OpenCV: 局所特徴量による類似画像検索/分類
 概要
概要
画像の局所特徴量は回転や拡大縮小によって分布が変換しない特徴ベクトルである。つまり特徴量の分布の形が似ている画像は特徴点の配置が似ている画像であることが予想される。この局所特徴量を \(n\) 次元空間上でクラスタ化し、画像ごとに算出した Bag of Visual Words (Bag of Features とも) を使用して画像の類似度を得ることで、撮影されている物体の特徴に基づいた画像検索を行うことを目的とする。
Bag of Visual Words
主に自然言語処理の分野で使われている Bag of Words (BoW) は文書の特徴を「単語ごとの出現回数」で表した特徴ベクトルである。コーパスに含まれる単語数を \(k\)、コーパスの \(i\) 番目に位置する単語を \(w_i \in \{w_1, \ldots, w_k\}\)、文書 \(d\) における単語 \(w_i\) の出現回数を \(t_{i,d}\) としたとき、ある文書 \(d\) の BoW は \(T_d = (t_{1,d}, t_{2,d}, \ldots, t_{k,d})\) で表される。つまり BoW とは文書ごとの単語出現数のヒストグラム(度数分布)を作ることと等しい。また \(T_d\) の成分を文書に含まれる単語数で割ればその文書での単語ごとの生起確率分布となる。
BoW と同じ様に説明すると、Bag of Visual Words は画像の特徴を「特徴点が属するクラスタごとの出現回数」で表した特徴ベクトルである。まず局所特徴量の \(n\) 次元空間を \(k\) 個のクラスタに分割する。\(n\) 次元空間の \(i\) 番目に位置するクラスタを \(w_i \in \{w_1, \ldots, w_k\}\)、画像 \(d\) においてクラスタ \(w_i\) に属する特徴点の出現回数を \(t_{i,d}\) としたとき、ある画像 \(d\) の BoVW は \(T_d = (t_{1,d}, t_{2,d}, \ldots, t_{k,d})\) で表される。これはクラスタ = コーパス (ボキャブラリ) として BoW での出現単語ヒストグラムを出現クラスタヒストグラムに置き換えたことと同じである。
このような Bag of Visual Words を使用することで、類似文書検索など、自然言語処理分野で BoW を用いた理論を画像の特徴量にも応用することができる。
アルゴリズム
検索対象の画像を特徴量でインデックス化する大まかな手順は以下の通り。
- 検索対象の全画像の特徴点から \(n\) 次元ベクトルの局所特徴量を抽出する
- すべての特徴量を \(n\) 次元空間上に配置し \(k\) 個の特徴クラスタに分割してそれぞれの重心を算出する
- それぞれの特徴量ごとに所属する特徴クラスタを求め、画像が含んでいる特徴クラスタのヒストグラムを作成する
また画像の特徴量の類似度に基づく検索 (スコアリング) は以下の手順で行う。
- 与えられた画像の特徴点から \(n\) 次元ベクトルの局所特徴量を抽出する
- それぞれの特徴量ごとに所属する特徴クラスタを求め、画像が含んでいる特徴クラスタのヒストグラムを作成する
- すべての検索対象画像のヒストグラムとの分布の類似度を求め、類似度の高い順に出力する
ここで 1)局所特徴量の求め方 2)クラスタリング方法 3)クラスタの所属判定 4)分布類似度の求め方などのアルゴリズムは考慮の余地があるだろう。
特徴量によるインデックス化
検索対象の画像から特徴点を検出し、各点に対する特徴ベクトル (descriptor) を算出する。特徴点は画像の左上を (0, 0) とした (x, y) 座標でプロットした位置に特徴が検出された事を意味する。特徴ベクトルは特徴点それぞれに対して拡大/縮小や回転で不変なベクトル値である。
例として仏像、車、ギターの画像を検索のためにインデックス化する。下の図では仏像の画像から 1118 個の特徴点が検出され、それぞれ 64 次元の特徴ベクトルが算出されている。

OpenVC での特徴点の検出と特徴ベクトルの算出は Feature2D.detectAndCompute() で同時に行うことができる。ここではグレースケールの KAZA を使用している (したがって色合いによる特徴は無視される)。
detector = cv2.KAZE_create()
image = cv2.imread(file, cv2.IMREAD_GRAYSCALE)
keypoints, descriptions = detector.detectAndCompute(image, None)画像含まれる特徴点の数を \(m\) とした場合、keypoints は \(m \times 2\)、descriptors は \(m \times n\) の行列として表される。\(m\) は画像によって異なる。
