論文翻訳: XFT: Practical Fault Tolerance Beyond Crashes
NUDT*
EURECOM
IBM Research–Zurich
Grenoble INP
IBM Research–Zurich
 Abstract
Abstract
長年にわたる集中的な研究にもかかわらずビザンチン障害耐性 (BFT) システムは現実に適用されていない。これはクラッシュ障害耐性 (CFT) と比較してリソース、プロトコルの複雑さ、性能の面で BFT の追加コストが発生するためである。BFT のこのオーバーヘッドはビザンチン障害のあるマシンだけではなく、同時にネットワーク全体のメッセージ配信スケジュールも完全に制御できる強力な敵対者を想定しているため、通信の非同期性を効率的に誘発し、または正しいマシンを任意に分断することができる。しかし多くの実務家にとってはこのような強力な攻撃は無意味に見える。
この論文では信頼性と安全性の高い分散システムを構築するための新しいアプローチであるクロス障害耐性 (cross fault tolerance) (XFT) を導入し、古典的なステートマシンレプリケーション (SMR) 問題に適用する。XFT は Paxos や Raft などの非同期 CFT SMR プロトコルの信頼性を保証するだけではなく、ネットワークの非同期性とともにビザンチン障害を許容するもので、レプリカの過半数が正しく同期的に通信する限りその信頼性を保証する。これにより CFT のコスト (実際にはすでに支払い済み) で XFT システムの開発が可能になるが、厳密には CFT より強力な回復力があり、場合によっては BFT 自体よりも強力である。
XFT のショーケースとして最初の XFT SMR プロトコルである XPaxos を紹介し、地理レプリケーションの設定で展開する。XPaxos は CFT XMR よりも遙かに強力な障害耐性を持ちながら余分なリソースコストはかからず、最新の CFT プロトコルと同等の性能を発揮する。
Table of Contents
- Abstract
- 1 導入
- 2 システムモデル
- 3 XFT モデル
- 4 XPaxos プロトコル
- 5 性能評価
- 6 信頼性分析
- 7 関連する研究とまとめ
- Acknowledgements
- References
- 翻訳抄
- *EURECOM PhD 仮定に在籍していたときの研究。
1 導入
単純なハードウェア障害であれ大規模災害であれ、あらゆる種類のサービス中断に対する耐性は現代の分散システムが生き残るための鍵となる。クラウド規模のアプリケーションは、あらゆる障害がその背後にあるビジネスに直接影響を与えるため、本質的に障害耐性を持たなければならない [24]。
最新の生産システム (例えば [13, 8]) ではクラッシュしたマシンの障害だけではなく、ネットワーク分断や非同期などのネットワーク障害 (この障害は他の正しいマシン同士が適時に通信できないことを反映している) も許容する分散プロトコルを採用し、信頼性のナイン数1を増やしている。これらのシステムの中核には、通常クラッシュフォールトトレラント (CFT) コンセンサスに基づくステートマシンレプリケーション (SMR) のプリミティブがある [36, 10]。
これらのシステムは、悪意のある敵対的な動作だけではなく、ハードウェアのエラー、ストレージシステムからの古いデータや破損したデータ、物理的な影響によって発生するメモリエラー、ソフトウェアのバグ、回路の微細化によるハードウェア障害、状態の破損やデータ損失を引き起こす人間のミスなどから発生する非クラッシュ (またはビザンチン [29]) 障害に対処できない。しかし実際にこのような問題が発生しており、これらの障害のそれぞれが主要な生産システムをダウンさせ、そのサービスを破損させたという公の記録がある [14, 4]。
Lamport, Shostak, Pease の独創的な研究 [29] 以来 30 年以上にわたって集中的な研究が行われてきたにもかかわらず、これまでのところ非クラッシュ障害を雇用するための実用的な答えは表れていない。特に、この問題の解決を約束した非同期ビザンチン障害耐性 (BFT) [9] は CFT と比較して余計なコストがかかることが大きな理由でこの期待に応えていない。すなはち Paxos [27] や Raft [34] などの CFT では \(2t+1\) 個のレプリカだけで済むのに対して、非同期 (つまり "eventually synchronous" [18]) BFT SMR では \(t\) 個の非クラッシュ障害を許容するためには少なくとも \(3t+1\) 個のレプリカを使用しなければならない [7] ことである。
非同期 BFT のオーバーヘッドは敵対者に与えられた並外れた力によるものであり、敵はビザンチン障害マシンとネットワーク全体の両方を協調的に制御することができる。特に古典的な BFT の敵対者は、そうでない正常なマシンを任意にいくつでも分断することができる。実務者による観察 [25] に沿い、我々はこの敵対的モデルは実際に展開されたシステムで観察される現象としては強すぎると主張する。例えば偶発的な非クラッシュ障害は通常、ネットワークの分断には繋がらない。悪意のある非クラッシュ障害に遭遇しても広域ネットワークや地理レプリケーションシステムでネットワーク全体が故障することはほとんどない。このような障害の背後にある共通の原因として有名な万能な攻撃者は、設計段階でよく使用される単純化方法であり実際には同等の普及は見られない。
この論文では非クラッシュ (ビザンチン) 障害とネットワーク障害 (非同期) の両方を許容する、効率的で回復力のある分散システムを構築するための新しいアプローチである XFT (cross fault tolerance の略) を紹介する。簡単に言えば XFT は以下のような回復力のあるシステムの構築を可能にする。
- 非同期 CFT と比較して余分なリソース (レプリカ) を使用しない。
- 非同期 CFT (つまりビザンチン故障がない状況) の信頼性保証をすべて保持する。
- ビザンチン故障が起きたとしても、過半数のレプリカが正しく互いに同期的に通信できる限り (つまり少数のレプリカがビザンチン障害であるか、ネットワーク障害のためにパーティション分断されている場合)、ビザンチン障害が発生しても正しいサービス (すなはち safety と liveness [2]) を提供することができる。
特に XFT は広域または地理レプリケーションされたシステム [13] や、敵対者が十分なネットワーク分断とビザンチン障害のあるマシンの動作を同時に容易に調整することが容易ではないそのほかの展開に適していると考えている。
XFT のショーケースとして、XFT モデルにおける最初のステートマシンレプリケーションプロトコルである XPaxos を紹介する。XPaxos は Paxos や Raft といった最新の CFT SMR プロトコルに比べクラッシュを超える障害を効率的かつ実用的に許容し、現実的な障害シナリオをより多くカバーすることを可能にする。XPaxos は \(2t+1\) レプリカを使用するためリソースのオーバーヘッドはない。XPaxos の性能を検証するために世界中の Amazon EC2 データセンター全体で地理的にレプリケーションされた設定で XPaxos を展開した。特に、クラウドシステム向けの著名で広く使用されているコーディネーションサービスである ZooKeeper [19] に XPaxos を統合した。EC2 の評価では XPaxos は WAN に最適化された Paxos バリアントとほぼ同等のスループットとレイテンシーを示し、利用可能な最高の BFT プロトコルよりも大幅に優れていることが示されている。我々の評価では XPaxos は ZooKeeper に組み込まれているネイティブの CFT SMR プロトコル [20] よりも優れている。
最後に、おそらく驚くべきことに XFT はマシン障害とネットワーク障害が独立かつ同一分布の確率変数としてある確率で発生するという仮定の下で、最新の BFT よりも厳密に強い信頼性保証を提供できることを示した。この目的のために、リソース最適化 CFT、BFT、そして XFT (例: XPaxos) プロトコルの一貫性 (system safety) と可用性 (system liveness) のナイン数を算出する。XFT は常に CFT より厳密に強力な一貫性と可用性を保証し、常に BFT より厳密に強力な可用性を保証し、信頼性分析からは BFT より一貫性を厳密に保証する場合があることを示した。
この論文の構成は以下の通りである。セクション 2 でシステムモデルを定義し、次にセクション 3 で XFT モデルを定義する。セクション 4 とセクション 5 では、それぞれ XPaxos と地理的複製コンテキストにおける XPaxos の評価について述べる。セクション 6 では XFT と CFT および BFT との比較による信頼性分析を簡略化している。セクション 7 では関連する研究を概観し結論を述べる。スペースの都合上、XPaxos の完全な正しさの証明は [31] で行っている。
- 1例えば 5-ナインの信頼性とは、システムが少なくとも 99.999% の時間駆動し正しく動作しうることを意味する。つまり故障は平均して 10 年に 1 時間程度にとどまるということである。
2 システムモデル
マシン. 我々はレプリカとも呼ばれる \(n=|\Pi|\) 個のマシンの集合 \(\Pi\) を含むメッセージパッシング分散システムについて考える。さらにクライアントマシンからなる別の集合 \(C\) が存在する。
クライアントとレプリカはビザンチン障害の影響を受けることがある: 我々は、マシンが単にすべての計算と通信を停止するクラッシュ障害と、マシンが任意に行動するが我々の使用している暗号プリミティブ (暗号論的ハッシュ、MAC、メッセージダイジェスト、電子署名) を破ることはできない非クラッシュ障害とを区別する。故障していないマシンを正しい (correct) と呼ぶ。マシンが正しいかクラッシュ障害の場合、我々はマシンを良性 (benign) であると言う。さらにある時点 \(s\) におけるレプリカの故障数を次のように表す。
- \(t_c(s)\): クラッシュ障害のレプリカ数
- \(t_{nc}(s)\): 非クラッシュ障害のレプリカ数
ネットワーク. 各レプリカのペアは信頼性の高い point-to-point 双方向通信で接続されている。さらに各クライアントは任意のレプリカと通信できる。
