論文翻訳: Zab: High-performance broadcast for primary-backup systems
Yahoo! Research
{fpj,breed,serafini}@yahoo-inc.com
 Abstract
Abstract
Zab は ZooKeeper 協調サービスのために設計された crash-recovery アトミックブロードキャストアルゴリズムである。ZooKeeper はプライマリ・バックアップ方式を採用しており、プライマリプロセスがクライアントの処理を実行し、Zab を用いて対応する状態変化の増加分をバックアッププロセスに伝達する1。状態の変更はそれまでに生成された一連の変更に依存するため、Zab である状態変更を提供する場合、その変更に依存する他のすべての変更が先じて提供されていなければならないことを保証しなければならない。プライマリはクラッシュする可能性があるため、プライマリがクラッシュしても Zab はこの要件を満たさなければならない。
ZooKeeper を利用するアプリケーションはサービスの高性能化が求められており、同時に複数のクライアント操作が可能であることが重要な目標となっている。Zab は最大で 1 つのプライマリが状態更新をブロードキャストし、それを状態に組み込めることを保証し、新しいプライマリを構築するときに同期フェーズを使用することで、複数の未処理状態の操作を可能にする。この同期フェーズが完了する前に新しいプライマリは新しい状態変更をブロードキャストすることはない。最後に、Zab は状態変更の識別スキームを使用しており、欠落した変更をプロセスが容易に識別することができる。この機能は効率的なリカバリーの鍵となる。
これまでの実験と経験から我々の設計は我々のアプリケーションのパフォーマンス要件を満たす実装が可能であることが分かった。我々が実装した Zab は毎秒数万回のブロードキャストが可能で、我々の Web 規模のアプリケーションのような要求の高いシステムには十分である。
Index Terms - Fault tolerance, Distributed algorithms, Primary backup, Asynchronous consensus, Atomic broadcast
- 123rd International Symposium on Distributed Computing, DISC 2009 において Zab の予備的な説明が簡潔に発表された。
Table of Contents
- Abstract
- I. 導入
- II. システムモデル
- III. 問題提起
- IV. アルゴリズムの説明
- V. Zab の詳細
- VI. 分析
- VII. 評価
- VIII. 関連する研究
- IX. 結論
- References
- 翻訳抄
I. 導入
アトミックブロードキャストは分散コンピューティングでしばしば使われるプリミティブであり、ZooKeeper もまたアトミックブロードキャストを使用するアプリケーションである。ZooKeeper は Yahoo! クローラーなどのプロダクション Web システムで 3 年間以上使われている高可用性の協調サービス (coordination service) である。Web クローラーのようなアプリケーションは多数のプロセスで構成されていることが多く、信頼性の高い設定データの保存や実行中のプロセス状態の保持といった重要な調整タスクを ZooKeeper に依存している。大規模なアプリケーションが ZooKeeper に依存していることを考慮すると、そのサービスは障害状況を隠蔽しリカバリーできなければならない [1]。
ZooKeeper はレプリケーションされたサービスであり、進行するためには過半数 (より一般的には定足数 (quorum)) のサーバがクラッシュしていないことが必要である。従来の crash-recovery プロトコル [2], [3], [4] と同様に、クラッシュしたサーバが回復すればアンサンブルに復帰することができる。ZooKeeper はプライマリ・バックアップ方式 [5], [6], [7] を採用し、レプリカプロセスの状態を一貫して維持する。ZooKeeper では、プライマリプロセスがクライアントからの要求をすべて受け取り、それらを実行して ZooKeeper Atomic Broadcast プロトコル - Zab を用いて、非可換で増分的な状態変更をトランザクションの形でバックアップレプリカに伝播する。プライマリがクラッシュした場合、プロセスはリカバリプロトコルを実行し、通常の操作を再開する前に共通の一貫した状態に合意するとともに、状態変更をブロードキャストするための新しいプライマリを確立する。プライマリ役となるためにプロセスは一定数のプロセスから支持を得なければならない。プロセスはクラッシュやリカバリーが可能であるため、時間の経過とともに複数のプライマリが存在することもあり、実際には同じプロセスが複数回プライマリ役となることもある。時間の経過とともに異なるプライマリを区別するために、我々は確立されたプライマリのそれぞれにインスタンス値を関連付ける。特定のインスタンス値は最大で 1 つのプロセスに対応する。我々のインスタンスの概念はグループ通信 [8] のビュー特性の一部を共有しているがいくつのあ重要な違いがあることに注意。グループ通信では特定のビューのすべてのプロセスがブロードキャストを行うことができ、いずれかのプロセスが参加または離脱すると設定変更が発生する。Zab ではプライマリがクラッシュしたり定足数からの支持を失った場合にのみプロセスは新しいビュー (またはプライマリインスタンス) に変更される。
Zab を設計する上で重要な点は、各状態の変化は前の状態に対して増分的であることであり、状態変更の順序には暗黙の依存性が存在するということである。このため状態変更を任意の順序で適用することはできず、あるプライマリによって生成された状態変更のプレフィックスが配信され、サービスの状態に適用されることを保証することが重要である。状態変更は冪等であり、適用順序が配信順序と一致している限り同じ状態変更を複数回適用しても不整合は発生しない。したがって at-least once セマンティクスを補償するだけで十分であることから実装も難しくはない。
Zab は ZooKeeper コアの重要なコンポーネントであるため高性能でなければならない。ZooKeeper のアプリケーションの中には多数のプロセスを包含し ZooKeeper を広範囲に使用するものもある。これまでのシステムは長期に渡るアプリケーションの状態変更を調整するように設計されてきた [9], [10], [11]。しかし我々はアプリケーションがクラスタ環境 (多数のノードがうまく接続されているデータセンター) で広く使用できるように高いスループットと低いレイテンシを持つように設計した。
しかし我々が ZooKeeper を設計する過程でアトミックブロードキャストを単独で結論づけることが困難であることが分かった。アプリケーションには満たさなければならない要件や目標があり、アプリケーションと一緒にアトミックブロードキャストを推敲することで異なるプロトコル要素や興味深い最適化も可能となる。
複数の未処理トランザクション (multiple outstanding transactions): 我々の想定では、複数の未処理の ZooKeeper 操作を可能にすることと、ZooKeeper クライアントから同時に送信された操作のプレフィクスが FIFO 順にコミットされることが重要である。しかし Paxos [2] のような複製ステートマシンを実装する従来のプロトコルはこのような機能を直接有効化することができない。プライマリが個別にトランザクションを提案する場合、習得した (learned) トランザクションの順序は順序の依存性を満たさないことがあり、結果として習得したトランザクションの順序を変更せずに使用することができない。この問題を解決する方法として複数のトランザクションを 1 つの Paxos プロポーザルにまとめて一度に最大で 1 つの未処理プロポーザルを持つ方法が知られている。このような設計はバッチサイズの選択によってはスループットまたはレイテンシーのどちらかに悪影響を及ぼす。
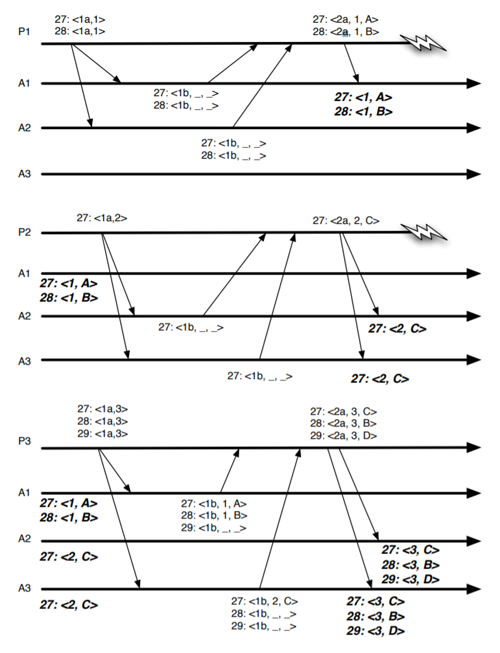
Fig 1 は我々の要件の下で Paxos に見つかった問題を示している。この図は 3 人の提案者がいるケースで、生成される状態変更の順序に関する我々の要求に違反した実行を示している。提案者 P1 はシーケンス番号 27 と 28 に対してフェーズ 1 を実行する。提案者 P1 は投票番号 1 のフェーズ 2 でシーケンス番号 27 と 28 に対してそれぞれ値 \(A\) と \(B\) を提案する。両方の提案はアクセプター A1 によってのみ受理される。提案者 P2 はアクセプター A2 と A3 に対してフェーズ 1 を実行し、投票番号 2 のシーケンス番号 27 に対してフェーズ 2 で \(C\) を提案するところに行きつく。最終的に提案者 P3 はフェーズ 1 とフェーズ 2 を実行し、定足数のアクセプターがシーケンス番号 27 に \(C\) を、シーケンス番号 28 に \(B\) を、29 に \(D\) を選択することができた。
このような実行は、\(B\) が示す状態変更が因果的に \(C\) ではなく \(A\) に依存することから受け入れることができない。その結果、シーケンス番号 \(i\) に \(A\) が選択されている場合にのみ \(B\) をシーケンス番号 \(i+1\) に選択でき、\(B\) が示す状態変更が \(C\) と両立できず \(A\) の後にのみ適用できることから、\(C\) は \(B\) より先に選択することはできない。
効率的な回復 (efficient recovery): 我々の想定における重要な目標の一つはプライマリのクラッシュから効率的に回復することである。高速な回復のためには、新しいプライマリがアプリケーション状態をリカバリーするために使うトランザクションのシーケンスを容易に決定できるトランザクション識別スキーム (transaction identification scheme) を使用する。我々の方式ではトランザクション識別子は、インスタンス値と、そのインスタンスに対してプライマリプロセスがブロードキャストしたシーケンスの特定のトランザクションの位置のペアである。多分この方式では、最も高い識別子を持つトランザクションを受け入れたプロセスのみが新しいプライマリへトランザクションをコピーする必要があり、他のトランザクションは回復する必要がない。この観測は、新しいプライマリがクォーラムの各プロセスから最も高いトランザクション識別子を収集するだけで、どのトランザクションをどのプロセスから回収するかを決定できることを示唆している。
