Rust: プロファイリング
 概要
概要
ソフトウェア開発におけるプロファイリング (profiling) とは、プログラムのボトルネックやメモリリークを発見することを目的とした CPU 時間やメモリ使用量の計測である。ソフトウェアの最適なパフォーマンスを引き出すためにはソースコードを最適に調整する作業が重要であるが、一般にプロファイリングはその優先順位や費用対効果を推定するための事前調査を目的として実施される。
Table of Contents
トレースプロファイラ (tracing profiler) またはイベントベースプロファイラ (event-based profiler) は特定のイベントに対するプロファイル情報を収集する。代表的な動作は関数ごとの開始/終了時間を計測するプロファイリングである。これは、直感的ではあるものの、対象のイベントが多くなるほど収集するデータ量も増大し、システムコールの多発により目的のプロファイリングに与える影響も大きくなる。
統計的プロファイラ (statistical profiler) はプログラム実行中に定期的にプログラムカウンターをサンプリングする。結果の数値は完全に正確ではないが、どの処理が全体のどれだけを占めているかを現実的な統計的近似値として示すことができる。トレースプロファイラに比べて収集するデータ量が少なく、フットプリントも小さいという利点がある。
samply によるプロファイリング
samply は Rust 製のサンプリングプロファイラである。ただし、Rust アプリケーションに限らず様々なネイティブ実行プログラムのプロファイルデータを収集でき、結果を Firefox Profile で表示できる形式で出力する。
samply は Linux, mac OS, Windows などの主要な OS で動作する。特に、Windows 環境では利用できるプロファイリングツールが限られてる中、pprof や perf といった他のプロファイラと比べて気軽に利用できる点が大きなメリットである。
インストールと基本的な使い方
samply は cargo を使用してインストールできる。また Rust がセットアップされていない環境でも単独でインストールすることもできる。
$ cargo install samply$ samply --versionsamply 0.13.1
Windows の場合はバックエンドに Windows ADK の xperf を使用するので、先に Windows ADK をインストールして xperf を使用できるようにしておく。
samply record に続いてプロファイリングを行いたいコマンドを引数付きで指定する。例えば以下の例は Windows 標準の ping コマンドを samply を使ってサンプリングした結果である。
$ samply record ping -n 3 google.comgoogle.com [142.251.222.46]に ping を送信しています 32 バイトのデータ: 142.251.222.46 からの応答: バイト数 =32 時間 =2ms TTL=116 142.251.222.46 からの応答: バイト数 =32 時間 =3ms TTL=116 142.251.222.46 からの応答: バイト数 =32 時間 =3ms TTL=116 142.251.222.46 の ping 統計: パケット数: 送信 = 3、受信 = 3、損失 = 0 (0% の損失)、 ラウンド トリップの概算時間 (ミリ秒): 最小 = 2ms、最大 = 3ms、平均 = 2ms Stopping xperf... Processing ETL trace... Local server listening at http://127.0.0.1:3000 Press Ctrl+C to stop.
