論文翻訳: Kafka: a Distributed Messaging System for Log Processing
 ABSTRACT
ABSTRACT
ログ処理はコンシューマ向けインターネット企業においてデータパイプラインの重要な構成要素となっている。我々は、大量のログデータを低レイテンシーで収集・配信するために開発した分散メッセージングシステム、Kafka を紹介する。我々のシステムは、既存のログアグリゲーターとメッセージングシステムのアイディアを取り入れており、オフラインとオンラインの両方のメッセージ消費に適している。我々は、システムを効率的でスケーラブルにするため、Kafka において慣例にとらわれないいくつかの実用的な設計上の選択を行った。実験結果は、Kafka が 2 つの一般的なメッセージングシステムと比較して優れた性能を持つことを示している。我々は Kafka を本番環境でしばらく使用しており、毎日数百ギガバイトの新しいデータを処理している。
一般用語: 管理、性能、設計、実験
キーワード: メッセージング、分散、ログ処理、スループット、オンライン
Table of Contents
- ABSTRACT
- 1 導入
- 2 関連研究
- 3 Kafka アーキテクチャと設計原則
- 4 LinkedIn における Kafka の利用
- 5 実験結果
- 6 結論と今後の課題
- 7 REFERENCES
- 翻訳抄
1 導入
規模の大きいインターネット鏡では膨大な量の「ログ」データが生成される。このデータには通常 (1) ログイン、ページビュー、クリック、「良いね」、共有、コメント、検索クエリーと言ったユーザアクティビティイベント、(2) サービスのコールスタック、コールレイテンシー、エラーなどの運用メトリクス、および各マシンの CPU、メモリ、ネットワーク、ディスク使用率などのシステムメトリクスが含まれる。ログデータは長年、ユーザエンゲージメント、システム使用状況、その他のメトリクスを追跡する分析ツールとして使用されてきた。しかし、近年のインターネットアプリケーションの傾向により、アクティビティデータはサイト機能で直接利用される本番環境データパイプラインの一部となっている。これらの用途には、(1) 検索の関連性、(2) アクティビティストリームにおけるアイテムの人気度や共起頻度に基づいたレコメンド、(3) 広告ターゲティングとレポート、(4) スパムや不正なデータスクレイピングなどの不正行為から保護するセキュリティアプリケーション、(5) ユーザのステータス更新や行動を集約して「友達」や「つながり」が閲覧できるニュースフィード機能などがある。
こうしたログデータの本番環境でのリアルタイム利用は、データシステムに新たな課題をもたらす。なぜなら、その量が「実際の」データよりも桁違いに大きいためである。例えば、検索、レコメンド、広告といった分野ではクリックスルー率を細かく計算する必要が多く、ユーザのクリック一つ一つだけでなく、クリックされなかったページ上の数十項目にについてもログ記録が生成される。China Mobile は毎日 5~8 TB の通話記録を収集しており [11]、Facebook はさまざまなユーザアクティビティイベントを約 6 TB 収集している [12]。
こうしたデータを処理する初期のシステムの多くは、分析のために本番サーバからログファイルを物理的にスクレイピングしていた。近年では、Facebook の Scribe [6]、Yahoo! の Data Highway [4]、Cloudera の Frame [3] など、いくつかの専用分散ログアグリゲーターが構築されてきた。これらのシステムは主に、ログデータを収集してデータウェアハウスや Hadoop [8] にロードしてオフラインで利用できるように設計されている。LinkedIn (ソーシャルネットワークサイト) では、従来のオフライン分析に加えて、前述のリアルタイムアプリケーションのほとんどを数秒以内の遅延でサポートする必要があることが分かった。
我々は、従来のログアグリゲーターとメッセージングシステムの利点を組み合わせた、ログ処理のための新しいメッセージングシステム Kafka [18] を構築した。Kafka は分散型でスケーラブルであり、高いスループットを提供する。一方で Kafka はメッセージングシステムに類似した API を提供し、アプリケーションがログイベントをリアルタイムで利用できるようにする。Kafka はオープンソース化されており、LinkedIn の運用環境で 6 ヶ月以上にわたって成功裏に本番運用されておる。Kafka はあらゆる死緩いのログデータをオンラインとオフラインの両方で利用できる単一のソフトウェアを利用できるため、我々のインフラストラクチャを大幅に改善する。この論文の残りの部分は次のように構成される。セクション 2 では従来のメッセージングシステムとログアグリゲータを再検討する。セクション 3 では Kafka アーキテクチャとその主要な設計原則について説明する。セクション 4 では LinkedIn における Kafka の導入について説明し、セクション 5 では Kafka の性能結果について述べる。セクション 6 では今後の課題について議論し、結論を述べる。
2 関連研究
従来のエンタープライズメッセージンシステム [1][7][15] [17] は長年存在して非同期データフローを処理するためのイベントバスとして重要な役割を果たしてきた。しかし、これらがログ処理に適さない理由がいくつかある。第一に、エンタープライズシステムが提供する機能にミスマッチがある。これらのシステムは豊富な配信保証の提供に重点を置くことが多い。例えば IBM Websphere MQ [7] はアプリケーションが複数のキューにメッセージをアトミックに挿入できるトランザクションサポートを備えている。JMS [14] 仕様では、個々のメッセージは消費後に確認応答を受け取ることができるが順序が乱れることがある。このような配信保証はログデータの収集には過剰であることが多い。例えば、いくつかのページビューイベントが時々失われることがあっても大きな問題ではない。これらの不要な機能は API とシステム基板実装の両方を複雑化させる傾向がある。第二に、多くのシステムは主要な設計制約としてスループットに重点を置いていない。例えば JSM にはプロデューサが複数のメッセージを明示的に単一のリクエストにバッチ化できる API がない。これは各メッセージが完全な TCP/IP ラウンドトリップを必要とすることを意味し、我々の領域のスループット要件には実現不可能である。第三に、これらのシステムは分散サポートが弱い。メッセージを複数のマシンにパーティション化して保存する簡単な方法がない。最後に、多くのメッセージングシステムはメッセージがほぼ即座に消費されることを前提としているため、消費されていないメッセージのキューは常にかなり小さい。継続的な消費ではなく定期的な大規模ロードを行うデータウェアハウスアプリケーションのようなオフラインコンシューマのように、メッセージの蓄積が許されるとパフォーマンスが著しく低下する。
