Keras: CNN中間層出力の可視化
 概要
概要
Keras 2.2 を使用して CNN の中間層がどのような出力を行っているかを可視化する。ここでは学習済みモデルに VGG16 + ImageNet を使用しカワセミの写真のどの部分を特徴としてとらえているかを示すためのヒートマップを作成する (このヒートマップで示される特徴に対する反応の強さをこのページでは暫定的に特徴強度と呼ぶ)。
CNN で使用される一般的な畳み込み層の出力テンソルは (batch, width, height, intensity) の形状を持っている。例えばカラー画像における RGB カラーチャネルは、それぞれ赤緑青の特徴強度を表していることと等価である。画像データの縦横サイズは畳み込みが進むにつれて小さくなり特徴強度のバリエーションが増えてゆく。この特徴強度を xy 座標上のヒートマップで表したものは CNN が画像のどの部分を特徴としてとらえているかを表している。
特徴強度の可視化は CNN の視点での判断基準を可視化することと同じであり、自分で作成し学習したモデルの考察や、誤分類が発生したときの原因分析にも有用であろう。
手順
1. 画像の読み込み
まず VGG16 の入力サイズ 224x224 に合わせて入力用の画像を読み込む。入力画像には、これから使用する VGG16 が ImageNet で学習した時と同じ正規化処理 vgg16.preprocess_input() を前処理として施す必要がある。対象は 1 枚だけなので expand_dims() で batch 軸方向に拡張する。

from keras.applications.vgg16 import VGG16, preprocess_input
from keras.preprocessing import image
import numpy as np
img = image.load_img(file, target_size=(224, 224))
img = image.img_to_array(img)
img = np.expand_dims(img, axis=0)
img = preprocess_input(img)
print("IMAGE: %s" % str(img.shape)) # IMAGE: (1, 224, 224, 3)2. CNNモデルの読み込みと強度の取得
次に、Keras で使用できる ImageNet 学習済みの VGG16 をロードし、入力の Input 層と分類の Dense 層を除外した畳み込み層 [1:19] のみから出力テンソルを取り出して活性化モデルを作成する。
from keras import models
from keras.applications.vgg16 import VGG16
model = VGG16(weights="imagenet")
layers = model.layers[1:19]
layer_outputs = [layer.output for layer in layers]
activation_model = models.Model(inputs=model.input, outputs=layer_outputs)
activation_model.summary()
activations = activation_model.predict(img)
for i, activation in enumerate(activations):
print("%2d: %s" % (i, str(activation.shape)))この活性化モデルに対して predict() を実行すると各レイヤーごとの特徴強度 (活性化の強さ) が出力される。例えば 3 層目の出力は大きさ 112x112 の特徴強度が 64 種類存在している。
0: (1, 224, 224, 64)
1: (1, 224, 224, 64)
2: (1, 112, 112, 64)
3: (1, 112, 112, 128)
4: (1, 112, 112, 128)
5: (1, 56, 56, 128)
6: (1, 56, 56, 256)
7: (1, 56, 56, 256)
8: (1, 56, 56, 256)
9: (1, 28, 28, 256)
10: (1, 28, 28, 512)
11: (1, 28, 28, 512)
12: (1, 28, 28, 512)
13: (1, 14, 14, 512)
14: (1, 14, 14, 512)
15: (1, 14, 14, 512)
16: (1, 14, 14, 512)
17: (1, 7, 7, 512)3. 特徴強度の可視化
ここで最後のレイヤーの 512 個の特徴強度の中から平均強度が最も高い特徴強度に注目してみよう。
print(max(activations[-1][0].transpose(2, 0, 1), key=lambda x: np.mean(x)).tolist())特徴強度の実体は 2 次元の行列である。カワセミ画像を入力することによって以下の 7×7 行列が得られる。
特徴強度を表す行列はその部分の活性化の強度を表している。つまり行列をヒートマップ化し元の画像の等倍に引き延ばして重ねると、画像のどの部分を特徴としてとらえる特徴強度かを可視化することができる。この例の特徴強度はカワセミのくちばしと足の組み合わせを特徴として認識していることがうかがえる。
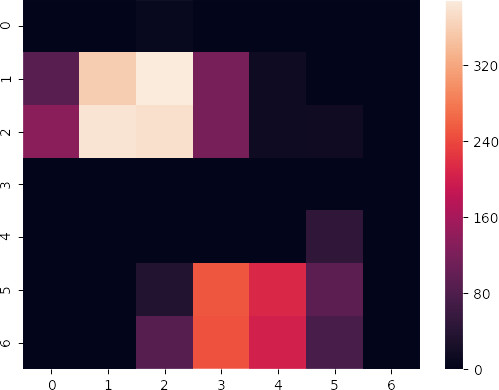

