論文翻訳: Efficient Estimation of Word Representations in Vector Space
Google Inc., Mountain View, CA
tmikolov@google.com
Google Inc., Mountain View, CA
kaichen@google.com
Google Inc., Mountain View, CA
gcorrado@google.com
Google Inc., Mountain View, CA
jeff@google.com
 Abstract
Abstract
我々は非常に大規模なデータセットから単語の連続ベクトル (continuous vector) 表現を算出するための 2 つの新しいモデルのアーキテクチャを提案する。これらの表現の品質を単語の類似性タスクで測定し、その結果を異なる種類のニューラルネットワークに基づく従来の最高の性能を持つ技術と比較した。そこで我々ははるかに低い計算コストで精度が大幅に上昇することを観測した。具体的には 16 億単語のデータセットから高品質の単語ベクトルを学習するのに要した時間は 1 日以下だった。さらに、これらのベクトルが構文的および意味的な単語の類似性を測定するためのテストセットにおいて最先端の性能を提供することを示す。
Table of Contents
1 導入
現在の NLP システムや技術は単語を原子単位として扱っている - これらは語彙内でのインデックスとして表現されているため単語間に類似性という概念は存在しない。この選択にはいくつかの良い理由がある - シンプルさ、堅牢性、そして膨大なデータで訓練されたシンプルなモデルはより少ないデータで訓練された複雑なシステムよりも優れている。例えば統計的言語モデリングに使用される一般的な N-gram モデルがある - 今日では、事実上すべての利用可能なデータ (数兆語 [3]) で N-gram を訓練することが可能である。
しかし多くのタスクでは単純な手法では限界がある。例えば自動音声認識に関連するドメイン内のデータ量は限られており、その性能は通常、高品質に書き起こされた音声データのサイズ (多くの場合、わずか数百万ワード) に左右される。機械翻訳では多くの言語の既存のコーパスには数十億語以下の単語しか含まれていない。そのため、基本的な技術を単純にスケールアップしても大きな進歩は得られず、より高度な技術に注力しなければならない状況がある。
近年の機械学習技術の進歩に伴って、より複雑なモデルをより大きなデータセットで学習することが可能となり、一般的に単純なモデルよりも優れた性能を発揮している。おそらく最も成功したコンセプトは単語の分散表現を使用することであろう [10]。例えばニューラルネットワークに基づいた言語モデルは N-gram モデルを大幅に上回る性能を発揮する [1, 27, 17]。
1.1 論文の目標
この論文の主な目的は、数十億の単語と数百億の語彙を含む膨大なデータセットから高品質の単語ベクトルを学習するために利用できる手法を紹介することである。我々の知る限り、これまでに提案されたアーキテクチャはいずれも単語ベクトルの次元が 50〜100 と控えめで、数億単語以上の学習に成功したものもない。
我々は最近提案されたベクトル表現の質を測定する手法を使用する。この手法では、類似した単語は互いに近くなる傾向があるだけでなく、単語が複数の類似度 [20] を持つ可能性があることを想定している。これは語形変化 (inflectional language) の文脈で以前に観測されていた。例えば名詞は複数の語尾を持つことがあり、元のベクトル空間の部分空間で類似した単語を検索すると、類似の語尾を持つ単語を見つけることができる [13, 14]。
少々驚くべきことに単語表現の類似性は単純な文法上の規則性を超えていることが分かった。単純な代数演算が単語ベクトルに対して実行される単語オフセット技法を用いると、例えば vector("King") - vector("Man") + vector("Woman") の結果 Queen というベクトル表現に最も近いベクトルが得られることが示された [20]。
この論文では、単語間の線形規則性を維持する新しいモデルアーキテクチャを開発することで、これらのベクトル演算の精度を最大化することを試みる。我々は構文的規則性と意味的規則性の両方を測定するために新しい包括的なテストセット1を設計し、そのような規則性の多くが高い精度で学習できていることを示す。さらに、学習時間と精度が単語ベクトルの次元と学習データ量にどのように依存するかについて議論する。
1.2 過去の研究
単語を連続ベクトルとして表現することには長い歴史がある [10, 26, 8]。ニューラルネットワーク言語モデル (NNLM) を推定するために非常に一般的なモデルアーキテクチャは [1] で提案された。そこでは、単語ベクトル表現と統計的言語モデルを共同で学習するために、一つの線形射影層と一つの非線形隠れ層を持つフィードフォーワードニューラルネットワークが使用された。この研究は他の多くの研究者によって追随されている。
NNLM のもう一つの興味深いアーキテクチャが [13, 14] で紹介されている。そこではまず単一の隠れ層を持つニューラルネットワークを使って単語ベクトルを学習する。次にこの単語ベクトルを使用して NNLM の学習を行う。このように、完全な NNLM を構築しなくても単語ベクトルは学習される。この研究では、このアーキテクチャを直接拡張し、単純なモデルを用いて単語ベクトルを学習する最初のステップのみに焦点を当てる。
