XML Path Language (XPath) 2.0
- このバージョン:
- http://www.w3.org/TR/2007/REC-xpath20-20070123/
- 最新バージョン:
- http://www.w3.org/TR/xpath20/
- 以前のバージョン:
- http://www.w3.org/TR/2006/PR-xpath20-20061121/
- 編者:
- Anders Berglund (XSL WG), IBM Research <alrb@us.ibm.com>
- Scott Boag (XSL WG), IBM Research <scott_boag@us.ibm.com>
- Don Chamberlin (XML Query WG), IBM Almaden Research Center, via http://www.almaden.ibm.com/cs/people/chamberlin/
- Mary F. Fernández (XML Query WG), AT&T Labs <mff@research.att.com>
- Michael Kay (XSL WG), Saxonica, via http://www.saxonica.com/
- Jonathan Robie (XML Query WG), DataDirect Technologies, via http://www.ibiblio.org/jwrobie/
- Jérôme Siméon (XML Query WG), IBM T.J. Watson Research Center <simeon@us.ibm.com>
このドキュメントの最新の訂正を参照してください。これには仕様の修正が含まれて居ます。
翻訳も参照。
このドキュメントは仕様外のフォーマットでも利用可能です: XML.
Copyright © 2007 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C の責任範囲、商標、ドキュメントの適用の規定が適用されます。
概要
XPath 2.0 は [XQuery/XPath Data Model (XDM)] で定義されているデータモデルに則した値の処理を行うことのできる式言語である。データモデルは整数、文字列、ブール代数のような原子値と同じような XML ドキュメントのツリー表現、および XML ドキュメントのノード参照と原子値の両方を含むシーケンスを提供する。XPath 式の結果は入力ドキュメントからのノード選択や原子値、より一般的にはデータモデルで許されるあらゆるシーケンスである。この言語の名前は示差的特長である XML ツリーノードを階層的アドレッシングを意味するパス式に由来する。XPath 2.0 は [XPath 1.0] によりリッチなデータタイプのサポートと、ドキュメントが XML スキーマ検証された時に有効になる型情報の利用機能を追加したスーパーセットである。後方互換モードは XPath 2.0 においてでもほとんど全ての XPath 1.0 式が引き続き同じ結果を示すことを保障するために提供される; この方針に対する例外は [I Backwards Compatibility with XPath 1.0] に記す。
このドキュメントの状態
このセクションでは出版時点でのこの文章の状態を記載している。他の文章がこの文章に取って代わるかもしれない。現在の W3C 出版物一覧とこの技術レポートの最新版は http://www.w3.org/TR/ のW3C technical reports index に存在する。
この文章は勧告へ進んだ 8 つの文章セット (XQuery 1.0, XQueryX 1.0, XSLT 2.0, Data Model, Functions and Operators, Formal Semantics, Serialization, XPath 2.0) のうちの一つである。
この文章は W3C 勧告である。W3C XSL Working Group と W3C XML Query Working Group の共同成果であり、それぞれ XML Activity の一部である。
この文章は W3C メンバー、ソフトウェア開発者、その他 W3C グループおよび関係団体によってレビューされ、ディレクタによって W3C 勧告として支持されている。安定板ドキュメントであり、参考資料や引用として使用することができる。勧告を作成することでの W3C の役割は仕様に注意を促し、広範囲への配布を促進することである。これは Web の機能性と相互操作性を強化する。
この使用に関する Proposed Recommendation からの実質的な変更は行われていない。
このドキュメントの誤りは W3C の public Bugzilla system (http://www.w3.org/XML/2005/04/qt-bugzilla) へ報告してください。もしこのシステムがアクセス可能でないなら W3C XSL/XPath/XQuery パブリックコメントメーリングリスト public-qt-comments@w3.org に報告することもできる。Bugzilla かメールかにかかわらず、報告の表題に“[XPath]”と入れるならそれは非常に役に立つ。それぞれの Bugzilla エントリとメールメッセージは 1 つのエラー報告だけを入れるべきである。報告や応答に関するアーカイブは http://lists.w3.org/Archives/Public/public-qt-comments/ で利用可能である。
この文章は 5 February 2004 W3C Patent Policy の元で作成されている。W3C は XML Query Working Group の配布可能物と関連する public list of any patent disclosures、および XSL Working Group の配布可能物と関連する public list of any patent disclosures も管理する; それらのページは特許を明確にするための指示を含んでいる。Essential Claim(s) を所有していると思っている特許について知識を持つ個人は section 6 of the W3C Patent Policy に従って情報を明らかにしなければならない。
1 イントロダクション
XPath の第一の目的は [XML 1.0] や [XML 1.1] ツリーの一部を指示することである。XPath は XML 文章の階層構造を通じての操作するパス表記法という使用から名付けられている。XPath はコンパクトであり、URI や XML 属性値を含む使用を簡素化する非 XML 構文を使用している。
[定義: XPath は表面的な構文ではなく XML ドキュメントの抽象・論理構造を扱う。データモデルとして知られるこの論理構造は [XQuery/XPath データモデル (XDM)] で定義されている。]
XPath は [XSLT 2.0] や [XQuery] のようなホスト言語に埋め込んで使用できるよう設計されている。XPath はマッチングに使用できる固有のサブセットを持っている (ノードがパターンに一致するかどうかを評価できる)。XPath のこの使用は [XSLT 2.0] で詳述されている。
XQuery バージョン 1.0 は XPath バージョン 2.0 の拡張仕様である。XPath 2.0 と XQuery 1.0 の両方で構文的に正しく正常に実行できるどんな式も両方の言語で同じ結果を返すだろう。これらの言語は密接に関連しているため、一貫性を保障するためにこれらの文法と言語説明は共通のソースから生成されている。またそれらの仕様策定者たちも共に作業している。
XPath も以下の仕様に依存し、そして密接に関わっている:
[XQuery/XPath データモデル (XDM)] はすべての XPath 表記の基礎をなすデータモデルを定義する。
[XQuery 1.0 と XPath 2.0 形式セマンティクス] は XPath の静的セマンティクスを定義し、公式な定義を求める実装者たちに有用な動的セマンティクスの公式 (規定ではないが) 説明を含んでいる。
XPath の型付け機構は[XML Schema] に基づいている。
XPath がサポートしているビルトイン関数ライブラリと演算子は [XQuery 1.0 と XPath 2.0 関数および演算子] で定義されている。
この文章は [XML 1.0] で使用されている基本 EBNF と同じ表記法を用いて記述している。特に明記しない限り (A.2 構文構造参照)、空白文字に表記上の意味はない。構文停止はそれらが記述する特徴と共に導入されている。完全な文法は付録 [A XPath 文法] で示している。付録は normative 版である。
このドキュメントの構文提示において、名前が付けられているシンボルは下線が引かれており、リテラルテキストはダブルクォートで囲まれている。例えば以下の提示は関数呼び出しの構文を記述している:
| [48] | FunctionCall |
::= | QName "(" (ExprSingle ("," ExprSingle)*)? ")" |
この提示は以下のように読む必要がある: 関数呼び出しは、後ろに開き括弧が続く QName で構成される。開き括弧には省略可能な引数リストが続く。(もし指定されるなら) 引数リストはコンマで区切られたひとつ以上の式で構成される。この引数リストは閉じ括弧が続く。
言語処理の特定の局面は、この仕様において実装定義か実装依存として記述される。
[定義: 実装定義は実装間で異なる面があることを示しているが、それぞれ固有実装の実装者によって示されなければならない]
[定義: 実装依存は実装間で異なる面があることを示しており、この仕様やどの W3C 仕様でも定義されず、いかなる固有実装の実装者でも示す必要がない]
この仕様において実装定義や実装依存として記述されている言語局面は XPath が埋め込まれるホスト言語の仕様によって制限を受ける可能性がある。
