Hypertext Transfer Protocol - HTTP/1.1
UC Irvine
J. Gettys
J. Mogul
DEC
H. Frystyk
T. Berners-Lee
MIT/LCS
January 1997
Request for Comments: 2068
Category: Standards Track
この記述の状態
このドキュメントはインターネットコミュニティのためのインターネット標準トラックプロトコルを詳述し、改善のための論議と提案を要求する。標準化の状態とこのプロトコルは "インターネット公式プロトコル標準" (STD 1) の最新版を参照してください。この記述の配布は無制限である。
概要
Hypertext Transfer Protocol (HTTP) は共同的ハイパーメディア情報システム配布システムのためのアプリケーションレベルプロトコルである。これはリクエストメソッドの拡張を通じて、ネームサーバやオブジェクト配布管理システムなど、さまざまな作業に対して使用する事のできる一般的で国に依存しないオブジェクト指向プロトコルである。HTTP の機構はデータ表現のタイプ付けやネゴシエーションを行う事であり、転送データに依存しないシステムを構築できる。
HTTP は 1990 から World-Wide Web グローバル情報イニシアティブとしてすでに使用されている。この仕様書は "HTTP/1.1" として言及されるプロトコルを定義する。
目次
1 Introduction.............................................7 1.1 Purpose ..............................................7 1.2 Requirements .........................................7 1.3 Terminology ..........................................8 1.4 Overall Operation ...................................11 2 Notational Conventions and Generic Grammar..............13 2.1 Augmented BNF .......................................13 2.2 Basic Rules .........................................15 3 Protocol Parameters.....................................17 3.1 HTTP Version ........................................17 3.2 Uniform Resource Identifiers ........................18 3.2.1 General Syntax ...................................18 3.2.2 http URL .........................................19 3.2.3 URI Comparison ...................................20 3.3 Date/Time Formats ...................................21 3.3.1 Full Date ........................................21 3.3.2 Delta Seconds ....................................22 3.4 Character Sets ......................................22 3.5 Content Codings .....................................23 3.6 Transfer Codings ....................................24 3.7 Media Types .........................................25 3.7.1 Canonicalization and Text Defaults ...............26 3.7.2 Multipart Types ..................................27 3.8 Product Tokens ......................................28 3.9 Quality Values ......................................28 3.10 Language Tags ......................................28 3.11 Entity Tags ........................................29 3.12 Range Units ........................................30 4 HTTP Message............................................30 4.1 Message Types .......................................30 4.2 Message Headers .....................................31 4.3 Message Body ........................................32 4.4 Message Length ......................................32 4.5 General Header Fields ...............................34 5 Request.................................................34 5.1 Request-Line ........................................34 5.1.1 Method ...........................................35 5.1.2 Request-URI ......................................35 5.2 The Resource Identified by a Request ................37 5.3 Request Header Fields ...............................37 6 Response................................................38 6.1 Status-Line .........................................38 6.1.1 Status Code and Reason Phrase ....................39 6.2 Response Header Fields ..............................41 7 Entity..................................................41 7.1 Entity Header Fields ................................41 7.2 Entity Body .........................................42 7.2.1 Type .............................................42 7.2.2 Length ...........................................43 8 Connections.............................................43 8.1 Persistent Connections ..............................43 8.1.1 Purpose ..........................................43 8.1.2 Overall Operation ................................44 8.1.3 Proxy Servers ....................................45 8.1.4 Practical Considerations .........................45 8.2 Message Transmission Requirements ...................46 9 Method Definitions......................................48 9.1 Safe and Idempotent Methods .........................48 9.1.1 Safe Methods .....................................48 9.1.2 Idempotent Methods ...............................49 9.2 OPTIONS .............................................49 9.3 GET .................................................50 9.4 HEAD ................................................50 9.5 POST ................................................51 9.6 PUT .................................................52 9.7 DELETE ..............................................53 9.8 TRACE ...............................................53 10 Status Code Definitions................................53 10.1 Informational 1xx ..................................54 10.1.1 100 Continue ....................................54 10.1.2 101 Switching Protocols .........................54 10.2 Successful 2xx .....................................54 10.2.1 200 OK ..........................................54 10.2.2 201 Created .....................................55 10.2.3 202 Accepted ....................................55 10.2.4 203 Non-Authoritative Information ...............55 10.2.5 204 No Content ..................................55 10.2.6 205 Reset Content ...............................56 10.2.7 206 Partial Content .............................56 10.3 Redirection 3xx ....................................56 10.3.1 300 Multiple Choices ............................57 10.3.2 301 Moved Permanently ...........................57 10.3.3 302 Moved Temporarily ...........................58 10.3.4 303 See Other ...................................58 10.3.5 304 Not Modified ................................58 10.3.6 305 Use Proxy ...................................59 10.4 Client Error 4xx ...................................59 10.4.1 400 Bad Request .................................60 10.4.2 401 Unauthorized ................................60 10.4.3 402 Payment Required ............................60 10.4.4 403 Forbidden ...................................60 10.4.5 404 Not Found ...................................60 10.4.6 405 Method Not Allowed ..........................61 10.4.7 406 Not Acceptable ..............................61 10.4.8 407 Proxy Authentication Required ...............61 10.4.9 408 Request Timeout .............................62 10.4.10 409 Conflict ...................................62 10.4.11 410 Gone .......................................62 10.4.12 411 Length Required ............................63 10.4.13 412 Precondition Failed ........................63 10.4.14 413 Request Entity Too Large ...................63 10.4.15 414 Request-URI Too Long .......................63 10.4.16 415 Unsupported Media Type .....................63 10.5 Server Error 5xx ...................................64 10.5.1 500 Internal Server Error .......................64 10.5.2 501 Not Implemented .............................64 10.5.3 502 Bad Gateway .................................64 10.5.4 503 Service Unavailable .........................64 10.5.5 504 Gateway Timeout .............................64 10.5.6 505 HTTP Version Not Supported ..................65 11 Access Authentication..................................65 11.1 Basic Authentication Scheme ........................66 11.2 Digest Authentication Scheme .......................67 12 Content Negotiation....................................67 12.1 Server-driven Negotiation ..........................68 12.2 Agent-driven Negotiation ...........................69 12.3 Transparent Negotiation ............................70 13 Caching in HTTP........................................70 13.1.1 Cache Correctness ...............................72 13.1.2 Warnings ........................................73 13.1.3 Cache-control Mechanisms ........................74 13.1.4 Explicit User Agent Warnings ....................74 13.1.5 Exceptions to the Rules and Warnings ............75 13.1.6 Client-controlled Behavior ......................75 13.2 Expiration Model ...................................75 13.2.1 Server-Specified Expiration .....................75 13.2.2 Heuristic Expiration ............................76 13.2.3 Age Calculations ................................77 13.2.4 Expiration Calculations .........................79 13.2.5 Disambiguating Expiration Values ................80 13.2.6 Disambiguating Multiple Responses ...............80 13.3 Validation Model ...................................81 13.3.1 Last-modified Dates .............................82 13.3.2 Entity Tag Cache Validators .....................82 13.3.3 Weak and Strong Validators ......................82 13.3.4 Rules for When to Use Entity Tags and Last- modified Dates..........................................85 13.3.5 Non-validating Conditionals .....................86 13.4 Response Cachability ...............................86 13.5 Constructing Responses From Caches .................87 13.5.1 End-to-end and Hop-by-hop Headers ...............88 13.5.2 Non-modifiable Headers ..........................88 13.5.3 Combining Headers ...............................89 13.5.4 Combining Byte Ranges ...........................90 13.6 Caching Negotiated Responses .......................90 13.7 Shared and Non-Shared Caches .......................91 13.8 Errors or Incomplete Response Cache Behavior .......91 13.9 Side Effects of GET and HEAD .......................92 13.10 Invalidation After Updates or Deletions ...........92 13.11 Write-Through Mandatory ...........................93 13.12 Cache Replacement .................................93 13.13 History Lists .....................................93 14 Header Field Definitions...............................94 14.1 Accept .............................................95 14.2 Accept-Charset .....................................97 14.3 Accept-Encoding ....................................97 14.4 Accept-Language ....................................98 14.5 Accept-Ranges ......................................99 14.6 Age ................................................99 14.7 Allow .............................................100 14.8 Authorization .....................................100 14.9 Cache-Control .....................................101 14.9.1 What is Cachable ...............................103 14.9.2 What May be Stored by Caches ...................103 14.9.3 Modifications of the Basic Expiration Mechanism 104 14.9.4 Cache Revalidation and Reload Controls .........105 14.9.5 No-Transform Directive .........................107 14.9.6 Cache Control Extensions .......................108 14.10 Connection .......................................109 14.11 Content-Base .....................................109 14.12 Content-Encoding .................................110 14.13 Content-Language .................................110 14.14 Content-Length ...................................111 14.15 Content-Location .................................112 14.16 Content-MD5 ......................................113 14.17 Content-Range ....................................114 14.18 Content-Type .....................................116 14.19 Date .............................................116 14.20 ETag .............................................117 14.21 Expires ..........................................117 14.22 From .............................................118 14.23 Host .............................................119 14.24 If-Modified-Since ................................119 14.25 If-Match .........................................121 14.26 If-None-Match ....................................122 14.27 If-Range .........................................123 14.28 If-Unmodified-Since ..............................124 14.29 Last-Modified ....................................124 14.30 Location .........................................125 14.31 Max-Forwards .....................................125 14.32 Pragma ...........................................126 14.33 Proxy-Authenticate ...............................127 14.34 Proxy-Authorization ..............................127 14.35 Public ...........................................127 14.36 Range ............................................128 14.36.1 Byte Ranges ...................................128 14.36.2 Range Retrieval Requests ......................130 14.37 Referer ..........................................131 14.38 Retry-After ......................................131 14.39 Server ...........................................132 14.40 Transfer-Encoding ................................132 14.41 Upgrade ..........................................132 14.42 User-Agent .......................................134 14.43 Vary .............................................134 14.44 Via ..............................................135 14.45 Warning ..........................................137 14.46 WWW-Authenticate .................................139 15 Security Considerations...............................139 15.1 Authentication of Clients .........................139 15.2 Offering a Choice of Authentication Schemes .......140 15.3 Abuse of Server Log Information ...................141 15.4 Transfer of Sensitive Information .................141 15.5 Attacks Based On File and Path Names ..............142 15.6 Personal Information ..............................143 15.7 Privacy Issues Connected to Accept Headers ........143 15.8 DNS Spoofing ......................................144 15.9 Location Headers and Spoofing .....................144 16 Acknowledgments.......................................144 17 References............................................146 18 Authors' Addresses....................................149 19 Appendices............................................150 19.1 Internet Media Type message/http ..................150 19.2 Internet Media Type multipart/byteranges ..........150 19.3 Tolerant Applications .............................151 19.4 Differences Between HTTP Entities and MIME Entities...........................................152 19.4.1 Conversion to Canonical Form ...................152 19.4.2 Conversion of Date Formats .....................153 19.4.3 Introduction of Content-Encoding ...............153 19.4.4 No Content-Transfer-Encoding ...................153 19.4.5 HTTP Header Fields in Multipart Body-Parts .....153 19.4.6 Introduction of Transfer-Encoding ..............154 19.4.7 MIME-Version ...................................154 19.5 Changes from HTTP/1.0 .............................154 19.5.1 Changes to Simplify Multi-homed Web Servers and Conserve IP Addresses .................................155 19.6 Additional Features ...............................156 19.6.1 Additional Request Methods .....................156 19.6.2 Additional Header Field Definitions ............156 19.7 Compatibility with Previous Versions ..............160 19.7.1 Compatibility with HTTP/1.0 Persistent Connections............................................161
 1 イントロダクション
1 イントロダクション
1.1 目的
Hypertext Transfer Protocol (HTTP) は共同的ハイパーメディア情報配布システムのためのアプリケーションレベルプロトコルである。HTTP は 1990 から World-Wide Web グローバルインフォメーションイニシアティブによる使用によって存在している。HTTP/0.9 と呼ばれる HTTP の最初のバージョンはインターネット上で未加工のデータを転送するための簡単なプロトコルであった。RFC 1945 [6] で定義されている HTTP/1.0 は、転送データに対するメタ情報とリクエスト/レスポンスセマンティクスの修飾子を含めた MIME-like なメッセージフォーマットを使用する事でプロトコルを改善した。しかしながら、HTTP/1.0 はプロキシ、キャッシングの階層構造と永続的な接続の必要性、仮想ホストの効果の熟慮を十分に取っていなかった。さらに、自身を "HTTP/1.0" と称する不完全に実装されたアプリケーションの激増により、双方の通信アプリケーションが互いに真の能力を発揮するための適切なプロトコルバージョンの変更が必要となった。
この仕様書は "HTTP/1.1" と呼ばれるプロトコルを定義している。このプロトコルはその機能の確実な実装を保証するため HTTP/1.0 よりもより厳格な要求を加えている。
現実的なの情報システムは単純な参照や包括的検索、front-end 更新、注釈よりもより多くの機能性を必要としている。HTTP は要求目的を示すメソッドを開放的 (open-ended) セットにしている。これは、メソッドが適用されるリソースを示す場所 (URL) [4] や名前 (URN) となる Uniform Resource Identifier (URI) [3][20] によって供給される参照規律に基づいている。メッセージは Multipurpose Internet Mail Extensions (MIME) として定義されているインターネットメールで使用されている形式に似たフォーマットで渡される。
HTTP はユーザエージェントが SMTP [16], NNTP [13], FTP [18], Gopher[2], WAIS [10] プロトコルなどを使用している別の情報システムへのプロキシ/ゲートウェイと通信を行うための一般的なプロトコルとしても使用される。このように、HTTP は多様なアプリケーションから利用できるリソースへの基本的なハイパーメディアアクセスを可能にする。
1.2 要求
この仕様書は入念な要求それぞれの意味を定義するために RFC 1123 [8] と同じ言葉を使用している。これらの言葉は:
- MUST: ならない
- この言葉や形容詞 "必要とされる" はそのその項目が仕様書において絶対に必要である事を意味する。
- SHOULD: すべきである
- この言葉や形容詞 "推奨される" はこの項目を無効とするのに妥当な理由が存在する、特有の状況が存在するかもしれない事を意味する。しかし、完全な実装を行うのであれば、別の方法をとる前によく理解して状況を注意深く考えるべきである。
- MAY: かもしれない, 事がある, 可能性がある
- この言葉もしくは形容詞 "オプション的" はこの項目が正確に任意である事を意味する。たとえば、特有の市場がその項目を要求している場合や製品の改良のためベンダはその項目を選ぶかもしれないし、別のベンダは同じ項目を除外するかもしれない。
もし実装したプロトコルが MUST 要求を一つでも満足していないなら、インプリメンテーションは従順ではない。プロトコルのすべての MUST とすべての SHOULD 要求を満たしているインプリメンテーションは "無条件に従順" と呼ばれる。プロトコルの全 MUST 要求を満たしているが、すべての SHOULD 要求を満たしているわけではないものは "条件付きで従順である" と呼ばれる。[訳注: 日本語訳において曖昧さが生じるため、厳密な使用は原文参照]
1.3 用語
この仕様書は HTTP 通信の参加者とオブジェクトが行う役割を表す幾つかの言葉を使用している。
- 接続
- 通信を目的とする二つのプログラムの間で確立されるトランスポート層仮想回路 (transport layer virtual circuit)。
- メッセージ
- 8 ビットバイト (octet) のシーケンスで構成された 4 章で定義される構文と一致するものと、接続を経由して転送されたもので成り立つ HTTP 通信の基本ユニット。
- リクエスト
- 5 章で定義されているような HTTP リクエストメッセージ。
- レスポンス
- 6 章で定義されているような HTTP レスポンスメッセージ。
- リソース
- 3.2 章で定義されている URI で識別できるネットワーク上のデータオブジェクトやサービス。リソースは複数の表現 (多様な言語、データフォーマット、サイズ、解像度のような) もしくは別の方法で変化させて利用できるかもしれない。
- エンティティ
- リクエストやレスポンスの結果として転送される情報。7 章で表されているように、エンティティは entity-header フィールド形式のメタ情報や entity-body 形式の内容 (Content) で構成される。
- 表現
- 12 章で表されるように、内容ネゴシエーションを行ったレスポンスに含まれるエンティティ。詳細なレスポンスステータスに関連した複数の表現が存在するかもしれない。
- 内容ネゴシエーション
- 12 章で表されるように、あるリクエストに対してサービスを行うときに適切な表現を選択するためのメカニズム。どのようなレスポンスのエンティティ表現もネゴシエーションする事ができる (エラーレスポンスを含む)。
- バリアント
- リソースは発生したあらゆる瞬間に、自分と関連する一つ以上の表現を持つかもしれない。これらの表現のそれぞれは `バリアント' と称される。`バリアント' という言葉の使用はリソースが内容ネゴシエーションに従っている事を暗黙的に意味するというわけではない。
- クライアント
- リクエスト送信の目的のため接続を確立するプログラム。
- ユーザエージェント
- リクエストを開始するクライアント。ブラウザ、エディタ、スパイダー (ウェブをわたるロボット) やその他のエンドユーザツールなどがある。
- サーバ
- レスポンスを送り返して要求を実行する目的で接続を受け入れるアプリケーションプログラム。作成されたどのようなプログラムもクライアントとサーバの両方の機能を持つことができる。われわれがクライアントやサーバという言葉を使用する場合、ある接続でプログラムが行う役割のみを指し、一般的なプログラムの機能を意味するのではない。同様に、どのようなサーバも個々のリクエストの性質に基づいて動作を変化させ、オリジンサーバ、プロキシ、ゲートウェイやトンネルの動作をすることができる。
- オリジンサーバ
- 与えられたリソースが存在もしくは制作されるサーバ。
- プロキシ
- 他のクライアントに代わってリクエストを作成する目的で、サーバとクライアントの両方の動作を演じる中間プログラム。リクエストはプロキシ内部で、または可能な変換を伴って別のサーバに渡すことで実行される。プロキシはこの仕様書のクライアントとサーバ両方を実装しなければならない。
- ゲートウェイ
- ある別のサーバへの中継者を演じるサーバ。プロキシと違い、リクエストされたりソースのオリジンサーバであるかのように要求を実行する。リクエストしているクライアントはゲートウェイと通信している事を意識する必要はない。
- トンネル
- 二つの接続間で機械的な中継をする役割の中間プログラム。トンネルは HTTP リクエストにより開始されたものかもしれないが、一度活性化すると HTTP 通信の当事者とみなされない。トンネルは中継している接続の両端がクローズされたときに存在を終了する。
- キャッシュ
- プログラムがレスポンスメッセージを保存するローカルな場所か、メッセージの保存、検索や削除を制御するサブシステム。キャッシュは後のレスポンスタイムを減らしたりネットワークバンド幅を減少するため、リクエストと同じ処理となるキャッシュ可能なレスポンスを保存する。トンネルとして動作しているサーバはキャッシュを使うことができないが、どんなクライアントもサーバもキャッシュを含むことができる。
- キャッシュ可能
- もしキャッシュが次回のリクエスト応答で使用するためにレスポンスメッセージのコピーを保存する事が認められるならば、レスポンスはキャッシュ可能である。HTTP レスポンスのキャッシュ可能性を決定するためのルールは 13 章で定義される。たとえリソースがキャッシュ可能だとしても、キャッシュがあるリクエストに対してキャッシュされたコピーを使えるかどうかに追加的な制約があるかもしれない。
- 直接的
- もしレスポンスが一つ以上のプロキシ経由によるためであろう不要な遅延なしに直接オリジンサーバから来たなら、レスポンスは直接的 (first-hand) である。レスポンスの正当性をオリジンサーバに直接確認した場合もレスポンスは直接的となる。
- 明確な満期時間
- オリジンサーバが意図する、キャッシュがさらなる確証動作なしにエンティティを返すべきではないという意味の時間。
- 発見的な満期時間
- 明確な満期時間が利用できないときにキャッシュが割り当てる満期時間。
- 年齢
- レスポンスの年齢は、それがオリジンサーバから送られるか、正当性が首尾良く確証されてからの時間である。
- 新鮮さの持続期間
- レスポンスの生成時間とその満期時間の間の長さ。
- 新鮮
- もしレスポンスの年齢がその新鮮な存在期間を超えていなければ、レスポンスは新鮮である。
- 新鮮でない/古くなった
- もしレスポンス年齢が新鮮な存在期間を超えていれば、レスポンスは新鮮でない。
- 意味的に透過
- リクエストしているクライアントにもサーバにもキャッシュの使用が影響を与えないとき (パフォーマンスを向上させるという効果を除いて)、キャッシュは個別のレスポンスを尊重して "意味的に透過" な態度をとる。キャッシュが意味的に透過であるとき、クライアントはサーバが直接処理したものと正確に同じレスポンス (hop-to-hop ヘッダを除いて) を受け取る。
- 正当性確証子
- キャッシュエントリがエンティティのコピーと等しいかどうかを調べるために使用されるプロトコル要素 (エンティティタグや Last-Modified 時刻など)。
1.4 全体的な操作
HTTP プロトコルはリクエスト/レスポンスプロトコルである。クライアントはサーバへの接続上で、プロトコルバージョン、リクエストメソッド、URI、そしてそれらの後に続くリクエスト修飾子、クライアント情報、可能であれば内容本体の MIME-like メッセージ形式でサーバにリクエストを送る。サーバは、メッセージのプロトコルバージョンと成功やエラーコードを意味するステータス行に続けてサーバ情報、エンティティメタ情報、可能であればエンティティボディ内容を含む MIME-like メッセージで応答する。HTTP と MIME の関係は付録 19.4 に記述されている。
ほとんどの HTTP 接続はユーザエージェントによって開始され、オリジンサーバ上のリソースに適用するリクエストで成り立つ。最も簡単な場合、ユーザエージェント (User Agent) とオリジンサーバ (Origin Server) との間の単一接続経由で成し遂げられるだろう。
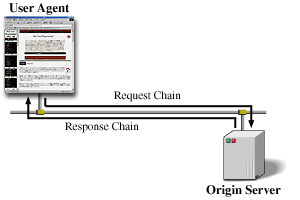
より複雑な状況は一つ以上の仲介者がリクエスト/レスポンス連鎖に現れるときに起こる。三つの一般的な仲介者: プロキシ、ゲートウェイそしてトンネルが存在する。プロキシは絶対形式の URI のリクエストを受け取り、メッセージのすべてもしくは一部を書き換え、URI によって識別されるサーバに再フォーマットされたリクエストを転送するエージェントである。ゲートウェイはある別のサーバ (複数かもしれない) の上の層として動作し、もし必要ならリクエストを末端サーバのプロトコルに変換する受信エージェントである。トンネルはメッセージを変更する事なく二つの接続間の中継点として動作する。トンネルは通信が (ファイアウォールのような) 仲介者を通して伝えられる必要があるときや、仲介者がメッセージの内容を理解できないときに使用される。
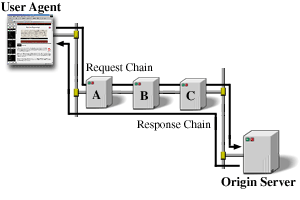
上記の図はユーザエージェントとオリジンサーバの間の三つの仲介者 (A, B, C) を表している。連鎖全体を移動するリクエストやレスポンスメッセージは四つに分割された接続を通して渡される。いくつかの HTTP 通信オプションは (非トンネルの) 隣接にのみ、連鎖の端末点にのみ、そして連鎖上のすべての接続に適用できるため、この区別は重要である。ダイアグラムは線形であるがそれぞれの当事者は複数同時通信を行う事ができる。たとえば、B は A のリクエストを処理すると同時に、A 以外のたくさんのクライアントからリクエストを受信しているかもしれないし、C 以外のサーバにリクエストを転送しているかもしれない。
トンネルとして動作していない通信のすべての当事者は内部的なキャッシュやリクエスト処理を使用できる。もし連鎖上の当事者の一つがそのリクエストに適用できるキャッシュされたレスポンスを持っているなら、キャッシュはリクエスト/レスポンス連鎖を短くするの効果をもつ。もし B が Origin Server から C を経由して来た、以前の (User Agent や A にキャッシュされていない) レスポンスのキャッシュコピーを持っているなら、以下はその結果となる連鎖を説明している。
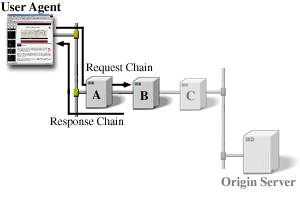
すべてのレスポンスが有効にキャッシュ可能というわけではなく、いくつかのリクエストはキャッシュの動作に特別な要求を行う修飾子を含む事ができる。キャッシュの動作やキャッシュ可能なレスポンスに対する HTTP の要求は 13 章で定義されている。
事実、現在 World Wide Web 上で実験されて配置されているキャッシュとプロキシのアーキテクチャやコンフィギュレーションは幅広い多様性を持つ。これらのシステムは国際通信でバンド幅を節約するためのプロキシキャッシュの国際間階層や、キャッシュエンティティのブロードキャスト・マルチキャストを行うシステム、キャッシュされたデータのサブセットを CD-ROM で配布する組織などを含んでいる。HTTP システムは高バンド幅通信の社内イントラネット上で、そして非力なラジオ通信や断続的な接続を使う PDA 経由のアクセスで使用される。HTTP/1.1 の目的は、高い信頼性と、通信に失敗するなら少なくとも失敗の確実な指示が必要となるウェブアプリケーションを構築する人々のニーズに合うプロトコル構造を導入する事であるが、同時に既に設置されている構成の広い多様性をサポートする事でもある。
HTTP 通信は常に TCP/IP 接続上で行う。デフォルトポートは TCP 80 であるが、他のポートを使用する事もできる。これは HTTP がインターネットや他のネットワーク上で別のプロトコルの最上部として実装されるのを妨害しない。HTTP は確実な転送のみを前提とする。そのような保証を供給するどんなプロトコルでも使用できる。この問題でプロトコルのデータ転送単位の HTTP/1.1 リクエストとレスポンスのマッピングはこの仕様書の範囲外である。
HTTP/1.0 において、ほとんどのインプリメンテーションは個々のリクエスト/レスポンス交換のために新しい接続を使用していた。HTTP/1.1 では、接続を一つ以上のリクエスト/レスポンス交換に使用できるが、レスポンスの種類によっては接続がクローズされるかもしれない (8.1 章参照)。
2 表記法的慣習と一般文法
2.1 拡張 BNF
このドキュメントにおいて詳述されるメカニズムのすべては、単調 Backus-Naur Form (BNF) と RFC 822 [9] で使用されているもとの類似した拡張 BNF の両方で記述されている。実装者はこの仕様書を理解するためこの表記法に精通している必要がある。拡張 BNF は以下の構造を追加している。
- name = definition
- ルールの name は ("<" と ">" で囲んであるものを除いて) 単純にそれ自身の名前であり、その定義を等号 "=" 文字によって分割している。空白は一つ以上の行に及ぶルール定義を示すために使用される連続行の指示においてのみ意味を持つ。特定の基本ルールは SP, LWS, HT, CRLF, DIGIT, ALPHA などのように大文字である。角括弧は、それらの存在がルール名の使用の理解を容易にするであろうときに使用される。
- "literal"
- クォーテーション記号はリテラルテキストを囲む。もし別に明言されなければ、テキストは大文字小文字を区別しない。
- rule1 | rule2
- ("|") で区切られた要素は二者択一である。たとえば "yes | no" は yes か no ととることができる。
- (rule1 rule2)
- 括弧で囲まれた要素は単一の要素として扱われる。従って、"(elem (foo | bar) elem)" はトークンシーケンス "elem foo elem" と "elem bar elem" を認める。
- *rule
- 要素に先行する "*" 文字は繰り返しを意味する。完全な形式は element の最低 <n>、最大 <m> の存在を示している "<n>*<m>element" である。デフォルト値は 0 と無限であり、"*(element)" はゼロを含むどんな回数も可能である。"1*element" は最低一つ、"1*2element" は一つか二つが可能である。
- [rule]
- 角括弧は省略可能な要素を囲む。"[foo baf]" は "*1(foo bar)" と等しい。
- N rule
- 具体的な繰り返し: "<n>(element)" は "<n>*<n>(element)" と等しい。これは、(element) が正確に <n> 存在する。従って 2DIGIT は二つの数字であり、3ALPHA は三つのアルファベット文字の文字列である。
- #rule
- "*" と類似した "#" 構造は要素のリストを定義するために定義されている。完全な形式は element 最低 <n>、最大 <m> の存在を示している "<n>#<m>element" であり、それぞれは一つ以上のコンマ (",") と省略可能な連続空白 (LWS) で区切られる。これは普通とても簡単にリストのフォームを作る。"( *LWS element *(LWS "," *LWS element))" のルールは "1#element" として表す事ができる。この構造が使用されているどこでも、null 要素が許されるが、与えられた要素の数に影響しない。"(element), , (element)" は許されるが、二つの要素として数えられる。それゆえ、最低一つの要素が必要とされるところでは最低一つの null でない要素が与えられなければならない。デフォルト値は 0 と無限である。"#element" はゼロを含むどんな数も認め、"1#element" は最低一つを必要とし、"1#2element" は一つか二つを認めている。
- ; comment
- ルールテキストの右からある距離を置いて始まるセミコロンは、行末まで続くコメントを開始している。これはこの仕様書で並行した有用な記述を加えるための簡単な方法である。
- implied *LWS
- この仕様書によって記述される文法は word-based である。別の方法で明記していなければ、連続した空白 (LWS) はフィールドの解釈を変更しないで二つの隣接した言葉 (トークンや quoted-string) の間や隣接したトークンとデリミタ (tspecials) の間に追加する事ができる。二つのトークンの間にはそれらが単一のトークンとして解釈されないように最低一つのデリミタ (tspecials) が存在しなければならない。
2.2 基本ルール
以下のルールは基本的な構造説明を記述するためこの仕様書全体に渡って使用されている。文字セットとしてコード化された US-ASCII は ANSI X3.4-1986[12] で定義されている。
OCTET = <データの 8-bit シーケンスすべて>
CHAR = <すべての US-ASCII 文字 (8 ビットバイト 0 - 127)>
UPALPHA = <すべての US-ASCII 大文字 "A".."Z">
LOALPHA = <すべての US-ASCII 小文字 "a".."z">
ALPHA = UPALPHA | LOALPHA
DIGIT = <すべての US-ASCII 数字 "0".."9">
CTL = <すべての US-ASCII 制御文字
(8 ビットバイト 0 - 31) と DEL (127)>
CR = <US-ASCII CR, キャリッジリターン (13)>
LF = <US-ASCII LF, ラインフィード (10)>
SP = <US-ASCII SP, スペース (32)>
HT = <US-ASCII HT, 水平タブ (9)>
<"> = <US-ASCII ダブルクォート記号 (34)>
HTTP/1.1 はエンティティボディ以外のすべてのプロトコル要素に対する行末として CR LF シーケンスを定義している (耐性のあるアプリケーションのための付録 19.3 章参照)。エンティティボディ内の行末マーカーは 3.7 章で記述されているように、その関連するメディアタイプによって定義される。
CRLF = CR LF
HTTP/1.1 ヘッダは続く行が空白か水平タブで開始しているなら複数行にまたがって折り返す事ができる。折り返しているものを含むすべての連続空白は SP と同じ意味を持つ。
LWS = [CRLF] 1*( SP | HT )
TEXT ルールはメッセージパーサーによって解釈されるのを目的とする説明的なフィールドの内容と値にのみ使用される。*TEXT の言葉は、RFC 1522 [14] のルールにしたがってエンコードされたときのみ、ISO-8859-1 [22] 以外の文字セットの文字を含む事ができる。
TEXT = <CTL 以外で LWS を含むすべての OCTET>
16 進数文字はいくつかのプロトコル要素において使用される。
HEX = "A" | "B" | "C" | "D" | "E" | "F"
| "a" | "b" | "c" | "d" | "e" | "f" | DIGIT
多くの HTTP/1.1 ヘッダフィールド値は LWS か特別な文字によって区切られた言葉から成り立つ。これらの特別な文字がパラメータ値内で使用されるためには引用された文字列内に存在しなければならない。
token = 1*<CTL や tspecial を除くすべての CHAR>
tspecials = "(" | ")" | "<" | ">" | "@"
| "," | ";" | ":" | "\" | <">
| "/" | "[" | "]" | "?" | "="
| "{" | "}" | SP | HT
コメントは、いくつかの HTTP ヘッダ内でコメント文字を括弧で囲む事により加える事ができる。コメントは、それらのフィールド値定義の一部として "comment" を含んでいるフィールドにおいてのみ許される。その他のすべてのフィールドにおいては、括弧はフィールド値の一部とみなされる。
comment = "(" *( ctext | comment ) ")"
ctext = <"(" と ")" を含むすべての TEXT>
テキストの文字列はダブルクォート記号を使って引用されているなら、単一の言葉として解析される。
quoted-string = ( <"> *(qdtext) <"> )
qdtext = < <"> 以外のすべての TEXT>
バックスラッシュ文字 ("\") は quoted-string と comment 構造内でのみ単一文字引用メカニズムとして使用されるだろう。
quoted-pair = "\" CHAR
3 プロトコルパラメータ
3.1 HTTP バージョン
HTTP はプロトコルのバージョンを含むる "<major>.<minor>" 番号スキームを使用する。プロトコルのバージョン付け処理は、この転送を使って得られる機構というよりも、サーバに対してメッセージのフォーマットを示したり、今後の HTTP 転送を理解する為の能力を表す。転送動作に影響を及ぼさなかったり、拡張可能なフィールド値を追加するだけのメッセージ構成要素の追加に対して、バージョン番号のどんな変更も行われない。<minor> 番号はプロトコルによってなされる変更が一般的なメッセージ解析アルゴリズムを変更しない機能を追加するときに増やされるが、これはメッセージセマンティクスを追加し、送り側の追加的な性能を暗黙的に意味するだろう。<major> 番号はプロトコル内のメッセージのフォーマットが変更されるときに増やされる。
HTTP メッセージのバージョンはメッセージの最初の行の HTTP-Version フィールドで示される。
HTTP-Version = "HTTP" "/" 1*DIGIT "." 1*DIGIT
メジャー番号とマイナー番号は分割した整数値として扱われるべきであり、一文字以上に増やされる事に注意する。従って、HTTP/12.3 よりも順序的に下となる HTTP/2.4 は HTTP/2.13 よりも下のバージョンである。先行するゼロは受け取り側によって無視されなければならず、送られてはならない。
この仕様書により定義されるような Request や Response メッセージを送るアプリケーションは "HTTP/1.1" の HTTP-Version を含まなければならない。このバージョン番号の使用は送り側のアプリケーションが少なくとも条件付きでこの仕様書に準じていると言う事を示す。
アプリケーションの HTTP バージョンはアプリケーションが少なくとも条件付きで準じている最も高い HTTP バージョンである。
プロキシとゲートウェイアプリケーションはプロトコル上で転送するバージョンの違うメッセージに注意しなければならない。プロトコルバージョンは送り側のプロトコル機能を示すため、プロキシ/ゲートウェイは決して実際のバージョンよりも大きなバージョン指標が付いたメッセージを送ってはならない。もしより高いバージョンのリクエストを受けたなら、エラーを返すか、トンネル動作にスイッチする。そのプロキシ/ゲートウェイのバージョンよりも低いバージョンのリクエストは転送される前にアップグレードできる。そのリクエストのプロキシ/ゲートウェイのレスポンスはリクエストと同じメジャーバージョンでなければならない。
注意: HTTP のバージョン間の変換は含まれるバージョンによって要求されるか禁止されているヘッダフィールドの修正を含んでいる。
3.2 Uniform Resource Identifiers
URI は多くの名前: WWW address, Universal Document Identifier, Universal Resource Identifier 最終的には Universal Resource Locator(URL) と Name(URN) で既に知られている。HTTP が関心を持たれる限り、Uniform Resource Identifier は![]() 名前、ロケーションやその他の特徴で
名前、ロケーションやその他の特徴で![]() リソースを識別する簡単にフォーマットされた文字列である。
リソースを識別する簡単にフォーマットされた文字列である。
3.2.1 一般構文
HTTP における URI は、絶対形式か当事者たちが置かれている状況に依存する幾つかの既知 URI の相対形式で表される。二つの形式は絶対形式の URI が常にコロンを後に持つスキーム名で開始しているという事実により区別される。
URI = ( absoluteURI | relativeURI ) [ "#" fragment ]
absoluteURI = scheme ":" *( uchar | reserved )
relativeURI = net_path | abs_path | rel_path
net_path = "//" net_loc [ abs_path ]
abs_path = "/" rel_path
rel_path = [ path ] [ ";" params ] [ "?" query ]
path = fsegment *( "/" segment )
fsegment = 1*pchar
segment = *pchar
params = param *( ";" param )
param = *( pchar | "/" )
scheme = 1*( ALPHA | DIGIT | "+" | "-" | "." )
net_loc = *( pchar | ";" | "?" )
query = *( uchar | reserved )
fragment = *( uchar | reserved )
pchar = uchar | ":" | "@" | "&" | "=" | "+"
uchar = unreserved | escape
unreserved = ALPHA | DIGIT | safe | extra | national
escape = "%" HEX HEX
reserved = ";" | "/" | "?" | ":" | "@" | "&" | "=" | "+"
extra = "!" | "*" | "'" | "(" | ")" | ","
safe = "$" | "-" | "_" | "."
