論文翻訳: TiDB: A Raft-based HTAP Database
PingCAP
{huang, liuqi, cuiqiu, fangzhuhe, maxiaoyu, xufei, shenli, tl, z, menglong, weiwan, liucong, zhangjian, jay, wuxuelian, songlingyu, sunruoxi, yusp, zhaolei, nick, liquanpei, tangxin}@pingcap.com
 Abstract
Abstract
我々はこの課題を解決するために
Table of Contents
- Abstract
- 1. 導入
- 2. Raft ベース HTAP
- 3. アーキテクチャ
- 4. マルチ Raft ストレージ
- 5. HTAP エンジン
- 6. 実験
- 7. 関連する研究
- 8. 結論
- 9. REFERENCES
- 翻訳抄
1. 導入
リレーショナルデータベース管理システム (RDBMS) は、そのリレーショナルモデル、強力なトランザクション保証、そして SQL インターフェースを備えていて一般的である。業務システムのような従来のアプリケーションで広く採用されている。しかし古い RDBMS はスケーラビリティと高可用性を提供しない。そのため 2000 年代の初頭 [11] のインターネットアプリケーションでは Google Bigtable [12] や DynamoDB [36] のような NoSQL システムが好まれた。NoSQL システムは一貫性の要件を緩和し、高いスケーラビリティと Key-Value ペア、グラフ、ドキュメントなどの代替データモデルを提供する。しかし、多くのアプリケーションは強力なトランザクション、データの一貫性、SQL インターフェースも必要とするため NewSQL システムが登場した。CockroachDB [38] や Google Spanner [14] などの NewSQL システムは、
これらのシステムは "
最新性とは分析クエリーによってどれだけ新しいデータが処理されるかを意味する [34]。最新のデータをリアルタイムで分析することには大きなビジネス価値がある。しかし、Extraction-Transformation-Loading (ELT) 処理に基づくものなど、一部の HTAP ソリューションではこれは保証されておらず、OLTP システムは ETL 処理を通じて定期的に最新データのバッチを OLAP システムにリフレッシュする。ETL には数時間から数日のコストがかかるためリアルタイム分析は提供できない。ETL フェーズは最新の更新を OLAP システムへのストリーミングで置き換えて同期時間を短縮することができるが、これら 2 つのアプローチにはグローバルなデータガバナンスモデルがないため、一貫性のセマンティクスを考慮するのがより複雑になる。複数のシステムとのインターフェースにより追加のオーバーヘッドが発生する。
分離性とは、OLTP クエリーと OLAP クエリーのそれぞれのために分離された性能を保証することである。一部のインメモリデータベース (HyPer [18] など) では分析クエリーによって同じサーバ上のトランザクション処理から最新バージョンのデータを読み取ることができる。このアプローチでは最新のデータを提供するが、OLTP と OLAP の両方で高い性能を達成することはできない。これはデータ同期のペナルティとワークロードの干渉によるものである。この効果は [34] において HTAP ベンチマークである CH-benCHmark [13] を HyPer と SAP HANA 上で実行して調査されている。この調査ではシステムが分析クエリーを共同実行すると、達成可能な最大 OLTP スループットが大幅に低下することが判明した。SAP HANA [22] のスループットは少なくとも 3 倍、HyPer は少なくとも 5 倍低下した。同様の結果は MemSQL [24] でも確認されている。さらに、インメモリデータベースは単一のサーバにのみ配備されている場合に高可用性とスケーラビリティを提供できない。
分離された性能を保証するには OLTP と OLAP 要求を異なるハードウェアリソース上で実行する必要がある。本質的な難しさは、単一のシステム内で OLTP ワークロードからの OLAP 要求に対して最新のレプリカを維持することである。一貫性あるレプリカを維持することは可用性のためにも必要であることに注意 [29]。高可用性は Paxos [20] や Raft [29] などのよく知られたコンセンサスアルゴリズムを使って実現できる。これらはレプリカを同期させるために複製ステートマシンをベースにしている。これらのコンセンサスアルゴリズムを拡張して HTAP ワークロードに一貫性のあるレプリカを提供することが可能だが、我々の知る限りこのアイディアはこれまでに研究されていない。
このアイディアに従って、我々は Raft ベースの HTAP データベースである TiDB を提案する。TiDB は Raft コンセンサスアルゴリズムに
TiDB はコンセンサスアルゴリズムに基づく NewSQL システムを HTAP システムへと進化させる革新的なソリューションを提供する。NewSQL のシステムは Google Spanner や CockroachDB のようにデータベースを複製することで OLTP 要求に対する高可用性、スケーラビリティ、データ耐久性を確保する。通常、これらのシステムはコンセンサスアルゴリズムに代表される複製メカニズムによってデータレプリカ間でデータを同期する。ログ複製に基づき、NewSQL システムは OLAP 要求専用の列レプリカを提供できるため、TiDB のように HTAP 要求を分離してサポートできる。
結論として、我々の貢献は以下のように結ばれる。
我々はコンセンサスアルゴリムに基づく HTAP システムの構築を提案し、Raft ベースの HTAP データベースである TiDB を実装している。これは、HTAP ワークロードに高可用性、一貫性、スケーラビリティ、データ最新性および分離を提供するオープンソースプロジェクト [7] である。
我々はリアルタイム OLAP クエリー用の列ストアを生成するために、Raft アルゴリズムに学習者ロールを導入する。
我々はマルチ Raft ストレージシステムを実装し、システムがより多くのノードに拡張しても高い性能を提供できるようにその読み取りと書き込みを最適化する。
我々は大規模な HTAP クエリー用に SQL エンジンをあつらえる。このエンジンは列ベースのストアと列ストアを最適に選択できる。
我々は HTAP ベンチマークである CH-benCHmark を使用して OLTP、OLAP、および HTAP に関する TiDB の性能を評価する包括的な実験を実施する。
この論文の残りの部分は次のように構成されている。セクション 2 では主要なアイディアである Raft ベースの HTAP について説明し、セクション 3 では TiDB アーキテクチャについて説明する。セクション 4 とセクション 5 では TiDB のマルチ Raft ストレージと HTAP エンジンについて詳しく説明する。セクション 6 では実験的評価について説明する。セクション 7 では関連する研究を要約する。最後にセクション 8 で論文を締めくくる。
2. Raft ベース HTAP
Raft や Paxos などのコンセンサスアルゴリズムは一貫性がありスケーラブルで可用性の高い分散システムを構築するための基盤である。これらのアルゴリズムの強みは複製ステートマシンを使用してデータがリアルタイムで確実にサーバ間で複製されることである。我々はこの機能を適用させ HTAP のワークロードごとに異なるサーバにデータを複製する。この方法では、OLTP ワークロードと OLAP ワークロードが互いに分離されることを保証するだけではなく、OLAP 要求がデータの最新性かつ一貫したビューを持つことも保証する。我々の知る限りこのようなコンセンサスアルゴリズムを使用して HTAP データベースを構築するという先行研究はない。
Raft アルゴリズムは理解しやすく実装しやすいように設計されているため、我々の Raft 拡張では本番環境に耐えうる HTAP データベースの実装に重点を置いている。Figure 1 に示すように、我々のアイディアは大まかには次のようなものである: データはトランザクションクエリーを処理するために行形式で複数の Raft グループに保存される。各グループはリーダーとフォロワーで構成されている。各グループには、リーダーからデータを非同期に複製するために学習者ロールを追加する。このアプローチはオーバーヘッドが少なくデータの一貫性が保たれる。学習者に複製されたデータは列ベースの形式に変換される。クエリーオプティマイザは行ベースと列ベースの両方のレプリカにアクセスする物理プランを探索するように拡張されている。
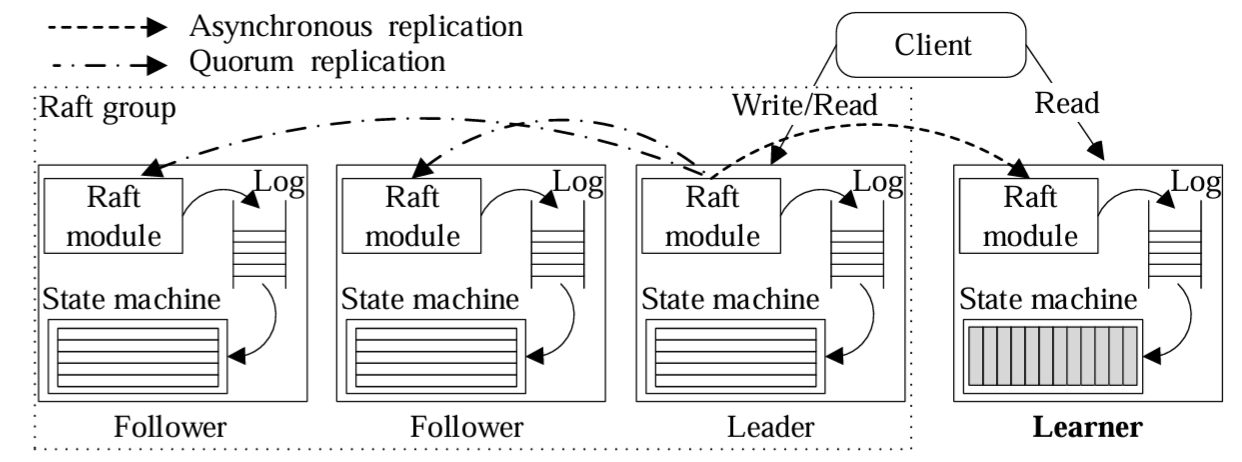
標準の Raft グループでは各フォロワーがリーダーとなって読み込みおよび書き込み要求に対応できる。したがって、単にフォロワーを増やしてもリソースを分離することはできない。さらに、フォロワーを追加するとリーダーはクライアントに応答する前により大きな定足数のノードからの応答を待つ必要があるためグループの性能に影響する。そこで我々は Raft コンセンサスアルゴリズムに学習者の役割を追加した。学習者はリーダーの選出には参加せず、ログ複製を行う定足数の一部でもない。リーダーから学習者へのログ複製は非同期であり、リーダーはクライアントに応答する前に成功を待つ必要はない。リーダーと学習者間の強い一貫性は読み取り時に強制される。評価セクションで示すように、設計上、リーダーと学習者間のログ複製の遅延は少ない。
トランザクションクエリーは効率的なデータ更新を必要とするが、一方で結合や集約のような分析クエリーは列のサブセットを読み込む必要があり、それらの列の行数は膨大である。行ベースの形式ではインデックスを活用してトランザクションを効率的に処理することができる。列ベースの形式はデータ圧縮とベクトル化処理を効率的に利用できる。そのため、Raft 学習者に複製するとき、行ベースの形式から列ベースの形式に変換される。さらに学習者は別の物理リソースに配備することができる。その結果、トランザクションクエリーと分析クエリーは分離されたリソースで処理される。
我々の設計は新たな最適化機会も提供する。データは行ベースの形式と列ベースの形式の両方で一貫性が保たれるため、我々のクエリーオプティマイザーはどちらかまたは両方のストアにアクセスする物理プランを作成することができる。
我々は、HTAP データベースの最新性と分離性の要件を満たすために Raft を拡張するというアイディアを提示した。HTAP データベースを本番環境で使用できるようにするために、我々は主に次のような多くのエンジニアリング上の課題を克服してきた:
高い並行読み取り/書き込みをサポートするスケーラブルな Raft ストレージシステムを構築するにはどうすれば良いか? データ量が Raft アルゴリズムによって管理される各ノードの利用可能領域を超える場合、データをサーバに分散するためのパーティション戦略が必要になる。また、基本的な Raft プロセスではリクエストは順番に処理され、クライアントに応答する前にすべてのリクエストが Raft ノードの定足数によって承認される必要がある。このプロセスにはネットワークとディスクの操作が含まれるため時間がかかる。このオーバーヘッドにより、特に大規模なデータセットではリーダーがリクエストを処理するボトルネックとなる。
データの最新性を保つためにログを低レイテンシで学習者に同期させるにはどうすれば良いか? 進行中のトランザクションは非常に大きなログを生成することがある。これらのログは最新のデータを読み取ることができるように学習者で素早くリプレイされ実体化される必要がある。ログデータを列形式に変換するとスキーマの不一致でエラーが発生することがある。これによりログの同期が遅れる可能性がある。
トランザクションクエリーと分析クエリーの両方を、保証された性能で効率的に処理するにはどうしたらよいか? 大規模なトランザクションクエリーでは、複数のサーバに分散された膨大な量のデータを読み書きする必要がある。分析クエリーもまた大量のリソースを消費するため、オンライントランザクションに影響を与えないようにする必要がある。実行オーバーヘッドを削減するために、行形式ストアと列形式ストアの両方で最適なプランを選択する必要もある。
次のセクションではこれらの課題を解決するための TiDB の設計と実装について詳しく説明する。
3. アーキテクチャ
このセクションでは Figure 2 に示す TiDB の高レベル構造について説明する。TiDB は MySQL プロトコルをサポートしており、MySQL 互換のクライアントからアクセスできる。TiDB は、分散ストレージ層、
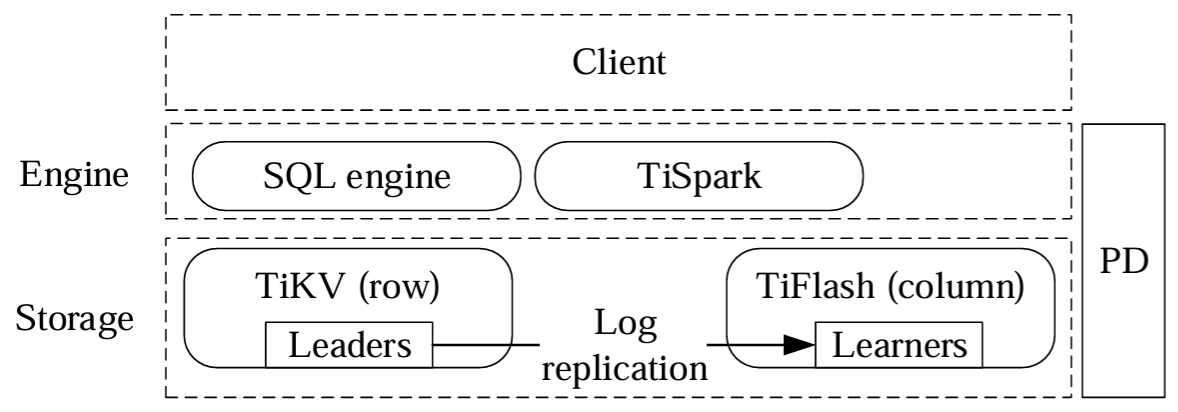
分散ストレージ層は行ストア (TiKV) と列ストア (TiFlush) で構成されている。論理的には、TiKV に格納されるデータは順序づけされた Key-Value マップである。各タプルは Key-Value ペアにマップされている。キーはテーブル ID と行 ID で構成され、値は実際の行データである。テーブル ID と行 ID は一意な整数であり、行 ID は主キー列から取得される。例えば 4 つの列を持つタプルは次のようにエンコードされる。\[ Key: \{ table \{ tableID \}\_record \{ rowID \} \\ Value: \{ col0, col1, col2, col3 \} \] スケールアウトするために、我々は範囲パーティション戦略を使用して、大きな Key-Value マップを多数の連続した範囲である
計算エンジン層はステートレスでスケーラブルである。我々のあつらえた SQL エンジンはコストベースのクエリーオプティマイザーと分散クエリーエクゼキューターを備えてい後続る。TiDB はトランザクション処理をサポートするために Percolator [33] に基づく 2 フェーズコミット (2PC) プロトコルを実装している。クエリーオプティマイザはクエリーに基づいて TiKV と TiFlush からの読み込みを最適に選択することができる。
TiDB のアーキテクチャは HTAP データベースの要件を満たしている。TiDB の各コンポーネントは高可用性とスケーラビリティを実現するように設計されている。ストレージ層は Raft アルゴリズムを用いてデータレプリカ感の一貫性を実現している。TiKV と TiFlush 間の低レイテンシの複製により分析クエリーで最新のデータを提供する。クエリーオプティマイザーは、TiKV と TiFlush 間の強力なデータ一貫性と組み合わせることで、トランザクション処理にほとんど影響を与えることなく高速な分析クエリー処理を提供する。
上記のコンポーネントに加えて TiDB は Spark とも統合しており、TiDB と Hadoop 分散ファイルシステム (HDFS) に保存されているデータを統合するのに役立つ。TiDB には、TiDB へのデータのインポートとエクスポート、および他のデータベースから TiDB へのデータ移行を行うためのエコシステムツールが豊富に用意されている。
次のセクションでは分散ストレージ層、SQL エンジン、および TiSpark について詳しく説明し、本番環境対応の HTAP データベースである TiDB の機能を紹介する。
4. マルチ Raft ストレージ
Figure 3 は TiDB における分散ストレージ層のアーキテクチャを示している (同じ形状のオブジェクトは同じ役割を果たす)。ストレージ層は行ベースのストアである TiKV と列ベースのストアである TiFlush で構成されている。ストレージは大きなテーブルを大きな Key-Value マップにマッピングし、それを TiKV に格納された多数のリージョンに分割する。各リージョンは Raft コンセンサスアルゴリズムを使ってレプリカ感の一貫性を維持し高可用性を実現する。データが TiFlush に複製されるとき、テーブルスキャンを容易にするために空く数のリージョンを 1 つのパーティションにマージすることができる。TiKV と TiFlush 間のデータは非同期のログ複製によって一貫性が保たれる。分散ストレージ層では複数の Raft グループがデータを管理するため、我々はこれをマルチ Raft ストレージと呼んでいる。次のセクションでは TiKV と TiFlush について詳しく説明し、TiDB を本番環境に耐えうる HTAP データベースとするための最適化に焦点を当てる。
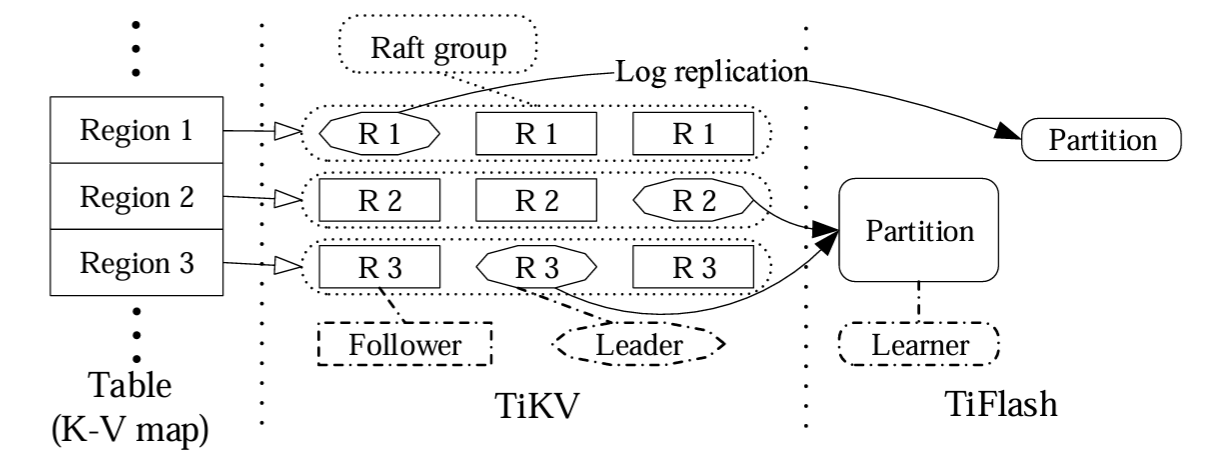
4.1 行ベースストレージ (TiKV)
TiKV デプロイメントは多数の TiKV サーバで構成される。リージョンは Raft を使用して TiKV サーバ間で複製される。各 TiKV サーバは、異なるリージョンの Raft リーダーまたはフォロワーになることができる。各 TiKV サーバ上では、データとメタデータは、組み込み可能で永続的な Key-Value ストアである RocksDB [5] に永続化される。各リージョンには構成可能な最大サイズがあり、デフォルトは 96MB である。Raft リーダーの TiKV サーバは、対応するリージョンの読み取り/書き込み要求を処理する。
Raft アルゴリズムが読み取りと書き込みの要求に応答すると、リーダーとフォロワーの間で基本的な Raft プロセスが実行される。
リージョンのリーダーは SQL エンジン層から要求を受信する。
リーダーは要求をログに追加する。
リーダーは新しいログエントリをフォロワーに送信し、フォロワーはログエントリをログに追加する。
リーダーはフォロワーが応答するのを待つ。ノードの定足数が正常に応答した場合、リーダーは要求をコミットしてローカルに適用する。
リーダーは結果をクライアントに送信し、入ってくる要求の処理を続ける。
このプロセスによりデータの一貫性と高可用性が確保される。しかし、ステップがシーケンシャルに発生するため効率的なパフォーマンスは得られず、大きな I/O オーバーヘッドが (ディスクとネットワークの両方で) 発生する可能性がある。次のセクションでは、このプロセスをどのように最適化し、高い読み取り/書き込みスループットを達成したか、すはなち、セクション 2 で説明した最初の課題をどのように解決したかについて説明する。
4.1.1 リーダーとフォロワー間の最適化
上記のプロセスでは 2 番目と 3 番目のステップに依存関係がないことから並行して実行できる。したがって、リーダーはローカルでログを追加し、同時にフォロワーにログを送信する。リーダーがログの追加に失敗してもフォロワーの定足数がログの追加に成功すればログをコミットできる。3 番目のステップでは、リーダーはフォロワーにログを送信するときにログエントリをバッファリングしてそれらをバッチで送信する。ログを送信した後、リーダーはフォロワーの応答を待つ必要はない。代わりに、成功したと仮定し、予測されたログインデックスでさらにログを送信することができる。エラーが発生した場合、リーダーはログインデックスを調整して複製要求を再送信する。4 番目のステップでは、リーダーがコミットされたログエントリを適用するとき、この段階では一貫性にリスクがないため、別スレッドによって非同期に処理できる。これらの最適化に基づいて Raft プロセスは次のように更新されている:
リーダーは SQL エンジン層から要求を受け取る。
リーダーは対応するログをフォロワーに送信し、並行してローカルにログを追加する。
リーダーはクライアントからのリクエストを受信し続け、ステップ 2 を繰り返す。
リーダーはログをコミットし、別のスレッドに送って適用する。
ログの適用後、リーダーは結果をクライアントに返す。
この最適化されたプロセスでは、クライアントからのどのリクエストも依然としてすべての Raft ステップを実行するが、複数のクライアントからのリクエストは並行して実行されるため、全体的なスループットが向上する。
4.1.2 クライアントからの読み取り要求の高速化
TiKV リーダーからのデータ読み取りは
Raft は、リーダーがデータの書き込みに成功すると、サーバ間でログを同期することなくリーダーが読み取り要求に応答できることを保証する。しかし、リーダー選出後に、リーダーの役割は Raft グループ内のサーバ間で移動する可能性がある。リーダーからの読み取りを実現するために、TiKV は [29] で説明されているように以下の読み取り最適化を実装している。
最初のアプローチは
もう一つのアプローチは
リーダーに加えてフォロワーもクライアントからの読み取り要求に応答できる。これは
4.1.3 大規模なリージョン管理
大規模なリージョンはサーバのクラスタに分散される。サーバとデータのサイズは動的に変化し、リージョンは一部のサーバ、特にリーダーレプリカに集中することがある。これにより一部のサーバのディスクが過剰に使用され、他のサーバのディスクは空いている状態になる。さらに、サーバがクラスタに追加されたりクラスタから削除されることもある。
サーバ間でリージョンのバランスを取るために、
一方で、大規模なリージョンを維持するにはハートビートの送信とメタデータの管理が必要であり、ネットワークとストレージのオーバーヘッドが大きくなる可能性がある。しかし Raft グループにワークロードがなければハートビートは不要である。リージョンのワークロードの混雑度に応じて、我々はハートビートの送信頻度を調整することができる。これによりネットワークの遅延やノードの過負荷といった問題に遭遇する可能性が低くなる。
4.1.4 動的なリージョンの分割とマージ
大きなリージョンは、適切な時間内に読み書きできないほどホットになる可能性がある。ホットなリージョンや大きなリージョンはワークロードをより適切に分散するためにより小さなリージョンに分散されるべきである。一方で、多くのリージョンが小さくめったにアクセスされない可能性もあるが、システムは依然としてハートビートとメタデータを維持する必要がある。場合によっては、このような小さなリージョンを維持するとネットワークと CPU のオーバーヘッドが大きく増加する。そのため小さなリージョンはマージする必要がある。リージョン間の順序を維持するために、キー空間内の隣接するリージョンのみを結合することに注意。PD は観測されたワークロードに基づいて TiKV に分割および結合コマンドを動的に送信する。
