論文翻訳: Deep Clustering for Unsupervised Learning of Visual Features
Mathilde Caron, Piotr Bojanowski, Armand Joulin, and Matthijs Douze
Facebook AI Research
 Abstract
Abstract
概要: クラスタリングはコンピュータ・ビジョンで広く適用され研究されている教師なし学習方法の一種である。しかし大規模なデータセット上での視覚的特徴量の end-to-end 学習にクラスタリングを適用させる研究は殆ど行われていない。本研究では、ニューラルネットワークのパラメータと、その結果として得られた特徴量のクラスタ割り当てを組み合わせて学習するクラスタリング手法である DeepCluster を提示する。DeepCluster は標準的なクラスタリングアルゴリズムである k-means を使用して特徴量を反復的にグループ化し、そのクラスタ割り当てを次の学習の教師として使用しネットワークの重みを更新する。DeepCluster は ImageNet や YFCC100M のような大規模データセットにおいて畳み込みニューラルネットワークを用いた教師なし学習に適用される。ここで得られたモデルは現在の水準における全ての標準的なベンチマークを大きなマージンで上回って優れている。
キーワード: 教師なし学習 (unsupervised learning), クラスタリング (clustering)
Table of Contents
1 導入
事前学習済みの畳込みニューラルネットワーク、いわゆる convnet はほとんどのコンピュータビジョン・アプリケーションの構成要素となっている [1, 2, 3, 4]。それらは限られた量のデータで学習したモデルの一般化を改善するために利用できる優れた汎用機能をもたらす [5]。大規模な完全教師データセットである ImageNet [6] の存在は convnet の事前訓練の進歩を促進している。しかし、Stock と Cisse [7] は ImageNet における最先端 (state-of-the-art) の分類器のパフォーマンスは大部分が過小評価されており、未解決のまま残っている誤差はほとんどないという経験的な証拠を示している。これは、近年、斬新なアーキテクチャが数多く提唱されているにもかかわらず、パフォーマンスが飽和している理由の一部を説明している [2, 8, 9]。実際のところ、物体分類の特定の領域をカバーする 100 万の画像を含む ImageNet は今日の基準では比較的小さいといえる。前進するための本質的な方法は潜在的に何十億もの画像から成り立つより大規模で多様なデータセットを構築することである。これは、コミュニティによりクラウドソーシャルの専門知識が何年にも渡って蓄積されているにもかかわらず、手作業による膨大な注釈を必要とする [10]。未加工のメタデータでラベルを置換すると予期しない結果をもたらす可視表現に偏りを生じさせる [11]。教師なしでインターネット規模のデータセットを訓練する方法が必要とされている。
教師なし学習は機械学習コミュニティ [12] で広く研究されており、クラスタリング、次元削減、あるいは密度推定のアルゴリズムはコンピュータビジョンのアプリケーションで常用されている [13, 14, 15]。例えば "Bag of Features" モデルは良好な画像レベルの特徴量を生成するために handcrafted local descriptors クラスタリングを使用する [16]。それらの成功の主な理由は、人工衛星や医療画像のような特定の領域やデータセットや、深さのような新しい様式で取り込まれた注釈が常に大量に入手できるわけではない画像に適用できることである。いくつかの研究では密度推定や次元削減に基づく教師なし方法を深層モデルに適用することが可能であり [17, 18] 有能な万能可視特徴をもたらすことが示されている [19, 20]。画像分類におけるクラスタ化手法の原始的な成功にもかかわらず、convnets の end-to-end 学習に適用させるための提案は非常に少なく、また決して大規模ではなかった [21, 22]。問題は、主にクラスタ化手法は固定的な特徴量上の線形モデルに対して設計されており、特徴量を同時に学習する必要がある場合はほとんど機能しないとこうことである。例えば k-means とともに convnet で学習すると、特徴量はゼロ化され、クラスタは単一のエンティティに集約されるという意味のない解につながる (訳注: つまり全ての特徴が単一のクラスタに偏り精度100%となる)。
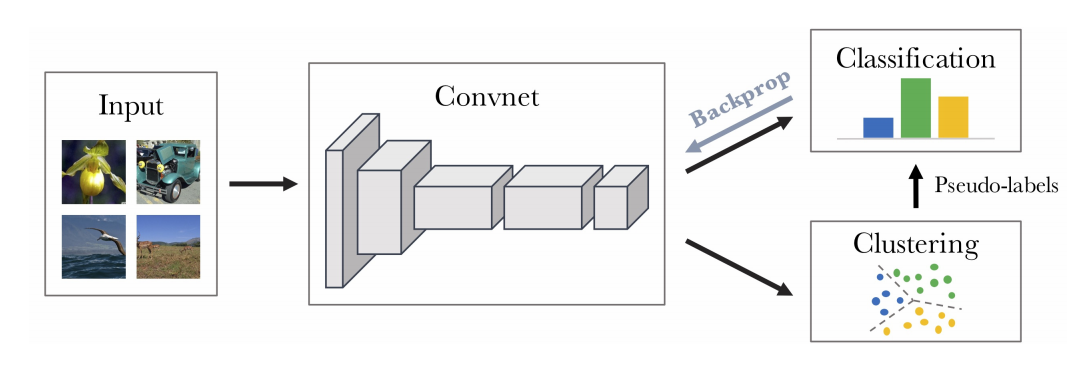
本研究では大規模な end-to-end 学習のための新しいクラスタリング手法を提案する。我々は、クラスタリングフレームワークを用いて有用な汎用視覚的特徴を得ることができることを示す。図1 に要約した我々のアプローチは、画像記述子のクラスタリングと、クラスタ割り当てを予測させることによる convnet の重みの更新とを交互に行うことからなる。分かりやすさのため我々の研究は k-means に焦点を当てるが Power Iteration Clustering (PIC) [23] のような他のクラスタリング手法も利用できる。全体を通してのパイプラインは、多くの一般的な技法を再利用することから convnet の標準的な教師あり学習と非常に近い [24]。自己教師あり学習 [25], [26, 27] と異なり、クラスタリングはドメイン知識がほとんど不要で入力からの特定のシグナルも必要ないという利点がある [28, 28]。この単純さにもかかわらず、我々のアプローチは過去に公開されている教師なし方法よりも ImageNet の分類タスクと転移タスクの両方において大幅に高いパフォーマンスを実現している。
最後に、我々は実験プロトコル、特に訓練セットと convnet アーキテクチャを置き換えることによって我々のフレームワークの堅牢性を探る。実験の結果セットは、Doersch ら [25] によって始められた論議を、教師なし方法のパフォーマンスに対するそれらの選択の影響まで拡張する。我々のアプローチはアーキテクチャの変更に対して堅牢であることを実証する。VGG [30] による AlexNet の置き換えは特徴量の品質とその後の転移パフォーマンスを大幅に向上させる。さらに重要なことは教師なしモデルの学習セットとして ImageNet を使用することである。ImageNet はネットワークのパフォーマンスでのラベルの影響を理解するのに役立つが、細分化された画像の分類コンテストで使うために特定の画像の配分を継承している: バランスの取れた分類で構成されており様々な種類の犬が含まれている。我々はその代替として Thomee ら [31] の YFCC100M データセットからのランダムな Flickr 画像を考察する。我々はこのアプローチがこの矯正されていないデータ配分で学習したときに最先端のパフォーマンスを維持していることを示す。最後に、現在のベンチマークは分類レベル情報を取得するための教師なし convnet の機能に焦点を当てている。また我々は、実態レベル情報を取得する能力を計測するための画像検索ベンチマークでそれらを評価することを提案する。
本稿では以下のような貢献を行っている: (i) k-means のような標準的なクラスタリングアルゴリズムと連携し、最小限の追加手順を要求する convnet の end-to-end 学習のための斬新な教師なし方法; (ii) 教師なし学習で使用される多くの標準的な転移タスクの最先端のパフォーマンス; (iii) 矯正されていない画像配分で訓練した場合における従来技法より上の性能; (iv) 教師なしの特徴量学習における現在の評価プロトコルに関する論議。
2 関連研究