Paxos によるリカバリーでは、プロセスはシーケンス番号ごとに異なる値 (異なる投票番号) を受理する可能性があるため、プロセスが値を受理した最後のシーケンス番号を保持するだけでは不十分である。その結果、新しいプライマリはプライマリが値 (我々の文脈ではトランザクション) を習得していない過去のすべてのシーケンス番号に対して Paxos のフェーズ 1 を実行しなければならない。
投稿の概要 (summary of contributions): 我々は協調サービスのためのアトミックブロードキャストプロトコルである Zab の設計について述べる。Zab はプライマリ-バックアップシステムにおける高性能なアトミックブロードキャストプロトコルである。従来のアトミックブロードキャストプロトコルと比較して Zab は異なる正しさの特性を満たす。特に、プライマリ-バックアップシステムで重要なプライマリ順序 (primary order) と呼ばれる特性を提案する。この特性は、複数の未処理トランザクションを許容しながら、異なるプロセスがプライマリの役割を果たす際に、時間経過に伴う状態変更を正しく順序付けるために必要である。プセクション III-B で説明するようにライマリ順序は因果順序 (causal order) とは異なる。Zab はプライマリ順序の特性を使用していることから PO アトミックブロードキャストプロトコルであると言える。最後に、トランザクションを識別する我々のスキームは Paxos のような古典的なアルゴリズムと比較してより速い回復を可能にする。
II. システムモデル
システムはプロセスの集合 \(\Pi = \{p_1,p_2,\ldots,p_3\}\) で構成されており、各プロセスは安定した記憶装置を備えている。プロセスは繰り返して進行し、メッセージを交換することで通信する。プロセスはクラッシュしたり回復することがある。ここでプロセスがクラッシュしていないことをアップ、クラッシュしていることをダウンとする。回復しているプロセスはアップであり、処理の進行については十分なプロセスが最終的に十分に長い時間アップしていることを想定する。実際には定足数のプロセスがアップであり、十分に長い時間の間にお互いがメッセージ交換できるのであれば進行していることになる。ここではクォーラムシステム \(\mathcal{Q}\) が明示的に定義されており、\(\mathcal{Q}\) が以下を満たすと仮定する:
定義 II.1. (Quorum System) \(\Pi\) 上のクォーラムシステム \(\mathcal{Q}\) は次のようなものである: \[ \begin{array}{l} \bigwedge \ \forall Q \in \mathcal{Q} : Q \subseteq \Pi \\ \bigwedge \ \forall Q_1, Q_2 \in \mathcal{Q}: Q_1 \cap Q_2 \ne \emptyset \end{array} \]
プロセスはメッセージを交換するために双方向のチャネルを使用する。より正確には、プロセス \(p_1\) と \(p_2\) のチャネル \(c_{ij}\) はそれぞれのプロセスが一対の入力バッファと出力バッファを持つようなものである。プロセス \(p_j\) にメッセージ \(m\) を送信する呼び出しはイベント \({\it send}(m,p_j)\) で表され、このイベントは \(p_i\) の \(c_{ij}\) に対する出力バッファに \(m\) を挿入する。メッセージは送信イベントの順序に従って送信され、入力バッファに挿入される。入力バッファから次のメッセージ \(m\) を受信する呼び出しはイベント \({\it recv}(m,p_i)\) で表される。
我々が提案するアルゴリズムは反復的に、各反復で 3 フェーズがあることから、チャネルの特性を特定するために反復 (iteration) の概念を使用する。\(p_i\) の反復 \(k\) と \(p_j\) の反復 \(k'\) の間に \(p_i\) が \(p_j\) へ送信したメッセージのシーケンスを \(\sigma_{k,j'}^{i,j}\) とする。プロセス \(p_i\) と \(p_j\) 間のチャネルは以下の特性を満たすと仮定する:
- 整合性 (integrity)
-
プロセス \(p_i\) がメッセージ \(m\) を送信している場合にのみプロセス \(p_j\) は \(p_i\) からメッセージ \(m\) を受信する。
- プレフィクス
-
プロセス \(p_j\) がメッセージ \(m\) を受信し、\(\sigma_{k,k'}^{i,j}\) 内に \(m' \prec m\) となるような \(m'\) が存在するならば、\(p_j\) は \(m\) より前に \(m'\) を受信する。
- 単一反復 (single iteration)
-
チャネル \(c_{ij}\) に対するプロセス \(p_j\) の入力バッファは最大で一回の反復からメッセージが含まれている。
チャネルの実装: これらの特性を実装し liveness を確保するためには fair-lossy リンクを仮定すれば十分である (クラッシュリカバリーモデルにおける fair-lossy の正確な定義は Boichat and Guerraoui [12] の研究にある)。実際には我々は TCP 接続2を使用する。新しい反復の開始時に \(p_i\) と \(p_j\) の間の接続を確立する。そうすることで送信されたメッセージのみが受信されること (整合性)、プロセス \(p_i\) からプロセス \(p_j\) に送信されるメッセージのシーケンスのプレフィクスが受信されること、接続を閉じて新しい接続を確立するとプロセスは 1 つの反復からのメッセージのみを持つことが保証される。
- 2RFC 793: http://tools.ietf.org/html/rfc793
III. 問題提起
ZooKeeper のプライマリ-バックアップ方式を採用しており、リクエストの実行や状態変更を PO アトミックブロードキャストでバックアッププロセスに伝達する (Fig 2)。このためプライマリだけがブロードキャストを行うことができる。プライマリプロセスがクラッシュした場合、新しいプライマリを選択する外部のメカニズムが存在すると仮定する。しかし、ブロードキャストを許可されたアクティブなプライマリプロセスがどんな時でも最大 1 つまでしか存在できないことを保証することが重要である。我々の実装では、プライマリ選出のメカニズムはブロードキャスト層で使用するメカニズムと密接に結合している。仕様上は、常に最大で 1 つのプライマリがアクティブであることを保証するような、プライマリを選出するための何らかのメカニズムが存在すると仮定すれば十分である。時間が経過すると \(\rho_e \in \Pi\) となるようなプライマリの非拘束シーケンス \(\rho_1 \rho_2 \cdots \rho_e \rho_{e+1} \cdots\) を得る。\(e \lt e'\) であれば \(\rho_{e'} \prec \rho_e\)、プライマリ \(\rho_e\) はプライマリ \(\rho_{e'}\) に先行すると言う。プライマリが先行するとは、時間の経過とともにプライマリとなるプロセスの順序を意味する。実際にはプロセスは回復することができるため、\(\rho_e\) と \(\rho_{e'}\) が同じプロセスであるが異なるインスタンスを参照しているような \(e \ne e'\) の \(\rho_e\) と \(\rho_{e'}\) が存在することもある。
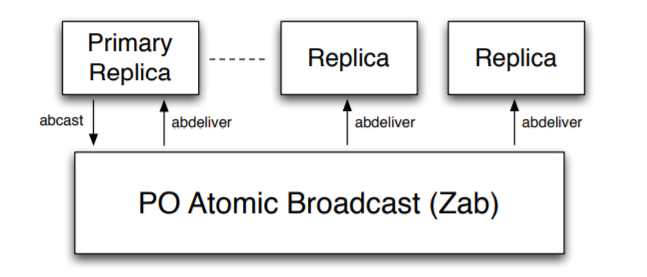
プライマリがブロードキャストするトランザクションに一貫性があることを保証するためには、Zab 層がリカバリーの完了を示したときにのみプライマリが状態更新の生成を開始する必要がある。プロセスはこのために \({\it ready}(e)\) 呼び出しを実装していると仮定する。この呼出は Zab レイヤーがアプリケーション (プライマリおよびバックアップのレプリカ) に対して状態変更のブロードキャストを開始できることを知らせるために使用される。\({\it ready}(e)\) の呼び出しはプライマリが自分のインスタンスを決定するために使用する変数 instance の値も変更する。プライマリは instance の値を使用してブロードキャスト時のトランザクション識別子のエポックを設定する。ここで \(e\) の値は異なるプライマリインスタンスに対して一意であると仮定する。インスタンスの値の一意性は Zab によって保証されている。
プライマリがバックアッププロセスに伝達する状態更新をトランザクションと呼ぶ。トランザクション \(\langle v,z \rangle\) は、トランザクション値 \(v\) とトランザクション識別子 \(z\) (または \(z\)xid) の2つのフィールドを持つ。それぞれのトランザクション識別子 \(z = \langle e, c \rangle\) はエポック \(e\) とカウンター \(c\) の 2 つの要素を持つ。トランザクション識別子のエポックを示すために \({\it epoch}(z)\)、\(z\) のカウンター値を示すために \({\it counter}(z)\) を使用する。\(e \lt e'\) と示すことで、エポック \(e\) がエポック \(e'\) より早いと言う。同様にエポック \(e\) は \(e'\) より遅いと言う。
特定のプライマリ \(\rho_e\) に対して \({\it epoch}(z) = \) instance \(= e\) であり、新しいトランザクションごとにカウンター \(c\) をインクリメントする。トランザクション識別子 \(z\) が識別子 \(z'\) に先行することを \(z \prec_z z'\) と言い、\({\it epoch}(z) \lt {\it epoch}(z')\)、または \({\it epoch}(z) = {\it epoch}(z')\) かつ \({\it counter}(z) \lt {\it counter}(z')\) であることを示すために使用する。また \(z \prec_z z'\) または \(z = z'\) のどちらかであることを示すために \(z \preceq_z z'\) を使用する。
プライマリがブロードキャストするトランザクションを持つと \({\it abcast}(\langle v, z \rangle)\) を呼び出す。プロセスは \({\it abdeliver}(\langle v,z \rangle)\) を呼び出してトランザクション \(\langle v,z\rangle\) を受け取る (またはコミットする)。\({\it abcast}(\langle v,z\rangle)\) の呼び出しは、プライマリがクラッシュした場合やプライマリの変更があった場合には成功が保証されていない。そのため、プライマリがブロードキャストする一連の状態変化のうち状態更新のシーケンスのプレフィクスのみが配信される。トランザクションを配信するとプロセスはそれを txns 集合に追加する。