後に、この単語ベクトルを使用することで多くの自然言語処理アプリケーションを大幅に改善し簡素化できることが示された [4, 5, 29]。単語ベクトル自体の推定は様々なモデルアーキテクチャを使用して実行され、様々なコーパスで学習された [4, 29, 23, 19, 9]。結果として得られた単語ベクトルの一部は将来の研究と比較に利用できるようになった2。しかし我々の知る限り、これらのアーキテクチャは対角重み行列が使用される対角双線形モデルの特定のバージョン [23] を除いて、[13] で提案されたものよりも学習にかかる計算コストが大幅に高かった。
- 1テストセットは www.fit.vutbr.cz/˜imikolov/rnnlm/word-test.v1.txt にある。
- 2http://ronan.collobert.com/senna/, http://metaoptimize.com/projects/wordreprs/, http://www.fit.vutbr.cz/˜imikolov/rnnlm/, http://ai.stanford.edu/˜ehhuang/
2 モデルアーキテクチャ
よく知られている潜在意味分析 (LSA; Latent Semantic Analysis) や潜在ディリクレ配分 (LDA; Latent Dirichlet Allocation) など、単語の連続表現を推定するためにさまざまなタイプのモデルが提案されている。この論文ではニューラルネットワークによって学習された単語の分散表現に注目する。ニューラルネットワークは単語間の線形規則性を維持するという点で LSA よりも有意に性能が良いことが以前に示されている [20, 31]; さらに LDA は大規模なデータセットでは計算コストが非常に高くなる。
[18] と同様に、異なるモデルアーキテクチャを比較するためにまずモデルの計算複雑性を、モデルを完全に訓練するためにアクセスする必要のあるパラメータ数として定義する。次に計算複雑性を最小限に抑えながら精度を最大化することを試みる。
以下のすべてのモデルにおいて学習の複雑性は次の式に比例する。\[ \begin{equation} O = E \times T \times Q \end{equation} \] ここで \(E\) は学習のエポック数、\(T\) は学習セットの単語数、\(Q\) はモデルアーキテクチャごとにさらに定義される。一般的な選択肢 \(E=3\) から \(50\)、\(T\) は最大 10 億である。すべてのモデルは確率的勾配降下法とバックプロパゲーション [26] を用いて学習される。
2.1 フィードフォワード型ニューラルネット言語モデル (NNLM)
確率的フィードフォワード型ニューラルネットワーク言語モデルは [1] で提案されている。このモデルは入力層、投影層、隠れ層、出力層で構成されている。入力層では \(N\) 個の前単語が 1-of-\(V\) 符号化を使用してエンコーディングされる。ここで \(V\) は語彙のサイズである。次に入力層は共有の射影行列を使用して \(N \times D\) 次元の射影層 \(P\) に射影される。常に \(N\) 個の入力のみがアクティブであるため投影層の合成は比較的低コストな操作である。
NNLM アーキテクチャは投影層の値が密であるため投影層と隠れ層の間の計算が複雑になる。一般的な \(N=10\) の場合、投影層 (\(P\)) のサイズは 500 から 2000 になり、隠れ層のサイズ \(H\) は通常 500 から 1000 単位となる。さらに隠れ層は語彙内のすべての単語の確率分布を計算するために使用され、その結果として次元 \(V\) を持つ出力層が得られる。したがって各学習例あたりの計算量は \[ \begin{equation} Q = N \times D + N \times D \times H + H \times V \end{equation} \] となる。ここで支配的な項は \(H \times V\) である。しかしそれを回避するための現実的な解決策がいくつか提案されている; ソフトマックスの階層バージョンを使用する [25, 23, 18] か、学習中に正規化されないモデル [4, 9] を使用して正規化モデルを完全に回避する。語彙の二分木表現では評価する必要のある出力単位は \(\log_2 V\) まで減らすことができる。したがって複雑さのほとんどは \(N \times D \times H\) の項によって引き起こされる。
我々のモデルでは語彙をハフマン二分木として表現する階層的ソフトマックスを使用する。これは、単語の頻度がニューラルネット言語モデルのクラスを取得するのに有効であるという以前の観測に基づいている [16]。ハフマン木は頻繁に使用される単語に短いバイナリコードを割り当てるため、評価する必要のある出力ユニットの数をさらに減らすことができる。平衡二分木では \(\log_2 V\) の出力を評価する必要がある、ハフマン木に基づく階層的ソフトマックスでは \(\log_2 ({\it Unigram\_perplexity}(V))\) 程度しか評価を必要としない。例えば語彙サイズが 100 万単語の場合は評価が約 2 倍に高速化される。計算のボトルネックは \(N \times D \times H\) の項であるため、これはニューラルネットワーク LM にとって決定的な高速化ではないが、我々は後に隠れ層を持たない、ソフトマックスの正規化の効率に大きく依存するアーキテクチャを提案する。
2.2 リカレント型ニューラルネット言語モデル (RNNLM)