特徴量の教師なし学習: 我々の研究に関連するいくつかのアプローチは教師なしで深層モデルを学習する。Coates と Ng [32] も convnet を再学習するために k-means を使用しているが、各レイヤーをボトムアップで習得しながら end-to-end で学習する。その他のクラスタリング損失 [21, 22, 33, 34] は convnet の特徴と画像のクラスタを併せて学習していると考えられてきたが、最新の convnet アーキテクチャを完全に研究するスケールではテストされたことがない。特に興味深いことに Yang ら [21] は反復的なフレームワークで convnet の特徴とクラスタリングを繰り返し学習する。彼らのモデルは小さなデータセットでは有望なパフォーマンスを実現するが、convnet が競争的となるために必要な画像数を増やすことは困難である。我々の研究に近いものとして Bojanowski と Joulin [19] はネットワークに流れる情報を保とうとする損失とともに大規模なデータセットの可視的特徴を学習する。彼らのアプローチは SVM [36] と同様の方法で画像を区別するが我々はより単純にクラスタリングしている。
自己教師あり学習: "自己教師学習" [37] と呼ばれる教師なし学習のよく見かける形式は、未加工の入力データから直接計算された "疑似ラベル" によって、人間が注釈を加えたラベルを置き換えるための仮託 (pretext) タスクを使用する。例えば Doersch ら [25] は画像の継ぎ接ぎの相対位置の予測を使用する。Noroozi と Favaro [26] はネットワークを訓練してシャッフルした継ぎ接ぎを空間的に並べ替える。Paulin ら [39] は画像検索設定を使用して継ぎ接ぎレベルの Convolutional Kernel Network [40] を学習する。その他のものは、連続したフレーム感のカメラ変換を予測したり [41]、追跡された継ぎ接ぎの時間的コヒーレンスを利用したり [29]、動きに基づいてビデオをセグメント化することによって、ビデオで利用可能な時間的信号を活用する。空間的および時間的コヒーレンスから離れて、画像色彩化 [28, 42]、クロスチャンネル予想 [43]、音声 [44] またはインスタンス数 [45] など、他の多くの信号が模索されている。我々の研究とは対象的に、これらのアプローチはドメイン依存であり、転移する特徴を導くことができる仮託タスクを慎重に設計する専門知識を必要とする。
生成的モデル: 近年、教師なし学習は画像生成に対して多くの進歩を遂げている。典型的には、パラメータ化された写像はオートエンコーダー [18, 48, 49, 50, 51]、生成的敵対ネットワーク (GAN) [17] やより直接的な再構成損失 [52] によって、事前定義されたランダムノイズと画像との間で学習させられる。特に興味深いのは GAN の識別器は可視的特徴を生み出すことができるが、それらの性能は比較的残念である [20]。Donahue ら [20] と Dumoulin ら [53] は GAN にエンコーダーを追加することにより、競争力の高い可視的特徴が生成されることを示している。
3 方法
convnet の教師あり学習の短い紹介の後、我々の教師なしアプローチとその最適化の得意性について説明する。
3.1 前書き
統計的学習に基づくコンピュータビジョンへの近代的なアプローチは良好な画像特徴化を必要とする。このコンテキストにおいて convnet は生の画像を固定次元のベクトル空間にマッピングするための一般的な選択肢である。十分なデータで訓練すると、標準的な分類ベンチマークで継続して最良なベンチマークを達成する [8, 54]。我々は convnet の写像を \(f_\theta\) で表す。ここで \(\theta\) は対応するパラメータの集合である。我々はこの写像を特徴量または表現として画像に適用する事によって得られるベクトルを参照する。与えられた \(N\) 個の画像からなる訓練セットを \(X = \{x_1, x_2, \ldots, x_N\}\) とすると、我々は写像 \(f_{\theta*}\) が良好な汎用特徴量をもたらすようなパラメータ \(\theta*\) を求めたい。
これらのパラメータは伝統的に教師ありによって学習される。すなはち各画像 \(x_n\) は \(\{0,1\}^k\) のラベル \(y_n\) に関連付けられる。このラベルは \(k\) 個の可能な事前定義された分類の一つに対する画像のメンバシップを表している。パラメータ化された分類器 \(gw\) は特徴 \(f_\theta(x_n)\) の上で正しいラベルを予測する。分類器のパラメータ \(W\) と写像のパラメータ \(\theta\) は以下の問題を最適化することによって併せて学習される: \[ \begin{equation} \min_{\theta,W} \frac{1}{N} \sum_{n=1}^N \ell\left(gw(f_\theta(x_n)), y_n\right) \label{eq1} \end{equation} \] ここで \(\ell\) は負の対数 softmax 関数とも呼ばれる多項ロジスティック損失である。このコスト関数はミニバッチの確率的勾配降下 [55] および勾配を計算するための逆伝播 [56] を用いて最小化される。
3.2 クラスタリングによる教師なし学習
\(\theta\) がガウス分布からサンプリングされているとき、学習なしでは \(f_\theta\) は良好な特徴量を生成しない。しかし、標準的な転移タスクでのそのようなランダム特徴量のパフォーマンスは期待値 (chance level) を遥かに上回る。例えば ImageNet の期待値は 0.1% だが (訳注: ImageNet は 1000 の分類ラベルを持つ)、ランダム AlexNet の最後の畳込みレイヤーの上にある多層パーセプトロン分類器は 12% の正解率を達成する [26]。ランダムな convnet の優れたパフォーマンスは入力信号に先立って強さを与える畳み込み構造に密接に結びついている。この研究のアイディアは弱い信号を利用して convnet の判別可能な力をブートストラップすることである。我々は convnet の出力をクラスタ化し、続くクラスタ割り当てを "疑似ラベル" として使用することで式 (\(\ref{eq1}\)) を最適化する。この深層クラスタリング (DeepCluster) アプローチは特徴量を繰り返し学習しそれらをグループ化する。
クラスタリングは広く研究されており様々な状況に対して多くのアプローチが開発されている。比較のポイントがない場合、我々は標準的なクラスタリングアルゴリズム k-means に焦点を当てる。他のクラスタリングアルゴリズムによる予備結果はこの選択が重要でないことを示している。この場合、k-means は入力としてベクトルのセット、本稿の場合では特徴量 \(f_\theta(x_n)\) を取り、幾何学的な基準に基づいて \(k\) 個の異なるグループにクラスタリングする。より正確には、以下の問題を解くことで \(d\times k\) 重心行列 \(C\) と各画像 \(n\) のクラスタ割り当て \(y_n\) を併せて学習する: \[ \begin{equation} \min_{C \in \mathbb{R}^{d\times k}} \frac{1}{N} \sum_{n=1}^N \min_{y_n \in \{0,1\}^k} \|f_\theta(x_n) - C_{y_n} \|_2^2 \ \ \ \mbox{such that} \ \ y_n^{\mathrm{T}} 1_k = 1 \label{eq2} \end{equation} \] この問題を解くと最適な割り当ての集合 \((y_n^*)_n \leq N\) と重心行列 \(C\) が得られる。これらの割り当ては疑似ラベルとして使用される; 我々は重心は使用しない。
全体として、DeepCluster は式 (\(\ref{eq2}\)) を使用した疑似ラベルを生成するための特徴量のクラスタリングと、式 (\(\ref{eq1}\)) を使用したそれらの疑似ラベルの推測による convnet のパラメータ更新を交互に行う。このタイプの交互の手順は自明解 (trivial solution) になりがちである; そのような縮退解を回避する方法について次章で説明する。
3.3 自明解の回避