unsafe = CTL | SP | <"> | "#" | "%" | "<" | ">"
national = <ALPHA, DIGIT, reserved, extra, safe,
unsafeany を除くすべての OCTET>
URL 構文や意味の定義的な情報は RFC 1738 [4] と RFC 1808 参照。HTTP サーバはアドレスの rel_path 部分を表す事のできる予約されていない文字セットにおいて制限されていないし、HTTP プロキシは RFC 1738 で定義されていない URI のリクエストを受信できるかもしれないため、この上記の BNF は RFC 1738 のよって示されているような正当な URLに入る事を許されていない国際文字を含む。
HTTP プロトコルは URI の優先的な長さに関してどんな制限も設けていない。サーバは当事者たちが送付してくるどんなリソースの URI も処理できなければならなず、もしそのような URI を生成する GET ベースのフォームを用意するなら、無制限の長さの URI を処理できるべきである。もし URI がサーバが処理できる限界 (10.4.15 章参照) よりも長いなら 414 (Request-URI Too Long) ステータスを返すべきである。
注意: サーバは古いクライアントやプロキシ実装が 255 バイトを超える長さを適切にサポートしていないかもしれないため、そのような長さの URI への依存に関して注意すべきである。
3.2.2 http URL
"http" スキームは HTTP プロトコル経由でネットワークリソースの位置を定めるために使用される。このセクションでは http URL に対するスキーム記述構文とセマンティクスを定義している。
http_URL = "http:" "//" host [ ":" port ] [ abs_path ]
host = <A legal Internet host domain name
or IP address (in dotted-decimal form),
as defined by Section 2.1 of RFC 1123>
port = *DIGIT
もし port が空であったり省略されていれば、ポート 80 が仮定される。そのセマンティクスは、識別するリソースがそのホストのそのポートで TCP 接続のための接続待ちをしているサーバの場所を特定し、リソースに対する Request-URI は abs_path である。可能であれば URI での IP アドレスの使用は避るべきである (RFC 1900 [24] 参照)。もし abs_path が URI で与えられなければ、リソースに対する Request-URI として使われるとき "/" として与えられなければならない (5.1.2 章)。
3.2.3 URI の比較
もし二つの URI が一致しているかどうかを判別するためそれらを比較するなら、クライアントは以下を例外として URI 全体の大文字と小文字を区別した 8 ビットバイト同士を比較すべきである:
- 与えられた空やそうでない部分がその URI のデフォルト部分と等価である。
- ホスト名の比較は大文字小文字を区別してはならない。
- スキーム名の比較は大文字と小文字を区別してはならない。
- 空の abs_path は "/" の abs_path と等価である。
これら以外の "予約された" もしくは "危険な" セット (3.2 章参照) 文字はそれらの ""%" HEX HEX" エンコーディングと等しい。
たとえば、以下の三つの URI は等価である:
http://abc.com:80/~smith/home.html
http://ABC.com/%7Esmith/home.html
http://ABC.com:/%7esmith/home.html
3.3 日付/時刻フォーマット
3.3.1 完全な日付
HTTP アプリケーションは歴史的に日付/時刻スタンプの表現のため三つの異なるフォーマットを認めている。
Sun, 06 Nov 1994 08:49:37 GMT ; RFC 822, RFC 1123 で改定された
Sunday, 06-Nov-94 08:49:37 GMT ; RFC 850, RFC 1036 により時代遅れ
Sun Nov 6 08:49:37 1994 ; ANSI C の asctime() フォーマット
最初のフォーマットはインターネット標準としてより好まれ、RFC 1123 (RFC822 の改定) で定義されている物の固定長サブセットに相当する。第二のフォーマットは一般的に使用されているが、時代遅れの RFC 850 [12] 日付フォーマットをベースにし、4 桁年号が欠落している。日付の値を解析する HTTP/1.1 クライアントとサーバは (HTTP/1.0 との互換性のため) 三つすべてのフォーマットを受け入れなければならないが、それらがヘッダフィールドで HTTP-date 値を表す時には RFC 1123 フォーマットのみを使用しなければならない。
注意: 日付の値の受取側は、しばしば SMTP や NNTP のプロキシ/ゲートウェイを経由して受送信されたメッセージを考慮して、非 HTTP アプリケーションによって送られるであろう日付の値を受け入れるような強固さを持つ事が推奨される。
すべての HTTP 日付/時刻スタンプは例外を除いてグリニッジ標準時刻 (GMT)で表されなければならない。これはタイムゾーンに対する三文字略として"GMT" の包括によって最初の二つのフォーマットで示され、asctime フォーマットの解釈のときに仮定されなければならない。
HTTP-date = rfc1123-date | rfc850-date | asctime-date
rfc1123-date = wkday "," SP date1 SP time SP "GMT"
rfc850-date = weekday "," SP date2 SP time SP "GMT"
asctime-date = wkday SP date3 SP time SP 4DIGIT
date1 = 2DIGIT SP month SP 4DIGIT
; day month year (e.g., 02 Jun 1982)
date2 = 2DIGIT "-" month "-" 2DIGIT
; day-month-year (e.g., 02-Jun-82)
date3 = month SP ( 2DIGIT | ( SP 1DIGIT ))
; month day (e.g., Jun 2)
time = 2DIGIT ":" 2DIGIT ":" 2DIGIT
; 00:00:00 - 23:59:59
wkday = "Mon" | "Tue" | "Wed"
| "Thu" | "Fri" | "Sat" | "Sun"
weekday = "Monday" | "Tuesday" | "Wednesday"
| "Thursday" | "Friday" | "Saturday" | "Sunday"
month = "Jan" | "Feb" | "Mar" | "Apr"
| "May" | "Jun" | "Jul" | "Aug"
| "Sep" | "Oct" | "Nov" | "Dec"
注意: HTTP で要求される日付/時刻スタンプフォーマットはプロトコルストリーム内でのそれらの使用にのみ適用される。クライアントとサーバはユーザへの提示や、ログイン要求などに対してこれらのフォーマットを使用する必要はない。
3.3.2 秒差
幾つかの HTTP ヘッダフィールドはメッセージが受信された時刻後の 10 進数で表される秒の整数として記述される時間値を認めている。
delta-seconds = 1*DIGIT
3.4 文字セット
HTTP は MIME のために表されているような "文字セット" 用語と同じ定義を使用する:
"文字セット" 用語はこのドキュメントで 8 ビットバイトシーケンスを文字シーケンスに変換するための一つ以上のテーブルで使用される方法を提示するために使用されている。すべての文字が与えられた文字セットで利用できるわけではなかったり、固有の文字を表すため文字セットが一つ以上の 8 ビットバイトシーケンスを供給する場合において、別の指示で無条件な変換が必要でない事に注意。この定義は US-ASCII のような簡単な単一テーブルマッピングから、ISO 2022 の技術を使うような複雑なテーブルをスイッチする方法まで、さまざまな種類の文字エンコーディングを認める目的を持つ。しかしながら、MIME 文字セット名に関連したこの定義は 8 ビットバイトから文字に行われるマッピングを完全に詳述しなければ ならない 。特に、正確なマッピングを決定するための外部のプロフィール情報の使用は許されない。
注意: この "文字セット" 用語の使用は "文字エンコーディング" としてより一般的に参照されている。しかしながら、HTTP と MIME が同じ登録を共有しているため、用語も共有される事が大切である。
HTTP 文字セットは大文字と小文字を区別しないトークンによって識別される。トークンの完全セットは IANA Character Set 登録機構 [19] によって定義される。
charset = token
とはいえ、HTTP は文字値として使用される任意のトークンを認めている。IANA Character Set 登録機構によって定義済みの値を持つどんなトークンもその登録機構で定義された文字セットを表さなければならない。アプリケーションは文字セットのそれらの使用に IANA 登録機構により定義されたこれらを制限すべきである。
3.5 内容コーディング
内容コーディング値はエンティティに適用されているもしくは適用できるエンコーディング変換を示す。内容コーディングは、その根本的なメディアタイプのアイデンティティを失ったり情報の欠落がおこなわれないで、圧縮されたり別の有用な変換が行われたドキュメントを許可するために使用される。しばしば、エンティティはコード化された形態で保存され、直接転送され、受け取り側によってのみデコードされる。
content-coding = token
すべての content-coding 値は大文字と小文字を区別しない。HTTP/1.1 は Accept-Encoding (14.3 章) と Content-Encoding (14.12 章) ヘッダフィールドにおいて content-coding 値を使用する。値が content-coding で表されるとはいえ、より重要な事はデコーディングメカニズムがエンコーディングを取り除く必要があるだろうという事を示す事である。
Internet Assigned Numbers Authority (IANA) は content-coding 値トークンに対する登録機構を代行している。初めに、登録機構は以下のトークンを含んでいる:
- gzip
- RFC 1952 [25] に示されているファイル圧縮プログラム "gzip" (GNU zip) により作られるエンコーディングフォーマット。このフォーマットは 32 bit CRC 付きの Lempel-Ziv コーディング (LZ77) である。
- compress
- 一般的な UNIX ファイル圧縮プログラム "compress" で作られるエンコーディングフォーマット。このフォーマットは Lempel-Ziv-Welch コーディング (LZW) に適合している。
注意: エンコーディングフォーマットの確認のためのプログラム名の使用は望ましくなく、将来的なエンコーディングを妨害する。ここでのこれらの使用は歴史的な慣例の代表であり、良いデザインではない。HTTP の以前のインプリメンテーションへの互換性のため、アプリケーションは "x-gzip" と "x-compress" をそれぞれ "gzip" と "compress" に等価であるとみなすべきである。- deflate
- RFC 1951 [29] で記述される "deflate" 圧縮メカニズムと結合した、RFC 1950 [31] で定義されている "zlib" フォーマット。
新しい conetnt-coding 値トークンが登録されるべきである。クライアントとサーバの間での内部操作性を認めるため、新しい値を実装する必要のある内容コーディングアルゴリズムの仕様は公的に利用でき独立したインプリメンテーションに適し、この章で定義された内容コーディングの目的に従うべきである。
3.6 転送コーディング
転送コーディング値はネットワークを通して "安全な転送" を保証するためエンティティボディに適用されている、される事のできる、する必要のあるエンコーディング変換を示す。これは転送コーディングが元のエンティティではなくメッセージの特性である内容エンコーディングとは異なる。
transfer-coding = "chunked" | transfer-extension
transfer-extension = token
すべての transfer-encoding 値は大文字小文字を区別しない。HTTP/1.1 は Transfer-Encoding ヘッダフィールド (14.40 章) で転送コーディング値を使用している。
転送エンコーディングは MIME の Content-Transfer-Encoding 値と類似している。これは 7-bit 転送サービス上でバイナリデータの安全な転送を可能にするために設計されている。しかしながら、安全な転送の焦点は完全な 8 bit転送プロトコルに対して異なる。HTTP では、メッセージボディに特有の危険さは、明確なボディ長 (7.2.2 章) を決定する事が困難なことや、共有された転送経路上でデータの暗号化を望む事だけである。
chunked エンコーディングは、それぞれエンティティヘッダフィールドを含んでいるオプション的なフッタが続くそれ自身のサイズ指標をつけて、チャンクの連続としてそれを転送するためにメッセージのボディを修正する。これは、受取人が全メッセージを受信した事を確かめるための必要な情報とともに転送される動的に生成された内容を認めている。
Chunked-Body = *chunk
"0" CRLF
footer
CRLF
chunk = chunk-size [ chunk-ext ] CRLF
chunk-data CRLF
hex-no-zero = <HEX excluding "0">
chunk-size = hex-no-zero *HEX
chunk-ext = *( ";" chunk-ext-name [ "=" chunk-ext-value ] )
chunk-ext-name = token
chunk-ext-val = token | quoted-string
chunk-data = chunk-size(OCTET)
footer = *entity-header
chunked エンコーディングはサイズがゼロにされたチャンクとそれに続くフッタにより終了する。これは空行によって終わる。フッタの目的は動的に生成されたエンティティに付いての情報を供給するための効果的な方法を備える事である。アプリケーションは、電子署名や別の機能のための Content-MD5 や HTTP の将来的な拡張のように、フッタに対して適切であるようなものとして明白に定義されていないフッタのヘッダフィールドを送ってはならない。
Chunked-Body デコーディングのための例題過程は付録 19.4.6 で紹介されている。
すべての HTTP/1.1 アプリケーションは "chunked" 転送コーディングを受信しデコードできなければならず、それらが理解できない転送コーディング拡張は無視されなければならない。理解できない transfer-coding 付きのエンティティボディを受信したサーバは 501 (Unimplemented) を返して接続を閉じるべきである。サーバは HTTP/1.0 クライアントに転送エンコーディングを送ってはならない。
3.7 メディアタイプ
HTTP は Content-Type (14.18 章) と Accept (14.1 章) ヘッダフィールドにおいてオープンや拡張データタイプ定義やタイプネゴシエーションを供給するために Internet Media Type を使用する。
media-type = type "/" subtype *( ";" parameter )
type = token
subtype = token
パラメータは attribute/value ペアの形態でタイプ/サブタイプが続くであろう。
parameter = attribute "=" value
attribute = token
value = token | quoted-string
タイプ、サブタイプやパラメータ属性名は大文字と小文字を区別しない。パラメータ値はパラメータ名のセマンティクスに依存して大文字小文字の区別が行われるであろう。連続した空白文字 (LWS: Linear white space) はタイプとサブタイプの間や属性とその値の間で使われてはならない。メディアタイプを識別するユーザエージェントはユーザに検知したどんな問題も知らせるため、この type/subtype 定義により表されるような MIME タイプに対するパラメータを処理 (もしくはユーザエージェントによりこの type/subtype を処理するために使われるどんな外部アプリケーションにも処理されるように) しなければならない。
注意: 幾つかの古い HTTP アプリケーションはメディアタイプパラメータを認識しない。この時、古い HTTP アプリケーションにデータを送るため、インプリメンテーションはそれらがこの type / subtype 定義により要求されるときのみメディアタイプを使用すべきである。
メディアタイプ値は Internete Assigned Number Authority (IANA) によって登録される。メディアタイプ登録手続きは RFC 2048 [17] において概説されている。登録されていないメディアタイプの使用は慎むべきである。
3.7.1 公式化とテキストデフォルト
インターネットメディアタイプは公式の形式で登録される。一般的には、HTTPメッセージ経由で転送されるエンティティボディはその転送に前述の適切な公式形式で表されなければならない。例外は次のパラグラフで定義されるような "text" タイプである。
公式形式において、"text" タイプのメディアサブタイプはテキスト行末に CRLF を使う。HTTP はこの要求をゆるめ、それがエンティティボディ全体に対して一貫ししているとき、行末を表すのに単独の CR や LF をつけたテキストメディアの転送を認めている。HTTP アプリケーションは HTTP 経由で受信されるテキストメディアにおいて行末表現であるものとして CRLF, CR や LF を受け入れなければならない。追加として、もしテキストが、幾つかのマルチバイト文字セットに対する場合であるように、CR と LF それぞれに対して8 ビット文字 13 と 10 が使われていないような文字セットに相当するならば、HTTP は行末の CR と LF の評価を表すためのこの文字セットによって定義されているどんな 8 ビット文字の使用をも認める。行末に関するこの柔軟性はエンティティボディのテキストメディアにのみ適用される。単独の CR や LF は HTTP 制御構造 (ヘッダフィールドやマルチパート境界など) のすべてにおいて CRLF に置き換えられてはならない。
もしあるエンティティボディが Content-Encoding でエンコードされているならば、根本的なデータはエンコードされるために上記で定義される形態とならなければならない。
"charset" パラメータはデータの文字セット (3.4 章) を定義するための、幾つかのメディアタイプで使用されている。明確な charset パラメータが送り側から供給されない場合、"text" タイプのメディアサブタイプは HTTP 経由でそれが受信されるときデフォルトの "ISO-8859-1" の charset 値を持つと定義される。"ISO-8859-1" やそのサブセット以外の文字セットにおけるデータは適切な charset 値付きでラベル付けされなければならない。
幾つかの HTTP/1.0 ソフトウェアは charset パラメータを使っていない Content-type ヘッダを "受取人が推測する" を意味するものとして間違って中間処理している。この振る舞いを無効にする事を望む送り側は charset が ISO-8859-1 であるような charset を含んでも良く、それが受取人を混乱させないであろうという事を知っている場合にはそのようにすべきである。
不幸にも、幾つかの古い HTTP/1.0 クライアントは明白な charset パラメータを適切に処理していない。HTTP/1.0 の受け取り側は送り側によって供給される charset ラベルを尊重しなければならない。そして charset を "推測する" 準備のあるユーザエージェントは、もしそれらがその charset をサポートしているならば、ドキュメントを最初に表示するときに受取人の好みよりも Content-Type フィールドからの charset を使わなければならない。
3.7.2 マルチパートタイプ
MIME は "multipart" タイプ![]() 単一の message-body の中への一つ以上のエンティティのカプセル化を幾つかを備えている。MIME [7] で定義されているように、すべてのマルチパートタイプは共通の構文を割り当て、メディアタイプ値の一部として境界パラメータを含まなければならない。メッセージボディはそれ自身プロトコル要素の一部であり、それゆえ body-parts 間の行末を表すために CRLF のみを使用しなければならない。MIME と違い、どのマルチパートメッセージのエピローグも空でなければならない。HTTP アプリケーションは (たとえ元のマルチパートがエピローグを含んでいても) エピローグを伝えてはならない。
単一の message-body の中への一つ以上のエンティティのカプセル化を幾つかを備えている。MIME [7] で定義されているように、すべてのマルチパートタイプは共通の構文を割り当て、メディアタイプ値の一部として境界パラメータを含まなければならない。メッセージボディはそれ自身プロトコル要素の一部であり、それゆえ body-parts 間の行末を表すために CRLF のみを使用しなければならない。MIME と違い、どのマルチパートメッセージのエピローグも空でなければならない。HTTP アプリケーションは (たとえ元のマルチパートがエピローグを含んでいても) エピローグを伝えてはならない。
HTTP では、マルチパート body-parts はその部分の意味に重要な意義を持つヘッダフィールドを含むかもしれない。Content-Location ヘッダフィールド (14.15 章) は URL によって識別されうるそれぞれの同封されたエンティティの body-part において含まれるべきである。
一般的には、HTTP ユーザエージェントは MIME ユーザエージェントがマルチパートタイプの受領上でするであろうと同じまたは似たような振る舞いに習うべきである。アプリケーションが認識されないマルチパートサブタイプを受け取ったなら、アプリケーションはそれを "multipart/mixed" に相当するものとして扱わなければならない。
注意: "multipart/form-data" タイプは RFC 7867 [15] で表されるように特に POST リクエストメソッド経由で処理するのにふさわしいフォームデータを転送するために既に定義されている。
3.8 製品のトークン
製品のトークンはソフトウェアの名前とバージョンによってそれ自身を識別するアプリケーションと通信する事ができるように使用される。製品のトークンで使用されているほとんどのフィールドは空白で区切られたリストされるアプリケーションを意味する部分を構成している sub-product を認めている。習慣的に製品はアプリケーションを識別するためのそれらの重要性の順にリストされる。
product = token ["/" product-version]
product-version = token
例:
User-Agent: CERN-LineMode/2.15 libwww/2.17b3
Server: Apache/0.8.4
製品トークンは短く要点を成すべきである![]() 宣伝や別の不要な情報の使用は明らかに禁止される。とはいえどんなトークン文字も製品バージョンに現れると思われる。このトークンはバージョン識別子に対してのみ使われるべきである (同じ製品の連続したバージョンが製品値の製品バージョン部分においてのみ異なるべきであるように)。
宣伝や別の不要な情報の使用は明らかに禁止される。とはいえどんなトークン文字も製品バージョンに現れると思われる。このトークンはバージョン識別子に対してのみ使われるべきである (同じ製品の連続したバージョンが製品値の製品バージョン部分においてのみ異なるべきであるように)。
3.9 優先値
HTTP 内容ネゴシエーション (12 章) はさまざまな交渉可能なパラメータの相対的な重要性 ("ウェイト") を示す短い "浮動小数点" 数を使う。ウェイトは実数値 0 から 1 までに標準化され、0 は最小値で 1 は最大値である。HTTP/1.1 アプリケーションは小数点以下の 3 つの数字以上を生成してはならない。これらの値のユーザ設定もこの様式にかぎられるべきである。
qvalue = ( "0" [ "." 0*3DIGIT ] )
| ( "1" [ "." 0*3("0") ] )
"Quality value" はそれらの値が単に要請される特質の相対的な格付けを示すため誤称である。
3.10 言語タグ
言語タグは別の人間との情報コミュニケーションのため、人間によって話されたり書かれたり、別の方法で伝えられる自然言語を識別する。コンピュータ言語は明らかに除外される。HTTP は Accept-Language や Content-Language フィールドにおいて言語タグを使用する。第一の言語タグと空でも良いサブタグの連続である。
language-tag = primary-tag *( "-" subtag )
primary-tag = 1*8ALPHA
subtag = 1*8ALPHA
ホワイトスペースはタグの中では認められず、すべてのタグは大文字と小文字を区別しない。言語タグの名前空間は IANA によって管理されている。例として以下を含むタグがある:
en, en-US, en-cockney, i-cherokee, x-pig-latin
ここでどんな二文字の第一タグも ISO 639 言語短縮系であり、サブタグの初めにつけられるどんな二文字も ISO 3166 国コードである。(上記最後の 3 タグは登録されていないタグである; しかし最後のすべては将来的に登録されるかもしれないタグの例である。)
3.11 エンティティタグ
エンティティタグは要求された同じリソースからの二つ以上のエンティティを比較するために使用される。HTTP/1.0 は ETag (14.20 章)、If-Match (14.25章)、If-None-Match (14.26 章)、及び If-Range (14.27 章) ヘッダフィールドでエンティティタグを使用する。それらがどのよう使われ、キャッシュが正しいと確認するものとして比較されるかの定義は 13.3.3 章で成される。エンティティタグはひょっとすると weakness インジケータが前方に付く、非空白の引用文字列とみなされるかもしれない。
entity-tag = [ weak ] opaque-tag
weak = "W/"
opaque-tag = quoted-string
"string entity tag" はもしそれらが 8 ビット文字と等価とみなされるときのみリソースの 2 つのエンティティによって分けられるであろう。
"W/" プレフィクスによって示される "weak entity tag" はエンティティが等価でありセマンティクスにおいてそれぞれ重要な変更がないそれぞれを用いる事ができるときのみ、リソースの 2 つのエンティティによって分けられる。weak エンティティタグは不十分な比較に対してのみ使用される。
エンティティタグは特有のリソースと結び付けられたすべてのエンティティのすべてのバージョンを超えてユニークでなければならない。与えられたエンティティタグの値はそれらのエンティティの等価性に付いてすべてを暗に意味することなしに異なる URI での要求によって得られるエンティティに対して使用されうる。
3.12 レンジユニット
HTTP/1.1 はクライアントに、レスポンス内に含まれるレスポンスエンティティの (範囲の) 一部だけリクエストする事を可能にしている。HTTP/1.1 は Range (14.36 章) と Content-Range (14.17 章) においてレンジユニットを使用する。エンティティはさまざまな構造上のユニットにしたがったサブレンジのなかで分解されるだろう。
range-unit = bytes-unit | other-range-unit
bytes-unit = "bytes"
other-range-unit = token
HTTP/1.1 で定義されている唯一のレンジユニットは "bytes" である。HTTP/1.1 インプリメンテーションは別のユニットを使用して述べられたレンジを無視するだろう。HTTP/1.1 はレンジに付いての知識に依存しないようなアプリケーションのインプリメンテーションを認めるように設計されている。
4 HTTP メッセージ
4.1 メッセージタイプ
HTTP メッセージはクライアントからサーバへの要求とサーバからクライアントへの応答で成り立つ。
HTTP-message = Request | Response ; HTTP/1.1 messages
要求 (5 章) と応答 (6 章) メッセージはエンティティ転送 (メッセージの負担荷重) のため RFC 822 [9] の一般的なメッセージフォーマットを使用する。メッセージの両方のタイプは一つの開始行、一つ以上のヘッダフィールド(ヘッダとしても知られる)、ヘッダフィールドの終了を示す (CRLF の前に何もない行のような) 空行、そして任意のメッセージボディからなる。
generic-message = start-line
*message-header
CRLF
[ message-body ]
start-line = Request-Line | Status-Line
強固の重要性において、サーバは Request-Line が期待される所においてすべての受け取った空行も無視すべきである。言いかえれば、もしサーバがメッセージの開始におけるプロトコルストリームで読み出しを行って、最初に CRLF を受信したなら、その CRLF は無視すべきである。
注意: あるバグを持った HTTP/1.0 クライアントインプリメンテーションは POST リクエストの後に余分な CRLF を生成する。BNF によって明らかに禁止される事を再度述べると、HTTP/1.1 クライアントは余分な CRLF が先行する要求を行ってはならない。
4.2 メッセージヘッダ
一般ヘッダ (4.5 章)、レスポンスヘッダ (6.2 章)、及びエンティティヘッダ(7.1 章) を含む HTTP ヘッダフィールドは RFC 822 [9] の 3.1 章で与えられているもとの同じ一般的なフォーマットに従う。それぞれのヘッダフィールドはコロン (":") が後に続く名前とフィールド値から成る。フィールド名は大文字と小文字を区別しない。フィールド値は、一つの SP が好まれるが、幾つかの LWS を先頭に付ける事もできる。ヘッダフィールドは最低一つ以上のSP や HT をそれぞれの行頭につける事で複数行にまたがる事ができる。アプリケーションは、共通形式を超えたあらゆるものの受け入れに失敗する幾つかのインプリメンテーションが存在するであろうため、HTTP 構造を生成するとき "共通形式" に従うべきである。
message-header = field-name ":" [ field-value ] CRLF
field-name = token
field-value = *( field-content | LWS )
field-content = <the OCTETs making up the field-value
and consisting of either *TEXT or combinations
of token, tspecials, and quoted-string>
異なるフィールド名を持つヘッダフィールドの受信される順序は重要性を持たない。しかしながら、リクエストヘッダやレスポンスヘッダに先立って一般ヘッダフィールドを最初に送りエンティティフィールドを最後にする事が "良い慣例" である。
同じフィールド名を持つ複合メッセージヘッダフィールドは、そのようなヘッダフィールドに対するエンティティフィールド値がコンマで区切られたリスト[#(value) のような] として定義される場合、かつその場合にのみ、メッセージに存在しうる。コンマによってそれぞれ分けられるそれぞれの続く field-value を最初に追加する事により、メッセージのセマンティクスを変える事無しにある "header-name: header-value" ペアでの複合ヘッダフィールドを結合する事が可能でなければならない。それゆえ同じフィールド名を持つヘッダフィールドが受信される順番は、連結されたフィールド値の中間処理に重要であり、したがってプロキシはメッセージが転送されるときにそれらのヘッダ値の順番を変えてはならない。
4.3 メッセージボディ
HTTP メッセージの message-body はリクエストやレスポンスに関連するentity-body を運ぶために使用される。message-body は Transfer-Encodingヘッダフィールド (14.40 章) によって示された転送コーディングが適用されたときのみ entity-body とは異なる。
message-body = entity-body
| <entity-body encoded as per Transfer-Encoding>
Transfer-Encoding はアプリケーションにより安全を保障しメッセージのふさわしい転送を行うために適用されるすべての転送コーディングを示すために使用される。Transfer-Encoding はそのメッセージの性質であり、エンティティの性質ではない。したがってそれはリクエスト/レスポンス連鎖に伴うすべてのアプリケーションによって追加されたり削除されたりされうる。
message-body がメッセージにおいてみとめられるようなルールはリクエストとレスポンスの違いではない。
リクエストにおける message-body の存在はリクエストの message-headerでの Content-Length や Transfer-Encoding ヘッダフィールドの抱合によって伝えられる。message-body はリクエストメソッド (5.1.1 章) がentity-body を許可しているときのみリクエストに含まれるであろう。
レスポンスメッセージに対して、message-body がメッセージに含まれているかどうかはリクエストメソッドとレスポンスステータスコード (6.1.1 章) の両方に依存する。HEAD リクエストメソッドのどんなレスポンスも、たとえentity-header フィールドがそうであるように導いていたとしても、message-body を含んではならない。1xx (Information)、204 (no content)、及び304 (not modified) レスポンスのどれも message-body を含んではならない。他のすべてのレスポンスは長さがゼロである以外は message-bodyを含む。
4.4 メッセージの長さ
message-body がメッセージに含まれるとき、このボディの長さは以下の一つで決定される。
- message-body を含んではいけない (1xx, 204, 304 レスポンスや HEAD リクエストに対するすべてのレスポンス) すべてのレスポンスメッセージは entity-header フィールドがメッセージにおいて与えられるてもヘッダフィールドの後の最初の空行で常に終了する。
- もし Transfer-Encoding ヘッダフィールド (14.40 章) が与えられ、"chunked" 転送コーディングが適用されているようならば、長さは chunked エンコーディング (3.6 章) によって定義される。
- もし Content-Length ヘッダフィールド (14.14 章) が与えられるなら、そのバイト値は message-body の長さを示す。
- もしメッセージが自身で区切りを持つメディアタイプ "multipart/byteranges" を使うなら、これはその長さを定義する。このメディアタイプは、受取人がそれを解析できる事を送り側が知っている事無しに使用されてはならない。リクエストにおけるマルチバイト幅指定子付きの Range ヘッダの存在は、クライアントが multipart/byterange レスポンスを解析できる事を暗黙的に意味する。
- 接続を閉じるサーバによる。(接続を閉じる事はリクエストボディの終了を使用するために使う事ができない。これはサーバがレスポンスを送り返す可能性がないであろう為である。)
HTTP/1.0 アプリケーションの互換性のため、message-body を含む HTTP/1.1リクエストは、サーバが HTTP/1.1 に準じていると分かっている場合を除いて有効な Content-Length ヘッダフィールドをを含まなければならない。もしmessage-body と Content-Length を含んでいるリクエストが与えられなければ、サーバはメッセージの長さが決定できないとき 400 (bad request) や有効な Content-Length を受信する事を要求するなら 411 (length required)を返すべきである。
エンティティを受け取るすべての HTTP/1.1 アプリケーションは "chunked"転送エンコーディング (3.6 章) を受け入れなければ成らず、したがってメッセージ長が前もって決定されていないときメッセージに対して使用されるこのメカニズムを認めなければならない。
メッセージは Content-Length ヘッダフィールドと "chunked" 転送エンコーディングの両方を含んではならない。もし両方が受信されたら、Content-Length が無視されなければならない。
Content-Length が、message-body が認められるメッセージにおいて与えられたとき、そのフィールド値は message-body における 8 ビット文字の数と正確に一致しなければならない。HTTP/1.1 ユーザエージェントは不正な長さが受信されたり検出されたとき通知しなければならない。
4.5 一般ヘッダフィールド
リクエストとレスポンスメッセージの両方のための一般的な適用性を持つ幾つかのヘッダフィールドがあるが、これは転送されたエンティティには適用されない。これらのヘッダフィールドは伝えられているメッセージに対してのみ適用される。
general-header = Cache-Control ; Section 14.9
| Connection ; Section 14.10
| Date ; Section 14.19
| Pragma ; Section 14.32
| Transfer-Encoding ; Section 14.40
| Upgrade ; Section 14.41
| Via ; Section 14.44
一般ヘッダフィールド名はプロトコルバージョンにおける変換に伴う連動においてのみ確実に拡張される事ができる。しかしながら、新しいヘッダフィールドや実験的なヘッダフィールドは、もしコミュニケーションにおけるすべてのパーティがそれらを一般ヘッダフィールドであると認識できるなら、一般的なヘッダフィールドのセマンティクスが与えられるであろう。認識されないヘッダフィールドは entity-header フィールドとして扱われる。
5 リクエスト
メッセージの最初の行内のクライアントからサーバへのリクエストメッセージはリソースに適用されるメソッド、リソースの識別子、使用されているプロトコルのバージョンを含んでいる。
Request = Request-Line ; Section 5.1
*( general-header ; Section 4.5
| request-header ; Section 5.3
| entity-header ) ; Section 7.1
CRLF
[ message-body ] ; Section 7.2
5.1 リクエスト行
Request-Line は Request-URI とプロトコルバージョンが後にく続メソッドトークンで開始し CRLF で終了する。最後の CRLF シーケンス以外の CR もLF もみとめられない。
Request-Line = Method SP Request-URI SP HTTP-Version CRLF
5.1.1 メソッド
Method トークンは Request-URI により識別されるリソースに行われるためのメソッドを示す。メソッドは大文字と小文字を区別する。
Method = "OPTIONS" ; Section 9.2
| "GET" ; Section 9.3
| "HEAD" ; Section 9.4
| "POST" ; Section 9.5
| "PUT" ; Section 9.6
| "DELETE" ; Section 9.7
| "TRACE" ; Section 9.8
| extension-method
extension-method = token
リソースにより認められるメソッドのリストは Allow ヘッダフィールド (14.7 章) で記述される。レスポンスのリターンコードは、許されるメソッドのセットが動的に変化できるため、メソッドが現在リソースに許されていてもいなくても常にクライアントに伝えられる。もしサーバがメソッドを理解できても要求されたリソースに対して許されていなければ、サーバはステータスコード 405 (Method Not Allowed) を返すべきであり、もしサーバがそのメソッドを認識できなかったり実装されていない場合には 501 (NotImplemented) を返すべきである。サーバが理解しているメソッドのリストは Public レスポンスヘッダフィールド (14.35 章) でリストされる。
GET と HEAD メソッドはすべての一般目的サーバによってサポートされなければならない。他のすべてのメソッドはオプションである。しかしながら、もし上記のメソッドがインプリメントされているなら、それらは 9 章で記述されているものと同じセマンティクスで実装されなければならない。
5.1.2 Request-URI
Request-URI は Uniform Resource Identifier (3.2 章) であり、リクエストを適用するリソースを識別する。
Request-URI = "*" | absoluteURI | abs_path
Request-URI に対する 3 つのオプションはリクエストの性質に依存する。アスタリスク "*" はリクエストが特有のリソースではなくサーバ自身に適用する意味を持ち、使われているメソッドがリソースに適用される必要がないときにのみ許される。一つの例は以下のようになる。
OPTIONS * HTTP/1.1
absoluteURI フォームはリクエストがプロキシにより生成されたものであるときに必要となる。プロキシは有効なキャッシュからリクエストやサービスの転送を要求され、レスポンスを返す。プロキシは別のプロキシや直接 absoluteURIによって示されたサーバにリクエストを転送する事ができる。リクエストのループを回避するため、一つのプロキシはエイリアス、ローカルバリエーション、数値での IP アドレスを含めてそのサーバ名のすべてのを認識できなければならない。Request-Line の例は以下のようになる:
GET http://www.w3.org/pub/WWW/TheProject.html HTTP/1.1
HTTP の将来のバージョンにおけるすべてのリクエストの absoluteURI の移行を考慮して、もし HTTP/1.1 クライアントがプロキシへそれらをリクエストとしてのみ生成するであろうならば、すべての HTTP/1.1 サーバはリクエストにおける absoluteURI 形式を受け入れなければならない。
Request-URI のもっとも一般的な形式はオリジンサーバやゲートウェイ上のリソースを識別するために使用される事である。この場合 URI の絶対パスはRequest-URI として伝えられなければならなず (3.2.1 章, abs_path 参照)、URI のネットワークロケーション (net_loc) は Host ヘッダフィールドにおいて転送されなければならない。たとえば、上記のように元のサーバから直接回収する事を望むクライアントはホスト "www.w3.org" のポート 80 にTCP 接続を確立し、Request の残りが後に続く以下の行を送信する:
GET /pub/WWW/TheProject.html HTTP/1.1
Host: www.w3.org
絶対パスは空ではない事に注意。元の URI で何も与えられていなければ、"/"(サーバのルート) を与えなければならない。
プロキシが Request-URI においてどんなパスも持たないリクエストを受け取り、記述されたメソッドがリクエストのアスタリスク形式をサポートできるなら、リクエスト連鎖の最後のプロキシは最終的な Request-URI として "*" をつけたリクエストを転送しなければならない。たとえば、リクエスト
OPTIONS http://www.ics.uci.edu:8001 HTTP/1.1
はプロキシによってホスト "www.ics.uci.edu" のポート 8001 に接続した後
OPTIONS * HTTP/1.1
Host: www.ics.uci.edu:8001
を転送するであろう。
Request-URI は 3.2.1 章で記述されるフォーマットで伝えられる。オリジンサーバはリクエストを適切に解釈するためにその Request-URI をデコードしなければならない。サーバは不正な Request-URI に適切なステータスコードで答えるべきである。
転送されるリクエストにおいて、プロキシは上記の null abs_path を "*" に置き換える以外、プロキシがその内部的な実装で行うどんな事でも、Request-URI の "abs_path" を書き換えてはならない。
注意: オリジンサーバが予約された目的のための予約されていない URL 文字を不適当に使用しているとき、"書き換え禁止" ルールはプロキシがリクエストの意味を変えないようにする。実装者は既に幾つかの以前の HTTP/1.1 プロキシが Request-URI を書き換える事が知られていると言う事を知るべきである。
5.2 リクエストによるリソース識別
HTTP/1.1 オリジンサーバはインターネットリクエストにより識別された正確なリソースが Request-URI と Host ヘッダフィールドの両方で検査する事により決定されると言う事を知るべきである。
リソースにリクエストされたホストによって異なる事を認めていないオリジンサーバは Host ヘッダフィールド値を無視する事ができる。(ただしHTTP/1.1 での Host サポートの別の要求のため 19.5.1章参照。)
リクエストされたホストを元にしてリソースを区別する (しばしば仮想ホストや空虚なホスト名として参照される) オリジンサーバは HTTP/1.1 リクエストの要求されたリソースを決定するために以下のルールに従わなければならない:
- もし Request-URI が absoluteURI ならば、ホストは Request-URI の一部である。リクエストにおけるどんな Host ヘッダフィールド値も無視されなければならない。
- もし Request-URI が absoluteURI でなく、リクエストが Host ヘッダフィールドを含んでいるならば、ホストは Host ヘッダフィールド値によって決定される。
- もしルール 1 や 2 で決定されるようなホストがそのサーバで正当なホストでないならば、レスポンスは 400 (Bad Request) エラーメッセージでなければならない。
Host ヘッダフィールドの欠落した HTTP/1.0 リクエストの受け取り側はどんな正確なリソースが要求されているかを決定するため (特有のホストにユニークな何かに対する URI パスの試験のような) 発見的方法を使用する事を試みる事ができる。
5.3 リクエストヘッダフィールド
request-header フィールドはクライアントにリクエストやクライアント自身に関する追加的な情報をサーバに渡す事を可能にする。これらのフィールドはこれらはプログラミング言語のメソッド呪文と等価なセマンティクスを伴ってリクエスト修飾子として動作する。
request-header = Accept ; Section 14.1
| Accept-Charset ; Section 14.2
| Accept-Encoding ; Section 14.3
| Accept-Language ; Section 14.4
| Authorization ; Section 14.8
| From ; Section 14.22
| Host ; Section 14.23
| If-Modified-Since ; Section 14.24
| If-Match ; Section 14.25
| If-None-Match ; Section 14.26
| If-Range ; Section 14.27
| If-Unmodified-Since ; Section 14.28
| Max-Forwards ; Section 14.31
| Proxy-Authorization ; Section 14.34
| Range ; Section 14.36
| Referer ; Section 14.37
| User-Agent ; Section 14.42
request-header フィールド名はこのプロトコルバージョンにおける変更の関連においてのみ正確に拡張する事ができる。しかしながら、もし通信においてすべてのパーティがそれらを request-header フィールドと認識するならば、新しいものや実験的なヘッダフィールドは request-header フィールドのセマンティクスが与えられる可能性がある。認識されないヘッダフィールドはentity-header フィールドとして扱われる。