コマンドが完了しプロファイル結果が保存されると、ブラウザが起動してスレッドのタイムラインや CPU 使用率、スタックトレースなどを詳細に表示される。
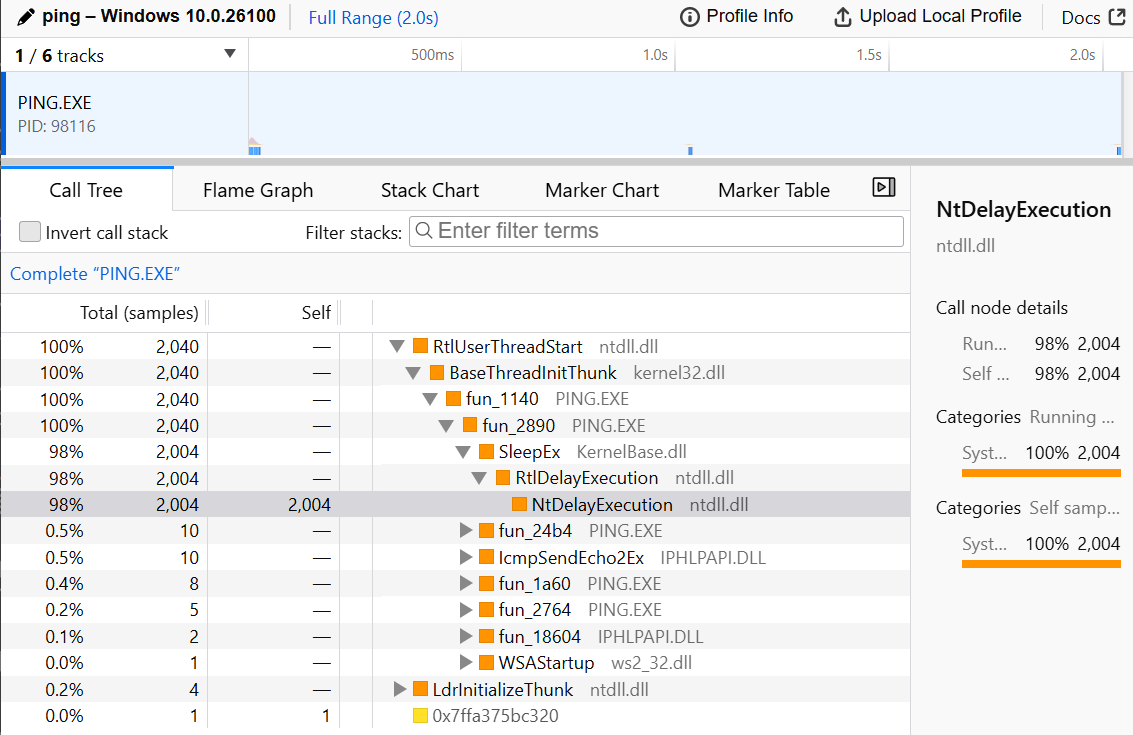
ここで、ブラウザの URL 欄に https://profiler.firefox.com と表示されているので、一見するとプロファイリング結果がどこかにアップロードされたように見えるがそのようなことはない点に注意。samply はプロファイルが終了するとまず localhost:3000 で HTTP サーバを起動しプロファイル結果をホストする。次に、Firefox Profiler のサイトの UI 上のスクリプトが、クエリーパラメータに指定された localhost:3000 からプロファイル結果を取得して表示する。localhost:3000 は外部から直接アクセスできないため、プロファイル結果の表示は外部に送られることなくローカルで完結している。用心深い人は少しヒヤリとするかもしれないが、何かが外部に暴露しているわけではない。
逆に、結果を公開して他者と共有したい場合は、画面上のアップロード機能を使用してアップロードして恒久リンクを取得できる。
プロファイリングを行う
Rust 開発では、cargo test やリリースビルドの実行ファイルをプロファイルすることもできるが、プロファイル用のベンチマークを作成し cargo bench をプロファイルするのが目的の機能を選択できリリースビルドに近いので都合が良い。まずはプロファイル用のケースをベンチマークとして実行できるようにする。以下の例では Criterion を使用し、debug = true でデバッグシンボルを含めたリリース最適化されたバイナリを作成している。
[package]
name = "samply-bench"
version = "0.1.0"
edition = "2024"
[dependencies]
[dev-dependencies]
criterion = "0.7"
[profile.bench]
debug = true
[[bench]]
name = "my_benchmark"
harness = false
pub fn reverse_string(s: &str) -> String {
s.chars().rev().collect()
}
use criterion::{Criterion, criterion_group, criterion_main};
use samply_bench::reverse_string;
fn bench_reverse_string_small(c: &mut Criterion) {
c.bench_function("reverse string small", |b| {
let s = "hello world".repeat(10);
b.iter(|| {
reverse_string(&s);
});
});
}
fn bench_reverse_string_large(c: &mut Criterion) {
c.bench_function("reverse string large", |b| {
let s = "hello world".repeat(1000);
b.iter(|| {
reverse_string(&s);
});
});
}
criterion_group!(
benches,
bench_reverse_string_small,
bench_reverse_string_large
);
criterion_main!(benches);
$ cargo bench
Finished `bench` profile [optimized + debuginfo] target(s) in 0.07s
Running unittests src\lib.rs (target\release\deps\samply_bench-fc7089ceba15f1e7.exe)
...
reverse string small time: [344.25 ns 345.85 ns 347.74 ns]
change: [−5.2606% −3.3861% −1.9221%] (p = 0.00 < 0.05)
Performance has improved.