システムは、マシンがメッセージを交換できず要求に対する応答を時間内に取得できない可能性があるという意味で非同期であるかもしれない。つまりネットワーク障害が起こりうる; 我々はいくつかの正しいレプリカが適時で通信できないこと、つまり 2 つの正しいレプリカ間で交換されたメッセージが、すべてのレプリカが知っている遅延 \(\Delta\) 以内に配信、処理できない場合をネットワーク障害と定義する。\(\Delta\) はデプロイに依存するパラメータであることに注意: 我々はセクション 5 の地理的レプリケーションにおける \(\Delta\) の実用的な選択について論議する。最後に、最終的にネットワーク障害が発生しない最終的に同期 (eventually synchronous) システム [18] を仮定する。
過度の処理遅延は、マシンの障害に関係する問題ではなく、ネットワークの問題としてモデル化していることに注意。この選択は意識的に行っており、この研究で検討されるプロトコルの一般的なクラスでは、正しいマシンのローカル処理時間はネットワーク遅延と比較して問題になることはないという経験に基づいている。
ネットワーク障害の数を定量化するためにまず分断されたレプリカの定義を示す。
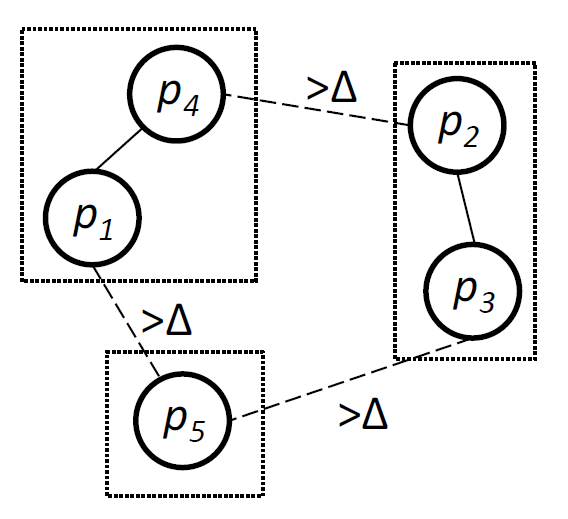
定義 1. (分断されたレプリカ) \(p\) がレプリカの最大の部分集合に含まれない場合、\(p\) は分断されている。部分集合内ではレプリカのすべてのペアは遅延 \(\Delta\) 内で互いに通信することができる。
最大サイズの部分集合が複数存在する場合、そのうちの 1 つだけを最大サイズのサブセットとして認識する。例えば Figure 1 では分断されたパーティション数は 3 で、\(p_1\), \(p_4\), \(p_5\) のグループまたは \(p_2\), \(p_3\), \(p_5\) のグループのどちらかをカウントする。分断されたレプリカの数は最大 \(n-1\) にもなることがあり、これは 2 つのレプリカが遅延 \(\Delta\) 内に互いに通信できないことを意味する。\(p\) が分断されていない場合、レプリカ \(p\) は同期的であると言う。ここで、ある時点 \(s\) におけるネットワーク障害を次のように定量化する。
- \(t_p(s)\): 正しいが分断されているレプリカ数
問題. この論文では決定論的ステートマシンレプリケーション問題 (SMR) [36] に焦点を当てる。つまり、SMR ではクライアントが要求を出し、その要求はレプリカによってコミットされる。SMR は以下を保証する。
安全性 (safety) または一貫性 (consistency): (a) コミットされたクライアントの要求を、すべての正しいレプリカ間で全順序 (total order) を強制することによって; そして (b) 有効性 (validity) を強制する、つまり正しいレプリカが以前にクライアントによって呼び出されている場合にのみ要求をコミットすることによって。
活性性 (liveness) または可用性 (availability): すべての正しいレプリカで正しいクライアントによる要求は最終的にコミットされ、アプリケーションレベルの応答をクライアントに返すことによって。
3 XFT モデル
このセクションでは XFT モデルを導入し、確率されているクラッシュ障害耐性 (CFT) とビザンチン障害耐性 (BFT) モデルとの関連付けを行う。
3.1 XFT の概要
古典的な CFT と BFT はマシン障害のみを明示的にモデル化している。これらは同期モデル (我々の感覚ではネットワーク障害は除外される)、または非同期モデル (任意の数のネットワーク障害含む) のどちらかの直行するネットワーク障害モデルと組み合わされる。したがって先行研究は次の 4 カテゴリに分類できる: 同期 CFT [16, 36]、非同期 CFT [36, 27, 33]、同期 BFT [29, 17, 6]、そして非同期 BFT [9, 3]。
これに対し XFT はマシン障害とネットワーク障害の次元の境界をし亜定義する: XFT はネットワーク障害の数に関係なくマシンのクラッシュ障害を許容し、同時に、障害または分断されたマシンの数がしきい値内にあれば、マシンの非クラッシュ障害を許容する信頼性の高いプロトコルを設計することを可能にしている。
XFT を定式化するためにまず、実際の非クラッシュマシン (レプリカ) 障害と、様々な種類の障害が多数存在する非常に厳しいシステム条件である無秩序 (anarchy) を次のように定義する。
定義 2 (無秩序). システムはある時点 \(s\) において \(t_{nc} \gt 0\) かつ \(t_c(s) + t_{nc}(s) + t_p(s) \gt t\) であれば無秩序である。
ここで \(t\) は \(t \lt \lfloor \frac{n-1}{2} \rfloor\) のようなレプリカ故障のしきい値である。つまり無秩序の状態ではあるレプリカは非クラッシュ障害であり、正しく同期的なレプリカの過半数は存在しない。無秩序の定義を用いれば、任意の分散コンピューティング問題に対してその安全性の関数として XFT プロトコルを定義することができる [2]。
定義 3 (XFT プロトコル). システムが無秩序になることのないすべての実行においてプロトコル \(P\) が安全性を満たす場合、\(P\) は XFT プロトコルである。
通常、XFT プロトコルの活性性は問題や実装に依存する。例えばこの論文で検討する決定論的 SMR の場合、XPaxos プロトコルはレプリカの過半数が正しく同期していれば最終的に活性性を満たす。これは最適 (optimal) であることを示すことができる。
| レプリカ障害のタイプごとの最大数 | |||||
|---|---|---|---|---|---|
| 非クラッシュ障害 | クラッシュ障害 | 分断レプリカ | |||
| 非同期 CFT (例: Paxos [28]) | 一貫性 | \(0\) | \(n\) | \(n-1\) | |
| 可用性 | \(0\) | \(\lfloor \frac{n-1}{2} \rfloor\) (合計) | |||
| 非同期 BFT (例: PBFT [9]) | 一貫性 | \(\lfloor \frac{n-1}{3} \rfloor\) | \(n\) | \(n-1\) | |
| 可用性 | \(\lfloor \frac{n-1}{3} \rfloor\) (合計) | ||||
| (認証済み) 同期 BFT (例: [29]) | 一貫性 | \(n-1\) | \(n\) | \(0\) | |
| 可用性 | \(n-1\) (合計) | \(0\) | |||
| XFT (例: XPaxos) | 一貫性 | \(0\) | \(n\) | \(n-1\) | |
| \(\lfloor \frac{n-1}{2} \rfloor\) (合計) | |||||
| 可用性 | \(\lfloor \frac{n-1}{2} \rfloor\) (合計) | ||||
3.2 XFT vs. CFT/BFT
Table 1 は XFT と CFT/BFT の SMR における一貫性・可用性の保証に関する違いを示している。
最新の非同期 CFT プロトコル [28, 34] はクラッシュ障害レプリカや分断レプリカが任意数であっても一貫性を保証している。また過半数 (\(t \ge \lfloor \frac{n-1}{2} \rfloor\)) のレプリカが正しくかつ同期的であれば常に可用性を保証している。CFT プロトコルは 1 つのマシンでも非クラッシュ障害となれば CFT プロトコルは一貫性も可用性も保証しない。
最適な非同期 BFT プロトコル [9, 22, 3] は任意数のクラッシュ障害や分断レプリカであっても、最大 \(t = \lfloor \frac{n-1}{3} \rfloor\) の非クラッシュ障害レプリカまでであれば一貫性を保証している。また合計で最大 \(\lfloor \frac{n-1}{3} \rfloor\) 個の障害、すなはちレプリカの 2/3 以上が正しくかつ分断されていなければ可用性を保証している。BFT は非クラッシュ障害がない場合に CFT より可用性が低下する可能性があることに注意 ─ CFT とは異なり、クラッシュ障害と分断されたレプリカの合計が \([n/3,n/2)\) の範囲にある場合、可用性が保証されない。
同期 BFT プロトコル (例えば [29]) は、正しいが分断されているレプリカの存在を考慮しない。このため非常に強い仮定が必要となる ─ そしてメッセージ認証に電子署名を使用する同期型 BFT プロトコル (いわゆる認証付きプロトコル) は非クラッシュ障害レプリカを \(n-1\) 個まで許容することができる。
対照的に、我々の XPaxos のような最適な回復力を持つ XFT プロトコルでは 2 つのモードでの一貫性を保証する: (i) 非クラッシュ障害がない場合、任意数のクラッシュ障害と分断されたレプリカ (つまり CFT と同等) で一貫性を保証し、また (ii) 非クラッシュ障害がある場合、レプリカの過半数が正しくかつ分断されていなければ、つまりすべての種類の障害 (マシンやネットワーク故障) の合計が \(\lfloor \frac{n-1}{2} \rfloor\) を超えなければ一貫性を保証する。同様にレプリカの過半数が正しくかつ分断されてなければ可用性を保証する。
XFT は非同期 CFT モデルと同期 BFT モデルの組み合わせのようなものと考えたくなるかもしれない。しかしこれは誤解を招くものであり、実際の非クラッシュ障害の場合でも XFT は認証付き同期 BFT とは比較にならない。特に、影響力の大きいビザンチン将軍プロトコル [29] のような認証付き同期 BFT プロトコルは 1 つの分断されたレプリカで一貫性に違反する可能性がある。例えば、\(n=5\) のレプリカでは、3 つのレプリカが正しくかつ同期的、1 つのレプリカが正しいが分断、1 つのレプリカが非クラッシュ障害での実行は、XFT モデルでは一貫性の保持が必須だが、ビザンチン将軍問題プロトコルでは一貫性に違反する可能性がある。2
さらに Table 1 から XFT は非同期 CFT よりも可用性と一貫性の両方について厳密に強力な保証を提供することが明らかである。また XFT は非同期 BFT よりも強力な可用性を厳密に保証している。最後に、XFT の一貫性保証は非同期 BFT の保証とは比較にならない。一方、無秩序の状態でなければ XFT は非クラッシュ障害の数が \([n/3,n/2)\) の範囲で一貫性を持つが非同期 BFT はそうではない。一方、XFT と異なり非同期 BFT は非クラッシュ障害の数が \(n/3\) 未満であれば無秩序でも一貫性を持つ。これらの点についてはセクション 6 でさらに論議し、独立障害の特殊なケースを想定した XFT と非同期 CFT/BFT の信頼性比較も定量化する。
