論文翻訳: Spanner: Google's Globally-Distributed Database
Google, Inc.
 Abstract
Abstract
Spanner は Google のスケーラブルでマルチバージョン、グローバル分散、同期複製されたデータベースである。これはグローバル規模でデータを分散し、外部一貫性のある分散トランザクションをサポートする初のシステムである。このホワイトペーパーでは Spanner の構造、機能セット、さまざまな設計上の決定の根拠、およびクロックの不確実性を明らかにする新しい時間 API について説明する。この API とその実装は、外部一貫性、過去の非ブロッキング読み取り、ロックフリーの読み取り専用トランザクション、アトミックスキーマ変更など、Spanner 全体でさまざまな強力な機能をサポートするために不可欠である。
Table of Contents
- Abstract
- 1 導入
- 2 実装
- 3 TrueTime
- 4 並行性制御
- 5 評価
- 6 関連する研究
- 7 今後の作業
- 8 考察
- Acknowledgements
- References
- A Paxos リーダーリース管理
- 翻訳抄
1 導入
Spanner は Google で設計、構築、配備されたスケーラブルなグローバル分散データベースである。最も抽象度の高いレベルでは、世界中のデータセンターに散らばる Paxos [21] ステートマシンにデータを分散させるデータベースである。グローバルな可用性と地理的なローカリティのためにレプリケーションを使用する。クライアントはレプリカ間で自動的にフェイルオーバーする。Spanner は、データ量やサーバ数が変化すると自動的にマシン間でデータを再シャーディングし、負荷分散や障害に対応するためにマシン間で (データセンター間でさえも) データを自動的に移行する。Spanner は数百のデータセンターと数兆のデータベース行にわたる数百万のマシンまで拡張できるように設計されている。
アプリケーションは大陸内または大陸間でデータを複製することで広域の自然災害に直面しても高可用性のために Spanner を使用できる。我々の最初の顧客は Google の広告バックエンド F1 [35] の書き換えだった。F1 は米国全土に分散した 5 つのレプリカを使用している。他のほとんどのアプリケーションはおそらく 1 つの地理的領域内の 3~5 個のデータセンターにデータを複製すると思われるが、比較的独立した障害モードを持つ。つまりほとんどのアプリケーションは 1 つまたは 2 つのデータセンター障害に耐えられる限り、高可用性よりも低レイテンシを選択するだろう。Spanner の主な焦点はデータセンター間で複製されたデータの管理だが、分散システムインフラストラクチャの上に重要なデータベース機能を設計および実装することにも多くの時間を費やしてきた。多くのプロジェクトが Bigtable [9] を好んで使用しているにもかかわらず、たとえば複雑で進化するスキーマを持つアプリケーションや、広域レプリケーションが存在する中で強い一貫性を求めるアプリケーションなど、一部の種類のアプリケーションでは Bigtable は使いにくいというユーザからの苦情を常に受けてきた (同様の主張は他の著者によってもなされている [37])。Google の多くのアプリケーションは、書き込みスループットが比較的低いにもかかわらず、セミリレーショナルデータモデルと同期レプリケーションのサポートのために Megastore [5] を使用することを選択した。その結果、Spanner は Bigtable のようなバージョン管理された Key-Value ストアから、時制マルチバージョンデータベース (temporal multi-version database) へと進化した。データはスキーマ化されたセミリレーショナルテーブルに保存される。データはバージョン管理され、各バージョンにはコミット時刻で自動的にタイムスタンプが付与される。古いバージョンのデータは設定可能なガーベッジコレクションポリシーの対象となる。またアプリケーションは古いタイムスタンプのデータを読み込むことができる。Spanner は汎用トランザクションをサポートし、SQL ベースのクエリ言語を提供する。
Spanner はグローバルに分散されたデータベースとしていくつかの興味深い特徴を提供している。第一に、データのレプリケーション構成はアプリケーションによってきめ細かく動的に制御できる。アプリケーションは、どのデータがどのデータセンターに含まれているか、データがユーザからどのくらい離れているか (読み取りレイテンシを制御するため)、レプリカが互いにどのくらい離れているか (書き込みレイテンシを制御するための)、いくつのレプリカが維持されているか (耐久性 (durability)、可用性、読み取りパフォーマンスを制御するため) を制御するための制約を指定できる。またデータセンター間でリソース使用量のバランスを取るためにシステムによって動的かつ透過的にデータセンター間でデータを移動させることもできる。第二に、Spanner には分散データベースでは実装の難しい 2 つの特徴がある。外部一貫性 (externally consistent) [16] のある読み取りと書き込み、およびタイムスタンプでデータベース全体でグローバルに一貫性のある読み取りを提供することである。これらの機能により Spanner は進行中のトランザクションが存在する場合でもグローバル規模で一貫性のあるバックアップ、一貫性のある MapReduce 実行 [12]、アトミックなスキーマ変更をサポートすることができる。
これらの機能はトランザクションが分散していても Spanner がグローバルに意味のあるコミットタイムスタンプをトランザクションに割り当てるという事実によって可能になる。タイムスタンプは直列化順序 (serialization order) を反映する。加えて、直列化順序は外部一貫性 (または同等の線形化可能性 (linearlizability) [20]) を満たす。あるトランザクション \(T_1\) が別のトランザクション \(T_2\) の開始前にコミットされた場合、\(T_1\) のコミットタイムスタンプは \(T_2\) のコミットタイムスタンプより小さくなる。Spanner はグローバル規模でこのような保証を提供する最初のシステムである。
これらの特性を実現する主な要因は新しい TrueTime API とその実装である。API はクロックの不確実性を直接公開し、Spanner のタイムスタンプの保証は実装が提供する境界に依存する。不確実性が大きい場合、Spanner は速度を落としてその不確実性を待つ。Google のクラスタ管理ソフトウェアは TrueTime API の実装を提供してる。この実装では複数の最新クロックリファレンス (GPS と原子時計) を使用することで不確実性を小さく (一般に 10ms 未満) 抑えている。
セクション 2 では Spanner 実装の構造、機能セット、および設計に取り入れられた技術的な決定について説明する。セクション 3 では新しい TrueTime API について説明しその実装の概要を示す。セクション 4 では Spanner が TrueTime を使用して外部一貫性のある分散トランザクション、ロックフリーの読み取り専用トランザクション、およびアトミックスキーマ変更を実装する方法について説明する。セクション 5 では Spanner のパフォーマンスと TrueTime の動作に関するベンチマークをいくつか示し、F1 の経験について説明する。セクション 6、7、8 では関連する研究と今後の作業について説明し結論をまとめる。
2 実装
このセクションでは Spanner 実装の構造とその根拠について説明する。
まずレプリケーションとローカリティの管理に使用され、データ移動の単位となるディレクトリ抽象化について説明する。最後に、Spanner のデータモデル、Spanner がリレーショナルデータベースのように見える理由と、アプリケーションがデータローカリティを制御する方法について説明する。
Spanner のデプロイはユニバース (universe) と呼ばれる。Spanner がグローバルにデータを管理することを考えると実行されるユニバースはほんのわずかである。我々は現在、テスト/プレイグランドユニバース、開発/本番環境ユニバース、そして本番環境専用ユニバースを運用している。
Spanner はゾーンの集合として編成されており、各ゾーンには Bigtable サーバ [9] のデプロイメントにほぼ相当する。ゾーンは管理デプロイメントの単位である。ゾーンの集合はデータをレプリケートできる場所の集合である。新しいデータセンターがサービスを開始し、古いデータセンターが停止すると、それぞれ実行中のシステムにゾーンを追加したり実行中のシステムからゾーンを削除したりできる。ゾーンは物理的な分離の単位でもある。例えば、異なるアプリケーションのデータを同じデータセンター内の異なるサーバセットに分割する必要がある場合など、データセンターには 1 つまたは複数のゾーンが存在することがある。
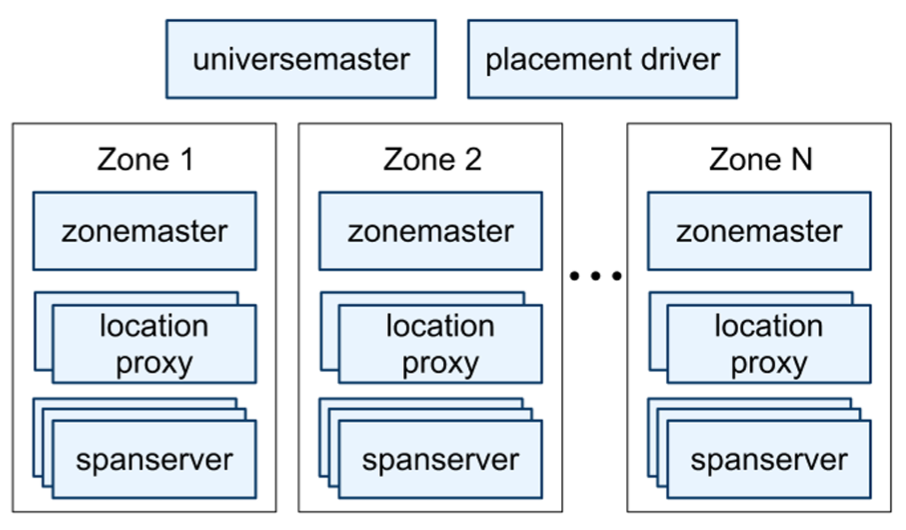
Figure 1 は Spanner ユニバース内のサーバを示している。ゾーンには 1 つのゾーンマスター (zonemaster) と、100 から数千のスパンサーバ (spanserver) がある。前者はスパンサーバにデータを割り当て、後者はクライアントにデータを提供する。ゾーンごとのロケーションプロキシ (location proxy) は、クライアントがデータを提供するために割り当てられたスパンサーバを見つけるために使用される。ユニバースマスター (universe master) と配置ドライバ (placement driver) は現在シングルトンである。ユニバースマスターは主にコンソールで対話型のデバッグ用にすべてのゾーンのステータス情報を表示する。配置ドライバは分単位のタイムスケールでゾーン間のデータの自動移動を処理する。配置ドライバは、更新されたレプリケーション制約を満たすために、または負荷を分散するために移動が必要なデータを見つけるためにスパンサーバと定期的に通信する。スペースの都合上、ここではスパンサーバについてのみ詳しく説明する。
2.1 スパンサーバソフトウェアスタック