自明解の存在はニューラルネットワークにおける教師なし学習に特有なものではなく、識別分類器とラベルを併せて学習する任意の手段に特有である。識別クラスタリングは線形モデルに適用してもこの問題を抱えている [57]。一般的に、解決策はクラスタあたりの最小ポイント数の制約またはペナルティに基づいている [58, 59]。これらの項はデータセット全体に渡って計算され、大規模データセットの convnet の学習には適用されない。この章ではこれらの自明解の原因を簡潔に説明し簡単でスケーラブルな解決策を示す。
空のクラスタ: 識別モデルは分類間の決定境界を学習する。最適な境界決定はすべての入力を単一のクラスタに割り当てることである [57]。この問題は、空のクラスタを防ぐメカニズムがないため発生し convnet と同様に線型モデルでも発生する。特徴量の量子化 [60] で使用される一般的な技法は k-means 最適化の間に空のクラスタを自動的に再割り当てすることからなる。より正確には、クラスタが空になったときに空でないクラスタをランダムに選択し、小さくランダムに摂動させたその重心を空のクラスタの新しい重心として使用する。続いて空でないクラスタに属するポイントを 2 つのクラスタに再割り当てする。
自明パラメータ化: 大多数の画像がごく少数のクラスタに割り当てられている場合、パラメータ \(\theta\) はそれらの間を排他的に区別しているだろう。1つのクラスタを除くすべてのクラスタがシングルトンとなるような最も極端なシナリオにおいて式 (\(\ref{eq1}\)) を最小にすることは、入力に関係なく convnet が同じ予測を出力する自明パラメータ化 (trivial parametrization) を引き起こす。この問題は 1 分類あたりの画像数が非常に不均衡であるような場合に教師あり分類でも発生する。例えばハッシュタグのようなメタデータは分布全体を支配するいくつかのラベルを持つ Zipf 分布を示す [61]。この問題を回避するための戦略は分類または疑似ラベルの一様分布に基づいて画像をサンプリングすることである。これは式 (\(\ref{eq1}\)) における損失関数への入力の関与を、それに割り当てられたクラスタのサイズの逆数で重み付けることと等価である。
3.4 実装の詳細
convnet アーキテクチャ: 過去の研究との比較のために、我々は標準的な AlexNet [54] アーキテクチャを使用する。これは 96, 256, 384, 384, 256 フィルタを持つ 5 つの畳み込み層と 3 つの全結合層から成る。我々は Local Response Normalization 層を削除しバッチ正規化層 [24] を使用する。またバッチ正規化付きの VGG-16 [30] アーキテクチャも検討する。教師なし法はしばしば色調に対して直接作用せず、振り替え手段として異なる戦略が考慮されている [25, 26]。我々は Sobel フィルターに基づく固定線形変換を適用して色を除去し局所的なコントラストを増加させている [19, 39]。
訓練データ: 特に断りのない限り ImageNet [6] で DeepCluster を訓練する。これには 1,000 分類に一様に分布する 130 万個の画像が含まれている。
最適化: ネットワークを訓練する際に、中央に切り取った画像の特徴量をクラスタリングしてデータ拡張 (data augmentation) (ランダムな水平フリップやランダムリサイズ、アスペクト比) を実行する。これは特徴量の学習に有用なデータ拡張に対する普遍性を強制する [33]。ネットワークはドロップアウト [62]、一定のステップサイズ、重み \(\theta\) の \(\ell_2\) ペナルティと 0.9 のモーメントで訓練される。各ミニバッチには 256 個の画像が含まれている。クラスタリングのために特徴量は 256 次元にPCA 次元削減され \(\ell_2\) 正規化で白化される。我々は Johnson ら [60] の k-means 実装を使用する。全データセット上での順行走査が必要であるため k-means の実行に 3 分の 1 がかかることに注意。\(n\) エポックごとにクラスタの再割り当てを行ったが、ImageNet での我々の構成(エポック事のクラスタリング更新) でほぼ最適であったことが分かった。Flickr ではエポックの概念が消える: パラメータ更新とクラスタ再割り当てのトレードオフの選択はより微妙である。従って我々は ImageNet とほぼ同じ構成のままにした。我々は 500 エポックでモデルを訓練した。これは AlexNet に対して Pascal P100 GPU で 12 日かかった。
ハイパーパラメータの選択: 下位タスク、つまり fine tuning なしの PASCAL VOC 検証セット上の物体分類におけるハイパーパラメータを選択する。我々は Krähenbühl1 の公開コードを使用する。
4 実験
予備実験では訓練中の DeepCluster の動作を調べる。そして DeepCluster で学習したフィルターを定性的に評価し、我々のアプローチと標準ベンチマークの過去の最先端モデルとを比較した。
4.1 予備調査
我々は次のように定義された正規化相互情報量 (NMI; Normalized Mutual Information) によって同じデータの異なる 2 つの割り当て \(A\) と \(B\) で共有される情報を計測する: \[ {\rm NMI}(A; B) = \frac{I(A; B)}{\sqrt{H(A)H(B)}} \] ここで \(I\) は相互情報量、\(H\) はエントロピーを表す。この測定はクラスタや真のラベルからのどのような割り当てにでも適用できる。2 つの割り当て \(A\) および \(B\) が独立している場合 NMI は 0 に等しい。それらのどちらかが他方から決定論的に予測可能である場合 NMI は 1 に等しい。
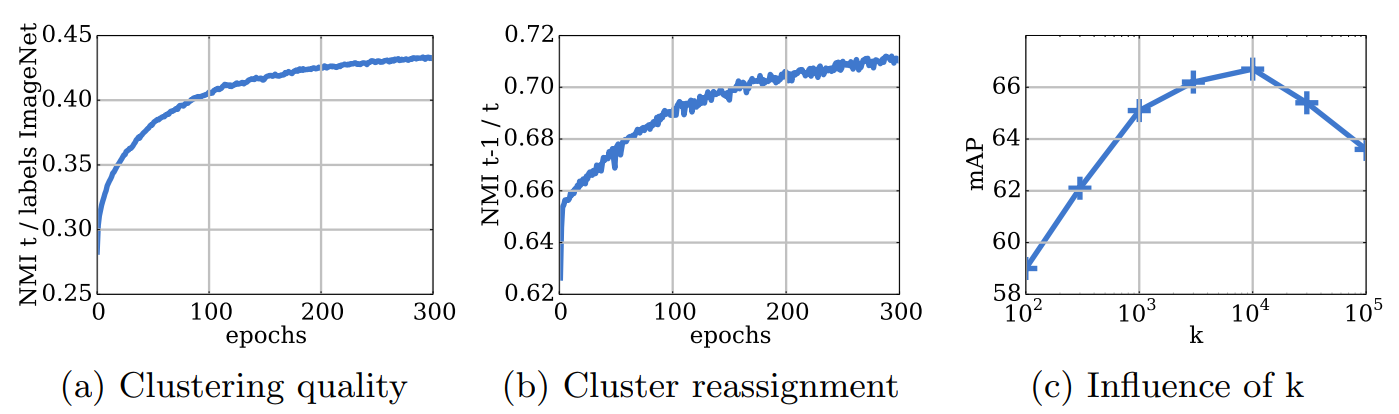
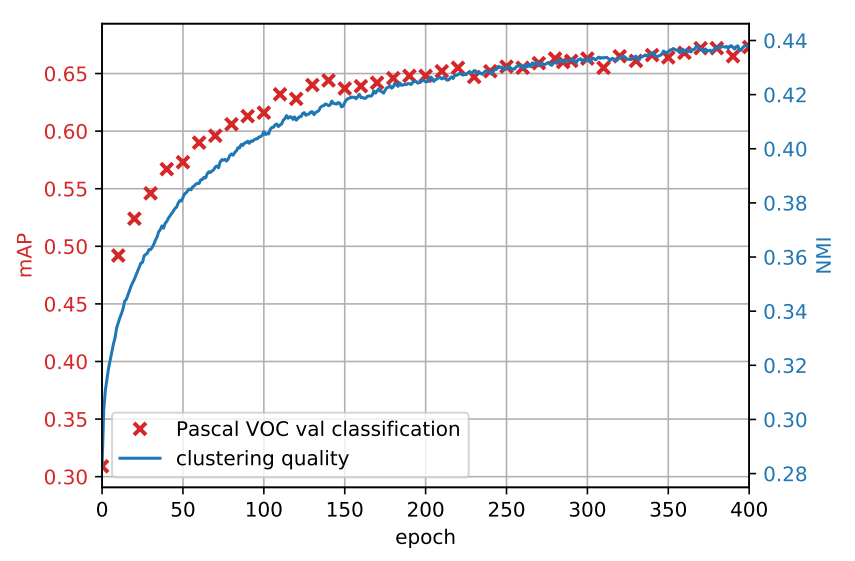
クラスタとラベルの関係: 図 2 (a) は訓練中のクラスタ割り当てと ImageNet ラベル間の NMI 進展を示している。これは分類レベルの情報を推測するためのモデルの性能を測定している。この計測はどのようなモデル選択にも適用できるわけではなく、この分析でのみ使用する。クラスタとラベル間の依存関係は時間と共に増加し、我々の機能が物体分類に関する情報を徐々に獲得していることを示している。
エポック間の再割り当て数: 各エポックは画像を新しいクラスタのセットに再割り当てするが安定性は保証されない。エポック \(t-1\) と \(t\) におけるクラスタ間の NMI を測定することは我々のモデルの実際の安定性に洞察をもたらす。図2 (b) はこの計測の訓練中の進展を示している。NMI が増加、つまり再割り当てが少なくなり、クラスタは時間と共に安定している。しかし NMI は 0.8 未満で飽和している。つまり、画像のかなりの部分がエポック間で恒常的に再割り当てされている。実際、これは訓練には影響を与えず、モデルは発散しない。
クラス多数の選択: 我々は k-means で使用されたクラスタ数 \(k\) がモデルの品質に及ぼす影響を測定する。我々はハイパーパラメータの選択過程、すなはち PASCAL VOC 2007 分類検証セット上の mAP と同じダウンストリームタスクを報告する。対数スケールで \(k\) を変化させ図2 (c) の 300 エポック後の結果を報告する。すべての \(k\) に対する同じ数のエポック後の性能は直接比較できないかも知れないが、これはこの研究で使用されたハイパーパラメータの選択過程を判定している。最良の性能は \(k=10,000\) で得られている。我々が ImageNet でモデルを訓練するなら \(k=1,000\) が最良の結果を出すと推測されるが、明らかにいくらかのオーバーセグメンテーションが有益である。
4.2 可視化
最初のレイヤーフィルター: 図3 は未処理の RGB 画像と Sobel フィルタリングで前処理された画像に DeepCluster で訓練された AlexNet の最初の層のフィルタを示している。未加工の画像で convnet を学習することの難しさはこれまでにも注目されている [19, 25, 26, 39]。図3 の左枠に示すように、ほとんどのフィルタは一般的に物体分類に対してほとんど役に立たない色情報のみを補足する。Sobel で前処理したフィルタは園児検出器のように動作している。