- 2XFT は認証付き同期 BFT より強力ではない。後者はネットワーク障害が全くない状態でより多くのマシン障害を許容するためである。
3.3 XFT をどこで使うか?
XFT の背後にある直感は、無秩序のような "極端に悪い" システム状態は非常にまれであり、無秩序で一貫性を保証することは非同期 BFT のプレミアムを払う価値がないかもしれないという仮定から始まる。
実際にはこの仮定は多くの導入事例で妥当なものである。XFT は敵対者が十分な数のネットワーク分断と非クラッシュ障害マシンアクションを同時に簡単に調整できないユースケースを想定している。いくつかの興味深いユースケースの候補としては以下のようなものがある。
"偶発的な" 非クラッシュ障害の許容. 悪意ある行動や意図的な攻撃の駅用を受けにくいシステムでは、XFT を使用してネットワーク障害とはほぼ無関係と想定される"偶発的な" 非クラッシュ障害から保護することができる。このような場合、XFT を使用することで BFT のオーバーヘッドを大幅に削減しながら CFT システムを強化することができる。
広域ネットワークと地理的レプリケーションシステム. XFT は、攻撃者が攻撃を調整してビザンチンマシンを侵害すると同時に十分な数ののレプリカを分割することが困難だったりコストがかかりすぎるなら、システムが悪意的な非クラッシュ障害の影響を受けやすいケースであっても有用であることが明らかかもしれない。XFT にとって特に興味深いのは冗長な通信経路を利用してネットワークレベルの DoS 攻撃を受けにくい (例えばマルチキャストストームやフラッディングのない) WAN および地理的レプリケーションシステムである。
ブロックチェーン. XFT にとって興味深い地理的レプリケーションシステムの特殊なケースはブロックチェーンシステムである。ビットコイン [32] のような典型的なブロックチェーンシステムでは、参加者が悪意を持って行動する金銭的動機を持っていたとしても、(多数の) 正しい参加者間のコミュニケーションを侵害する手段や機能が不足しているかもしれない。このような文脈において XFT は、ビットコインスタイルの proof-of-work [40] ではなく、ステートマシンに基づくいわゆるパーミッション型ブロックチェーンに対して特に興味深いものである。
4 XPaxos プロトコル
4.1 XPaxos 概要
XPaxos は XFT モデルに特化して設計された新しいステートマシンレプリケーション (SMR) プロトコルである。XPaxos は特に地理的レプリケーション設定で優れたパフォーマンスを発揮することを目標としている。これはネットワークがボトルネックとなり、リンクのレイテンシーが高く、異種間リンクの帯域幅が比較的小さいことを特徴とした環境である。
簡単に言うと XPaxos は次の 3 つの主要コンポーネントで構成されている:
レプリカ間で要求を複製し全順序付けする通常ケース (common-case) プロトコル。これは大まかに言えば最先端の CFT プロトコル (例えば Paxos の Phase 2) のレプリカ間の通信メッセージパターンと複雑性を持ち、デジタル署名の使用によって強化されたものである。
新しいビュー変更プロトコル。これはあるビュー (システム構成) から別のビューへ分散的なリーダーレス方式で情報が転送される。
障害検知 (FD) メカニズム。無秩序状態においてシステムを一貫性のない状態にする非クラッシュ障害を、無秩序ではない状態で検知するのに役立つ。FD メカニズムのゴールは、システム内での長期にわたる非クラッシュ障害 (特に "データ損失" 障害) の影響を最小化し、システムを無秩序に追い込むのに十分な数のクラッシュ障害やネットワーク障害が発生する前にそれらを検出できるようにすることである。
XPaxos は一連のビューで編成されている [9]。XPaxos の中心的な考え方は、あるビューで通常ケースの操作中に、XPaxos がクライアントの要求を同期グループのメンバーである (全レプリカ \(n=2t+1\) 個のうちの) \(t+1\) レプリカにのみ同期的に複製することである。各ビュー番号 \(i\) はすべてのレプリカが知っているマッピングを使って同期グループ \(sg_i\) を一意に決定する。各同期グループは一つのプライマリと \(t\) 個のフォロワーで構成され、これらをまとめてアクティブレプリカと呼ぶ。このビューの残りの \(t\) 個のレプリカはパッシブレプリカと呼ばれる; オプションでパッシブレプリカは遅延レプリケーションアプローチ [26] を用いてアクティブレプリカから順序を学習する。同期グループ内ではマシンまたはネットワーク障害が発生しない限りビューは変更されない。
通常ケース (セクション 4.2) では、クライアントは電子署名された要求をプライマリに送信し、それが \(t+1\) 個のアクティブレプリカに複製される。これらの \(t+1\) 個のレプリカは複製されたすべての要求の証明に電子的に署名しローカルの commit ログに記録する。commit ログはビュー変更の一貫性を維持するための基礎となる。
XPaxos のビュー変更 (セクション 4.3) はリーダーだけではなく同期グループ全体が再構成される。新しい同期グループ \(sg_{i+1}\) の \(t+1\) 個すべてのアクティブレプリカは前のビューからビュー \(i+1\) に状態を転移しようと試みる。この分散的なアプローチは CFT および BFT プロトコル (例えば [27, 9] における古典的な再構成/ビュー変更とは対照的であり、単一のレプリカ (プライマリ) のみがビュー変更を主導し以前のビューからの状態を転送する。この違いは非クラッシュ障害が存在する場合 (ただし完全に無秩序ではない)、XPaxos のビュー間で一貫性 (すなはち全順序) を維持するために重要である。この XPaxos の斬新かつ分散化されたビュー変更方式は、非クラッシュ障害の存在下であっても無秩序状態でなければ新しい同期グループ \(sg_{i+1}\) からの少なくとも一つの正しいレプリカが古い同期グループからの任意の正しいレプリカに接触できるため、前のビューから正しい状態を転送できることを保証している。
最後に、XPaxos の FD スキームの背後にある主なアイディアは次の通り。ビュー変更では、(古い同期グループの) クラッシュ障害ではないレプリカが新しい同期グループの正しいレプリカに最新の情報を転送しない場合がある。この "データ損失" 障害はシステムが無秩序状態にあるときに一貫性が失われる可能性があり危険である。しかしこのような障害は、これらの正しいレプリカが新しい同期グループの正しいレプリカと同期的に通信できるのであれば、(古い同期グループの) いくつかの正しいレプリカの commit ログから電子署名を用いて検出することができる。XPaxos の FD ではある意味、一貫性を破るのに十分な数のクラッシュマシンまたは分断されたマシン (つまり無秩序状態) と一緒になって初めて重大な非クラッシュマシン障害が発生することになる。
以降は、通常ケース (セクション 4.2)、ビュー変更 (セクション 4.3)、および障害検出 (セクション 4.4) コンポーネントの XPaxos コアについて説明する。XPaxos の最適化についてはセクション 4.5 で、XPaxos の正しさについてはセクション 4.6 で説明する。スペースの関係上、完全な擬似コードと正しさの証明は [31] に含まれている。
4.2 通常ケース
Figure 2 は一般的なケース \((t \gt 2)\) と特殊なケース \(t = 1\) における XPaxos の通常メッセージパターンを示している。XPaxos は特に \(t=1\) のケースの最適化されていている。この場合、各ビューのアクティブレプリカは 2 つだけであるためプロトコルは非常に効率的である。また \(t=1\) という特殊なケースは実際には非常に重要である (例えば Spanner [13] 参照)。以下では、まず XPaxos の通常ケース (common case) を説明し、次に \(t=1\) の特殊なケースに焦点を当てる。
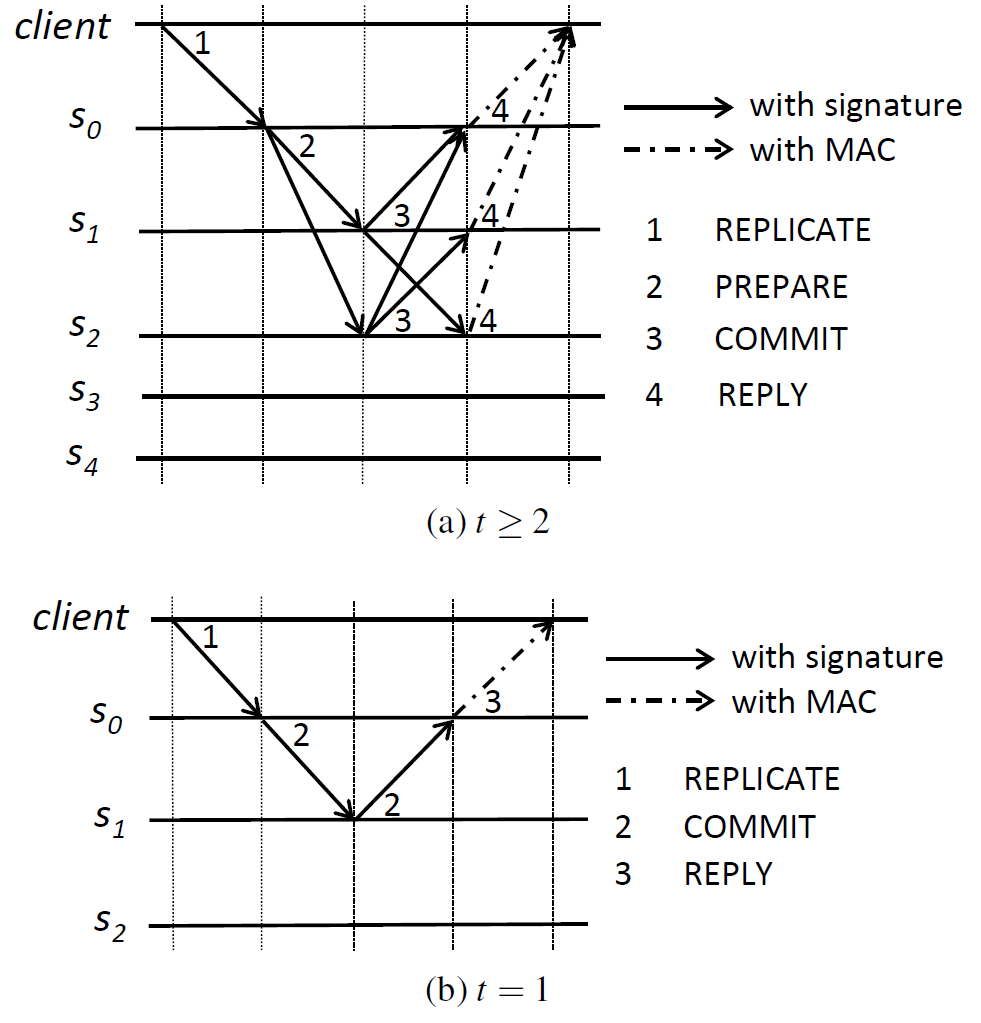
表記方法. メッセージ \(m\) のダイジェストを \(D(m)\) と表記し、\(\langle m \rangle_{\sigma_p}\) はマシン \(p\) の秘密鍵で署名した \(D(m)\) と \(m\) の両方を含むメッセージを表す。署名検証のためすべてのマシンは他のすべてのプロセスの公開鍵を知っていると仮定する。
4.2.1 一般的なケース \((t \gt 2)\)
XPaxos の通常ケースのメッセージパターンを Figure 2a に示す。具体的には、プライマリ (\(s_0\) とする) がクライアント \(c\) から署名付きリクエスト \({\it req} = \langle {\rm REPLICATE},op,ts_c,c \rangle_{\sigma_c}\) を受け取ると (\(op\) はクライアントの操作、\(ts_c\) はクライアントのタイムスタンプ)、(1) シーケンス番号 \(sn\) をインクリメントして \({\it req}\) に \(sn\) を割り当て、(2) メッセージ \({\it prep} = \langle {\rm PREPARE}, D({\it req}), sn, i \rangle_{\sigma_{s_0}}\) を署名して \(\langle {\it req}, {\it prep} \rangle\) を prepare ログ \({\it PrepareLog}_j[sn]\) に記録する (\(s_0\) が \({\it req}\) を準備したとする)、そして (3) \(\langle {\it req}, {\it prep} \rangle\) を他のすべてのアクティブレプリカ(すなはち \(t\) 個のフォロワー) に転送する。