このセクションではスパンサーバの実装に焦点を当て、レプリケーションと分散トランザクションが Bigtable ベースの実装にどのようにレイヤー化されているかを説明する。ソフトウェアスタックを Figure 2 に示す。下部では各スパンサーバがタブレットと呼ばれるデータ構造の 100~1000 個のインスタンスを担当している。タブレットは次のマッピングのバッグを実装するという点で Bigtable のタブレット抽象化と似ている: \[ ({\sf key}:{\sf string}, {\sf timestamp}:{\sf int64}) \to {\sf string} \] Bigtable とは異なり、Spanner はデータにタイムスタンプを割り当てる。これは Spanner が Key-Value ストアというよりマルチバージョンデータベースに近い重要な点である。タブレットの状態は Colossus と呼ばれる分散ファイルシステム (Google File System [15] の後継) 上の B-Tree のようなファイルと先行書き込みログ (write-ahead log) に格納される。
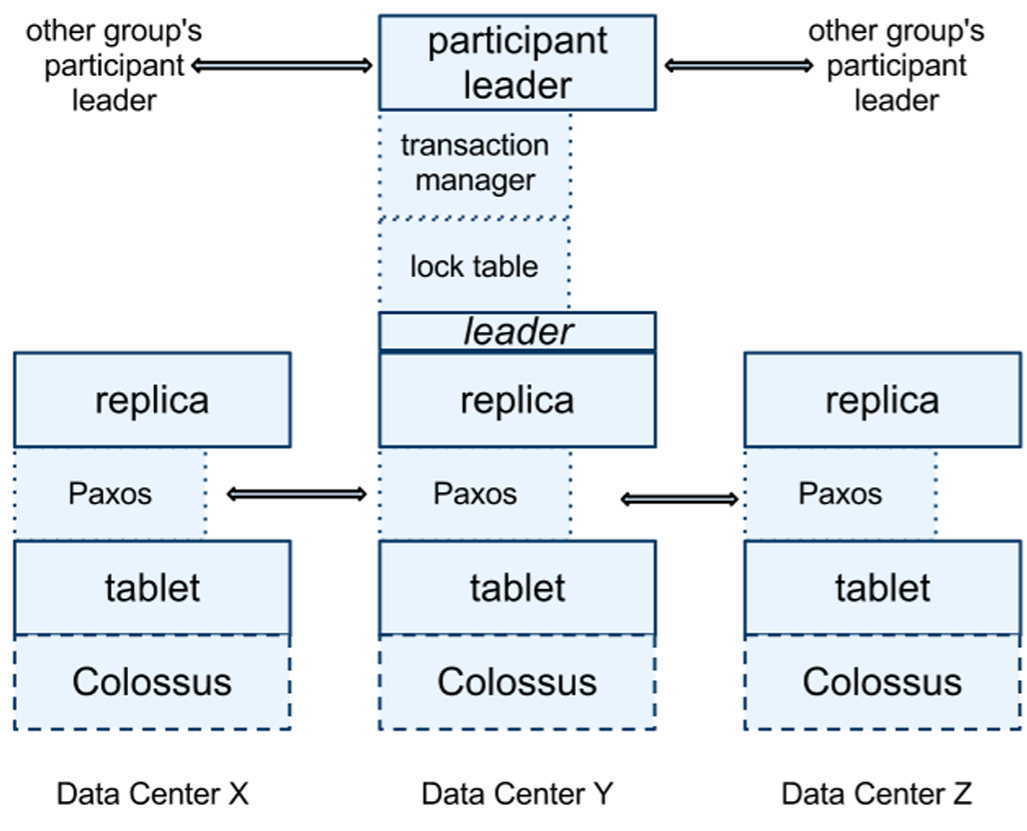
レプリケーションをサポートするために、各スパンサーバは各タブレット上に 1 つの Paxos ステートマシンを実装する (初期の Spanner はタブレットごとに複数の Paxos ステートマシンをサポートしていてより柔軟なレプリケーション構成が可能だったが、この設計は複雑だったため我々は放棄した)。各ステートマシンは対応するタブレットにメタデータとログを保存する。Paxos 実装は時間ベースのリーダーリース (leader lease) を持つ長期リーダーをサポートしており、その長さはデフォルト 10 秒である。現在の Spanner 実装ではすべての Paxos 書き込みは 1 回はタブレットのログに、もう 1 回は Paxos ログに、合わせて 2 回記録される。この選択は便宜的なものでありいずれ改善する予定である。我々の Paxos 実装はパイプライン化されており、WAN のレイテンシがある場合でも Spanner のスループットを向上させることができる。ただし書き込みは Paxos によって順番に適用される (この事実はセクション 4 で依存する)。
Paxos のステートマシンは一貫して複製されたマッピングのバッグを実装するために使用される。各レプリカの Key-Value マッピングの状態は対応するタブレットに格納される。書き込みは、リーダーで Paxos プロトコルを開始する必要がある。読み込みは、十分に最新の任意のレプリカの基礎となるタブレットから直接状態にアクセスする。レプリカの集合はまとめて Paxos グループになる。
リーダーである各レプリカでは、各スパンサーバがロックテーブルを実装して並行性制御 (concurrency control) を実行する。ロックテーブルには 2 フェーズロックの状態が含まれる。これはキーの範囲をロック状態にマッピングする (長寿命の Paxos リーダーを持つことはロックテーブルを効率的に管理するために重要である)。Bigtable と Spanner の両方は長時間有効なトランザクション (例えば数分かかるレポート生成など) を想定して設計されている。これらのトランザクションは、競合がある場合に楽観的並行性制御ではパフォーマンスが低下する。トランザクション読み取りなどの同期を必要とする操作はロックテーブルでロックを取得し、その他の操作はロックテーブルをバイパスする。
リーダーである各レプリカでは、各スパンサーバは分散トランザクションをサポートするためにトランザクションマネージャも実装している。トランザクションマネージャは参加者リーダー (participant leader) を実装するために使用される。グループ内の他のレプリカは参加者スレーブ (participant slave) と呼ばれる。トランザクションに関係する Paxos グループが 1 つだけの場合 (ほとんどのトランザクションの場合)、ロックテーブルと Paxos が一緒にトランザクション性を提供するため、トランザクションマネージャをバイパスできる。トランザクションに複数の Paxos グループが関係する場合、それらのグループのリーダーが協調して 2 フェーズコミットを実行する。参加者グループの 1 つがコーディネータとして選ばれる。そのグループの参加者リーダーはコーディネータリーダー (coordinator leader) と呼ばれ、そのグループのスレーブはコーディネータスレーブ (coordinator slave) と呼ばれる。各トランザクションマネージャの状態は基礎となる Paxos グループに保存される (したがって複製される)。
2.2 ディレクトリと配置
Key-Value マッピングのバッグに加えて、Spanner 実装は共通のプレフィクスを共有する連続したキーの集合であるディレクトリと呼ばれるバケッティング抽象化をサポートする (ディレクトリという用語の選択は歴史的な偶然であり、バケットという用語の方がより適切かも知れない)。このプレフィクスの由来についてはセクション 2.3 で説明する。ディレクトリをサポートすることで、アプリケーションはキーを注意深く選択してデータのローカリティを制御できる。
ディレクトリはデータ配置 (data placement) の単位である。ディレクトリ内のすべてのデータは同じレプリケーション構成を持つ。Paxos グループ間でデータを移動する場合、Figure 3 に示すように、ディレクトリごとに移動される。Spanner は Paxos グループの負荷を軽減したり、頻繁にアクセスされるディレクトリを同じグループにまとめたり、またはディレクトリのアクセス元により近いグループに移動するためにディレクトリを移動することがある。ディレクトリはクライアント操作の実行中に移動できる。50MB のディレクトリは数秒で移動できると予想される。
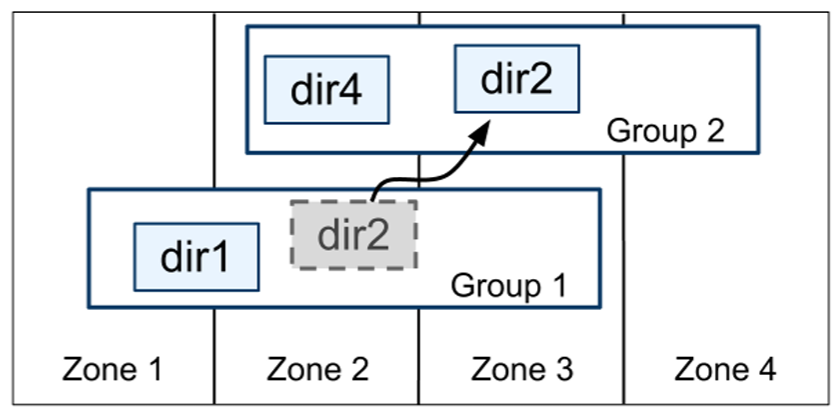
Paxos グループに複数のディレクトリが含まれる可能性があるという事実は、Spanner タブレットが Bigtable タブレットと異なることを示唆している。前者は行スペースの辞書式に連続した単一のパーティションである必要はない。代わりに、Spanner タブレットは行スペースの複数のパーティションをカプセル化できるコンテナである。この決定は頻繁にアクセスされる複数のディレクトリを一緒に配置できるようにするために行われた。
movedir は Paxos グループ間でディレクトリを移動するために使用されるバックグラウンドタスクである [14]。movedir は Paxos グループへのレプリカの追加や削除にも使用される [25]。これは Spanner が Paxos 内の構成変更をまだサポートしていないためである。進行中の読み取りと書き込みが大量のデータ移動によりブロックされないように、movedir は単一のトランザクションとして実装されていない。代わりに movedir はデータの移動を開始することを登録しバックグラウンドでデータを移動する。名目上の (nomial) データ量以外をすべて移動すると、トランザクションを使用して名目上のデータをアトミックに移動し 2 つの Paxos グループのメタデータを更新する。
ディレクトリはアプリケーションが地理的レプリケーション特性 (略して配置 (placement)) を指定できる最小単位でもある。配置指定言語 (placement-specific language) の設計ではレプリケーション構成を管理する責任が分離されている。管理者はレプリカの数と種類、およびレプリカの地理的な配置という 2 つの次元を制御する。管理者はこの 2 つの次元で名前付きオプションのメニューを作成するだろう (例えば North America, replicated 5 ways with 1 witness)。アプリケーションは各データベースや個々のディレクトリにこれらのオプションの組み合わせをタグ付けすることでデータの複製方法を制御する。例えば、アプリケーションは各エンドユーザのデータを各自のディレクトリに保存し、ユーザ \(A\) のデータはヨーロッパに 3 つのレプリカを持ち、ユーザ \(B\) のデータは北米に 5 つのレプリカを持つことができる。
ここでは説明をわかりやすくするために過度に単純化している。実際、Spanner はディレクトリが大きくなりすぎるとディレクトリを複数のフラグメントに分割する。フラグメントは異なる Paxos グループ (つまり異なるサーバ) から提供される場合がある。movedir は実際にはディレクトリ全体ではなくフラグメントをグループ間で移動する。
2.3 データモデル
Spanner はアプリケーションに、スキーマ化されたセミリレーショナルテーブル、クエリー言語、および汎用トランザクションに基づくデータモデルのデータ機能セットを公開する。これらの機能をサポートすることになった背景にはさまざまな要因がある。スキーマ化されたセミレプリケーションテーブルと同期レプリケーションをサポートする必要性は Megastore [5] の人気によって裏付けられている。Google 内の少なくとも 300 のアプリケーションが Megastore を使用している (比較的パフォーマンスが低いにもかかわらず)。その理由は、Megastore のデータモデルが Bigtable より管理しやすく、データセンター間の同期レプリケーションをサポートしているためである (Bigtable はデータセンター間での結果一貫性 (eventually-consistent) のあるレプリケーションしかサポートしていない)。Megastore を使用している有名な Google アプリケーションの例としては、Gmail, Picasa, Calendar, Android Market, AppEngine などがある。対話型データ分析ツールとして Dremel [28] の人気が高いことを考えると Spanner で SQL のようなクエリ言語をサポートする必要性も明らかだった。最後に、Bigtable には行をまたぐトランザクションがないため苦情が頻発しており、Percolator [32] はその欠点に対処するために開発された部分もある。一般的な 2 フェーズコミットは性能や可用性の問題を引き起こすためにサポートにはコストがかかりすぎると主張する著者もいる [9, 10, 19]。我々は、アプリケーションプログラマがトランザクションの不足を常に考慮してコーディングするよりも、ボトルネックが発生したときにトランザクションの使いすぎによる性能問題に対処する方が良いと考えている。Paxos で 2 フェーズコミットを実行すると可用性の問題は軽減される。アプリケーションのデータモデルは、実装でサポートされているディレクトリバケットの Key-Value マッピング上に階層化されている。
アプリケーションはユニバース内に 1 つ以上のデータベースを作成する。各データベースにはスキーマ化されたテーブルを無制限に含めることができる。テーブルは、行、列、およびバージョン付けされた値を持つリレーショナルデータベースのテーブルのように見える。Spanner のクエリ言語については詳しく説明しないが、SQL に ProtocolBuffers 値フィールドをサポートするためにいくつかの拡張を加えたようなものである。