4. 特徴強度の保存
特徴強度はレイヤーが深くなるにつれて数が多くなるため目的のレイヤー出力のみに絞り込むと良いだろう。ここではプーリング層から出力される特徴強度のみを可視化する。
from keras.layers import MaxPooling2D
activations = [activation for layer, activation in zip(layers, activations) if isinstance(layer, MaxPooling2D)]各レイヤーの活性化強度ごとにヒートマップを作成して保存する。ここでは PyPlot ベースの seaborn を使用している。
import matplotlib.pyplot as plt
import seaborn as sns
for i, activation in enumerate(activations):
num_of_image = activation.shape[3]
max = np.max(activation[0])
for j in range(0, num_of_image):
plt.figure()
sns.heatmap(activation[0, :, :, j], vmin=0, vmax=max, xticklabels=False, yticklabels=False, square=False)
plt.savefig("%d_%d.png" % (i+1, j+1))
plt.close()結果
以下は block1_pool から block5_pool のそれぞれから得られた出力のうち、平均強度が高い 5 つを抽出したヒートマップである。












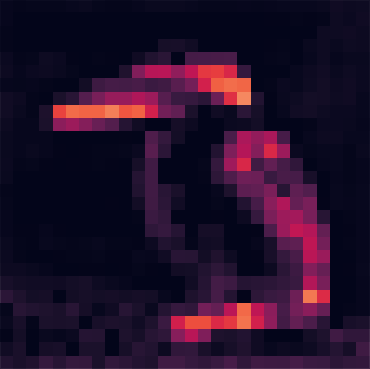






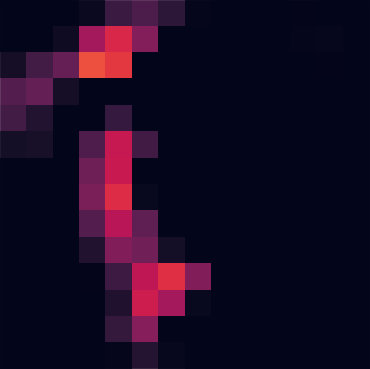



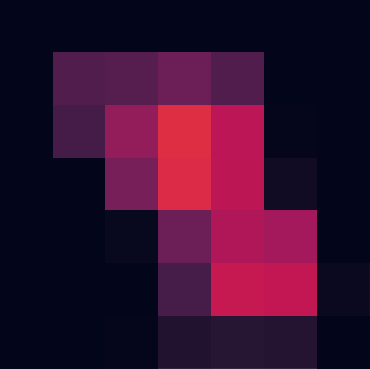

入力に近い層では「輪郭」や「塗り色の塊」を特徴としてとらえていたのに対して、層が深くなるにつれ「頭部」や「背中」といったような、物体を特徴付ける部分に注目するように畳み込まれてゆく。
また層ごとにすべての特徴強度を結合したヒートマップは以下のようになる。

