論文翻訳: In Search of an Understandable Consensus Algorithm (Extended Version)
Stanford University
 Abstract
Abstract
Raft は複製されたログを管理するためのコンセンサスアルゴリズムである。これは (Multi-) Paxosと同等の結果を生み出し Paxos と同程度に効率的だが、その構造は Paxos とは異なる; Raft によって Paxos よりも理解しやすく実用的なシステムを構築するためのより良い基盤が提供される。わかりやすさを高めるために Raft はリーダー選挙、ログ複製、安全性といった合意の重要な要素を分離し、考慮すべき状態の数を減らすためにより強力な一貫性を強制する。ユーザ調査の結果から Raft は Paxos よりも習得しやすいことを示している。Raft にはクラスタメンバーシップを変更するための新しいメカニズムも含まれている。これは安全性を保証するためにオーバーラップした多数決を使用する。
Table of Contents
- Abstract
- 1 導入
- 2 複製ステートマシン
- 4 理解可能性のデザイン
- 5 Raft コンセンサスアルゴリズム
- 6 クラスタのメンバーシップ変更
- 7 ログ圧縮
- 8 クライアントとの相互伝達
- 9 実装と評価
- 10 関連する研究
- 11 結論
- 12 Acknowledgments
- References
- 参考文献
1 導入
コンセンサスアルゴリズムは一部のメンバーの障害に耐え得る一貫性グループとして機能させることができる。このため信頼性の高い大規模ソフトウェアシステムを構築する上で重要な役割を果たす。Paxos[15, 16] は過去 10 年間のコンセンサスアルゴリズム議論を支配してきた; コンセンサスのほとんどの実装は Paxos に基づいているか、それに影響されたものであり、Paxos はコンセンサスについて学生に教えられる主要な手段となった。
しかし残念ながら Paxos は明快さを向上させる数多くの試みにもかかわらず理解が非常に困難である。さらに、そのアーキテクチャは現実的なシステムをサポートするために複雑な変更を必要とする。その結果、システム構築者と学生の両方が Paxos と格闘することになる。
我々は Paxos と格闘した後、システム構築と教育のためのより良い基盤を提供できる新しいコンセンサスアルゴリズムを模索することに着手した。我々のアプローチは、主たる目的が理解しやすさであるという点で珍しいものである: 実用的なシステムのためにコンセンサスアルゴリズムを定義し、それを Paxos よりはるかに習得しやすい方法で説明できるだろうか? さらに、システム構築者にとって不可欠な直感的な開発を容易にするためのアルゴリズムを望んでいた。アルゴリズムが機能することだけではなく、それが機能する理由が明らかであることも重要だった。
この研究の成果が Raft と呼ばれるコンセンサスアルゴリズムである。Raft の設計では、分解 (Raft はリーダー選挙、ログ複製および安全性を分離する) や空間状態の縮小 (Raft は Paxos と比較して非決定性の程度とサーバが互いに矛盾を起こしうる手段を減らしている) など、分かりやすさ向上させるための特定の手法を適用した。2 つの大学の 43 人の学生を対象としたユーザ調査では Paxos よりも Raft の方がはるかに理解しやすいことがわかった。
Raft は多くの点で既存のコンセンサスアルゴリズム (特に Oki, Liskov の Viewstamped Replication[29, 22]) と似ているがいくつかの新しい機能がある。
強力なリーダー: Raft は他のコンセンサスアルゴリズムよりも強力なリーダーシップを使用する。例えばログエントリはリーダーから他のサーバにのみ流れる。これにより、複製されたログの管理が簡単になり Raft を理解しやすくなる。
リーダー選挙: Raft はリーダーを選出するためにランダムタイマーを使用する。これは既存のコンセンサスアルゴリズムでも必要なハートビートにごく僅かなメカニズムを追加するだけで競合を簡単かつ迅速に解決する。
メンバーシップの変更: Raft のメカニズムはクラスタ内のサーバセットを変更するために、移行中に 2 つの異なる構成の大部分が重複するという新しい連結コンセンサス (joint consensus) アプローチを使用する。これによりクラスタは構成変更中でも正常に動作し続けることができる。
Raft は教育目的および実装の基盤として Paxos やその他のコンセンサスアルゴリズムより優れていると考えている。他のアルゴリズムよりも単純で理解しやすい; 実用的なシステムの需要を満たすために十分に記述されている。オープンソースの実装がいくつか存在しいくつかの企業で使用されている; その安全性は正式に特定され証明されている; そしてその効率は他のアルゴリズムに匹敵している。
本稿の残りの部分では、複製されたステートマシン問題 (2章)、Paxos の長所と短所 (3章)、一般的な理解可能性の説明 (4章)、Raft 合意アルゴリズムの説明 (5〜8章)、Raft の評価 (9章)、そして関連する研究の議論 (10章) を紹介する。
2 複製ステートマシン
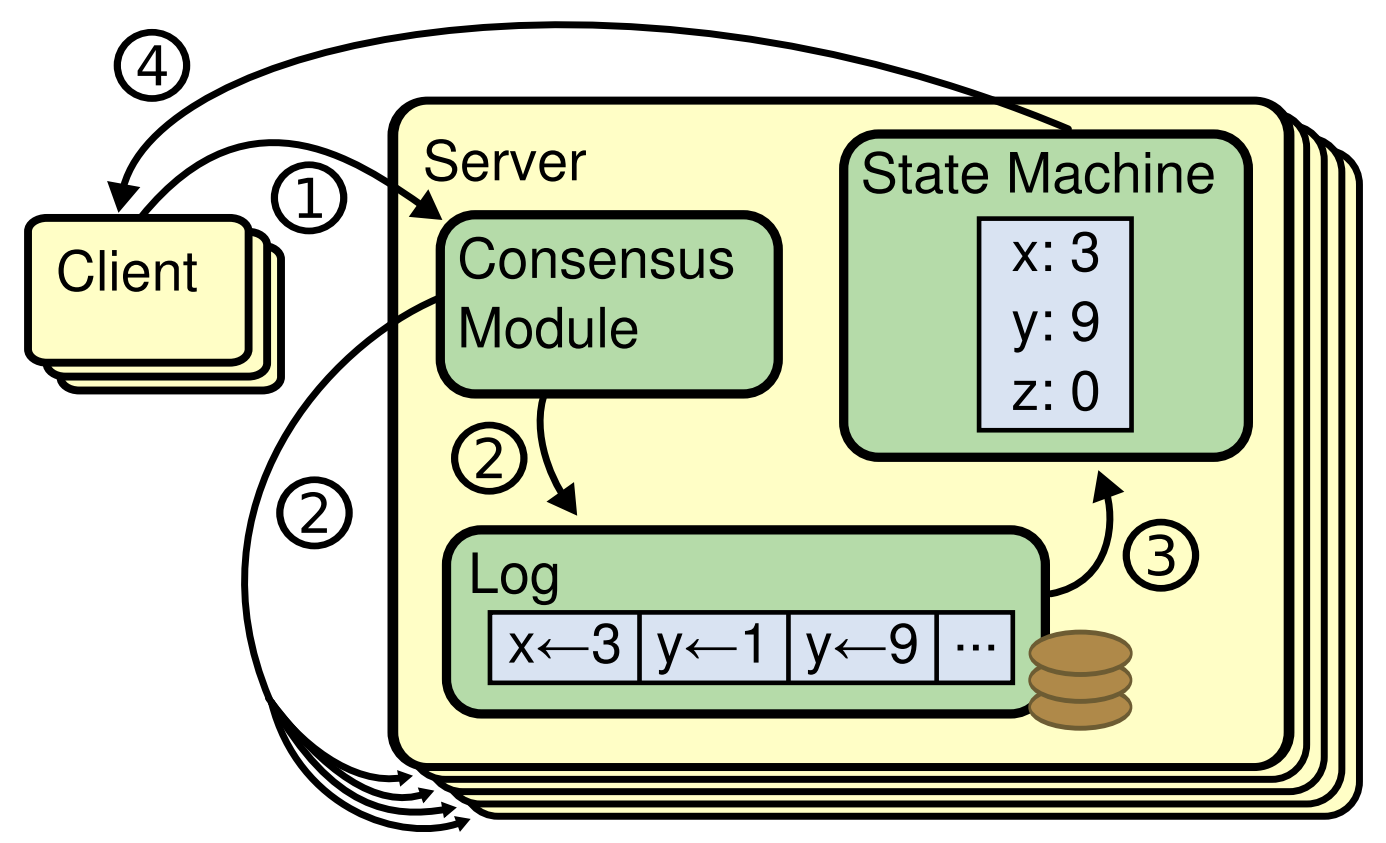
コンセンサスアルゴリズムは通常、複製ステートマシン (replicated state machine) のコンテキストで発生する[37]。このアプローチでは、サーバ集合上のステートマシンが同じ状態の同一のコピーを演算し、一部のサーバが停止しても動作を継続することができる。複製ステートマシンは分散システムにおける様々な障害耐性問題を解決するために使用されている。例えば GFS[8], HDFS[38], RAMCloud[33] のように単一のクラスタリーダを持つ大規模システムでは、通常、リーダ選出を管理しリーダーのクラッシュ後も存続する必要のある構成情報を格納するために別の複製ステートマシンを使用する。複製ステートマシンの例には Chubby[2] と ZooKeeper[11] を含む。
Figure 1 に示すように、通常、複製ステートマシンは複製されたログを使用して実装される。各サーバはそのステートマシンが順番に実行する一連のコマンドを含むログを保存する。各ログには同じコマンドが同じ順序で含まれているため、各ステートマシンは同じコマンドシーケンスを処理する。ステートマシンは決定論的であるためそれぞれが同じ状態とおなじ出力シーケンスを算出する。
複製されたログの一貫性を保つことがコンセンサスアルゴリズムの仕事である。サーバ上のコンセンサスモジュールは、クライアントからコマンドを受け取りそれらをログに追加する。他のサーバ上のコンセンサスモジュールと通信し、一部のサーバで障害が発生した場合でも最終的にすべてのログに同じリクエストが同じ順序で含まれるようにする。コマンドが正しく複製されると、各サーバのステートマシンはログの順序どおりにそれらを処理し、出力がクライアントに返される。結果としてサーバは単一の信頼性の高いステートマシンを形成するように見える。
現実的なシステムのためのコンセンサスアルゴリズムは典型的に以下の特徴を有する:
ネットワーク遅延、パーティション分断、パケット損失・重複・並べ替えなど、すべての非ビザンチン状況下での安全性 (safety) を確保する (誤った結果が返されることはない)。
大部分のサーバが駆動しており、相互に、およびクライアントと通信できる限り、これらは完全に機能する (可用 (available))。つまり 5 台のサーバからなる一般的なクラスタ構成において、2台のサーバ障害に耐えることができる。サーバは停止することによって失敗すると想定される。それらは後で安定した記憶装置上の状態から回復し、再びクラスタに参加するかもしれない。
ログの一貫性を保証するためにタイミングに依存しない: 不完全な時計と極端なメッセージの遅れは、最悪の場合、可用性の問題を引き起こす可能性がある。
一般的なケースでは、クラスタの大部分が1回のリモートプロシジャコールに応答するとすぐにコマンドが完了する; 少数の低速なサーバがシステム全体のパフォーマンスに影響を与えない。
3 Paxos では何が問題か
過去10年間で Leslie Lamport の Paxos プロトコル[15]はコンセンサスと同義となった: これは授業で最も一般的に使用されているプロトコルであり、ほとんどの合意の実装はこれを出発点として使用している。Paxos では最初に、単一の複製されたログエントリのような、単一の決定で合意に達することができるプロトコルを定義する。このサブセットを単一決定 Paxos (single-decree Paxos) と呼ぶ。そして Paxos はこのプロトコルの複数のインスタンスを組み合わせて、ログのような一連の決定を容易にする (multi-Paxos)。Paxos は安全性と生存性の両方を保証しクラスタのメンバーシップ変更をサポートする。その正しさは証明されており、通常の場合は効率的である。
残念ながら Paxos には 2 つの重大な欠点がある。最初の欠点は Paxos が非常に理解しにくいことだ; 完全な説明[15] はよく知られているように不明瞭で、多大なる努力のみでそれを理解することに成功した人はほとんどいない。その結果、Paxos を簡単な言葉で説明しようとする試みがいくつか存在した[16, 20, 21]。これらの説明は単一決定のサブセットに焦点を当てていたが、それでもまだ挑戦的であった。NSDI 2012 参加者の非公式調査では、経験豊富な研究者の中でも Paxos に慣れている人はほとんどいなかった。我々は独力で Paxos と格闘したが、簡単な説明を読んで独自の代替プロトコルを設計するまでプロトコルを完全に理解することができなかった。そしてそれにはほぼ 1 年を費やした。
我々は Paxos の不明瞭さはその基礎である単一決定のサブセットの選択に由来していると仮定している。単一決定 Paxos は密度が高く繊細である。これには単純で直感的な説明がなく、独立して理解することができない 2 つの段階に分けられている。このため、なぜ単一決定プロトコルが機能するかについて直感的に理解することが困難である。multi-Paxos の構成規則はかなりの複雑さと繊細さが追加される。我々は、複数の決定について合意に達することの全体的な問題 (すなはち単一のエントリではなく一つのログ) をより直接的で明白な他の方法で分解することができると信じている。
Paxos の 2 番目の問題は、実用的な実装を構築するための適切な基盤が提供されていないことである。その理由の一つは multi-Paxos 用に広く合意されたアルゴリズムがないことである。Lamport の説明は主に単一決定 Paxos に関するものである; 彼は multi-Paxos への可能なアプローチをスケッチしたが、それには多くの詳細が欠けていた。[26], [39], [13] のように Paxos を具体化して最適化しようとする試みはいくつかあったが、これらは互いに Lamport のスケッチとは異なっていた。Chubby[4] のようなシステムは Paxos のようなアルゴリズムを実装しているが、ほとんどどの場合それらの詳細は公表されていない。
さらに Paxos アーキテクチャは実用的なシステムを構築するのには適していない; これは単一決定分解 (decomposition) のもう一つの結果である。例えば、ログエントリを個別に収集してからそれらを順次ログに統合することに利点はほとんどない; 複雑さを増すだけである。もう一つの問題は、Paxos がそのコアで対称的な peer-to-peer アプローチを使用していることだ (それは最終的にパフォーマンスの最適化として弱いリーダーシップを示唆しているが)。これは、決定が一つだけ行われる単純化された世界では意味があるが、このアプローチを使用する実用的なシステムはほとんど存在しない。一連の決定を下す必要がある場合は、最初にリーダーを選出し、次にリーダーに決定を調整させるほうが簡単かつ迅速である。
結果として実用的なシステムは Paxos にはほとんど似ていない。それぞれの実装は Paxos から始まり、それを実装する際の難しさを発見し、それからかなり異なるアーキテクチャを開発する。これは時間がかかり、間違いが発生しやすく、Paxos を理解するために問題が悪化する。Paxos の定式化はその正しさを証明するために良い方法かもしれないが、実際の実装は Paxos と大きく異なるため証明にはほとんど価値がない。Chubby 実装者からの以下のコメントが典型的である:
There are significant gaps between the description of the Paxos algorithm and the needs of a real-world system. . . . the final system will be based on an unproven protocol [4].