分割操作はリージョンをいくつかの新しい小さなリージョンに分割する。各リージョンは元のリージョン内の連続したキーの範囲をカバーする。右端の範囲をカバーするリージョンは元のリージョンの Raft グループを再利用し、その他のリージョンは新しい Raft グループを利用する。分割プロセスは Raft 処理における通常の更新要求と同様である:
PD はリージョンのリーダーに分割コマンドを発行する。
分割コマンドを受信したリーダーは、コマンドをログに変換し、そのログをすべてのフォロワーノードに複製する。ログには分割コマンドのみが含まれ、実際のデータは更新されない。
定足数がログを複製するとリーダーは分割コマンドをコミットし、コマンドは Raft グループ内のすべてのノードに適用される。適用プロセスでは元のリージョンの範囲とエポックメタデータを更新し、残りの範囲をカバーする新しいリージョンを作成する。コマンドはアトミックに適用されてディスクに同期されることに注意。
分割されたリージョンの各レプリカに対して Raft ステートマシンが作成され、新しい Raft グループを形成して動作し始める。元のリージョンのリーダーは分割結果を PD に報告し、分割プロセスが完了する。
分割プロセスは過半数のノードが分割ログをコミットすると成功することに注意。他の Raft ログをコミットするのと同様だが、前ノードがリージョンの分割を完了する必要は無い。分割後にネットワークが分断されていたら最新のエポックを持つノードグループが勝利する。メタデータの変更のみが必要なためリージョン分割のオーバーヘッドは少ない。分割コマンドの終了後、PD の通常のロードバランシングにより新しく分割されたリージョンがサーバ間で移動することがある。
隣接する 2 つのリージョンのマージは 1 つのリージョンを分割するのと逆である。PD は 2 つのリージョンのレプリカを移動して別々のサーバに共存させる。その後、2 つのリージョンの共存レプリカは 2 フェーズ操作、つまり、一方のリージョンのサービスを停止してもう一方のリージョンとマージすることによって各サーバ上でローカルにマージされる。この方法は 2 つの Raft グループ間のログ複製プロセスを使用してもマージに合意することができないため、リージョンを分割するのとは異なっている。
4.2 列ベースのストレージ (TiFlush)
上記のように TiKV からのデータ読み取りを最適化しても、TiKV の行形式のデータは高速分析には適していない。そこで我々は TiDB にカラム型ストレージ (TiFlush) を組み込む。TiFlush は
ユーザは SQL ステートメントを使ってテーブルに行形式のレプリカを設定することができる: \[ {\it ALTER \ \ TABLE} \ \ x \ \ {\it SET \ \ TiFLASH \ \ REPLICA} \ \ n; \] ここで \(x\) はテーブル名、\(n\) はレプリカ数でデフォルト値は 1 である。列レプリカの追加はテーブルに非同期で列インデックスを追加するのと似ている。TiFlash の各テーブルは TiKV の複数の連続した領域に従って多数のパーティションに分割され、各パーティションは連続した範囲のタプルをカバーする。パーティションが大きいほど範囲スキャンが容易になる。
TiFlash インスタンスを初期化すると、関連するリージョンの Raft リーダーは新しい学習者にデータを複製し始める。データが多すぎて高速に同期できない場合、リーダーはそのデータのスナップショットを送信する。初期化が完了すると TiFlash インスタンスからの更新をリッスンし始める。学習者ノードはログのパッケージを受信すると、ログの再生、データ形式の変換、ローカルストレージ内の参照値の更新など行ってログをローカルのステートマシンに適用する。
次のセクションでは TiFlash がログを効率的に適用し、TiKV との一貫性のあるビューを維持する方法について説明する。これはセクション 2 で説明した 2 つ目の課題を満たすものである。
4.2.1 ログ再生
Raft アルゴリズムに従って、学習者ノードが受信したログは線形化可能である。コミットされたデータの線形化可能なセマンティクスを維持するために、ログは先入れ先出し (FIFO) 戦略に従って再生される。ログ再生には 3 つのステップがある:
ログの圧縮: セクション 5.1 で後述するトランザクションモデルに従って、トランザクションログは
事前書き込み済み 、コミット済み 、ロールバック済み の 3 つのステータスに分類される。ロールバックされたログのデータはディスクに書き込む必要が無いため、圧縮プロセスではロールバック済みログに従って無効な事前書き込み済みログを削除し、有効なログをバッファに入れる。タプルのデコード: バッファ内のログは行形式のタプルにデコードされ、トランザクションに関する冗長な情報を削除する。そしてデコードされたタプルは行バッファに入れられる。
データ形式の変換: 行バッファ内のデータサイズがサイズ制限を超えるか、その期間が時間間隔制限を超える場合、これらの行形式タプルは列データに変換されてローカルパーティションのデータプールに書き込まれる。変換はローカルにキャッシュされたスキーマを参照し、このスキーマは後述するように定期的に TiKV と同期されている。
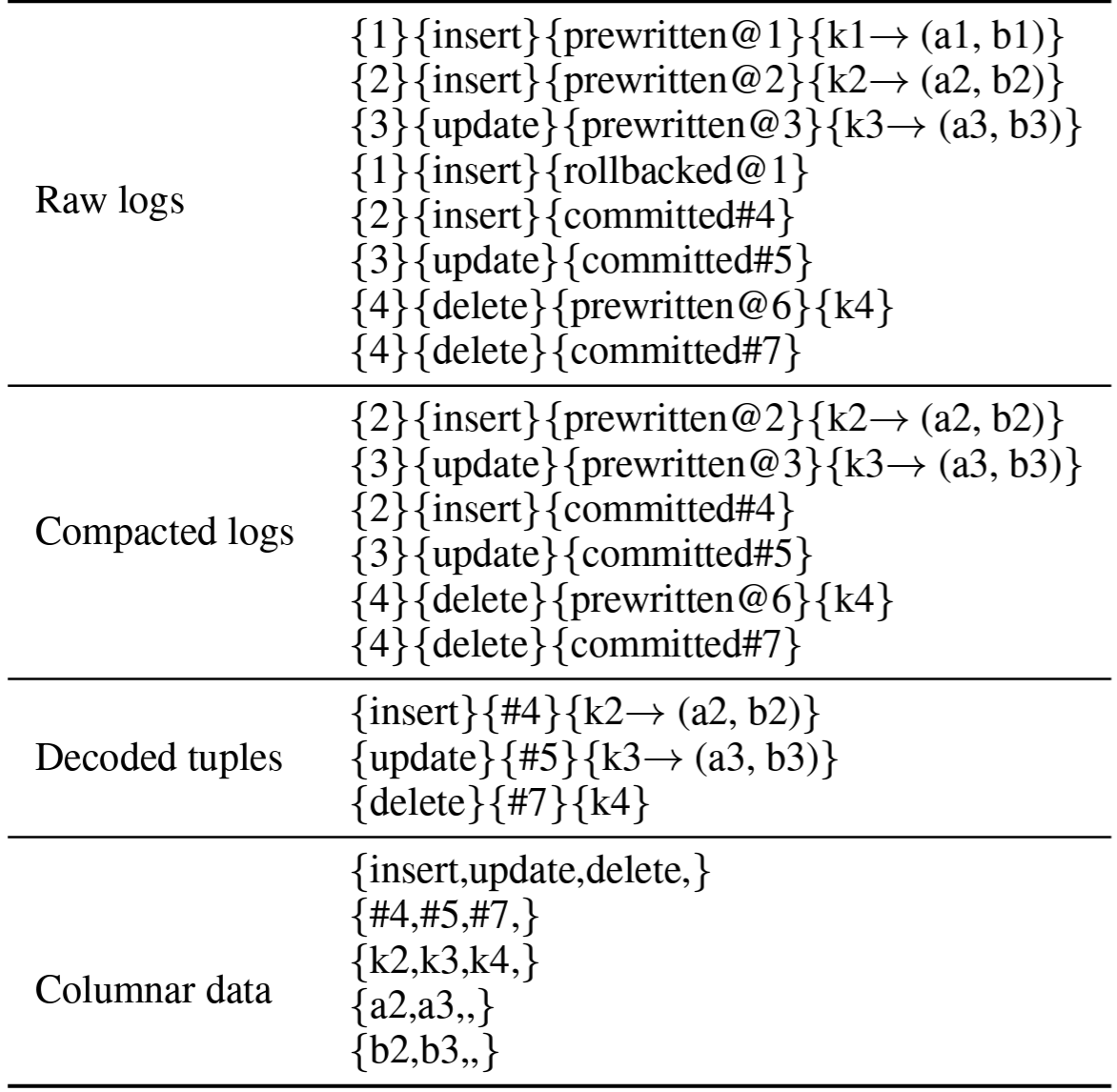
ログ再生プロセスの詳細を説明するために次の例を考えてみよう。我々は各 Raft ログ項目を transaction ID-operation type[transaction status][@start_ts][#commit_ts]operation data として抽象化する。典型的な DML によると operation type にはタプルの挿入、更新、削除が含まれる。transaction status は事前書き込み済み、コミット済み、またはロールバック済みのいずれかである。operation data は、具体的に挿入または更新されたタプル、または削除されたキーのいずれかである。
Table 1 に示す我々の例では、2 つのタプルを挿入し、1 つのタプルを更新し、1 つのタプルの削除を試みる 8 つの項目が生ログに含まれている。しかし k1 の挿入はロールバックされるため、8 つの生ログのうち 6 つの項目のみが保存され、そこから 3 つのタプルがデコードされる。最後に、デコードされた 3 つのタプルは operation types, commit timestamps, keys および 2 つのデータ列の 5 つの列に変換される。これらの列は DeltaTree に追加される。
4.2.2 スキーマ同期
タプルをリアルタイムで列形式に変換するには、学習者ノードは最新のスキーマを認識している必要がある。このようなスキーマを意識した処理はタプルをバイト配列としてエンコードする TiKV 上のスキーマレス操作とは異なる。最新のスキーマ情報は TiKV に保存される。TiFlash が TiKV に最新スキーマを要求する回数を減らすために、各学習者ノードはスキーマのキャッシュを保持する。このキャッシュはスキーマ同期機能によって TiKV のスキーマと同期される。キャッシュされたスキーマが古い場合、デコードされるデータとローカルスキーマの間に不一致が生じ、データを変換しなければならない。スキーマ同期の頻度とスキーマの不一致の回数はトレードオフの関係にある。我々は 3 段階の戦略を採用する:
定期的な同期: スキーマ同期機能は定期的に TiKV から最新のスキーマを取得しローカルキャッシュに変更を適用する。ほとんどの場合、このカジュアルな同期によってスキーマの同期頻度を減らすことができる。
強制的な同期: スキーマ同期機能が不一致のスキーマを検出すると、TiKV から最新のスキーマを積極的に取得する。これは、タプルとスキーマの間で列番号が異なる場合、または列の値がオーバーフローした場合にトリガーされる可能性がある。
4.2.3 列デルタツリー
列データの書き込みと読み取りを高スループットで効率的に行うために、我々は新しい列ストレージエンジンである DeltaTree を設計した。これはデルタ更新を即座に追加し、後で各パーティションの以前の安定バージョンとマージする。Figure 4 に示すように、デルタ更新と安定データは DeltaTree に別々に格納されている。安定スペースでは、パーティションデータはチャンクとして格納され、各チャンクはパーティションのタプルのより狭い範囲をカバーする。さらに、これらの行形式のタプルは列ごとに格納される。対照的に、デルタは TiKV が生成した順序でデルタスペースに直接追加される。TiFlash の列データの格納形式は Parquet [4] と似ている。また行グループは列チャンクに格納する。異なる点は、TiFlash は行グループの列データとそのメタデータを Parquet のように 1 つのファイルに格納するのではなく、異なるファイルに格納してファイルを並行して更新する。TiFlash は一般的な LZ4 [2] 圧縮を使用してデータファイルを圧縮し、ディスクサイズを節約する。
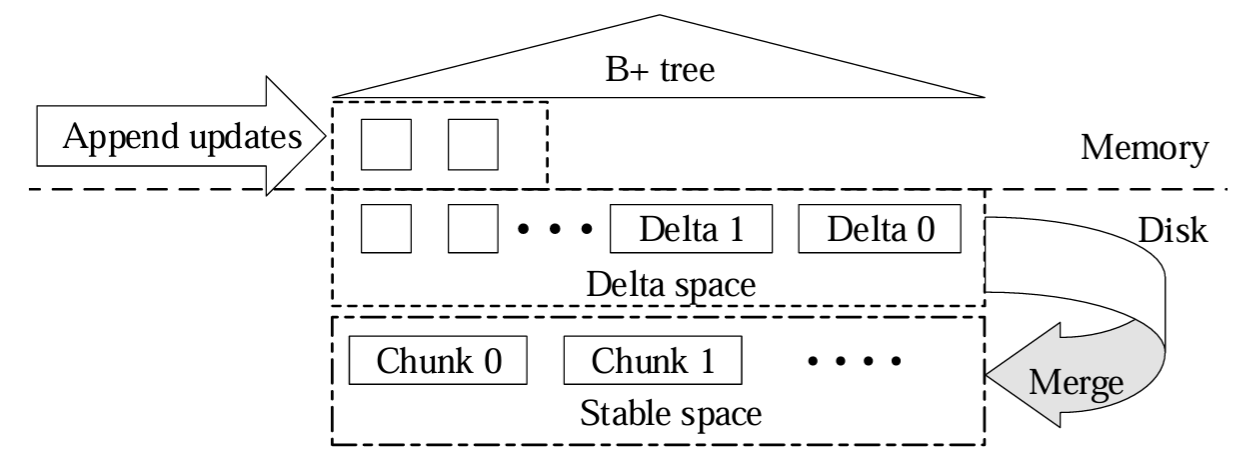
新しく入ってくるデルタは、挿入されたデータまたは削除された範囲のアトミックバッチである。これらのデルタはメモリにキャッシュされディスクに実体化される。これらは順番に格納されるため
ある特定のタプルの最新データを読み取る場合には、関連するデルタがどこに分散しているかわからないため、すべてのデルタファイルをその安定したタプルとマージする必要がある (つまり読み取り増幅)。このような処理は多数のファイルを読み取るためコストがかかる。さらに、多くのデルタファイルにはストレージスペースを浪費し安定したタプルとのマージを遅くする役に立たないデータ (つまりスペース増幅) が含まれている可能性がある。そのためデルタファイルを定期的に安定スペースにマージする。デルタに挿入されたタプルは安定に追加され、変更されたタプルはオリジナルのタプルを置き換え、削除されたタプルは移動される。マージされたチャンクはディスク内の元のチャンクをアトミックに置き換える。
デルタのマージは、関連するキーがデルタスペース内で無秩序になっているためコストがかかる。このような無秩序さはまた、デルタを安定したチャンクと統合して読み取り要求に対する最新データを返す速度も低下させる。そこで我々はデルタスペースの最上位に B+Tree を構築する。更新の各デルタ項目は、そのキーとタイムスタンプで順序付けられた B+Tree に挿入される。この順序の優先順位は、読み取り要求に応答するときにキーの範囲の更新を効率的に見つけたり、デルタスペースで単一のキーを検索するのに役立つ。また B+Tree 内の順序付けられたデータは安定したチャンクとのマージが容易である。
我々は Raft ログに従って更新されながらデータが読み取られる TiFlash の
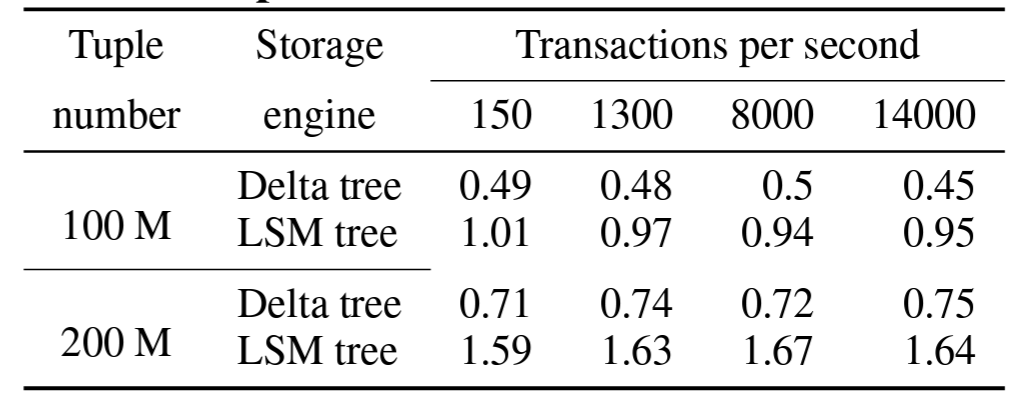