Found 4 outliers among 100 measurements (4.00%)
2 (2.00%) high mild
2 (2.00%) high severe
reverse string large time: [10.999 µs 11.054 µs 11.120 µs]
change: [−1.8640% −0.8916% +0.0410%] (p = 0.07 > 0.05)
No change in performance detected.
Found 9 outliers among 100 measurements (9.00%)
3 (3.00%) high mild
6 (6.00%) high severe
ベンチマークとして実行できることを確認したら samply record 経由で起動してプロファイリングを実行する。
$ samply record cargo bench
...
Stopping xperf...
Processing ETL trace...
Local server listening at http://127.0.0.1:3000
Press Ctrl+C to stop.
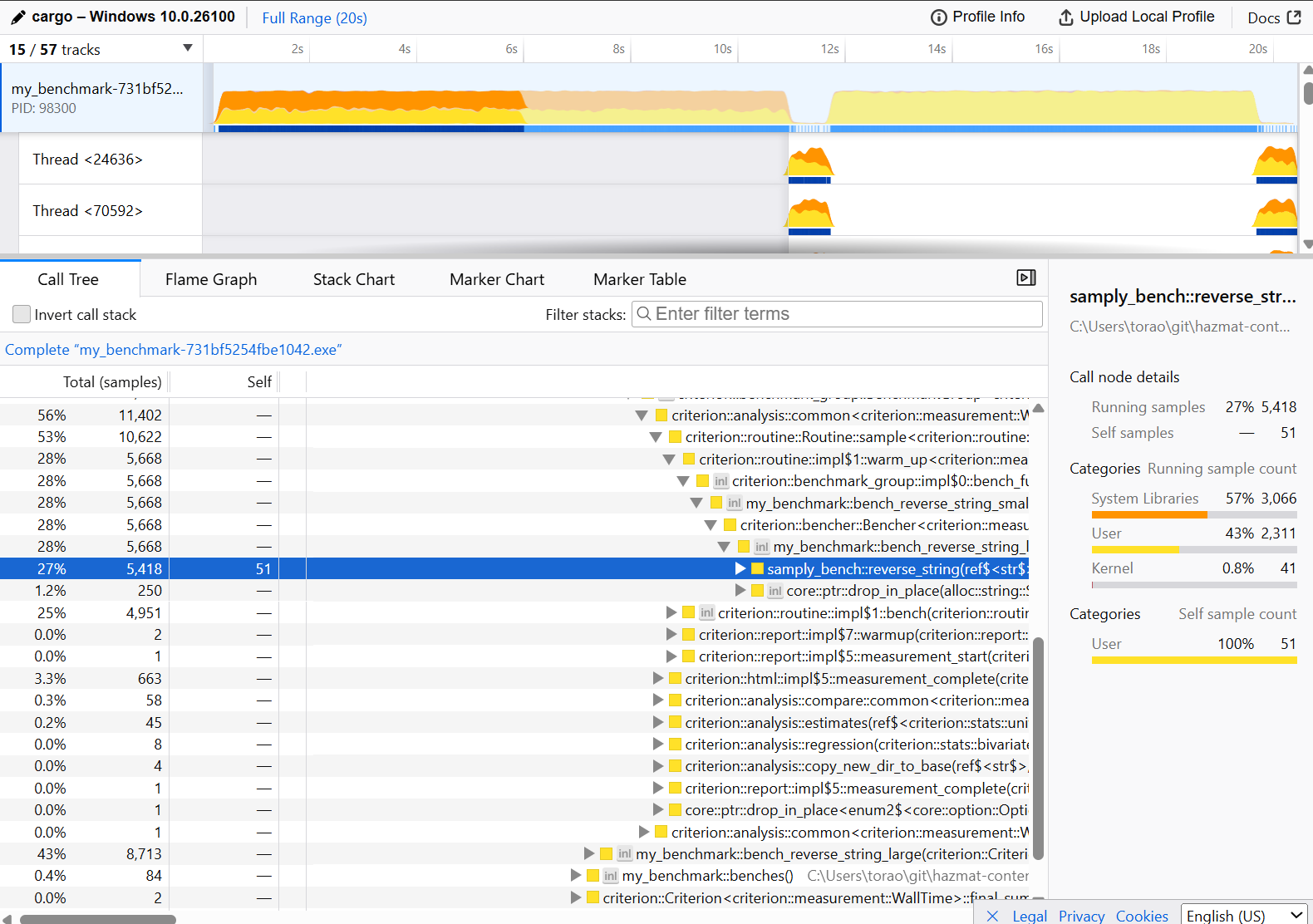
reverse_string() の呼び出しが全体の時間の 27% を占めているのが分かる。samply record には任意のコマンドや実行オプションを指定できるため、特定のベンチマークのみを実行したり、リリースビルド済み実行ファイルを指定してプロファイルを行うことができる。
perf によるプロファイリング
perf は Linux カーネルとともに開発されている Linux 向けの統計的プロファイラである。単独のコマンドのプロファイル情報のみならず、カーネルのシステムコールを含むシステム全体のプロファイル情報を収集することができる (コマンドがどのような言語やツールチェーンで作られているかには依存しない)。
Ubuntu 環境であれば apt 経由で perf をインストールすることができる。libc6-dbg は perf の実行に必須ではないが、プロファイル情報に libc のシンボルが表示されるようになる。
torao@beryl:~$ uname -r
5.15.0-41-generic
torao@beryl:~$ sudo apt install linux-tools-generic
...
torao@beryl:~$ perf version
perf version 5.15.39Windows や macOS で perf を使いたい場合は VirtualBox などの完全仮想化環境に構築した Linux で行う必要がある。これは、Windows の WSL 2 環境 (WSL 2 バックエンドの Docker を含む) や LinuxKit をコンテナサブシステムとする Docker 環境では Linux カーネルがハードウェアパフォーマンスカウンターをサポートしていないためである。