この文章は XPath の動的セマンティクスを規定的に定義する。XPath の静的セマンティクスは [XQuery 1.0 と XPath 2.0 形式セマンティクス] で規定的に定義されている。この文章で "Note" と付けられている例や資料は説明的な目的で提供しているもので規定するものではない。
2 基本事項
XPath の基本的な材料は [Unicode] 文字の式である (使用される Unicode のバージョンは実装定義)。言語はキーワード、記号、演算子で構成される数種類の式を含むことができる。一般に、式の操作対象は他の式である。XPath は式を完全な短縮形で記述できる。
Note:
この仕様は [Unicode] 文字列の文字セットエンコーディングに関して仮定や必要条件を含みません。
XPath もXML のように大文字と小文字を区別する。XPath のキーワードは小文字であり、非予約語についても、A.3 予約関数名に挙げられた接頭辞の付かない特定の関数名を除いて、XPath 式の名前は言語キーワードと同じであることを許している。
[定義: データモデルにおいて、値はシーケンス (Sequence) を含む] [定義: シーケンスは順序付けられた 0 以上の項目 (Item) である] [定義: 項目は原子値 (Atomic Value) あるいはノード (Node) である] [定義: 原子値は [XML Schema] で定義されている原子型 (Atomic Type) の値空間における値である] [定義: ノードは [XQuery/XPath データモデル (XDM)] で定義されているノード種別 (Node Kind) のひとつのインスタンスである] それぞれのノードはユニークなノード識別 (Node Identify) と型に関連付いた値 (Typed Value)、そして文字列値 (String Value)を持っている。加えていくつかのノードは名前を持っている。ノードの型に関連付いた値は 0 個以上の原子値のシーケンスである。ノードの文字列値は型 xs:string の値である。ノードの名前は型 xs:QName の値である。
[定義: まさに 1 項目のみを含んでいるシーケンスは単体 (Singleton) と呼ばれる] 項目はその項目を含んでいる単体シーケンスと同一である。シーケンスがネストされることはない - 例えば、値 1, (2, 3) と ( ) を単一のシーケンスに結合すると (1, 2, 3) となる。[定義: ひとつも項目を含まないシーケンスは空シーケンスと呼ばれる]
[Definition: The term XDM instance is used, synonymously with the term value, to denote an unconstrained sequence of nodes and/or atomic values in the data model.]
Names in XPath are called QNames, and conform to the syntax in [XML Names]. [Definition: Lexically, a QName consists of an optional namespace prefix and a local name. If the namespace prefix is present, it is separated from the local name by a colon.] A lexical QName can be converted into an expanded QName by resolving its namespace prefix to a namespace URI, using the statically known namespaces [err:XPST0081]. [Definition: An expanded QName consists of an optional namespace URI and a local name. An expanded QName also retains its original namespace prefix (if any), to facilitate casting the expanded QName into a string.] The namespace URI value is whitespace normalized according to the rules for the xs:anyURI type in [XML Schema]. Two expanded QNames are equal if their namespace URIs are equal and their local names are equal (even if their namespace prefixes are not equal). Namespace URIs and local names are compared on a codepoint basis, without further normalization.
This document uses the following namespace prefixes to represent the namespace URIs with which they are listed. Use of these namespace prefix bindings in this document is not normative.
xs = http://www.w3.org/2001/XMLSchemafn = http://www.w3.org/2005/xpath-functionserr = http://www.w3.org/2005/xqt-errors(see 2.3.2 Identifying and Reporting Errors).
Element nodes have a property called in-scope namespaces. [Definition: The in-scope namespaces property of an element node is a set of namespace bindings, each of which associates a namespace prefix with a URI, thus defining the set of namespace prefixes that are available for interpreting QNames within the scope of the element. For a given element, one namespace binding may have an empty prefix; the URI of this namespace binding is the default namespace within the scope of the element.]
In [XPath 1.0], the in-scope namespaces of an element node are represented by a collection of namespace nodes arranged on a namespace axis. In XPath Version 2.0, the namespace axis is deprecated and need not be supported by a host language. A host language that does not support the namespace axis need not represent namespace bindings in the form of nodes.
[Definition: Within this specification, the term URI refers to a Universal Resource Identifier as defined in [RFC3986] and extended in [RFC3987] with the new name IRI.] The term URI has been retained in preference to IRI to avoid introducing new names for concepts such as "Base URI" that are defined or referenced across the whole family of XML specifications.
2.1 式コンテキスト
[Definition: 与えられた式に対する式コンテキストは式の結果に影響するすべての情報で構成されている。] この情報は静的コンテキスト、動的コンテキストと呼ばれる 2 つのカテゴリにまとめられる。.
2.1.1 静的コンテキスト
[Definition: The static context of an expression is the information that is available during static analysis of the expression, prior to its evaluation.] This information can be used to decide whether the expression contains a static error. If analysis of an expression relies on some component of the static context that has not been assigned a value, a static error is raised [err:XPST0001].
The individual components of the static context are summarized below. A default initial value for each component may be specified by the host language. The scope of each component is specified in C.1 Static Context Components.