より深い層の探索: 我々は活性化を最大にする入力画像を学習することで対象のフィルタの品質を評価する [65, 66]。我々は、対象のフィルタと、同じ層の他のフィルタとの間のクロスエントロピー関数を付けて、Yosinki ら [64] によって記述された過程に従う。図4 は YFCC100M からの 100 万画像のサブセットからの上位 9 個の活性化画像と同様にそれらの合成画像を示す。予想通り、ネットワークのより深い層ではより大きなテクスチャ構造を獲得しているようである。しかし、図5 (訳注:図4の誤記と思われる) の 2 段目に示すように、最後の畳み込み層の一部のフィルタは以前のレイヤーですでにキャプチャされたテクスチャを単純に複製するように見える。この結果は conv3 または conv4 の性能が conv5 よりも識別性が高いという Zhang ら [43] の観測を裏付けるものである。

最後に、図5 は意味に一貫性があると思われるいくつかの conv5 フィルタの上位 9 個の活性化画像を示す。上段のフィルタには物体分類との関連性が高い構造に関する情報が含まれている。下段のフィルタは図面や抽象的な図形のようなスタイルで発動するようである。

4.3 活性化による線形分類
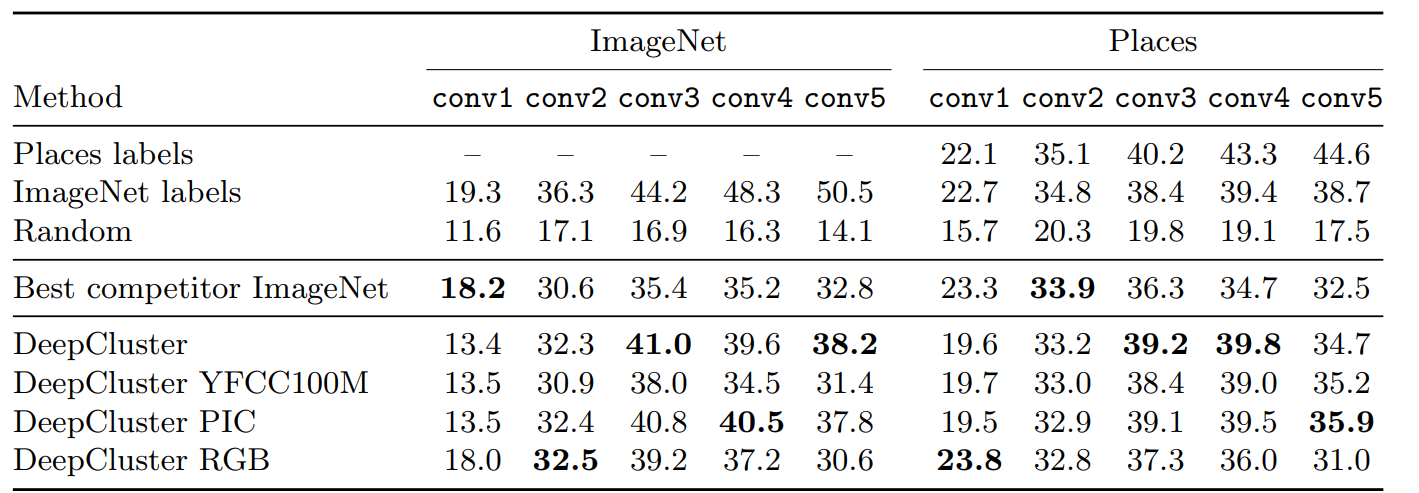
Zhang ら [43] に従い、我々は別の凍結済み畳み込み層の上で線形分類器を訓練する。教師つき特徴量とのレイヤー比較による層は convnet がタスク固有化、すなはち物体分類に特化し始める場所を示している。我々は ImageNet と Places データセット [67] でのこの実験結果を表1 に報告する。我々は訓練セットのクロスバリデーションによってハイパーパラメータを選択する。ImageNet において、DeepCluster は conv2 から conv5 レイヤーで最先端技術を 1-6% 上回っている。conv3 レイヤーで最大の改善が見られるが、conv1 レイヤーの性能は悪く、これはおそらく Sobel フィルタで色情報が破棄されるためである。4.2 節のフィルタ可視化と矛盾なく、conv3 は conv5 よりも優れている。最後に、DeepCluster と教師あり AlexNet の性能の違いは上位層で大きく増加している: conv2-conv3 レイヤーでの差は約 4% に過ぎないが、この差は conv5 で 12.3% に上昇する。これは、おそらく AlexNet が分類レベルの情報のほとんどを保持する場所であることを示している。補足資料では、MLP が最後の層で訓練されているかについても報告する; DeepCluster は最先端技術より 8% 優れている。
Places データセットに対する同じ実験ではいくつかの興味深い洞察が得られた: DeepCluster のように ImageNet で訓練した教師ありモデルでは上位層 (conv4 と conv5) の性能が低下する。さらに、DeepCluster は ImageNet ラベルで訓練されたものと同等の conv3-4 をもたらす。これは、対象のタスクが ImageNet でカバーされる領域から十分に離れている場合、ラベルの重要性が低いことを示している。
4.4 Pascal VOC 2007
最後に Pascal VOC での画像分類、物体検出、セマンティックセグメンテーションに対する DeepCluster の定量的評価を行う。Pascal VOC (2,500画像) は訓練セットのサイズが比較的小さいため、重い計算至言で訓練されたモデルが少数のインスタンスを有するタスクまたはデータセットに適用されるという設定は "現実の" アプリケーションに近い。検出結果は fast-rcnn2 を使用して得られる; セグメンテーション結果は shelhamer ら3 のコードを使用して得られる。分類と検出に対して、我々は Pascal VOC 2007 のテストセットでの性能を報告し、検証セットでのハイパーパラメータを選択する。セマンティックセグメンテーションに対しては、関連する研究に従い Pascal VOC 2012 の検証セットでの性能を報告する。
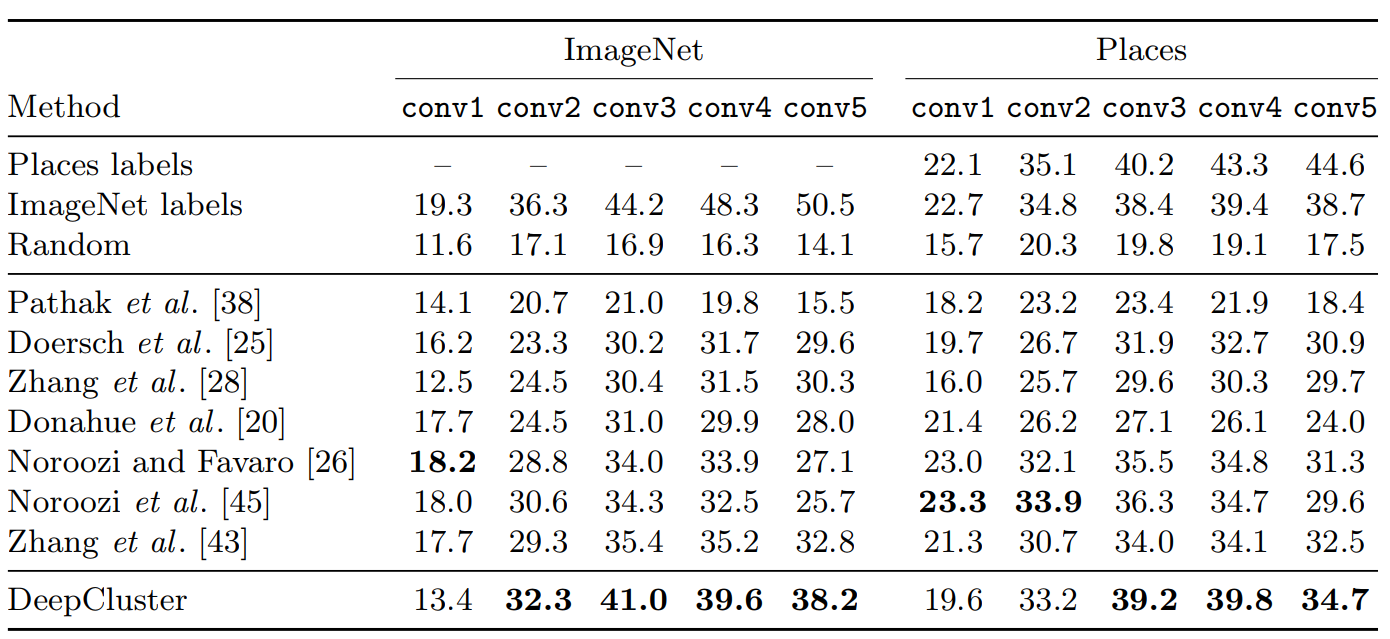
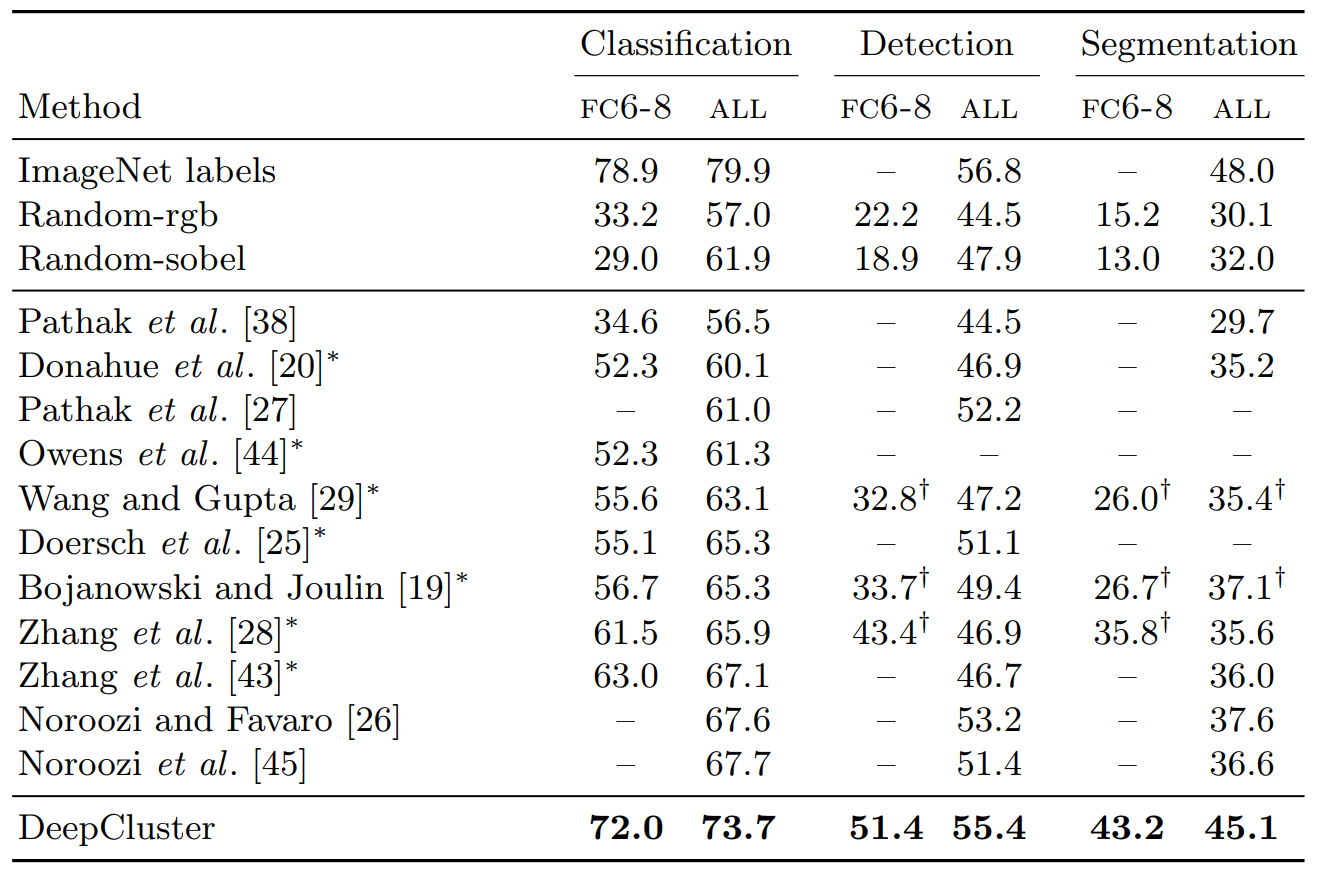
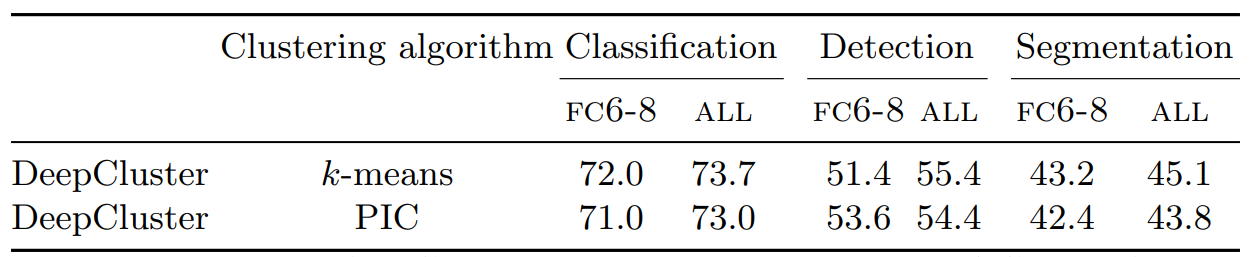
表2 は DeepCluster と他の特徴量学習アプローチとを 3 つのタスクで比較した概要である。これまでの実験で我々はすべての設定において 3 つのタスクすべてで以前の教師なし方法より優れている。最先端技術に対する fine-tuning による改善はセマンティックセグメンテーションで最大となる (7.5%)。検出においては、DeepCluster は以前に公表された方法よりもわずかに優れた性能しか示していない。興味深いことに、fine-tuning されたらランダムネットワークは多くの教師なし方法と比較して性能が向上するが、FC6-8 のみが学習されると性能は低下する。このため、我々は DeepCluster といくつかの比較対象については FC6-8 による犬種戸とセグメンテーションを報告する。これらのタスクは fine-tuning が不可能な実際のアプリケーションに近いものである。この状況では、我々のアプローチと最先端技術とのギャップがより大きくなる (分類において 9% 以上)。
5 論議
教師なし方法の評価に対する現在の標準は ImageNet で訓練され分類レベルのタスクでテストされた AlexNet アーキテクチャの使用を必要とする。DeepCluster でのこのパイプラインによって導入された様々なバイアスを理解し計測するために、我々は異なる訓練セット、異なるアーキテクチャおよびインスタンスレベルの認識タスクを検討する。
5.1 ImageNet versus YFCC100M
ImageNet は細分化された物体分類コンテスト [69] のために設計されたデータセットである。これはオブジェクト指向であり、手動で注釈付けが行われ、バランスの取れた物体カテゴリに編成されている。設計上、DeepCluster はバランスの取れたクラスタを優先し、上記に論議したように、クラスタ数 \(k\) は ImageNet のラベル数といくぶん一致している。これは ImageNet で訓練したときに他の教師なしアプローチよりも DeepCluster が不公平な利点を得ている可能性がある。この影響を測定するために YFCC100M データセット [31] のランダムに選択された 100 万画像のサブセットを事前訓練用に検討する。YFCC100M に使用されているハッシュタグに関する統計によれば、起訴となる "オブジェクト分類" は厳格にバランスが取れてないことが示唆されているため [61]、DeepCluster にはあまり好ましくないデータ分布をもたらしている。
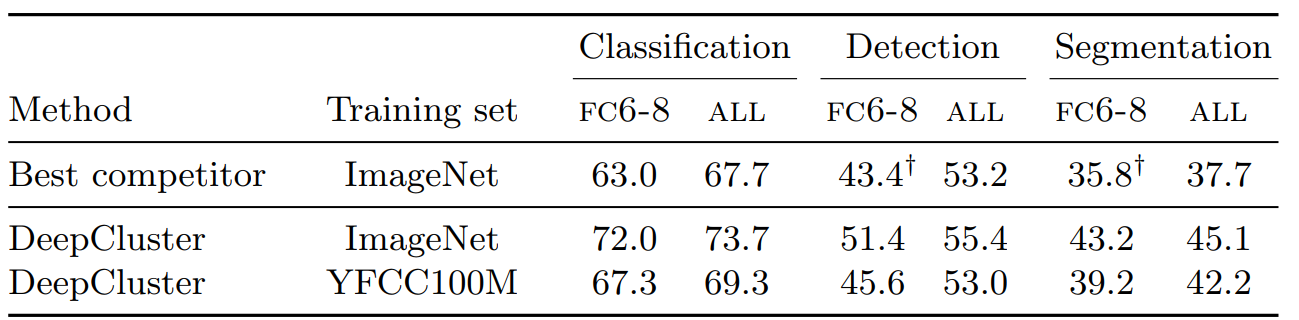
表3 は ImageNet と比較して YFCC100M で事前学習した DeepCluster の Pascal VOC での性能の違いを示している。Doersch ら [25] が指摘したように、このデータセットはオブジェクト指向ではないためパフォーマンスが数パーセント低下することが予想される。しかし、未矯正の Flickr 画像を訓練した場合でも DeepCluster はほとんどのタスクで大幅に上回っている (分類で +4.3%、セマンティックセグメンテーションで +4.5%)。補足資料の残りの結果については同様の結論で報告する。この実験では DeepCluster が画像分布の変更に対して堅牢であることが検証され、その分布が設計に適していなくても最先端の汎用ビジュアル機能をもたらしている。
5.2 AlexNet versus VGG
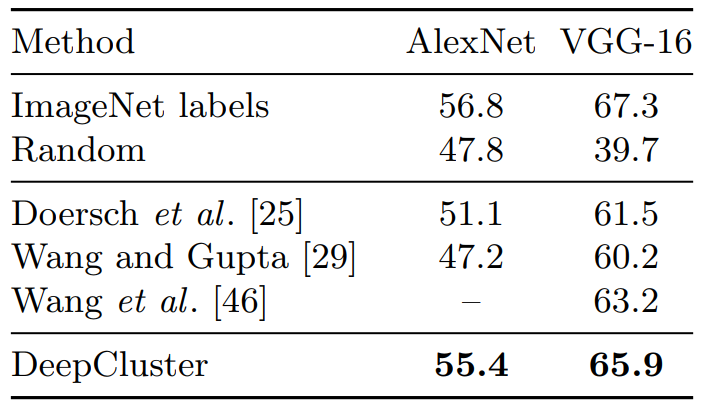