ここ数年で多数の特殊なログアグリゲーターが構築されてきた。Facebook は Scribe というシステムを使用している。各フロントエンドマシンはソケットを介して複数の Scribe マシンにログを送信できる。各 Scribe マシンはログエントリを集約し、定期的に HDFS [9] または NFS デバイスにダンプする。Yahoo! の Data Highway プロジェクトも同様のデータフローを持っている。複数のマシンがクライアントからのイベントを集約して「分単位」のファイルをロールアウトして HDFS に追加される。Flume は Claudera が開発した比較的新しいログアグリゲーターである。これは拡張可能な「パイプ」と「シンク」をサポートしてストリーミングログデータを非常に柔軟に処理する。また、より統合された分散サポートも備えている。しかし、これらのシステムのほとんどはログデータをオフラインで消費することを前提に構築されており、しばしば実装の詳細 (例えば「分単位のファイル」など) をコンシューマに不必要に後悔してしまうことがよくある。さらに、これらのほとんどは「プッシュ」モデルを使用しており、ブローカーがコンシューマにデータを送信。LinkedIn では、各コンシューマが最大速度でメッセージを取得でき、処理能力を超える速度でプッシュされたメッセージによるフラッディングを回避できるため、「プル」モデルの方がアプリケーションに適していると考えている。プル型モデルはコンシューマの巻き戻しも容易で、この利点についてはセクション 3.2 の最後で議論する。
最近、Yahoo! Research は HedWig [13] と呼ばれる新しい分散 pub/sub システムを開発した。WedWig は高度にスケーラブルで可用性が高く、強力な耐空性を保証する。しかし、これら主にデータストアのコミットログを保存することを目的としている。
3 Kafka アーキテクチャと設計原則
既存システムの限界に対応するために、我々は新しいメッセージングベースのログアグリゲータ Kafka を開発した。まず Kafka の基本概念を紹介する。特定の方のメッセージのストリームはトピック (topic) によって定義される。プロデューサはトピックにメッセージを公開できる。公開されたメッセージはブローカーと呼ばれる一連のサーバに保存される。コンシューマは、ブローカーから 1 つ以上のトピックをサブスクライブし、ブローカーからデータをプロすることでサブスクライブしたメッセージを消費する。
メッセージングは概念的にシンプルであり、我々はこれを反映して Kafka API も同様にシンプルにするよう努めた。API がどのように使用されるかを示すサンプルコードを提示する。プロデューサのサンプルコードを以下に示す。メッセージは、バイトのペイロードのみを含むものとして定義される。ユーザは、メッセージをエンコードするために好みのシリアライゼーション手法を選択できる。効率性のため、、プロデューサは単一の公開リクエストで一連のメッセージを送信できる。
サンプルプロデューサコードproducer = new Producer(…);
message = new Message("test message str".getBytes());
set = new MessageSet(message);
producer.send("topic1", set); トピックをサブスクライブするには、コンシューマはまずそのトピックに対して 1 つ以上のメッセージストリームを作成する。そのトピックに公開されたメッセージは、これらのサブストリームに均等に分散される。Kafka がメッセージをどのように配分するかの詳細については後のセクション 3.2 で説明する。各メッセージストリームは、継続的に生成されるメッセージのストリーム上でイテレーターインターフェースを提供する。次に、コンシューマはストリーム内のすべてのメッセージを反復処理してメッセージのペイロードを処理する。従来のイテレータとは異なり、メッセージストリームイテレータは終了しない。現在コンシュームするメッセージがない場合、イテレータは新しいメッセージがトピックに公開されるまでブロックする。我々は、複数のコンシューマがトピック内のすべてのメッセージの単一のコピーを共同で消費するポイント・ツー・ポイント配信モデルと、複数のコンシューマがそれぞれトピックの独自のコピーを取得する pub/sub モデルの両方をサポあーとする。
サンプルコンシューマコードstreams[] = Consumer.createMessageStreams("topic1", 1)
for (message : streams[0]) {
bytes = message.payload();
// do something with the bytes
} Kafka の全体的なアーキテクチャ図を Figure 1 に示す。Kafka は本質的に分散型であるため、Kafka クラスタは通常、複数のブローカーで構成される。負荷分散のためトピックは複数のパーティションに分割され、各ブローカーはそれらのパーティションの 1 つ以上を格納する。複数のプロデューサとコンシューマが同時にメッセージを公開および取得できる。セクション 3.1 では、ブローカー上の単一のパーティションのレイアウトと、パーティションへのアクセスを効率的にするために我々が選択したいくつかの設計選択について説明する。セクション 3.2 では、分散環境でプロデューサとコンシューマが複数のブローカーとどのようにやりとりするかを説明する。セクション 3.3 では Kafka の配信保証について議論する。