検索対象のすべての画像に対してこれらの特徴ベクトルを算出し、\(n\) 次元空間に配置して \(k\) 個のクラスタとそれぞれの重心 (あるいはコードブック) を抽出する。下のイメージ図は便宜上 2 次元にしているが実際は \(n\)=64 次元空間を \(k\)=5 クラスタに分割している想定。
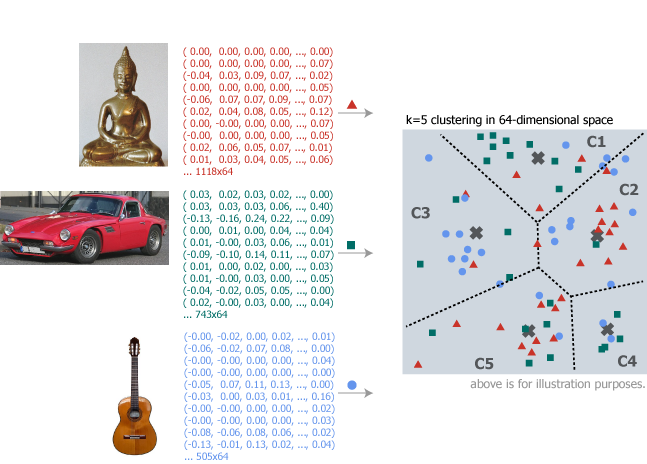
OpenCV では BOWKMeansTrainer クラスを使用して k-means によるクラスタリングと重心を算出することができる。例の図では \(k\)=5 だが現実的には \(10^1 \sim 10^3\) オーダーの値をとる。
# 特徴量空間を k クラスタに分け重心を求める
k = 5
detector = cv2.KAZE_create()
bowTrainer = cv2.BOWKMeansTrainer(k)
for file in files:
image = cv2.imread(file, cv2.CV_GRAYSCALE)
if image is not None:
_, descriptors = detector.detectAndCompute(image, None)
if descriptors is not None:
bowTrainer.add(descriptors.astype(float32))
centroids = bowTrainer.cluster()
centroids はクラスタごとの重心を示している \(k \times n\) 行列である。この重心に対する距離によって特徴ベクトルがどのクラスタに属しているかを判断する。
画像それぞれに対してクラスタごとに特徴ベクトルの所属数を数え上げヒストグラムを作成する。
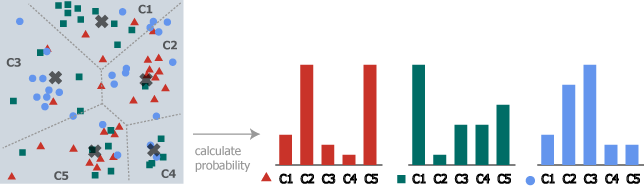
OpenCV では画像とクラスタ重心から特徴ベクトルのクラスタごとの確率分布を算出するユーティリティ BOWImgDescriptorExtractor が用意されている。画像ごとのヒストグラムは特徴点数で割って正規化し確率分布 (カテゴリカル分布) となっている。
matcher = cv2.BFMatcher()
extractor = cv2.BOWImgDescriptorExtractor(detector, matcher)
extractor.setVocabulary(centroids)
probs = []
for file in files:
descriptor = None
image = cv2.imread(file, cv2.IMREAD_GRAYSCALE)
if image is not None:
keypoints = detector.detect(image, None)
if keypoints is not None:
descriptor = extractor.compute(image, keypoints)[0]
probs.append(descriptor)
画像ごとの特徴点 keypoints は記憶領域が許せばクラスタ作成時のものを保持しておいても良い。
最後に、類似画像検索のインデックスとして保存しておく情報は以下の二点である。
- クラスタ重心 (ある特徴ベクトルを与えられたときどのクラスタに属するかを判別する情報)
- 各画像ごとのヒストグラム
特徴量によるスコアリング
インデックス時と同じように、検索する画像の特徴ベクトルからヒストグラムを算出する。
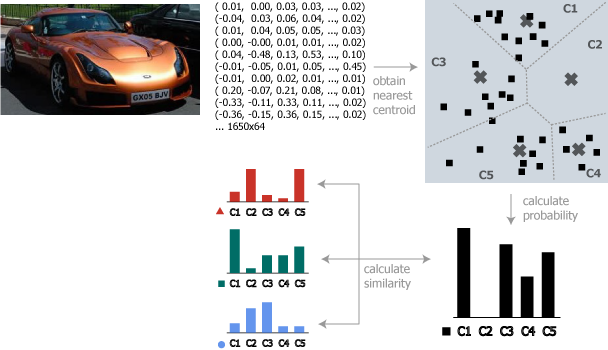
Histogram Intersection はヒストグラムの簡易的な類似度算出式である。これは 2 つのヒストグラムの重なっている部分を合計する。画像 \(x\) におけるクラスタ \(i\) の生起確率を \(P_x(i)\) とした場合、画像 \(a\) と \(b\) の確率分布の類似度は以下のように表すことができる。
\[ {\it Similarity}_{a,b} = \sum_{i=1}^k \min \left\{ P_a(i), P_b(i) \right\} \]OpenCV で得られるヒストグラムは正規化された確率分布になっているため、重なりの合計値は類似度として使用することができる。
実装
操作はインデックス作成と検索とに分かれている。BOWTrainer
| 特徴点抽出 | KAZE | カラーモデル | グレイスケール |
|---|---|---|---|
| クラスタリング | k-means | 類似度 | ヒストグラム交差 |
# -*- encoding: utf-8 -*-
import cv2