Spanner のデータモデルは行に名前が必要であるという点で純粋なリレーショナルではない。より正確には、すべてのテーブルには 1 つ以上の主キー列の順序付けられたセットが必要である。この要件により Spanner はまだ Key-Value ストアのように見えるが、主キーは行の名前を形成し、各テーブルは主キー列から非主キー列へのマッピングを定義する。行が存在するのは、行のキーに何らかの値 (たとえ NULL であっても) が定義されている場合のみである。このような構造を強制すると、アプリケーションがキーの選択を通じてデータのローカリティを制御できるので便利である。
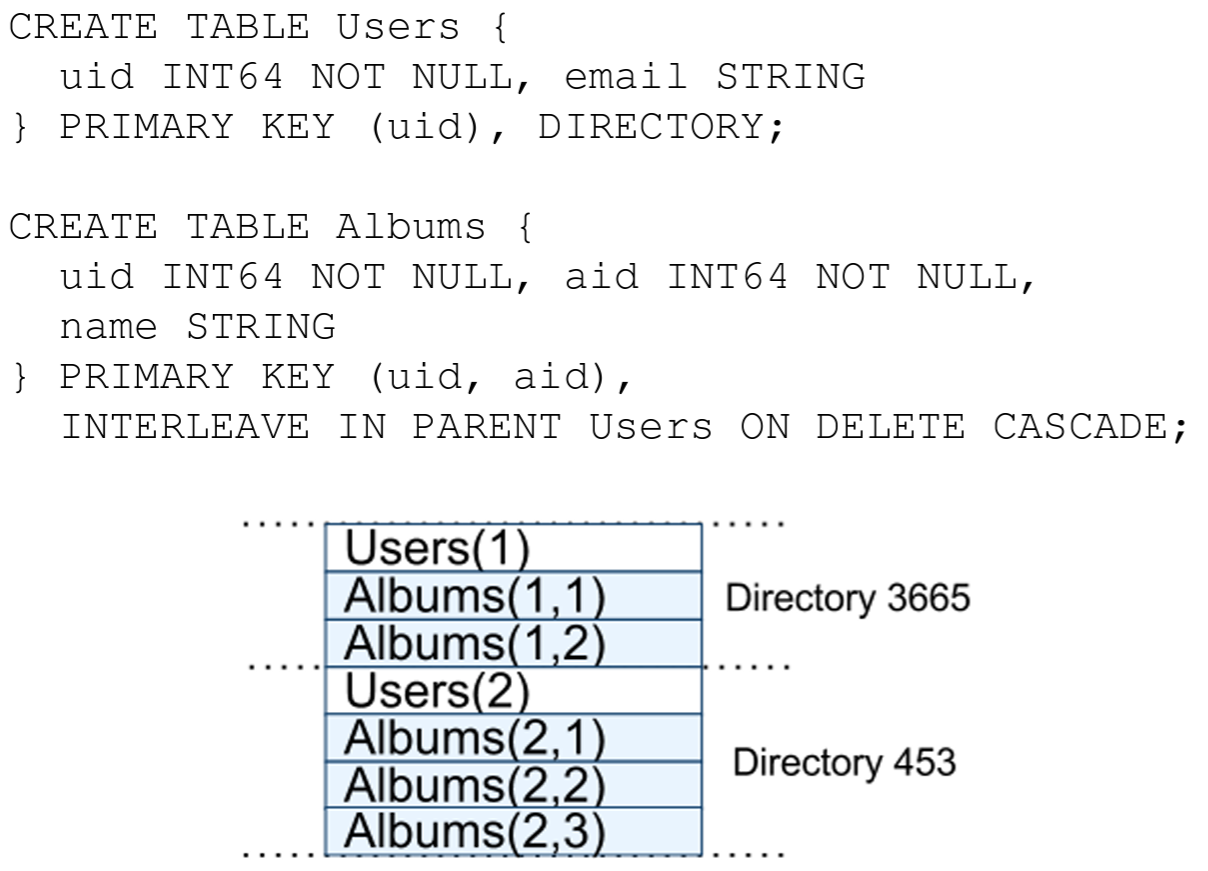
Figure 4 はユーザごと、アルバムごとに写真のメタデータを保存するための Spanner スキーマの例が示されている。スキーマ言語は Megastore と似ているが、すべての Spanner データベースはクライアントによって 1 つ以上のテーブル階層に分割されなければならないという要件が追加されている。クライアントアプリケーションは INTERLEAVE IN 宣言によってデータベーススキーマの階層を宣言する。階層の最上位テーブルはディレクトリテーブルである。\(K\) をキーとするディレクトリテーブルの各行と、辞書式に \(K\) で始まる子孫テーブルのすべての行がディレクトリを形成する。ON DELETE CASCADE は、ディレクトリテーブルの行を削除すると関連付けられている子行もすべて削除されることを示している。またこの図はサンプルデータベースのインターリーブレイアウトも示している。例えば Albums(2,1) は Albums テーブルの user_id 2, album_id 1 の行を表している。このようにしてテーブルをインターリーブしてディレクトリを形成することは、クライアントが複数のテーブル間に存在するローカリティ関係を記述できるようにするため重要である。これはシャード化された分散データベースで優れたパフォーマンスを得るために必要である。これがなければ Spanner は最も重要なローカリティ関係を認識できない。
3 TrueTime
このセクションでは TrueTime API について説明し、その実装の概要を示す。詳細は別の論文に譲るが、我々の目標はこのような API を持つことの実証することである。Table 1 に API のメソッドを示す。TrueTime は時間を \(TTinterval\) として明示的に表す。\(TTinterval\) は時間の不確実性が束縛された区間である (クライアントに不確実性の概念を与えない標準的な時間インターフェースとは異なる)。\(TTinterval\) のエンドポイントは \(TTstamp\) 型である。\(TT.now()\) メソッドは、\(TT.now()\) が呼び出された絶対時間を含むことが保証されている \(TTinterval\) を返す。時間エポックはうるう秒の不鮮明さを含む UNIX 時間に類似している。瞬間誤差の境界 (instantaneous error bound) を \(\epsilon\) と定義する。これは間隔幅の半分であり、平均誤差の境界 (average error bound) を \(\bar{\epsilon}\) と定義する。\(TT.after()\) メソッドと \(TT.before()\) メソッドは \(TT.now()\) の便利なラッパーである。

イベント \(e\) の絶対時間を関数 \(t_{abs}(e)\) で表す。より正式には、TrueTime は呼び出し \(tt = TT.now()\) に対して \(tt.earliest\) \(\le\) \(t_{abs}(e_{now})\) \(\le\) \(tt.least\) であることを保証する。ここで \(e_{now}\) は呼び出しのイベントである。
TrueTime が使用する基本的な時間参照は GPS と原子時計である。TrueTime が 2 種類の時間参照を使用するのは、それらの故障モードが異なるためである。GPS 基準ソースの脆弱性には、アンテナや受信機の障害、ローカル無線干渉、相関障害 (たとえば不正確なうるう秒処理やスプーフィングなどの設計上の欠陥)、GPS システムの停止が含まれている。原子時計は、GPS や他の原子時計とは相関しない方法で故障する可能性があり、長期間にわたると周波数誤差によって大幅にドリフトする可能性がある。
TrueTime はデータセンターごとのタイムマスターマシンのセットと、マシンごとに 1 つのタイムスレーブデーモンによって実装される。マスターの大半には専用アンテナを備えた GPS 受信機がある。これらのマスターは、アンテナの故障、電波干渉、スプーフィングの影響を減らすために物理的に分離されている。残りのマスター (我々はアルマゲドンマスターと呼ぶ) には原子時計が搭載されている。原子時計はそれほど高価ではなく、アルマゲドンマスターのコストは GPS マスターのコストと同程度である。すべてのマスターの時間参照は定期的に相互比較される。また各マスターはその参照が時間を進める速度を自分のローカルクロックと照合し、大幅な相違がある場合は自らを排除する。同期の間、アルマゲドンマスターは、保守的に適用されたワーストケースのクロックドリフトに由来する、徐々に増加する時間の不確実性をアドバタイズする。GPS マスターは通常ゼロに近い不確実性をアドバタイズする。
各デーモンはさまざまなマスター [29] をポーリングして 1 つのマスターからの誤差に関する脆弱性を減らす。一部は近くのデータセンターから選択された GPS マスターで、残りはより遠いデータセンターの GPS マスターといくつかのアルマゲドンマスターである。デーモンは Marzullo のアルゴリズム [27] の変種を適用して嘘つきの検出と拒否を行い、ローカルマシンのクロックを嘘つきでないマシンに同期させる。壊れたローカルクロックから保護するために、コンポーネントの仕様と動作環境から得られる最悪ケースの境界よりも大きな周波数の逸脱を示すマシンは排除される。
同期の間、デーモンは徐々に増加する時間の不確実性をアドバタイズする。\(\epsilon\) は、保守的に適用されたワーストケースのローカルクロックのドリフトから得られる。\(\epsilon\) はタイムマスターの不確実性とタイムマスターへの通信遅延にも依存する。我々の実働環境では、\(\epsilon\) は一般的に時間の鋸歯状関数であり、各ポーリング間隔で約 1~7 ms の範囲で変化する。したがって \(\bar{\epsilon}\) はほとんどの場合 4 ms である。デーモンのポーリング間隔は現在 30 秒であり、現在適用されているドリフトレートは毎秒 200 マイクロ秒に設定されており、これらを併せると 0~6 ms の鋸歯状境界となる。残りの 1 ms はタイムマスターとの通信遅延によるものである。障害が発生した場合、この鋸歯状から外れることがある。例えば、時折タイムマスターが使用できなくなることでデータセンター全体で \(\epsilon\) が増加する可能性がある。同様に、マシンやネットワークリンクに過負荷がかかると時折局所的な \(\epsilon\) スパイクが発生することがある。
4 並行性制御
このセクションでは TrueTime を使用して並行性制御に関する正確性 (correctness) 特性を保証する方法、またその特性を使用して外部一貫性トランザクション、ロックフリーの読み取り専用トランザクション、過去の非ブロッキング読み取りなどの機能を実装する方法について説明する。これらの機能により、例えばタイムスタンプ \(t\) 時点でのデータベース全体の監査読み取り (audit read; 監査=一貫性のあるスナップショットをグローバルに読み取ることを強調した表現?) で \(t\) の時点でコミットされたすべてのトランザクションの影響を正確に確認できることが保証される。
今後は Paxos から見た書き込み (writes as seen by Paxos) (文脈が明確でない限り Paxos 書き込み (Paxos writes) と呼ぶ) と Spanner クライアントの書き込みを区別することが重要になる。たとえば 2 フェーズコミットでは prepare フェーズの Paxos 書き込みが生成されるが、それに対応する Spanner 書き込みはない。
4.1 タイムスタンプ管理
Table 2 に Spanner がサポートする操作の種類を示す。Spanner の実装では、読み書きトランザクション (read-write transaction)、読み取り専用トランザクション (read-only transaction) (事前宣言されたスナップショット分離トランザクション)、およびスナップショット読み取り (snapshot read) がサポートされている。スタンドアロンの書き込みは読み書きトランザクションとして実装され、スナップショット以外のスタンドアロン読み取りは読み取り専用トランザクションとして実装される。どちらとも内部的に再実行される (クライアントは独自の再試行ループを書く必要はない)。
| 操作 | タイムスタンプ論議 | 並行性制御 | レプリカが必要 |
|---|---|---|---|
| 読み書きトランザクション | §4.1.2 | 悲観的 | リーダー |
| 読み取り専用トランザクション | §4.1.4 | ロックフリー | タイムスタンプの場合はリーダー、読み取りの場合は任意、§4.1.3 に従う |
| スナップショット読み取り, クライアント提供タイムスタンプ |
─ | ロックフリー | 任意、§4.1.3 に従う |
| スナップショット読み取り, クライアント提供境界 |
§4.1.3 | ロックフリー | 任意、§4.1.3 に従う |
読み取り専用トランザクションはスナップショット分離 [6] のパフォーマンス上の利点があるトランザクションの一種である。読み取り専用トランザクションは、書き込みのない単なる読み書きトランザクションではなく、書き込みを行わないことを事前に宣言しなければならない。読み取り専用トランザクションの読み取りはシステムが選択したタイムスタンプでロックせずに実行されるため、入ってくる書き込みがブロックされることはない。読み取り専用トランザクションの読み取り実行は、十分に最新などのレプリカ上でも進めることができる (セクション 4.1.3)。
読み取り専用トランザクションでもスナップショット読み取りでも、一度タイムスタンプが選択されるとそのタイムスタンプのデータがガーベッジコレクションされていない限りビューは固定される (commit is inevitable; 直訳:確定は必然である)。その結果、クライアントは再試行ループ内で結果をバッファリングすることを避けることができる。サーバが故障した場合、クライアントはタイムスタンプと現在の読み取り位置を繰り返すことで、内部的に別のサーバで問い合わせを継続することができる。