Table 2 に示すように、デルタツリーからの読み取りはタプル数が 1 億でも 2 億でも、またトランザクションのワークロードに関係なく LSM-Tree より約 2 倍高速である。これは、デルタツリーでは各読み取りが B+Tree でインデックス付けされたデルタファイルの 1 レベルのみにアクセスするのに対し、LSM-Tree ではより多くの重複ファイルにアクセスするためである。デルタファイルの比率がほぼ同じであるため、書き込みワークロードが異なっても性能はほぼ安定している。DeltaTree の書き込み増幅率 (16.11) は LSM-Tree (4.74) より大きいが、これも雇用範囲内である。
4.2.4 読み取りプロセス
フォロワー読み取りと同様に、学習者ノードはスナップショットを提供するために特定のタイムスタンプで TiFlash からデータを読み取ることができる。読み取り要求を受信すると、学習者はリーダーにインデックス読み取り要求を送信して、要求されたタイムスタンプをカバーする最新のデータを取得する。これに応答して、リーダーは参照されたログを学習者に送信し、学習者はログを再生して保存する。ログが DeltaTree に書き込まれると、読み取り要求に応答するために DeltaTree から特定のデータが読み込まれる。
5. HTAP エンジン
セクション 2 で述べた 3 つ目の課題、すなはち大規模トランザクションと分析クエリーの処理を解決するために、我々はトランザクションと分析クエリーを評価する SQL エンジンを提供する。SQL エンジンは Percolator モデルを適用して分散クラスタにおいて楽観的ロックと悲観的ロックを実装する。SQL エンジンはルールベースとコストベースのオプティマイザ、インデックスを使用し、計算をストレージ層へプッシュダウンすることで分析クエリーを高速化する。我々はまた Hadoop エコシステムに接続して OLAP 機能を強化するために TiSpark を実装する。HTAP 要求は分離されたストアとエンジンサーバで別々に処理できる。特に SQL エンジンと TiSpark は、行ストアと列ストアの両方を同時に使用して最適な結果を得ることでメリットを得られる。
5.1 トランザクション処理
TiDB は
TiDB では、トランザクションは SQL エンジン、TiKV、PD の間で次のように協調的に行われる:
SQL エンジン: トランザクションを調整する。クライアントからの書き込みおよび読み取りの要求を受け取り、データを Key-Value 形式に変換し、2 フェーズコミット (2PC) を使用してトランザクションを TiKV に書き込む。
PD: 論理リージョンと物理ロケーションを管理し、グローバルで厳密に増加するタイムスタンプを提供する。
TiKV: 分散トランザクションインターフェースを提供し、MVCC を実装し、データをディスクに永続化する。
TiDB は楽観的ロックと悲観的ロックの両方を実装する。これらは、1 つのキーを主キーとして選択し、それをトランザクションの状態を表すために使用して 2PC をベースにトランザクションを実行する Percolator モデルから採用されている。楽観的トランザクションのプロセスは Figure 5 の左側に示されている (簡略化のため図では例外処理を無視している)。
クライアントから "begin" コマンドを受け取った SQL エンジンは、トランザクションの開始タイムスタンプ (start_ts) として使用するタイムスタンプを PD に問い合わせる。
SQL エンジンは TiKV からデータを読み取り、ローカルメモリに書き込むことで SQL DML を実行する。TiKV はトランザクションの start_ts より前の最新のコミットタイムスタンプ (commit_ts) を持つデータを提供する。
SQL エンジンはクライアントからコミットコマンドを受信すると 2PC プロトコルを開始する。これはランダムに主キーを選択し、すべてのキーを並列にロックして事前書き込みを送信する。
すべての事前書き込みが成功すると、SQL エンジンは PD にトランザクションの commit_ts のタイムスタンプを要求し、コミットコマンドを TiKV に送信する。TiKV は主キーをコミットし成功応答を SQL エンジンに返す。
SQL エンジンはクライアントに成功を返す。
SQL エンジンはセカンダリキーをコミットし、さらに TiKV にコミットコマンドを送信することで、ロックを非同期かつ並列にクリアする。
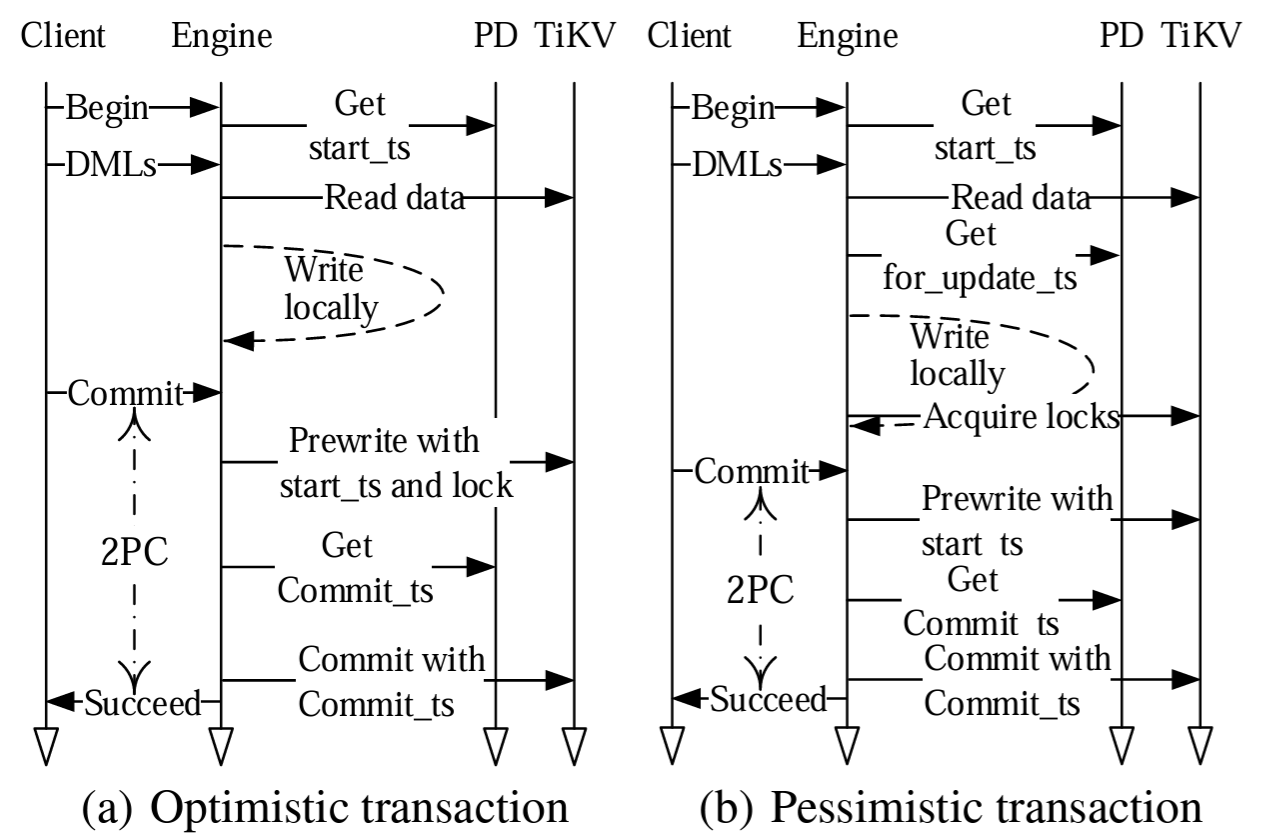
楽観的とランザックションと悲観的トランザクションの主な違いはロックを取得するタイミングである。楽観的トランザクションでは、ロックは事前書き込みフェーズ (上記のステップ 3) でインクリメンタルに取得される。悲観的トランザクションでは、ロックは事前書き込み前 (ステップ 2 の一部) の DML 実行時に取得される。つまり、いったん事前書き込みが開始されるとトランザクションは他のトランザクションとの競合で失敗することはない (ネットワーク分断やその他の問題で失敗する可能性はある)。
悲観的トランザクションでキーをロックするとき、SQL エンジンは for_update_ts と呼ばれる新しいタイムスタンプを取得する。SQL エンジンがロックを取得できない場合、トランザクション全体をロールバックして再試行するのではなく、そのロックからトランザクションを再試行することができる。データを読み取るとき TiKV は start_ts ではなく for_update_ts を使用してキーのどの値を読み取ることができるかを決定する。このように、悲観的トランザクションはトランザクションの部分的な再試行があっても RR 分離レベルを維持する。
悲観的トランザクションでは、ユーザはリードコミット (RC) 分離レベルのみを要求することもできる。これによりトランザクション間の競合が少なくなることで性能は向上するが、トランザクションの分離度は低くなる。実装の違いは、RR では読み取りが別のトランザクションによってロックされたキーにアクセスしようとすると TiKV が競合を報告する必要があるのに対し、RC では読み取りのロックを無視できる点である。
TiDB は中央集中型のロックマネージャなしで分散トランザクションを実装している。ロックは TiKV に保存されるため高いスケーラビリティと可用性が得られる。さらに、SQL エンジンと PD サーバは OLTP 要求を処理できるほどのスケーラビリティを盛っている。サーバ間で多数のトランザクションを同時に実行することで高度な並列処理が実現する。
タイムスタンプは PD から要求される。各タイムスタンプには物理時刻と論理時刻が含まれている。物理時刻はミリ秒制度の現在時刻を指し、論理時刻は 18 ビットである。したがって理論的には PD は 1 ミリ秒あたり \(2^{18}\) 個のタイムスタンプを割り当てることができる。実際にはタイムスタンプの割り当てには数サイクルしかかからないため、1 秒間に約 100 万個のタイムスタンプを生成することができる。クライアントはオーバーヘッド、特にネットワークレイテンシを償却するために一度にバッチでタイムスタンプを要求する。現在のところタイムスタンプの取得は我々の実験や多くの本番環境でも性能のボトルネックにはなっていない。
5.2 分析処理
このセクションではオプティマイザ、インデックス、我々が仕立てた SQL エンジンと TiSpark でのプッシュダウン計算など、OLAP クエリーを対象とした最適化について説明する。
5.2.1 SQL エンジンにおけるクエリーの最適化
TiDB は、論理プランを生成するクエリーの
インデックスはデータベースのクエリー性能を向上させるために重要であり、通常は point-get クエリーや範囲クエリーで使用され、ハッシュ結合やマージ結合でより安価なデータスキャン経路を提供する。TiDB は分散環境で動作するようにスケーラブルなインデックスを実装している。インデックスの維持には大量のリソースが消費され、オンライントランザクションと分析に影響する可能性があるため、バックグラウンドで非同期にインデックスの構築や削除を行う。インデックスはデータと同じようにリージョンごとに分割され、Key-Value として TiKV に格納される。一意キーインデックス上のインデックス項目は次のようにエンコーディングされる: \[ Key: \{ table \{ tableID \}\_index\{indexID\}\_indexedColValue\} \\ Value: \{null\} \] 一意出ないインデックス上のインデックス項目は次のようにデコードされる: \[ Key: \{table\{tableID\}\_index\{indexID\}\_indexedColValue\_rowID\} \\ Value: \{null\} \] インデックスを使用するには、インデックスの関連部分を含むリージョンを見つけるためにバイナリ検索が必要である。インデックス選択の安全性を高め、物理的な最適化のオーバーヘッドを削減するために、我々は
物理プラン (CBO の結果) はプル型列挙モデル [17] を使用して SQL エンジン層によって実行される。実行は一部の計算をストレージ層にプッシュダウンすることでさらに最適化することができる。ストレージ層では計算を実行するコンポーネントを
5.2.2 TiSpark
TiDB が Hadoop エコシステムに接続できるように、TiDB はマルチ Raft ストレージ上に TiSpark を追加する。TiSpark は SQL に加えて機械学習ライブラリなどの強力な計算をサポートし、TiDB 外部からのデータを処理できる。
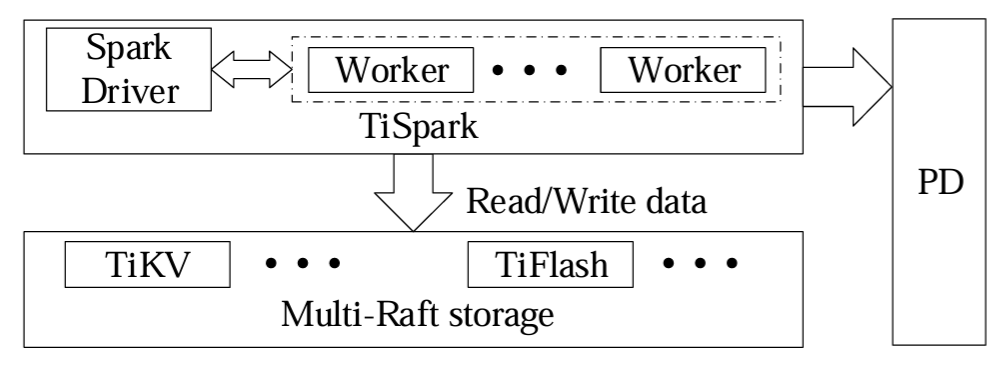
Figure 6 は TiSpark と TiDB の統合方法を示す。TiSpark では Spark ドライバが TiKV からメタデータを読み取ってテーブルスキーマやインデックス情報を含む Spark カタログを構築する。Spark ドライバは PD にタイムスタンプを要求して TiKV から MVCC データを読み取ることで、データベースの一貫したスナップショットの取得を保証する。SQL エンジンと同様に Spark ドライバはストレージ層のコプロセッサに計算をプッシュダウンして利用可能なインデックスを使用することができる。これは Spark オプティマイザによって生成されたプランを変更することで行われる。また我々は一部の読み取り操作をカスタマイズし、TiKV と TiFlash からのデータを読み取ってそれらを Spark ワーカーの行に組み立てる。例えば TiSpark は複数の TiDB リージョンから同時に読み取ってストレージレイヤーからインデックスデータを並列に取得できる。Spark の特定のバージョンへの依存を減らすために、これらの機能のほとんどは追加パッケージに失踪されている。
