Recurrent Neural Network
 概要
概要
Recurrent Neural Network (RNN; 再帰型ニューラルネットワーク) は時系列の情報パターンを認識するように設計されたニューラルネットワーク。自然言語処理、遺伝子、センサーデータ、株式など、データのシーケンスを節に分解して時系列として扱うことができるデータを対象としている。このような時系列データの事前学習により、あるシーケンスパターンの続きにどのようなデータが出現するかを予測する。
RNN は学習期間が長くなると過去の入力の影響が低下する (古い情報を忘れる)。この問題を解決するために重要な情報を選択的に長期間記憶するよう改良したアルゴリズムが LSTM である。
RNN の構造
DNN は入力層、隠れ層、出力層で構成されていたが
RNN ではある時点 \(t-1\) の隠れ層の出力を次の時点 \(t\) での入力に用いる。文字を順に読み込んで次の文字を予測する RNN は以下のようになる。
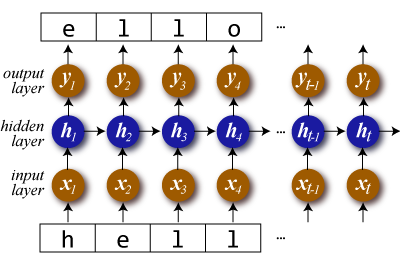
ここで隠れ層 \(\vector{h}_t\) を RNN セルと呼ぶ。
\(s_t\) を時点 \(t\) における状態、\(x_t\) を時点 \(t\) における入力、\(w_{\rm rec}\), \(w_x\) を重み、\(b_{\rm rec}\), \(b_x\) をバイアスとしたとき RNN セルの状態 \(s_t\) は以下のように表すことができる。\[ s_t = f(s_{t-1} w_{\rm rec} + b_{\rm rec} + x_t w_x + b_x) \] 状態 \(s_t\) は時間と共に変化し 1 時点毎の遅延でフィードバックされる。この遅延フィードバックループは時点間の状態情報を記憶するメモリモデルを提供する。
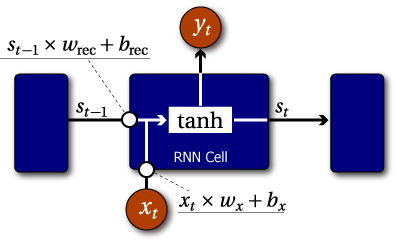
ある時点 \(t\) での出力 \(y_t\) は一般的にその近傍の 1 つ以上の状態 \(s_{t-i} \sim s_{t+j}\) から算出される。
ある時点の状態は遅延フィードバックが進むにつれ何度も \(w_{\rm rec}\) が積算されて影響が極小化する (あるいは発散する)。つまり RNN は入力シーケンスに重要な特徴を見いだしたとしても早くに忘却してしまう特性を持っている。
プログラミング
以下 deeplearning4j を対象とする。
入出力データの構造
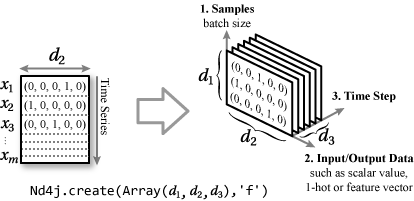
Feedforward Neural Network での入出力が「バッチサイズ × ベクトル幅」の 2 次元行列だったのに対して RNN (LSTM) は時系列を追加した 3 三次元の形となる。バッチサイズはベクトル処理効率のためにまとめて処理する単位、サンプル数はバッチサイズに基づいてグループ化した 1 処理単位 (DataSet) でのデータ数とする。
ある時点 \(t\) の特徴ベクトル \(\vector{x}_t = (x_{t1}, x_{t2}, \ldots, x_{tn})\) が時系列順に \(m\) 個存在する場合、\[ \vector{X} = \left\{ \begin{array}{c} \vector{x}_1 \\ \vector{x}_2 \\ \vdots \\ \vector{x}_m \end{array} \right\} = \left\{ \begin{array}{c} (x_{11}, x_{12}, \ldots, x_{1n}) \\ (x_{21}, x_{22}, \ldots, x_{2n}) \\ \vdots \\ (x_{m1}, x_{m2}, \ldots, x_{mn}) \\ \end{array} \right\} \]
\(\vector{X}\) で表される時系列ベクトルデータに対して、同じ時点数 \(m\) を持つ \(\vector{Y}\) を出力するモデル \[ \vector{y}_t = f(\vector{x}_t) \] ここで \[ \vector{y}_t = \vector{x}_{t+\alpha} \]
時系列に並んだベクトル値から deeplearning4j の入力/出力に利用できる形に変換する必要がある (DL4j では出力をラベルと呼んでいる)。
最も簡単な方法はバッチサイズ 1 で一つの DataSet にすべての学習データを詰め込むことだ。単に RNN/LSTM の挙動を見たいだけであればこれで十分だろう。net.fit(dataSet) をepoch 回数繰り返して学習を行う。
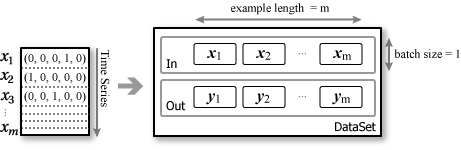
計算速度を高めたり、学習データがメモリに乗り切らないほどの量であれば、バッチサイズ × example length ごとに DataSet を分割する DataSetIterator を実装する。この場合、端数部分の DataSet の扱いに注意しなければならない。
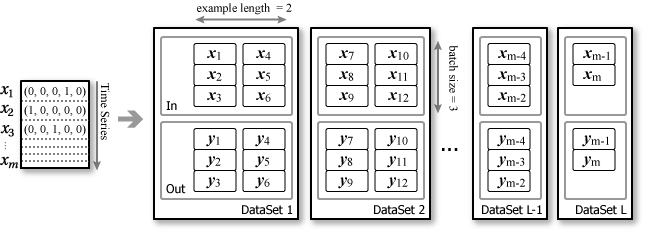
DataSet はデータが時系列順に並んで入出力ペアの整合性がとれていれば学習データのどこから始まっていても構わない (たぶんその調整は精度や収束速度に影響するだろう)。例えば上記の図で DataSet 2 を \((x_2, y_2)\) から開始しても良いし、\((x_4, y_4)\) (つまり batch size ごと) から開始しても良い。DataSet ごとにランダムに開始時点を選んでも良い。
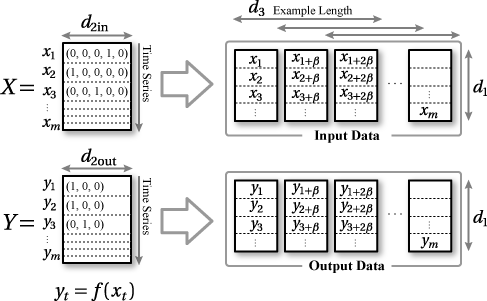
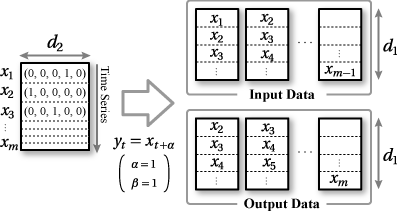
deeplearning4j の入力/出力は [サンプル数(ミニバッチサイズ), 入力ベクトル, DataSet は