Paxos アルゴリズムの説明と実際のシステムのニーズには大きなギャップがある. . . . 最終的なシステムは証明されていないプロトコルに基づくことになる [4]。
これらの問題のために、我々は Paxos がシステム構築または教育のどちらにも良い基盤を提供しないと結論づけた。大規模ソフトウェアシステムにおけるコンセンサスの重要性を考えると、我々は Paxos より優れた特性を持つ代替コンセンサスアルゴリズムを設計できるかを確かめることにした。Raft はその実験の結果である。
4 理解可能性のデザイン
Raft の設計にはいくつかの目標がある: システム構築のために完全で実用的な基盤を提供しなければならないことから、開発者に要求される設計作業を大幅に削減しなければならない; あらゆる条件下で安全であり、典型的な操作の条件下で利用可能でなければならない; 一般的な操作に対して効率的でなければならない。しかし、我々の最も重要な目標、そして最も難しい課題は理解しやすさ (understandability) だった。大勢の人々がアルゴリズムを快適に理解することが可能でなければならない。加えて、システム構築者が現実世界の実装で避けられない拡張を行うことができるように、アルゴリズムに関する直感を開発することが可能でなければならない。
Raft の設計には、代替アプローチの中から選択しなければならない点が数多く存在した。このような状況で我々は理解しやすさに基づいて選択肢を評価した: 各選択肢を説明するのはどの程度難しいのか? (例えばその状態空間はどれほど複雑であり繊細な意味を持っているか?)、そして読者がアプローチとその意味を完全に理解することがどれほど簡単か?
そのような分析には高い主観性が存在することを我々は認識している; それにもかかわらず、我々は一般的に適用可能な 2 つのテクニックを使用した。1つ目の手法はよく知られている問題分解のアプローチである: なるべく個別に解決、説明、理解できるよう、我々は問題を可能な限り別々の部分に分割した。例えば Raft ではリーダー選挙、ログの複製、安全性、そしてメンバーシップの変更を分割した。
2つ目のアプローチは、考慮すべき状態の数を減らし、システムをより一貫性のあるものにし、可能であれば非決定性を排除することによって状態空間を単純化することだった。具体的には、一連のログには穴ができることが許されず、Raft はログが互いに矛盾する可能性のある方法を制限する。ほとんどの状況で我々は非決定性を排除しようと試みたが、その非決定性が実際に理解可能性を改善するいくつかの状況があった。特に、ランダム化されたアプローチでは非決定性が導入されているが、それらはすべての可能な選択肢を同じように扱う (“どれを選択しても変わらない”) ことで状態空間を縮小する傾向がある。Raft のリーダー選挙アルゴリズムを単純化するために我々はランダム化を使用している。
5 Raft コンセンサスアルゴリズム
Raft は 2 章で説明したように複製されたログを管理するためのアルゴリズムである。Figure 2 は参考のためアルゴリズムを要約した形式で概要化し、Figure 3 はアルゴリズムの重要な特性をまとめたものである; これらの図の要素のついてはこのセクションの残りの部分で説明する。
Raft は最初にリーダー (leader) を選出し、複製されたログの管理に関する完全な責任をリーダーに与えることによってコンセンサスを実装する。リーダーはクライアントからログエントリを受け取り、それらを他のサーバに複製し、それぞれのサーバのステートマシンにログエントリを適用しても安全な場合はサーバに通知する。リーダーを持つことは複製されたログの管理が用意になる。例えばリーダーは他のサーバに問い合わせることなくログの新しいエントリをどこに配置するかを決定でき、データはリーダから他のサーバへ単純な方法で流れる。リーダーがフェイルしたり他のサーバと切断される可能性があり、その場合は新しいリーダーが選出される。
リーダー的なアプローチを考えると、Raft はコンセンサス問題を 3 つの比較的独立したサブ問題に分解している。これらについては後述のサブセクションで説明する。
リーダー選挙: 既存のリーダーが失敗した場合は新しいリーダーが選出されなければならない (5.2 節)。
ログ複製: リーダーはクライアントからログエントリを受け取り、それらをクラスタ全体に複製し、他のログを自分のものと一致させる必要がある (5.3 節)。
安全性: Raft の重要な安全性は Figure 3 の State Machine Safety Property である。特定のログエントリがそのステートマシンに適用されているサーバが存在する場合、他のサーバは同じログインデックスに対して異なるコマンドを適用することができない。5.4 節では Raft がこのプロパティをどのように保証するかについて説明する。解決方法は 5.2 節で説明した選挙アルゴリズムの追加の制限を含んでいる。
コンセンサスアルゴリズムを提示した後、この章では可用性の問題とシステム内のタイミングの役割について説明する。
| currentTerm | サーバから見えている最新のターム (初回起動時に 0 に初期化され単調増加する)。 |
|---|---|
| votedFor | 現在投票している候補者ID。 |
| log[] | ログエントリ; 各エントリにはステートマシンのコマンドおよびリーダーによってエントリが受信されたタームが含まれている (最初のインデックスは 1)。 |
| commitIndex | コミットされていることが分かっているログエントリの最大インデックス (0に初期化され単調増加)。 |
|---|---|
| lastApplied | ステートマシンに適用されたログエントリの最大インデックス (0 に初期化され単調増加)。 |
| nextIndex[] | 各サーバに対して、そのサーバに送信する次のログエントリのインデックス (リーダーの最後のログインデックス + 1 に初期化)。 |
|---|---|
| matchIndex[] | 各サーバに対して、そのサーバで複製されていることが分かっている最も大きいログエントリのインデックス (0に初期化され単調増加)。 |
ログエントリを複製するためにリーダーによって呼び出される (§5.3); ハートビートとしても使用される (§5.2)。
| term | リーダーのターム。 |
|---|---|
| leaderId | フォロワーがクライアントをリダイレクトできるようにするため。 |
| prevLogIndex | 新しいエントリの直前のログエントリのインデックス。 |
| prevLogTerm | prevLogIndex のターム。 |
| entries[] | 保存するログエントリ (ハートビートの場合は空; 効率のため複数を送信することが可能)。 |
| leaderCommit | リーダーの commitIndex。 |
| term | currentTerm, リーダーが自分自身を更新する |
|---|---|
| success | フォロワーが prevLogIndex と prevLogTerm に一致するエントリを含んでいた場合は true。 |
- commandIndex > lastApplied の場合: lastApplied をインクリメントし、log[lastApplied] をステートマシンに適用 (§5.3)。
- RPC リクエストまたはレスポンスがターム T > currentTerm を含む場合: currentTerm = T に設定し、フォロワーに転向 (§5.1)。
- 候補者とリーダーからの RPC に応答する。
- 現在のリーダーからの AppendEntries RPC を受信することなく選挙タイムアウトが経過したり、候補者に投票を与える前に選挙タイムアウトを経過した場合: 候補者に転向。
- 候補者に転向したら選挙を開始する:
- currentTerm を増やす。
- 選挙タイマーのリセット。
- RequestVote RPC を他のすべてのサーバに送信。
- 過半数ののサーバから投票があった場合: リーダーに転向。
- AppendEntries RPC を新しいリーダーから受信した場合: フォロワーに転向。
- 選挙のタイムアウトが経過した場合: 新しい選挙を開始。
- 選出時: 最初の空の AppendEntries RPC (ハートビート) を各サーバに送信。選挙のタイムアウトを防ぐためアイドル期間中に繰り返す (§5.2)。
- クライアントからコマンドを受信した場合: ローカルログにエントリを追加する。エントリがステートマシンに適用された後に応答する (§5.3)。
- フォロワーの最後のログインデックスが nextIndex 以上の場合: nextIndex から始まるログエントリを含む AppendEntries RPC を送信。
- N > commitIndex、過半数の matchIndex[i] ≧ N、log[N].term == currentTerm となる N が存在する場合: commitIndex = N に設定 (§5.3, §5.4)。
Election Safety: 与えられたターム内で選出されるリーダーは一人まで。§5.2
Leader Append-Only: リーダーはログ内のエントリを上書きまたは削除することはない。新しいエントリを上書きするのみ。§5.3
Log Matching: 2つのログに同じインデックスとタームのエントリが含まれている場合、ログは指定されたインデックスまでのすべてのエントリで同一。§5.3
Leader Completeness: 与えられたターム中にログエントリがコミットされれば、そのエントリはすべての中で最も大きいタームとしてリーダーのログに現れる。§5.3
State Machine Safety: サーバがそのステートマシンの特定のインデックスにあるログエントリを適用した場合、他のサーバが同じインデックスに対して異なるログエントリを適用することは決して無い。§5.4.3
5.1 Raft の基本
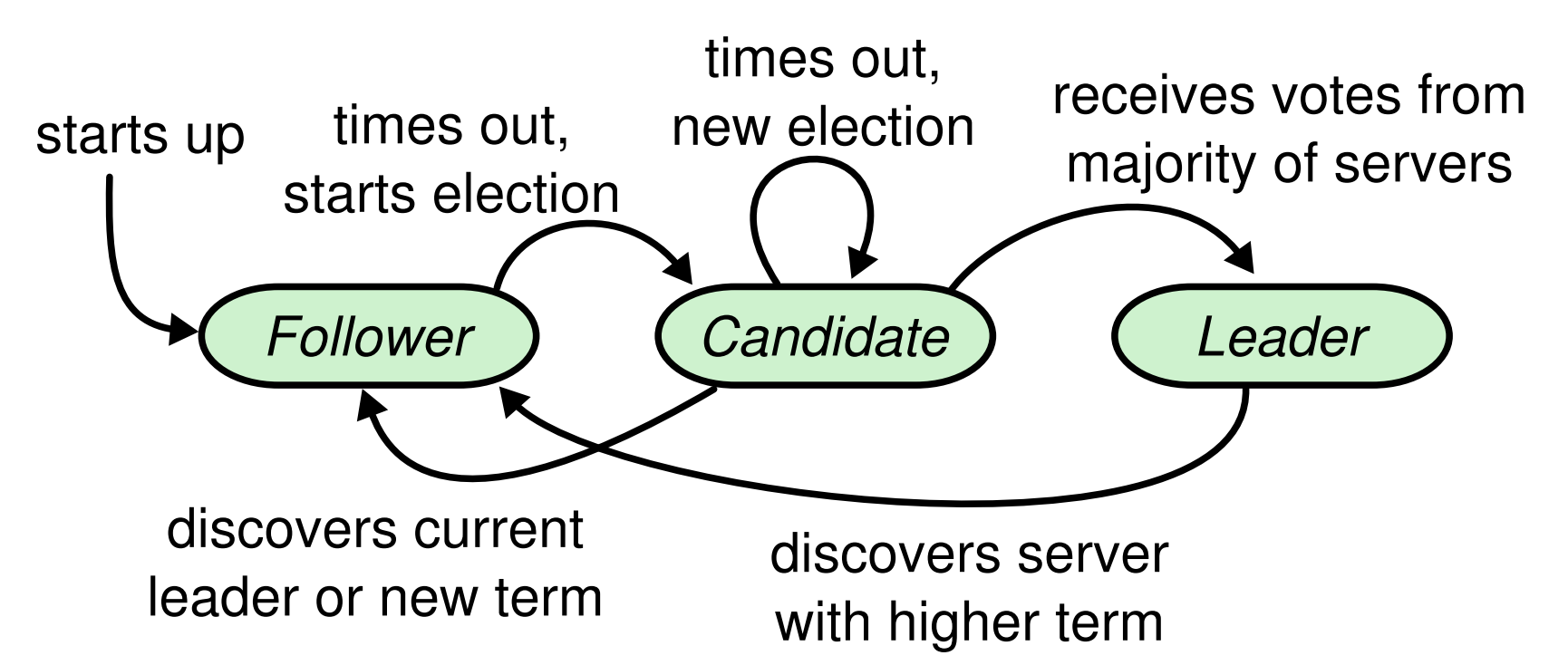
Raft クラスタには複数のサーバが含まれている; 5 台は典型的な数で、システムは 2 台までの障害を許容できる。各サーバは常にリーダー (leader)、フォロワー (follower)、候補者 (candidate) の 3 つの状態のいずれかとなる。通常の運用ではリーダーは 1 つだけで、他のすべてのサーバはフォロワーである。フォロワーは受動的である: それらは自分自身でリクエストを発行することはなく、単にリーダーや候補者からのリクエストに応じる。リーダーはすべてのクライアント要求を処理する (フォロワーがクライアントの要求を受け取った場合、フォロワーはそれをリーダーにリダイレクトする)。3 つ目の状態である候補者は 5.2 節で説明するように新しいリーダーを選出するために使用される。この状態遷移図を Figure 4 に示す; 遷移については後述する。

Raft は Figure 5 に示すように時間を任意の長さのターム (term) に分割する。タームは連続した整数で番号付けされている。それぞれのタームは選挙 (election) で始まり、選挙では 5.2 節で説明するように1つ以上の候補者がリーダーになろうとする。状況によってこの選挙は分割投票 (split vote) が行われることがある。この場合、タームはリーダーなしで終わり、新しいターム (新しい選挙) が速やかに開始する。Raft は与えられたタームに最大でも 1 人のリーダーがいることを保証する。
異なるサーバ上では異なるタイミングでターム間の遷移を観測することがあり、場合によってはサーバは選挙やターム全体さえ観測しないこともある。タームは Raft では論理クロック[14]として機能し、それらは古いリーダーのような遅れた情報をサーバが検出することを可能にする。各サーバには現在のターム (current term) 番号が格納されており、このターム番号は時間とともに単調増加する。現在のタームはサーバが通信するときには必ず交換される。一方のサーバの現在のタームが他のサーバのタームよりも小さい場合には、現在のタームが大きい値に更新される。候補者またはリーダーがそのタームが期限切れであることを発見すると、それはすぐにフォロワーに戻る。サーバが期限切れのターム番号を含むリクエストを受信した場合、そのリクエストは拒否される。
Raft サーバは RPC を使用して通信を行い、基本的なコンセンサスアルゴリズムは 2 種類の RPC のみを必要とする。RequestVote RPC は選挙中に候補者によって開始され (5.2 節)、AppendEntries RPC はログエントリを複製しハートビートの形式を提供するためにリーダーによって開始される (5.3 節)。7 章ではサーバ間のスナップショットを転送するための 3 つ目の RPC を追加している。サーバは時間内にレスポンスを受け取れなかった場合 RPC を再実行し、最高のパフォーマンスを得るために並列して RPC を発行する。