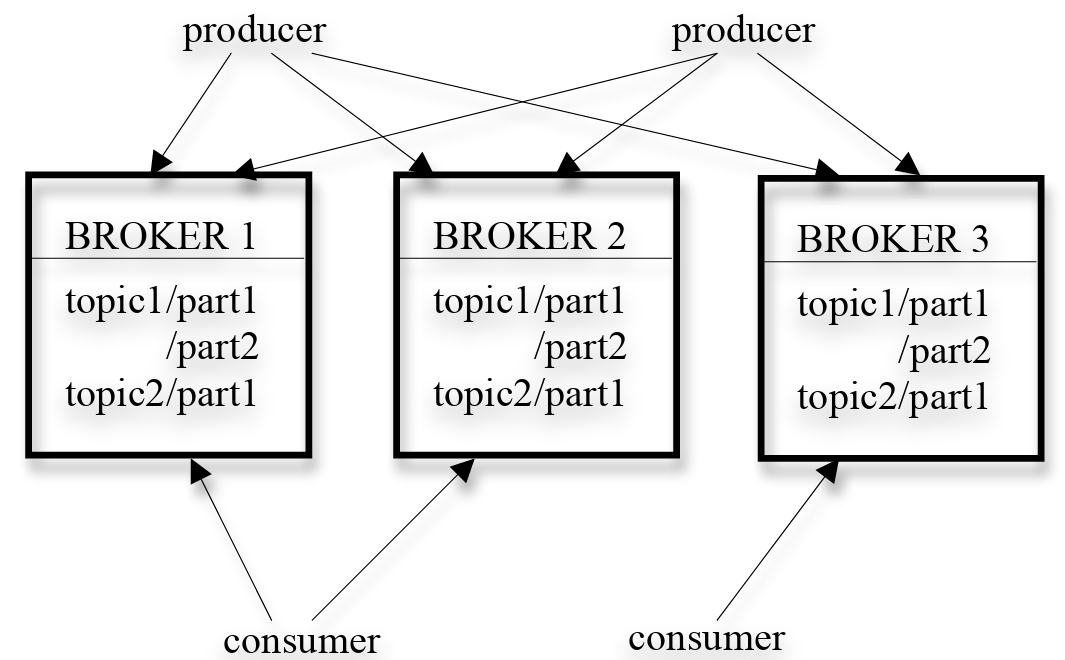
3.1 単一パーティション上での効率性
我々はシステムを効率的にするために Kafka でいくつかの決定を行った。
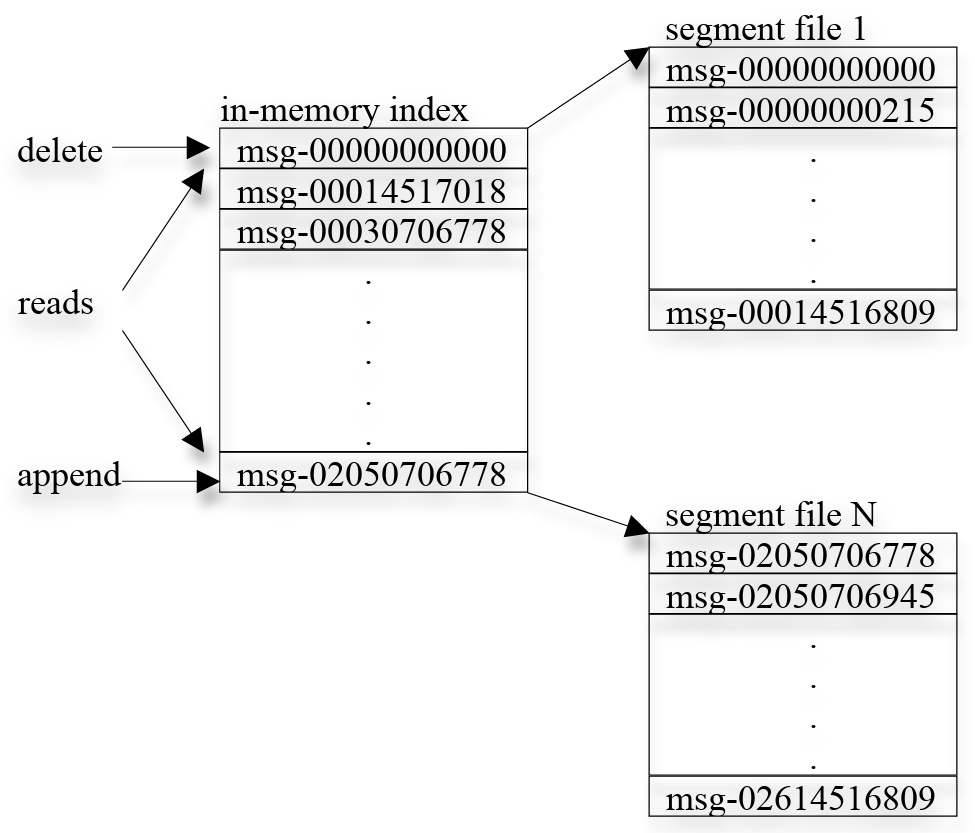
シンプルなストレージ. Kafka は非常にシンプルなストレージレイアウトを持つ。トピックの各パーティションは論理ログに対応する。物理的には、ログはほぼ同じサイズ (例えば 1GB) の一連のセグメントファイルとして実装される。プロデューサがパーティションにメッセージをパブリッシュするたびに、ブローカーは単純にメッセージを最後のセグメントファイルに追加する。性能向上のために、設定可能な数のメッセージがパブリッシュされるか、一定の時間が経過した後にのみ、セグメントファイルをディスクにフラッシュする。メッセージは、フラッシュされた後にのみコンシューマにパブリッシュされる。
一般的なメッセージングシステムとは異なり、Kafka に保存されるメッセージには明示的なメッセージ ID がない。代わりに、各メッセージはログ内の論理オフセットによってアドレス指定される。これにより、メッセージ ID を実際のメッセージ位置にマッピングする補助的なシーク集約型なランダムアクセスインデックス構造を維持するオーバーヘッドを回避できる。我々のメッセージ ID は増加するが連続ではないことに注意。次のメッセージ ID を計算するには、現在のメッセージの長さをその ID に加える必要がある。以降、我々はメッセージ ID とオフセットを同じ意味で使用する。
コンシューマは常に特定のパーティションからメッセージを順番にコンシュームする。コンシューマが特定のメッセージオフセットを確認応答すると、それはコンシューマがそのパーティション内のそのオフセットより前のすべてのメッセージを受信したことを意味する。内部的には、コンシューマはブローカーに対して非同期プルリクエストを発行し、アプリケーションがコンシュームするためのデータバッファを準備する。各プルリクエストにはコンシュームを開始するメッセージのオフセットと、取得する許容バイト数が含まれる。各ブローカーは、すべてのセグメントファイルの最初のメッセージのオフセットを含む、ソートされたオフセットリストをメモリに保持する。ブローカーは、オフセットリストを検索することで要求されたメッセージが存在するセグメントファイルを特定し、データをコンシューマに返送する。コンシューマはメッセージを受信すると、次にコンシュームするメッセージのオフセットを計算し、次のプルリクエストでそれを使用する。Kafka ログのレイアウトとインメモリインデックスを Figure 2 に示す。各ボックスはメッセージのオフセットを示している。
効率的な転送. 我々は Kafka へのデータ転送については非常に慎重である。前述のように、プロデューサは 1 回の送信リクエストで複数のメッセージセットを送信できる。コンシューマ API は一度に 1 つのメッセージを反復処理するが、内部的には、コンシューマからの各プルリクエスト通常数百キロバイトとなる一定サイズまで複数のメッセージを取得する。
我々が行ったもう 1 つの型破りな選択は、Kafla レイヤーでメッセージをメモリに明示的にキャッシュすることを避けることである。代わりに、我々は基板となるファイルシステムのページキャッシュに依存する。これには二重バッファリングを回避するという利点がある。つまり、メッセージはページキャッシュのにのみキャッシュされる。これには、ブローカープロセスが再起動してもウォームキャッシュが保持されるという利点もある。Kafka はメッセージをプロセス内に全くキャッシュしないため、メモリのガーベッジコレクションにおけるオーバーヘッドがほとんどなく、VM ベースの言語による効率的な実装が実現可能になる。最後に、プロデューサとコンシューマの両方がセグメントファイルにシーケンシャルにアクセスし、コンシューマはプロデューサよりわずかに遅れることが多いため、通常のオペレーティングシステムのキャッシュヒューリスティック (具体的には Write スルーキャッシュと先読み) が非常に効率的である。我々は本番環境とコンシューマの両方において、数テラバイトのデータまで、データサイズに対して線形の一貫した性能を持つことを発見した。
我々はさらにコンシューマのためのネットワークアクセスを最適化する。Kafka はマルチサブスクライバーシステムであり、単一のメッセージが異なるコンシューマアプリケーションによって複数回消費されル可能性がある。ローカルファイルからリモートソケットにバイトを送信する一般的なアプローチは、(1) ストレージメディアから OS のページキャッシュにデータを読み取る、(2) ページキャッシュ内のデータをアプリケーションバッファにコピーする、(3) アプリケーションバッファを別のカーネルバッファにコピーする、(4) カーネルバッファをソケットに送信する、というステップが含まれる。これには 4 回のデータコピーと 2 回のシステムコールが含まれる。Linux およびその他の Unix オペレーティングシステムにはファイルチャネルからソケットチャネルに直接バイトを転送できる sendfile API [5] が存在する。これは通常ステップ (2) と (3) で導入される 2 回のコピーと 1 回のシステムコールを回避する。Kafka は sendfile API を利用して、ブローガーからコンシューマへのログセグメントファイル内のバイトを効率的に配信する。