教師ありの設定では、VGG や ResNet [8] のようなより深いアーキテクチャは ImageNet のに対して AlexNet よりも遙かに高い精度を持っている。これらのアーキテクチャを教師なし方法で使用する場合も同じ改善が期待される。表4 では ImageNet を DeepCluster でトレーニングした VGG-16 と AlexNet を比較し fine-tuning による Pascal VOC 2007 物体検出タスクでテストした。我々は他の教師なしアプローチで得られた数値も報告している [25]。アプローチに関係なく、より深いアーキテクチャでは対象タスクの性能が大幅に向上する。DeepCluster を使用して VGG-16 を訓練することで最先端技術を上回る性能が得られ、教師ありのトップラインを 1.4% 下回る位置に運ぶ。教師なしアプローチと教師ありアプローチの違いは両方のアーキテクチャで同じ程度にとどまる (つまり 1.4%) ことに留意されたい。最後に、ランダムな評価基準とのギャップはより大きなアーキテクチャの場合に増加し、教師ありのデータがほとんどない場合に複雑なアーキテクチャに対する教師なし事前学習の妥当性を正当化する。
5.3 インスタンス検索の評価
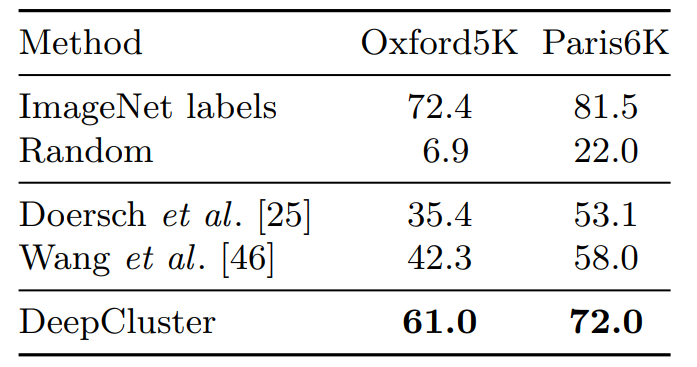
これまでのベンチマークでは教師なしのネットワークが分類レベルの情報を取得する能力を計測していた。インスタンスレベルで画像を区別できるかは評価されていない。そのために我々は下流のタスクとして画像検索を提案する。我々は Tolias ら [70] の実験手順に従い Oxford Buildings [71] と Paris [72] の 2 つのデータセットに従った。表5 では Doerch ら [25] および Wang ら [46] を除いて Sobel フィルタリングで得られる異なる手法で訓練された VGG-16 の性能を報告している。この前処理は Oxford のデータセット上の教師あり VGG-16 の mAP を 5.5 ポイント向上させるが Paris では改善しない。これは DeepCluster の場合と同様の利点を持つが 19 ポイントの平均差を考慮していない。興味深いことに、ランダムな組み合わせでは事前に学習したモデルと比較してこのタスクでは特に不十分である。これは、画像検索は事前学習が不可欠であり、下流タスクとしてそれを研究することは、教師なしアプローチによって生成される性能の品質についてさらなる洞察を与える事ができることを示唆している。
6 結論
本稿では教師なし学習のためのスケーラブルなクラスタリング手法を提案する。これは convnet によって生成された特徴量を k-means でクラスタリングすることと、クラスタ割り当てを識別的な損失の疑似ラベルとして推測することによってその重みを更新することとを繰り返す。ImageNet や YFCC100M のような大規模データセットで訓練されれば、あらゆる標準的な転移タスクにおいてこれまでの最先端技術よりも大幅に優れた性能を達成する。我々のアプローチは入力についてほとんど想定を置かず、多くのドメイン固有知識を必要としていないことから、アノテーションが不足しているドメイン固有の深層表現を学習する良い候補となり得る。
References
- Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object detection with region proposal networks. In: NIPS. (2015)
- Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. arXiv preprint arXiv:1606.00915 (2016)
- Weinzaepfel, P., Revaud, J., Harchaoui, Z., Schmid, C.: Deepflow: Large displacement optical flow with deep matching. In: ICCV. (2013)
- Carreira, J., Agrawal, P., Fragkiadaki, K., Malik, J.: Human pose estimation with iterative error feedback. In: CVPR. (2016)
- Sharif Razavian, A., Azizpour, H., Sullivan, J., Carlsson, S.: Cnn features off-theshelf: an astounding baseline for recognition. In: CVPR workshops. (2014)
- Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: CVPR. (2009)
- Stock, P., Cisse, M.: Convnets and imagenet beyond accuracy: Explanations, bias detection, adversarial examples and model criticism. arXiv preprint arXiv:1711.11443 (2017)
- He, K., Zhang, X., Ren, S., Sun, J.: Delving deep into rectifiers: Surpassing humanlevel performance on imagenet classification. In: ICCV. (2015)
- Huang, G., Liu, Z., Weinberger, K.Q., van der Maaten, L.: Densely connected convolutional networks. arXiv preprint arXiv:1608.06993 (2016)
- Kovashka, A., Russakovsky, O., Fei-Fei, L., Grauman, K., et al.: Crowdsourcing in computer vision. Foundations and Trends R in Computer Graphics and Vision 10(3) (2016) 177–243
- Misra, I., Zitnick, C.L., Mitchell, M., Girshick, R.: Seeing through the human reporting bias: Visual classifiers from noisy human-centric labels. In: CVPR. (2016)
- Friedman, J., Hastie, T., Tibshirani, R.: The elements of statistical learning. Volume 1. Springer series in statistics New York (2001)
- Turk, M.A., Pentland, A.P.: Face recognition using eigenfaces. In: CVPR. (1991)
- Shi, J., Malik, J.: Normalized cuts and image segmentation. TPAMI 22(8) (2000) 888–905
- Joulin, A., Bach, F., Ponce, J.: Discriminative clustering for image cosegmentation. In: CVPR. (2010)
- Csurka, G., Dance, C., Fan, L., Willamowski, J., Bray, C.: Visual categorization with bags of keypoints. In: Workshop on statistical learning in computer vision, ECCV. (2004)
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. In: NIPS. (2014)
- Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