A. コア特性
我々のシステムの ZooKeeper はプロセスの状態を一貫して維持するために以下の特性を必要とする:
- 整合性 (integrity)
-
あるプロセスが \(\langle v,z\rangle\) を受け取ったなら、あるプロセス \(p_i \in \Pi\) が \(\langle v,z\rangle\) をブロードキャストしている。
- 全順序 (total order)
-
あるプロセスが \(\langle v',z'\rangle\) より前に \(\langle v,z\rangle\) を受け取ったなら、\(\langle v',z'\rangle\) を受け取ったすべてのプロセスは \(\langle v,z\rangle\) も受け取っており、\(\langle v',z'\rangle\) より前に \(\langle v,z\rangle\) を受け取っている。
これらの 1 つの特性はトランザクションが勝手に発生したり消滅しないことと、トランザクションを受け取るプロセスが一貫した順序に従ってトランザクションを受け取れなければならないことを保証する。ただし全順序の特性は、2 つのプロセスが別々のトランザクションのシーケンスを配信するような実行ができてしまう。このような好ましくない実行を防ぐために次のような特性が必要である:
- 合意 (agreement)
-
あるプロセス \(p_i\) が \(\langle v,z\rangle\) を受け取り、あるプロセス \(p_j\) が \(\langle v',z'\rangle\) を受け取ったなら、\(p_i\) が\(\langle v',z'\rangle\) を受け取るか \(p_j\) が \(\langle v,z\rangle\) を受け取るかどちらかである。
この合意に関する記述は以前の研究とは異なっていることに注意。以前の研究において合意はアトミックブロードキャストの livenss 特性として提示されており [13]、これには Rodrigues and Raynal の研究 [3] のように良いプロセスのような抽象化が必要である。我々は代わりに 2 つのプロセスの状態が発散しないことを保証する safety の特性として合意を記述する。liveness についてはセクション V と VI で議論する。
前述の 3 つの safety 特性はプロセスの一貫性を保証するものである。しかし、特定のプライマリから進行中の複数の変更を可能にするためにはもう一つの特性を満たす必要がある。それぞれの状態変更は前の状態に基づいていることから、前の状態の変更がスキップされたなら依存する変更もスキップされなければならない。この性質をプライマリ順序 (primary order) と呼び、我々はこれを 2 つに分けている。
- ローカルプライマリー順序 (local primary order)
-
プライマリが \(\langle v',z'\rangle\) をブロードキャストする前に \(\langle v,z\rangle\) をブロードキャストしたなら、\(\langle v',z'\rangle\) を受け取ったプロセスは \(\langle v',z'\rangle\) より前に \(\langle v,z\rangle\) も受け取らなければならない。
- グローバルプライマリー順序 (global primary order)
-
\(\langle v,z\rangle\) と \(\langle v',z'\rangle\) を次のようにする:
- プライマリ \(\rho_i\) は \(\langle v,z\rangle\) をブロードキャストする
- プライマリ \(\rho_j\), \(\rho_i \prec \rho_j\) は \(\langle v',z'\rangle\) をブロードキャストする
あるプロセス \(p_i \in \Pi\) が \(\langle v,z\rangle\) と \(\langle v',z'\rangle\) の両方を受け取ったなら、\(p_i\) は \(\langle v',z'\rangle\) より前に \(\langle v,z\rangle\) を受け取らなければならない。
なお、ローカルプライマリー順序は 1 つのプライマリインスタンスに対する FIFO 順序に相当し、グローバルプライオリティ順序は Fig 1 で説明したような実行を防ぐことができる。
最後に、プライマリは生成された状態更新が一貫していることを保証しなければならない。つまりプライマリは前のエポックのトランザクションを受け取った後にのみ、そのエポックでのブロードキャストを開始することができる。この挙動は以下の特性によって保証されている:
- プライマリの整合性 (primary integrity)
-
プライマリ \(\rho_e\) が \(\langle v,z\rangle\) をブロードキャストし、あるプロセスが \(\langle v',z'\rangle\) を受け取り、その \(\langle v',z'\rangle\) が \(e' \lt e\) となるような \(\rho_{e'}\) によってブロードキャストされている場合、\(\rho_e\) は \(\langle v,z\rangle\) をブロードキャストする前に \(\langle v',z'\rangle\) を受け取らなければならない。
B. 因果アトミックブロードキャストとの比較
PO アトミックブロードキャストは増分的な状態変更の生成で暗黙的に確立されている因果順序を維持するように設計されている。このセクションでは因果アトミックブロードキャストと PO アトミックブロードキャストを比較し、それらが比較できないことを論じる。
因果順序の定義はイベントの優先順位 (precedence) (または happens before) 関係に基づいている [14]。ブロードキャストプロトコルでは、イベントはブロードキャストか受け取りのどちらかである。\({\it abcast}(\langle v,z\rangle)\) が \({\it abcast}(\langle v',z'\rangle)\) に先行することを \(\langle v,z\rangle \prec_c \langle v',z'\rangle\) と表すことにする。アトミックブロードキャストプロトコルの因果順序特性は、典型的に以下のように定義される (Défago ら [13] の定義から採用):
定義 III.1 (因果順序): \(\langle v,z\rangle \prec_c \langle v',z'\rangle\) かつ、あるプロセス \(p\) が \(\langle v',z'\rangle\) を受け取るなら、プロセス \(p\) は \(\langle v',z'\rangle\) より前に \(\langle v,z\rangle\) も受け取らなければならない。
この特性は PO アトミックブロードキャストでは満たされない。Fig 3 は \({\it epoch}(z)\) \(\lt\) \({\it epoch}(z')\) \(\lt\) \({\it epoch}(z'')\) となる因果関係を持つ 2 つのトランザクション \(\langle v,z\rangle\) と \(\langle v'',z''\rangle\) でトランザクション \(\langle v,z\rangle\) を受け取っていない場合の例である。議論を簡単にするために 2 つのプロセスのイベントのみを提示する。
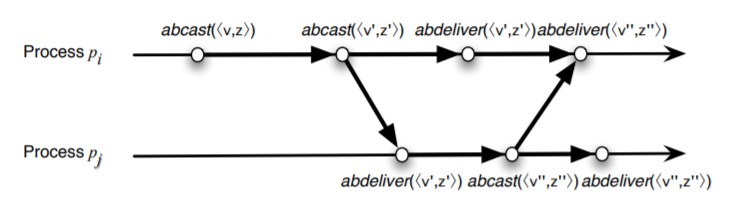
PO アトミックブロードキャストの受信順序は因果順序より厳密に弱いプライマリ因果順序 (primary causal order) 関係 \(\prec_{PO}\) を尊重している。事実、異なるプライマリから送信されたトランザクションは、実際には同じプロセスから送信されたものであっても必ずしも因果関係があるとはみなされない。我々は以下の条件のいずれかが成立する場合に限り、イベント \(\epsilon\) がイベント \(\epsilon'\) に PO 先行する、あるいは等価的に \(\epsilon \to_{PO} \epsilon'\) と言う:
- \(\epsilon\) と \(\epsilon'\) が同じプロセスに局所的に存在し、\(\epsilon\) が \(\epsilon'\) の前に発生し、かつ次の少なくとも一つが成立する: \(\epsilon \ne {\it abcast}(\langle v,z\rangle)\), \(\epsilon' \ne {\it abcast}(\langle v',z'\rangle)\), \({\it epoch}(z) = {\it epoch}(z')\)
- \(\epsilon = {\it abcast}(\langle v,z\rangle)\) かつ \(e' = {\it abdeliver}(\langle v,z\rangle)\)
- \(\epsilon \to_{PO} \epsilon''\) かつ \(\epsilon' = {\it abdeliver}(\langle v,z\rangle)\) となるような \(\epsilon''\) が存在する。
この \(\prec_{PO}\) 関係は PO-優先 (PO-precedence) 関係に基づいて定義されており、因果順序の定義に置いて \(\prec_c\) を \(\prec_{PO}\) に置き換えることで PO 因果順序特性が得られる。
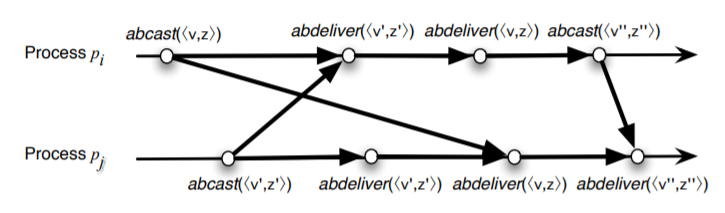
PO アトミックブロードキャストは厳密な因果関係 (strict causality) と呼ばれる重要な追加特性も実装している。あるプロセスが \(\langle v,z\rangle\) と \(\langle v',z'\rangle\) を受け取った場合、\(\langle v,z\rangle \prec_{PO} \langle v',z'\rangle\) または \(\langle v',z'\rangle \prec_{PO} \langle v,z\rangle\) のいずれかとなる。トランザクションは増分的な更新であるため厳密な因果関係が必要である。トランザクションは、因果関係のある更新の連鎖の結果である、トランザクションの生成に使用された状態にのみトランザクションを適用できる。しかし因果順序では、因果関係のないトランザクションが受信されることもある。