ステートレスなブローカー. 他のほとんどのメッセージングシステムとは異なり、Kafka では各コンシューマがどこまでコンシュー蒸したかに関する情報は、ブローカーではなくコンシューマ自身によって保持される。この設計によりブローカーの複雑さとオーバーヘッドが大幅に削減される。しかし、ブローカーはすべてのサブスクライバーがメッセージをコンシュー蒸したかどうかを知らないため、これによりメッセージの削除が難しくなる。Kafka は保持ポリシーにシンプルな時間ベースの SLA を使用することでこの問題を解決する。メッセージは、ブローカーに一定期間 (通常 7 日間) 以上保持された後に自動的に削除される。この解決策は実際に上手く機能する。オフラインコンシューマを含むほとんどのコンシューマは、毎日、毎時、またはリアルタイムでコンシュームを完了する。Kafka の性能がより大きなデータサイズで低下しないという事実により、このような長期保持が実現可能になる。
この設計には重要な副次的利点がある。コンシューマは意図的に古いオフセットまで巻き戻して (rewind back) データを再コンシュームすることができる。これはキューの一般的な契約に違反するが、多くのコンシューマにとって不可欠な機能であることが証明されている。例えば、コンシューマのアプリケーションロジックにエラーがあった場合、アプリケーションはエラーの修正後に特定のメッセージを再生できる。これは我々のデータウェアハウスや Hadoop システムへの ETL データロードにとって重要である。別の例として、コンシュームされたデータは定期的に永続ストア (例えば全文インデクサーなど) にフラッシュされることがある。コンシューマがクラッシュした場合、フラッシュされていないデータは失われる。この場合、コンシューマはフラッシュされていないメッセージの最小オフセットをチェックポイントし、再起動時にそのオフセットから再コンシュームすることができる。コンシューマの巻き戻しはプッシュモデルよりもプルモデルの方がはるかにサポートしやすいことに注意。
3.2 分散協調
ここではプロデューサとコンシューマが分散環境でどのように動作するかを説明する。各プロデューサは、ランダムに選択されたパーティション、またはパーティショニングキーとパーティショニニング関数によって意味的に決定されるパーティションにメッセージをパブリッシュできる。ここではコンシューマがブローカーとどのようにやりとりするかに焦点を当てる。
Kafka にはコンシューマグループ (consumer group) の概念がある。各コンシューマグループは、サブスクライブされたトピックのセットを共同でコンシュームする 1 つ以上のコンシューマで構成される。つまり、各メッセージはグループ内のコンシューマの 1 つだけに配信される。異なるコンシューマグループは、それぞれ独立してサブスクリライブされたメッセージの完全なセットをコンシュームし、コンシューマグループ間で調整は必要ない。同じグループ内のコンシューマは、異なるプロセスまたは異なるマシン上に構成することができる。我々の目標は調整のオーバーヘッドを過度に増やすことなく、ブローカーに保存されたメッセージをコンシューマ間で均等に分割することである。
我々の最初の決定はトピック内のパーティションを並列性の最小単位にすることである。これは、1 つのパーティションからのすべてのメッセージが、任意の時点で各コンシューマグループの 1 つのコンシューマによってのみコンシュームされることを意味する。複数のコンシューマが 1 つのパーティションを同時にコンシュームできるようにした場合、どのコンシューマがどのメッセージをコンシュームするかを調整する必要があり、これはロックと状態維持のオーバーヘッドが必要になる。我々の設計は対照的に、コンシュームプロセスはコンシューマが負荷をリバランスするときにのみ (これは稀なイベント) 調整する必要がある。負荷を真に分散させるには、トピック内のパーティション数が各グループ内のコンシューマ数よりもはるかに多くなければならない。これは、トピックを過剰にパーティション化することで簡単に実現できる。
我々が行った二つ目の決定は、中央の『マスター』ノードを持つ代わりにコンシューマが分散的に相互調整できるようにすることである。マスターを追加すると、マスターの障害についてさらに心配する必要があるためシステムが複雑になる可能性がある。調整を容易にするために、我々は高可用性のコンセンサスサービスである ZooKeeper [10] を採用する。ZooKeeper は非常にシンプルなファイルシステムに似た API を持つ。パスの作成、パスの値を設定、パスの値を読み取り、パスを削除、パスの子をリストすることが可能である。さらに ZooKeeper には、(a) パスにウォッチャーを設定でき、パスの子または値が変更されたときに通知を受けることがができる、(b) パスは一過的に (ephemeral) (永続的 (persistent) ではなく) 一過性で作成でき、これは作成したクライアントが消えたときにパスが ZooKeeper によって自動的に削除されることを意味する、(c) ZooKeeper はデータを複数のサーバに複製するためにデータは高い信頼性と可用性を持つ、という興味深い機能がある。
Kafka は ZooKeeper を (1) ブローカーとコンシューマの追加/削除の検出、(2) そのイベントが発生したときの各コンシューマでリバランスプロセスのトリガー、(3) コンシュー無関係の維持と書くパーティションのコンシューム済みオフセットの追跡、というタスクに使用する。具体的には、各ブローカーまたはコンシューマの起動時に、ZooKeeper 内のブローカーレジストリまたはコンシューマレジストリにその情報を保存する。ブローカーレジストリにはブローカーのホスト名とポート、および底に保存されているトピックとパーティションのセットが含まれている。コンシューマレジストリにはコンシューマが属するコンシューマグループと、サブスクライブするトピックのセットが含まれている。各コンシューマグループは ZooKeeper 内の所有権レジストリとオフセットレジストリに関連付けられている。所有権レジストリにはサブスクライブされた各パーティションごとに 1 つのパスがあり、パス値は現在このパーティションからコンシュームしているコンシューマの ID である (ここで我々はコンシューマがこのパーティションを所有しているという用語を使用する)。オフセットレジストリはサブスクライブされた各パーティションに対してパーティション内で最後にコンシュームされたメッセージのオフセットを保存する。
