画像収集
 概要
概要
機械学習を行う目的で対象物の画像を収集する方法について現時点での手順をまとめておく。処理は大まかに以下のステップを想定しているが:
- 画像検索サイトの API を使用して対象物が写っていると思しき画像の URL を収集する。
- 収集した URL の画像をローカルストレージにダウンロードする。
- 画像認識 API を使用して明らかに収集対象ではない画像をフィルタリングする。
上記 2. に関しては各言語の標準あるいは追加ライブラリで一般的に可能な手段であるためここでは扱わない。
実行の最適化
画像収集スクリプトを作成するときに注意すべき効率化の点について述べる。ただし、これらの点はこの記述のサンプルコードには含まれていないので実装時に各自で考慮されたい。
呼び出し回数の上限が設定されている API を有効活用するために検索結果のキャッシュを実装することは非常に重要である。また最も時間がかかる処理が収集した URL からの画像ダウンロードであることから、すでに取得済みの画像 URL に対してダウンロードをスキップする判断を加えることは実行時間を大幅に削減できる。このようなキャッシュ機構は、強制的に最新の情報を収集するために任意のタイミングで無効化しキャッシュを更新する手段を用意しておく必要があるだろう。
画像検索 API で収集した URL から画像ファイルをダウンロードする部分が最も時間のかかる処理である。これは point to point 間のネットワーク遅延の問題である。画像 URL が特定のサイトに偏っていないのであればダウンロードを並列化することは時間短縮に有効である。ただし、一般的なブラウザの挙動に合わせて、同一のサイトに対して並列して行われるリクエスト数は最大 2~5 接続程度にすべきである。多数のダウンロードを並列して行うとサイトに対する攻撃となりうる。
画像検索と収集
機械学習を目的とした良質な画像セットを収集するには以下の 2 つの点を考慮すべきである。
第一に、検索クエリーの対象物が「主体」として撮影されている画像を多く集めることが機械学習のモデル作成に有効であることは明らかだろう。ここで収集対象が動植物であればラテン語の学名を使用したほうがよりノイズが少なく対象物を主体として撮影した画像を得ることができる。例えば「シイタケ」で検索した結果にはホイル焼きのような料理、乾燥シイタケのような加工品、イラストやゆるキャラなども含まれるが、シイタケの学名である「Lentinula edodes」で検索した結果からはそれらの多くが排除される (これは検索言語である日本語圏にシイタケ食の文化があり生活に身近であることも関係している)。
ただしどのように検索クエリーを工夫しても明らかに目的外の画像が紛れ込むのを止めることはできない。シイタケの育成を説明するページではその資料として原木が主体となる画像も載せているだろう。このような「明らかに目的の対象物ではない」画像のフィルタリングは後述する画像認識によるフィルタリングの章で説明する。
第二に、機械学習のモデル作成には大量の画像が必要である。しかし、大手検索エンジンが概ね世界中のページをカバーしていると仮定すれば、いくつもの画像検索サイトで同じクエリーを検索しても似たような URL セットしか入手できないことは想像に難くない。また、優秀な検索エンジンはクエリーの言語を優先的に順位づけするが、画像収集の目的においてはその画像が使われているページの言語は関係がない。このため画像収集スクリプトはマイナーな画像検索サイトを横断検索できるようにするよりも、検索者が単にクエリーの言語を変える方が新しい画像を発見できる機会は多くなる。