各フォロワー \(s_j\) (\(1 \le j \le t\)) はプライマリとクライアントの署名を検証し、自分のローカルのシーケンス番号が \(sn-1\) と等しいことをチェックし、\(\langle {\it req},{\it prep} \rangle\) を prepare ログ \({\it PrepareLog}_j[sn]\) に記録する。次に \(s_j\) はローカルのシーケンス番号を \(sn\) に更新し、リクエスト \({\it req}\)、シーケンス番号 \(sn\)、ビュー番号 \(i\) のダイジェストに署名し、すべてのアクティブレプリカに \(\langle {\it COMMIT},D({\it req}),sn,i \rangle_{\sigma_{s_j}}\) を送信する。
\(t\) 個の署名付き COMMIT メッセージ (各フォロワーから1つずつ) を受け取り、それに一致するエントリが prepare ログにある場合、アクティブレプリカ \(s_k\) (\(0 \le k \le t\)) は \({\it prep}\) と \(t\) 個の署名済み COMMIT メッセージをその commit ログ \({\it CommitLog}_{s_k}[sn]\) に記録する。このとき \(s_k\) は \({\it req}\) をコミットすると言う。最後に、\(s_k\) は \({\it req}\) を実行し、クライアントに認証済み応答を送る (フォロワーは応答のダイジェストのみを送るだろう)。クライアントは \(t+1\) 個すべてのアクティブレプリカから一致する REPLY メッセージを受信するとリクエストをコミットする。
リクエストをコミットせずにタイムアウトしたクライアントは、そのリクエストをすべてのアクティブなレプリカにブロードキャストする。アクティブレプリカはそのようなリクエストをプライマリに転送して再送タイマーを起動し、正しいアクティブレプリカはこのタイマー内でクライアントのリクエストがコミットされることを期待する。
4.2.2 単一障害耐性 \((t = 1)\)
\(t=1\) のとき、XPaxos の通常ケースは 2 つのアクティブレプリカ間で 2 つのメッセージのみを含むように単純化される (Figure 2b)。
クライアント \(c\) から署名済みリクエスト \({\it req} = \langle {\it REPLICA},op,ts_c,c \rangle_{\sigma_c}\) を受け取ると、プライマリ (\(s_0\)) はシーケンス番号 \(sn\) をインクリメントし、メッセージ \(m_0=\langle{\rm COMMIT},D({\it req}),sn,i\rangle_{\sigma_{s_0}}\) で \({\it req}\) とビュー番号 \(i\) のダイジェストに沿って \(sn\) に署名し、\(\langle {\it req},m_0 \rangle\) を prepare ログ (\({\it PrepareLog}_{s_0}[sn]\)) に保存し、メッセージ \(\langle {\it req},m_0 \rangle\) をフォロワー \(s_1\) に送信する。
フォロワー \(s_1\) が \(\langle {\it req},m_0\rangle\) を受信するとクライアントとプライマリの署名を検証し、ローカルのシーケンス番号が \(sn-1\) と等しいかチェックする。もしそうならフォロワーはローカルのシーケンス番号を \(sn\) に更新し、応答 \(R({\it req})\) を生成してリクエストを実行し、メッセージ \(m_1\) に署名する; \(m_1\) は \(m_0\) と似ているがクライアントのタイムスタンプと応答のダイジェストも含んでいる: \(m_1=\langle{\rm COMMIT},\langle D({\it req}), sn, i, req.ts_c, D(R({\it req}))\rangle_{\sigma_{si}}\)。フォロワーはタプル \(\langle {\it req},m_0,m_1\rangle\) を commit ログ (\({\it CommitLog}_{s_1}[sn] = \langle{\it req},m_0,m_1\rangle\)) に保存し、プライマリに \(m_1\) を送信する。
プライマリはフォロワーから有効な COMMIT メッセージ (自身の prepare ログに一致するエントリがある) を受け取るとリクエストを実行し、応答 \(R({\it req})\) と \(m_1\) に含まれるフォロワーのダイジェストを比較し、\(\langle{\it req},m_0,m_1\rangle\) を自身の commit ログに保存する。最後に、\(m_1\) を含む承認済み応答を \(c\) に返し、\(c\) はすべてのダイジェストとフォロワーの署名が一致する場合にリクエストをコミットする。
4.3 ビュー変更
直感. 一貫性 (全順序) を強制するためには XPaxos では正しいレプリカの commit ログに含まれる順序づけされたリクエストが鍵である。XPaxos のビュー変更を説明するために、それぞれが \(t+1\) 個のレプリカを含むビュー \(i\) と \(i+1\) の同期グループ \(sg_i\) と \(sg_{i+1}\) について考える。\(sg_i\) でコミットされたリクエストの証明が \(sg_i\) のたった一つの正しいレプリカに記録されているかもしれないことに注意。それにもかかわらず XPaxos のビュー変更は (無秩序状態を除いて) これらの証明が新しいビュー \(i+1\) に転送されることを保証しなければならない。この目的のために我々は単一のレプリカ (通常次のビューのプライマリ) によってビュー変更が主導される伝統的なビュー変更手法 [9, 22, 12] から離れる必要があった。代わりに XPaxos ビューチェンジでは \(sg_{i+1}\) のすべてのアクティブレプリカが前のビューでコミットされたリクエストに関する情報を取得する。直感的には、\(sg_{i+1}\) の過半数が正しい同期レプリカであれば \(sg_{i+1}\) の (少なくとも一つの) 正しい同期レプリカと接触しており、最新の正しい commit ログを新しいビュー \(i+1\) に転送する。
以下ではまず各ビューのアクティブレプリカの選択方法について説明する。次にビュー変更がどのように開始されるかを説明し、最後にビュー変更がどのように実行されるかを説明する。
4.3.1 アクティブレプリカの選択
ビュー \(i\) のアクティブレプリカを選択するために、\(t+1\) 個のレプリカを含むすべてのセット (つまり \(\begin{pmatrix} 2t+1 \\ t+1 \end{pmatrix}\) 個のセット) を列挙し、ラウンドロビン方式デビュー全体で同期グループとして交互に使用することができる。さらに、各同期グループはプライマリを一意に決定する。ビュー番号から同期グループへのマッピングはすべてのレプリカで既知であると仮定する (例えば Table 2 参照)。
上記の単純な方法はレプリカが少数の場合 (例えば \(t=1\) や \(t=2\)) に適しているが、レプリカの数が多い場合は同期グループの組み合わせ数が非効率的になるかもしれない。このため XPaxos は、リーダーだけをローテーションさせた後に各ビューで \(f\) 個のフォロワー集合の選択に決定論的検証可能疑似ランダム関数に頼るように修正することができる。しかしそのような方式の正確な詳細はこの論文の範囲を超えるだろう。
| 同期グループ (\(i \in \mathbb{N}_n\)) | ||||
|---|---|---|---|---|
| \(sg_i\) | \(sg_{i+1}\) | \(sg_{i+2}\) | ||
| アクティブレプリカ | プライマリ | \(s_0\) | \(s_0\) | \(s_1\) |
| フォロワー | \(s_1\) | \(s_2\) | \(s_2\) | |
| パッシブレプリカ | \(s_2\) | \(s_1\) | \(s_0\) | |
4.3.2 ビュー変更の開始
ビュー \(i\) の同期グループ (\(sg_i\) と表記) が進行しない場合に XPaxos はビュー変更を実行する。\(sg_i\) のアクティブレプリカのみがビュー変更を開始できる。アクティブレプリカ \(s_j \in sg_i\) は (i) \(s_j\) が他のアクティブレプリカからプロトコルに適合しないメッセージ (例えば不正な署名など) を受信したり、(ii) \(s_j\) の再送タイマーが切れたり、(iii) \(s_j\) が適時方式 (timely manner) でビュー \(i\) へのビュー変更を完了しなかったり、(iv) \(sg_i\) の他のレプリカからビュー \(i\) の有効な SUSPECT メッセージを受信した場合にビュー変更を開始する。ビュー変更が開始されると \(s_j\) は現在のビューへの参加を停止し、他のすべてのレプリカに \(\langle {\rm SUSPECT},i,s_j\rangle_{s_j}\) を送信する。
