (セクション 7.2.6 参照) 中に講義の問題をデバッグすることができた。講義を録画しておくことで、問題を特定し、確実に修正することができた。
参加者は異なる順序で講義を視聴しても、全く同じ資料を見ることができた。
学生は自分のペースで、自分のスケジュールに合わせて講義を視聴することができた。彼らはセグメントを繰り返し視聴したり、ビデオの速度を上げ下げすることができた。我々は講義に時間制限を設けなかったため、学生は自分のペースで視聴することができた。
ビデオ講義は研究の記録として残り、繰り返しの研究で使用することも可能であった。研究に参加していない人々も、これらのビデオを使用して独自にアルゴリズムを学習している (我々の Raft の講義は 2014 年 8 月現在で YouTube で 14,480 回、Paxos 講義は 9,200 回視聴されている。
考えられる欠点としては、学生が講義中に質問をすることができなかった点が挙げられる。一方で、質問は録画された講義の一貫性という利点を損なう可能性もあった。例えば、質問によって片方の講義でより多くの内容が提示されたり、スタンフォードとバークレーのグループ間で追加の差異が生じたりする可能性があった。また、録画された講義が研究への参加にどう影響したかは不明である。スタンフォードの参加率は高かったものの、バークレーでは講義を授業時間内で実施していれば、より高い参加率を得られた可能性も考えている。
我々はバイアスを減らすために、ビデオ講義はできるだけ個人的な要素を排除するように努めた。例えば、ビデオには講義スライドのみを映し出し、John Ousterhout 自身は映さなかった。しかし Ousterhout のナレーションでさえ微妙なバイアスがかかっていた可能性がある (彼自身はそうならないように努めていたが)。懸念のある読者は講義ビデオを実際に視聴して自身で判断されたい。我々は、そのようなバイアスを測定または軽減するための正式な手法を知らない。
ビデオ講義に加えて、参加者には準備のためのわずかな追加資料 (講義ノートとアルゴリズムの要約) を配布した。参加者には、アルゴリズムについて独学で学ぶこと (例えば論文を読むなど) を推奨しなかったが、クイズ前に復習し、クイズ中に参照するための参加資料があると役に立つと考えた。より参照しやすいように講義スライドのコピーを利用可能にし、Raft については (凝縮された) 1 ページの要約、Paxos については (疎な) 3.5 ページの要約という形でアルゴリズムの概要を提供した。これは Appendix A.4 に含まれている。
7.2.3 理解度のテスト
この研究における主要な課題は参加者のアルゴリズム理解度をどのように測定するかであった。我々は参加者にアルゴリズムを実装させることを検討した。そうすれば実用的なシステムを構築する能力をより直接的に測定できるであろう。もし実現可能であれば、このアプローチはクイズよりも優れていただろう。しかし多くの課題があったためこの方法は採用しなかった。第一に、Raft または Paxos の大部分を実装するには、ほとんどの専門家でさえ数週間かかると推定される。もし是を参加者に要求すれば、多くの参加者を集めることはできなかったであろうし、統計的に有意な結論を導き出すこともできなかったかもしれない。さらに、システム開発能力は人によって大きく異なるため、統計的に有意な結論を導き出すためには大規模なサンプリングが必要となるか、参加者全員に両方のアルゴリズムを実装させる必要があったであろう。いずれの選択肢も参加者に時間的負荷がかかるため実際には困難であっただろう。たとえ参加の問題が解決されたとしても、実装を互いに比較して測定することは依然として困難であっただろう。徹底的な評価には、正しさ、コードの複雑さ、コストなどの指標を含める必要があり、これらすべてを測定することは困難である。
代わりに、我々は参加者にクイズを受けさせることで理解度を測定することを選択した。これにより参加者の時間を短縮できた。その結果、各参加者に両方のアルゴリズムを学習させることができ、これにより学習能力や試験慣れにおける個人差を考慮することが容易になった。さらに、数値化されたクイズスコアに基づいて参加者の成績を比較することは容易であった。
クイズを作成する上で最も困難だった課題は、いかに公正にするかであった。当初、両方のアルゴリズムに等しく適用できる質問を使用すること検討したが、そのような質問は、片方のアルゴリズムがそのトピックをより直接的にカバーしているため、そのアルゴリズムにとっては自明すぎる傾向があった。代わりに、難易度が類似する場合にのみ、類似の問題を使用することにした。
クイズを公正にするために、我々は以下の戦略を使用した。まず、各質問を難易度別に分類した。
簡単な問題は、基本的に記憶を頼りにするものであった。解答は講義中にほとんど推論することなく見つけられるものであった。学生がこれらのほとんどすべてを正しく解答することを期待した。
中程度の問題は、参加者に講義で紹介されているアルゴリズムを適用することを要求するものであったが、どの手順を適用するかは容易に判断できるはずのものである。
難しい問題は、参加者がどのルールを適用するかを見つけ出し、それらを新しい方法で組み合わせ、講義内容を超えて推論することを必要とするものであった。これらの問題に完璧に答えられる学生はごく少数という想定だった。
同じ難易度カテゴリの質問は、講義内容からの同程度の推論や推定が必要となるはずである。我々は「クイズに合わせた指導」という懸念を軽減するために、講義作成後に問題を (再) 分類した。
第二に、各質問に予想される所要時間に基づいて点数を割り当てた。点数は John Ousterhout の教育経験に基づいて、十分に準備を整えた学生が質問に解答するのにかかる時間を反映するように意図したものであった。例えば約 5 分かかると予想される質問は 5 点であった。
第三に、我々はクイズをカテゴリと配点でバランスを取った。各クイズには、簡単な質問が 4 点、中程度の質問は 26 点、難しい質問が 30 点で含まれていた。また、各クイズの問題を並べて比較し、難易度が同等であることを確認した。
このように作成したクイズの難易度はほぼ同じであると考えているが、確実なことは言えない。読者には Appendix A に掲載されているクイズを確認して自身で判断することを求める。
ほとんどの問題は、自由回答形式の短い回答を必要としている。客観的な採点が容易な多肢選択式の問題も検討した。しかし、回答を誘導する可能性が低く、参加者の理解度をより効率的にテストできると判断し、自由回答形式を採用した。
クイズは時間制限があったため、参加者が問題に精通できないようにした。我々は、参加者が問題を試行し、ビデオ全体を再度視聴して回答を修正するために十分な時間を与えることを望まなかった。
クイズから最大限の情報を引き出すために意図的に難易度を高くした。例えば、満点を取る参加者が誰も居ないことを望んだ。なぜなら、満点を取ると参加者間の差異を区別することができなくなるためである。しかし後になってクイズが少し難しすぎたことが判明した。最高得点は 60 点満点中 46.5 点に過ぎなかった。例えば、ほとんどの学生が各クイズの問 8 で 0 点だった。もしこれらの問題をより簡単にしていれば、参加者間の違いをより明確に区別できたかもしれない。
7.2.4 採点
我々はクイズを 2 段階に分けて採点した。最初の (予備的な) 採点はより主観的な理解度に基づいて点数を割り当てた。2 回目の (最終的な) 採点ではより客観的に点数を割り当てた。我々の手順は以下のステップでまとめられる:
Diego Ongaro と John Ousterhout が妥当な採点基準 (rubric) を作成した。
Ongaro が比較的迅速にクイズを採点した (参加者全員を、特定の質問ごとにランダムな順序で一度に採点し、質問ごとに Paxos と Raft を交互に採点した)。
Ongaro と Ousterhout は、見つかった問題点に基づいて採点基準を修正した。
Ongaro がクイズをより慎重に再採点した (参加者全員を、特定の質問ごとに予備スコアの順序で一度に採点し、質問ごとに Paxos と Raft を交互に採点した)。
最終的な採点基準は、クイズの問題と共に Appendix A に含まれている。
我々は、クイズスコアから可能な限り多くの情報を得るために、部分的な得点を付与した。例えば、空欄の回答は理解していないことを示し、一方で回答の方向性が正しいものは何らかの理解があることを示している。我々はこれらのケースを区別するため、参加者が解答で示した理解度に応じて点数を付与するように努めた。
改善の余地があった点が 2 つある。第一に、採点基準の完成と採点調整を行う前に、予備的な得点と結果を自身で見てしまったことである。これは避けるべきであった。なぜならば、例えば 2 回目の採点ラウンドで Paxos の回答が僅差だと判断した場合、得点を減らしたかもしれないという疑念が生じるためである。この手順の側面については疑問があるものの、それほど懸念することではない。なぜなら、2 回目の採点後も成績、全体的な結果、結論はほぼ同じだったからである。例えば、Raft の平均は予備採点後が 25.74 点、最終採点後が 25.72 点だった。Paxos の平均は予備採点後が 20.77 点で、その後 20.98 に修正された。
第二に、クイズの採点を我々自身が行ったことでバイアスを生じさせた可能性がある。なぜなら、この研究が Raft が Paxos よりも理解しやすいことを示すことを期待していたからである。採点基準の作成と回答の採点には (回答は互いに大きく異なることがあるため) アルゴリズムに関する専門知識が必要であるため、我々自身がこれらの作業を行うのが最も容易であった。しかし、採点基準を用いて我々の採点を確認するために、公平な採点者を雇うこともできた。
7.2.5 アンケート
当初、参加者にクイズを行う代わりに、Raft が Paxos よりも理解しやすいかを尋ねることを検討した。しかしそのようなアンケートはそれ単独ではあまり信頼性が高くないことを知らされた。例えば、参加者は我々の望む結果であると信じるならば Raft に対して好意的に回答するかもしれない (社会的望ましさバイアス; social desirability bias)。あるいは質問の文言に影響を受ける可能性もある。我々は主要な結果を得るためにクイズに落ち着いたものの、参加者の意見を聞くことには依然として一定の価値があるため、2 回目のクイズ後に参加者が記入する短いアンケートを含めた。
我々のアンケートには 5 段階尺度 (リッカート項目; Linkert items) を用いた 6 つの質問と、一般的なフィードバックやコメントを尋ねる 1 つの自由回答形式の質問が含まれていた。参加者の参加を促すためアンケートは簡潔になるように努めた。この方法であれば回答を収集し定量化することは容易であった。
7.2.6 パイロット調査
この種の研究における課題の一つは、もし問題が発生し研究をやり直す必要が生じた場合に多大なコストがかかることである。このリスクを軽減するため、我々は研究を開始する前に事前に手順の問題を発見し解決しようと試みた。そのため、我々は 2 回のパイロット調査を実施し、それぞれに通常の調査には参加していない 2-4 人のボランティア参加者を含めた。各パイロットクイズには 90 点分の質問を含めた。これにより、当初の予定よりも多くの問題を試すことができ、不適切な問題を排除する選択肢も得られた (我々のパイロットクイズには最終問題よりも多くの簡単な質問が含まれていたが、クイズを短くするためにそのほとんどを削減した)。パイロット調査中に講義とクイズに関する多くの問題を修正した。パイロットプロセスは研究の成功に不可欠であったと感じている。
7.3 手法
このセクションでは、Raft ユーザ調査の手法をより正式な APA (アメリカ心理学会; American Psychological Association) 形式で記述する。ここでは、セクション 7.2 で議論されたトピックほど概念的ではないものの、研究にとって重要な多くの技術的な詳細が含まれている。
7.3.1 研究デザイン
この実験は、各参加者が Paxos アルゴリズムと Raft アルゴリズムの両方でクイズを受けるという被験者内 (within-subjects) デザインを採用した。順序効果を考慮するためカウンターバランス (counterbalanced) も取られた。参加者の約半分は Paxos を学習して Paxos クイズに回答し、その後 Raft を学習して Raft クイズに回答した。残りの半分は Raft を学習して Raft クイズに回答し、その後 Paxos を学習して Paxos クイズに回答した。
主な独立変数は 2 つあった:
どのアルゴリズムか (Paxos か Raft か)?
どの順序か (Paxos の次に Raft、または Raft の次に Paxos)?
影響は軽微であることを期待しつつ、さらに 2 つの独立変数を記録した:
参加者はどの学校出身か (スタンフォードかバークレーか)?
参加者は以前に Paxos の経験があったか?
7.3.2 参加者
我々はスタンフォード大学とバークレー大学の学生に研究への参加を依頼した。Table 7.1 は各グループの参加状況と、何人の参加者が調査の各パートを完了したかをまとめている。
スタンフォード大学の 33 人の参加者は、2013 年 1 月から 3 月にスタンフォード大学で提供され、David Mazières が教鞭を執った Advanced Operating System (CS240) コースから募集された。学生は学部上級生と大学院生であり、少数の遠隔専門学生 (SCPD) も含まれていた。彼らには、調査への「妥当な参加」に対してコースの成績の 5% が授与されることを知らされた。(調査に参加しないことを選択した場合の代替案も提供された。) また、この調査で取り上げた問題がコースの最終試験で再出題される可能性があることも知らされた。
バークレー大学の参加者 16 人は、2013 年 1 月から 5 月にカリフォルニア大学バークレー校で開講され、Ali Ghodsi が教鞭を執った Distributed Computing (CS294-91) コースから募集された。学生はほとんどが大学院レベルであったが、少なくとも 1 人の学部生がこのコースを受講していた。学生には、コースの一環として研究に参加すべきであると漠然と示唆されたものの、参加を促す明確なインセンティブは提供されなかった。
7.3.3 資料
参加者は、パスワードで保護されたウェブサイトを通じて学習資料にアクセスした。このウェブサイトにより、参加者は自分のペースでいつでも学習を進めることができた。ウェブサイトで利用可能な様々な資料については以下で詳細に説明する。
講義
それぞれのアルゴリズムには対応するビデオ講義が用意されていた。講義スライドは John Ousterhout によってデザインおよび作成された。Paxos の講義は Lorenzo Alvisi、Ali Ghodsi、David Mazières のスライドから借用した。Raft の講義は、Raft を記述した論文の草稿に基づいていた。スライドは、調査ウェブサイトで Microsoft PowerPoint と PDF の両形式で参加者に提供された。ビデオは「スクリーンキャスト」形式を採用し、ビデオコンポーネントにはスライドとスタイラスのオーバーレイのみが表示され、音声コンポーネントは Ousterhout が口頭でスライドを説明するものであった。Figure 7.1 はスタイラスのオーバーレイが表示されたスライドの例を示している。ビデオは事前に録画されており、両グループの学生が全く同じビデオを使用できた。動画は YouTube 動画ホスティングウェブサイトと MP4 フォーマットでダウンロードできるように提供された。
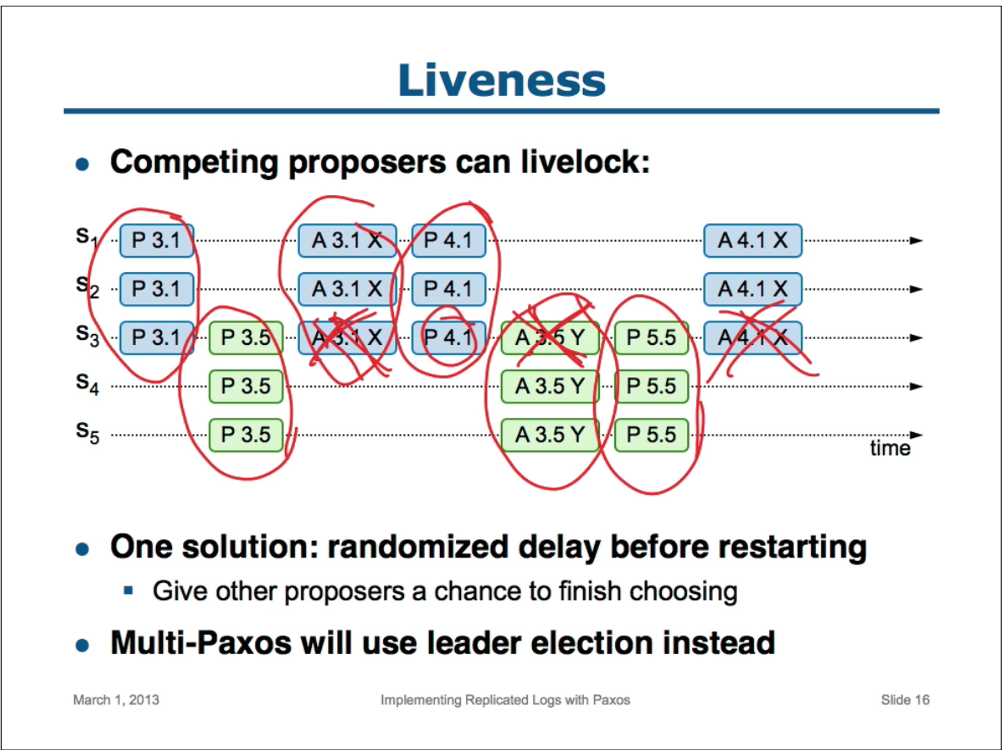
Raft の講義は、リーダー選出、ログ複製、Safety、クライアントとの対話、そしてメンバーシップ変更へのジョイントコンセンサスアプローチといったトピックを扱った。Paxos の講義は、単一決定 Paxos、Multi-Paxos、クライアントとの対話、メンバーシップ変更、そして実践で必要となるいくつかの最適化 (リーダー選出など) を含む、同等の複製ステートマシンを作成するのに十分な内容を扱った。ログ圧縮はどちらの講義にも含まれなかった。
我々は約 1 時間の長さのビデオ講義を作成することを目指した。講義のバランスを取るために、資料を同程度に詳細なレベルで、同等の数の例を用いてカバーするように務めた。その結果、Paxos の講義は Raft の講義よりわずかに長くなった。Table 7.2 は様々な指標を用いてそれらの長さを比較している。
| アルゴリズム | 講義スライド | 講義時間 (MM:SS) | 講義単語数 |
|---|---|---|---|
| Raft | 31 | 58:18 | 10,053 |
| Paxos | 33 (+6%) | 66:34 (+14%) | 11,234 (+12%) |
補助資料
どちらの講義にもアルゴリズムの要約がオプションで含まれていた。Raft の講義では、要約は 1 枚のスライドであった (参加者はこれを読むためにスライドを拡大する必要があった)。Paxos については、講義に加え、単一決定 Paxos および Multi-Paxos アルゴリズムの 3.5 ページの要約が学習ウェブサイト上で提供された。これらは Appendix A.4 に含まれている。参加者がクイズで高得点を得るために要約を見る必要はなかったが、迅速な参照資料および復習資料として提供された。参加者が実際に要約を見たかどうかは追跡しなかった。
クイズ
それぞれのアルゴリズムにはウェブベースのクイズが含まれていた。クイズとその解答、および採点基準は Appendix A に記載している。クイズでは、アルゴリズムの基礎的な理解度をテストし、学生にコーナーケースについて推論することも求めた。問題のほとんどは自由記述の短い回答を必要とした。各クイズは、難易度の異なる 8 つの問題 (一部は複数パートの問題) で構成されていた。問題は難易度評価尺度を用いて分類した (セクション 7.2.3 参照)。
最初の問題 (4 点) は「簡単」と評価した。
次の 4 つの問題 (26 点) は「中程度」と評価した。
最後の 3 つの問題 (30 点) は「難しい」と評価した。
点数は、十分に準備した学生が回答するのにかかる分数を反映することを意図した。参加者には点数が提示されたが、クイズの問題には難易度が明確に表示されていなかった。
残念ながら、この調査で使用した Paxos クイズの問 4 には誤植があった。調査で使用された元の質問と訂正箇所、および採点方法については Appendix A に記載されている。
参加者は、各クイズを 60 分以内に完了するように指示された。ウェブサイトには分単位のカウントダウンカウンターが設定されていた (より細かい粒度のカウンターは不必要な不安を引き起こす可能性があると助言された)。学生が 60 分以内に回答を提出することを強制する技術的な措置は採用されなかった。60 分が経過するとこのカウンターはマイナスになった。しかしながら、参加者のウェブブラウザは経過したクイズの全時間を報告し、サーバは参加者が最初に開いた時刻と各クイズを提出した時刻の記録を保持した。制限時間を 10% 以上超えた参加者はわずか 4 人であった (それらのクイズもセクション 7.4.1 で提示される結果に含めている)。
アンケート
2 回目のクイズに続いて、参加者には短いウェブベースのアンケートに回答するように求められた。これは Appendix A.3 に記載されている。アンケートは 5 段階尺度 (リッカート項目) を用いた 6 つの質問と、一般的なフィードバックやコメントのための 1 つの自由回答形式の質問で構成されていた。これには、Paxos に関する事前の経験や、どちらのアルゴリズムを他方よりも実装したいか、あるいは説明したいかについての質問が含まれていた。
7.3.4 従属指標
参加者のクイズの成績はこの調査の主要な従属指標となった。Diego Ongaro は採点指標に基づきランダムな順序でクイズを採点した。Ongaro は採点中、参加者の大学を知らされなかった (そして参加者の身元については当時も現在も知らされていない)。アンケートにおける参加者の選好もまた従属指標となった。
7.3.5 手順
参加者は電子メールでランダムに順序グループ (Paxos が先か Raft が先か) に割り当てられた。この電子メールでは、参加者に対して 1 つ目のクイズを月曜日の午後 11 時 59 分までに、2 つ目のクイズを同じ週の金曜日の午後 11 時 59 分までに完了するように指示した (ただし、期限前および期限後の回答も受け付けた)。電子メールには学習ウェブサイトへのリンクと、各参加者固有のログイン情報が含まれていた。
学習ウェブサイトには上記の資料が掲載され、参加者はいつでもウェブサイトにアクセスできた。ビデオの視聴や補足資料の閲覧には時間制限は設けられなかった。ウェブサイトは、クイズを開くと 60 分以内に完了する必要があることを指示した。クイズの解答はウェブサイトで頻繁に保存され、参加者がクイズページを再度開いた場合でも回答を再読込した。2 番目のクイズを提出した後、ウェブサイトは参加者にアンケートの記入を促した。
7.4 結果
このセクションでは我々の実験から得られた結果を提示する。セクション 7.4.1 ではクイズの結果を記述し、セクション 7.4.2 ではアンケートの結果を記述する。
7.4.1 クイズ
Figure 7.2 はクイズスコアの生の分布を示しており、Raft のスコアは Paxos のスコアよりも数ポイント高い傾向がある。Raft の平均スコアは Paxos の平均スコアよりも 4.74 点、すなわち 22.6% 高い。この差を確認するために統計的有意性検定 (statistical significance test) を用いた。Raft のスコアが Paxos のスコアよりも高いという片側仮説に基づき、対応のない Student の t-検定 (unpaired Student's t-test) を実施した。この検定により、Raft のスコア (\(M=25.72\), \(SD=10.33\)) は Paxos のスコア (\(M=20.98\), \(SD=8.57\)) よりも \(t(85.55)=2.39\), \(p=0.009\) で有意に高いことが判明した。平たく言えば、我々のサンプルから 99% の信頼度で Raft クイズの真のスコア分布が Paxos クイズの真のスコア分布より高いと言える (同一の分布において偶然にこのような誤差が生じる確率はわずか 1% であり、通常、\(p\) 値が 5% 未満であれば統計的に有利であると見なされる)。
我々はまた、学習能力と受験能力における個人差も考慮したいと考えた。参加者が両方のアルゴリズムについて学習し、クイズを受けたため、各参加者のクイズスコアの差を見ることができた (6 人の参加者は 1 つのクイズしか受けなかったためここでは除外する)。
Figure 7.3 と Figure 7.4 は各参加者のクイズスコアをそれぞれプロットしたものである。43 人の参加者のうち 33 人が Raft クイズで Paxos クイズよりも高いスコアを出したことを示している。Figure 7.3 は参加者がアルゴリズムを学習しクイズを受けた順番を重ねて示しており、Figure 7.4 は参加者の Paxos に関する事前の経験を重ねて示している。これらはいずれも、Raft クイズでより高いスコアを出した参加者と明らかに相関しているようには見えない。
Figure 7.5 は、参加者のスコアが試験間でどのように異なるかの全体的な分布を示しており、データの全体的な挙動を比較しやすくしている。参加者は Raft クイズで Paxos クイズよりも中央値で 6.5 点、すなわち 31.7% 高いスコアを獲得した。参加者の Raft スコアが一般的に Paxos スコアより高いという片側仮説を使用して、対応のあるサンプルの \(t\)-検定を実施した。この検定では、個人の Raft スコア (\(M=25.73\), \(SD=10.56\)) が Paxos スコア (\(M=20.79\), \(SD=8.64\)) よりも \(t(42)=3.39\), \(p=0.001\) で有意に高いことが判明した。平たく言えば、我々のサンプルから 99.9% の信頼度で、Raft クイズのスコアの真の分布が Paxos クイズスコアの真の分布よりも大きいと 99.9% の信頼度で言える (同一の分布でこのような差が偶然に生じる確率はわずか 0.1% である)。
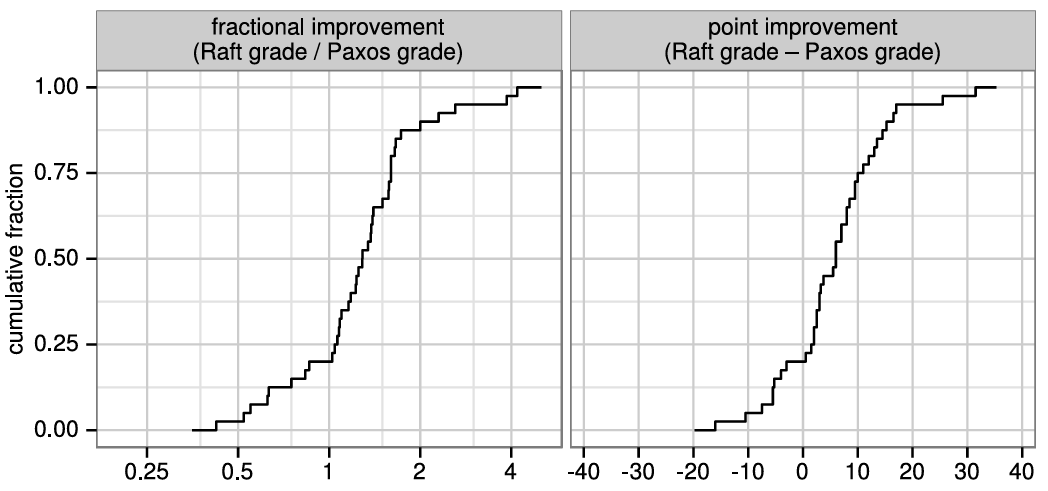
我々はまた、学生がシステムを学習した順序がクイズスコアに影響するかについても興味があった。Figure 7.6 は、Raft クイズを最初に受けたか 2 番目に受けたかによってグループ化された参加者のクイズスコアを示している。この図から、Raft クイズを最初に受けた参加者は、Paxos クイズを最初に受けた参加者よりも Raft クイズで約 5 点高いスコアを出したように見える。この結果を調査するため、同じクイズについて 2 つのグループのスコアが本当に異なっていたかを判断するために統計的検定を用いた。両方向でグループが異なっていたという両側仮説で、対応のない \(t\)-検定を実施した。これらの結果では、グループ間に統計的に有意な差が無いことを示した。Raft におけるそのような差は、類似の実験を実施すれば 16.8% の確率で偶然に発生する可能性がある。しかし、過去の Paxos 経験も考慮に入れると、順序は統計的に有意な要因であるように見える。この点については、線形回帰モデルの構成要素として次に説明する。
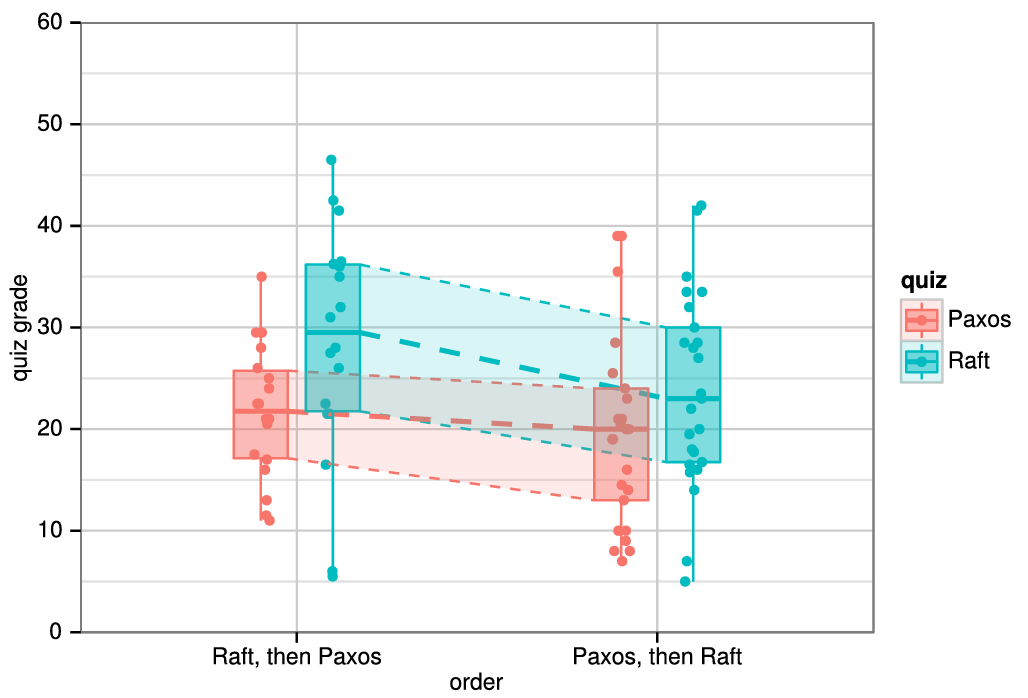
破線は、異なる順序グループ間での同じクイズのボックスプロット上の分位点を結んでいる。例えば、太い青の破線は、Raft クイズを最初に受けたグループ (左) の Raft クイズの中央値スコアと、Raft クイズを 2 番目に受けたグループ(右) の Raft クイズの中央値スコアを結んでいる。もしクイズの順序が参加者の成績に影響しなかった場合、これらの破線はほぼ水平になるであろう。
参加者の個々のクイズスコアは、さらに詳細を提供するために各ボックスプロットに重ねて表示されている。各点の \(x\) 座標は重複を減らすためにランダムにオフセットされている。
クイズスコアに対する様々な要因の影響を調査するために線形回帰モデルを作成した。このモデルでは、参加者が 1 回目のクイズを受けているか 2 回目のクイズを受けているか、過去の Paxos 経験、そして彼らの大学を考慮した。順番と過去の Paxos 経験が Raft クイズまたは Paxos クイズに異なる影響を与えるかを検証するため、線形モデルにはそれぞれ 2 つの変数を含めた。つまり、モデルには以下の変数が含まれる:
Quiz (クイズ): Paxos または Raft。
Second quiz, Raft (2 番目のクイズで Raft): 参加者は Raft クイズの前に Paxos クイズを受け、Quiz が Raft。
Second quiz, Paxos (2 番目のクイズで Paxos): 参加者は Paxos クイズの前に Raft クイズを受け、Quiz が Paxos。
Prior Paxos experience, Raft (過去の Paxos 経験で Raft): Quiz が Raft の場合で参加者が過去に Paxos の経験。それ以外の場合は 0。この要素をモデルに含めるため、参加者の過去の Paxos 経験は Appendix A.3 にある英語の回答ラベルから 0 から 4 までの整数にマッピングされた。
Prior Paxos experience, Paxos (過去の Paxos 経験で Paxos): Quiz が Paxos の場合で参加者が過去に Paxos の経験。それ以外の場合は 0。
School (大学): スタンフォードまたはバークレー。
我々の最初のモデル (Table 7.3) では、学校要因が有意でないと報告されたため、それを含まない 2 番目のモデルを作成した。Table 7.4 に示す 2 番目のモデルは、クイズスコアの分散の 19% を説明する。残りの 81% には少なくとも学習能力と試験慣れにおける個人差が含まれる。順序を考慮すると、このモデルは、Paxos を初めて経験する学生の場合、Raft クイズで Paxos クイズより 12.5 点高くなると予測する。
線形モデルはまた、Paxos の前に Raft を学習した学生は両方のクイズでより高いスコアになると予測している (Raft クイズで 6.3 点、Paxos クイズで 3.6 点)。この差は Raft クイズで統計的に有意 (\(p=0.031\)) だが、Paxos クイズではそうではない (\(p=0.209\))。我々は、参加者が最初に Paxos を学習したことで混乱させたり意欲を失わせたりしたため、その後の Raft クイズの成績が悪化したのではないかと推測している。
| 変数 | 推定値 | 標準誤差 | \(t\) 値 | \(p\) 値 |
|---|---|---|---|---|
| 切片 | 10.61 | 3.32 | 3.19 | 0.002 |
| Quiz is Raft | 12.99 | 4.46 | 2.92 | 0.005 |
| Second quiz, Raft | -6.74 | 2.87 | -2.35 | 0.021 |
| Second quiz, Paxos | 4.09 | 2.87 | 1.42 | 0.158 |
| Prior Paxos experience, Paxos | 4.65 | 1.54 | 3.02 | 0.003 |
| Prior Paxos experience, Raft | 3.11 | 1.54 | 2.02 | 0.046 |
| School is Berkeley | 3.26 | 2.28 | 1.43 | 0.157 |
| 変数 | 推定値 | 標準誤差 | \(t\) 値 | \(p\) 値 |
|---|---|---|---|---|
| 切片 | 11.27 | 3.31 | 3.40 | 0.001 |
| Quiz is Raft | 12.54 | 4.74 | 2.80 | 0.006 |
| Second quiz, Raft | -6.30 | 2.87 | -2.19 | 0.031 |
| Second quiz, Paxos | 3.64 | 2.87 | 1.27 | 0.209 |
| Prior Paxos experience, Paxos | 4.88 | 1.54 | 3.18 | 0.002 |
| Prior Paxos experience, Raft | 3.35 | 1.54 | 2.18 | 0.032 |
Figure 7.7 は、問題の難易度別に分類されたクイズスコアの分布を示している。「簡単」の問題は 4 点しかなかったためグラフでは「中程度」のカテゴリと結合している。グラフは、スコアのほとんどすべての違いが簡単/中程度のカテゴリの質問に起因し、「難しい」カテゴリのスコア差は極わずかであることを示している。「難しい」問題は難易度が高すぎたため、参加者の平均スコアは「難しい」カテゴリの獲得可能な点数のうち約 4 分の 1 しか得点できなかった (Paxos で平均 7.45 点、Raft で平均 7.94 点)。したがって「難しい」カテゴリの参加者間で大きな違いは見られなかった。
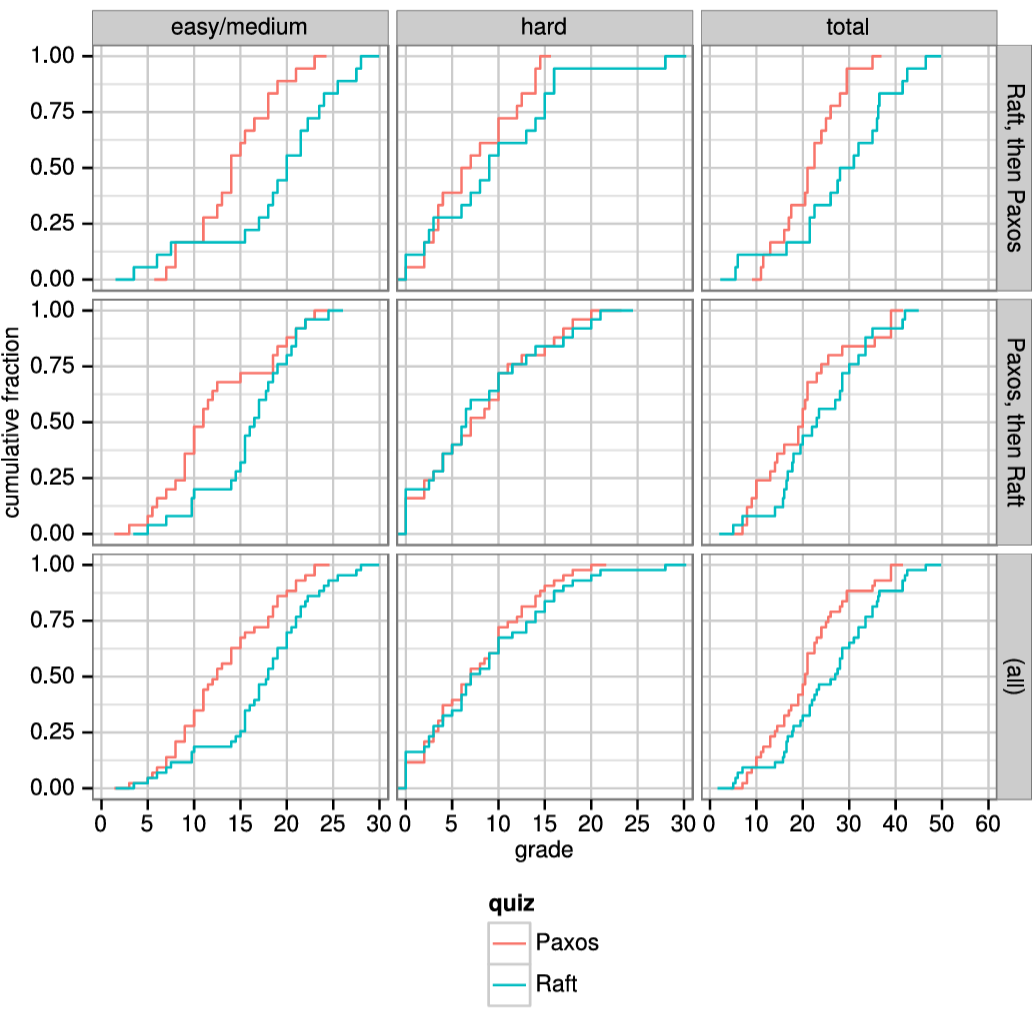
難易度: easy/medium の列は、クイズの「簡単」と「中程度」の問題に対する参加者のスコアを示している (30 点満点)。hard の列は、クイズの「難しい」の問題に対する参加者のスコアを示している (30 点満点)。total の列は参加者の合計得点を示している (60 点満点)。Figure 7.8 はこれを個々の問題ごとに分類している。
順序: "Raft, then Paxos" の行は Raft クイズを受けた後に Paxos クイズを受けた参加者のスコアを示している。"Paxos, then Raft" の行は、Paxos クイズを受けた後に Raft クイズを受けた参加者のスコアを示す。"(all)" の列は両方のクイズを受けたすべての参加者のスコアを示している。
Figure 7.8 はクイズのスコアを個々の問題ごとに分類している。我々の分類に基づくと、問題 1 は簡単な難易度、問題 2 から 5 は中程度の難易度、問題 6 から 8 は難しい難易度であった。中程度のカテゴリにおいて、単独で大きな差を生むような個別の問題は見当たらなかった。クイズ間の問題の難易度を対比させようと試みたが (例えば Raft クイズの Q3 は Paxos クイズの Q3 とほぼ同じ難易度であるべきだが)、それらはほとんど異なる問題であり、直接比較するのは困難である。
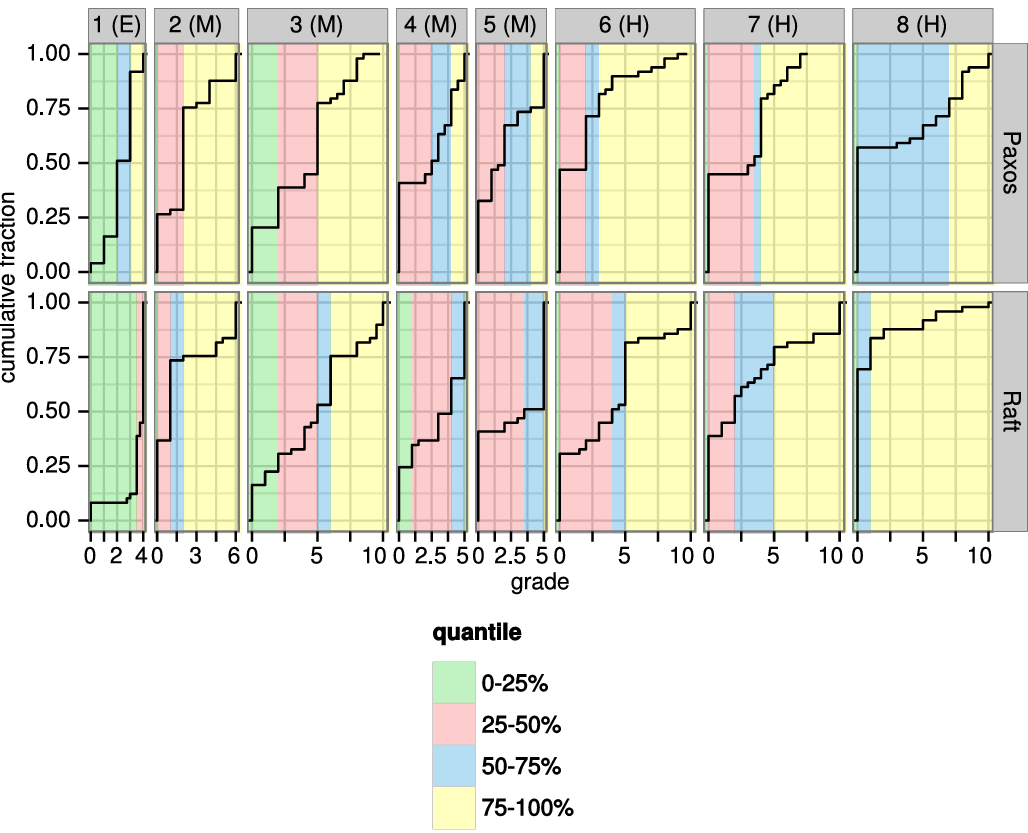
各グラフの曲線はデータの CDF を示す。\(y\) 軸は特定の点数以下の参加者の累積割合である (右側/下側がより良い)。
各グラフの \(x\) 軸の範囲は各問題の得点に対応しており、1 点あたりの幅はすべてのグラフで同じである。例えば 10 点満点の問題は 5 点問題のグラフの 2 倍の幅を持つ。
各グラフは一目で概要を確認できるように色分けされている。凡例に示すように、データの各分位点は異なる色で陰影付けされている。各グラフの幅がその点数に比例して拡大されているため、陰影のサイズ (面積) はグラフが表す得点の数に比例する。
7.4.2 アンケート
参加者は 2 回目のクイズを受けた後、3 つのグループのアンケート質問に回答した。質問は Paxos と Raft のこれまでの経験、講義やクイズにバイアスがあったと感じたかどうか、そしてどちらのアルゴリズムが実装または説明しやすいと感じるかについて尋ねた。また、参加者には自由記述のコメントやフィードバックも求められた。アンケートの全文と質問の内容は、自由記述のコメントやフィードバックと共に Appendix A.3 に掲載されている。
バークレー校の参加者の多くと、スタンフォード校の参加者の一部は過去に Paxos の経験があった。Figure 7.9 はアンケートの質問に対する回答を示している。スタンフォードでは質問に回答した 31 人の参加者のうち 9 人が少なくともある程度 Paxos に触れたことがあった。バークレーでは質問に回答した 11 人の参加者のうち 6 人が少なくともある程度 Paxos に触れたことがあった。Raft に触れたことがあると回答した参加者はいなかった (41 人の参加者がこの質問に回答)。当時 Raft はまだ新しい技術であったため、これは予想されたことであった。
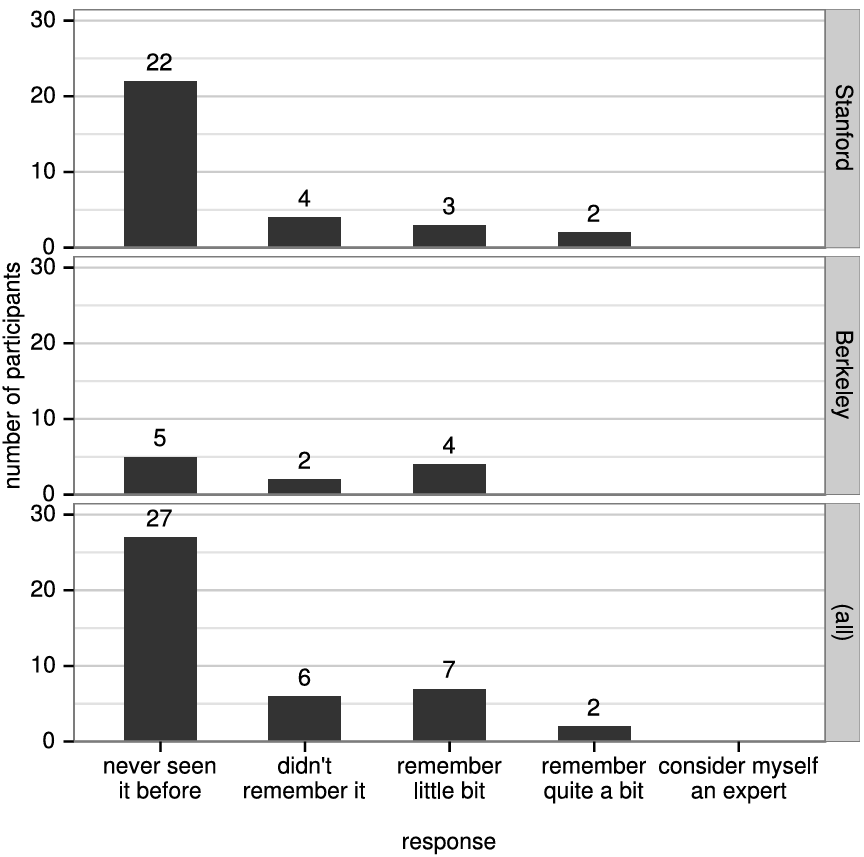
参加者には、講義の質が類似していると感じるか、そしてクイズの難易度が類似していると感じるかも尋ねられた。Figure 7.10 はそれらの回答を示している。42 人中 23 人の参加者が、Raft の講義は Paxos の講義より少なくともいくらか優れていると回答し、42 人中 20 人の参加者が、Paxos のクイズは Raft のクイズより少なくともいくらか難しいと回答した。しかし、これらの回答は信頼性が低い可能性がある。参加者にとって資料の本質的な難しさや理解度と講義の質を分離すること、あるいはそれらの成績とクイズの難易度を分離することは困難であったかもしれない。したがって、我々はこれを研究の完全性を裏付ける強力な証拠とは考えていない。
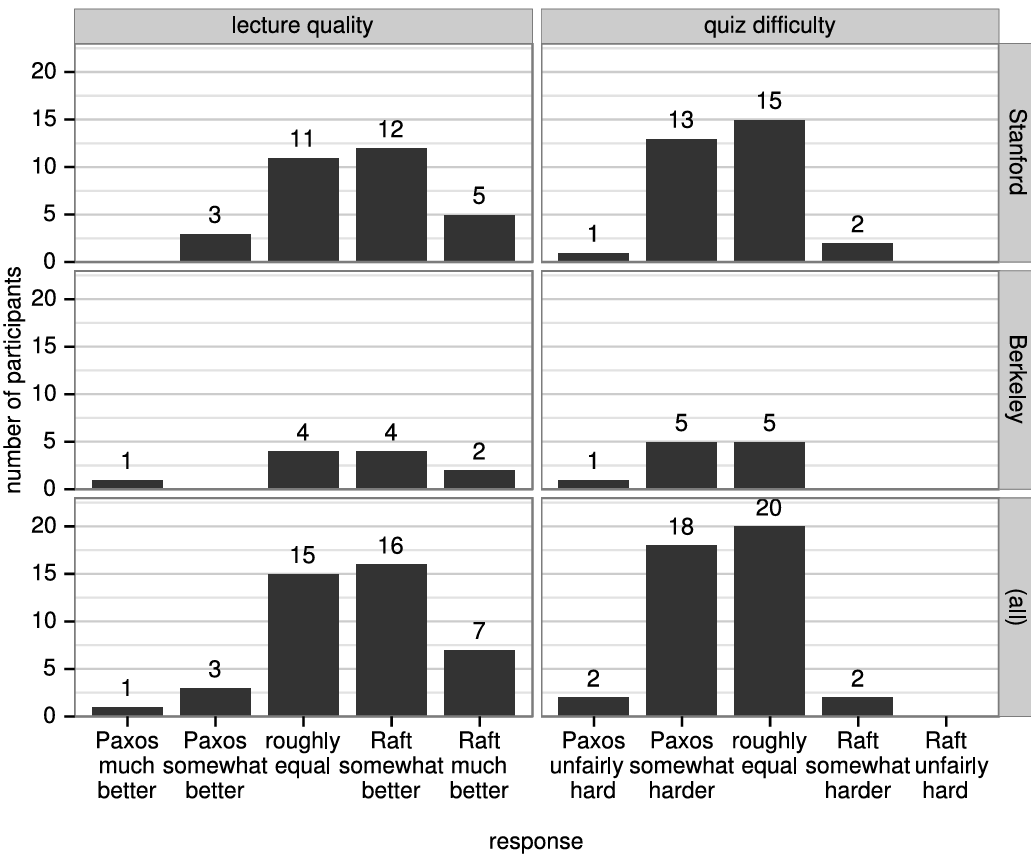
左: 提示された資料の性質を考慮すると、ビデオ講義の質はほぼ同等だったと思うか?