import numpy as np
import os.path
import sys
import pickle
detector = cv2.KAZE_create()
color_model = cv2.IMREAD_GRAYSCALE
def calc_clusters(files, k):
"""
指定された画像ファイルから局所特徴量を抽出し K 個のクラスタに分割した重心を算出する。
:param files: クラスタを算出する画像ファイル
:param k: クラス多数
:return: [クラスタ重心, ファイルごとの特徴点]
"""
trainer = cv2.BOWKMeansTrainer(k)
keypoints = []
for i, file in enumerate(files):
image = _read_image(file, color_model)
if image is not None:
ks, ds = detector.detectAndCompute(image, None)
if ds is not None:
trainer.add(ds.astype(np.float32))
keypoints.append(ks)
return [trainer.cluster(), keypoints]
def calc_probabilities(files, centroids, keypoints = None):
"""
指定されたクラスタ重心を使用してそれぞれのファイルのクラスタ所属確率(ヒストグラム)を算出する。
:param files: クラスタ所属確率を計算する画像ファイル
:param centroids: クラスタごとの重心
:param keypoints: 算出済みの特徴点 (None の場合は内部で算出)
:return: 画像ファイルごとのクラスタ所属確率
"""
matcher = cv2.BFMatcher()
extractor = cv2.BOWImgDescriptorExtractor(detector, matcher)
extractor.setVocabulary(centroids)
probs = []
for i, file in enumerate(files):
descriptor = None
image = _read_image(file, color_model)
if image is not None:
ks = None
if keypoints is not None and keypoints[i] is not None:
ks = keypoints[i]
else:
ks = detector.detect(image, None)
if ks is not None:
descriptor = extractor.compute(image, ks)[0]
probs.append(descriptor)
return probs
def calc_similarity(prob1, prob2):
"""
指定されたクラスタ所属確率の類似度を算出する。
:param prob1: クラスタ所属確率1
:param prob2 クラスタ所属確率1
:return: クラスタ所属確率の類似度
"""
return sum(map(lambda x: min(x[0], x[1]), zip(prob1, prob2)))
def _read_image(file, flag = color_model):
"""
指定された画像を読み込んで画像として返す。cv2.imread() は Windows で日本語のパスに対応していないため。
:param file: 読み込む画像ファイル
:param color_model 画像のカラーチャネル
:return: 画像
"""
with open(file, "rb") as f:
binary = np.fromfile(file, dtype=np.uint8)
return cv2.imdecode(binary, flag)
if __name__ == "__main__":
command = sys.argv[1]
k = 128
if command == "index":
# インデックス作成
index = sys.argv[2]
files = sys.argv[3:]
centroids, _ = calc_clusters(files, k)
with open(index, "wb") as f:
pickle.dump({"centroids": centroids, "files": files}, f)
elif command == "search":
index = sys.argv[2]
file = sys.argv[3]