4.1.1 Paxos リーダーリース
Spanner の Paxos 実装では、リーダーシップを長期間維持するために (デフォルトは 10 秒) 時間指定のリース (timed lease) を使用している。リーダー候補は時間指定のリース投票 (timed lease votes) の要求を送信し、定足数 (quorum) のリース票を受信すると、リーダーはリースを得たことを知る。レプリカは書き込みに成功すると暗黙的にリース票を延長し、リーダーは期限切れに近づくとリース票の延長を要求する。リーダーのリース間隔 (lease interval) は、リーダーがリース票の定足数を持っていることがわかったときに開始し、リーダーが (いくつかのリースが期限切れになったため) リース票の定足数を持たなくなったときに終了すると定義する。Spanner は、各 Paxos グループにおいて各 Paxos リーダーのリース間隔が他のすべてのリーダーのリース間隔とは不連続 (disjoint) である、という不連続不変性 (disjointness invariant) に依存する。付録 A ではこの不変性の適用について説明する。
Spanner 実装では Paxos リーダーがそのスレーブのリース票を解放して退位することを許可している。Spanner は不連続不変量を維持するために退位が許容されるタイミングについて制約する。\(s_{max}\) をリーダーが使用する最大タイムスタンプと定義する。以降のセクションでは \(s_{max}\) がいつ進められるかを説明する。リーダーは退位する前に \(TT.after(s_{max})\) が true となるまで待たなければならない。
4.1.2 RW トランザクションへのタイムスタンプの割り当て
トランザクションの読み取りと書き込みは 2 フェーズロックを使用する。その結果、すべてのロックが取得された後で任意のロックが解放される前であれば、いつでもタイムスタンプを割り当てることができる。特定のトランザクションに対して、Spanner はトランザクションのコミットを表す Paxos 書き込みに Paxos が割り当てたタイムスタンプを割り当てる。
Spanner は単調性不変性 (monotonicity invariant) に依存する。これは、Spanner において各 Paxos グループ内で Paxos の書き込みに単調増加順でタイムスタンプを割り当てるというものである。単一のリーダーレプリカは単調増加の順序で簡単にタイムスタンプを割り当てることができる。この不変性は不連続不変性を利用することでリーダー間で強制される。リーダーは、そのリーダーリースの間隔内でのみタイムスタンプを割り当てなければならない。タイムスタンプ \(s\) が割り当てられるたびに、不連続性を保持するために \(s_{max}\) が \(s\) に進められることに注意。
Spanner はまた次の外部一貫性不変性 (external consistency invariant) も強制する。トランザクション \(T_2\) の開始がトランザクション \(T_1\) のコミット後に発生した場合、\(T_2\) のコミットタイムスタンプは \(T_1\) のコミットタイムスタンプより大きくなければならない。トランザクション \(T_i\) の開始とコミットのイベントを \(e_i^{start}\) と \(e_i^{commit}\) と定義し、またトランザクション \(T_i\) のコミットタイムスタンプを \(s_i\) とすると、この不変性は \(t_{abs}(e_1^{commit}) \lt t_{abs}(e_2^{start})\) \(\Rightarrow\) \(s_1 \lt s_2\) となる。トランザクションを実行してタイムスタンプを割り当てるプロトコルは、以下に示す 2 つのルールに従う。書き込み \(T_i\) に対するコーディネーターリーダーでのコミット要求の到着イベントを \(e_i^{server}\) と定義する。
開始. 書き込み \(T_i\) に対するコーディネーターリーダーは、\(e_i^{server}\) の後に計算された \(TT.now().latest\) の値以上のコミットタイムスタンプ \(s_i\) を割り当てる。参加者リーダーはここでは重要でないことに注意。セクション 4.2.1 では参加者リーダーが次のルールの実装にどのように関与するかについて説明する。
コミット待機. コーディネーターリーダーは \(TT.after(s_i)\) が true になるまで \(T_i\) でコミットされたデータをクライアントから見えないようにする。コミット待機は \(s_i\) が \(T_i\) の絶対コミット時間より小さいこと、つまり \(s_i \lt t_{abs}(e_i^{commit})\) であることを保証する。コミット待機の実装はセクション 4.2.1 で説明する。証明: \[ \begin{eqnarray*} s_1 & \lt & t_{abs}(e_1^{commit}) & \mbox{(commit wait)} \\ t_{abs}(e_1^{commit}) & \lt & t_{abs}(e_2^{start}) & \mbox{(assumption)} \\ t_{abs}(e_2^{start}) & \le & t_{abs}(e_2^{server}) & \mbox{(causality)} \\ t_{abs}(e_2^{server}) & \le & s_2 & \mbox{(start)} \\ s_1 & \lt & s_2 & \mbox{(transitivity)} \end{eqnarray*} \]
4.1.3 タイムスタンプで読み取りを提供する
セクション 4.1.2 で説明した単調性不変性により、Spanner はレプリカの状態が読み取りを満足させるのに十分最新であるかを正しく判断できる。すべてのレプリカは、レプリカが最新である最大のタイムスタンプである安全時間 (safe time) \(t_{safe}\) と呼ばれる値を追跡する。\(t \le t_{safe}\) の場合、レプリカはタイムスタンプ \(t\) で読み取りを果たすことができる。
\(t_{safe} = \min(t_{safe}^{Paxos}, t_{safe}^{TM})\) と定義する。ここで各 Paxos ステートマシンは安全時間 \(t_{safe}^{Paxos}\) を持ち、各トランザクションマネージャは安全時間 \(t_{safe}^{TM}\) を持つ。\(t_{safe}^{Paxos}\) はより単純である。これは Paxos の書き込みが適用された最も高いタイムスタンプである。タイムスタンプは単調に増加し、書き込みは順番に適用されるため、Paxos に対して \(t_{safe}^{Paxos}\) 以下で書き込みが発生することはない。
prepared された (ただしコミットされていない) トランザクション、つまり 2 フェーズコミットの 2 つの間にあるトランザクションが 0 個の場合、レプリカでの \(t_{safe}^{TM}\) は \(\infty\) である (参加者スレーブの場合、\(t_{safe}^{TM}\) は実際にはレプリカのリーダーのトランザクションマネージャを指し、スレーブは Paxos 書き込み時に渡されるメタデータを通じてその状態を推測できる)。そのようなトランザクションが存在する場合、参加者レプリカはそのようなトランザクションがコミットされるかどうかをまだ知らないため、それらのトランザクションによって影響を受ける状態は非決定的である。セクション 4.2.1 で説明するように、コミットプロトコルはすべての参加者が prepared トランザクションのタイムスタンプの下限を知っていることを保証する。トランザクション \(T_i\) の (グループ \(g\) に対する) すべての参加者リーダーは、prepare タイムスタンプ \(s_{i,g}^{prepare}\) をその prepare レコードに割り当てる。コーディネーターリーダーは、すべての参加者グループ \(g\) にわたってトランザクションのコミットタイムスタンプが \(s_i \ge s_{i,g}^{prepare}\) であることを保証する。したがって、グループ \(g\) 内のすべてのレプリカに対して、\(g\) で prepared されたすべてのトランザクション \(T_i\) について、\(g\) で prepared されたトランザクション全体で \(t_{safe}^{TM} = \min_i(s_{i,g}^{prepare}) - 1\) である。
4.1.4 ROトランザクションへのタイムスタンプの割り当て
読み取り専用トランザクションは、タイムスタンプ \(s_{read}\) を割り当て [8]、次にトランザクションの読み取りを \(s_{read}\) でのスナップショット読み取りとして実行する、という 2 つのフェーズで実行される。スナップショット読み取りは十分に最新のレプリカであればどのレプリカでも実行できる。
セクション 4.1.2 で書き込みに対して提示したものと類似の議論により、単純に \(s_{read} = TT.now().latest\) を代入することでトランザクション開始後のいつでも外部一貫性が維持される。しかしながら、\(t_{safe}\) が十分に進んでいない場合、このようなタイムスタンプでは \(s_{read}\) でのデータ読み取りの実行をブロックすることを要求する可能性がある (加えて不連続性を維持するために \(s_{read}\) の値を選択すると \(s_{max}\) も進む可能性があることに注意)。ブロックの可能性を減らすために Spanner は外部一貫性を維持する最も古いタイムスタンプを割り当てるべきである。セクション 4.2.2 ではそのようなタイムスタンプの選択方法について説明する。
4.2 詳細
このセクションでは、先に省略した読み書きトランザクションと読み取り専用トランザクションの実用的な詳細の一部と、アトミックなスキーマ変更を実装するために使用される特別なトランザクションタイプの実装について説明する。そして説明した基本的なスキームのいくつかの改良について説明する。
4.2.1 読み書きトランザクション
Bigtable と同様に、トランザクション内で発生した書き込みはコミットされるまでクライアントでバッファリングされる。その結果、トランザクション内の読み取りからはトランザクションの書き込みの影響は見えない。この設計は Spanner でうまく機能する。なぜなら読み取りは読み取ったデータのタイムスタンプを返し、コミットされていない書き込みはまだタイムスタンプが割り当てられていないためである。