リカレントニューラルネットワークに基づく言語モデルは、コンテキスト長 (モデル \(N\) の次元) を指定しなければならないといったフィードフォワード型 NNLM の特定の制限を克服するために提案されている。また理論的に RNN は浅いニューラルネットワークよりも複雑な波t−んを効率的に表現できる [15, 2]。RNN モデルは射影層を持たず、入力層、隠れ層、出力層のみである。このタイプのモデルの特別な点は、時間遅延接続を使用して隠れ層とそれ自身を接続するリカレント行列である。これにより、過去の情報は現在の入力と以前の時間ステップにおける隠れ層の状態に基づいて更新される隠れ層の状態に基づいて表現できるため、リカレントモデルはある種の短期記憶を形成することができる。
RNN モデルの学習サンプルあたりの複雑性は次のようになる: \[ \begin{equation} Q = H \times H + H \times V \end{equation} \] ここで単語表現 \(D\) は隠れ層 \(H\) と同じ弦を持つ。ここでも階層的ソフトマックスを使うことで \(H \times V\) の項は \(H \times \log_2 V\) に削減することができる。複雑さの大部分は \(H \times H\) から生じる。
2.3 ニューラルネットワークの並列学習
巨大なデータセットでモデルを学習するために、我々はフィードフォワード NNLM やこの論文で提案した新しいモデルを含むいくつかのモデルを DistBelief [6] と呼ばれる大規模分散フレームワーク上に実装した。このフレームワークでは同じモデルを複数のレプリカで並列に実行することができ、各レプリカはすべてのパラメータを保持する集中サーバを介して購買の更新を同期する。この並列学習では Adagrad [7] と呼ばれる適応的学習率を持つミニバッチ非同期勾配降下法を用いる。このフレームワークでは 100 以上のモデルレプリカを使用するのが一般的であり、各レプリカはデータセンター内の異なるマシンで多くの CPU コアを使用する。
3 新しい対数線形モデル
このセクションでは単語の分散表現を学習するための計算複雑性を最小化する 2 つの新しいモデルアーキテクチャを提案する。前のセクションの主な観察からは、複雑性の多くはモデルの非線形隠れ層に起因するということだった。これがニューラルネットワークを非常に魅力的にしているが、我々はニューラルネットワークほど正確にデータを表現できないかもしれないが、より多くのデータで効率的に学習できる可能性があるより単純なモデルを探求することにした。
この新しいアーキテクチャは我々の以前の研究 [13, 14] で提案されたアーキテクチャをそのまま踏襲している。そこでニューラルネットワーク言語モデルは 2 つのステップでうまく学習できることが発見されている。最初に単純なモデルを使用して連続単語ベクトルが学習され、次に N-gram NNLM がこれらの分散単語表現に基づいて学習される。その後、単語ベクトルの学習に焦点を当てたかなりの数の研究が行われたが、我々は [13] で提案されたアプローチが最も単純なものであると考えている。関連するモデルもかなり以前に提案されていることに注意 [26, 8]。
3.1 連続 Bag-of-Words モデル
最初に提案されたアーキテクチャはフィードフォワード NNLM に似ているが、非線形の隠れ層が削除され、射影層が (射影行列だけではなく) すべての単語に対して共有される。したがってすべての単語が同じ位置に投影される (それらのベクトルは平均化される)。履歴中の単語の順序は射影に影響しないため、このアーキテクチャを Bag-of-Words モデルと呼ぶ。さらに我々は未来の単語も使用する。4 つの未来の単語と 4 つの履歴の単語を入力とする対数線形分類器を構築することで、次のセクションで紹介するタスクで最高のパフォーマンスが得られた。学習基準は現在の (中間) 単語を正しく分類することである。このとき学習の複雑性は次のようになる: \[ \begin{equation} Q = N \times D + D \times \log_2 V \label{eq4} \end{equation} \] 標準的な Bag-of-Words モデルと異なり、コンテキストの連続分散表現を使用するため、このモデルをさらに CBOW と呼ぶ。モデルのアーキテクチャを Figure 1 に示す。入力層と社営巣の間の重み行列は NNLM と同様にすべての単語位置で共有されることに注意。
3.2 連続 Skip-gram モデル
二番目のアーキテクチャは CBOW に似ているが、コンテキストに基づいて現在の単語を予測するのでは無く、同じ文中の別のがん語に基づいて単語の分類を最大化しようとするものである。ヨリ成果買うには、現在の各単語を連続射影層を備えた対数線形分類器への入力として使用し、現在の単語の前後の特定の範囲内の単語を予測する。範囲を広げると結果として得られる単語ベクトルの品質が向上するが、計算複雑性も増加することが分かった。通常、より遠い単語は近い単語よりも現在の単語との関連性が低いため、学習例におけるこれらの単語からのサンプリングを少なくすることで遠い単語への重みを低くする。
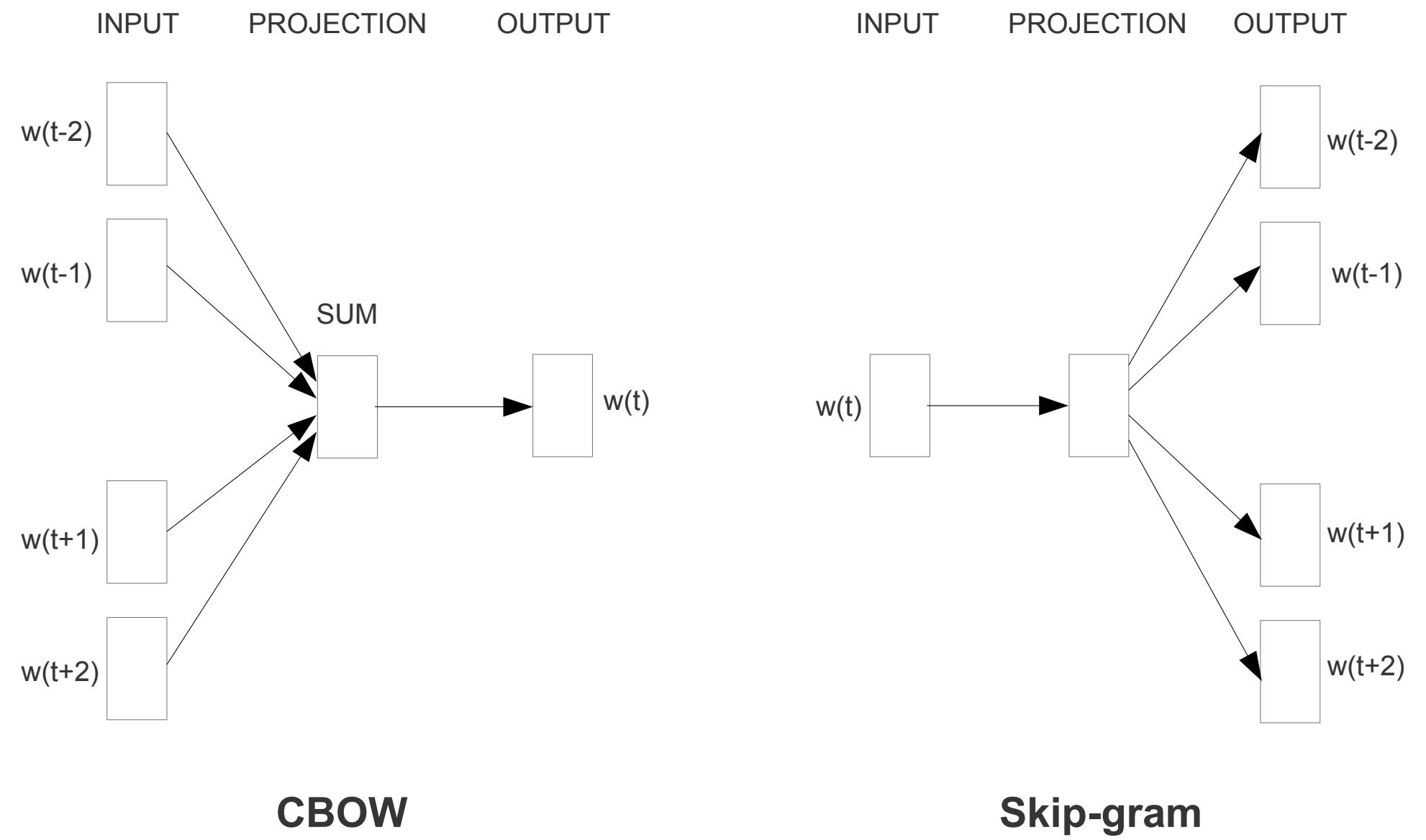
このアーキテクチャの学習複雑性は次のようになる: \[ \begin{equation} Q = C \times (D + D \times \log_2 V) \label{eq5} \end{equation} \] ここで \(C\) は単語の最大距離である。したがって \(C=5\) とすると、各学習単語に対して \(\langle 1; C \rangle\) 範囲内の数 \(R\) をランダムに選択し、履歴から \(R\) 個の単語と未来から \(R\) 個の単語を正しいラベルとして使用することになる。このため現在の単語を入力として \(R+R\) 個の各単語を出力として \(R\times 2\) 回の単語分類を行う必要がある。次の実験では \(C=10\) とする。
4 結果