Fig 4 は \(\langle v,z\rangle\) と \(\langle v',z'\rangle\) が因果的に独立しているにもかかわらず両方とも配信されているため因果順序 (および PO 因果順序) を満たすが厳密な因果関係ではない実行を示している。この例では 2 つのプリミティブがいずれも他のプリミティブより強くないことが分かる。
PO アトミックブロードキャストが PO 因果順序と厳密な因果関係を実装しているということはコア特性から直接導かれる [15]。
IV. アルゴリズムの説明
Zab には discovery, synchronization, broadcast の 3 つのフェーズがある。それぞれのプロセスは一度にこのプロトコルの 1 つの反復を実行し、プロセスはいつでもフェーズ 1 に進むことで現在の反復を止めて新しい反復を開始することができる。Zab プロセスがプロトコルにしたがって実行できる役割にはリーダーとフォロワーの 2 つがある。リーダーは同時にプライマリの役割を実行し、プライマリのブロードキャスト呼び出しの順序に従ってトランザクションを提案する。フォロワーはプロトコルのステップにしたがってトランザクションを受け入れる。リーダーはフォロワーとしてのステップも実行する。
各プロセスはリーダーオラクル (leader oracle) を実装しており、リーダーオラクルはリーダー候補 \(\ell\) の識別子を提供する。フェーズ 1 では、プロセスはそのリーダーオラクルを参照して自身が従うべき他のプロセス \(\ell\) を決定する。あるプロセスのリーダーオラクルが自分をリーダーと決定した場合、そのプロセスはプロトコルのリーダーステップを実行する。しかしそのオラクルによってリーダーに選ばれただけではリーダーシップを確立するには不十分である。リーダーシップを確立するためにプロセスは同期フェーズ (フェーズ 2) を完了する必要がある。
| \(f.p\) | フォロワー \(f\) が認めた最後の新しいエポック提案、初期は \(\perp\) |
| \(f.a\) | フォロワー \(f\) が認めた最後の新しいリーダー提案、初期は \(\perp\) |
| \(h_f\) | フォロワー \(f\) の履歴、初期は \(\langle \rangle\) |
| \(f.{\it zxid}\) | \(h_f\) で最後に受理されたトランザクション識別子 |
Zab のフェーズ詳細および後の分析では、我々は次の表記を使用する:
定義 IV.1 (履歴): 各フォロワー \(f\) は受理したトランザクションの履歴 \(h_f\) を持つ。履歴はシーケンスである。
定義 IV.2 (初期履歴): エポック \(e\) の初期履歴 \(I_e\) は、エポック \(e\) のフェーズ 1 が終了した時点での \(e\) のリーダー候補の履歴である。
定義 IV.3 (ブロードキャスト値): \(\beta_e\) はプライマリ \(\rho_e\) が \({\it abcast}(\langle v,z\rangle)\) を使用してブロードキャストしたトランザクションのシーケンスである。
プロトコルの 3 フェーズは以下の通り:
フェーズ 1 (Discovery): フォロワー \(f\) とリーダー \(\ell\) は次のステップを実行する:
- ステップ \(f.1.1\) フォロワーはリーダー候補 \(\ell\) に最後の promise を \({\it CEPOCH}(f.p)\) メッセージで送信する。
- ステップ \(\ell.1.1\) フォロワーの定足数 \(Q\) から \({\it CEPOCH}(e)\) を受け取ると、リーダー候補 \(\ell\) は \(Q\) のフォロワーに \({\it NEWEPOCH}(e')\) を提案する。エポック番号 \(e'\) は \({\it CEPOCH}(e)\) メッセージで受け取ったどの \(e\) よりも大きいものである。
- ステップ \(f.1.2\) リーダー候補 \(\ell\) から \({\it NEWEPOCH}(e')\) を受け取ると、\(f.p \lt e'\) であれば \(f.p \leftarrow e'\) として新しいエポックの提案 \({\it NEWEPOCH}(e')\) を確認する。肯定的応答 \({\it ACK\mbox{-}E}(f.a, h_f)\) はフォロワーの現在のエポック \(f.a\) とその履歴が含まれている。フォロワーはフェーズ 1 を完了する。
- ステップ \(\ell.1.2\) \(Q\) の各フォロワーから確認を受け取ると、\(Q\) の 1 人のフォロワー \(f\) の履歴を初期状態 \(I_{e'}\) として選択する。フォロワー \(f\) は、\(Q\) 内の各フォロワー \(f'\) に対して \(f'.a \lt f.a\) または \((f'a = f.a) \land (f'.{\it zxid} \prec_z f.{\it zxid}\) となるようなものである。リーダー候補はフェーズ 1 を完了する。
フェーズ 2 (Syncronization): フォロワー \(f\) とリーダー \(\ell\) は次のステップを実行する:
- ステップ \(\ell.2.1\) リーダー候補 \(\ell\) は \(Q\) のすべてのフォロワーに \({\it NEWLEADER}(e',I_{eU})\) を提案する。
- ステップ \(\ell\) から \(f.2.1\) \({\it NEWLEADER}(e',I_{e'})\) メッセージを受信すると、\(f.p \ne e'\) であればフォロワーは新しいイテレーションを開始する。もし \(f.p = e'\) なら次の動作をアトミックに実行する:
- \(e'\) に \(f.a\) を設定
- \(\langle v,z\rangle \in I_{e'}\) のそれぞれに対して、\(\langle e',\langle v,z\rangle\rangle\) を受理し、\(h_f=T\) とする
- ステップ \(\ell.2.2\) 定足数のフォロワーから \({\it NEWLEADER}(e',I_{e'})\) の確認応答を受け取ると、リーダーはすべてのフォロワーにコミットメッセージを送信しフェーズ 2 を完了する。
- ステップ \(f.2.2\) リーダーからのコミットメッセージを受け取ると、\(I_{e'}\) に含まれるトランザクション \(\langle v,z\rangle\) それぞれに対して \({\it abdeliver}(\langle v,z\rangle)\) を呼び出すことで \(I_{e'}\) の順序にしたがって初期履歴 \(I_{e'}\) のトランザクションをすべて配信し、フェーズ 2 を完了する。
フェーズ 3 (ブロードキャスト): フォロワー \(f\) とリーダー \(\ell\) は以下のステップを実行する:
- ステップ \(\ell.3.1\) リーダー \(\ell\) は \(Q\) のすべてのフォロワーに対して、zxid の昇順で、提案 \(\langle e',\langle v,z\rangle\rangle\) のそれぞれに対して、\({\it epoch}(z)=e'\) かつ \(z\) が \(e'\) で以前にブロードキャストされたすべての zxid 値を引き継ぐように提案する。
- ステップ \(\ell.3.2\) 定足数のフォロワーから特定の提案 \(\langle e',\langle v,z\rangle\rangle\) の確認応答を受け取ると、リーダーはすべてのフォロワーにコミット \({\it COMMIT}(e',\langle v,z\rangle)\) を送信する。
- ステップ \(f.3.1\) フォロワー \(f\) は、もし自分がリードしているなら最初に \({\it ready}(e')\) を呼び出す。
- ステップ \(f.3.2\) フォロワー \(f\) は受信順にしたがって \(\ell\) からの提案を受け入れ \(h_f\) に追加する。
- ステップ \(f.3.3\) フォロワー \(f\) は \({\it COMMIT}(e',\langle v,z\rangle)\) を受け取ると \({\it abdeliver}(\langle v,z\rangle)\) を起動してトランザクション \(\langle v,z\rangle\) をコミットする。これは \(\langle v',z'\rangle \in h_f\), \(z' \prec_z z\) となるようなすべてのトランザクション \(\langle v,z\rangle\) をコミットしたことになる。
- ステップ \(\ell.3.3\) フェーズ 3 の間にフォロワー \(f\) から \({\it CEPOCH}(e)\) を受け取ると、リーダー \(\ell\) は \({\it NEWEPOCH}(e')\) と \({\it NEWLEADER}(e',I_{e'} \circ \beta_{e'})\) を提案しなおす。
- ステップ \(\ell.3.4\) \(f\) から \({\it NEWLEADER}(e',I_{e'} \circ \beta_{e'})\) 提案の確認応答を受けると \(f\) にコミットメッセージを送信する。リーダー \(\ell\) も \(Q \leftarrow Q \cup \{f\}\) とする。
このプロトコルの実現には \({\it ACK\mbox{-}E}(f.a,h_f)\) と \({\it NEWLEADER}(e',I_{e'})\) で完全な履歴を送信する必要はなく、履歴上の最後のトランザクション識別子より後の欠落しているトランザクションを送信するだけであることに注意。またメッセージサイズを小さくするためにフェーズ 3 の確認応答やコミットメッセージの値を省略することも可能である。
次のセクションでは Zab プロトコルの詳細といくつかの実装方法について説明する。
V. Zab の詳細
我々の Zab 実装では、Zab プロセスはリーダーを探している状態 (ELECTION 状態)、フォローしている状態 (FOLLOWING 状態)、リードしている状態 (LEADING 状態) のいずれかとなる。プロセスが開始するとまず ELECTION 状態となる。この状態でプロセスは新しいリーダーを選出するか自身がリーダーになろうとする。選出されたリーダーを見つけた場合、プロセスは FOLLOWING 状態に移行してリーダーのフォローを開始する。FOLLOWING 状態のプロセスはフォロワーである。プロセスがリーダーに選出された場合 LEADING 状態に移行してリーダーとなる。リードするプロセスはフォロワーでもあることから LEADING 状態と FOLLOWING 状態は排他的ではない。フォロワーは、リーダーが故障したりリーダーシップを放棄したことを検知すると ELECTION に移行し、リーダーは、リーダーを支持するフォロワーが定足数に満たなくなったことを検知すると ELECTION に移行する。