4.3.3 ビュー変更の実行
ビュー \(i\) のアクティブレプリカから SUSPECT メッセージを受信すると (Figure 3 のメッセージパターン参照)、レプリカ \(s_j\) はビュー \(i\) のメッセージ処理を停止し、\(sg_{i+1}\) の \(r+1\) 個のアクティブレプリカにメッセージ \(m =\) \(\langle{\rm VIEW\mbox{-}CHANGE},\) \(i+1,\) \(s_j,\) \({\it CommitLog}_{s_j}\rangle_{\sigma_{s_j}}\) を送信する。VIEW-CHANGE メッセージは \(s_j\) の commit ログ \({\it CommitLog}_{s_j}\) を含んでいる。commit ログは空でも良い (例えば \(s_j\) がパッシブであった場合)。
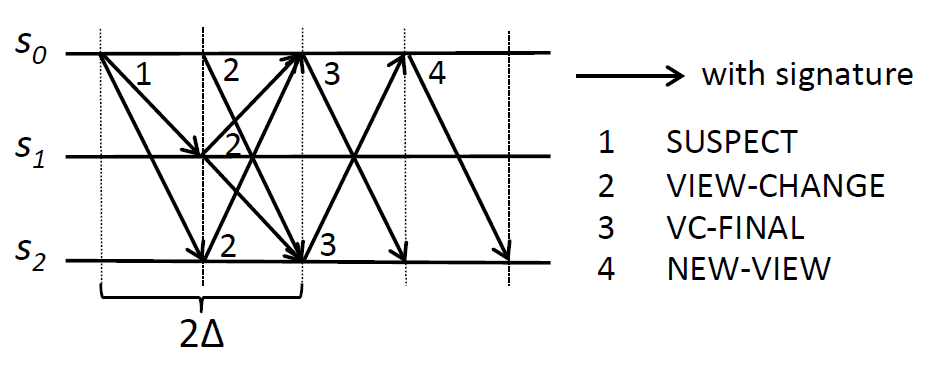
XPaxos では、新しいビューのすべてのアクティブなレプリカが新しいプライマリだけではなく最新の状態と証明 (つまり VIEW-CHANGE メッセージ) を収集する必要があることに注意。そうしないと、無秩序状態でなくても、故障した新しいプライマリが最新の状態を意図的に省略することができてしまう。ビュー \(i+1\) のアクティブレプリカ \(s_j\) は全員から少なくとも \(n-t\) 個の VIEW-CHANGE メッセージを待機するが、\(2\Delta\) 時間まで待って可能な限り多くのメッセージを収集しようと試みる。
上記のプロトコルを完了すると、各アクティブレプリカ \(s_j \in sg_{i+1}\) は受信したすべての VIEW-CHANGE メッセージを集合 \({\it VCSet}_{s_j}^{i+1}\) に挿入する。そして \(s_j\) はビュー \(i+1\) の各アクティブレプリカに \(\langle{\rm VC\mbox{-}FINAL},i+1,s_j,{\it VCSet}_{s_j}^{i+1}\rangle_{\sigma_{s_j}}\) 送信する。これにより、受信した VIEW-CHANGE メッセージはアクティブレプリカ間で交換さる。
各アクティブレプリカ \(s_j \in sg_{i+1}\) は \(sg_{i+1}\) のすべてのレプリカから VC-FINAL メッセージを受信しなければならなず、その後に \(s_j\) は VC-FINAL メッセージに背負わされている \({\it VCSet}_*^{i+1}\) セットを結合して値 \({\it VCSet}_{s_j}^{i+1}\) を拡張する。そして、アクティブレプリカはシーケンス番号 \(sn\) それぞれに対してすべての VIEW-CHANGE メッセージの中で最大のビュー番号を持つ commit ログを選択し、\(sn\) でコミットされたリクエストを確認する。
その後、ビュー \(i+1\) で選択されたリクエストを準備してコミットするために、新しいプライマリ \(ps_{i+1}\) は \(sg_{i+1}\) の各アクティブレプリカに \(\langle{\rm NEW\mbox{-}VIEW},\) \(i+1,\) \({\rm PrepareLog}\rangle_{\sigma_{ps_{i+1}}}\) を送信する。ここで配列 \({\it PrepareLog}\) には選択されたリクエストごとにビュー \(i+1\) で生成された prepare ログが含まれている。各アクティブレプリカ \(s_j \in sg_{i+1}\) は NEW-VIEW メッセージを受信すると通常ケース (セクション 4.2 参照) で説明したように \({\it PrepareLog}\) の prepare ログを処理する。
最後に、各アクティブレプリカ \(s_j \in sg_{i+1}\) は \({\it PrepareLog}\) 内のすべての選択したリクエストがビュー \(i+1\) でコミットされることを確認する。この条件が満たされると XPaxos は新しいリクエストの処理を開始する。
4.4 障害検出
XPaxos は無秩序状態での一貫性を保証しない。したがって非クラッシュ障害が十分長く持続し、最終的に十分なクラッシュ障害とネットワーク障害と重なった場合、長期的に XPaxos の一貫性に違反する可能性がある。このような持続期間の長い障害に対処するために (そうでなければオプションで) XPaxos の障害検出 (fault detection) (FD) メカニズムを提案する。
大まかに言えば FD は次の性質を保証する: マシン \(p\) が無秩序状態で不整合を引き起こすような非クラッシュ障害を無秩序ではない状態で被った場合、XPaxos の FD は (無秩序ではない状態で) \(p\) に故障があるものとして検出する。言い換えると無秩序ではない状態で発生する潜在的に致命的な障害は XPaxos の FD によって検出される。
ここでは \(t=1\) ケース (詳細は [31] 参照) で、無秩序状態の XPaxos に不整合を引き起こすことのできる特定の非クラッシュ障害 ─ 非クラッシュ障害レプリカがビュー変更前に commit ログの一部を失うことによるデータ欠損障害に焦点を当て、FD がどのように機能するかをスケッチする。直感的にはデータ欠損障害は電子署名を使うだけでは防ぐことができないため危険である。
我々の FD メカニズムは XPaxos のビュー変更を次のように変更する必要がある: レプリカは commit ログを交換するだけではなく prepare ログも交換する。\(t=1\) ではプライマリのみが prepare ログを保持していることに注意 (セクション 4.2 参照)。新しいビューでは、転送された commit および prepare ログに含まれているすべてのリクエストをプライマリが準備しフォロワーがコミットする。
この変更により、(先行するビュー \(i\) の) 故障プライマリが一貫性を破るには commit ログと prepare ログの両方でデータ欠損障害を呈する必要がある。しかし、(i) ビュー \(i\) の (正しい) フォロワーはビュー変更を応答し、(ii) プライマリの prepare ログがフォロワーの commit ログのそれぞれのエントリに因果的に先行するため、プライマリの prepare ログのデータ欠損障害は無秩序ではない状態で検出されるだろう。フォロワーの commit ログの署名を単純に検証することによりプライマリの故障は検出される。逆にビュー \(i\) のフォロワーの commit ログでのデータ欠損障害は、ビュー \(i\) のプライマリの commit ログでの署名を検証することで無秩序ではない状態で検出される。
4.5 XPaxos の最適化
上述の通常ケースプロトコルとビュー変更プロトコルは正しさを保証するには十分だが、我々は XPaxos にいくつかの標準的なパフォーマンス最適化を適用した。具体的には (ビュー変更時の状態転送を短縮するための) パッシブレプリカへのチェックポイントや遅延レプリケーション [26]、および (スループットを改善するための) バッチ処理とパイプラインなどが挙げられる。以下にこれらの最適化の概要を説明する。詳細は [31] を参照。
チェックポイント. 他のレプリケーションプロトコルと同様に XPaxos もビュー変更を高速化し (commit ログを短縮することで) ガーベッジコレクションを可能にするチェックポイント機構を備えている。そのためすべての CHK リクエスト (CHK は設定可能なプラメータ) で XPaxos は同期グループ内の状態をチェックポイント化する。そしてチェックポイントの証明はパッシブレプリカに遅延して伝播される。
遅延レプリケーション. ビュー変更時の状態転送を高速化するために同期グループ内の各フォロワーは commit ログを 1 つのパッシブレプリカに遅延で伝搬する。遅延レプリケーションでは (前のビューではパッシブレプリカだったかも知れない) 新しいアクティブレプリカがビュー変更時に他のレプリカから不足している状態を取得するだけでよいかもしれない。
バッチ処理とパイプライン処理. 暗号化操作のスループットを向上させるため、プライマリは prepare 時にいくつかのリクエストをバッチ化する。プライマリは \(B\) 個のリクエストを待機し、そしてバッチ化されたリクエストに署名して各フォロワーに送信する。プライマリが制限時間内に \(B\) 個未満のリクエストしか受信しなかった場合、プライマリは受信したすべてのリクエストをバッチ化する。
4.6 正しさの議論
一貫性 (全順序性). XPaxos は次の不変条件を強制しており、これは全順序性の鍵である。
補題 1. 無秩序ではない状態で、ビュー \(i\) において良性のクライアント \(c\) がシーケンス番号 \(sn\) のリクエスト \({\it req}\) をコミットし、ビュー \(i' \gt i\) で良性のレプリカ \(s_k\) が \(sn\) のリクエスト \({\it req}'\) をコミットした場合、\({\it req} = {\it req}'\) である。