torao@lazurite:~$ uname -r
5.10.102.1-microsoft-standard-WSL2 ❌ Windows WSL2root@e91231e975f2:/# uname -r
5.10.76-linuxkit ❌ Docker for macOSpi@pirite:~ $ uname -r
5.15.21-v8+ ❌ Raspberry Pi OS
実行統計の表示
ここでは --release オプション付きでビルドされた target/release/terp というコマンドを例にプロファイリングの方法を説明する。繰り返しになるが perf を使用するプロファイリングは Rust には依存しない。
torao@beryl:~/git/terp$ cargo clean
torao@beryl:~/git/terp$ cargo build --releaseまず perf を使ってプログラムの実行統計を調べてみよう。
torao@beryl:~/git/terp$ sudo perf stat -- target/release/terp
Performance counter stats for 'target/release/terp':
3.74 msec task-clock # 0.953 CPUs utilized
0 context-switches # 0.000 /sec
0 cpu-migrations # 0.000 /sec
161 page-faults # 43.075 K/sec
14,025,884 cycles # 3.753 GHz
26,601,658 instructions # 1.90 insn per cycle
5,210,002 branches # 1.394 G/sec
112,760 branch-misses # 2.16% of all branches
0.003921140 seconds time elapsed
0.000000000 seconds user
0.003958000 seconds sysこの実行統計を使用して、パフォーマンス調整の前後でコンテキストスイッチ回数や CPU サイクル数、ページフォルト回数の改善が見られたかを知ることができるだろう。
プロファイル情報の収集
プログラムのプロファイリングは perf record で行う。ファイルを指定しなければプロファイル情報は perf.data に保存される。
torao@beryl:~/git/terp$ sudo perf record -- target/release/terp
...
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.030 MB perf.data (228 samples) ]
torao@beryl:~/git/terp$ ls
total 100
...