block1_pool
112x112x64

block2_pool
56x56x128
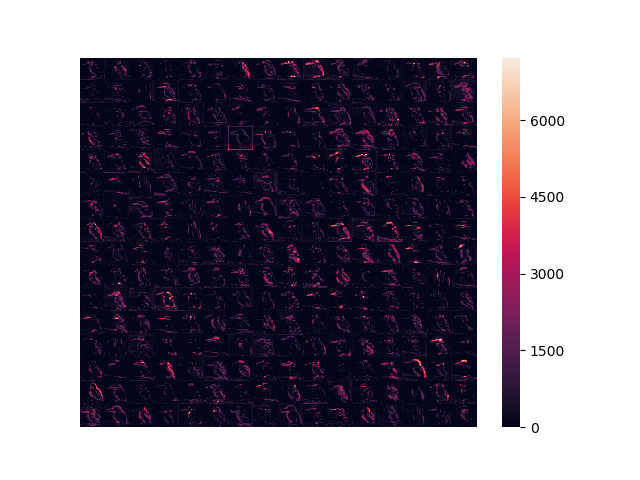
block3_pool
28x28x256
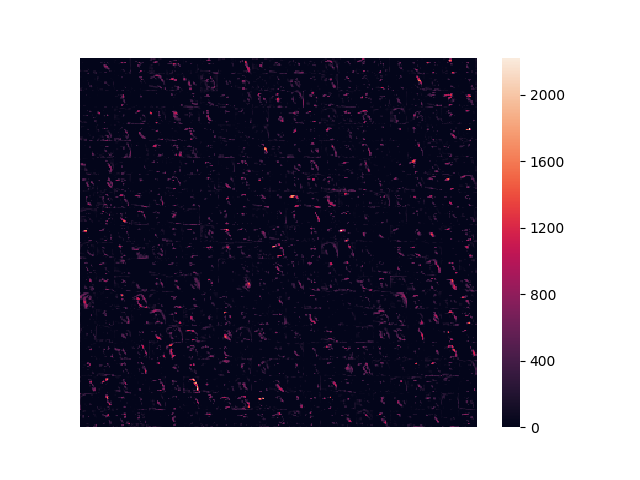
block4_pool
14x14x512
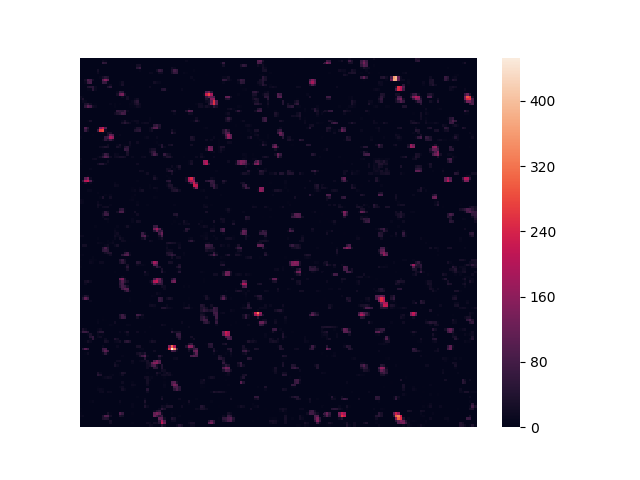
block5_pool
7x7x512
ここで特徴強度の変遷を注意深く見てみよう。
特徴強度を俯瞰すると、入力画像に対してほとんど反応していない真っ黒な特徴強度が存在していることが分かる。浅い層では多くの特徴強度が画像全体に反応していたのに対して、層が進むにつれ明暗の差がはっきりしてゆき、また特徴強度自体のサイズも小さくなる。最終的に特徴強度は「点」に近い表現まで畳み込まれる。
これらの輝点はカワセミ特有の「くちばし」や「背中」などに反応して光っている特徴量と考えられるだろう。逆に、車に対する「タイヤ」や「フェンダー」に対して光る点が存在していてもカワセミの画像に対しては反応しない。つまり、畳み込み後の特徴強度の輝点の分布は画像がどのような特徴を持っているかを表現している。
そして、そのように適度に畳み込んだ特徴強度を 1 次元に flat 化した情報は、画像の特徴量をカテゴリカル分布で示していることと等しい。言い換えれば、畳み込みは 2 次元の画像を特徴ベクトルに変換する課程ともいえる。画像を適切な特徴ベクトルに変換できれば様々な分類器を検討することができるだろう。実際、ここで使用した VGG16 は畳み込み層の後に全結合の分類層が続く構造を持っている。
出力サイズについても考えてみよう。VGG16 での畳み込みは最終的に 7×7 で出力している。1×1 の点まで縮小しない理由は、画像を縦横 7 等分したどの位置にその特徴が現れているかを反映させることで、特徴どうしの配置を考慮できるようにするためである。
プログラミング
以下のスクリプトはプーリング層の出力となった特徴強度をすべて連結してヒートマップを作成する。
# -*- encoding: utf-8 -*-
from keras.layers import MaxPooling2D
from keras.applications.vgg16 import VGG16, preprocess_input
from keras.preprocessing import image
from keras import models
import numpy as np
import math
import matplotlib.pyplot as plt
import seaborn as sns
def make_intermediate_images(file):
# VGG16 の入力に合わせた大きさで画像を読み込み
img = image.load_img(file, target_size=(224, 224))
img = image.img_to_array(img)
img = np.expand_dims(img, axis=0)
img = preprocess_input(img)
print("IMAGE: %s" % str(img.shape))
# ImageNet データセットで学習済みの VGG16 をロード
# 畳み込み層 + プーリング層のみを取り出して (Input レイヤーと分類層は除外) 各レイヤーの出力テンソルから活性化モデルを作成する
model = VGG16(weights="imagenet")
layers = model.layers[1:19]
layer_outputs = [layer.output for layer in layers]
activation_model = models.Model(inputs=model.input, outputs=layer_outputs)
activation_model.summary()
activations = activation_model.predict(img)
for i, activation in enumerate(activations):
print("%2d: %s" % (i, str(activation.shape)))