右: 資料の理解度を測るという点で、クイズはほぼ同等であったと思うか?
上のグラフはスタンフォードの参加者からの回答、中央のグラフはバークレーの参加者からの回答、下のグラフは全参加者の合計回答数を示す。
Figure 7.11 は参加者が実装または説明しやすいと感じたアルゴリズムを示している。圧倒的多数の参加者が双方のアルゴリズムについて Raft を好んだ。41 人中 33 人の参加者が、Raft の方が少なくともいくらか実装が簡単だと回答し、41 人中 33 人の参加者が Raft の方が少なくともいくらか説明が簡単だと回答した。しかし、これらの自己申告による感覚は、参加者のクイズスコアよりも信頼性が低い可能性があり、参加者は Raft が理解しやすいという我々の仮説に関する知識によってバイアスを受けている可能性がある。
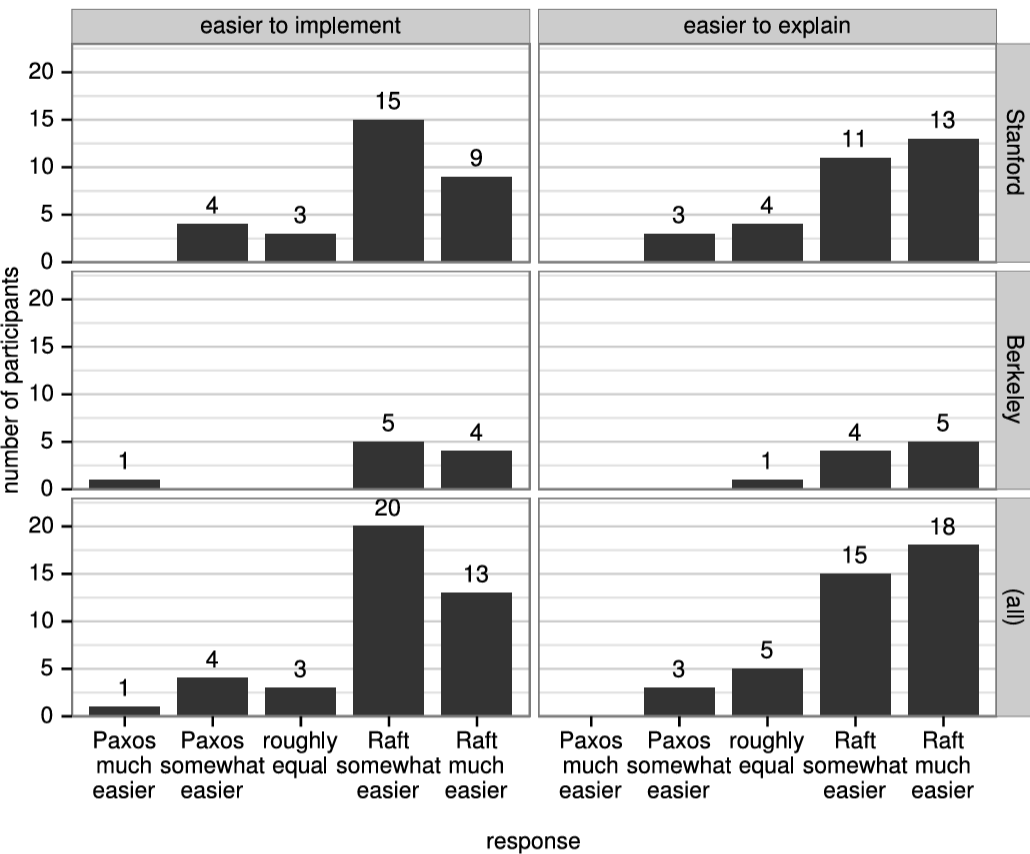
左: もしあなたがある企業で働いており、複製ステートマシンを実装する仕事を持っていた場合、機能的で、正しく、効率的なシステムを実装するのに、どちらのアルゴリズムがより簡単であると思うか?
右: もしあなたが Raft も Paxos も見たことがないコンピュータサイエンスの大学院生に、どちらかのアルゴリズムを説明しなければならないとしたら、どちらが説明しやすいと思うか?
上のグラフはスタンフォードの参加者からの回答、中央のグラフはバークレーの参加者からの回答、下のグラフは全参加者の合計回答数を示す。
7.5 実験アプローチに関する議論
当初、我々はユーザ調査の実施可能性や説得力に疑問を抱いていたが、Raft の理解しやすさという主張を評価する上で最も適切な方法であると感じた。そこで、Raft が Paxos よりも理解しやすいという経験的証拠を提供するためにユーザ調査を実施した。この研究自体は成功したと考えているものの、システムコミュニティからは特に良い評価は得られなかった。このセクションでは、研究に費やした時間と労力に見合う価値があったかを検討し、この種の実験がシステムコミュニティで効果的であるかどうかを明らかにする。
Raft に関する最初の論文提出時 (2012 年) に、Raft アルゴリズムは Paxos よりも理解しやすいと主張したが、これには客観的な証拠がほとんどなかった。匿名の査読者の方々はこの弱点を正しく指摘した。彼らの査読からの抜粋は、評価が行われていないことが理解しやすさに関する我々の主張が弱かったことを証明している:
Raft が Paxos よりも理解しやすいかは明確ではない。理解しやすさは新規性の重要な主張であるものの、この主張は実際には評価されておらず、真実ではない可能性がある。… 著者が具体的な「成功の指標」を示し、その指標に基づいてシステムを評価していれば、大いに役立っただろうと思う。… 理解しやすさを指標として用いるという考え方は確かに良いが、そのように指標を用いて Raft を実際に特徴付けようとする試みが全くなかった。
… 私はアルゴリズムを理解した、つまり、それは Raft が確かに理解しやすいという事実を物語っているかもしれない。
だがそうは言っても、Raft が確かにより理解しやすいことを示す方法が必要であると私は思う。それを行うためのいくつかの考え方:
コードの複雑度の指標を用いて Raft と Paxos の実装を比較する。
学生に Raft と Paxos を説明し、どちらがより理解しやすいかを見る。理解度のテストは、擬似コードの記述、アルゴリズムの動作に関するクイズ、またはアルゴリズムを拡張して別の動作をさせることなどがあり得る。
我々は著者らに「理解しやすさ」の尺度を定義し、プロトコルがこれらの目標を満たしているかを体系的に検討することを奨励する。
これらのフィードバックに基づき、我々は Raft ユーザ調査を実施してその結果を 2 回目の論文投稿に含めた。残念ながら、この研究はほとんどの査読者を納得させなかったようで、彼らはそれに大きな価値を見いださなかったようである。中には査読でのこの研究について言及すらしていなかった査読者も居た。また、我々がユーザ調査の講義とクイズをオンラインで参照するように促していたにもかかわらず、講義の内容やクイズの質問について懸念を表明した査読者も居た。論文は最終的に数回の試行を経て (2014 年に) 採択されたが、我々は査読者が概ね否定的な意見を持っていたにもかかわらず受理されたと感じている。以下の抜粋はユーザ調査に関する査読者の意見を要約したものである。
ユーザ調査はそれほど有用ではない。
評価は乏しい。その定性的な論点 (Raft はよりシンプル ⇒ Raft はより理解しやすい ⇒ Raft の実装はより正確) は十分に裏付けられておらず、読者の直感に左右される可能性がある。… この論文の評価はユーザ調査にかかっている。テストはコーナーケースをテストしたか? 学生はどちらかのシステムを形式的に証明する必要があったか?
セクション 7 クライアントとログ圧縮が空であることに失望した! 選択肢があるなら、私ならセクション 8 実装と評価> を省略してセクション 7 を含めて欲しかった。
ユーザ調査は良いアイディアだが、最終的に論文にあまり貢献しているとは思えない。アルゴリズムが理解しやすいかどうかは読者自身が判断するものであり、論文の最終的な影響は、ユーザ調査ではなく、この判断にかかっている。
ユーザ調査は興味深い。
Paxos をより明確に説明すれば、ユーザ調査の結果が変わるかが不明である。「理解しやすさ」に関する妥当なユーザ調査。
ユーザ調査は称賛に値するものの、潜在的に大きなバイアスの源があるため、最終的にはかなり非科学的であるように思われる。
Raft が Paxos よりも本当に「より理解しやすい」かどうかをよりよく特徴付けようとする著者らの試みを評価する。そして、研究の設計にも注意が払われた (例えば、ユーザを分割したり、異なる順序でテストを提示するなど)。しかし、もし我々の目標が本当に無作為化比較試験であるならば、実験者が 2 つのプロトコルの説明を書いたという事実は、論文に紛れ込んだ可能性のあるかなり明白なバイアスについて、私には少なからぬ疑念を抱かせます。ユーザ調査は斬新で興味深い (バイアス要因は存在するが)。
ユーザ調査は興味深く、示唆に富んでいるが、サンプルサイズと中立性の両面において代表性に欠けている。理解度調査は興味深いと思うが、おそらく少しやり過ぎである。通常、研究者は 2 つのプロトコルを比較し、どちらがよりシンプルかを自ら判断できる。… しかし、私は時には多少のやり過ぎには反対しない。しかし「学生は Paxos に関する質問よりも Raft に関する質問に 23% も高い回答精度で答えることができた」といった文言で研究を要約すると、そのような数字がどの程度意味があるのかについてすぐに疑問が生じる。特に 23% という数字は正確な数字のように見えるが、実際にはチュートリアルやテストの構成方法に大きく依存する (あなた方が行ったように、公平性を確保するための強力な対策が取られている場合でも)。考えられる 2 つの問題は、2 つの異なるプロトコルについて全く同じ質問をすることはできないこと、そしてたとえできたとしても、理解可能性という問題を理解するためにどの質問が適切または公平な質問なのかが明確でないことです。
自己申告の理解度テストと問題への解答の正確さに基づくユーザ調査は、特に説得力があるとは言えない。学生に Paxos と Raft の両方をコードで実装させ、その後、かかった時間、コードの行数、全体的な正確さを客観的に比較できれば、より説得力があるだろう。
具体的な提案: 少数の学生に Paxos と Raft の両方を通信プリミティブから実装させ、客観的な理解度測定値を提供してください。理解度に関するセクションのサンプルサイズは、良好な \(t\) 検定の数値ではあるが、懸念されるほど小さいと感じた。より良いテストは、素朴な (naïve) 実装における考慮されていない障害モードの数かもしれない。私は Raft が大差で勝つと予想する。
さらに [88] の教材をレビューすると、「理解可能性の研究」の実施方法に欠陥があることが示唆されているようです。Multi-Paxos の一部の実装はリーダーによって順序付けされる並行提案をサポートしている。しかし Raft が同じことをどのように行うかは不明である。論文の記述から判断すると、Raft は Append エントリ (Append RPC の実行) を逐次順序していると思う。したがって、特性の異なる 2 つのアルゴリズムの理解度を比較しているのではないでしょうか?
学生のフィードバックを用いた評価は興味深いと思います。しかし、どのようなクイズが出されているかを知らなければ、あなたの結論に納得することは難しいでしょう。
著者は、理解可能性に関する主観的な主張を、セクション 8.1 理解可能性で勇敢に評価しました。素晴らしいです。
我々査読者と学生はユーザ調査を気に入らなかった。これは不要であり、説得力もない。説得力を持たせるために情報を追加しても紙面のコストに見合うものではないだろう。
さらに、Raft のユーザ調査の実施は、時間と労力の点で本質的にコストが高く、リスクを伴うものです。通常、システム論文は機械実験を通じてその性能を定量的に評価する。そのような実験はコストが低くターンアラウンドが速い。これは、人間を対象とする心理学実験と比較して、いくつかの魅力的な特徴をもたらす:
再現性 (Repeatability): 性能評価は通常、簡単で安価に再現できる。多くの場合、それらは自動化されているため、実験の繰り返しにおいて実験者のミスが生じる余地はほとんどない。一方、心理学実験は一般的に人間の介入をはるかに多く必要とするため、コストがかかり、繰り返し実施する際にミスが発生しやすくなる。
反復性 (Iteration): 容易に繰り返し実施できる実験であれば、実験結果に基づいてシステム、環境、または実験内容を変更することができる。追加のコストはほとんど、あるいは全くかからない。しかし、心理学実験では、新しい参加者グループで研究全体をやり直す必要があるため、これは非常にコストがかかる可能性がある。
漸進的な結果 (Incremental results): ユーザ調査では、結果が出る前、あるいは基本的なアイディアが理にかなっているかを知る前に、ほぼすべての作業を完了する必要がある。そのため、このような実験は、初期の粗粒度の結果をほとんど労力をかけず得られることが多い性能評価よりもはるかにリスクが高いものとなる。
一方、斬新なアプローチによって、これらの特性の一部を人間を対象とする心理学実験にもたらすことができる。例えば、ある研究では Dow ら [24] はウェブ解析を用いて広告インプレッションを比較した。これは客観的で再現性があり、反復を可能にし、漸進的である。同様の手法は一部の分野における理解度評価にも適用できる可能性がある。大規模公開オンライン講座 (MOOCs) もまた、研究者に数千人の受講生を教育・評価する場として提供することで、理解度を評価するための有用な実験プラットフォームとなり得る。
査読者の懸念にもかかわらず、我々はユーザ調査をこの研究の不可欠な部分であると考えている。その結果は、Raft が Paxos より理解しやすいという唯一の客観的な証拠である。この結果は、研究の講義が同等の質であり、そのクイズが同等の難易度であるという前提に基づいている。これを証明する方法はないものの、手法は同等の講義とクイズを作成することを目指しており、資料は読者がレビューするために利用可能である。この前提に基づけば、懐疑的な読者にとっても結果は説得力を持つはずである。
7.6 結論
Raft のユーザ調査は、Raft の理解可能性を Paxos と比較した。この研究では、Paxos または Raft を 1 時間学習した学生は、Raft に関する問題に対して、Paxos に関する同等の問題よりも高い回答精度が得られることが示された。我々は研究における主要なバイアスの源をすべて排除したと信じており、研究は我々が望んだ主要な結果を示した。しかしながら、この調査には多大な時間と労力を要した。将来の技術、例えばオンラインコースの活用などが、より低コストで同様の結果を達成できるようになることを期待している。
Raft ユーザ調査は、機械ベースの性能評価に重点を置く傾向のあるシステム研究者にとっては型破りなものであった。我々の研究は、Raft の理解可能性を支持する確固たる証拠を提供し、我々の知る限り、教育と学習に基づくコンセンサスアルゴリズムを客観的に評価した最初の研究である。システムコミュニティは、このような研究を慎重に検討すべきであると我々は信じている。なぜなら、これらの研究は他の方法では説得力のある評価ができなかった新しい種類の貢献を通じて、我々の集合的な知識を進歩させることを可能にするためである。
Chapter 8 - 正しさ
コンセンサスの目的は、複製ステートマシンの間で一貫性を維持することであるため、正確性は重要な関心事である。アルゴリズム自体が正確であるだけではなく、他の開発者も実際のシステムでそれを正確に実装できる必要がある。我々は Raft の正しさについて、理解と直感によって基盤を構築し、実用的な範囲で形式手法を適用するという実用的なアプローチを採用した。
Raft 事態の正しさを確立するために、我々は基本的な Raft アルゴリズムの形式仕様とその安全性に関する証明を開発した。これらはセクション 8.1 で説明されており、完全版は Appendix B に掲載している。完全なシステムには他にも多くのコンポーネント (具体的には、メンバーシップ変更、ログ圧縮、クライアントとの相互作用) が必要だが、これは Raft の正確性を証明する上で重要なステップである。セクション 8.2 では現在の証明に至るまでに試した他の手法について論じる。
我々の目的は、他の人が Raft を用いて正しいシステムを構築できるようにすることであり、セクション 8.3 ではそのためのアプローチを記述する。我々はシステム構築者が Raft を完全に理解していれば、正しい実装をより容易に開発できるという仮説を立てている。これは理解可能性が非常に重要であるもう一つの理由である。Raft の説明は明確かつ正確に行うよう努めたが、自然言語の持つ問題点の一つは、不正確さや曖昧さが生じやすいことである。そのため、我々はシステム構築者に対して、数学的言語を用いて完全に正確に記述されている Raft の形式仕様と自身の理解を比較することを推奨する。
8.1 基本的な Raft アルゴリズムの形式仕様と証明
第 3 章で説明したコンセンサスメカニズムの形式仕様と Safety の証明を開発した。これらは Appendix B に掲載している。形式仕様は、Figure 3.1 に要約された情報を TLA+ 仕様言語 [50] を用いて完全に正確に記述する。形式仕様は約 450 行で、証明の対象となる。また、Raft を実装する人にとっては形式仕様自体も有用である。
形式仕様では、任意の数のサーバで構成される完全な Raft クラスタの状態を定義する。すべてのサーバのログが空である初期状態 (Init) を定義し、ある状態から別の状態へのすべての可能な遷移 (Next) を定義する。遷移にはいくつかの種類がある。ネットワークはメッセージを複製または破棄する可能性があり、サーバは (適切な条件下で) メッセージを受信したり、タイムアウトしたり、再起動したり、リーダーになったり、コミットインデックスを進めたり、クライアントのリクエストを受信したり、RequestVote リクエストを送信したり、AppendEntries リクエストを送信ことができる。各遷移にはそれが起こりうる条件が含まれている。例えば、サーバは候補者状態にある場合にのみ投票を要求できる。
この仕様は、以下の仮定に基づいて非同期システム (時間の概念を持たない) をモデル化している:
メッセージはサーバに到達するまでに任意数のステップ (遷移) を経る場合がある。メッセージを送信すると遷移が発生する (メッセージの受信) が、特定のタイミングは設定されていない。
サーバは停止して故障し、その後、ディスク上の安定したストレージから再起動する可能性がある。
ネットワークは、メッセージの順序を変更したり、破棄したり、複製する可能性がある。
形式仕様は第 3 章で提示した Raft アルゴリズムよりもやや一般的である。これらの違いにより、形式仕様はより広範な実装に適用可能となり、また一部の状態線維がより直行的になるため証明が簡素化される。形式仕様がアルゴリズムの記述と異なる点の一つは、RPC ではなくメッセージパッシングを使用していることである。これにより、AppendEntries レスポンス形式に若干の変更が必要となるが、レスポンスとリクエストをペアにする必要がなくなる。また、この使用では、ほとんどの実装が同じ最終状態に到達するまでに要する遷移よりも多くの遷移が発生する。各遷移はアトミックに評価されるため、これは実装における小さなアトミック領域をモデル化している。これにはいくつかの例がある:
サーバがタイムアウトしても、同じステップでは自分自身に投票を付与しない。代わりに、非同期の RequestVote リクエストメッセージで自身の投票を要求する。また、候補者が最終投票を受け取った後、別の遷移でリーダーになる。
リーダーは AppendEntries 応答を受信してもコミットインデックスを進めない。代わりに別の遷移でそれを行う。これにより、単一サーバクラスタを構成するリーダーも、同じ遷移を通じてコミットインデックスを増加できるため、直交性が向上する。
AppendEntries リクエストを受信すると、サーバはフォロワー状態に戻るか、ログの末尾から最後の 1 エントリを切り捨てるか、ログの末尾に 1 エントリだけ追加するか、または 1 アトミックステップで応答する (その後、さらにステップを進めてリクエストの処理を継続できる)。このアトミック領域を 1 度に 1 エントリだけまでに減らすことは、永続ストレージに書き込む実装にとって重要であることが判明した。たとえば、エントリが複数のファイルにまたがる場合、ほとんどのファイルシステムではすべてのエントリをアトミックに切り捨てることはできないだろう。この仕様では、実装においてエントリを 1 つ以上、後ろから前へ安全に切り捨てることができることを示している。
サーバは、より大きなタームを持つメッセージを受信すると、現在のタームと状態を更新し、その後、別の遷移でメッセージを処理する。
一方、理解しやすさを損なうため、この仕様はできうる限りの一般化がされていない。例えば、一部の遷移では、アトミックに設定する必要がない場合でも 2 つの変数が設定される。
この証明は State Machine Safety 特性を検証する。証明は完全 (仕様のみに依存) かつ比較的正確 (約 3,500 語) である。証明の主要なアイディアはセクション 3.6.3 に要約されている。ほとんどの補題 (部分証明) は、実行時の初期状態から到達可能なすべての状態に対して成立することを示す。帰納法を用いて、それらはある状態において不変条件が成立すると仮定し、すべての可能な次の状態において成立することを示している。
証明では実行における以前の状態の変数を参照することがしばしば必要となる。これを正確にするために、仕様には履歴変数が追加されている。これらの変数は、過去のイベントに関する情報を後続の状態に引き継ぐ。例えば、elections と呼ばれる 1 つの履歴変数は、実行におけるすべての成功した選挙記録を保持する。これには各サーバが投票を行った時点での完全なログと、新しいリーダーの完全なログが含まれる。履歴変数は仕様では決して読み取られず、実際の実装には全く存在しない。それらは証明においてのみ「アクセス」される。
8.2 事前の検証試行に関する考察
現在の証明に至るまでに我々は 3 つのアプローチを試みた:
まず、Raft の初期バージョンを Murphi モデルチェッカー [23] でチェックした。Murphi は完全な状態空間を探索して Safety に違反する状態がないかを検査する。状態空間はすぐに膨張し、Murphi では (妥当な時間内に) 完了できない状態になったため、各ログのエントリ数を最大 4、ターム数を 4、サーバ数を最大 5 となるようにシステムサイズを制限せざるを得なかった。Murphi は Raft の初期バージョンに 1 つのバグを発見した。これは、ログエントリが不完全にコミットされた後に連続して複数のリーダーがクラッシュした場合、ログの不整合を引き起こすものだった。また、Raft の初期バージョンではコミットメントルールが Figure 3.7 のようなシナリオを考慮していないという重要なバグを見逃した。Murphi がこのバグを見逃したのは、モデルサイズの制約が原因だった可能性が高い (幸いにもこれは David Mazières が発見した)。
我々は、仕様に対して TLA モデルチェッカーを適用しようと試みた。この方法で仕様を作成した際にバグを発見したが、より大規模なモデルでは上手くスケールしないため、このアプローチは断念した。
TLA 証明システム [21] の使用も試みた。TLA 証明システムは、TLA 仕様の特性を形式的に証明するための階層言語を導入し、そのような証明のための機械チェッカーも備えている。我々は TLA 証明システムを用いて Leader Completeness 特性を機械的に証明したが、この証明は機械的に検証されていない不変条件に依存していた (例えば、仕様の型安全性を証明しなかった)。残念ながら、完全な証明の規模で TLA 証明システムを使用するのはあまりにも面倒で時間がかかると感じた。一つの問題は、TLA が型付けされていないことで、より汎用的である一方、より面倒にもなることだ [59]。
我々は、正しさを証明するツールには様々な点で限界があることが分かった。我々の経験では、モデル検査は証明を開発するよりも桁違いに簡単だった。それらは基本的に単純化された Raft 実装を書くことを要求し、その後は分散システムよりもさらに簡単に実行およびデバッグできる (モデルチェッカーは問題が発生すると完全な実行トレースを出力する)。残念ながら、我々はモデルを十分な大きさのパラメータで検証し、その正しさを完全に確信できるまでには至らなかった。
一方で、Raft の証明には大きな進展が見られるまでに約 6 週間の学習と考察を要した。証明の作成には、プログラミングとは異なるスキルセットと創造性が必要である。最終的な結果は Raft の Safety に対する自信を高めるために役立ったが、その証明にはバグがあるかもしれない。完全な Raft 仕様の規模では、機械的に検証された証明のみが確実にバグフリーとなり得る。Raft の機械検証された証明は、より高性能なツール (例えば Coq [7]) を使用すれば実現可能だと考えており、最近では Multi-Paxos [101] 用の機械検証された証明も作成されている。しかし、必要な時間はおそらく数ヶ月程度になるだろう。
8.3 正しい実装の構築
Raft の正しい実装を構築するには多くのアプローチがある。最も安全なアプローチは証明済みの Raft 仕様から実装を自動的に生成することである。ツールが適切であれば仕様を実装に変換する際にエラーが発生しないことが保証される。最近の研究ではこれが Multi-Paxos で実現可能であることが示されており [101]、我々は Raft でも同様であると予想している。しかし、このアプローチは今のところ普及していない。これはおそらく、実際のシステムには性能など、生成されたコードでは対応が難しい追加の要件があるためだろう。
実装を生成しないのであれば、実装者はバグが発生する可能性を減らすように実装を設計し、本番環境でバグに遭遇する可能性を減らすように実装をテストすべきである。このセクションの残りの部分では、有効性はまだ評価していないが効果的と思われるいくつかのアプローチについて説明する。読者は Chubby [15] で使用されたテスト戦略にも興味を持つかもしれない。
Howard は ocaml-raft を正しく構築するための優れた設計について記述している [37, 36]。この設計では Raft の状態遷移をすべて一つのモジュールに集約し、遷移がいつ発生すべきかを決定するすべてのコードは別の場所に配置されている。各遷移はアサーションを用いて前提条件をチェックし、システムレベルのコードが混在していないため、コードは Raft 仕様の中核部分に似ている。状態変数を操作するすべてのコードが一箇所に集められているため、制限された方法で状態変数が遷移することを検証しやすい。別のモジュールが適切なタイミングで遷移を呼び出す。さらに、ocaml-raft は単一プロセス内でクラスタ全体をシミュレートできるため、実行中に仮想サーバ間で Raft の不変条件をアサートできる。例えば、実行時の各タームでリーダーが最大 1 人であることをチェックできる。
End-to-End テストには Jepsen と Knossos という有用なツールがあり、すでに 2 つの Raft 実装で (読み取り専用リクエスト処理において) バグを発見している [45]。Jepsen は分散システムにネットワーク分断を注入してシステムがデータを失うかを判断する。Knossos は分散システムに対するクライアントの操作履歴を分析し、それらの履歴が線形化可能でない方法を探す。これらを組み合わせることで、Raft システムの強力な End-to-End テストとして使用できる。
最も発見が難しいバグの中には、リーダー交替や部分的なネットワーク障害など、発生頻度の低い状況でのみ発生するものがある。したがって、テストではこのようなイベントの発生確率を高めることを目指すべきである。これには 3 つの方法がある。
第一に、Raft サーバはテストで稀なイベントが発生するように環境を構成できる。例えば選挙タイムアウトを非常に短く設定し、ハートビート間隔を非常に高く設定すると、より多くのリーダー交替が発生するだろう。また、サーバが頻繁にスナップショットを取得するようにすると、より多くのサーバが遅延し、ネットワーク経由でスナップショットを受信する必要が生じるだろう。
第二に、テストのために稀なイベントが発生するように環境を操作できる。例えばサーバをランダムに再起動してクラスタメンバーシップ変更を頻繁に (または継続的に) 呼び出して、それらのコードパスを実行できる。サーバのリソースを競合させるために他のプロセスを起動するとタイミング関連のバグが露呈するかもしれない。また本番稼働環境では稀にしか発生しないイベントを発生させるために、例えば次のように、ネットワークを様々な方法で操作することができる。
メッセージをランダムに破棄する (そしてサーバとリンク間の破棄頻度を変化させる)。
メッセージにランダムな遅延を追加する。
ネットワークリンクをランダムに無効化したり復元する。
ネットワークをランダムに分断する。
第三に、テストをより長い期間実行することで稀な問題を発見する可能性が高まる。より多くのマシンでテストを並行して実行できる。さらに、クラスタ全体を単一のサーバ上で個別のプロセスとして実行することでネットワーク遅延を削減でき、ディスクオーバーヘッドは RAM のみに永続化することで削減できる (例えば tmpfs [64] などの RAM ベースのファイルシステムを使用する)。これらの手法は完全に現実的ではないが、実装をはるかに短い時間で積極的にテストすることができる。
8.4 結論
Raft の正しさに関する今回の評価は、Paxos ベースのシステムの多くで使用されているアルゴリズムと同等かそれ以上であることを示している。理論家は通常、Paxos の狭い仕様の Safety のみを証明してきたが、実務者はそれらの仕様から逸脱し、システムを大幅に拡張している。Raft の形式仕様は、第 3 章で示した基本的な Raft アルゴリズムのほぼ完全な実装であるため、完全に詳細化された Raft アルゴリズムのうち Safety が証明された部分がかなり大きい。クラスタメンバーシップ、ログ圧縮、クライアントとの相互作用の仕様化と証明、および基本的な Raft アルゴリズムの Liveness と可用性の特性については今後の課題とする。
Chapter 9 - リーダー選出評価
この章では、リーダーが故障し交替が必要になったときに行われる Raft のリーダー選出の性能について分析する。リーダーが故障することは稀な事象であると想定されるがタイムリーに扱われるべきである。我々は Raft が一般的なデプロイメントにおいてほんの一瞬で確実に新しいリーダーを選出することを望んでいる。
残念ながら、リーダー選出にかかる時間やメッセージ数に上限を設けることは困難である。FLP 不可能性 [28] の結果によると、純粋な非同期モデルでのコンセンサスプロトコルは決定論的に終了することができない。このことは Raft に置ける分割投票 (Split Vote) に現れ、リーダー選出中に何度も進行を妨げる可能性がある。また、Raft はリーダー選出時にランダムなタイムアウトを利用しているため、その分析は確率的である。したがって、リーダー選出が高い確率でうまく機能すると言えるのはさまざまな仮定の下でのみとなる。例えば、サーバはタイムアウトをランダムな分布から選択する必要があり (同期が取られているわけではない)、クロックはほぼ同じ速度で進行していなければならず、サーバとネットワークは適切なタイミングで動作している (または停止している) 必要がある。これらの仮定が一定期間満たされない場合、クラスタはその期間中にリーダーを選出できない可能性がある (ただし Safety は常に維持される)。
本章では Raft のリーダー選出アルゴリズムの性能について以下の結論を導く:
分割投票が発生しない場合、選挙は平均して選挙タイムアウト範囲の約 3 分の 1 で完了する。利用可能なサーバの数が多いクラスタでは、最初のサーバが早くタイムアウトすると予想されるため、選挙は若干早く完了する。(セクション 9.1)
選挙タイムアウトの範囲が十分に広い場合、分割投票率は低くなる。我々の片方向ネットワーク遅延 (one-way network lantecy) の 10-20 倍の範囲を推奨している。これにより、適度な規模のクラスタでは分割投票率が常に 40% 未満に抑えられ、通常はそれより大幅に低くなる。クラスタでサーバの障害発生が増えると、利用可能な投票数が少なくなるため、より多くの分割投票を経験することになる。(セクション 9.2)
リーダーを選出するために必要な選挙ターム数は幾何分布に従い、期待値は \(\frac{1}{1-\mbox{split vote rate}}\) である。したがって、分割投票率が 50% と高い場合であってもリーダーを選出するのに必要な選挙タームは平均で 2 タームである。選挙タイムアウトを片方向ネットワーク遅延の 10-20 倍に設定したクラスタでは、平均して片方向ネットワーク遅延の 20 倍未満でリーダー選出を行うことができる。(セクション 9.3)
リーダー選出はローカルネットワークでも広域ネットワークでも実際に良好に機能する。実世界の LAN では、積極的なタイムアウトを設定した場合、我々のシステムは平均 35ms でリーダーを選出できたが、実際にはより保守的なタイムアウト範囲を使用することを推奨する。US 全土にまたがる模擬 WAN では、選出は通常 0.5 秒で完了し、5 台のサーバのうち 2 台が故障した場合でも、選出の 99.9% は 3 秒で完了する。(セクション 9.4)
一部のサーバが他のサーバに投票を許可しない場合でも、RequestVote RPC におけるログ比較によってリーダー選挙のパフォーマンスに大きな影響を与えない。(セクション 9.5)
基本的なリーダー選出アルゴリズムでは、フォロワーが接続性を失い、そのタームをインクリメントした後、再び接続正を回復した場合に混乱を引き起こす可能性がある。セクション 9.6 では、このような混乱を回避するために基本的なアルゴリズムに追加のフェーズを追加して拡張している。
9.1 分割投票が起きない場合、Raft はどれくらいの早さでリーダーを選出するか?