-rw-rw-r-- 1 torao torao 1069 Jul 13 19:33 LICENSE
-rw------- 1 root root 43844 Jul 13 22:41 perf.data ✅
-rw-rw-r-- 1 torao torao 44 Jul 13 19:33 README.md
drwxrwxr-x 4 torao torao 4096 Jul 13 19:33 src/
drwxrwxr-x 3 torao torao 4096 Jul 13 22:40 target/perf record の実行オプションに -a を指定すると、対象プログラムのバックグラウンドで動作しているシステム全体のプロファイル情報も含めて収集することができる。
perf が収集するプロファイル情報は、どのような関数やシステムコールが実行されているかや、それらの実行時間が含まれている。このような情報はシステムに対する攻撃のヒントとなりうるため実行には特権モードが必要である (ただしカーネルパラメータを変更して特権モードなしで実行できるようにすることもできる)。
torao@beryl:~/git/terp$ perf record -- target/release/terp
Error:
Access to performance monitoring and observability operations is limited.
Consider adjusting /proc/sys/kernel/perf_event_paranoid setting to open
access to performance monitoring and observability operations for processes
without CAP_PERFMON, CAP_SYS_PTRACE or CAP_SYS_ADMIN Linux capability.
More information can be found at 'Perf events and tool security' document:
https://www.kernel.org/doc/html/latest/admin-guide/perf-security.html
perf_event_paranoid setting is 4:
-1: Allow use of (almost) all events by all users
Ignore mlock limit after perf_event_mlock_kb without CAP_IPC_LOCK
>= 0: Disallow raw and ftrace function tracepoint access
>= 1: Disallow CPU event access
>= 2: Disallow kernel profiling
To make the adjusted perf_event_paranoid setting permanent preserve it
in /etc/sysctl.conf (e.g. kernel.perf_event_paranoid = <setting>)プロファイル情報の確認と表示
プロファイル情報を収集したらまず統計的に信用できる程度のサンプリングが行われたかを確認する必要がある。-n オプション付きでレポートを表示してみよう。
torao@beryl:~/git/terp$ sudo perf report -nデフォルトで perf.data が読み込まれるが -i [file] でファイルを指定することもできる。
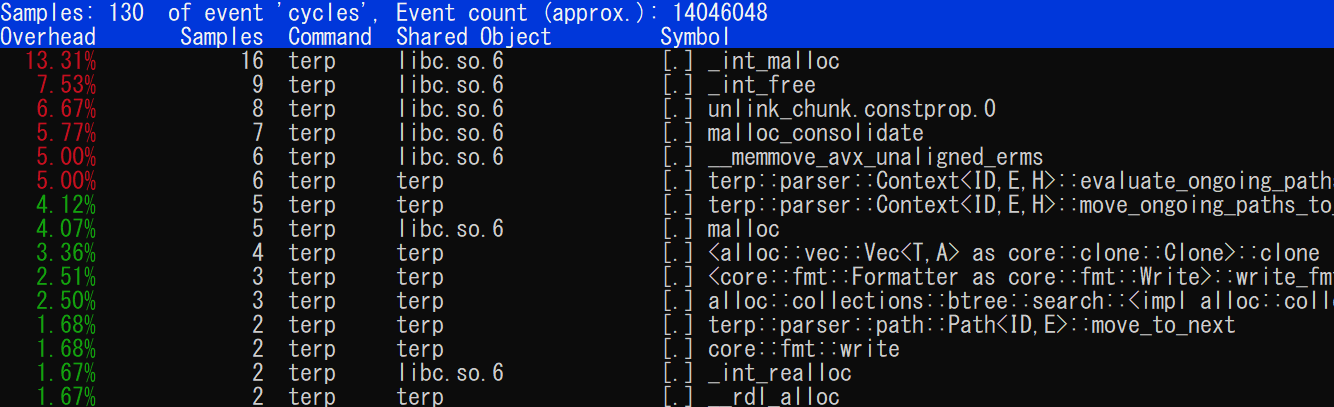
perf report による最もシンプルなプロファイリング結果表示。ここで左上の Samples の数値に注意。Fig 3 の例は「プログラム実行中に 130 回のサンプリングを行い、うち 16 回が libc の _init_malloc を実行中だった」ことを意味している。つまり Samples が少ないプロファイル情報は統計的に近似した結果を表していない可能性がある。この場合、-F max オプションでカーネルで定義されている最大サンプリング頻度を指定したり、目的の処理をループ実行するなどプログラムを修正してプロファイリングをやり直す必要がある。
今回のプロファイリングに使用した Rust コードは libc のメモリの割当と開放に関係する処理が上位の多くを締めていることが分かる。
コールグラフ表示
パフォーマンス改善を行うためには枝葉の関数を知るだけでは不十分で、それらがどこから多く呼び出されているかも知る必要がある。これは呼び出し関係を含めたコールグラフで表示すると分かりやすい。
-g オプションを使ってコールスタック情報をつけてプロファイル情報を収集するとコールグラフを表示することができる。
torao@beryl:~/git/terp$ sudo perf record -g -- target/release/terp
...