読み書きトランザクション内の読み取りはデッドロックを回避するため wound-wait [33] を使用する。クライアントは適切なグループのリーダーレプリカに読み取りを発行し、リーダーレプリカは読み取りロックを獲得し、最新のデータを読み取る。クライアントのトランザクションがオープンしている間、参加者リーダーがトランザクションをタイムアウトしないようにクライアントは keep-alive メッセージを送信する。クライアントがすべての読み取りを完了し、すべての書き込みをバッファリングすると、2 フェーズコミットを開始する。クライアントはコーディネーターグループを選択し、各参加者リーダーにコーディネーター識別子と任意のバッファリングされた書き込みを含むコミットメッセージを送信する。クライアントが 2 フェーズコミットを実行することで、広域リンクを介してデータが 2 回送信されることを回避できる。
非コーディネーター参加者リーダー (non-coordinator-participant leader) はまず書き込みロックを取得する。そして (単調性を維持するため) 以前のトランザクションに割り当てたどのタイムスタンプよりも大きい prepare タイムスタンプを選択し、Paxos を通じて prepare レコードをログに記録する。その後、各参加者はその prepare タイムスタンプをコーディネーターに通知する。
コーディネーターリーダーも最初に書き込みロックを取得するが prepare フェーズはスキップする。コーディネーターリーダーは他のすべての参加者から通知があった後、トランザクション全体のタイムスタンプを選択する。コミットタイムスタンプ \(s\) は、(セクション 4.1.3 で説明した制約を満たすために) すべての prepare タイムスタンプ以上でなければならず、コーディネーターがコミットメッセージを受信した時点の \(TT.now().latest\) より大きく、(これも単調性を保つために) リーダーが以前のトランザクションに割り当てたすべてのタイムスタンプより大きくなければならない。その後、コーディネーターリーダーは Paxos を通じてコミットレコードを記録する (あるいは他の参加者を待っている間にタイムアウトした場合は中止する)。
コーディネーターレプリカがコミットレコードを適用できるようにする前に、コーディネーターリーダーは \(TT.after(s)\) まで待ち、セクション 4.1.2 で説明したコミット待機ルールに従う。コーディネーターリーダーは \(TT.now().latest\) に基づいて \(s\) を選択し、そのタイムスタンプが過去となることが保証されるまで待機するため、予想される待機時間は少なくとも \(2 \ast \bar{\epsilon}\) である。この待機は通常、Paxos の通信とオーバーラップする。コミット待機の後、コーディネーターはコミットタイムスタンプをクライアントと他のすべての参加者リーダーに送信する。各参加者リーダーは Paxos を介してトランザクションの結果をログに記録する。すべての参加者は同じタイムスタンプを適用してロックを解放する。
4.2.2 読み取り専用トランザクション
タイムスタンプを割り当てるには、読み取りに関与するすべての Paxos グループ間のネゴシエーションフェーズが必要である。その結果、Spanner ではすべての読み取り専用トランザクションに対してスコープ式 (scope expression) が必要になる。これはトランザクション全体で読み取られるキーを要約する式である。Spanner はスタンドアロンクエリーのスコープを自動的に推論する。
スコープの値が単一の Paxos グループによって提供される場合、クライアントはそのグループのリーダーに読み取り専用トランザクションを発行する (現在の Spanner 実装では Paxos リーダーでの読み取り専用トランザクションのタイムスタンプを選択するだけである)。そのリーダーは \(s_{read}\) を割り当てて読み取りを実行する。単一サイトの読み取りでは、Spanner は一般に \(TT.now().latest\) より優れている。Paxos グループで最後にコミットされた書き込みのタイムスタンプを \(LastTS()\) と定義する。prepared トランザクションがない場合、割り当て \(s_{read}=LastTS()\) は外部一貫性を簡単に満たす。これでトランザクションは最後の書き込みの結果を見ることになり、したがってその書き込みの後に順序付けられる。
スコープの値が複数の Paxos グループによって処理される場合、いくつかの選択肢がある。最も複雑な選択肢は、\(LastTS()\) に基づいて \(s_{read}\) をネゴシエートするためにすべてのグループのリーダーと通信ラウンドを実行することである。Spanner は現在、より単純な選択肢を実装している。クライアントはネゴシエーションラウンドを回避し、\(s_{read} = TT.now().latest\) で読み取りを実行する (これは安全な時間が進むまで待機するかもしれない)。トランザクション内のすべての読み取りは十分に最新のレプリカに送信することができる。
4.2.3 スキーマ変更トランザクション
Spanner は TrueTime によりアトミックなスキーマ変更をサポートできるようになる。参加者数 (データベース内のグループ数) が数百万になる可能性があることから、標準のトランザクションを使用することは不可能である。Bigtable は 1 つのデータセンターでアトミックなスキーマ変更をサポートしているが、そのスキーマ変更によってすべての操作がブロックされる。
Spanner スキーマ変更トランザクションは、一般に標準のトランザクションをノンブロッキングにしたものである。まず、prepare フェーズで登録される将来のタイムスタンプが明示的に割り当てられる。その結果、数千ものサーバにまたがるスキーマ変更が、他の並行性アクティビティの混乱を最小限に抑えて完了できる。次に、スキーマに暗黙的に依存する読み取りと書き込みは、時刻 \(t\) に登録されているスキーマ変更のタイムスタンプと同期する。これはタイムスタンプが \(t\) より前であれば続行できるが、タイムスタンプが \(t\) より後であればスキーマ変更トランザクションの背後でブロックする必要がある。TrueTime がなければ、スキーマ変更を \(t\) で発生するように定義しても意味がない。
4.2.4 改良点
上記で定義した \(t_{safe}^{TM}\) には prepared トランザクションが 1 つあると \(t_{safe}\) が先に進めなくなるという弱点がある。その結果、読み取りがトランザクションと衝突していないとしても、後のタイムスタンプで読み出しを発生させることができない。このような誤った衝突は、キー範囲から prepared トランザクションのタイムスタンプへのきめ細かい (fine-grained) マッピングを \(t_{safe}^{TM}\) に追加することで取り除くことができる。この情報は既にキー範囲をロックメタデータにマッピングしているロックテーブルに格納できる。読み取りが到着したときにその読み取りが競合するキー範囲のきめ細かい安全時間と照合するだけで良い。
上で定義した \(LastTS()\) にも同様に、トランザクションがコミットされた直後、競合しない読み取り専用トランザクションはそのトランザクションに続くように \(s_{read}\) を割り当てなければならないという弱点がある。この結果、読み取りの実行が遅れる可能性がある。この弱点はロックテーブル内のキー範囲からコミットタイムスタンプへのきめ細かなマッピングで \(LastTS()\) を拡張することで同様に解決できる (我々はまだこの最適化を実装していない)。読み取り専用トランザクションが到着すると、競合する prepared トランザクションが存在しない限り (これはきめ細かい安全時間から判断できる)、トランザクションが競合するキー範囲の \(LastTS()\) の最大値を得ることでそのタイムスタンプを割り当てることができる。
上記で定義した \(t_{safe}^{Paxos}\) には Paxos 書き込みがない場合に前進できないという弱点がある。つまり \(t\) 時点でのスナップショット読み取りは、最後の書き込みが \(t\) より前に起きた Paxos グループでは実行することができない。Spanner はリーダーリース間隔が不連続であることを利用してこの問題に対処する。各 Paxos リーダーは将来の書き込みのタイムスタンプが発生するしきい値より上を維持することで \(t_{safe}^{Paxos}\) を進める。これは、Paxos シーケンス番号 \(n\) から、Paxos シーケンス番号 \(n+1\) に割り当てられる可能性のある最小タイムスタンプへのマッピング \(MinNextTS(n)\) を維持する。レプリカは \(n\) まで適用すると \(t_{safe}^{Paxos}\) を \(MinNextTS(s)-1\) まで進めることができる。
単一のリーダーは \(MinNextTS()\) の約束 (promise) を簡単に実行できる。\(MinNextTS()\) によって約束されたタイムスタンプはリーダーリースの範囲内にあるため、不連続不変性によってリーダー間で \(MinNextTS()\) の約束が強制される。リーダーがリーダーリースの終端を超えて \(MinNextTS()\) を進めたい場合、まずそのリースを延長する必要がある。不連続性を維持するために \(s_{max}\) は常に \(MinNextTS()\) の最高値まで進められることに注意。
リーダーはデフォルトで 8 秒ごとに \(MinNextTS()\) 値を進める。したがって prepared トランザクションが存在しなければ、アイドル状態の Paxos グループ内の正常なスレーブは最悪でも 8 秒以上前のタイムスタンプで読み取りを実行できる。リーダーはスレーブからの要求に応じて \(MinNextTS()\) 値を進めることもできる。
5 評価
我々はまずレプリケーション、トランザクション、可用性に関する Spanner のパフォーマンスを測定する。つぎに TrueTime の動作に関するデータと、最初のクライアントである F1 のケーススタディを示す。
5.1 マイクロベンチマーク