centroids = None
files = None
with open(index, "rb") as f:
obj = pickle.load(f)
centroids = obj["centroids"]
files = obj["files"]
# 類似画像検索
prob = calc_probabilities([file], centroids)[0]
probs = calc_probabilities(files, centroids)
rank = []
for f, p in zip(files, probs):
if p is not None:
sim = calc_similarity(prob, p)
rank.append([f, sim])
rank = sorted(rank, key = lambda x: - x[1])
for f, sim in rank:
print("%.3f %s" % (sim, f))
elif command == "similarity":
files = sys.argv[2:]
centroids, keypoints = calc_clusters(files, k)
probs = calc_probabilities(files, centroids, keypoints)
for i, f1 in enumerate(files):
sys.stdout.write(("," if i is not 0 else "") + f1)
sys.stdout.write("\n")
for i, f1 in enumerate(files):
sys.stdout.write(f1)
for j, f2 in enumerate(files):
sim = calc_similarity(probs[i], probs[j])
sys.stdout.write("," + ("%.3f" % sim))
sys.stdout.write("\n")
実行結果
まず検索対象の画像からクラスタ重心を算出しインデックス sample.pickle を作成する (検索対象の画像それぞれの KeyPoint も保存しておくべきだが長くなるので省略)。
> python similar-image-retrieval.py index sample.pickle img\buddha.jpg img\guitar.jpg img\vehicle.jpg
次に画像 (クエリー) とインデックスを指定して検索を実行。

> python similar-image-retrieval.py search sample.pickle query.jpg
0.500 img\vehicle.jpg
0.473 img\buddha.jpg
0.182 img\guitar.jpgインデックスに使用した各画像との類似度は以下のようになった。意外と仏像が高く出たがギターとは類似していない。



TIPS
クラスタリングの改善
k-means は速いクラスタリングアルゴリズムではない。を使用した \(n\) 次元クラスタリングの処理が非常に遅い。これは k-means のためである。
画像分類のように主体となっている物体が既知であれば、その代表的な特徴点を持つ画像のみに絞っても良いかもしれない。
cv2.error: OpenCV(3.4.1) C:\projects\opencv-python\opencv\modules\features2d\src\matchers.cpp:744: error: (-215) _queryDescriptors.type() == trainDescType in function cv::BFMatcher::knnMatchImplKeyPoint の保存
KeyPoint クラスは中身が C++ で実装されているため Pickle を使っても正しくシリアライズされない。以下のようにフィールドを展開して保存/復元する必要がある。
def _dump(keypoints):
return [{"pt": p.pt, "size": p.size, "angle": p.angle, "response": p.response, "octave": p.octave, "class_id": p.class_id} for p in keypoints]
def _load(objs):
return [cv2.KeyPoint(x=p["pt"][0], y=p["pt"][1], _size=p["size"], _angle=p["angle"], _response=p["response"], _octave=p["octave"], _class_id=p["class_id"]) for p in objs]