Raft におけるリーダー選出の最も一般的なケースでは分割投票が発生しない。このセクションでは、この仮定の下でリーダー選出にかかる時間を分析する。これは、Raft クラスタが正しく構成されていれば通常の選挙ではほとんど分割投票が発生しないため、クラスタの通常のケースと想定される。最初にタイムアウトしたサーバがクラスタの過半数から票を集めてリーダーになることができる。イベントのタイムラインを Figure 9.1 に示す。
分割投票が起きない場合、リーダー選出にかかる時間は、最初のサーバがタイムアウトするまでの時間によって決まる。タイムアウトのタイミングについては Figure 9.2 に示されている。各サーバは、最後にハートビートを受信してから、一様にランダムなタイムアウトまで待機する。直感的には、個々のサーバは選出タイムアウトの範囲の半分でタイムアウトすると予想されるが、サーバの数が増えると最初のサーバがより早くタイムアウトする可能性が高くなる。
| 変数 | 型 | 意味 |
|---|---|---|
| \(s\) | 自然数 | 利用可能なサーバ数 |
| \(n\) | 自然数 | クラスタ全体のサイズ (利用不可能なサーバを含む) |
| \(c\) | 自然数 | 互いに近い時間でタイムアウトするサーバの数 |
| \(l\) | 時間 | 定数の片方向ネットワーク遅延 \(L の特殊なケース\) |
| \(L\) | 時間の乱数 | 片方向ネットワーク遅延 |
| \(W\) | 時間の乱数 | タームと投票をディスクに英ぞてきに書き込む時間 |
| \(T_i\) | 時間の乱数 | サーバ \(i\) のタイムアウト |
| \(M_s\) | 時間の乱数 | \(s\) 個のサーバの中で最も早いタイムアウト |
| \(D_{c,s}\) | 時間の乱数 | \(s\) 個のサーバのうち最も早い \(c\) 個のタイムアウトの差 |
| \(E_s\) | 時間の乱数 | 選挙を完了する時間 |
ここで問題をより正確に定義し、最初のサーバがタイムアウトするタイミングを解析的に導出する。本章で定義した変数は Table 9.1 にまとめている。各サーバはライムアウトを (範囲 \([0,1]\) の) 標準一様分布からランダムに選ぶとする。\(s\) 台のサーバのそれぞれがタイムアウトするタイミングを表す確率変数を \(T_1\ldots T_s\) とする。\(M_s\) は \(T_1\ldots T_s\) の最小値とし、最初のサーバがタイムアウトするタイミングを表す確率変数とする。その累積分布関数 (CDF) は、\(M_s\) が特定の時刻 \(t\) 以下となる確率を定義する。これは、\(t\) 後にすべてのサーバがタイムアウトする確率から 1 を引いた値に相当する: \[ \begin{eqnarray*} {\rm Pr}(M_s \le t) & = & 1 - {\rm Pr}(M_s \gt t) \\ & = & 1 - \prod_{i=1}^s {\rm Pr}(T_i \gt t) \\ & = & 1 - \prod_{i=1}^s {\rm Pr}(1 - t) \\ & = & 1 - (1 - t)^s \end{eqnarray*} \] 例えば、5 台のサーバで構成されるクラスタで以前のリーダーが故障した場合を考える。残りの 4 台のサーバのうち最も早くタイムアウトするサーバが、選挙タイムアウト範囲の最初の 1/4 のどこかでタイムアウトする確率は \({\rm Pr}(M_4 \le \frac{1}{4}) = 1 - (1 - \frac{1}{4})^4 \approx 0.68\) である。Figure 9.3 は \(s\) の様々な値に対する CDF グラフを示している。
\(M_s\) の確率密度関数 (PDF) は CDF の微分である: \[ \begin{eqnarray*} f_{M_s}(t) & = & \frac{d}{dt}{\rm Pr}(M_s \le t) \\ & = & \frac{d}{dt} (1-(1-t)^s) \\ & = & -\frac{d}{dt}(1-t)^s \\ & = & s(1-t)^{s-1} \end{eqnarray*} \] \(M_s\) の期待値 (平均) は PDF から計算される: \[ \begin{eqnarray*} \boldsymbol{E}[M_s] & = & \int_0^1 t f_{M_s}(t) dt \\ & = & \int_0^1 t(s(1-t)^{s-1}) dt \\ & = & - \left. \frac{(1-t)^s(st+1)}{s+1} \right|_{t=0}^1 \\ & = & \frac{1}{s+1} \end{eqnarray*} \] 例えば、4 台のサーバが利用可能な場合、最初のタイムアウトは選挙タイムアウト範囲の \(\frac{1^{\rm th}}{5}\) で発生すると期待される。幸いなことに、この非常に単純な式は Raft の選挙性能全体を最適に推定するものとなる。なぜなら、分割投票が発生しない場合、最初の候補者がタイムアウトするとすぐに選挙が完了するからである。
より正確には、分割投票がなければ、完全な選挙であればリーダーがクラッシュした時点で候補者がタイムアウトして投票を要求する必要がある: \[ \begin{eqnarray*} E_s & = & \mbox{baseline election timeout $+M_s+$ time to request votes $-$ heartbeat adjustment} \\ E_s & = & 1 + M_s + 2L + W - U(0, \frac{1}{2}) \\ \boldsymbol{E}[E_s] & = & 1 + \frac{1}{s+1} + 2\boldsymbol{E}[L] + \boldsymbol{E}[W] - \frac{1}{4} \end{eqnarray*} \] ここで、選挙タイムアウトは \([1,2]\) の範囲から選択され、\(L\) はネットワーク遅延、\(W\) は投票結果をディスクに永続的に書き込む時間である。リーダーノードはハートビート送信直後ではなく、ハートビート間隔内でランダムにクラッシュすることが予想されるため、そのタイミングを考慮し \([0,\frac{1}{2}]\) の範囲から一様乱数で選択された値が差し引かれる。
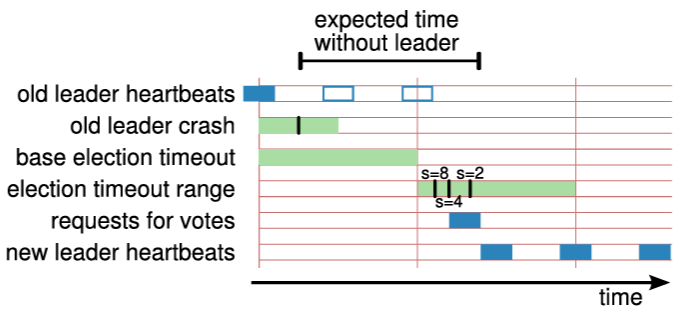
"old leader heartbeats" 行は、旧リーダーが完了した最後のハートビートと、クラッシュしていなければ次に送信していただろうハートビートの送信時刻を示している。
"old leader crash" 行は、旧リーダーがクラッシュする間隔を示している。この時間は、ハートビート間隔内で一様にランダムな分布に従うと仮定される。間隔の中間にある縦線はその期待値 (平均値) である。
"base election timeout" 行は、すべてのフォロワーが旧リーダーからの追加のハートビートを待機する間隔を示している。
"election timeout range" 行は、サーバがタイムアウトして旧リーダーを置き換えるための選挙を開始する間隔を示す。縦線は、残りのサーバ数 (それぞれ 8 台、4 台、2 台) ごとに予想される最短タイムアウト値を示している。
"requests for votes" 行は、候補者が他のサーバに RequestVote RPC を送信し、投票を受け取るタイミングを示している。
"new leader heartbeats" 行は、神リーダーがリーダーになった直後にハートビート RPC を送信し、その後定期的にハートビート RPC を送信していることを示す。
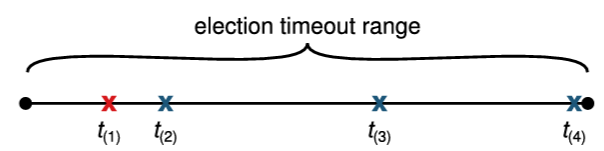
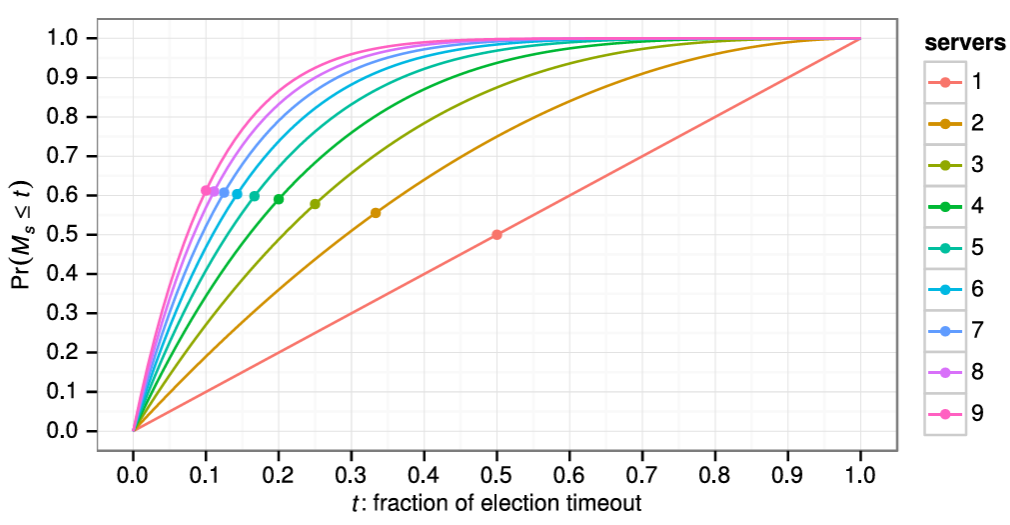
9.2 分割投票はどの程度一般的か?
前のセクションでは、分割投票が発生しない場合の通常の選挙の性能を分析した。実際には、2 つ以上の候補者がほぼ同時にタイムアウトし、分割投票につながる可能性がある。分割投票は選挙タイムアウトの遅延を増加させ、頻繁に発生すると選挙の性能に劇的な影響を与える可能性がある。このセクションでは、まずネットワーク遅延が一定であるという単純化された仮定の下で分割投票を分析し、その後にこの仮定を緩和する。
固定遅延での分割投票率
ネットワーク遅延が固定されているなら分割投票は簡単に計算できる。クラスタ内の任意の 2 つのサーバ間の片方向遅延を定数 \(l\) とし、選挙タイムアウト範囲の割合として測定する。ネットワーク遅延が固定されているため、最初にタイムアウトしたサーバは、\(l\) 以内にタイムアウトしないすべてのサーバからの票を確実に取得する。それ以外のサーバはそれぞれ自身に投票するため、それらのサーバからの票は一切取得しない。したがって、分割投票の確率は \(l\) 以内にタイムアウトする候補者が多すぎる確率である。例えば 5 台のサーバで構成されるクラスタで、利用可能なサーバが 4 台しかない場合を考える。Figure 9.4 に示すように、\(l\) 以内にタイムアウトするサーバが 2 台だけであれば、最も早いサーバは自身と他の 2 台のサーバから票を集めてリーダーになることができる。しかし \(l\) 以内にタイムアウトするサーバが 3 台となると、最も早いサーバは他の 1 台のサーバにしか到達できず、投票は分割される。
分割投票が発生する一般的な式を導出するため、互いに \(l\) 以内にタイムアウトするサーバ数を \(c\) とし、クラスタ全体のサイズを \(n\) とする。最初のサーバは自身の投票に加え、最初のサーバから少なくとも \(l\) より後にタイムアウトする \(s-c\) 個のサーバからの投票を受け取る。したがって、分割投票は以下の条件が成立するときに発生する: \[ \mbox{votes needed} \gt \mbox{votes available to earliest server} \\ \begin{eqnarray*} \left\lfloor\frac{1}{2}\right\rfloor + 1 & \gt & 1 + (s - c) \\ c & \gt & s - \left\lfloor\frac{n}{2}\right\rfloor \end{eqnarray*} \]
分割投票の発生頻度は、少なくとも \(c\) 個のサーバが互いに \(l\) 以内の間隔でタイムアウトする頻度に依存する。\(D_{c,s}=T_{(c)}-T_{(1)}\) とする。ここで \(T_{(i)}\) は \(s\) 個のサーバのうち昇順で \(i\) 番目のサーバのタイムアウト時間を表す確率変数である。\(D_{c,s}\) は最初のサーバがタイムアウトしてから \(c\) 番目のサーバがタイムアウトするまでの時間である。分割投票の確率は \({\rm Pr}(D_{c,s}\lt l)\) となり、ここで \(c\) は上記の式 \((s-\left\lfloor\frac{n}{2}\right\rfloor+1)\) で決定される。
ここで、\(D_{c,s}\) の CDF を \({\rm Pr}(D_{c,s} \le l)\) と導出する。最初のサーバが \(t\) でタイムアウトしたとする。まず \(t \lt 1 - l\) の場合、後続の各サーバは \(t\) から \(l\) 時間以内に確率 \(\frac{l}{1-t}\) でタイムアウトする。2 番目から \(c\) 番目のサーバが \(t\) から \(l\) 以内にタイムアウトし、残りの \(s-c\) 個のサーバがタイムアウトしない確率は次のように与えられる: \[ \binom{s-1}{c-1} \left(\frac{l}{1-t}\right)^{c-1} \left(\frac{1-t-l}{1-t}\right)^{s-c} \] 代わりに、\(t \ge 1-l\) の場合、最初のサーバの後にタイムアウトするサーバは、\(t\) から \(l\) 以内にタイムアウトしなければならない。したがって、\(s\) 個のサーバのすべてが最初のサーバより \(l\) 以内にタイムアウトする確率は 1 であり、どのサーバも最初のサーバより \(l\) 以内にタイムアウトしない確率は 0 である。これらをまとめると CDF は次のようにできる: \[ \begin{eqnarray*} \Pr(D_{c,s} \le l) & = & \sum_{k=c}^s \left( \begin{array}{l} \displaystyle \int_0^{1-l} \text{Pr(exactly } k \text{ servers time out in } t \text{ to } (t+l) \text{ range } | M_s=t) f_{M_s}(t) dt + \\ \displaystyle \int_{1-l}^1 \text{Pr(exactly } k \text{ servers time out in } t \text{ to } (t+l) \text{ range } | M_s=t) f_{M_s}(t)dt \end{array} \right) \\ & = & \sum_{k=c}^s \left( \int_0^{1-l} \text{Pr(exactly } k \text{ servers time out in } t \text{ to } (t+l) \text{ range } | M_s=t) f_{M_s}(t) dt \right) + \\ && \int_{1-l}^1 f_{M_s}(t) dt \\ & = & \sum_{k=c}^s \left( \int_0^{1-l} \binom{s-1}{k-1} \left(\frac{l}{1-t}\right)^{k-1} \left(\frac{1-t-l}{1-t}\right)^{s-k} f_{M_s}(t) dt \right) + \\ && \int_{1-l}^1 f_{M_s}(t)dt \\ & = & \sum_{k=c}^s \left( \int_0^{1-l} \left(\frac{l}{1-t}\right)^{k-1} \left(\frac{1-t-l}{1-t}\right)^{s-k} s(1-t)^{s-1} dt \right) + \\ && \int_{1-l}^1 s(1-t)^{s-1} dt \\ & = & \sum_{k=c}^s \binom{s-1}{k-1} \left.\left( -\frac{s}{s-k+1} l^{k-1}(1-t-l)^{s-k+1} \right)\right|_{t=0}^{1-l} + \\ && \left.(-(1-t)^s)\right|_{t=1-l}^1 \\ & = & \left( \sum_{k=c}^s \binom{s-1}{k-1} \frac{s}{s-k+1} l^{k-1}(1-l)^{s-k+1} \right) + l^s \\ & = & \left( \sum_{k=c}^s \frac{(s-1)!(s)}{(k-1)!(s-k)!(s-k+1)} l^{k-1} (1-l)^{s-k+1} \right) + l^s \\ & = & \left( \sum_{k=c}^s \frac{s!}{(k-1)!(s-k+1)!} l^{k-1}(1-l)^{s-k+1} \right) + l^s \\ & = & \left( \sum_{k=c}^s \binom{s}{k-1} l^{k-1}(1-l)^{s-k+1} \right) + l^s \\ & = & \left( \sum_{k=c-1}^{s-1} \binom{s}{k} l^{k}(1-l)^{s-k} \right) + l^s \\ & = & \sum_{k=c-1}^s \binom{s}{k} l^k (1-l)^{s-k} \end{eqnarray*} \] (CDF は二項分布にやや似ているため、より簡単な導出方法が存在する可能性が示唆される。)
例えば、利用可能なサーバが 4 台 (\(s=4\)) の 5 サーバクラスタを考える。分割投票は、最初の 3 サーバが互いに \(l\) 以内でタイムアウトした場合 \(c=3\) に発生する。選挙タイムアウト範囲が 100 ミリ秒の場合、最初の 3 サーバは互いに \(l\) 以内でタイムアウトして分割投票が発生する:
約 0.06% の選挙において、片方向ネットワーク遅延が 1ms の場合、\({\rm Pr}(D_{3,4} \le .01)\);
約 5.2% の選挙において、片方向ネットワーク遅延が 10ms の場合、\({\rm Pr}(D_{3,4} \le .1)\);
約 18.1% の選挙において、片方向ネットワーク遅延が 20ms の場合、\({\rm Pr}(D_{3,4} \le .2)\).
Figure 9.5 は様々なクラスタサイズにおける CDF 式をグラフ化したものである。まず注目すべき点は障害が分割投票に大きな影響を与えることである。特にクラスタが元のメンバーの過半数ぎりぎり (bare majority) まで減少している場合にその影響は顕著である。例えば、\(l=0.2\) の 5 サーバクラスタでは、1 回の障害発生で 20% 未満の分割投票が発生する。同じくラスタで 2 回目の障害が発生すると、選挙タームの約半分で分割投票が発生する。最悪のシナリオに備えるため、選挙タイムアウトの範囲は、クラスタ内の利用可能なサーバ数が過半数ぎりぎりの場合に許容できる値になるように設定する必要がある。
第二に、より大きなクラスタでは、同じ数の障害が発生した場合でも分割投票は少なくなるが、より多くの障害を許容できるため、最悪のケースでは分割投票率がさらに高くなる。例えば、\(l=0.2\) の 9 サーバクラスタでは、2 台の障害後でも分割投票率は約 15% にとどまるが (5 サーバクラスタでは 50%)、しかし 4 台の障害が発生して過半数ぎりぎりまでに低下すると、9 サーバクラスタは 70% 近い分割投票率を経験することになる。
第三に、利用可能なサーバ数を一定に保つと、全体のクラスタのサイズが大きいほど分割投票の確率が高くなる。例えば \(l=0.2\) の場合、6 台の利用可能なサーバを持つ 9 台のサーバクラスタは約 35% の確率で分割投票になるが、6 台の利用可能なサーバを持つ 7 台のサーバクラスタは約 10% の割合でしか分割投票とならない。これは全体のクラスタサイズが大きいほど選挙に勝つために多くの票数を必要とするためであり、分割投票を生み出すために \(l\) 以内のタイムアウトが発生する候補者の数が少ないからである。
最後に、グラフから、ネットワーク遅延がほぼ一定であると仮定した場合、選出タイムアウトの範囲を片方向ネットワーク遅延の 10-20 倍 (つまり \(l=0.1\) に設定すると、すべてのクラスタで分割投票率が低くなることが示唆される。この構成では 9 台のサーバで構成されるクラスタで 4 台の障害が発生すると分割投票率は 40% になるが、ほとんどの一般的なクラスタでは分割投票率はもっと低くなる。多くの環境で選出タイムアウトを小さくする (\(l\) を大きくする) ことも機能するかも知れないが、確実に機能するためにはより慎重にテストを行う必要がある。
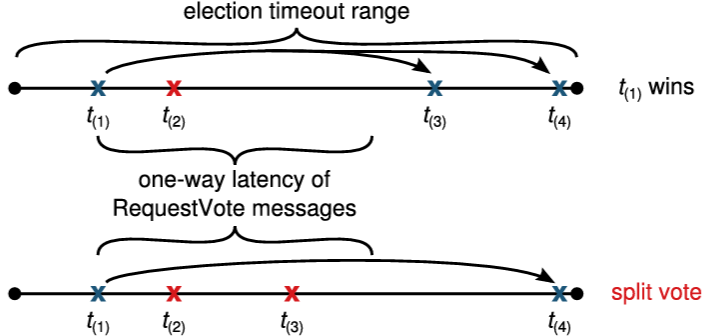
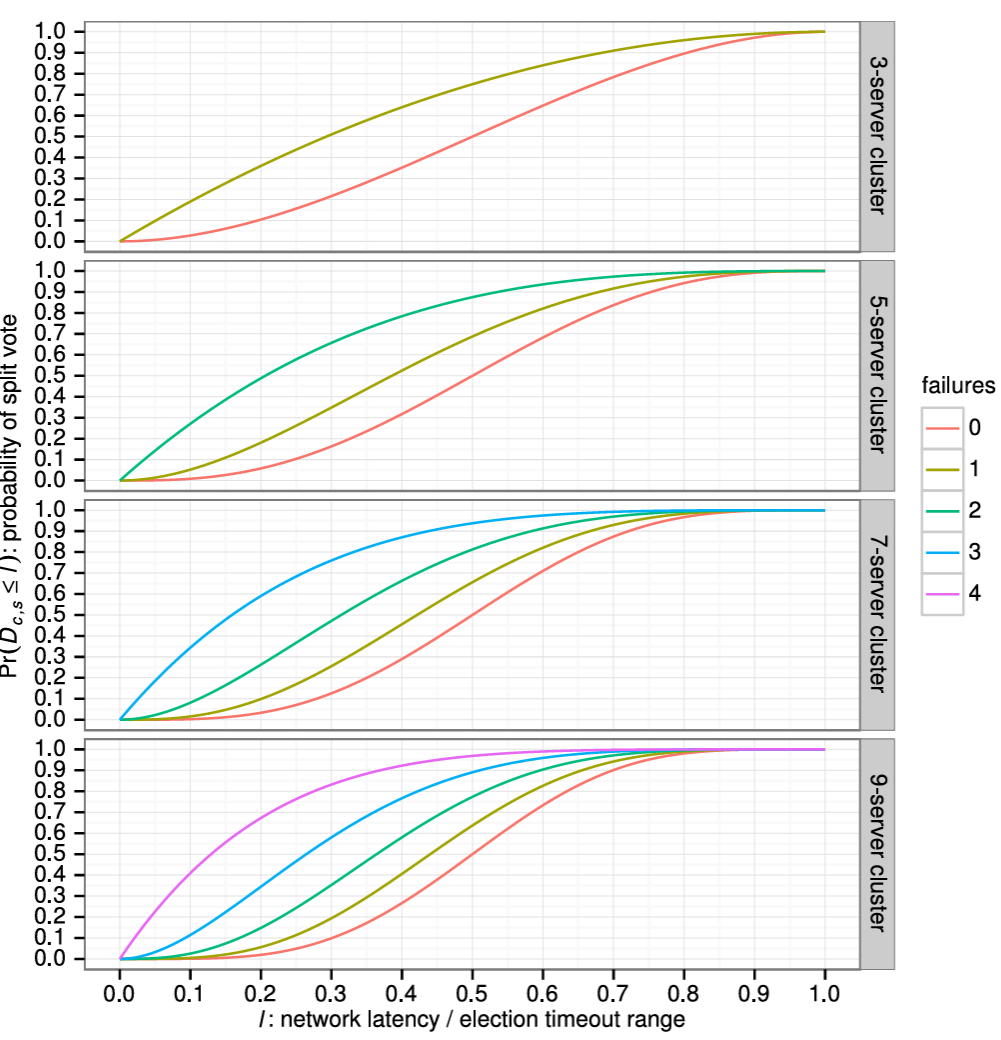
変動遅延での分割投票率
ネットワーク遅延が変動する場合、分割投票率の計算はより複雑になる。問題は、あるサーバが送信した RequestVote メッセージが、他のサーバから先に送信された RequestVote メッセージを追い越してしまう可能性があることである。そのため、最初にタイムアウトしたサーバは、自分自身に投票していないサーバの投票をすべて集めることが保証されなくなる。最初のサーバは、投票リクエストを最初に送信するため依然として勝利する可能性が最も高い候補だが、その優位性はタイムアウトのタイミングに依存する。したがって、変動遅延の場合、分割投票率は (競争が激しくなるため) いくらか高くなると予想される。
これは数学的にモデル化するのではなく小規模なシミュレーションを実施した。それぞれの実行は以下の手順に従った (最適化前):
\(s\) 台の各サーバにランダムなタイムアウトを割り当てる。
タイムアウトまでに投票を行っていないサーバは、自身に投票し、ランダムな遅延時間後に他のサーバに RequestVote メッセージを配信するようにスケジュールする。
いずれかのサーバが過半数の投票を集めると選挙は投票したと見なされる。そうでない場合は分割投票と見なされる。
10,000 回の実行後、分割投票の割合が計算された。
Figure 9.6 は、シミュレーションによって計算された、\([l_{\rm min},l_{\rm max}]\) 範囲の一様にランダムな遅延を持つメッセージの分割投票率を示す。(一様にランダムな遅延は現実的な分布ではないかもしれないが、最も単純なケースであり、より複雑な分布を推定するのに役立つ。) これらのグラフから得られる全体的な結論は固定遅延の場合と同じである。つまり、障害が増えると分割投票率が大幅に高くなる。
過半数ぎりぎりのサーバのみが利用可能なクラスタ (各列の一番下のグラフ) では、等高線は非常に直線的で傾きは約 -2 である。平均ネットワーク遅延を一定に保つと、これらはほぼ同じ分割投票率となる。これは、過半数ぎりぎりのクラスタでの分割投票率が可変遅延範囲の平均を用いた固定遅延モデルで正確に近似できることを示している。例えば、9 台のサーバで 4 台が故障したクラスタでは、\([0.1,0.2]\) の範囲からランダムに選択された可変遅延は、固定遅延 \(0.15\) の場合と同様の分割投票率となる。
故障の少ないクラスタでは、等高線は必ずしも直線的ではなく、一般的に傾きが小さい (より平坦である)。例えば故障のない 5 台のサーバクラスタでは、0.1-0.2 の可変遅延は約 0.2 の固定遅延の場合とほぼ同等の分割投票率となる (等高線の傾きは約 -1 に過ぎない)。一般的に、分割投票は可変遅延範囲の最大値を用いた固定遅延モデルで境界を設定することができる。これは図に示したデータポイントの約 78% に当てはまる。しかし、この近似は、大規模なクラスタで最も障害が少ない場合に最も機能しない。これは、それらの等高線が最も大きく湾曲しているためである。
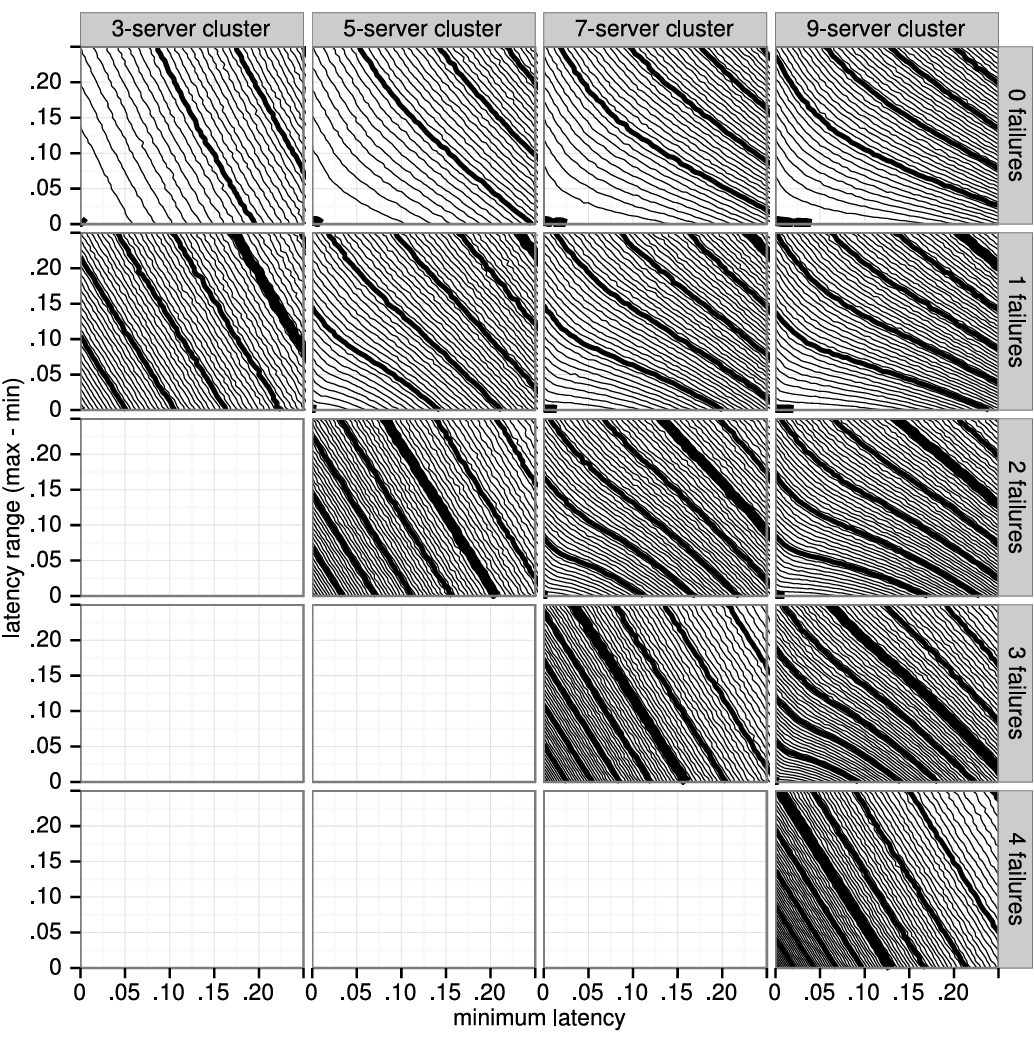
例えば 5 サーバクラスタにおいて 1 台のサーバが故障したときの分割投票が発生する確率は、2 列目と 2 行目のグラフで見つけることができる。遅延が 0.1 から 0.2 の間でランダムかつ均一に選択される場合、最小遅延が 0.1、遅延範囲が 0.1 の点では、等高線を数えることで分割投票率が約 16% であることがわかる。2 つのサーバが故障した場合、同じクラスタでの分割投票の確率はほぼ 40% になる。
9.3 分割投票が発生した場合、Raft はどのくらいの早さでリーダーを選出するか?
分割投票の発生率が与えられれば選挙全体の時間を見積もることができる。Raft は分割投票がなければ選挙タームが正常に完了するとすぐに新しいリーダーを選出する。分割投票が発生していると、すべてのサーバがタイマーをリセットしている可能性が高くなる。これは、サーバが投票するときにタイマーをリセットするためで (ただしログが異なる場合は必ずしもそうではない; セクション 9.5 参照)、次の選挙タームは全く新しい選挙と同じ成功率となり同程度の時間がかかる。言い換えれば、各選挙タームは本質的に無記憶であり、選挙に必要な選挙タームの数は幾何分布としてモデル化できる。ここで、成功確率は分割投票が発生しない確率である。したがって、Raft の選挙は平均して \(\frac{1}{1-\mbox{split vote rate}}\) の選挙タームで完了すると予想される。
特定の選挙タームで分割投票が発生した場合、その選挙タームは約 \(1+M_s\) 時間単位と、サーバの選挙タイマーをリセットするための片方向ネットワーク遅延がかかる。候補者が自身への投票をディスクに記録する時間は含めない。これは RequestVote メッセージと重複できるためである (この最適化により、候補者は自身の投票が永続的に記録されるまで、自身の投票をリーダーシップとして数えない可能性がある)。投票が分割された場合、クラスタは次の選挙タームが始まるまでもう一度選挙タイムアウトを待つ必要がある。これが分割投票ごとに繰り返され、その後、分割投票が起きなかった選挙のターム (セクション 9.1 から) が追加される。したがって、選挙の合計時間 \(E_s\) は以下のようになる: \[ \begin{eqnarray*} E_s & = & \left( \sum_\mbox{split votes} \mbox{time for split vote} \right) + \left( \mbox{time for election with no split vote} \right) \\ E_s & = & \left( \sum_\mbox{split votes} (1+M_s+L) \right) + \left( 1+M_s+2L+W-U(-,\frac{1}{2}) \right) \\ \boldsymbol{E}[E_s] & = & \left( \left( \frac{1}{1-\mbox{split vote rate}} - 1 \right) \times \left( 1 + \frac{1}{s+1} + \boldsymbol{E}[L] \right) \right) + \left( 1 + \frac{1}{s+1} + 2\boldsymbol{E}[L] + \boldsymbol{E}[W] - \frac{1}{4} \right) \\ \boldsymbol{E}[E_s] & = & \frac{1}{1-\mbox{split vote rate}} \times \left(1+\frac{1}{s+1}+\boldsymbol{E}[L]\right) + \boldsymbol{E}[L] + \boldsymbol{E}[W] - \frac{1}{4} \end{eqnarray*} \] ここで \(L\) は片方向ネットワーク遅延、\(W\) は永続ディスク書き込み遅延である。
Howard [37] は、分割投票が発生した後の選挙タームを短縮するための最適化を提案している。この最適化では、フォロワーのタイムアウトと候補者のタイムアウトを分離し、候補者はより狭い範囲の分布からより短いタイムアウトを選択する。これにより、分割投票が発生した後、より速い反復が実現されるが、追加の分割投票のリスクがある。本章の残りではこの最適化は使用しない。
Figure 9.7 は \(\boldsymbol{E}[E_s]\) と \({\rm Pr}(D_{c,s} \le l)\) の式を組み合わせて、ネットワーク Figure 9.7 は \(\boldsymbol{E}[E_s]\) と \({\rm Pr}(D_{c,s} \le l)\) の式を組み合わせて、ネットワーク遅延が固定されている場合のリーダー選出にかかる予想時間をプロットしたものである。グラフから、十分に拾いタイムアウト範囲を持つ Raft クラスタは、利用可能なサーバの過半数ぎりぎりで運用されている場合でも、通常、片方向ネットワーク遅延の 20 倍以内でリーダーを選出できることがわかる。これは、ほとんどのデータセンターにおける Raft の展開で、典型的なリーダー選出時間が 100 ミリ秒未満を達成できることを示唆している。片方向遅延が 200 ミリ秒となるような最悪ケースのグローバルな導入であっても、通常 4 秒以内にリーダーを選出できるはずである。(一部のサーバが他の惑星に展開されている場合、選挙タームはさらに長くなる可能性がある。)
各曲線には屈曲点がある。タイムアウト範囲が短すぎると、他のサーバが投票を収集する前にタイムアウトしてしまうサーバが多すぎて選挙タームが悪化する。タイムアウト範囲が十分に大きくなると (クラスタにも依るが、ネットワーク遅延の約 3-6 倍)、曲線はわずかに右上がりの直線になる。これは、選挙がほんとどまたはまったく分割投票なしで完了するものの、各タイムアウトが経過するまで長く待たなければならないためである。
このグラフは選挙タイムアウトをどのように設定すべきかについての洞察を提供する。実際には保守的な設定が最適であろう。グラフ上の最小点は、各クラスタ構成で可能な最短の平均選挙タームを表している。しかし、この最小時間を達成することは非常に危険である。なぜなら、最小値は曲線の屈曲点に近い位置にあるためである。もし実際のネットワーク遅延が予想よりわずかに高くなった場合、システムがグラフの左側の領域に押しやられ、選挙タームが急増する可能性がある。したがって、システムをより堅牢にするために、平均選挙タームをわずかに犠牲にして、より右側にシステムを設定する方が良い。そのため、片方向ネットワーク遅延の 10 倍のタイムアウト範囲を使用することを推奨する (実際のネットワーク遅延が予想の 5 倍になったとしても、ほとんどのクラスタは適切なタイミングでリーダーを選出できるはずである)。
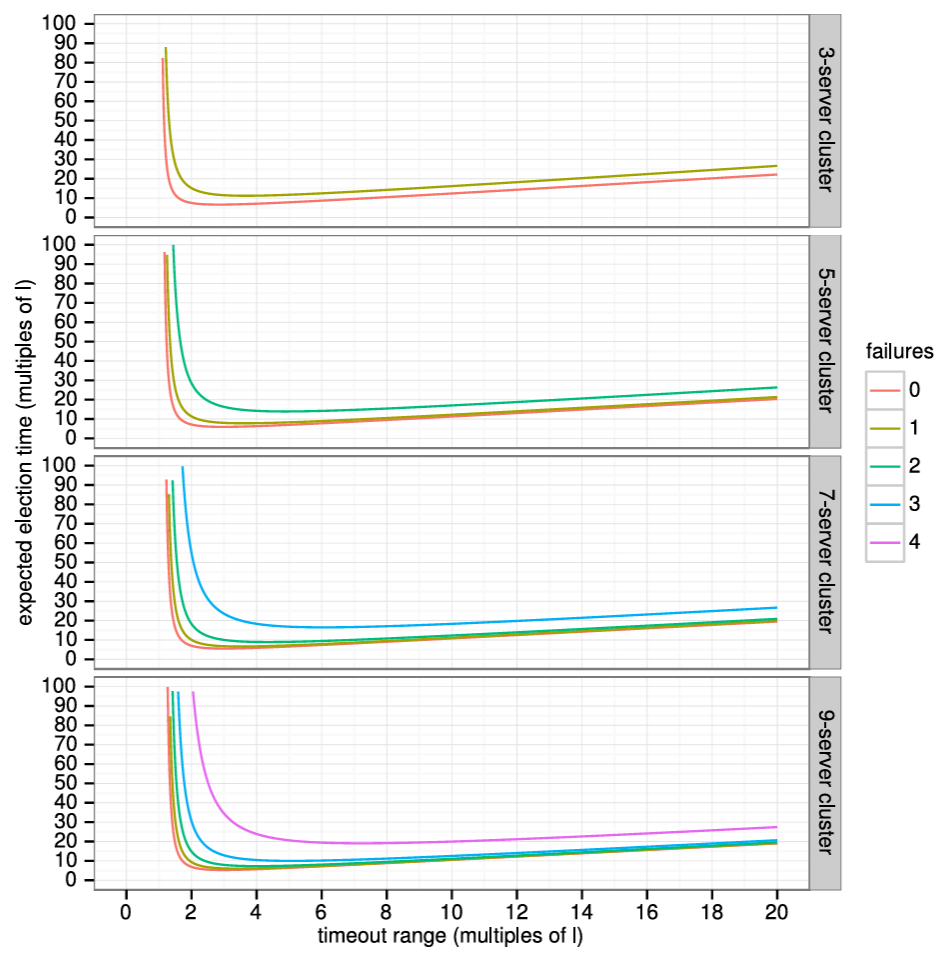
9.4 完全な Raft アルゴリズムは実際のネットワークでどれくらい速くリーダーを選出するか?
これまでの章では Raft におけるリーダー選出の仕組みについて簡略化されたモデルに基づいていた。我々は、Raft が実世界でどれくらい速くリーダーを選出できるかを知りたいと考えた。そこで、本章では Raft のリーダー選出アルゴリズムを LAN 環境での実世界ベンチマークと、低速な WAN 環境での現実的なシミュレータを用いて評価する。
LAN での実世界実装
LogCabin を用いて、ギガビットイーサーネットワークで接続された 5 台のサーバ上で Raft のリーダー選出アルゴリズムの性能を計測した。実験設定の概要を Table 9.2 に示す。ベンチマークでは、5 台のサーバからなるクラスタのリーダーを繰り返しクラッシュさせ、クラッシュを検出し新しいリーダーを選出するのにかかる時間を計測した。ベンチマークでは、古いリーダーがクラッシュしてから、他のサーバが新しいリーダーの最初のハートビートを受信するまでの時間を測定した (Figure 9.1 参照)。リーダーはハードビート間隔内でランダムにクラッシュさせられ、その間隔はすべてのテストで最小選挙タイムアウトの半分であった。したがって、可能な最小ダウンタイムは最小選挙タイムアウトの約半分であった。
このベンチマークでは、リーダー選出の最悪のシナリオを生成しようとした。まず、古いリーダーが終了する前に、そのハートビート RPC を同期させた。これにより、フォロワーの選挙タイマーがほぼ同時に開始され、タイムアウト値が十分にランダム化されていない場合、多くの分割投票につながった。次に、各試行におけるサーバは異なるログ長を持っていたため、4 台のサーバのうち 2 台はリーダーになる資格がない (ただし、セクション 9.2 で、これが選挙タームに与える影響は極わずかであることが示されている)。
Figure 9.8(a) は、タイムアウト範囲が十分に広い場合、選挙が 1 ミリ秒未満で完了することを示している。選挙タイムアウトにわずかなランダム性を加えるだけで、選挙における分割投票を回避するのに十分である。ランダム性がない場合、リーダー選出は分割投票の多さが原因で常に 10 秒以上かかっていた。これはわずか 5 ミリ秒のランダム性を追加するだけで大幅に改善され、ダウンタイムの中央値は 287 ミリ秒となった。より多くのランダム性を使用すると最悪ケースが改善される。ランダム範囲を 50 ミリ秒とした場合、(1000 回以上の試行での) 最悪の完了時間は 513 ミリ秒だった。
Figure 9.8(b) は、選挙タイムアウトを短縮することでダウンタイムを削減できることを示している。12-24 ミリ秒の選挙タイムアウトでは、リーダーを選出するのに平均でわずか 35 ミリ秒しかかかっていない (最長の試行では 152 ミリ秒かかった)。ただし、この時点を超えてタイムアウトを下げると Raft のタイミング要件に違反する。リーダーは、他のサーバが新しい選挙を開始する前にハートビートをブロードキャストすることが困難になる。これにより不必要なリーダーの変更が発生し、システム全体の可用性が低下する可能性がある。150-300 ミリ秒のような保守的な選挙タイムアウトを使用することを推奨する。このようなタイムアウトは不必要なリーダー交替を引き起こす可能性が低く、分割投票の発生率も低く、それでも優れた可用性を提供する。
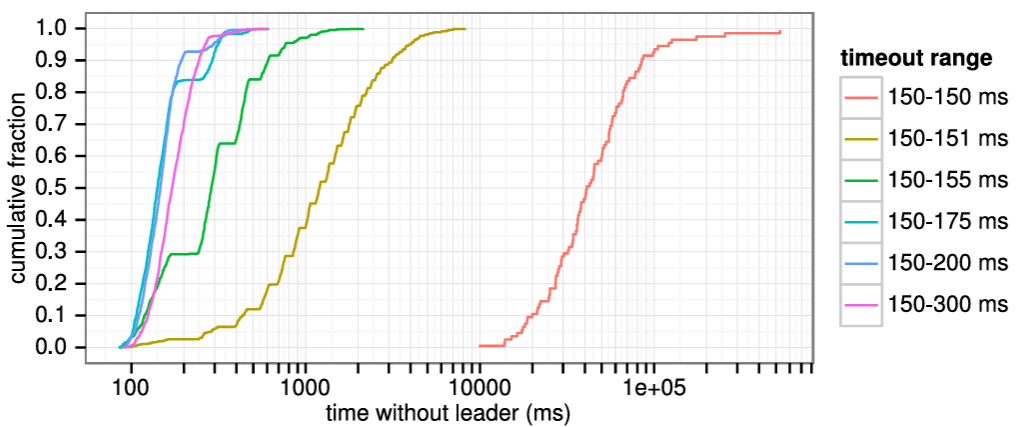
(a) 選挙タイムアウトにおけるランダム性の範囲を変化させた場合の新しいリーダー選出時間。
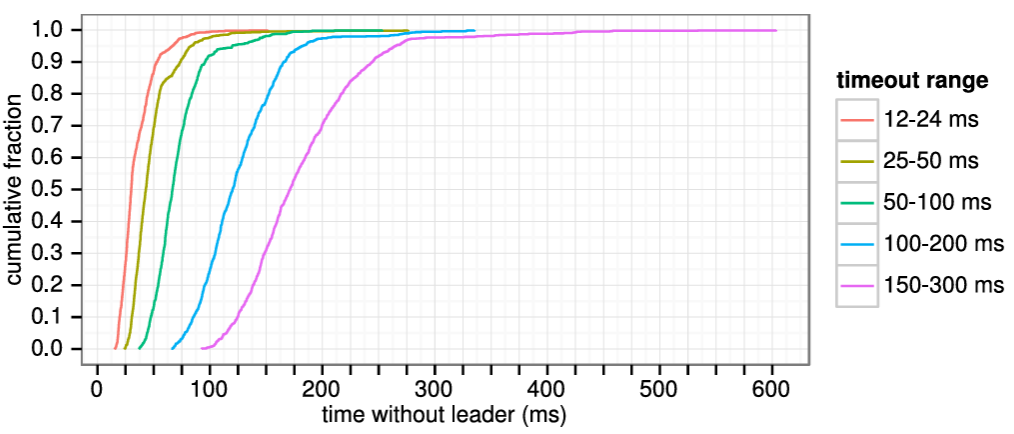
(b) 最小選挙タイムアウトをスケーリングした場合の新しいリーダー選出時間。
シミュレートされた WAN ネットワーク
より広範囲のリーダー選出シナリオを調査するために AvailSim [85] と呼ばれるシミュレータを開発した。実世界のテストクラスタの固定ネットワークとは異なり、AvailSim ではシミュレートされたネットワークの遅延を任意に設定できる。(AvailSim はリーダー選出シナリオとアルゴリズムの広い範囲をインタラクティブに探索したが、本章では関連する結果の一部のみが含まれている。)
AvailSim は完全な Raft システムに近似しているが、その選挙タームの結果は実際の選挙とは 2 つの点で異なる:
AvailSim の各サーバは新しい選挙タイマーで開始する。実際には、リーダーはハートビート間のランダムな時点でクラッシュする。したがって、AvailSim によって生成される選挙タームは、平均してハートビート間隔の半分だけ長くなる。
AvailSim はメッセージの処理やディスクへの書き込み時間を追加しない (これらはシミュレーターでは極めて高速である)。CPU 時間はネットワーク遅延に比べて短いはずであり、ディスクはリーダー選挙において重要な役割を果たす必要はない (セクション 9.3 参照)。
AvailSim を使用して US 全土にまたがる WAN を近似した。各メッセージには 30-40 ミリ秒の均一な範囲からランダムに選択された遅延が割り当てられ、サーバの選挙タイムアウト範囲はそれに応じて 300-600 ミリ秒 (片方向ネットワーク遅延の約 10-20 倍) に設定された。
Figure 9.9 は、この WAN 環境で 5 台のサーバからなるクラスタがどれくらいの早さでリーダーを選出するかを示している。5 台のサーバのうち 1 台だけが故障した場合、平均選挙タームは約 475 ミリ秒で完了し、選出の 99.9% は 15 秒以内に完了する。5 台のサーバのうち 2 台が故障した場合でも、平均選挙タームは約 650 ミリ秒 (片方向ネットワーク遅延の約 20 倍) かかり、選挙の 99.9% は 3 秒で完了する。これらの選挙タームは、ほとんどの WAN 展開で十分すぎるほど適切であると我々は考えている。
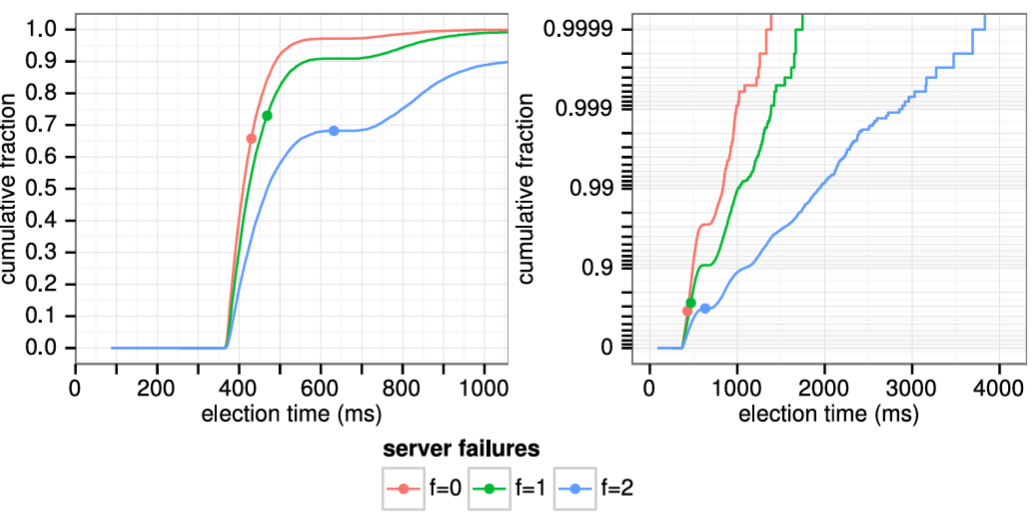
左のグラフは選挙タームの CDF (累積分布関数) をプロットしている。右のグラフは、分布の裾野の詳細を拡大するために、同じ曲線を逆対数 \(y\) 軸でプロットしている。各 CDF は 10,000 回のシミュレーションされた選挙を要約している。各曲線上の点は平均選挙タームを示している。
| コード | LogCabin [86], written in C++11 |
|---|---|
| OS | x86-64 RHEL6 (Linux 2.6.32) |
| CPU | Xeon X3470 (4 コア 8 ハイパースレッド) |
| ディスク | Crucial M4 SSD (サーバごとに 1 SSD) 上の ext4 ファイルシステム |
| 構成 | インメモリステートマシン、ログ圧縮なし |
9.5 ログが異なる場合の動作はどうか?