ZooKeeper 内に作成されたパスは、ブローカーレジストリ、コンシューマレジストリ、所有権レジストリでは一過性であり、オフセットレジストリでは永続的である。ブローカーが障害を起こすとそのブローカー上のすべてのパーティションがブローカーレジストリ内から自動的に削除される。コンシューマの障害により、コンシューマレジストリ内のエントリと、所有権レジストリ内で所有しているすべてのパーティションが失われる。各コンシューマはブローカーレジストリとコンシューマレジストリの両方に ZooKeeper ウォッチャーを登録し、ブローカーセットまたはコンシューマグループに変更が発生するたびに通知を受け取る。
コンシューマの初期起動時、またはウォッチャーを介してブローカー/コンシューマの変更を通知されたとき、コンシューマはリバランスプロセスを開始してコンシュームすべき新しいパーティションのサブセットを決定する。このプロセスは Algorithm 1 に示す。ZooKeeper からブローカーとコンシューマレジストリを読み取ることで、コンシューマはまず、サブスクライブされた各トピック \(T\) に対して利用可能なパーティションのセット (\(P_T\)) と、\(T\) をサブスクライブしているコンシューマのセット (\(C_T\)) を計算する。次に、\(P_T\) を \(|C_T|\) 個のチャンクに範囲分割し、決定論的に 1 つのチャンクを所有するように選択する。コンシューマが選択した各パーティションに対して、所有権レジストリにパーティションの新しい所有者として自身を書き込む。最後に、コンシューマは所有する各パーティションからデータをプルするメソッドを開始し、オフセットレジストリに保存されているオフセットから開始する。メッセージがパーティションからプルされるにつれて、コンシューマは定期的にオフセットレジストリ内の最新のコンシューム済みオフセットを更新する。
グループ内に複数のコンシューマが存在する場合、それぞれがブローカーまたはコンシューマの変更について通知を受ける。ただし、通知はコンシューマでわずかに異なる時刻で届く可能性がある。したがって、あるコンシューマが別のコンシューマによってまだ所有されているパーティションの所有権を取得しようとする可能性がある。これが起きた場合、最初のコンシューマは現在所有しているすべてのパーティションを解放するだけであり、少し待ってからリバランスプロセスを再試行する。実際には、リバランスプロセスは数回の再施行後に安定することが多い。
新しいコンシューマグループが作成されると、オフセットレジストリに利用可能はオフセットはない。この場合、コンシューマは、我々がブローカー上で提供する API を使用してサブスクライブしている各パーティションで利用可能な最小または最大のオフセット (構成によって異なる) から開始する。
- \(C_i\) がサブスクライブしているトピック \(T\) ごとに {
- 所有権レジストリから \(C_i\) が所有するパーティションを削除
- ZooKeeper からブローカーとコンシューマレジストリを読み取り
- \(P_T = \) トピック \(T\) のすべてのブローカーで利用可能なパーティションを計算
- \(C_T = \) トピック \(T\) をサブスクライブしている \(G\) 内のすべてのコンシューマを計算
- \(P_T\) と \(P_T\) をソート
- \(j\) を \(C_T\) 内の \(C_i\) のインデックス位置とし、\(N = |P_T|/|C_T|\) とする
- \(P_T\) 内の \(j*N\) から \((j+1)*N-1\) までのパーティションををコンシューマ \(C_i\) に割り当て
- 割り当てられた各パーティション \(p\) について {
- 所有権レジストリで \(p\) の所有者を \(C_i\) に設定
- \(O_p =\) オフセットレジストリに保存されているパーティション \(p\) のオフセットに設定
- スレッドを起動して、オフセット \(O_p\) からパーティション \(p\) のデータをプル
3.3 配信保証
一般に、Kafla は at-least-once 配信のみを保証する。exactly-once 配信には通常 2-フェーズコミットが必要とするが、我々のアプリケーションには必要ない。ほとんどの場合、メッセージは各コンシューマグループに exactly-once 配信されるが、コンシューマプロセスが正常なダウンなしでクラッシュした場合、障害が発生したコンシューマが所有するパーティションを引き継ぐコンシューマプロセスは、ZooKeeper に正常にコミットされた最後のオフセット以降の重複メッセージを取得する可能性がある。アプリケーションが重複を気にする場合、コンシューマに返されるオフセットを使用するか、メッセージ内の一意のキーを使用するかのいずれかの方法で、独自の重複排除ロジックを追加する必要がある。これは通常 2-フェーズコミットよりも費用対効果の高いアプローチである。
Kafka は単一のパーティションからのメッセージが順序通りにコンシューマに配信されることを保証する。ただし、異なるパーティションから来るメッセージの順序については保証がない。
ログの破損を回避するため、Kafka はログ内の各メッセージに CRC を保存する。ブローカーに I/O エラーがある場合、Kafka は一貫性のない CRC を持つメッセージを削除するリカバリプロセスを実行する。メッセージレベルで CRC を持つことにより、メッセージが生成またはコンシュームされた後のネットワークエラーをチェックすることもできる。
ブローカーがダウンすると、ブローカーに保存されているまだコンシュームされていないメッセージはすべて利用不可能になる。ブローカー上のストレージが恒久的な損傷を受けた場合、まだコンシュームされていないメッセージは永久に失われる。将来的には、我々は各メッセージを複数のブローカーに冗長的に保存するために Kafka に組み込みレプリケーションを追加することを計画している。