5.2 リーダー選挙
Raft はハートビートを使用してリーダー選挙をトリガーする。起動したサーバはフォロワーとして開始する。サーバは、リーダーまたは候補者から有効な RPC を受信している間はフォロワーの状態を維持する。リーダーは権限を維持するために定期的なハートビート (ログエントリを持たない AppendEntries RPC) をすべてのフォロワーに送信する。フォロワーが選挙タイムアウト (election timeout) と呼ばれる時間内にこの連絡を受け取らなかった場合、実行可能なリーダーが存在しないと判断して新しいリーダーを選出するための選挙を開始する。
選挙を開始するため、フォロワーは現在のタームを 1 つ増やして候補者の状態に遷移する。次に自分自身に投票し、それと並行してクラスタ内の他のサーバに RequestVote RPC を発行する。候補者は次の 3 つのいずれかが起きるまで状態を続ける: (a) 選挙で勝利 (b) 他のサーバがリーダとなった (c) 勝者が確定しないまま期間が過ぎた。これらの結果は下記のパラグラフで個別に説明する。
候補者は同じタームでクラスタ全体の過半数のサーバから投票を受けた場合に選挙で勝利する。各サーバは所定の期間内に先着順で最大 1 人の候補者に投票を行う (注意: 投票に関する追加の制限が 5.4 章に追加されている)。この多数決ルールにより最大 1 人の候補者が特定の期間の選挙に勝利できる (Figure 3 の Election Safety Property)。候補者が選挙に勝利するとリーダーとなる。その後、他のすべてのサーバにハートビートメッセージを送信して権限を確立して新しい選挙の発生を防ぐ。
投票を待機している間、候補者はリーダであると主張する他のサーバから AppendEntries RPC を受け取るかもしれない。(その RPC に含まれる) リーダーのタームが少なくとも候補者の現在のタームと同じ大きさの場合、候補者はリーダーを正当なものとして認識しフォロワー状態に戻る。RPC のタームが候補者の現在のタームより小さい場合、候補者は RPC を拒否し候補者状態を継続する。
3 番目に考慮される結果は候補者が選挙に勝っても負けてもいない状況である: 多数のフォロワーが同時に候補者となる場合、投票が分散して候補者が過半数を獲得することができなくなる。これが起きた場合、各候補者はタイムアウトし、そのタームを1つ増加させて次のラウンドの RequestVote RPC を開始することによって新しい選挙を開始する。しかし、追加の対策がなければ分割票は無制限に繰り返される可能性があるだろう。
Raft は分割投票がまれであり、起きたとしても迅速に解決されるようにランダム化した投票タイムアウトを使用する。最初の段階で投票が分割されないようにするために、選挙のタイムアウトは一定期間 (例: 150-300ms) からランダムに選択される。これはサーバに格差をつけるため、ほとんどの場合、単一のサーバのみがタイムアウトする; そのサーバは選挙に勝ち、他のサーバがタイムアウトする前にハートビートを送信する。分割投票を処理するために同じメカニズムが使用される。各候補者は選挙の開始時にランダム化された選挙タイムアウトを再開し、次の選挙を開始する前にそのタイムアウトが経過するのを待つ。これにより新しい選挙で別の投票が行われる可能性が低くなる。9.2 節ではこのアプローチがリーダーを迅速に選出することを示している。
選挙は、設計上の選択肢の中で理解可能性が我々の選択をどのように導いたかの例である。当初はランキングシステムを使用することを計画していた: 各候補者には競合する候補の中から選択のために使用される一意のランクが割り当てられていた。候補者がより高位の別の候補者を発見した場合、より簡単に高位の候補者が選挙に勝つことができるように、それ自身はフォロワーに戻る。このアプローチでは可用性に関する繊細な問題が発生することがわかった (上位のサーバに障害が発生した場合、下位のサーバがタイム・アウトして再び候補者になる必要がある)。アルゴリズムを数回調整したが各調整後に新しいコーナーケースが発生した。最終的に、我々はランダム化された再試行アプローチがより明白で分かりやすいと結論づけた。
5.3 ログ複製

リーダーが選出されるとリーダーはクライアントのリクエストを処理し始める。各クライアントリクエストには複製ステートマシンによって実行されるコマンドが含まれている。リーダーは新しいエントリとしてコマンドをそのログに追加し、次にエントリを複製するために並行して他の各サーバに AppendEntries RPC を発行する。エントリが安全に複製されると (後述) リーダーがそのエントリをステートマシンに適用し、その実行結果をクライアントに返す。フォロワーがクラッシュしたり、動作が遅くなったり、ネットワークパケットが失われた場合、リーダーはすべてのフォロワーが最終的にすべてのログエントリを保存するまで (クライアントに応答した後でも) AppendEntries RPC を無制限に再実行する。
ログは Figure 6 に示すように構成されている。各ログエントリには、エントリがリーダによって受信されたときにステートマシンコマンドとターム番号が格納される。ログエントリのターム番号はログ間の矛盾を検出し Figure 3 の一部のプロパティを確認するために使用される。各ログエントリにはログ内の位置を識別する整数のインデックスも含まれている。
リーダーはステートマシンにログエントリを適用しても安全であると判断する; このようなエントリはコミット済みと呼ばれる。Raft はコミットされたエントリは永続的であり、最終的には利用可能なすべてのステートマシンによって実行されることを保証する。ログエントリは、そのエントリを作成したリーダーから過半数のサーバに複製されるとコミットされる (例えば Figure 6 のエントリ 7)。またこれは直前のリーダーによって作成されたエントリを含む、リーダーが持つログ内の前のエントリをすべてコミットする。5.4 節ではリーダーの交代後にこのルールを適用する際の繊細な点について説明し、またこのコミットの定義は安全であることも示している。リーダーはコミットされていることが分かっている最大のインデックスを追跡し、将来の AppendEntries RPC (そのハートビートを含む) にそのインデックスを含めて、他のサーバが最終的に見つけられるようにする。フォロワーはログエントリがコミットされたことを知ると、そのエントリをそのローカルステートマシンに (ログ順に) 適用する。
我々は異なるサーバ間でのログの高レベルな一貫性を維持するために Raft ログメカニズムを設計した。これはシステムの動作が単純化され、より予測可能になるだけではなく安全性を確保するための重要な要素となる。Raft は Figure 3 の Log Matching Property を構成する以下の特性を保持している:
異なるログの 2 つのエントリに同じインデックスとタームがある場合、それらは同じコマンドを保持している。
異なるログの 2 つのエントリに同じインデックスとタームがある場合、それ以前のすべてのエントリにおいてログは同一である。
最初の特性は、リーダーが特定のターム内に特定のログインデックスを使用して最大 1 つのエントリを作成し、ログエントリがログ内で位置を変更されることはないという事実に基づいている。2 番目の特性は AppendEntries によって行われる単純な一貫性チェックによって保証される。AppendEntries RPC を送信するとき、リーダーは新しいエントリの直前のエントリのインデックスとタームをログに含める。フォロワーがそのログ内で同じインデックスとタームを持つエントリを見つけられない場合、新しいエントリを拒否する。一貫性チェックは誘導ステップとして機能する: ログ初期の空の状態は Log Matching Property を満たし、一貫性チェックはログが拡張されるたびに Log Matching Property を維持する。その結果、AppendEntries が正常にリターンしたときは必ず、リーダーはフォロワーのログが新しいエントリまでは自分のログと同一であることを認識することができる。
通常の操作ではリーダーとフォロワーのログは一貫したままであることから AppendEntries の一貫性チェックが失敗することはない。しかしリーダーがクラッシュするとログが矛盾したままになる可能性がある (古いリーダーはログ内のすべてのエントリを完全に複製していない可能性がある)。これらの矛盾は一連のリーダーとフォロワーのクラッシュを悪化させる可能性がある。Figure 7 はフォロワーのログが新しいリーダーのログとどのように異なるかを示している。フォロワーは、リーダーに存在するエントリが欠落しているか、リーダーに存在しない追加のエントリがあるか、あるいはその両方である可能性がある。ログに存在しない異質のエントリは複数のタームにまたがるかもしれない。
Raft では、リーダーはフォロワーのログにそれ自身の複製を強制することによって矛盾を処理する。つまり、フォロワーログの競合するエントリはリーダーのログエントリで上書きされる。5.4 節ではこれがもう一つの制限と相まって安全であることを示している。

フォロワーのログを自分のログと一致させるには、リーダーは 2 つのログが一致する最新のログエントリを見つけ、それ以降はフォロワーのログ内のすべてのエントリを削除し、それ以降のすべてのリーダーエントリをフォロワーに送信する必要がある。これらのすべての動作は AppendEntries RPC によって実行される一貫性チェックに応答して発生する。リーダーは各フォロワーの nextIndex を管理する。これは、リーダーがそのフォロワーに送信する次のログエントリのインデックスである。リーダーが最初に権限を得ると、すべての nextIndex 値を、自身のログ内の最後の値の直後にあるインデックスに初期化する (Figure 7 の 11)。フォロワーのログがリーダーのログと矛盾する場合、次の AppendEntries RPC で AppendEntries 一貫性チェックが失敗するだろう。拒否の後、リーダーは nextIndex をデクリメントして AppendEntries RPC を再実行する。やがて nextIndex はリーダーとフォロワーのログが一致するポイントに到達する。これが起きると AppendEntries が成功し、フォロワーのログ内の競合するエントリが削除され、(存在する場合) リーダーのログからエントリが追加される。AppendEntries が成功するとフォロワーのログはリーダーのログと一致し残りのタームについてはそのままになる。
必要であれば、拒否される AppendEntries RPC を削減するためにプロトコルを最適化することができる。例えば AppendEntries 要求を拒否するとき、フォロワーは競合するエントリのタームとそのタームに対して格納されている最初のインデックスを含めることができる。この情報によりリーダーは nextIndex をデクリメントしてそのターム内の競合するエントリすべてを回避することができる; エントリごとに 1 つの RPC ではなく、競合するエントリを持つ各タームに対して 1 つの AppendEntries RPC が必要となるだろう。実際にはフェイルはめったに起きず、多くの矛盾するエントリが存在することはありそうではないため、この最適化が必要であるかは疑問である。
このメカニズムでは、リーダーが権限を得たときにログの整合性を回復するための特別な措置を講じる必要はない。通常の操作を開始するだけで AppendEntries の一貫性チェックの失敗に応じてログが自動的に収束する。リーダー自身がログ内のエントリを上書きまたは削除することはない (Figure 3 の Leader Append-Only Property)。
このログ複製メカニズムは 2 章で説明されている望ましいコンセンサス特性を示している: Raft は過半数のサーバが駆動している限り、新しいログエントリを受け入れ、複製し、適用することができる; 通常の場合、新しいエントリは 1 ラウンドの RPC でクラスタの過半数に複製できる; そして 1 つの遅いフォロワーがパフォーマンスに影響を与えることはない。
5.4 Safety
前章では Raft がリーダーを選出しログエントリを複製する方法について説明した。しかし、これまでに説明したメカニズムは各ステートマシンが全く同じコマンドを同じ順序で実行することを保証するのには十分ではない。例えば、リーダーが複数のログエントリをコミットしている間、フォロワーが利用可能でない場合、そのフォロワーがリーダーに選出されてしまうと、それらのエントリを新しいエントリで上書きすることが可能である; その結果、異なるステートマシンが異なるコマンドシーケンスを実行する可能性がある。