この章のほとんどでは、サーバが純粋に先着順で投票を受けることを前提としてきた。実際には、Raft はサーバが投票を受ける方法を制限している。RequestVote RPC には候補者のログに関する情報が含まれており、投票者のログが候補者のログよりも新しい場合、投票者は投票せず、自身の選挙タイマーもリセットしない。
我々はこの投票制限がリーダー選出の性能にどのような影響 (あるとすれば) を与えるかを調査するために AvailSim を使用した。シミュレーションはセクション 9.4 と同じ WAN ネットワークで構成したが、各サーバには異なるログを設定した。したがって、故障したサーバが 0 台、1 台、2 台のいずれかであるかに応じて、5 台のサーバのうちリーダーになる資格があるのはそれぞれ 3 台、2 台、または 1 台となった。
Figure 9.10 にその結果を示す。性能はサーバが等しいログを持っていた場合と非常によく似ている。曲線はわずかに異なる形状 (より鋭い角を持つ) だがその影響は小さい。したがって、ログの比較がリーダー選出のパフォーマンスに悪影響を与えているとは考えられない。
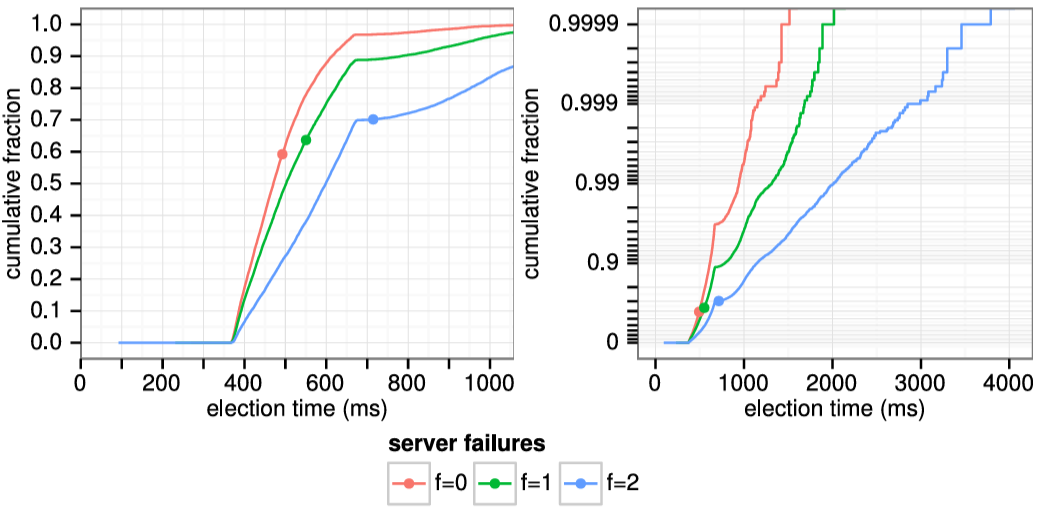
9.6 サーバがクラスタに復帰するときの混乱の防止
Raft のリーダー選出アルゴリズムの欠点の一つは、クラスタから分断されたサーバが接続性を回復したとき混乱を引き起こす可能性が高いことである。サーバが分断されるとハートビートを受信できなくなる。その結果、すぐにタームをインクリメントして選挙を開始するが、リーダーになるために十分な票を集めることができない。しばらくして接続性が回復すると、(サーバの RequestVote リクエストまたは AppendEntries レスポンスを通じて) その大きなターム番号がクラスタの他のサーバに伝播される。これによりクラスタのリーダーは退任せざるを得なくなり、新しいリーダーを選ぶために新たな選挙を行わなければならなくなる。幸いなことに、このようなイベントは稀であり 1 回の退任でリーダーが 1 人だけになる。
必要に応じて Raft の基本的なリーダー選出アルゴリズムにフェーズを追加して拡張し、このような混乱を防ぐ Pre-Vote アルゴリズムを形成することができる。Pre-Vote アルゴリズムでは、候補者はクラスタの過半数が投票を許可する意思があることが分った場合にのみ、タームをインクリメントする (候補者のログが十分に最新であり、投票者が有効なリーダーから少なくともベースラインの選挙タイムアウトの間にハートビートを受信していない場合)。これは ZooKeeper のアルゴリズム [42] にヒントを得たもので、サーバは新しいエポックを計算して NewEpoch メッセージを送信する前に過半数の票を受け取る必要がある (ただし、ZooKeeper ではサーバは投票を要請せず、他のサーバが票を提供する)。
Pre-Vote アルゴリズムは、ネットワーク分断されたサーバが再参加する際に混乱を引き起こす問題を解決する。サーバがネットワークから分断されている間はクラスタの過半数から許可を得ることができないためタームをインクリメントすることができない。その後、サーバがクラスタに再参加しても、他のサーバはリーダーから定期的にハートビートを受信しているためそのタームをインクリメントできない。サーバがリーダー自身からハートビートを受信すると (同じタームで) フォロワー状態に戻る。
さらなる堅牢性が必要な場合には Pre-Vote 拡張の使用を推奨する。我々は AvailSim のさまざまなリーダー選挙シナリオでもテストしたが、選出の性能に大きな悪影響は見られなかった。
9.7 結論
Raft のリーダー選出アルゴリズムは様々なシナリオで優れた性能を発揮する。実環境の LAN では平均数十ミリ秒以内にリーダーを選出することができる。選挙タイムアウトを片方向ネットワーク遅延の 10-20 倍の範囲からランダムに選択した場合、リーダーは平均して片方向ネットワーク遅延の約 20 倍以内に選出される。テールの選出時間も非常に短く、例えば片方向ネットワーク遅延が 30-40 ミリ秒の場合、選出の 99.9% は 3 秒未満で完了する。
Chapter 10 - 実装と性能
この章では Raft の実装とログ複製における性能について論じる。
10.1 実装
我々は、ネットワークサービスとして実装された複製ステートマシンである LogCabin の一部として Raft を実装した。当初、LogCabin は RAMCloud [90] の構成情報を保存し、RAMCloud コーディネーターのフェイルオーバーを支援するために開発された。当初 LogCabin には Paxos を実装する計画だったが、そこで直面した困難が Raft の開発へとつながった。その後、LogCabin は Raft における新しいアイディアのテストプラットフォームとして、また、完全で実用的なシステムを構築する上での課題を理解していることを検証する手段として活用された。LogCabin における Raft の実装は、テスト、コメント、空白行を除いて訳 2000 行の C++ コードで構成されている。ソースコードは自由に利用可能である [86]。そのアーキテクチャについては次のセクションで論じる。
LogCabin に加えて、数多くのサードパーティ製オープンソース Raft 実装が様々な開発段階にある [92]。これらの多くは、アクターモデル [106, 73, 68] やイベント駆動型プログラミング [75, 99, 107] など、LogCabin とは異なるアーキテクチャを採用している。また様々な企業が Raft ベースのシステムを導入している [92]。例えば Facebook は現在、レプリケーションに Raft を使用する Apache HBase [3] のフォークである HydraBase をテストしている [29]。
10.1.1 スレッドアーキテクチャ
Raft は Figure 10.1 に示すようなスレッドを用いたシンプルな実装アーキテクチャに適している。これは唯一の可能なアーキテクチャではないが、LogCabin ではこのアプローチを採用している。各サーバは単一のロックを持つモニター形式で管理されている共有状態変数の集合で構成されている。5 つのスレッドグループがモニターを呼び出して状態を操作する。
Peer Thread: クラスタ内の他のサーバと同じ数のピアスレッドが存在する。各ピアスレッドは、他のサーバのいずれかへの RPC を管理する。各スレッドはコンセンサス状態のモニターに入り、条件変数を使用して、指定されたサーバとの通信を必要とするイベントを待機する。その後、モニターを離れ (ロックを解放し)、RPC を発行する。RPC が完了 (または失敗) するとピアスレッドはコンセンサス状態のモニターに再突入し、RPC に基づいて状態変数を更新し、通信を必要とする次のイベントを待機する。
Service Thread: 複数のスレッドがクライアントや他のサーバからの受信リクエストを処理する。これらのスレッドはコンセンサス状態モニターの外で受信リクエストを待機し、その後にモニターに入って各リクエストを実行する。
State Machine Thread: 1 つのスレッドがステートマシンを実行する。このスレッドはコンセンサス状態モニターに入り、コミットされた次のログエントリを待機する。エントリが利用可能になるとモニターを終了し、コマンドを実行し、次のコマンドを待機するためのモニターに入る。
Timer Thread: 1 つ目のスレッドがフォロワーと候補者の両方の選挙タイマーを管理する。ランダムな選挙タイムアウトが経過すると、新しい選挙を開始する。2 つ目のスレッドは、リーダーとしてクラスタの過半数と通信できない場合、サーバをフォロワー状態に戻す。これによりクライアントは別のサーバでリクエストを再試行できる (セクション 6.2 参照)。
Log Sync Thread: サーバがリーダーである場合、1 つのスレッドがログエントリを永続的にディスクに書き込む。これはコンセンサス状態のロックを保持せずに行われるため、フォロワーへのレプリケーションは並行して進められる (セクション 10.2.1 参照)。簡素化のため、フォロワーと候補者はログ同期スレッドを使用せず、コンセンサスロックを保持したままサービススレッドから直接ディスクに書き込む。
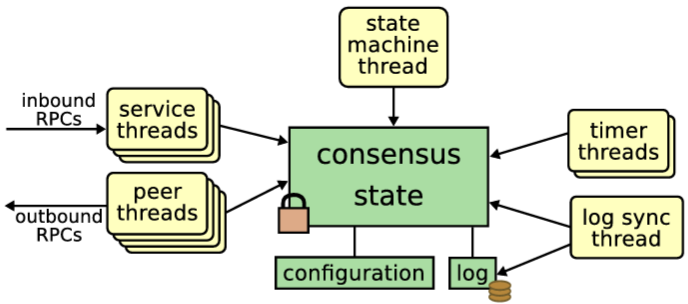
10.2 性能に関する考慮事項
Raft の性能は、Multi-Paxos などの他のコンセンサスアルゴリズムと同様である。性能に対して最も重要なケースは、確立されたリーダーが新しいログエントリを複製する場合である。Raft はリーダーからクラスタの半分への 1 回のラウンドトリップという最小限のメッセージ数でこれを実現する。Raft の性能をさらに向上させることも可能である。例えば、Raft は、後述するようにより高いスループットと低いレイテンシのためにリクエストのバッチ処理とパイプライン処理を容易にサポートする。第 11 章では、他のアルゴリズム向けに文献で提案されている様々な最適化について論じているが、これらの多くは Raft にも適用できる可能性がある。これは今後の課題とする。
Figure 10.2(a) は Raft がクライアントのリクエストを処理するために必要な手順を示している。通常、最も時間のかかる手順は、新しいログエントリをディスクに書き込み、ネットワーク全体に複製することである。ディスクへの書き込みには、高速なソリッドステートディスクで 10μs、低速な磁気ディスクで 10ms かかる場合があり、一方、今日のネットワークのレイテンシは、高度に最適化されたデータセンターネットワークで 5μs のラウンドトリップ時間から、世界中に広がるネットワークで 400ms のラウンドトリップ時間まで様々である。ローカルエリアネットワークの我々の実験では、使用するソリッドステートディスクのモデルに応じて、ディスクまたはネットワークのいずれかのレイテンシが支配的であった。
10.2.1 リーダーのディスクへの並列書き込み
性能を最適化する有用な方法の一つは、Raft のクリティカルパスからディスク書き込みを削除することである。単純な実装では、リーダーは新しいログエントリをディスクに書き込み、その後にログエントリをフォロワーへ複製する。その後、フォロワーはエントリを自身のディスクに書き込む。これによりリクエスト処理の経路上で 2 回の逐次的なディスク書き込みが発生し、ディスク書き込みが支配的な要因となるデプロイメントでは大きなレイテンシが加算される。
幸いにも、リーダーは自身のディスクへの書き込みと、フォロワーへの複製およびフォロワーによるディスク書き込みを並行して行うことができる (Figure 10.2(b) 参照)。これを単純に処理するために、リーダーは自身のマッチインデックス (match index) を使用して、最新のエントリが自身のディスクに永続的に書き込まれたことを示す。リーダーの現在のタームのエントリが過半数のマッチインデックスによってカバーされると、リーダーはコミットインデックスを進めることができる。過半数のフォロワーがエントリを自身のディスクに書き込んだ場合、リーダーは自身がディスクに書き込む前であってもエントリをコミットできる。これは依然として Safety である。LogCabin はこの最適化を実装している。
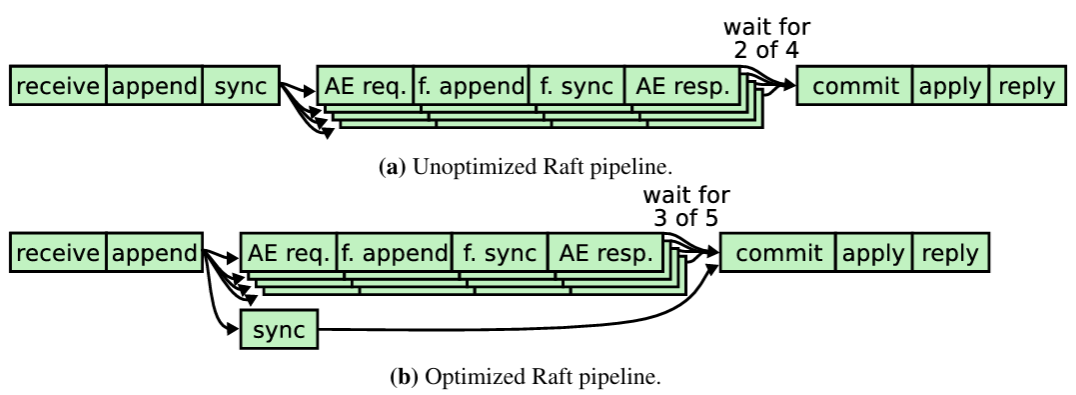
10.2.2 バッチ処理とパイプライン処理
Raft はログエントリのバッチ処理とパイプライン処理をサポートしており、これらはどちらも最高のパフォーマンスを得るために重要である。リクエスト処理のコストの多くは、複数のリクエストをバッチ処理にまとめることで償却される。例えば、2 つのエントリを別々のパケットに分割してネットワーク経由で送信するよりも、1 つのパケットで送信する方がはるかに高速である。また、2 つのエントリを一度にディスクに書き込む方が高速である。したがって、大規模なバッチ処理はスループットを最適化し、システムが高い負荷にある場合に有用である。一方、パイプライン処理は、あるエントリを処理中に別のエントリの処理を開始できるようにすることで、中程度の負荷でのレイテンシを最適化する。たとえば、フォロワーが前のエントリをディスクに書き込んでいる間に、リーダーはパイプライン処理によって次のエントリをネットワーク経由でフォロワーに複製できる。高負荷時であっても、ある程度のパイプライン処理によってリソースをより効率的に利用することでスループットを向上させることができる。たとえば、フォロワーはエントリをディスクに書き込む前にネットワーク経由でエントリを受信する必要がある。バッチ処理ではこれらのリソースを同時に使用することはできないが、パイプライン処理では可能である。パイプライン処理は、ある程度バッチ処理の妨げにもなる。たとえば、複数の小さなリクエストをパイプライン処理するよりも、リクエストを遅延させてフォロワーに 1 つの大きなバッチ処理を送信する方が全体的に高速になる場合がある。
Raft では AppendEntries が 1 回の RPC で複数の連続するエントリの送信をサポートしているためバッチ処理を自然に実装できる。LogCabin のリーダーは、フォロワーの next index からログの末尾までの間にある利用可能なエントリを、最大 1MB まで送信する。1MB という制限は任意だが、フォロワーへの頻繁なハートビートを送信しつつ、ネットワークとディスクを効率的に使用するには十分なサイズである (1 回の RPC が大きくなりすぎると、フォロワーはリーダーの故障を疑い、選挙を開始する可能性がある)。フォロワーはその後、1 回の AppendEntries リクエストから取得したすべての新しいエントリを一度にディスクに書き込み、ディスクを効率的に利用する。
Raft はパイプライン処理も十分にサポートしている。AppendEntries の一貫性チェックはパイプライン処理が Safety であることを保証する。実際、リーダーはエントリを任意の順序で Safety に送信できる。パイプライン処理をサポートするために、リーダーは各フォロワーの next index を楽観的に扱う。つまり、前のエントリの送信後、前のエントリの確認応答を待つのではなく、ただちに次のインデックスを送信する。これにより、別の RPC が前のエントリの後に次のエントリをパイプライン処理できる。RPC が失敗した場合、記録処理はもう少し複雑になる。RPC がタイムアウトした場合、リーダーは next index を元の値まで減算して再試行する必要がある。AppendEntries の一貫性チェックに失敗した場合、リーダーは next index をさらに減算して前のエントリの送信を再試行するか、前のエントリの確認応答を待ってから再試行する。この変更を行っても、LogCabin の元のスレッドアーキテクチャではフォロワーごとに 1 つの RPC しかサポートできなかったため、パイプライン処理は依然として妨げられていた。そこでピアごとにスレッドを 1 つではなく複数生成するように変更した。
順序変更 (reordering) によって再送信が非効率になる可能性があるため、このパイプライン処理のアプローチは、メッセージが通常のケースで順番通りに配信されると期待される場合に最も効率的である。幸いにも、ほとんどの環境ではメッセージが頻繁に順序変更されることはない。たとえば、LogCabin のリーダーは各フォロワーに対して単一の TCP 接続を使用し、障害が疑われる場合にのみ新しい接続に切り替える。単一の TCP 接続はネットワークレベルの順序変更をアプリケーションから隠蔽するため、LogCabin のフォロワーが AppendEntries リクエストを順序通りに受信しないことは稀である。ネットワークがリクエストを頻繁に順序変更する場合、アプリケーションは順序の異なるリクエストをログに順序通りに追加できるようになるまで一時的にバッファリングすることで恩恵を受けることができる。
Raft システムの全体的な性能はバッチとパイプラインのスケジューリング方法に大きく依存する。高負荷時に 1 つのバッチに十分なリクエストが蓄積されない場合、全体的な処理効率が低下し、スループットの低下とレイテンシの増加につながる。一方、1 つのバッチに蓄積されるリクエストが多すぎると、先行するリクエストが後続のリクエストの到着を待つためレイテンシが不必要に高くなる。
我々は現在も最良のポリシーを調査中だが、我々の目的は動的なワークロード下でリクエストの平均遅延を最小化することである。LogCabin にパイプラインを実装する前は単純な二重バッファリング手法を使用していた。リーダーは各フォロワーに対して 1 つの未処理 RPC を保持する。その RPC が戻ると、その間に蓄積されたログエントリがあればそれを含んだ次の RPC を送信した。エントリがなければ、次のエントリが追加され次第、次の RPC が送信された。このアプローチは負荷に合わせて動的に調整できるため魅力的である。負荷が増加するとすぐにエントリが蓄積され、次のバッチのサイズが大きくなり効率が向上する。負荷が減少するとバッチのサイズが縮小されレイテンシが低下する。我々はパイプライン処理においてもこの動作を維持したいと考えている。直感的には、2 階層のパイプラインでは、最初のバッチの処理時間の半分が経過した時点で 2 番目のバッチを開始し、平均遅延を半分に抑えたいと考えている。しかし、バッチが半分完了した時期を推測するにはラウンドトリップ時間の推定が必要となる。LogCabin で使用する最適なポリシーについては現在も調査中である。
10.3 暫定的な性能結果
LogCabin の性能についてはまだ詳細な分析を行っていないが、いくつかの初期計測を行っている。実験セットアップを Table 10.1 に示す。ベンチマークでは単一のクライアントプロセスが LogCabin クラスタのリーダーに接続する。様々な数のクライアントスレッドが複製ステートマシンに操作を発行し、1024 バイトの値を設定する。各クライアントスレッドは共有 TCP 接続上でリクエストを繰り返し発行し、リーダーのステートマシンからの結果を待ってから次のリクエストを発行する。
Figure 10.3(a) は LogCabin の現在のスループットを示している。100 スレッドのマルチスレッドクライアントを使用すると、3 サーバクラスタは 1 秒あたり約 19,500 キロバイトサイズの書き込みを維持する。予想通り、クラスタの規模が大きくなるにつれリーダーがより多くのエントリをフォロワーに送信する必要があるため性能が低下する。
Figure 10.3(b) は LogCabin の現在のレイテンシを示している。1 キロバイトサイズの書き込みレイテンシは、単一サーバクラスタで 0.7 ミリ秒、2~5 サーバクラスタでは約 1.0 ミリ秒である。これには 1 キロバイトをディスクに永続的に書き込む時間も含まれている。これはベンチマークで約 0.25 ミリ秒と測定された。
初期計測結果は良好で、現在の性能は多くの種類のアプリケーションにとって十分であると考えている。しかし、まだ改善の余地は大きくある。たとえば、ギガビットイーサネットでは 3 サーバクラスタの性能は 1 秒あたり約 60,000 キロバイトのサイズに制限されるが、LogCabin の現在のスループットはその 3 分の 1 に過ぎない。
| コード | LogCabin [86], written in C++11 |
|---|---|
| OS | X86-64 RHEL6 (Linux 2.6.32) |
| CPU | Xeon X3470 (4 コア, 8 ハイパースレッド) |
| ディスク | Intel DC S3500 SSD 上の ext4 ファイルシステム (サーバあたり 1 SSD; write caching オフ) |
| ネットワーク | 1 ギガビットイーサの TCP 上の Protocol Buffers [11] |
| 構成 | インメモリステートマシン、ログ圧縮なし |
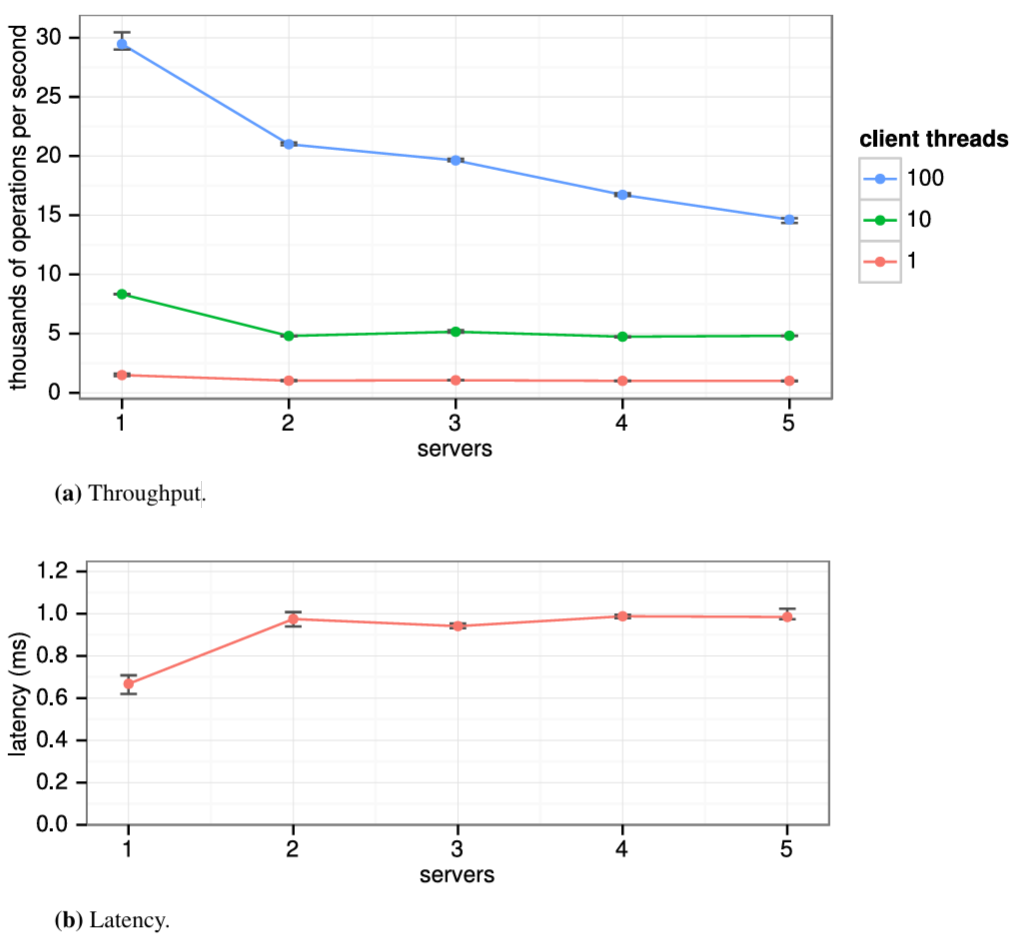
10.4 結論
将来的に分析したい Raft の性能側面は数多くある。通常の運用で特に重要な点として、特に、様々な負荷下で重要なのは書き込み操作と読み取り操作のレイテンシとスループットである。例外的な状況下では様々なパフォーマンス上の疑問が生じる。それらについても分析を行いたいと考えている。
クライアントはどれだけ早くリーダーを見つけられるか?
新しいリーダーは最初のエントリをどれくらい速くコミットするか? これにはフォロワーのログの分岐箇所をどれだけ速く発見するかも含まれる。
フォロワーの障害が通常の運用にどのような影響を与えるか?
クラスタの再構成にはどれくらいの時間がかかり、通常の運用にはどのような影響を与えるか?
ログの圧縮にはどれくらいの時間がかかり、通常の運用にはどのような影響を与えるか?
- サーバ/クラスタが再起動するにはどれくらいの時間がかかるか?