Table 3 は Spanner のマイクロベンチマークである。これらの測定はタイムシェアリングマシンで実行された。この各スパンサーバは 4GB RAM と 4 コア (AMD Barcelona 2200MHz) のスケジューリングユニットである。クライアントは別のマシンで実行された。各ゾーンには 1 台のスパンサーバが含まれていた。クライアントとゾーンはネットワーク距離が 1ms 未満のデータセンターのセットに配置された (このようなレイアウトは一般的なはずで、ほとんどのアプリケーションではすべてのデータを世界中に分散させる必要はない)。テスト用のデータベースは 2500 のディレクトリを持つ 50 の Paxos グループで作成した。操作は 4KB のスタンドアロンの読み取りと書き込みである。すべての読み取りはコンパクション後にメモリから提供されたため、Spanner のコールスタックのオーバーヘッドのみを測定している。加えて、ロケーションキャッシュをウォームアップするために測定されない読み取りを 1 ラウンド行った。

レイテンシの実験ではサーバでのキューイングを回避するためにクライアントから十分に少ない操作しか行わなかった。1 レプリカの実験ではコミット待機時間は約 5ms、Paxos レイテンシは約 9ms だった。レプリカの数が増えても Paxos はグループのレプリカで並列実行されるためレイテンシは標準偏差を小さくしてほぼ一定のまま保たれる。レプリカ数が増えるにつれて定足数を達成するためのレイテンシは 1 つのスレーブレプリカの速度低下の影響を受けにくくなる。
スループットの実験ではサーバの CPU を飽和させるようにクライアントから十分な数のオペレーションを発行した。スナップショット読み取りは最新のレプリカで実行できるため、そのスループットはレプリカ数に応じてほぼ直線的に増加する。単一リードの読み取り専用トランザクションは、タイムスタンプの割り当てをリーダーで行う必要があるため、リーダーでのみ実行される。読み取り専用トランザクションのスループットは有効なスパンサーバの数が増加するためレプリカ数と共に増加した。実験の構成ではスパンサーバの数はレプリカの数と等しく、リーダーはゾーン間でランダムに分散された。書き込みスループットは同じ実験的アーティファクトから恩恵を受けている (これはレプリカが 3 から 5 に増えた時のスループットの増加を説明している)。ただし、その恩恵よりレプリカの数が増加するにつれて書き込みごとに実行される作業量の直線的な増加が上回る。
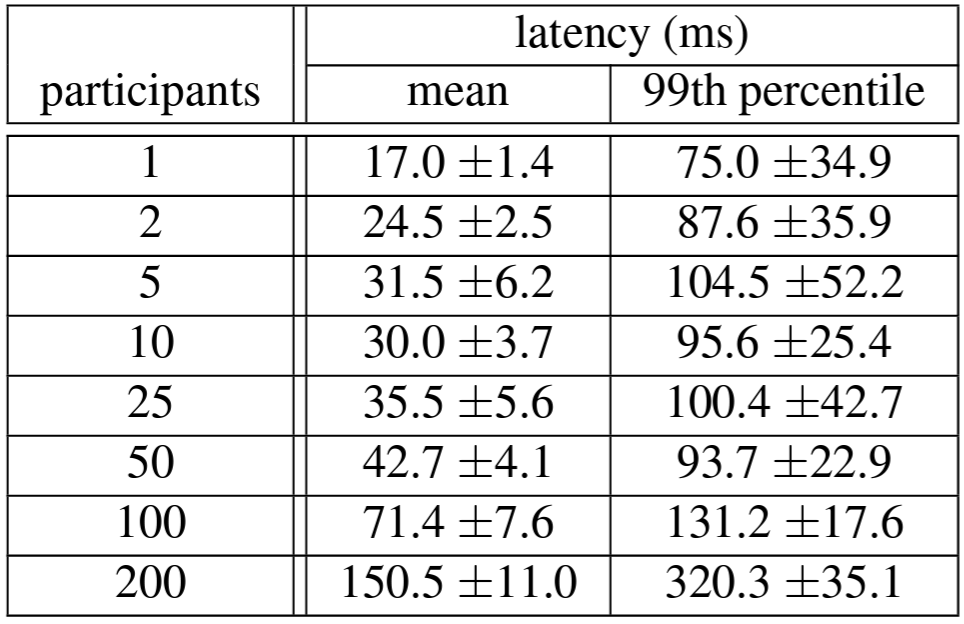
Table 4 は 2 フェーズコミットが適切な数の参加者までスケールできることを示している。これはそれぞれ 25 台のスパンサーバを持つ 3 つのゾーンで実行された一連の実験を要約したものである。参加者を 50 まで拡張することは平均と 99 パーセンタイルの両面で適切であり、参加者が 100 になるとレイテンシが顕著に増加し始める。
5.2 可用性
Figure 5 は複数のデータセンターで Spanner を実行することによる可用性の利点を示している。これはデータセンターに障害が発生したときのスループットに関する 3 つの実験結果が示されており、すべて同じ時間スケールに重ねている。テストユニバースは 5 つのゾーン \(Z_i\) で構成され、各ゾーンには 25 個のスパンサーバがあった。テストデータベースは 1250 個の Paxos グループにシャーディングされ、100 のテストクライアントが 50K read/sec の集計速度で継続的に非スナップショット読み取りを発行した。すべてのリーダーは明示的に \(Z_1\) に配置した。各テストの開始から 5 秒後に 1 つのゾーン内のすべてのサーバを強制終了した。non-leader は \(Z_2\) を強制終了、leader-hard は \(Z_1\) を強制終了、leader-soft は \(Z_1\) を強制終了するが最初にすべてのサーバにリーダーシップを引き継ぐように通知している。
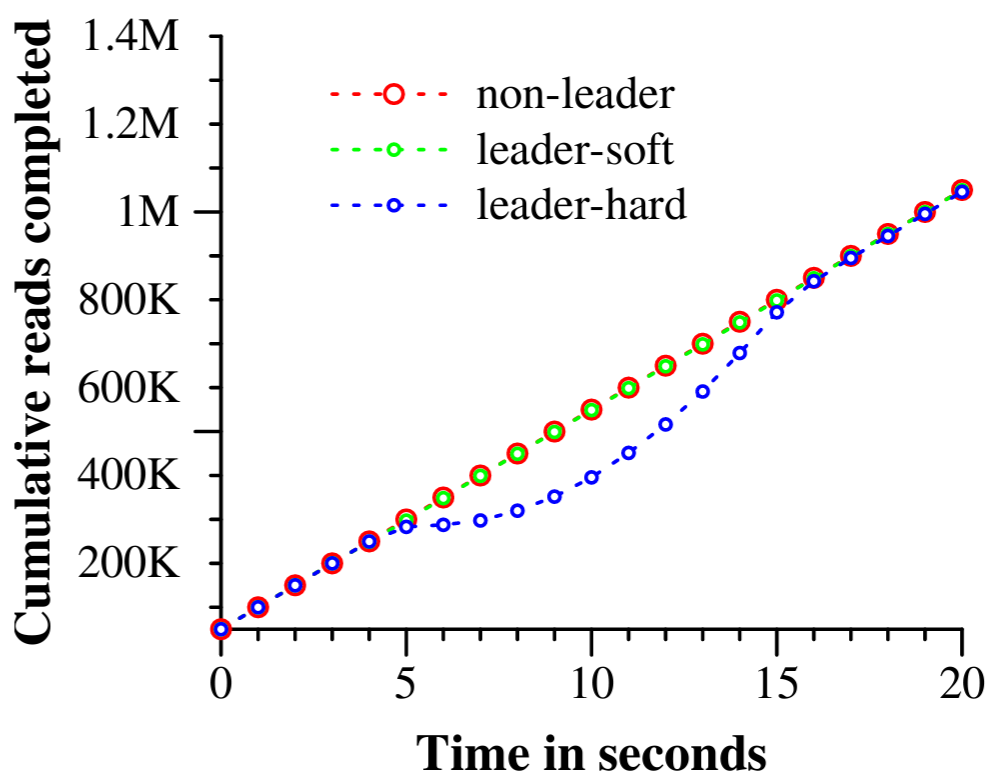
\(Z_2\) を強制終了しても読み取りスループットには影響しない。リーダーに別のゾーンにリーダーシップを引き継ぐ時間を与えながら \(Z_1\) を強制終了しても影響は軽微で、スループットの低下はグラフでは見えないが 3~4% 程度である。一方、警告なしに \(Z_1\) を強制終了すると深刻な影響があり、完了率はほとんど 0 になる。しかしリーダーが再選出されると、実験の 2 つのアーティファクト、つまりシステムには余剰容量があり、リーダーが利用できない間は操作がキューに入れられることにより、システムのスループットは約 100K read/sec に上昇する。その結果、システムのスループットは上昇した後に定常状態で再び横ばいになる。
Paxos のリーダーリースが 10 秒に設定されているという事実の影響も確認できる。我々がゾーンを強制停止させると、各グループのリーダーリースの有効期限は次の 10 秒間に均等に分散されるはずである。停止したリーダーからの各リースの有効期限が切れるとすぐに新しいリーダーが選出される。強制終了時間から約 10 秒後、すべてのグループにリーダーが現われてスループットが回復している。リース時間を短くするとサーバの停止が可用性に与える影響を減らすことができるが、リース更新のネットワークトラフィックが増えるだろう。現在、リーダーの故障時にスレーブが Paxos リーダーのリースを解放するメカニズムを設計し実装しているところである。
5.3 TrueTime
TrueTime に対して、\(\epsilon\) は本当にクロックの不確実性の境界なのか? そしてどの程度悪化するのか? という 2 つの質問に答える必要がある。前者について最も深刻な問題はローカルクロックのドリフトが 200 us/sec を超える場合である。これにより TrueTime の前提が壊れる事になる。我々のマシンの統計によれば CPU の不良はクロックの不良の 6 倍の確率で発生する。つまりクロックの問題ははるかに深刻なハードウェアの問題に比べて非常に稀である。結果として TrueTime の実装は Spanner が依存する他のソフトウェアと同じくらい信頼できると考えている。
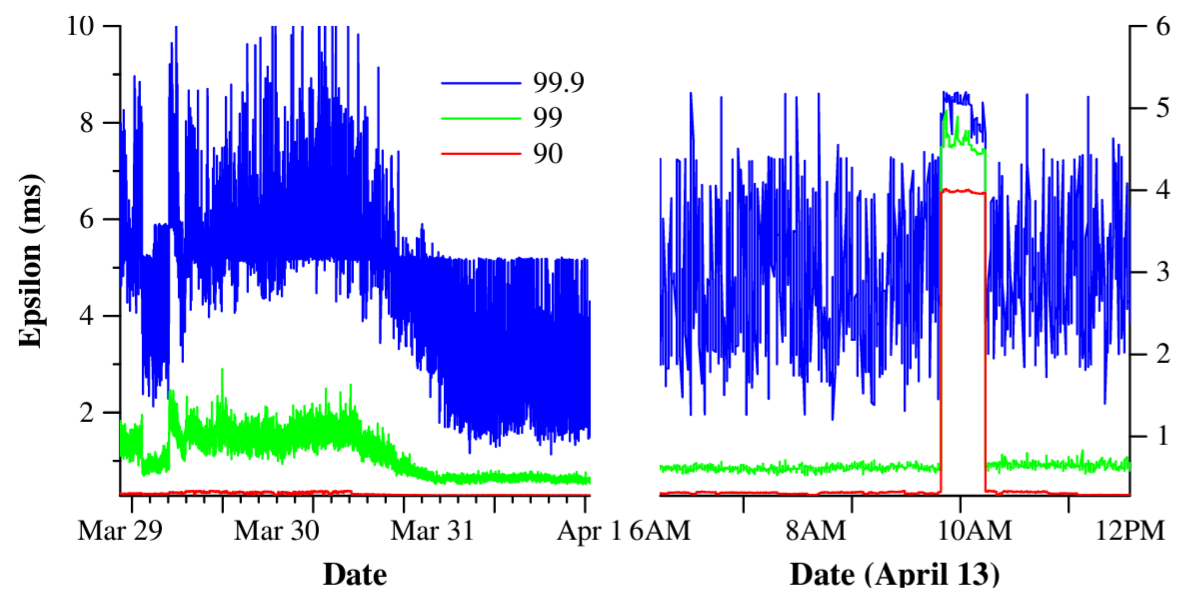
Figure 6 は最大 2200 km 離れたデータセンター間の数千台のスパンサーバマシンで取得された TrueTime データを示している。これはタイムスレーブデーモンがタイムマスターをポーリングした直後にサンプリングされた \(\epsilon\) の 90、99、99.9 パーセンタイルをプロットしている。このサンプリングはローカルクロックの不確かさによる \(\epsilon\) の鋸歯状波が排除されているため、タイムマスターの不確実性 (通常は 0) とタイムマスターへの通信遅延を合算したものが測定されている。
データによると \(\epsilon\) の基本値を決定する 2 つの要素は通常問題ではないことがわかる。しかし \(\epsilon\) の値を大きくする要因となる重大なテールレイテンシの問題が発生することがある。3 月 30 日に始まったテールレイテンシの減少はネットワークリンクの輻輳を軽減する透過的なネットワークの改善によるものであった。4 月 13 日に \(\epsilon\) が約 1 時間増加したのは、定期メンテナンスのためにデータセンターの 2 つのタイムマスターがシャットダウンされたことが原因である。我々は引き続き TrueTime スパイクの原因の調査と除去を続けている。
5.4 F1
Spanner は 2011 年初頭に Google の広告バックエンドである F1 [35] の書き換えの一環として本番環境のワークロードで実験的に評価され始めた。このバックエンドは元々 MySQL データベースをベースにしており、手作業でさまざまな方法でシャーディングされていた。圧縮されていないデータセットは数十テラバイトであり、多くの NoSQL インスタンスと比較すると小さいが、シャーディングされた MySQL では問題を引き起こすほどの大きさだった。MySQL のシャーディングスキームでは各顧客とすべての関連データが固定シャードに割り当てられた。このレイアウトにより顧客単位でインデックスと複雑なクエリー処理を使用できるようになったが、アプリケーションのビジネスロジックでシャーディングに関する知識を必要とした。顧客数とそのデータの増加に伴ってこの収益上重要なデータベースを再シャーディングすることは非常にコストがかかることだった。最後の再シャーディングには 2 年以上の膨大な労力を要し、リスクを最小限にするために数十のチームにまたがる調整とテストが必要だった。この作業は定期的に行うには複雑すぎ、そのためチームは一部のデータを外部の Bigtable に保存して MySQL データベースの成長を制限しなければならなかったが、これによりトランザクションの動作とすべてのデータに対するクエリー機能が損なわれた。
F1 チームが Spanner の仕様を選択した理由にはいくつかある。一つ目は Spanner を使用することで手動で再シャーディングする必要がなくなる点、二つ目は Spanner は同期レプリケーションと自動フェイルオーバーを提供する点である。MySQL のマスター-スレーブレプリケーションではフェイルオーバーが難しく、データ損失やダウンタイムのリスクがあった。三つ目は、F1 では強力なトランザクションセマンティクスが必要なため、他の NoSQL システムの使用は現実的ではなかった。アプリケーションのセマンティクスには任意のデータにわたるトランザクションと一貫性のある読み取りが必要である。また F1 チームはデータのセカンダリインデックスも必要としており (Spanner はまだセカンダリインデックスの自動サポートを提供していないため)、Spanner のトランザクションを使用して独自の一貫性のあるグローバルインデックスを実装することができた。
すべてのアプリケーション書き込みは MySQL ベースのアプリケーションスタックではなくデフォルトで F1 を経由して Spanner に送信されるようになった。F1 は米国西海岸に 2 つ、東海岸に 3 つのレプリカを持っている。このレプリカサイトの選択は、潜在的な大規模自然災害による停止に対処するためであり、またフロントエンド側の選択でもある。逸話的に (anecdotally) Spanner の自動フェイルオーバーは彼らにはほとんど見えなかった。ここ数ヶ月で計画外のクラスタ障害が発生したが、F1 チームがしなければならなかったことは、フロントエンドが移動した場所の近くに Paxos リーダーを優先的に配置するために、Spanner に指示するためにデータベースのスキーマを更新しただけだった。
Spanner のタイムスタンプセマンティクスにより、F1 はデータベースの状態から計算されたメモリ内のデータ構造を効率的に維持できるようになった。F1 はすべての変更の論理的な履歴ログを維持し、これはすべてのトランザクションの一部として Spanner 自体に書き込まれる。F1 はタイムスタンプでデータの完全なスナップショットを取得してデータ構造を初期化し、その後に増分変更を読み取って更新する。