4 LinkedIn における Kafka の利用
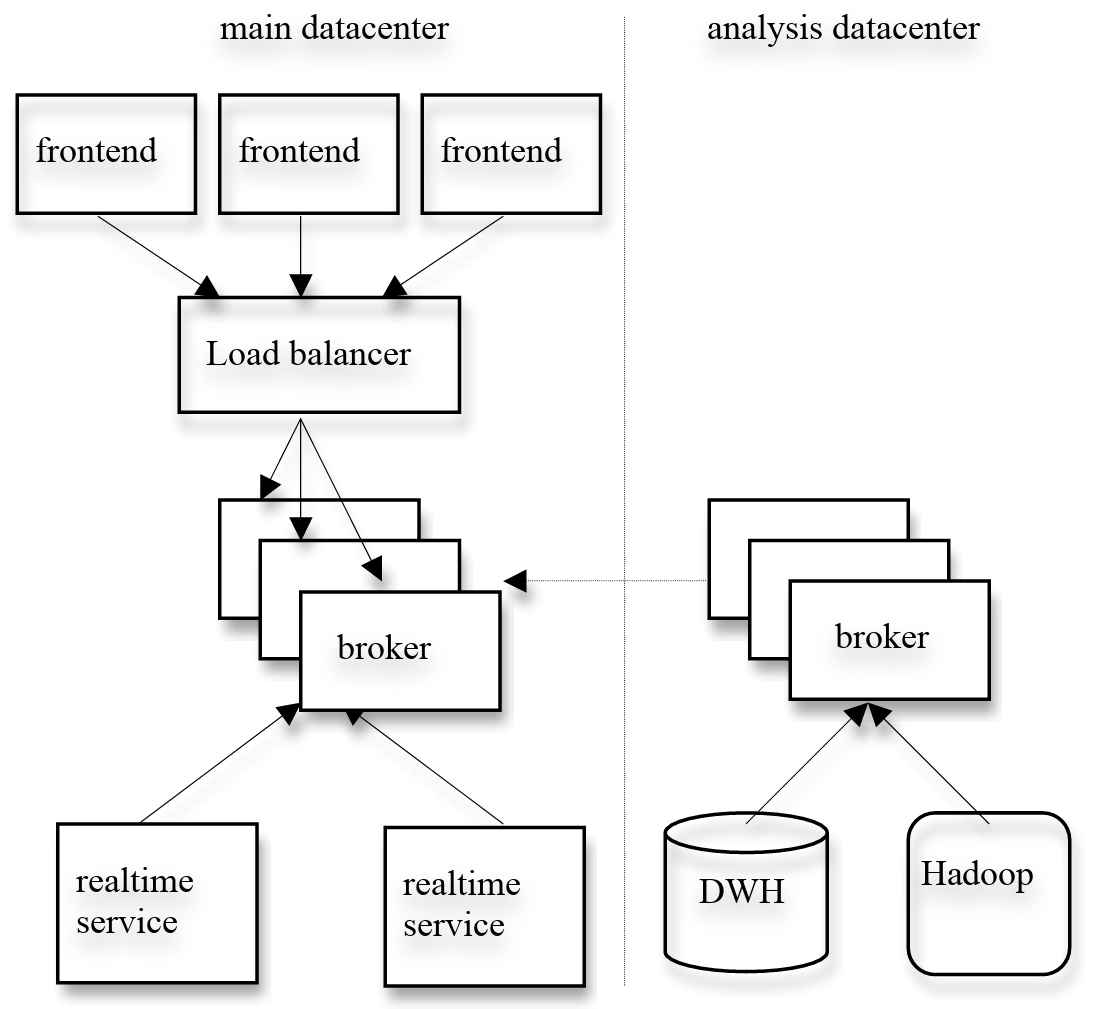
このセクションでは LinkedIn における Kafka の使用方法について説明する。Figure 4 は我々のデプロイの簡略版を示している。我々はユーザ向けサービスが稼働するデータセンターごとに 1 つの Kafka クラスタを配置している。フロントエンドサービスはさまざまな種類のログデータを生成し、それらをバッチでローカルの Kafka ブローカーにパブリッシュする。我々はハードウェアロードバランサを使用してパブリッシュリクエストを一連の Kafka ブローカーに均等に分散している。Kafka のオンラインコンシューマは同じデータセンター内のサービスで稼働する。
我々はまたオフライン分析用に別のデータセンターに Kafka クラスタをデプロイしており、これは我々の Hadoop クラスタやその他のデータウェアハウスインフラストラクチャの地理的に近い場所に配置されている。この Kafka インスタンスは、稼働中のデータセンターの Kafka インスタンスからデータをプルするための組み込みコンシューマのセットを実行する。次に、データロードジョブを実行してこの Kafka のレプリカクラスタから Hadoop や我々のデータウェアハウスにデータをプルし、そこでデータに対してさまざまなレポートジョブや分析プロセスを実行する。また、この Kafka クラスタはプロトタイピングにも使用しており、生のイベントストリームに対して簡単なストリームを実行してアドホッククエリーを実行する機能を備えている。過度なチューニングを行わなくてもパイプライン全体のエンドツーエンドのレイテンシは平均約 10 秒あり、我々の要件を満たすには十分な性能である。
現在、Kafka は 1 日あたり数逆ギガバイトのデータと 10 億近いメッセージを蓄積しており、この数はレガシーシステムを Kafka に移行するにつれて大幅に増加すると予想される。将来的にはさらに多くの種類のメッセージが追加される予定である。リバランスプロセスは、運用スタッフがソフトウェアやハードウェアのメンテナンスのためにブローカーを起動または停止したときに、自動的にコンシュームをリダイレクトできる。
また、我々のトラッキングにはパイプライン全体でデータ損失がないことを検証する監査システムも含まれている。これを容易にするために、各メッセージは生成時のタイムスタンプとサーバ名が付与される。各プロデューサは一定の時間枠内に各トピックに対してそのプロデューサが発行したメッセージ数を記録する監視イベントを定期的に生成するように計装されている。プロデューサは監視イベントを別のトピックで Kafka にパブリッシュする。次にコンシューマは、特定のトピックから受信したメッセージの数をカウントし、それらのカウントを監視イベントと照合してデータの正確性を検証できる。
Hadoop クラスタへのロードは、MapReduce ジョブが Kafka から直接データを読み取れるようにする特別な Kafka 入力フォーマットを実装することで達成される。MapReduce ジョブは生データをロードし、将来の効率的な準備のために次にそれをグループ化して圧縮する。ここでもステートレスブローカーとメッセージオフセットのクライアント側での保存が重要な役割を果たす。これにより、タスクの失敗と再起動を想定する MapReduce タスク管理は、タスクの再起動時メッセージが重複したり失われたりすることなく、自然な方法でデータロードを処理できる。データとオフセットの両方は、ジョブが正常に完了した場合にのみ HDFS に保存される。
我々は効率的でスキーマの進化をサポートするシリアライゼーションプロトコルとして Avro [2] を選択した。各メッセージには、Avro スキーマの ID とシリアライズすれたバイトを保存する。このスキーマにより、データプロデューサとコンシューマ間の互換性を確保する契約を強制できる。我々はスキーマ ID を実際のスキーマにマッピングするために、軽量なスキーマレジストリサービスを使用する。コンシューマがメッセージを取得すると、スキーマレジストリでスキーマを検索し、それを使用してバイトをオブジェクトにデコードする (このルックアップは値が不変であるためスキーマごとに 1 回だけ行う必要がある)。
5 実験結果
我々は実験的研究を実施し、Kafka と JMS のオープンソース実装として広く普及している Apache ActiveMQ v5.4 [1]、および優れた性能で知られるメッセージングシステムである RabbitMQ v2.4 [16] の性能を比較した。我々は ActiveMQ のデフォルトの永続メッセージストアである KahaDB を使用した。ここでは示さないが、代替の AMQ メッセージストアもテストしており、その性能は KahaDB と非常に似ていることが分かった。可能な限り、すべてのシステムで同等の設定を使用するように試みた。
我々は、それぞれ 8 個の 2 GHz コア、16 GB のメモリ、RAID 10 構成の 6 台のディスクを持つ 2 台の Linux マシンで実験を実施した。2 台のマシンは 1Gb のネットワークリンクで接続されている。1 台のマシンをブローカーとして使用し、もう 1 台のマシンをプロデューサまたはコンシューマとして使用した。
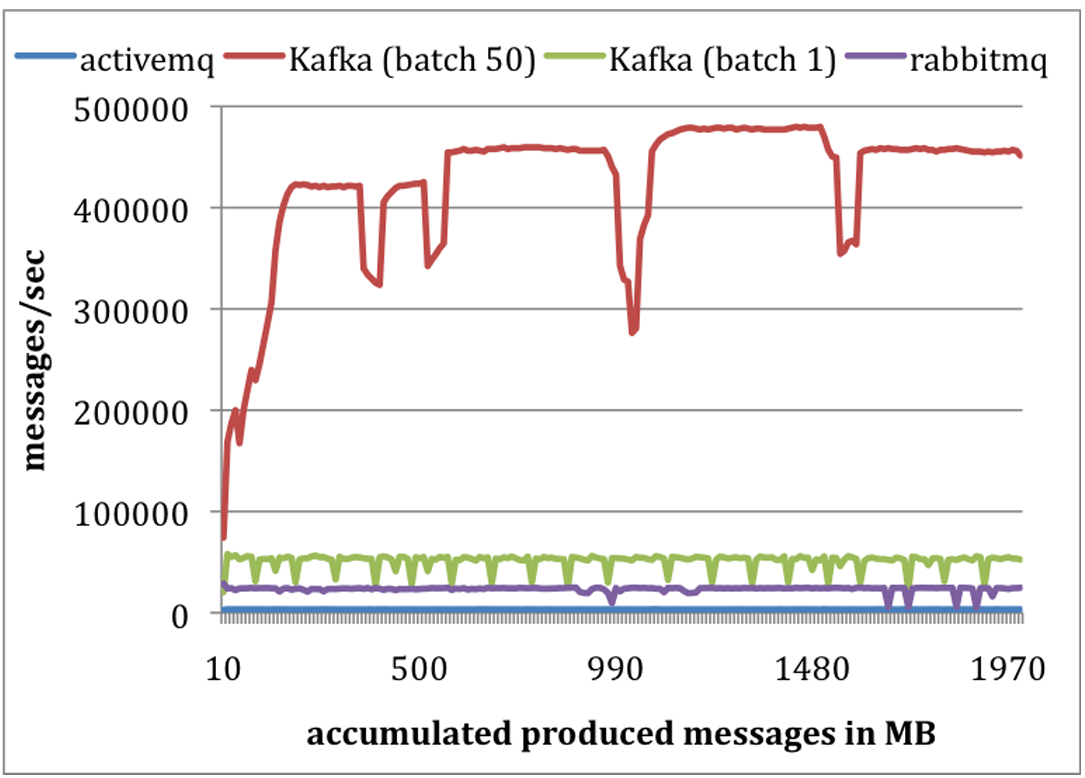
プロデューサテスト: 我々はすべてのシステムでメッセージを永続ストアに非同期にフラッシュするようにブローカーを設定した。各システムで 1 つのプロデューサを実行して各 200 バイトのメッセージを合計 1000 万件パブリッシュした。我々は Kafka プロデューサをバッチサイズ 1 と 50 でメッセージを送信するように設定した。ActiveMQ と RabbitMQ にはメッセージをバッチ処理する簡単な方法がないようで、バッチサイズ 1 を適用したと仮定する。結果を Figure 4 に示す。X 軸は時間経過と共にブローカーに送信されたデータ量を MB で表し、Y 軸は 1 秒あたりのメッセージ数でプロデューサのスループットを表す。平均して、Kafka はバッチサイズ 1 で毎秒 50,000 件、バッチサイズ 50 で毎秒 400,000 件の速度でメッセージをパブリッシュできる。これらの数値は ActiveMQ よりも桁違いに高く、RabbitMQ よりも少なくとも 2 倍高い。