6 レスポンス
リクエストメッセージを受信して解釈した後、サーバは HTTP レスポンスメッセージを返す。
Response = Status-Line ; Section 6.1
*( general-header ; Section 4.5
| response-header ; Section 6.2
| entity-header ) ; Section 7.1
CRLF
[ message-body ] ; Section 7.2
6.1 Status-Line
Response メッセージの最初の行はステータスコード番号とそれに関連したテキストフレーズが後に続くプロトコルバージョンからなる Status-Line であり、それぞれの要素は SP 文字によって区切られる。最後の CRLF シーケンス以外ではどんな CR も LF もみとめられない。
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
6.1.1 Status-Code と Result-Phrase
Status-Code 要素はリクエストを理解し満たした試みの 3 文字数字の結果コードである。これらのコードは 10 章ですべて定義されている。Response-Phrase は Status-Code の短いテキスト記述を与える目的を持つ。Status-Code は自動処理によって使う事を目的とし Reason-Phrase は人間のユーザのためである。クライアントは Reason-Phrase を調べたり表示したりする事を必要とされない。
Status-Code の最初の数字はレスポンスの分類である。最後の二つの数字はどんな分類ルールも持たない。最初の数字には 5 つの値がある:
- 1xx: Informational - リクエストは受け入れられ、処理を続けている
- 2xx: Success - 動作は正常に受信され、理解され、受け入れられた
- 3xx: Redirection - リクエストを完了するためさらにそれ以上の動作を行わなければならない
- 4xx: Client Error - リクエストは間違った構文か果たす事のできないものを含んでいる
- 5xx: Server Error - サーバは明白に正当なリクエストを果たすのに失敗した
HTTP/1.1 で定義された個々のステータスコード数値及びそれに相当するResason-Phrase のセットの例の値は以下に示される。ここでリストされたreason phrase は勧められるだけである![]() これらはプロトコルに影響がない範囲でローカルに相当するものに置き換える事ができる。
これらはプロトコルに影響がない範囲でローカルに相当するものに置き換える事ができる。
Status-Code = "100" ; Continue
| "101" ; Switching Protocols
| "200" ; OK
| "201" ; Created
| "202" ; Accepted
| "203" ; Non-Authoritative Information
| "204" ; No Content
| "205" ; Reset Content
| "206" ; Partial Content
| "300" ; Multiple Choices
| "301" ; Moved Permanently
| "302" ; Moved Temporarily
| "303" ; See Other
| "304" ; Not Modified
| "305" ; Use Proxy
| "400" ; Bad Request
| "401" ; Unauthorized
| "402" ; Payment Required
| "403" ; Forbidden
| "404" ; Not Found
| "405" ; Method Not Allowed
| "406" ; Not Acceptable
| "407" ; Proxy Authentication Required
| "408" ; Request Time-out
| "409" ; Conflict
| "410" ; Gone
| "411" ; Length Required
| "412" ; Precondition Failed
| "413" ; Request Entity Too Large
| "414" ; Request-URI Too Large
| "415" ; Unsupported Media Type
| "500" ; Internal Server Error
| "501" ; Not Implemented
| "502" ; Bad Gateway
| "503" ; Service Unavailable
| "504" ; Gateway Time-out
| "505" ; HTTP Version not supported
| extension-code
extension-code = 3DIGIT
Reason-Phrase = *<TEXT, excluding CR, LF>
HTTP ステータスコードは拡張可能である。HTTP アプリケーションは、すべての登録されたステータスコードの理解が明らかに望ましいが、それらすべての意味を理解する必要はない。しかしながら、アプリケーションは最初の数字によって示されるような、どんなステータスコードの分類も理解しなければならなず、認識されないレスポンスがキャッシュされてはならないという例外を除いて、すべての認識されないレスポンスをそのクラスの x00 ステータスコードに相当するようなものとして扱わなければならない。たとえば、431 の認識されないステータスコードがクライアントに受信されたなら、そのリクエストに何か不備があると言う安全な推測が行え、それが 400 ステータスコードを受信したかのようにレスポンスを扱える。このような場合、このエンティティがこの異常なステータスを説明しているであろう人間が読める情報をたぶん含んでいるため、ユーザエージェントはレスポンスで返されたエンティティをユーザに示すべきである。
6.2 レスポンスヘッダフィールド
レスポンスヘッダフィールドはサーバが Status-Line に置けないレスポンスに関する追加的な情報を渡す事を可能にする。これらのヘッダフィールドはサーバとさらにそれ以上の Request-URI によって識別されたリソースへのアクセスに関する情報を与える。
response-header = Age ; Section 14.6
| Location ; Section 14.30
| Proxy-Authenticate ; Section 14.33
| Public ; Section 14.35
| Retry-After ; Section 14.38
| Server ; Section 14.39
| Vary ; Section 14.43
| Warning ; Section 14.45
| WWW-Authenticate ; Section 14.46
response-header フィールド名は確かにこのプロトコルのバージョンにおける変更に関連で拡張される事ができる。しかしながら、もし通信におけるすべてのパーティがそれらを response-header フィールドであると認識するなら、新しいものや実験的なヘッダフィールドは response-header フィールドのセマンティクスを与えられる可能性がある。
7 エンティティ
リクエストメソッドやレスポンスステータスによって特に妨げられていないなら、リクエストとレスポンスメッセージはエンティティを転送する事ができる。幾つかのレスポンスは entity-header だけを含むだろうが、一つのエンティティは entity-header フィールドと entity-body から成る。
この章において、送り側と受け側の両方がクライアントとサーバのどちらかを表し、エンティティを送信するものと受信するものに依存する。
7.1 エンティティヘッダフィールド
entity-header フィールドは entity-body や、もしボディが与えられないならリクエストによって識別されたリソースに関するオプション的な情報を定義する。
entity-header = Allow ; Section 14.7
| Content-Base ; Section 14.11
| Content-Encoding ; Section 14.12
| Content-Language ; Section 14.13
| Content-Length ; Section 14.14
| Content-Location ; Section 14.15
| Content-MD5 ; Section 14.16
| Content-Range ; Section 14.17
| Content-Type ; Section 14.18
| ETag ; Section 14.20
| Expires ; Section 14.21
| Last-Modified ; Section 14.29
| extension-header
extension-header = message-header
extension-header メカニズムは追加的な entity-header フィールドがプロトコルを変更する事なしに定義されるようにしているが、これらのフィールドは受け取り側によって認識可能であると仮定される。認識されないヘッダフィールドは受け取り側によって無視されプロキシによって転送されるべきである。
7.2 エンティティボディ
HTTP リクエストやレスポンスで送られる entity-body (もしあれば) はentity-header フィールドによって定義されるフォーマットとなりエンコーディングされている。
entity-body = *OCTET
entity-body は 4.3 章で表されるように、message-body が示されたときにのみメッセージにおいて示される。entity-body はメッセージの安全性と妥当性を保証するために適用されるであろうすべての Transfer-Encoding をデコードする事によって message-body から得られる。
7.2.1 タイプ
一つの entity-body がメッセージに含まれるとき、このボディのデータタイプは Content-Type と Content-Encoding ヘッダフィールド経由で決定される。これらは命令されたエンコーディング 2 層モデルを定義する:
entity-body := Content-Encoding( Content-Type( data ) )
Content-Type は根本的なデータのメディアタイプを詳述する。Content-Encoding は、たいていデータ圧縮の目的のため、要求されたリソースの特性であるデータに適用されたどんな追加的な内容コーディングをも示すために使用される事ができる。デフォルトのエンコーディングはない。
entity-body を含むどんな HTTP/1.1 もそのボディのメディアタイプを定義するための Content-Type ヘッダフィールドを含むべきである。もしメディアタイプが Content-Type ヘッダによって与えられないなら、そしてそのような場合に限り、受け取り側は内容と/もしくはリソースを識別するために使用されている URL の名前拡張子の調査によってメディアタイプを推測する事を試みる事ができる。もしメディアタイプが分からないままなら、受け取り側はそれをタイプ "application/octet-stream" として扱うべきである。
7.2.2 長さ
entity-body の長さはすべての転送エンコーディングが取り除かれた後のmessage-body の長さである。4.4 章はどのように message-body の長さが決定されるかを定義している。
8 接続
8.1 永続的な接続
8.1.1 目的
永続的な接続以前、別々の TCP 接続はそれぞれの URL を回収するため HTTPサーバのロードを増加しインターネットの混雑を引き起こすに確立されていた。インラインイメージや別の関連したデータの使用はしばしばクライアントが短時間に同じサーバへ複数のリクエストを行うような必要性を生じさせる。これらの実行問題の分析は [30][27] で利用可能である。プロトタイプインプリメンテーションからの分析と結果は [26] である。
永続的な HTTP 接続は幾つかの利点を持つ。
- より少ない TCP コネクションのオープンやクローズにより、CPU 時間を節約し TCP プロトコルコントロールブロックのために使用されるメモリも節約する。
- HTTP リクエストとレスポンスは接続上でパイプラインされる事ができる。パイプライン化はクライアントにそれぞれのレスポンスを待つ事なしに複数のリクエストを行う事を可能にし、より少ない経過時間のより効果的に使用される単一の TCP 接続を可能にする。
- ネットワーク混雑は TCP オープンや、TCP sufficient time にネットワークの混雑状況を決定するのをまかせることによって引き起こされるパケットの数の減少によって減少させられる。
- エラーは TCP 接続を閉じる罰則なしに報告される事ができるため、HTTP はより上品に発展する。HTTP の将来のバージョンを使用するクライアントは楽天的に新しい機能を試みるであろうが、もし古いサーバと通信するなら、エラーの後の古いセマンティクスが伴う再試行も報告される。
HTTP インプリメンテーションは永続的な接続を実装すべきである。
8.1.2 全体の操作
HTTP/1.1 とそれ以前の HTTP バージョンの間の重要な違いは永続的な接続がすべての HTTP 接続のデフォルトの動作であると言う事である。これは、別の方法で示されない限り、クライアントはサーバが永続的な接続を維持するだろうと言う事を仮定するであろう。
永続的な接続はクライアントとサーバが TCP 接続のクローズの合図を行えることによるメカニズムを提供する。この合図は Connection ヘッダフィールドを使用するところで使う。ひとたびクローズが合図されたら、クライアントはその接続にそれ以上のリクエストを送ってはならない。
8.1.2.1 ネゴシエーション
HTTP/1.1 サーバは HTTP/1.1 クライアントが connection-token "close" を含んでいる Connection ヘッダがリクエストにおいて送られなければ永続的な接続を維持するつもりである事を想定する事ができる。もしサーバがレスポンスを送信した後にすぐに接続をクローズする事を選んだら、connection-token close を含んでいる Connection ヘッダを送信するべきである。
HTTP/1.1 クライアントは接続がオープンしたままである事を期待する事ができる。しかしサーバからのレスポンスが connection-token close を伴うConnection ヘッダを含んでいるかどうかに基づいてそのオープンを維持するかを決めるだろう。クライアントがそのリクエスト以上に接続を維持する事を望まない場合、connection-token close を含んでいる Connection ヘッダを送るべきである。
もしクライアントとサーバのどちらかが Connection ヘッダで close トークンを送ったなら、そのリクエストは接続に対する最後のものとなる。
それが明確に合図された以外は、クライアントとサーバは永続的な接続が 1.1よりも低い HTTP バージョンに対して維持されている事を仮定すべきではない。HTTP/1.0 クライアントとの下位互換性のより多くの情報のため 19.7.1章参照。
永続性を維持するため、接続上のすべてのメッセージは 4.4 章で定義されているように、(それが接続の閉鎖によって定義されないような) 自身で定義されたメッセージの長さを持たなければならない。
8.1.2.2 パイプライン化
永続的な接続をサポートするクライアントはそのリクエストを (それぞれのレスポンスを待つことなしに複数のリクエストを送る) "パイプライン" する事ができる。サーバはリクエストが受信されたのと同じ順番でそれらのリクエストのレスポンスを返さなければならない。
永続的な接続を想定し接続確立のすぐ後にパイプラインを行うクライアントは、もし最初のパイプラインされた試行が失敗したならそれらの接続を再試行するための準備をすべきである。もしクライアントがそのような再試行を行わならば、その接続が永続的であると分かる前にパイプラインを行ってはならない。もしサーバがすべての通信のレスポンスを返す前に接続をクローズするなら、クライアントはそれらのレスポンスを再送信するための準備をしなければならない。
8.1.3 プロキシサーバ
プロキシが 14.2.1 で示されている Connection ヘッダの特質を正確に実装する事は特に重要である。
プロキシサーバはそれが接続しているクライアントとオリジンサーバ (または別のプロキシサーバ) にそれぞれ永続的な接続の合図をしなければならない。それぞれの永続的な接続は一つの転送リンクにのみ適用される。
プロキシサーバは HTTP/1.0 クライアントと永続的な接続を確立してはならない。
8.1.4 実際的な考察
サーバは常にそれらがもはや相互接続を維持しないあるタイムアウト値をもつであろう。クライアントが同じサーバを経てより多くの接続を行おうとしているかもしれないため、プロキシサーバはこれをより大きな値にすべきである。永続的な接続の使用はクライアントとサーバのどちらかのためのこのタイムアウトの長さに必要性を置かない。
クライアントとサーバがタイムアウトを望むとき、それは転送接続上で上品なクローズを発行すべきである。クライアントとサーバは両方とも他方の転送のクローズを絶えず監視し、適切にそれに応じるべきである。もしクライアントかサーバが別の側のクローズを早急に検出しなければ、ネットワーク上の不必要なリソース消耗を引き起こすかもしれない。
クライアント、サーバもしくはプロキシはどんな時も転送接続をクローズする事ができる。たとえば、クライアントはサーバが "idle" 接続をクローズしようとするのと同時に新しいリクエストを送り始めるかもしれない。サーバの観点では、接続はそれがアイドルである間にクローズされているが、クライアントから見ればリクエストは進行中である。
これはクライアント、サーバやプロキシが非同期のクローズイベントから回復できなければならない事を意味する。クライアントソフトウェアは転送接続を再度オープンし、リクエストメソッドが idempotent (9.1.2 章参照) である限りユーザインタラクションなしに中止されたリクエストを再送信するべきである。他のメソッドは自動的に再試行されてはならない。とはいえ、ユーザエージェントは人間のオペレータにリクエストを再試行する事の選択を申し出ることもできる。
しかしながら、この自動再試行はもし二回目のリクエストが失敗するなら繰り返すべきではない。
もし全く可能なら、サーバは常に接続ごとに最低一つのリクエストを返すべきである。サーバはネットワークやクライアントの失敗に気づく以外、レスポンスの転送中に接続をクローズすべきではない。
永続的な接続を使用するクライアントはそれらが与えられたサーバへ維持する同時接続の数を制限すべきである。シングルサーバクライアントはどんなサーバやプロキシへも最大で 2 接続を維持すべきである。プロキシは別のサーバやプロキシへの 2*N 接続以上を使用すべきである。ここで Nは同時のアクティブユーザの数である。これらのガイドラインは HTTP レスポンスタイムを改善し、インターネットや他のネットワークの混雑を避ける目的を持つ。
8.2 メッセージ転送要求
一般的な要求:
- HTTP/1.1 サーバは永続的な接続を維持し、クライアントが再試行するだろうという期待を伴う接続の終了よりも、一時的な過負担を解決するための TCP フロー制御メカニズムを使用すべきである。前者の技術はネットワーク混雑を悪化させる。
- message-body を送信する HTTP/1.1 (かそれ以降の) クライアントはそれがリクエストを送信している間、エラー状況のためにネットワーク接続を監視すべきである。もしクライアントがエラー状況に会ったら、早急にボディの転送を中止すべきである。もしボディが "chunked" エンコーディング (3.6 章) を使用して送られているなら、ゼロの長さのチャンクと空のフッタがメッセージの終わりを早まってマークするために使用されるであろう。もしボディが Content-Length によって先に述べられたなら、クライアントはクライアントは接続をクローズしなければならない。
- HTTP/1.1 (かそれ以降) クライアントは通常のレスポンスが後に続く 100 (Continue) を受け入れなければならない。
- HTTP/1.0 (かそれ以前) のクライアントからのリクエストを受信する HTTP/1.1 (かそれ以降) のサーバは 100 (continue) レスポンスを伝えてはならない。通常に完了されるためのリクエストを待つ (従って中間処理されたリクエストを避ける) か早まって接続をクローズすべきである。
HTTP/1.1 (かそれ以降の) クライアントからのこれらの要求に従うメソッドを受け取る上で、HTTP/1.1 (かそれ以降の) サーバは 100 (Continue) ステータスで返答して入力ストリームからの読み込みを続けるか、エラーステータスを返すかどちらかを行わなければならない。もしエラーステータスを返すなら、転送接続 (TCP) を閉じるかもしれないし読み込みを続けてリクエストの残りを破棄するかもしれない。もしエラーステータスを返すならリクエストされたメソッドを実行してはならない。
クライアントはサーバに使用された少なくとももっとも最近のバージョン番号を覚えておくべきである。もし HTTP/1.1 クライアントがサーバからHTTP/1.1 かそれ以降のレスポンスを見つけ、サーバからどんなステータスをも受け取る前に接続がクローズしたことが分かれば、クライアントはリクエストメソッドが idempotent (9.2.1 章参照) な限りユーザインタラクションなしにリクエストを再試行すべきである。他のメソッドは自動的に再試行されてはならない。とはいえユーザエージェントはリクエストを再試行する選択を人間のオペレータに申し出るかもしれない。もしクライアントがリクエストの再試行をするのであれば、クライアントは
- 最初にリクエストヘッダフィールドを送らなければならず、このとき
- サーバがクライアントが続けるべき場合である、100 (Continue) レスポンスかエラーステータスを応答するまで待たなければならない。
もし HTTP/1.1 クライアントがサーバから HTTP/1.1 かそれ以降のレスポンスを確認しないなら、サーバが HTTP/1.0 かそれ以前を実装しているとみなし、100 (Continue) レスポンスは使われないだろう。もしクライアントがサーバからのどんなステータスをも受け取る前に接続のクローズを確認した場合、クライアントはリクエストを再試行すべきである。もしクライアントがこのHTTP/1.0 サーバにリクエストを再試行したなら、確実なレスポンスを得るのを確信させるため以下の "binary exponential backoff" アルゴリズムを使用すべきである。
- サーバへの新しい接続を初期化する
- request-header を転送する
- サーバへの見積もられた round-trip time (その接続を確立するためにかかった時間に基づくような)か、もし round-trip time が利用できなければ定数値5 秒で変数 R を初期化する。
- T = R * (2**N) を計算、ここで N はこのリクエストの前の試行の回数である。
- サーバからのエラーレスポンスまで、もしくは T 秒まで (どちらか先に来たほう) 待機
- もし何もエラーが受信されなければ、T 秒後リクエストのボディを転送する。
- もしクライアントがコネクションが早まってクローズされたのを確認したら、リクエストが受け入れるまでステップ 1 から繰り返し、エラーレスポンスが受け取られるか、ユーザが待てなくなって再試行プロセスを終了する。
どんなサーババージョンでも、もしエラーステータスが受信されたらクライアントは
- 続けてはならず、
- もしメッセージの送信を完了していなければ接続をクローズしなければならない。
100 (Continue) を受け取った後だがどんな別のステータスも受信する前に接続がクローズしたという事を確認した HTTP/1.1 (かそれ以降の) クライアントはリクエストを再試行すべきであり、100 (Continue) レスポンスを待つ必要がない (がもしこれがインプリメンテーションを簡単にするならばそうするであろう)。
9 メソッド定義
HTTP/1.1 のための一般的なメソッドのセットは下に定義される。このセットは拡張可能であるが、追加的なメソッドは別別に拡張されたクライアントとサーバに対して同じセマンティクスを割り当てていると仮定されない。
Host request-header フィールド (14.23 章) はすべての HTTP/1.1 リクエストに伴わなければならない。
9.1 安全で Idempotent なメソッド
9.1.1 安全なメソッド
実装者はソフトウェアがインターネット上でのそれらの相互作用においてユーザを表していると言う事に気づくべきであり、ユーザにそれらがそれら自身や他のものに対して予想されない意味を持つような事に耐えるであろうどんな動作にも気づけるよう注意すべきである。
特に、GET と HEAD メソッドが回収以外の動作をとる意味は決して持たないべきであると言う事は慣例的に確立されている。これらのメソッドは "安全" とみなしたほうが良い。これはユーザが可能な安全でない動作が要求されていると言う事実を気づかされるように、ユーザエージェントに POST, PUT, DELETEのような別のメソッドを示すのを可能にする。
本質的に、サーバが GET リクエストの実行の結果として副作用を生成しないのを保証する事は不可能である。事実、幾つかの動的なリソースがこの機構であるとみなされる。ここでの重要な区別はユーザが副作用ををリクエストしなかったと言う事である。それゆえそれらに対して責任をもてない。
9.1.2 Idempotent メソッド
メソッドは N > 0 と同一なリクエストの副作用が単一のリクエストと同じであると言う "idempotence" の特性を (エラーや満期問題からのわきに) 持つかもしれない。メソッド GET, HEAD, PUT と DELETE はこの特性を割り当てる。
9.2 OPTIONS
OPTIONS メソッドは Request-URI によって識別されるリクエスト/レスポンス連鎖で利用可能な通信オプションに関する情報のための要求を表している。このメソッドはクライアントにリソース動作を暗に意味したりリソース回収を初期化する事なしに、リソースやサーバの能力に関連するオプションや/もしくは要求を決定する事を可能にする。
サーバのレスポンスがエラーでなければ、レスポンスは通信オプションとみなされるもの以外のエンティティ情報 (Allow は適切であるが、Content-Typeはそうでない) を含んではならない。このメソッドのレスポンスはキャッシュされない。
もし Request-URI がアスタリスク ("*") なら、OPTIONS リクエストは全体としてサーバへ適用する目的をもつ。200 レスポンスは、一般もしくはレスポンスヘッダフィールドに適用できるすべてのものに加えて、この仕様書によって定義されていないすべての拡張を含む、サーバによって実装されているオプション的な機能 (Public のような) を示すどんなヘッダフィールドをも含むべきである。5.1.2 で表されるように、"OPTIONS *" リクエストはどんなパス情報もなしに目的のサーバを Request-URI において記述する事によりプロキシを通して適用される。
もし Request-URI がアスタリスクでなければ、OPTIONS リクエストはそのリソースと通信する時に利用可能なオプションのを申し込む。200 レスポンスは一般もしくは response-header フィールドに適用できるすべてのものに加えて、この仕様書で定義されていないどんな拡張も含む、サーバによって実装されたオプション的な機能やそのリソースに適用できる (Allow のような) オプション的な機能を示すどんなヘッダをも含むべきである。もし OPTIONS リクエストがプロキシを通過するなら、プロキシはそのレスポンスをプロキシの能力に適用したりこのプロキシを通して有効でない事が分かっているこれらのオプションを除外する編集を行ってはならない。
9.3 GET
GET メソッドは Request-URI で識別される (エンティティの形式においての)情報ならなんでも回収する事を意味する。もし Request-URI が data-producing プロセスを参照しているなら、それはリソースのエンティティとして返されるであろう作られたデータである。これはもしそのテキストがプロセスの出力で生じるのでなければ、プロセスのソーステキストではない。
もし If-Modified-Since, If-Unmodified-Since, If-Match, If-None-Matchや If-Range ヘッダフィールドをリクエストメッセージが含んでいるなら、GET メソッドのセマンティクスは "条件付き GET" に変わる。条件付き GETメソッドはエンティティがその条件付きヘッダフィールドによって表される状況の元でのみ転送される事をリクエストする。条件付き GET メソッドはキャッシュされるエンティティに複数のリクエストを必要としたりクライアントによってすでに保持されたデータを転送する事なしに再び新しくされる事を可能にする事により、ネットワークの不必要な使用を減少する目的を持つ。
もしリクエストメッセージが Range ヘッダフィールドを含んでいるなら、GET メソッドのセマンティクスは "部分的 GET" に移行する。14.36 章で示されるように、部分的 GET は転送されるエンティティの一部のみを要求する。部分的 GET メソッドは partially-retrived エンティティにクライアントによって既に保持されているデータを転送する事なしに完全なものにするのを可能にするで、ネットワークの不必要な使用を減少する目的がある。
もし 13 章で表される HTTP キャッシングのための要求につながるなら、そしてそのような場合にのみ、GET リクエストへのレスポンスはキャッシュ可能となる。
9.4 HEAD
HEAD メソッドはサーバがレスポンスにおいて message-body を返してはならない事を除いて GET と同一である。HEAD リクエストへのレスポンスにおいて HTTP ヘッダに含まれるメタ情報は GET リクエストへのレスポンスで送られる情報と同一であるべきである。このメソッドは entity-body 自身を転送する事なしにリクエストによって意味されるエンティティに付いてのメタ情報を得るために使用される。このメソッドはよくハイパーテキストリンクの正当性、アクセス可能性、最近の修正をテストするために使用される。
HEAD リクエストへのレスポンスはレスポンスに含まれる情報がそのリソースからの前もってキャッシュされたエンティティを更新するために使用できると言う意味でキャッシュ可能である。もし新しいフィールド値がキャッシュされたエンティティが現在のエンティティと違う (Content-Length, Content-MD5,ETag や Last-Modified の変更を示すような) 事を示しているなら、キャッシュはそのキャッシュエンティティを古くなったものとして扱わなければならない。
9.5 POST
POST メソッドは目的のサーバが Request-Line における Request-URI により識別されるリソースの新しい従属として、リクエストにおいて同封されるエンティティを受け入れる事を要求するために使用される。POST は一定の方法に以下の機能のカバーを可能にするようにデザインされている
- 既存リソースの注釈
- 告示板、ニュースグループ、メーリングリストや記事の類似グループへのメッセージの送信
- フォーム提出の結果のような、data-handling プロセスへのブロックデータの供給
- 操作の追加を経たデータベースの拡張
POST メソッドによって実行される実際の機能はサーバによって決定され、通常は Request-URI に依存する。ポストされたエンティティはファイルがそれを含むディレクトリに従属し、ニュース記事がそれがポスとされたニュースグループに従属し、レコードがデータベースに従属しているのと同じ方法でそのURI に従属している。
POST メソッドによって実行される動作は URI によって識別されるリソースの結果ではないかもしれない。この場合、200 (OK) か 204 (No Content) が適切なレスポンスステータスであり、レスポンスが結果を表すエンティティを含んでいるかいないかに依存する。
もしリソースがオリジンサーバで既に制作されたなら、レスポンスは 201(Created) となるべきであり、リクエストのステータスを表すエンティティを含んで新しいリソースと Location ヘッダ (14.30 章参照) を参照する。
もしそのレスポンスが適切な Cache-Control や Expires ヘッダフィールドを含んでいないなら、このメソッドのレスポンスはキャッシュ可能ではない。しかしながら、303 (See Other) レスポンスはユーザエージェントにキャッシュ可能なリソースの検索を指示するために使用される。
POST リクエストは 8.2 章のメッセージ転送要求セットに従わなければならない。
9.6 PUT
PUT リクエストは同封されたエンティティが供給された Request-URI の元に保存される事を要求する。もし Request-URI が既に存在するリソースを参照しているなら、同封されるエンティティはオリジンサーバにあるそれの修正版としてみなされるべきである。もし Request-URI が既存のリソースを指してなく、その URI がリクエストしているユーザエージェントによって新しいリソースであると定義される事ができるなら、オリジンサーバはその URI に伴うリソースを制作できる。もし新しいリソースが制作されたら、オリジンサーバはユーザエージェントに 201 (Created) レスポンスで知らせなければならない。もし既存のリソースが置き換えられたら、200 (OK) か 204(No Content) レスポンスコードのどちらかがリクエストの成功した終了を示すために送られるべきである。もしその Request-URI にリソースが制作されなかったり置き換えられなければ、問題の本質を反映する適切なエラーレスポンスが与えられるべきである。エンティティの受け取り側は理解できなかったり実装していないどんな Content-* ヘッダ (Content-Range のような) も無視してはならず、そのような場合には 501 (Not Implemented)レスポンスを返さなければならない。
もしリクエストがキャッシュを通り抜けたり Request-URI が現在キャッシュされている一つ以上のエンティティと識別するなら、これらのエンティティは古くなったものとして扱われるべきである。このメソッドのレスポンスはキャッシュできない。
POST と PUT リクエストの間の基本的な違いは Request-URI の意味の違いに反映される。POST リクエストにおける URI は同封されたエンティティを処理するであろうリソースを識別する。リソースは data-accepting プロセス、ある別のプロトコルへのゲートウェイ、または注釈を受け入る分割されたエンティティであろう。それに対して、PUT リクエストにおける URI はリクエストとともに同封されたエンティティ![]() ユーザエージェントはどんな URI が意図されているかを知っているが、サーバはある別のリソースへのリクエストを適用するのを仮定してはならない
ユーザエージェントはどんな URI が意図されているかを知っているが、サーバはある別のリソースへのリクエストを適用するのを仮定してはならない ![]() を識別する。もしサーバがそのリクエストが別の URI に適用される事を望むなら、301 (Moved Permanently)レスポンスを返さなければならない。この時ユーザエージェントはリクエストをリダイレクトするかどうかに関してそれ自身決定するかもしれない。
を識別する。もしサーバがそのリクエストが別の URI に適用される事を望むなら、301 (Moved Permanently)レスポンスを返さなければならない。この時ユーザエージェントはリクエストをリダイレクトするかどうかに関してそれ自身決定するかもしれない。
HTTP/1.1 はどのように PUT メソッドがオリジンサーバの状態に影響を及ぼすかを定義しない。
PUT リクエストは 8.2 章でのメッセージ転送要求セットに従わなければならない。
9.7 DELETE
DELETE メソッドはオリジンサーバが Request-URI により識別されるリソースを削除する事を要求する。このメソッドはオリジンサーバで人の介入 (もしくは別の方法) によって無効にさせられているかもしれない。たとえオリジンサーバから返されたステータスコードが動作がうまく完了したと言う事を示しているとしても、クライアントは操作が実行された事を保証できない。しかしながら、もしリソースを削除したりアクセスできない場所へ移動したりする事を目的としていないなら、レスポンスが与えられたときサーバは成功を示すべきではない。
成功したレスポンスはもしレスポンスがステータスで表しているエンティティを含んでいるなら 220 (OK)、もし動作がまだ行われていないなら 202(Accepted)、もしくはもしレスポンスが OK だがエンティティを含んでいないなら 204 (No Content) であるべきである。
もしリクエストがキャッシュを通過し Request-URI が一つ以上の現在キャッシュされているエンティティと同一なら、これらのエンティティは古くなったものとして扱われるべきである。このメソッドのレスポンスはキャッシュできない。
9.8 TRACE
TRACE メソッドはメッセージのリモート、application-layer loop-back を実施するために使用される。リクエストの最後の受取人は 200 (OK) レスポンスの entity-body としてクライアントに受け取られるメッセージを反映すべきである。最後の受取人はリクエストでゼロ (0) の Max-Forwards 値 (14.31章参照) を受け取るオリジンサーバか最初のプロキシもしくはゲートウェイのどちらかである。TRACE リクエストはエンティティを含んではならない。
TRACE はクライアントになにがリクエスト連鎖の別の端で受け取られているかを見ることや、テストのためのデータや情報の診断を使用することを可能にする。リクエスト連鎖のトレースとしてそれが動作するため、Via ヘッダフィールド (14.44 章) の値が特に重要である。Max-Forwards ヘッダフィールドはクライアントにリクエスト連鎖の大きさに制限を与える事を可能にし、これは無限ループのメッセージ転送のプロキシ連鎖をテストするために有用である。
もし成功したなら、レスポンスは entity-body に "message/http" のContent-Type を伴うリクエストメッセージの全体を含むべきである。このメソッドのレスポンスはキャッシュされてはならない。
10 ステータスコード定義
それぞれの Status-Code は後に続くメソッドの記述とレスポンスにおいて必要とされるすべてのメタ情報を含んで以下に表される。
10.1 Informational 1xx
このステータスコードは暫定的なレスポンスを示し、空行で終了するStatus-Line とオプション的なヘッダからのみなる。HTTP/1.0 がどんな 1xxステータスコードも定義されていないため、サーバは実験的な状況下以外でHTTP/1.0 クライアントに 1xx レスポンスを送ってはならない。
10.1.1 100 Continue
クライアントはそのリクエストを続ける。この仮のレスポンスはリクエストの最初の部分が受け取られ、サーバによってまだ受け付けられていない事をクライアントに伝えるために使用される。クライアントはリクエストの残りを送る事でつづけるか、もし既にリクエストが完了していれば、このレスポンスを無視すべきである。サーバはリクエストが完了した後に最終的なレスポンスを送らなければならない。
10.1.2 101 Switching Protocols
サーバは理解し、Upgrade メッセージヘッダフィールド (14.41 章) 経由で、この接続で使用されているアプリケーションプロトコルにおいて移行するためクライアントのリクエストに応じようとしている。サーバは 101 レスポンスを終了する空行をのあと、すぐにレスポンスの Upgrade ヘッダフィールドによって定義されたそれらのプロトコルをスイッチするだろう。
プロトコルはそうすべき事ほうが都合が良いときにのみスイッチされるだろう。たとえば、HTTP のより新しいバージョンにスイッチする事はより古いバージョン以上に都合が良いし、real-time にスイッチする事は同期のプロトコルがそのような機能を使うリソースを配布するときに都合が良いだろう。
10.2 Successful 2xx
このステータスコードの分類はクライアントのリクエストがうまく受信され、理解され、そして受け入れられた事をしめす。
10.2.1 200 OK
リクエストは成功している。レスポンスに伴って返された情報はリクエストに使用されたメソッドに依存する。たとえば:
GET リクエストされたリソースに相当するエンティティがレスポンスとして送
られた。
HEAD リクエストされたリソースに相当する entity-header フィールドが
message-body を伴わないでレスポンスとして送信された。
POST 動作の結果を記述もしくは含んでいるエンティティ
TRACE 端末サーバによって受信されたリクエストメッセージを含んでいるエン
ティティ
10.2.2 201 Created
リクエストは果たされ、制作された新しいリソースが結果として生じた。新たに作り出されたリソースは Location ヘッダにより与えられるリソースに対する具体的な最高の URL を伴って、レスポンスのエンティティにおいて返された URI によって参照される。オリジンサーバは 201 ステータスコードを返す前にリソースを制作しなければならない。もし動作が動作がすぐに実行されなければ、サーバは代わりに 202 (Accepted) レスポンスを返信すべきである。
10.2.3 202 Accepted
リクエストは処理のために受け入れられたが、処理は完全になされていない。処理が実際に起こるとき拒否されるかもしれないので、リクエストが最終的に動作されるかどうかは不明である。このような非同期操作からステータスコードを再送信するための機構は存在しない。
202 レスポンスは意図的に non-committal である。この目的はユーザエージェントのサーバへの接続がプロセスが完了されるまで持続することなしに、ある別のプロセス (多分一日に一度しか実行されない batch-oriented プロセス)のためのリクエストをサーバが受け入れるのを可能にするためである。このレスポンスによって返されるエンティティはリクエストの現在の状態の指示と、状態モニタへのポインタかユーザがリクエストを失敗していると予期できるある評価のどちらかを含むべきである。
10.2.4 203 Non-Authoritative Information
entity-header において返されたメタ情報が、オリジンサーバから利用できるような決定的なセットではなく、ローカルもしくはサードパーティコピーから集められたものである。示されたセットは元のバージョンのサブセットかスーパーセットであろう。たとえば、リソースに関するローカルな注釈情報を含む事はオリジンサーバによって知らされるメタ情報のスーパーセットとなるかもしれない。このレスポンスコードの使用は必要でなく、レスポンスが200 (OK) とは別であろう時にのみ適切である。
10.2.5 204 No Content
サーバはリクエストを実行したが、送り返すための新しい情報が存在しない。もしクライアントがユーザエージェントなら、リクエストの送信を行ったところからそのドキュメントのビューを変えるべきではない。このレスポンスは主に、ユーザエージェントのアクティブドキュメントビューを変える事なしに、アクションに対するインプットを起こせるようにするのを目的とする。レスポンスは entity-body の形式に新しいメタ情報を含むかもしれない。これはユーザエージェントのアクティブビューにおいて現在のドキュメントに適用されるべきである。
204 レスポンスは message-body を含まなければならず、従って常にヘッダフィールドの後の最初の空行で終了する。
10.2.6 205 Reset Content
サーバはリクエストを実行し、ユーザエージェントは送信されたリクエストをもたらしたドキュメントビューをリセットすべきである。このレスポンスは主にアクションに対する入力が、ユーザが別の入力動作を簡単にできるように、与えられた入力におけるフォームのクリアが続く、ユーザ入力を経由して起こせるようにする目的を持つ。レスポンスはエンティティを含んではならない。
10.2.7 206 Partial Content
サーバはリソースに対する部分的 GET リクエストを実行した。リクエストはRange ヘッダフィールド (14.36 章) を含まなければならない。レスポンスはこのレスポンスに含まれるレンジを示す Content-Range ヘッダフィールド(14.17 章) か、それぞれの部分に Content-Range フィールドを含むmultipart/byteranges Content-Type のどちらかを返さなければならない。もし multipart/byteranges が使用されなければ、レスポンスにおけるContent-Length ヘッダフィールドは message-body で転送される 8 ビットバイトの実際の数と一致しなければならない。
Range や Content-Range ヘッダをサポートしないキャッシュは 206 (Partial)レスポンスをキャッシュしてはならない。
10.3 Redirection 3xx
このステータスコードの分類はそれ以上の動作がリクエストを実行するためにユーザエージェントによって行われる必要のある事を示す。もし二番目のリクエストで使用されているメソッドが GET か HEAD なら、そしてその場合にのみ、ユーザへの影響なしにユーザエージェントによって実行されるであろう。ユーザエージェントはそのようなリダイレクションがたいてい無限ループを示すため、自動的に 5 回以上リダイレクトすべきではない。
10.3.1 300 Multiple Choices
それぞれがその具体的なロケーションを伴う表現セットのすべてのに相当する要求されたリソースや、agent-driven ネゴシエーション情報 (12 章) がユーザ (もしくはユーザエージェント) が提案された表現を選択でき、そのロケーションにリクエストをリダイレクトできるように供給されている。[訳注: 要求されたリソースに該当するものが複数存在する。]
もしそれが HEAD リクエストでなければ、レスポンスはリソース特性のリストを含むエンティティや、ユーザやユーザエージェントがもっとも適切なもの選ぶ事のできるロケーションを加えるべきである。エンティティフォーマットは Content-Type ヘッダフィールドで与えられるメディアタイプによって表される。データフォーマットやユーザエージェントの能力に依存する事から、もっとも適切な選択が自動的に行われるかもしれない。しかしながらこの仕様書はそのような自動選択に対してどのような標準も定義しない。
もしサーバが表現の実行された選択を持っているなら、それは Locationフィールドにおける表現に対する具体的な URL を含むべきである。このレスポンスはもし別のものを示していなければキャッシュする事ができる。
10.3.2 301 Moved Permanently
リクエストされたリソースは新しい恒久的な URI に割り当てられ、以降そのリソースへの参照は返された URI の一つを使用すべきである。リンク編集機能を持つクライアントは、可能であればサーバにより返された新しい参照の一つ以上の Request-URI を参照するように自動的な再リンクすべきである。このレスポンスはもし別のものを示していなければキャッシュ可能である。
もし新しい URI がロケーションならば、その URL はレスポンスにおいてLocation フィールドによって与えられるべきである。リクエストメソッドが HEAD でなければ、レスポンスのエンティティは新しい URI へのハイパーリンクを書き留める短いハイパーテキストを含むべきである。
もし 301 ステータスコードが HEAD や GET 以外のリクエストのレスポンスとして受信されたら、レスポンスが配布されたもとの条件が変わっているかもしれないため、ユーザエージェントはユーザによって確認される事なくリクエストのリダイレクトを自動的に行ってはならない。
注意: 301 ステータスコードを受信した後 POST リクエストを自動的にリダイレクトするとき、幾つかの既存の HTTP/1.0 ユーザエージェントは誤ってそれを GET リクエストに変える。
10.3.3 302 Moved Temporarily
リクエストされたリソースは一時的に別の URL で存在している。このリダイレクションは場合によって変更されるかもしれないため、クライアントは後のリクエストにその Request-URI を使いつづけるべきである。このレスポンスは Cache-Control か Expires ヘッダフィールドによって示されている場合にのみキャッシュ可能である。
もし新しい URI がロケーションであれば、その URL はレスポンス内のLocation ヘッダによって与えられる。リクエストメソッドが HEAD でなければ、レスポンスのエンティティは新しい URI へのハイパーリンクの書き留めてある短いハイパーテキストを返すべきである。
もし 302 ステータスコードが GET や HEAD 以外のリクエストのレスポンスで受信されたら、リクエストが配信された状況と異なるかもしれないため、ユーザエージェントはユーザの確認なしにリクエストのリダイレクトを自動的に行ってはならない。