Raft における我々の性能目標は、Multi-Paxos のような既存のアルゴリズムに匹敵しつつ、理解しやすさを向上させることであった。最速のシステムを構築するというよりも、他の人々が性能において競争力のあるコンセンサスベースのシステムを構築できるようにしたいと考えた。LogCabin はまだ十分に最適化されていないが、暫定的な結果は妥当なレイテンシとスループットが達成することを示している。3 台のサーバクラスタに 1 キロバイトサイズのオブジェクトを書き込む場合、1 つのクライアントスレッドで 1 操作ごとに約 1.0 ミリ秒かかり、100 個のクライアントスレッドを使用するとシステムは 1 秒あたり 19,500 操作を処理する。
Chapter 11 - 関連研究
この章では、関連研究の文脈において Raft の長所と短所について考察する。セクション 11.1 ではまず他のコンセンサスアルゴリズムについて簡単に紹介し、Raft と大まかなレベルで比較する。次にセクション 11.2 からセクション 11.8 にかけて、これらのコンセンサスアルゴリズムが Raft とどのように比較されるかについて、より具体的な詳細に焦点を当てる。最後に、セクション 11.9 では、理解可能性の評価に関連する研究について議論する。
11.1 コンセンサスアルゴリズムの概要
このセクションでは、Raft と比較可能な既存のコンセンサスアルゴリズム、具体的には Paxos、Viewstamped Replication、および Zab を紹介する。これらのアルゴリズムは Raft と同様に停止故障 (fail-stop) を処理するがビザンチン障害は処理せず、Safety を時間に依存しない (実用的なコンセンサスアルゴリズムの主要な特性はセクション 2.1 を参照)。読者らは van Renesse らによるこれらのアルゴリズムに関する理論的な比較 [109] にも興味を持つかも知れない。
異なるシステムモデル向けには他のコンセンサスアルゴリズムも存在するが、それらはあまり一般的には利用されていない。特に、任意の故障や不正行為が起こりうるビザンチンコンセンサスに対応するアルゴリズムがいくつかある [13, 65, 76]。これらは故障停止モデル下のアルゴリズムよりも複雑で性能も低くなる。
11.1.1 Paxos
Paxos (最も一般的には Multi-Paxos) は今日最も広く展開されているコンセンサスアルゴリズムである。
Chubby [11, 15] のロックサービス、Megastore [5] および Spanner [20] のストレージシステムなど、Google の複数のシステムでは Paxos を使用している。Chubby はクラスタメタデータに使用される一方、Megastore と Spanner はすべてのデータストレージに Paxos を使用している。
Microsoft も様々なシステムで Paxos を使用している。Microsoft の Autopilot サービス [40] (Bing で使用) および Windows Azure Storage [12] はメタデータに Paxos を使用している。Azure の Active Directory Available Proxy [4] では、任意の REST サービスに対する一連のリクエストの合意形成に Paxos を使用している。
オープンソースの Ceph ストレージシステムは、クライアントがオブジェクトの場所を見つけることを可能にするデータ構造であるクラスタマップを保存するために Paxos を使用する [112, 14]。
最近では Cassandra [1] や Riak [6] などの結果整合性のあるデータストアが、一部のデータに対して線形化可能なアクセスを提供するために Paxos を追加した。Cassandra は Basic Paxos [26] の最適化されていない実装を使用しているようで、Riak の将来のリリースには Multi-Paxos [9] の実装が含まれる予定である。
Paxos は、コンセンサスプロトコルファミリー全体を指す広範な用語である。Lamport による Paxos の元の記述 [48] は、完全なシステムのスケッチを提示しているが、実装するには詳細が不足している。その後に発表されたいくつかの論文は Paxos を説明しようと試みているが [49, 60, 61]、それらのアルゴリズムを実装するのに十分なほど完全には説明していない。Paxos には、不足している詳細を補い、実装のためのよりよい基盤を提供するために Paxos を修正する、他の多くの改良版がある [108, 46]。さらに、我々は Raft のユーザ研究の一環としてビデオ講義で独自の Paxos の説明と改良版を作成した [88]。我々が使用した Multi-Paxos の派生形は Figure A.2 に要約されている。残念ながら、これらの Paxos の改良版はすべて互いに異なっている。これは読者にとって負担であり、比較も困難にしている。結局のところ、ほとんどの実装は Paxos の文献とほとんど類似点がなく、中には Raft に似ているほど Paxos から大きく逸脱しているものもある。Raft の論文の初期草稿を読んだある Spanner 開発者は公演中に次のように述べた。
Our Paxos implementation is actually closer to the Raft algorithm than to what you read in the Paxos paper. [43]
我々の Paxos 実装は、実際には Paxos の論文で読むものよりも Raft のアルゴリズムに近いのです。
この章の目的のために、Raft を Multi-Paxos の詳細な説明に見られる一般的なアイディアと比較しようと試みたが、特定のアルゴリズムに議論を限定したわけではない。
第 2 章では、Paxos がいかに理解しにくく、システム構築の基盤として不適切であるかについて議論した。その単一決定の定式化は分解が困難であり、Multi-Paxos ではログの非決定性が過剰で構造が不足している (例えばログに穴が開いている可能性がある)。Multi-Paxos は性能最適化のために非常に弱いリーダーシップしか使用していない。これらの問題が Paxos を不必要に複雑にし、学生とシステム構築者の両方に負担をかけている。
11.1.2 リーダーベースのアルゴリズム
Viewstamped Replication と Zab は Raft と構造が近く、したがって Paxos に対する Raft の利点の多くを共有する 2 つのリーダーベースのコンセンサスアルゴリズムである。Raft と同様に、各アルゴリズムはまずリーダーを選出し、そのリーダーが複製ログを管理する。これらのアルゴリズムは、リーダー選出の処理方法と、リーダー交代後のログ不整合の修復方法が Raft と異なる。次のセクションではこれらの違いについてさらに詳しく説明する。
Oki と Liskov による Viewstamped Replication は Paxos とほぼ同時期に開発されたリーダーベースのコンセンサスアルゴリズムである。元の記述 [83, 82] は分散トランザクションプロトコルと密接に絡み合っていたため、多くの読者がその貢献を見落とした可能性がある。中心となるコンセンサスアルゴリズムは Viewstamped Replication Revisited [66] と呼ばれる最新の更新で分離されており、Mazières [77] も Liskov の更新前に中心アルゴリズムの詳細について拡張している。Viewstamped Replication は実際には広く使用されていないが、Harp File System [67] で使用されていた。
Zab [42] は ZooKeeper Atomic Broadcast の略で、Viewstamped Replication に似たはるかに新しいアルゴリズムである。これは、現在最も人気のあるオープンソースのコンセンサスシステムである Apache ZooKeeper コーディネーションサービス [38] で使用されている。Zab 用のクラスタメンバーシップ変更メカニズムが最近開発され [104]、将来の ZooKeeper リリースで提供される予定である [113]。
Raft は非リーダーの機能を最小限に抑えるため、Viewstamped Replication や Zab よりもメカニズムが少ない。たとえば、我々は Viewstamped Replication Revisited と Zab が基本的なコンセンサスとメンバーシップ変更に使用するメッセージタイプを数えた (ログ圧縮とクライアントとのやりとりはアルゴリズムからほぼ独立しているので除く)。Viewstamped Replication Revisited と Zab はそれぞれ 10 種類のメッセージタイプを定義しているのに対して、Raft はわずか 4 種類のメッセージタイプ (2 種類の RPC リクエストとそのレスポンス) しか定義していない。Raft のメッセージは他のアルゴリズムのメッセージよりも若干情報密度が高いが、全体としてはよりシンプルである。さらに、Viewstamped Replication と Zab はリーダー交代時にログ全体を転送するという観点から記述されている。これらのメカニズムを実用的なものにするためには、いくつかのメッセージタイプが必要になるだろう。
Zab は並行リクエストを発行するクライアントに対して Raft よりもわずかに強力な保証を提供する。クライアントが複数のリクエストをパイプライン処理した場合、Zab はそれらが順序通りにコミットされる (もしコミットされるなら) ことを保証する。この特性は FIFO クライアント順序 (FIFO client order) と呼ばれる。これにより、例えばクライアントは一連の変更を発行した後にロックを解放するといったことをすべて非同期に行うことができる。他のクライアントは、ロックを解放する前に複製ステートマシンに反映された変更を確認することになる。Paxos は、コマンドが制約の少ないログエントリに割り当てられるためこの特性を満たさない ([42] 参照)。Raft と Viewstamped Replication はリーダーが新しいエントリをログに順番通りに追加するため Zab と同様の保証を提供できる。ただし、ネットワークやクライアントの再試行によってクライアントのコマンドをリーダーに順序変更させないようにするには追加の注意が必要となるだろう。
11.2 リーダー選出
このセクションでは、様々なコンセンサスアルゴリズムがリーダー選出にどのように取り組んでいるかについて説明する。Raft は非常にシンプルなメカニズムを採用しているが、他のアルゴリズムは一般的により複雑で、実用的な利点を提供していない。
広義ではリーダー選出には以下の 4 つの問題が含まれており、続くサブセクションで詳細に説明する。
故障したリーダーの検出
Raft はハートビートとタイムアウトを使用する。退任したリーダーの無効化
Raft では候補者は投票を募り、ログを複製しながら新しいターム番号を伝播する。新しいリーダーとなるサーバの選出
Raft はランダムなタイムアウトを使用し、通常、最初にタイムアウトした候補者がリーダーになる。投票は 1 タームあたり最大 1 人のリーダーしか存在しないことを保証する。リーダーがすべてのコミット済みエントリを保持していることを保証
Raft では、投票中のログ比較チェックにより、新しいリーダーが既にすべてのコミット済みエントリを保持していることを保証する。ログエントリの転送は行われない。
11.2.1 故障したリーダーの検出と無効化
現実のあらゆる環境において、故障したサーバと低速なサーバを区別することは不可能である。これは非同期システムの重要な特性である。幸いなことに、実用的なコンセンサスアルゴリズムは、リーダーが単に低速なだけであるにもかかわらず故障したと疑われる場合でも Safety を維持する。したがって、故障検出は故障したサーバを最終的に検出するだけで良く (完全性; completeness)、高い確率で利用可能なサーバを疑わないこと (正確性; accuracy) は必要ない。これらの緩い要件はハートビートとタイムアウトを用いることで実用的なシステムで容易に満たされる。
ハートビートとタイムアウトに基づいて構築された様々な故障検出器 (failure detector) が理論的な文献 [16] で議論されている。\(\Diamond P\) (またはそれと同等の \(\Omega\)) は優れた理論的特性を持つ故障検出器である。これは最終的に (ある未知の期間の後)、完全に健全 (correct) で正確 (accurate) な状態になる。これは、疑いが誤りであるたびにタイムアウトを増やすことで実現される。最終的にはタイムアウトが非常に大きくなり誤った疑いを全く行わなくなる。しかしこの挙動は可用性を重視する現実のシステムにとっては非実用的である。タイムアウト値が大きくなりすぎると、クラスタはリーダーの故障を検出するのに長すぎる時間を待つことになる。リーダーが遅い場合、確実に障害が発生しているかどうかを待つよりも、誤って故障を疑う方が賢明である。そのため Raft のタイムアウト値はシステムの可用性要件を満たすのに十分な低さに設定されている。
Paxos、Zab、Viewstamped Replication は故障検出機能を指定していないか、タイムアウトの使用について簡単に言及しているものの詳細を記述していない。これは、障害検出へのアプローチがコンセンサスアルゴリズムとはほとんど独立しているからかもしれない。しかし、我々はハートビートを他のメッセージと組み合わせることには実用的な利点があることを見出した。例えば、Raft の AppendEntries RPC はハートビートとして機能するだけではなく、フォロワーに対して最新のコミットインデックスを通知する役割も果たす。
障害検出機能は、リーダーが実際には低速出るにもかかわらず誤って故障したと報告する可能性があるため、疑わしいリーダーは無効化する必要がある。様々なコンセンサスアルゴリズムは単調増加する番号 (Raft ではターム、Paxos では提案番号、Viewstamped Replication ではビュー、Zab ではエポックと呼ばれる) を使用することで同様にこれを処理する。サーバはより大きな番号を観測すると、それ以降はより小さな番号を持つリーダーからのリクエストを受け付けなくなる。Raft を含むほとんどのアルゴリズムは、サーバがそのようなリクエストを受信すると、送信者にそのリクエストが古いことを通知する。ただし、Paxos の一部の記述では受信者は応答しない。
アルゴリズムは 2 つの異なる方法でサーバにターム番号を割り当てる。Zab と Raft は投票を通じて 1 タームあたり最大 1 人のリーダーしか存在しないことを保証する。サーバが過半数の票を集めることができれば、そのサーバはログエントリの複製にそのターム番号を排他的に使用できる。Paxos と Viewstamped Replication は、サーバが特定の番号を巡って競合しないように、番号の空間を分割する (例えばラウンドロビン方式でサーバに番号を割り当てるなど)。いずれの場合も投票が発生する必要があるため、これら 2 つのアプローチの間には実質的な違いはないようである。
11.2.2 新しいリーダーの選出と、それがすべてのコミット済みエントリを持つことの保証
Table 11.1 にまとめられているように、アルゴリズムによってリーダーとして選択するサーバが異なる。Paxos と Zab は任意のサーバをリーダーとして選択できるのに対し、他のアルゴリズムはリーダーになれるサーバを制限する。Paxos と Zab のアプローチの利点の一つは、リーダー選出時にどのサーバがリーダーになるべきかという設定に対応できることである。例えば、特定のデータセンターのサーバがリーダーとして機能するときにデプロイメントが最高の性能を発揮する場合、Paxos または Zab はそのサーバをリーダーにできる。他のアルゴリズムは、どのサーバがリーダーになれるかを制約しているためこのようなことができない。この設定に対応するには、別途、第 3 章で Raft について説明されているようなリーダーシップ転送メカニズムを必要とする。
| アルゴリズム | 新しいリーダー | 票収集役 | 選好の考慮 |
|---|---|---|---|
| Paxos | 任意のサーバ | 新しいリーダー | はい |
| VR | 最新のログを持っているサーバ | ビューマネージャ | いいえ |
| VRR | ビュー番号によって決定 | 新しいリーダー | いいえ |
| Zab | 任意のサーバ | 新しいリーダー | はい |
| Raft | 最新のログを持っているサーバ | 新しいリーダー | いいえ |
Viewstamped Replication Revisited では、どのサーバがリーダーになるかを選択するために異なるラウンドロビン方式を採用している。リーダーはビュー (ターム) 番号の関数である。\(n\) 台のサーバからなるクラスタでは、サーバ \(\) は \(v % n = i\) のときにビュー \(v\) のリーダーとなる。このアプローチの利点は、クライアントが現在のビュー番号に基づいてリーダーを推測して見つけられる可能性が高いことである (そのためには、クライアントは現在の構成とビュー番号を追跡する必要がある)。ただし、ビューで指定されたリーダーが利用できない場合や、サーバ間で現在のビューに関して認識が異なる場合、追加の遅延が発生する可能性がある。
元の Viewstamped Replication アルゴリズムは、クラスタの過半数と同程度に最新のログを持つサーバのみがリーダーになれるという点で Raft に最も近い。これは新しいリーダーへのログエントリの転送を回避できるという大きな利点がある。これによりデータフローがクライアントからリーダー、そしてフォロワーへの一方向になり簡素化される。Viewstamped Replication では 1 つのサーバ (ビューマネージャ) で選出プロセスを管理し、別のサーバがリーダーとなる。ビューマネージャは、クラスタの過半数で最も最新のログを持つサーバを新しいリーダーとして選択肢、そのサーバに新しいリーダーシップの役割を通知する。Raft では、同じサーバが選出とリーダーの役割の両方を実行するため、いくつかのメカニズムが回避され、状態空間の複雑さが軽減される。Zab はまた、Raft のように十分に最新のログを持つリーダーを選択するという最適化案を提案しており、この最適化は ZooKeeper に実装されるようようである [94]。
Paxos、ViewStamped Replication Revisited、そして (最適化されていない) Zab はログに基づいてリーダーを選択しないため、新しいリーダーがすべてのコミット済みエントリを保持していることを保証するために追加のメカニズムを必要とする。Paxos では、リーダーは通常、コミット済み値を知らない各ログエントリについて単一決定 Paxos の両方のフェーズを実行し、利用可能なサーバがそれ以上のプロポーザルを認識していないログインデックスに到達するまで実行する。これは、新しいリーダーが追いつくまでにかなりの遅延を引き起こす可能性がある。Viewstamped Replication Revisited と Zab は、サーバがログ全体を新しいリーダーに送信し、新しいリーダーが最も最新のログを採用するように説明されている。これは優れたモデルだが、大きなログでは非現実的である。どちらの論文も送信するエントリ数を減らすことで最適化することを提案しているが、詳細は説明されていない。
11.3 ログ複製とコミット
すべてのコンセンサスアルゴリズムは、新しいログエントリを他のサーバに送信する方法と、それらをいつコミット済みとしてマークするかを規定する。これは通常、リーダーからの 1 回の通信ラウンドで行われ、複数のエントリの複製を高速化するためにバッチ処理とパイプライン処理を適用するのが簡単である。
各アルゴリズムは、どの程度順序を無視して処理できるかが異なる。Raft、Zab、Viewstamped Replication はすべて、フォロワーのログが常にリーダーのログと一貫性を保つように、エントリを順番にログに追加してコミットする必要がある。Multi-Paxos では伝統的に、サーバが任意の順序でエントリの値を受け入れ、コミットすることを許容する。しかしコマンドは依然として順番通りにステートマシンに適用する必要があるため、これは Paxos に顕著な性能上の利点をもたらさない。Raft やログを順序通りに維持する他のアルゴリズムも順序を無視してログエントリを転送することは可能である。ただし、この方法ではログに追加することはできない (これらのアルゴリズムでは、必要に応じてサーバはログ外のエントリをバッファリングして追加準備ができるまで保存できる)。
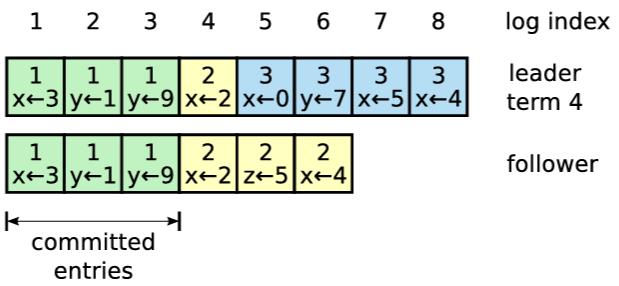
Figure 11.1 に示すように、新しいリーダーがログ内の既存のエントリをどのように扱うかという点でもアルゴリズムは異なる:
Paxos では、新しいリーダーは未コミットのエントリを見つけるたびに単一決定 Paxos の 2 つのフェーズを実行し、すべてのエントリを現在の提案番号で置き換えて再番号付けを行う。これにより、ローカルの値がコミットされるか、既存のコミット済み値が発見される。その間、新しいリーダーはレプリケーションとコミットを実行できるが、以降のログスロットにクライアントコマンドを適用することはできない。
Viewstamped Replication Revisited と Zab では、新しいリーダーは自身のタームを開始する前に最初のログ全体を各フォロワーに転送し、ログ全体が新しいビューで実質的に再番号付けされる。これは大きなログでは非実用的であり、実際に派より少ないエントリを送信するように最適化されるべきだが、詳細は公開されていない。2 つのサーバが両方とも最後のビューに参加していた場合、送信するエントリを決定するのは比較的簡単に判断できるが、そうでない場合は判断が難しくなる (図のように各エントリにターム番号がない場合、1 つのアイディアはログプレフィクスの累積ハッシュを比較することである)。
Raft の新しいリーダーは他のサーバのログを自身のログと一致させるために最小限のエントリのみを転送する。ログがどこで分岐するかを発見するためにハートビートで何度かやりとりしたあと、相違のあるエントリのみを転送する。この機能の鍵は、エントリが再番号付けされないことであり、これにより同じエントリは常にすべてのログで同じインデックスとタームを持つ。この特性がなければ、一部のサーバは元のターム番号でエントリを持ち、他のサーバは新しいターム番号でエントリを持つことになる。後続のリーダーはどのサーバが同じコマンドを持っているか分からないため、これらのコピーを不必要に上書きしなければならないだろう。
Raft はログ全体ではなくログエントリを転送することで VR や Zab よりも多くの中間状態を可能にする。Raft ではこれらの中間状態は曖昧であるため、コミットメントには使用できない (Figure 3.7)。これには 3 つの帰結がある。
第一に、もし我々が何らかの方法でクラスタ全体のスナップショットを観測できたとすると、Raft ではエントリが過半数のサーバに存在しているにもかかわらずコミットされていない可能性がある。エントリがコミットされているかどうかを判断するには、代わりに、将来のリーダーがそのエントリを保持している必要があるか、つまり、現在のログでリーダーに選出される可能性があるすべてのサーバのログにそのエントリが存在するかを問う必要がある。もしそうであればそのエントリはコミット済みであるし、そうでなければコミットされていない。これは、他なおアルゴリズムよりも全知の観測者 (omniscient observer) にとって複雑な推論を必要とする。エントリの複製がいくつ存在するかを数えるのではなく、本質的にコンセンサスアルゴリズムを実行する必要があるのである。
第二に、Raft の動作中は 2 段階のコミットメントルールがある。このルールでは、前のタームからのエントリは直接コミット済みとしてマークされない。現在のタームのエントリが過半数に到達したときににみコミット済みとマークされる (この時点であいまいさは解消される)。これは実装に大きな負担をかけるものではなく、単に 1 つの if 文を追加するだけで済む。興味深いことに、このコミットメントルールは単一決定コンセンサス定式化 (single-decree consensus formulation) では実現できない。ログの定式化に依存しているため、後続のエントリが先行のエントリをコミットできる。
最後に、Raft ではリーダーの無限の変更が無限のスペースを必要とする可能性がある。具体的には、リーダーは前のエントリをコミットして圧縮するためにエントリを作成する必要があるが、もしリーダーが先にクラッシュした場合、そのログには追加のエントリが含まれることになる。理論上は、このプロセスが繰り返されてストレージ容量が枯渇する可能性がある。しかし、リーダー選出がこれほど頻繁に成功し、同時に頻繁に失敗するという状況は考えにくいため、我々はこれが実用上の重大な懸念であるとは考えていない。
Raft のコミットメントアプローチの代替案としては、Viewstamped Replication Revisited と同様に、ログに余分なタームを追加する方法が考えられる。ログのタームは、エントリをフォルgに複製した最新のリーダーのタームとなる。ログのタームは通常、ログ内の最後のエントリのタームと同じになるが、新しいリーダーが自身の最初のログと一致するまでフォロワーに追いつかせている間は一時的に先行するだろう。選出時にもし最後のエントリのタームではなくログのタームが使用されるなら、コミットメントルールは簡素化できるだろう。コミットメントには、過半数のサーバがそのエントリと同じログタームを持つことが条件となる。Viewstamped Replication との類似性からこのアプローチは機能すると考えるが、その正確性はまだ証明されていない。欠点は、これによりサーバの現在のターム、ログのターム、そして個々のエントリ内のタームという 3 つのタームを扱う必要がある点である。曖昧さが解消されるまでコミットメントを遅らせる方が簡単だと我々は考えている。
11.4 クラスタメンバーシップ変更
クラスタメンバーシップ変更には、他の研究で様々なアプローチが提案または実装されてきた。これらのほとんどは任意のクラスタメンバーシップ変更を実装しているが、Raft は単一サーバの追加と削除に限定している。簡素化のために変更を単一サーバの追加と削除に制限することを議論した先行研究は知らないが、先行システムでこれが実装されている可能性は高いと考えている。このセクションの残りの部分ではセクション 4.3 で示した任意のクラスタメンバーシップ変更に対する Raft のジョイントコンセンサスアプローチとの関連研究を比較する。
任意の構成変更全体で Safety を確保するためには、変更は二段階アプローチを使用する必要がある。二段階を実装する方法は様々である。例えば [66] のような一部のシステムは、第一段階で古い構成を無効にしてクライアントリクエストを処理できないようにする。次に、第二段階で新しい構成を有効にする。Raft における任意の構成変更のアプローチでは、まずクラスタはジョイントコンセンサスと呼ばれる移行構成に切り替わる。ジョイントコンセンサスがコミットされると、システムは新しい構成に移行する。
11.4.1 \(\alpha\)-ベースのアプローチ
Lamport [48, 49] は Paxos において \(i\) 番目のログエントリが \(i+\alpha\) 番目のログエントリのクラスタメンバーシップを決定することを提案した。このアプローチにおける二段階は以下の通り:
新しい構成はログエントリ \(i\) で合意される。次に
新しい構成はログエントリ \(i+\alpha\) で有効になる。
クラスタは構成変更中であっても \(\alpha\) の制限内でリクエストを処理できる。
残念ながら \(\alpha\) は通常運用中の Paxos クラスタの並行度も制限する。もしエントリ \(i\) がまだコミット済みか判明していない最初のエントリである場合、最終的に \(i\) が構成を変更する可能性があり、したがってサーバは \(i\) のコミットメントを知るまでエントリ \(i+\alpha\) 以降の提案を送信できない。\(\alpha\) は通常運用中に十分なパイプライン処理/バッチ処理を可能にするために大きく設定できるが、その場合、構成変更が有効になるまでに時間がかかる。これを緩和するために、サーバはその間の \(\alpha-1\) 個のログエントリに no-op エントリを提案することができる。
Lamport の提案は Safety に関する懸念を非常にシンプルに扱っているが、Liveness と可用性に関する多くの疑問が未解決のママである。例えば、新しいサーバは自身のステートマシンを前進させるために古いクラスタからすべての決定を学習する必要がある。新しいサーバはこれらのエントリをどのようにして取得するのか? 古いサーバはシャットダウンできるタイミングをどのように知るのか? そもそも新しいサーバは古い構成や新しい構成が何であるかをどうやって知るのか?
SMART [69] はこれらの疑問に答えようとする試みである。SMART では、核物理サーバが 1 つ以上の仮想サーバをホストし、各仮想サーバは静的な構成を持つ単一クラスタに参加する。SMART は、ある構成がクライアント要求の受付をいつ終了し、いつ終了すべきかを決定するために、\(\alpha\) のようなアプリーチを使用する。古い構成がメンバーシップ変更リクエストを受信すると、新しい構成を特定のログインデックス (\(\alpha\) エントリ後) から開始するように通知する。古い構成からの最後のログが新しい構成のサーバの過半数に送信されると、新しい構成はクライアントのリクエストの処理を開始でき、古い構成の仮想サーバはシャットダウンできる。
SMART のメンバーシップ変更モデルは効率的に実装するのが難しいかもしれない。変更中に、もし 1 つの物理サーバが古いクラスタと新しいクラスタの両方に属している場合、それぞれの構成ごとに 1 つずつ、合計 2 つの仮想サーバを同時に実行する必要がある。この空間効率を高めるために、サーバの状態の一部は、単一の物理サーバ上のすべての仮想サーバで共有される別の実行モデルに移動される。残念ながらこれは実装のメカニズムと複雑さを大幅に増加させる。一方 Raft では各サーバは一度に 1 つの構成のみに参加し、常に自身のログ内の最新の構成を使用する。
\(\alpha\) と SMART のアプローチは Raft のコミットメントルールと互換性がない。Raft では、リーダーが自身のログに追加できない場合、既存のエントリをコミット済みとしてマークできない可能性がある。例えば、リーダーが未コミットのエントリの限界に達し、その後再起動して再びリーダーになったと仮定する。\(\alpha\) の制限により、リーダーは現在のタームで新しいエントリを作成できず、したがって既存のエントリをコミット済みとしてマークできないだろう。このケースで \(\alpha\) と Raft は競合する。\(\alpha\) は新しいエントリを追加するためにコミットメントを必要とするが、Raft はコミットメントのために新しいエントリの追加を必要とする。
Raft のコミットメントルールが問題でなければ (例えば Viewstamped Replication のコミットメントルールを代わりに使用する場合)、メンバーシップ変更に対する \(\alpha\) または SMART のアプローチは機能するが、Raft のリーダーベースのアプローチは新たな課題を提起する。Raft ではログエントリはリーダーから他のサーバにのみ送信されるため、古いクラスタのリーダーは自身のすべてのエントリを新しいクラスタに複製する必要がある (そして古いクラスタにコミットする必要がある)。したがって、古いクラスタのリーダーは新しいクラスタのサーバを自身の構成の非投票メンバーとして追加する必要がある。\(\alpha\) のアプローチでは古いクラスタでリーダーを維持する必要があるため、単一の Raft クラスタ内に 2 つのリーダーが存在するシナリオが発生する (ただし SMART ではそうではないが)。古いクラスタのリーダーはログを \(i+\alpha\) まで複製するがそれ以降は書き込むことはできず、一方で新しいクラスタのリーダーは \(i+\alpha\) までのエントリがコミット済みであると認識しており \(i+\alpha\) を超える新しいログエントリを複製する。たとえ 2 つのリーダーがログエントリに関して競合しなくても追加のメカニズムなしでは可用性の問題を引き起こす可能性が高い。SMART アプローチはリーダーが異なるクラスタのメンバーであるため、複数の並行リーダーを許可するという点で非常にシンプルである。
11.4.2 リーダー選出中のメンバーシップ変更
オリジナルの Viewstamped Replication アルゴリズムにはメンバーシップ変更が含まれていなかったが、Viewstamped Replication Revisited と Mazières の論文 [77] はそれぞれオリジナルのアルゴリズムを拡張してメンバーシップ変更をサポートしている。どちらのアプローチも、クラスタにリーダーがいない状態デビュー間のメンバーシップを変更する。したがって、どちらもメンバーシップ変更中にクライアントのリクエストを処理することはできず、リーダーが新しいサーバにエントリを転送する必要のある Raft とは互換性がない。
Viewstamped Replication Revisited では、新しい構成が古い構成の特別なログエントリとしてコミットされ、その後にビュー変更 (リーダー選出) を開始する。新しい構成のサーバは新しいビュー (ターム) に参加する前に古いクラスタから自身を更新する必要がある。その間はクライアントリクエストを処理することはできない。リーダーおよび十分な数のサーバが自身を更新すると、クラスタはクライアントのリクエスト処理を再開する。このアプローチの 2 つのフェーズは以下の通りである:
古いサーバが新しいビューに移動し、クライアントリクエストを停止する。そして
新しいサーバが必要なログエントリを取得すると、クライアントリクエストの処理を再開する。
Mazières は、クラスタのメンバーシップがビュー変更の一部として実行される別のアプローチを提示している [77]。新しいビューを形成するために、クラスタはリーダーとなる者とクラスタメンバーになる者の両方について合意に達する。このアプローチの 2 つのフェーズは次の通り:
サーバが新しいビューへの招待を受け入れると、古いビューのリーダーからのリクエストの受け入れを停止する。
サーバがビューの変更が合意されたことを認識すると、新しいビューのリーダーからのリクエストの受け入れを開始する。
介在するビュー変更が失敗するケースでは、サーバは新しいビューでの操作を開始するために、古いクラスタの過半数と新しいクラスタの過半数の両方からの合意を必要とすることがある。これはジョイントコンセンサスに似ているが特別な場合にのみ使用される。
Mazières のアプローチでは、ビューの変更中にログエントリをコミットするリーダーが存在しないため、ログエントリではなく追加のメッセージを使用して動作する。これには構成の合意と伝達のための追加のメカニズムが必要だが、Raft ではこれが不要である。Raft のアルゴリズムは、メンバーシップ変更中でも通常のリクエストを処理できるという利点もある。対照的に、Viewstamped Replication Revisited と Mazières のアプローチはどちらもメンバーシップ変更中にすべての通常の処理を一時的に停止しなければならない。
Raft には「状態転送 (state transfer)」のための独立したメカニズムがないため、Viewstamped Replication Revisited と Mazières のアプローチはどちらも Raft では機能しない。Raft では、古いサーバは新しいサーバにログエントリを複製してコミットするのに十分な時間リーダーを維持する必要があるが、Viewstamped Replication Revisited と Mazières のアプローチではクラスタがリーダーなしでログエントリを複製できることが要求される。
11.4.3 Zab
Zab のメンバーシップ変更アプローチは Raft のジョイントコンセンサスアプローチに最も近いものであり、基本的な考え方は Raft でも機能するだろう。Zab のアプローチにおける 2 つのフェーズは次の通り:
新しい構成を含むログエントリが、古いクラスタの過半数と新しいクラスタの過半数の両方にコミットされる。古いリーダーは新しい構成エントリ以降のエントリを複製し続けることはできるが、(自身が新しいクラスタの一部でない限り) それ以降のエントリをコミット済みとしてマークすることはできない。
次に、古いクラスタのリーダーは新しいクラスタに Activate メッセージを送信し、構成エントリのコミットを新しいクラスタに通知する。これにより新しいクラスタはリーダーを選出して処理を継続できるようになる。古いリーダーが新しいクラスタの一部でもある場合、リーダーとして継続できる。
Raft のジョイントコンセンサスアプローチはメンバーシップ変更中の状態をログにより明示的に記録する。Raft では新しい構成をアクティブ化するために 2 番目のログエントリを使用するが、Zab はログに記録されない Activate メッセージを使用する。これにより、サーバの現在の構成がログと最新のコミット済み構成の両方に依存するため、Zab の遷移と障害回復はより複雑になる。一方 Raft では、サーバは常にログに記録されている最新の構成を使用し、障害は追加のメカニズムなしで処理される。
古いリーダーが新しいクラスタにも参加している場合、このサーバがメンバーシップ変更中およびそれ以降もリーダーとして継続するため、どちらのアルゴリズムもクライアント操作を停止することはない。しかしクラスタから削除されるリーダーの扱いは Zab と Raft とで 2 つの点で異なる:
Raft では、削除されるリーダーは降格するまでログエントリをコミットし続ける。一方 Zab では、ログエントリに記録された構成変更エントリ以降のログエントリを削除されるリーダーがコミットしない場合がある。ただし、それらのエントリは複製することができ、この制限の影響は小さいだろう。
Zab では、リーダーがクラスタから離脱するとすぐに新しいサーバがリーダー選出を開始し、古いリーダーはただちに新しいサーバをリーダーに指名できる。Raft では、新しいサーバは選出タイムアウトを待つが、Raft のリーダーシップ転送機能拡張 ( 第 3 章で説明) を使用すれば、同様にこの遅延を回避できる。
ZooKeeper は任意のサーバからの読み取りを許可しており、追加のメカニズムなしでは、メンバーシップ変更後にクライアントがサーバ間で不均衡になる可能性がある。例えば最近クラスタに追加されたサーバは接続しているクライアント数が不均衡に少なくなる。この論文では、メンバーシップ変更後にクライアント負荷を新しいサーバにリバランスするための確率的アルゴリズムを説明しており、これは任意のサーバからの読み取りを許可する Raft 実装にも有用であろう。
11.5 ログ圧縮
ログ圧縮はあらゆるコンセンサスベースのシステムに不可欠な要素であるが、残念ながら多くの論文でこのトピックは軽視されている。その理由は 2 つ考えられる:
ログ圧縮に関する問題のほとんどはすべてのコンセンサスアルゴリズムに等しく適用可能である。すべてのアルゴリズムは最終的にログエントリをコミットする必要があり、コミットされたエントリはコンセンサスアルゴリズムに大きな影響を与えることなく (合意は既に達成されているため) 圧縮できる。したがって、理論的な観点から見ると、圧縮はコンセンサスアルゴリズムとほとんど直交しており、コンセンサスアルゴリズムに関する論文には理論的に属さないのかもしれない。
ログ圧縮には設計上の多くの選択肢が関係しており、その一部は実装によって異なる可能性がある。異なるアプローチは、複雑性、性能、およびリソース使用率のトレードオフ方法が異なり、実装は要件によって大きく異なる場合がある (例えば非常に小さなステートマシンから非常に大きなステートマシンまで)。一部の著者はアルゴリズムを可能な限り一般的な用語で記述しようとするが、そのような大きな設計空間に直面すると、すべての可能な実装を網羅することは困難である。
この論文ではいくつかの形式のログ圧縮について議論した。設計上の最大の選択肢は、増分アプローチ (セクション 5.3 で説明) と、よりシンプルだが効率の低いスナップショットのどちらかを選択することである。コンセンサスに基づく多くのシステムは何らかの形でスナップショットを使用している。Raft のスナップショットアプローチは Chubby [15] のものと非常によく似ており、同様のスナップショットアプローチは Viewstamped Replication Revisited [66] でも簡潔に概説されている。
ZooKeeper [38] はファジースナップショット (fuzzy snapshot) を使用している。ZooKeeper のスナップショットは、コピーオンライト (copy-on-write) 手法を使用して一貫性のあるスナップショットを取るのではなく、後の変更を部分的に反映することができる。このため特定の時点でのシステムの正確な状態を表していない。スナップショットに既に適用されているか不確実な変更は、サーバ起動時に再適用され、結果的に一貫した状態となる。
残念ながらファジースナップショットは米国特許 [95] で保護されており、一貫制のあるスナップショットよりも難解である。
11.6 複製ステートマシン vs. プライマリコピーアプローチ
オリジナルの Viewstamped Replication 論文と ZooKeeper は従来の複製ステートマシンと若干異なる動作をし、代わりにプライマリコピーアーキテクチャ (primary copy architecture) を採用している。プライマリコピーアーキテクチャは Figure 11.2 に示されている。各サーバがコンセンサスモジュール、ステートマシン、およびログを持つという点では複製ステートマシンに似ている。しかしプライマリ (リーダー) のステートマシンは、クライアントからのリクエストがコミットされるのを待つことなく到着し次第ただちに処理する。そして各リクエストから生じる状態を計算し、元のリクエストではなく最終的な状態がコンセンサスを用いてログに複製される。ログエントリがコミットされると、クライアントリクエストの影響がクライアントに外部化される。(線形化可能性のためには、プライマリはクライアント応答もログエントリに含めるべきであり、これによりクライアントが再試行した場合にバックアップサーバが同じレスポンスを返すことができる。第 6 章参照。)
コンセンサスアルゴリズムの観点では、プライマリコピー方式は複製ステートマシンと非常によく似ている。したがって Raft アルゴリズムのほとんどすべてがプライマリコピー方式にも同様に適用できる。ただし、プライマリコピー方式ではステートマシンとシステム全体がやや複雑になる。これらは 3 つの点で異なる。
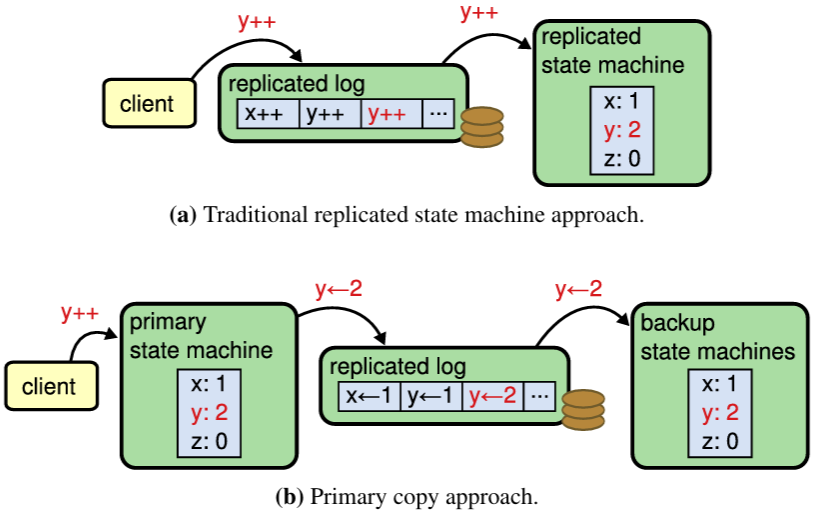
まず、プライマリコピー方式におけるプライマリのステートマシンはログに未コミットのエントリを反映するが、複製ステートマシンではコミットされたエントリのみを反映する。この区別は、プライマリがクライアントリクエストを受信したときに結果の状態を生成するために必要であるが、これにより 2 つの複雑な問題が生じる。まずステートマシンは未コミット状態を外部化しないように注意する必要がある。そして、別のサーバがプライマリになったときに以前のプライマリのステートマシンは最近の変更をロールバックする必要がある。
次に、複製ステートマシン方式におけるログは、結果的に何も効果がなかったものも含め、すべてのクライアントリクエストを含む。例えば条件が満たされなかった条件付き書き込み操作であってもログ領域を占有することになる。プライマリコピー方式では、プライマリはこのような失敗した操作のためにログに何か新しい情報を追加する必要はない (応答を外部化しても安全になるまで待つだけで良い)。一方で、どちらの方式でもログは最終的に圧縮されるため、これがシステム容量に大きな影響を与える可能性は低い。
さらに、複製ステートマシン方式のステートマシンは決定論的でなければならない。これは、すべてのサーバが同じ一連のクライアントリクエストを適用した後に同じ結果に到達しなければならないためである。例えば、クライアントリクエストの結果は各サーバの現在時刻に依存してはならない。しかしプライマリコピー方式ではプライマリのステートマシンが決定論的である必要はない。生成する状態変化が決定論的である限り、プライマリはリクエストに対して任意の処理を実行できる。幸いなことに、複製ステートマシンはほとんどの場合、ハイブリッドアプローチを用いることでこの制限を克服できる。クライアントリクエストを受信したサーバは、そのリクエストを複製ログに追加する前に現在時刻や乱数などの追加の非決定論的入力でそのリクエストを拡張できる。これによりすべてのサーバのステートマシンは拡張されたリクエストを決定論的に処理できるようになる。
11.7 性能
多くの論文で Paxos やその他のコンセンサスアルゴリズムの性能強化を提案している。これらの性能強化は有用だろうが、実装者はどの性能強化が自身の状況において適切かを判断する必要がある。関連研究における性能強化について説明する前に、これらの決定において重要となり得るいくつかの考慮事項について議論する。
第一に、コンセンサスの性能は理解可能性や実装の容易さよりも二次的な要素となり得るだろうと本研究の先駆者たちは認識している。例えば Boxwood [72] は一度に 1 つのログエントリのみを処理する (つまりバッチ処理やパイプライン処理を行わず逐次処理する) Paxos 実装を使用している。著者らは次のように述べている:
これにより、我々の目的のためにプロトコルの有効性を犠牲にすることなく実装がわずかに容易になる。
アプリケーションが最終的にその恩恵を受けないのであれば、性能上の理由でより複雑なアルゴリズムや実装を使用するのは賢明ではないだろう。
第二に、単一のコンセンサスグループの性能は根本的に制限される。これは、各操作にクラスタ内のサーバの半数以上を関与させなければならないためである。各サーバがコマンドの過半数を処理する必要があるため、コンセンサスグループのスループットは最良でも単一サーバの 2 倍を超えることはできない。コンセンサスを大規模なクラスタに拡張する唯一の方法は、より多くの独立したコンセンサスグループ (第 2 章参照) を使用し、グループ間の同期を最小限に抑えることである。
可能なレイテンシ改善も制限されており、特にデータセンターネットワークでは顕著である。レイテンシの最良ケースは、クライアントは、クラアントに最も近いクラスタの過半数に直接複製することである。一方、リーダーベースのアルゴリズムでは、クライアントはリーダーに複製し、次にリーダーがクラスタ内の他のサーバの最も近い半分に複製する。したがって、改善の可能性はクライアントとサーバの地理的な配置に依存する。最悪の場合、レイテンシはリクエストごとに地球を 2 周する状況から 1 周する状況に改善できる。
第三に、アルゴリズムを根本的に変更することなく、いくつかの重要な性能向上が達成できる。
コンセンサスの実用的な実装のほとんどは、何らかの形式でログエントリのパイプライン処理および/またはバッチ処理を採用している。第 10 章では Raft におけるバッチ処理とパイプライン処理について議論しており、Santos と Schiper [100] は Paxos の文脈でバッチ処理とパイプライン処理のトレードオフを分析している。残念ながら、彼らはレイテンシを犠牲にしてスループットを最適化することを提案しており、彼らのモデルには安定ストレージへの書き込みが含まれていない。
リーダーベースのアルゴリズムにおいてスループットの制限要因となることの多いリーダーのアウトバウンドネットワーク使用量も、通常はアルゴリズムを根本的に変更することなく削減できる。例えばリーダーはチェーンレプリケーション [30, 110] (まずリーダーが最初のフォロワーに複製し、そのフォロワーが 2 番目のフォロワーに複製する、というように続く) やネットワークマルチキャストを使用してエントリをフォロワーに複製できる。このとき、すべてのフォロワーはログエントリのコピーを受信するが、リーダーは描くログエントリを 1 回だけ送信すれば良い。あるいは、フォロワーはコマンドのバッチかを互いのメモリに複製し、リーダーはコマンドデータ全体を送信することなく、これらのバッチを複製露軍順序付けることができる。この S-Paxos [8] は Paxos の詳細を具現化している。
最後に、このセクションで述べた多くの性能最適化は、残念ながら米国で特許を取得している。我々は認識している特許について読者に警告しよう務めてきたし、米国におけるソフトウェア特許が早急に改革または廃止されることを心から願っている (電子フロンティア財団がその理由を説明している [25])。
11.7.1 リーダーのボトルネック削減
多くの最適化はリーダーを性能ボトルネックとして削減することに焦点を当てている。単一サーバであるリーダーはリソースが限られており、広域展開においては不便な場所に設置される可能性がある。そのため最適化によって以下の効果が得られる可能性がある:
ネットワークリンクをよりバランス良く使用することでスループットを向上する;
リーダーを介した (おそらく長い) ネットワークホップを回避することでレイテンシを低減する;
サーバ間の負荷をより均等に分散させる。
残念ながら、これらの最適化のほとんどは Raft の強力なリーダーアプローチと相反する。Raft は理解可能性とメカニズム削減のための強力なリーダーを活用しているが、この主要な設計上の選択は通常の操作におけるリーダーの関与を減らすことと対立する。したがって、Raft がこれらの最適化をサポートするように変更した場合、最終的な結果は Raft アルゴリズムとは大きく異なり、おそらく理解することが著しく困難になるだろう。
リーダーのローテーション (Mencius)
Lamport らは米国特許 [56] において、複製されたログを分割し、異なるログインデックスごとに異なるサーバをリーダーとして動作させるというアイディアを説明している。例えば、クラスタ内のすべてのサーバにラウンドロビン方式でリーダーを割り当てることができる。Mencius [74] はこのアイディアを Paxos に適用して実用的な実装に必要な多くの詳細を考案している。例えば、Mencius 内のサーバはクライアントからの提案リクエストがない場合に効率的に自分のターンをスキップできる。
Mencius はすべてのサーバがリクエストを提案できるためクラスタのスループットを向上させることができる。また、サーバが広域リンクで隔てられている場合であっても、クライアントは近くのサーバにリクエストを送信できるためレイテンシも改善される。しかしその設計には性能に関して 2 つの潜在的な欠点がある:
低速なサーバはログエントリを適用するステートマシンをさらに遅延させる可能性がある。これは、コンセンサスが進行するためには値を提案するか、自分のターンをスキップする必要がある (あるいは、さらに悪いことだが、別のサーバがターンを取り消す必要がある) ためである。これはレイテンシに影響を与えるがスループットには影響しない。
同様に、いずれかのサーバに障害が発生すると、クラスタが割り当てたログエントリを取り消すまで性能低下を引き起こす可能性がある。一方、Multi-Paxos では非リーダーが故障しても通常は性能に影響しない。
Raft は Mencius のような操作をサポートするように拡張できると考えている。しかし、それは Raft にあまりにも多くの複雑さを追加するため、最終的な結果は Raft と全く異なるものになる可能性がある。
リーダーの負荷をクライアントにオフロード (Fast Paxos)
Fast Paxos [52] (米国特許 [53] で保護) はリーダーのボトルネックを軽減する方法を説明している。これはリーダーにコマンドを提案させるのではなく、クライアントがクラスタサーバに直接コマンドを提案する。これは、クライアントがリーダーから遠く離れており、またリーダーも他のサーバから遠く離れている場合にレイテンシの面で有利となる。またネットワークホップがなくなるため、すべてのサーバが単一のデータセンターに配置されているケースでもレイテンシを改善できる。
クライアントがリクエストを直接提案できるようにするために、リーダーはまずクラスタ上で Paxos の第 1 フェーズを実行し、提案されてはいるが未コミットのログエントリを解決して、クライアントにその提案番号を伝える。その後、クライアントはリーダーの提案番号を使用してクラスタ内のすべてのサーバにコマンドを直接提案できる。クライアントはコマンドにログインデックスを指定せず、代わりに、各サーバがそのコマンドを最初の未使用ログエントリに割り当てる。単一のクライアントが特定の時間にコマンドを提案した場合、サーバは通常、そのコマンドのログインデックスについて合意する。クライアントが同じログインデックスに対して高速クォーラム (fast quorum) のサーバにコマンドを受け入れさせた場合、そのコマンドはコミットされる。高速クォーラムは通常 \(\lceil 3N/4 \rceil\) 台のサーバを必要とする。
実際には、クライアントはコマンドの実行結果としてステートマシンの出力を知る必要がある場合がよくあり、コマンドがコミットされたことを知るだけでは必ずしも十分ではない。そのため、クライアントではなく、何らかのサーバがコマンドがコミットされたことを知る必要がある。サーバはコミットが実際に行われたかを判断するために、受け入れたコマンドと共に受け入れ応答を相互に送信できる。サーバがコマンドがコミットされたことを知ると、そのコマンドを (ログ順に) 適用し、ステートマシンの結果をクライアントに返すことができる。
2 つのクライアントが異なる値を同時に提案した場合、コマンドは高速クォーラムを使用してコミットされない可能性がある。この状況はリーダーによる調整か、非調整で回復される。調整された回復では、リーダーは受け入れられた値の 1 つを選択し、通常は \(\lfloor N/2 \rfloor+1\) 台のサーバを必要とする低速クォーラム (slow quorum) を使用して Paxos の第 2 フェーズを開始する。非調整の回復では、サーバは独立して同じ値を選択しようと試み、高速クォーラムを使用して再度試行する。
Fast Paxos は低負荷時のレイテンシ削減に役立つが、クライアント間で頻繁に競合が発生するような状況下では回復コストによって性能改善が打ち消される可能性がある。さらに、Fast Paxos はメッセージングパターンと 2 種類のクォーラムの使用においてかなり複雑であるため、これほど多くの処理をクライアントに移行することは望ましくない可能性がある。Raft を Fast Paxos と同様に動作させることは可能かもしれないが、この場合も最終的な結果は Raft とはあまり似ていないだろう。
可換性の活用 (Generalized および Egalitarian Paxos)
Generalized Paxos [51] および Egalitarian Paxos [80] は、どちらもステートマシンコマンドにおける可換性 (非干渉性) を利用している。直感的には、コマンド A と B が可換であれば、あるステートマシンは A の後に B を適用し、別のステートマシンは B の後に A を適用しても同じ状態に到達する。これをサポートするには、ステートマシンはどの操作が可換であるかを識別する必要があり、コンセンサスアルゴリズムはこの情報を用いて競合が発生する時期を判断する。競合が発生しなければ処理は非常に効率的だが、同時に提案されたコマンドが互いに可換ではない場合、アルゴリズムで追加の通信ラウンドを必要とする。
Generalized Paxos [51] (米国特許 [56] で保護) は Fast Paxos を拡張し、操作が可換である場合の回復を回避する。これは、複数のクライアントがコマンドを提案している場合でも、それらのコマンドが干渉しない限り Fast Paxos の高速パス性能をを達成できる。Egalitarian Paxos [80] では、クライアントは最も近いサーバにコマンドを送信し、同時に提案された他のコマンドが干渉しない限り、任意のサーバが 1 回の通信ラウンドでコマンドをコミットできる。Egalitarian Paxos の高速クォーラムは Generalized Paxos よりも 1 サーバ分少ない。
Generalized Paxos と Egalitarian Paxos はどちらも、操作が可換であればコマンドをコミットするためのリーダーを必要としないため、サーバ間で負荷を良好に分散する。またリーダーを含める必要がないため (クライアントに最も近いサーバのみを関与させれば良いため)、WAN 設定で Raft より低いレイテンシを達成することもできる。しかし、これらのプロトコルはどちらも Paxos に大幅な複雑さを追加する。