異なるバージョンの単語ベクトルの品質を比較するために、過去の論文では通常、サンプルとなる単語とその最も類似した単語を表す表を使用し、それらを直感的に理解していた。France という単語は Italy や他のいくつかの国と類似していることを示すのは簡単だが、それらのベクトルを次のようにより複雑な類似性タスクに適用する場合ははるかに困難となる。これは単語間にはさまざまな種類の類似点が存在する可能性があるという過去の観察に基づいている。例えば単語 big は small が smaller に似ているのと同じ意味で bigger に似ている。別のタイプの関係の例としては、big - biggest と small - smallest という単語のペアが考えられる [20]。さらに "biggest が big と似ているのと同じ意味で small に似ている単語は何ですか?" と訪ねるように、同じ関係を持つ 2 つの単語ペアを質問として表現する。
やや意外なことに、これらの質問は単語のベクトル表現を使用して単純な代数演算を行うことで答えることができる。biggest が big に似ているのと同じ意味で small に似ている単語を見つけるには、単純にベクトル \(X={\it vector}({\it "biggest"})-{\it vector}({\it "big"})+{\it vector}({\it "small"})\) を計算すれば良い。次に \(X\) に最も近い単語をベクトル空間上でコサイン距離で計測して検索し、それを質問の答えとして使用する (この検索中に入力された質問単語は破棄される)。単語ベクトルが適切に訓練されていればこの方法を使用した正しい答え (単語 smallest) を見つけることができる。
最後に、大量のデータで高次元の単語ベクトルを学習させると、その結果得られたベクトルを使用して都市とその都市が属する国、例えばフランスはパリに、ドイツはベルリンにというように、単語間の非常に微妙な意味的関係に答えることができることが分かった。このような意味的関係を持つ単語ベクトルは、機械翻訳、情報検索、質問応答システムなど既存の多くの NLP アプリケーションを改善するために使用できる可能性がある。また今後開発される他のアプリケーションを可能にするかもしれない。
4.1 タスク詳細
単語ベクトルの品質を測定するために 5 種類の意味的質問と 9 種類の構文的質問を含む包括的なテストセットを定義する。各カテゴリから 2 つの例を Table 1 に示す。全体として 8869 の意味的質問と 10675 の構文的質問がある。各カテゴリの質問は 2 つのステップで作成された。まず類似する単語のペアのリストを手動で作成する。次に 2 つの単語ペアを接続して大きな質問リストを作成する。例えばアメリカの 68 の大都市とそれらが属する州のリストを作成し、2 つの単語のペアをランダムに選択して約 2.5K の質問を作成した。テストセットには単一のトークンワードのみが含まれているため複数単語のエンティティは存在しない (New York など)。
すべての質問タイプおよび各質問タイプ (意味、構文) 別に総合的な精度を評価する。上記の方法で算出したベクトルに最も近い単語が質問の正しい単語と完全に同じ場合にのみ、正しく回答されたものと見なす。また現在のモデルには単語の形態素に関する入力情報がないため100% の精度を達成することは不可能である可能性が高いことも意味する。ただし、特定の用途における単語ベクトルの有用性はこの精度指標と正の相関関係があるはずだと考えている。単語の構造に関する情報、特に統語的な質問についての情報を取り入れることでさらなる進歩を達成できる。
| 関係のタイプ | ワード・ペア 1 | ワード・ペア 2 | ||
|---|---|---|---|---|
| 共通の首都 | Athens | Greece | Oslo | Norway |
| すべての首都 | Astana | Kazakhstan | Harare | Zimbabwe |
| 通貨 | Angola | kwanza | Iran | rial |
| 州内都市 | Chicago | Illinois | Stockton | California |
| 男性-女性 | brother | sister | grandson | granddaughter |
| 形容詞から副詞へ | apparent | apparently | rapid | rapidly |
| 対義 | possible | impossible | ethical | unethical |
| 比較級 | great | greater | tough | tougher |
| 最上級 | easy | easiest | lucky | luckiest |
| 現在分詞 | think | thinking | read | reading |
| 国籍形容詞 | Switzerland | Swiss | Cambodia | Cambodian |
| 過去形 | walking | walked | swimming | swam |
| 複数名刺 | mouse | mice | dollar | dollars |
| 複数動詞 | work | works | speak | speaks |
4.2 精度の最大化
単語ベクトルの学習には Google News コーパスを使用した。このコーパスは約 6B のトークンが含まれている。語彙のサイズは最も頻度の高い 100 万語に制限した。より多くのデータを使用してより高次元の単語ベクトルを使用すれば精度が向上することが予想されるため、時間的制約のある最適化問題に直面していることは明らかである。可能な限り良好な結果を迅速に得るモデルアーキテクチャの最適な選択を推定するために、まず語彙を最頻出の 30k 語に制限した訓練データのサブセットで学習したモデルを評価した。CBOW アーキテクチャを使用し単語ベクトルの次元を買え、訓練データの量を増やした結果を Table 2 に示す。