注意: 302 ステータスコードを受信した後の POST リクエストを自動的にリダイレクトするとき、ある既存の HTTP/1.0 ユーザエージェントは間違ってGET リクエストに変えてしまう。
10.3.4 303 See Other
リクエストに対するこのレスポンスは別の URI の形で発見され、このリソースを GET メソッドを使用して回収すべきである。このメソッドは主にPOST-activated スクリプトの出力がユーザエージェントを選択されたリソースへリダイレクトするのを可能にするために存在する。新しい URI は元々リクエストされたリソースに対する参照ではない。303 レスポンスはキャッシュ可能でないが、二番目の (リダイレクトされた) リクエストへのレスポンスはキャッシュ可能である。
もし新しい URI がロケーションであれば、その URL はレスポンスの Locationフィールドによって与えられるべきである。リクエストメソッドが HEADでなければ、レスポンスのエンティティは新しい URI へのハイパーリンクが書き留めてある短いハイパーテキストを含んでいるべきである。
10.3.5 304 Not Modified
クライアントが条件付き GET リクエストを実行し、アクセスが許可されたが、そのドキュメントは更新されていなかったときに、サーバはこのステータスコードで応答すべきである。レスポンスは message-body を含んではならない。
レスポンスは以下のヘッダフィールドを含まなければならない:
- Date
- もしヘッダが同じリクエストに対して既に 200 レスポンスで送られているようならば、ETag と/もしくは Content-Location。
- もし field-value が同じバリアントに対する直前のレスポンスで送られたものと異なるのであれば、Expires, Cache-Control, と/もしくは Vary。
もし条件付き GET が耐久性のあるキャッシュ認証マネージャ (13.3.3 章参照)を使ったなら、レスポンスは別の entity-header を含むべきではない。別の点で (条件付き GET が強固でない認証マネージャを使ったような場合)、レスポンスは別の entity-header を含んではならない。これはキャッシュされた entity-body と更新されたヘッダの間での不一致を防ぐためである。
もし 304 レスポンスが現在キャッシュされていないエンティティを示すなら、キャッシュはレスポンスを無視し、条件なしのリクエストを反復しなければならない。
もしキャッシュがキャッシュエンティティを更新するために受信された 304レスポンスを使用するなら、キャッシュはレスポンスで与えられたどんな新しいフィールド値をも反映させるため、エンティティを更新しなければならない。
304 レスポンスは message-body を含んではならないし、従って常にヘッダフィールドに続く最初の空行で終了する。
10.3.6 305 Use Proxy
リクエストされたリソースは Location フィールドによって与えられるプロキシを通してアクセスされなければならない。Location フィールドはプロキシの URL を与える。受け取り側はプロキシ経由でリクエストを再送信すると思われる。
10.4 Client Error 4xx
ステータスコードの 4xx クラスはクライアントが間違えてたようであるという場合を目的とする。HEAD リクエストの応答以外は、サーバはエラー状況が一時的なものでも恒久的なものでも、その説明を含んでいるエンティティを加えるべきである。これらのステータスコードはすべてのリクエストメソッドに適用されうる。ユーザエージェントはユーザに、加えられたエンティティすべてを表示すべきである。
注意: もしクライアントがデータを送信しているなら、TCP を使用しているサーバインプリメンテーションは、サーバが入力接続をクローズする前に、クライアントがレスポンスを含んでいるパケットの受領を知らせるのを保証するように気をつけるべきである。もしクライアントがクローズ後にデータを送信しつづければ、サーバの TCP スタックはクライアントにリセットパケットを送るだろう。これはクライアントの HTTP アプリケーションがリクエストを読み出して中間処理する前に、それが知らせられなかった入力バッファを消去するだろう。
10.4.1 400 Bad Request
不正な構文のリクエストのためサーバは理解できなかった。クライアントは修正しないままそのリクエストを再送信すべきではない。
10.4.2 401 Unauthorized
リクエストはユーザ認証を必要とする。レスポンスはリクエストされたリソースに適用できる誰何を含む WWW-Authenticate ヘッダフィールド (14.46 章)を含まなければならない。クライアントは適当な Authorization ヘッダフィールド (14.8 章) を伴うリクエストを反復する事ができる。もしリクエストがすでに Authorization 証明を含んでいるのであれば、この 401 レスポンスは、認証がそれらの証明に対して拒否された事を示す。もし 401 レスポンスが前のレスポンスと同じ誰何を含み、ユーザエージェントが既に最低一回認証を試みているなら、そのエンティティが関連した診断情報を含んでいるであろうため、ユーザエージェントはレスポンスで与えられたエンティティを表示するべきである。HTTP アクセス認証は 11 章において説明されている。
10.4.3 402 Payment Required
このコードは将来の使用のため予約されている。
10.4.4 403 Forbidden
サーバはリクエストを理解したが、それを実行する事を拒絶した。Authorizationは役に立たないだろうし、リクエストは繰り返されるべきではない。もしリクエストメソッドが HEAD でなく、サーバがなぜリクエストが実行されなかったかを公にするなら、エンティティにおいて拒絶の理由を述べるべきである。このステータスコードは一般に、サーバがなぜリクエストが拒絶されたかを正確に示す事を望まないときや、別のレスポンスが適用できない時に使用される。
10.4.5 404 Not Found
サーバが Request-URI に一致するものを見つけられなかった。その状態が一時的なものでも恒久的なものでも与えられる指示はない。
もしサーバがこの情報をクライアントに利用させたくなければ、代わりにステータスコード 403 (Forbidden) を使用する事ができる。ある内部的にコンフィギュレーション可能なメカニズムによって、古いリソースが恒久的に利用できなかったり、それが転送アドレスを持たない事をサーバが知っているなら、410 (Gone) ステータスコードが使用されるべきである。
10.4.6 405 Method Not Allowed
Request-Line に記述されたメソッドは Request-URI によって識別されるリソースに許可されていない。レスポンスはリクエストされたリソースへの正当なメソッドのリストを含む Allow ヘッダを含まなければならない。
10.4.7 406 Not Acceptable
リクエストによって識別されるリソースは、リクエストで送られた accept ヘッダによれば受け入れられず、内容の特性を持つ生成したレスポンスエンティティのみが行える。
HEAD リクエストでなければ、レスポンスは利用できるエンティティの特性やユーザやユーザエージェントがもっとも適切なものを選べるロケーションのリストを含んでいるエンティティを含むべきである。エンティティフォーマットは Content-Type ヘッダフィールドで与えられるメディアタイプによって示されている。フォーマットやユーザエージェントの能力に依存するため、もっとも適切な選択は自動的に実行されるだろう。しかしながら、この仕様書ではそのような自動選択のどんな標準をも定義しない。
注意: HTTP/1.1 サーバは、リクエストで送られた accept ヘッダにより受け入れできないレスポンスを返す事が許されている。いくつかの場合、これは 406 レスポンスを送る事が望ましいだろう。もし受け入れられるなら、ユーザエージェントは決定するため送られてきたレスポンスのヘッダを詳しく調べる事が推奨される。もしレスポンスが受け入れられないなら、ユーザエージェントはそれ以上のデータの受信を一時的に停止し、それ以降の動作の決定のためユーザにたずねる べきである 。
10.4.8 407 Proxy Authentication Required
このコードは 401 (Unauthorized) と似ているが、クライアントがプロキシに最初に認証されなければならない事を示す。プロキシはリクエストされたリソースに対してプロキシが適用できる誰何を含む、Proxy-Authenticate ヘッダ (14.33 章) を返さなければならない。クライアントは適当なProxy-Authorization ヘッダフィールド (14.34 章) を伴うリクエストを繰り返す事ができる。HTTP アクセス認証は 11 章で説明されている。
10.4.9 408 Request Timeout
クライアントはサーバの待ち時間内にリクエストをもたらさなかった。クライアントはその後に修正しないでリクエストを繰り返す事ができる。
10.4.10 409 Conflict
リクエストはリソースの現在の状態との矛盾のため完了されなかった。このコードはユーザが矛盾を解決し、リクエストを再提出できる事が期待される状況のみに許される。レスポンスボディはユーザが矛盾したリソースを認識するための十分な情報を含まなければならない。理論的には、このレスポンスエンティティはユーザやユーザエージェントが問題を修正するための十分な情報であろう。しかしながら、それは不可能だろうしその必要もない。
矛盾は PUT リクエストへのレスポンスにおいてもっとも発生しがちである。もしバージョン処理が使用され、PUT のエンティティが初期の (サードパーティ) リクエストによって作られたそれらと矛盾しているリソースの試行を含んでいるならば、サーバはリクエストが完了できなかった事を示す 409レスポンスを使用するできる。この場合、レスポンスエンティティはContent-Type レスポンスによって定義されるフォーマットで二つのバージョンの違いのリストを含むべきである。
10.4.11 410 Gone
リクエストされたリソースがサーバにおいてもはや有功ではなく、転送先のアドレスも分かっていない。この状況は恒久的なものとみなされるべきである。リンク編集機能を持つクライアントはユーザに確認した後 Request-URI の参照を削除すべきである。もしサーバが、その状況が恒久的なものかどうか知らないか決定するための機能を持っていなければ、代わりにステータスコード 404 (Not Found) が使用されるべきである。別の方法で示されなければこのレスポンスはキャッシュできる。
主に 410 レスポンスは、リソースが故意に利用不可能であったり、サーバのオーナーが削除されたリソースへのリモートリンクを望んでいる事を受取側に通知する事により、ウェブメンテナンスの作業を補助する目的を持つ。そのような出来事は、限られた期間の宣伝サービスや、もはや動作していない個々のサーバに関連するリソースに対して一般的である。"過ぎ去った" ような恒久的に利用できないすべてのリソースをマークしたり、どんな期間の長さ![]() これはサーバオーナーの自由な許可である
これはサーバオーナーの自由な許可である![]() までもマークを維持しておく必要はない。
までもマークを維持しておく必要はない。
10.4.12 411 Length Required
サーバは定義された Content-Length なしにリクエストを受け入れる事を拒絶した。もし message-body の長さを含んでいる正当な Content-Length ヘッダフィールドをリクエストメッセージに追加するなら、クライアントはリクエストを繰り返す事ができる。
10.4.13 412 Precondition Failed
request-header フィールドの一つ以上で与えられた前提条件は、それがサーバでテストされたときに偽であると評価された。このレスポンスコードはクライアントが前提条件を現在のリソースのメタ情報 (ヘッダフィールドデータ)に置いたり、従ってリクエストされたメソッドを示されたリソース以外のものに適用させないようにするためのものである。
10.4.14 413 Request Entity Too Large
リクエストエンティティがサーバが想定ているかもしくは処理できる以上の長さのため、サーバはリクエストを処理する事を拒絶している。サーバはクライアントにリクエストを続けさせないため接続を閉じるかもしれない。
もし状態が一時的なら、サーバはそれが一時的でありクライアントが再試行できる経過時間を示す Retry-After ヘッダフィールドを含むべきである。
10.4.15 414 Request-URI Too Long
サーバ中間処理するために想定している以上に Request-URI が長いため、サーバはリクエストをサービスする事を拒絶している。このまれな状態は、クライアントが不適当に長いクエリー情報を伴った POST リクエストを GETリクエストに変換したか、クライアントがリダイレクションの URL "ブラックホール" に陥ったか、サーバがクライアントにより Request-URI を読み出したり操作したりするための固定長バッファを使用しているいくつかのサーバに存在するセキュリティホールを利用していると思われるアタックを受けている時にのみ起こる傾向がある。
10.4.16 415 Unsupported Media Type
リクエストのエンティティは、リクエストされたメソッドに対してリクエストされたリソースがサポートしていないフォーマットであるため、サーバはリクエストのサービスを拒絶している。
10.5 Server Error 5xx
数字 "5" から始まるレスポンスステータスコードは、サーバがエラー状態にあるか、リクエストを実行する能力がないのに気づいた場合を示す。HEAD リクエストに相当する場合以外、サーバはエラー状況とそれが一時的なものか恒久的なものかの説明を含むエンティティを追加すべきである。ユーザエージェントはユーザに追加されたすべてのエンティティを表示すべきである。これらのレスポンスコードはどんなリクエストメソッドにも適用できる。
10.5.1 500 Internal Server Error
サーバはリクエストの実行を妨げる予期しない状態に遭遇した。
10.5.2 501 Not Implemented
サーバはリクエストを実行するのに必要な機能をサポートしていない。これはサーバがリクエストメソッドを認識できなく、どんなリソースに対してもそれをサポートする能力がないときの適当なレスポンスである。
10.5.3 502 Bad Gateway
ゲートウェイやプロキシとして動作しているようなサーバが、リクエストを実行しようとしている上層のサーバのから不正なレスポンスを受け取った。
10.5.4 503 Service Unavailable
サーバは一時的な過負荷やサーバのメンテナンスため現在リクエストを扱えない。これはある遅延の後に軽減されるであろう一時的な状態も含む。もし分かるなら、遅延時間の長さを Retry-After ヘッダで示す事ができる。もしRetry-After が与えられなければ、クライアントはそれを 500 レスポンスと同様に処理すべきである。
注意: 503 ステータスコードの存在は、サーバが過負荷状態になったときにそれを使わなければならないと言う事を暗黙的に意味している。いくつかのサーバは単純に接続拒否を望む事ができる。
10.5.5 504 Gateway Timeout
ゲートウェイやプロキシとして動作するサーバは、リクエストを完了するためにアクセスした上層のサーバから適時のレスポンスを受信しなかった。
10.5.6 505 HTTP Version Not Supported
サーバはリクエストメッセージで使用された HTTP プロトコルのバージョンをサポートしていない、もしくはサポートを拒否している。3.1 章で表されるように、サーバはクライアントと同じメジャーバージョンを使用してリクエストを完了できないか意図的にしない事をこのエラーメッセージのほかに示している。レスポンスは、なぜこのバージョンがサポートされていないか、どんな別のプロトコルがこのサーバによってサポートされているかを記述したエンティティを含むべきである。
11 アクセス認証
HTTP は、サーバがクライアントにリクエストを促すためや、クライアントが認証情報を提供するために使うことができる簡単な challenge-response認証メカニズムを提供する。これは、認証スキームを確認するため、拡張可能な大文字小文字を区別しないトークンに続く、そのスキームの認証をなすために必要なパラメータを含むコンマで区切られた属性値ペアのリストを使用する。
auth-scheme = token
auth-param = token "=" quoted-string
401 (Unauthorized) レスポンスメッセージはオリジンサーバによりユーザエージェントの認証を促すために使用される。このレスポンスはリクエストされたリソースに適用される最低一つの誰何を含む WWW-Authenticate ヘッダフィールドを含まなければならない。
challenge = auth-scheme 1*SP realm *( "," auth-param )
realm = "realm" "=" realm-value
realm-value = quoted-string
realm 属性 (大文字小文字を区別しない) は誰何を発行するすべての認証スキームに対して要求される。アクセスされているサーバの公式ルート URL(5.1.2 章参照) との連帯動作において、realm 値 (大文字小文字を区別する)は保護された領域を定義する。これらの realm はサーバ上の保護されたリソースが、それぞれ自身の認証スキームと/もしくはデータベース認証を伴う保護された領域のセットに分割されるようにする。realm 値は、一般的にオリジンサーバによって割り当てられている、認証スキームに特有の追加的なセマンティクスを持つ文字列である。
サーバへ自身の認証を望む![]() 常に 401 や 411 レスポンスを受信した後、必ずではないが
常に 401 や 411 レスポンスを受信した後、必ずではないが![]() ユーザエージェントはリクエストに Authorization ヘッダフィールドを加える事でそれを行う事ができる。Authorization フィールド値はリクエストされたリソースの realm に対するユーザエージェントの認証情報を含む信用証明からなる。[訳注: 信用証明=credential]
ユーザエージェントはリクエストに Authorization ヘッダフィールドを加える事でそれを行う事ができる。Authorization フィールド値はリクエストされたリソースの realm に対するユーザエージェントの認証情報を含む信用証明からなる。[訳注: 信用証明=credential]
credentials = basic-credentials
| auth-scheme #auth-param
ユーザエージェントによって自動的に信用証明が適用される領域は、保護された領域により決定される。もし直前のリクエストが認証されているなら、同じ信用証明は認証スキーム、パラメータ、そして/もしくはユーザ設定により決定された期間の間、その保護された領域の中での別のすべてのリクエストに対して再使用できる。もし別のものが認証スキームによって定義されていなければ、単一の保護領域はそのサーバの範囲外まで及ぶ事はできない。
もしサーバがリクエストで送られる信用証明を受け入れたくなければ、401(Unauthorized) レスポンスを返すべきである。レスポンスはリクエストされたリソースに適用できる (多分新しい) 誰何を含んでいる WWW-Authenticateヘッダフィールドと、拒絶を説明するエンティティを加えなければならない。
HTTP プロトコルはアプリケーションをアクセス認証のためのこの簡単なchallenege-response メカニズムに制限しない。転送レベルにおける暗号化やメッセージのカプセル化などのように、認証情報を詳述するための追加的なヘッダフィールドを伴う追加的なメカニズムを使用する事ができる。しかしながら、これらの追加的メカニズムはこの仕様書では定義されない。
プロキシはユーザエージェント認証に関して完全に透明でなければならない。それらは WWW-Authenticate と Auhtorization ヘッダに手を付けないで転送し、14.8 章で見つけられるルールに従わなければならない。
HTTP/1.1 はクライアントが Proxy-Authenticate と Proxy-Auhorization でプロキシから、そしてプロキシへ認証情報を渡せるようにしている。
11.1 Basic 認証スキーム
"basic" 認証スキームは、ユーザエージェントがそれぞれの realm に自身のユーザ ID とパスワードを伴って認証されなければいけないモデルをもとにしている。realm 値はそのサーバ上の別の realm との同一性のためにだけ比較される非空白文字列だとみなされるべきである。サーバは、保護されたRequest-URI の領域に対してユーザ ID とパスワードが正しいと証明できるときのみリクエストをサービスするだろう。オプション的な認証パラメータは存在しない。
保護領域内の URI に対して認証されていないリクエストの受領の上で、サーバは以下のような誰何を返す事ができる。
WWW-Authenticate: Basic realm="WallyWorld"
ここで "WallyWorld" は Request-URI の保護領域を識別するため、サーバによって割り当てられた文字列である。
認証を受けるため、クライアントは信用証明において base64 エンコードが行われた文字列のなかで、単一のコロン (":") 文字で区切られたユーザ ID とパスワードを送信する。
basic-credentials = "Basic" SP basic-cookie
basic-cookie = <base64 [7] encoding of user-pass,
except not limited to 76 char/line>
user-pass = userid ":" password
userid = *<TEXT excluding ":">
password = *TEXT
ユーザ ID は大文字と小文字を区別するだろう。
もしユーザエージェントがユーザ ID "Aladdin" とパスワード "open sesame"を送りたければ、それは以下のヘッダフィールドを使用するだろう:
Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ==
Basic 認証に関連するセキュリティ考察のため 15 章参照。
11.2 認証スキームの要約
HTTP のための digest 認証は RFC 2069 [32] において詳述されている。
12 内容ネゴシエーション
ほとんどの HTTP レスポンスは人間のユーザによる解釈のための情報を含んでいるエンティティを追加するだろう。もちろん、リクエストと一致する "もっとも利用可能な" エンティティをユーザに供給するのが望ましい。あいにく、サーバやキャッシュに対してすべてのユーザが "best" であるような同じ設定を行っているわけではないし、すべてのユーザエージェントがすべてのエンティティタイプを等しく表現できるわけではない。この理由により、HTTP は"内容ネゴシエーション" ![]() 複数の利用可能な表現がある時、与えられたレスポンスに対して最も良い表現を選択するための処理
複数の利用可能な表現がある時、与えられたレスポンスに対して最も良い表現を選択するための処理![]() に対する幾つかのメカニズムの機能を持つ。
に対する幾つかのメカニズムの機能を持つ。
注意: 互いの表現が同じメディアタイプを示すが、異なる言語などそのタイプの別の潜在性を使用するため、これは "フォーマットネゴシエーション" と呼ばれない。
entity-body を含むどのようなレスポンス (エラーレスポンスを含む) もネゴシエーションを受けさせる事ができる。
HTTP で可能な server-driven と agent-driven の二種類の内容ネゴシエーションが存在する。二種類のネゴシエーションは直交し、したがって別々にもしくは条件により使用する事ができる。率直なネゴシエーションと呼ばれる組み合わせの一つの方法は、キャッシュが続くリクエストに対するserver-driven ネゴシエーションを提供するため、オリジンサーバにより供給される agent-driven ネゴシエーション情報を使用するときに発生する。
12.1 Server-driven ネゴシエーション
もしレスポンスのための最良な表現の選択がサーバに設けられたアルゴリズムによって行われたなら、これは server-driven ネゴシエーションと呼ばれる。選択は、リクエストの利用可能な表現 (それが変化できる次元; 言語,content-coding など)や、リクエストメッセージの特有なヘッダフィールドの内容、もしくはリクエストに適する別の情報 (クライアントのネットワークアドレスなど)に基づいている。
server-driven ネゴシエーションは、利用可能な表現の中から選択するためのアルゴリズムがユーザエージェントに説明するのが難しいときや、サーバが最初のレスポンスといっしょにクライアントにその "最良の推測" を送るのを望むとき (もし "最良の推測" がユーザにとって十分によいなら、次のリクエストの round-trip delay を避けたいため) に有利である。サーバの推測を改善するため、ユーザエージェントはそのようなレスポンスのためのその設定を記述するヘッダフィールド (Accept, Acctpt-Length, Accept-Encoding など)を加える事ができる。
server-driven ネゴシエーションは以下の不都合を持つ:
- ユーザエージェントの能力とレスポンスの使用目的 (ユーザはスクリーンに表示させたいのか紙に印刷したいのか?) の両方の完全な情報が必要なため、サーバがすべてのユーザに "最良" であるものを正確に決定するのは不可能である。
- リクエストごとにユーザエージェントにその能力を記述させるのは非常に能率が悪く (レスポンスが複数の表現を持っている確率は少ないため)、ユーザプライバシーの潜在的な違反となりうる。
- リクエストへのレスポンス生成のため、オリジンサーバのインプリメンテーションとアルゴリズムを複雑にする。
- 複数のユーザリクエストに同じレスポンスを使う公開キャッシュの能力を制限するかもしれない。
HTTP/1.1 は、ユーザエージェントの能力とユーザ設定の記述を通してserver-driven ネゴシエーションを可能にするための、以下のリクエストヘッダフィールドを含んでいる: Accept (14.1 章), Accept-Charset (14.2 章),Accept-Encoding (14.3 章), Accept-Length(14.4 章) そして User-Agent(14.42 章)。しかしながら、オリジンサーバはそれらの次元に限定されていないし、リクエストヘッダフィールドの外部やこの仕様書で定義されていない拡張ヘッダフィールド内部の情報を含め、リクエストのすべての状況に基づいてレスポンスを変える事ができる。
HTTp/1.1 オリジンサーバは server-driven ネゴシエーションに基づくすべてのキャッシュ可能なレスポンスで適切な Vary ヘッダフィールド (14.43 章)を追加しなければならない。この Vary ヘッダフィールドはレスポンスが異なる (オリジンサーバが複数の表現からその "最良の推測" レスポンスを取り出す次元) かもしれない次元を記述する。
HTTP/1.1 公開キャッシュは Vary ヘッダフィールドがレスポンスに含まれているときそれを認識し、キャッシングと内容ネゴシエーション間の相互作用に付いて述べている 13.6 章で言及されてる要求に従わなければならない。
12.2 Agent-driven ネゴシエーション
agent-driven ネゴシエーションの場合、レスポンスのための最良の表現の選択は、オリジンサーバからの初期レスポンスを受信した後にユーザエージェントによって実行される。選択は、最初のレスポンスのヘッダフィールド (付録19.6.2.1 で述べられているように、この仕様書ではフィールド名 Alterenatesを予約する) や entity-body の中に含まれる、利用可能なレスポンスの表現のリストに基づき、それぞれ自身の URI によって区別される。その表現のなかからの選択は自動的 (もしユーザエージェントがそうする能力があれば)、もしくは生成されたメニュー (多分ハイパーテキスト) からのユーザ選択による手動で行われるだろう。
agent-driven ネゴシエーションは、レスポンスが一般的に使用されている次元 (タイプ、言語、エンコーディングのような) と異るとき、オリジンサーバがリクエストの評価からユーザエージェントの能力を決定できないとき、一般的には、公開キャッシュがサーバの負荷を分散し、ネットワークの使用を減らすために使用されているときに有利である。
agent-driven ネゴシエーションは、複数のうち最良な表現を得るために次のリクエストが必要となる不都合に苦しむ。次のリクエストはキャッシングが使用されている時にのみ効率的である。さらに、自動選択をサポートするどんなメカニズムも拡張として発展したり HTTP/1.1 で使用したりを禁止しないが、この仕様書ではそれらのメカニズムを定義しない。
HTTP/1.1 はサーバが決定しなかったり server-driven ネゴシエーションで使用する異なるレスポンスを供給できないとき、agent-driven ネゴシエーションを可能にするため、300 (Multiple Choices) と 406 (Not Acceptable)ステータスコードを定義する。
12.3 率直なネゴシエーション
率直なネゴシエーションは server-driven と agent-driven ネゴシエーションの両方の組み合わせである。(agent-driven ネゴシエーションとして)キャッシュがリソースの利用可能な表現のリストの形式を供給され、キャッシュによって相違の次元が完全に理解できたとき、キャッシュはそのリソースの次のリクエストに対するオリジンサーバに代わって server-driven ネゴシエーションを実行する能力を持つようになる。
率直なネゴシエーションは、オリジンサーバに別の方法で要求されるネゴシエーション作業の分散と、キャッシュが正しいレスポンスを正しく推測する事ができるとき agent-driven ネゴシエーションの次のリクエストによる後れを省略するという利点を持つ。
この仕様書ではそのようなどんなメカニズムの拡張としての発展や HTTP/1.1での使用をも禁止しないが、率直なネゴシエーションのためのどんなメカニズムも定義しない。もしすべての HTTP/1.1 クライアントで正しい中間操作を保証するためキャッシュ可能なら、率直なネゴシエーションを実行する HTTP/1.1キャッシュはレスポンスに (その相違の次元を定義する) Vary ヘッダフィールドを追加しなければならない。オリジンサーバによって供給されるagent-driven ネゴシエーション情報は率直にネゴシエーションされたレスポンスを加えられるべきである。
13 HTTP におけるキャッシング
[訳注: この章は曖昧な表現や難解な表現がたくさん含まれていたので、詳細に付いては原文を参照してください。]
HTTP は典型的な情報配布のために使用される。ここでパフォーマンスはレスポンスキャッシュの使用により改善する事ができる。HTTP/1.1 プロトコルは可能な限りキャッシング作業を行う目的の幾つかの要素を含んでいる。これらの要素はプロトコルの別の局面で込み入り、それらは相互に作用するため、メソッド、ヘッダ、レスポンスコードなどの詳細な記述とは別に HTTP の基本的なキャッシングデザインを説明する事は有用である。
もし非常にパフォーマンスを高めなかったらキャッシングは役に立たないだろう。HTTP/1.1 におけるキャッシングの到達点は、多くの場合においてリクエストを送る必要を除去し、そして別の多くの場合において全レスポンスを送る必要を除去する。前者は多くの操作に対して必要とされるネットワークround-trip の幾つかを減少する。われわれはこの目的のため "満期" メカニズム (13.2 章参照) を使用する。後者は必要なネットワークバンド幅を減らす。われわれはこの目的のため "確証" メカニズム (13.3 章参照) を使用する。
パフォーマンス、有効性、そして分離した操作のための要求は、われわれにセマンティクス透過性の到達点を緩めることを要求する。HTTP/1.1 プロトコルはオリジンサーバ、キャッシュ、クライアントが必要なときに透過性を明白に減らせるようにする。しかしながら、非透過な操作は非エキスパートユーザを混乱させ、あるサーバアプリケーション (商品の注文用などの) と適合性がないため、プロトコルは:
- クライアントやオリジンサーバによってゆるめられたとき、明白なプロトコルレベルリクエストによってのみ
- キャッシュやクライアントによって緩められたとき、エンドユーザに明白な警告を伴うのみ
透過性が緩められている事を必要とする。しかしながら、HTTP/1.1 プロトコルはこれらの重要な要素を備えている:
- すべてのパーティによって要求される全セマンティクス透過性を供給するプロトコル機構。
- オリジンサーバやユーザエージェントが明白に非透過操作をリクエストし、制御できるようにするプロトコル機構。
- キャッシュがリクエストされたセマンティクス透過性の概略を保存しないレスポンスに警告を付け加えられるようにするための機能。
基本原理はクライアントがセマンティクス透過性のどんな潜在的な緩和も検出可能でなければならないと言う事である。
注意: サーバ、キャッシュもしくはクライアント実装者はこの仕様書において明確に論議されないデザイン決定に直面するだろう。もし決定がセマンティクス透過性に影響するなら、注意深く完全な分析が透過性の破壊で重要な恩恵を表す以外、実装者は透過性を維持する本題から離れた間違いを犯している。
[訳注: セマンティクス透過性意味的な透過性
13.1.1 キャッシュの正当性
正当なキャッシュはリクエストに、以下の状況の一つに合うリクエスト(13.2.5, 13.2.6, 13.12 章参照) にふさわしい、キャッシュによって保たれたもっとも最新のレスポンスで答えなければならない:
- オリジンサーバがレスポンスの正当性再確証によってオリジンサーバで返されたものの等価性が確認されている。
- "十分新鮮" (13.2 章参照) である。デフォルトの場合、これはクライアント、サーバ、キャッシュの最低の限定的な新鮮さ要求に合う事を意味する (14.9 章参照)。もしオリジンサーバがそう指定するなら、オリジンサーバ単独の新鮮さ要求である。
- もしクライアントやオリジンサーバに対する新鮮さ要求が違反されるならそれは警告を含む (13.1.5 と 14.45 章参照)。
- 適切な 3.4 (Not Modified), 305 (Proxy Redirect) やエラー (4xx か 5xx)レスポンスメッセージである。
もしキャッシュがオリジンサーバと通信できないなら、正しいキャッシュはレスポンスがキャッシュから正しく対応できているなら上記のものを返すべきである。もしそうでなければ、通信失敗があった事を示すエラーか警告を返さなければならない。
もしキャッシュが、リクエストしているクライアントに普通に転送するレスポンス (レスポンス全体か 304 (Not Modified) レスポンスのどちらか) を受け取るか、受け取ったレスポンスがもはや新鮮でなければ、キャッシュはそれを新しい Warning を追加する事なしに (存在するどんな Warning ヘッダも削除する事なく) リクエストしているクライアントに転送すべきである。レスポンスが転送において古くなっているかもしれないため、キャッシュは単純にそのレスポンスの再評価を試みるべきではない。これは無限ループを引き起こすかもしれない。Warning の伴わない古くなったレスポンスを受け取ったユーザエージェントはユーザに示す警告を表示できる。
13.1.2 警告
キャッシュが直接的でも "十分新鮮" でもないレスポンスを返すとき (13.1.1 章での 2 つの状態の意味において)、Warning レスポンスヘッダを使用して、警告をその影響に結び付けなければならない。この警告はクライアントが適切な動作を行えるようにする。
警告は cache-related と別のものの両方の、別の目的で使用されるかもしれない。エラーステータスコードではなく、警告の使用は真の失敗とこれらのレスポンスを区別する。
警告が決してレスポンスの等価性を弱めないため、それらは常にキャッシュ可能である。これは警告が危険を伴わない HTTP/1.0 キャッシュを通過する事ができる事を意味する。そのようなキャッシュはレスポンスにおける entity-header として単純にその警告を通過するだろう。
警告は 0 から 99 までの番号が割り当てられる。この仕様書は、クライアントやキャッシュが幾つかの (すべてではない) 場合において自動的な動作を行えるように、現在警告に割り当てられているそれぞれのコード番号と意味を定義する。
警告は警告テキストも含んでいる。このテキストは適切な自然言語 (多分クライアントの Accept ヘッダに基づいた) におけるものであり、どんな文字セットが使用されているかのオプション的な指示を含んでいる。
同じコードの複数の警告を含む、複数の警告は (オリジンサーバかキャッシュのどちらかによって) レスポンスに付随される。たとえば、サーバが英語とバスク語の両方でテキストの同じ警告を供給できる。
複数の警告がレスポンスに付随するとき、ユーザにそれらすべてを表示するのは実用的でも合理的でもない。HTTP のこのバージョンは表示するための警告と順位示すための厳密な優先ルールを詳述しないが、幾つかの発見的方法を提案する。
Warning ヘッダと現在定義されている警告は 14.45 章において述べられている。
13.1.3 キャッシュ制御メカニズム
HTTP/1.1 における基本的なキャッシュアルゴリズム (server-specified 満期期間と確認動作をするもの) はキャッシュするという蓄積的な命令である。いくつかの場合、サーバもしくはクライアントは HTTP キャッシュに明白な命令を提供する必要があるかもしれない。われわれはこの目的のため Cache-Controlヘッダを使用する。
Cache-Control ヘッダは、クライアントもしくはサーバがそれぞれのリクエストやレスポンスにおける命令の多様性を伝えられるようにする。これらの命令は典型的にデフォルトキャッシングアルゴリズムを無効にする。一般的なルールとして、もしヘッダ値の間に明白な矛盾が存在するなら、ほとんどの限定的な解釈が適用されるべきである (これは、セマンティクス等価性を維持するような物である)。しかしながら、いくつかの場合において、Cache-Control 命令は、セマンティクス等価性の概略を弱めるように明白に詳述される (たとえば、"max-stale" や "public")。
Cache-Control 命令は 14.9 章において詳細に記述されている。
13.1.4 明白なユーザエージェント警告
多くのユーザエージェントは、ユーザに基本的なキャッシングメカニズムを置き換える事ができるようにさせている。たとえば、ユーザエージェントはユーザにキャッシュされたエンティティ (明らかに古くなっている) が決して認証されていない事をしていできるようにするだろう。もしくは、ユーザエージェントはリクエストごとに "Cache-Control: max-stale=3600" をいつも追加するかもしれない。ユーザは非透過性動作もしくは通常でない無効なキャッシングになる動作のどちらかを明らかに要請しなければならない。
もしユーザが基本的なキャッシングメカニズムを無効にするなら、ユーザエージェントは、サーバの透過的要求に合っていないという情報の表示となるたびに (特に、もし表示されたエンティティが古くなっていると分かっているなら)明らかにユーザに示すべきである。プロトコルは、ユーザエージェントがレスポンスが古くなっているかどうかを決定できるようにしているため、この指示はそれが実際に起こったときにのみ表示される必要がある。この指示はダイアログボックスである必要はない。これはアイコン (たとえば、腐った魚の絵)や別の仮想標識であっても良い。
もしユーザがキャッシュの有効性を以上に減少する方法のキャッシングメカニズムを設定しているなら、ユーザが不注意に余分なリソースを消費したり過度の待ち時間に苦しまないように、ユーザエージェントは続けて指示を表示 (たとえば、炎の中の通貨の絵) するべきである。
13.1.5 ルールと警告の例外
いくつかの場合、キャッシュのオペレータはクライアントにより要求されないとき、古くなったレスポンスを返すように設定する事を選ぶ事もできる。この決定は気軽に行われるべきではなく、有効性やパフォーマンスの理由、特にキャッシュがオリジンサーバに不十分に接続されてしまう時に必要であろう。キャッシュが古くなったレスポンスを返す時、(Warnign ヘッダを使用して)そのようにマークしなければならない。これはクライアントソフトウェアが潜在的な問題があるかもしれないと言う事をユーザに警告できるようにする。
ユーザエージェントが直接的もしくは新鮮なレスポンスを得ると言う処理を行う事もできる。この理由により、もし技術的もしくはポリシー的な理由のため応ずる事が不可能でなければ、クライアントが直接的もしくは新鮮なレスポンスを明らかに要請しているなら、キャッシュは古くなったレスポンスを返すべきではない。
13.1.6 Client-controlled 動作
オリジンサーバ (とレスポンスの年齢へのそれらの寄与によるより少ない範囲、中間のキャッシュに) が満期情報のプライマリリソースである間、いくつかの場合クライアントは、キャッシュされたレスポンスを返すかどうかを確認しないで、それに関してのキャッシュの決定を制御する必要があるかもしれない。クライアントは Cache-Control ヘッダのいくつかの命令を使ってこれを行う。
クライアントのリクエストは、正当性を確認しないでレスポンスを受け取るのを意図して最大年齢を記述する事ができる。ゼロの値の記述する事は強制的にキャッシュにすべてのレスポンスの正当性を再確認させる。クライアントはまたレスポンスが満期になる前に残される最小期間を記述する事ができる。これらのオプションの両方はキャッシュの動作への制約を増加し、キャッシュのセマンティクス透過性の概略をそれ以上緩める事ができない。
クライアントは古くなったレスポンスを受け入れる意図で、最大でもある古さの最大量まで記述する事もできる。これはキャッシュの制約を緩め、オリジンサーバの記述されたセマンティクス透過性の制約に違反するかもしれないが、接続が切れた操作や貧弱な接続面における高い有効性をサポートする必要があるかもしれない。
13.2 満期モデル
13.2.1 Server-Specified 満期
HTTP キャッシングは、キャッシュがオリジンサーバにリクエストを送るのを完全に避けられるとき最良に動作する。リクエストを避ける第一のメカニズムは、レスポンスが次のリクエストを満足させるために使用される事も含めて、オリジンサーバが将来における明確な満期期間を提供する事である。言いかえれば、キャッシュがサーバに先に接続する事なしに新鮮なレスポンスを返せる。
われわれの期待は、満期期間に達する前にエンティティが変更されそうにない![]() 意味的に重要な意義を持つ方法で
意味的に重要な意義を持つ方法で![]() という確信において、サーバがリソースに将来的に明白な満期期間を割り当てているだろう事である。これは普通、サーバの満期期間が注意深く選ばれている限り、セマンティクス透過性を維持する。
という確信において、サーバがリソースに将来的に明白な満期期間を割り当てているだろう事である。これは普通、サーバの満期期間が注意深く選ばれている限り、セマンティクス透過性を維持する。
満期メカニズムは、リクエストしているクライアントに中間的に転送された直接的レスポンスにではなく、キャッシュから取得したレスポンスのみに適用する。
もしオリジンサーバが強制的に、意味的に透過なキャッシュをそれぞれのリクエストで正当性を確認するよう望むなら、過去における明白な満期期間が割り当てられるだろう。これはレスポンスが既に古く、キャッシュは次のリクエストでそれを使用する前にその正当性を確認すべきであると言う事を意味する。強制的に正当性を再確認するためのより限定的な方法は 14.9.5 章参照。
どのように設定されているかに拘らず、もしオリジンサーバが強制的にすべての HTTP/1.1 キャッシュをリクエストごとに正当性の確認をさせるように望むなら、"must-revalidate" Cache-Control 命令 (14.9 章参照) を使用すべきである。
サーバは Expires ヘッダか Cache-Control ヘッダの max-age 命令のどちらかを使用して明確な満期期間を記述する。
満期期間は強制的にユーザエージェントの表示を更新したり、リソースを再ロードしたりさせるために使用する事はできない。そのセマンティクスはキャッシングメカニズムにのみ適用され、そしてそのようなメカニズムは、そのリソースに対する新しいリクエストが始められたときのリソース満期ステータスのみをチェックする必要がある。キャッシュと履歴メカニズムの違いの説明のための 13.13 章参照。
13.2.2 発見的な満期
オリジンサーバが常に明確な満期期間を提供するわけではないため、典型的にHTTP キャッシュは、本当の満期期間を判断するため別のヘッダ値(Last-Modified 時間のような) を使うアルゴリズムを使用する、発見的な満期期間を割り当てる。HTTP/1.1 仕様書は具体的なアルゴリズムを提供しないが、別の結果への最悪の場合の制約を課す。発見的な満期期間がセマンティクス透過性を損なうため、それらは慎重に使用されるべきであり、われわれはオリジンサーバが可能な限り明白な満期期間を提供する事を推奨する。
13.2.3 年齢計算
キャッシュされたエンティティが新鮮かどうか知るため、キャッシュはその年齢がその新鮮さ持続期間を超えているかどうかを知る必要がある。われわれは後者がそのように計算されるかを 13.2.4 章において論議する。この章はどのようにレスポンスやキャッシュエンティティの年齢を計算するかを記述する。
この論議では、われわれは "now" と言う言葉を "計算が行われているホストの現在の時刻" という意味で使用する。HTTP を使用しているホスト、ただし、特にオリジンサーバとキャッシュを実行しているホストはそれらのクロックを世界的に正確な標準時刻に同期させるため NTP [28] やそれに似たプロトコルを使用すべきである。
HTTP/1.1 はオリジンサーバがレスポンスごとに、レスポンスが生成された時間を与える Date ヘッダを送る必要がある事に注意。われわれは自動操作のための適切な形式において "date_value" と言う言葉を Date ヘッダの値を示すものとして使用する。
HTTP/1.1 はキャッシュ間の年齢情報を伝える補助のための Age レスポンスヘッダを使用する。Age ヘッダ値はオリジンサーバでレスポンスが制作されてからの時間量の送り側の見積もりである。オリジンサーバに正当性が再確認された、キャッシュされたレスポンスの場合、Age 値は元のレスポンスではなく、正当性の再確認の時間に基づいている。
本質的に Age 値は、オリジンサーバからの経路に沿って存在するキャッシュのそれぞれでレスポンスが存在する時間と、ネットワーク経路に沿う転送にかかった時間の合計である。
われわれは自動操作のための適切な形式で、"age_value" という言葉を Ageヘッダの値を示すために使用する。
レスポンスの年齢は二つの勧善に独立した方法で計算する事ができる。
- もしローカルクロックがオリジナルサーバのクロックと合理的に同期しているなら、now から date_value を引く。もし結果が負となれば、ゼロに置き換える。
- もしレスポンス経路上のすべてのキャッシュが HTTP/1.1 を実装しているなら age_value。
われわれはレスポンスの年齢計算のための二つの独立な方法に、いつそれが受信されたかを与える事で、これらを
corrected_received_age = max(now - date_value, age_value)
として組み合わせる事ができ、おおよそ同期しているクロックかすべてがHTTP/1.1 経路のどちらかを持つならば信頼できる (保守的な) 結果を得る。
もし経路内に HTTP/1.0 キャッシュが存在するなら、受信しているキャッシュのクロックがほぼ同調している限り正しい受信年齢が計算されているため、この補正は経路上の HTTP/1.1 キャッシュそれぞれに適用される事に注意。われわれは両端末のクロック同期をはかる必要がなく (それが良い方法だが)、明確にクロック同期をはかる処置は存在しない。
ネットワークに課される遅延のため、ある重要な間隔が、サーバがレスポンスを生成する時間と、次の外部行きのキャッシュやクライアントに受け取られる時間から経過するかもしれない。もし訂正されなければ、これの遅延は不適当に低い年齢をもたらす事ができる。
返された Age 値をもたらしたリクエストは、その Age 値の生成より前に開始されていなければならないため、そのリクエストが開始された時間を記録する事により、ネットワークによって課された遅延を訂正する事ができる。Age 値が受信されたとき、レスポンスが受信された時間ではなくリクエストが開始された時間との相対値と解釈しなければならない。このアルゴリズムはどれくらいの遅延が発生したかに拘らず保守的な動作に帰着する。それで、われわれは:
corrected_initial_age = corrected_received_age
+ (now - request_time)
ここで "request_time" はこのレスポンスを引き起こしたリクエストが送信されたときの時間 (ローカルクロックによる) である。
キャッシュがレスポンスを受け取ったときの年齢計算アルゴリズムの要約は:
/*
* age_value
* is the value of Age: header received by the cache with
* this response.