インターネットにおける言語の使用![]() によればネット上の言語の利用者数は英語に続いて中国語、スペイン語などが続いている。コンテンツ量が利用者数に比例すると仮定すれば、英語と中国語の表現で検索するだけでネット上の画像の約 50% に届くだろう。
によればネット上の言語の利用者数は英語に続いて中国語、スペイン語などが続いている。コンテンツ量が利用者数に比例すると仮定すれば、英語と中国語の表現で検索するだけでネット上の画像の約 50% に届くだろう。
検索対象の適切な多言語表現が分からない場合は Wikipedia の対象ページから他の言語ページをたどってみると良い。
Bing Image Search API
Bing は世界規模の検索エンジンであり、1 リクエストあたりに収集できる画像 URL 数も多く、今のところ最も画像の収集に有用な API である。API のデモからクエリーに対してどのような画像がヒットするかを確認することができる。
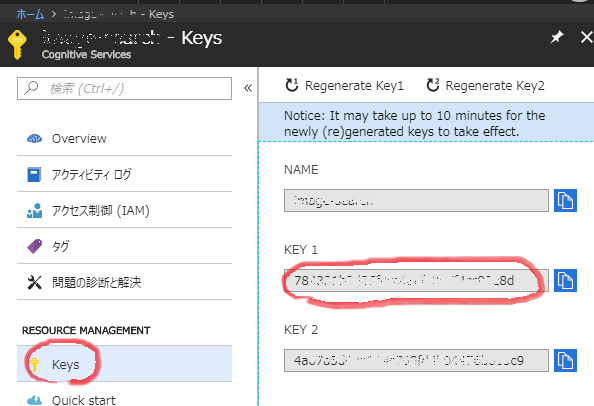
API Key の入手
Bing Image Search の API を使用するために Azure ダッシュボードから API キーを取得しなければならない。Azure にアカウントを持っていない場合はアカウントを作成する。
- Azure Portal にログインし「リソースの作成」を選択。
- 「Marketplace を検索」で「Bing Search」を検索して Bing Search v7 を作成。
- URL とリソースグループ名を適当に入力して作成。
- ダッシュボードから作成したリソースを選択してキーを取得 (KEY 1, KEY 2 のどちらでも良い)。
API の呼び出し
Azure ダッシュボードで取得した API キーは画像検索リクエストのリクエストヘッダに設定する。その他のリクエストパラメータについてはクエリーパラメータのリファレンスを参照。
以下のスクリプトは Node.js 8.9 を使用して Bing Image Search から画像検索を行い結果の URL を標準出力に出力している。
const request = require("request")
const urlencode = require("urlencode")
const searchURL = "https://api.cognitive.microsoft.com/bing/v7.0/images/search"
function search(apiKey, query, offset, count){
const url = searchURL + "?" + urlencode.stringify({
mkt: "ja-jp", imageType: "Photo", offset: offset, count: Math.min(150, count), q: query
})
request({
method: "GET", url: url, json: true, headers: { "Ocp-Apim-Subscription-Key": apiKey }
}, (error, response, body) => {
if(! error && response.statusCode === 200){
// console.log(JSON.stringify(body))
body.value.forEach(item => process.stdout.write(item.contentUrl + "\n"))