良性のクライアント \(c\) は、\(c\) が \(sg_i\) の \(t+1\) 個のアクティブレプリカから一致する応答を受信した後にのみ、ビュー \(i\) 内のシーケンス番号 \(sn\) のリクエスト \({\it req}\) をコミットする。これは \(sg_i\) のすべての良性のレプリカがシーケンス番号 \(sn\) の下で \({\it req}\) を commit ログに保存することを意味する。以下では \(i'=i+1\) という特殊なケースに焦点を当てる。これは [31] で示されている、ビュー間の帰納法による補題 1 の証明のための基本ステップとなるものである。
ビュー \(i'=i+1\) における \(sg_{i+1}\) のすべての (良性) レプリカは、他のレプリカから転送された commit ログを含んでいる \(n-1=t+1\) 個の VIEW-CHANGE メッセージと、\(2\Delta\) に設定したタイマーが終了するまで待機することは以前に述べた。そして \(sg_{i+1}\) のレプリカは VC-FINAL メッセージ内でこの情報を交換する。無秩序ではない状態では \(sg_{i+1}\) には少なくとも 1 つの正しくかつ同期的な \(s_j\) というレプリカが存在する。したがってビュー \(i+1\) の \({\it req}'\) をシーケンス番号 \(sn\) の下でコミットする良性レプリカ \(s_k\) は \(s_j\) から VC-FINAL を受け取っているはずである。一方、\(s_j\) は \(t+1\) 個の VIEW=CHANGE メッセージ (そして \(2\Delta\) タイマー) を待機したため、ある正しい同期レプリカ \(s_x \in sg_i\) (このようなレプリカは \(sg_i\) で非クラッシュ障害か分断されているレプリカが最大 \(t\) であるため \(sg_i\) に存在する) から VIEW-CHANGE メッセージを受信した。\(s_x\) はビュー \(i\) の commit ログで \(sn\) の下に \({\it req}\) を保存したので、この情報を VIEW-CHANGE メッセージで \(s_j\) に転送し、\(s_j\) はこの情報を VC-FINAL で \(s_k\) に転送する。したがって \({\it req}={\it req}'\) に従う。
可用性. XPaxos の可用性は同期グループが正しい同期レプリカのみを含む場合に保証される。最終的に同期がとれていれば最終的にネットワーク障害が発生しないと考えることができる。また XPaxos は、アクティブレプリカの役割をローテーションする \(t+1\) 個のレプリカのすべての組み合わせで、最終的に XPaxos のビュー変更が \(t+1\) 個の正しくかつ同期的なアクティブレプリカで完了することを保証している。
5 性能評価
このセクションでは XPaxos のパフォーマンスを評価し、ワールドワイドなクラウドプラットフォームである Amazon EC2 を使って Zyzzyva [22]、PBFT [9]、WAN 向けに最適化された Paxos [27] と比較する。我々は XFT や BFT などのビザンチン障害耐性プロトコルに適していると考えて地理レプリケーションの WAN 設定を選択した。実際 WAN 設定では (i) マシン間をつなぐスイッチのような単一障害点がなく、(ii) 電力喪失、嵐、そのほかの自然災害による相関障害がなく、(iii) 敵対者がネットワークをフラッディングしネットワーク障害と非クラッシュ障害を相関させることが困難である (最後の点は XFP に関係している)。
このセクションの残りの部分では、まず実験的なセットアップ (セクション 5.1) を評価し、つぎに無障害シナリオ (セクション 5.2) および障害発生時 (セクション 5.3) でパフォーマンス (スループットとレイテンシー) を評価する。最後に、実際のサプリケーションである ZooKeeper コーディネーションサービス [19] (セクション 5.4) を使用して、ネイティブの ZooKeeper と上記 4 つのレプリケーションプロトコルを用いた ZooKeeper 変種のパフォーマンス比較を行う (セクション 5.4)。
5.1 Experimental setup
5.1.1 Synchrony and XPaxos
5.1.2 Protocols under test
5.1.3 Experimental testbed and benchmarks
5.2 Fault-free performance
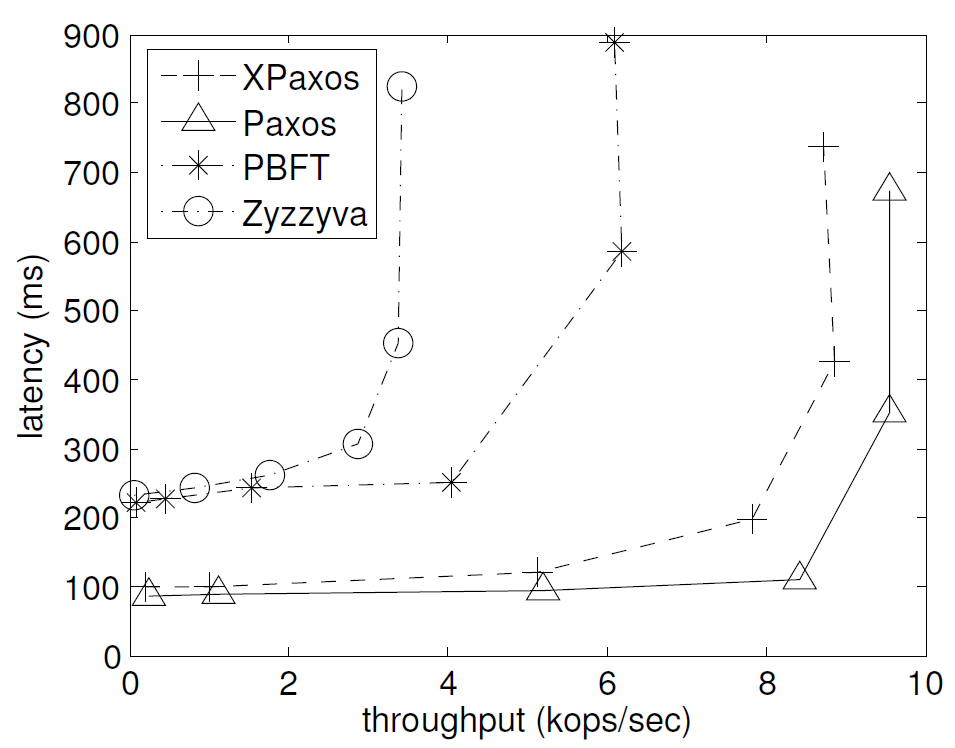
まず 1/0 と 4/0 のマイクロベンチマークを使用して Table 3 のようなレプリカ構成で \(t=1\) のケースでのプロトコル性能を比較した。その結果は Figure 4a と Figure 4b に示す。それぞれのグラフの X 軸はスループット (kops/sec)、Y 軸はレイテンシー (ms) を示している。
| PBFT | Zyzzyva | Paxos | XPasos | EC2 Region |
|---|---|---|---|---|
| プライマリ | プライマリ | プライマリ | プライマリ | US West (CA) |
| アクティブ | アクティブ | アクティブ | フォロワー | US East (VA) |
| パッシブ | パッシブ | Tokyo (JP) | ||
| パッシブ | - | - | Europe (EU) |
(a) 1/0 ベンチマーク, \(t=1\)
(b) 4/0 ベンチマーク, \(t=1\)
(c) 1/0 ベンチマーク, \(t=2\)
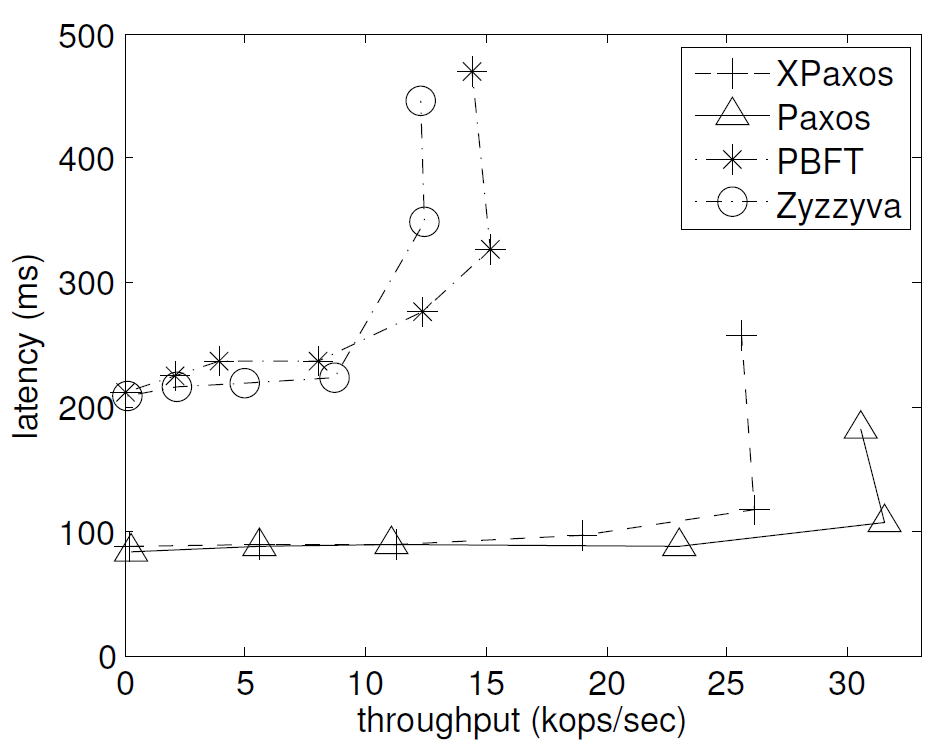
見ての通り、いずれのベンチマークにおいても XPaxos は PBFT や Zyzzyva を大きく上回るパフォーマンスを達成している。これはワールドワイドなクラウド環境ではネットワークがボトルネックとなり、PBFT や Zazzyva などの BFT プロトコルのメッセージパターンが高価になる傾向がある。PBFT と比較すると XPaxos のメッセージパターンは単純であるためスループットが向上する。また Zazzyva と比較すると XPaxos はリーダーにかかる負担が少なく、通常ケースでは Zyzzyva の 3 分の 1 のレプリカ (つまり \(t\) 個のフォロワー vs 他のすべての \(3t\) 個のレプリカ) でリクエストを複製する。さらに XPaxos の性能は Paxos に非常に近い。Paxos と XPaxos はどちらも \(t=1\) の場合に 2 つのレプリカ間でラウンドトリップを実装しているため非常に効率的である。
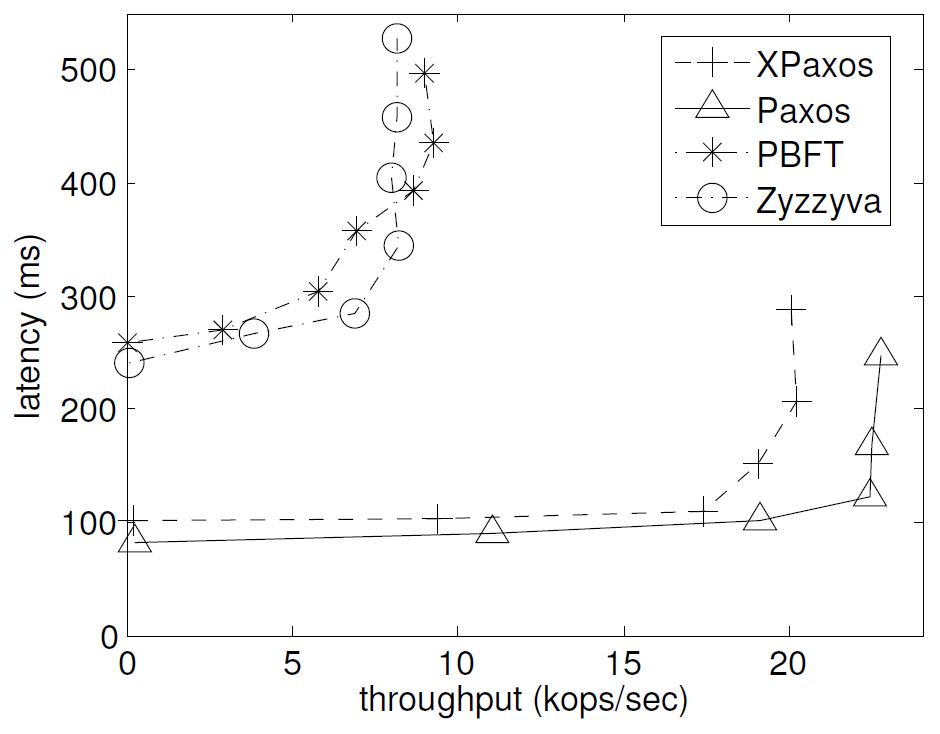
次に XPaxos の障害スケーラビリティを評価するために 2 つの障害 \(t=2\) を許容する構成で 1/0 マイクロベンチマークを実施した。この実験には CA (カリフォルニア)、OR (オレゴン)、VA (バージニア)、JP (東京)、EU (アイルランド)、AU (シドニー)、SG (シンガポール) の EC2 データセンターを使用している。我々は Paxos と XPaxos のアクティブレプリカを最初の \(t+1\) データセンターに設置し、他のパッシブレプリカを次の \(t\) データセンターに設置する。PBFT では最初の \(2t+1\) データセンターをアクティブレプリカに、最後の \(t\) データセンターをパッシブレプリカに使用する。最後に、Zyzzyva はすべてのレプリカをアクティブレプリカに使用する。
XPaxos は PBFT と Zyzzyva より明らかに優れており Paxos と非常に近いパフォーマンスを達成していることが分かる。さらに PBFT や Zyzzyva とは異なり、Paxos と XPaxos は \(t=1\) のケースに関してパフォーマンスの低下が中程度にとどまっている。
5.3 障害時の性能
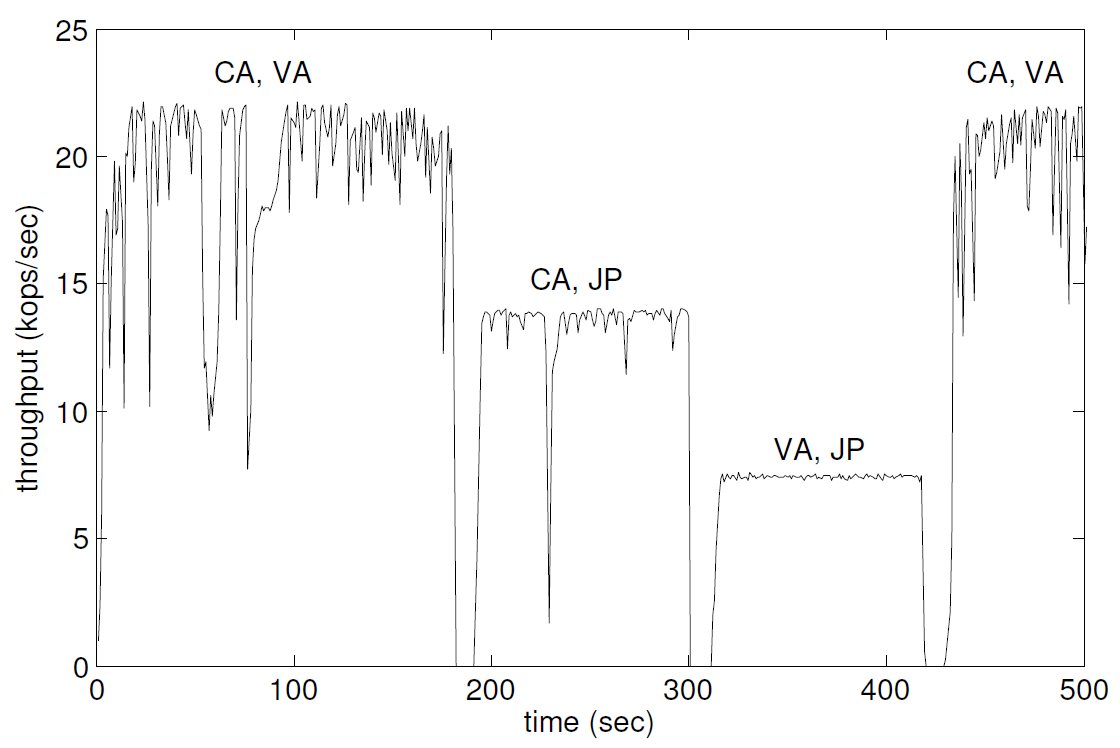
このセクションでは障害発生時の XPaxos の挙動を分析する。1 つの障害を許容するために 3 つのレプリカ (CA, VA, JP) で 1/0 マイクロベンチマークを実行する (Table 3 参照)。実験では CA と VA をアクティブレプリカとして開始し、CA に 2500 のクライアントを配置する。時刻 180 秒で VA のフォロワーをクラッシュさせる。時刻 300 秒で CA のレプリカをクラッシュさせる。時刻 420 秒で JP の第三レプリカをクラッシュさせる。各レプリカはクラッシュから 20 秒後に回復する。またタイムアウト \(2\Delta\) (セクション 2.3 のビュー変更の状態転送に使用) は 2.5 秒に設定されている (セクション 5.1.1 参照)。Figure 5 に XPaxos のスループットを時間関数として示すが、これは各ビューのアクティブレプリカも示している。クラッシュごとにシステムは 10 秒以内でビューを変更しており、地理分散した環境では非常に合理的であることが分かる。この高速なビュー変更サブプロトコルの実行は、パッシブレプリカを更新し続ける XPaxos の遅延レプリケーションの結果である。また XPaxos のスループットがビューによって変化することも確認されている。これはプライマリとフォロワー間、プライマリとクライアント間のレイテンシーがビューごとに異なるためである。