[Definition: XPath 1.0 compatibility mode. This value is
trueif rules for backward compatibility with XPath Version 1.0 are in effect; otherwise it isfalse.][Definition: Statically known namespaces. This is a set of (prefix, URI) pairs that define all the namespaces that are known during static processing of a given expression.] The URI value is whitespace normalized according to the rules for the
xs:anyURItype in [XML Schema]. Note the difference between in-scope namespaces, which is a dynamic property of an element node, and statically known namespaces, which is a static property of an expression.[Definition: Default element/type namespace. This is a namespace URI or "none". The namespace URI, if present, is used for any unprefixed QName appearing in a position where an element or type name is expected.] The URI value is whitespace normalized according to the rules for the
xs:anyURItype in [XML Schema].[Definition: Default function namespace. This is a namespace URI or "none". The namespace URI, if present, is used for any unprefixed QName appearing in a position where a function name is expected.] The URI value is whitespace normalized according to the rules for the
xs:anyURItype in [XML Schema].[Definition: In-scope schema definitions. This is a generic term for all the element declarations, attribute declarations, and schema type definitions that are in scope during processing of an expression.] It includes the following three parts:
[Definition: In-scope schema types. Each schema type definition is identified either by an expanded QName (for a named type) or by an implementation-dependent type identifier (for an anonymous type). The in-scope schema types include the predefined schema types described in 2.5.1 Predefined Schema Types. ]
[Definition: In-scope element declarations. Each element declaration is identified either by an expanded QName (for a top-level element declaration) or by an implementation-dependent element identifier (for a local element declaration). ] An element declaration includes information about the element's substitution group affiliation.
[Definition: Substitution groups are defined in [XML Schema] Part 1, Section 2.2.2.2. Informally, the substitution group headed by a given element (called the head element) consists of the set of elements that can be substituted for the head element without affecting the outcome of schema validation.]
[Definition: In-scope attribute declarations. Each attribute declaration is identified either by an expanded QName (for a top-level attribute declaration) or by an implementation-dependent attribute identifier (for a local attribute declaration). ]
[Definition: In-scope variables. This is a set of (expanded QName, type) pairs. It defines the set of variables that are available for reference within an expression. The expanded QName is the name of the variable, and the type is the static type of the variable.]
An expression that binds a variable (such as a
for,some, oreveryexpression) extends the in-scope variables of its subexpressions with the new bound variable and its type.[Definition: Context item static type. This component defines the static type of the context item within the scope of a given expression.]
[Definition: Function signatures. This component defines the set of functions that are available to be called from within an expression. Each function is uniquely identified by its expanded QName and its arity (number of parameters).] In addition to the name and arity, each function signature specifies the static types of the function parameters and result.
The function signatures include the signatures of constructor functions, which are discussed in 3.10.4 Constructor Functions.
[Definition: Statically known collations. This is an implementation-defined set of (URI, collation) pairs. It defines the names of the collations that are available for use in processing expressions.] [Definition: A collation is a specification of the manner in which strings and URIs are compared and, by extension, ordered. For a more complete definition of collation, see [XQuery 1.0 and XPath 2.0 Functions and Operators].]
[Definition: Default collation. This identifies one of the collations in statically known collations as the collation to be used by functions and operators for comparing and ordering values of type
xs:stringandxs:anyURI(and types derived from them) when no explicit collation is specified.][Definition: Base URI. This is an absolute URI, used when necessary in the resolution of relative URIs (for example, by the
fn:resolve-urifunction.)] The URI value is whitespace normalized according to the rules for thexs:anyURItype in [XML Schema].[Definition: Statically known documents. This is a mapping from strings onto types. The string represents the absolute URI of a resource that is potentially available using the
fn:docfunction. The type is the static type of a call tofn:docwith the given URI as its literal argument. ] If the argument tofn:docis a string literal that is not present in statically known documents, then the static type offn:docisdocument-node()?.Note:
The purpose of the statically known documents is to provide static type information, not to determine which documents are available. A URI need not be found in the statically known documents to be accessed using
fn:doc.[Definition: Statically known collections. This is a mapping from strings onto types. The string represents the absolute URI of a resource that is potentially available using the
fn:collectionfunction. The type is the type of the sequence of nodes that would result from calling thefn:collectionfunction with this URI as its argument.] If the argument tofn:collectionis a string literal that is not present in statically known collections, then the static type offn:collectionisnode()*.Note:
The purpose of the statically known collections is to provide static type information, not to determine which collections are available. A URI need not be found in the statically known collections to be accessed using
fn:collection.[Definition: Statically known default collection type. This is the type of the sequence of nodes that would result from calling the
fn:collectionfunction with no arguments.] Unless initialized to some other value by an implementation, the value of statically known default collection type isnode()*.
2.1.2 動的コンテキスト
[Definition: The dynamic context of an expression is defined as information that is available at the time the expression is evaluated.] If evaluation of an expression relies on some part of the dynamic context that has not been assigned a value, a dynamic error is raised [err:XPDY0002].
The individual components of the dynamic context are summarized below. Further rules governing the semantics of these components can be found in C.2 Dynamic Context Components.
The dynamic context consists of all the components of the static context, and the additional components listed below.
[Definition: The first three components of the dynamic context (context item, context position, and context size) are called the focus of the expression. ] The focus enables the processor to keep track of which items are being processed by the expression.
Certain language constructs, notably the path expression E1/E2 and the predicate E1[E2], create a new focus for the evaluation of a sub-expression. In these constructs, E2 is evaluated once for each item in the sequence that results from evaluating E1. Each time E2 is evaluated, it is evaluated with a different focus. The focus for evaluating E2 is referred to below as the inner focus, while the focus for evaluating E1 is referred to as the outer focus. The inner focus exists only while E2 is being evaluated. When this evaluation is complete, evaluation of the containing expression continues with its original focus unchanged.
[Definition: The context item is the item currently being processed. An item is either an atomic value or a node.][Definition: When the context item is a node, it can also be referred to as the context node.] The context item is returned by an expression consisting of a single dot (
.). When an expressionE1/E2orE1[E2]is evaluated, each item in the sequence obtained by evaluatingE1becomes the context item in the inner focus for an evaluation ofE2.[Definition: The context position is the position of the context item within the sequence of items currently being processed.] It changes whenever the context item changes. When the focus is defined, the value of the context position is an integer greater than zero. The context position is returned by the expression
fn:position(). When an expressionE1/E2orE1[E2]is evaluated, the context position in the inner focus for an evaluation ofE2is the position of the context item in the sequence obtained by evaluatingE1. The position of the first item in a sequence is always 1 (one). The context position is always less than or equal to the context size.[Definition: The context size is the number of items in the sequence of items currently being processed.] Its value is always an integer greater than zero. The context size is returned by the expression
fn:last(). When an expressionE1/E2orE1[E2]is evaluated, the context size in the inner focus for an evaluation ofE2is the number of items in the sequence obtained by evaluatingE1.[Definition: Variable values. This is a set of (expanded QName, value) pairs. It contains the same expanded QNames as the in-scope variables in the static context for the expression. The expanded QName is the name of the variable and the value is the dynamic value of the variable, which includes its dynamic type.]