この章ではどのサーバがリーダーに選出されるかに制限を加えることで Raft アルゴリズムを完成させる。この制限により特定のタームのリーダーに、以前のタームでコミットされた全てのエントリが含まれるようになる (Figure 3 の Leader Completeness Property)。選挙の制限を与え、そして我々はコミットメントのためのルールをより正確にする。最後に Leader Completeness Property の証明スケッチを提示し、それが複製ステートマシンの正しい挙動にどのように繋がるかを示す。
5.4.1 選挙の制限
リーダーベースのコンセンサスアルゴリズムでは、リーダーは最終的に全てのコミットされたログエントリを保存しなければならない。Viewstamped Replication [22] のようないくつかのコンセンサスアルゴリズムでは、コミットされた全てのログエントリを初期状態で持ち合わせていないサーバであってもリーダーとして選出されることができる。これらのアルゴリズムでは選挙プロセス中またはその直後に、不足しているエントリを識別して新しいリーダーに送信するための追加のメカニズムが含まれている。残念ながらこれはかなりの追加メカニズムと複雑さをもたらす。Raft はより単純なアプローチを採用しており、各新しいリーダーが選出された瞬間から、以前のタームでコミットされたすべてのエントリが存在することを保証する。それらのエントリをリーダーに転送する必要はない。つまりログエントリはリーダーからフォロワーへの一方向にのみ流れ、リーダーはログ内の既存のエントリを上書きすることはない。
Raft は、ログにすべてのコミット済みエントリを含んでいない候補者が選挙で勝てないように投票プロセスを使用している。候補者が選出されるためにはクラスタの過半数とコンタクトする必要がある。つまり、コミットされた全てのエントリは、これらのサーバの少なくとも一つに存在しなければならないことを意味している。候補者のログがそれら過半数サーバの他のログと少なくとも同じ最新のものである場合 (ここで "最新" は後述で正確に定義する)、それは全てのコミット済みエントリを保持しているだろう。RequestVote RPC はこの制限を実装している: PRC には候補者のログに関する情報が含まれており、自身のログが候補者のログより最新の場合に投票者は投票を拒否する。
Raft はログ内の最後のエントリのインデックスとタームを比較することで 2 つのログのどちらが最新かを判断する。ログが異なるタームの最終エントリを持つ場合、新しいタームのログが最新である。ログが同じタームで終わっている場合、どちらか長い方のログが最新のものである。
5.4.2 直前タームからのコミットエントリ
5.3 節で説明したとおり、リーダーは現在のタームからのエントリが過半数のサーバに格納された時点でコミットされたことを認識する。エントリをコミットする前にリーダーがクラッシュした場合、以降のリーダーはエントリの複製を完了させようとする。しかし、リーダーは、過半数のサーバに保存されたからといって直ちに以前のタームのエントリがコミットされたと結論づけることはできない。Figure 8 は古いログエントリが過半数のサーバに格納されているにもかかわらず、将来のリーダーがそのエントリを上書きしてしまう状況を示している。
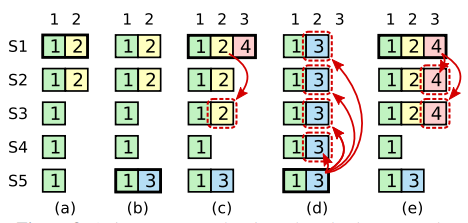
Figure 8 のような問題を排除するために、Raft はレプリカをカウントすることによって直前のタームのログエントリをコミットすることはない。レプリカをカウントすることで、リーダーの現在のタームからのログエントリのみがコミットされる; 現在のタームからのエントリがこのようにコミットされると、Log Matching Property により、それ以前の全てのエントリが間接的にコミットされる。リーダーは古いログエントリがコミット済みであると安全に結論できる状況 (例えばそのエントリが全てのサーバに格納されている場合) もあるが、Raft は単純化のためにより保守的なアプローチを採用している。
Raft では、リーダーが以前のタームからエントリを複製するときにログエントリが元のターム番号を保持するため、コミットルールに余計な複雑さを生じる。他のコンセンサスアルゴリズムでは、新しいリーダーが以前の "ターム" からエントリを再複製する場合、新しい "ターム番号" を使用して再複製する必要がある。Raft のアプローチでは、ログエントリが時間の経過やログ全体で同じターム番号を保持するため、ログエントリを容易に判断できる。さらに、Raft の新しいリーダーはその他のアルゴリズムよりも前のタームから送られるログエントリが少ない (他のアルゴリズムではコミットする前に冗長なログエントリを送信して再番号付けしなければならない)。
5.4.3 Safety の議論
完全な Raft アルゴリズムを与えたことで、我々は Leader Completeness Property が成立することをより正確に論議することができる (この論議は安全性の証明に基づいている; 9.2 節参照)。我々は Leader Completeness Property が成立しないと仮定し、その矛盾を証明する。ターム \(T\) のリーダー (leaderT) がそのタームのログエントリをコミットするが、そのログエントリがある将来のタームのリーダーによって保存されなかったと仮定する。リーダー (leaderU) がエントリを保存しない最小のターム \(U \gt T\) を考える。
コミットされたエントリは leaderU が選出された時点のログにはまだ存在していないはずである (リーダーは決してエントリを削除したり上書きしない)。
leaderT はクラスタの過半数にエントリを複製し、leaderU はクラスタの過半数から得票を得た。従って Figure 9 に示すように、少なくとも 1 つのサーバ ("the voter") が leaderT のエントリを受け入れ leaderU に投票した。the voter は矛盾に到達するための鍵である。
the voter は leaderU に投票する前に leaderT からコミットされたエントリを受け取っていなければならない; そうでなければ leaderT からの AppendEntries リクエストは拒絶されている (その時点のタームは \(T\) より大きくなっているだろう)。
leaderU に投票したときでも the voter はエントリを保存している。これは間に入る全てのリーダーがそのエントリを (仮定により) 含んでおり、リーダーは決してエントリを削除せず、フォロワーはリーダーと競合するエントリのみを削除するためである。
the voter は leaderU に票を与えたため、leaderU のログは the voter のログとおなじ程度に最新でなければならない。これは 2 つの矛盾のうちの 1 つを導く。
第 1 に、the voter と leaderU が同じ最終ログタームを共有している場合、leaderU のログは the voter のログの全てのエントリを含むように、少なくとも the voter のログと同じ長さである必要がある。これは矛盾している。なぜなら、the voter はコミットされたエントリを持ち、leaderU はそうでないと想定されたからである。
そうでない場合、leaderU の最終ログタームは the voter よりも長くなっている必要がある。さらに、the voter の最終ログタームが \(T\) 以上だったため、それは \(T\) より大きい (ターム \(T\) でコミットされたエントリを含んでいる)。leaderU の最後のログエントリを作成した以前のリーダーは (仮定により) そのログにコミットされたエントリを含んでいなければならない。そして Log Maching Property により leaderU のログにはコミットされたエントリも含まれていなければならないが、これは矛盾している。
これで矛盾は解決した。\(T\) より大きなタームをもつ全てのリーダーは、ターム \(T\) でコミットされたターム \(T\) からの全てのエントリを含まなければならない。
Log Matching Property は将来のリーダーが Figure 8 (d) のインデックス 2 のような、間接的にコミットされるエントリも含む事を保証する。

Leader Completeness Property を与えることで Figure 3 の State Machine Safety Property を証明することができる。この特性は、あるサーバが特定のインデックスのログエントリをステートマシンに適用した場合、他のサーバが同じインデックスに対して異なるログエントリを適用することはないことを示している。サーバがログエントリをそのステートマシンに適用する時点で、そのログはそのエントリまでリーダーのログと同一でなければならず、またエントリはコミットされていなければならない。ここで、任意のサーバが特定のログインデックスを適用する最も低いタームについて考慮する。Log Completeness Property により、より高いタームのすべてのリーダーが同じログエントリを保存することが保証されるため、より後のタームでインデックスを適用するサーバも同じ値を適用する。従って State Machine Safety Property が成立する。
最後に、Raft はサーバにログインデックス順をエントリに適用することを要求する。State Machine Safety Property と組み合わせると、全てのサーバがそれぞれそれぞれのステートマシンに全く同じログエントリのセットを同じ順序で適用するだろう。
5.5 フォローワーと候補者のクラッシュ
ここまではリーダーのフェイルに焦点を当ててきた。フォロワーのクラッシュと候補者のクラッシュはリーダーのクラッシュより遙かに扱いが簡単で、どちらも同じ方法で対処することができる。フォロワーまたは候補者がクラッシュした場合、以後それに送信された RequestVote および AppendEntries RPC は失敗するだろう。Raft はそれらの失敗を無制限に再試行することによって処理する; クラッシュしたサーバが再起動した場合、RPC は正常に完了する。サーバが RPC の完了後、応答する前にクラッシュした場合、サーバは再起動後に再び同じ RPC を受け取るだろう。Raft RPC は冪等であるため、これによって害が生じることはない。例えばフォロワーのログにすでに存在するログエントリを含む AppendEntries リクエストを受信した場合、新しいリクエストのエントリは無視される。
5.6 タイミングと可用性
Raft に対する我々の要求の一つは安全性がタイミングに依存しないことである。ある事象が予想よりも早く、または遅く発生したからといってシステムが誤った結果を生成してはならない。しかし、可用性 (クライアントにタイムリーに応答するシステムの能力) は必然的にタイミングに依存しなければならない。例えば、メッセージの交換がサーバ障害の間の典型的な時間よりも長くかかる場合、候補者は選挙に勝つために十分な時間状態を維持していられないだろう; 安定したリーダーが居なければ Raft は処理を進めることができない。
リーダーの選出は Raft においてタイミングが最も重要な側面である。Raft は、システムが以下のタイミング要件 (timing requirement) を満たす限り安定したリーダーを選出し維持することができる。\[ {\it broadcastTime} \ll {\it electionTimeout} \ll {\it MTBF} \]
この不等式において \({\it broadcastTime}\) はサーバがクラスタ内の全てのサーバに RPC を並行して送信し、その応答を受信するまでにかかる平均時間; \({\it electionTimeout}\) は 5.2 節で説明した選挙タイムアウト; \({\it MTBF}\) は 1 台のサーバの平均障害時間である。リーダーはフォロワーが選挙を開始しないようにするためのハートビートメッセージを確実に送信できるように、ブロードキャスト時間は選挙タイムアウトより 1 桁小さくする必要がある; 選挙タイムアウトに使われている乱数アプローチを考えると、この不等号は分割投票の可能性も低くする。システムが着実に進行するように選挙タイムアウトは MTBF よりも数桁小さく必要がある。リーダーが故障するとシステムはおおよそ選挙タイムアウトの間利用できなくなるだろう; 我々は全体の時間のほんの一部を表現したいと思う。