* date_value
* is the value of the origin server's Date: header
* request_time
* is the (local) time when the cache made the request
* that resulted in this cached response
* response_time
* is the (local) time when the cache received the
* response
* now
* is the current (local) time
*/
apparent_age = max(0, response_time - date_value);
corrected_received_age = max(apparent_age, age_value);
response_delay = response_time - request_time;
corrected_initial_age = corrected_received_age + response_delay;
resident_time = now - response_time;
current_age = corrected_initial_age + resident_time;
キャッシュがレスポンスを送信するとき、レスポンスがローカルに居座っていた時間を corrected_initial_age に加えなければならない。Age ヘッダを使用して、次の受信キャッシュにこのトータル年齢を転送しなければならない。
クライアントはレスポンスが直接的である事を確実に知らせる事ができない事に注意。しかし Age ヘッダの存在はレスポンスが明確に直接的でない事を示している。もしレスポンスの Date はクライアントのローカルなリクエスト時間より早いなら、多分 (深刻なクロックのずれがなければ)レスポンスは直接的ではない。
13.2.4 満期計算
レスポンスが新鮮かどうかを決定するため、その新鮮さ持続時間と年齢を比較する必要がある。年齢は 13.2.3 章で記述されているように計算される。この章はどのように新鮮さ持続時間を計算するかと、どのようにレスポンスの期限が切れているかを判断するかを記述する。以下の論議において、値は数値計算に対する適当な形式において表される。
われわれは "expires_value" を Expires ヘッダの値を示すものとして使用する。また "max_age_value" をレスポンスにおける Cache-Control ヘッダ(14.10 章参照) の max-age 命令によって伝えられた秒数の適切な値を示すものとして使用する。
max-age 命令は Expires より優先され、もし max-age がレスポンスにおいて与えられているなら計算は簡単である:
freshness_lifetime = max_age_value
さもなければ、もし Expires がレスポンスで与えられているなら、計算は:
freshness_lifetime = expires_value - date_value
それらの情報すべてがオリジンサーバからのものであるため、これらの計算のどちらもクロックのずれに影響されない事に注意。
もしレスポンスに Expires も Cache-Control: max-age も現れなく、レスポンスがキャッシングの別の制限を含んでいなければ、キャッシュは発見的な方法を使って新鮮さ持続時間を計算できる。もし値が 24 時間よりも大きいなら、もし Warning 13 警告がまだ追加されていなければ、キャッシュは年齢が 24 時間以上のすべてのレスポンスにその警告を追加しなければならない。
もしレスポンスが Last-Modified 時間を持っているなら、発見的な満期値は多くてもその時間からの間隔のある分数にすべきである。この分数の典型的な設定は 10% であろう。
レスポンスの期限が切れたかどうかを決定する計算は全く簡単である:
response_is_fresh = (freshness_lifetime > current_age)
13.2.5 満期値を曖昧にしないこと
満期値が楽天的に割り当てられるため、二つのキャッシュ要素が同じリソースに対する異なる新鮮さ値を含む事が可能である。
もし回収を実行しているクライアントが自身のキャッシュにおいて既に新鮮であるリクエストに対して直接的でないレスポンスを受け取り、キャッシュに存在するエンティティの Date ヘッダが新しいレスポンスでの Date ヘッダより新しいなら、クライアントはレスポンスを無視する事ができる。もしそうであれば、オリジンサーバに強制的にチェックするため、"Cache-Control:max-age=0" 命令を伴うリクエストを再試行できる。
もしキャッシュが異なる正当性確認子を持つ同じ表現の二つの新鮮なレスポンスを持つなら、より最近の Date ヘッダを持つものを使用しなければならない。この状況は、キャッシュが別のキャッシュとレスポンスを共有するためや、クライアントが明白に新鮮なキャッシュエンティティの再ロードや正当性の再評価を行う事を要求したため生じるかもしれない。
13.2.6 複数のレスポンスを曖昧にしないこと
クライアントが複数の経路でレスポンスを受け取る事ができるので、いくつかのレスポンスがあるキャッシュのセットを通って流れ、別のレスポンスが別のキャッシュのセットを通って流れる事から、クライアントはオリジンサーバがレスポンスを送ったのと異なる順番でレスポンスを受け取るかもしれない。もし古いレスポンスがまだ明白に新鮮であれば、クライアントはもっとも最近生成されたレスポンスを使用する事が望まれる。
後のレスポンスがより早い満期期間を故意に運ぶことができるため、エンティティタグも満期値も順序付けをレスポンスに課すことができない。しかしながら、HTTP/1.1 仕様書はレスポンスごとに Date ヘッダの伝達を要求し、Date値は一つの秒の粒状性を定める。
クライアントがキャッシュエンティティの正当性再確認を試行し、受信したレスポンスが既存のエンティティに対する Date ヘッダよりも古い Date ヘッダを含んでいるとき、クライアントすべての中間キャッシュにオリジンサーバへそれらのコピーの正当性確認を行わせるため、
Cache-Control: max-age=0
を加えるかすべての中間キャッシュにオリジンサーバからの新しいコピーを得させるため、
Cache-Control: no-cache
を加えたリクエストを無条件に繰り返すべきである。
もし Date 値が等しいなら、クライアントはレスポンスのどちらかを使う事ができる (もしくはそれが極端に打算的なら、新しいレスポンスを要求できる)。それらの満期期間が重複しているなら、同じ秒の間に生成されたレスポンスの決定的な選択ができるクライアントにサーバは依存してはならない。
13.3 確証モデル
キャッシュがクライアントのリクエストへのレスポンスとして使えそうな、古くなったエンティティを持っているとき、そのキャッシュされたエンティティがまだ使用可能かどうかを確かめるため、最初にオリジンサーバ (ひょっとすると新鮮なレスポンスを持っている中間キャッシュ) へチェックしなければならない。キャッシュされたエンティティで良いなら全レスポンスの再転送のオーバーヘッドを受けなければならない事を望まないため、そしてキャッシュされたエンティティが正当でないなら余分な round trip のオーバーヘッドを受けなければならない事を望まないため、HTTP/1.1 プロトコルは条件付きメソッドの使用をサポートしている。[訳注: 正当性確証子![]() validator]
validator]
条件付きメソッドをサポートするための重要なプロトコル機構は "キャッシュ正当性確証子" に関係するものである。オリジンサーバがレスポンス全体を生成するとき、それにキャッシュエンティティに保存されるある種の正当性確証子を付ける。クライアント (ユーザエージェントやプロキシキャッシュ) がキャッシュエンティティを持つ物に対してリソースのための条件付きリクエストを作るとき、リクエストにおいて関連する正当性確証子を追加する。
この時サーバはその正当性確証子とエンティティに対する現在の正当性確証子とを調べ、それらがもし一致するなら、エンティティボディを伴わない特別なレスポンスコード (通常は 304 (Not Modified)) を返す。従って、もし正当性確証子が一致するならレスポンスすべてを転送する事を避け、一致しないなら余分な round trip を避ける。
注意: 正当性確証子が一致しているかどうかを決定するために使用される比較機能は 13.3.3 章 に定義されている。
HTTP/1.1 において、メソッド (通常は GET) を暗に条件付きにする特別なヘッダ (正当性確証子を含んでいるもの) を含む事を除いて、条件付きリクエストは同じリソースに対する通常のリクエストと正確に同じに見える。
プロトコルはキャッシュ正当性確認条件の肯定的意図と否定的意図の両方を含んでいる。これは、正当性確証子が一致するなら、そして正当性確証子が一致しないならメソッドが実行されるということのどちらかを要求する事が可能である。
注意: もしこれが Cache-Control 命令によって明白に禁止されていなければ、正当性確証子が欠落しているレスポンスはその期限が切れるまでキャッシュにキャッシュされ、保存されるだろう。しかしながら、もしそれがエンティティに対する正当性確証子を持っていないならキャッシュは条件付き回収を行う事ができなく、これはその期限が切れた後も再び新しくできないだろうと言う事を意味する。
13.3.1 Last-modified 日時
Last-Modified エンティティヘッダフィールド値はキャッシュ正当性確証子としてしばしば使用される。簡単な条件では、キャッシュエンティティはエンティティが Last-Modified 値から更新されていないなら正当であるとみなす事ができる。
13.3.2 エンティティタグキャッシュ確証子
ETag エンティティヘッダフィールド値、エンティティタグは "曖昧な" キャッシュ正当性確証子を可能にする。これは、修正日時を保存する事が不都合な状況、HTTP 日付値の秒解像度が十分でない状況、オリジンサーバが修正日時の使用から起こるであろう特定の矛盾を避ける事を望む状況でより信頼できる確証を可能にするだろう。
エンティティタグは 3.11 章で記述される。エンティティタグと使用されるヘッダは 14.20, 14.25, 14.26, 14.43 章で記述される。
13.3.3 弱い確証子と強い確証子
オリジンサーバとキャッシュの両方は同じエンティティを表すかどうかを決定するために二つの確証子を比較するだろう。このためエンティティ (エンティティボディかエンティティヘッダ) が何らかの方法で変わっているなら通常は除外されるだろう。このとき関連される確証子はその上で変更しているだろう。もしこれが真ならば、われわれはこの確証子を "強い確証子" と呼ぶ。
しかしながら、サーバがエンティティ変更の重要でない局面はなく意味的に重要な変更でのみ確証子を変更する事を好む場合がありうる。リソースを変更するとき常に変更されるわけではない確証子は "弱い確証子" である。
エンティティタグは通常 "強い確証子" であるが、このプロトコルは "弱い"ようなエンティティタグにマークを付けるためのメカニズムを備えている。弱い値はエンティティの意味が変更するとき変わるが、エンティティの小片が変更するときに変わるものは強い確証子と考える事ができる。または、弱い確証子は意味的に等しいエンティティのセットに対する識別子の一部であるが、具体的なエンティティに対する識別子の一部であるものは強い確証子とみなす事ができる。
注意: 強い確証子の一つの例は安定した記憶装置においてエンティティが変更されるたび毎回増加する整数である。リソースを一秒間以内に二度更新することは可能なため、エンティティの更
新時間は、もしそれが秒解像度に相当するなら弱い確証子である。弱い確証子のサポートはオプションである。しかしながら、弱い確証子は同
等のオブジェクトのより効果的なキャッシング考慮に入れている。たとえば、もしあるサイトのヒットカウントが日や週ごとでほとんど更新されないなら、多分それは十分に良く、その期間内のすべての値は多分 "十分に良く" 等しい。確証子の "使用" は、クライアントがリクエストを生成し正当性確証ヘッダ
フィールドに確証子が含むときか、サーバが二つの確証子を比較するときのどちらかである。
強い確証子はどんな状況にも使う事もできる。弱い確証子はエンティティの正確な等価性に依存しない状況においてのみ使用可能である。たとえば、どちらかの種類がエンティティ全体の条件付き GET のために使用可能である。しかしながら、クライアントが内部的に矛盾するエンティティになってしまうため、強い確証子のみがサブレンジ回収のために使用する事ができる。
HTTP/1.1 プロトコルが確証子に定義している機能は比較のみである。比較状況が弱い確証子の使用を許すかどうかに依存する、二つの比較機能がある。
- 強い比較機能: 等しさを検討するため、両方の確証子はあらゆる方法で同一でなければならなく、両方の確証子は共に弱くない。
- 弱い比較機能: 等しさを検討するため、両方の確証子はあらゆる方法で同一でなければならない。ただし、これらのどちらかもしくは両方は結果に影響することなく "弱い" とマークされている。
弱い比較機能は単純な (非サブレンジ) GET リクエストに使用する事ができる。強い比較機能は別のすべての場合に使用されなければならない。
明確に弱いとマークされていなければエンティティタグは強い。3.11 章はエンティティタグのための構文を与えている。
Last-Modified 時間がリクエストにおいて確証子として使用されているとき、以下のルールを使ってそれが強いと推定できなければ絶対的に弱い:
- 確証子はオリジンサーバによってエンティティに対する実際の現在の確証子と比較され、
- オリジンサーバが、関連したエンティティが与えられた確証子が及ぶ秒の間に二度変更していない事を確かに知っている。
- クライアントが関連するエンティティに対するキャッシュエンティティを持っているため、確証子が If-Modified-Since か If-Unmodified-Since ヘッダでクライアントによって使用されようとしているところであり、
- キャッシュエンティティが、オリジンサーバが元のレスポンスを送ったときの時刻を与える Date 値を含み、
- 表された Last-Modified 時刻は Date 値から最低 60 秒前である。
- 確証子が中間キャッシュによってエンティティに対するそのキャッシュエンティティに保存されている確証子と比較され、
- このキャッシュエンティティが、オリジンサーバが元のレスポンスを送ったときの時刻を与える Date 値を含み、
- 表された Last-Modified 時刻は Date 値から最低 60 秒前である。
この方法は、二つの異なるレスポンスが同じ秒にオリジンサーバから送られ、両方は同じ Last-Modified 時刻を持っていたなら、これらのレスポンスの少なくとも一つはその Last-Modified 時刻と同じ Date 値を持っているであろうという事実を当てにしている。独断的な 60 秒制限は Date と Last-Modified 値が別のクロックからやレスポンスの準備の間の幾分異なる時間に生成されたと言う可能性を警戒している。もしインプリメンテーションが 60秒はとても短いと信じるなら 60 秒より大きい値を使用できる。
もしクライアントが Last-Modified 時刻のみを持ち曖昧な確証子を持たない値のサブレンジ回収を実行したければ、Last-Modified 時刻がここで記述された意図において強い場合のみこれを行う事ができる。
全ボディ GET リクエスト以外のキャッシュ条件付きリクエストを受信しているキャッシュやオリジンサーバは条件を評価するために強い比較機能を使わなければならない。
このルールは HTTP/1.1 キャッシュとクライアントが HTTP/1.0 サーバから得られている値のサブレンジ回収を安全に実行できるようにする。
13.3.4 いつエンティティタグと Last-Modified 時刻を使うかのルール
われわれはさまざまな確証子タイプがいつ何の目的で使用されるべきかに関する、オリジンサーバ、クライアント、キャッシュのためのルールと推薦のセットを指定する。
HTTP/1.1 オリジンサーバは:
- それを生成するのを実行可能ならエンティティタグ確証子を送るべきである。
- パフォーマンス考慮が弱いエンティティタグの使用を支持しているか、強いエンティティタグを送るのを実行不可能なら、強いエンティティタグの代わりに弱いエンティティタグを送る事ができる。
- Last-Modified 値を送るのが実行可能で、If-Modified-Since ヘッダにおいてこの日付の使用から結果として生じる、セマンティクス透過性における故障の危険が深刻な問題を引き起さなければ、Last-Modified 値を送るべきである。
言いかえれば、HTTP/1.1 オリジンサーバに対してより望まれる動作は強いエンティティタグと Last-Modified 値の両方を送る事である。
合法的であるため、強いエンティティタグは関連するエンティティ値が変わるどんな点でも変わらなければならない。弱いエンティティタグは関連するエンティティタグが意味上で重要な点において変わるとき変わるべきである。
注意: 意味的に透過なキャッシングを供給するため、オリジンサーバは二つの異なるエンティティに対する特定の強いエンティティタグ値の再使用、もしくは二つの意味的に異なるエンティティに対する特定の弱いエンティティタグ値の再使用を避けなければならない。キャッシュエンティティは満期期間に関係なく任意な長期間持続するかもしれない。それで、キャッシュが過去のある点で得られた確証子を使用するエンティティの正当性を確認することを再び試みないだろうという事を期待するのは不適当であろう。
HTTP/1.1 クライアントは:
- もしオリジンサーバによってエンティティタグが供給されているなら、あらゆるキャッシュ条件付きリクエスト (If-Match か If-None-Match) でこのエンティティタグを使わなければならない。
- もしオリジンサーバによって Last-Modified 値のみが提供されているなら、非サブレンジキャッシュ条件付きリクエスト (If-Modified-Since を使った) においてこの値を使用すべきである。
- もし HTTP/1.0 サーバによって Last-Modified 値のみが提供されるなら、サブレンジキャッシュ条件付きリクエスト (If-Unmodified-Since を使った) においてこの値を使用する事ができる。ユーザエージェントは難しい場合、これを無効にする方法を供給すべきである。
- もしオリジンサーバによってエンティティタグと Last-Modified 値の両方が供給されれば、キャッシュ条件付きリクエストにおいて両方の確証子を使うべきである。これは HTTP/1.0 と HTTP/1.1 キャッシュが適切に応答できるようにする。
リクエストを受信した上で、クライアントのキャッシュエンティティがキャッシュ自身のキャッシュエンティティと一致しているかどうかを決定するとき、HTTP/1.1 キャッシュはもっとも限定的な確証子を使用しなければならない。これはリクエストがエンティティタグと最終更新時刻確証子 (If-Modified-Since か If-Unmodified-Since) の両方を含んでいるときにのみ問題となる。
正当性の注意: これらのルールの後の一般的な原理は、HTTP/1.1 サーバとクライアントはそれらのレスポンスやリクエストで利用可能であるような余分でない情報と同量の転送を行うべきである。この情報を受信している HTTP/1.1 はそれらが受信する確証子に関してもっとも保守的な推測を行うだろう。HTTP/1.0 クライアントとキャッシュはエンティティタグを無視するだろう。一般的に、これらのシステムによって受信され使用される Last-Modified 値は透過的で効果的なキャッシングをサポートするだろう。そして HTTP/1.1 オリジンサーバは Last-Modified 値を供給すべきである。HTTP/1.0 システムによって確証子として Last-Modified 値の使用が深刻な問題を引き起こすというまれな場合、HTTP/1.1 オリジンサーバはこれを供給すべきではない。
13.3.5 Non-validating Conditionals
エンティティタグ後の原則は、サービスの著者のみがリソースのセマンティクスが適切なキャッシュ確証メカニズムを選択するのに十分であると知り、バイト等価よりも複雑な確証子識別機能のどんな物の仕様書も虫の缶を開けるだろう。従って、別のヘッダの比較 (HTTP/1.0 互換性のための Last-Modified を除く) はキャッシュエンティティの正当性確証の目的で決して使用されない。
13.4 レスポンスのキャッシュ可能性
Cache-Control (14.9 章) 命令で特に強いられていないなら、キャッシュシステムはキャッシュエンティティとして成功したレスポンス (13.8 章参照) を常に保存でき、それが新鮮なら正当性確証なしにそれを返す事ができ、正当性確証の後それを返す事ができる。もしレスポンスに関連するキャッシュ確証子も明白な満期期間もなければ、われわれはキャッシュされる事を期待しないが、特定のキャッシュはこの期待に違反する事ができる (たとえば、ほとんどもしくは全くネットワーク接続が利用できないとき)。クライアントは、Date ヘッダと現在時刻を比較する事によってそのようなレスポンスがキャッシュから取られた事をたいてい検出できる。
いくつかの HTTP/1.0 キャッシュはどんな Warning も示さないでこの期待に違反する事で知られる事に注意。
しかしながら、いくつかの場合キャッシュがエンティティを保持し、続くリクエストへのレスポンスとしてそれを返すことは不適切かもしれない。これは絶対的なセマンティクス透過性がサービスの著者によって必要であると思われるため、もしくはセキュリティやプライバシーの配慮のためであろう。それゆえ、サーバが、あるリソースエンティティやそれについての部分がそれらの配慮にかまわずキャッシュされるかもしれないと言う事を示す事ができるようにCache-Control 命令は供給される
14.8 章では、共有されているキャッシュが普通、そのリクエストがAuthorization ヘッダを含んでいたなら、以前のクエストへのレスポンスを保存したり返したりできない事に注意。
200, 203, 206, 300, 301, 410 のステータスコードを伴って受信されたレスポンスは、Cache-Control 命令がキャッシングを禁止していなければ、キャッシュによって保存され、満期メカニズムにしたがって、引き続くリクエストへの応答において使用されるだろう。しかしながら、Range と Content-Rangeヘッダをサポートしていないキャッシュは 206 (Partial Content) レスポンスをキャッシュしてはならない。
それら以外のステータスコードを伴うって受信されたレスポンスは、明らかにそれを認める Cache-Control 命令や別のヘッダが存在しなければ、引き続くリクエストへの応答として返されてはならない。たとえば、これらは以下を含んでいる: Expires ヘッダ (14.21 章); "max-age", "must-revalidate","proxy-revalidate" もしくは "public" Cache-Control 命令 (14.9 章)。
13.5 キャッシュからのレスポンス構築
HTTP キャッシュの目的は、将来的なリクエストへの応答での使用のため、リクエストへのレスポンスで受信された情報を保存する事である。多くの場合、キャッシュはリクエストへのレスポンスの適切な一部を単純に返す。しかし、もしキャッシュが以前のレスポンスに基づくキャッシュエンティティを持っているなら、新しいレスポンスの部分をキャッシュエンティティで持っているものとを結び付ける事ができる。
13.5.1 End-to-end と Hop-by-hop ヘッダ
キャッシュや非キャッシュプロキシの動作を定義する目的のため、われわれはHTTP ヘッダを二つのカテゴリに分ける:
- リクエストやレスポンスの最後の受取人に転送されなければならないend-to-end ヘッダ。レスポンスでの end-to-end ヘッダはキャッシュエンティティの一部として保存されなければならず、キャッシュエンティティから形成されたあらゆるレスポンスで転送されなければならない。
- 一つの転送レベル接続に対してのみ意味を持ち、キャッシュによって保存されたりプロキシによって転送されたりしない hop-by-hop ヘッダ。
以下の HTTP/1.1 ヘッダは hop-by-hop ヘッダである:
- Connection
- Keep-Alive
- Public
- Proxy-Authenticate
- Transfer-Encoding
- Upgrade
HTTP/1.1 で定義されている他のすべてのヘッダは end-to-end ヘッダである。
HTTP の将来のバージョンにおいて導入される hop-by-hop ヘッダは 14.10 章で記述されるように、Connection ヘッダにおいてリストされなければならない。
13.5.2 修正されないヘッダ
Digest Authentication のような、HTTP/1.1 プロトコルのいくつかの機能は特定の end-to-end ヘッダの値に依存する。キャッシュや非キャッシュプロキシは、このヘッダの定義がそれを必要としたり特にそれが許されている以外は、end-to-end ヘッダを修正すべきではない。
キャッシュや非キャッシュプロキシはリクエストやレスポンスにおいて以下のフィールドのどんな物も修正してはならないし、まだ存在していなければこれらのどれも追加できない:
- Content-Location
- ETag
- Expires
- Last-Modified
キャッシュや非プロキシサーバは、あらゆるリクエストにおいてやno-transform Cache-Control 命令を含んでいるリクエストにおいて、以下のフィールドのどれも修正したり追加してはならない:
- Content-Encoding
- Content-Length
- Content-Range
- Content-Type
キャッシュや非キャッシュプロキシは no-transform を含まないレスポンスにおいてこれらのフィールドを修正したり追加したりできるが、もしそうするなら、レスポンスでまだそれが現れていなければ Warnign 14(Transformation applied) を追加しなければならない。
警告: もしより強固な認証メカニズムが将来の HTTP バージョンで導入されるなら、end-to-end ヘッダの不必要な修正は認証失敗を引きを超すかもしれない。このような認証メカニズムはここでリストされないヘッダフィールドの値を当てにするだろう。
13.5.3 ヘッダの連結
キャッシュがサーバに正当性確証リクエストを送り、サーバが 304 (NotModified) レスポンスを示したとき、キャッシュはリクエストに返すレスポンスを構築しなければならない。キャッシュはこの出て行くレスポンスのエンティティボディとしてキャッシュエンティティに保存されたエンティティボディを使う。もしキャッシュがキャッシュエンティティを削除しようと決めなければ、キャッシュエンティティに伴って保存された end-to-end ヘッダを入ってきたレスポンスで受け取った相当するヘッダと置き換えなければならない。
言いかえれば、入ってきたレスポンスで受けた end-to-end ヘッダのセットはキャッシュエンティティに伴って保存されているすべての相当する end-to-endヘッダを置き換える。キャッシュはこのセットに Warning ヘッダ (14.45 章参照) を追加できる。
もし入ってきたレスポンスのヘッダフィールド名がキャッシュエンティティ内の一つ以上のヘッダに相当するなら、それらすべてのヘッダは置き換えられる。
注意: このルールはオリジンサーバがあるエンティティに対する以前のレスポンスに関連するすべてのヘッダを更新するため 304 (Not Modified) レスポンスを使えるようにするが、それが常に意味を持ったり常に正しくそうされるとは限らない。
13.5.4 バイトレンジの組み合わせ
リクエストが一つ以上の Range 詳述を含んだり、接続が早まって切断されたりするため、レスポンスはエンティティボディのバイトのサブレンジのみを転送できる。そのようないくつかの転送の後、キャッシュは同じエンティティボディのいくつかの範囲を受信する事ができる。
もしキャッシュがエンティティに対するサブレンジの保存された空でないセットを持ち、入ってきたレスポンスが別のサブレンジを転送するなら、キャッシュは以下の両方の条件が合う場合に新しいサブレンジを既存のセットと結合できる:
- 入ってきたレスポンスとキャッシュエンティティの両方はキャッシュ確証子を持たなければならない。
- 二つのキャッシュ確証子は強い比較機能を使って一致しなければならない (13.3.3 章参照)。
もし要求のどちらかが合わなければ、キャッシュはもっとも最近の部分的なレスポンス (レスポンスごとに転送された Date 値に基づかれる、これらの値が等しいか欠けているなら入ってきたレスポンス) のみを使用しなければならず、別の部分的な情報を破棄しなければならない。
13.6 キャッシングネゴシエーションされたレスポンス
レスポンスにおける Vary ヘッダフィールドの存在によって示されるような、server-driven 内容ネゴシエーション (12 章) の使用は、キャッシュが引き続くリクエストのためにそのレスポンスを使える事によりその条件と手続きを変更する。
キャッシュにどんなヘッダフィールドの次元がキャッシュ可能なレスポンスの複数の表現の一つを選択するために使用されるかを知らせるため、サーバはVary ヘッダフィールド (14.43 章) を使わなければならない。キャッシュは、引き続くリクエストが Vary レスポンスヘッダにおいて詳述されたすべてのヘッダフィールドに対する同じか同等の値を持つ時のみ、そのリソース上の引き続くリクエストに返すための選択された表現 (その特有のレスポンスに含まれるエンティティ) を使う事ができる。これらのヘッダフィールドの一つ以上に対して異なる値を持つリクエストはオリジンサーバに転送されるであろう。
もしエンティティタグが表現に割り当てられていたなら、転送されたリクエストは条件付きであり、Request-URI に対するそのすべてのキャッシュエンティティから If-None-Match ヘッダフィールドのエンティティタグを含むべきである。もしキャッシュが現在保存しているエンティティのどれかがリクエストされたエンティティと一致するなら、サーバはキャッシュにエンティティが適切である事を伝えるため 304 (Not Modified) レスポンスにおいて ETagヘッダを使う事ができ、それによりこれはサーバにキャッシュが現在保存しているエンティティのセットを伝える。もし新しいレスポンスのエンティティタグが既存のエンティティのそれと一致するなら、新しいレスポンスは既存のエンティティのヘッダフィールドを更新するために使用されるべきであり、その結果はクライアントに返されなければならない。
Vary ヘッダフィールドはキャッシュにその表現がリクエストヘッダに束縛されない基準を使用して選ばれた事を知らせる事もできる。この場合、キャッシュが条件付きリクエストでサーバへ新しいリクエストを送らないか、サーバがエンティティが使用されるべきである事を示すエンティティタグや Content-Length を含む 304 (Not Modified) を伴って応答しないなら、キャッシュは引き続くリクエストの応答においてレスポンスを使用してはならない。
もし既存のキャッシュエンティティのいかなる物も関連するエンティティに対する部分的な内容のみを含むなら、リクエストがそのエンティティによる完全に満たされた範囲に対するものでなければそのエンティティタグは If-None-Match ヘッダに含まれてるべきではない。
もし Content-Location フィールドが同じ Request-URI に対する既存のキャッシュエンティティのそれと一致し、エンティティタグが既存のエンティティのそれと異なり、Date が既存のそれよりも最近のものである成功したレスポンスをキャッシュが受信したなら、既存のエンティティは将来的なリクエストへのレスポンスで返されるべきではなく、キャッシュから削除されるべきである。
13.7 共有されたキャッシュと共有されていないキャッシュ
セキュリティやプライバシーの理由のため、"共有された" キャッシュと "共有されていない" キャッシュの区別を付ける事が必要である。共有されていないキャッシュは単一のユーザによってのみ利用可能なものである。この場合のアクセス可能性は適切なセキュリティメカニズムによって施行されるべきである。他のすべてのキャッシュは "共有された" キャッシュとみなされる。この仕様書の別の章はプライバシーの損失やアクセス制御の失敗を防止するため、共有されたキャッシュの操作へのある制約を置いている。
13.8 エラーや不完全なレスポンスのキャッシュ動作
不完全なレスポンス (たとえば、Content-Length ヘッダで記述されたものより少ないデータのバイトを伴うもの) を受信するキャッシュはレスポンスを保存する事ができる。しかしながら、キャッシュは部分的なレスポンスとしてこれを扱わなければならない。部分的なレスポンスは 13.5.4 章で定義されているように結合する事ができる。その結果は完全なレスポンスかもしれないしまだ部分的かもしれない。206 (Partial Content) を使用して明確にそのように示す以外は、キャッシュはクライアントに部分的なレスポンスを返してはならない。
もしエンティティの正当性再確証を試みるときキャッシュが 5xx レスポンスを受信したら、リクエストしているクライアントにこのレスポンスを転送するか、サーバが応答に失敗したかのように動作するかどちらかを行う事ができる。後者の場合、キャッシュされたエンティティが "must-revalidate" Cache-Control 命令 (14.9 章参照) を含んでいないなら、以前に受信したレスポンスを返す事ができる。
13.9 GET と HEAD の副作用
オリジンサーバがそれらのレスポンスのキャッシングを明白に禁止していなければ、どんなリソースへの GET や HEAD メソッドの適用もそれらのレスポンスがキャッシュから取り出されたなら、誤った動作につながる副作用をもたらすべきではない。これらは副作用をもたらす事ができるが、キャッシュはそのキャッシング決定においてそのような副作用を検討する事を必要とされていない。キャッシュは常にキャッシングにおいてオリジンサーバの明確な制限を観察する事を期待される。
われわれはこのルールのある例外を言及する: いくつかのアプリケーションが重要な副作用を伴う操作を実行するためにクエリー URL (これらは rel_path部分に "?" を含む) を伴う GET や HEAD を伝統的に使用しているため、キャッシュはサーバが明白な満期期間を与えなければ、そのような URL へのレスポンスを新鮮であるように扱ってはならない。これはそのような URI に対する HTTP/1.0 サーバからのレスポンスがキャッシュから取り出されるべきではないと言う事を特に意味している。関係する情報のため 9.1.1 章参照。
13.10 更新や削除後の無効化
オリジンサーバへのあるメソッドの影響は一つ以上の既存のキャッシュエントリを無効な非透過にさせるかもしれない。これは、それらは "新鮮で" あり続けるかもしれないが、それらはオリジンサーバが新しいリクエストに対して返すであろうものに正確に反映されていないと言う事である。
そのようなキャッシュエントリすべてが無効であると示す事を保証するためのHTTP プロトコルのためのどんな方法も存在しない。たとえば、オリジンサーバに変更を引き起こすリクエストはキャッシュエントリが保存されているプロキシを通り抜けていないかもしれない。しかしながら、いくつかのルールは間違った動作の可能性を減らす補助をする。
この章では、フレーズ "エンティティを無効にする" は、キャッシュがその保存媒体からそのエンティティのすべてのインスタンスを削除すべきであるか、"無効" としてそれらをマークすべきでありそれらが引き続くリクエストへのレスポンスにおいて返される前に義務的に正当性の再確証を行う必要があると言う事のどちらかを行うと言う意味である。
いくつかの HTTP メソッドはエンティティを無効にする事ができる。これはRequest-URI によって参照されるエンティティか、Location や Content-Location レスポンスフィールド (もし存在するなら) によって参照されるエンティティのどちらかである。これらのメソッドは:
- DELETE
- POST
サービスアタック拒否を防ぐため、Location もしくは Content-Location ヘッダでの URI に基づく無効化はホスト部分が Request-URI におけるものと同じである場合にのみ実行されなければならない。
13.11 義務的な Write-Through
修正をオリジンサーバのリソースにもたらす事を期待されるすべてのメソッドは、オリジンサーバへ通されて書かれなければならない。これは現在 GETと HEAD 以外のすべてのメソッドを含んでいる。キャッシュは向かうサーバへのリクエストを転送し、向かうサーバから相当するレスポンスを受け取る前にクライアントからのそのようなリクエストに応じてはならない。キャッシュが向かうサーバが応答する前に 100 (Continue) レスポンスをおくるのは妨げない。
一貫した更新を提供する事の困難や、write-back 以前のサーバ、キャッシュ、ネットワークの失敗から生じる問題のため、("write-back" や "copy-back"として知られる) 代わりは HTTP/1.1 において認められていない。
13.12 キャッシュの交替
もし同じリソースに対するすべての既存のレスポンスがキャッシュされている一方で、新しいキャッシュ可能な (14.9.2, 13.2.5, 13.2.6, 13.8 章参照) レスポンスがリソースから受信されたなら、キャッシュは現在のリクエストへの応答に新しいレスポンスを使用すべきである。それをキャッシュ保存媒体に挿入する事ができ、もし他のすべての要求に合うなら、前もって古いレスポンスを返させるようにさせる将来的なリクエストへの応答のため使用する事ができる。キャッシュ保存媒体に新しいレスポンスを挿入するなら、13.5.3 章のルールに従うべきである。
注意: 既存のキャッシュされたレスポンスより古い Date ヘッダ値を持つ新レスポンスはキャッシュ可能ではない。
13.13 履歴リスト
ユーザエージェントはしばしば "Back" ボタンと履歴リストのような履歴メカニズムをもち、セッションにおいて以前に回収されたエンティティを再表示するために使う事ができる。
履歴メカニズムとキャッシュは異なる。特に履歴システムはリソースの現在の状態の意味的に透過なビューを表示する事を試行すべきではない。むしろ、履歴システムはリソースが回収されたときにユーザが見たものを正確に表示する事が意味される。
デフォルトにより、満期期間は履歴メカニズムに適用しない。もしそのエンティティがまだ保存されているなら、ユーザが特にエージェントを期限切れの履歴ドキュメントをリフレッシュするように設定していなければ、履歴メカニズムはエンティティの期限が切れていてもそれを表示すべきである。
これは、履歴システムがユーザにビューが古くなっている事を知らせる事を禁止すると解釈されるべきではない。
注意: もし履歴リストメカニズムがユーザに古くなったリソースの表示を不必要に禁止するなら、サービスの著者が別の方法を望むとき、HTTP 満期制御とキャッシュ制御を強制的に使用させない傾向があるだろう。ユーザが前もって回収したリソースを見るためのナビゲーション制御 (BACK のような) を使うとき、サービスの著者はエラーメッセージや警告メッセージがこのユーザにもたらされない事を重要だと考慮するかもしれない。たとえ時々そのようなリソースがキャッシュされるべきではなく、早急に期限が切れるべきだとしても、履歴メカニズムとして不適当に機能していることの影響で苦しまないため、ユーザインターフェース考慮はサービス著者をキャッシングを妨げる別の方法 (例: "once-only" URL) に強制的に頼らせることができる。
14 ヘッダフィールド定義
この章ではすべての標準 HTTP/1.1 ヘッダの構文とセマンティクスを定義する。エンティティヘッダフィールドに対して、エンティティを誰が送信し誰が受信するかに依存して、送り側と受け取り側の両方はクライアントかサーバのどちらかを参照する。
14.1 Accept
Accept リクエストヘッダフィールドはレスポンスのために許容できるあるメディアタイプを詳述するために使用される。Accept ヘッダはインラインイメージのためのリクエストの場合のように、リクエストが希望されるタイプの小さなセットに特に制限されている事を示すために使用されうる。
Accept = "Accept" ":"
#( media-range [ accept-params ] )
media-range = ( "*/*"
| ( type "/" "*" )
| ( type "/" subtype )
) *( ";" parameter )
accept-params = ";" "q" "=" qvalue *( accept-extension )
accept-extension = ";" token [ "=" ( token | quoted-string ) ]
"*/*" がすべてのメディアタイプを示し、"type/*" がそのタイプのすべてのサブタイプを示すように、アスタリスク "*" 文字は範囲内のグループメディアに使用される。media-range はその範囲に適用できるメディアタイプパラメータを含む事ができる。
それぞれの media-range は、相対的なクオリティ因子を示すための "q" で始まるパラメータである、一つ以上の accept-params を続ける事ができる。最初の "q" パラメータは media-range パラメータを accept-params に分割する。クオリティ因子は 0 から 1 スケールの qvalue を使用してユーザやユーザエージェントがその media-range に対する優先度の相対的な度合いを示せるようにする。デフォルトの値は q=1 である。
注意: メディアタイプパラメータを Accept 拡張パラメータと分けるための"q" パラメータ名の使用は歴史的な慣例によるものである。これは "q" でら始まるメディアタイプパラメータ名すべてを media-range として使用する邪魔になる。そのような出来事は IANA メディアタイプ登録機構で "q" パラメータの欠如と、Accept ですべてのメディアタイプパラメータのまれな使用を与えられそうにないと信じられている。将来的なメディアタイプは "q" と名前が付けられたすべてのパラメータを登録する事を思いとどまらせるべきである。
例
Accept: audio/*; q=0.2, audio/basic
は "audio/basic が好まれるが、もしクオリティで 80% を上回って利用可能なら audio タイプのどんな物でも送ってほしい" と解釈すべきである。
もし Accept ヘッダフィールドがないなら、クライアントはすべてのメディアタイプを受け入れるとみなされる。もし Accept ヘッダがあり、サーバが関連した Accept フィールド値に従って適用できるレスポンスを送信できないなら、サーバは 406 (Not Acceptable) レスポンスを返すべきである。
より複雑な例は:
Accept: text/plain; q=0.5, text/html,
text/x-dvi; q=0.8, text/x-c
これは言葉で言うと "text/html と text/x-c が望むメディアタイプであるが、もしそれらが存在しないなら text/x-div エンティティを送り、もしそれも存在しないなら text-plain エンティティを送ってほしい" と解釈されるだろう。
メディアレンジはより具体的なメディアレンジや具体的なメディアタイプで置き換えられる。もし複数のメディアレンジが与えられたタイプに当てはまるなら、もっとも具体的な参照が優先する。たとえば、
Accept: text/*, text/html, text/html;level=1, */*
は以下のように優先される:
- ) text/html;level=1
- ) text/html
- ) text/*
- ) */*
与えられたタイプに関連するメディアタイプクオリティ因子は、そのタイプに一致する最高の優先権を伴うメディアレンジを見つける事により決定される。たとえば、
Accept: text/*;q=0.3, text/html;q=0.7, text/html;level=1,
text/html;level=2;q=0.4, */*;q=0.5
は関連する以下の値をもたらす:
text/html;level=1 = 1
text/html = 0.7
text/plain = 0.3
image/jpeg = 0.5
text/html;level=2 = 0.4
text/html;level=3 = 0.7
注意: ユーザエージェントはあるメディアレンジのためのクオリティ値のデフォルトセットを備え付けているかもしれない。しかしながら、ユーザエージェントが別のレンダリングエージェントと互いに影響し合わないような閉鎖的なシステムでなければ、このデフォルトセットはユーザによって設定できるようにすべきである。
14.2 Accept-Charset
Accept-Charset リクエストヘッダフィールドはどのような文字セットがレスポンスに適用できるかを示すために使用される。このフィールドは、より包括的もしくは特別な目的の文字セットを理解する能力があるクライアントが、それらの文字セットでドキュメントを表す能力のあるサーバにその性能を合図できるようにしている。ISO-8859-1 文字セットはすべてのユーザエージェントに適用できると想定される。
Accept-Charset = "Accept-Charset" ":"
1#( charset [ ";" "q" "=" qvalue ] )
文字セット値は 3.4 章で記述される。それぞれの文字セットは文字セットに対するユーザの優先度を表す関連するクオリティ値を与える事ができる。デフォルト値は q=1 である。例は以下のようになる。
Accept-Charset: iso-8859-5, unicode-1-1;q=0.8
もし Accept-Charset ヘッダが与えられていないなら、デフォルトはどんな文字も受け入れると言う事である。Accept-Charset ヘッダが与えられ、サーバが Accept-Charset ヘッダに従って適用できるレスポンスを返す事ができなければ、サーバは 406 (Not Acceptable) ステータスコードを伴うエラーレスポンスを送信するべきであるが、受け入れでできないレスポンスの送信もみとめられる。
14.3 Accept-Encoding
Accept-Encoding リクエストヘッダフィールドは Accept と似ているが、レスポンスにおいて受け入れが可能な内容コーディング値 (14.12 章) を制限する。
Accept-Encoding = "Accept-Encoding" ":"
#( content-coding )
この使用の例は
Accept-Encoding: compress, gzip
もしリクエストで Accept-Encoding ヘッダが与えられていなければ、サーバはクライアントがどんな内容コーディングも受け入れるであろうと言う事を仮定できる。Accept-Encoding ヘッダが与えられ、サーバが Accept-Encodingに従って受け入れ可能なレスポンスを送る事ができなければ、サーバは 406(Not Acceptable) ステータスコードを伴うエラーレスポンスを送信すべきである。
空の Accept-Encoding 値は何も受け入れられない事を表している。
14.4 Accept-Language
Accept-Language リクエストヘッダフィールド値は Accept と似ているが、リクエストに対するレスポンスとしてより優先される自然言語のセットを制限する。
Accept-Language = "Accept-Language" ":"
1#( language-range [ ";" "q" "=" qvalue ] )
language-range = ( ( 1*8ALPHA *( "-" 1*8ALPHA ) ) | "*" )
それぞれの language-range は、そのレンジによって詳述される言語に対するユーザの優先度の評価を制限する、関連するクオリティ値を与える事ができる。クオリティ値のデフォルトは "q=1" である。たとえば、
Accept-Language: da, en-gb;q=0.8, en;q=0.7
は "デンマーク語が優先されるが、イギリス英語と英語の別のタイプも受け入れるつもりがある" と言う事を意味する。もし言語タグと厳密に等価か、プレフィクスに続く最初のタグ文字が "-" であるようなそのタグのプレフィクスと厳密に等価であれば、language-range は言語タグと一致する。もしAccept-Language フィールドにおいて与えられるなら、特別なレンジ "*" はAccept-Language フィールドで別のどんなレンジ表現にも一致しないすべてのタグと一致する。
注意: このプレフィクス一致ルールの使用は、ユーザがあるタグの言語を理解するならこのタグがプレフィクスであるようなタグが付くすべての言語も理解するだろうと言う事が常に正しい方法において、言語タグが言語に割り当てられると言う事をを暗黙的に意味する。このプレフィクスルールはもしそれがこれに当てはまるならプレフィクスタグの使用を単純に認めている。
Accept-Language フィールドによって言語タグに割り当てられる言語クオリティ因子は、言語タグと一致するフィールドでもっとも長い言語タグのクオリティ値である。もしフィールド内のどの language-range ともタグが一致しなければ、言語クオリティ因子は 0 に割り当てられる。もしリクエストで Accept-Language が与えられなければ、サーバはすべての言語が等しく受け入れ可能であるとみなすべきである。もし Accept-Language ヘッダが与えられるなら、0 以上のクオリティ因子を割り当てられたすべての言語が受け入れられる。
リクエストごとにユーザの完全な言語上の優先を伴う Accept-Language を送ことは、ユーザのプライバシー期待に反するだろう。この問題の論議のため、15.7 章参照。
注意: 言語理解は個々のユーザに高く依存するため、クライアントアプリケーションはユーザに利用可能な言語上の優先度の選択ができるようにする事が勧められる。もしこの選択が利用できるものとならなければ、Accept-Language はリクエストに与えられてはならない。
14.5 Accept-Ranges
Accept-Ranges レスポンスヘッダフィールドはサーバがリソースに対するレンジリクエストの受理を示せるようにしている:
Accept-Ranges = "Accept-Ranges" ":" acceptable-ranges
acceptable-ranges = 1#range-unit | "none"
byte-range リクエストを受け入れたオリジンサーバは以下を送る事ができるが:
Accept-Ranges: bytes