[Definition: Function implementations. Each function in function signatures has a function implementation that enables the function to map instances of its parameter types into an instance of its result type. ]
[Definition: Current dateTime. This information represents an implementation-dependent point in time during the processing of an expression, and includes an explicit timezone. It can be retrieved by the
fn:current-dateTimefunction. If invoked multiple times during the execution of an expression, this function always returns the same result.][Definition: Implicit timezone. This is the timezone to be used when a date, time, or dateTime value that does not have a timezone is used in a comparison or arithmetic operation. The implicit timezone is an implementation-defined value of type
xs:dayTimeDuration. See [XML Schema] for the range of legal values of a timezone.][Definition: Available documents. This is a mapping of strings onto document nodes. The string represents the absolute URI of a resource. The document node is the root of a tree that represents that resource using the data model. The document node is returned by the
fn:docfunction when applied to that URI.] The set of available documents is not limited to the set of statically known documents, and it may be empty.If there are one or more URIs in available documents that map to a document node
D, then the document-uri property ofDmust either be absent, or must be one of these URIs.Note:
This means that given a document node
$N, the result offn:doc(fn:document-uri($N)) is $Nwill always be True, unlessfn:document-uri($N)is an empty sequence.[Definition: Available collections. This is a mapping of strings onto sequences of nodes. The string represents the absolute URI of a resource. The sequence of nodes represents the result of the
fn:collectionfunction when that URI is supplied as the argument. ] The set of available collections is not limited to the set of statically known collections, and it may be empty.For every document node
Dthat is in the target of a mapping in available collections, or that is the root of a tree containing such a node, the document-uri property ofDmust either be absent, or must be a URIUsuch that available documents contains a mapping fromUtoD."Note:
This means that for any document node
$Nretrieved using thefn:collectionfunction, either directly or by navigating to the root of a node that was returned, the result offn:doc(fn:document-uri($N)) is $Nwill always be True, unlessfn:document-uri($N)is an empty sequence. This implies a requirement for thefn:docandfn:collectionfunctions to be consistent in their effect. If the implementation uses catalogs or user-supplied URI resolvers to dereference URIs supplied to thefn:docfunction, the implementation of thefn:collectionfunction must take these mechanisms into account. For example, an implementation might achieve this by mapping the collection URI to a set of document URIs, which are then resolved using the same catalog or URI resolver that is used by thefn:docfunction.[Definition: Default collection. This is the sequence of nodes that would result from calling the
fn:collectionfunction with no arguments.] The value of default collection may be initialized by the implementation.
2.2 処理モデル
XPath はデータモデルと式コンテキストに関して定められる。

Figure 1: 処理モデル概要
Figure 1 provides a schematic overview of the processing steps that are discussed in detail below. Some of these steps are completely outside the domain of XPath; in Figure 1, these are depicted outside the line that represents the boundaries of the language, an area labeled external processing. The external processing domain includes generation of an XDM instance that represents the data to be queried (see 2.2.1 Data Model Generation), schema import processing (see 2.2.2 Schema Import Processing) and serialization (see 2.2.4 Serialization). The area inside the boundaries of the language is known as the XPath processing domain, which includes the static analysis and dynamic evaluation phases (see 2.2.3 Expression Processing). Consistency constraints on the XPath processing domain are defined in 2.2.5 Consistency Constraints.
2.2.1 データモデル生成
Before an expression can be processed, its input data must be represented as an XDM instance. This process occurs outside the domain of XPath, which is why Figure 1 represents it in the external processing domain. Here are some steps by which an XML document might be converted to an XDM instance:
A document may be parsed using an XML parser that generates an XML Information Set (see [XML Infoset]). The parsed document may then be validated against one or more schemas. This process, which is described in [XML Schema], results in an abstract information structure called the Post-Schema Validation Infoset (PSVI). If a document has no associated schema, its Information Set is preserved. (See DM1 in Fig. 1.)
The Information Set or PSVI may be transformed into an XDM instance by a process described in [XQuery/XPath Data Model (XDM)]. (See DM2 in Fig. 1.)
The above steps provide an example of how an XDM instance might be constructed. An XDM instance might also be synthesized directly from a relational database, or constructed in some other way (see DM3 in Fig. 1.) XPath is defined in terms of the data model, but it does not place any constraints on how XDM instances are constructed.
[Definition: Each element node and attribute node in an XDM instance has a type annotation (referred to in [XQuery/XPath Data Model (XDM)] as its type-name property.) The type annotation of a node is a schema type that describes the relationship between the string value of the node and its typed value.] If the XDM instance was derived from a validated XML document as described in Section 3.3 Construction from a PSVIDM, the type annotations of the element and attribute nodes are derived from schema validation. XPath does not provide a way to directly access the type annotation of an element or attribute node.
The value of an attribute is represented directly within the attribute node. An attribute node whose type is unknown (such as might occur in a schemaless document) is given the type annotation xs:untypedAtomic.
The value of an element is represented by the children of the element node, which may include text nodes and other element nodes. The type annotation of an element node indicates how the values in its child text nodes are to be interpreted. An element that has not been validated (such as might occur in a schemaless document) is annotated with the schema type xs:untyped. An element that has been validated and found to be partially valid is annotated with the schema type xs:anyType. If an element node is annotated as xs:untyped, all its descendant element nodes are also annotated as xs:untyped. However, if an element node is annotated as xs:anyType, some of its descendant element nodes may have a more specific type annotation.
2.2.2 スキーマインポート処理
The in-scope schema definitions in the static context are provided by the host language (see step SI1 in Figure 1) and must satisfy the consistency constraints defined in 2.2.5 Consistency Constraints.
2.2.3 式処理
XPath defines two phases of processing called the static analysis phase and the dynamic evaluation phase (see Fig. 1). During the static analysis phase, static errors, dynamic errors, or type errors may be raised. During the dynamic evaluation phase, only dynamic errors or type errors may be raised. These kinds of errors are defined in 2.3.1 Kinds of Errors.