ブロードキャスト時間と MTBF はシステムの基礎となる特徴だが、選挙タイムアウトは選択しなければならないものである。通常 Raft の RPC は受信者が安定したストレージに情報を保存する必要があるため、ブロードキャスト時間はストレージ技術によって 0.5ms から 20ms の範囲になる。その結果、選挙タイムアウトは 10ms から 500ms あたりになるだろう。典型的なサーバ MTBF は数ヶ月以上であり、これはタイミング要件を容易に満たす。
6 クラスタのメンバーシップ変更

これまではクラスター構成 (コンセンサスアルゴリズムに参加しているサーバセット) は固定されていると仮定してきた。しかし実際にはフェイルしたサーバを交換するケースやレプリケーションの多重度を変更する場合など構成の変更が必要となることがある。これはクラスタ全体をオフラインにし設定ファイルを変更してからクラスタを再起動することでも実行できるが、変更中はクラスタを利用できなくなる。さらに手動の手順があるケースではオペレータのミスが発生する危険がある。これらの問題を回避するために構成変更を自動化して Raft コンセンサスアルゴリズムに組み込むことにした。
構成変更メカニズムが安全であるためには、移行中の同じタームに 2 人のリーダーが選出される可能性があってはならない。残念ながらサーバが古い構成から新しい構成に直接切り替えるというアプローチは安全ではない。全てのサーバを一度にアトミックに切り替えることは不可能であるため、移行中にクラスタが 2 つの独立した過半数に分割される可能性がある (Figure 10 参照)。
安全性を確保するために、構成変更は 2 フェーズのアプローチをとる必要がある。この 2 つのフェーズを実装する方法はいくつかある。例えば、いくつかのシステム (例えば[22]) は最初のフェーズを使用して古い設定を無効にし、クライアントの要求を処理できないようにする; その後、第 2 フェーズで新しい設定が有効になる。Raft では、クラスタは最初に連結コンセンサス (joint consensus) と我々が呼んでいる移行構成に切り替わる; 連結コンセンサスが得られるとシステムは新しい構成に移行する。連結コンセンサスは新旧両方の構成を組み合わせたものである:
- ログエントリは両方の構成の全てのサーバに複製される。
- どちらの構成のサーバもリーダーとして機能する。
- 合意 (選挙とエントリコミットメント) は新旧両方で個別に過半数が必要。
連結コンセンサスにより個々のサーバは安全性を犠牲にする異なる期間に構成を移動することができる。さらに、クラスタは構成変更中もクライアント要求の処理を継続することができる。
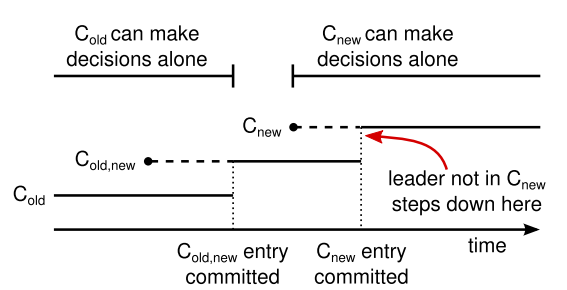
クラスタ構成は複製されたログ内の特別なエントリを使用して保存および伝達される; Figure 11 は構成変更プロセスを示している。リーダーが Cold から Cnew に構成変更する要求を受け取ると、連結コンセンサス (図内の Cold,new) の構成をログエントリとして保存し、前述のメカニズムを使用してそのエントリを複製する。あるサーバが新しい構成エントリをログに追加すると、それ以降の全ての判断にその構成を使用する (エントリがコミットされているかどうかにかかわらず、サーバは常にログ内の最新の構成を使用する)。つまり、リーダーは Cold,new のログエントリがいつコミットされるかを判断するために Cold,new のルールを使うことになる。リーダーがクラッシュした場合、選出された候補者が Cold,new を受け取っているかどうかに応じて Cold または Cold,new のどちらかの下で新しいリーダーを選択できる。いずれにせよ、この期間内に Cnew は一方的な決定を下すことはできない。
Cold,new がコミットされると、Cold も Cnew も相手の承認なしに決定を下すことはできなくなる。また Leader Completeness Property により Cold,new ログエントリを持つサーバのみがリーダーとして選出されることが保証される。これでリーダーが Cnew を指定するログエントリを作成し、クラスタに複製しても安全となった。繰り返すが、この構成は各サーバで確認されしだい有効になる。新しい構成が Cnew の規則に従ってコミットされると、古い構成は無関係になり、新しい設定に含まれていないサーバはシャットダウンできるようになる。これで Figure 11 に示すように Cold と Cnew の両方が一方的な決定を下すことはなくなり安全性が保証される。
再構成に対処するための問題がさらに 3 つ存在する。最初の問題は、新しいサーバが初期状態でログエントリを保存していないであろうことである。この状態でクラスタに追加された場合、それらが追いつくまでかなりの時間を要する可能性がある。その間、新しいログエントリをコミットすることができなくなるかも知れない。可用性のギャップを避けるため、Raft は構成変更の前に新しいサーバが非投票メンバーとしてクラスタに参加する追加のフェーズを導入する (リーダーはそれらにログエントリを複製するが過半数とは見なされない)。新しいサーバが残りのクラスタに追いつくと、上記のような構成変更を進めることができる。
2 つ目の問題は、クラスタリーダーが新しい構成の一部にならない可能性があることである。この場合、リーダーは Cnew ログエントリをコミットした後にステップダウンする (フォロワー状態に戻る)。これは、リーダーが自分自身を含まないクラスタを管理している一定の期間 (Cnew をコミットしている間) があることを意味し、ログエントリは複製されるが自分自身は過半数としてカウントしない。これは、新しい構成が独立して動作できる最初のポイントであるため、Cnew がコミットされたときにリーダーの移行が発生する (Cnew からリーダーを選ぶことは常に可能であろう)。それ以前は Cold のサーバしかリーダーに選出されないかもしれない。
3つ目の問題は、削除されたサーバ (Cnew にはいないサーバ) がクラスタを混乱させる可能性があると言うことである。これらのサーバはハートビートを受信しないためタイムアウトして新しい選挙を行おうとする。そしてそれらは新しいターム番号で RequestVote RPC を送信し、それが現在のリーダーをフォロワー状態に戻すことになる。最終的に新しいリーダーが選出されるが、削除されたサーバは再びタイムアウトし、このプロセスが繰り返されるため可用性が低下する。
この問題を防ぐため、サーバは現在のリーダーが存在すると確信している場合に RequestVote RPC を無視する。具体的には、サーバが現在のリーダーから何かを伝えられてから最小選挙タイムアウト内に RequestVote RPC を受信した場合、そのサーバはタームを更新したり投票を付与することを行わない。これは、各サーバが選挙を開始するために少なくとも最小選挙タイムアウトを待つ通常の選挙には影響しない。しかしこれは削除されたサーバからの混乱を回避するのには役に立つ: もしリーダーがそのクラスタにハートビートを到達させられるのであれば、より大きなターム番号によって退陣することはないだろう。
7 ログ圧縮
Raft のログは通常の操作中に多くのクライアントリクエストを取り込むことでより大きくなってゆくが、現実のシステムでは限りなく拡大することは不可能である。ログが大きくなるにつれ、より多くの空間を占有し再生に多くの時間がかかる。これは、ログに蓄積された不要な情報を破棄する何らかのメカニズムがないことには、最終的に可用性の問題に繋がるだろう。
スナップショットは圧縮の最も簡単なアプローチである。スナップショットの作成では、現在のシステム状態全体が安定した記憶装置上のスナップショットに書き込まれ、その時点までのログ全てが破棄される。スナップショットは Chubby と ZooKeeper で使用されており、この章の残りの部分では Raft でのスナップショットについて詳述する。
ログクリーニング[36]や Log Structured Merge Tree[30, 5] (LSM-Tree) のような、圧縮に対するインクリメンタルアプローチも可能である。これらは一度にデータの一部だけに作用するため圧縮の負荷を時間の経過とともに均等に分散させることができる。これらはまず削除され上書きされたオブジェクトを多数集めたデータ領域を選択し、次にその領域の生存オブジェクトをよりコンパクトに書き換えて領域を開放する。これはスナップショットと比較してかなりの追加メカニズムと複雑さを要求し、常にデータセット全体に対して操作を行うことで問題を単純化する。ログクリーニングは Raft に修正を必要とするが、ステートマシンはスナップショットと同じインターフェースを使用して LSM ツリーを実装することができる。
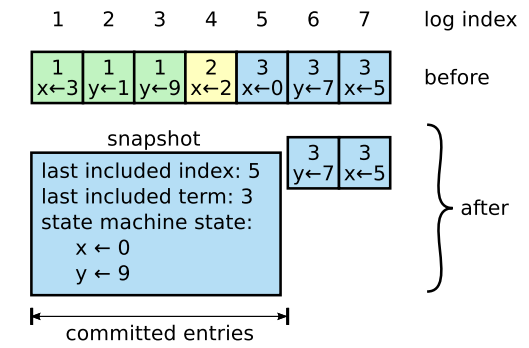
Figure 12 は Raft でのスナップショット作成の基本概念を示している。各サーバは独立してスナップショットを作成し、ログ内のコミットされたエントリのみをカバーする。ほとんどの作業はステートマシンが現在の状態をスナップショットに書き込むことである。Raft もスナップショットに少量のメタデータも含める: last included index は、スナップショットが置き換えるログ内の最後のエントリ (ステートマシンが適用した最後のエントリ) のインデックスであり、last included term はこのエントリのタームである。これらは、エントリが直前のログインデックスとタームを必要とすることから、スナップショットに続く最初のログエントリに対して AppendEntries 一貫性チェックをサポートするために保存される。クラスタメンバーシップの変更 (6 章) を有効にするため、スナップショットには最後に追加されたインデックス時点での最新の構成もログに含める。サーバがスナップショットの書き込みを完了すると、最後に追加されたインデックスまでの全てのログエントリと以前のスナップショットを全て削除することができる。
スナップショットのチャンクをフォロワーに送信するためにリーダーによって呼び出される。リーダーは常にチャンクを順番に送信する。
| term | リーダーのターム |
|---|---|
| leaderId | フォロワーがクライアントをリダイレクトできるように |
| lastIncludedIndex | スナップショットによって置き換えられたエントリの最終インデックス |
| lastIncludedTerm | lastIncludedIndex のターム |
| offset | スナップショットファイル内でのチャンクを特定するオフセットバイト |
| data[] | offset から開始する、スナップショットチャンクの生バイト |
| done | 最後のチャンクの場合 true |
| term | リーダーに対して自分自身を更新する currentTerm |
|---|
- term < currentTerm であれば直ちに応答する
- 最初のチャンク (offset が 0) の場合はスナップショットファイルを作成する
- スナップショットファイルの指定されたオフセットにデータを書き込む
- done が false であれば応答し引き続きデータチャンクを待機する
- スナップショットファイルを保存し、より小さなインデックスを持つ既存のスナップショットや部分的なスナップショットを全て破棄する
- 既存のログエントリがスナップショットの最後に含まれるエントリと同じインデックスおよびタームを持つ場合は、それに続くエントリを保持して応答する
- ログ全体を破棄する
- スナップショットの内容を使用してステートマシンをリセットする (およびスナップショットのクラスター構成を読み込む)
通常、サーバはそれぞれがスナップショットを作成するが、リーダーは時々遅れているフォロワーにスナップショットを送信しなければならない。このケースはリーダーがフォロワーに送信する必要のある次のログエントリをすでに破棄している場合に発生する。幸いこのような状況は通常の運用では考えられない: リーダーに追いついてきたフォロワーはすでにこのエントリを持っているはずである。しかしながら非常に遅いフォロワーやクラスタに参加する新しいサーバ (6 章) はそうではない。そのようなフォロワーを最新状態にするには、リーダーがネットワーク上にスナップショットを送信することである。
リーダーは InstallSnapshot と呼ばれる新しい RPC を使って遅すぎるフォロワーにスナップショットを送信する; Figure 13 参照。フォロワーはこの RPC を使ってスナップショットを受信したときに既存のログエントリをどうするか決定する必要がある。通常、スナップショットにはまだ受信者のログにない新しい情報が含まれているだろう。この場合、フォロワーはそのログ全体を破棄する; 全てはスナップショットによって置き換えられ、スナップショットと競合する未コミットのエントリが存在する可能性がある。また、フォロワーが持つログの前方を記述するスナップショットを (再送信またはミスにより) 受信した場合、スナップショットの対象となっているログエントリは削除されるが、スナップショット以降のエントリは引き続き有効であり保持される。