Table 5 は F1 のディレクトリごとのフラグメント数の分布を示している。各ディレクトリは通常、F1 より上位のアプリケーションスタック内の顧客に対応する。大半のディレクトリ (つまり顧客) は 1 つのフラグメントのみで構成されているため、それらの顧客のデータへの読み取りと書き込みは 1 つのサーバのみで発生することが保証されている。フラグメントが 100 を超えるディレクトリは、すべて F1 のセカンダリインデックスを含むテーブルであり、このようなテーブルの数個以上のフラグメントに書き込まれることは非常に稀である。F1 チームがこのような動作を確認したのは、トランザクションとして調整されていないバルクデータのロードを行ったときのみである。
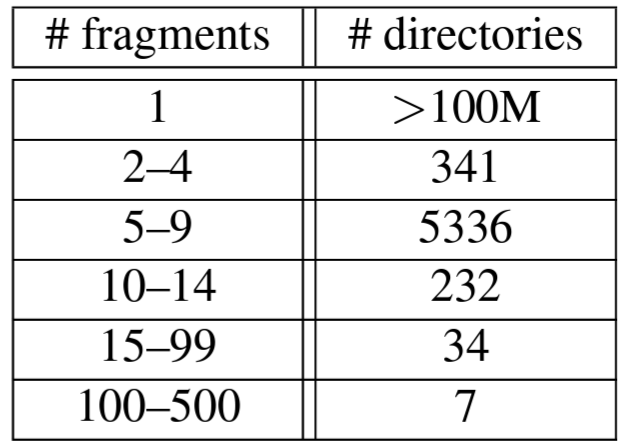
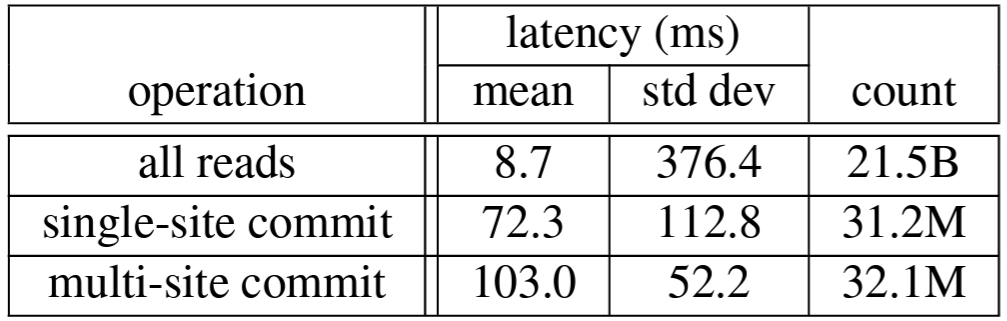
Table 6 は F1 サーバで測定された Spanner 操作のレイテンシを示している。Paxos のリーダー選択では東海岸のデータセンターのレプリカがより高い優先順位を与えられている。表中のデータはこれらのデータセンターの F1 サーバで測定されたものである。書き込み待機時間の標準偏差が大きいのはロック競合によるかなり大きなテールによって発生している。読み取りレイテンシの標準偏差がさらに大きくなっているのは Paxos リーダーが 2 つのデータセンターに分散しており、そのうちの 1 つのみ SSD を搭載したマシンを使用しているという事実が一因である。さらに、この測定には 2 つのデータセンターからのシステム内のすべての読み取りが含まれ、読み取りバイト数の中央値と標準偏差はそれぞれ 1.6 KB と 119 KB だった。
6 関連する研究
ストレージサービスとしてデータセンター間の一貫したレプリケーションは Megastore [5] と DynamoDB [3] によって提供されている。DynamoDB は Key-Value のインターフェースを提供し、リージョン内でのみレプリケーションを行う。Spanner は Megastore に倣い同様のセミリレーショナルデータモデルとスキーマ言語も提供している。Megastore は高いパフォーマンスを実現していない。Bigtable の上に階層化されているため通信コストが高くなる。また長寿命のリーダーもサポートしておらず、複数のレプリカが書き込みを開始する可能性がある。異なるレプリカからのすべての書き込みは論理的に競合していなくても Paxos プロトコルでは必然的に競合し、1 秒当たり数回の書き込みで Paxos グループのスロープットは崩壊する。Spanner はより高いパフォーマンス、汎用トランザクション、外部一貫性を提供する。
Pavlo ら [31] はデータベースと MapReduce [12] の性能を比較している。彼らは分散 Key-Value ストア [1, 4, 7, 41] に階層化されたデータベース機能を調査するために行われた他のいくつかの取り組みを 2 つの世界が収束している証拠として指摘している。我々はその結論に同意するが、複数のレイヤーを統合する事には利点があることを実証する。例えば並行性制御をレプリケーションと統合することで Spanner におけるコミット待機のコストを削減することができる。
レプリケートされたストアの上にトランザクションを重ねる概念は、少なくとも Gifford の学位論文 [16] まで遡る。Scatter [17] は一貫性のあるレプリケーションの上にトランザクションを重ねる最近の DHT ベースの Key-Value ストアである。Spanner は Scatter よりも高レベルのインターフェースを提供することに重点を置いている。Gray と Lamport [18] は Paxos に基づく非ブロッキングのコミットプロトコルについて述べている。彼らのプロトコルは 2 フェーズコミットよりも多くのメッセージングコストを要し、広域に分散されたグループでのコミットコストを悪化させる。Walter [36] はデータセンター内では機能するがデータセンター間では機能しないスナップショット分離の変種を提供してる。対照的に、我々の読み取り専用トランザクションはすべての操作で外部一貫性をサポートしているためより自然なセマンティクスを提供する。
最近、ロックのオーバーヘッドを削減または排除する研究が相次いでいる。Calvin [40] は並行性制御を排除し、タイムスタンプを事前に割り当ててタイムスタンプ順にトランザクションを実行する。HStore [39] と Granola [11] はそれぞれ独自のトランザクションタイプの分類をサポートしており、その一部はロックを回避することもできる。これらのシステムはいずれも外部一貫性を提供していない。Spanner はスナップショット分離をサポートすることで競合の問題に対処している。
VoltDB [42] はシャード化されたインメモリデータベースで、ディザスタリカバリのために広域でのマスタースレーブレプリケーションをサポートしているが、より一般的なレプリケーション構成はサポートしていない。これはスケーラブルな SQL [38] をサポートしようとする市場の動きである NewSQL と呼ばれるものの一例である。MarkLogic [26] や Oracle の Total Recall [30] など、過去には多くの商用データベースが読み取りを実装している。Lomet と Li [24] はこのような時制データベースの実装戦略について説明している。
Farsite は (TrueTime よりもはるかに緩い) 信頼できるクロック参照 [13] に対するクロックの不確実性の境界を導き出し、Farsite でのサーバリースは Spanner が Paxos リースを維持するのと同じ方法で維持された。緩く同期されたクロックは先行研究 [2, 23] で並行性制御の目的で使用されている。TrueTime を使用すると、Paxos ステートマシンのセット全体にわたってグローバルな時間が推論できることは示した。
7 今後の作業
我々は昨年の大半を F1 チームと協力し Google の広告バックエンドを MySQL から Spanner に以降するために取り組んできた。我々は監視およびサポートツールを積極的に改善しパフォーマンスを調整している。さらに、バックアップ/リストアシステムの機能とパフォーマンスと改善にも取り組んでいる。現在、Spanner スキーマ言語、セカンダリインデックスの自動メンテナンス、負荷ベースの自動再シャーディングを実装している。長期的にはいくつかの機能を調査する予定である。楽観的に考えれば読み込みを並列して行うことは追求すべき価値のある戦略かも知れないが、初期の実験では適切な実装は自明ではないことが示されている。加えて、最終的には Paxos 構成の直接変更 [22, 34] をサポートする予定である。
多くのアプリケーションは比較的近いデータセンター間でデータをレプリケートすると予想されるため、TrueTime \(\epsilon\) がパフォーマンスに顕著な影響を与える可能性がある。我々は 1ms 未満に短縮するのに乗り越えられない壁はないとみている。タイムマスタークエリーの間隔は短縮できるし、選りすぐれたクロック液晶は比較的安価である。タイムマスタークエリのレイテンシはネットワーク技術の改善によって短縮できるほか、代替の時間分散技術によって回避できる可能性もある。
最後に、明らかに改善する余地がある。Spanner はノード数でスケーラブルであるが、ノードローカルデータ構造は単純な Key-Value アクセス用に設計されているため複雑な SQL クエリーでは比較的パフォーマンスが低くなる。DB の文献にあるアルゴリズムやデータ構造は単一ノードのパフォーマンスを大幅に改善できる可能性がある。次に、クライアントの負荷の変化に応じてデータセンター間でデータを自動的に移動することが我々の長年の目標である。しかしこの目標を効果的なものにするためには、クライアントアプリケーションプロセスをデータセンター間で自動的かつ協調的な方法で移動する機能も必要である。プロセスの移動はデータセンター間でのリソースの獲得と割り当てを管理するというさらに困難な問題を引き起こす。
8 考察
要約すると、Spanner は 2 つの研究コミュニティのアイディアを組み合わせて拡張したものである。データベースコミュニティからは使い慣れた使いやすいセミリレーショナルインターフェース、トランザクション、SQL ベースのクエリー言語。システムコミュニティからはスケーラビリティ、自動シャーディング、フォールトトレランス、一貫性のあるレプリケーション、外部一貫性、広域分散。Spanner の誕生以来、我々は現在の設計と実装に至るまで 5 年を費やしてきた。この長い反復フェーズの一部は Spanner がグローバルにレプリケートされた名前空間の問題に取り組むだけでなく、Bigtable にかけていたデータベース機能にも重点を置く必要があるという認識がゆっくりと進んだことによるものである。
我々の設計、Spanner の機能セットの要は TrueTime であるという側面が際立っている。時間 API でクロックの不確実性を具現化することでより強力な時間セマンティクスを持つ分散システムを構築できることを示した。さらに、基礎となるシステムがクロックの不確実性に対してより厳しい境界を適用すると、より強力なセマンティクスのオーバーヘッドが減少する。コミュニティとして、我々は分散アルゴリズムを設計する際に、緩く同期されたクロックや弱い時間 API に依存することはもうない。
Acknowledgements
Many people have helped to improve this paper: our shepherd Jon Howell, who went above and beyond his responsibilities; the anonymous referees; and many Googlers: Atul Adya, Fay Chang, Frank Dabek, Sean Dorward, Bob Gruber, David Held, Nick Kline, Alex Thomson, and Joel Wein. Our management has been very supportive of both our work and of publishing this paper: Aristotle Balogh, Bill Coughran, Urs H¨ olzle, Doron Meyer, Cos Nicolaou, Kathy Polizzi, Sridhar Ramaswany, and Shivakumar Venkataraman.