11.7.2 サーバ数の削減 (witnesses)
障害耐性を損なうことなく、ほとんどの操作に関与するサーバの数を減らす方法はいくつか存在する。これらは Table 11.2 にまとめられている。最初の方法はすべてのコンセンサスアルゴリズムで機能するもので、エントリをクラスタ全体にではなく単純に最小限の過半数に複製する ([80] では「倹約的 (thrifty)」と呼ばれている)。これによりリーダーはエントリをクラスタの半分にしか複製する必要がないため、通常動作時のリーダーのネットワーク負荷は半減する (アイドル時に他のサーバへエントリを複製できる)。しかし、この最適化でクォーラムに参加する必要のあるサーバが大幅に遅れている可能性があるため、サーバ障害が発生したときに遅延が発生する可能性がある。Paxos では、新しいサーバは以前のエントリを受け入れる前に後のエントリを受け取ることができるためこの影響は最も少なくなる。一方で Viewstamped Replication、Zab、Raft での影響は大きくなる。新しいサーバのログは、新しいエントリを受け入れる前に完全に最新の状態に更新されている必要があるためである。
| レプリケーション | サーバ | ステートマシン | サーバ故障時の遅延 |
|---|---|---|---|
| 従来のコンセンサス | 5 | 5 | 遅延なし |
| Thrifty | 5 | 3 | 順不同ログ (out-of-order logs) では遅延なし; 順序付きログ (in-order logs) では欠落エントリを複製する |
| Harp/Cheap Paxos | 3 + 2 | 3 | 遅延なし |
| プライマリ/バックアップ | 3 | 3 | 故障したサーバを削除するために外部システムと通信 |
Harp [67] は Viewstamped Replication をさらに一歩進めて Witness を導入している。Witness は投票にのみ参加し、通常はログレプリケーションには参加せず、ステートマシンも持たないサーバである。サーバが故障すると Witness が介入して、そのサーバが回復するか交換されるまでそのログエントリを保存する。この Witness により、メインサーバの一部に障害が発生した場合でも、クラスタは合意に基づく決定を下すことができる。Witness に必要なリソースは通常のサーバよりも低いため、限られたハードウェア上で実行することも、他のサーバ上のセカンダリプロセスとして実行することもできる。Raft も同様の方法で Witness をサポートできると考えている。Cheap Paxos [57] (米国特許 [58] で保護) は Harp に似ているが、Witness としてさらに低性能のサーバしか必要ないと主張している。
プライマリ/バックアップレプリケーション方式では、回復時間をさらにトレードオフするが、クラスタの一部のサーバを完全に削除する (これはセクション 11.6 で議論した複製ステートマシンとプライマリコピーの区別とは直交する)。このアプローチは Apache Kafka [93] で使用されている。プライマリはログエントリをすべてのバックアップに複製し、すべてのバックアップの確認応答を待機してから各エントリをコミットする。プライマリが故障した場合、どのバックアップのログも新しいプライマリになるのに適しているが、古いプライマリが復帰した場合に備えてクラスタから除外する必要がある。バックアップが故障した場合、それも将来的に適格なプライマリになることから除外する必要がある。グループは、外部のコンセンサスサービスを使用して新しいプライマリを選択し、サーバをプライマリにならないようにすることができる。障害後に元のレプリケーション係数 (replication factor) に戻すには、プライマリは新しいサーバをキャッチアップさせ、その後、外部のコンセンサスサービスでそのサーバをプライマリになる資格があるとしてマークする。\(n\) 個のサーバを持つクラスタでは、このアプローチは \(n-1\) 個の故障から回復でき (回復中に外部のコンセンサスサービスの助けを借りて)、各ログエントリを複製するために \(n-1\) 個のメッセージしか送信する必要がない。しかし、障害からの回復にはより時間がかかる可能性があり、同様にコンセンサスほどは Straggler (低速サーバ) をマスクすることもできない。
11.7.3 永続ストレージへの書き込みの回避
多くの論文では、耐久性のために安定ストレージではなくレプリケーションを使用することを提案している。例えば Viewstamped Replication Revisited では、サーバはログエントリを安定ストレージに書き込まない。サーバが再起動すると、最新の情報を学習するまでログは投票に使用されない (ディスクはネットワーク転送を回避するための最適化にのみ使用される)。このトレードオフは、壊滅的なイベントが発生した場合にデータ損失が発生する可能性があることである。例えば、クラスタの過半数が同時に再起動した場合、クラスタはエントリを失っている可能性があって新しいビューを形成できなくなるであろう。Raft も同様の方法でディスクレスをサポートするように拡張できるが、通常、可用性やデータ損失のリスクはそのメリットを上回ると考えている。
11.8 正確性
コンセンサスコミュニティは、その正確性に関する取り組みを主に Safety の証明に注力してきた。単一決定 Paxos [48, 91, 55]、Multi-Paxos [10, 101]、EPaxos [79]、Zab [41] など、広く受け入れられているコンセンサスアルゴリズムのほとんどは何らかの形で Safety が証明されている。Viewstamped Replication [66] については非公式なスケッチしか見つかっていない。
証明には様々な形式がある。証明は一軸で見ると形式度の低いものから高いものまである。非公式なスケッチは直感を得るのに役立つが、エラーを見落とす可能性がある。Raft では、我々はかなり詳細な (準形式的な) 証明を開発し、直感のための非公式なスケッチも盛り込んだ。最も形式的な証明は機械検証済みである。これはコンピュータプログラムでその正しさを検証できるほど非常に精密である。これらの証明は必ずしも理解しやすいわけではないが、証明されたステートメントの真実性を完全に確信を持って確立する。機械検証済みの証明は分散システムではまだ標準的ではないが(例えばプログラミング言語界隈ではより一般的である)、そのため我々自身でそれを作成するのに苦労した。しかし最近の研究ではこのアプローチが支持されており [54, 101]、EventML [101] の著者らは Multi-Paxos の正しさを証明することで、彼らのアプローチがコンセンサスにとって実行可能であることを示している。機械検証済みの証明と非公式なスケッチを組み合わせることで両方の良い点を享受でき、分散システムコミュニティがその方向へ進むことを期待している。
証明はまた現実世界のシステムにどれだけ直接的に適用できるかという点でも異なる。証明の中には非常に単純化されたモデル上で特性を証明するものもある。これは理解を助けるものの、完全なシステムの正しさに対する直接的な価値は限られている。例えば、現実のシステムは単一決定 Paxos とは大きく異なるためその証明からあまり恩恵を受けられない可能性がある。一方、より完全な使用に基づいて動作する証明もある (例えば Appendix B に示した Raft の証明や EPaxos [79] の証明)。現実世界の実装はこれらの仕様に近く、したがってこれらの証明は現実世界のコード上で特性を証明することに近くなる。一部の証明システムは、実際に動作する実装を生成することさえ可能であり、仕様から実装への翻訳におけるエラーの可能性を排除する (例えば EventML [101])。しかしこのアプローチはこれまで実際にはあまり普及していない。おそらく、現実世界のシステムには生成コードでは対応が難しい性能などの追加の要件があるためだろう。
Liveness や可用性の証明はあまり見つかっていない (Raft についても貢献できていない)。これらの特性は形式化するのが難しいかもしれないが、将来的にはどの点により重点が置かれることを期待している。
11.9 理解可能性
ヒューマンファクターに関する研究は、コンピュータサイエンスの他の分野、特にヒューマンコンピュータインタラクション (HCI) では一般的である。HCI 研究者は通常、経験的測定値を使用して設計を繰り返し改善し、研究から得られる漸進的な結果を設計の改善に役立てている。これを可能にするには、研究は比較的容易に繰り返し実行でき、比較的低コストでなければならない。典型的な HCI 研究では、参加者にユーザインターフェースを使用してタスクを学習および実行してもらうが、これは準備がほとんど不要で、参加者 1 人あたり数分しかかからない場合もある。一方、我々の主な目的は、Raft の改善を繰り返すことではなく、Raft と Paxos を比較することであり、Raft 研究のコストが反復的なアプローチの適用を困難にした (教材とクイズを準備する必要があり、各参加者は研究に数時間を投資する必要があった)。Raft が Paxos よりも理解しやすいことを示した今、Raft のより良いバリエーション、あるいはその説明のよりよいバリエーションを見つけるために、さらなる反復的な研究 (A/B テスト) を行うことは実現可能かもしれない。
NetComplex [18] は人的要因を完全に回避し「ネットワークシステム設計におけるアルゴリズムの複雑さの概念を定量化する指標」を提案した。この指標は状態の分散依存関係を計算した。ここで各状態変数の複雑さはその依存関係の複雑さの合計である。この論文はまた、この指標に従って 2-フェーズコミットと単一決定 Paxos の複雑さを比較している。予想通り Paxos の方が複雑であると結論づけている。
アルゴリズムの複雑さや理解可能性を定量化する公式が非常に有用であることは明らかである。しかし、NetComplex の論文で提案されている公式が正しいものであるかどうかは分からない。複雑さには多くの要因が寄与しており、それらの相対的な重要性や相互作用は十分に理解されていない。また、提案された公式を、論文で示された例よりもはるかに大規模な Raft アルゴリズム全体に適用する方法も明らかではない (しかし、その結果を見ることには非常に興味がある)。
Chapter 12 - 結論
この論文の目的は、コンセンサスの学習と複製ステートマシンを構築するためのよりよい基盤を創出することであった。我々自身がコンセンサスを学習しようと試みた際、既存のアルゴリズムを理解するために必要な時間と労力があまりにも大きく、多くの学生や実務家にとってこの負担が支障となるのではないかと懸念した。また、コンセンサスを用いた完全かつ実用的なシステムを構築するまでに膨大な設計作業が残されていた。そこで我々は Raft をより理解しやすく、より実用的なアルゴリズムとして設計し、学習とシステム構築の両方にとってより良い基盤となるようにした。
Raft の設計には、その理解しやすさに貢献するいくつかの側面がある。高レベルでは、このアルゴリズムは Paxos とは異なる方法で分解されている。まずリーダーを選出し、次にリーダーが複製ログを管理する。この分解により、Raft の様々な部分問題 (リーダー選出、ログ複製、Safety) について比較的独立して推論することが可能になる。また、強いリーダーを持つことで状態空間の複雑さを最小限に抑えることができる。なぜなら、競合はリーダーシップが変更された場合にのみ発生するからである。Raft のリーダー選出は競合を回避し解決するためにランダムなタイムアウトを利用するため、非常にシンプルなメカニズムで行われ、通常は 1 ラウンドの RPC でリーダーが選出される。投票ルールによってリーダーのログにはコミット済みのすべてのログエントリが既に含まれていることが保証されているため、直接ログ複製に進むことができる。Raft のログ複製も、ログが時間と共に変化する方法や、ログ間で差異を制限する方法により、コンパクトで理解しやすい仕組みになっている。
Raft は実用的なシステムによく適合している。さらなる改良なしに実装できるほど詳細に記述されており、完全なシステムにおけるすべての主要な問題を解決し、効率的である。Raft はシステム構築により適した異なるアーキテクチャを採用している。コンセンサスはしばしば単一の値に関する合意として定義されるが、Raft では複製ステートマシンを構築するために必要な複製ログの観点からコンセンサスを定義した。Raft はリーダーを活用することで複製ログを効率的に管理する。リクエストのコミットにはリーダーからの 1 ラウンドの RPC しか必要としない。さらに、この論文では完全なシステムを構築する上でのすべての主要な課題に対する設計空間を明確に示している。
Raft は一度に単一のサーバを追加または削除することでクラスタメンバーシップを変更できる。これらの操作は、変更中に少なくとも 1 つのサーバが過半数と重複するため Safety を簡単に維持する。より複雑なメンバーシップ変更は、一連の単一サーバ変更として実装される。Raft では変更中でもクラスタが通常通りに動作を継続できる。
Raft はスナップショットと増分アプローチの両方を含む、いくつかのログ圧縮方法をサポートしている。サーバは、コミットされたログ部分を独立して圧縮する。基本的な考え方は、ログの開始に関する責任を Raft 自身からサーバのステートマシンに移すことである。
クライアントとのやりとりはシステム全体が正しく機能するために不可欠である。Raft はクライアント操作に対して線形化可能性を提供し、読み取り専用リクエストは性能向上のために複製ログをバイパスするが、同じ一貫性保証は提供する。
この論文では、理解可能性、正しさ、リーダー選出とログ複製の性能など、Raft の様々な側面を分析し評価した。ユーザ調査では 43 人中 33 人が Raft に関する質問により良く回答でき、41 人中 33 人が Raft の方が Paxos よりも実装または説明が容易であると考えていると述べた。Safety の証明は Raft の正しさを確立するのに役立ち、形式仕様は Raft の説明における曖昧さを排除するため実務家にとって有用である。ランダムリーダーな選出アルゴリズムは様々なシナリオで良好に動作することが示され、通常 1 秒未満でリーダーを選出する。最後に、測定結果から LogCabin の現在のバージョンが 3 サーバクラスタで毎秒 20,000 キロバイトの書き込みに対応していることが示された。
我々は Raft が産業界で急速に採用されていることに勇気づけられている。これは Raft の理解可能性と実用性に起因すると考えている。ある人物のジレンマ (one person's dilemma) は Raft が解決しようとした問題と Raft がもたらすメリットの両方を浮き彫りにしている。Nate Hardt は Scale Computing で Paxos ベースのシステムを構築し、過去 1 年間その実装の問題を解決するのに苦労していた。彼は現在、効率的で動作するシステムに近づいているが、Raft を発見したとこで、Raft でシステムを再構築することを検討している。彼は Raft のアルゴリズムをより簡単に理解し、完全なシステムのすべての側面を学べるため、彼のチームが Raft の実装により容易に協力できると信じている。幸いにも、新しいコンセンサスプロジェクトに着手する他の人たちにとっては、より簡単な選択肢がある。既に多くの人々が学習の喜びのために Raft システムを構築しており、これは Raft の理解可能性を物語っている。また本番環境で利用するために Raft を実装している人々もいる。これは Raft の実用性の高さを物語っている。
12.1 学び得た教訓
私は大学院での数年間、本番環境レベルの品質のシステムを構築する方法から研究を行う方法まで、多くのことを学んだ。このセクションでは、私が他の研究者やシステム構築者に伝えることができる重要な教訓のいくつかを簡潔に述べる。
12.1.1 複雑性について
かつて John は私に「複雑性に対する耐性が高い」と言った。最初、私はそれを褒め言葉、つまり他の能力の低い人間にはできないことをこなせるという意味だと思った。しかし後にそれは批判だと気づいた。私のアイディアとコードは、本来解決すべき問題を解決したが、それは全く新しい一連の問題を引き起こした。それらは説明し、学習し、維持し、拡張するのが困難になるだろう。
Raft では、我々は意図的に複雑性に不寛容であり、それを上手く利用した。我々は分散コンセンサスという本質的に複雑な問題に対して可能な限り理解しやすい解決策で取り組むことを目指した。これは多大な複雑性を管理する必要があったものの、他の人々にとってその複雑性を最小限に抑えることにつながった。
すべてのシステムには複雑性の予算 (budget) がある。システムはユーザに何らかの利点を提供するが、複雑性がこれらの利点を上回れば、そのシステムはもはや価値を失う。分散コンセンサスは根本的に複雑な問題であり、完全かつ実用的な解決策に到達するだけでも、その複雑性の予算の大部分を費やす必要がある。Raft 以前の多くのコンセンサスアルゴリズムやシステムは、その複雑性の予算を使い果たしていたと私は考えており、これがコンセンサスベースのシステムがあまり容易に利用できない理由を説明できるかもしれない。Raft がこの計算を変え、これらのシステムを構築する価値があるものにしたことを願っている。
12.1.2 理論と実践の橋渡しについて
我々がこの研究を始めたのは、コンセンサスを用いたシステムを構築したいと思ったが、それが驚くほど難しいことに気づいたからである。これは過去にコンセンサスを試みたが諦めてしまった多くの人々の共感を呼んだが、多くの学者にはその価値が理解されなかった。物事をシンプルかつ明白にすることで Raft は学術関係者にとってほとんど面白くないものに映る。学術コミュニティは、理解可能性そのものを重要な貢献とは見なさず、彼らは他の次元における斬新さを求めているのである。
学術界は理論と実践のギャップを埋める研究に対してもっとオープンになるべきだ。この種の研究は、理論上は新しい機能をもたらすことはないかも知れないが、より多くの学生や実務家に新しい能力 (functionality) を与えたり、少なくとも彼らの負担を大幅に軽減したりすることはできる。「この研究を教え、使い、推奨するだろうか?」という問いは結局のところ我々の分野にとって重要であるにもかかわらず、あまりにも無視されがちである。
ギャップを埋める作業はしばしば学術研究から生まれる必要がある。産業界では製品の出荷期限が迫っているため、実務家はニーズを満たすのにちょうど良いアドホックな解決策に頼ってしまうのが常である。(Chubby の著者らが Paxos [15] について行ったように) 彼らは課題を指摘することはできるが、最適な解決策を見つけるために必要な時間を通常は投資できない。Raft に関しては、我々は十分であることに満足せず、それが我々の研究を価値あるものにしていると考えている。我々は考え得る限りの設計上の選択肢をすべて検討した。これは産業界では対応が難しいほどの深いところまで綿密に検討する必要があったが、多くの人々が恩恵を受けられる貴重な結果を生み出した。
12.1.3 研究課題の見つけ方について
私が大学院に入学した頃、取り組むべき興味深い研究課題をどう見つけたら良いかが分からなかった。今となっては世の中にあまりにも多くの問題が存在するので馬鹿げているように見える。それらを見つけるには様々なアプローチがあるが、私は次のアプローチが効果的だと気づいた。
まず何かを構築し始めること。作りたいという意欲さえあれば、それが何であるかはそれほど重要ではない。例えば、自分が使いたいアプリケーションを作るのも良いし、習得したい新しいプログラミング言語で既存のプロジェクトを書き直すのも良いだろう。
次に、指標を一つ選び、その指標に合わせてシステムを最適化する。Raft では最も理解しやすいアルゴリズムを設計することを目指した。他のプロジェクトでは、性能、セキュリティ、正確性、ユーザビリティなど様々な指標を最適化している。
このアプローチの鍵となるのは、あらゆる段階で指標を最大化するための最善の方法は何かを自問することである。既存の解決策が十分ではないという発見につながることが多く、研究プロジェクトとなる可能性が出てくる。
すると、取り組むべき問題が全くない状態から、問題が多すぎる状態へと変化し、どの問題を選択するかという課題が生じる。これは難しい判断を迫られる可能性がある。概念的に興味深く、取り組むのが楽しく、大きな影響を与える可能性のあるプロジェクトを探すことを推奨する。
12.2 最終コメント
この論文は分散コンセンサスにおける理論と実践のギャップを埋めることを目的としている。分散コンセンサスに関するこれまでの学術研究の多くは理論的な性質なものであり、実用的なシステムの構築に適用するのが困難であった。一方、コンセンサスに基づく現実世界のシステムの多くはアドホックな性質を帯びており、実務者は自らのニーズを満たす程度の解決策で止まってしまい、その影響や代替案は十分に検討されていなかった。Raft では、理解しやすさを重視しながら、完全なコンセンサスアルゴリズムの設計空間を徹底的に検討し、さらに、アイディアの実用性を保証するために、完全なコンセンサスベースのシステムを構築した。これがコンセンサスの教育と将来のシステム構築の両方にとって優れた基盤となることを願っている。
Appendix A - ユーザ調査資料
この付録には、Raft ユーザ調査 (第 7 章) で使用した様々な資料が含まれている。
セクション A.1 には Raft クイズの質問、解答、採点基準が記載されている。
セクション A.2 には Paxos クイズの質問、解答、採点基準が記載されている。
セクション A.3 にはアンケートと、参加者から寄せられた自由記述のコメントとフィードバックが記載されている。
セクション A.4 には調査期間中に参加者に提供された Raft および Paxos アルゴリズムの要約が記載されている。
A.1 Raft クイズ
採点上の注意: 誤った情報によって減点される場合でも、すべての設問のすべてのセクションの最低配点は 0 点である。
(4 点) 以下の図は Raft サーバのログ構成の例を示している (ログエントリの内容は示されておらず、そのインデックスとタームのみが表示されている)。各ログを個別に検討したとき、そのログ構成が Raft の適切な実装で発生する可能性があるかを「はい」または「いいえ」で答えよ。解答が「いいえ」の場合はその理由も説明せよ。
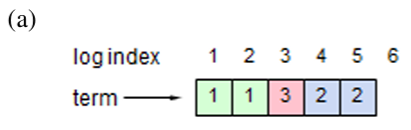
解答
いいえ: ログにおいてタームは単調に増加する。具体的には、エントリ (4, 2) を作成したリーダーは、現在のタームが 3 であるリーダーから (3, 3) を受け取ることしかできず、したがってその現在のタームも 3 となる。そのため (4, 2) を作成できない。
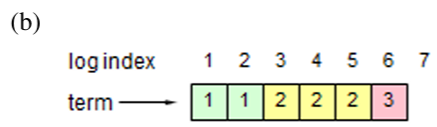
解答
はい
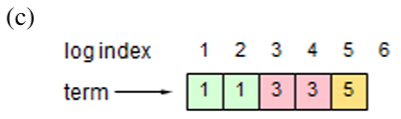
解答
はい
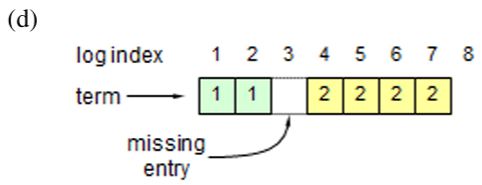
解答
いいえ: ログには穴が存在しない。具体的にはリーダーはログに追加するのみで、AppendEntries の一貫性チェックで穴が見つかることはない。
採点
各パートにつき 1 点の合計 4 点。解答が「はい」の場合、「はい」と答えると 1 点で「いいえ」と答えると 0 点。補足説明は無視する。解答が「いいえ」の場合、「いいえ」と答えると得点の半分、正しい説明があれば残り半分が加算される。補足説明はそれほど多くを必要としない。「はい」と答えると 0 点。補足説明は無視される。
(6 点) 以下の図は 5 台のサーバで構成されるクラスタのログの状態を示している (エントリの内容は表示されていない)。どのログエントリがステートマシンに安全に適用できるかを答え、その理由を説明せよ。
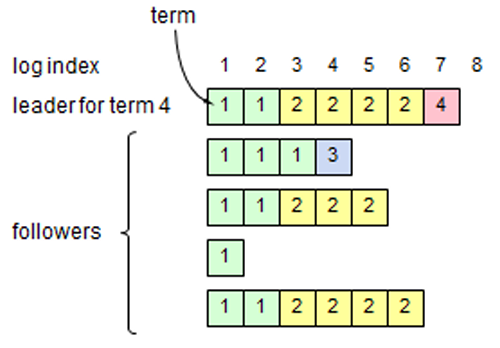
解答
エントリ (1, 1) と (2, 1) を安全に適用できる: まず、クォーラムに保存されていないエントリは安全に適用することができない。これは、少数派が故障する可能性があり、(過半数を形成する) 他のサーバはそのエントリを知ることなく処理を進められないからである。したがって、エントリ (1, 1), (2, 1), (3, 2), (4, 2), (5, 2) のみを考慮すればよい。次に、どのサーバがリーダーに選出されうるかを特定し、これらのエントリを削除する原因となる可能性がないかを確認する必要がある。サーバ 2 は、そのログが S3, S4, S5 と同じかそれ以上に完全であるためリーダーに選出される可能性がある。そうすると、サーバ 2 はエントリ (3, 2), (4, 2), (5, 2) を削除する可能性があるため、これらのエントリを適用するのは安全ではない。したがって、安全に適用できる可能性があるエントリとして残っているのは、エントリ (1, 1), (2, 1) である。サーバ 3 と 4 はログが十分に完全ではないためリーダーに選出できない。サーバ 5 はリーダーに選出される可能性があるが、それは (1, 1) と (2, 1) を含んでいる。したがって (1, 1) および (2, 1) のみが安全に適用されうる。
採点
合計 6 点。「エントリ (1, 1) と (2, 1)」または「エントリ 1 と 2」(曖昧さがないため) と答えた場合は 3 点。この 3 点には部分点はないが、誤った解答でも説明に対しては部分点が与えられる場合がある。説明に対して 3 点: エントリはクォーラムに保存されていなければならないと答えた場合は +1 点、サーバ 2 がリーダーに選出される可能性があり、それはインデックス 2 を超えるエントリを脅かすと答えた場合は +2 点。「リーダーのタームのエントリの 1 つがサーバの過半数に到達するまで、ターム 2 のエントリはコミットできないから 1 と 2」という解答は 4.5 点 (このような解答が 3 つあった。正しいが、参加者が理由を理解してたかは不明)。「エントリ 1~5 は過半数に保存されているため」は誤答で 1 点。「エントリ 1~6 は過半数に保存されているため」は誤答で 0 点 (エントリ 6 は過半数に保存されていない)。
(10 点) 以下の図は、6 台のサーバからなるクラスタにおいて、ターム 7 に選出された直後のログを示している (ログエントリの内容は表示されておらず、インデックスとタームのみが示されている)。正常に機能する Raft システムにおいて、図中の各フォロワーで示されているようなログ構成が発生する可能性があるかを、フォロワー (a) から (e) までそれぞれ「はい」「いいえ」で答えよ。発生する可能性がある場合、それがどのようにして起こるかを説明せよ。発生する可能性がない場合、それがなぜ発生しないかを説明せよ。
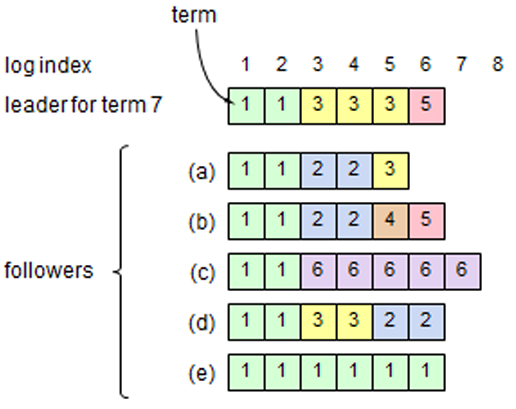
解答
いいえ: エントリ (5, 3) はログプレフィクスを一意に識別する (AppendEntries の一貫性チェックによる)。しかし、このフォロワーはエントリ (5, 3) を持ち、その以前のログプレフィクスがリーダーとは異なる。
いいえ: エントリ (6, 5) はログプレフィクスを一意に識別する (AppendEntries の一貫性チェックによる)。しかし、このフォロワーはエントリ (6, 5) を持ち、それ以前のログプレフィクスがリーダーとは異なる。
はい: クラスタ内の他のサーバについてあまり確定的なことは言えないため、このサーバはターム 6 で (1, 1), (2, 1) から始まるログを持つリーダーであった可能性があり、ログに多くのエントリを書き込んだ後、ターム 7 の現在のリーダーと通信しなかった可能性がある。これは、エントリ (3, 3), (4, 3), (5, 3), (6, 5) がターム 5 でコミットされなかったことを前提としているが、これはあり得る。
いいえ: ログ内のタームは単調に増加する。具体的には、エントリ (5, 2) を作成したリーダーは、ターム 3 のリーダーからしか (4, 3) を受け取れなかったはずであり、そのためそのときのタームも 3 であったはずである。そうであれば、エントリ (5, 2) を作成することはできなかったはずである。
はい: 例えば、(e) はターム 1 のリーダーであり、エントリ (1, 1), (2, 1) をコミットした後に他のサーバから分断されたが、クライアントからのリクエスト処理を続行しようとした可能性がある。
採点
合計 10 点。各パートは 2 点。ブール値に +1 点、正しい説明に +1 点。ブール値が正しくない場合、説明には点数は付与されない。ブール値が正しければ、あまり多くの補足説明は必要ない。
(5 点) ハードウェアまたはソフトウェアのエラーによって、リーダーが特定のフォロワー用に保存していた nextIndex 値が破損したとする。これがシステムの Safety を損なう可能性があるかを簡潔に説明せよ。
解答
いいえ: nextIndex の値が小さすぎる場合、リーダーは余分な AppendEntries リクエストを送信するだけで、各リクエストはフォロワーのログには影響を与えず (一貫性チェックにはパスするが、フォロワーのログのいずれのエントリとも競合せず、フォロワーがまだ持っていないエントリをフォロワーに提供することもない)、成功応答はリーダーに nextIndex を増やすべきであることを示すだろう。nextIndex の値が大きすぎる場合も、リーダーは余分な AppendEntries リクエストを送信するが、これらの一貫性チェックは失敗し、フォロワーはリクエストを拒否し、リーダーは nextIndex をデクリメントして再試行するだろう。いずれのケースでも重要な状態は変更されないため、これは Safety を維持する動作である。
採点
合計 5 点。「いいえ」と解答した場合は +1 点。nextIndex が小さすぎる場合の動作を説明した場合は +2 点。nextIndex が大きすぎる場合の動作を説明した場合は +2 点。nextIndex が小さすぎる場合にフォロワーがログを切り捨てるという回答は、それが Safety の違反につながる可能性があるから -1 点。ブール値が誤っている場合でも、正しい説明に対しては部分点を与えて良い。
(5 点) Raft を実装したサーバをすべて同じデータセンターに配置したとする。次に、各サーバを世界中に分散した異なるデータセンターに配置すると仮定する。単一データセンター版の Raft と比較して、広域版の Raft に何か変更を加える必要があるか、もしあるならどのような変更が必要か、そしてその理由を述べよ。
解答
選挙タイムアウトを長く設定する必要がある: 予想されるブロードキャスト時間が長くなるため、候補者が再びタイムアウトする前に選挙を完了する機会を持つように、選挙タイムアウトをブロードキャスト時間よりもはるかに長く設定すべきである。アルゴリズムの残りの部分はタイミングに依存しないため変更の必要はない。
採点
合計 5 点。満点を得るには、回答に選出タイムアウトの増加を記述し、その根拠としてレイテンシの増加または何らかのライブロックに言及する必要がある。選出について具体的に言及せずに「タイムアウトの増加」について言及している回答は最大 3.5 点とする (これにより 4 つの回答が影響を受ける)。不要な変更や任意の変更 (性能改善など) は、そのように正く認識されれば無視される。必要な変更として特定されたその他の変更については減点される。
(10 点) 各フォロワーは、自身の現在のターム、最新の投票、およびフォロワーが受け入れたすべてのログエントリの 3 つの情報をディスクに保存する。
フォロワーがクラッシュし、再起動時に自身の最新の投票情報が失われたとする。このフォロワーがクラスタに再参加しても安全かを「はい」「いいえ」で答え、その理由を説明せよ。ここでアルゴリズムに変更がないと仮定する。
解答
いいえ: これにより、そのサーバが同じタームで 2 回投票することが可能となり、その結果ほぼすべての問題が破綻する。例えば 3 台のサーバの場合: S1 は S1 と S2 の票を取得してターム 2 のリーダーとなる。S2 が再起動し、ターム 2 で投票したことを忘れる。S3 が S2 と S3 の票を取得してターム 2 の 2 番目のリーダーとなる。これで S1 と S3 は同じインデックスとタームを持ちながら異なる値を持つ異なるエントリをターム 2 でコミットできるようになる。
次に、フォロワーのログがクラッシュ中に切り捨てられ、末尾のエントリの一部が失われたと仮定する。このフォロワーがクラスタに再参加しても安全かを「はい」「いいえ」で答え、その理由を説明せよ。ここでアルゴリズムに変更がないと仮定する。
解答
いいえ: これにより、コミットされたエントリがクォーラムに保存されず、同じインデックスに対して別のエントリがコミットされる場合がある。例えば 3 台のサーバの場合: S1 はターム 2 のリーダーとなり、自身と S2 に index=1, term=2, value=X を追加する。S1 は committedIndex を 1 に設定し、X がコミットされたことをクライアントに返す。S2 が再起動してログからエントリが失われる。(ログが空の) S3 は、その空のログが少なくとも S2 のログと同等に完全であるため、ターム 3 でリーダーとなる。S3 は自身と S2 に index=1, term=3, value=Y を追加する。S3 は committedIndex を 1 に設定し、Y がコミットされたことをクライアントに返す。
採点
合計 10 点。各パート 5 点: ブール値で +1 点、正しい説明で +4 点 (上記のような詳細なシナリオは不要)。パート (a) で満点を得るには、フォロワーが 2 回投票できるだけではなく、同じタームに複数のリーダーが選出される可能性があることを回答に含める必要がある。ブール値が正しくない場合、説明に対して点数は与えられない。
(10 点) ビデオで説明されているように、他のサーバがリーダーはクラッシュしていると判断して新しいリーダーを選出した後でも、前のリーダーは動作を継続することは可能である。新しいリーダーはクラスタの過半数に連絡してそれらのタームを更新するため、古いリーダーはこれらのサーバのいずれかと通信すればすぐに退任する。しかし、その間、古いリーダーはリーダーとしての役割を継続し、新しいリーダーからまだ連絡を受けていないフォロワーにリクエストを発行できる。さらに、クライアントは古いリーダーにリクエストを送信し続けることができる。古いリーダーは選挙が完了した後に受信した新しいログエントリをコミットすることはできないことは分かっている。なぜなら、これらをコミットするには選出された過半数のサーバのうち少なくとも 1 つに連絡する必要があるためである。しかし、古いリーダーが、選挙開始前に受信した古いログエントリのコミットを完了する AppendEntries RPC を正常に完了することがあるかを「はい」「いいえ」で答えよ。もしあり得るなら、それがどのように起き得るかを説明し、Raft プロトコルに問題が発生するかについて検討せよ。もしあり得ないなら、その理由を説明せよ。
解答
はい: これは新しいリーダーにもコミット対象のエントリが含まれている場合にのみ発生するため、問題は引き起こさない。5 台のサーバでこれが起こる例を示す: 空のログを持つ S1 は、S1、S2、S3 の票でターム 2 のリーダーとなる。S1 は、自身と S2 に index=1, term=2, value=X の追加を完了する。ログに index=1, term=2, value=X を持つ S2 は、S2、S4、S5 の票でターム 3 のリーダーとなる。S1 は、S3 に index=1, term=2, value=X の追加を完了する。この時点で、S1 は現在のリーダーではないにもかかわらず、index=1, term=2, value=X のコミットを完了している。
この動作は安全である。なぜなら、新しいリーダーもそのエントリを含んでいなければならず、したがってそれは永続的に存続するためである。エントリは、新しいリーダー \(L\) に投票するサーバ \(S\) に保存されている必要があり、\(S\) がその新しいリーダーに投票する前に \(S\) に保存されている必要がある。ログの完全性チェックによると、\(S\) が \(L\) に投票できるのは \(L.lastLogTerm \gt S.lastLogTerm\) または \((L.lastLogTerm == S.lastLogTerm\) かつ \(L.lastLogIndex \ge S.lastLogIndex)\) の場合のみである。もし \(L\) が \(S\) に続く最初のリーダーである場合、2 番目のケースに該当し、その場合 \(L\) には我々が懸念しているエントリを含む \(S\) のすべてのエントリが含まれている必要がある。もし \(L'\) が \(S\) に続く 2 番目のリーダーである場合、\(L'\) は \(L\) からエントリを受け取った場合にのみ \(S\) よりも大きな最後のタームを持つことができるはずである。しかし \(L\) は自身のエントリを \(L'\) に複製する前に、我々が懸念しているエントリを \(L'\) に複製している必要があるため、これも安全である。そして、この議論は将来のすべてのリーダーに対して機能的に成立する。
採点
合計 10 点。これが可能であることを示した場合は 4 点:「はい、可能です」と答えた場合は +1 点。残りの 3 点については、解任されたリーダーが新しいリーダーの投票者の 1 人に対して、そのサーバが投票する前に AppendEntries リクエストを完了していたことを回答に含める必要がある。問題ではないと主張した場合は 6 点:「問題ない」と答えた場合は +1 点。残りの 5 点については、投票者がエントリを持っている必要があるため、ログの完全性チェックにより新しいリーダーもエントリを持っていることが保証されるという回答を含める必要がある。起こり得ないと主張した場合、得点は付与されない。これは Raft にとっての問題であると主張した場合でも、シナリオに対しては得点が与えられる場合がある。
(10 点) 構成変更中、現在のリーダーが \(C_{\rm new}\) に含まれていない場合、\(C_{\rm new}\) のログエントリがコミットされると現在のリーダーは退任する。しかし、これはリーダーが所属するクラスタの一部ではない期間が存在することを意味する (リーダーに保存されている現在の構成エントリは \(C_{\rm new}\) であり、これにはリーダーは含まれない)。\(C_{\rm new}\) がリーダーを含まない場合、リーダーが \(C_{\rm new}\) にログを保存してすぐ退任するようにプロトコルを変更したと仮定する。このアプローチで起こりうる最悪の事態は何かを答えよ。
解答
アルゴリズムの解釈によって 2 つの正解が考えられる。解答 1 ではサーバが現在の構成の一部でなくなるとそれ以上は候補にならないという実装を前提としている。問題は、その後に \(C_{\rm old}\) 内の別のサーバがリーダーに選出されて \(C_{\rm new}\) をログに追加した後、ただちに退任する可能性があることである。さらに悪いことに、これが \(C_{\rm old}\) のサーバの過半数で繰り返される可能性がある。\(C_{\rm old}\) の過半数が \(C_{\rm new}\) エントリを保存すると、ログの完全性チェックにより、このエントリを持たない \(C_{\rm old}\) のサーバは選出されなくなるため、それ以上繰り返されることはない (\(C_{\rm new,old}\) に必要な \(C_{\rm old}\) の過半数はこのサーバに投票できなくなる)。その後、\(C_{\rm new}\) に属するサーバが選出されなければならず、クラスタも継続する。したがって、最悪ケースは \(|C_{\rm old}|/2\) 回程度の余分な選挙と選挙タイムアウトを繰り返すだけである。解答 2 では、現在の構成の一部ではないサーバでも候補になることを許可する素朴な実装を想定している。この場合の最悪の事態は、リーダーが退任するとすぐに再選出され (ログはまだ完全である)、再び退任し、これを無限に繰り返すことである。
採点
合計 10 点。満点を得るには、回答において \(C_{\rm new}\) に含まれていないサーバが選出される可能性があること、これが繰り返される可能性があること、この繰返し回数の妥当な上限値、そしてこれが可用性または Liveness の問題を引き起こすことに言及する必要がある。
A.2 Paxos クイズ
採点上の注意: 誤った情報によって減点される場合でも、すべての設問のすべてのセクションの最低配点は 0 点である。
(4 点) 以下の図は Multi-Paxos サーバの可能なログ構成を示す (各ログエントリ内の数値はその acceptedProposal 値を示す)。各ログを個別に検討したとき、そのログ構成が Multi-Paxos の適切な実装で発生する可能性があるかを「はい」または「いいえ」で答えよ
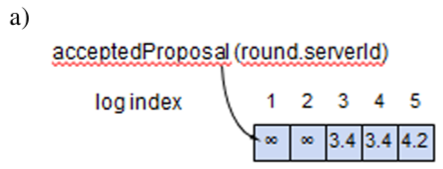
解答
はい
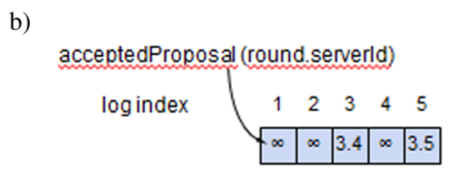
解答
はい
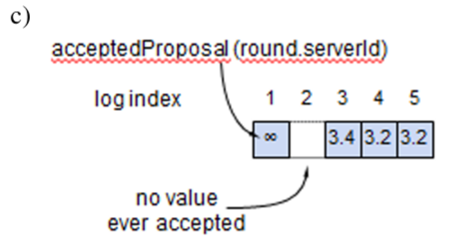
解答
はい
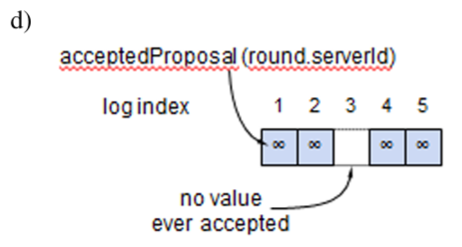
解答
はい
採点
ブーリアン 1 つにつき 1 点 (部分点なし)。
(6 点) Basic Paxos において、クラスタに 5 台のサーバがあり、そのうち 3 台が値 \(X\) を持つ提案 5.1 を Accept したとする。この状況が発生したあと、クラスタ内のいずれかのサーバが異なる値 \(Y\) を Accept する可能性があるかを「はい」「いいえ」で答え、その理由を説明せよ。
解答
はい: S1、S2、S3 が (5.1, \(X\)) を受理した場合でも、他のサーバは古い提案番号を持つ \(Y\) を引き続き受理する可能性がある。例えば、S4 が 3.4 を Prepare し、値がないことを発見する。その後 S1 は S1、S2、S3 のみで 5.1 を Prepare する。その後、S1 は S1、S2、S3 のみで Accept を完了する。そして S4 は依然として S4 と S5 で (3.4, \(Y\)) による Accept を完了できる。
採点
合計 6 点。「はい」と答えた場合は 2 点、付随する説明に対して 4 点。説明では、\(Y\) の Propose が 5.1 と同等か、5.1 より小さい番号であることを示さなければならない (そうでない場合は 2 点)。「いいえ、新しい提案はすべて Prepare フェーズで (5.1, \(X\)) を発見する必要があるからです」という誤答には 2 点。「いいえ」を含むその他の誤った解答は 0 点。
(10 点) あるサーバが Multi-Paxos のリーダーとして動作することを決定し、他のサーバは現在リーダーとして動作していないと仮定する。さらに、そのサーバが一定期間リーダーとして動作を続け、ログエントリに多くのコマンドが選択されるように調整し、その期間中に他のサーバがリーダーとして動作しようとしないものとする。
この期間中にサーバが発行しなければならない Prepare RPC のラウンド数の下限はいくつか、解答を説明し、できるだけ正確に記述せよ。
解答
noMoreAccepted=true の Prepare 応答がクォーラムに達して直ちに返された場合、下限は 1 ラウンドの Prepare RPC である。
この期間中にサーバが発行しなければならない Prepare RPC のラウンド数の上限はいくつか、解答を説明し、できるだけ正確に記述せよ。
解答
上限は、リーダーで選択されていないスロット (そのスロットで Acceptor が提案を受け入れたスロット) ごとに Prepare RPC 1 回である。これは、リーダーが選択されていないスロットの 1 つに対して Prepare を発行するたびに、既に何らかの値を受け入れている Acceptor を発見した場合に発生する可能性がある。その場合、リーダーはそのスロットにこの値を採用し、次のスロットで試行を続ける必要がある。
採点
合計 10 点。各パートに 5 点。パート (a):「1」と答えた場合は +2 点、付随する説明に対して +3 点。説明には noMoreAccepted またはその背後にコンセプトへの言及が含まれている必要がある。パート (b): フォロワーが受け入れたエントリの数を述べた場合は +3 点、リーダー上で選択されているエントリを差し引いた場合は +2 点。「noMoreAccepted が過半数で true となるまで」とだけ述べている回答は 2 点 (正しいが、スライドから理解せずにこれを抜き出した可能性がある)。パート (b) で \(O(1)\) または \(O(Len(leader's\ log))\) とした回答には得点は与えられない。
(5 点) Acceptor が Proposer から提供された firstUnchosenIndex を使用してエントリを受理済みとしてマークするとき、まずマークするエントリの提案番号を確認する必要がある。この確認をスキップしたと仮定した場合、システムが誤動作するシナリオを説明せよ。
訂正: 設問は「エントリを受理済みとしてマークする」ではなく「エントリを選択済みとしてマークする」とすべきであった。我々の調査で使用されたクイズにはこの誤りが含まれており、回答を採点するまで気づかなかった。
解答
発生しうる誤動作は、異なる値が選択されているにもかかわらずサーバが値を「選択済み」としてマークすることである。これを示すには、少なくとも 2 つの競合する提案、3 つのサーバ、および 2 つのログエントリが必要である: S1 は S1、S2 に対する Prepare ラウンドを n=1.1, index=1 で完了する。S1 は S1 (自身) に対してのみ n=1.1, v=X, index=1 の Accept ラウンドを 1 つだけ完了する。S1 は、S2、S3 に対する Prepare ラウンドを n=2.2, index=1 で完了し、両方から noMoreAccepted=true を受け取る。S2 は S2、S3 に対して n=2.2, v=Y, index=1 の Accept ラウンドを完了する。S2 はインデックス 1 を選択済みとマークする。S2 は S1、S2、S3 に体居て n=2.2, v=Z, index=2, firstUnchosenIndex=2 の Accept ラウンドを完了する。ここで、S1 は n=1.1, v=X を選択済みと設定し、X をそのステートマシンに適用することで誤動作したことになる。これは誤りで、実際には Y が選択されている。
採点
合計 5 点。残念ながら、ほとんどの解答はシナリオについて我々が期待したほど具体的ではなかった。満点を得るには、提案番号が異なるだけではなく、以前に受理された値が提案者で選択された値と異なることを特定する必要がある。これは、資料を丸暗記した人と、アルゴリズムがなぜそのそのようになっているかをある程度理解している人を区別するのに役立つ。この要素が欠けている解答は、理解度を示す程度に応じて最大 4 点 (通常は 2~3 点) が与えられる。設問の文言が誤っていたため、回答中の「受理」と「選択」という言葉を混同しても減点は行われなかった (回答は、可能な限り最大点を与えるために、これらの言葉がどのように交換されていても読まれた)。
(5 点) 提案番号の 2 つの部分 (ラウンド番号と一意のサーバ ID) が入れ替わり、サーバ ID が上位ビットにあると仮定する。
これが Paxos の Safety を損なうかを「はい」「いいえ」で答え、理由を簡潔に説明せよ。
解答
いいえ: Safety は提案が (Multi-Paxos の特定のインデクスに対して) 一意に番号付けされていることのみを要求するためである。サーバ ID は各サーバに一意であり、ラウンド番号は依然として単調に増加するため、この一意性は維持される。
これが Paxos の Liveness を損なうかを「はい」「いいえ」で答え、理由を簡潔に説明せよ。
解答
はい: 例えば、最大の ID を持つサーバがクラスタ内のすべてのサーバに Prepare RPC を発行し、その後永続的に故障する可能性がある。この場合、残りのサーバの minProposal 値は残りの Proposer にとって高すぎるため、他の Proposer は処理を進めることができなくなる。
採点
合計 5 点。Safety に +2 点、Liveness に +3 点。Safety については「いいえ」と答えた場合は 1 点、正しい説明は 1 点。多くの補足説明は必要ない。「はい」と答えた場合は点を与えられず、付随する説明は無視される。Liveness については、「はい」と答えた場合は 1 点、正しい説明は 2 点。「いいえ」と答えた場合は点を与えられず、付随する説明は無視される。
(10 点) ある Proposer が初期値 v1 で Basic Paxos プロトコルを実行したが、プロトコルの実行中または実行後に (不明な時点で) クラッシュしたとする。Proposer が再起動し、以前と同じ提案番号を使用して、異なる初期値 v2 でプロトコルを最初から再実行したと仮定する。これが安全であるかを「はい」「いいえ」で答え、理由を説明せよ。
解答
いいえ: 異なる提案は異なる提案番号を持たなければならない。3 台のサーバを使用して起き得る問題の例を次に示す: S1 は S1、S2 で Prepare(n=1.1) を完了する。S1 は S1 で Accept(n=1.1, v=v1) を完了する。S1 は再起動する。S1 は S2、S3 で Prepare(n=1.1) を完了する (そして受理済みの提案がないことに気づく)。S1 は S2、S3 で Accept(n=1.1, v=v2) を完了する。S1 はクライアントに対し v2 が選択されたと応答する。S2 は S1、S2 で Prepare(n=2.2) を完了し、次を受け取る: S1 から acceptedProposal=1.1, acceptedValue=v1、S2 から acceptedProposal=1.1, acceptedValue=v2、S2 は任意の v1 を使用することを選択する。S2 は S1、S2、S3 で Accept(n=2.2, v=v1) を完了する。S2 はクライアントに対し v1 が選択されたと応答する。
クラッシュ前のリクエストがクラッシュ後に配信されることによって発生しうる別の問題がある。S1 は S1、S2 で Prepare(n=1.1) を完了する。S1 は S1 で Accept(n=1.1, v=v1) を完了する。S1 は S2、S3 に Accept(n=1.1, v=v1) を送信するが、まだ受信されていない。S1 は再起動する。S1 は S2、S3 とともに Prepare(n=1.1) を完了する (そして受理済みの提案がないことに気づく)。S1 は S2、S3 とともに Accept(n=1.1, v=v2) を完了する。S1 はクライアントに v2 が選択されたことを応答する。すると S2 と S3 は Accept(n=1.1, v=v1) リクエストを受信して acceptedValue を v1 に上書きする。クライアントは v2 が選択されたことが通知されているにもかかわらず、クラスタの状態は v1 が選択された状態となる。
採点
合計 10 点。「いいえ」と解答した場合は 2 点、正しい説明をした場合は 8 点。満点を得るには、v2 の Prepare フェーズで v1 が発見されず、Safety に違反する何らかの部分があることを説明する回答が必要である。「はい」と回答した場合は点は与えられず、付随する説明も無視される。
(10 点) Accept RPC が成功すると Acceptor は minProposal を n (Accept RPC 内の提案番号) に設定する。これによって minProposal 値が実際に変更される (つまり minProposal が n と等しくならない) シナリオを説明せよ。またこのコードがない場合、システムが正しく動作しないシナリオを説明せよ。
解答
逆算すると、サーバは Prepare を受信していない Accept を受信している必要がある。そうでなければ、その minProposal は最新になっているはずである。そして、これが問題となるには後続の Accept が誤って拒否されない必要がある。Basic Paxos と 5 台のサーバを使用する。S1 は S1、S2、S3 で Prepare(n=1.1) を完了する (受理されている提案がないことに気づく)。S5 は S3、S4、S5 で Prepare(n=2.5) を完了する (受理されている提案がないことに気づく)。S5 は S2、S3、S5 で Accept(n=2.5, v=X) を完了する。これは、S2 の Accept リクエスト処理時に minProposal が 2.5 になるケースである。S5 はクライアントに X が選択されたという結果を返す。S1 は S2 で Accept(n=1.1, v=Y) を完了する。これは通常拒否されるはずだが、Accept 中に S2 の minProposal が更新されていなければ受理されるだろう。S3 は S1、S2、S4 で Prepare(n=3.3) を完了する (そして n=1.1, v=Y に気づく)。S3 は S1, S2, S3, S4, S5 で Accept(n=3.3, v=Y) を完了する。S3 はクライアントに Y が選択されたことを応答する。
採点
合計 10 点。Accept 中に minProposal がどのように設定されうるかを示す最初の 3 つのステップに対して 4 点。システムがどのように誤動作するかを示した場合は 6 点。満点を得るには Safety 違反を含める必要がある。
(10 点) Multi-Paxos における構成変更を考える。ここで古い構成はサーバ 1, 2, 3 で構成され、新しい構成はサーバ 3, 4, 5 で構成されている。新しい構成がログのエントリ \(N\) に対して選択され、エントリ N から \(N+\alpha\) も選択されたとする (両端を含む)。この時点で、古いサーバ 1 と 2 は新しい構成の一部ではないためシャットダウンされている仮定する。これがシステムで引き起こす可能性がある問題を説明せよ。
解答
これらのサーバの firstUnchosenIndex が \(N+\alpha\) より小さい可能性があるため、新しいクラスタの Liveness に問題を引き起こす可能性がある。例えば、最悪の場合、サーバ 3 が恒久的に故障し、サーバ 1 と 2 は (講義で提示したアルゴリズムだけを使用した場合) サーバ 4 と 5 に値を転送しようとしない可能性がある。すると、サーバ 4 と 5 はサーバ 1, 2, 3 と通信できないため、スロット 1 から \(N+\alpha-1\) までの選択値 (両端を含む) を学習できなくなる。サーバ 4 と 5 のステートマシンは初期状態から先に進行できなくなるだろう。
採点
合計 10 点。完全な回答では、新しいサーバには選択されたエントリが不足していることを述べ、解決策としてサーバ 3 を排除する必要がある。サーバ 3 がすべての情報を持っている必要があると示唆した回答は (それは故障する可能性があるため) 最大 7 点となる。サーバ 3 がすべての情報を持っているだけで十分であると示唆した回答は (それは故障する可能性があるため) 最大 8 点となる。問題がないと誤答した場合は点を与えられない。1 から \(N-1\) (両端を含む) 範囲の一部のスロットが選択されていないという誤答した場合は点を与えられない。これは、\(N\) から \(N+\alpha\) (両端を含む) が選択されていると言うことは、\(\alpha\) の定義により 1 から \(N+\alpha\) (両端を含む) が選択されていることを意味するためである。
A.3 アンケート
Paxos について、これまでどの程度触れてきたか評価してください。
- 見たことがない
- 見たことはあるが、覚えていない
- 見たことはあるが、少ししか覚えていない
- 見たことはあり、かなり覚えている
- 見たことがあり、専門家だと考える
回答: 回答は Figure 7.9 に示されている。
Raft について、これまでどの程度触れてきたかを評価してください。
- 見たことがない
- 見たことはあるが、覚えていない
- 見たことはあるが、少ししか覚えていない
- 見たことはあり、かなり覚えている
- 見たことがあり、専門家だと考える
回答: 参加者の中に Raft を見たことがあると報告したものはいなかった。
講義内容の性質を考慮すると、双方のビデオ講義の質はほぼ同じだったと思うか?