5.4 マイクロベンチマーク: ZooKeeper
我々の研究が実際のアプリケーションに与える影響を評価するために、この研究で検討したすべてのプロトコル、Zyzzyva, PBFT, PAXOS, XPaxos を用いて ZooKeeper コーディネーションサービス [19] をレプリケーションしたときに達成された性能を測定した。また区仕込みの Zab プロトコル [20] を用いてシステムを複製したときの ZooKeeper 本来のパフォーマンスとの比較も行った。このプロトコルにはクラッシュ耐性があり、\(t\) 個の障害を許容するために \(2t+1\) 個のレプリカを必要とする。
我々は ZooKeeper 3.4.6 のコードベースを使用している。ZooKeeper 内部への様々なプロトコルの統合は Zab プロトコルを置き換えることによって行われた。本来の ZooKeeper との公平な比較のために、本来の ZooKeeper を少し修正し特定のノードをプライマリとして使用 (および維持) するように強制した。レプリケーションプロトコルのパフォーマンスに焦点を当て、システムの他のボトルネック (下層クラウド環境ではあまり効率的ではないストレージ I/O など) と衝突しないように、ZooKeeper のデータとログディレクトリを揮発性の tmpfs ファイルシステムに保存する。テストした構成は 1 つの障害を許容する (\(t=1\))。ZooKeeper クライアントはプライマリ (CA) と同じリージョンに配置した。各クライアントは 1kB の書き込み操作を閉ループで行っている。
Figure 6 はその結果を表したものである。X 軸はスループット (kops/sec)、Y 軸はレイテンシー (ms) である。このマイクロベンチマークでは明らかに Paxos と XPaxos が BFT プロトコルを上回り、XPaxos は Paxos に近い性能を達成していることがわかる。さらに驚くべきことに、XPaxos はクラッシュ障害のみを許容する組み込みの Zab プロトコルよりも効率的であることがわかる。両プロトコルとも WAN 環境のボトルネックはリーダーの帯域幅だが、Zab のリーダーは他の \(2t\) 個すべてのレプリカにリクエストを送るのに対して XPaxos のリーダーは \(t\) フォロワーにのみリクエストを送るため、XPaxos のほうが高いピークスループットを得ることができている。

6 信頼性分析
このセクションでは最先端の非同期 CFT および BFT プロトコルと分析的に比較することにより XPaxos の信頼性の保証を説明する。解析を簡単にするために、マシンの故障状態は独立した同一分布の確率変数であると考える。
レプリカが正しい確率を \(p_{correct}\) とし、同様にクラッシュ障害である確率を \(p_{crash}\) とする。レプリカが良性である確率は \(p_{bening} = p_{correct} + p_{crash}\) である。したがってレプリカは \(p_{non\mbox{-}crash} = 1 - p_{penign}\) の確率で非クラッシュ障害である。またレプリカが分断されない確率 \(p_{synchrony}\) を仮定する。\(p_{synchrony}\) は \(\Delta\)、ネットワーク、システム環境の関数である。最後に、レプリカが分断されている確率は \(1-p_{synchrony}\) に相当する。
業界の慣行に合わせて信頼のナイン数で信頼性保証と生涯シナリオの網羅性を測定する。具体的には一貫性のナインと可用性のナインを区別し、異なる障害モデルを比較するためにこれらの指標を使用する。確率 \(p\) を対応する "ナイン" の数に変換する関数 \(9of(p)=\lfloor -\log_{10}(1-p)\rfloor\) を導入する。例えば \(9of(0.999)=3\) である。簡潔さのため \(9_{bening}\) は \(9of(p_{bening})\) を表し、そのほかに対象とする確率も同様である。
XPaxos がどの非同期 CFT や BFT プロトコルよりも優れた可用性を明確に保証していることを考え (Table 1 参照)、ここでは一貫性の保証を比較することに焦点を当てるが、これは可用性の比較ほど明らかではない。可用性の分析は [31] に記載されている。
6.1 XPaxos vs. CFT
6.2 XPaxos vs. BFT
7 関連する研究とまとめ
この論文では非クラッシュ障害を許容する効率的なプロトコルの設計を可能にする新しいフォールトトレランスモデルである XFT を紹介した。我々は、同等の通信複雑性、性能、リソースコストを持つ最高のクラッシュ障害耐性 (CFT) プロトコルよりもはるかに多くの信頼ナイン数を特徴とする最新のステートマシンレプリケーションプロトコルである XPaxos で XFT を実証した。すなはち XPaxos は \(2t+1\) 個のレプリカを使って CFT の信頼性保証をすべて提供するが、XPaxos レプリカの過半数が正しく同期的に相互通信できる限り、非クラッシュ障害を許容することもできる。
XFT は完全にソフトウェアで実現されるため、信頼済みハードウェアで BFT のリソースコストを \(2t+1\) レプリカに削減する既存のアプローチ [15, 30, 21, 39] とは根本的に異なる。
XPaxos はまた、ASC-硬化 (ASC-hardening) を使って CFT プロトコルにビザンチン障害のサブセットを許容させる PASC [14] とも異なっている。ASC-硬化は各レプリカで状態の 2 コピーを保持することでアプリケーションを修正している。そして "障害の多様性" 仮定、つまり故障が状態の両コピーを同じように破損しないという仮定の下でビザンチン障害を許容する。XPaxos とは異なり PASC はレプリカ全体 (例えば両方の状態コピー) に影響を与えるビザンチン故障を許容しない。
この論文では障害クラスごとに許容される障害の数を変化させた場合の影響については調査していない。要するに、ハイブリッド故障モデルとして知られ [38] で導入されたこのアプローチは、安全性が保証されるべきであるにもかかわらず非クラッシュ障害のしきい値 (\(b\) とする) と、可用性が確保されるべき (任意のクラスの) 障害数のしきい値 \(t\) (ここでしばしば \(b \le t\)) とを区別する。ハイブリッド故障モデルとその改良 [11, 35] は我々の XFT アプローチと直行しているように見える。
特に Visigoth Fault Tolerance (VFT) [35] はハイブリッド障害モデルの最近の改良版である。VFT は非クラッシュ障害とクラッシュ障害に異なるしきい値を持つだけではなく、VFT プロトコルが許容できるネットワーク障害のしきい値を定義することでネットワークの同期と非同期の間のスペースを調整する。ただし VFT は非クラッシュ障害とネットワーク障害に別々の障害しきい値を設定する点で XFT とは異なる。VFT のしきい値の具体的な値を選択することで XFT を表現することができないため、この違いは表記上のものでhななく基本的な違いである。例えば XPaxos は \(2f+1\) 個のレプリカ、\(t\) 個の分断されたレプリカ、\(t\) 個の非クラッシュ障害、\(t\) 個のクラッシュ障害を同時にではないが許容する。VFT でこのような要件を指定すると少なくとも \(3t+1\) 個のレプリカが必要となる。さらに VFT プロトコルは XPaxos より複雑な通信パターンがある。とはいえ VFT の概念の多くは XFT と直行していることに変わりない。将来的にはハイブリッド障害モデル (VFT などの改良を含む) と XFT の相互作用を調査することは興味深いだろう。
この論文では上記で概説した研究の方向性だけではなく今後の研究の道筋も示している。例えば分散ストレージやブロックチェーンなど、SMR を基板とする多くの重要な分散コンピューティング問題は XFT のプリズムを通した新しい視点に値すると考えられる。
Acknowledgements
We thank Shan Lu and anonymous OSDI reviewers for their invaluable comments that helped us considerably to improve the paper. Shengyun Liu’s work was supported in part by the National Key Research and Development Program (2016YFB1000101) and the China Scholarship Council. This work was also supported in part by the EU H2020 project SUPERCLOUD (grant No. 643964) and the Swiss Secretariat for Education, Research and Innovation (contract No. 15.0025).