Within each phase, an implementation is free to use any strategy or algorithm whose result conforms to the specifications in this document.
2.2.3.1 Static Analysis Phase
[Definition: The static analysis phase depends on the expression itself and on the static context. The static analysis phase does not depend on input data (other than schemas).]
During the static analysis phase, the XPath expression is parsed into an internal representation called the operation tree (step SQ1 in Figure 1). A parse error is raised as a static error [err:XPST0003]. The static context is initialized by the implementation (step SQ2). The static context is used to resolve schema type names, function names, namespace prefixes, and variable names (step SQ4). If a name of one of these kinds in the operation tree is not found in the static context, a static error ([err:XPST0008] or [err:XPST0017]) is raised (however, see exceptions to this rule in 2.5.4.3 Element Test and 2.5.4.5 Attribute Test.)
The operation tree is then normalized by making explicit the implicit operations such as atomization and extraction of 有効ブール値s (step SQ5). The normalization process is described in [XQuery 1.0 and XPath 2.0 Formal Semantics].
Each expression is then assigned a static type (step SQ6). [Definition: The static type of an expression is a type such that, when the expression is evaluated, the resulting value will always conform to the static type.] If the Static Typing Feature is supported, the static types of various expressions are inferred according to the rules described in [XQuery 1.0 and XPath 2.0 Formal Semantics]. If the Static Typing Feature is not supported, the static types that are assigned are implementation-dependent.
During the static analysis phase, if the Static Typing Feature is in effect and an operand of an expression is found to have a static type that is not appropriate for that operand, a type error is raised [err:XPTY0004]. If static type checking raises no errors and assigns a static type T to an expression, then execution of the expression on valid input data is guaranteed either to produce a value of type T or to raise a dynamic error.
The purpose of the Static Typing Feature is to provide early detection of type errors and to infer type information that may be useful in optimizing the evaluation of an expression.
2.2.3.2 Dynamic Evaluation Phase
[Definition: The dynamic evaluation phase is the phase during which the value of an expression is computed.] It occurs after completion of the static analysis phase.
The dynamic evaluation phase can occur only if no errors were detected during the static analysis phase. If the Static Typing Feature is in effect, all type errors are detected during static analysis and serve to inhibit the dynamic evaluation phase.
The dynamic evaluation phase depends on the operation tree of the expression being evaluated (step DQ1), on the input data (step DQ4), and on the dynamic context (step DQ5), which in turn draws information from the external environment (step DQ3) and the static context (step DQ2). The dynamic evaluation phase may create new data-model values (step DQ4) and it may extend the dynamic context (step DQ5)—for example, by binding values to variables.
[Definition: A dynamic type is associated with each value as it is computed. The dynamic type of a value may be more specific than the static type of the expression that computed it (for example, the static type of an expression might be xs:integer*, denoting a sequence of zero or more integers, but at evaluation time its value may have the dynamic type xs:integer, denoting exactly one integer.)]
If an operand of an expression is found to have a dynamic type that is not appropriate for that operand, a type error is raised [err:XPTY0004].
Even though static typing can catch many type errors before an expression is executed, it is possible for an expression to raise an error during evaluation that was not detected by static analysis. For example, an expression may contain a cast of a string into an integer, which is statically valid. However, if the actual value of the string at run time cannot be cast into an integer, a dynamic error will result. Similarly, an expression may apply an arithmetic operator to a value whose static type is xs:untypedAtomic. This is not a static error, but at run time, if the value cannot be successfully cast to a numeric type, a dynamic error will be raised.
When the Static Typing Feature is in effect, it is also possible for static analysis of an expression to raise a type error, even though execution of the expression on certain inputs would be successful. For example, an expression might contain a function that requires an element as its parameter, and the static analysis phase might infer the static type of the function parameter to be an optional element. This case is treated as a type error and inhibits evaluation, even though the function call would have been successful for input data in which the optional element is present.
2.2.4 直列化
[Definition: Serialization is the process of converting an XDM instance into a sequence of octets (step DM4 in Figure 1.) ] The general framework for serialization is described in [XSLT 2.0 and XQuery 1.0 Serialization].
The host language may provide a serialization option.
2.2.5 一貫性制約
In order for XPath to be well defined, the input XDM instance, the static context, and the dynamic context must be mutually consistent. The consistency constraints listed below are prerequisites for correct functioning of an XPath implementation. Enforcement of these consistency constraints is beyond the scope of this specification. This specification does not define the result of an expression under any condition in which one or more of these constraints is not satisfied.
Some of the consistency constraints use the term data model schema. [Definition: For a given node in an XDM instance, the data model schema is defined as the schema from which the type annotation of that node was derived.] For a node that was constructed by some process other than schema validation, the data model schema consists simply of the schema type definition that is represented by the type annotation of the node.
For every node that has a type annotation, if that type annotation is found in the in-scope schema definitions (ISSD), then its definition in the ISSD must be equivalent to its definition in the data model schema. Furthermore, all types that are derived by extension from the given type in the data model schema must also be known by equivalent definitions in the ISSD.
For every element name EN that is found both in an XDM instance and in the in-scope schema definitions (ISSD), all elements that are known in the data model schema to be in the substitution group headed by EN must also be known in the ISSD to be in the substitution group headed by EN.
Every element name, attribute name, or schema type name referenced in in-scope variables or function signatures must be in the in-scope schema definitions, unless it is an element name referenced as part of an ElementTest or an attribute name referenced as part of an AttributeTest.
Any reference to a global element, attribute, or type name in the in-scope schema definitions must have a corresponding element, attribute or type definition in the in-scope schema definitions.
For each mapping of a string to a document node in available documents, if there exists a mapping of the same string to a document type in statically known documents, the document node must match the document type, using the matching rules in 2.5.4 SequenceType Matching.
For each mapping of a string to a sequence of nodes in available collections, if there exists a mapping of the same string to a type in statically known collections, the sequence of nodes must match the type, using the matching rules in 2.5.4 SequenceType Matching.
The sequence of nodes in the default collection must match the statically known default collection type, using the matching rules in 2.5.4 SequenceType Matching.
The value of the context item must match the context item static type, using the matching rules in 2.5.4 SequenceType Matching.
For each (variable, type) pair in in-scope variables and the corresponding (variable, value) pair in variable values such that the variable names are equal, the value must match the type, using the matching rules in 2.5.4 SequenceType Matching.
In the statically known namespaces, the prefix
xmlmust not be bound to any namespace URI other thanhttp://www.w3.org/XML/1998/namespace, and no prefix other thanxmlmay be bound to this namespace URI.