基本的な配信プロトコルは 2 フェーズコミット [16] と気味合い的に似ている。プライマリはブロードキャストする値を FIFO 順に選んでトランザクション \(\langle v,z\rangle\) を作成する。トランザクションをブロードキャストする要求を受け取ると、リーダーはトランザクションの zxid 順にしたがって \(\langle e,\langle v,z\rangle\rangle\) を提案する。フォロワーは提案を受け入れ、リーダに \({\it ACK}(e,\langle v,z\rangle)\) を送り返すことで承認する。フォロワーはローカルの安定したストレージに提案を書き込み終わるまで確認応答を返さないことに注意。定足数のプロセスが提案を承認するとリーダーは \({\it COMMIT}(e,\langle v,z\rangle)\) を発行する。プロセスが提案 \(\langle e,\langle v,z\rangle\rangle\) に対するコミットメッセージを受信すrと、そのプロセスは \(z' \prec_z z\) となるような zxid \(z'\) で未配信の提案をすべて配信する。
リーダーとプライマリを同じプロセスに割り当てることには実用上の利点がある。我々が採用しているプライマリ-バックアップ方式では、サービスの状態に組み込むことのできる更新情報を生成できるプロセスが、多くても一度に 1 つとなる必要がある。プライマリは Zab を使用して状態更新を伝搬し、リーダーは提案を開始する必要がある。リーダーとプライマリはそれぞれ異なる機能に対応しているが選挙 (election) という共通の要件を持っている。この 2 つを共存させることでプライマリとリーダーとで別々に選挙を行う必要がなくなる。また、それらが同居していればトランザクションをブロードキャストする呼び出しがローカルになるという事実も重要である。このためリーダーとプライマリを同居させることにした。
A. 新しいリーダーの確立
リーダー選出は 2 段階を経て行われる。最初に、あるプロセスを新しいリーダーとして出力するリーダー選出アルゴリズムを実行する。我々は、アップしていてプロセスの定足数が選択したプロセスを高確率で選択するようなプロトコルを使用することができる。この特性は \(\Omega\) 故障検出 (\(\Omega\) failure detector) [17] によって満たすことができる。

Fig 5 は新しいリーダーが確立した時のリーダーとフォロワー両方のイベントを示している。選出されたリーダーは与えられたエポック \(e\) において、提案履歴の合意と、自分自身が \(e\) のリーダーとしての合意に成功するフェーズ 2 を完了するまで確立しない。確立したリーダー及び確立したエポックを以下のように定義する:
定義 V.1. (確立されたリーダー ; established leader): リーダー \(\ell_e\) はエポック \(e\) に対して、\(\ell_e\) の \({\it NEWLEADER}(e,I_e)\) 提案がフォロワーの定足数 \(Q\) に受け入れられれば確立される。
定義 V.2. (確立されたエポック ; established epoch): エポック \(e\) は、\(e\) に対して確立されたリーダーが存在すれば確立される。
あるプロセスがリーダー選出アルゴリズムの出力を検査して自身がリーダー候補であると判断すると、フェーズ 1 の新しい反復を開始する。リーダーは、最新のエポックと最高の zxid を持つフォロワー \(f\) からの履歴を \({\it ACK\mbox{-}E}(f.a, h_f)\) で選択するとフェーズ 1 を完了する。これらのステップは、リーダー候補がフェーズ 1 を完了したときに、\(Q\) のフォロワーが以前のエポックからの提案を受け入れないことを保証するために必要である。フォロワーの履歴は任意の長さとなりうるため \({\it ACK\mbox{-}E}(f.a, h_f)\) で履歴の全体を送信することは効率的ではない。リーダー候補が任意のフォロワーからトランザクションをコピーする必要があるかを判断するためにはフォロワーの最後の zxid があれば十分であり、欠落したトランザクションのみをコピーする。
フェーズ 2 では、リーダーは自分を新しいエポックのリーダーとして提案し、新しいエポックの初期履歴を含む \({\it NEWLEADER}(e,I_e)\) 提案を送信する。\({\it ACK\mbox{-}E}(f.a,h_f)\) と同様に完全な初期履歴を送信する必要はなく、代わりに欠落しているトランザクションのみを送信する。定足数のフォロワーから新しいリーダー提案の確認応答を受け取るとリーダーが確立され、その時点で新しい提案をコミットする。フォロワーは初期履歴を配信し、あたし胃リーダー提案のコミットメッセージを受信したらフェーズ 2 を完了する。
一つの興味深い最適化は、定足数のプロセスの中で最新のエポックを持ち最大の zxid を持つトランザクションを受け入れたリーダーを選択するリーダー選挙プリミティブを使用することである。このようなリーダーは新しいエポックの初期履歴を直接提供する。
B. リーダー役
リーダーは接続されているすべてのフォローワーに操作をキューイングして提案する。高いスループットと低いレイテンシーを実現するために、リーダーはフォロワーに提案を定常的に送信する。またチャネルの特性を利用してフォロワーが提案を順番に受け取ることを保証する。この実装では、プロセス間のメッセージ交換に TCP 接続を使用している。あるフォロワーへの接続がクローズした場合、その接続にキューイングされていた提案は破棄され、リーダーは対応するフォロワーがダウンしたとみなす。
接続クローズによるクラッシュの検出は我々にとって適切な選択ではなかった。接続タイムアウト値は OS の設定や接続の状態によって数分から数時間に及ぶことがある。OS の再設定を避け、有用な方法できめ細かく相互にクラッシュを検出するために、リーダーとフォロワーは定期的にハートビートを交換する。リーダーがタイムアウト時間内に定足数のフォロワーからのハートビートを受信しなかった場合、リーダーはそのエポックのリーダーシップを破棄し ELECTION 状態に遷移する。リーダーが選出されるとアルゴリズムの新しい反復を開始し、フェーズ 1 に進行するプロトコルの新しい反復を開始する。
C. フォロワー役
フォロワーはリーダー選挙を抜けるとリーダーに接続する。フォロワー \(f\) はリーダーをサポートするために新しいエポックの提案を確認し、提案された新しいエポックが \(f.p\) よりも遅い場合にのみ行う。フォロワーは一度に 1 つのリーダーにしか従わず、タイムアウト間隔内にハートビートを受信している限りはリーダーとの接続を維持する。もし時間内にハートビートが到達しなかったり TCP 接続がクローズすると、フォロワーはリーダーを放棄して ELECTION に移行しアルゴリズムのフェーズ 1 に進む。
Fig 5 はフォロワーがリーダーをサポートするために実行するプロトコルを示している。フォロワーは自分の現在のエポック \(f.a\) をエポックメッセージ (\({\it CEPOCH}(f.a)\)) でリーダーに送信する。リーダーは定足数のフォロワーから現在のエポックメッセージを受け取ると新しいエポック提案 (\({\it NEWEPOCH}(e)\)) を送信する。フォロワーは新しいエポック提案に対して、最新のエポックと最高の zxid を承認し、リーダーはそれを使って新しいエポックの初期履歴を選択する。
フェーズ 2 では、フォロワーはその \(f.a\) 値を \(e\) に設定し、初期履歴のトランザクションを受け入れることで新しいリーダー提案 (\({\it NEWLEADER}(e,I_e)\)) を承認する。フォロワーはエポック \(e\) の新しいエポック提案を受理すると、同じエポック \(e\) に対する他の新しいエポック提案の確認応答を送信しないことに注意。この特性により 2 つのプロセスが同じエポックにリーダーとして確立できないことを保証する。新しいリーダー提案に対してリーダーからコミットメッセージを受け取ると、フォロワーはフェーズ 2 を完了しフェーズ 3 に進行する。フェーズ 3 では、フォロワーはリーダーから新しい提案を受け取る。フォロワーは新しい提案を自分の履歴に追加し、それを承認する。フォロワーはリーダーからのコミットメッセージを受け取るとこれらのプロポーザルを配信する。
新しいリーダーが出現したときも、フォロワーが既存のリーダーに接続したときも、フォロワーとリーダーはリカバリープロトコルに従うことに注意。リーダーが既に確立されている場合は \({\it NEWLEADER}(e,I_e)\) 提案は既にコミットされているので \({\it NEWLEADER}(e,I_e)\) 提案に対する確認応答はすべて無視される。
D. Liveness
Zab には操作を提案しコミットするリーダーの存在が必要である。リーダーシップを維持するために、リーダーであるプロセス \(\ell\) がフォロワーにメッセージを送り、フォロワーからメッセージを受け取ることができなければならない。実際、プロセス \(\ell\) がリーダーシップを維持するためには、定足数のフォロワーがアップしていてそれらがリーダーとして \(\ell\) を選択していることを必要とする。この要件は Malkhi ら [18] の \(\diamond f\)-accessibility と leader stability 特性によく従っている。liveness の要件を深く分析し論議する、Malkhi らの研究と比較することはこの研究の範囲外である。
VI. 分析
このセクションでは Zab の正しさを証明するための議論を示す。より詳細な証明はテクニカルレポート [15] に掲載されている。最初に定義のリストを提示し、続いてプロトコルが満たさなければならない不変性のセットを提示する。
A. 定義
この分析では以下の追加表記を使用している。
定義 VI.1 (選択されたトランザクション): ある \(e\) に対して定足数のフォロワーが提案 \(\langle e,\langle v,z\rangle\rangle\) を受理するとき、トランザクション \(\langle v,z\rangle\) は選択される (chosen)。