TiSpark が一般的なコネクタとは異なる点が 2 つある。複数のデータリージョンを同時に読み取れるだけでなく、ストレージ層からインデックスデータを並列に取得することもできる。インデックスを読み取ることで Spark のオプティマイザが最適なプランを選択して実行コストを削減できる。一方、TiSpark は Spark の生のオプティマイザから生成されたプランを修正し、実行の一部をストレージ層のコプロセッサにプッシュダウンすることで実行オーバーヘッドをさらに削減する。TiSpark はストレージ層からデータを読み取ることに加えてトランザクションを使用してストレージ層に大量のデータをロードすることもサポートしている。これを実現するために TiSpark は 2 フェーズコミットを採用してテーブルをロックする。
5.3 分離と調整
リソースの分離はトランザクションクエリーも性能を保証する効果的な方法である。分析クエリーは、CPU、メモリ、I/O 帯域幅などのリソースを大量に消費することがよくある。これらのクエリーがトランザクションクエリーと一緒に実行されるとトランザクションクエリーが大幅に遅延する可能性がある。この一般的な原則は過去の研究 [24, 34] で検証されている。TiDB ではこの問題を回避するために、分析クエリーとトランザクションクエリーを別々のエンジンサーバでスケジュールし、TiKV と TiFlash を別々のサーバに展開する。トランザクションクエリーは主に TiKV にアクセスするが、分析クエリーは主に TiFlash にアクセスする。Raft を介した TiKV と TiFlash 間のデータ一貫性を維持するためのオーバーヘッドは低いため、TiFlash で分析クエリーを実行してもトランザクション処理の性能にはほとんど影響しない。
TiKV と TiFlash の間でデータは一貫しているため、クエリーは TiKV または TiFlash のどちらから読み取っても実行できる。その結果、我々のクエリーオプティマイザはより大きな物理プランスペースから選択でき、最適なプランは潜在的に TiKV と TiFlash の両方から読み取ることができる。TiKV はテーブルにアクセスするときに行スキャンとインデックススキャンを提供し、TiFlash は列スキャンをサポートする。
これら 3 つのアクセス経路は実行コストとデータ順序の特性がそれぞれ異なる。行スキャンと列スキャンは主キーによる順序付けを提供し、インデックススキャンはキーのエンコードから複数の順序付けを提供する。異なる経路のコストはタプル/行/インデックスの平均サイズ (\({\tt S_{tuple/col/index}}\)) とタプル/リージョンの推定数 (\({\tt N_{tuple/reg}}\)) によって異なる。我々はデータスキャンのオーバーヘッドを \({\tt f_{scan}}\)、ファイルの検索コストを \({\tt f_{seek}}\) と表記する。クエリーオプティマイザは式 (\(\ref{eq1}\)) に従って最適なアクセス経路を選択する。式 (\(\ref{eq2}\)) に示すように、行スキャンのコストは連続した行データのスキャンとリージョンファイルのシークから生じる。列スキャンのコスト (式 (\(\ref{eq3}\))) は \({\tt m}\) 列のスキャンの合計である。インデックス付きの列がテーブルスキャンに必要な列を満たさない場合、インデックススキャン (式 (\(\ref{eq4}\))) ではインデックスファイルのスキャンコストとデータファイルのスキャンコスト (つまり二重読み取り) を考慮する必要がある。通常、二重読み取りではタプルがランダムにスキャンされるため、式 (\(\ref{eq5}\)) ではより多くのファイルを探すことになる。\[ \begin{eqnarray} {\tt C_{opt\_scan}} & = & \min({\tt C_{col\_scan}, C_{row\_scan}, C_{index\_scan}}) \label{eq1} \\ {\tt C_{row\_scan}} & = & {\tt S_{tuple} \cdot N_{tuple} \cdot f_{scan} + N_{reg} \cdot f_{seek}} \label{eq2} \\ {\tt C_{col\_scan}} & = & \sum_{{\tt j}=1}^{\tt m} ({\tt S_{col\_j} \cdot N_{tuple} \cdot f_{scan} + N_{reg\_j} \cdot f_{seek}}) \label{eq3} \\ {\tt C_{index\_scan}} & = & {\tt S_{index} \cdot N_{tuple} \cdot f_{scan} + N_{reg} \cdot f_{seek} + C_{double\_read}} \label{eq4} \\ {\tt C_{double\_read}} & = & \begin{cases} {\tt 0} & \mbox{(if without double read)} \\ {\tt S_{tuple} \cdot N_{tuple} \cdot f_{scan} + N_{tuple} \cdot f_{seek}} \end{cases} \label{eq5} \end{eqnarray} \]
クエリーオプティマイザが行形式ストアと列形式ストアの両方を選択して同じクエリー内の異なるテーブルにアクセスする例として "select T.*, S.a from T join S on T.b=S.b where T.a between 1 and 100" について考える。これは T と S が行ストアの列 a にインデックスを持ち、列レプリカも持つ典型的な結合クエリーである。行ストアからは T にアクセスし、列ストアからは S にアクセスするには、インデックスを使用するのが最適である。これは、クエリーが T からの完全なタプルの範囲を必要とし、インデックスを介してタプルでデータにアクセスする方が列ストアよりも安価であるためである。一方、列ストアを使用する場合は S の 2 つの完全な列をフェッチする方が安価である。
TiKV と TiFlash の調整によって依然として分離された性能を保証できる。分析クエリーの場合、フォロワー読み取りを介して TiKV にアクセスできるのは小さな範囲のスキャンまたは point-get スキャンのみであり、リーダーへの影響はほとんど無い。また分析クエリーに対する TiKV のデフォルトのアクセステーブルサイズを最大 500 MB に制限している。トランザクションクエリーは一意性などの制約を確認するために TiFlash から列指向データにアクセスすることがある。我々は特定のテーブルに複数の列指向レプリカを設定し、そのうちの 1 つのテーブルレプリカをトランザクションクエリー専用としている。トランザクションクエリーを別のサーバで処理することで分析クエリーへの影響が回避される。
6. 実験
このセクションではまず TiDB の OLTP と OLAP の能力を個別に評価する。OLAP については、SQL エンジンが TiKV と TiFlash を選択する能力を調査し、TiSpark を他の OLAP システムと比較する。次に、TiKV と TiFlash 間のログ複製の遅延を含む TiDB の HTAP 性能を計測する。最後に我々は分離の観点から TiDB と MemSQL を比較する。
6.1 実験セットアップ
クラスタ. 我々は 6 台のサーバで構成されるクラスタで包括的な実験を行う。各サーバには 188 GB のメモリと 2 つの Intel® Xeon® CPU E5-2630 v4 プロセッサ、つまり 2 つの NUMA ノードを搭載している。各プロセッサは 10 個の物理コア (20 スレッド) と 25MB の共有 L3 キャッシュを持つ。サーバは CentOS バージョン 7.6.1810 を実行し、10Gbps のイーサネットネットワークで接続されている。
ワークロード. 我々の実験は CH-benCHmark を使用したハイブリッド OLTP および OLAP ワークロードで実施される。ソースコードはオンラインで公開されている [7]。このベンチマークは標準の OLTP および OLAP ベンチマークである TPC-C と TCP-H で構成されている。このベンチマークは TCP-C ベンチマークの未修正バージョンから構築されている。OLAP 部分には HPC-H にヒントを得た 22 の分析クエリーが含まれており、そのスキーマは TPC-H から CH-benCHmark スキーマに適合され、さらに TPC-H のリレーションが 3 つ欠落している。実行時に 2 つのワークロードは複数のクライアントによって同時に発行され、実験ではクライアントの数が異なる。スループットはそれぞれ 1 秒あたりのクエリー数 (QPS) または 1 秒あたりのトランザクション数 (TPS) で測定される。CH-benCHmark のデータ単位は TCP-C と同様にウェアハウスと呼ばれる。100 ウェアハウスで 70GB のメモリを使用する。
6.2 OLTP 性能
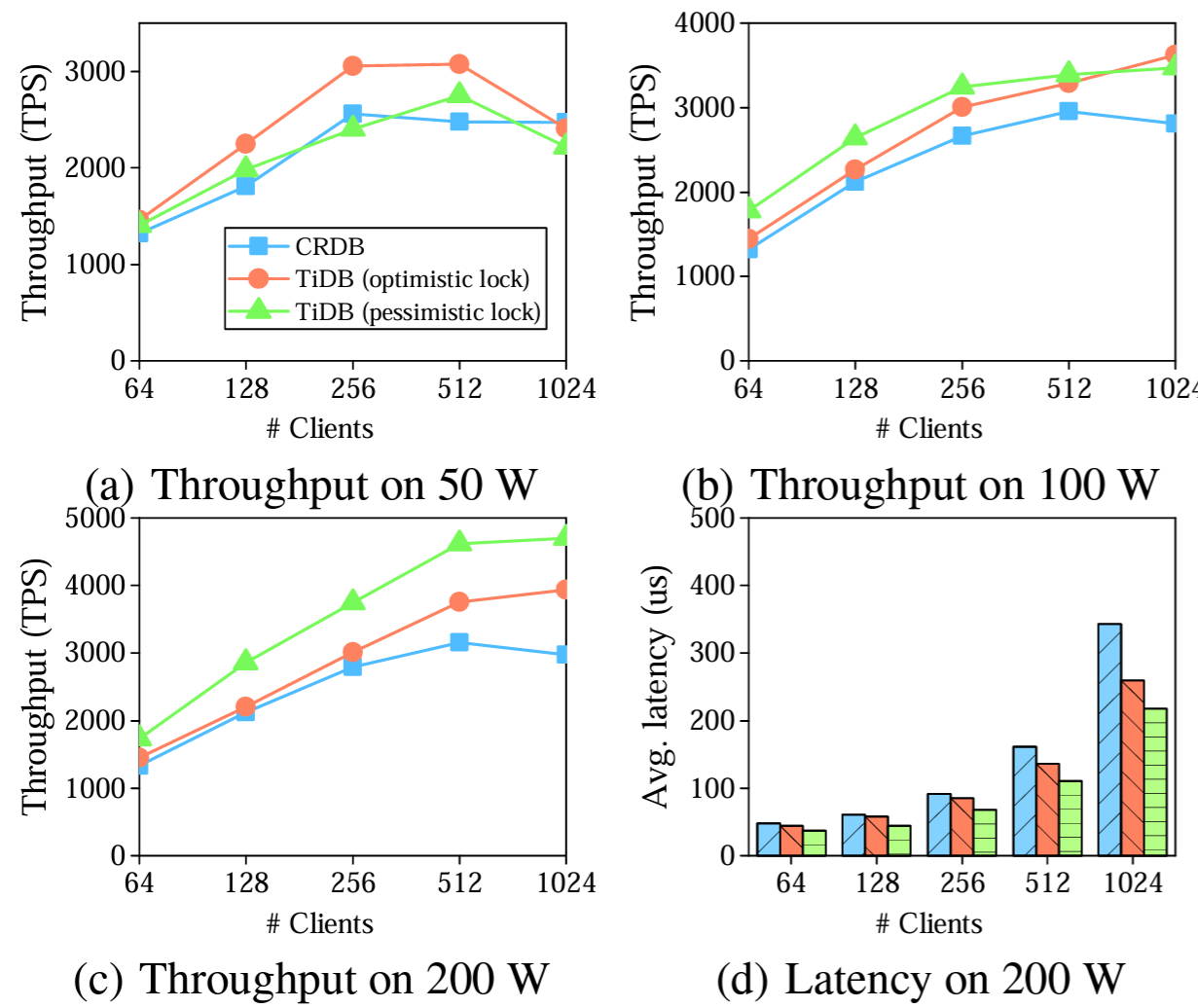
我々は CH-benCHmark の OLTP 部分、つまり TPC-C ベンチマークの下で楽観的ロックまたは悲観的ロックによる TiDB のスタンドアロン OLTP 性能を評価する。我々は TiDB の性能を、別の分散 NewSQL データベースである CockroachDB (CRDB) と比較する。CRDB は 6 台の
Figure 7(b) と 7(c) のスループットのグラフは Figure 7(a) とは異なっている。Figure 7(a) では、クライアント数が 256 未満では TiDB のスループットは楽観的ロックも悲観的ロックもクライアント数と共に増加する。クライアント数が 256 を超えると楽観的ロックのスループットは安定してその後に低下し始め、楽観的ロックのスループットは 512 クライアントで最大となりその後に低下する。Figure 7(b) と (c) の TiDB スループットは増加し続けている。この結果は、高い並列性と小さなデータサイズでリソースの競合が最も激しくなるという予想の通りである。
一般的に、データサイズが小さく並列性が高い場合 (50 または 100 ウェアハウスで 1024 クライアント) を除き、楽観的ロックの方が悲観的ロックの方が性能が優れている。そうでない場合はリソースの競合が激しく多くの楽観的トランザクションが再試行される。200 のウェアハウスではリソースの保持がより軽くなるため楽観的ロックの方がより良い性能となる。
ほとんどの場合、特に大規模なウェアハウスで楽観的ロックを使用する場合では、TiDB のスループットは CRDB よりも高くなる。公平な比較のために悲観的ロックを採用しても (CRDB は常に悲観的ロックを使用する) TiDB の性能は依然として高くなっている。我々はこの TiDB の性能上の利点はトランザクション処理と Raft アルゴリズムの最適化によるものと考えている。
Figure 7(d) はクライアントが増えてゆくと、特にスループットが最大に達した後に、より多くのリクエストをより長い時間待機する必要があるためレイテンシが大きくなることを示している。これはウェアハウスが少ないとレイテンシが大きくなる理由でもある。特定のクライアントでは、スループットが高くなると TiDB と CRDB のレイテンシが短くなる。50 ウェアハウスと 100 ウェアハウスでも同様の結果が得られる。