const total = body.totalEstimatedMatches
const remains = count - body.value.length
if(remains !== count && remains > 0 && offset + body.value.length <= total){
const nextOffset = body.nextOffset
search(apiKey, query, nextOffset, remains)
}
}
})
}
search("784*****************************", "シイタケ", 0, 200)1 回のリクエストで取得できる (つまり count に指定できる)最大値は 150 である。上記のコードでは、取得した URL が目的の個数より少なく、かつ、検索結果がさらにある場合に再帰的に続きの読み出しを行っている。
スクリプトの実行は Node.js と npm が必要である。
> npm init
> npm install request urlencode
> node bing.js
http://upload.wikimedia.org/wikipedia/commons/thumb/6/64/Shiitakegrowing.jpg/250px-Shiitakegrowing.jpg
http://pds.exblog.jp/pds/1/201012/27/86/f0218186_15555448.jpg
http://www.kusudama.jp/recipe/keyword/d0mt3h000000873w-img/d0mt3h0000008743.jpg
... (200 lines)リクエスト制約
アカウント登録から12ヶ月間の無料使用期間中は月 3,000 リクエスト、秒間 3 リクエストまで。API キーの有効期限は 7 日間。
Google Custom Search API
検索最大手であるが画像検索 API の制限により 1 日あたり最大で 1000 個の URL しか収集することができず、機械学習の目的には十分なデータ収集ができるとは言い難い。
カスタム検索エンジン ID と API Key の入手
Google での画像検索はサイト内検索など特定のパターン検索を行う Custom Search API を使用する (過去にあった画像検索 API はこの API に統合された)。
- Google アカウントを使用してコントロールパネルにサインイン。
- 「新しい検索エンジン」を作成する。「検索するサイト」は後で削除するので適当なサイト (例えば google.com) で良い。
- 「検索エンジンを編集」で新しく作成したカスタム検索を選択する。
- 「検索するサイト」に入力した仮置きのサイトを削除し、画像検索をオン、ウェブ全体の検索を有効にする。
- カスタム検索エンジンの ID を取得する。
- カスタム検索エンジン JSON API から API Key を入手する。
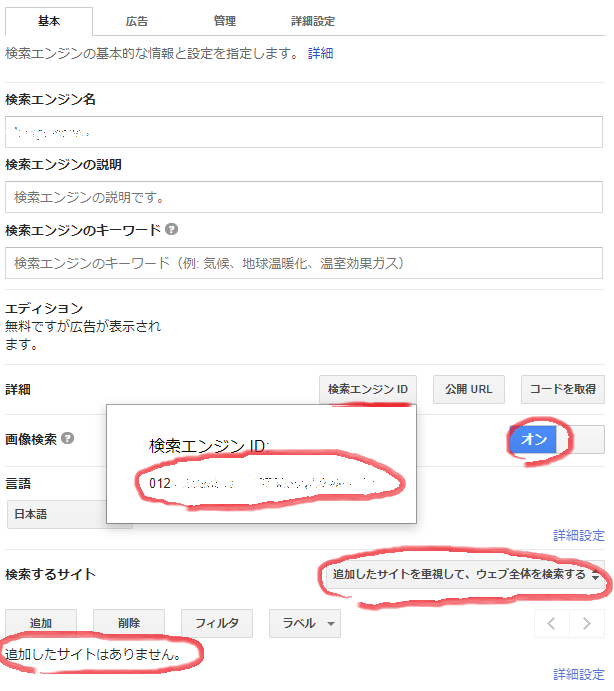
「検索するサイト」は特定のサイトに存在する画像を重視して検索結果を得たい場合に使用すると良い。
API 呼び出し
Google カスタム検索ではカスタム検索エンジン ID と API キーは共にリクエストパラメータに指定する。リクエストやレスポンスの使用はリファレンスを参照。