# プーリング層の出力のみに絞る (畳み込み層の出力も可視化できるが量が多くなるため)
activations = [(layer.name, activation) for layer, activation in zip(layers, activations) if isinstance(layer, MaxPooling2D)]
# 出力層ごとに特徴画像を並べてヒートマップ画像として出力
for i, (name, activation) in enumerate(activations):
num_of_image = activation.shape[3]
cols = math.ceil(math.sqrt(num_of_image))
rows = math.floor(num_of_image / cols)
screen = []
for y in range(0, rows):
row = []
for x in range(0, cols):
j = y * cols + x
if j < num_of_image:
row.append(activation[0, :, :, j])
else:
row.append(np.zeros())
screen.append(np.concatenate(row, axis=1))
screen = np.concatenate(screen, axis=0)
plt.figure()
sns.heatmap(screen, xticklabels=False, yticklabels=False)
plt.savefig("%s.png" % name)
plt.close()
# max = np.max(activation[0])
# fs = activation[0].transpose(2, 0, 1) # (intensity, width, height)
# fs = sorted(fs, key=lambda x: -np.mean(x))[:5]
# for j, f in enumerate(fs):
# plt.figure()
# sns.heatmap(f, vmin=0, vmax=max, xticklabels=False, yticklabels=False, square=True, cbar=False)
# plt.savefig("%s-%d.png" % (name, j+1))
if __name__ == "__main__":
import sys, keras, tensorflow
print("Python %s" % sys.version)
print("Keras %s" % keras.__version__)
print("TensorFlow %s" % tensorflow.__version__)
print("Seaborn %s" % sns.__version__)
make_intermediate_images(sys.argv[1])
実行を確認したバージョンは以下の通り。
Python 3.6.0 (v3.6.0:41df79263a11, Dec 23 2016, 08:06:12) [MSC v.1900 64 bit (AMD64)]
Keras 2.2.0
TensorFlow 1.8.0
Seaborn 0.8.1エラー
VGG16 の Input レイヤーを外さないまま活性化モデルを作成した時に発生したエラー。Input レイヤーは inputs=model.input で別に指定しているため Input が二重になってしまったようだ。outputs を Conv2D と MaxPooling2D のみにしたら解消された。
tensorflow.python.framework.errors_impl.InvalidArgumentError: input_1:0 is both fed and fetched.参照
- Francois Chollet (2018)PythonとKerasによるディープラーニング, マイナビ出版
- 中間レイヤーの出力を得るには?
- サンプル画像: Malachite kingfisher (Corythornis cristatus stuartkeithi)