| 次元性 / 学習ワード | 24M | 49M | 98M | 196M | 391M | 783M |
|---|---|---|---|---|---|---|
| 50 | 13.4 | 15.7 | 18.6 | 19.1 | 22.5 | 23.2 |
| 100 | 19.4 | 23.1 | 27.8 | 28.7 | 33.4 | 32.2 |
| 300 | 23.2 | 29.2 | 35.3 | 38.6 | 43.7 | 45.9 |
| 600 | 24.0 | 30.1 | 36.5 | 40.8 | 46.6 | 50.4 |
次元を増やしたり学習データを増やしたりしてもある時点から改善効果は減少してゆくことが分る。このためベクトルの次元と学習データの量の両方を同時に増やす必要がある。この観察は些細なことに思えるかも知れないが、現在、比較的大量のデータで単語ベクトルを訓練することが一般的だが、その計数はわずか (50 - 100 のように) であることに注目すべきである。式 \(\ref{eq4}\) を考慮すると、学習データ量を 2 倍に増やすとベクトルサイズを 2 倍に増やすのと同等の計算量の増加が生じる。
Table 2 と Table 4 に報告されている実験では、確率的勾配降下法と逆伝播法を使用した 3 つの学習エポックを使用した。開始学習率は 0.025 を選択し、それを直線的に減少させて最後の学習エポック終了時にゼロに近づくようにした。
4.3 モデルアーキテクチャの比較
まず同じ学習データを使用し、同じ 640 次元の単語ベクトルを用いて、単語ベクトルを導出するための異なるモデルアーキテクチャを比較する。さらなる実験では、新しい意味的・構文的単語関係テストセットの完全な問題セット、つまり 30k 語彙に制限されていない質問を使用する。また [20] で紹介された、単語間の構文の類似性に焦点を当てたテストセットの結果も掲載する3。
学習データは封数の LDC コーパスで構成されており [18] で詳細に説明されている (320M 語、82k 語彙)。これらのデータを用いて、シングル CPU で約 8 週間かけて事前学習したリカレントニューラルネットワーク言語モデルとの比較を行った。我々は DistBelief 並列学習 [6] を使用して、8 個の前単語の履歴を使用して同じ 640 個の隠れユニットを持つフィードフォワード NNLM を訓練した (投影層のサイズが 640✕8 であるため NNLM は RNNLM より多くのパラメータを持つ)。
Table 3 では RNN の単語ベクトル ([20] で使用されているもの) は構文上の質問で良好に機能していることが分る。RNNLM の単語ベクトルは RNN よりも大幅にパフォーマンスが優れているが、RNNLM の単語ベクトルは非線形の隠れ層に直接接続されているためこれは驚くべきコトではない。CBOW アーキテクチャは構文タスクでは NNLM よりも優れており、意味タスクに関してはほぼ同等に機能する。最後に、Skip-gram アーキテクチャは構文タスクに関しては CBOW よりも僅かに劣るが (それでも NNLM よりは優れている)、意味部分に関しては他のすべてのモデルよりもはるかに優れている。
| モデルアーキテクチャ | 意味的・構文的単語関係テストセット | MSR 単語関係性テストセット [20] | |
|---|---|---|---|
| 意味的精度 [%] | 構文適性度 [%] | ||
| RNNLM | 9 | 36 | 35 |
| NNLM | 23 | 53 | 47 |
| CBOW | 24 | 64 | 61 |
| Skip-gram | 55 | 59 | 56 |
次に 1 CPU のみで学習したモデルを評価して公開されている単語ベクトルと比較した。比較を Table 4 に示す。CBOW モデルは Google ニュースデータのサブセットで約 1 日で学習され、SKip-gram モデルの学習時間は約 3 日だった。
| モデル | ベクトル次元性 | 学習単語 | 精度 [%] | ||
|---|---|---|---|---|---|
| 意味的 | 構文的 | 総合 | |||
| Collobert-Weston NNLM | 50 | 660M | 9.3 | 12.3 | 11.0 |
| Turian NNLM | 50 | 37M | 1.4 | 2.6 | 2.1 |
| Turian NNLM | 200 | 37M | 1.4 | 2.2 | 2.1 |
| Mnih NNLM | 50 | 37M | 1.8 | 9.1 | 5.8 |
| Mnih NNLM | 100 | 37M | 3.3 | 13.2 | 8.8 |
| Mikolov RNNLM | 80 | 320M | 4.9 | 18.4 | 12.7 |
| Mikolov RNNLM | 640 | 320M | 8.6 | 36.5 | 24.6 |
| Huang NNLM | 50 | 990M | 13.3 | 11.6 | 12.3 |
| Our NNLM | 20 | 6B | 12.9 | 11.6 | 12.3 |
| Our NNLM | 50 | 6B | 27.9 | 55.8 | 43.2 |
| Our NNLM | 100 | 6B | 34.2 | 64.5 | 50.8 |
| CBOW | 300 | 783M | 15.5 | 53.1 | 36.1 |