フォロワーはリーダーの知識がなくてもスナップショットを撮ることができるため、このスナップショット作成アプローチは Raft の強力なリーダー原理から出発している。しかし、我々はこの出発が正当であると考えている。リーダーを持つことは合意に達する際に矛盾する決定を回避するのに役立つが、スナップショット作成時にはすでに合意に達しているため決定が矛盾することはない。データはリーダーからフォロワーに流れるだけでフォロワーだけがデータを再編成できる。
我々はリーダーのみがスナップショットを作成し、そのスナップショットを各フォロワーに送信するというリーダーベースの代替アプローチを検討した。しかしこれには 2 つの欠点がある。まず各フォロワーにスナップショットを送信するとネットワーク帯域幅が消費されスナップショット生成プロセスが遅延する。各フォロワーは各自のスナップショットを作成するために必要な情報をすでに持っているはずである。通常、各サーバがローカル状態からスナップショットを作成する方がネットワーク経由でスナップショットを送受信するよりも遙かに安価である。第二に、リーダーの実装がより複雑になることである。例えば、リーダーは新しいクライアント要求をブロックしないために、新しいログエントリのレプリケーションと並行してフォロワーにスナップショットを送信する必要がある。
スナップショットのパフォーマンスに影響を与える問題がさらに 2 つ存在する。まずサーバはいつスナップショットを作成するか決定しなければならない。もしサーバのスナップショットが頻繁すぎればディスクの帯域幅と電力が無駄である; もしスナップショットの頻度が低すぎればストレージ容量を使い果たす恐れがあり、再起動中にログを再生するのに必要な時間が長くなる。簡単な方法の一つは、ログがバイト単位での固定サイズに達したときにスナップショットを作成することである。このサイズがスナップショットの予想サイズより大幅に大きく設定されている場合、スナップショットによるディスク帯域幅のオーバーヘッドは小さいだろう。
二つ目のパフォーマンス問題は、スナップショットの作成にかなりの時間を要する可能性があることである。これにより通常の操作に遅延が発生することは望ましくない。解決策は、書き込まれるスナップショットに影響を与えず新しい更新を受け入れることができるように copy-on-write 技術を使用することである。例えば機能的なデータ構造を備えたステートマシンは本来的にこれをサポートしている。あるいは、オペレーティングシステムの copy-on-write サポート (例えば Linux での fork) を使用してステートマシン全体の in-memory スナップショットを作成することができる (我々の実装ではこのアプローチを使用している)。
8 クライアントとの相互伝達
この章ではクライアントがクラスタのリーダーを見つける方法や Raft が線形化可能なセマンティクス[10]をサポートする方法など、クライアントと Raft が対話する方法について説明する。これらの問題は他の全てのコンセンサスベースのシステムに当てはまり、Raft のソリューションもそれらのシステムと同じである。
Raft のクライアントはリクエストの全てをリーダに送信する。クライアントは最初に起動したときランダムに選択されたサーバに接続する。クライアントの最初の選択肢がリーダーでなかった場合、そのサーバはクライアントの要求を拒否し、自分が受信している最新のリーダーに関する情報を提供する (AppendEntries にはリーダーのアドレスが含まれている)。リーダーがクラッシュするとクライアント要求はタイムアウトする; クライアントはランダムに選択したサーバで再試行する。
Raft のゴールは線形化可能なセマンティクス (各操作は呼び出しから応答までのある時点で、瞬時に、正確に一回 (exactly once) 実行されるように見える) を実装することである。しかし、これまでに説明したように Raft はコマンドを複数回実行することができる。例えばログエントリをコミットした後、クライアントに応答する前にリーダーがクラッシュした場合、クライアントは新しいリーダーを使用してそのコマンドを再実行することでコマンドは 2 回実行されることになる。この解決方法は、クライアントが各コマンドに固有のシリアル番号を割り当てることである。そしてステートマシンは各クライアントに対して処理された最新のシリアル番号を関連する応答と共に追跡する。すでに実行されているシリアル番号のコマンドを受信した場合は要求を再実行せず即座に応答する。
読み取り専用操作はログに何も書き込むことなく処理することができる。しかし、リクエストに応答するリーダーが、それ自身が認識していないより新しいリーダーに交代している可能性があるため、追加の対策を講じなければ古いデータを返す危険がある。線形可能な読み込みは古いデータを返してはならず、Raft はログを使わずにこれを保証するために 2 つの追加の対策が必要である。まず、リーダーはどのエントリがコミット済みかについての最新情報を持っている必要がある。Leader Completeness Property はリーダーが全てのコミットされたエントリを保持していることを保証するが、そのタームの開始時にはどのエントリまでコミットされているか分からない場合がある。それを知るためにはそのタームでエントリをコミットする必要がある。Raft では各リーダーがそのタームの開始時にログに空の no-op エントリをコミットさせることでこの問題を処理する。次に、リーダーは読み取り専用リクエストを処理する前に自分が退任しているかどうかを確認する必要がある (より新しいリーダーが選出されている場合、その情報は古くなっている可能性がある)。Raft はリーダーが読み取り専用リクエストに応答する前にクラスタの過半数とハートビートを交換するようにすることでこの問題を処理する。あるいは、リーダーはハートビートの機構を使ってリース[9]の一形態を提供することもできるが、この安全性はタイミングに依存するだろう (これは bounded clock skew を前提としている)。
9 実装と評価
我々は RAMCloud[33]の設定情報を格納し、RAMCloud コーディネーターのフェイルオーバーを支援する複製ステートマシンの一部として Raft を実装した。Raft の実装には、テスト、コメント、空白行を除いておよそ 2000 行の C++ コードが含まれている。ソースコードは自由に入手が可能である[23]。この論文のドラフトに基づいて開発の様々な段階にある約 25 の独立したサードパーティオープンソース Raft 実装[34]も存在する。また様々な企業が Raft ベースのシステムを展開している[34]。
このセクションの残りの部分では理解可能性、正確性、およびパフォーマンスの 3 つの観点で Raft を評価する。
9.1 理解可能性
Paxos に対する Raft の理解しやすさを測定するためにスタンフォード大学の Advanced Operation Systems コースと UC Berkeley の Distributed Computing コースの上級学部生と大学院生を使って実験的研究を行った。Raft と Paxos で別々のビデオ講義を録画し、対応するクイズを作成した。Raft の講義ではログ圧縮以外の内容について説明した; Paxos の講義では単一決定 Paxos, multi-decree Paxos、再構成、実際に必要ないくつかの最適化 (リーダー選挙など) など、同等の複製ステートマシンを作成するのに十分な題材を取り上げた。このクイズでは、アルゴリズムの基本的な理解度をテストしたほか、学生にコーナーケースについての推論も求めた。各生徒は 1 つのビデオを見て対応するクイズに答え、2 番目のビデオを見て 2 番目のクイズに答えた。参加者の約半数は最初に Paxos パートを行い残りの半数は最初に Raft パートを行い、研究の最初の部分から得られたパフォーマンスと、経験における個人差の両方を説明した。各クイズの参加者のスコアを比較して、参加者が Raft をよりよく理解しているかを確認した。
Paxos と Raft の比較はできるだけ公平となるよう勤めた。43 人の参加者のうち 15 人が Paxos を使った経験があると報告しており、Paxos の動画は Raft の動画より 14% 長かった。Table 1 に要約されているように、我々の偏りの潜在的な原因を緩和するための措置を講じてきた。全ての資料はレビュー用に利用することができる[28,31]。
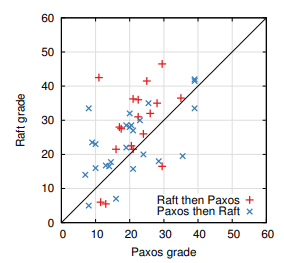
平均して参加者は Paxos クイズより Raft クイズの方が 4.9 ポイント高かった (60点満点中 Raft 平均スコアは 25.7、平均 Paxos スコアは 20.8 だった); Figure 14 はそれぞれのスコアを示している。対応する t 検定では 95% の信頼度で、Raft スコアの真の分布は Paxos スコアの真の分布より少なくとも 2.5 ポイント大きい平均値を示した。
我々はまた未知の学生のクイズスコアを三つの要因に基づいて予測する線形回帰モデルを作成した: 彼らがどのクイズを取ったか、彼らの過去の Paxos 経験の程度、および彼らがアルゴリズムを学んだ順序である。このモデルはクイズの選択が Raft に有利な 12.5 ポイント差を生むと予測している。これは観測された 4.9 ポイントの差よりも有意に高く、実際の学生の多くが過去に Paxos を経験しており、それが Paxos をかなり助けたのに対して、Raft もわずかに助けている。奇妙なことにこのモデルではすでに Paxos のクイズを受けた人の Raft スコアが 6.3 ポイント下がると予測している; 理由は不明だが統計的に有意であると思われる。
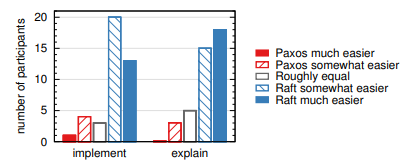
また、クイズの後に参加者を調査しどのアルゴリズムが実装または説明しやすいかを確認した; これらの結果を Figure 15 に示す。参加者の圧倒的多数が Raft の方が実装と説明が容易であると報告している (各質問 41 中 33)。しかしながら、これらの自己報告の感想は参加者のクイズスコアより信頼性が低く、参加者は Raft が理解しやすいという我々の仮説の知識によってバイアスを受けた可能性がある。
Raft の利用者調査に関する詳細な考察は[31]で利用可能である。
| Concern | Steps taken to mitigate bias | Materials for review[28,31] |
|---|---|---|
| 講義品質の同等性 | どちらも同じ講師。いくつかの大学で使用されている既存の資料に基づいて改良された Paxos の講義。Paxos の講義は 14% 長くなった。 | ビデオ |
| クイズ難易度の同等性 | 問題をグループ化し、試験間でペアにする。 | クイズ |
| 評価の公正性 | Rubric を使用した。クイズを交互にランダムな順序で採点。 | rubric |
9.2 正確性
我々は 5 章で述べたコンセンサス機構のための正式な仕様 (formal specification) と安全性の証明を開発した。正式な仕様[31]は TLA+ 仕様記述言語[17]を用いて Figure 2 に要約された情報を完全に正確なものにしている。これは約 400 行の長さで証明の対象となる。また Raft を実装する全ての人にとっても有用であろう。我々は TLA 証明システム[7]を使用して Log Completeness Property を機械的に証明した。しかしこの証明は機械的にチェックされていない不変性に依存している (例えば仕様の型安全性は証明されていない)。さらに、我々は (仕様のみに依存するため) 完全で (約 3500 ワードの長さのため) 比較的正確である State Machine Safety 特性の非公式な証明[31]を作成した。
9.3 パフォーマンス
Raft の性能は Paxos のような他のコンセンサスアルゴリズムと似ている。パフォーマンスに対して最も重要なケースは確立されたリーダーが新しいログエントリをレプリケートする場合である。Raft はこれを最小限のメッセージ数 (リーダーからクラスタの半分への 1 回のラウンドトリップ) で実現している。また Raft のパフォーマンスをさらに向上させることも可能である。例えば、より高いスループットとより低い待ち時間のためのバッチ処理とパイプライン処理リクエストをサポートすることは容易である。他のアルゴリズムに対して様々な最適化が文献で提案されている; これらの多くは Raft にも適用できるが、我々は今後の研究に任せる。