そうする必要はない。クライアントはリソースに伴われるこのヘッダを受け取っていなくても byte-range リクエストを生成する事ができる。
あるリソースに対するどんなレンジのリクエストも受け入れないサーバはクライアントにレンジリクエストを想定していない事を知らせるため:
Accept-Ranges: none
を送る事ができる。
14.6 Age
Age レスポンスヘッダフィールドは、オリジンサーバでレスポンス (もしくはその正当性再確認) が生成されてからの時間のサーバ概算を知らせる。キャッシュされたレスポンスは、もしその年齢がその新鮮さ持続時間を超過していなければ "新鮮" である。Age 値は 13.2.3 章において詳述されるように計算される。
Age = "Age" ":" age-value
age-value = delta-seconds
Age 値は負でない 10 進整数値であり、秒を表している。
もしキャッシュが表現できる最大の正の整数よりも大きい値を受け取ったり、その年齢計算のすべてがオーバーフローになれば、2147483648 (2^31) の値を伴う Age ヘッダを送信しなければならない。HTTP/1.1 キャッシュはレスポンスごとに Age ヘッダを送らなければならない。キャッシュは最低 31ビットレンジの算術型を使用すべきである。
14.7 Allow
Allow エンティティヘッダは Request-URI によって識別されるリソースでサポートされるメソッドのセットをリストする。このフィールドの目的は厳密に言えば受け取り側にリソースに関連する正当なメソッドを知らせる事である。Allow ヘッダフィールドは 405 (Method Not Allowed) において必ず与えられなければならない。
Allow = "Allow" ":" 1#method
使用例:
Allow: GET, HEAD, PUT
このフィールドはクライアントに他のメソッドを試させないようにできる。しかしながら、Allow ヘッダフィールド値によって与えられる指示はフォローされるべきである。許可されたメソッドの実際のセットはオリジンサーバによってそれぞれのリクエストの時点で定義される。
Allow ヘッダフィールドは新しいもしくは置き換えられたリソースによってサポートされるメソッドを勧めるため PUT リクエストで供給される事ができる。サーバはこれらのメソッドをサポートする必要はなく、実際にサポートされているメソッドを与えるためレスポンスに Allow ヘッダを加えるべきである。
ユーザエージェントがオリジンサーバとの通信の別の意味を持つ事ができるため、記述されたメソッドすべてが理解できなければプロキシは Allow ヘッダを修正してはならない。
Allow ヘッダフィールドはどんなメソッドがサーバレベルで実装されているかを示さない。サーバはサーバ全体としてどんなメソッドが実装されているかを記述するため Public レスポンスヘッダフィールド (14.35 章) を使用する事ができる。
14.8 Authorization
サーバに自身を認証する事を望むユーザエージェント![]() たいてい、但し必要ではないが、401 レスポンスを受け取った後
たいてい、但し必要ではないが、401 レスポンスを受け取った後![]() はリクエストに Authorizationリクエストヘッダフィールドを加える事によってそうする事ができる。Authorization フィールド値はリクエストされているリソースの realm に対するユーザエージェントの認証情報を含む信用証明からなる。
はリクエストに Authorizationリクエストヘッダフィールドを加える事によってそうする事ができる。Authorization フィールド値はリクエストされているリソースの realm に対するユーザエージェントの認証情報を含む信用証明からなる。
Authorization = "Authorization" ":" credentials
HTTP アクセス認証は 11 章で記述されている。リクエストが認証され realmが記述されているなら、同じ信用証明はこの realm 内での別のすべてのリクエストに対して正当であるべきである。
共有されているキャッシュ (13.7 章参照) が Authorization ヘッダを含むリクエストを受け取ったら、以下に記述した例外の一つでなければ、他のすべてのリクエストの応答として相当するレスポンスを返してはならない:
- もしレスポンスが "proxy-revaliate" Cache-Control 命令を含んでいるなら、キャッシュはそのレスポンスを続くリクエストの応答に使用する事ができるが、プロキシキャッシュは最初に、オリジンサーバが新しいリクエストを認証できるように、新しいリクエストのリクエストヘッダを使用して、それをオリジンサーバについて正当性の再確認を行わなければならない。
- もしレスポンスが "must-revalidate" Cache-Control 命令を含んでいるなら、キャッシュはそのレスポンスを続くリクエストの応答に使用する事ができるが、すべてのキャッシュは最初に、オリジンサーバが新しいリクエストを認証できるように、新しいリクエストのリクエストヘッダを使用して、それをオリジンサーバについて正当性の再確認を行わなければならない。
- もしレスポンスが "public" Cache-Control 命令を含むなら、続くどんなリクエストの応答にも返す事ができる。
14.9 Cache-Control
Cache-Control 一般ヘッダは、リクエスト/レスポンス連鎖上のすべてのキャッシングメカニズムが従わなければならない命令を詳述するために使用される。命令は、キャッシュがリクエストやレスポンスを不利に妨害させないようにする事を目的とする動作を詳述する。典型的にこれらの命令はデフォルトキャッシングアルゴリズムを無効にする。キャッシュ命令はリクエストにおける命令のレスポンスが、同じ命令がレスポンスで与えられるべきであるという事を暗に意味しない事において単一指向性である。
HTTP/1.0 キャッシュは Cache-Control を実装していないかもしれなく、Pragma: no-cache ( 14.32 章 参照) のみを実装しているかもしれないと言う事に注意。
命令がリクエスト/レスポンス連鎖上のすべての受け取り人に適用できるため、そのアプリケーションの重要性に関係なく、キャッシュ命令はプロキシやゲートウェイアプリケーションを通り抜けなければならない。具体的なキャッシュのための cache-directive を詳述するのは不可能である。
Cache-Control = "Cache-Control" ":" 1#cache-directive
cache-directive = cache-request-directive
| cache-response-directive
cache-request-directive =
"no-cache" [ "=" <"> 1#field-name <"> ]
| "no-store"
| "max-age" "=" delta-seconds
| "max-stale" [ "=" delta-seconds ]
| "min-fresh" "=" delta-seconds
| "only-if-cached"
| cache-extension
cache-response-directive =
"public"
| "private" [ "=" <"> 1#field-name <"> ]
| "no-cache" [ "=" <"> 1#field-name <"> ]
| "no-store"
| "no-transform"
| "must-revalidate"
| "proxy-revalidate"
| "max-age" "=" delta-seconds
| cache-extension
cache-extension = token [ "=" ( token | quoted-string ) ]
どんな 1#field-name パラメータもなしに命令が現れたら、命令はリクエストやレスポンス全体に適用される。そのような命令が 1#field-name パラメータを伴って現れたら、指定されたフィールド (複数かもしれない) のみに適用され、リクエストやレスポンスの残りの部分には適用されない。このメカニズムは拡張可能である。HTTP プロトコルの将来のバージョンのインプリメンテーションはこれらの命令を HTTP/1.1 で定義されていないヘッダフィールドに適用する事ができる。
cache-control 命令はこれらの一般的なカテゴリに分類される。
- キャッシュ可能なものの制限; オリジンサーバのみがこれらを課す事ができる。
- キャッシュによって保存されるものの制限; オリジンサーバとユーザエージェントのどちらかによってこれらを課す事ができる。
- 基本的な満期メカニズムの変更; オリジンサーバとユーザエージェントのどちらかによってこれらを課す事ができる。
- キャッシュの正当性再確認と再読み込みの抑制; ユーザエージェントのみがこれらを課す事ができる。
- エンティティの変換の抑制。
- キャッシングシステムの拡張。
14.9.1 キャッシュ可能なもの
もしリクエストメソッド、リクエストヘッダフィールド、レスポンスステータスがキャッシュ可能であると示しているなら、デフォルトによりレスポンスはキャッシュ可能である。13.4 章はキャッシュ可能性のためのこれらのデフォルトを要約している。以下の Cache-Control レスポンス命令はオリジンサーバにレスポンスのデフォルトのキャッシュ可能性を無効にできるようにする。
- public
- たとえそれが通常はキャッシュ可能でなかったり、非共有キャッシュ内でのみキャッシュ可能であったとしても、レスポンスがすべてのキャッシュによってキャッシュ可能である事を示す (追加の詳細のため Authorization, 14.8 章も参照)。
- private
- レスポンスメッセージのすべてもしくは一部が単一のユーザのために用意された物である事を示し、供給されたキャッシュによってキャッシュされてはならない。これはオリジンサーバが、レスポンスの記述された部分があるユーザにのみ用意されたもので、別のユーザによるリクエストのための正当なレスポンスではないことを言明できるようにする。private (非共有) キャッシュはそのレスポンスをキャッシュできる。
注意: この private と言う命令の使用はレスポンスがキャッシュできるところのみを制御し、メッセージ内容のプライバシーは保証できない。
- no-cache
- レスポンスメッセージのすべてもしくは一部はどんな所でもキャッシュされてはならない。これは、オリジンサーバがクライアントリクエストに古くなったレスポンスを返すよう設定されているキャッシュによるキャッシングを行えないようにする。
注意: ほとんどの HTTP/1.0 キャッシュはこの命令を認識したりしたがったりする事はないだろう。
14.9.2 キャッシュによって保存できるもの
保存しない命令の目的は取り扱いが慎重な情報 (たとえばバックアップテープ上のもの) の不注意な漏洩や保留を防ぐ事である。保存しない命令はメッセージ全体に適用し、レスポンスかリクエストのどちらかで送られる。もしリクエストで送られるなら、キャッシュはこのリクエストかそれへのレスポンスのどちらかのどんな部分も保存してはならない。それがレスポンスで送られるならキャッシュはこのレスポンスやそれを引き起こしたリクエストのどちらかを保存してはならない。この命令は非共有と共有キャッシュの両方に適用する。この状況における "保存してはならない" は、キャッシュが不揮発性保存媒体にその情報を故意に保存してはならなく、それを転送した後可能な限り早急に揮発性保存媒体から情報の削除を試みる最高の努力を行わなければならない。
さらにその命令がレスポンスに関連しているとき、ユーザはキャッシングシステムの外側にそのようなレスポンスを明白に保存できる (例: "Save As" ダイアログを伴って)。履歴バッファはこれらの通常操作の一部としてこのようなレスポンスを保存する事ができる。
この命令の目的はキャッシュデータ構造への予期されないアクセス経由で情報の偶発的な漏洩について心配されるあるユーザやサービスの著者の言明された要求に合うためである。この命令の使用はいくつかの場合においてプライバシーを改善するだろうが、われわれはプライバシーを保証するための信頼できるもしくは十分なメカニズムのどのような方法におけるものでもない事を警告する。特に、悪意のあるキャッシュや妥協されたキャッシュはこの命令を認識したりしたがったりしないかもしれない。そして通信ネットワークは盗聴に無防備であるかもしれない。
14.9.3 基本満期メカニズムの修正
エンティティの満期期間は Expires ヘッダ (14.21 章) を使ってオリジンサーバにより詳述できる。あるいは、レスポンスで max-age 命令を使って記述する事もできる。
模試レスポンスが Expires ヘッダと max-age 命令の両方を含んでいるなら、たとえ Expires ヘッダがより限定的だとしても、max-age 命令は Expires ヘッダに取って代わる。このルールは与えられたリクエストに対してオリジンサーバが HTTP/1.0 キャッシュよりも HTTP/1.1 (とその上位) キャッシュに長い満期期間を供給できるようにする。これは、もし多分同期していないクロックのため特定の HTTP/1.0 キャッシュが不適当に年齢や満期期間の計算をする場合に有用であろう。
注意: 最も古いキャッシュ
他の命令はユーザやユーザエージェントが基本満期メカニズムを修正できるようにする。これらの命令はリクエストにおいて記述できる:
- max-age
- クライアントが記述された秒時間よりも大きな年齢を持たないレスポンスを受け入れようと思っている事を示す。max-stale 命令が含まれていないならクライアントは古くなったレスポンスを受け入れようと思っていない。
- min-fresh
- クライアントは新鮮さ持続期間が少なくとも秒においてその現在の年齢プラス記述された時間であるレスポンスを受け入れようと思っている事を示す。これは、クライアントが少なくとも記述された秒数に対してまだ新鮮であるレスポンスを望んでいると言う事である。
- max-stale
- クライアントはその満期期間を超えているレスポンスを受け入れようと思っている事を示す。もし max-stale が値を割り当てられているなら、クライアントは多くても記述された秒数によってその満期期間をすでに超えているレスポンスを受け入れようと思っている。もし max-stale に値が割り当てられていないなら、クライアントはどんな年齢の古くなったレスポンスも受け入れようと思っている。
リクエストの max-stale 命令かキャッシュがレスポンスの満期期間を置き換えるように構成されているかのどちらかにより、もしキャッシュが古くなったレスポンスを返すなら、キャッシュは Warning 10 (Response is stale) を使って古くなったレスポンスに Warning ヘッダを追加しなければならない。
14.9.4 キャッシュの正当性再確証と再ロード制御
時々ユーザエージェントは、キャッシュがオリジンサーバ (オリジンサーバへの経路上の次のキャッシュではなく) にキャッシュエンティティの再確証を行ったり、オリジンサーバからそのキャッシュエンティティの再ロードを要求する事を望み要求するかもしれない。end-to-end 正当性再確証はキャッシュとオリジンサーバのどちらかがキャッシュされたレスポンスの満期期間を過大評価している場合に必要であろう。end-to-end 再ロードはキャッシュエンティティがある理由のため古くなっている場合に必要であろう。
end-to-end 正当性再確証は、クライアントが自身のローカルにキャッシュされたコピーを持っていないとき![]() われわれはこの場合を "詳述されない end-to-end 正当性再確証" と呼ぶ
われわれはこの場合を "詳述されない end-to-end 正当性再確証" と呼ぶ![]() や、クライアントがローカルにキャッシュされたコピーを持っているとき
や、クライアントがローカルにキャッシュされたコピーを持っているとき![]() われわれはこの場合を "詳述された end-to-end 正当性再確証" と呼ぶ
われわれはこの場合を "詳述された end-to-end 正当性再確証" と呼ぶ![]() のどちらかで必要とされるだろう。
のどちらかで必要とされるだろう。
クライアントは Cache-Control リクエスト命令を使用してこれらの三種類の動作を詳述する事ができる:
- End-to-end reload
- リクエストが "no-cache" Cache-Control 命令や HTTP/1.0 クライアントの互換性のための "Pragma: no-cache" を含んでいる。リクエストにおいて no-cache 命令に伴うどんなフィールド名も含まれない。サーバはそのようなリクエストに応答するときキャッシュされたコピーを使ってはならない。
- Specific end-to-end revalidation
- リクエストは "max-age=0" Cache-Control 命令を含み、これは強制的にオリジンサーバへの経路上のそれぞれのキャッシュに次のキャッシュやサーバに対してそのエンティティを正当性再確証させる。最初のリクエストはクライアントの現在の確証子を伴うキャッシュ正当性確証条件を含んでいる。
- Unspecified end-to-end revalidation
- リクエストが "max-age=0" Cache-Control 命令を含み、これは強制的にオリジンサーバへの経路上のそれぞれのキャッシュに次のキャッシュやサーバに対してそのエンティティの正当性再確証させる。最初のリクエストはキャッシュ正当性確証条件を含んでいない。そのリソースに対するキャッシュエンティティを持っている経路上の最初のキャッシュ (もしあれば) はその現在の確証子を伴うキャッシュ正当性確認条件を追加する。
中間キャッシュが max-age=0 によって強制的にそのキャッシュエンティティの正当性再評価を行い、クライアントはリクエストに自身の確証子を供給するとき、供給された確証子はキャッシュエンティティに現在保存されている確証子と異なるかもしれない。この場合、キャッシュはセマンティクス透過性へ影響する事なくそれ自身のリクエストを作る事においてどちらかの確証子を使う事ができる。
しかしながら、確証子の選択はパフォーマンスに影響するかもしれない。最良のアプローチは中間キャッシュがそのリクエストを作るとき自身の確証子を使う事である。もしサーバが 304 (Not Modified) を返すならキャッシュはクライアントに 200 (OK) レスポンスとその新しく正当性が確証されたコピーを返すべきである。しかしながら、もしサーバが新しいエンティティとキャッシュ確証子をかえすなら、中間キャッシュは強い比較機能を使用して返された確証子とクライアントのリクエストにおいて与えられたそれとを比較すべきである。もしクライアントの確証子がオリジンサーバのものと等しいなら、中間キャッシュは単純に 304 (Not Modified) を返す。もしそうでなければ、200 (OK)レスポンスを伴う新しいエンティティを返す。
もしリクエストが no-cache 命令を含んでいるなら、min-fresh, max-stale,max-age を含むべきではない。
ネットワーク接続が極端に貧弱ないくつかの場合、クライアントはキャッシュが現在すでに保存しているそれらのレスポンスのみを返し、オリジンサーバに再ロードや正当性再確証を行わない事を望むだろう。これを行うため、クライアントはリクエストにおいて only-if-cached 命令を含む事ができる。もしこの命令を受信したら、キャッシュはリクエストの別の制約と一致するキャッシュされたエンティティを使用して返すか、504 (Gateway Timeout) ステータス付きで返すかどちらかを行うべきである。しかしながら、もしキャッシュのグループが良好な内部接続を伴う統合されているシステムとして操作されているなら、そのようなリクエストはキャッシュのそのグループ内に転送できる。
キャッシュがサーバの詳述した満期期間を無視するように構成できるため、そしてクライアントリクエストは max-stale 命令 (これは類似した影響を持つ)を含む事ができるため、プロトコルはどのような続く使用でもオリジンサーバにキャッシュエンティティの正当性再確証を要求するためのメカニズムを含む。must-revalidate 命令がキャッシュによって受信されたレスポンスに存在する時、そのキャッシュは最初にオリジンサーバにそれを正当性再確証する以外は引き続くリクエストに応答するため古くなった後のエンティティを使ってはならない (例: キャッシュは毎回 end-to-end 再確証をしなければならず、もし、単にオリジンサーバの Expires か max-age 値に基づいているなら、キャッシュされたレスポンスは古くなっている)。
must-revalidate 命令はあるプロトコル機構のための信頼できる操作をサポートするために必要である。すべの状況において HTTP/1.1 キャッシュは must-revalidate 命令に従わなければならない。特に、もしキャッシュが何らかの理由でオリジンサーバに達せないなら、504 (Gateway Timeout) レスポンスを生成しなければならない。
黙って実行されない財務的処理のように、エンティティのリクエストを再確証する事の失敗が不適当な操作と言う結果になる場合、かつその場合に限り、サーバは must-revalidate 命令を送るべきである。受け取り側はこの命令に違反するどんな自動動作も行ってはならず、もし再確証が失敗するならエンティティの確証が行われていないコピーを自動的に供給してはならない。
これは奨励されないが、ひどい接続制約の元で操作しているユーザエージェントはこの命令に違反する事ができるが、もしそうするなら、確証されていないレスポンスが供給された事をユーザに明確に警告しなければならない。この警告は確証されていないアクセスそれぞれに供給されなければならず、ユーザの明確な確認を必要とすべきである。
proxy-revalidate 命令が非共有ユーザエージェントキャッシュに適用されない事を除いて、proxy-revalidate 命令は must-revalidate 命令と同じ意味を持つ。多くのユーザにサービスしているプロキシは毎回再確証することを必要とする (それぞれのユーザが認証されている事を保証するため) 一方で、これはユーザのキャッシュに保存される事を許可する認証されたリクエストへのレスポンスに使用され、後にそれの再確証を必要としないでレスポンスを返す事ができる (それがこのユーザによって既に一度認証されているため)。このような認証されたレスポンスはそれらがすべてキャッシュされるようにするためpublic キャッシュ制御命令を必要とする事に注意。
14.9.5 非変換命令
中間キャッシュ (プロキシ) の実装者はあるエンティティボディのメディアタイプを変換する事が有用である事に気づいている。たとえば、プロキシはキャッシュスペースを節約するためや遅い通信上のトラフィックの量を減らすため画像フォーマットの変換を行う事ができる。HTTP は今日までこれらの変換に付いて語らない。
しかしながら、これらの変換がある種のアプリケーションのために意図されたエンティティボディに適用されるときに深刻な操作上の問題が既に起きている。たとえば、医学上の映像のためのアプリケーション、科学的なデータ分析、end-to-end 認証にそれらを使うもの、元のエンティティボディと全く同一のビット対ビットのエンティティボディの受信に依存するすべてである。
それゆえ、もしレスポンスが非変換命令を含んでいるなら、中間キャッシュやプロキシは非変換命令に従うものとして 13.5.2 章でリストされているそれらのヘッダを変更してはならない。これはキャッシュやプロキシがこれらのヘッダによって詳述されたエンティティボディのどのような局面も変更してはならない事を意味している。
14.9.6 キャッシュ制御拡張
Cache-Control ヘッダフィールドはそれぞれにオプション的に割り当てられた値を伴う一つ以上のキャッシュ拡張トークンを使用する事で拡張可能である。情報的拡張 (キャッシュ動作で変更を必要としないもの) は他の命令のセマンティクスを変えないで追加できる。動作的拡張命令は既存の基本キャッシュ命令への修飾子として動作する事により機能するために設計されている。新しい命令を理解しないアプリケーションが標準命令によって詳述される動作をデフォルトとし、新しい命令を理解するそれらは標準命令に関係する必要性を置き換えるようにそれを認識するように、新しい命令と標準命令の両方は適用される。この方法において、Cache-Control 命令の拡張はその基本プロトコルの変更を要求する事なく作る事ができる。
この拡張メカニズムは、それに特有の HTTP バージョンによって定義されるすべての cache-control 命令に従い、特有の拡張に従い、理解できない命令をすべて無視する HTTP キャッシュに依存する。
たとえば、仮に "private" 命令の修飾子として動作する "community" と呼ばれる新しいレスポンス命令を考える。われわれはこの新しい命令を、この値で名前付けされた集団のメンバによって共有されるすべてのキャッシュ、さらに非共有キャッシュのみがレスポンスをキャッシュできると言う意味に定義する。"UCI" 集団がそれらの共有されたキャッシュでプライベートレスポンスとは別に使用できるように望むサーバは、以下を含む事でそれを行える。
Cache-Control: private, community="UCI"
キャッシュが "community" キャッシュ拡張を理解しないなら、それが "private"命令を確かめて理解し、従ってデフォルトの安全な動作を行うため、このヘッダフィールドを確かめたキャッシュは正しく動作するだろう。
認識できないキャッシュ命令は無視されなければならない。キャッシュ動作がキャッシュが拡張を理解しないなら最小限正しいままであるであろうように、HTTP/1.1 キャッシュにより認識されないようなすべてのキャッシュ命令は標準命令 (やレスポンスのデフォルトキャッシュ可能性) と結合するだろう。
14.10 Connection
Connection 一般ヘッダフィールドは、送り側がその固有の接続を望まれるオプションを詳述できるようにし、その先の接続でプロキシによって通信されてはならない。
Connection ヘッダは以下の文法を持つ:
Connection-header = "Connection" ":" 1#(connection-token)
connection-token = token
HTTP/1.1 プロキシはメッセージが転送される前に Connection ヘッダフィールドを解析し、このフィールドのそれぞれの connection-token に対して、どんなヘッダも connection-token と同じ名前が付随するメッセージから取り除かなければならない。追加的なヘッダフィールドはもしこの接続オプションに関連するパラメータが存在しなければ送られないかもしれないため、追加的なヘッダフィールドに相当するどんな物によってでもなく、接続オプションは Connection ヘッダフィールドの connection-token の存在によって合図される。HTTP/1.1 は、送り側が接続がレスポンスの完了後にクローズされるであろう事を合図するため "close" 接続オプションを定義する。たとえば、リクエストかレスポンスヘッダフィールドのどちらかにおける
Connection: close
は、現在のリクエスト/レスポンスの完了後に接続が `永続的' (8.1 章) とみなすべきではないと言う事を示している。
永続的な接続をサポートしていない HTTP/1.1 アプリケーションは、それぞれのメッセージに "close" 接続オプションを加えなければならない。
14.11 Content-Base
Content-Base エンティティヘッダフィールドはエンティティにおける相対的な URL を解決するためのベース URI を記述するために使用される。このヘッダフィールドは RFC 1808 において Base として記述され、これは改訂されると思われる。
Content-Base = "Content-Base" ":" absoluteURI
もし Content-Base フィールドが与えられなければ、エンティティのベースURI はその Content-Location (もし Content-Location URI が絶対 URI なら)かリクエストを始めるために使用された URI のどちらかによって、この順番の優先度で定義される。しかしながら、エンティティボディ内の内容のベースURI はエンティティボディの中で再定義されているかもしれないと言う事に注意。
14.12 Content-Encoding
Content-Encoding エンティティヘッダフィールドはメディアタイプの修飾子として使用される。これが与えられるとき、その値はどんな付加されたコーディングがエンティティボディに適用されているか、従って Content-Typeヘッダフィールドによって参照されるメディアタイプを得るために、どんなコーディングメカニズムを適用しなければならないかを示している。Content-Encoding は第一に、ドキュメントがその根本的なメディアタイプの個性を失わないで圧縮できるように使用されている。
Content-Encoding = "Content-Encoding" ":" 1#content-coding
内容コーディングは 3.5 章で定義されている。その使用例は以下のようになる。
Content-Encoding: gzip
Content-Encoding は Request-URI によって識別されるエンティティの特質である。典型的には、エンティティボディはこのエンコーディングを伴って保存され、レンダリングや類似した使用前にのみデコードされる。
もし複数のエンコーディングがエンティティに適用されているなら、内容コーディングはそれらが適用された順番でリストされなければならない。
エンコーディングパラメータに関する付加的な情報は、この仕様書で定義されていない別のエンティティヘッダフィールドによって供給する事ができる。
14.13 Content-Language
Content-Length エンティティヘッダフィールドは同封されたエンティティのために用意された視聴者の自然言語を記述する。これがエンティティボディ内に使用されているすべての言語と等しいわけではないと言う事に注意。
Content-Language = "Content-Language" ":" 1#language-tag
言語タグは 3.10 章で定義されている。Content-Language の第一の目的は、ユーザがユーザの提案した言語に従うエンティティを見分け、識別できるようにするためである。従って、もし本体の内容がデンマーク語を読める視聴者に対してのみ用意されているのであれば、適切なフィールドは以下のようになる。
Content-Language: da
もし Content-Language が記述されていなければ、デフォルトは内容がすべての言語の視聴者のために用意されているものである。これは、送り側がそれをどんな自然言語に特有のものかを考慮しない、もしくは送り側が用意されている言語に関して知らないと言う事を意味する事ができる。
複数の言語は複数の視聴者のために用意された内容に対してリストされる事ができる。たとえば、オリジナルのマオリ語と英語バージョンで同時に与えられる "Treaty of Waitangi" の解釈は、以下のように呼ばれる。
Content-Language: mi, en
しかしながら、複数の言語が一つのエンティティ内で与えられるという理由で複数の言語の視聴者のために用意されていると言う事を意味するわけではない。"A First lesson in Latin" のような初心者の言語入門書が良い例であり、これは明らかに英語を読める視聴者によって使用される事を目的としている。この場合、Content-Language は "en" のみを含むべきである。
Content-Language はどのようなメディアタイプにも適用できる![]() これはテキストドキュメントにのみ限定されていない。
これはテキストドキュメントにのみ限定されていない。
14.14 Content-Length
Content-Length エンティティヘッダフィールドは 8 ビットバイトの 10 進数値で受信側に送られるメッセージボディのサイズ、もしくは HEAD メソッドの場合には GET リクエストのときに送られるであろうエンティティボディのサイズを示している。
Content-Length = "Content-Length" ":" 1*DIGIT
例は以下のようになる。
Content-Length: 3495
アプリケーションはエンティティのメディアタイプに関係なく、転送されるメッセージボディのサイズを示すためにこの値を使用すべきである。たとえばリクエストが正当な Content-Length を持ち、Transfer-Encoding:chunked かマルチパートボディを使用するため、エンティティボディを含んでいる HTTP/1.1 リクエストの終端を受け取り側が確実に決定できなければならない。
0 以上のどんな Content-Length も正当な値である。404 章は Content-Lengthが与えられないときのメッセージボディの長さをどのように決定するかを記述している。
注意: "message/external-body" の内容タイプ内で使用されているオプション的なフィールドだと言う部分で、このフィールドの意味は MIME で定義されているものと非常に異なる。HTTP では、メッセージの長さが転送される前に決定できるときに送る べきである 。
14.15 Content-Location
Content-Location エンティティヘッダフィールドはメッセージに同封されたエンティティに対するリソースロケーションを供給するために使用される。リソースがそれに関連する複数のエンティティを持ち、それらが個別にアクセスされるような場合、サーバは返される固有のバリアントに対して Content-Location を提供すべきである。それに加え、サーバはリソースエンティティに相当するリソースへの Content-Location を提供すべきである。
Content-Location = "Content-Location" ":"
( absoluteURI | relativeURI )
もし Content-Base ヘッダフィールドが与えられなければ、Content-Locationの値はエンティティに対するベース URL を定義する (14.11 章参照)。
Content-Location 値はリクエストされた元の URI への代用ではない。リクエストの時点でこの固有なエンティティに相当するリソースのロケーションのステートメントのみである。もし要請がその固有なエンティティのソースを識別する事なら、将来的なリクエストは Content-Location URI を使用する事ができる。
キャッシュは、エンティティを回収するために使用された URI と異なるContent-Location を伴うものが、その Content-Location URI の後のリクエストに応じるために使用できると言う事を仮定できない。しかしながら、Content-Location は 13.6 章で述べられているように、単一のリクエストされたリソースから回収される複数のエンティティを区別するために使用する事ができる。
もし Content-Location が相対的な URI なら、その URI はレスポンスにおいて供給されるすべての Content-Base URI と相対的であると解釈される。もしContent-Base が与えられていなければ、相対的 URI は Request-URI と相対的であると解釈される。
14.16 Content-MD5
RFC 1864 [23] で定義されているように、Content-MD5 エンティティヘッダフィールドはエンティティボディの end-to-end メッセージ完全チェック(MIC: Message Integrity Check) を供給のする目的の、エンティティボディの MD5 要約である。(注意: MIC は転送においてエンティティボディの偶発的変更を検知するのに優れているが、悪意のあるアタックに対して試験済みではない。)
Content-MD5 = "Content-MD5" ":" md5-digest
md5-digest = <base64 of 128 bit MD5 digest as per RFC 1864>
Content-MD5 ヘッダフィールドはエンティティボディの完全チェックとして機能するためオリジンサーバによって生成される。オリジンサーバのみがContent-MD5 ヘッダフィールドを生成する事ができる。プロキシやゲートウェイは、end-to-en 完全チェックとしてのその値を無効にするためこれを生成してはならない。ゲートウェイやプロキシを含むすべてのエンティティボディ受信者は、このヘッダフィールドの要約値が受信したエンティティボディのものと一致するかをチェックする事ができる。
MD5 要約は、適用されているすべての Content-Encoding ![]() ただしメッセージボディに適用されているどんな Transfer-Encoding も含まない
ただしメッセージボディに適用されているどんな Transfer-Encoding も含まない![]() を含むエンティティボディの内容に基づいて計算されている。もしメッセージがTransfer-Encoding を伴って受信されたら、そのエンコーディングはContent-MD5 値をチェックする前に取り除かれていなければならない。
を含むエンティティボディの内容に基づいて計算されている。もしメッセージがTransfer-Encoding を伴って受信されたら、そのエンコーディングはContent-MD5 値をチェックする前に取り除かれていなければならない。
もし Transfer-Encoding が適用されていなければ、要約はエンティティボディが送られるであろう物として、そしてその順に、エンティティボディの 8 ビットバイトで厳密に計算されると言う結果を持つ。
HTTP は、この要約が MIME 合成式メディアタイプ (たとえば multipart/* とmessage/rfc822) に対して計算される事を許すため RFC 1864 を拡張するが、前述のパラグラフで定義されているように、これは要約がどのように計算されるかの変更ではない。
注意: これのいくつかの影響が存在する。合成式タイプに対するエンティティボディは、それぞれが自身の MIME と HTTP ヘッダ (Content-MD5, Content-Transfer-Encoding, Content-ENcoding ヘッダを含む) を伴うたくさんのボディパートを含む事ができる。もしボディパートが Content-Transfer-Encoding や Content-Encoding ヘッダを持つなら、ボディパートの内容は適用されたエンコードを受け、ボディパートにはそのように
注意: Content-MD5 の定義が HTTP に対して MIME エンティティボディのための RFC 1864 におけるものと正確に同じである間、HTTP エンティティボディへの Content-MD5 の適用がその MIME エンティティボディへの適用と異なるいくつかの方法が存在する。MIME と違い、ある物は HTTP が Content-Transfer-Encoding を使用してなく、Transfer-Encoding と Content-Encoding を使用していることである。別のものは HTTP が MIME よりも頻繁にバイナリ内容を使用しているという事であり、そのような場合、要約を計算するために使用されているバイト順序がタイプに対して定義された転送バイト順序であるという事を注意する価値がある。最後に、HTTP はいくつかの行末慣習のどんな物でも、そして CRLF を使用する本当の公式形式ではないテキストタイプでの転送を認めている。CRLF へすべての行末の変換は要約を計算したりチェックしたりする前に行われるべきではない。実際に転送されたテキストで使用されている行末変換は要約の計算を行っているときに変更されないままにしておくべきである。
14.17 Content-Range
Content-Range エンティティヘッダは、全エンティティボディにおいて部分的なボディが挿入されるべき所の、記述された部分的なエンティティボディを伴って送信される。これは全エンティティボディの総計サイズも示している。サーバがクライアントに部分的なレスポンスを返すとき、レスポンスによって補われたレンジの程度とエンティティボディ全体の長さの両方を記述しなければならない。
Content-Range = "Content-Range" ":" content-range-spec
content-range-spec = byte-content-range-spec
byte-content-range-spec = bytes-unit SP first-byte-pos "-"
last-byte-pos "/" entity-length
entity-length = 1*DIGIT
byte-ranges-specifier 値と違い、byte-content-range-spec は一つのレンジのみを詳述し、そしてレンジの最初と最後のバイトの両方に対する完全なバイト位置を含まなければならない。
last-byte-pos 値がその first-byte-pos 値よりも小さいか、entity-length値が last-byte-pos 値以下の byte-content-range-spec は不正である。不正な byte-content-range-spec を受け取った受け取り側は、それとそれに伴って転送されたすべての内容を無視しなければならない。
以下はエンティティが全 1234 バイトを含んでいる事を仮定した byte-content-range-spec 値の例である。
- 最初の 500 バイト:
bytes 0-499/1234 - 次の 500 バイト:
bytes 500-999/1234 - 最初の 500 バイト以外のすべて:
bytes 500-1233/1234 - 最後の 500 バイト:
bytes 734-1233/1234
HTTP メッセージが単一のレンジの内容を含んでいるとき (例えば、単一のレンジに対するリクエストや、重複しているが全く隙間がないレンジのセットに対するリクエストのレスポンス)、この内容は実際に転送されたバイトの数を示している Content-Range ヘッダと Content-Length ヘッダを伴って送られる。例えば、
HTTP/1.1 206 Partial content
Date: Wed, 15 Nov 1995 06:25:24 GMT
Last-modified: Wed, 15 Nov 1995 04:58:08 GMT
Content-Range: bytes 21010-47021/47022
Content-Length: 26012
Content-Type: image/gif
HTTP メッセージが複数のレンジの内容を含んでいるとき (例えば、複数の重複していないレンジに対するリクエストのレスポンス)、これらはマルチパート MIME メッセージとして送られる。この目的で使用されるマルチパートMIME 内容タイプはこの仕様書で "multipart/byteranges" と定義されている。その定義に対しては付録 19.2 章参照。
MIME multipart/byteranges メッセージをデコードできないクライアントは、単一のリクエストで複数のバイトレンジを求めるべきではない。
クライアントが一つのリクエストで複数のバイトレンジを要求するとき、サーバはリクエストにおいて現れる順番でそれらを返すべきである。
もし byte-range-spec が不正なためサーバがそれを無視するなら、サーバは不正な Content-Range ヘッダフィールドが存在していなかったかのようにリクエストを扱うべきである (通常、これはすべてのエンティティを含んでいる 200 レスポンスを返す意味となる)。この理由は、クライアントがそのような不正なリクエストを作るであろう場合は、エンティティが直前のリクエストによって回収されたエンティティよりも小さいときのみと言うことである。
14.18 Content-Type
Content-Type エンティティヘッダフィールドは受信側に送られたエンティティボディのメディアタイプ、もしくは HTED メソッドの場合、GET のリクエストで送られるメディアタイプを示している。
Content-Type = "Content-Type" ":" media-type
メディアタイプは 3.7 章で定義されている。このフィールドの例は以下のようになる。
Content-Type: text/html; charset=ISO-8859-4
エンティティのメディアタイプを区別するための方法のさらなる論議は 7.2.1 章で供給される。
14.19 Date
Date 一般ヘッダフィールドはメッセージがもたらされた日付と時間に相当し、RFC 822 における orig-date と同じセマンティクスを持つ。フィールド値はHTTP-date であり、これは 3.3.1 章で記述されている。
Date = "Date" ":" HTTP-date
この例は以下のようになる。
Date: Tue, 15 Nov 1994 08:12:31 GMT
もしメッセージがユーザエージェント (リクエストの場合) もしくはオリジンサーバ (レスポンスの場合) への直接接続で受け取られたものなら、日付は受信した端末での現在時刻であるとみなす事ができる。しかしながら、日付![]() それが発生したものが信じているような
それが発生したものが信じているような![]() はキャッシュされたレスポンスを評価するために重要である。クライアントは PUT や POST リクエストの場合のように、エンティティボディを含んでいるメッセージ内でのみ Date ヘッダフィールドを送るべきであり、その場合でもオプションである。Date ヘッダフィールドを含まない受信されたメッセージは、もしメッセージが受け取り側によってキャッシュされていたり Date を必要とするプロトコル経由でゲートウェイされているなら、受け取り側によってそれを割り当てるべきである。
はキャッシュされたレスポンスを評価するために重要である。クライアントは PUT や POST リクエストの場合のように、エンティティボディを含んでいるメッセージ内でのみ Date ヘッダフィールドを送るべきであり、その場合でもオプションである。Date ヘッダフィールドを含まない受信されたメッセージは、もしメッセージが受け取り側によってキャッシュされていたり Date を必要とするプロトコル経由でゲートウェイされているなら、受け取り側によってそれを割り当てるべきである。
理論上では、日付はエンティティが生み出されたちょうど瞬間を表すべきである。事実上、日付はそのセマンティクス値に影響する事のない、メッセージ発生の間のあらゆる時間に生成されうる。
Date のフォーマットは 3.3 章で HTTP-date として定義されているような完全な日付と時間である。それは RFC1223 [8] 日付フォーマットで送られなければならない。
14.20 ETag
ETag エンティティヘッダフィールドは関連するエンティティに対するエンティティタグを定義する。エンティティタグに使用されているヘッダは 14.20, 14.25, 14.43 章で記述される。エンティティタグは同じリソースの別のエンティティと比較のために使用する事ができる (13.3.2 章参照)。
ETag = "ETag" ":" entity-tag
例:
ETag: "xyzzy"
ETag: W/"xyzzy"
ETag: ""
14.21 Expires
Expires エンティティヘッダフィールドはレスポンスが古くなったとみなされる経過時間の日付/時間を与える。古くなったキャッシュエンティティは、もしオリジンサーバに (もしくはエンティティの新鮮なコピーを持っている中間キャッシュに) 最初に正当性を確認されたのでなければ、通常はキャッシュ(プロキシキャッシュかユーザエージェントキャッシュのどちらか) によって返されないだろう。満期モデルの更なる論議は 13.2 章参照。
Expires フィールドの存在は、元のリソースがその時間よりも前に、もしくはそれより後に変更もしくは存在を終了だろうという事を暗黙的に意味する。
フォーマットは 3.3 章における HTTP-date によって定義されるような完全な日付と時刻である。これは RFC1123 日付フォーマットでなければならない:
Expires = "Expires" ":" HTTP-date
この使用例は以下のようになる。
Expires: Thu, 01 Dec 1994 16:00:00 GMT
注意: もしレスポンスが max-age 命令を伴う Cache-Control を含んでいるなら、その命令は Expires フィールドに置き換えられるであろう。
HTTP/1.1 クライアントとキャッシュは別の不正な日付フォーマット、特に値"0" を含むものを、過去のものである (例えば "既に期限切れ") として扱わなければならない。
レスポンスを "既に期限切れ" としてマークするためには、オリジンサーバはDate ヘッダ値と等しい Expires 日付を使うべきである(13.2.4 章の満期計算のルール参照)。
レスポンスを "決して期限が切れない" としてマークするためには、オリジンサーバはレスポンスが送られた時間からおおよそ一年の日付を使用すべきである。HTTP/1.1 サーバは将来において一年以上の Expires 日付を送るべきではない。
デフォルトでキャッシュ可能でない以外のレスポンスの将来におけるある時間の日付値を伴う Expires ヘッダフィールドの存在は、もし Cache-Controlヘッダフィールド (14.9 章) による別の方法が指定されていなければ、レスポンスがキャッシュ可能である事を示している。
14.22 From
もしそれが与えられるなら、From リクエストヘッダフィールドはリクエストしているユーザエージェントをコントロールする人間のユーザのインターネット E-mail アドレスを含むべきである。このアドレスは RFC 822 (RFC 1123によって更新された) でのメールボックスによる定義として、マシンの利用に適しているべきである:
From = "From" ":" mailbox
この例は以下のようになる。
From: webmaster@w3.org
このヘッダフィールドはログを取る目的と、不正なリクエストや望まれていないリクエストの原因を識別するための意味として使用する事ができる。これはアクセス保護の安全でない形式として使用されるべきではない。このフィールドの解釈はリクエストが与えられた人の支持の上に実行されている事であり、その人は実行されるメソッドに対する責任を負う。特に、ロボットエージェントは受信側で問題起きたときロボットの実行に責任のある人へ連絡できるようにするためこのヘッダを含めるべきである。
このフィールドにおけるインターネット E-mail アドレスはリクエストを発行するインターネットホストと分離される事ができる。例えばリクエストがプロキシを通しているとき、元の発行者のアドレスが使用されるべきである。
注意: クライアントはユーザのプライバシー利害やそれらのサイトのセキュリティポリシーと矛盾するため、ユーザの承認なしに From ヘッダフィールドを送る べきではない 。ユーザが可能にしたりしなかったり、リクエストに先立ってどんな時でもこのフィールドの値を修正できる事が強く推奨される。