定義 VI.2 (選択されたトランザクションのシーケンス): \(C_e\) はエポック \(e\) で選択されたトランザクションのシーケンスである。\(f \in Q\) のそれぞれが提案 \(\langle e\langle v,z\rangle\rangle\) を受理しているような定足数のフォロワー \(Q\) が存在するとき、トランザクション \(\langle v,z\rangle\) はエポック \(e\) で選択される。
定義 VI.3 (ブロードキャストフェーズでブロードキャストされる選択された提案のシーケンス): \(CB_e\) はエポック \(e\) のブロードキャストフェーズでの選択された提案のシーケンスである。
定義 VI.4 (配信されたトランザクションのシーケンス): \(\Delta_f\) はフォロワー \(f\) が一意に配信したトランザクションのシーケンスである。これは txns の要素の識別子によって誘導されるシーケンスである。
定義 VI.5 (ブロードキャストフェーズで配信されたトランザクションのシーケンス): \(D_f\) はフォロワー \(f\) がエポック \(f.a\) の B フェーズにいる間に配信されたトランザクションのシーケンスである。
定義 VI.6 (フォロワーの最後にコミットされたエポック): 特定のフォロワー \(f\) について、\(e\) がコミットされていることを \(f\) が観測した最後のエポック \(e\) を \(f.e\) と表す。
B. 不変性
以下の特性はプロトコルが各ステップで維持する不変性であり、セクション IV のプロトコルに対して簡単な方法で検証することができる。我々はこれらを Zab のコア特性を証明する際に使用する。
不変性 1. フォロワー \(f\) は、その現在のエポックが \(f.a = e\) の場合にのみ提案 \(\langle e,\langle v,z\rangle\rangle\) を受理する。
不変性 2. エポック \(e\) のブロードキャストフェーズにおいて、\(f.a = e\) であるようなフォロワー \(f\) は提案を受け入れ、zxid 順序に従ってトランザクションを配信する。
不変性 3. フェーズ 1 では、フォロワー \(f\) は自分の履歴をエポックの初期履歴として提供する前に、任意のエポック \(e' \lt e\) のリーダーからの提案を受け入れないことを約束する。
不変性 4. あるエポック \(e\) の初期履歴 \(I_e\) はあるフォロワーの履歴である。メッセージ \({\it ACK\mbox{-}E}(f.a,h_f)\) (フェーズ 1) と \({\it NEWLEADER}(e,I_e)\) (フェーズ 2) はそれぞれ \(h_f\) と \(I_e\) のトランザクションを変更したり、並べ替えたり、消失しない。
不変性 5. \(f\) をフォロワーとする。\(D_f \sqsubseteq \beta_{f.e}\) である。
C. Safety 特性
ここではセクション III で導入した特性の証明スケッチを紹介する。なお我々の定義とアルゴリズムの説明をより一致させるために、いくつかの記述ではプロセスではなくフォロワー、リーダー、プライマリという用語を使用している。
(原文参照)
D. Liveness 特性
提題 7. 以下のように仮定する:
- フォロワーの定足数 \(Q\) がアップである。
- \(Q\) のフォロワーが同じプロセス \(\ell\) を選択し、\(\ell\) がアップである。
- \(Q\) 内のフォロワーと \(\ell\) 間のメッセージは適時受信される。
もし \(\ell\) がトランザクション \(\langle v,z\rangle\) を提案したなら、\(\langle v,z\rangle\) は最終的にコミットされる。
証明のスケッチ: プロトコルの新しい反復を開始するとき、フォロワーは \(\ell\) とメッセージを交換するフェーズ 1 を実行する。アルゴリズムにより、リーダーは新しいエポック番号 \(e'\) を選択して、\(Q\) のフォロワーから \({\it CEPOCH}(e)\) で受信したエポック番号より大きい番号にする。この結果 \(\ell\) から \({\it NEWEPOCH}(e')\) を受け取ると、\(Q\) のフォロワーはその提案を承認しフェーズ 2 に進行する。
定足数のフォロワーがフェーズ 2 で提案 \({\it NEWLEADER}(e',I_{e'})\) を受け取り、処理して承認すると、リーダー \(\ell\) は提案 \({\it NEWLEADER}(e',I_{e'})\) をコミットしフェーズ 3 に進行する。\(\ell\) からの提案 \(\langle e',\langle v,z\rangle\rangle\) は \(\{\ell\} \cup Q\) のすべてのプロセスがアップし続け、メッセージの受信が適時で、\(\ell\) が故障していると疑うプロセスがない場合、最終的にフェーズ 3 でコミットされる。
VII. 評価
Zab とその他の ZooKeeper サーバの実装は Java で書かれている。Zab を評価するために 13 台の同一のサーバで構成されるクラスタを使用した。このサーバはデュアルクアッドプロセッサの Xeon 2.50GHz CPU、16G RAM、ギガビットネットワークインターフェース、提案履歴用の専用 1T SATA ハードドライブを備えている。サーバは RHEL 5 (Kernel 2.6.18-53.1.13.el5) で ext3 ファイルシステムを使用している。また Sun の JVM 1.6 バージョンを使用している。
Zab は ZooKeeper から分離できないため、Zab と直接やり取りするために ZooKeeper の内部にフックする特別なベンチマーク用ラッパーを書いた。ベンチマークラッパーは Zab のリーダーに 25 万件のリクエストのバッチを生成させ、1000 件のリクエストを未処理のままにしておく。Java の初回起動時に行われるクラスのロードとインクリメンタルコンパイルによって初回実行時には悪影響がある。また最初の実行時にトランザクションを記録するためにファイルが割り当てられているが、これは後の実行時に再利用される。このような起動時の影響を避けるために、いくつかのウォームアップバッチを実行した後、約 10 個のバッチを連続して実行している。ベンチマークでは最大 13 台のサーバを使用しているが、一般的な ZooKeeper は 3~7 台のサーバを使用しているため、13 台という数字は一般的な構成に比べて大きい。ベンチマークでは一般的な処理サイズである 1024 バイトの処理を行った。
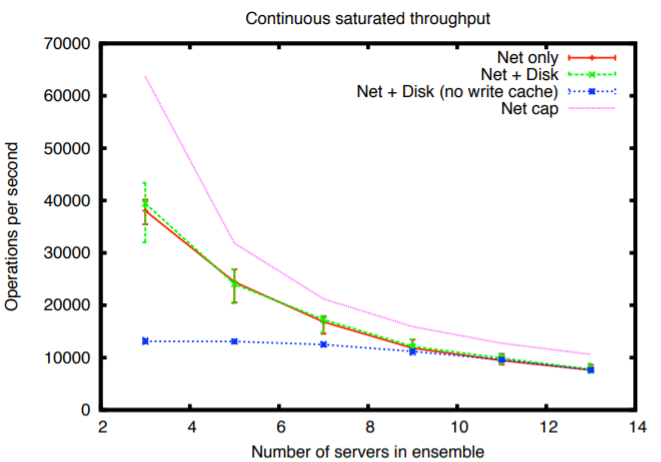
a) スループット: Zab を使用して操作のレプリケーションにかかる時間をベンチマークしました。Fig 6 はサーバ数に対するスループットの変換を示している。一つの系列はディスクに何も書き込まれていないときのスループットを示している。これはプロトコル自体とネットワークのパフォーマンスを分離したものである。我々は単一のギガビットネットワークインターフェースを使用しているため送信帯域には上限がある。Fig 6 にはこの上限を考慮した場合の理論上の最大レプリケーションスループットも示している。リーダーはすべてのフォロワーに操作を伝達するためサーバ数が増加するとスループットは低下する。
我々は fdatasync システムコールを使用してリクエストをディスクに同期させているが、この呼び出しはリクエストをディスクに強制的に送るだけで必ずしもディスクメディアに送るわけではない。デフォルトでは、ディスクはディスク自体に書き込みキャッシュを持ち、ディスクメディアに書き込まれる前に書き込み要求が完了する。書き込みがディスクメディアに到達していないときに停電すると書き込みが失われる可能性がある。この図と次の図が示すようにディスクキャッシュをオフにすると高い代償が発生する。ディスクキャッシュや、RAID コントローラーに搭載されているようなバッテリーバックアップされたキャッシュで動作している場合、ディスクのパフォーマンスはネットワークのみの場合とほとんど変わらず、どちらもネットワークを飽和状態にしている。
ディスク書き込みキャッシュをオフにすると Zab は I/O バウンドとなり、スループットはサーバ数に対してほぼ一定となる。7 台以上のサーバではトランザクションがディスクに記録されるときに同一ネットワークのみにボトルネックが存在するため、サーバ数が増えるとスループットが低下してしまう。
サーバの数を増やすとリーダーのネットワークカードが飽和状態となり、サーバ数の増加に対してスループットが低下する。この飽和状態を回避するためにブロードキャストツリーやチェーンレプリケーション [7] を使用して提案をブロードキャストすることができるが、我々の性能は本番環境で必要とされるものよりはるかに高いためこのような代替手段は検討していない。
b) レイテンシー: Fig 7 はリーダーが単一の操作をコミットする際のレイテンシーを示している。ping を使用してサーバ間の基本的なレイテンシーを測定したところ 100 マイクロ秒だった。ベンチマークタイマーの分解能はミリ秒である。
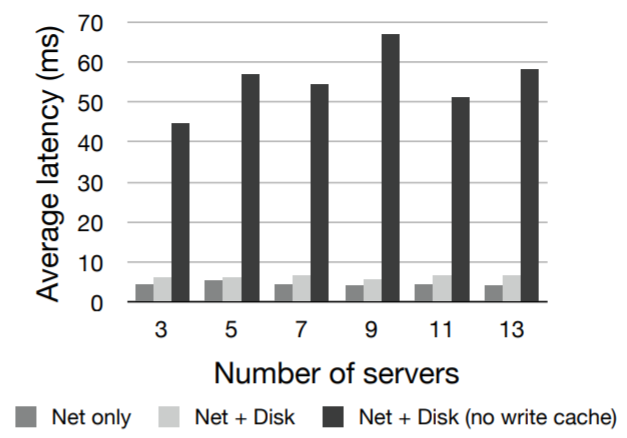
スループットと同様にディスクの書き込みキャッシュをオフにするとパフォーマンスに大きな影響が出る。我々は事前に割り当てられたファイルを使用しシーケンシャルに書き込みを行い、ディスクにデータを同期させるためだけに fdatasync を使用している。残念ながら Linux カーネルはバージョン 2.6.26 まで "only sync data" フラグを認識しない。同期時のパフォーマンスペナルティは回転の遅延とシーク (約 20 ミリ秒) 程度で済むはずである。しかしメタデータの更新があるためペナルティは高くなる。この余分なアクセス時間はレイテンシーとスループットの両方に影響する。
VIII. 関連する研究
Paxos. Paxos では新しく選ばれたリーダーが 2 つのフェーズを実行する。最初のフェーズ (read フェーズ) では新リーダーが他のすべてのプロセスに連絡して、以前のリーダーが提案してコミットした可能性のある値を読み取る。第二のフェーズは write フェーズと呼ばれ、新リーダーは自分の値を提案する。Paxos と比較した Zab の最も重要な違いは同期 (synchronization) という追加のフェーズを使用していることである。新しいリーダー候補 \(\ell\) は我々が discovery と呼ぶ read フェーズを実行し、その後に同期フェーズを実行することで確立を試みる。同期フェーズでは新しいリーダー \(\ell\) は、過去のエポックで確立されたリーダーから提案されたトランザクションを定足数のフォロワーが確実に配信するようにする。この同期フェーズは因果関係の衝突を防ぎこの特性が遵守されることを保証する。実際、この同期フェーズでは新しいエポック \(e\) のトランザクションが提案される前に、定足数内のすべてのプロセスが前のエポックのトランザクションを配信することが保証される。同期フェーズが完了すると Zab も Paxos と同様の write フェーズを実行する。