| Skip-gram | 300 | 783M | 50.0 | 55.9 | 53.3 |
さらに報告される実験では 1 回の学習エポックのみを使用した (ここでも学習率を線形に減少させて学習の終了時にゼロに近づけた)。Table 5 に示すように 1 エポックを使用して 2 倍のデータでモデルを訓練すると、同じデータを 3 エポックで反復する場合と同等以上の結果が得られ、さらに僅かな速度向上が得られる。
| モデル | ベクトル次元性 | 学習単語 | 精度 [%] | 学習時間 [days] | ||
|---|---|---|---|---|---|---|
| 意味的 | 構文的 | 総合 | ||||
| 3 エポック CBOW | 300 | 783M | 15.5 | 53.1 | 36.1 | 1 |
| 3 エポック Skip-gram | 300 | 783M | 50.0 | 55.9 | 53.3 | 3 |
| 1 エポック CBOW | 300 | 783M | 13.8 | 49.9 | 33.6 | 0.3 |
| 1 エポック CBOW | 300 | 1.6B | 16.1 | 52.6 | 36.1 | 0.6 |
| 1 エポック CBOW | 600 | 783M | 15.4 | 53.3 | 36.2 | 0.7 |
| 1 エポック Skip-gram | 300 | 783M | 45.6 | 52.2 | 49.2 | 1 |
| 1 エポック Skip-gram | 300 | 1.6B | 52.2 | 55.1 | 53.8 | 2 |
| 1 エポック Skip-gram | 600 | 783M | 56.7 | 54.5 | 55.5 | 2.5 |
4.4 モデルの大規模並列学習
先に述べたように我々は DistBelief と呼ばれる分散フレームワークで様々なモデルを実装した。以下はミニバッチ非同期勾配降下法と Adagrad [7] と呼ばれる適応学習率プロシジャを用いて Google News 6B データセットで学習したいくつかのモデルの結果を報告する。学習中には 50 から 100 のモデルのレプリカを使用した。データセンターのマシンは他の実駆動タスクと共有されており、使用量がかなり変動する可能性があるため CPU コアの数は見積もりである。分散フレームワークのオーバーヘッドにより CBOW モデルと Skip-gram モデルの CPU 使用率は単一マシンの実装よりもはるかに近いことに注意。結果を Table 6 に報告する。
| モデル | ベクトル次元性 | 学習単語 | 精度 [%] | 学習時間 [days ✕ CPU cores] | ||
|---|---|---|---|---|---|---|
| 意味的 | 構文的 | 総合 | ||||
| NNLM | 100 | 6B | 34.2 | 64.5 | 50.8 | 14 ✕ 180 |
| CBOW | 1000 | 6B | 57.3 | 68.9 | 63.7 | 2 ✕ 140 |
| Skip-gram | 1000 | 6B | 66.1 | 65.1 | 65.6 | 2.5 ✕ 125 |
4.5 Microsoft Research 文章完成チャレンジ
Microsoft Sentence Completion Challenge は言語モデルやその他の NLP 技術を進歩させるためのタスクとして最近導入された [32]。このタスクは 1040 個の文から構成され、各文に一つの単語が欠落している。5 つの妥当な選択肢の中から文の残りの部分と最も整合性のある単語を選択することが目標である。このセットでは N-gram、LSA ベースモデル [32]、対数双線形モデル [24]、および現在このベンチマークで精度 55.4% という最先端の性能を保持しているリカレントニューラルネットワークの組み合わせ [19] など、いくつかの手法のパフォーマンスが既に報告されている
我々はこのタスクにおける Skip-gram アーキテクチャの性能を調査した。まず [32] で提供されている 50M 単語での 640 次元モデルを学習する。次に未知の単語を入力として、テストセット内の各文のスコアを計算し、文内の周囲のすべての単語を予測する。最終的な文のスコアはこれらの個々の予測の合計となる。文のスコアを使用して最も可能性の高い文を選択する。
以前の結果と新しい結果の簡単な要約を Table 7 に示す。Skip-gram モデル自体はこのタスクに関して LSA 類似度よりスクレタパフォーマンスを発揮するわけではないが、このモデルからのスコアは RNNLM で取得されたスコアと補完的であり、重み付けされた組み合わせは精度 58.9% (セットの開発部分で 59.2%、セットのテスト部分で 58.7%) という新しい最先端の結果が得られる。
| アーキテクチャ | 精度 [%] |
|---|---|
| 4-gram [32] | 39 |
| 平均 LSA 類似度 [32] | 49 |
| 対数双曲線モデル [24] | 54.8 |
| RNNLM [19] | 55.4 |
| Skip-gram | 48.0 |
| Skip-gram + RNNLM | 58.9 |
- 3テストセットを提供してくれた Geoff Zweig に感謝。
5 学習された関係の例