潜在的なボトルネックになる可能性があるため、我々は PD からのタイムスタンプ要求の性能を評価する。1200 のクライアントを使用して継続的にタイムスタンプを要求する。クライアントはクラスタ内のさまざまなサーバに配置されている。TiDB をエミュレートするように、各クライアントはバッチで PD にタイムスタンプ要求を送信する。Table 3 に示すように、6 台のサーバはそれぞれ 1 秒間に 602594 個のタイムスタンプを受信できる。これは TPC-C ベンチマークの実行時に要求される速度の 100 倍以上である。TPC-C を実行すると TiDB は 1 サーバあたり最大で毎秒 6000 個のタイムスタンプを要求する。サーバ数を増やすと、各サーバで受信されるタイムスタンプの数は減少するが、タイムスタンプの総数はほとんど変わらない。この速度は現実の需要を大きく上回っている。レイテンシに関しては 1ms または 2ms かかる要求は極わずかである。現時点では、我々は PD からタイムスタンプを取得することは TiDB の性能のボトルネックにはなっていないと結論づけている。

6.3 OLAP 性能
我々は TiDB の OLAP 性能を 2 つの観点から評価する。まず 100 個のウェアハウスを持つ CH-benCHmark の OLAP 部分で、SQL エンジンが行ストアまたは列ストアのいずれかを最適に選択する能力を評価する。我々は、TiKV のみ、TiFlash のみ、TiKV と TiFlash の両方の 3 種類のストレージをセットアップして、各クエリを 5 回実行して平均実行時間を計算した。Figure 8 に示すように 1 種類のストレージからのみデータをフェッチした場合はどちらのストレージも優れていないが、TiKV と TiFlash の両方からデータを要求すると常に優れた性能を発揮する。
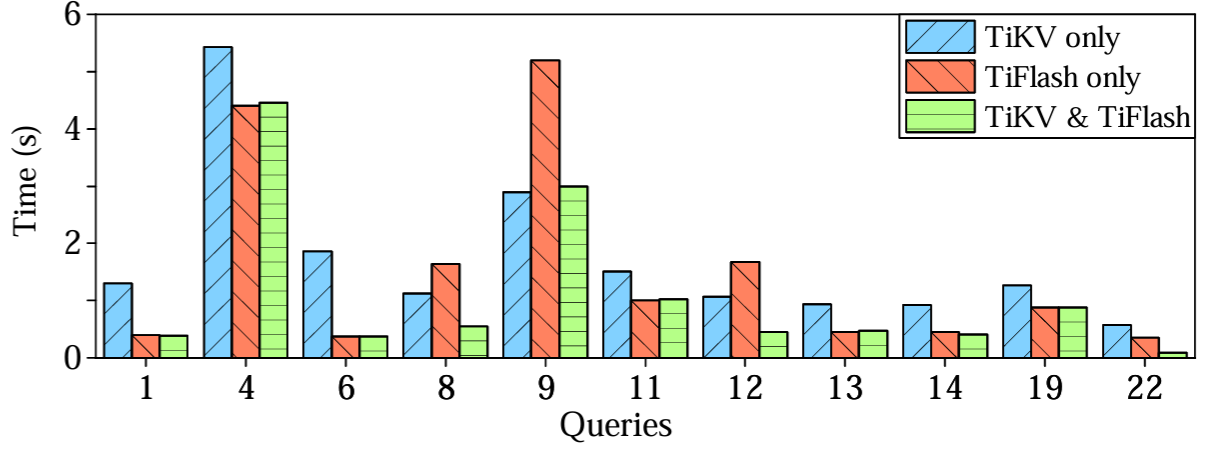
Q8, Q12 および Q22 では興味深い結果を生み出している。Q8 と Q12 では TiKV のみの方が TiFlash のみの場合よりも時間が短いが、Q22 では時間がかかっている。TiKV と TiFlash のケースの方が TiKV のみのケースや TiFlash のみのケースよりも性能が優れている。
Q12 は主に 2 つのテーブル結合を含むが、各ストレージタイプで異なる物理実装が採用されている。TiKV のみのケースではインデックス結合が使用され、テーブル ORDER_LINE から複数の
Q22 では、exists() サブクエリーがアンチ-セミ結合に変換される。TiKV のみのケースではインデックス結合を使用し、TiFlash のケースではハッシュ結合を使用する。しかし Q12 の実行とは異なりインデックス結合を使用するとハッシュ結合よりもコストがかかる。インデックス結合のコストは、TiFlash からネイブテーブルをフェッチし、TiKV のインデックスを使用して外部テーブルを検索することで削減される。したがって、TiKV と TiFlash のケースが最も時間が短くなる。
Q8 はより複雑である。これには 9 個のテーブルとの結合が含まれている。TiKV のみのケースでは、2 回のインデックスマージ結合と 6 回のハッシュ結合が必要で、インデックスを使用して 2 つのテーブル (CUSTOMER と OORDER) を検索する。このプランは 1.13 秒かかり、TiFlash のみケースの 8 回のハッシュ結合 (1.64 秒) より優れている。TiKV と TiFlash のケースではそのオーバーヘッドはさらに削減され、6 回のハッシュ結合で TiFlash からデータをスキャンする以外は物理プランはほとんど変更されない。この改善により実行時間は 0.55 秒に短縮される。これらの 3 つのクエリーで葉、TiKV または TiFlash のみを使用した場合の性能はさまざまであり、それらを組み合わせることで最良の結果が得られる。
Q1, Q4, Q6, Q11, Q13, Q14, Q19 では TiFlash のみのケースの方が TiKV のみのケースよりも性能が良く、TiKV と TiFlash のケースでは TiFlash のみのケースと同じ性能が得られている。これらの 7 つのクエリーで葉理由が異なる。Q1 と Q6 は主に 1 つのテーブルに対する集約で構成されているため、TiFlash の列ストアで実行する方が時間がかからず最適な選択となる。これらの結果は過去の研究で説明されている列ストアの利点を協調している。Q4 と Q11 はそれぞれ同一の物理プランを用いて個別に実行されている。ただし、TiFlash からのデータスキャンは TiKV よりも安価であるため、TiFlash の身のケースでは実行時間が短く、これも最適な選択である。Q13, Q14, Q19 にはそれぞれ 2 回のテーブル結合が含まれており、ハッシュ結合として実装されている。TiKV のみのケースでは、ハッシュテーブルをプローブするとインデックスリーダーを最小するが、これも TiFlash からデータをスキャンするよりもコストが高くなる。
Q9 はマルチ結合クエリーである。TiKV のみのケースでは、インデックスを使用する一部のテーブルでインデックスマージ結合を実行する。これは TiFlash でハッシュ結合を実行するより安価であるため最適な選択となる。Q7, Q20, Q21 は同様の結果をもたらしているが、スペースが限られているため省略する。22 個の TPC-H クエリーのうち残りの 8 個のクエリーは 3 つのストレージ設定で同等の性能を示している。
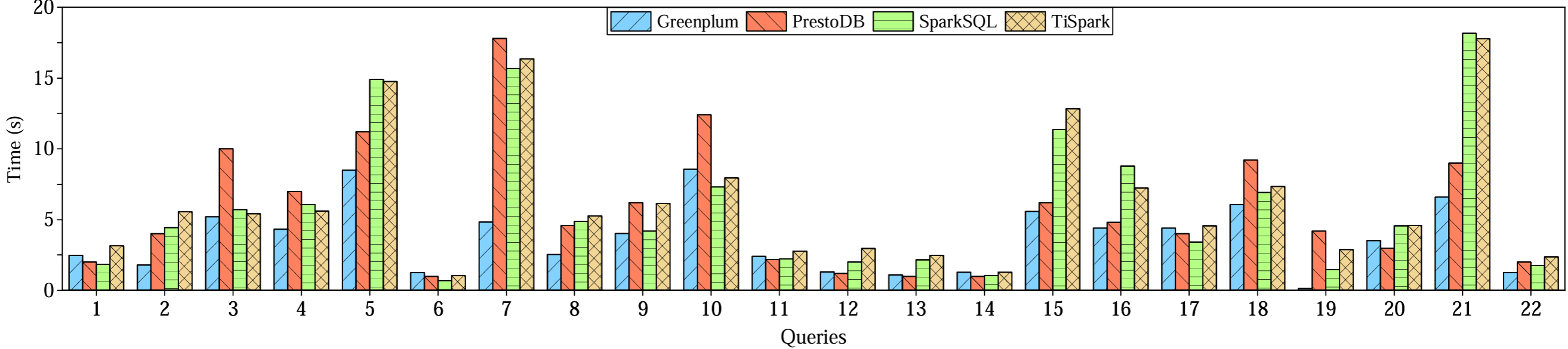
さらに、500 ウェアハウスの CH-benCHmark の 22 個の分析クエリーを使用して TiSpark と SparkSQL、PrestoDB、Greenplum を比較する。各データベースは 6 台のサーバにインストールされている。SparkSQL と PrestoDB では、データは Hive の列指向 Parquet ファイルとして保存される。Figure 9 はこれらのシステムの性能を比較したものである。TiSpark の性能は同じエンジンを使用しているため SparkSQL に匹敵する。性能の差はかなり小さく、主に異なるストレージシステムへのアクセスに起因する。圧縮された Parquet ファイルのスキャンの方が低コストであるため、SparkSQL は通常 TiSpark よりも優れている。ただし TiSpark がより多くの計算をストレージ層にプッシュできる場合、その利点が相殺されるケースもある。TiSpark を PrestoDB や Greenplum を比較することは、SparkSQL (TiSpark の基礎となるエンジン) と他の 2 つのエンジンとの比較になる。ただしそれ以上は本稿の範囲外であるため詳細には議論しない。
6.4 HTAP 性能
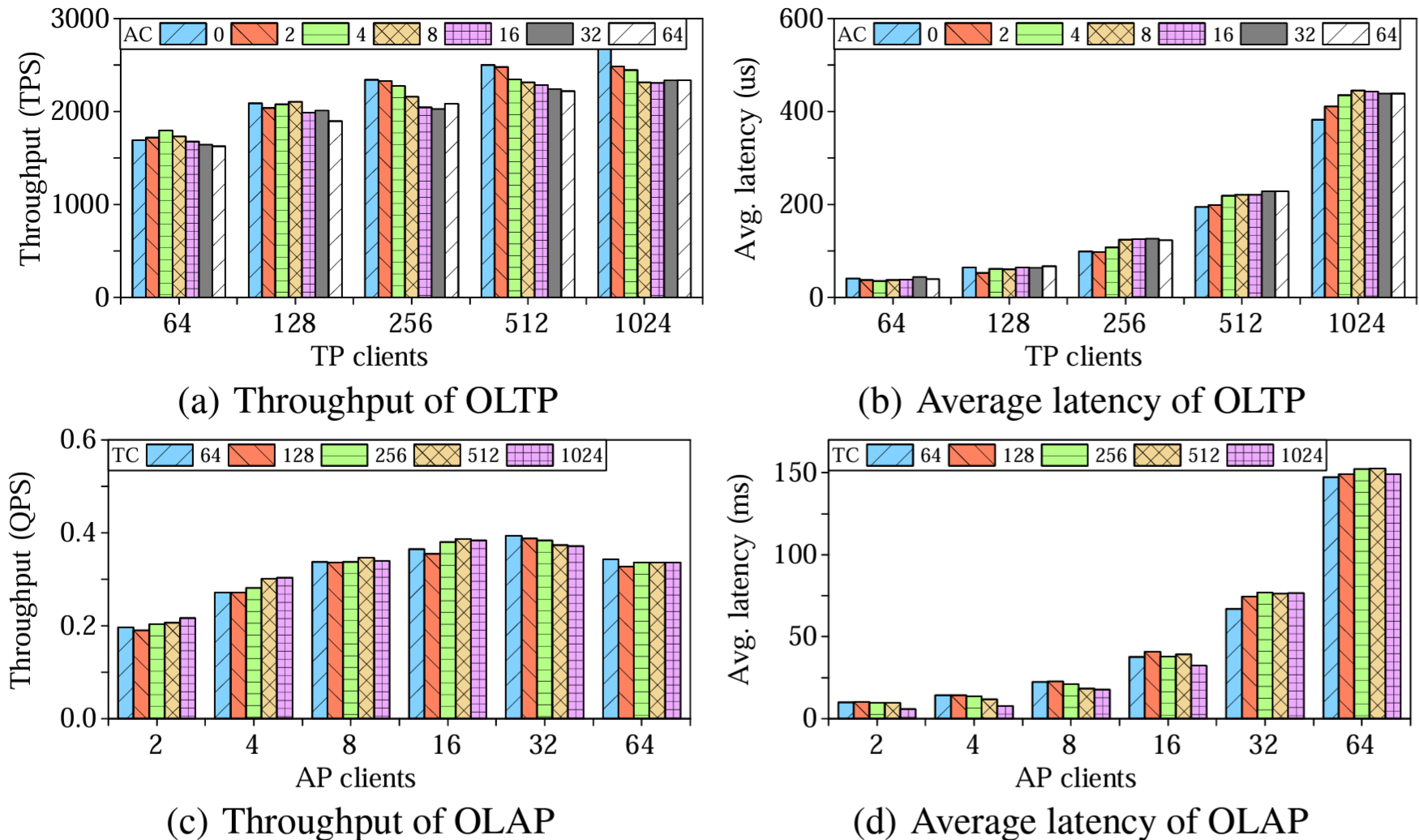
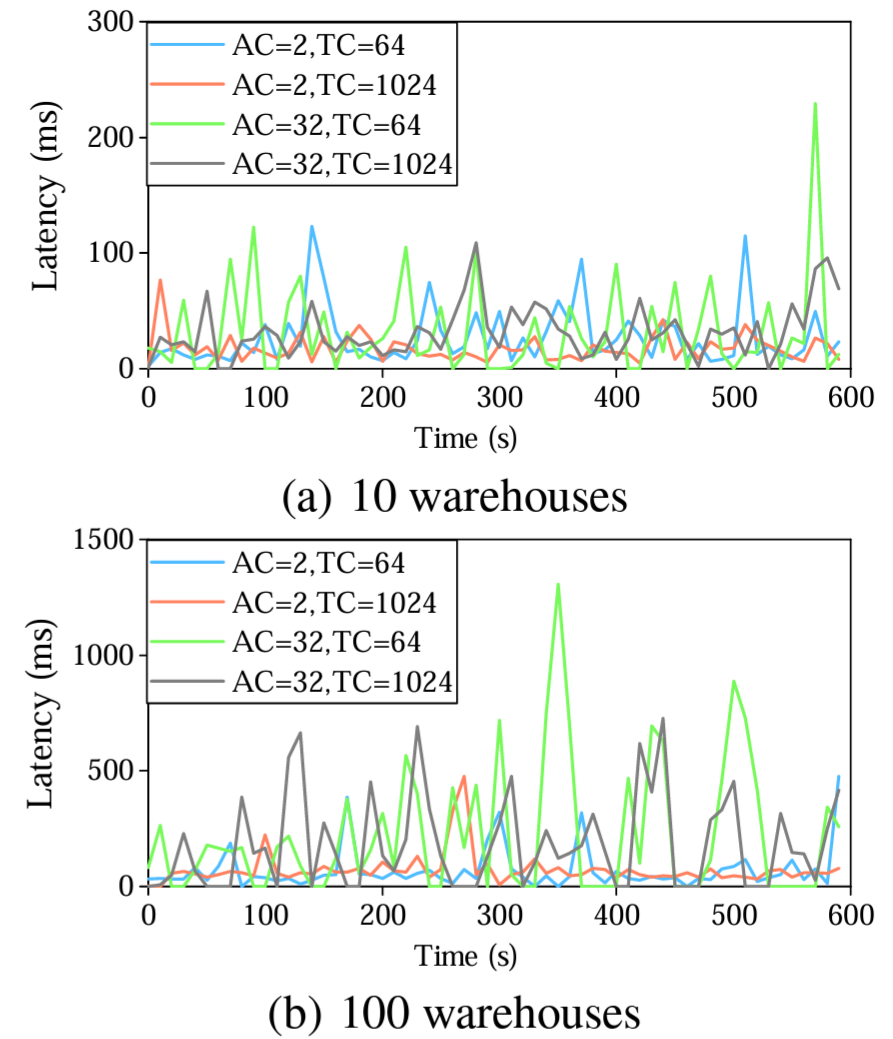
我々はトランザクション処理 (TP) と分析処理 (AP) の性能を調査するだけではなく、トランザクションクライアント (TC) と分析クライアント (AC) に分けて、CH-benCHmark 全体に基づくハイブリッドワークロードで TiDB を評価する。これらの実験は 100 ウェアハウスで実施した。データは TiKV にロードされ、同時に TiFlash に複製される。TiKV は 3 台のサーバに配置され、TiDB の SQL エンジンインスタンスによってアクセスされる。TIFlash はその他の 3 台のサーバに配置され、TiSpark インスタンスと共存している。この構成で分析クエリーとトランザクションクエリーが別々に処理される。各実行は 10 分で、ウォームアップ期間を 3 分間設けた。我々は TP ワークロードと AP ワークロードのスループットと平均レイテンシを計測した。
Figure 10(a) と 10(b) はさまざまな数の TP クライアントと AP クライアントにおけるトランザクションのスループットと平均レイテンシを (それぞれ) 示している。スループットは TP クライアント数が多いほど増加し、512 クライアントをわずかに下回った時点で最大値に達する。TP クライアントが同じであれば、AP クライアントを使用しない場合と比較して、分析処理クライアントを増やすと TP のスループットが最大 10% 低下する。これは、TiKV と TiFlash 間のログ複製が、特にセクション 6.6 の MemSQL の性能とは対照的に高い分離性を達成していることを示している。この結果は [24] の結果と同様である。
トランザクションの平均レイテンシは上限無く増加する。これは、クライアントの数が増えてリクエストが多くなってもすぐに完了できず待機する必要があるためである。待機時間はレイテンシの増加を説明している。
Figure 10(c) と 10(d) に示されている同様のスループットとレイテンシの結果は AP リクエストに対する TP の影響を示している。AP クエリーはコストが高くリソースを奪い合うため、AP スループットは 16 の AP クライアントですぐに最大に達する。このような競合によって AP クライアントが増加するとスループットが低下する。AP クライアント数が一定であればスループットはほぼ同じままで、最大でも 5% の低下するだけである。これは TP が AP の実行に大きな影響を与えないことを示している。分析クエリーの平均レイテンシの増加はクライアント数が増えるほど待機時間が増えることに起因する。
6.5 ログ複製遅延
リアルタイムの分析処理を実現するためには、トランザクションの更新が即座に TiFlash から見える必要がある。このようなデータの最新性は TiKV と TiFlash 間のログ複製遅延によって決定される。我々はトランザクションクライアントと分析クライアントの数を変えて CH-benCHmark を実行してログ複製の時間を計測した。CH-benCHmark を 10 分間実行する間にすべての複製の遅延を記録し、10 秒ごとに平均遅延を計算する。また 10 分間のログ複製遅延の分布を計算し Table 4 に示す。
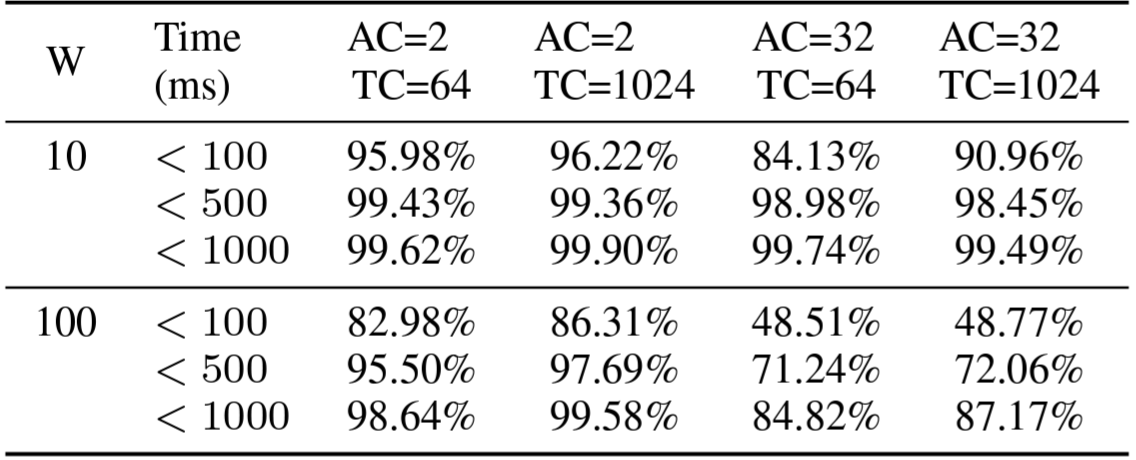
Figure 11(a) に示すように、ログ複製遅延は 10 個のウェアハウスで常に 300ms 未満であり、ほとんどの遅延は 100ms 未満である。Figure 11(b) は、ウェアハウスが 100 個になると遅延が増加し、ほとんどの遅延は 1000ms 未満であることを示している。Table 4 により正確な詳細を示している。ウェアハウスが 10 個では、クライアントの設定に関係なく、ほぼ 99% のクエリーのコストが 500ms 未満である。ウェアハウスが 100 個では、2 個と 32 個の分析クライアントで、それぞれ約 99% と 85% のクエリーが 1000ms 未満だった。これらのメトリクスは、TiDB が HTAP ワークロードで約 1 秒のデータ最新性を保証できることを強調している。