確立されたリーダーは常にエポック番号に関連付けられている。Paxos の投票番号と同様に、各エポック番号は 1 つのプロセスにしか関連付けられてない。Zab では単純なシーケンス番号を用いる代わりに、トランザクションは zxid というペア \(\langle\)epoch, counter\(\rangle\) で識別される。このような zxid はまずエポック順に並べられ、次にカウンター順に並べられる。定足数の各プロセスから受け入れられた履歴を読み込んだ後、新たに確立されたリーダーは、フォロワーの定足数全体に複製するために、最新のエポックを持つフォロワーの中で \({\it zxid}\) が最も高い履歴を選択する。このような選択は、配信されるトランザクションの順序が時間の経過とともにプライマリの順序と一致することを保証するために重要である。Paxos では、リーダーは代わりに各シーケンス番号のトランザクション (または値) を独立して選択する。
Abstract Paxos. Zab は Lampson [19] による Paxos の抽象的な記述に従っている。コンセンサスの各インスタンスにおいて Zab のリーダーはアンカーとなる値を選択し、それを受け入れるエージェント (フォロワー) の定足数ろ得ようとし、最後にその値をエージェントの定足数に記録して終了する。Zab では、あるコンセンサスインスタンスに対して値を提案する権利を 1 人のリーダーにのみ与えており、アルゴリズムに寄ってリーダーは各インスタンスに対して最大で 1 つの値を提案することから、あるコンセンサスインスタンスに対してどの値をアンカーとするかを決定することは容易である。このため、アンカーリングされた値は、リーダーが提案した値か、値なし (no-op) のいずれかとなる。Zab ではコンセンサスインスタンスは zxid に従って順序付けられている。Zab はコンセンサスインスタンスのシーケンスをエポックに分割し、エポックのコンセンサスインスタンスに対して 1 人のリーダーだけが値を提案することができる。
Lampson は Viewstamped レプリケーションプロトコルにはコンセンサスアルゴリズムが組み込まれていると述べている [19]。Viewstamped レプリケーションが提案するアプローチはトランザクション処理とビュー変更アルゴリズムを組み合わせたものである [20]。ビュー変更あるごリウムは、あるビューのレプリカ (彼らの用語ではコホート (cohort)) の大多数が知っているイベントが後続のビューにも依存することを保証する。Zab のようにこの複製アルゴリズムはエポック内で提案されたイベントの順序を保証する。
Passive replication. パッシブレプリケーションでは 1 つのプロセスがクライアントの操作を実行し、状態変更を残りのレプリカに伝達する。Budhiraja らはプライマリ-バックアップ同期システムのアルゴリズムと限界について説明している [5]。プライマリ-バックアップは Vertical Paxos [21] の特殊ケースでもある。Vertical Paxos は構成変更を構成マスターに依存している。各構成は新しい構成ごとに増加する投票番号に関連付けられ、各構成の提案者は対応する投票番号を使って値を提案する。Vertical Paxos も Paxos であることには変わりなく、コンセンサスの各インスタンスは時間の経過とともに異なる投票で複数の値が提案される可能性があり、したがって Introduction で述べた我々の設定では望ましくない動作を引き起こす。
Crash-recovery protocols. Rodrigues と Raynal はコンセンサス実装を用いたクラッシュリカバリー・アトミックブロードキャストプロトコルを提案している [3]。彼らは配信されたメッセージの重複を避けるために A-deliver-sequence という呼び出しを用いて順序付けられたメッセージのシーケンスを得る。Mena と Schiper はアトミックブロードキャストの仕様に commit プリミティブを追加することを提案している [4]。コミットされていないメッセージは二回配信することができる。Zab では合意された順序を守る限りメッセージを二回配信することができる。Boichat と Guerraoui は全順序ブロードキャストのためのモジュラーで増分的なアプローチを提案しており、彼らの最も強いアルゴリズムは Paxos に対応している [12]。
Group Communication Systems. Birman と Joseph は分散環境をプログラミングするための計算モデルとして仮想同期 (virtual synchrony) を提案している [22], [23]。基本的な考え方は、すべてのプロセスが同じイベントを同じ順序で観測することを保証するというものである。この保証はメッセージ配信イベントだけではなく、障害、回復、グループメンバーシップの変更などにも適用される。仮想同期環境ではアトミックブロードキャストが重要だが、因果ブロードキャストのような他の弱い形式のブロードキャストでもアプリケーションは仮想同期の特性を得ることができる。
このようなプログラミングモデルとは異なり Zab はプロセスの静的なアンサンブルを想定しており、定足数がリーダーを支持しなくなった場合を除き、リーダー以外のプロセスの故障時にビューやエポックの変更を行わない。また Birman と Joseph の ABCAST プロトコルとは異なり、Zab は ZooKeeper アプリケーションに自然にマッチするためメッセージの発信にシーケンサーを使用する。
Chockler らはグループ通信システムの特性を調査している [8]。彼らは、強い全順序性、弱い全順序性、信頼できる全順序性の 3 つを提示している。信頼のある全順序性は最も強い性質であり、タイムスタンプ関数で全順序付けられたメッセージのプレフィクスがビューで配信されることを保証する。Zab の特性はこれに近いものだが、各ビューは最大で 1 つのプロセスがブロードキャストしているという 1 つの重要な違いがある。1 つのビューに 1 つのプロセスがブロードキャストすることで、順序付けがそのプロセスのブロードキャストによって直接確立されるため、特性の実装が簡単になる。
Partitionable atomic broadcast. COReL は分断可能な環境のためのアトミックブロードキャストプロトコルである [24]。COReL はグループ通信レイヤー Transis [25] に依存しており、プライマリコンポーネントのプロセスがメッセージを完全に順序付けることができる。Zab と同様に。COReL は構成が変更されるとリカバリが終了するまで新しいメッセージを導入せず因果関係の不変性を保証する。ただし COReL はすべてのプロセスがメッセージを開始できることを前提としているため順序保証が異なる。
特定のプライマリコンポーネントでの単一のプロセスのブロードキャストを制限しても、因果関係に関する配信保証があるため、我々の設計では Zab を COReL に置き換えることはできない。因果関係は構成を超えて保持され、以前の構成でブロードキャストされたメッセージが後の構成のメッセージの後に配信されるような実行を引き起こす。Fig 3 の例で説明すると、COReL の因果不変性により \({\it epoch}(z) \lt {\it epoch}(z'')\) となるようなトランザクション \(\langle v'',z''\rangle\) が存在していたとしても \(\langle v,z\rangle\) は \(\langle v',z'\rangle\) より前に配信されなければならない。状態の更新が果敢ではないため、我々の設計ではこのような挙動は不整合を引き起こす。
IX. 結論
ZooKeeper を設計する際に、複数の未処理トランザクションを持つプライマリ-バックアップをサポートする効率的なアトミックブロードキャストプロトコルが必要だった。我々の設計の重要な要件はプライマリの変更に伴う効率的なリカバリーと状態の一貫性だった。我々はプライマリ-バックアップの正しいリカバリーを保証するためにはプライマリの順序が必要であると考えた。Paxos のようなプロトコルを検討したが、Paxos はレプリケーションシステムを実装するための一般的な選択肢であるにもかかわらず、バッチ化なしに複数の未処理トランザクションがある場合にはこの特性を満たさないことが分かった。
Zab はプライマリー順序を保証し複数の未処理トランザクションを可能にする。我々が実装した Zab はこれらの特性を保証しながら優れたスループット性能を提供することができた。Zab はプライマリがクラッシュしてもプライマリオーダーを保証するために 3 つのフェーズを実装している。この特性が満たされることを保証するための重要なフェーズは同期である。プライマリが変更されると、新しいプライマリが新しいトランザクションをブロードキャストする前に、定足数のプロセスが同期フェーズを実行しなければならない。このフェーズを実行することで、以前のエポックでブロードキャストされたトランザクションのうち、すでに選択された、または選択されるはずのトランザクションのすべてが新しいエポックのトランザクションの初期履歴に含まれることが保証される。
Zab は各識別子に最大 1 つの値を保証するトランザクション識別子の割り当て方式を採用している。この方式では、あるプロセスが最後に受け入れたトランザクション識別子を比較するだけで、正しいトランザクション履歴を選択することができるため、プライマリクラッシュを効率的に回復することができる。
Zab は ZooKeeper の一部として運用されており、我々のワークロードの要求を満たしてくれている。ZooKeeper のパフォーマンスは広く採用されるための鍵となっている。
References
- P. Hunt, M. Konar, F. P. Junqueira, and B. Reed, “ZooKeeper: Wait-free coordination for Internet-scale systems,” in USENIX ATC’10: Proceedings of the 2010 USENIX Annual Technical Conference. USENIX Association, 2010.
- L. Lamport, “The part-time parliament,” ACM Transactions on Computer Systems, vol. 16, no. 2, pp. 133–169, May 1998.