const request = require("request")
const urlencode = require("urlencode")
const searchURL = "https://www.googleapis.com/customsearch/v1"
function search(customEngine, apiKey, query, offset, count){
const url = searchURL + "?" + urlencode.stringify({
cx: customEngine, key: apiKey, startIndex: offset, q: query
})
request({ method: "GET", url: url, json: true }, (error, response, body) => {
if(! error && response.statusCode === 200){
// console.log(JSON.stringify(body, null, 2))
const images = body.items
.map(item => item.pagemap.cse_image)
.filter(image => typeof image !== "undefined")
images.forEach(image => process.stdout.write(image[0].src + "\n"))
const remains = count - images.length
if(remains !== count && remains > 0){
search(customEngine, apiKey, query, offset + body.items.length, remains)
}
}
})
}
search("002******************************", "AIz*************************************", "シイタケ", 0, 15)
リクエスト制限
JSON Custom Search API の無料枠は 1 日 100 リクエストまで。1 度のリクエストで取得できる検索結果は 10 件まで。100 ページより先は取得できない。
画像認識によるフィルタリング
画像検索の結果を用いて画像の収集まで行った時点で、収集した画像ファイルに「確かに検索クエリーとは一致するが本来収集目的としていた対象物とは明らかに関係のない画像」が多数含まれることに気づくだろう。それらの画像は学習モデルの精度低下につながることから除去したほうが良い。ここでは画像認識 API のラベル付けを使用して画像が対象としている何かが撮影されているかをフィルタリングを行う。
Azure のタグ付けは 86 種類のカテゴリに分類する
AWS Rekognition
Amazon Rekognition は画像のラベル抽出、顔認識、テキスト抽出 (OCR)、ポルノコンテンツ判定 (節度) などの機能をもつ機械学習サービス。今回はこのラベル付け機能を利用する。ラベル付けがどのように機能するかは管理コンソールのデモで確認することができる。
なお AWS CLI の rekognition コマンドを使えばコードを書かなくても利用可能である。
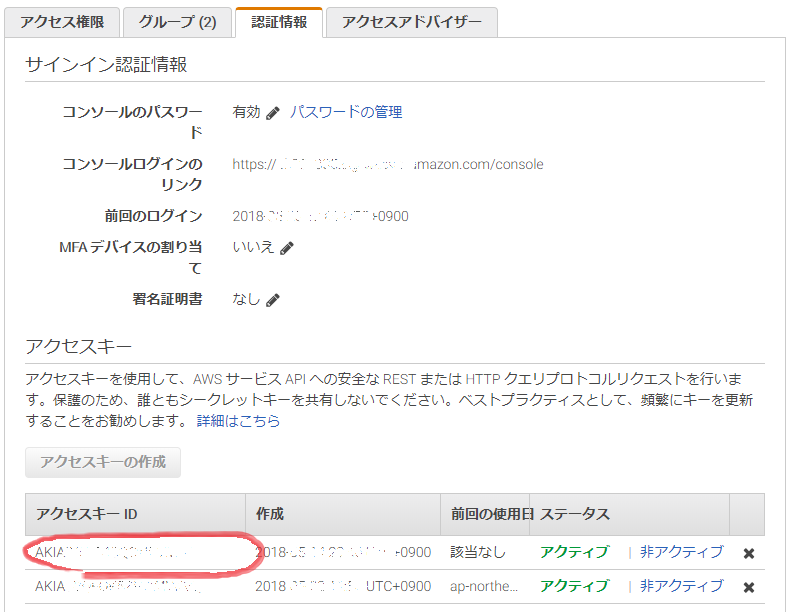
アクセスキーID/シークレットアクセスキーの取得
- AWS マネジメントコンソールの IAM で新規ユーザを追加するか、既存の権限を確認。