Table 8 は様々な関係に従う単語を示している。我々は前述のアプローチに従う: つまり 2 つの単語ベクトルを減算することで関係が定義され、その結果が別の単語に加算されてる。例えば Paris - France + Italy = Roma となる。見て分るように精度は非常に良好だがさらなる改善の余地が多くあることは明らかである (完全一致を前提とした我々の精度指標を用いると、Table 8 の結果は約 60% のスコアしか得られないことに注意)。我々はより大きな次元を持つさらに大きなデータセットで学習された単語ベクトルであれば、パフォーマンスが大幅に向上し新しい革新的なアプリケーションの開発が可能になると信じている。精度を向上させるもう一つの方法は、関係の例を複数提供することである。関係ベクトルを形成するために一つではなく 10 個の例を使用することにより (個々のベクトルを平均化する)、意味的・構文的テストで最良のモデルの精度が絶対的に約 10% 向上することが確認された。
| 関係 | 例 1 | 例 2 | 例 3 |
|---|---|---|---|
| France - Paris | Italy: Roma | Japan: Tokyo | Florida: Tallahassee |
| big - bigger | small: larger | cold: colder | quick: quicker |
| Miami - Florida | Baltimore: Maryland | Dallas: Texas | Kano: Hawaii |
| Einstein - scientist | Messi: midfielder | Mozart: violinist | Picasso: painter |
| Sarkozy - France | Berlusconi: Italy | Merkel: Germany | Koizumi: Japan |
| copper - Cu | zink: Zn | gold: Au | uranium: plutonium |
| Berlisconi - Silvio | Sarkozy: Nicolas | Putin: Medvedev | Obama: Barack |
| Microsoft - Windows | Google: Android | IBM: Linux | Apple: iPhone |
| Microsoft - Ballmer | Google: Yahoo | IBM: McNealy | Apple: Jobs |
| Japan - sushi | Germany: bratwurst | France: tapas | USA: pizza |
またベクトル演算を様々なタスクの解決に応用することも可能である。例えば単語リストの平均ベクトルを計算し、最も遠い単語ベクトルを見つけることによって、リスト外の単語を選択する精度が高いことが確認されている。これはある種の人間の知能テストでよく使われているタイプの問題である。このような手法を使ってまだまだ多くの発見があることは明らかである。
6 結論
この論文では、構文的および意味的な言語タスクのコレクションに関する様々なモデルによって導き出された単語のベクトル表現の品質を研究した。その結果、一般的なニューラルネットワークモデル (フィードフォワードとリカレントの両方) と比較して非常に単純なモデルアーキテクチャを使用することで高品質の単語ベクトルを学習できることが分った。これは計算複雑性がはるかに低いため、はるかに大きなデータセットから非常に正確な高次元単語ベクトルを計算することが可能である。DistBelief 分散フレームワークを使えば基本的に語彙のサイズに制限がなく、1 兆単語を含むコーパス上でも CBOW モデルと Skip-gram モデルを学習できるはずである。これは、これまでに発表された同様のモデルの最良の結果よりも数桁大きい。
最近、単語ベクトルが従来の技術水準を大幅に上回ることが示された興味深いタスクに SemEval-2012 Task 2 [11] がある。公開されている RNN ベクトルを他の手法と併用することで、従来の最良の結果 [31] と比較して Spearman の順位相関で 50% 以上の増加を達成した。ニューラルネットワークベースの単語ベクトルは感情分析 [12] や言い換え検出 [28] など、他の多くの NLP タスクに応用されてきた。これらのアプリケーションはこの論文で説明されているモデルアーキテクチャから恩恵を受けることが期待できる。
我々の進行中の研究では、単語ベクトルが知識ベースのファクトの自動拡張や、既存のファクトの正しさの検証にうまく適用できることが示されている。機械翻訳の実験結果も非常に有望である。将来的には、我々の技術を潜在関係分析 [30] などと比較することも興味深い。我々の包括的なテストセットは、研究コミュニティが既存の単語ベクトルを推定するための技術を改善するのに役立つと信じていると。また高品質な単語ベクトルが将来の NLP アプリケーションの重要な構成要素になることも期待している。
7 フォローアップ作業
この論文の最初の版が書かれた後、我々は連続 bag-of-words と skip-gram アーキテクチャの両方を使用して単語ベクトルを計算するためのシングルマシンのマルチスレッド C++ コードを公開した4。この学習速度はこの論文で報告されたものよりもかなり高速であり、典型的なハイパーパラメータを選択した場合 1 時間当た数十億語のオーダーとなる。また 1000 億語以上の単語で学習した名前付きエンティティを表す 140 万以上のベクトルも公開している。今後の我々のフォローアップ作業の一部は今後の NIPS 2013 paper [21] で公開される予定である。
- 4このコードは https://code.google.com/p/word2vec/ で公開されている。
References
- Y. Bengio, R. Ducharme, P. Vincent. A neural probabilistic language model. Journal of Machine Learning Research, 3:1137-1155, 2003.