- L. Rodrigues and M. Raynal, “Atomic broadcast in asynchronous crashrecovery distributed systems and its use in quorum-based replication,” IEEE Transactions on Knowledge and Data Engineering, vol. 15, no. 5, pp. 1206–1217, 2003.
- S. Mena and A. Schiper, “A new look at atomic broadcast in the asynchronous crash-recovery model,” in SRDS ’05: Proceedings of the 24th IEEE Symposium on Reliable Distributed Systems. Washington, DC, USA: IEEE Computer Society, 2005, pp. 202–214.
- N. Budhiraja, K. Marzullo, F. B. Schneider, and S. Toueg, Distributed systems (2nd Ed.). ACM Press/Addison-Wesley Publishing Co., 1993, ch. 8: The primary-backup approach, pp. 199–216.
- D. Powell, “Distributed fault tolerance - lessons learned from Delta4,” in Revised Papers from a Workshop on Hardware and Software Architectures for Fault Tolerance. London, UK: Springer-Verlag, 1994, pp. 199–217.
- R. van Renesse and F. B. Schneider, “Chain replication for supporting high throughput and availability,” in OSDI’04: Proceedings of the 6th conference on Symposium on Operating Systems Design & Implementation. USENIX Association, 2004, pp. 91–104.
- G. V. Chockler, I. Keidar, and R. Vitenberg, “Group communication specifications: a comprehensive study,” ACM Comput. Surv., vol. 33, pp. 427–469, December 2001.
- M. Burrows, “The Chubby lock service for loosely-coupled distributed systems,” in OSDI ’06: Proceedings of the 7th symposium on Operating systems design and implementation, 2006, pp. 335–350.
- T. D. Chandra, R. Griesemer, and J. Redstone, “Paxos made live: An engineering perspective,” in PODC ’07: Proceedings of the twenty-sixth annual ACM symposium on Principles of distributed computing. ACM, 2007, pp. 398–407.
- J. MacCormick, N. Murphy, M. Najork, C. A. Thekkath, and L. Zhou, “Boxwood: Abstractions as the foundation for storage infrastructure,” in OSDI’04: Proceedings of the 6th conference on Symposium on Operating Systems Design & Implementation, 2004, pp. 105–120.
- R. Boichat and R. Guerraoui, “Reliable and total order broadcast in the crash-recovery model,” J. Parallel Distrib. Comput., vol. 65, pp. 397–413, April 2005.
- X. Dèfago, A. Schiper, and P. Urbàn, “Total order broadcast and multicast algorithms: Taxonomy and survey,” ACM Comput. Surv., vol. 36, no. 4, pp. 372–421, 2004.
- L. Lamport, “Time, clocks, and the ordering of events in a distributed system,” Communications of the ACM, vol. 21, pp. 558–565, July 1978.
- F. Junqueira, B. Reed, and M. Serafini, “Dissecting Zab,” Yahoo! Research, Sunnyvale, CA, USA, Tech. Rep. YL-2010-007, 12 2010.
- J. Gray, “Notes on data base operating systems,” in Operating Systems, An Advanced Course. London, UK: Springer-Verlag, 1978, pp. 393–481.
- T. D. Chandra, V. Hadzilacos, and S. Toueg, “The weakest failure detector for solving consensus,” in PODC ’92: Proceedings of the eleventh annual ACM symposium on Principles of distributed computing. ACM, 1992, pp. 147–158.
- D. Malkhi, F. Oprea, and L. Zhou, “Omega meets Paxos: Leader election and stability without eventual timely links,” in DISC’05: Proceedings of the International Conference on Distributed Computing, vol. 3724, Sep 2005, pp. 199–213.
- B. Lampson, “The ABCD’s of Paxos,” in PODC ’01: Proceedings of the twentieth annual ACM symposium on Principles of distributed computing. ACM, 2001, p. 13.
- B. M. Oki and B. H. Liskov, “Viewstamped replication: A new primary copy method to support highly-available distributed systems,” in PODC ’88: Proceedings of the seventh annual ACM Symposium on Principles of distributed computing. ACM, 1988, pp. 8–17.
- L. Lamport, D. Malkhi, and L. Zhou, “Vertical paxos and primarybackup replication,” in PODC ’09: Proceedings of the 28th ACM symposium on Principles of distributed computing. ACM, 2009, pp. 312–313.
- K. Birman and T. Joseph, “Exploiting virtual synchrony in distributed systems,” SIGOPS Oper. Syst. Rev., vol. 21, no. 5, pp. 123–138, 1987.
- K. Birman and T. A. Joseph, “Reliable communication in the presence of failures,” ACM Trans. Comput. Syst., vol. 5, no. 1, pp. 47–76, 1987.
- I. Keidar and D. Dolev, “Efficient message ordering in dynamic networks,” in PODC ’96: Proceedings of the fifteenth annual ACM symposium on Principles of distributed computing. ACM, 1996, pp. 68–76.
- Y. Amir, D. Dolev, S. Kramer, and D. Malkhi, “Transis: A communication subsystem for high availability,” in Proceedings of 22nd International Symposium on Fault-Tolerant Computing (FTCS), 1992, pp. 76–84.
翻訳抄
ZooKeeper のプライマリ-バックアップ間でトランザクションのアトミックブロードキャストに使われている ZAB に関する 2011 年の論文。
- JUNQUEIRA, Flavio P.; REED, Benjamin C.; SERAFINI, Marco. Zab: High-performance broadcast for primary-backup systems. In: 2011 IEEE/IFIP 41st International Conference on Dependable Systems & Networks (DSN). IEEE, 2011. p. 245-256.