2.3 エラー処理
2.3.1 エラーの種類
As described in 2.2.3 Expression Processing, XPath defines a static analysis phase, which does not depend on input data, and a dynamic evaluation phase, which does depend on input data. Errors may be raised during each phase.
[Definition: A static error is an error that must be detected during the static analysis phase. A syntax error is an example of a static error.]
[Definition: A dynamic error is an error that must be detected during the dynamic evaluation phase and may be detected during the static analysis phase. Numeric overflow is an example of a dynamic error. ]
[Definition: A type error may be raised during the static analysis phase or the dynamic evaluation phase. During the static analysis phase, a type error occurs when the static type of an expression does not match the expected type of the context in which the expression occurs. During the dynamic evaluation phase, a type error occurs when the dynamic type of a value does not match the expected type of the context in which the value occurs.]
The outcome of the static analysis phase is either success or one or more type errors, static errors, or statically-detected dynamic errors. The result of the dynamic evaluation phase is either a result value, a type error, or a dynamic error.
If more than one error is present, or if an error condition comes within the scope of more than one error defined in this specification, then any non-empty subset of these errors may be reported.
During the static analysis phase, if the Static Typing Feature is in effect and the static type assigned to an expression other than () or data(()) is empty-sequence(), a static error is raised [err:XPST0005]. This catches cases in which a query refers to an element or attribute that is not present in the in-scope schema definitions, possibly because of a spelling error.
Independently of whether the Static Typing Feature is in effect, if an implementation can determine during the static analysis phase that an expression, if evaluated, would necessarily raise a type error or a dynamic error, the implementation may (but is not required to) report that error during the static analysis phase. However, the fn:error() function must not be evaluated during the static analysis phase.
[Definition: In addition to static errors, dynamic errors, and type errors, an XPath implementation may raise warnings, either during the static analysis phase or the dynamic evaluation phase. The circumstances in which warnings are raised, and the ways in which warnings are handled, are implementation-defined.]
In addition to the errors defined in this specification, an implementation may raise a dynamic error for a reason beyond the scope of this specification. For example, limitations may exist on the maximum numbers or sizes of various objects. Any such limitations, and the consequences of exceeding them, are implementation-dependent.
2.3.2 エラーの報告と識別
The errors defined in this specification are identified by QNames that have the form err:XPYYnnnn, where:
errdenotes the namespace for XPath and XQuery errors,http://www.w3.org/2005/xqt-errors. This binding of the namespace prefixerris used for convenience in this document, and is not normative.XPidentifies the error as an XPath error.YYdenotes the error category, using the following encoding:STdenotes a static error.DYdenotes a dynamic error.TYdenotes a type error.
nnnnis a unique numeric code.
Note:
The namespace URI for XPath and XQuery errors is not expected to change from one version of XPath to another. However, the contents of this namespace may be extended to include additional error definitions.
The method by which an XPath processor reports error information to the external environment is implementation-defined.
An error can be represented by a URI reference that is derived from the error QName as follows: an error with namespace URI NS and local part LP can be represented as the URI reference NS#LP. For example, an error whose QName is err:XPST0017 could be represented as http://www.w3.org/2005/xqt-errors#XPST0017.
Note:
Along with a code identifying an error, implementations may wish to return additional information, such as the location of the error or the processing phase in which it was detected. If an implementation chooses to do so, then the mechanism that it uses to return this information is implementation-defined.
2.3.3 動的エラーの処理
Except as noted in this document, if any operand of an expression raises a dynamic error, the expression also raises a dynamic error. If an expression can validly return a value or raise a dynamic error, the implementation may choose to return the value or raise the dynamic error. For example, the logical expression expr1 and expr2 may return the value false if either operand returns false, or may raise a dynamic error if either operand raises a dynamic error.
If more than one operand of an expression raises an error, the implementation may choose which error is raised by the expression. For example, in this expression:
($x div $y) + xs:decimal($z)
both the sub-expressions ($x div $y) and xs:decimal($z) may raise an error. The implementation may choose which error is raised by the "+" expression. Once one operand raises an error, the implementation is not required, but is permitted, to evaluate any other operands.
[Definition: In addition to its identifying QName, a dynamic error may also carry a descriptive string and one or more additional values called error values.] An implementation may provide a mechanism whereby an application-defined error handler can process error values and produce diagnostic messages.
A dynamic error may be raised by a built-in function or operator. For example, the div operator raises an error if its operands are xs:decimal values and its second operand is equal to zero. Errors raised by built-in functions and operators are defined in [XQuery 1.0 and XPath 2.0 Functions and Operators].
A dynamic error can also be raised explicitly by calling the fn:error function, which only raises an error and never returns a value. This function is defined in [XQuery 1.0 and XPath 2.0 Functions and Operators]. For example, the following function call raises a dynamic error, providing a QName that identifies the error, a descriptive string, and a diagnostic value (assuming that the prefix app is bound to a namespace containing application-defined error codes):
fn:error(xs:QName("app:err057"), "Unexpected value", fn:string($v))
2.3.4 エラーと最適化
Because different implementations may choose to evaluate or optimize an expression in different ways, certain aspects of the detection and reporting of dynamic errors are implementation-dependent, as described in this section.
An implementation is always free to evaluate the operands of an operator in any order.
In some cases, a processor can determine the result of an expression without accessing all the data that would be implied by the formal expression semantics. For example, the formal description of filter expressions suggests that $s[1] should be evaluated by examining all the items in sequence $s, and selecting all those that satisfy the predicate position()=1. In practice, many implementations will recognize that they can evaluate this expression by taking the first item in the sequence and then exiting. If $s is defined by an expression such as //book[author eq 'Berners-Lee'], then this strategy may avoid a complete scan of a large document and may therefore greatly improve performance. However, a consequence of this strategy is that a dynamic error or type error that would be detected if the expression semantics were followed literally might not be detected at all if the evaluation exits early. In this example, such an error might occur if there is a book element in the input data with more than one author subelement.
The extent to which a processor may optimize its access to data, at the cost of not detecting errors, is defined by the following rules.
Consider an expression Q that has an operand (sub-expression) E. In general the value of E is a sequence. At an intermediate stage during evaluation of the sequence, some of its items will be known and others will be unknown. If, at such an intermediate stage of evaluation, a processor is able to establish that there are only two possible outcomes of evaluating Q, namely the value V or an error, then the processor may deliver the result V without evaluating further items in the operand E. For this purpose, two values are considered to represent the same outcome if their items are pairwise the same, where nodes are the same if they have the same identity, and values are the same if they are equal and have exactly the same type.