- Bojanowski, P., Joulin, A.: Unsupervised learning by predicting noise. ICML (2017)
- Donahue, J., Kr¨ahenb¨uhl, P., Darrell, T.: Adversarial feature learning. arXiv preprint arXiv:1605.09782 (2016)
- Yang, J., Parikh, D., Batra, D.: Joint unsupervised learning of deep representations and image clusters. In: CVPR. (2016)
- Xie, J., Girshick, R., Farhadi, A.: Unsupervised deep embedding for clustering analysis. In: ICML. (2016)
- Lin, F., Cohen, W.W.: Power iteration clustering. In: ICML. (2010) Deep Clustering for Unsupervised Learning of Visual Features 17
- Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: ICML. (2015)
- Doersch, C., Gupta, A., Efros, A.A.: Unsupervised visual representation learning by context prediction. In: ICCV. (2015)
- Noroozi, M., Favaro, P.: Unsupervised learning of visual representations by solving jigsaw puzzles. In: ECCV. (2016)
- Pathak, D., Girshick, R., Doll´ar, P., Darrell, T., Hariharan, B.: Learning features by watching objects move. CVPR (2017)
- Zhang, R., Isola, P., Efros, A.A.: Colorful image colorization. In: ECCV. (2016)
- Wang, X., Gupta, A.: Unsupervised learning of visual representations using videos. In: ICCV. (2015)
- Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
- Thomee, B., Shamma, D.A., Friedland, G., Elizalde, B., Ni, K., Poland, D., Borth, D., Li, L.J.: The new data and new challenges in multimedia research. arXiv preprint arXiv:1503.01817 (2015)
- Coates, A., Ng, A.Y.: Learning feature representations with k-means. In: Neural networks: Tricks of the trade. Springer (2012) 561–580
- Dosovitskiy, A., Springenberg, J.T., Riedmiller, M., Brox, T.: Discriminative unsupervised feature learning with convolutional neural networks. In: NIPS. (2014)
- Liao, R., Schwing, A., Zemel, R., Urtasun, R.: Learning deep parsimonious representations. In: NIPS. (2016)
- Linsker, R.: Towards an organizing principle for a layered perceptual network. In: NIPS. (1988)
- Malisiewicz, T., Gupta, A., Efros, A.A.: Ensemble of exemplar-svms for object detection and beyond. In: ICCV. (2011)
- de Sa, V.R.: Learning classification with unlabeled data. In: NIPS. (1994) 38. Pathak, D., Krahenbuhl, P., Donahue, J., Darrell, T., Efros, A.A.: Context encoders: Feature learning by inpainting. In: CVPR. (2016)
- Paulin, M., Douze, M., Harchaoui, Z., Mairal, J., Perronin, F., Schmid, C.: Local convolutional features with unsupervised training for image retrieval. In: ICCV. (2015)
- Mairal, J., Koniusz, P., Harchaoui, Z., Schmid, C.: Convolutional kernel networks. In: NIPS. (2014)
- Agrawal, P., Carreira, J., Malik, J.: Learning to see by moving. In: ICCV. (2015)
- Larsson, G., Maire, M., Shakhnarovich, G.: Learning representations for automatic colorization. In: ECCV. (2016)
- Zhang, R., Isola, P., Efros, A.A.: Split-brain autoencoders: Unsupervised learning by cross-channel prediction. arXiv preprint arXiv:1611.09842 (2016)
- Owens, A., Wu, J., McDermott, J.H., Freeman, W.T., Torralba, A.: Ambient sound provides supervision for visual learning. In: ECCV. (2016)
- Noroozi, M., Pirsiavash, H., Favaro, P.: Representation learning by learning to count. In: ICCV. (2017)
- Wang, X., He, K., Gupta, A.: Transitive invariance for self-supervised visual representation learning. arXiv preprint arXiv:1708.02901 (2017)
- Doersch, C., Zisserman, A.: Multi-task self-supervised visual learning. In: ICCV. (2017)
- Bengio, Y., Lamblin, P., Popovici, D., Larochelle, H.: Greedy layer-wise training of deep networks. In: NIPS. (2007)
- Huang, F.J., Boureau, Y.L., LeCun, Y., et al.: Unsupervised learning of invariant feature hierarchies with applications to object recognition. In: CVPR. (2007) 18 Mathilde Caron et al.