References
- Crypto++ library 5.6.2. http://www.cryptopp.com/, 2014.
- B. Alpern and F. Schneider. Recognizing safety and liveness. Distributed Computing, 2(3):117-126, 1987.
- P.-L. Aublin, R. Guerraoui, N. Knežević, V. Quéma, and M. Vukolić. The next 700 BFT protocols. ACM Trans. Comput. Syst., 32(4):12:1–12:45, Jan. 2015.
- P. Bailis and K. Kingsbury. The network is reliable. Commun. ACM, 57(9):48–55, 2014.
- J. Baker, C. Bond, J. C. Corbett, J. J. Furman, A. Khorlin, J. Larson, J. Leon, Y. Li, A. Lloyd, and V. Yushprakh. Megastore: Providing scalable, highly available storage for interactive services. In Fifth Biennial Conference on Innovative Data Systems Research (CIDR), pages 223–234, 2011.
- P. Berman, J. A. Garay, and K. J. Perry. Towards optimal distributed consensus. In Proc. 30th IEEE Symposium on Foundations of Computer Science (FOCS), pages 410–415, 1989.
- G. Bracha and S. Toueg. Asynchronous consensus and broadcast protocols. J. ACM, 32(4):824–840, 1985.
- B. Calder, J. Wang, A. Ogus, et al. Windows Azure storage: A highly available cloud storage service with strong consistency. In Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles, SOSP ’11, pages 143–157. ACM, 2011.
- M. Castro and B. Liskov. Practical Byzantine fault tolerance and proactive recovery. ACM Trans. Comput. Syst., 20(4):398–461, Nov. 2002.
- T. D. Chandra, R. Griesemer, and J. Redstone. Paxos made live: An engineering perspective. In Proceedings of the Twenty-Sixth Annual ACM Symposium on Principles of Distributed Computing, PODC2007, pages 398–407, 2007.
- A. Clement, M. Kapritsos, S. Lee, Y. Wang, L. Alvisi, M. Dahlin, and T. Riche. Upright cluster services. In Proceedings of the 22nd ACM Symposium on Operating Systems Principles, SOSP’09, pages 277–290, 2009.
- A. Clement, E. L. Wong, L. Alvisi, M. Dahlin, and M. Marchetti. Making byzantine fault tolerant systems tolerate byzantine faults. In Proceedings of the 6th USENIX Symposium on Networked Systems Design and Implementation, NSDI 2009, pages 153-168, 2009.
- J. C. Corbett, J. Dean, M. Epstein, et al. Spanner: Google’s globally-distributed database. In Proceedings of the 10th USENIX conference on Operating Systems Design and Implementation, OSDI’12, pages 251–264, Berkeley, CA, USA, 2012. USENIX Association.
- M. Correia, D. G. Ferro, F. P. Junqueira, and M. Serafini. Practical hardening of crash-tolerant systems. In 2012 USENIX Annual Technical Conference, pages 453–466, 2012.
- M. Correia, N. F. Neves, and P. Verissimo. How to tolerate half less one Byzantine nodes in practical distributed systems. In Proceedings of the 23rd IEEE International Symposium on Reliable Distributed Systems, SRDS ’04, pages 174–183. IEEE Computer Society, 2004.
- F. Cristian, H. Aghili, R. Strong, and D. Dolev. Atomic broadcast: From simple message diffusion to Byzantine agreement. Information and Computation, 118(1):158–179, 1995.
- D. Dolev and H. R. Strong. Authenticated algorithms for Byzantine agreement. SIAM Journal on Computing, 12(4):656–666, Nov. 1983.
- C. Dwork, N. Lynch, and L. Stockmeyer. Consensus in the presence of partial synchrony. J. ACM, 35, April 1988.
- P. Hunt, M. Konar, F. P. Junqueira, and B. Reed. ZooKeeper: Wait-free coordination for internet-scale systems. In 2010 USENIX Annual Technical Conference, pages 11–11, 2010.
- F. P. Junqueira, B. C. Reed, and M. Serafini. Zab: High-performance broadcast for primary-backup systems. In Proceedings of the Conference on Dependable Systems and Networks (DSN), pages 245256, 2011.
- R. Kapitza, J. Behl, C. Cachin, T. Distler, S. Kuhnle, S. V. Mohammadi, W. Schröder-Preikschat, and K. Stengel. CheapBFT: Resourceefficient Byzantine fault tolerance. In Proceedings of the 7th ACM European Conference on Computer Systems, EuroSys ’12, pages 295–308, New York, NY, USA, 2012. ACM.
- R. Kotla, L. Alvisi, M. Dahlin, A. Clement, and E. Wong. Zyzzyva: Speculative Byzantine fault tolerance. ACM Trans. Comput. Syst., 27(4):7:1–7:39, Jan. 2010.
- T. Kraska, G. Pang, M. J. Franklin, S. Madden, and A. Fekete. MDCC: multi-data center consistency. In Eighth Eurosys Conference 2013, pages 113–126, 2013.
- K.Krishnan. Weathering the unexpected. Commun. ACM, 55:48–52, Nov. 2012.
- P. Kuznetsov and R. Rodrigues. BFTW3: Why? When? Where? Workshop on the theory and practice of Byzantine fault tolerance. SIGACT News, 40(4):82–86, Jan. 2010.
- R. Ladin, B. Liskov, L. Shrira, and S. Ghemawat. Providing high availability using lazy replication. ACM Trans. Comput. Syst., 10(4):360–391, Nov. 1992.
- L. Lamport. The part-time parliament. ACM Trans. Comput. Syst., 16:133–169, May 1998.
- L. Lamport. Paxos made simple. ACM SIGACT News, 32(4):18–25, 2001.
- L. Lamport, R. Shostak, and M. Pease. The Byzantine generals problem. ACM Trans. Program. Lang. Syst., 4:382–401, July 1982.
- D. Levin, J. R. Douceur, J. R. Lorch, and T. Moscibroda. TrInc: Small trusted hardware for large distributed systems. In Proceedings of the 6th USENIX Symposium on Networked Systems Design and Implementation, NSDI’09, pages 1–14. USENIX Association, 2009.
- S. Liu, P. Viotti, C. Cachin, V. Quéma, and M. Vukolić. XFT: Practical fault tolerance beyond crashes. CoRR, abs/1502.05831, 2015.
- S. Nakamoto. Bitcoin: A peer-to-peer electronic cash system. May 2009.
- B. M. Oki and B. H. Liskov. Viewstamped replication: A new primary copy method to support highly-available distributed systems. In Proceedings of the Seventh Annual ACM Symposium on Principles of Distributed Computing, PODC ’88, pages 8–17, New York, NY, USA, 1988. ACM.
- D. Ongaro and J. K. Ousterhout. In search of an understandable consensus algorithm. In Proc. USENIXAnnual Technical Conference, pages 305-319, 2014.
- D. Porto, J. a. Leit˜ao, C. Li, A. Clement, A. Kate, F. Junqueira, and R. Rodrigues. Visigoth fault tolerance. In Proceedings of the Tenth European Conference on Computer Systems, EuroSys ’15, pages 8:1–8:14, New York, NY, USA, 2015. ACM.
- F. B. Schneider. Implementing fault-tolerant services using the state machine approach: A tutorial. ACM Comput. Surv., 22(4):299–319, 1990.
- Y. Sovran, R. Power, M. K. Aguilera, and J. Li. Transactional storage for geo-replicated systems. In Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles, SOSP ’11, pages 385–400, New York, NY, USA, 2011. ACM.
- P. M. Thambidurai and Y. Park. Interactive consistency with multiple failure modes. In Proceedings of the Seventh Symposium on Reliable Distributed Systems, SRDS, pages 93–100, 1988.
- G. S. Veronese, M. Correia, A. N. Bessani, L. C. Lung, and P. Ver´ıssimo. Efficient Byzantine fault-tolerance. IEEE Trans. Computers, 62(1):16–30, 2013.
- M. Vukolić. The quest for scalable blockchain fabric: Proof-of-work vs. BFT replication. In Open Problems in Network Security - IFIP WG 11.4 International Workshop, iNetSec 2015, pages 112-125, 2015.
翻訳抄
ビザンチン障害耐性を持つ XPaxos の 2016 の論文。ビザンチン故障、非ビザンチン故障、パーティション分断障害の合計が \(f\) 以下であれば、全体で \(N=2f+1\) プロセスの構成で安全な SMR を行うことができる。
- Liu, S., Viotti, P., Cachin, C., Quéma, V., & Vukolić, M. XFT: Practical fault tolerance beyond crashes. In 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16). 2016. p. 485-500.