14.23 Host
Host リクエストヘッダフィールドはユーザや参照しているリソースによって与えられるオリジナル URL から得られるような (一般的には 3.2.2 章で記述されているような HTTP URL)、リクエストされているリソースのインターネットホストとポート番号を記述する。Host フィールド値は元の URL によって与えられるオリジンサーバやゲートウェイのネットワークロケーションを表さなければならない。これはオリジンサーバやゲートウェイに、同じ IP アドレス上の複数のホスト名のルート "/" URL のような、内部的にあいまいな URLを区別できるようにする。
Host = "Host" ":" host [ ":" port ] ; Section 3.2.2
どんなポート情報も後に続いていない "host" はリクエストされたサービスに対するデフォルトポート (例えば HTTP URL は "80") を暗黙的に意味する。例えば、<http://www.w3.org/pub/WWW/> に対するオリジンサーバのリクエストは以下を含まなければならない。
GET /pub/WWW/ HTTP/1.1
Host: www.w3.org
クライアントはインターネット上のすべての HTTP/1.1 リクエストメッセージ(例えば、リクエストされたサービスに対するインターネットホストアドレスを含む URL に対するリクエストに相当するすべてのメッセージ上で) に Hostヘッダフィールドを含まなければならない。もし Host フィールドがまだ与えられていなければ、HTTP/1.1 プロキシはインターネット上でそれを転送する前にリクエストメッセージに Host フィールドを追加しなければならない。すべてのインターネットベース HTTP/1.1 サーバは Host ヘッダフィールドが欠如したすべての HTTP/1.1 リクエストメッセージに 400 ステータスコードを返さなければならない。
Host に関連する別の要求に対して 5.2 と 19.5.1 章参照。
14.24 If-Modified-Since
If-Modified-Since リクエストヘッダフィールドは GET メソッドを条件付きにさせるために使用される。もしリクエストされたバリアントがこのフィールドで記述された時間から更新されていなければ、エンティティはサーバから返されない。代わりに 304 (Not Modified) レスポンスがメッセージボディを伴わないで返されるだろう。
If-Modified-Since = "If-Modified-Since" ":" HTTP-date
このフィールドの例は:
If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT
Range ヘッダがなく If-Modified-Since ヘッダを伴う GET メソッドは、識別されたエンティティが If-Modified-Since ヘッダによって与えられる日付から更新されている場合のみ転送される。これを決定するアルゴリズムは以下の場合を含んでいる。
- a) もしリクエストが通常は 200 (OK) 以外の何かを結果として生じるか、渡された If-Modified-Since 日付が不正であるなら、レスポンスは通常の GET と明らかに同じである。サーバの現在時刻より後の日付は不正である。
- b) もしバリアントが If-Modified-Since 日付から更新されているなら、レスポンスは通常の GET と明らかに同じである。
- c) もしバリアントが正当な If-Modified-Since 日付から更新されていなければ、サーバは 304 (Not Modified) レスポンスを返さなければならない。
この機構の目的は最小のトランザクションオーバーヘッドでキャッシュされた情報の効果的な更新を行えるようにすることである。
- Range リクエストヘッダフィールドは If-Modified-Since の意味を訂正する事に注意。全詳細は 14.36 章参照。
- If-Modified-Since 時刻はサーバによって解釈され、そのクロックはクライアントとは同期していないかもしれないと言う事に注意。
もしクライアントが同じリクエストに対して Last-Modified ヘッダから取り出される日付の代わりに If-Modified-Since ヘッダの日付を独断的に使用するなら、この日付はサーバの理解できる時間で解釈されると言う事実を知るべきである事に注意。クライアントはクライアントとサーバの間の時間の異なる識別のため、クロックの非同期やその周りの問題を考慮すべきである。これは、ドキュメントが最初のリクエストや続くリクエストの If-Modified-Since 日付の時間内に変更しているかどうかと言う時間経過条件の可能性と、If-Modified-Since 日付がサーバのクロックに補正していないクライアントのクロックに由来するかどうかと言うクロックが相対的に異なる可能性を含んでいる。クライアントとサーバの間の時間基準の違いの補正はネットワーク潜在のため最良の近似である。
14.25 If-Match
If-Match リクエストヘッダフィールドはメソッドを条件付きにさせるように使用される。リソースから前もって得られた一つ以上のエンティティを持つクライアントは、If-Match ヘッダフィールドにおいてそれらに関連したエンティティタグのリストを含める事により、それらのエンティティの一つが最新である事を確かめる。この機構の目的は最小のトランザクションオーバーヘッドでキャッシュされた情報の効果的な更新を行なえるようにする事である。更新リクエストに加えて、リソースを不適切なバージョンに不注意に修正できないようにも使用される。特殊な場合として、値 "*" はリソースの現在のあらゆるエンティティと一致する。
If-Match = "If-Match" ":" ( "*" | 1#entity-tag )
もしリソースでの GET に類似したリクエストへのレスポンス (If-Modifiedヘッダを伴わない) において返されたエンティティタグのどれとも一致しなかったり、"*" が与えられ最新のあらゆるエンティティがそのリソースに対して存在するなら、サーバは If-Match ヘッダフィールドが存在しないものとしてリクエストされたメソッドを実行できる。
サーバは If-Match のエンティティタグを比較するための強固な比較機能 (3.11 章参照) を使用しなければならない。
もしエンティティタグのどれとも一致しなかったり、"*" が与えられて最新のエンティティが存在していなければ、サーバはリクエストされたメソッドを実行してはならず、412 (Precondition Failed) レスポンスを返さなければならない。この動作は PUT のようにリソースを更新するメソッドが、クライアントが最後にそれを回収してから変更したリソースを置き換えさせない事をクライアントが望むときにもっとも有用である。
もし If-Match ヘッダフィールドを伴わないリクエストが 2xx ステータス以外の何かを結果として生じるなら、If-Match ヘッダは無視されなければならない。
"If-Match: *" の意味は、メソッドがオリジンサーバによって (ひょっとすると Vary メカニズムを使っているキャッシュによる、14.43 章参照) 選択された表現が存在するなら実行されるべきであり、表現が存在しなければ実行されてはならない。
リソースを更新する目的のリクエスト (例えば PUT) は、リクエストメソッドが If-Match 値に相当するエンティティがもはやそのリソースの表現でないなら適用されてはならない事を合図するため、If-Match ヘッダフィールドを含める事ができる。これはユーザが、リソースが彼らの知らないうちに既に変更されているならリクエストを成功させたくないことを示せるようにする。例えば:
If-Match: "xyzzy"
If-Match: "xyzzy", "r2d2xxxx", "c3piozzzz"
If-Match: *
14.26 If-None-Match
If-None-Match リクエストヘッダフィールドは条件が付けられるメソッドを使用させる。リソースから前もって得られた一つ以上のエンティティを持っているクライアントが、If-None-Match ヘッダフィールドでそれらに関連するエンティティタグのリストを追加する事により、それらのエンティティのどれもが最新でない事を確かめられる。この機構の目的は最小のトランザクションオーバーヘッドでキャッシュされた情報の効果的な更新を行えるようにする事である。更新リクエストにおいて、存在が知られていないリソースの不注意な修正を阻止するためにも使用される。
特別な場合として、値 "*" はリソースのすべてのエンティティと一致する。
If-None-Match = "If-None-Match" ":" ( "*" | 1#entity-tag )
もしエンティティタグどれもリソースでの GET に類似したリクエストのレスポンス (If-None-Match ヘッダを伴わない) において返されたエンティティタグエンティティタグと一致したり、"*" が与えられどんな最新のエンティティももそのリソースに対して存在するなら、サーバはリクエストされたメソッドを実行してはならない。代わりに、もしリクエストメソッドが GET もしくは HEAD なら、サーバは一致したエンティティの一つの cache-related エンティティヘッダフィールド (特に ETag) を含んでいる 304 (Not Modified)レスポンスで応じるべきである。別のすべてのリクエストメソッドに対しては、サーバは 412 (Precondition Failed) のステータスで応じなければならない。
二つのエンティティタグが一致するかどうかをどのように決定するかのルールは 13.3.3 章参照。弱い比較機能は GET や HEAD リクエストにのみ使用できる。
もしエンティティタグのどれとも一致しなかったり、"*" が与えられ最新のエンティティが存在しないのなら、サーバは If-None-Match ヘッダフィールドが存在しなかったようにリクエストされたメソッドを実行できる。
もし If-None-Match ヘッダフィールドを伴わないリクエストが 2xx ステータス以外の何かを結果として生じるなら、If-None-Match ヘッダは無視されなければならない。
"If-None-Match: *" の意味は、メソッドがオリジンサーバによって (ひょっとしたら Vary メカニズムを使用しているキャッシュによって) 選択された表現が存在するなら実行されてはならず、そして表現が存在しないのなら実行されるべきである。この機構は PUT 操作との競合を阻止することにおいて有用である。
例:
If-None-Match: "xyzzy"
If-None-Match: W/"xyzzy"
If-None-Match: "xyzzy", "r2d2xxxx", "c3piozzzz"
If-None-Match: W/"xyzzy", W/"r2d2xxxx", W/"c3piozzzz"
If-None-Match: *
14.27 If-Range
もしクライアントがそのキャッシュにエンティティの部分的なコピーを持ち、そのキャッシュにエンティティ全体の最新のコピーを持つ事を望んでいるなら、(If-Unmodified-Since と If-Match のどちらかもしくは両方を使用して) 条件付き GET に伴う Range リクエストヘッダを使う事ができる。しかしながら、エンティティが既に修正されているため条件が失敗するなら、クライアントは最新のエンティティボディ全体を取得するため二番目のリクエストを作らなければならないだろう。
If-Range ヘッダはクライアントが二番目のリクエストへ "short-circuit" を可能にする。口語体では、この意味は `もしエンティティが変更されていないなら、私が持っていない部分を送ってくれ; もしそうでなければ新しいエンティティ全たくを送ってくれ' となる。
If-Range = "If-Range" ":" ( entity-tag | HTTP-date )
もしクライアントがエンティティに対するエンティティタグを持たず、Last-Modified 日付を持っているなら、If-Range ヘッダにその日付を使用できる(サーバは正当な HTTP-date を区別でき、エンティティタグのすべての形式を多くても 2 文字検査する事によって区別できる)。If-Range ヘッダは Rangeヘッダとともにのみ使用されるべきであり、リクエストが Range ヘッダを含んでいなかったりサーバがサブレンジ操作をサポートしていなければ無視されなければならない。
もし If-Range ヘッダにおいて与えられるエンティティタグがエンティティに対する最新のエンティティタグと一致するなら、サーバは 206 (PartialContent) レスポンスを使用してエンティティタグの記述されたサブレンジを供給すべきである。もしエンティティタグが一致しなければ、サーバは 200(OK) レスポンスを使用してエンティティ全体を返すべきである。
14.28 If-Unmodified-Since
If-Unmodified-Since リクエストヘッダフィールドはメソッドを条件付きにするために使用される。もしリクエストされたリソースがこのフィールドに記述された時間から更新されていなければ、サーバは If-Unmodified-Since ヘッダが与えられていないようなリクエストされた操作を実行するべきである。
もしリクエストされたバリアントが記述された時間から更新されているなら、サーバはリクエストされた操作を実行してはならず、412 (PreconditionFailed) を返さなければならない。
If-Unmodified-Since = "If-Unmodified-Since" ":" HTTP-date
フィールドの例は以下のようになる:
If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT
もしリクエストが標準的に (例えば If-Unmodified-Since ヘッダが伴わないような) 2xx ステータス以外の何かを結果としてもたらす場合、If-Unmodified-Since ヘッダは無視されるべきである。
もし記述された日付が不正なら、ヘッダは無視される。
14.29 Last-Modified
Last-Modified エンティティヘッダフィールドはオリジンサーバがバリアントの最終更新時間だと思っている日付と時間を示す。
Last-Modified = "Last-Modified" ":" HTTP-date
この使用例は以下のようになる。
Last-Modified: Tue, 15 Nov 1994 12:45:26 GMT
このヘッダフィールドの正確な意味はオリジンサーバのインプリメンテーションと元のリソースの性質に依存する。ファイルではこれはちょうどファイルシステムの最終更新時間である。動的に追加されたエンティティではその構成部分に対する最終更新時間のセットのもっとも最近のものである。データベースゲートウェイではそのレコードの最終更新タイムスタンプである。仮想オブジェクトでは内部的な状態が変更された最後の時間である。
オリジンサーバはメッセージ発生のサーバの時間よりも遅れた Last-Modified日付を送ってはならない。この場合、リソースの最終変更は未来におけるある時間を示し、サーバはその日付をメッセージ発生の日付と取り替えなければならない。
オリジンサーバはそのレスポンスの Date 値を生成する時刻に可能な限り近いエンティティの Last-Modified 値を得るべきである。これは特にエンティティがレスポンスの生成された時間の近くで変更されたなら、受け取り側にエンティティの変更時間の正確な査定を行えるようにする。
HTTP/1.1 サーバは実行可能であれば Last-Modified を送るべきである。
14.30 Location
Location レスポンスヘッダフィールドはリクエストの完了や新しいリソースの確認のため受け取り側に Request-URI 以外のロケーションへリダイレクトするために使用される。201 (Created) レスポンスに対して、Location はリクエストによって生成された新しいリソースのものである。3xx レスポンスでは、ロケーションはリソースに自動リダイレクトするためサーバが提案したURL を示すべきである。フィールド値は単一の絶対 URL からなる。
Location = "Location" ":" absoluteURI
この例は以下のようになる。
Location: http://www.w3.org/pub/WWW/People.html
注意: Content-Location ヘッダフィールド ( 14.15 章 ) は、Content-Locationがリクエストに同封されたエンティティのロケーションを示すと言う点で Location とは異なる。それゆえレスポンスは Location と Content-Location の両方ののヘッダフィールドを含む事ができる。いくつかのメソッドのキャッシュ要求に対する 13.10 章 も参照。
14.31 Max-Forwards
Max-Forwards リクエストヘッダフィールドは、帰りの次のサーバにリクエストを転送できるプロキシやゲートウェイの数を制限するため TRACE メソッド(14.31 章) で使用される。これはクライアントが中間連鎖において支障やループがあると思われるリクエスト連鎖のトレースを試行するときに有用である。
Max-Forwards = "Max-Forwards" ":" 1*DIGIT
Max-Forwards 値はこのリクエストメッセージが転送可能な残りの回数を示す10 進整数である。
Max-Forwards ヘッダフィールドを含んでいる TRACE リクエストを受け取るプロキシやゲートウェイそれぞれは、リクエストを転送する前にこの値をチェックして更新すべきである。もしゼロ (0) の値を受け取ったら、受取人はリクエストを転送すべきではなく、代わりにレスポンスエンティティボディとして (9.8 章で記述されているように) 受け取ったリクエストのメッセージを含んでいる 200 (OK) レスポンスを伴って、最後の受取人として応じるべきである。もし受け取った Max-Forwards 値がゼロよりも大きいなら、転送されるメッセージは 1 つ減少した値を伴う更新された Max-Forwards フィールドを含むべきである。
Max-Forwards ヘッダフィールドはこの仕様書によって定義されている別のすべてのメソッド、そしてこのメソッド定義の一部として明白に参照されていないすべての拡張メソッドに対して無視されるべきである。
14.32 Pragma
Pragma 一般ヘッダフィールドはリクエスト/レスポンス連鎖上のすべての受取人に適用できるインプリメンテーション記述命令を追加するために使用される。すべての pragma 命令はプロトコルの観点からオプション的な動作を詳述する。しかしながら、いくつかのシステムはこの命令と一致する動作を要求する事ができる。
Pragma = "Pragma" ":" 1#pragma-directive
pragma-directive = "no-cache" | extension-pragma
extension-pragma = token [ "=" ( token | quoted-string ) ]
no-cache ディレクティブがレスポンスメッセージにおいて与えられるとき、アプリケーションはたとえ要求されているもののキャッシュされたコピーを持っていても、リクエストをオリジンサーバに転送すべきである。この pragma命令は no-cache キャッシュ命令 (14.9 章) と同じセマンティクスを持ち、HTTP/1.0 との下位互換性のためここで定義される。クライアントは no-cacheリクエストが HTTP/1.1 に準じているか分からないサーバに送られるとき両方のヘッダフィールドを加えなければならない。
pragma 命令がリクエスト/レスポンス連鎖上のすべての受取人に受け入れられるため、そのプロキシやゲートウェイアプリケーションの重要性に拘らず、Pragma 命令はそれらのアプリケーションを通過しなければならない。具体的な受取人に対する pragma を詳述する事は不可能である。しかしながら、受取人に関係しないどんな pragma 命令もその受取人によって無視されるべきである。
HTTP/1.1 クライアントは Pragma リクエストヘッダを送信すべきではない。HTTP/1.1 キャッシュは "Pragma: no-cache" をクライアントが"Cache-Control: no-cache" を送ったように扱うべきである。新しい Pragma命令は HTTP において定義されないだろう。
14.33 Proxy-Authenticate
Proxy-Authenticate レスポンスヘッダフィールドは 407 (Proxy AuthenticationRequired) レスポンスの一部として追加されなければならない。フィールド値はこの Request-URI に対してプロキシに適用できる認証スキームやパラメータを示す誰何からなる。
Proxy-Authenticate = "Proxy-Authenticate" ":" challenge
HTTP アクセス認証プロセスは 11 章で記述される。WWW-Authenticate と違い、Proxy-Authenticate ヘッダフィールドは現在の接続にのみ適用され、それより手前のクライアントに渡されるべきではない。しかしながら、中間プロキシがそれより手前のクライアントからの信用証明を要求する事で、それ自身の信用証明を得る必要があるかもしれない。このような事情はプロキシがProxy-Authenticate ヘッダフィールドをフォローしている様に現れるだろう。
14.34 Proxy-Authorization
Proxy-Authorization リクエストヘッダフィールドはクライアントが認証を必要とするプロキシでそれ自身 (もしくはそのユーザ) を識別できるように使用される。Proxy-Authorization フィールド値は、プロキシに対するユーザエージェントの認証情報と/もしくはリクエストされたリソースの realm を含む信用証明からなる。
Proxy-Authorization = "Proxy-Authorization" ":" credentials
HTTP アクセス認証プロセスは
11 章
で記述されている。Authrization と違い、Proxy-Authorization ヘッダフィールドは、Proxy-Authorization フィールドを使用して認証を要求した [訳注: クライアントから見て] 次の外向きのプロキシにのみあてはめられる。連鎖において複数のプロキシが使用されているとき、Proxy-Authorization ヘッダフィールドは信用証明を受け取る事を期待している最初の外向きのプロキシによって消滅する。もしそれが与えられたリクエストをプロキシどうしが協力して認証すると言う事によるメカニズムであるなら、プロキシはクライアントリクエストから次のプロキシに信用証明を中継
できる
。
14.35 Public
Public レスポンスヘッダフィールドはサーバによって提供されるメソッドのセットのリストである。このフィールドの目的は厳密に言えば受け取り側に通常でないメソッドに関してサーバの能力を知らせるためである。メソッドはリストされるメソッドは Request-URI に適用できてもできなくても良い。Allow ヘッダフィールド (14.7 章) は固有の URI に対してみとめられるメソッドを示すために使用できる。
Public = "Public" ":" 1#method
使用例は以下のようになる。
Public: OPTIONS, MGET, MHEAD, GET, HEAD
このヘッダフィールドはクライアントに直接接続しているサーバにのみ適用できる (例えば接続の連鎖における最も近い隣側)。もしレスポンスがプロキシを通過するなら、プロキシは Public ヘッダフィールドを削除するかそれ自身の能力で受け入れられるものに置き換えるかどちらかを行わなければならない。
14.36 Range
14.36.1 Byte Ranges
すべての HTTP エンティティがバイトのシーケンスとしての HTTP メッセージで表されるため、バイトレンジの概念はすべての HTTP エンティティに対して意味がある (しかしながら、すべてのクライアントとサーバがバイトレンジ操作をサポートする必要はない)。
HTTP におけるバイトレンジ仕様はエンティティボディ (メッセージボディと同じである必要はない) におけるバイトのシーケンスに適用される。
バイトレンジ操作は単一のエンティティにおけるバイトの単一の範囲もしくは範囲のセットを詳述できる。
ranges-specifier = byte-ranges-specifier
byte-ranges-specifier = bytes-unit "=" byte-range-set
byte-range-set = 1#( byte-range-spec | suffix-byte-range-spec )
byte-range-spec = first-byte-pos "-" [last-byte-pos]
first-byte-pos = 1*DIGIT
last-byte-pos = 1*DIGIT
byte-range-spec の first-byte-pos 値は範囲の最初のバイトのオフセットを与える。last-byte-pos 値は範囲の最後のバイトのオフセットを与える。これは、記述されたバイト位置が含まれている。バイトオフセットはゼロから開始する。
もし last-byte-pos 値が与えられるなら、byte-range-spec における first-byte-pos 以上でなければならず、そうでなければ byte-range-spec は不正である。不正な byte-range-spec を受け取った側はそれを無視しなければならない。
もし last-byte-pos 値がなかったりエンティティボディの現在の長さ以上なら、last-byte-pos はバイトにおいて多くともエンティティボディの現在の長さのそれと等しくなる。
last-byte-pos のその選択により、クライアントはエンティティのサイズを知らなくても回収されるバイトの数値を限定できる。
suffix-byte-range-spec = "-" suffix-length
suffix-length = 1*DIGIT
suffix-byte-range-spec は suffix-length 値によって与えられる長さの、エンティティボディのサフィックスを記述するために使用される (これは、この形式がエンティティボディの最後の N バイトを示す)。もしエンティティが記述された suffix-length より小さい場合、エンティティボディ全体が使用される。
byte-range-specifier 値の例 () は以下のようになる (長さ 10000 のエンティティボディを仮定):
- 最初の 500 バイト (バイトオフセット 0-499 を含む):
bytes=0-499 - 次の 500 バイト (バイトオフセット 500-999 を含む):
bytes=500-999 - 最後の 500 バイト (バイトオフセット 9500-9999 を含む):
bytes=-500 - もしくは
bytes=9500- - 最初と最後のバイトのみ (0 と 9999 のバイト):
bytes=0-0,-1 - 次の 500 バイトの公式な仕様ではないがいくつかの合法的方法 (バイトオフセット 500-999 を含む):
bytes=500-600,601-999 bytes=500-700,601-999
14.36.2 Range Retrieval Requests
条件付きもしくは条件なし GET メソッドを使用した HTTP 回収リクエストは、Range リクエストヘッダを使用してエンティティ全体の代わりにエンティティの一つ以上のサブレンジを要求できる。これはリクエストの結果として返されるエンティティに適用する。
Range = "Range" ":" ranges-specifier
サーバは Range ヘッダを無視できる。しかしながら、Range が部分的に失敗した転送の回復と大きいエンティティの部分的な回収を効果的に支援するため、HTTP/1.1 オリジンサーバと中間キャッシュは可能であればバイトレンジをサポートすべきである。
もしサーバが Range ヘッダをサポートし、記述されたレンジがエンティティに対して適切であれば:
- 条件なし GET における Range ヘッダの存在は GET が別の方法で成功したなら、返される物を変更する。言いかえれば、レスポンスは 200 (OK) の代わりに 206 (Partial Content) のステータスコードを伝える。
- 条件付き GET (If-Modified-Since, If-None-Match の一つもしくは両方または If-Unmodified-Since と If-Match の一つもしくは両方を使用したリクエスト) における Range の存在は、GET が別の方法で成功し条件が真ならば、返されるものを変更する。もし条件が偽ならば返されるレスポンスは 304 (Not Modified) を装う。
いくつかの場合、If-Range ヘッダ (14.27 章) を使うよりも Range ヘッダを追加したほうがより適切である。
もしレンジをサポートするプロキシが Range リクエストを受信したら向かうサーバにそれを転送し、応答においてエンティティ全体を受信したら、そのクライアントが要求した範囲のみを返すべきである。もしそのキャッシュ割り当て方針と一致するなら受信したレスポンスのエンティティをそのキャッシュに保存すべきである。
14.37 Referer
Referer[sic] リクエストヘッダフィールドはクライアントがサーバの利益![]() Request-URI が得られたリソースのアドレス (URI)
Request-URI が得られたリソースのアドレス (URI) ![]() を記述できるようにする ("referrer", ヘッダフィールドの綴りは間違っている)。Referer リクエストヘッダフィールドはサーバに興味、ログ、キャッシュの最適化などのためのリソースへの逆リンクのリストを生成できるようにする。現在使用されていないリンクやミス入力されたリンクをメンテナンスのためトレースできるようにもする。もし Request-URI が自身の URI を持たないリソースから得られたなら、Referer フィールドは送られてはならない。これはユーザキーボードから入力されたような場合である。
を記述できるようにする ("referrer", ヘッダフィールドの綴りは間違っている)。Referer リクエストヘッダフィールドはサーバに興味、ログ、キャッシュの最適化などのためのリソースへの逆リンクのリストを生成できるようにする。現在使用されていないリンクやミス入力されたリンクをメンテナンスのためトレースできるようにもする。もし Request-URI が自身の URI を持たないリソースから得られたなら、Referer フィールドは送られてはならない。これはユーザキーボードから入力されたような場合である。
Referer = "Referer" ":" ( absoluteURI | relativeURI )
例:
Referer: http://www.w3.org/hypertext/DataSources/Overview.html
もしフィールド値が部分的な URI なら、Request-URI に対する相対的なものと解釈されるべきである。この URI はフラグメントを含んではならない。
注意: リンクのソースがプライベート情報であったり別のプライベート情報ソースを示すかもしれないため、ユーザが Referer フィールドが送られるかどうかを選択できる事を強く勧める。例えば、ブラウザクライアントは公然/匿名の閲覧のためのトルグスイッチを持つ事ができ、これはそれぞれ Referer と From 方法の送信を有効/無効にするだろう。
14.38 Retry-After
Retry-After レスポンスヘッダフィールドは、どれくらいの間サービスが利用できないかをリクエストしているクライアントに示すため、503 (ServiceUnavailable) レスポンスを伴って使用される。このフィールドの値は HTTP-date かレスポンスの時間後の整数秒数 (10 進数) のどちらかである。
Retry-After = "Retry-After" ":" ( HTTP-date | delta-seconds )
この使用の二つの例は以下のようになる。
Retry-After: Fri, 31 Dec 1999 23:59:59 GMT
Retry-After: 120
後者は 2 分間の遅延である。
14.39 Server
Server レスポンスヘッダフィールドはオリジンサーバでリクエストを扱うために使用されているソフトウェアに関する情報を含んでいる。フィールドは複数の製品トークン (3.8 章) とサーバとすべての重要なサブプロダクトを識別するコメントを含む事ができる。製品トークンはアプリケーションを識別するためにそれらの重要性の順でリストされる。
Server = "Server" ":" 1*( product | comment )
例:
Server: CERN/3.0 libwww/2.17
もしレスポンスがプロキシを通して転送されているなら、プロキシアプリケーションは Server レスポンスヘッダを置き換えてはならない。代わりに、Via フィールド (14.44 章で記述される) を含むべきである。
注意: サーバの具体的なソフトウェアバージョンを示す事は、サーバマシンをあるセキュリティホールが知られているソフトウェアに対するより無防備なアタックを許す。サーバ実装者はこのフィールドを設定可能なオプションにする事が奨励される。
14.40 Transfer-Encoding
Transfer-Encoding 一般ヘッダフィールドは、送り側から受け取り側へメッセージボディを安全に転送するために、それに適用されている変換のタイプがなんであるかを示す。これは転送コーディングがメッセージの特質であり、エンティティの特質ではないと言う点で Content-Encoding とは異なる。
Transfer-Encoding = "Transfer-Encoding" ":" 1#transfer-coding
転送コーディングは 3.6 章で定義されている。一つの例は以下のようになる。
Transfer-Encoding: chunked
ほとんどの HTTP/1.0 アプリケーションは Transfer-Encoding ヘッダを理解していない。
14.41 Upgrade
Upgrade 一般ヘッダは、クライアントがどんな追加的な通信プロトコルをサポートしてるかと、サーバがプロトコルをスイッチするための適切なものを見つけたなら、何を優先して使うかを記述できるようにする。サーバは 101 (SwitchingProtocols) レスポンスにおいてプロトコルがスイッチしている事を示すためUpgrade ヘッダフィールドを使用しなければならない。
Upgrade = "Upgrade" ":" 1#product
たとえば以下のようになる。
Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11
Upgrade ヘッダフィールドは HTTP/1.1 からある別の互換性のないプロトコルに移行するための簡単なメカニズムを供給するのを目的とする。たとえ現在のリクエストが HTTP/1.1 を使って作られたとしても、クライアントがより高いメジャーバージョン番号を伴う HTTP の最新バージョンのような、別のプロトコルを使つかうのを要求する事を表せる事によりそれを行う。これは、もし利用可能なら "より良い" プロトコルを優先して使うサーバを示すとき、クライアントがより一般的にサポートしているプロトコルでリクエストを開始できるようにする事により、非互換プロトコル間の難しい移行を取り除く (ここで"より良い" はサーバによって決定され、ひょっとするとリクエストされたメソッドと/もしくはリソースの特質にしたがっている)。
Upgrade ヘッダフィールドは存在する転送層接続上のアプリケーション層プロトコルをスイッチするためにのみ適用される。Upgrade はプロトコルのを主張するために使用できない。サーバによるその受諾と使用はオプションである。プロトコル変換後のアプリケーション層通信の能力と本質は選択されたプロトコルに完全に依存する。とはいえプロトコル変更後の最初の動作は Upgradeヘッダフィールドを含む初めの HTTP リクエストへのレスポンスでなければならない。
Upgrade ヘッダフィールドは直接接続においてのみ適用する。したがって、upgrade キーワードは Upgrade が HTTP/1.1 メッセージで与えられるとき、Connection ヘッダフィールド (14.10 章) において供給されなければならない。
Upgrade ヘッダフィールドは異なる接続へのプロトコルのスイッチを示すために使用される。この理由により、301, 302, 303, 305 リダイレクションレスポンスを使用する事がより適切である。
この仕様書では 3.1 章の HTTP バージョンルールと、この仕様書の将来的な更新によって定義されるような、Hypertext Transfer Protocol のファミリによって使用されうプロトコル名 "HTTP" のみを定義する。しかしながら、これはクライアントとサーバの両方が名前を同じプロトコルに関結び付けている時のみ有用であろう。
14.42 User-Agent
User-Agent リクエストヘッダフィールドはリクエストを開始したユーザエージェントに関する情報を含んでいる。これは統計上の目的、プロトコル違反のトレース、そして特有のユーザエージェントの制限を回避するために合わせたレスポンスのためのユーザエージェントの自動認識のために存在する。ユーザエージェントはリクエストにこのフィールドを加えるべきである。このフィールドはそのエージェントとユーザエージェントの重要な一部を形成するすべてのサブプロダクトを識別するための複数の製品トークン (3.8 章) とコメントを含める事ができる。慣例により、製品トークンはそのアプリケーションを識別するためのそれらの重要性の順にリストされる。
User-Agent = "User-Agent" ":" 1*( product | comment )
例:
User-Agent: CERN-LineMode/2.15 libwww/2.17b3
14.43 Vary
Vary レスポンスヘッダフィールドは、レスポンスエンティティがserver-driven ネゴシエーション (12 章) を使用してレスポンスの利用可能な表現から選択されたと言う合図を送るためサーバによって使用される。Varyヘッダでリストされるフィールド名はそれらのレスポンスヘッダである。Variフィールド値は、ヘッダフィールドの与えられたセットが、表現が変化する上での次元を包囲する事、もしくは変化の次元が指定されなく ("*") 従って将来的なリクエストのどんな局面でも変化しうると言う事のどちらかを示す。
Vary = "Vary" ":" ( "*" | 1#field-name )
HTTP/1.1 サーバは server-driven ネゴシエーションに従っているあらゆるキャッシュ可能なレスポンスに付随する適切な Vary ヘッダフィールドを加えなければならない。そうする事は、これがユーザエージェントにレスポンスが変化する上での次元に関する有用な情報を提供するであろうため、キャッシュがそのリソース上の将来のリクエストを適切に解釈し、ユーザエージェントにそのリソース上のネゴシエーションの存在に関して知らせる事ができる。
Vary フィールド値によって名前が付けられたヘッダフィールドのセットは、"selecting" リクエストヘッダとして知られる。
Request-URI が Vary ヘッダを含んでいる一つ以上のキャッシュエントリを記述しているような、続くリクエストをキャッシュが受け取ったとき、もしキャッシュされた Vary ヘッダにおいて名前が付けられているヘッダのすべてが新しいリクエストに存在しなく、前のリクエストからの保存された selectingリクエストヘッダのすべてが新しいリクエストにおける相当するヘッダに一致しないなら、キャッシュは新しいリクエストへのレスポンスを構築するためのそのようなキャッシュエンティティを使用してはならない。
もし最初のリクエストにおける selecting リクエストヘッダが、BNF に相当するものによってみとめられる場所に連続した空白 (LWS) を追加したり削除したり、さらに/もしくは 4.2 章のメッセージヘッダに関するルールをフォローする、同じフィールド名が伴う複数のメッセージヘッダフィールドを組み合わせる事で、二番目のリクエストにおける selecting リクエストヘッダに変換できるなら、そしてその場合にのみ、二つのリクエストからの selecting リクエストヘッダは一致すると定義される。
"*" の Vary フィールド値は、記述できないパラメータ![]() ひょっとするとリクエストヘッダフィールドの内容以外のもの (例: クライアントのネットワークアドレス)
ひょっとするとリクエストヘッダフィールドの内容以外のもの (例: クライアントのネットワークアドレス) ![]() がレスポンス表現の選択において役割を果たすことを合図する。このリソース上の続くリクエストはオリジンサーバによってのみ適切に解釈され、従ってキャッシュはリソースに対してキャッシュされている新鮮なレスポンスを持っているとき、リクエストを転送 (条件付きかもしれない) しなければならない。キャッシュによる Vary ヘッダの使用は 13.6 章参照。
がレスポンス表現の選択において役割を果たすことを合図する。このリソース上の続くリクエストはオリジンサーバによってのみ適切に解釈され、従ってキャッシュはリソースに対してキャッシュされている新鮮なレスポンスを持っているとき、リクエストを転送 (条件付きかもしれない) しなければならない。キャッシュによる Vary ヘッダの使用は 13.6 章参照。
Vary フィールド値は、レスポンスに対して選択された表現がもっとも適切な表現の選択でリストされたリクエストヘッダフィールド値のみを検討する、選択アルゴリズムに基づいている事を合図する。レスポンスが新鮮である時間の持続期間の間、同じ選択がリストされたフィールド名に対する同じ値を伴って将来的なリクエストのために作られるだろうという事をキャッシュは仮定できる。
与えられたフィールド名はこの仕様書で定義されている標準リクエストヘッダフィールドのセットに限定されない。フィールド名は大文字小文字を区別しない。
14.44 Via
Via 一般ヘッダフィールドはゲートウェイとプロキシにより、リクエストにおけるユーザエージェントとサーバの間、そしてレスポンスにおけるオリジンサーバとクライアントの間の中間プロトコルと受け取り側を示すために使用される。これは RFC 822 の "Recieved" フィールドと類似し、メッセージの転送を追跡し、リクエストループを避け、リクエスト/レスポンス連鎖上のすべての送り主のプロトコル能力を確認するために使用される。
Via = "Via" ":" 1#( received-protocol received-by [ comment ] )
received-protocol = [ protocol-name "/" ] protocol-version
protocol-name = token
protocol-version = token
received-by = ( host [ ":" port ] ) | pseudonym
pseudonym = token
received-protocol はリクエスト/レスポンス連鎖のそれぞれのセグメント上のサーバやクライアントによって受け取られたメッセージのプロトコルバージョンを示す。received-protocol バージョンはメッセージが転送されるとき、すべての受取人に見える上流のアプリケーションのプロトコル能力に関する情報のように Via フィールド値に付け加えられる。
もしそれが "HTTP" であれば、そしてその場合にのみ、protocol-name はオプションである。received-by フィールドは通常、後にメッセージを転送した受取人のサーバやクライアントのホストとオプション的なポート番号である。しかしながら、もし実際のホストが取り扱いに慎重を要する情報だとみなせば、これは received-protocol のデフォルトポートとみなす事ができる。
複数の Via フィールド値はメッセージを転送したそれぞれのプロキシやゲートウェイに相当する。それぞれの受取人は、末端の結果が転送しているアプリケーションの並びに応じてならべられるようにその情報を追加しなければならない。
コメントは User-Agent や Server ヘッダフィールドに類似し、受取人のプロキシやゲートウェイのソフトウェアを識別するための Via ヘッダフィールドにおいて使用する事ができる。しかしながら、Via ヘッダフィールドにおけるすべてのコメントはオプションであり、メッセージを転送した先のあらゆる受取人によって削除されるかもしれない。
たとえば、リクエストメッセージは HTTP/1.0 ユーザエージェントから内部的な "fred" というコートネームのプロキシに送られ、それは HTTP/1.1 を使用して nowhere.com の公開プロキシにリクエストを転送し、それはオリジンサーバ www.ics.uci.edu にリクエストを転送するで完了する。www.ics.uci.eduにより受け取られたリクエストは以下のような Via ヘッダフィールドを持つだろう:
Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1)
ネットワークファイアウォールを通る門となるプロキシとゲートウェイはデフォルトにより、ファイアウォール領域内のホストの名前とポートを転送すべきではない。この情報は明白に許可された場合にのみ広められるべきである。もし許可されていなければ、ファイアウォールの背後のどんなホストの recieved-by ホストもそのホストに対する適切な偽名によっておきかえられるべきである。
内部構造の隠蔽に非常に強いプライバシーを必要とする組織のため、プロキシは Via ヘッダフィールドのエントリの順序あるサブシーケンスをそのような単一のエントリと全く同一の received-protocol 値を結合する事ができる。たとえば、以下のようになる
Via: 1.0 ricky, 1.1 ethel, 1.1 fred, 1.0 lucy
は以下のように折り畳める
Via: 1.0 ricky, 1.1 mertz, 1.0 lucy
複数のエンティティがすべて同じ組織の管理下になく、ホストがまだ偽名に置き換えられていないなら、アプリケーションは複数のエントリを結合すべきではない。アプリケーションは異なる received-protocol 値を持つエントリを結合しなければならない。
14.45 Warning
Warning レスポンスヘッダフィールドは、レスポンスステータスコードによって反映されていないレスポンスの状態に関する追加的な情報を伝えるために使用される。この情報は典型的には![]() 排他的ではないが
排他的ではないが![]() キャッシング操作からセマンティクス透過性の欠如の可能性に関する警告に使用される。
キャッシング操作からセマンティクス透過性の欠如の可能性に関する警告に使用される。
Warnign ヘッダは以下を使用してレスポンスに付随して送られる。
Warning = "Warning" ":" 1#warning-value
warning-value = warn-code SP warn-agent SP warn-text
warn-code = 2DIGIT
warn-agent = ( host [ ":" port ] ) | pseudonym
; the name or pseudonym of the server adding
; the Warning header, for use in debugging
warn-text = quoted-string
レスポンスは一つ以上の Warning ヘッダを伝える事ができる。
warn-text は自然言語であり、レスポンスを受け取った人間のユーザにもっとも理解できそうな文字セットである。この結論はキャッシュやユーザのロケーション、リクエストにおける Accept-Language フィールド、レスポンスにおける Content-Length フィールドなどのような、すべての利用で切る情報に基づいている。デフォルトは文字セット ISO-8859-1 を使用した英語である。
もし ISO-8859-1 以外の文字セットが使用されるなら、RFC 1522 [14] で記述されている方法を使用して warn-text をエンコードしなければならない。
どのようなサーバやキャッシュもレスポンスに Warning ヘッダを追加する事ができる。新しい Warning ヘッダは存在する Warning ヘッダの後に追加されるべきである。キャッシュはレスポンスとして受信したどんな Warning ヘッダも削除してはならない。しかしながら、もしキャッシュがうまくキャッシュエントリの正当性を確認したなら、具体的な Warning コードとして記述してあるようなもの以外のそのエントリに前もって付随したすべての Warningヘッダを削除すべきである。このとき、レスポンスの正当性確認において受信したすべての Warning ヘッダを追加しなければならない。言いかえれば、Warning ヘッダはもっとも最近の適切なレスポンスに付随しているものである。
複数の Warinig ヘッダがレスポンスに追加されるとき、ユーザエージェントはレスポンス内でそれらが現れる順に可能な限り多くを表示すべきである。もし警告のすべてを表示できなければ、ユーザエージェント発見的方法に習うべきである。
- レスポンスにおいて先に現れる Warning は、レスポンスにおいて後に現れる物より高い優先度を持つ。
- ユーザの優先している文字セットの Warning は、同じ warn-code と同じ warn-agent が伴う別の文字セットの警告よりも高い優先度を持つ。
複数の Warning ヘッダを生成するシステムは、このユーザエージェント動作の意図どうりにそれらを整理するべきである。
これは現在定義されている、それぞれ英語で推奨される warn-text を伴うwarn-code とその意味の説明である。
- 10 Response is stale
- 返されたレスポンスが古くなっているときはいつでも含まなければならない。キャッシュはすべてのレスポンスにこの警告を追加できるが、レスポンスが新鮮であるとわかるまでこれを削除してはならない。
- 11 Revalidation failed
- サーバに到達できなかったため、レスポンスの正当性再評価が失敗したと仮定されるためキャッシュが古いレスポンスを返した場合に追加されなければならない。キャッシュはどんなレスポンスにもこの警告を追加できるが、レスポンスが正当性の再評価に成功するまで削除されてはならない。
- 12 Disconnected operation
- ネットワークの残りからキャッシュの意図した切断により追加されるべきである。SHOULD be included if the cache is intentionally disconnected from the rest of the network for a period of time.