There is an exception to this rule: If a processor evaluates an operand E (wholly or in part), then it is required to establish that the actual value of the operand E does not violate any constraints on its cardinality. For example, the expression $e eq 0 results in a type error if the value of $e contains two or more items. A processor is not allowed to decide, after evaluating the first item in the value of $e and finding it equal to zero, that the only possible outcomes are the value true or a type error caused by the cardinality violation. It must establish that the value of $e contains no more than one item.
These rules apply to all the operands of an expression considered in combination: thus if an expression has two operands E1 and E2, it may be evaluated using any samples of the respective sequences that satisfy the above rules.
The rules cascade: if A is an operand of B and B is an operand of C, then the processor needs to evaluate only a sufficient sample of B to determine the value of C, and needs to evaluate only a sufficient sample of A to determine this sample of B.
The effect of these rules is that the processor is free to stop examining further items in a sequence as soon as it can establish that further items would not affect the result except possibly by causing an error. For example, the processor may return true as the result of the expression S1 = S2 as soon as it finds a pair of equal values from the two sequences.
Another consequence of these rules is that where none of the items in a sequence contributes to the result of an expression, the processor is not obliged to evaluate any part of the sequence. Again, however, the processor cannot dispense with a required cardinality check: if an empty sequence is not permitted in the relevant context, then the processor must ensure that the operand is not an empty sequence.
Examples:
If an implementation can find (for example, by using an index) that at least one item returned by
$expr1in the following example has the value47, it is allowed to returntrueas the result of thesomeexpression, without searching for another item returned by$expr1that would raise an error if it were evaluated.some $x in $expr1 satisfies $x = 47
In the following example, if an implementation can find (for example, by using an index) the
productelement-nodes that have anidchild with the value47, it is allowed to return these nodes as the result of the path expression, without searching for anotherproductnode that would raise an error because it has anidchild whose value is not an integer.//product[id = 47]
For a variety of reasons, including optimization, implementations are free to rewrite expressions into equivalent expressions. Other than the raising or not raising of errors, the result of evaluating an equivalent expression must be the same as the result of evaluating the original expression. Expression rewrite is illustrated by the following examples.
Consider the expression
//part[color eq "Red"]. An implementation might choose to rewrite this expression as//part[color = "Red"][color eq "Red"]. The implementation might then process the expression as follows: First process the "=" predicate by probing an index on parts by color to quickly find all the parts that have a Red color; then process the "eq" predicate by checking each of these parts to make sure it has only a single color. The result would be as follows:Parts that have exactly one color that is Red are returned.
If some part has color Red together with some other color, an error is raised.
The existence of some part that has no color Red but has multiple non-Red colors does not trigger an error.
The expression in the following example cannot raise a casting error if it is evaluated exactly as written (i.e., left to right). Since neither predicate depends on the context position, an implementation might choose to reorder the predicates to achieve better performance (for example, by taking advantage of an index). This reordering could cause the expression to raise an error.
$N[@x castable as xs:date][xs:date(@x) gt xs:date("2000-01-01")]To avoid unexpected errors caused by expression rewrite, tests that are designed to prevent dynamic errors should be expressed using conditional expressions. Conditional expressions raise only dynamic errors that occur in the branch that is actually selected. Thus, unlike the previous example, the following example cannot raise a dynamic error if
@xis not castable into anxs:date:$N[if (@x castable as xs:date) then xs:date(@x) gt xs:date("2000-01-01") else false()]
2.4 コンセプト
このセクションでは XPath 式の処理において重要ないくつかの考え方を説明する。
2.4.1 ドキュメント順序
An ordering called document order is defined among all the nodes accessible during processing of a given expression, which may consist of one or more trees (documents or fragments). Document order is defined in [XQuery/XPath Data Model (XDM)], and its definition is repeated here for convenience. [Definition: The node ordering that is the reverse of document order is called reverse document order.]
Document order is a total ordering, although the relative order of some nodes is implementation-dependent. [Definition: Informally, document order is the order in which nodes appear in the XML serialization of a document.] [Definition: Document order is stable, which means that the relative order of two nodes will not change during the processing of a given expression, even if this order is implementation-dependent.]
Within a tree, document order satisfies the following constraints:
The root node is the first node.
Every node occurs before all of its children and descendants.
Namespace nodes immediately follow the element node with which they are associated. The relative order of namespace nodes is stable but implementation-dependent.
Attribute nodes immediately follow the namespace nodes of the element node with which they are associated. The relative order of attribute nodes is stable but implementation-dependent.
The relative order of siblings is the order in which they occur in the
childrenproperty of their parent node.Children and descendants occur before following siblings.
The relative order of nodes in distinct trees is stable but implementation-dependent, subject to the following constraint: If any node in a given tree T1 is before any node in a different tree T2, then all nodes in tree T1 are before all nodes in tree T2.
2.4.2 原子化
The semantics of some XPath operators depend on a process called atomization. Atomization is applied to a value when the value is used in a context in which a sequence of atomic values is required. The result of atomization is either a sequence of atomic values or a type error [err:FOTY0012]. [Definition: Atomization of a sequence is defined as the result of invoking the fn:data function on the sequence, as defined in [XQuery 1.0 and XPath 2.0 Functions and Operators].]
The semantics of fn:data are repeated here for convenience. The result of fn:data is the sequence of atomic values produced by applying the following rules to each item in the input sequence:
If the item is an atomic value, it is returned.
If the item is a node, its typed value is returned (err:FOTY0012 is raised if the node has no typed value.)
Atomization is used in processing the following types of expressions:
Arithmetic expressions
Comparison expressions
Function calls and returns
Cast expressions
2.4.3 効果的なブール値
Under certain circumstances (listed below), it is necessary to find the 有効ブール値 of a value. [Definition: The 有効ブール値 of a value is defined as the result of applying the fn:boolean function to the value, as defined in [XQuery 1.0 and XPath 2.0 Functions and Operators].]
The dynamic semantics of fn:boolean are repeated here for convenience:
If its operand is an empty sequence,
fn:booleanreturnsfalse.If its operand is a sequence whose first item is a node,
fn:booleanreturnstrue.If its operand is a singleton value of type
xs:booleanor derived fromxs:boolean,fn:booleanreturns the value of its operand unchanged.If its operand is a singleton value of type
xs:string,xs:anyURI,xs:untypedAtomic, or a type derived from one of these,fn:booleanreturnsfalseif the operand value has zero length; otherwise it returnstrue.If its operand is a singleton value of any numeric type or derived from a numeric type,
fn:booleanreturnsfalseif the operand value isNaNor is numerically equal to zero; otherwise it returnstrue.In all other cases,
fn:booleanraises a type error [err:FORG0006].