- 「プログラムによるアクセス」をチェック。
- 「アクセス権限の追加」で (グループが作成されていない場合は新規に作成し) グループ権限に AmazonRekognitionFullAccess を付与。
- 「ユーザ」の「認証情報」タブからアクセスキーを作成。アクセスシークレットキーは作成時にのみ表示できるのでコピーしておく。
Rekognition API 呼び出し
npm install aws-sdk で AWS SDK for Node.js をインストールする。Rekognition の API は AWS.Rekognition リファレンス参照。ES2015 以外の言語でも基本的に似たような処理になるはず。
const aws = require("aws-sdk")
const fs = require("fs")
function search(accessKeyId, secretAccessKey, file){
const rekognition = new aws.Rekognition({
accessKeyId: accessKeyId, secretAccessKey: secretAccessKey, region: "ap-northeast-1"
})
rekognition.detectLabels({
Image: {
Bytes: fs.readFileSync(file)
}
}, (error, data) => {
// console.log(error, data)
if(error){
process.stderr.write("ERROR: " + error + "\n")
} else {
data.Labels.forEach(label => {
process.stdout.write(label.Confidence.toFixed(1) + ": " + label.Name + "\n")
})
}
})
}
search("AKI*****************", "QYr************************************", "シイタケ/1.jpg")
この例では簡易化のためアクセスキーとシークレットアクセスを直接指定しているが、サーバ等で動作させるのであれば AWS CLI で環境にセットアップし credentials:... で指定した方が運用には優しいかも知れない。
実行結果は以下の通り。

> node rekognition.js
99.2: Fungus
79.7: Animal
79.7: Beak
79.7: Bird
64.4: Agaric
64.4: Flora
64.4: Mushroom
64.4: Plant次に Rekognition を使って収集したシイタケ画像セットから明らかにキノコでない画像を除外する。
画像検索により収集したシイタケ画像セット

AWS Rekognition を使用して信頼度 75% 以上のラベルを抽出し、それらに Fungus (菌類), Agaric, Mushroom, Amanita のいずれかが含まれているかで分類を行った。対象ラベルの判断はいくつかの画像をサンプル実行してヒューリスティックに決めたものである。
キノコが写っているとみなされた画像

キノコが写っていないとみなされた画像
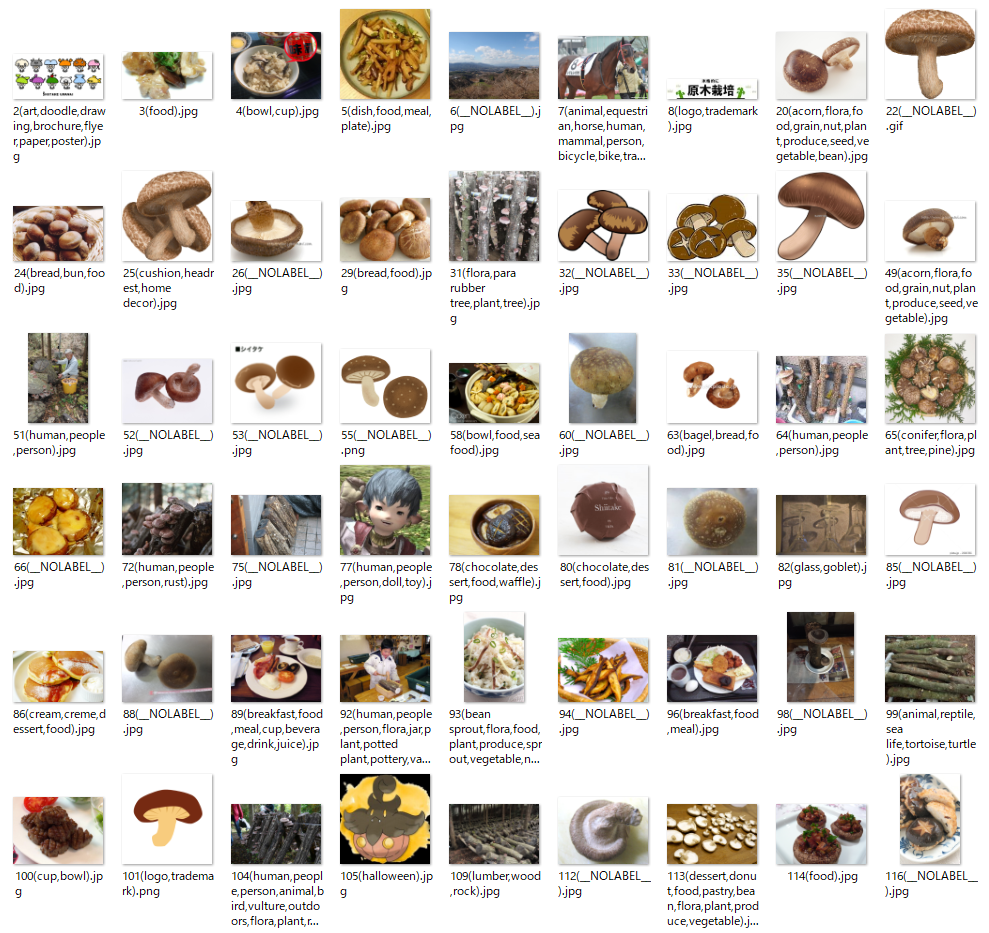
分類語の画像セットを見ると「明らかにキノコでない画像」は概ね排除されていることが分かるだろう。