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.054 MB perf.data (252 samples) ]先程と同様に perf report で表示すると、左側に + 記号が表示され + で展開できるようになっていることが分かるだろう。
torao@beryl:~/git/terp$ sudo perf report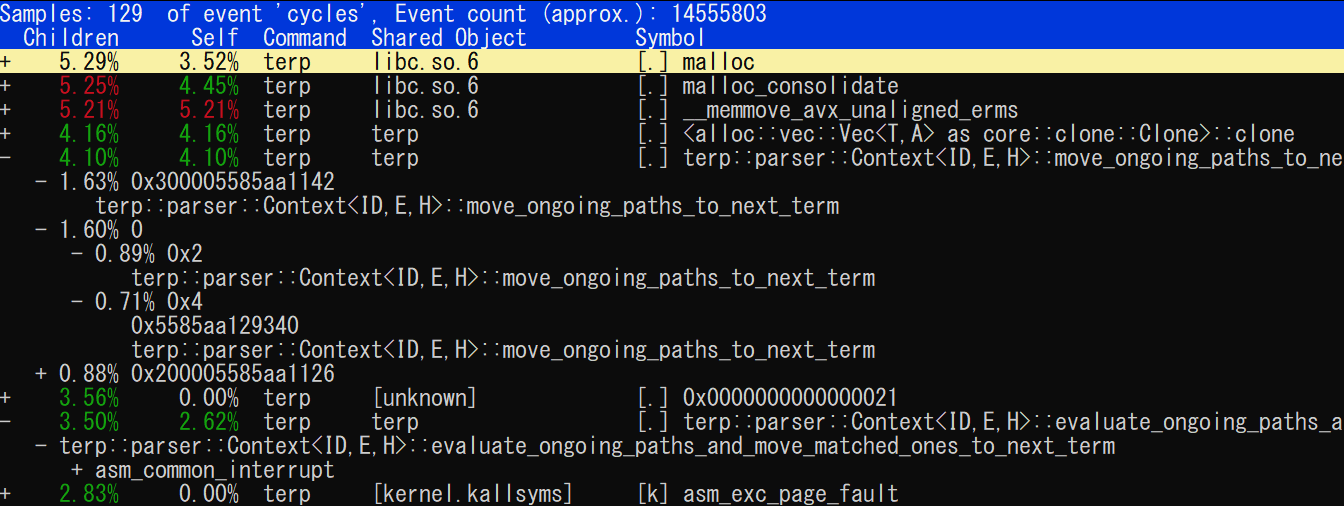
perf report の表示。Flame Graph 表示
コマンドラインで表示するコールグラフは便利ではあるものの、全体を俯瞰してみるには Frame Graph のほうが向いている。perf record -g で収集したプロファイリング情報を Flame Graph に変換するための Perl スクリプトをダウンロードする。
torao@beryl:~/git/terp$ wget https://raw.githubusercontent.com/brendangregg/FlameGraph/master/stackcollapse-perf.pl
torao@beryl:~/git/terp$ wget https://raw.githubusercontent.com/brendangregg/FlameGraph/master/flamegraph.plプロファイル情報をテキストデータに変換し、スクリプトで Frame Graph の SVG ファイルを作成する。
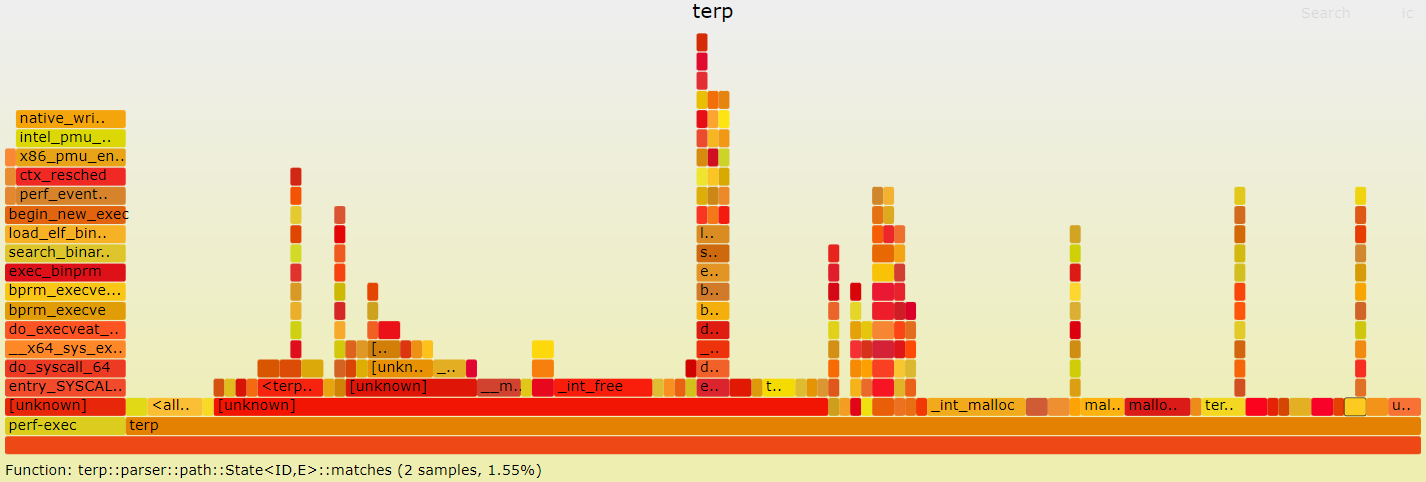