- Paxos の講義がはるかに優れていた
- Paxos の講義がやや優れていた
- ほぼ同じだった
- Raft の講義がやや優れていた
- Raft の講義がはるかに優れていた
回答: 回答は Figure 7.10 に示されている。
資料の理解度をテストする上で、クイズはほぼ同じであったと思うか?
- Paxos の問題は不当に難しかった
- Paxos の問題はやや難しかった
- ほぼ同じだった
- Raft の問題はやや難しかった
- Raft の問題は不当に難しかった
回答: 回答は Figure 7.10 に示されている。
あなたが企業で働いていて、複製ステートマシンを実装する仕事があるとする。機能し、正しく、効率的なシステムで実装するのがより簡単なアルゴリズムはどちらか?
- Paxos がはるかに簡単だろう
- Paxos がやや簡単だろう
- ほぼ同じだろう
- Raft がやや簡単だろう
- Raft がはるかに簡単だろう
回答: 回答は Figure 7.11 に示されている。
Raft と Paxos のどちらかを、どちらも初めて見るコンピュータサイエンスの大学院生に説明しなければならないとする。どちらが説明しやすいか?
- Paxos がはるかに簡単だろう
- Paxos がやや簡単だろう
- ほぼ同じだろう
- Raft がやや簡単だろう
- Raft がはるかに簡単だろう
回答: 回答は Figure 7.11 に示されている。
その他にコメントはあるか?
回答: 以下に参加者の回答をランダムな順序で提出通りに再現する (誤りを含む):
クイズの問題に答えるために、Paxos の講義の一部をもう一度見直さなければならなかった。Raft の問題のほとんどは記憶から答えることができた。
ビデオの視聴開始が少し遅れた。クイズを受ける前に内容をしっかり理解する時間が十分になかったため、いくつかの部分を未完成のままにしてしまった。Raft の講義の冒頭にあるスライド 1 枚にまとめられた概要は良かった。
どちらも非常に複雑だ!
講義ビデオは素晴らしいできだった。
Raft はよりシンプルかもしれないが、講義ははるかに理解しにくかった。特に、各ステップの要件 (リーダー選出や、エントリがコミットされる時期の考慮) が段階的に構築され、講義全体に散らばっていたため、私には全体を頭の中でまとめるのが本当に難しかった。言い換えれば、プロトコルの各部分と、なぜ特定のチェックが必要なのかは理解できたが、クイズでは Raft の動作を統合して予想し、チェック (コミットやリーダー選出など) が互いにどのように相互作用するかを理解する必要があったため、全体をまとめ上げて全体像を把握する能力がなかった。
漠然と Raft と Paxos はあまりにも似すぎている気がしている。おそらく同じですらあるが、Paxos を完全に理解していないので区別できない。
Raft は Multi-Paxos と同等であるように見えるが、Multi はまだ証明も実装もされていないのか? Paxos が実際にどのように使われているのか少し混乱している。
クールなアイディアだ。Paxos がこうあるべきだったと思う。
Raft は MultiPaxos よりも簡単だと感じた。Multi Paxos の可能なログ状態について推論するのは Raft よりも難しく感じた。いくつかの不明確な細かい点があった。1 つは最適化についてで、リーダーが (はるかに遅れている) フォロワーのログを追いつかせようとするとき、一致するまで 1 エントリずつ進む。おそらく、フォロワーが最新のエントリで応答したり、(または、往復回数を減らすために、一定の距離を置いて複数のエントリを交換することで、) このプロセスは高速化できるかもしれない。おそらく、この種の最適化はシンプルさのために省略されたのだろう。2 番目の点は \(C_{\rm new+old}\) (これは \(C_{\rm old}\) と \(C_{\rm new}\) のマシンの結合と仮定) です。また、フォロワーが新しい構成を引き継いだとき、自分がその構成に含まれていない場合、フォロワーは自身を離脱するのでしょうか? 講義ではリーダーの場合について議論した。
Raft と Paxos が非常に似ていることには明らかに気づいた。Raft は実際には別の方法で提示された Paxos であるとさえ感じるほどだ。しかし、Raft は概念的に把握しやすく、説明しやすく、実装しやすいと確信した。ただし、Paxos の各要素が Raft のように戦略的に提示されれば、違いははるかに目立たなくなるだろうとは思う。
クイズが長すぎた。与えられた時間内に完了できなかった。また、このようなものに触れたことがないことを考えると、たった 1 時間の講義ではクイズの設問に答えるのは困難だった。ビデオ講義とは別に、いくつかの例があればもっと良かっただろう。
Raft は概念的にはるかに簡単だが、それがどの程度一般的かつ効果的に実装されているかに興味がある。Paxos の方が人気があるので、より信頼性の高い実装が期待できるだろう。しかし、Raft がさらに人気を集め、主流の分散コンセンサスプロトコルになることを願っている。
Paxos は Raft ほど細かい点がないので理解しやすい。しかし Paxos のビデオは Raft のビデオほど設問の役には立たない。
Ousterhout は素晴らしい。講義をありがとうございました!
Raft は、特にリーダー・フォロワーの性質のおかげではるかに理解しやすいと感じたのは私だけだろうか? 唯一の分散決定はリーダー選出であるが、これは Paxos ではすべてが分散決定でありログが乱雑になるのに比べると簡単である。どちらも優れたアルゴリズムだが、どちらかを使う必要がある場合は Raft を選ぶだろう (実際の性能にもよるが Raft の方がおそらく優れているだろう)。
構成に関する最後の部分だけがあまり明確ではなかった。他のすべては概念的に簡単であった。
私はまず Raft のクイズを受けた。Raft がコンセンサス問題をいかにエレガントに解決したかを見て、Paxos のアプローチは多くの不要な複雑さに満ちているように思えた。
ビデオは少し退屈だった。
A.4 補足資料
Figure A.1 は、Raft 講義スライドの一部としてユーザ調査の参加者に提供された Raft アルゴリズムの要約を示す。Figure A.2 は、調査ウェブサイト上の別文書として参加者に提供された Paxos の要約を示す。
Raft プロトコル要約
- 候補者とリーダーからの RPC に応答
- 選挙タイムアウトが経過しても以下のいずれも実行されない場合、候補者に転じる
- 有効な AppendEntries の受信
- 候補者へ投票の付与
- currentTerm をインクリメントし自身に投票
- 選挙タイムアウトをリセット
- 他のすべてのサーバに RequestVote RPC を送信し、以下のいずれかを待機
- 過半数のサーバから票を受信: リーダーになる
- 新しいリーダーから AppendEntries RPC を受信: 候補者を退任
- 選挙が解決されず選挙タイムアウトが経過: タームをインクリメントし新しい選挙を開始
- より上位のタームを発見: 候補者を退任
- 各フォロワーの nextIndex を最終インデックス+1 に初期化
- 各フォロワーに最初の空の AppendEntries RPC (ハートビート) 送信; アイドル期間中は選挙タイムアウトを防ぐためにこの処理を繰り返す
- クライアントからのコマンドを受け付け、ローカルログに新しいエントリを追加
- フォロワーの最後のログインデックス ≧ nextIndex の場合、nextIndex から始まるログエントリを含む AppendEntries RPC を送信し、成功の場合は nextIndex を更新
- ログ不整合により AppendEntries が失敗した場合、nextIndex をデクリメントして再試行
- ログエントリが過半数に保存され、現在のタームのエントリが過半数のサーバに保存されている場合、コミット済みとしてマーク
- currentTerm が変更された場合は退任
各サーバは RPC に応答する前に以下の情報を安定ストレージに同期的に永続化する:
| currentTerm | サーバが確認した最後のターム (初回起動時は 0 に初期化) |
|---|---|
| votedFor | 現在のタームで票を受信した候補者ID (投票を受信していない場合は null) |
| log[] | ログエントリ |
| term | リーダーがエントリを受信したターム |
|---|---|
| index | ログ内のエントリの位置 |
| command | ステートマシンへのコマンド |
候補者が投票を集めるために呼び出される。
| candidateId | 投票をリクエストしている候補者 |
|---|---|
| term | 候補者のターム |
| lastLogIndex | 候補者の最後のログエントリのインデックス |
| lastLogTerm | 候補者の最後のログエントリのターム |
| term | currentTerm (候補者が自身を更新するためのもの) |
|---|---|
| voteGranted | true は候補者投票を獲得した意味 |
- term > currentTerm の場合、currentTerm ← term (リーダーまたは候補者の場合は退任)
- term == currentTerm の場合、votedFor が null または candidateId であり、候補者のログがローカルログと同等以上の完全性を持っている場合、投票を許可し、選挙タイムアウトをリセット
リーダーによって呼び出され、ログエントリを複製して不整合を検出する。ハートビートとしても使用される。
| term | リーダーのターム |
|---|---|
| leaderId | フォロワーがクライアントをリダイレクトできるようにするため |
| prevLogIndex | 新しいエントリの直前のログエントリのインデックス |
| prevLogTerm | prevLogIndex エントリのターム |
| entries[] | 保存するログエントリ (ハートビートの場合は空) |
| commitIndex | コミット済みとして認識されている最後のエントリ |
| term | currentTerm (リーダーが自身を更新するためのもの) |
|---|---|
| success | フォロワーに prevLogIndex と prevLogTerm に一致するエントリが含まれていた場合 true |
- term < currentTerm の場合、戻る
- term > currentTerm の場合、currentTerm ← term
- 候補者またはリーダーの場合、退任
- 選挙タイムアウトをリセット
- term が prevLogTerm と一致する prevLogIndex のエントリが含まれていない場合、失敗を返す
- 既存のエントリが新しいエントリと競合する場合、最初の競合エントリからすべての既存のエントリを削除
- ログにまだ存在しない新しいエントリを追加
- 新しくコミットされたエントリでステートマシンを進行
Paxos 概要
Diego Ongaro and John Ousterhout
March 6, 2013
この文書は Basic Paxos (単一決定) コンセンサスプロトコルと Multi-Paxos の簡潔な概要を提供するものである。これは、Paxos と Raft コンセンサスアルゴリズムを比較するユーザ研究の一環として開発された、Paxos を紹介する 1 時間のビデオ講義の補足資料として作成された。Multi-Paxos は文献で厳密に規定されていない。ここでの我々の目標は、Leslie Lamport の "The Part-Time Parliament" で Paxos について記述したオリジナルの内容に忠実に従い、かなり完全な使用を提供することを目指している。ここで説明する Multi-Paxos のバージョンは実装されておらず、その正しさは証明されていない。
- 提案番号 (\(n\)) = (ラウンド番号, サーバID)
- \(T\): リーダー選出アルゴリズムで使用される固定タイムアウト値
- \(\alpha\): Multi-Paxos における同時実行数制限
- \(T\) ミリ秒ごとに、他のすべてのサーバに空のハートビートを送信する。
- サーバは、過去 \(2T\) ミリ秒以内により高い ID を持つサーバからのハートビートメッセージを受信していない場合、リーダーとして動作する。
- minProposal: このサーバが受け入れる最小の提案番号、または Prepare リクエストを一度も受信していない場合は 0。
- acceptedProposal: サーバが最後に受理した提案番号、または一度も受理していない場合は 0。
- acceptedValue: サーバが最後に受理した提案の値、または一度も受理していない場合は null
- maxRound: サーバが観測している最大のラウンド番号。
リクエストフィールド:
- \(n\): 新しい提案番号。
Prepare リクエストを受信すると、\(n\) ≧ minProposal であれば、Acceptor は minProposal を \(n\) に設定する。この応答は、将来 \(n\) 未満の提案番号を持つ Accept メッセージを拒否する Promise を構成する。
レスポンスフィールド:
- acceptedProposal: Acceptor の acceptedProposal
- acceptedValue: Acceptor の acceptedValue
リクエストフィールド:
- \(n\): Prepare で使用されたのと同じ提案番号
- \(v\): Prepare レスポンスの中で最も番号の大きいものから選ばれた値、または何もなければクライアント要求からの値
Accept リクエストを受信し、\(n \ge\) minProposal の場合の場合:
- acceptableProposal = \(n\) に設定
- acceptableValue = \(v\) に設定
- minProposal = \(n\) に設定
レスポンスフィールド:
- \(n\): Acceptor の minProposal
- \(n\) を新しい提案番号とする (maxRound をインクリメントして保持)
- すべての Acceptor に Prepare(\(n\)) リクエストをブロードキャスト
- 過半数の Acceptor から Prepare レスポンス (reply.acceptedProposal, reply.acceptedValue) を受信した場合:
- \(v\) を次のように設定: レスポンス内の reply.acceptedProposal の最大値が 0 でない場合、対応する reply.acceptedValue を使用。それ以外の場合は inputValue を使用。
- Accept(\(n\), \(v\)) リクエストをブロードキャスト
- (reply.n\) を含む Accept レスポンスを受信した場合:
- reply.n > \(n\) の場合、maxRound を \(n\) に設定し、ステップ 1 からやり直し。
- 過半数の Acceptor から \(n\) に対する Accept レスポンスを受信するまで待機
- \(v\) を返す
各 Acceptor は以下の情報を保存:
- lastLogIndex: このサーバが提案を受け入れた最大のエントリ
- minProposal: このサーバがログエントリに対して受け入れる最小の提案番号。Prepare リクエストを一度も受信していない場合は 0。これはすべてのエントリにグローバルに適用される。
各 Acceptor はログも保存する。各ログエントリ \(i \in\) [1, lastLogIndex] には以下のフィールドがある:
- acceptedProposal[i]: サーバがこのエントリに対して最後に受理した提案番号。一度も受理していない場合は 0、acceptedValue[i] が選択されていることが分かっている場合は∞。
- acceptedValue[i]: サーバがこのエントリに対して最後に受理した提案の値。一度も受理していない場合は null。
firstUnchosenIndex を、acceptedProposal[i] < ∞ となる i > 0 の最小のログインデックスとして定義する。
- maxRound: Proposer が認識した最大のラウンド数
(ここでは Proposer と Acceptor を厳密に分離していない。Proposer が Acceptor の状態を読み書きできる場合がある。)
- nextIndex: クライアントのリクエストに使用する次のエントリのインデックス
- prepared: true は Prepare リクエストを発行する必要がないことを意味 (Acceptor の過半数が Prepare リクエストに対して noMoreAccepted true で応答している); 初期値は false
リクエストフィールド:
- \(n\): 新しい提案番号
- index: Proposer が情報を要求するログエントリ
Prepare リクエストを受信すると、request.n ≧ minProposal の場合、Acceptor は minProposal を request.n に設定する。レスポンスは、request.n より小さい提案番号を持つ Accept リクエスト (すべてのログエントリに対する) を拒否することを Promise するものである。
レスポンスフィールド:
- acceptedProposal: Acceptor の acceptedProposal[index]
- acceptableValue: Acceptor の acceptedValue[index]
- noMoreAccepted: この Acceptor が index より大きいインデックスのログエントリの値を受理したことがない場合 true に設定
リクエストフィールド:
- n: 最新の Prepare で使用されたのと同じ提案番号
- index: ログエントリを識別する
- v: Prepare レスポンスの最も高い番号の値、または何もなければクライアントリクエストの値
- firstUnchosenIndex: 送信者の firstUnchosenIndex
Accept リクエスト受信時: n ≧ minProposal の場合、以下の処理を実行:
- acceptedProposal[index] = n に設定
- acceptedValue[index] = v に設定
- minProposal = n に設定
すべての index < request.firstUnchosenIndex に対して、acceptedProposal[index] = n であれば acceptedProposal[index] を∞に設定。
レスポンスフィールド:
- n: Acceptor の minProposal
- firstUnchosenIndex: Acceptor の firstUnchosenIndex
リクエストフィールド:
- index: ログエントリを識別
- v: エントリの index に選択された値
Success リクエストを受信すると、acceptedValue[index] に v を設定し、acceptedProposal[index] = ∞ とする。
レスポンスフィールド:
- firstUnchosenIndex: Acceptor の firstUnchosenIndex
送信者がレスポンスを受信し、reply.firstUnchosenIndex < firstUnchosenIndex であれば、送信者は Success(index = reply.firstUnchosenIndex, value = acceptedValue[reply.firstUnchosenIndex]) を送信。
- リーダーではない、またはリーダーの初期化が完了していない場合は false を返す
- prepared が true の場合:
- index = nextIndex とし、nextIndex をインクリメント
- ステップ 6 に進む
- index = firstUnchosenIndex、nextIndex = index + 1 とする
- n を新しい提案番号とする (インクリメントし maxRound を維持)
- すべての Acceptor に Prepare(n, index) をブロードキャスト
- 過半数の Acceptor から Prepare レスポンス (reply.acceptedProposal, reply.acceptedValue, reply.noMoreAccepted) を受信した場合:
- v を次のように設定する: レスポンス内の reply.acceptedProposal の最大値が 0 でない場合、対応する reply.acceptedValue を使用。それ以外の場合は inputValue を使用。
- 過半数の Acceptor が reply.noMoreAccepted を返した場合、prepared=true に設定
- すべての Acceptor に Accept(index, n, v) をブロードキャスト
- Accept レスポンス (reply.n, reply.firstUnchosenIndex) を受信した場合:
- reply.n > n の場合、reply.n から maxRound を設定、prepared=false を設定、ステップ 1 に進む
- reply.firstUnchosenIndex ≦ lastLogIndex かつ acceptedProposal[reply.firstUnchosenIndex] = ∞ の場合、Success(index = reply.firstUnchosenIndex, value = acceptedValue[reply.firstUnchosenIndex]) を送信
- 過半数の Acceptor から n に対する Accept レスポンスを受信すると:
- acceptedProposal[index] = ∞、acceptedValue[index] = v に設定
- v == inputValue であれば true を返す
- ステップ 2 に進む
- 構成はサーバの ID とアドレスのリストであり、特別なログエントリとして保存される
- エントリ \(i\) を選択するための構成は、エントリ \(i-\alpha\) 以下のログにおける最新の構成によって決定
- \(\alpha\) は同時実行性を制限: エントリ \(i\) が選択されるまで、エントリ \(i+\alpha\) を選択することはできない
Appendix B - Safety の証明と形式仕様
この付録には第 3 章で紹介した基本 Raft アルゴリズムの形式仕様と Safety の証明が含まれている。仕様と証明は第 8 章で紹介されている。
形式仕様は Figure 3.1 に要約されている情報を TLA+ 仕様言語 [50] を用いて完全に正確に記述している。これは証明の対象として機能し、Raft を実装する上で有用な参考資料となる。
証明は、仕様が State Machine Safety 特性を保持することを示している。証明の主要な考え方はセクション 3.6.3 に要約されているが、詳細な証明ははるかに厳密である。我々は Raft の Safety をより深いレベルで理解する上でこの証明が有用であると認識し、他の人々も同様にこれに価値を見出すかもしれない。しかし、この証明はかなり長く、人間が検証および維持するのは困難である。我々は基本的に正しいと考えているが、誤りや欠落が含まれている可能性もある。この規模では、機械検証された証明のみが明確にエラーフリーであると言える。
B.1 既約
この仕様は TLA+ 言語バージョン 2 [50] の構文と意味を使用する。証明では同じ構文と意味論を用いるが、便宜上、以下の点に軽微な変更を加える。
TLA+ と同様に \(foo'\) は特定の意味を持つ。すなわち、システムの次の状態における変数 \(foo\) の値である。
\(\langle index, term \rangle \in log\) は \(Len(log) \ge index \land log[index].term = term\) の場合にのみ定義される。
記号 \(||\) はログエントリの連結に用いられる。
ログエントリ内の値は含まれていない。これは、値は特定の \(\langle index, term \rangle\) に付随しており、それらがログエントリを一意に識別するためである。
B.2 仕様
このセクションでは Raft アルゴリズムの完全な形式記述を提供する。TLA+ ソースファイルのコピーは [87] で入手可能である。
参照: https://github.com/ongardie/raft.tla
--------------------------------- MODULE raft ---------------------------------
\* This is the formal specification for the Raft consensus algorithm.
\*
\* Copyright 2014 Diego Ongaro.
\* This work is licensed under the Creative Commons Attribution-4.0
\* International License https://creativecommons.org/licenses/by/4.0/
EXTENDS Naturals, FiniteSets, Sequences, TLC
\* The set of server IDs
CONSTANTS Server
\* The set of requests that can go into the log
CONSTANTS Value
\* Server states.
CONSTANTS Follower, Candidate, Leader
\* A reserved value.
CONSTANTS Nil
\* Message types:
CONSTANTS RequestVoteRequest, RequestVoteResponse,
AppendEntriesRequest, AppendEntriesResponse
----
\* Global variables
\* A bag of records representing requests and responses sent from one server
\* to another. TLAPS doesn't support the Bags module, so this is a function
\* mapping Message to Nat.
VARIABLE messages
\* A history variable used in the proof. This would not be present in an
\* implementation.
\* Keeps track of successful elections, including the initial logs of the
\* leader and voters' logs. Set of functions containing various things about
\* successful elections (see BecomeLeader).
VARIABLE elections
\* A history variable used in the proof. This would not be present in an
\* implementation.
\* Keeps track of every log ever in the system (set of logs).
VARIABLE allLogs
----
\* The following variables are all per server (functions with domain Server).
\* The server's term number.
VARIABLE currentTerm
\* The server's state (Follower, Candidate, or Leader).
VARIABLE state
\* The candidate the server voted for in its current term, or
\* Nil if it hasn't voted for any.
VARIABLE votedFor
serverVars == <<currentTerm, state, votedFor>>
\* A Sequence of log entries. The index into this sequence is the index of the
\* log entry. Unfortunately, the Sequence module defines Head(s) as the entry
\* with index 1, so be careful not to use that!
VARIABLE log
\* The index of the latest entry in the log the state machine may apply.
VARIABLE commitIndex
logVars == <<log, commitIndex>>
\* The following variables are used only on candidates:
\* The set of servers from which the candidate has received a RequestVote
\* response in its currentTerm.
VARIABLE votesResponded
\* The set of servers from which the candidate has received a vote in its
\* currentTerm.
VARIABLE votesGranted
\* A history variable used in the proof. This would not be present in an
\* implementation.
\* Function from each server that voted for this candidate in its currentTerm
\* to that voter's log.
VARIABLE voterLog
candidateVars == <<votesResponded, votesGranted, voterLog>>
\* The following variables are used only on leaders:
\* The next entry to send to each follower.
VARIABLE nextIndex
\* The latest entry that each follower has acknowledged is the same as the
\* leader's. This is used to calculate commitIndex on the leader.
VARIABLE matchIndex
leaderVars == <<nextIndex, matchIndex, elections>>
\* End of per server variables.
----
\* All variables; used for stuttering (asserting state hasn't changed).
vars == <<messages, allLogs, serverVars, candidateVars, leaderVars, logVars>>
----
\* Helpers
\* The set of all quorums. This just calculates simple majorities, but the only
\* important property is that every quorum overlaps with every other.
Quorum == {i \in SUBSET(Server) : Cardinality(i) * 2 > Cardinality(Server)}
\* The term of the last entry in a log, or 0 if the log is empty.
LastTerm(xlog) == IF Len(xlog) = 0 THEN 0 ELSE xlog[Len(xlog)].term
\* Helper for Send and Reply. Given a message m and bag of messages, return a
\* new bag of messages with one more m in it.
WithMessage(m, msgs) ==
IF m \in DOMAIN msgs THEN
[msgs EXCEPT ![m] = msgs[m] + 1]
ELSE
msgs @@ (m :> 1)
\* Helper for Discard and Reply. Given a message m and bag of messages, return
\* a new bag of messages with one less m in it.
WithoutMessage(m, msgs) ==
IF m \in DOMAIN msgs THEN
IF msgs[m] <= 1 THEN [i \in DOMAIN msgs \ {m} |-> msgs[i]]
ELSE [msgs EXCEPT ![m] = msgs[m] - 1]
ELSE
msgs
\* Add a message to the bag of messages.
Send(m) == messages' = WithMessage(m, messages)
\* Remove a message from the bag of messages. Used when a server is done
\* processing a message.
Discard(m) == messages' = WithoutMessage(m, messages)
\* Combination of Send and Discard
Reply(response, request) ==
messages' = WithoutMessage(request, WithMessage(response, messages))
\* Return the minimum value from a set, or undefined if the set is empty.
Min(s) == CHOOSE x \in s : \A y \in s : x <= y
\* Return the maximum value from a set, or undefined if the set is empty.
Max(s) == CHOOSE x \in s : \A y \in s : x >= y
----
\* Define initial values for all variables
InitHistoryVars == /\ elections = {}
/\ allLogs = {}
/\ voterLog = [i \in Server |-> [j \in {} |-> <<>>]]
InitServerVars == /\ currentTerm = [i \in Server |-> 1]
/\ state = [i \in Server |-> Follower]
/\ votedFor = [i \in Server |-> Nil]
InitCandidateVars == /\ votesResponded = [i \in Server |-> {}]
/\ votesGranted = [i \in Server |-> {}]
\* The values nextIndex[i][i] and matchIndex[i][i] are never read, since the
\* leader does not send itself messages. It's still easier to include these
\* in the functions.
InitLeaderVars == /\ nextIndex = [i \in Server |-> [j \in Server |-> 1]]
/\ matchIndex = [i \in Server |-> [j \in Server |-> 0]]
InitLogVars == /\ log = [i \in Server |-> << >>]
/\ commitIndex = [i \in Server |-> 0]
Init == /\ messages = [m \in {} |-> 0]
/\ InitHistoryVars
/\ InitServerVars
/\ InitCandidateVars
/\ InitLeaderVars
/\ InitLogVars
----
\* Define state transitions
\* Server i restarts from stable storage.
\* It loses everything but its currentTerm, votedFor, and log.
Restart(i) ==
/\ state' = [state EXCEPT ![i] = Follower]
/\ votesResponded' = [votesResponded EXCEPT ![i] = {}]
/\ votesGranted' = [votesGranted EXCEPT ![i] = {}]
/\ voterLog' = [voterLog EXCEPT ![i] = [j \in {} |-> <<>>]]
/\ nextIndex' = [nextIndex EXCEPT ![i] = [j \in Server |-> 1]]
/\ matchIndex' = [matchIndex EXCEPT ![i] = [j \in Server |-> 0]]
/\ commitIndex' = [commitIndex EXCEPT ![i] = 0]
/\ UNCHANGED <<messages, currentTerm, votedFor, log, elections>>
\* Server i times out and starts a new election.
Timeout(i) == /\ state[i] \in {Follower, Candidate}
/\ state' = [state EXCEPT ![i] = Candidate]
/\ currentTerm' = [currentTerm EXCEPT ![i] = currentTerm[i] + 1]
\* Most implementations would probably just set the local vote
\* atomically, but messaging localhost for it is weaker.
/\ votedFor' = [votedFor EXCEPT ![i] = Nil]
/\ votesResponded' = [votesResponded EXCEPT ![i] = {}]
/\ votesGranted' = [votesGranted EXCEPT ![i] = {}]
/\ voterLog' = [voterLog EXCEPT ![i] = [j \in {} |-> <<>>]]
/\ UNCHANGED <<messages, leaderVars, logVars>>
\* Candidate i sends j a RequestVote request.
RequestVote(i, j) ==
/\ state[i] = Candidate
/\ j \notin votesResponded[i]
/\ Send([mtype |-> RequestVoteRequest,
mterm |-> currentTerm[i],
mlastLogTerm |-> LastTerm(log[i]),
mlastLogIndex |-> Len(log[i]),
msource |-> i,
mdest |-> j])
/\ UNCHANGED <<serverVars, candidateVars, leaderVars, logVars>>
\* Leader i sends j an AppendEntries request containing up to 1 entry.
\* While implementations may want to send more than 1 at a time, this spec uses
\* just 1 because it minimizes atomic regions without loss of generality.
AppendEntries(i, j) ==
/\ i /= j
/\ state[i] = Leader
/\ LET prevLogIndex == nextIndex[i][j] - 1
prevLogTerm == IF prevLogIndex > 0 THEN
log[i][prevLogIndex].term
ELSE
0
\* Send up to 1 entry, constrained by the end of the log.
lastEntry == Min({Len(log[i]), nextIndex[i][j]})
entries == SubSeq(log[i], nextIndex[i][j], lastEntry)
IN Send([mtype |-> AppendEntriesRequest,
mterm |-> currentTerm[i],
mprevLogIndex |-> prevLogIndex,
mprevLogTerm |-> prevLogTerm,
mentries |-> entries,
\* mlog is used as a history variable for the proof.
\* It would not exist in a real implementation.
mlog |-> log[i],
mcommitIndex |-> Min({commitIndex[i], lastEntry}),
msource |-> i,
mdest |-> j])
/\ UNCHANGED <<serverVars, candidateVars, leaderVars, logVars>>
\* Candidate i transitions to leader.
BecomeLeader(i) ==
/\ state[i] = Candidate
/\ votesGranted[i] \in Quorum
/\ state' = [state EXCEPT ![i] = Leader]
/\ nextIndex' = [nextIndex EXCEPT ![i] =
[j \in Server |-> Len(log[i]) + 1]]
/\ matchIndex' = [matchIndex EXCEPT ![i] =
[j \in Server |-> 0]]
/\ elections' = elections \cup
{[eterm |-> currentTerm[i],
eleader |-> i,
elog |-> log[i],
evotes |-> votesGranted[i],
evoterLog |-> voterLog[i]]}
/\ UNCHANGED <<messages, currentTerm, votedFor, candidateVars, logVars>>
\* Leader i receives a client request to add v to the log.
ClientRequest(i, v) ==
/\ state[i] = Leader
/\ LET entry == [term |-> currentTerm[i],
value |-> v]
newLog == Append(log[i], entry)
IN log' = [log EXCEPT ![i] = newLog]
/\ UNCHANGED <<messages, serverVars, candidateVars,
leaderVars, commitIndex>>
\* Leader i advances its commitIndex.
\* This is done as a separate step from handling AppendEntries responses,
\* in part to minimize atomic regions, and in part so that leaders of
\* single-server clusters are able to mark entries committed.
AdvanceCommitIndex(i) ==
/\ state[i] = Leader
/\ LET \* The set of servers that agree up through index.
Agree(index) == {i} \cup {k \in Server :
matchIndex[i][k] >= index}
\* The maximum indexes for which a quorum agrees
agreeIndexes == {index \in 1..Len(log[i]) :
Agree(index) \in Quorum}
\* New value for commitIndex'[i]
newCommitIndex ==
IF /\ agreeIndexes /= {}
/\ log[i][Max(agreeIndexes)].term = currentTerm[i]
THEN
Max(agreeIndexes)
ELSE
commitIndex[i]
IN commitIndex' = [commitIndex EXCEPT ![i] = newCommitIndex]
/\ UNCHANGED <<messages, serverVars, candidateVars, leaderVars, log>>
----
\* Message handlers
\* i = recipient, j = sender, m = message
\* Server i receives a RequestVote request from server j with
\* m.mterm <= currentTerm[i].
HandleRequestVoteRequest(i, j, m) ==
LET logOk == \/ m.mlastLogTerm > LastTerm(log[i])
\/ /\ m.mlastLogTerm = LastTerm(log[i])
/\ m.mlastLogIndex >= Len(log[i])
grant == /\ m.mterm = currentTerm[i]
/\ logOk
/\ votedFor[i] \in {Nil, j}
IN /\ m.mterm <= currentTerm[i]
/\ \/ grant /\ votedFor' = [votedFor EXCEPT ![i] = j]
\/ ~grant /\ UNCHANGED votedFor
/\ Reply([mtype |-> RequestVoteResponse,
mterm |-> currentTerm[i],
mvoteGranted |-> grant,
\* mlog is used just for the `elections' history variable for
\* the proof. It would not exist in a real implementation.
mlog |-> log[i],
msource |-> i,
mdest |-> j],
m)
/\ UNCHANGED <<state, currentTerm, candidateVars, leaderVars, logVars>>
\* Server i receives a RequestVote response from server j with
\* m.mterm = currentTerm[i].
HandleRequestVoteResponse(i, j, m) ==
\* This tallies votes even when the current state is not Candidate, but
\* they won't be looked at, so it doesn't matter.
/\ m.mterm = currentTerm[i]
/\ votesResponded' = [votesResponded EXCEPT ![i] =
votesResponded[i] \cup {j}]
/\ \/ /\ m.mvoteGranted
/\ votesGranted' = [votesGranted EXCEPT ![i] =
votesGranted[i] \cup {j}]
/\ voterLog' = [voterLog EXCEPT ![i] =
voterLog[i] @@ (j :> m.mlog)]
\/ /\ ~m.mvoteGranted
/\ UNCHANGED <<votesGranted, voterLog>>
/\ Discard(m)
/\ UNCHANGED <<serverVars, votedFor, leaderVars, logVars>>
\* Server i receives an AppendEntries request from server j with
\* m.mterm <= currentTerm[i]. This just handles m.entries of length 0 or 1, but
\* implementations could safely accept more by treating them the same as
\* multiple independent requests of 1 entry.