我々は Raft の実装を使用して Raft のリーダー選出アルゴリズムのパフォーマンスを測定し、2 つの質問に回答した。第一に、選挙の過程は急速に収束するだろうか? 第二に、リーダーが故障した後に達成できるダウンタイムの最小値はどの程度か?
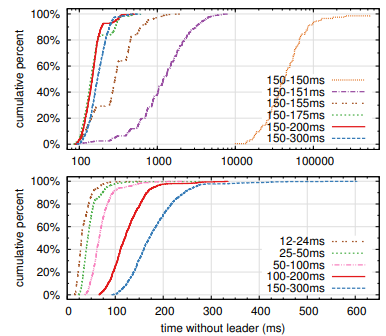
リーダー選出を測定するために我々は 5 台のサーバで構成されるクラスタのリーダーを繰り返しクラッシュさせ、クラッシュの検出から新しいリーダーの選出までにかかる時間を測定した (Figure 16 参照)。最悪のシナリオを生成するために、各トライアルにおけるサーバが異なるログ長を持たせていたため、いくつかの候補者はリーダーになる資格がなかった。さらに、分割投票を誘発させるためにテストスクリプトはプロセスを終了する前にリーダーからのハートビート RPC の同期ブロードキャストをトリガーした (これはクラッシュの前に新しいログエントリを複製するリーダーの動作に似ている)。リーダーは全てのテストの最小選挙タイムアウトの半分であるハートビート間隔内で均一にランダムにクラッシュした。従って、可能な最小ダウンタイムは最小選挙タイムアウトの約半分だった。
Figure 16 の上側のグラフは、選挙タイムアウトにおける少量のランダム化が選挙において分割投票を回避するのに十分であることを示している。ランダム性がない場合、我々のテストではたくさんの分割投票のためにリーダー選挙は一貫して 10 秒より長くかかった。わずか 5ms のランダム性を追加するだけでダウンタイムの中央値は 287ms になった。よりランダム性を使用すると最悪ケースの動作が改善される。ランダム性が 50ms の場合、最悪ケースの完了時間 (1000 以上のトライアル) は 513ms だった。
Figure 16 の一番下のグラフは選挙タイムアウトを短縮することでダウンタイムを短縮できることを示している。12~24ms の選挙タイムアウトではリーダーの選出に平均 35ms しかかからない (最長の試行は 152ms かかった)。しかし、この時点を超えてタイムアウトを短縮することは Raft のタイミング要件に違反する。つまりリーダーは、他のサーバが新しい選挙を開始する前にハートビートをブロードキャストすることが困難となる。これにより不必要にリーダー変更が発生し、システム全体の可用性が低下する可能性がある。150-300ms のような保守的な選挙タイムアウトを使用することが推奨される; このようなタイムアウトによって不必要にリーダーが変更される可能性は低く、良好な可用性が維持される。
10 関連する研究
コンセンサスアルゴリズムに関する出版物は数多くあり、その多くは以下のカテゴリの一つに分類される:
Paxos の欠けている詳細を補い、実装のためのより良い基盤を提供するようにアルゴリズムを変更する改良[26,39,13]。
Chubby[2,4]、ZooKeeper[11, 12]、Spanner[6] などのコンセンサスアルゴリズムを実装するシステム。Chubby と Spanner のアルゴリズムは詳細には公開されていないが、どちらも Paxos に基づいていると主張している。ZooKeeper のアルゴリズムはより詳細に公開されていて Paxos に基づいている。
Oki と Liskov の Viewstamped Replication (VR) は Paxos と同時期に開発されたコンセンサスに対する代替アプローチである。元々の記述[29]は分散トランザクションのためのプロトコルと絡み合っていたが、最近の更新[22]でコアの合意プロトコルが分離された。VR は Raft と多くの類似点を持つリーダーベースのアプローチを使用する。
Raft と Paxos の大きな違いは Raft の強力なリーダーシップである: Raft はリーダー選挙をコンセンサスプロトコルの重要な部分として使用し、リーダーにできるだけ多くの機能を集中させている。このアプローチにより理解しやすい単純なアルゴリズムが得られる。Paxos では、例えばリーダーの選出は基本合意プロトコルと直行している: これはパフォーマンス最適化としてのみ機能し合意を達成するためには必要ではない。しかし、これは付加的なメカニズムをもたらす: Paxos は、基本的な合意のための 2 段階のプロトコルと、リーダー選出のための別のメカニズムの両方を含む。対照的に Raft はリーダー選出をコンセンサスアルゴリズムに直接組み込み、それをコンセンサスの 2 つのフェーズの最初として使用する。この結果 Paxos よりメカニズムが小さくなる。
Raft と同様、VR と ZooKeeper もリーダーベースであり Paxos に対する Raft の優位性の多くを共有している。しかし Raft は VR や ZooKeeper ほどのメカニズムを持っていない。例えば Raft のログエントリは 1 方向 (AppendEntries RPC のリーダーから外に向かって) にのみ流れる。VR ログエントリは双方向に流れる (リーダーは選挙プロセスの間ログエントリを受け取ることができる); その結果、追加の複雑さが生じている。公開されている ZooKeeper の説明でもリーダーとの間でログエントリが転送されるが実装は明らかに Raft に似ている[35]。
Raft のメッセージタイプは我々が知っているどのコンセンサスベースのログレプリケーションのアルゴリズムよりも少なくなっている。例えば、我々は VR と ZooKeeper で使用されている基本的な合意とメンバーシップ変更のためのメッセージタイプをカウントした (ログ圧縮とクライアントインタラクションはアルゴリズムにほとんど依存しないため除外)。VR と ZooKeeper はそれぞれ 10 の異なるメッセージタイプを定義しているが、Raft は 4 つのメッセージタイプしか定義していない (2 つの RPC リクエストとその応答)。Raft のメッセージは他のアルゴリズムよりやや密だが全体としては単純である。加えて VR と ZooKeeper はリーダーの変更中にログ全体を送信するという観点で詳述されている; これらのメカニズムを実用的に最適化するには追加のメッセージタイプが必要となる。
Raft の強力なリーダーシップアプローチはアルゴリズムを単純化するが、パフォーマンスの最適化を妨げる。例えば Egalitarian Paxos (EPaxos) は環境によってはリーダーシップの無いアプローチ[27]でパフォーマンスを向上させることができる。EPaxos はステートマシンコマンドの交換性を利用する。同時に提案された他のコマンドが通信を行っている限り、どのサーバも 1 回の通信でコミットできる。しかし、同時に提案されたコマンドが互いに通信しない場合、EPaxos は追加の通信ラウンドを必要とする。どのサーバでもコマンドをコミットできるため EPaxos はサーバ間の負荷を適切に分散し WAN 設定では Raft よりも遅延を少なくすることができる。ただし Paxos は非常に複雑となる。
クラスタのメンバーシップを変更するいくつかの異なるアプローチが Lamport のオリジナルの提案[15]、VR[22]、SMART[24] など他の研究で提案または実装されている。我々が Raft のための連結コンセンサスアプローチを選んだのは Raft がコンセンサスプロトコルの残りの部分を活用しているため、メンバー変更に必要な追加のメカニズムがほとんどないためである。Lamport の \(\alpha\)-ベースのアプローチはリーダーが居なくてもコンセンサスに達することができると仮定しているため Raft にとっては選択肢ではなかった。VR および SMART と比較すると RAFT の再構成アルゴリズムには通常の要求の処理を制限することなくメンバーシップの変更が可能であるという利点がある; 対照的に、VR は構成変更中に全ての通常処理を停止し、SMART は未処理の要求の数に \(\alpha\) のような制限を課す。Raft のアプローチは VR や SMART よりも少ないメカニズムしか追加しない。
11 結論
多くの場合、アルゴリズムは正確性、効率性、簡潔性を主要な目的として設計される。これらはいずれも価値のある目的だが、我々は理解しやすさも重要だと考えている。他の目標はどれも、開発者がアルゴリズムを実用的な実装に変換するまでは達成できず、それは必然的に出版時の形式から逸脱して拡張されることになる。開発者がこのアルゴリズムを深く理解し、直感的でなければ、実装時に望ましい特性を維持することは難しいだろう。
本論文では、広く受け入れられているが深くまで見通せないアルゴリズムである Paxos が長年にわたって学生と開発者に挑戦してきた分散コンセンサスの問題を扱った。我々は新しいアルゴリズム Raft を開発し Paxos よりも理解しやすいことを示した。また我々は Raft がシステム構築のためのより良い基盤を提供するとも考えている。主要な設計目標として理解しやすさを使用することで Raft の設計へのアプローチが変わった; 設計が進むにつれ、問題の分解や状態空間の単純化など、いくつかの手法を繰り返し再利用することになった。これらの技術は Raft の理解しやすさを改善しただけでなく、その正しさを自分自身に納得させることを容易にした。
12 Acknowledgments
The user study would not have been possible without the support of Ali Ghodsi, David Mazières, and the students of CS 294-91 at Berkeley and CS 240 at Stanford. Scott Klemmer helped us design the user study, and Nelson Ray advised us on statistical analysis. The Paxos slides for the user study borrowed heavily from a slide deck originally created by Lorenzo Alvisi. Special thanks go to David Mazières and Ezra Hoch for finding subtle bugs in Raft. Many people provided helpful feedback on the paper and user study materials, including Ed Bugnion, Michael Chan, Hugues Evrard, Daniel Giffin, Arjun Gopalan, Jon Howell, Vimalkumar Jeyakumar, Ankita Kejriwal, Aleksandar Kracun, Amit Levy, Joel Martin, Satoshi Matsushita, Oleg Pesok, David Ramos, Robbert van Renesse, Mendel Rosenblum, Nicolas Schiper, Deian Stefan, Andrew Stone, Ryan Stutsman, David Terei, Stephen Yang, Matei Zaharia, 24 anonymous conference reviewers (with duplicates), and especially our shepherd Eddie Kohler. Werner Vogels tweeted a link to an earlier draft, which gave Raft significant exposure. This work was supported by the Gigascale Systems Research Center and the Multiscale Systems Center, two of six research centers funded under the Focus Center Research Program, a Semiconductor Research Corporation program, by STARnet, a Semiconductor Research Corporation program sponsored by MARCO and DARPA, by the National Science Foundation under Grant No. 0963859, and by grants from Facebook, Google, Mellanox, NEC, NetApp, SAP, and Samsung. Diego Ongaro is supported by The Junglee Corporation Stanford Graduate Fellowship.