Kafka の性能がはるかに優れていた理由はいくつかある。第一に、現在 Kafka プロデューサはブローカーからの確認応答を待たず、ブローカーが処理できる速度でメッセージを送信する。これによってパブリッシャーのスループットが大幅に向上した。バッチサイズ 50 では単一の Kafka プロデューサがプロデューサとブローカー間の 1GB リンクををほぼ飽和させた。これは、トラフィックのライブ配信に遅延が生じないようにするためにデータを非同期で送信する必要があるため、ログ集約のケースでは有効な最適化である。プロデューサに確認応答しないことで、パブリッシュされたすべてのメッセージがブローカーによって実際に受信される圃場がないことに注意。多くのタイプのログデータでは、ドロップされるメッセージの数が比較的少ない限り、耐久性とスループットをトレードオフすることが望ましい。しかし、我々は将来より重要なデータに対する耐久性の問題に対処することを計画している。
第二に、Kafka はより効率的なストレージフォーマットを備えている。平均して、Kafka では各メッセージのオーバーヘッドは 9 バイトだったが、ActiveMQ では 144 バイトだった。これは ActiveMQ が同じ 1,000 万件のメッセージを格納するのに Kafka より 70% も多くの空間を使用していたことを意味する。ActiveMQ のオーバーヘッドの 1 つは、JMS によって要求される思いメッセージヘッダに起因している。もう 1 つのオーバーヘッドはさまざまなインデックス構造を維持するためのコストである。ActiveMQ で最も負荷の高いスレッドの 1 つは、メッセージのメタデータと状態を維持するために B-Tree にアクセスすることにほとんどの時間を費やしていることを観察した。最後に、バッチ処理によって RPC オーバーヘッドを償却することでスループットを大幅に向上させた。Kafka ではバッチサイズを 50 件にすることでスループットがほぼ 1 桁向上した。
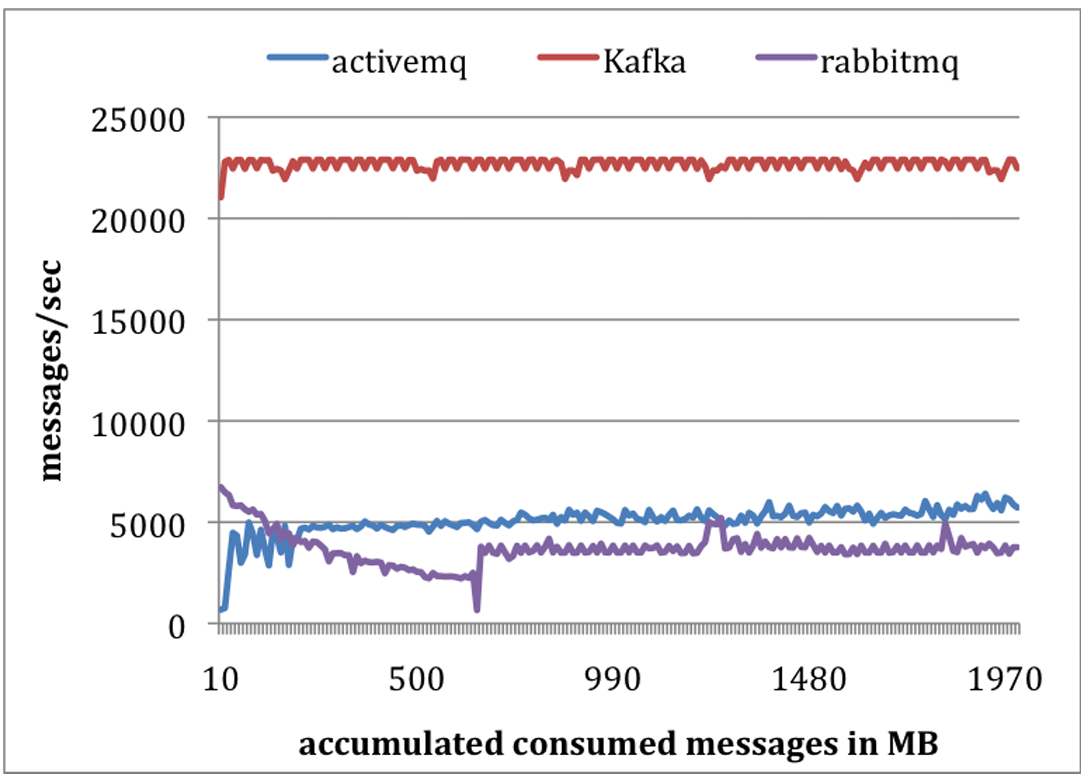
コンシューマテスト: 二つ目の実験ではコンシューマの性能をテストした。今回もすべてのシステムで単一のコンシューマを使用して合計 1,000 万件のメッセージを取得した。我々は各プルリクエストがほぼ同じ量のデータ (最大 1,000 件、約 200KB) をプリフェッチするようにすべてのシステムを設定した。ActiveMQ と RabbitMQ の両方でコンシューマの確認応答モードを自動に設定した。すべてのメッセージがメモリに収まるため、すべてのシステムは基盤となるファイルシステムのページキャッシュまたは何らかのインメモリバッファからデータを提供していた。結果を Figure 5 に示す。
Kafka は平均して毎秒 22,000 件のメッセージをコンシュームした。これは ActiveMQ および RabbitMQ の 4 倍以上である。我々はいくつかの理由を考えることができる。第一に、Kafka はより効率的なストレージフォーマットを持つため、Kafka ではブローカーからコンシューマへ転送されるバイト数が少なかった。第二に、ActiveMQ と RabbitMQ の両方のブローカーはすべてのメッセージの配信状態を維持する必要があった。我々はこのテスト中に ActiveMQ のスレッドの 1 つが KahaDB ページをディスクに書き込む処理でビジー状態になっていることを観察した。対照的に、Kafka ブローカーではディスク書き込みアクティビティは発生していなかった。最後に、sendfile API を使用することで Kafka は転送オーバーヘッドを削減している。
この実験での我々の目的が他のメッセージングシステムが Kafka より劣っていることではないことを述べてこのセクションを締めくくる。結局のところ、ActiveMA と RabbitMQ の両方は Kafka よりも多くの機能を備えている。重要なポイントは、特化したシステムによって達成できる潜在的性能を示すことである。
6 結論と今後の課題
我々は膨大な量のログデータストリームを処理するための新しいシステム Kafka を提示した。メッセージングシステムと同様に、Kafka はプルベースのコンシュームモデルを採用しており、アプリケーションは独自のレートでデータをコンシュームし、必要に応じてコンシュームを巻き戻すことができる。ログ処理アプリケーションに焦点を置くことで Kafka は従来のメッセージングシステムよりもはるかに高いスループットを実現する。また、統合された分散サポートを提供しスケールアウトも可能である。我々は LinkedIn でオフラインアプリケーションとオンラインアプリケーションの両方に Kafka を成功裏に使用してる。
将来探求したい方向性は数多くある。第一に、複数のブローカー間でメッセージを複製する組み込みレプリケーションを追加し、回復不可能なマシン障害の場合でも耐久性とデータ化要請を保証できるようにすることを計画している。我々は、非同期と同期の両方のレプリケーションモデルをサポートすることで、プロデューサのレイテンシと提供される保証の強度との間でトレードオフを可能にしたいと考えている。これによりアプリケーションは耐久性、可用性、スループットの要件に基づいて適切な冗長性レベルを選択できる。第二に、Kafka にストリーム処理機能を追加したいと考えている。リアルタイムアプリケーションは、Kafka からメッセージを取得した後、ウィンドウベースのカウントやセカンダリストア内のレコードまたは別ストリーム内のメッセージとの各メッセージの結合など、類似の走査を実行することが多い。これはパブリッシュ時に結合キーに基づいてメッセージを意味的にパーティション分割することでサポートされ、これにより特定のキーで送信されたすべてのメッセージが同じパーティションに送られ、単一のコンシューマプロセスに到達する。これによりコンシューママシンのクラスタ全体にわたる分散ストリーム処理の基盤となる。これに加えて、異なるウィンドウ関数や結合技術などの役に立つストリームユーティリティのライブラリが、この種のアプリケーションにとって有用であると考えている。