We have built upon the work of the Bigtable and Megastore teams. The F1team, andJeff Shute in particular, worked closely with us in developing our data model andhelpedimmenselyintracking downperformanceand correctness bugs. The Platforms team, and Luiz Barroso and Bob Felderman in particular, helped to make TrueTime happen. Finally, a lot of Googlers used to be on our team: KenAshcraft, Paul Cychosz, Krzysztof Ostrowski, Amir Voskoboynik, Matthew Weaver, Theo Vassilakis, and Eric Veach; or have joined our team recently: Nathan Bales, Adam Beberg, Vadim Borisov, Ken Chen, Brian Cooper, Cian Cullinan, Robert-Jan Huijsman, Milind Joshi, Andrey Khorlin, Dawid Kuroczko, Laramie Leavitt, Eric Li, Mike Mammarella, Sunil Mushran, Simon Nielsen, Ovidiu Platon, Ananth Shrinivas, Vadim Suvorov, and Marcel van der Holst.
References
- Azza Abouzeid et al. “HadoopDB: an architectural hybrid of MapReduce and DBMS technologies for analytical workloads”. Proc. of VLDB. 2009, pp. 922–933.
- A. Adya et al. “Efficient optimistic concurrency control using loosely synchronized clocks”. Proc. of SIGMOD. 1995, pp. 23-34.
- Amazon. Amazon DynamoDB. 2012.
- Michael Armbrust et al. “PIQL: Success-Tolerant Query Processing in the Cloud”. Proc. of VLDB. 2011, pp. 181–192.
- Jason Baker et al. “Megastore: Providing Scalable, Highly Available Storage for Interactive Services”. Proc. of CIDR. 2011, pp. 223–234.
- Hal Berenson et al. “A critique of ANSI SQL isolation levels”. Proc. of SIGMOD. 1995, pp. 1–10.
- Matthias Brantner et al. “Building a database on S3”. Proc. of SIGMOD. 2008, pp. 251–264.
- A. Chan and R. Gray. “Implementing Distributed Read-Only Transactions”. IEEE TOSE SE-11.2 (Feb. 1985), pp. 205–212.
- Fay Chang et al. “Bigtable: A Distributed Storage System for Structured Data”. ACM TOCS 26.2 (June 2008), 4:1–4:26.
- Brian F. Cooper et al. “PNUTS: Yahoo!’s hosted data serving platform”. Proc. of VLDB. 2008, pp. 1277–1288.
- James Cowling and Barbara Liskov. “Granola: Low-Overhead Distributed Transaction Coordination”. Proc. of USENIX ATC. 2012, pp. 223–236.
- Jeffrey Dean and Sanjay Ghemawat. “MapReduce: a flexible data processing tool”. CACM 53.1 (Jan. 2010), pp. 72–77.
- John Douceur and Jon Howell. Scalable Byzantine-Fault-Quantifying Clock Synchronization. Tech. rep. MSR-TR-2003-67. MS Research, 2003.
- John R. Douceur and Jon Howell. “Distributed directory service in the Farsite file system”. Proc. of OSDI. 2006, pp. 321–334.
- Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. “The Google filesystem”. Proc. of SOSP. Dec. 2003, pp. 29–43.
- David K. Gifford. Information Storage in a Decentralized Computer System. Tech. rep. CSL-81-8. PhD dissertation. Xerox PARC, July 1982.
- Lisa Glendenning et al. “Scalable consistency in Scatter”. Proc. of SOSP. 2011.
- Jim Gray and Leslie Lamport. “Consensus on transaction commit”. ACM TODS 31.1 (Mar. 2006), pp. 133–160.
- Pat Helland. “Life beyond Distributed Transactions: an Apostate’s Opinion”. Proc. of CIDR. 2007, pp. 132–141.
- Maurice P. Herlihy and Jeannette M. Wing. “Linearizability: a correctness condition for concurrent objects”. ACM TOPLAS 12.3 (July 1990), pp. 463–492.
- Leslie Lamport. “The part-time parliament”. ACM TOCS 16.2 (May 1998), pp. 133–169.
- Leslie Lamport, Dahlia Malkhi, and Lidong Zhou. “Reconfiguring a state machine”. SIGACT News 41.1 (Mar.2010), pp. 63-73.
- Barbara Liskov. “Practical uses of synchronized clocks in distributed systems”. Distrib. Comput. 6.4 (July 1993), pp. 211-219.
- David B. Lomet and Feifei Li. “Improving Transaction-Time DBMS Performance and Functionality”. Proc. of ICDE (2009), pp. 581–591.
- Jacob R. Lorchetal. “The SMART way to migrate replicated stateful services”. Proc. of EuroSys. 2006, pp. 103–115.
- MarkLogic. MarkLogic 5 Product Documentation. 2012.
- Keith Marzullo and Susan Owicki. “Maintaining the time in a distribute dsystem”. Proc. of PODC. 1983, pp. 295–305.
- Sergey Melniket al. “Dremel: Interactive Analysis of Web Scale Datasets”. Proc. of VLDB. 2010, pp. 330–339.
- D.L. Mills. Time synchronization in DCNET hosts. Internet Project Report IEN–173.COMSAT Laboratories, Feb. 1981.
- Oracle. Oracle Total Recall. 2012.
- Andrew Pavlo et al. “A comparison of approaches to large-scale data analysis”. Proc. of SIGMOD. 2009, pp. 165–178.
- Daniel Peng and Frank Dabek. “Large-scale incremental processing using distributed transactions and notifications”. Proc. of OSDI. 2010, pp. 1–15.
- Daniel J. Rosenkrantz, Richard E. Stearns, and Philip M. Lewis II. “System level concurrency control for distributed database systems”. ACM TODS 3.2 (June 1978), pp. 178–198.
- Alexander Shraer et al. “Dynamic Reconfiguration of Primary/Backup Clusters”. Proc. of USENIX ATC. 2012, pp. 425-438.
- Jeff Shute et al. “F1 — The Fault-Tolerant Distributed RDBMS Supporting Google’s Ad Business”. Proc. of SIGMOD. May 2012, pp. 777–778.
- Yair Sovran et al. “Transactional storage for geo-replicated systems”. Proc. of SOSP. 2011, pp. 385–400.
- Michael Stonebraker. Why Enterprises AreUninterested in NoSQL. 2010.
- Michael Stonebraker. Six SQL Urban Myths. 2010.
- Michael Stonebraker et al. “The end of an architectural era: (it’s time for a complete rewrite)”. Proc. of VLDB. 2007, pp. 1150-1160.
- Alexander Thomson et al. “Calvin: Fast Distributed Transactions for Partitioned Database Systems”. Proc. of SIGMOD. 2012, pp.1–12.
- Ashish Thusoo et al. “Hive — A Petabyte Scale Data Warehouse Using Hadoop”. Proc. of ICDE. 2010, pp. 996–1005.
- VoltDB. VoltDB Resources. 2012.
A Paxos リーダーリース管理
Paxos リーダーリース間隔の不連続性を保証する最も簡単な方法は、リース間隔が延長されるたびに、リーダーがリース間隔の同期 Paxos 書き込みを発行することである。後続のリーダーはその間隔を読み取り、その間隔が経過するまで待機する。
TrueTime を使用することでこのような余分なログ書き込みをすることなく不連続を保証することができる。潜在的な \(i\) 番目のリーダーは、レプリカ \(r\) からのリース投票の開始の下限を、\(e_{i,r}^{send}\) (リーダーによってリース要求が送信されたときと定義) の前に計算された \(v_{i,r}^{leader}\) \(=\) \(TT.now().earliest\) として保持する。各レプリカ \(r\) はリース \(e_{i,r}^{grant}\) でリースを許可する。これは \(e_{i,r}^{receive}\) (レプリカがリース要求を受信したとき) の後に発生する。リースは \(e_{i,r}^{receive}\) の後に計算された \(t_{i,r}^{end}\) \(=\) \(TT.now().latest + 10\) で終了する。レプリカ \(r\) は単一投票 (single-vote) ルールに従う。つまり \(TT.after(t_{i,r}^{end})\) が true になるまで別のリース投票を許可しない。このルールを \(r\) のさまざまなバージョン間で適用するため、Spanner はリースを付与する前に、付与仕様としているレプリカでリース投票を記録する。このログの書き込みは既存の Paxos プロトコルのログ書き込みに便乗できる。
\(i\) 番目のリーダーが定足数の投票を受け取ると (イベント \(e_i^{quorum}\))、リース間隔を \(lease_i\) \(=\) \([TT.now().latest, \min_r(v_{i,r}^{leader}) + 10]\) として計算する。\(TT.before(\min_r(v_{i,r}^{leader})+10)\) が false のとき、リーダーでリースが期限切れになったと見なされる。不連続性を証明するために、\(i\) 番目と \((i+1)\) 番目のリーダーは定足数で共通のレプリカを 1 つ持っていなければならないという事実を利用する。そのレプリカを \(r0\) とする。証明: \[ \begin{eqnarray*} lease_i . end & = & \min_r(v_{i,r}^{leader}) + 10 & \mbox{(by definition)} \\ \min_r(v_{i,r}^{leader}) + 10 & \le & v_{i,r0}^{leader} + 10 & \mbox{(min)} \\ v_{i,r0}^{leader} + 10 & \le & t_{abs}(e_{i,r0}^{send}) + 10 & \mbox{(by definition)} \\ t_{abs}(e_{i,r0}^{send}) + 10 & \le & t_{abs}(e_{i,r0}^{receive}) + 10 & \mbox{(causality)} \\ t_{abs}(e_{i,r0}^{receive}) + 10 & \le & t_{i,r0}^{end} & \mbox{(by definition)} \\ t_{i,r0}^{end} & \le & t_{abs}(e_{i+1}^{grant}) & \mbox{(single-vote)} \\ t_{abs}(e_{i+1,r0}^{grant}) & \le & t_{abs}(e_{i+1}^{quorum}) & \mbox{(causality)} \\ t_{abs}(e_{i+1}^{quorum}) & \le & lease_{i+1} . start & \mbox{(by definition)} \end{eqnarray*} \]
翻訳抄
Google が開発したスケーラブルで広域に分散されたデータベース Spanner に関する 2013 年の論文。TrueTime API を用いて分散トランザクションと線形化可能な外部一貫性を表現している。
- CORBETT, James C., et al. Spanner: Google’s Globally-Distributed Database. ACM Transactions on Computer Systems (TOCS), 2013, 31.3: 1-22.