- Masci, J., Meier, U., Cire¸san, D., Schmidhuber, J.: Stacked convolutional autoencoders for hierarchical feature extraction. Artificial Neural Networks and Machine Learning (2011) 52–59
- Vincent, P., Larochelle, H., Lajoie, I., Bengio, Y., Manzagol, P.A.: Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. JMLR 11(Dec) (2010) 3371–3408
- Bojanowski, P., Joulin, A., Lopez-Paz, D., Szlam, A.: Optimizing the latent space of generative networks. arXiv preprint arXiv:1707.05776 (2017)
- Dumoulin, V., Belghazi, I., Poole, B., Lamb, A., Arjovsky, M., Mastropietro, O., Courville, A.: Adversarially learned inference. arXiv preprint arXiv:1606.00704 (2016)
- Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: NIPS. (2012)
- Bottou, L.: Stochastic gradient descent tricks. In: Neural networks: Tricks of the trade. Springer (2012) 421–436
- LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proceedings of the IEEE 86(11) (1998) 2278–2324
- Xu, L., Neufeld, J., Larson, B., Schuurmans, D.: Maximum margin clustering. In: NIPS. (2005)
- Bach, F.R., Harchaoui, Z.: Diffrac: a discriminative and flexible framework for clustering. In: NIPS. (2008)
- Joulin, A., Bach, F.: A convex relaxation for weakly supervised classifiers. arXiv preprint arXiv:1206.6413 (2012)
- Johnson, J., Douze, M., J´egou, H.: Billion-scale similarity search with gpus. arXiv preprint arXiv:1702.08734 (2017)
- Joulin, A., van der Maaten, L., Jabri, A., Vasilache, N.: Learning visual features from large weakly supervised data. In: ECCV. (2016)
- Srivastava, N., Hinton, G.E., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.: Dropout: a simple way to prevent neural networks from overfitting. JMLR 15(1) (2014) 1929–1958
- Van De Sande, K., Gevers, T., Snoek, C.: Evaluating color descriptors for object and scene recognition. TPAMI 32(9) (2010) 1582–1596
- Yosinski, J., Clune, J., Nguyen, A., Fuchs, T., Lipson, H.: Understanding neural networks through deep visualization. arXiv preprint arXiv:1506.06579 (2015)
- Erhan, D., Bengio, Y., Courville, A., Vincent, P.: Visualizing higher-layer features of a deep network. University of Montreal 1341 (2009) 3
- Zeiler, M.D., Fergus, R.: Visualizing and understanding convolutional networks. In: ECCV. (2014)
- Zhou, B., Lapedriza, A., Xiao, J., Torralba, A., Oliva, A.: Learning deep features for scene recognition using places database. In: NIPS. (2014)
- Kr¨ahenb¨uhl, P., Doersch, C., Donahue, J., Darrell, T.: Data-dependent initializations of convolutional neural networks. arXiv preprint arXiv:1511.06856 (2015) 69. Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., et al.: Imagenet large scale visual recognition challenge. IJCV 115(3) (2015) 211–252
- Tolias, G., Sicre, R., J´egou, H.: Particular object retrieval with integral maxpooling of cnn activations. arXiv preprint arXiv:1511.05879 (2015)
- Philbin, J., Chum, O., Isard, M., Sivic, J., Zisserman, A.: Object retrieval with large vocabularies and fast spatial matching. In: CVPR. (2007) Deep Clustering for Unsupervised Learning of Visual Features 19
- Philbin, J., Chum, O., Isard, M., Sivic, J., Zisserman, A.: Lost in quantization: Improving particular object retrieval in large scale image databases. In: CVPR. (2008)
- Yosinski, J., Clune, J., Bengio, Y., Lipson, H.: How transferable are features in deep neural networks? In: NIPS. (2014)
- Liang, X., Liu, S., Wei, Y., Liu, L., Lin, L., Yan, S.: Towards computational baby learning: A weakly-supervised approach for object detection. In: ICCV. (2015)
- Douze, M., J´egou, H., Johnson, J.: An evaluation of large-scale methods for image instance and class discovery. arXiv preprint arXiv:1708.02898 (2017)
- Cho, M., Lee, K.M.: Mode-seeking on graphs via random walks. In: CVPR. (2012)
1 Additional results
1.1 ImageNet の分類
Noroozi と Favaro [26] は畳み込み層を凍結しラベルを使用して全結合層を ImageNet で再テストし、検証セットで精度を報告することにより、教師なし方法で訓練されたネットワークで評価することを提案している。この実験は AlexNet の畳み込み層に汎用機能が現れるという Yosinki ら [73] の観測に従っている。DeepCluster と教師なしで訓練された他の AlexNet ネットワークとの比較を表1 のランダムおよび教師あり比較対象と共に報告する。