torao@beryl:~/git/terp$ sudo perf script | perl stackcollapse-perf.pl | perl flamegraph.pl --title "terp" > flamegraph_terp.svg生成した SVG ファイルは Chrome などで表示することができる (この例の SVG ファイル)。カーソルを当てるとその処理が全体の何 % を締めているかが表示される。また各層をクリックして拡大表示することもできる。
より詳細なプロファイリング向けビルド
ここまでの例で挙げた方法は Rust 側でビルドオプションを変更する必要はなかった。しかし perf でより詳細なプロファイル情報を収集しようとするとデバッグ情報付きでリリースビルドを行う必要が出てくるかもしれない。そのような場合、通常のリリースビルドとは異なる設定を使う必要があるため、git 開発を行っているのであればプロファイリング用の git ブランチを作成して作業することをお勧めする。
リリースビルドのバイナリにデバッグ情報を含むようにするには Cargo.toml を修正して debug に値を指定する。これによりリースビルドのデフォルトのプロファイル設定を上書きすることができる。
[profile.release]
debug = 1上記の設定で --release フラグを付けてバイナリをビルドするとビルド完了時のメッセージが relase [optimized + debuginfo] に変わるだろう。
torao@beryl:~/git/terp$ cargo clean
torao@beryl:~/git/terp$ cargo build --release
Compiling terp v0.1.0 (/home/torao/git/terp)
Finished release [optimized + debuginfo] target(s) in 1.00sこのバイナリが問題なく実行できることも確認しておこう。
torao@beryl:~/git/terp$ target/release/terp
...
{kind=link}