HandleAppendEntriesRequest(i, j, m) ==
LET logOk == \/ m.mprevLogIndex = 0
\/ /\ m.mprevLogIndex > 0
/\ m.mprevLogIndex <= Len(log[i])
/\ m.mprevLogTerm = log[i][m.mprevLogIndex].term
IN /\ m.mterm <= currentTerm[i]
/\ \/ /\ \* reject request
\/ m.mterm < currentTerm[i]
\/ /\ m.mterm = currentTerm[i]
/\ state[i] = Follower
/\ \lnot logOk
/\ Reply([mtype |-> AppendEntriesResponse,
mterm |-> currentTerm[i],
msuccess |-> FALSE,
mmatchIndex |-> 0,
msource |-> i,
mdest |-> j],
m)
/\ UNCHANGED <<serverVars, logVars>>
\/ \* return to follower state
/\ m.mterm = currentTerm[i]
/\ state[i] = Candidate
/\ state' = [state EXCEPT ![i] = Follower]
/\ UNCHANGED <<currentTerm, votedFor, logVars, messages>>
\/ \* accept request
/\ m.mterm = currentTerm[i]
/\ state[i] = Follower
/\ logOk
/\ LET index == m.mprevLogIndex + 1
IN \/ \* already done with request
/\ \/ m.mentries = << >>
\/ /\ m.mentries /= << >>
/\ Len(log[i]) >= index
/\ log[i][index].term = m.mentries[1].term
\* This could make our commitIndex decrease (for
\* example if we process an old, duplicated request),
\* but that doesn't really affect anything.
/\ commitIndex' = [commitIndex EXCEPT ![i] =
m.mcommitIndex]
/\ Reply([mtype |-> AppendEntriesResponse,
mterm |-> currentTerm[i],
msuccess |-> TRUE,
mmatchIndex |-> m.mprevLogIndex +
Len(m.mentries),
msource |-> i,
mdest |-> j],
m)
/\ UNCHANGED <<serverVars, log>>
\/ \* conflict: remove 1 entry
/\ m.mentries /= << >>
/\ Len(log[i]) >= index
/\ log[i][index].term /= m.mentries[1].term
/\ LET new == [index2 \in 1..(Len(log[i]) - 1) |->
log[i][index2]]
IN log' = [log EXCEPT ![i] = new]
/\ UNCHANGED <<serverVars, commitIndex, messages>>
\/ \* no conflict: append entry
/\ m.mentries /= << >>
/\ Len(log[i]) = m.mprevLogIndex
/\ log' = [log EXCEPT ![i] =
Append(log[i], m.mentries[1])]
/\ UNCHANGED <<serverVars, commitIndex, messages>>
/\ UNCHANGED <<candidateVars, leaderVars>>
\* Server i receives an AppendEntries response from server j with
\* m.mterm = currentTerm[i].
HandleAppendEntriesResponse(i, j, m) ==
/\ m.mterm = currentTerm[i]
/\ \/ /\ m.msuccess \* successful
/\ nextIndex' = [nextIndex EXCEPT ![i][j] = m.mmatchIndex + 1]
/\ matchIndex' = [matchIndex EXCEPT ![i][j] = m.mmatchIndex]
\/ /\ \lnot m.msuccess \* not successful
/\ nextIndex' = [nextIndex EXCEPT ![i][j] =
Max({nextIndex[i][j] - 1, 1})]
/\ UNCHANGED <<matchIndex>>
/\ Discard(m)
/\ UNCHANGED <<serverVars, candidateVars, logVars, elections>>
\* Any RPC with a newer term causes the recipient to advance its term first.
UpdateTerm(i, j, m) ==
/\ m.mterm > currentTerm[i]
/\ currentTerm' = [currentTerm EXCEPT ![i] = m.mterm]
/\ state' = [state EXCEPT ![i] = Follower]
/\ votedFor' = [votedFor EXCEPT ![i] = Nil]
\* messages is unchanged so m can be processed further.
/\ UNCHANGED <<messages, candidateVars, leaderVars, logVars>>
\* Responses with stale terms are ignored.
DropStaleResponse(i, j, m) ==
/\ m.mterm < currentTerm[i]
/\ Discard(m)
/\ UNCHANGED <<serverVars, candidateVars, leaderVars, logVars>>
\* Receive a message.
Receive(m) ==
LET i == m.mdest
j == m.msource
IN \* Any RPC with a newer term causes the recipient to advance
\* its term first. Responses with stale terms are ignored.
\/ UpdateTerm(i, j, m)
\/ /\ m.mtype = RequestVoteRequest
/\ HandleRequestVoteRequest(i, j, m)
\/ /\ m.mtype = RequestVoteResponse
/\ \/ DropStaleResponse(i, j, m)
\/ HandleRequestVoteResponse(i, j, m)
\/ /\ m.mtype = AppendEntriesRequest
/\ HandleAppendEntriesRequest(i, j, m)
\/ /\ m.mtype = AppendEntriesResponse
/\ \/ DropStaleResponse(i, j, m)
\/ HandleAppendEntriesResponse(i, j, m)
\* End of message handlers.
----
\* Network state transitions
\* The network duplicates a message
DuplicateMessage(m) ==
/\ Send(m)
/\ UNCHANGED <<serverVars, candidateVars, leaderVars, logVars>>
\* The network drops a message
DropMessage(m) ==
/\ Discard(m)
/\ UNCHANGED <<serverVars, candidateVars, leaderVars, logVars>>
----
\* Defines how the variables may transition.
Next == /\ \/ \E i \in Server : Restart(i)
\/ \E i \in Server : Timeout(i)
\/ \E i,j \in Server : RequestVote(i, j)
\/ \E i \in Server : BecomeLeader(i)
\/ \E i \in Server, v \in Value : ClientRequest(i, v)
\/ \E i \in Server : AdvanceCommitIndex(i)
\/ \E i,j \in Server : AppendEntries(i, j)
\/ \E m \in DOMAIN messages : Receive(m)
\/ \E m \in DOMAIN messages : DuplicateMessage(m)
\/ \E m \in DOMAIN messages : DropMessage(m)
\* History variable that tracks every log ever:
/\ allLogs' = allLogs \cup {log[i] : i \in Server}
\* The specification must start with the initial state and transition according
\* to Next.
Spec == Init /\ [][Next]_vars
===============================================================================
B.3 証明
(訳注: 一部の証明は省略; 必要であれば原文を参照)
補題 1. 各サーバの \(currentTerm\) は単調増加する: \[ \begin{align} & \forall i \in Server: currentTerm[i] \le currentTerm'[i] \end{align} \]
証明. これは仕様からただちに導かれる。∎
補題 2. 各タームにつきリーダーは最大で 1 つである: \[ \begin{align*} & \forall e, f \in elections: e.eterm = f.eterm \Rightarrow e.eleader = f.eleader \end{align*} \]
これは Figure 3.2 の Election Safety 特性である
スケッチ. リーダーになるには定足数からの投票が必要であり、投票者はタームにつき 1 回しか投票できず、任意の 2 つの定足数グループは必ずどこかで重複する。
証明.
2 つの選挙 \(e\) と \(f\) を考える。どちらも \(elections\) のメンバーであり、\(e.eterm=f.eterm\) である。
\(elections\) メンバーの必要条件から \(e.evotes \in Quorum\) かつ \(f.evotes \in Quorum\) である。
\(voter\) を \(e.evotes \cap f.evotes\) の任意のメンバーとする。任意の 2 つの定足数グループは重複するため、このようなメンバーは必ず存在する。
\(voter\) が \(e.eterm\) で \(e.eleader\) に票を投じると、\(voter\) は \(e.eterm\) では別のサーバに投票することはできない (仕様より、一度 \(currentTerm\) をインクリメントすると同じサーバに再び投票することはできず (補題 1)、それまでは投票情報を安全に保持することが保証されている)。
\(e.eterm=f.eterm\) において、\(voter\) は \(e.eleader\) に投票し、かつ \(voter\) は \(f.eleader\) に投票しているため、\(e.eleader=f.eleader\) である。∎
補題 3. リーダーのログは、そのターム中は単調増加する: \[ \begin{align*} & \forall e \in elections: currentTerm[e.leader] = e.term \Rightarrow \\ & \hspace{32pt} \forall index \in 1..Len(log[e.leader]): log'[e.leader][index] = log[e.leader][index] \end{align*} \]
これは Figure 3.2 の Leader Append-Only 特性である。
スケッチ. リーダーであるサーバ \(i\) は自身のログにのみエントリを追加する。1 つのタームには最大で 1 つのリーダーしか存在しないため、\(i\) は同じターム内において他のサーバから AppendEntries リクエストを受け取ることはない。また \(i\) は自身のタームが増えるまで他のタームに対する AppendEntries リクエストを拒否する。
証明.
目標には \(elections\), \(currentTerm\), \(log\) の 3 つの変数が関与する。これらの変数を変更する遷移を順に考察する。そうでなければ、帰納的仮説により不変条件は自明に成立する。
新しい選挙が \(elections\) (すべての成功した選挙に関する情報を保持する履歴情報) に追加されると、リーダーのログは同じステップでは変更されない (\(log'[e.leader]=\log[e.leader]\)) ため、不変条件は維持される。
\(currentTerm[e.leader]\) は補題 1 により単調増加するため、一度 \(e.leader\) が新しいタームに移行すると、それ以降は不変条件を自明に満たす。
\(log\) はクライアントリクエストまたは AppendEntries リクエストのいずれかによって変更される:
ケース: クライアントリクエスト:
仕様により、リーダーはログエントリを追加するのみであり、不変条件は維持される。
ケース: AppendEntries リクエスト:
\(state[i]=Leader\) のサーバのみが、自身の \(currentTerm\) に対する AppendEntries リクエストを送信できる。
補題 2 により、\(e.term\) のリーダーとなり得る唯一のサーバは \(e.leader\) である。
サーバは自身に AppendEntries リクエストを送信しない (仕様を参照)。
\(e.leader\) は、自身のタームが \(e.term\) である間は AppendEntries リクエストを処理することはない。∎
補題 4. \(\langle index, term\rangle\) はプレフィクスを識別する: \[ \begin{align*} & \forall l, m \in allLogs: \\ & \hspace{16pt} \forall \langle index, term \rangle \in l : \langle index, term \rangle \in m \Rightarrow \\ & \hspace{32pt} \forall pindex \in 1..index: l[pindex] = m[pindex] \end{align*} \]
これは Figure 3.2 の Log Matching 特性である。
スケッチ. リーダーのみがエントリを作成し、他のリーダーによって再割り当てされることのないターム番号を新しいエントリに割り当てる (タームごとにリーダーは最大 1 つであるため)。さらに、AppendEntries の一貫性チェックにより、フォロワーが新しいエントリを受け入れるときに、リーダーがエントリを送信した時点でのリーダーのログと一貫性が保たれることが保証される。
主張. \(p\) が何らかのログ \(l \in allLogs\) のプレフィクスである場合、\(allLogs' = allLogs \cup \{p\}\) は不変条件 (この補題の記述) を維持する。
\(p\) のエントリは \(l\) のエントリと一致し、\(p\) は追加のエントリを提供しないことから、この不変条件はただちに導かれる。
実行に対する帰納法による証明.
初期状態: すべてのサーバのログは空であり、\(allLogs = \langle \rangle\) となるため、不変条件は自明に成立する。
帰納的ステップ: ログは以下のいずれかの方法で変更される:
ケース: リーダーがエントリを 1 つ追加する (クライアントリクエスト)
ケース: フォロワーが 1 つのエントリを削除する (AppendEntries リクエスト \(m\))
\(log'[follower]\) は \(log[follower]\) のプレフィクスであるため (上記の主張による)、不変条件は依然として成立する。
ケース: フォロワーが 1 つのエントリを追加する (AppendEntries リクエスト \(m\))
\(m.mlog\) はリーダーが AppendEntries リクエストを作成した時点でのリーダーのログのコピーである。
\(allLogs\) の定義により \(m.mlog \in allLogs\) である。
以下の 2 つのケースにおいて、\(log'[follower]\) が \(m.mlog\) のプレフィクスであることを示す。
ケース: \(m.mprevLogIndex=0\)
\(m.mentries\) は \(m.mlog\) のプレフィクスである。
リクエストを受け入れる必要条件として \(log[follower]\) は空である (仕様は、競合するエントリの削除、変更がない場合の応答、エントリの追記の遷移を分離している)。
リクエストを受け入れると \(log'[follower] = m.mentries\) となり、これは \(m.mlog\) のプレフィクスである。
ケース: \(m.mprevLogIndex \gt 0\)
\(start \, || \, \langle m.mprevLogIndex, m.mprevLogTerm \rangle \, || \, m.mentries\) は \(m.mlog\) のプレフィクスである。ここで \(start\) は何らかの (おそらく空の) ログプレフィクスである。
フォロワーは仮定によりリクエストを受け入れるため、そのログにはエントリ \(\langle m.mprevLogIndex, m.mprevLogTerm \rangle\) が含まれる。
帰納的仮説により、\(log[follower]\) にはプレフィクス \(start \, || \, \langle m.mprevLogIndex, m.mprevLogTerm \rangle\) が含まれる。
リクエストを受け入れた際、\(log'[follower]=start \, || \, \langle m.mprevLogIndex, m.mprevLogTerm \rangle \, || \, m.metrics\) となり、これは \(m.mlog\) のプレフィクスである。
\(log'[follower]\) は \(m.mlog\) のプレフィクスであるため、(上記の主張により) 不変条件は維持される。∎
補題 5. フォロワーがログにエントリを追記するとき、追記後のそのログは、リーダーが AppendEntries リクエストを送信した時点でのリーダーのログのプレフィクスとなる: \[ \begin{align*} & \forall i \in Server: state[i] \ne Leader \land Len(log'[i]) \gt Len(log[i]) \Rightarrow \\ & \hspace{12pt} \exists m \in {\rm DOMAIN} \ messages: \\ & \hspace{24pt} \land m.mtype = AppendEntriesRequest \\ & \hspace{24pt} \land \forall index \in 1..Len(log'[i]): \\ & \hspace{36pt} log'[i][index] = m.mlog[index] \end{align*} \]
これは補題 4 の証明における議論を言い換えたもので、他の補題の証明においても有用である。(補題 4 の帰納的仮説が鍵となるため、補題 4 より前に行うのは困難である。しかし、この補題の証明は補題 4 から容易に導かれる。)
スケッチ. フォロワーが自身のログに追記する新しいエントリは、リーダーのログにも存在していたものである。したがって、補題 4 により、フォロワーの新しいログは、かつてのリーダーのログのプレフィクスとなる。
証明. ………。∎
補題 6. あるサーバの現在のタームは、常にそのログ内のタームと少なくとも同じかそれ以上である: \[ \begin{align*} & \forall i in Server: \forall \langle index, term \rangle \in log[i]: term \le currentTerm[i] \end{align*} \]
スケッチ. サーバの現在のタームは単調増加する。リーダーが新しいエントリを作成すると、そのエントリに現在のタームを割り当てる。そしてフォロワーがリーダーから新しいエントリを受け入れると、フォロワーの現在のタームは、リーダーがエントリを送信した時点のタームと一致する。
証明. ………。∎
補題 7. 各ログにおいて、エントリのタームは単調増加する: \[ \forall l \in allLogs: \forall index \in 1..(Len(l)-1): l[index].term \le l[index+1].term \]
スケッチ. リーダーは、新しいエントリに自身の現在のタームを割り当てることでこれを維持する。そのタームは常にログ内のタームと同じかそれ以上である。フォロワーが新しいエントリを受け入れると、それらはリーダーがエントリを送信した時点のログと整合する。
証明. ………。∎
定義 1. あるエントリ \(\langle index, term \rangle\) は、ターム \(t\) 以降のすべてのリーダーのログに存在する場合、ターム \(t\) においてコミット済みであるとする。\[ \begin{align*} & committed(t) \stackrel{\mathrm{\triangle}}{=} \{ \langle index, term \rangle: \\ & \hspace{12pt} \forall election \in elections: election.eterm \gt t \Rightarrow \langle index, term \rangle \in election.elog \} \end{align*} \]
定義 2. あるエントリ \(\langle index, term \rangle\) は、\(term\) 中にクォーラム (リーダーを含む) によって承認された場合、即時コミット済みであるとする。補題 8 はこれらのエントリが \(term\) においてコミット済みであることを示す。\[ immediatelyCommitted \stackrel{\mathrm{\triangle}}{=} \{ \langle index, term \rangle \in anyLog: ... \} \]
補題 8. 即時コミット済みエントリはコミット済みである: \[ \begin{align*} & \forall \langle index, term \rangle \in immediatelyCommitted: \langle index, term \rangle \in committed(term) \end{align*} \]
補題 9 とともに、これは Figure 3.2 の Leader Completeness 特性である。
スケッチ. セクション 3.6.3 参照。
証明. ………。∎
定義 3. あるエントリ \(\langle index, term \rangle\) は、あるログにおいて、ターム \(t\) でコミット済みであるそのエントリの後に続く別のエントリが存在すれば、ターム \(t\) においてプレフィクスコミット済みである。補題 9 はこれらのエントリがターム \(t\) でコミット済みであることを示す。\[ \begin{align*} & prefixCommitted(t) \stackrel{\mathrm{\triangle}}{=} \{ \langle index, term \rangle \in anyLog: \\ & \hspace{12pt} \land anyLog \in allLogs \\ & \hspace{12pt} \land \exists \langle rindex, rterm \rangle \in anyLog: \\ & \hspace{24pt} \land index \lt rindex \\ & \hspace{24pt} \land \langle rindex, rterm \rangle \in committed(t) \} \end{align*} \]
補題 9. プレフィクスコミットされたエントリは、同じタームにコミットされる: \[ \forall t : prefixCommitted(t) \subseteq committed(t) \]
補題 8 とともに、これは Figure 3.2 の Leader Completeness 特性である。
スケッチ. あるエントリがコミットされた場合、それはすべてのエントリがコミットされるログのプレフィクスを識別する。なぜなら、それらのエントリは将来のすべてのリーダーのログにも存在するからである。
証明. ………。∎
定理 1. サーバは、自身の現在のタームにおいてコミット済みのエントリのみを適用する: \[ \begin{align*} & \forall i \in Server: \\ & \hspace{12pt} \land commitIndex[i] \le Len(log[i]) \\ & \hspace{12pt} \land \forall \langle index, term \rangle \in log[i] \\ & \hspace{24pt} index \le commitIndex[i] \Rightarrow \\ & \hspace{36pt} \langle index, term \rangle \in committed(currentTerm[i]) \end{align*} \]
これは Figure 3.2 の State Machine Safety 特性と等価である。(コミットインデックスに関する境界は、帰納的仮説を強化するために必要である。)
スケッチ. リーダーは、即時コミット済み、またはプレフィクスコミット済みのエントリをカバーするように \(commitIndex\) を進めるのみである。フォロワーは、リーダーのログのプレフィクスを持つ場合にのみ、リーダーの \(commitIndex\) から自身の \(commitIndex\) を更新する。
実行に対する帰納法による証明. ………。∎
Bibliography
- Apache Cassandra project website. https://cassandra.apache.org. 60, 148
- Apache Hadoop documentation: HDFS high availability, 2012. https://hadoop.apache.org/docs/r2.0.2-alpha/hadoop-yarn/hadoopyarn-site/HDFSHighAvailability.html. 1
- Apache HBase project website. https://hbase.apache.org. 139
- Azure Active Directory (AAD) Availability Proxy for .Net source code. https://github.com/WindowsAzureAD/availability-proxy-for-restservices. 148
- BAKER, J., BOND, C., CORBETT, J. C., FURMAN, J., KHORLIN, A., LARSON, J., LEON, J.-M., LI, Y., LLOYD, A., AND YUSHPRAKH, V. Megastore: providing scalable, highly available storage for interactive services. In Proc. CIDR’11, Conference on Innovative Data System Research (2011), pp. 223–234. 7, 147
- Basho Riak project website. http://basho.com/riak. 148
- BERTOT, Y., CASTRAN, P., HUET, G., AND PAULIN-MOHRING, C. Interactive theorem proving and program development: Coq’Art : the calculus of inductive constructions. Texts in Theoretical Computer Science. Springer, 2004. 115
- BIELY, M., MILOSEVIC, Z., SANTOS, N., AND SCHIPER, A. S-Paxos: offloading the leader for high throughput state machine replication. In Proc. SRDS’12, IEEE Symposium on Reliable Distributed Systems (2012), pp. 111–120. 163
- BLOMSTEDT, J. Bringing consistency to Riak. RICON West (conference talk), 2013. http://basho.com/ricon-west-videos-strong-consistency-in-riak/. 148
- BOICHAT, R., DUTTA, P., FRØLUND, S., AND GUERRAOUI, R. Deconstructing Paxos. SIGACT News 34, 1 (Mar. 2003), 47–67. 168
- BURROWS, M. The Chubby lock service for loosely-coupled distributed systems. In Proc. OSDI’06, USENIX Symposium on Operating Systems Design and Implementation (2006), USENIX, pp. 335–350. 5, 48, 147
- CALDER, B., WANG, J., OGUS, A., NILAKANTAN, N., SKJOLSVOLD, A., MCKELVIE, S., XU, Y., SRIVASTAV, S., WU, J., SIMITCI, H., HARIDAS, J., UDDARAJU, C., KHATRI, H., EDWARDS, A., BEDEKAR, V., MAINALI, S., ABBASI, R., AGARWAL, A., HAQ, M. F. U., HAQ, M. I. U., BHARDWAJ, D., DAYANAND, S., ADUSUMILLI, A., MCNETT, M., SANKARAN, S., MANIVANNAN, K., AND RIGAS, L. Windows Azure Storage: a highly available cloud storage service with strong consistency. In Proc. SOSP’11, ACM Symposium on Operating Systems Principles (2011), ACM, pp. 143–157. 148
- CASTRO, M., AND LISKOV, B. Practical Byzantine fault tolerance. In Proc. OSDI’99, USENIX Symposium on Operating Systems Design and Implementation (1999), USENIX, pp. 173–186. 147
- Ceph documentation: monitor config reference. http://ceph.com/docs/master/rados/configuration/mon-config-ref/. 148
- CHANDRA, T. D., GRIESEMER, R., AND REDSTONE, J. Paxos made live: an engineering perspective. In Proc. PODC’07, ACM Symposium on Principles of Distributed Computing (2007), ACM, pp. 398–407. 9, 10, 48, 115, 147, 160, 174
- CHANDRA, T. D., AND TOUEG, S. Unreliable failure detectors for reliable distributed systems. Journal of the ACM 43, 2 (Mar. 1996), 225–267. 151
- CHANG, F., DEAN, J., GHEMAWAT, S., HSIEH, W. C., WALLACH, D. A., BURROWS, M., CHANDRA, T., FIKES, A., AND GRUBER, R. E. Bigtable: a distributed storage system for structured data. In Proc. OSDI’06, USENIX Symposium on Operating Systems Design and Implementation (2006), USENIX, pp. 205–218. 58, 60
- CHUN, B.-G., RATNASAMY, S., AND KOHLER, E. NetComplex: a complexity metric for networked system designs. In Proc. NSDI’08, USENIX Conference on Networked Systems Design and Implementation (2008), USENIX, pp. 393–406. 169
- CORBET, J. Btrfs: subvolumes and snapshots, Jan. 2014. http://lwn.net/Articles/579009/. 57
- CORBETT, J. C., DEAN, J., EPSTEIN, M., FIKES, A., FROST, C., FURMAN, J. J., GHEMAWAT, S., GUBAREV, A., HEISER, C., HOCHSCHILD, P., HSIEH, W., KANTHAK, S., KOGAN, E., LI, H., LLOYD, A., MELNIK, S., MWAURA, D., NAGLE, D., QUINLAN, S., RAO, R., ROLIG, L., SAITO, Y., SZYMANIAK, M., TAYLOR, C., WANG, R., AND WOODFORD, D. Spanner: Google’s globally-distributed database. In Proc. OSDI’12, USENIX Symposium on Operating Systems Design and Implementation (2012), USENIX, pp. 251264. 7, 147
- COUSINEAU, D., DOLIGEZ, D., LAMPORT, L., MERZ, S., RICKETTS, D., AND VANZETTO, H. TLA+ Proofs. In Proc. FM’12, Symposium on Formal Methods (2012), D. Giannakopoulou and D. Méry, Eds., vol. 7436 of Lecture Notes in Computer Science, Springer, pp. 147–154. 114
- DEAN, J. Large-scale distributed systems at Google: current systems and future directions. LADIS’09: ACM SIGOPS International Workshop on Large Scale Distributed Systems and Middleware (keynote talk), 2009. 1
- DILL, D. L., DREXLER, A. J., HU, A. J., AND YANG, C. H. Protocol verification as a hardware design aid. In Proc. ICCD’92, International Conference on Computer Design (1992), IEEE, pp. 522–525. 114
- DOW, S. P., GLASSCO, A., KASS, J., SCHWARZ, M., SCHWARTZ, D. L., AND KLEMMER, S. R. Parallel prototyping leads to better design results, more divergence, and increased sel-fefficacy. ACM Transactions on Computer-Human Interaction 17, 4 (Dec. 2010), 18:1–18:24. 109
- ELECTRONIC FRONTIER FOUNDATION. Patents. https://www.eff.org/patent. 164
- ELLIS, J. Lightweight transactions in Cassandra 2.0, 2013. http://www.datastax.com/dev/blog/lightweight-transactions-in-cassandra-2-0. 148
- ESCRIVA, R., WONG, B., AND SIRER, E. G. HyperDex: a distributed, searchable key-value store. In Proc. SIGCOMM’12, ACM SIGCOMM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication (2012), ACM, pp. 25–36. 60
- FISCHER, M. J., LYNCH, N. A., AND PATERSON, M. S. Impossibility of distributed consensus with one faulty process. Journal of the ACM 32, 2 (Apr. 1985), 374–382. 117
- FONG, Z., AND SHROFF, R. HydraBase: The evolution of HBase@Facebook, 2014. https://code.facebook.com/posts/321111638043166/hydrabasethe-evolution-of-hbase-facebook/. 139
- GHEMAWAT, S., GOBIOFF, H., AND LEUNG, S.-T. The Google file system. In Proc. SOSP’03, ACM Symposium on Operating Systems Principles (2003), ACM, pp. 29–43. 7, 163
- GILL, P., JAIN, N., AND NAGAPPAN, N. Understanding network failures in data centers: measurement, analysis, and implications. In Proc. SIGCOMM’11, ACM SIGCOMM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication (2011), ACM, pp. 350–361. 1
- GLENDENNING, L., BESCHASTNIKH, I., KRISHNAMURTHY, A., AND ANDERSON, T. Scalable consistency in Scatter. In Proc. SOSP’11, ACM Symposium on Operating Systems Principles (2011), ACM, pp. 15–28. 7
- GRAY, C., AND CHERITON, D. Leases: an efficient fault-tolerant mechanism for distributed f ile cache consistency. In Proc. SOSP’89, ACM Symposium on Operating Systems Principles (1989), ACM, pp. 202–210. 74
- HERLIHY, M. P., AND WING, J. M. Linearizability: a correctness condition for concurrent objects. ACM Transactions on Programming Languages and Systems 12 (July 1990), 463492. 66, 70
- HOCH, E. Configuration changes. raft-dev mailing list, Feb. 2014. https://groups.google.com/d/msg/raft-dev/xux5HRxH3Ic/mz_PDK-qMJgJ. vii
- HOWARD, H. ocaml-raft source code. https://github.com/heidi-ann/ocamlraft. 115
- HOWARD, H. ARC: analysis of Raft consensus. Tech. Rep. UCAM-CL-TR-857, University of Cambridge, Computer Laboratory, July 2014. http://www.cl.cam.ac.uk/techreports/UCAM-CL-TR-857.pdf. 115, 130
- HUNT, P., KONAR, M., JUNQUEIRA, F. P., AND REED, B. ZooKeeper: wait-free coordination for Internet-scale systems. In Proc. ATC’10, USENIX Annual Technical Conference (2010), USENIX, pp. 145–158. 1, 5, 7, 50, 149, 160
- HyperLevelDB performance benchmarks. http://hyperdex.org/performance/leveldb/. 60
- ISARD, M. Autopilot: automatic data center management. SIGOPS Operating Systems Review 41, 2 (Apr. 2007), 60–67. 148
- JUNQUEIRA, F. P., REED, B. C., AND SERAFINI, M. Dissecting Zab. Tech. Rep. YL2010-0007, Yahoo! Research, 2010. http://labs.yahoo.com/files/YL-2010007.pdf. 168
- JUNQUEIRA, F. P., REED, B. C., AND SERAFINI, M. Zab: high-performance broadcast for primary-backup systems. In Proc. DSN’11, IEEE/IFIP Conference on Dependable Systems and Networks (2011), IEEE, pp. 245–256. 2, 137, 149
- KANTHAK, S. Spanner: Google’s distributed database. Strange Loop (conference talk), Sept. 2013. http://www.infoq.com/presentations/spanner-distributedgoogle. 148
- KINGSBURY, K. Jepsen series of articles on network partitions. http://aphyr.com/tags/jepsen, 2013–2014. 1
- KINGSBURY, K. Call me maybe: etcd and Consul http://aphyr.com/posts/316call-me-maybe-etcd-and-consul, 2014. 72, 115
- KIRSCH, J., AND AMIR, Y. Paxos for system builders: an overview. In Proc. LADIS’08, Workshop on Large-Scale Distributed Systems and Middleware (2008), ACM, pp. 3:1–3:6. 9, 148
- LAMPORT, L. Time, clocks, and the ordering of events in a distributed system. Communications of the ACM 21, 7 (July 1978), 558–565. 15
- LAMPORT, L. The part-time parliament. ACM Transactions on Computer Systems 16, 2 (May 1998), 133–169. 1, 8, 38, 148, 156, 168
- LAMPORT, L. Paxos made simple. ACM SIGACT News 32, 4 (Dec. 2001), 18–25. 1, 8, 9, 82, 148, 156
- LAMPORT, L. Specifying Systems, The TLA+ Language and Tools for Hardware and Software Engineers. Addison-Wesley, 2002. 112, 201
- LAMPORT, L. Generalized consensus and Paxos. Tech. Rep. MSR-TR-2005-33, Microsoft, Mar. 2005. https://research.microsoft.com/pubs/64631/tr-2005-33. pdf. 166
- LAMPORT, L. Fast Paxos. Distributed Computing 19, 2 (2006), 79–103. 165
- LAMPORT, L. Fast Paxos recovery, June 2009. US Patent 7,555,516. 165
- LAMPORT, L. Byzantizing Paxos by refinement. In Proc. DISC’11, International Symposium on Distributed Computing (2011), Springer-Verlag, pp. 211–224. 168
- LAMPORT, L. Personal communications, including TLAPS proof for single-decree Paxos, Feb. 2013. 168
- LAMPORT, L., HYDRIE, A., AND ACHLIOPTAS, D. Multi-leader distributed system, Aug. 2007. US Patent 7,260,611. 164, 166
- LAMPORT, L., AND MASSA, M. Cheap Paxos. In Proc.DSN’04,Conference on Dependable Systems and Networks (2004), IEEE, pp. 307–314. 167
- LAMPORT, L., AND MASSA, M. Cheap Paxos, Dec. 2010. US Patent 7,856,502. 167
- LAMPORT, L., AND PAULSON, L. C. Should your specification language be typed? ACM Transactions on Programming Languages and Systems 21, 3 (May 1999), 502–526. 114
- LAMPSON, B. W. How to build a highly available system using consensus. In Distributed Algorithms, O. Baboaglu and K. Marzullo, Eds. Springer-Verlag, 1996, pp. 1–17. 8, 148
- LAMPSON, B. W. The ABCD’s of Paxos. PODC’01: ACM Symposium on Principles of Distributed Computing (invited talk), 2001. http://research.microsoft.com/enus/um/people/blampson/65-ABCDPaxos/Abstract.html. 8, 148
- LevelDB: a fast and lightweight key/value database library by Google (source code). https://code.google.com/p/leveldb/. 60
- LevelDB documentation: file layout and compactions. https://leveldb.googlecode.com/svn/trunk/doc/impl.html. 49
- Linux documentation: tmpfs filesystem. https://www.kernel.org/doc/Documentation/filesystems/tmpfs.txt. 116
- LISKOV, B. From Viewstamped Replication to Byzantine fault tolerance. In Replication (2010), B. Charron-Bost, F. Pedone, and A. Schiper, Eds., vol. 5959 of Lecture Notes in Computer Science, Springer, pp. 121–149. 147
- LISKOV, B., AND COWLING, J. Viewstamped Replication revisited. Tech. Rep. MITCSAIL-TR-2012-021, MIT, July 2012. http://pmg.csail.mit.edu/papers/vrrevisited.pdf. 2, 3, 22, 149, 156, 160, 168
- LISKOV, B., GHEMAWAT, S., GRUBER, R., JOHNSON, P., SHRIRA, L., AND WILLIAMS, M. Replication in the Harp file system. In Proc. SOSP’91, ACM Symposium on Operating Systems Principles (1991), ACM, pp. 226–238. 149, 167
- LJUNGBLAD, M. archie/raft source code. https://github.com/archie/raft. 139
- LORCH, J. R., ADYA, A., BOLOSKY, W. J., CHAIKEN, R., DOUCEUR, J. R., AND HOWELL, J. The SMART way to migrate replicated stateful services. In Proc. EuroSys’06, ACM SIGOPS/EuroSys European Conference on Computer Systems (2006), ACM, pp. 103–115. 8, 156
- LVM2 (Linux Volume Management) resource page. https://sourceware.org/lvm2/. 57
- LYNCH, N. A. Distributed Algorithms. Morgan Kaufmann Publishers Inc., 1996. 6
- MACCORMICK, J., MURPHY, N., NAJORK, M., THEKKATH, C. A., AND ZHOU, L. Boxwood: abstractions as the foundation for storage infrastructure. In Proc. OSDI’04, USENIX Symposium on Operating Systems Design and Implementation (2004), USENIX, pp. 105120. 162
- MALAWSKI, K. akka-raft source code. https://github.com/ktoso/akka-raft. 139
- MAO, Y., JUNQUEIRA, F. P., AND MARZULLO, K. Mencius: building efficient replicated state machines for WANs. In Proc. OSDI’08, USENIX Symposium on Operating Systems Design and Implementation (2008), USENIX, pp. 369–384. 164
- MARTIN, J. Raft.js (kanaka) source code. https://github.com/kanaka/raft.js. 139
- MARTIN, J.-P., AND ALVISI, L. Fast Byzantine consensus. In IEEE Transactions on Dependable and Secure Computing (2005), pp. 402–411. 147
- MAZIÈRES, D. Paxos Made Practical. [Despite its name, the subject of this paper more closely resembles Viewstamped Replication, not Paxos.] http://www.scs.stanford.edu/˜dm/home/papers/paxos.pdf, Jan. 2007. 9, 149, 157, 158
- MAZIÈRES, D. Traditional Paxos (slides), 2013. https://ramcloud.stanford.edu/˜ongaro/dmpaxos.pdf. 82
- MORARU, I., ANDERSEN, D. G., AND KAMINSKY, M. A proof of correctness for Egalitarian Paxos. Tech. Rep. CMU-PDL-13-111, Parallel Data Laboratory, Carnegie Mellon University, 2013. http://www.pdl.cmu.edu/PDL-FTP/associated/CMU-PDL-13111.pdf. 168, 169
- MORARU, I., ANDERSEN, D. G., AND KAMINSKY, M. There is more consensus in egalitarian parliaments. In Proc. SOSP’13, ACM Symposium on Operating Systems Principles (2013), ACM, pp. 358–372. 166
- MURTHY, A. Apache Hadoop2.0 (alpha) released, 2012. http://hortonworks.com/blog/apache-hadoop-2-0-alpha-released/. 1
- OKI, B. M. Viewstamped Replication for highly available distributed systems. PhD thesis, Massachusetts Institute of Technology, Aug. 1988. MIT-LCS-TR-423. http://pmg.csail.mit.edu/papers/MIT-LCS-TR-423.pdf. 2, 149
- OKI, B. M., AND LISKOV, B. H. Viewstamped Replication: a new primary copy method to support highly-available distributed systems. In Proc. PODC’88, ACM Symposium on Principles of Distributed Computing (1988), ACM, pp. 8–17. 2, 3, 149
- O’NEIL, P., CHENG, E., GAWLICK, D., AND O’NEIL, E. The log-structured merge-tree (LSM-tree). Acta Informatica 33, 4 (1996), 351–385. 58, 60
- ONGARO, D. Availability simulator for Raft (source code). https://github.com/ongardie/availsim. 134
- ONGARO, D. LogCabin source code. https://github.com/logcabin/logcabin. 4, 45, 132, 139, 144
- ONGARO, D. Formal specification for Raft (source file), 2014. https://ramcloud.stanford.edu/˜ongaro/raft.tla. 202
- ONGARO, D., AND OUSTERHOUT, J. Raft user study materials. http://ramcloud.stanford.edu/˜ongaro/userstudy/. 77, 108, 148
- ONGARO, D., AND OUSTERHOUT, J. In Search of an Understandable Consensus Algorithm. In Proc. ATC’14, USENIX Annual Technical Conference (2014), USENIX. ii
- OUSTERHOUT, J., AGRAWAL, P., ERICKSON, D., KOZYRAKIS, C., LEVERICH, J., MAZI` ERES, D., MITRA, S., NARAYANAN, A., ONGARO, D., PARULKAR, G., ROSENBLUM, M., RUMBLE, S. M., STRATMANN, E., AND STUTSMAN, R. The case for RAMCloud. Communications of the ACM 54 (July 2011), 121–130. 7, 139
- PRISCO, R. D., LAMPSON, B. W., AND LYNCH, N. A. Revisiting the Paxos algorithm. Theoretical Computer Science 243, 1-2 (2000), 35–91. 168
- Raft consensus algorithm website. http://raftconsensus.github.io. v, 139
- RAO, J. Intra-cluster replication for Apache Kafka. ApacheCon NA (conference talk), Feb. 2013. http://www.slideshare.net/junrao/kafka-replicationapachecon2013. 167
- REED, B. Personal communications, May 17, 2013. 152
- REED, B., AND BOHANNON, P. Restoring a database using fuzzy snapshot techniques, May 2010. US Patent 7,725,440. 161
- RocksDB: a persistent key-value store for fast storage environments. http://rocksdb.org. 60
- ROSENBLUM, M., AND OUSTERHOUT, J. K. The design and implementation of a log-structured file system. ACM Transactions on Computer Systems 10 (Feb. 1992), 26–52. 58, 59
- RUMBLE, S. M. Memory and object management in RAMCloud. PhD thesis, Stanford University, Mar. 2014. http://purl.stanford.edu/bx554qk6640. 49, 58, 59, 60
- RUSEK, D., AND BAILLY, A. Barge source code. https://github.com/mgodave/barge. 139
- SANTOS, N., AND SCHIPER, A. Tuning Paxos for high-throughput with batching and pipelining. In Proc. ICDCN’12, International Conference on Distributed Computing and Networking (2012), Springer-Verlag, pp. 153–167. 163
- SCHIPER, N., RAHLI, V., VAN RENESSE, R., BICKFORD, M., AND CONSTABLE, R. L. Developing correctly replicated databases using formal tools. In Proc. DSN’14, IEEE/IFIP International Conference on Dependable Systems and Networks (2014). 115, 168, 169
- SCHNEIDER, F. B. Implementing fault-tolerant services using the state machine approach: a tutorial. ACM Computing Surveys 22, 4 (Dec. 1990), 299–319. 5
- SCHROEDER, B., AND GIBSON, G. A. Disk failures in the real world: what does an MTTF of 1,000,000 hours mean to you? In Proc. FAST’07, USENIX Conference on File and Storage Technologies (2007), USENIX, pp. 1–16. 1
- SHRAER, A., REED, B., MALKHI, D., AND JUNQUEIRA, F. Dynamic reconfiguration of primary/backup clusters. In Proc. ATC’12, USENIX Annual Technical Conference (2012), USENIX, pp. 425–437. 149
- SHVACHKO, K., KUANG, H., RADIA, S., AND CHANSLER, R. The Hadoop distributed file system. In Proc. MSST’10, IEEE Symposium on Mass Storage Systems and Technologies (2010), IEEE, pp. 1–10. 7
- STONE, A. J. Rafter source code. https://github.com/andrewjstone/rafter. 139
- TRANGEZ, N. Kontiki source code. https://github.com/NicolasT/kontiki. 139
- VAN RENESSE, R. Paxos made moderately complex. Tech. rep., Cornell University, 2012. http://www.cs.cornell.edu/home/rvr/Paxos/paxos.pdf. 9, 148
- VAN RENESSE, R., SCHIPER, N., AND SCHNEIDER, F. B. Vive la différence: Paxos vs. Viewstamped Replication vs. Zab. IEEE Transactions on Dependable and Secure Computing (2014). 147
- VAN RENESSE, R., AND SCHNEIDER, F. B. Chain replication for supporting high throughput and availability. In Proc. OSDI’04, USENIX Symposium on Operating Systems Design and Implementation (2004), USENIX, pp. 91–104. 163
- VARDA, K. Protocol Buffers: Google’s data interchange format, 2008. http://googleopensource.blogspot.com/2008/07/protocol-buffers-googlesdata.html. 132, 144
- WEIL, S., BRANDT, S. A., MILLER, E. L., LONG, D. D. E., AND MALTZAHN, C. Ceph: a scalable, high-performance distributed file system. In Proc. OSDI’06, USENIX Symposium on Operating Systems Design and Implementation (2006), USENIX, pp. 307–320. 148
- ZOOKEEPER-107: allow dynamic changes to server cluster membership (issue tracker). https://issues.apache.org/jira/browse/ZOOKEEPER-107. 149
翻訳抄
分散システムにおける障害耐性を実現するコンセンサスアルゴリズム Raft を詳述した 2014 年の論文。従来の Paxos の複雑さを解消し「理解可能性」を最重視して設計されており、リーダー選挙、ログ複製、クラスタメンバーシップ変更、ログ圧縮など、実運用に必要なあらゆる側面を包括的に議論している。理論の側面では TLA+ による形式的証明や理解度テストの分析を提示し、実践側面では実際のシステム実装における詳細な考慮事項やパフォーマンス、リーダーシップ転送といった課題への対象法を提示している。著者の Diego Ongaro は元の Raft 論文 [89] の著者。
- ONGARO, D. Consensus: Bridging Theory and Practice. PhD thesis, Stanford University, 2014.