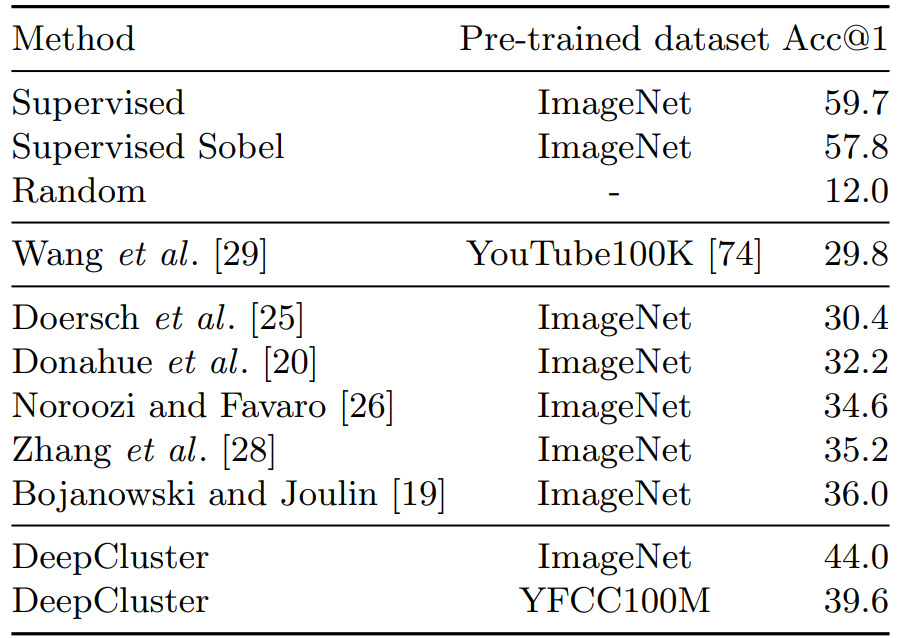
DeepCluster は最先端の教師なし方法より大幅に優れており、これまでの最良の方法より 8% 高い精度を達成している。これは DeepCluster が教師ありの設定で訓練されたネットワークとのギャップを半減挿せることを意味している。
1.2 停止基準
我々は DeepCluster で学習した機能が下流タスク - fine-tuning を行わない Pascal VOC の検証セット上の物体分類 - での訓練エポックに沿ってどのように進展するかを監視する。この計測値を使用してモデルのハイパーパラメータを選択し性能の改善がいつ停止するかを確認する。図1 において我々は、タスクの分類精度と、訓練を通してのクラスタリング品質 (クラスタ割り当てと真のラベルの間の NMI) の尺度の両方の進展を示す。当然のことながら、クラスタリングと性能の品質は同じ変遷に従う。パフォーマンスは 400 エポック後に飽和する。
2 さらなる論議
この章では DeepCluster の技術的な選択肢と代替についてより具体的に説明する。
2.1 代替のクラスタリングアルゴリズム
グラフクラスタリング: 我々は代替のクラスタリング方法として Power Iteration Clustering (PIC) [23] を考慮する。これは大規模なコレクションにおいて優れたパフォーマンスが得られることが示されている [75]。
PIC はグラフクラスタリング手法であるため、我々はすべての画像を画像記述子のユークリッド空間上の 5 つの近傍に接続することで最近傍グラフを作成する。我々は画像 \(x\) に適用されるパラメータ \(\theta\) を持つネットワークの出力を \(f_\theta(x)\) と表す。疎なグラフ行列 \(G = \mathbb{R}^{n\times n}\) を用いる。\(G\) の体格を 0 に設定し、非ゼロのエントリを \[ w_{ij} = e^{-\frac{\|f_\theta(x_i) - f_\theta(x_j)\|^2}{\sigma^2}} \] と定義する。ここで \(\sigma\) は帯域幅パラメータである。この研究では PCI のバリアント [75, 76] を使用する。これは:
- \(v \leftarrow [1/n, \ldots, 1/n]^\mathrm{T} \in \mathbb{R}^n\) に初期化;
- \(v \leftarrow N_1 (\alpha(G + G^\mathrm{T}) v + (1 - \alpha)v)\) を繰り返し, ここで \(alpha=10^{-3}\) は正規化パラメータであり \(N_1: v \mapsto v/\|v\|_1\) は L1-正規化関数である。
- \(G'\) を \(G\) の有効重みなしサブグラフとし、\(G\) の辺 \(i \to j\) を以下のようにする \[ j = \argmax_{j} w_{ij}(v_j - v_i) \] もし \(v_i\) が局所最大値 (つまり \(\forall j \neq i, v_j \leq v_i\)) であれば、そこから開始する辺は存在しない。クラスタは \(G'\) の連結成分によって与えられる。各クラスタは 1 つの局所最大値をもつ。
PIC クラスタリングの利点はクラスタ数を事前に設定する必要がないことである。ただし、パラメータ \(\sigma\) はクラスタ数に影響を与える: \(\sigma\) が大きいほど辺はより均一になり、クラス多数は減少する。\(\sigma\) が増加すると他方が丸められる。以下で我々は \(\sigma = 0.2\) とする。
我々の PIC 実装は最近傍グラフに依存しているため、図2 では DeepCluster の PIC 版とランダムな基準実装とで訓練されたネットワークを使用し、特徴空間内のいくつかのクエリー画像とその 3 つの最近傍ノードを示している。ランダムに初期化されたネットワークは、画像が単純な低レベルの構造を持つ場合 (例えば日没のクエリー) にかなりうまく機能する。図2 の一番上はランダムネットワークのクエリーがかなり良好なパフォーマンスであることを示しているが、一番下のクエリーはランダムネットワークが適切な一致を獲得するには複雑すぎることを示している。さらに、DeepCluster を使用してネットワークを訓練した後で最近傍の一致が大幅に改善されていることが分かる。

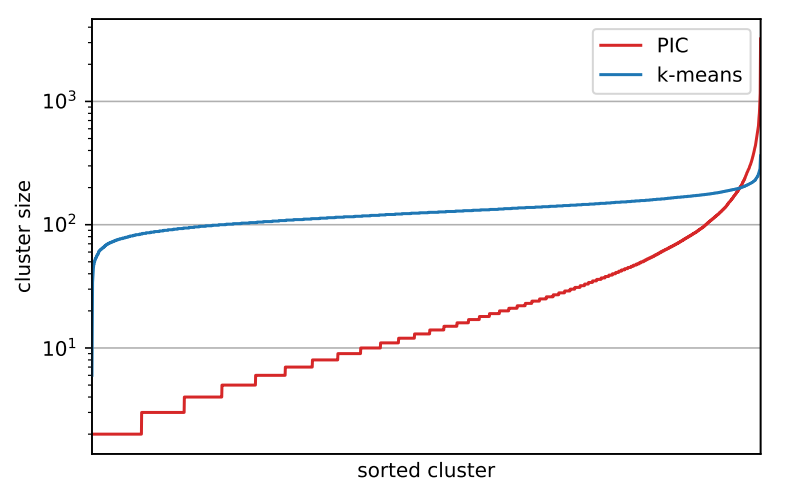
\(k\)-means の比較: まずクラスタ内の画像の分布について考察する。図3 で訓練の最後のエポックでの DeepCluster の PIC バージョンと、その k-means によって製壊死されたクラスタのサイズを示す (この分布はエポックに沿って安定している)。我々は k-means が PIC よりバランスの取れたクラスタを生成することが確認できる。実際、PIC の場合はクラスタの約 3 分の 1 が 10 未満のサイズだが、最も大きいクラスタには約 3,000 個のサンプルが含まれている。このように非常に不均衡なクラスタの状況において、最も大きいクラスタが訓練を支配しないように、我々の方法はクラスタ上の一様分布に基づいて画像をサンプリングすることで convnet を訓練することが重要である。
DeepCluster の PCI 版で訓練したモデルを使用した異なる Pascal VOC 転移タスクの結果を表2 に示す。この転移タスクでは DeepCluster の k-means および PIC 版で訓練されたモデルは同等の範囲で実行される。
2.2 DeepCluster の変種
表3 では、別の訓練セット、代替クラスタリング方法、または入力前処理なしなど、DeepCluster の様々なバリエーションを使用して訓練したモデルの結果を報告している。特に未加工 RGB 画像の DeepCluster パフォーマンスが大幅に低下することが分かった。表4 ではクラスタリング方法と事前訓練セットに応じて DeepCluster のパフォーマンスを比較する。このパフォーマンスは Pascal VOC の fine-tuning あり、なし、ImageNet の完全 MLP の再学習の 3 つの異なる分類タスクで評価する。我々は検証セットの分類精度を報告する。全体として、DeepCluster (k-means を伴う) の正規バージョンは、ImageNet と未矯正の YFCC100M データセットの両方で PIC バリアントよりも優れた結果をもたらすことがわかった。
3 追加の可視化
3.1 VGG-16 特徴量の可視化
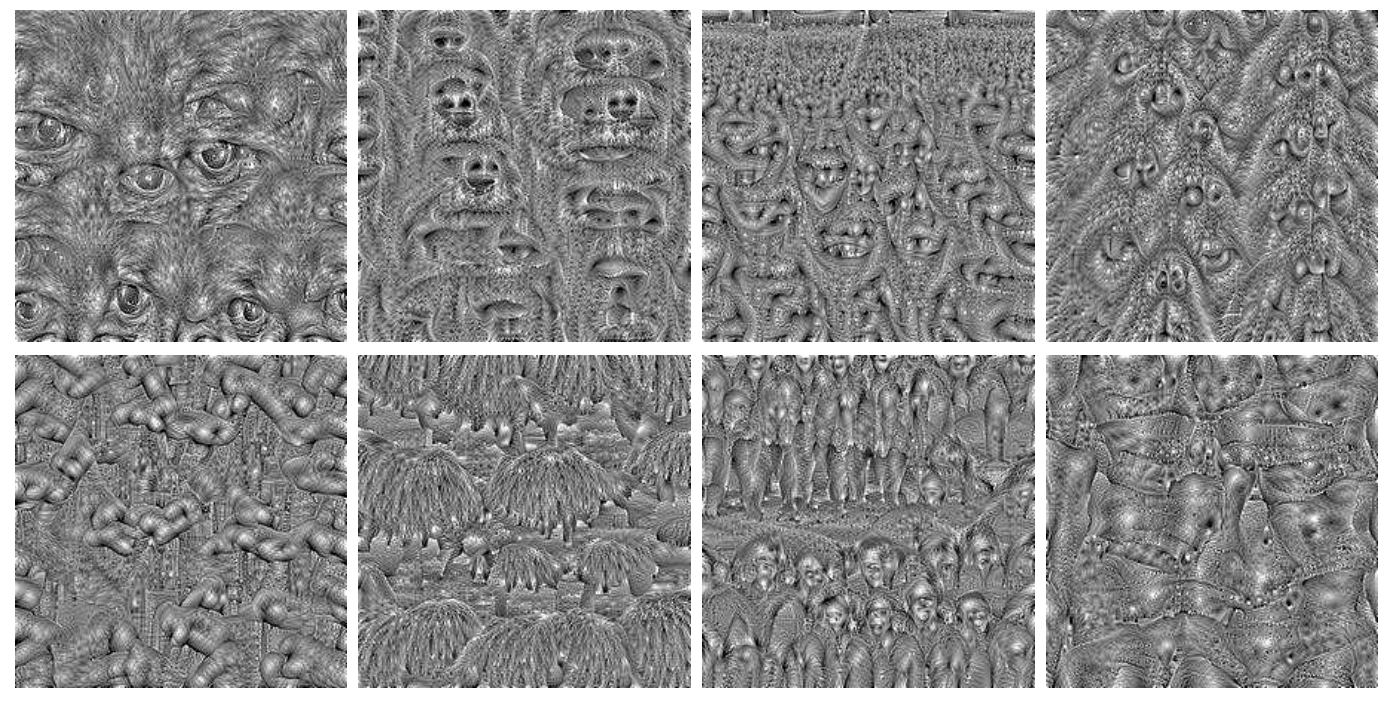
VGG-16 convnet が DeepCluster で学習した表現の品質を評価する。これを行うために、最後の畳み込み層において対象フィルタの平均活性化を最大にする入力画像を学習する。また Flickr の 100 万画像のランダムサブセットで対象フィルタの活性化を最大化する上位 9 枚の画像を表示する。図4 では上位 9 個の画像が意味的または様式的に一貫しているように見えるいくつかのフィルタを示す。どのような教師もなしに学習されたフィルタは非常に複雑なコウゾをとらえていることが分かった。特に図5 では、人間の特徴に焦点を当てているらしいフィルタに対応する合成画像を表示している。

3.2 AlexNet
教師なし学習アプローチが実際にどのクラスタを学習するかは興味深い。この論文の図2 (a) は我々のクラスターが ImageNet 分類と相関していることを示唆している。図6 で我々はどの概念が学習されているかを見るために ImageNet オントロジーでクラスタの純度を調べる。より正確には ImageNet オントロジー (純粋なクラスタ = 画像の 70% 以上がその synset (訳注: 1つまたはそれ以上の同意語の集合; a set of synonym) からのものである) において、異なる深さの異なる synset に対する純粋なクラスタに属する画像の割合を示す。相関はカテゴリ間で著しく異なり、動物と植物の相関が最も高い。
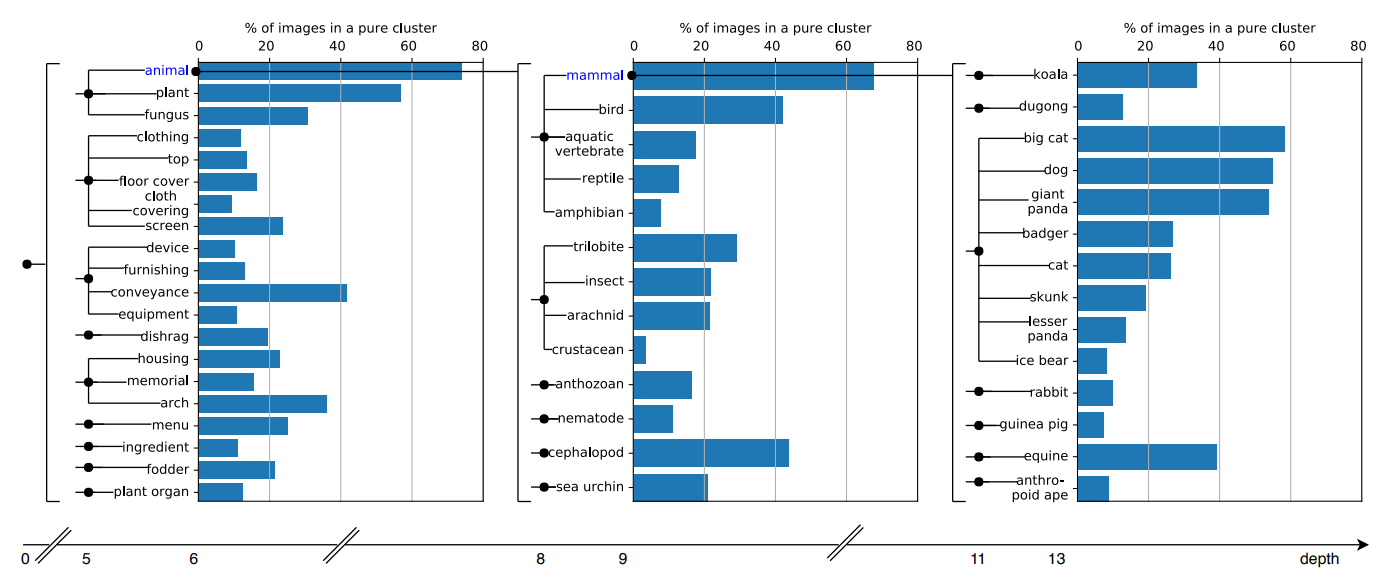
図7 では最後の畳み込み層の最初の 100 個の対象フィルタに対して YFCC100M からの 1,000 万画像のランダムサブセットから上位 9 個の活性化画像を表示している (我々は最上位に活性化された画像が人間を描画していないフィルタを選択した)。我々の方法は純粋に教師なしであるにもかかわらず、いくつかのフィルタは特定の分類の物体を含む画像で発動することがわかる。その他のフィルタは特定の様式やテクスチャに強く反応する。



翻訳抄
CNN と k-means を反復的に使用する教師なし画像特徴量クラスタリング学習 DeepCluster に関する 2018 年の論文。