7 REFERENCES
- http://activemq.apache.org/
- http://avro.apache.org/
- Cloudera’s Flume, https://github.com/cloudera/flume
- http://developer.yahoo.com/blogs/hadoop/posts/2010/06/enabling_hadoop_batch_processi_1/
- Efficient data transfer through zero copy: https://www.ibm.com/developerworks/linux/library/jzerocopy/
- Facebook’s Scribe, http://www.facebook.com/note.php?note_id=32008268919
- IBM Websphere MQ: http://www01.ibm.com/software/integration/wmq/
- http://hadoop.apache.org/
- http://hadoop.apache.org/hdfs/
- http://hadoop.apache.org/zookeeper/
- http://www.slideshare.net/cloudera/hw09-hadoop-based-data-mining-platform-for-the-telecom-industry
- http://www.slideshare.net/prasadc/hive-percona-2009
- https://issues.apache.org/jira/browse/ZOOKEEPER-775
- JAVA Message Service: http://download.oracle.com/javaee/1.3/jms/tutorial/1_3_1fcs/doc/jms_tutorialTOC.html.
- Oracle Enterprise Messaging Service: http://www.oracle.com/technetwork/middleware/ias/index093455.html
- http://www.rabbitmq.com/
- TIBCO Enterprise Message Service: http://www.tibco.com/products/soa/messaging/
- Kafka, http://sna-projects.com/kafka/
翻訳抄
従来のエンタープライズ向けメッセージング (JMS など) やログ集約基盤 (Scribe/Flume など) が高スループットのログ処理とリアルタイムのコンシュームの両立には不向きであるという課題に対して、LinkedIn が実運用で用いたメッセージングシステム Kafka の設計と性能を報告する 2011 年の論文。現在は Apache Kafka としてリアルタイムデータストリーミングのデファクトスタンダードとなっている。
- KREPS, Jay, et al. Kafka: A distributed messaging system for log processing. In: Proceedings of the NetDB. 2011. p. 1-7.
この論文の記述内容と現状の Apache Kafka の主な相違点 (AI 生成):
| 項目 | この論文 | 現状 |
|---|---|---|
| メタデータ管理/クラスタ調整 | ZooKeeper にブローカやコンシューマのレジストリ、オフセットを保持して再バランスを行う | Kafka 4.0 以降では ZooKeeper を廃止し、Kafka Raft (KRaft) によるメタデータ・クォーラムを採用 (KIP-500) |
| レプリケーション/耐障害性 | レプリケーションは将来拡張扱いで、単一ブローカ障害でデータ損失の可能性あり | ISR (In-Sync Replicas) とハイウォータによるコミット定義を採用。プロデューサ既定で enable.idempotence=true と acks=all が有効 (KIP-679) |
| コンシューマ・オフセット管理 | オフセットは ZooKeeper のレジストリに格納 | 内部トピック __consumer_offsets に保存し、レプリケーションで耐障害化 |
| 配信セマンティクス | at-least-once 保証で、exactly-once は不要としていた | トランザクション API と冪等プロデューサにより exactly-once を実現 (KIP-98, KIP-129)。Kafka Streams でも EOS が標準化 |
| フェッチ経路 | フェッチは常にリーダから行う | ネットワーク最適化で「最も近いレプリカ (フォロワー)」からフェッチ可能 (KIP-392) |
| ストレージ・アーキテクチャ | ローカルディスクのログを時間でローテーションし、一定期間保持 | Kafka 3.9 以降では Tiered Storage により古いセグメントを外部オブジェクトストアに階層化 (KIP-405) |
| ストリーム処理/データ連携 | 専用フレームワーク記述なし | Kafka Streams(軽量ストリーム処理)と Kafka Connect(外部システム連携)が公式機能 |
| コンシューマ・グループ・プロトコル | ZooKeeper を使った分散協調・再バランス | KIP-848 による新世代プロトコルで、非同期・増分的リバランスが可能。Kafka 4.x で標準化 |
| セキュリティ | ほぼ未言及 | TLS/SSL、SASL(PLAIN, SCRAM, GSSAPI, OAUTHBEARER)および ACL に対応し、OAUTHBEARER 認証もサポート |