- Y. Bengio, Y. LeCun. Scaling learning algorithms towards AI. In: Large-Scale Kernel Machines, MIT Press, 2007.
- T. Brants, A. C. Popat, P. Xu, F. J. Och, and J. Dean. Large language models in machine translation. In Proceedings of the Joint Conference on Empirical Methods in Natural Language Processing and Computational Language Learning, 2007.
- R. Collobert and J. Weston. A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning. In International Conference on Machine Learning, ICML, 2008.
- R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu and P. Kuksa. Natural Language Processing (Almost) from Scratch. Journal of Machine Learning Research, 12:2493-2537, 2011.
- J. Dean, G.S. Corrado, R. Monga, K. Chen, M. Devin, Q.V. Le, M.Z. Mao, M.A. Ranzato, A. Senior, P. Tucker, K. Yang, A. Y. Ng., Large Scale Distributed Deep Networks, NIPS, 2012.
- J.C. Duchi, E. Hazan, and Y. Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 2011.
- J. Elman. Finding Structure in Time. Cognitive Science, 14, 179-211, 1990.
- Eric H. Huang, R. Socher, C. D. Manning and Andrew Y. Ng. Improving Word Representations via Global Context and Multiple Word Prototypes. In: Proc. Association for Computational Linguistics, 2012.
- G.E. Hinton, J.L. McClelland, D.E. Rumelhart. Distributed representations. In: Parallel distributed processing: Explorations in the microstructure of cognition. Volume 1: Foundations, MIT Press, 1986.
- D.A. Jurgens, S.M. Mohammad, P.D. Turney, K.J. Holyoak. Semeval-2012 task 2: Measuring degrees of relational similarity. In: Proceedings of the 6th International Workshop on Semantic Evaluation (SemEval 2012), 2012.
- A.L. Maas, R.E. Daly, P.T. Pham, D. Huang, A.Y. Ng, and C. Potts. Learning word vectors for sentiment analysis. In Proceedings of ACL, 2011.
- T. Mikolov. Language Modeling for Speech Recognition in Czech, Masters thesis, Brno University of Technology, 2007.
- T. Mikolov, J. Kopecký, L. Burget, O. Glembek and J. Černocký. Neural network based language models for higly inflective languages, In: Proc. ICASSP 2009.
- T. Mikolov, M. Karafiát, L. Burget, J. Černocký, S. Khudanpur. Recurrent neural network based language model, In: Proceedings of Interspeech, 2010.
- T. Mikolov, S. Kombrink, L. Burget, J. Černocký, S. Khudanpur. Extensions of recurrent neural network language model, In: Proceedings of ICASSP 2011.
- T. Mikolov, A. Deoras, S. Kombrink, L. Burget, J. Černocký. Empirical Evaluation and Combination of Advanced Language Modeling Techniques, In: Proceedings of Interspeech, 2011.
- T. Mikolov, A. Deoras, D. Povey, L. Burget, J. Černocký. Strategies for Training Large Scale Neural Network Language Models, In: Proc. Automatic Speech Recognition and Understanding, 2011.
- T. Mikolov. Statistical Language Models based on Neural Networks. PhD thesis, Brno University of Technology, 2012.
- T. Mikolov, W.T. Yih, G. Zweig. Linguistic Regularities in Continuous Space Word Representations. NAACL HLT 2013.
- T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean. Distributed Representations of Words and Phrases and their Compositionality. Accepted to NIPS 2013.
- A. Mnih, G. Hinton. Three new graphical models for statistical language modelling. ICML, 2007.
- A. Mnih, G. Hinton. A Scalable Hierarchical Distributed Language Model. Advances in Neural Information Processing Systems 21, MIT Press, 2009.
- A. Mnih, Y.W. Teh. A fast and simple algorithm for training neural probabilistic language models. ICML, 2012.
- F. Morin, Y. Bengio. Hierarchical Probabilistic Neural Network Language Model. AISTATS, 2005.
- D. E. Rumelhart, G. E. Hinton, R. J. Williams. Learning internal representations by backpropagating errors. Nature, 323:533.536, 1986.
- H. Schwenk. Continuous space language models. Computer Speech and Language, vol. 21, 2007.
- R. Socher, E.H. Huang, J. Pennington, A.Y. Ng, and C.D. Manning. Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection. In NIPS, 2011.
- J. Turian, L. Ratinov, Y. Bengio. Word Representations: A Simple and General Method for Semi-Supervised Learning. In: Proc. Association for Computational Linguistics, 2010.
- P. D. Turney. Measuring Semantic Similarity by Latent Relational Analysis. In: Proc. International Joint Conference on Artificial Intelligence, 2005.
- A. Zhila, W.T. Yih, C. Meek, G. Zweig, T. Mikolov. Combining Heterogeneous Models for Measuring Relational Similarity. NAACL HLT 2013.
- G. Zweig, C.J.C. Burges. The Microsoft Research Sentence Completion Challenge, Microsoft Research Technical Report MSR-TR-2011-129, 2011.
翻訳抄
3 層のニューラルネットワークを使用して単語の分散表現 (単語埋め込み) を生成するアルゴリズム Word2vec に関する 2013 年の論文。
- Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. arXiv preprint arXiv:1301.3781, 2013.