Figure 11(a) と (b) を比較すると、遅延時間はデータサイズに関連していることがわかる。ウェアハウスの数が多いほどデータが増えて同期するログが増えるためレイテンシが大きくなる。さらに、遅延は分析リクエストの数にも依存するが、トランザクションクライアントの数による影響はより少ない。これは Figure 11(b) を見れば明らかである。32 個の AC は 2 個の AC よりレイテンシが大きくなる。しかし、分析クライアントの数が同じであればレイテンシに大きな違いは無い。より正確な結果を Table 4 に示す。100 個のウェアハウスと 2 つの AC ではクエリーの 80% 以上が 100ms 未満で完了するが、32 の AC で 100ms 未満で完了するのは 50% 未満である。これは、分析クエリーが増えるとログの複製頻度が高くなるためである。
6.6 MemSQL との比較
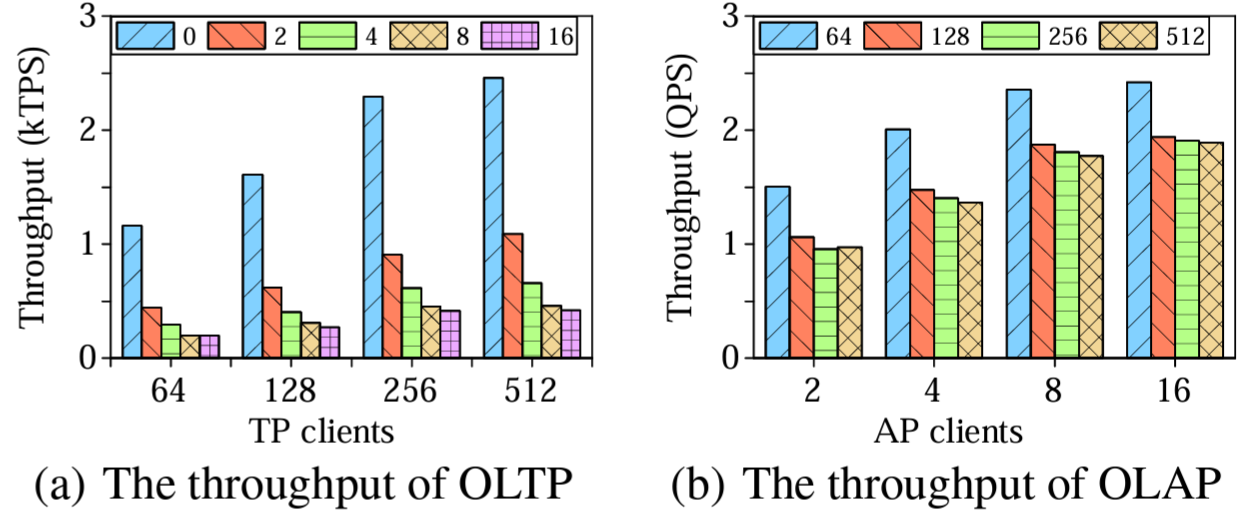
我々は CH-benCHmark を使用して TiDB と MemSQL 7.0 を比較する。この実験の目的は OLTP と OLAP 性能ではなく、最先端の HTAP システムの分離性問題を強調することを目的としている。MemSQL は大規模なトランザクションとリアルタイム分析の両方を処理する分散リレーショナルデータベースである。MemSQL は、マスター 1 台、アグリゲータ 1 台、リーフ 4 台の計 6 サーバに配置されている。MemSQL に 100 のウェアハウスをロードし、さまざまな数の AP クライアントと TP クライアントでベンチマークを実行した。ベンチマークは 5 分のウォームアップ期間を挟んで 10 分間実行された。
Figure 10 とは対照的に、Figure 12 はワークロードの干渉が MemSQL の性能に大きな影響を与えることを示している。特に AP クライアントの数が増えるとトランザクションのスループットが大幅に低下し、5 倍以上も低下する。TP クライアントが増えると AP スループットも低下するが、トランザクションクエリーは分析クエリーほど大量のリソースを必要としないため、このような影響はそれほど顕著ではない。
7. 関連する研究
HTAP システムを構築するための一般的なアプローチは、既存のデータベースからの発展、オープンソースの分析システムの拡張、またはゼロから構築することである。TiDB はゼロから構築されており、アーキテクチャ、データ生成、計算エンジン、一貫性保証において他のシシテムとは異なっている。
既存のデータベースからの発展. 成熟したデータベースは既存の製品をベースに HTAP ソリューションを提供でき、特に分析クエリーの高速化に重点を置いている。これらのデータベースはデータの一貫性と高可用性を個別に実現するためにカスタムアプローチを採用している。これとは対照的に、TiDB は Raft のログ複製を利用してデータの一貫性と高可用性を自然に実現している。
Oracle [19] は業界初のデュアルフォーマットインメモリ RDBMS として 2014 年に Database In-Memory を導入した。このオプションは、通常のトランザクションワークロードの性能を損なうことなく (あるいは向上させることなく) 分析クエリーワークロードにおける性能の壁を破ることを目的としている。列指向ストレージは読み取り専用のスナップショットであり、ある時点において一貫性があり、
SQL Server [21] は、分析ワークロード用の Apollo 列ストレージエンジンと、トランザクションワークロード用の Hekaton インメモリエンジンという 2 つの特化したストレージエンジンをコアに統合している。データ移行タスクは Hekaton テーブルの末尾から圧縮された列ストアに定期的にデータをコピーする。SQL Server は列ストアインデックスとバッチ処理を使用して分析クエリーを効率的に処理し、データスキャンに SIMD [15] を活用する。
SAP HANA は OLAP クエリーと OLTP クエリーを効率的に評価することをサポートし、それぞれに異なるデータ構成を使用する。OLAP のパフォーマンスを拡張するために、行ストアデータをサーバのクラスタ上に分散された列指向ストアに非同期にコピーする [22]。このアプローチにより MVCC データに 1 秒未満の可視性を提供する。ただし、エラーを処理してデータの一貫性を保つには多大な労力を必要とする。重要なことは、トランザクショナルエンジンが単一ノードにしか配置されていないため高可用性に欠けているという点である。
オープンソースシステムの転換. Apache Spark はオープンシステムのデータ分析フレームワークである。HTAP を実現するにはトランザクショナルモジュールが必要である。以下に挙げる多くのシステムはこの考え方に沿っている。TiSpark は拡張であるため、TiDB は Spark に深く依存しない。TiDB は TiSpark なしで独立した HTAP データベースである。
Wildfire [10, 9] は Spark をベースにした HTAP エンジンを構築する。同じ列指向データ構成である Parquet 上で分析リクエストとトランザクションリクエストの両方を処理する。並列更新には last-write-wins セマンティクスを採用し、読み取りにはスナップショット分離を採用している。高可用性のために、シャードログはコンセンサスアルゴリズムの助けを借りずに複数のノードに複製される。分析クエリーとトランザクションクエリーは別々のノードで処理できるが、最新の更新処理には顕著な遅延が発生する。Wildfire は大規模な HTAP ワークロードのために、統合されたマルチバージョンおよびマルチゾーンインデクシング手法を使用している [23]。
SnappyData [25] は OLTP、OLAP、ストリーム分析のための統合プラットフォームを提供する。これは高スループット分析用の計算エンジン (Spark) と、スケールアウト可能なインメモリトランザクションストア (GemFire) を統合している。最新の更新は行形式で保存され、分析クエリー用に列指向形式に変換される。トランザクションは GenFire の Paxos 実装を使用して 2PC プロトコルに従い、クラスター全体でコンセンサスと一貫したビューを確保する。
ゼロから構築. 多くの新しい HTAP システムは、ハイブリッドワークロードのさまざまな側面を研究してきた。これはインメモリコンピューティングを活用してパフォーマンス、最適なデータストレージ、および可用性を向上させることが含まれる。TiDB とは異なり、これらは高可用性、データの一貫性、スケーラビリティ、データ最新性、分離性を同時に提供することはできない。
MemSQL [3] はスケーラブルなインメモリ OLTP と高速な分析クエリーの利用法に対応するエンジンを備えている。MemSQL はデータベーステーブルを行または列指向形式で格納することができる。データの一部を行形式で保持し、データをディスクに書き込むときに高速分析のために列指向形式に変換できる。繰り返しクエリーを低レベルのマシンコードにコンパイルして分析クエリーを高速化し、多くのロックフリー構造を使用してトランザクション処理を支援する。しかしながら、HTAP ワークロードを実行するときに OLAP と OLTP が分離されたパフォーマンスを提供することはできない。
HyPer [18] はオペレーティングシステムの fork システムコールを使用して分析ワークロードのスナップショット分離を提供した。新しいバージョンでは MVCC 実装を採用し、シリアライザビリティ、高速トランザクション処理、高速スキャンを提供している。ScyPer [26] は論理または物理 REDO ログを使用して更新を伝播することによりリモートレプリカで大規模な分析クエリーを評価するために HyPer を拡張している。
BatchDB [24] は HTAP ワークロード用に設計されたインメモリデータベースエンジンである。BatchDB は専用のレプリカを使用したプライマリ-セカンダリ複製に依存しており、それぞれが特定のワークロードタイプ (OLTP または OLAP) 向けに最適化されている。トランザクションエンジンと分析エンジンの間の負荷相互作用を最小限に抑え、HTAP ワークロードの厳しい SLA の下で最新のデータに対するリアルタイム分析を可能にしている。行形式のレプリカに対して分析クエリーを実行するために、高可用性は保証されないことに注意。
Peloton [31] は自己駆動型 SQL データベース管理システムである。Peloton は実行時に HTAP ワークロードのデータ生成 [8] を適用させようとする。ロックフリーの多版型同時実行制御を使用してリアルタイム分析をサポートする。ただし、設計上はシングルノードのインメモリデータベースである。
Cockroach DB [38] は高可用性、データ一貫性、スケーラビリティ、および分離性を提供する分散 SQL データベースである。TiDB と同様に Raft アルゴリズム上に構築され分散トランザクションをサポートする。Cockroach DB はスナップショット分離より強力な分離特性、すなはちシリアライザビリティを提供している。ただし専用の OLAP または HTAP 機能はサポートしていない。
8. 結論
本番環境対応の HTAP データベーである TiDB を紹介した。TiDB は Raft アルゴリズムを使用する分散型の行ベースストアだえる TiKV 上に構築されている。我々はリアルタイム分析用に列指向学習者を導入し、TiKV からログを非同期で複製して行形式のデータを列形式に変換する。このような TiKV と TiFlash 間のログ複製によりオーバーヘッドをほとんどかけずにリアルタイムのデータ一貫性が実現する。TiKV と TiFlash は、トランザクションクエリーと分析クエリーの両方を効率的に処理するために別々の物理リソースに展開できる。TiDB はトランザクションクエリーと分析クエリーの両方でテーブルをスキャンするときにこれらを最適に選択してアクセスできる。実験結果では、TiDB は HTAP ベンチマークである CH-benCHmark で高い性能を発揮することが示されている。TiDB は NewSQL システムを HTAP システムに深亜kさせるための汎用ソリューションを提供する。
9. REFERENCES
- Clickhouse. https://clickhouse.tech.
- LZ4. https://github.com/lz4/lz4.
- MemSQL. https://www.memsql.com.
- Parquet. https://parquet.apache.org.
- RocksDB. https://rocksdb.org.
- Sysbench. https://github.com/akopytov/sysbench.
- TiDB. https://github.com/pingcap/tidb.
- J. Arulraj, A. Pavlo, and P. Menon. Bridging the Archipelago between Row-Stores and Column-Stores for Hybrid Workloads. In SIGMOD, pages 583–598. ACM, 2016.