References
- BOLOSKY, W. J., BRADSHAW, D., HAAGENS, R. B., KUSTERS, N. P., AND LI, P. Paxos replicated state machines as the basis of a high-performance data store. In Proc. NSDI’11, USENIX Conference on Networked Systems Design and Implementation (2011), USENIX, pp. 141–154.
- BURROWS, M. The Chubby lock service for looselycoupled distributed systems. In Proc. OSDI’06, Symposium on Operating Systems Design and Implementation (2006), USENIX, pp. 335–350.
- CAMARGOS, L. J., SCHMIDT, R. M., AND PEDONE, F. Multicoordinated Paxos. In Proc. PODC’07, ACM Symposium on Principles of Distributed Computing (2007), ACM, pp. 316–317.
- CHANDRA, T. D., GRIESEMER, R., AND REDSTONE, J. Paxos made live: an engineering perspective. In Proc. PODC’07, ACM Symposium on Principles of Distributed Computing (2007), ACM, pp. 398–407.
- CHANG, F., DEAN, J., GHEMAWAT, S., HSIEH, W. C., WALLACH, D. A., BURROWS, M., CHANDRA, T., FIKES, A., AND GRUBER, R. E. Bigtable: a distributed storage system for structured data. In Proc. OSDI’06, USENIX Symposium on Operating Systems Design and Implementation (2006), USENIX, pp. 205–218.
- CORBETT, J. C., DEAN, J., EPSTEIN, M., FIKES, A., FROST, C., FURMAN, J. J., GHEMAWAT, S., GUBAREV, A., HEISER, C., HOCHSCHILD, P., HSIEH, W., KANTHAK, S., KOGAN, E., LI, H., LLOYD, A., MELNIK, S., MWAURA, D., NAGLE, D., QUINLAN, S., RAO, R., ROLIG, L., SAITO, Y., SZYMANIAK, M., TAYLOR, C., WANG, R., AND WOODFORD, D. Spanner: Google’s globally-distributed database. In Proc. OSDI’12, USENIX Conference on Operating Systems Design and Implementation (2012), USENIX, pp. 251–264.
- COUSINEAU, D., DOLIGEZ, D., LAMPORT, L., MERZ, S., RICKETTS, D., AND VANZETTO, H. TLA+ proofs. In Proc. FM’12, Symposium on Formal Methods (2012), D. Giannakopoulou and D. M´ery, Eds., vol. 7436 of Lecture Notes in Computer Science, Springer, pp. 147–154.
- GHEMAWAT, S., GOBIOFF, H., AND LEUNG, S.-T. The Google file system. In Proc. SOSP’03, ACM Symposium on Operating Systems Principles (2003), ACM, pp. 29–43.
- GRAY, C., AND CHERITON, D. Leases: An efficient faulttolerant mechanism for distributed file cache consistency. In Proceedings of the 12th ACM Ssymposium on Operating Systems Principles (1989), pp. 202–210.
- HERLIHY, M. P., AND WING, J. M. Linearizability: a correctness condition for concurrent objects. ACM Transactions on Programming Languages and Systems 12 (July 1990), 463–492.
- HUNT, P., KONAR, M., JUNQUEIRA, F. P., AND REED, B. ZooKeeper: wait-free coordination for internet-scale systems. In Proc ATC’10, USENIX Annual Technical Conference (2010), USENIX, pp. 145–158.
- JUNQUEIRA, F. P., REED, B. C., AND SERAFINI, M. Zab: High-performance broadcast for primary-backup systems. In Proc. DSN’11, IEEE/IFIP Int’l Conf. on Dependable Systems & Networks (2011), IEEE Computer Society, pp. 245–256.
- KIRSCH, J., AND AMIR, Y. Paxos for system builders. Tech. Rep. CNDS-2008-2, Johns Hopkins University, 2008.
- LAMPORT, L. Time, clocks, and the ordering of events in a distributed system. Commununications of the ACM 21, 7 (July 1978), 558–565.
- LAMPORT, L. The part-time parliament. ACM Transactions on Computer Systems 16, 2 (May 1998), 133–169.
- LAMPORT, L. Paxos made simple. ACM SIGACT News 32, 4 (Dec. 2001), 18–25.
- LAMPORT, L. Specifying Systems, The TLA+ Language and Tools for Hardware and Software Engineers. AddisonWesley, 2002.
- LAMPORT, L. Generalized consensus and Paxos. Tech. Rep. MSR-TR-2005-33, Microsoft Research, 2005.
- LAMPORT, L. Fast paxos. Distributed Computing 19, 2 (2006), 79–103.
- LAMPSON, B. W. How to build a highly available system using consensus. In Distributed Algorithms, O. Baboaglu and K. Marzullo, Eds. Springer-Verlag, 1996, pp. 1–17.
- LAMPSON, B. W. The ABCD’s of Paxos. In Proc. PODC’01, ACM Symposium on Principles of Distributed Computing (2001), ACM, pp. 13–13.
- LISKOV, B., AND COWLING, J. Viewstamped replication revisited. Tech. Rep. MIT-CSAIL-TR-2012-021, MIT, July 2012.
- LogCabin source code. http://github.com/logcabin/logcabin
- LORCH, J. R., ADYA, A., BOLOSKY, W. J., CHAIKEN, R., DOUCEUR, J. R., AND HOWELL, J. The SMART way to migrate replicated stateful services. In Proc. EuroSys’06, ACM SIGOPS/EuroSys European Conference on Computer Systems (2006), ACM, pp. 103–115.
- MAO, Y., JUNQUEIRA, F. P., AND MARZULLO, K. Mencius: building efficient replicated state machines for WANs. In Proc. OSDI’08, USENIX Conference on Operating Systems Design and Implementation (2008), USENIX, pp. 369–384.
- MAZIERES, D. Paxos made practical. http://www.scs.stanford.edu/˜dm/home/papers/paxos.pdf, Jan. 2007.
- MORARU, I., ANDERSEN, D. G., AND KAMINSKY, M. There is more consensus in egalitarian parliaments. In Proc. SOSP’13, ACM Symposium on Operating System Principles (2013), ACM.
- Raft user study. http://ramcloud.stanford.edu/˜ongaro/userstudy/.
- OKI, B. M., AND LISKOV, B. H. Viewstamped replication: A new primary copy method to support highly-available distributed systems. In Proc. PODC’88, ACM Symposium on Principles of Distributed Computing (1988), ACM, pp. 8–17.
- O’NEIL, P., CHENG, E., GAWLICK, D., AND ONEIL, E. The log-structured merge-tree (LSM-tree). Acta Informatica 33, 4 (1996), 351–385.
- ONGARO, D. Consensus: Bridging Theory and Practice. PhD thesis, Stanford University, 2014 (work in progress). http://ramcloud.stanford.edu/˜ongaro/thesis.pdf.
- ONGARO, D., AND OUSTERHOUT, J. In search of an understandable consensus algorithm. In Proc ATC’14, USENIX Annual Technical Conference (2014), USENIX.
- OUSTERHOUT, J., AGRAWAL, P., ERICKSON, D., KOZYRAKIS, C., LEVERICH, J., MAZIERES ` , D., MITRA, S., NARAYANAN, A., ONGARO, D., PARULKAR, G., ROSENBLUM, M., RUMBLE, S. M., STRATMANN, E., AND STUTSMAN, R. The case for RAMCloud. Communications of the ACM 54 (July 2011), 121–130.
- Raft consensus algorithm website. http://raftconsensus.github.io.
- REED, B. Personal communications, May 17, 2013.
- ROSENBLUM, M., AND OUSTERHOUT, J. K. The design and implementation of a log-structured file system. ACM Trans. Comput. Syst. 10 (February 1992), 26–52.
- SCHNEIDER, F. B. Implementing fault-tolerant services using the state machine approach: a tutorial. ACM Computing Surveys 22, 4 (Dec. 1990), 299–319.
- SHVACHKO, K., KUANG, H., RADIA, S., AND CHANSLER, R. The Hadoop distributed file system. In Proc. MSST’10, Symposium on Mass Storage Systems and Technologies (2010), IEEE Computer Society, pp. 1–10.
- VAN RENESSE, R. Paxos made moderately complex. Tech. rep., Cornell University, 2012.
参考文献
- ONGARO, Diego; OUSTERHOUT, John. In Search of an Understandable Consensus Algorithm (Extended Version). In: 2014 USENIX annual technical conference (USENIX ATC 14). 2014. p. 305-319.
- ONGARO, Diego. Consensus: Bridging theory and practice. Stanford University, 2014.
- The Raft Consensus Algorithm
- Raft: Understandable Distributed Consensus
- Raft - The Understandable Distributed Protocol
- 分散合意アルゴリズム Raft を理解する