- 13 Heuristic expiration
- キャッシュが発見的に 24 時間以上の新鮮さ持続時間を選択し、レスポンスの年齢が 24 時間より大きい場合に追加されなければならない。
- 14 Transformation applied
- もしレスポンスにまだこの Warning コードが存在しなければ、レスポンスの内容コーディング (Content-Encoding ヘッダで示されるような) やメディアタイプ (Content-Type ヘッダで示されるような) を変更する変換がどんな物でも適用された場合、中間キャッシュやプロキシによって追加されなければならない。正当性再評価の後レスポンスから削除されてはならない。
- 99 Miscellaneous warning
- 警告テキストは人間のユーザに示したりログに取ったりするための任意の情報を追加できる。この警告を受け取っているシステムはどんな自動動作も行ってはならない。
14.46 WWW-Authenticate
WWW-Authenticate レスポンスヘッダフィールドは 401 (Unauthorized) レスポンスメッセージに含まれなければならない。このフィールド値はRequest-URI に適用できる認証スキームとパラメータを示す一つ以上の誰何からなる。
WWW-Authenticate = "WWW-Authenticate" ":" 1#challenge
HTTP アクセス認証プロセスは 11 章で記述される。誰何の内容はコンマで区切られた認証パラメータのリストのを自身に含んでいるかもしれないため、一つ以上の誰何を含んでいるかどうか、一つ以上の WWW-Authenticate ヘッダフィールドが供給されているかについて、ユーザエージェントは WWW-Authenticate フィールド値を特に注意深く解析しなければならない。
15 セキュリティ考察
この章はアプリケーション開発者、情報提供者、そしてユーザにこのドキュメントで記述されているような HTTP/1.1 のセキュリティ限界を知らせるつもりである。ディスカッションは示された問題の決定的な解決を含んでいないが、セキュリティリスクを減らすための幾つかの提案を行っている。
15.1 クライアントの認証
Basic 認証スキームはユーザ認証の安全な方法ではなく、エンティティを保護するどんな方法においてもそれを行わない。これは伝達媒体として使用される物理的なネットワークを横切ってクリアテキスト転送される。HTTP はセキュリティ工場のために使用される追加的な認証スキームや暗号化メカニズムの、もしくは Basic 認証の強化 (one-time パスワードを使用するためのスキームなど) の追加を妨げない。[訳注: クリアテキスト![]() 転送中継ホストで見られる可能性のあるテキスト。Basic 認証で使用される Base64 は簡単に暗号化を解く事ができる。]
転送中継ホストで見られる可能性のあるテキスト。Basic 認証で使用される Base64 は簡単に暗号化を解く事ができる。]
Basic 認証におけるもっとも深刻な欠点は物理ネットワーク上でユーザのパスワードの本質的なクリアテキスト転送をもたらすと言う事である。これは熟考した認証がアドレスを試みると言う問題である。
Basic 認証がパスワードのクリアテキスト転送を伴うため、取り扱いに慎重を要する情報や貴重な情報を保護するため (強化をする事無しに) 決して使用されるべきではない。
Basic 認証の一般的な使用は、たとえばサーバ上で正確な使用統計を集める目的ように、身元確認![]() ユーザに身元確認の意味となるユーザ名とパスワードを供給する事
ユーザに身元確認の意味となるユーザ名とパスワードを供給する事![]() の目的のためである。この方法で使用されるとき、もし保護されたドキュメントを横切る不正さが主だった関心を持たないなら、その使用に危険は伴わないと思いたくなる。もしサーバがユーザのユーザ名とパスワードの両方を配給し、特に彼または彼女のパスワードを選択する事をユーザに許さない場合にのみこれは正しい。複数パスワードの管理作業を避けるための単一のパスワードをしばしば再使用する幼稚なユーザのため危険が起こる。
の目的のためである。この方法で使用されるとき、もし保護されたドキュメントを横切る不正さが主だった関心を持たないなら、その使用に危険は伴わないと思いたくなる。もしサーバがユーザのユーザ名とパスワードの両方を配給し、特に彼または彼女のパスワードを選択する事をユーザに許さない場合にのみこれは正しい。複数パスワードの管理作業を避けるための単一のパスワードをしばしば再使用する幼稚なユーザのため危険が起こる。
もしサーバがユーザ自身のパスワードの選択を許可するなら、脅威はサーバ上のドキュメントを横切る不正さのみではなく、アカウントパスワードを使う事を選んでいるすべてのユーザのアカウントを横切る不正さである。もしユーザが自身のその意味のパスワードを選択できるように許されているなら、サーバはパスワードを含んでいるファイル (おそらく暗号化されている) を管理しなければならない。これらの多くは多分遠くのサイトからのユーザのアカウントパスワードであろう。もしこの情報が安全な様式で管理されているなら、そのようなシステムのオーナーや管理人は考えられるところでは義務を負っている。
Basic Authentication も偽のサーバによってだまされる事に無防備である。事実彼が悪意を持ったサーバやゲートウェイに接続しているとき、もしユーザが Basic 認証によって保護された情報を含んでいるホストに接続する事を信じるようにさせられるなら、アタッカーは後で使うためにパスワードを要求し保存してエラーを偽る。このタイプの攻撃は熟考した認証 [32] では不可能である。サーバ実装者はゲートウェイや CGI スクリプトによって偽造されているこの種の可能性に対してガードすべきである。特に、そのゲートウェイがクライアントによって探知できない方法でオリジナルサーバを装っている間、クライアントを複数処理に従事するための接続維持メカニズムを使用できるため、サーバがゲートウェイへの接続に単純に返す事はとても危険である。
15.2 認証スキームの選択提供
HTTP/1.1 サーバは 401 (Authenticate) レスポンスの複数の誰何結果を返す事ができ、それぞれの誰何は別のスキームで使用できる。ユーザエージェントに返される誰何の命令はサーバがそれらが選択されたのを望むであろう命令である。サーバは最初にその誰何を "もっとも安全な" 認証スキームで命令すべきである。ユーザエージェントはユーザに、ユーザエージェントが理解する最初のそれをさせる事を誰何として選択すべきである。
サーバが WWW-Authenticate ヘッダを使って認証スキームの選択を提供するとき、認証の "安全" は悪意のあるユーザが誰何のセットを取り込む事み、認証スキームのもっとも弱いものを使用する事で彼/彼女自身を認証しようとするようなことだけである。従って、その命令はサーバの情報よりもユーザの信頼証明を保護するのに役に立つ。
可能な man-in-the-middle (MITM) アタックはクライアントがユーザの信頼証明 (パスワードのような) を暴露するそれを使うであろう事を望んで、選択のセットに弱い認証スキームを追加するであろう。この理由により、クライアントは受け入れた選択から理解できるうちでもっとも強いスキームを常に使用すべきである。
さらに強い MITM アタックはすべての提出された選択を削除し、Basic 認証をリクエストする誰何を挿入するであろう。この理由により、この種のアタックに関して心配のあるユーザエージェントはかつてサーバによって要求されたもっとも強い認証スキームを覚えておき、それよりも弱いものを使う前にユーザに確認を必要とする警告メッセージを提供する事ができる。そのような MITM アタックが仕掛ける特に陰険な方法はだ混ざれやすいユーザに "free" キャッシングサービスを提供するであろう。
15.3 サーバログ情報の悪用
サーバはそれらの読み込み傾向や関心の対象で識別されるであろうユーザのリクエストに関する個人情報を保存する立場にある。この情報は本質において明らかに秘密であり、その扱いはある国において法によって抑制されているであろう。データを供給するために HTTP プロトコルを使用している人たちは、そのようなデータが発行された結果によって身元確認ができるどんな個人の許可なしに配布されさないという保証に対して責任がある。
15.4 取り扱いが慎重な情報の転送
一般的なデータ転送プロトコルに似て、HTTP は転送されるデータ内容を規制できないし、与えられたどんなリクエストの状況の内、どんな情報の特有の一部の慎重さを決定するどんな優先方法もない。それゆえ、アプリケーションはこの情報の供給者にとって可能であるようなこの情報上でのたくさんの制御を供給すべきである。四つのヘッダフィールドがこの状況において特に言及の価値がある: Server, Via, Referer 及び From。
サーバの具体的なソフトウェアのバージョンを示す事は、サーバマシンにセキュリティホールが知られているソフトウェアに対するアタックをより攻撃せやすくするかもしれない。実装者は Server ヘッダフィールドをコンフィギュレーションできるオプションとさせるべきである。
ネットワークファイアウォールを通すポータルを果たすプロキシは、ファイアウォールの向こうのホストを識別するヘッダ情報の転送に関する特別な用心を持つべきである。特に、それらは削除されるか受け入れる表現、ファイアウォールの向こうで制作されたすべての Via フィールドに置き換えるべきである。
Referer フィールドは調査されるための読み込み傾向やリンクの逆引きを認める。これはとても有用であるが、もしユーザの詳細が Referer に含まれている情報から分割されていなければ、その力は悪用される事ができる。さらに個人情報が既に削除されていても、Referer フィールドは公表が不適当であろうプライベートドキュメントの URI を示すかもしれない。
From フィールドで送られる情報はユーザのプライバシー利害や彼らのサイトのセキュリティポリシーに反するかもしれないし、それゆえユーザが有効、無効、フィールド値の変更ができるようにしなければ、それは転送されるべきではない。ユーザはユーザ設定やアプリケーションデフォルト設定においてこのフィールドの内容をセットできなければならない。
必要としているのではないが、われわれはユーザに From と Referer 情報の送信を有効、無効にする事を提供する便利なトルグインターフェースを提案する。
15.5 ファイルやパス名を基にしたアタック
HTTP オリジンサーバの実装は HTTP リクエストによって返されるドキュメントをサーバ管理者によって意図されたものだけに制限ようにを気をつけるすべきである。もし HTTP サーバがファイルシステムのコールを伴う HTTP URIを直接解釈するなら、サーバは HTTP クライアントへの配信を目的としないファイルを送付しないよう特に注意を払わなければならない。たとえば、UNIX, Microsoft Windows や他のオペレーティングシステムはカレントディレクトリの上のレベルのディレクトリを示すパス要素として ".." を使う。そのようなシステムにおいて、もし HTTP サーバ経由でアクセス可能である事が意図されている外のリソースへのアクセスを別の方法で許すならば、HTTP サーバは Request-URI におけるそのような構造のどんな物も許してはならない。同じく、サーバ内部でのみでの参照が意図されたファイル (アクセス制御ファイル、設定ファイルやスクリプトコードなど) は、それらが取り扱いに慎重を要する情報を含んでいるため、不適当な検索から保護されなければならない。経験からそのような HTTP サーバインプリメンテーションの小さなバグがセキュリティリスクに結びつく。
15.6 個人情報
HTTP クライアントはしばしば (ユーザの名前、ロケーション、メールアドレス、パスワード、暗号キーなどのような) 個人情報のたくさんの量を持ち、HTTP プロトコル経由で別のリソースへのこの情報の意図されない流出を妨げるように特に気をつけるべきである。われわれは、ユーザにそのような情報公開を制御するために用意される便利なインターフェースと、設計者や実装者がこの部分に特に注意する事を特に強く推奨する。歴史的な背景は、この部分のエラーがしばしば深刻なセキュリティとプライバシーの問題の両方となり、しばしば実装者の会社に対する不利な評判を高める事を示している。
15.7 Accept ヘッダに関連するプライバシー問題
Accept request-header はアクセスされたすべてのサーバにユーザに関する情報を示す事ができる。特に Accept-Language ヘッダは、しばしば特有の言語を理解する事が特有の民族グループの一員であることに強く関連させられているため、個人的な性質であるとみなすであろう情報を示す。リクエストごとで送られる Accept-Language ヘッダの内容をコンフィギュレーションするためのオプションを提供するユーザエージェントは、コンフィギュレーションプロセスがユーザに必要としているプライバシーの損失に気づかせるようなメッセージを含むようにすることが強く推奨される。
プライバシーの損失を制限するアプローチは、ユーザエージェントに対してデフォルトにより Accept-Language ヘッダを送信する事を除外し、サーバによって生成された Vary response-header フィールドのすべてを捜すことにより、そのような送信がサーバの品質を向上できることに気づいたなら、サーバにAccept-Language ヘッダを送る事を開始すべきかどうかをユーザに問うであろう。
特に、もしそれらが quality 値を含んでいるなら、リクエストごとに送られるユーザによって設定された精巧な Accept ヘッダフィールドは、比較的信頼でき long-lived ユーザを識別するものとしてサーバによって使用される事ができる。そのようなユーザを識別するものは内容供給者が click-trailtracking を行う事を許し、共同作業の内容供給者が cross-serverclick-trail 個々のユーザのフォーム提出と調和する事を許す。プロキシの向こう側でない多くのユーザのため、ユーザエージェントが実行されているホストのネットワークアドレスも long-lived ユーザを識別するものとして役に立つと言う事に注意。プロキシがプライバシーを高めるために使用されている環境において、ユーザエージェントはエンドユーザに accept ヘッダコンフィギュレーションオプションを提供する事に保守的であるべきである。極端なプライバシー手段として、プロキシは中継されたリクエストにおける acceptヘッダをフィルタできる。高いヘッダコンフィギュレーション性機能を供給する一般的な目的のユーザエージェントは伴う可能性のあるプライバシーの損失に関してユーザに警告すべきである。
15.8 DNS のごまかし
HTTP を使用しているクライアントは Domain Name Service に非常に頼り、従って一般的に IP アドレスと DNS 名の故意に間違った組み合わせをベースとしたセキュリティアタックがある。クライアントは IP アドレス/DNS 名の組み合わせの連続した正当性の想定において用心深くあるべきである。
特に、HTTP クライアントは直前のホスト名 lookup の結果キャッシュよりも、IP アドレス/DNS 名組み合わせの確認に対するそれらの name resolver に頼るべきである。多くのプラットフォームは適切な場合において既にローカルにホスト名 lookup をキャッシュでき、それらはそうするようにコンフィギュレーションされるべきである。しかしながら、これらの lookup はネームサーバによって報告された TTL (Time To Live) 情報がキャッシュされた情報が有用なままであるであろうようなものになるときのみキャッシュされるべきである。
もし HTTP クライアントがパフォーマンスの改善をなすためにホスト名 lookupの結果をキャッシュするなら、それらは DNS によって報告される TTL 情報を監視しなければならない。
もし HTTP クライアントがこのルールを監視しないなら、それらは直前にアクセスしたサーバの IP アドレスが変更されるときだまされる。ネットワークの数値再割り当てがますます一般的になってくる事が予想されるため、この形式のアタックの可能性は成長する。従ってこの要求を監視する事はこの潜在的なセキュリティの弱さを減らす。
この要求は同じ DNS 名を使用している複製されたサーバに対してクライアントの load-balancing 動作を改善し、この策略を使うサイトをアクセスする事においてユーザの直面している失敗の可能性を減らす。
15.9 Location ヘッダとごまかし
もし単一のサーバがお互い信頼していない複数の組織をサポートするなら、それらが権限を持っていないところで、それらがリソースを無効にしようとしないように気をつけるため、示された組織の制御の元に制作されたレスポンスのLocation ヘッダと Content-Location ヘッダの値をチェックしなければならない。
16 謝辞
This specification makes heavy use of the augmented BNF and generic constructs defined by David H. Crocker for RFC 822. Similarly, it reuses many of the definitions provided by Nathaniel Borenstein and Ned Freed for MIME. We hope that their inclusion in this specification will help reduce past confusion over the relationship between HTTP and Internet mail message formats.
The HTTP protocol has evolved considerably over the past four years. It has benefited from a large and active developer community ![]() the many people who have participated on the www-talk mailing list
the many people who have participated on the www-talk mailing list ![]() and it is that community which has been most responsible for the success of HTTP and of the World-Wide Web in general. Marc Andreessen, Robert Cailliau, Daniel W. Connolly, Bob Denny, John Franks, Jean-Francois Groff, Phillip M. Hallam-Baker, Hakon W. Lie, Ari Luotonen, Rob McCool, Lou Montulli, Dave Raggett, Tony Sanders, and Marc VanHeyningen deserve special recognition for their efforts in defining early aspects of the protocol.
and it is that community which has been most responsible for the success of HTTP and of the World-Wide Web in general. Marc Andreessen, Robert Cailliau, Daniel W. Connolly, Bob Denny, John Franks, Jean-Francois Groff, Phillip M. Hallam-Baker, Hakon W. Lie, Ari Luotonen, Rob McCool, Lou Montulli, Dave Raggett, Tony Sanders, and Marc VanHeyningen deserve special recognition for their efforts in defining early aspects of the protocol.
This document has benefited greatly from the comments of all those participating in the HTTP-WG. In addition to those already mentioned, the following individuals have contributed to this specification:
Gary Adams Albert Lunde
Harald Tveit Alvestrand John C. Mallery
Keith Ball Jean-Philippe Martin-Flatin
Brian Behlendorf Larry Masinter
Paul Burchard Mitra
Maurizio Codogno David Morris
Mike Cowlishaw Gavin Nicol
Roman Czyborra Bill Perry
Michael A. Dolan Jeffrey Perry
David J. Fiander Scott Powers
Alan Freier Owen Rees
Marc Hedlund Luigi Rizzo
Greg Herlihy David Robinson
Koen Holtman Marc Salomon
Alex Hopmann Rich Salz
Bob Jernigan Allan M. Schiffman
Shel Kaphan Jim Seidman
Rohit Khare Chuck Shotton
John Klensin Eric W. Sink
Martijn Koster Simon E. Spero
Alexei Kosut Richard N. Taylor
David M. Kristol Robert S. Thau
Daniel LaLiberte Bill (BearHeart) Weinman
Ben Laurie Francois Yergeau
Paul J. Leach Mary Ellen Zurko
Daniel DuBois
Much of the content and presentation of the caching design is due to suggestions and comments from individuals including: Shel Kaphan, Paul Leach, Koen Holtman, David Morris, and Larry Masinter.
Most of the specification of ranges is based on work originally done by Ari Luotonen and John Franks, with additional input from Steve Zilles.
Thanks to the "cave men" of Palo Alto. You know who you are.
Jim Gettys (the current editor of this document) wishes particularly to thank Roy Fielding, the previous editor of this document, along with John Klensin, Jeff Mogul, Paul Leach, Dave Kristol, Koen Holtman, John Franks, Alex Hopmann, and Larry Masinter for their help.
17 参照
[1] Alvestrand, H., "Tags for the identification of languages", RFC
1766, UNINETT, March 1995.
[2] Anklesaria, F., McCahill, M., Lindner, P., Johnson, D., Torrey,
D., and B. Alberti. "The Internet Gopher Protocol: (a distributed
document search and retrieval protocol)", RFC 1436, University of
Minnesota, March 1993.
[3] Berners-Lee, T., "Universal Resource Identifiers in WWW", A
Unifying Syntax for the Expression of Names and Addresses of Objects
on the Network as used in the World-Wide Web", RFC 1630, CERN, June
1994.
[4] Berners-Lee, T., Masinter, L., and M. McCahill, "Uniform Resource
Locators (URL)", RFC 1738, CERN, Xerox PARC, University of Minnesota,
December 1994.
[5] Berners-Lee, T., and D. Connolly, "HyperText Markup Language
Specification - 2.0", RFC 1866, MIT/LCS, November 1995.
[6] Berners-Lee, T., Fielding, R., and H. Frystyk, "Hypertext
Transfer Protocol -- HTTP/1.0.", RFC 1945 MIT/LCS, UC Irvine, May
1996.
[7] Freed, N., and N. Borenstein, "Multipurpose Internet Mail
Extensions (MIME) Part One: Format of Internet Message Bodies", RFC
2045, Innosoft, First Virtual, November 1996.
[8] Braden, R., "Requirements for Internet hosts - application and
support", STD 3, RFC 1123, IETF, October 1989.
[9] Crocker, D., "Standard for the Format of ARPA Internet Text
Messages", STD 11, RFC 822, UDEL, August 1982.
[10] Davis, F., Kahle, B., Morris, H., Salem, J., Shen, T., Wang, R.,
Sui, J., and M. Grinbaum. "WAIS Interface Protocol Prototype
Functional Specification", (v1.5), Thinking Machines Corporation,
April 1990.
[11] Fielding, R., "Relative Uniform Resource Locators", RFC 1808, UC
Irvine, June 1995.
[12] Horton, M., and R. Adams. "Standard for interchange of USENET
messages", RFC 1036, AT&T Bell Laboratories, Center for Seismic
Studies, December 1987.
[13] Kantor, B., and P. Lapsley. "Network News Transfer Protocol." A
Proposed Standard for the Stream-Based Transmission of News", RFC
977, UC San Diego, UC Berkeley, February 1986.
[14] Moore, K., "MIME (Multipurpose Internet Mail Extensions) Part
Three: Message Header Extensions for Non-ASCII Text", RFC 2047,
University of Tennessee, November 1996.
[15] Nebel, E., and L. Masinter. "Form-based File Upload in HTML",
RFC 1867, Xerox Corporation, November 1995.
[16] Postel, J., "Simple Mail Transfer Protocol", STD 10, RFC 821,
USC/ISI, August 1982.
[17] Postel, J., "Media Type Registration Procedure", RFC 2048,
USC/ISI, November 1996.
[18] Postel, J., and J. Reynolds, "File Transfer Protocol (FTP)", STD
9, RFC 959, USC/ISI, October 1985.
[19] Reynolds, J., and J. Postel, "Assigned Numbers", STD 2, RFC
1700, USC/ISI, October 1994.
[20] Sollins, K., and L. Masinter, "Functional Requirements for
Uniform Resource Names", RFC 1737, MIT/LCS, Xerox Corporation,
December 1994.
[21] US-ASCII. Coded Character Set - 7-Bit American Standard Code for
Information Interchange. Standard ANSI X3.4-1986, ANSI, 1986.
[22] ISO-8859. International Standard -- Information Processing --
8-bit Single-Byte Coded Graphic Character Sets --
Part 1: Latin alphabet No. 1, ISO 8859-1:1987.
Part 2: Latin alphabet No. 2, ISO 8859-2, 1987.
Part 3: Latin alphabet No. 3, ISO 8859-3, 1988.
Part 4: Latin alphabet No. 4, ISO 8859-4, 1988.
Part 5: Latin/Cyrillic alphabet, ISO 8859-5, 1988.
Part 6: Latin/Arabic alphabet, ISO 8859-6, 1987.
Part 7: Latin/Greek alphabet, ISO 8859-7, 1987.
Part 8: Latin/Hebrew alphabet, ISO 8859-8, 1988.
Part 9: Latin alphabet No. 5, ISO 8859-9, 1990.
[23] Meyers, J., and M. Rose "The Content-MD5 Header Field", RFC
1864, Carnegie Mellon, Dover Beach Consulting, October, 1995.
[24] Carpenter, B., and Y. Rekhter, "Renumbering Needs Work", RFC
1900, IAB, February 1996.
[25] Deutsch, P., "GZIP file format specification version 4.3." RFC
1952, Aladdin Enterprises, May 1996.
[26] Venkata N. Padmanabhan and Jeffrey C. Mogul. Improving HTTP
Latency. Computer Networks and ISDN Systems, v. 28, pp. 25-35, Dec.
1995. Slightly revised version of paper in Proc. 2nd International
WWW Conf. '94: Mosaic and the Web, Oct. 1994, which is available at
http://www.ncsa.uiuc.edu/SDG/IT94/Proceedings/DDay/mogul/
HTTPLatency.html.
[27] Joe Touch, John Heidemann, and Katia Obraczka, "Analysis of HTTP
Performance", <URL: http://www.isi.edu/lsam/ib/http-perf/>,
USC/Information Sciences Institute, June 1996
[28] Mills, D., "Network Time Protocol, Version 3, Specification,
Implementation and Analysis", RFC 1305, University of Delaware, March
1992.
[29] Deutsch, P., "DEFLATE Compressed Data Format Specification
version 1.3." RFC 1951, Aladdin Enterprises, May 1996.
[30] Spero, S., "Analysis of HTTP Performance Problems"
<URL:http://sunsite.unc.edu/mdma-release/http-prob.html>.
[31] Deutsch, P., and J-L. Gailly, "ZLIB Compressed Data Format
Specification version 3.3", RFC 1950, Aladdin Enterprises, Info-ZIP,
May 1996.
[32] Franks, J., Hallam-Baker, P., Hostetler, J., Leach, P.,
Luotonen, A., Sink, E., and L. Stewart, "An Extension to HTTP :
Digest Access Authentication", RFC 2069, January 1997.
18 著者達のアドレス
Roy T. Fielding Department of Information and Computer Science University of California Irvine, CA 92717-3425, USA Fax: +1 (714) 824-4056 EMail: fielding@ics.uci.edu Jim Gettys MIT Laboratory for Computer Science 545 Technology Square Cambridge, MA 02139, USA Fax: +1 (617) 258 8682 EMail: jg@w3.org Jeffrey C. Mogul Western Research Laboratory Digital Equipment Corporation 250 University Avenue Palo Alto, California, 94305, USA EMail: mogul@wrl.dec.com Henrik Frystyk Nielsen W3 Consortium MIT Laboratory for Computer Science 545 Technology Square Cambridge, MA 02139, USA Fax: +1 (617) 258 8682 EMail: frystyk@w3.org Tim Berners-Lee Director, W3 Consortium MIT Laboratory for Computer Science 545 Technology Square Cambridge, MA 02139, USA Fax: +1 (617) 258 8682 EMail: timbl@w3.org
19 付録
19.1 インターネットメディアタイプ message/http
HTTP/1.1 プロトコルを定義するための追加として、このドキュメントはインターネットメディアタイプ "message/http" に対する仕様を支給する。以下がIANA によって登録さている。
Media Type name: message
Media subtype name: http
Required parameters: none
Optional parameters: version, msgtype
version: メッセージに同封した ("1.1" のような) HTTP-Version 番号。
もしこれが与えられなければ、ボディの最初の行から決定する
事ができる。
msgtype: メッセージタイプ -- "request" か "response"。もしこれが与
えられなければ、タイプはボディの最初の行で決定する事がで
きる。
Encoding considerations: "7bit", "8bit" か "binary" のみが許される。
Security considerations: なし
19.2 インターネットメディアタイプ multipart/byteranges
もし HTTP メッセージが複合レンジの内容 (たとえば、複合 non-overlappingレンジに対するリクエストのレスポンス) を含んでいるなら、これらはマルチパート MIME メッセージとして転送される。この目的のためのマルチパートメディアは "multipart/byteranges" と呼ばれる。
multipart/byteranges メディアタイプは二つ以上の部分を含み、それぞれ自身に Content-Type と Content-Range フィールドを持つ。それらの部分はMIME 境界パラメータを使用して区切られる。
Media Type name: multipart
Media subtype name: byteranges
Required parameters: boundary
Optional parameters: none
Encoding considerations: "7bit", "8bit" か "binary" のみが許される
Security considerations: なし
例:
HTTP/1.1 206 Partial content Date: Wed, 15 Nov 1995 06:25:24 GMT Last-modified: Wed, 15 Nov 1995 04:58:08 GMT Content-type: multipart/byteranges; boundary=THIS_STRING_SEPARATES --THIS_STRING_SEPARATES Content-type: application/pdf Content-range: bytes 500-999/8000 ...the first range... --THIS_STRING_SEPARATES Content-type: application/pdf Content-range: bytes 7000-7999/8000 ...the second range --THIS_STRING_SEPARATES--
19.3 寛大なアプリケーション
このドキュメントは HTTP/1.1 メッセージの発生に対する要求を記述しているが、すべてのアプリケーションがそれらのインプリメンテーションにおいて正しくあるであろう事はない。それゆえわれわれはそれらの逸脱が明瞭に中間処理できるとき、作業を行うアプリケーションは逸脱に対して寛大である事を勧める。
クライアントは Status-Line の解析において、サーバは Request-Line を解析するときにおいて寛大であるべきである。特に、たとえただ一つの SP のみが必要だったとしても、これらはフィールド間の SP や HT 文字の連続を受け入れるべきである。
message-header フィールドに対する行末は CRLF シーケンスである。しかしながら、そのようなヘッダを解析するとき、われわれはアプリケーションが単一の LF を行末として認識し、先行する CR を無視する事を勧める。
entity-body の文字セットは、どんなラベルも US-ASCII や ISO-8859-1 ラベル以上に好まれない例外を除いて、そのボディで使用されている文字コードの最も低い共通の特徴としてラベル付けされるべきである。
解析における必要や日付のエンコーディングやデータエンコーディングに伴う別の潜在的な問題に対する追加的なルールは以下を含む:
- HTTP/1.1 クライアントとキャッシュは将来において 50 年以上現れると思われる RFC-850 日付が実際過去のものであると仮定する(これは "2000年" 問題を解決するのを助ける)。
- HTTP/1.1 インプリメンテーションは適当な値よりも早いような解析されたExpires 日付を内部的に表すだろう。しかし適当な値よりも遅いものとして解析された Expires を表してはならない。
- すべての expiration-ralated 計算は GMT で行われなければならない。ローカルタイムゾーンは計算や年齢や満期期間の比較にに影響を及ぼしてはならない。
- もし HTTP ヘッダが間違って GMT 以外のタイムゾーンの日付値を運んだなら、もっとも保守的な可能な変換を使用して GMT に変換されなければならない。
19.4 HTTP エンティティと MIME エンティティの違い
HTTP/1.1 はエンティティを表現や拡張できるメカニズムで公開の多様性で転送されるようにするため、インターネットメール (RFC 822) や MultipurposeInternet Mail Extensions (MIME) のために定義されている多くの構造を使用している。しかしながら、MIME [7] メールを論議し、HTTP は MIME において述べられているこれらかとは違う幾つかの特徴を持っている。これらの違いはバイナリ接続越しにパフォーマンスを最適化するため、新しいメディアタイプの使用においてより大きな自由を認めるため、日付の比較を容易にするため、そして幾つかの初期の HTTP サーバとクライアントの実行を認めるために注意深く選ばれている。
この付録は HTTP が MIME と異なる具体的な部分を表す。厳密な MIME 環境へのプロキシやゲートウェイはこの違いを知るべきであり必要な部分での適切な変換を供給すべきである。MIME 環境からの HTTP へのプロキシやゲートウェイも同じ変換が必要であるためこの違いを知る必要がある。
19.4.1 公式形式への変換
MIME はインターネットメールエンティティが転送される先の公式形式に変換されることが必要である。このドキュメントの 3.7.1 章は HTTP 越しに転送されるときの "text" メディアタイプのサブタイプに対してみとめられる形式を表している。MIME は "text" タイプを伴う内容が行末を CRLF として表し、行末シーケンス以外の CR や LF の使用を禁止する事を必要とする。HTTP はメッセージが HTTP 上で転送される時にテキスト内容の行末を示す CRLF、単独の CR、単独の LF を認めている。
HTTP から厳密な MIME 環境へのプロキシやゲートウェイはこのドキュメントの 3.7.1 章で表されるテキストメディアタイプに含まれるすべての行末をCRLF の MIME 公式形式に変換すべきである。しかしながら、これはContent-Encoding の存在や、HTTP が幾つかのマルチバイト文字セットのための場合として、8 ビットバイト 13 と 10 が CR と LF を表すように使われていない幾つかの文字セットの使用を認めていると言う事実によって困難にさせられている。
19.4.2 日付フォーマットの変換
HTTP/1.1 は日付比較の処理を簡単にするための日付フォーマット (3.3.1 章)の制限されたセットを使用する。別のプロトコルからのプロキシやゲートウェイはメッセージで与えられるどんな Date ヘッダも HTTP/1.1 フォーマットの一つに従い必要であれば日付を書きかえるべきである。
19.4.3 Content-Encoding の導入
MIME は HTTP/1.1 の Content-Encoding に相当するどんな概念も含んでいない。これがメディアタイプを置き換えるような動作をするため、HTTP からMIME 互換環境へのプロキシやゲートウェイは Content-Type ヘッダフィールドの値を変更するかメッセージを転送する前に entity-body をデコードするかどちらかを行わなければならない。(インターネットメールに対するContent-Type の幾つかの実験的なアプリケーションは既に Content-Encodingと等価の機能となる ";conversions=<content-coding>" のメディアタイプパラメータを使用している。しかしながら、このパラメータは MIME の一部ではない。)
19.4.4 No Content-Transfer-Encoding
HTTP は MIME の Content-Transfer-Encoding (CTE) フィールドを使用していない。MIME 互換プロトコルから HTTP へのプロキシやゲートウェイは HTTPクライアントにレスポンスメッセージを配信する前にすべての non-identifyCTE ("quoted-printable" や "base64") エンコーディングを取り除かなければならない。
HTTP から MIME 互換プロトコルへのプロキシやゲートウェイはメッセージがそのプロトコル上で安全に転送されるように正しいフォーマットとエンコーディングとする。ここで "安全な転送" は使用されているプロトコルの限界により定義される。そのようなプロキシやゲートウェイは、もしそうする事が目的のプロトコル上での安全な転送の可能性が良くなるなら、適切なContent-Transfer-Encoding を伴うデータのラベル付けをすべきである。
19.4.5 マルチパート Body-Parts における HTTP Header Fields
MIME では、一般的にマルチパート body-parts において "Content-" で始まる名前のフィールド以外のほとんどのヘッダフィールドは無視される。HTTP/1.1では、マルチパート body-parts はその部分の意味にとって重要な意義を持つあらゆる HTTP ヘッダフィールドを含む可能性がある。
19.4.6 Transfer-Encoding の導入
HTTP/1.1 は Transfer-Encoding ヘッダフィールド (14.40 章) を導入している。プロキシ/ゲートウェイは MIME に準じたプロトコル経由でメッセージを転送する前にどんな転送コーディングも削除しなければならない。
"chunked" 転送コーディング (3.6 章) をデコードするための処理は以下の疑似コードによって表される:
length := 0
read chunk-size, chunk-ext (if any) and CRLF
while (chunk-size > 0) {
read chunk-data and CRLF
append chunk-data to entity-body
length := length + chunk-size
read chunk-size and CRLF
}
read entity-header
while (entity-header not empty) {
append entity-header to existing header fields
read entity-header
}
Content-Length := length
Remove "chunked" from Transfer-Encoding
19.4.7 MIME-Version
HTTP は MIME に準じたプロトコル (付録 19.4 参照) ではない。しかしながら、HTTP/1.1 メッセージは MIME プロトコルの何のバージョンがメッセージを構成するために使用された事を示すための単一の MIME-Version 一般ヘッダフィールドを含む事ができる。この MIME-Version ヘッダフィールドの使用はメッセージが MIME プロトコルの完全な追従にある。プロキシ/ゲートウェイは厳密な MIME 環境に HTTP メッセージをエクスポートするとき、(可能であれば) 完全な追従にある事を保証するための責任がある。
MIME-Version = "MIME-Version" ":" 1*DIGIT "." 1*DIGIT
MIME バージョン "1.0" は HTTP/1.1 で使うデフォルトである。しかしながら、HTTP/1.1 メッセージの解析やセマンティクスはこのドキュメントで定義されMIME の仕様ではない。
19.5 HTTP/1.0 からの変更
このセクションでは HTTP/1.0 と HTTP/1.1 バージョン間の主な違いを要約する。
19.5.1 Changes to Simplify Multi-homed Web Servers and Conserve IP Addresses
クライアントとサーバは Host request-header をサポートし、もし HTTP/1.1リクエストから Host request-header (14.23 章) が欠落していればエラーを報告し、絶対 URI (5.1.2 参照) を受け入れるという必要条件はこの仕様書で定義されているもっとも重要な変更のひとつである。
古い HTTP/1.0 クライアントは IP アドレスとサーバの一対一関係を仮定していた。そのリクエストが宛てられた IP アドレスのほかに、リクエストの意図されたサーバを区別するための別の確立されたメカニズムは存在しなかった。
かつての古い HTTP クライアントはもはや一般的ではなく、上記にアウトライン化された変更は、単一のホストにたくさんの IP アドレスの割り当てがすでに深刻な問題を引き起こしている、大きな作業上の Web サーバを非常に簡略化ことで、インターネットで単一の IP アドレスから複数の Web サイトをサポートする事をできるようにする。インターネットも、ルートレベル HTTPURL で使用されている特殊な目的で考慮されたドメイン名の唯一の目的に割り当てられているような IP アドレスを回復する事ができる。Web の成長率とすでに配置されたサーバの数を与える事は、HTTP のすべてのインプリメンテーション (既存の HTTP/1.0 アプリケーションのアップデートも含む) がこれらの要求を正しく実装する事は非常に重要である:
- クライアントとサーバの両方は Host request-header をサポートしなければならない。
- Host request-header は HTTP/1.1 リクエストにおいて必要とされる。
- サーバはもし HTTP/1.1 リクエストが Host request-header を含んでいないならエラー 400 (Bad Request) を報告しなければならない。
- サーバは絶対 URI を受け入れなければならない。
19.6 追加的な機構
この付録は幾つかの既存の HTTP インプリメンテーションによって使用されているプロトコル要素をドキュメントしたが、ほとんどの HTTP/1.1 アプリケーションを超えて正確で一貫していない。実装者はこれらの機構を知るべきであるが、別の HTTP/1.1 アプリケーションにおいてそれらの存在や中間実行性を当てにできない。これらの幾つかは実験的な機構を提案され、いくつかは実験的な展開が基本の HTTP/1.1 仕様書において今申し入れられた欠如を見つける機能を記述する
19.6.1 追加的なリクエストメソッド
19.6.1.1 PATCH
PATCH メソッドは、Request-URI によって識別されるリソースの元のバージョンと、PATCH 動作後のリソースに望まれる内容との違いのリストを含んでいるエンティティが適用されている事を除いて、PUT と類似している。違いのリストはエンティティのメディアタイプ (例: "application/diff") によって定義されるフォーマットにおけるものであり、リソースの元のバージョンを望まれるバージョンに変換するため、サーバが必要な変更を再生成できるようにするための十分な情報を含んでいなければならない。
もしリクエストがキャッシュを通して渡され Request-URI が現在キャッシュされているエンティティを指すならば、このエンティティはキャッシュから削除されなければならない。このメソッドのレスポンスはキャッシュできない。
パッチされたリソースがどのように置かれるか、置きかえられる前のリソースに何が起きるかを決定するための実際のメソッドは、オリジンサーバによって完全に定義される。もしパッチされているリソースの元のバージョンがContent-Version ヘッダフィールドを含んでいるなら、リクエストエンティティは元の Content-Version ヘッダフィールドの値に相当する Derived-From ヘッダフィールドを含まなければならない。アプリケーションは、これらのフィールドをバージョン関係の構成とバージョン矛盾の解決のために使用する事が奨励される。
PATCH リクエストは 8.2 章で表されるメッセージ転送要求に従わなければならない。
PATCH を実装しているキャッシュは PUT に対して 13.10 章で定義されているようにキャッシュされたレスポンスを無効にすべきである。
19.6.1.2 LINK
LINK メソッドは Request-URI によって識別される既存のリソースと別の既存のリソースとの間に一つ以上のリンク関係を作る。LINK とリソース間につながりを作る事のできる別のメソッドの違いは、LINK メソッドがリクエストによってどんなメッセージボディをも送る事を認めず、直接的な新しいリソースの構築という結果にならないと言う事である。
もしリクエストがキャッシュを通して渡され、Request-URI が現在キャッシュされているエンティティを示すなら、このエンティティはキャッシュから削除されなければならない。このメソッドのレスポンスはキャッシュ可能である。
LINK を実装しているキャッシュは PUT に対して 13.10 章で定義されているようにキャッシュされたレスポンスを無効にすべきである。
19.6.1.3 UNLINK
UNLINK メソッドは Request-URI によって示される既存のリソースの間の一つ以上のリンク関係を削除する。これらの関係は LINK メソッドの使用や Linkヘッダをサポートしている別のメソッドによって作られたものであろう。リソースへのリンクの削除はリソースがその存在を終了し将来的な参照に対して受け付けられないようになるということを意味するのではない。
もしリクエストがキャッシュを通して渡され、Request-URI が現在キャッシュされているエンティティを示すなら、このエンティティはキャッシュから削除されなければならない。このメソッドのレスポンスはキャッシュ可能である。
UNLINK を実装するキャッシュは PUT に対して 13.10 章で定義してあるようにキャッシュされたレスポンスを無効にすべきである。
19.6.2 追加的なヘッダフィールド定義
19.6.2.1 Alternates
オリジンサーバがリソースの特徴的な属性と共に、リクエストされたリソースの別の利用可能な表現についてクライアントに知らせるための手段として、従ってユーザエージェントがそのユーザの意思により適した別の表現を引き続く選択で実行するためのより信頼できる手段を供給するため (agent-driven ネゴシエーションとして 12 章で記述されている)、Alternates レスポンスヘッダフィールドは提案されている。
Alternates ヘッダフィールドは、Vary ヘッダフィールドとそれの両方がレスポンスや利用可能な表現の解釈に影響しないでメッセージにおいて共存できる事で、Vary ヘッダフィールドと直交性を持っている。Alternates は、タイプや言語などの普通の次元上で異なるリソースのための Vary フィールドによって供給される server-driven ネゴシエーション上で意味のある改善を供給するだろうと言う事が期待される。
Alternates ヘッダフィールド将来的な仕様書で定義されるだろう。
19.6.2.2 Content-Version
Content-Version エンティティヘッダフィールドは進展するエンティティの解釈と関連するバージョンタグを定義する。19.6.2.3 章で定義されているDerived-Form フィールドと共に、これはグループや人々が反復的工程となる作業での構築で同時に作業できるようにする。このフィールドは、別々の表現において見出される作業や解釈よりも、単一の工程上の固有の作業の展開を認めるために使用されるべきである。
Content-Version = "Content-Version" ":" quoted-string
Content-Version フィールドの例は以下のようになる:
Content-Version: "2.1.2"
Content-Version: "Fred 19950116-12:26:48"
Content-Version: "2.5a4-omega7"
19.6.2.3 Derived-From
Derived-From エンティティヘッダフィールドは、同封されたエンティティが送り側が変更を行う前のリソースのバージョンタグである事を示すために使用される。このフィールドは、リソースへの連続する変更、特にそのような変更が並行して複数のソースから行われる時、それを統合する工程を管理する事を補助するために使用される。
Derived-From = "Derived-From" ":" quoted-string
このフィールドの使用例は以下のようになる:
Derived-From: "2.1.1"
もし送られたエンティティが前もって同じ URI に由来され、最後にそれを回収したとき Content-Version ヘッダがエンティティに含まれているなら、Derived-From フィールドは PUT や PATCH リクエストに対して必要とされる。
19.6.2.4 Link
Link エンティティヘッダフィールドは二つのリソースの間、一般的にはリクエストされたリソースと同じ別のリソースの間の関係を表現するための手段を供給する。エンティティは複数の Link 値を含む事ができる。メタ情報レベルの Link は典型的に階層構造とナビゲーションパスのような関係を示す。Link フィールドは HTML [5] における <LINK> 要素と意味的に同じである。
Link = "Link" ":" #("<" URI ">" *( ";" link-param )
link-param = ( ( "rel" "=" relationship )
| ( "rev" "=" relationship )
| ( "title" "=" quoted-string )
| ( "anchor" "=" <"> URI <"> )
| ( link-extension ) )
link-extension = token [ "=" ( token | quoted-string ) ]
relationship = sgml-name
| ( <"> sgml-name *( SP sgml-name) <"> )
sgml-name = ALPHA *( ALPHA | DIGIT | "." | "-" )
relationship 値は大文字小文字を区別しなく、sgml-name 構文の制約内で拡張できる。title パラメータは、人が読めるメニューの識別として使用されるように、リンク先のラベルとして使用できる。anchor パラメータは、このリソースや三次的リソースのフラグメントのような、現在のリソース全体以外のソースアンカーを示すために使用できる。
この使用例は以下のようになる:
Link: <http://www.cern.ch/TheBook/chapter2>; rel="Previous"
Link: <mailto:timbl@w3.org>; rev="Made"; title="Tim Berners-Lee"
最初の例は、chapter2 が論理的ナビゲーションパスにおいてこのソースの前のものであると言う事を示している。二番目は利用可能なリソースを制作した人が与えられた E-mail アドレスとして識別できる事を示す。
19.6.2.5 URI
この仕様書の過去のバージョンにおいて、URI ヘッダフィールドは将来的なAlternates フィールド (上記) はもちろん、既存の Location, Content-Location, Vary ヘッダフィールドの連動として使用されている。この第一の目的は名前とミラーロケーションを含むリソースへの追加的な URI のリストを含む事である。しかしながら、この単一のフィールド内を別の多くの機能と組み合わせる事は、これらの機能すべてに対して一貫した正しい実装を行う上で障害となる。さらに、われわれは名前やミラーロケーションの識別が Linkヘッダフィールドでより良く実行されるであろうとと思っている。
URI-header = "URI" ":" 1#( "<" URI ">" )
19.7 前のバージョンとの互換性
前バージョンへの追従を命令する事はプロトコル仕様書の範囲を超える。しかしながら、HTTP/1.1 は意図的に前バージョンを簡単にサポートするように設計されている。この仕様書を構成する時点を言及する事は価値がある。われわれは以下の商業的な HTTP/1.1 サーバを期待する:
- HTTP/0.9, 1.0 そして 1.1 リクエストに対する Request-Line のフォーマットの認識。
- HTTP/0.9, 1.0 そして 1.1 のフォーマットにおけるすべての正当なリクエストの理解。
- クライアントによって使用されている同じメジャーバージョンにおけるメッセージの適切な応答。
そしてわれわれは HTTP/1.1 クライアントに以下を期待する:
- HTTP/1.0 と 1.1 レスポンスの Status-Line のフォーマットの認識。
- HTTP/0.9, 1.0 や 1.1 のフォーマットのすべての正当なレスポンスの理解。
HTTP/1.0 のほとんどのインプリメンテーションのため、それぞれの接続はリクエストにクライアントにより確立され、レスポンスを送った後サーバによってクローズされる。幾つかのインプリメンテーションは 19.7.1.1 章で表される永続的な接続の Keep-Alive 版を実装している。
19.7.1 HTTP/1.0 永続的接続の互換性
幾つかのクライアントとサーバは HTTP/1.0 クライアントとサーバの永続的な接続のある前のインプリメンテーションと互換性を持つ事を望むかもしれない。HTTP/1.0 における永続的な接続はそれらがデフォルトの動作ではないものとして明らかにネゴシエーションされるべきである。永続的な接続の実験的なHTTP/1.0 は不完全であり、HTTP/1.1 における新しい機能はこれらの問題を改善するために設計されている。問題は幾つかの既存の 1.0 クライアントがConnection を理解しないプロキシサーバに Keep-Alive が送られることである。これは次に向かうサーバに誤ってそれを転送するかもしれない。これはKeep-Alive 接続を確立しレスポンスでのクローズを待っている HTTP/1.0 プロキシのハングアップを引き起こすであろう。この結果は HTTP/1.0 クライアントがプロキシと通信するときに Keep-Alive を使用する事を防がれなければならない事である。
しかしながら、プロキシとの通信は永続的な接続のもっとも重要な使用であり、その禁止は明らかに受け入れられない。それゆえ、われわれは Connection を無視する古いプロキシと通信するときに使用しても安全な、永続的な接続が望まれている事を示すためのある別のメカニズムを必要とする。永続的な接続はHTTP/1.1 メッセージのデフォルトである。われわれは非永続性を宣言するための新しいキーワード (Connection: close) を導入する。
以下は永続的な接続のオリジナル HTTP/1.0 形式を表す。
それがオリジンサーバと接続しているとき、HTTP クライアントは Persist connection-token への追加に Keep-Alive connection-token を送るかもしれない:
Connection: Keep-Alive
この時 HTTP/1.0 サーバは Keep-Alive connection token で応答するであろう。そしてクライアントは HTTP/1.0 (もしくは Keep-Alive) 永続的接続を続ける事ができる。
HTTP/1.1 サーバも Keep-Alive connection token を受領した上で HTTP/1.0クライアントに永続的な接続を確立する事ができる。しかしながら、HTTP/1.0クライアントとの永続的な接続は chunked 転送コーディングの使用を行えなく、それゆえそれぞれのメッセージの終了境界をマークするためのContent-Length を使用しなければならない。
クライアントは Connection ヘッダフィールドを解析するための HTTP/1.1 のルールを守らない HTTP/1.0 プロキシサーバのようなプロキシサーバにKeep-Alive connection token を送ってはならない。
19.7.1.1 Keep-Alive ヘッダ
Keep-Alive connection-token がリクエストやレスポンスで伝えられたとき、Keep-Alive ヘッダフィールドも含まれるかもしれない。Keep-Alive ヘッダフィールドは以下のような形式を取る:
Keep-Alive-header = "Keep-Alive" ":" 0# keepalive-param
keepalive-param = param-name "=" value
Keep-Alive ヘッダ自身はオプションであり、パラメータが送られたときのみに使用される。HTTP/1.1 はどんなパラメータも定義しない。
もし Keep-Alive ヘッダが送られたなら、相当する connection token が伝えられなければならない。Keep-Alive ヘッダは connection token なしに受信されたら無視されなければならない。
semantics:セマンティクス (意味論、記号論)。意味的に日本語に相当する言葉はないが、強いて言えば『単純な記号の並びなどに割り当てられる特別な意味』。/ challange:誰何 (すいか)。(番兵や門衛などが見知らぬ人を「だれか?」などと呼びとがめる事) HTTP アクセス認証や内容ネゴシエーションで使用した。/ representation:表現。中に含まれる情報が全く同じでも、データは異なる言語、画像フォーマット、圧縮形式など、さまざまなバリエーションを持つ事ができる点に注意。たとえば何かのグラフを表すのに GIF, JPEG, EPS などの画像フォーマットを使う事が考えられる (もしかしたら ASCII キャラクタ図形かもしれない) し、固有の表計算ソフトで与えられるかもしれない。また、全く同じ画像フォーマットでも圧縮形式が異なるかもしれない。つまり、データの情報が同じでもいくつかの異なる表現で与えられる事がある。/ 1999年6月完訳