- R. Barber, C. Garcia-Arellano, R. Grosman, R. Müller, et al. Evolving Databases for New-Gen Big Data Applications. In CIDR. www.cidrdb.org, 2017.
- R. Barber, M. Huras, G. M. Lohman, C. Mohan, et al. Wildfire: Concurrent Blazing Data Ingest and Analytics. In SIGMOD, pages 2077–2080. ACM, 2016.
- R. Cattell. Scalable SQL and NoSQL data stores. SIGMOD Rec., 39(4):12–27, 2010.
- F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, and R. Gruber. Bigtable: A Distributed Storage System for Structured Data. In OSDI, pages 205–218. USENIX Association, 2006.
- R. L. Cole, F. Funke, L. Giakoumakis, W. Guy, et al. The mixed workload CH-benCHmark. In DBTest 2011, page 8. ACM, 2011.
- J. C. Corbett, J. Dean, M. Epstein, A. Fikes, et al. Spanner: Google’s Globally Distributed Database. ACM Trans. Comput. Syst., 31(3):8:1–8:22, 2013.
- Z. Fang, B. Zheng, and C. Weng. Interleaved Multi-Vectorizing. PVLDB, 13(3):226–238, 2019.
- A. Floratou, U. F. Minhas, and F. Özcan. SQL-on-Hadoop: Full Circle Back to Shared-Nothing Database Architectures. PVLDB, 7(12):1295–1306, 2014.
- G. Graefe. Volcano - An Extensible and Parallel Query Evaluation System. IEEE Trans. Knowl. Data Eng., 6(1):120–135, 1994.
- A. Kemper and T. Neumann. HyPer: A hybrid OLTP&OLAP main memory database system based on virtual memory snapshots. In ICDE, pages 195–206. IEEE Computer Society, 2011.
- T. Lahiri, S. Chavan, M. Colgan, D. Das, A. Ganesh, et al. Oracle Database In-Memory: A dual format in-memory database. In ICDE, pages 1253–1258. IEEE Computer Society, 2015.
- L. Lamport. The Part-Time Parliament. ACM Trans. Comput. Syst., 16(2):133–169, 1998.
- P. Larson, A. Birka, E. N. Hanson, W. Huang, M. Nowakiewicz, and V. Papadimos. Real-Time Analytical Processing with SQL Server. PVLDB, 8(12):1740–1751, 2015.
- J. Lee, S. Moon, K. H. Kim, D. H. Kim, S. K. Cha, W. Han, C. G. Park, H. J. Na, and J. Lee. Parallel Replication across Formats in SAP HANA for Scaling Out Mixed OLTP/OLAP Workloads. PVLDB, 10(12):1598–1609, 2017.
- C. Luo, P. Tözün, Y. Tian, R. Barber, et al. Umzi: Unified Multi-Zone Indexing for Large-Scale HTAP. In EDBT, pages 1–12. OpenProceedings.org, 2019.
- D. Makreshanski, J. Giceva, C. Barthels, and G. Alonso. BatchDB: Efficient Isolated Execution of Hybrid OLTP+OLAP Workloads for Interactive Applications. In SIGMOD, pages 37–50. ACM, 2017.
- B. Mozafari, J. Ramnarayan, S. Menon, Y. Mahajan, S. Chakraborty, H. Bhanawat, and K. Bachhav. SnappyData: A Unified Cluster for Streaming, Transactions and Interactive Analytics. In CIDR. www.cidrdb.org, 2017.
- T. Mühlbauer, W. Rödiger, A. Reiser, A. Kemper, and T. Neumann. ScyPer: A Hybrid OLTP&OLAP Distributed Main Memory Database System for Scalable Real-Time Analytics. In DBIS, volume P-214 of LNI, pages 499–502. GI, 2013.
- N. Mukherjee, S. Chavan, M. Colgan, M. Gleeson, X. He, et al. Fault-tolerant real-time analytics with distributed Oracle Database In-memory. In ICDE, pages 1298–1309. IEEE Computer Society, 2016.
- P. E. O’Neil, E. Cheng, D. Gawlick, and E. J. O’Neil. The Log-Structured Merge-Tree (LSM-Tree). Acta Inf., 33(4):351–385, 1996.
- D. Ongaro and J. K. Ousterhout. In Search of an Understandable Consensus Algorithm. In USENIX ATC, pages 305–319. USENIX Association, 2014.
- F. Özcan, Y. Tian, and P. Tözün. Hybrid Transactional/Analytical Processing: A Survey. In SIGMOD, pages 1771–1775. ACM, 2017.
- A. Pavlo, G. Angulo, J. Arulraj, H. Lin, J. Lin, et al. Self-Driving Database Management Systems. In CIDR. www.cidrdb.org, 2017.
- A. Pavlo and M. Aslett. What’s Really New with NewSQL? SIGMOD, 45(2):45–55, 2016.
- D. Peng and F. Dabek. Large-scale Incremental Processing Using Distributed Transactions and Notifications. In OSDI, pages 251–264. USENIX Association, 2010.
- I. Psaroudakis, F. Wolf, N. May, T. Neumann, A. Böhm, A. Ailamaki, and K. Sattler. Scaling Up Mixed Workloads: A Battle of Data Freshness, Flexibility, and Scheduling. In TPCTC, volume 8904, pages 97–112. Springer, 2014.
- M. Sadoghi, S. Bhattacherjee, B. Bhattacharjee, and M. Canim. L-Store: A Real-time OLTP and OLAP System. In EDBT, pages 540–551. OpenProceedings.org, 2018.
- S. Sivasubramanian. Amazon dynamoDB: a seamlessly scalable non-relational database service. In SIGMOD, pages 729–730. ACM, 2012.
- M. Stonebraker and U. C¸ etintemel. “One Size Fits All”: An Idea Whose Time Has Come and Gone (Abstract). In ICDE, pages 2–11. IEEE Computer Society, 2005.
- R. Taft, I. Sharif, A. Matei, N. VanBenschoten, J. Lewis, et al. CockroachDB: The Resilient Geo-Distributed SQL Database. In SIGMOD, pages 1493–1509. ACM, 2020.
翻訳抄
トランザクション処理と分析処理を統合した HTAP データベースであり、Raft アルゴリズムに基づいて高可用性とスケーラビリティを実現する TiDB に関する 2020 年の論文。行ストア (TiKV) と列ストア (TiFlash) を組み合わせ、最新のデータをリアルタイムで効率的に処理する。これにより OLTP と OLAP のワークロードを分離しつつ、高性能なクエリ処理を提供する。
- HUANG, Dongxu, et al. TiDB: A Raft-based HTAP Database. Proceedings of the VLDB Endowment, 2020, 13.12: 3072-3084.