Note:
The static semantics of fn:boolean are defined in Section 7.2.4 The fn:boolean functionFS.
The 有効ブール値 of a sequence is computed implicitly during processing of the following types of expressions:
Logical expressions (
and,or)The
fn:notfunctionCertain types of predicates, such as
a[b]Conditional expressions (
if)Quantified expressions (
some,every)General comparisons, in XPath 1.0 compatibility mode.
Note:
The definition of 有効ブール値 is not used when casting a value to the type xs:boolean, for example in a cast expression or when passing a value to a function whose expected parameter is of type xs:boolean.
2.4.4 入力ソース
XPath has a set of functions that provide access to input data. These functions are of particular importance because they provide a way in which an expression can reference a document or a collection of documents. The input functions are described informally here; they are defined in [XQuery 1.0 and XPath 2.0 Functions and Operators].
An expression can access input data either by calling one of the input functions or by referencing some part of the dynamic context that is initialized by the external environment, such as a variable or context item.
The input functions supported by XPath are as follows:
The
fn:docfunction takes a string containing a URI. If that URI is associated with a document in available documents,fn:docreturns a document node whose content is the data model representation of the given document; otherwise it raises a dynamic error (see [XQuery 1.0 and XPath 2.0 Functions and Operators] for details).The
fn:collectionfunction with one argument takes a string containing a URI. If that URI is associated with a collection in available collections,fn:collectionreturns the data model representation of that collection; otherwise it raises a dynamic error (see [XQuery 1.0 and XPath 2.0 Functions and Operators] for details). A collection may be any sequence of nodes. For example, the expressionfn:collection("http://example.org")//customeridentifies all thecustomerelements that are descendants of nodes found in the collection whose URI ishttp://example.org.The
fn:collectionfunction with zero arguments returns the default collection, an implementation-dependent sequence of nodes.
2.5 型
The type system of XPath is based on [XML Schema], and is formally defined in [XQuery 1.0 and XPath 2.0 Formal Semantics].
[Definition: A sequence type is a type that can be expressed using the SequenceType syntax. Sequence types are used whenever it is necessary to refer to a type in an XPath expression. The term sequence type suggests that this syntax is used to describe the type of an XPath value, which is always a sequence.]
[Definition: A schema type is a type that is (or could be) defined using the facilities of [XML Schema] (including the built-in types of [XML Schema]).] A schema type can be used as a type annotation on an element or attribute node (unless it is a non-instantiable type such as xs:NOTATION or xs:anyAtomicType, in which case its derived types can be so used). Every schema type is either a complex type or a simple type; simple types are further subdivided into list types, union types, and atomic types (see [XML Schema] for definitions and explanations of these terms.)
Atomic types represent the intersection between the categories of sequence type and schema type. An atomic type, such as xs:integer or my:hatsize, is both a sequence type and a schema type.
2.5.1 事前定義済みスキーマ型
The in-scope schema types in the static context are initialized with a set of predefined schema types that is determined by the host language. This set may include some or all of the schema types in the namespace http://www.w3.org/2001/XMLSchema, represented in this document by the namespace prefix xs. The schema types in this namespace are defined in [XML Schema] and augmented by additional types defined in [XQuery/XPath Data Model (XDM)]. The schema types defined in [XQuery/XPath Data Model (XDM)] are summarized below.
[Definition:
xs:untypedis used as the type annotation of an element node that has not been validated, or has been validated inskipmode.] No predefined schema types are derived fromxs:untyped.[Definition:
xs:untypedAtomicis an atomic type that is used to denote untyped atomic data, such as text that has not been assigned a more specific type.] An attribute that has been validated inskipmode is represented in the data model by an attribute node with the type annotationxs:untypedAtomic. No predefined schema types are derived fromxs:untypedAtomic.[Definition:
xs:dayTimeDurationis derived by restriction fromxs:duration. The lexical representation ofxs:dayTimeDurationis restricted to contain only day, hour, minute, and second components.][Definition:
xs:yearMonthDurationis derived by restriction fromxs:duration. The lexical representation ofxs:yearMonthDurationis restricted to contain only year and month components.][Definition:
xs:anyAtomicTypeis an atomic type that includes all atomic values (and no values that are not atomic). Its base type isxs:anySimpleTypefrom which all simple types, including atomic, list, and union types, are derived. All primitive atomic types, such asxs:integer,xs:string, andxs:untypedAtomic, havexs:anyAtomicTypeas their base type.]Note:
xs:anyAtomicTypewill not appear as the type of an actual value in an XDM instance.
The relationships among the schema types in the xs namespace are illustrated in Figure 2. A more complete description of the XPath type hierarchy can be found in [XQuery 1.0 and XPath 2.0 Functions and Operators].
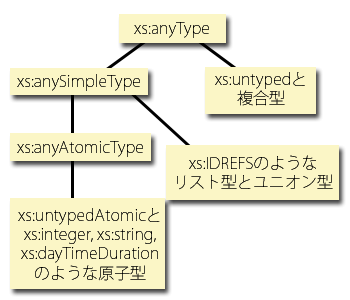
図 2: XPath で使用されているスキーマ階層
2.5.2 型に関連付けられた値と文字列値
あらゆるノードは型に関連付けられた値 (Typed Value) と文字列値 (String Value) を持つ。[定義: ノードの型に関連付けられた値とは原子値のシーケンスであり、ノードに fn:data 関数を適用することで取り出すことができる。] [定義: ノードの文字列値は文字列であり、ノードに fn:string を適用することによって取り出す事ができる。] fn:data と fn:string の定義は [XQuery 1.0 と XPath 2.0 関数および演算子] で行っている。
実装はノードの型に関連付けられた値と文字列値の両方を保持するかもしれないし、それらのうちの一つだけを保持しておいて他は必要に応じて取り出すかもしれない。ノードの文字列値はノードの型に関連付けられた値の有効な語彙式 (lexical representation) でなければならないが、ノードは元のソース文章からの文字列式を持ち続ける必要はない。例えば、ノードの型に関連付けられた値が xs:integer 値 30 であるなら、その文字列値は "30" または "0030" であろう。
ノードの型に関連付けられた値、文字列値、型注釈は密接に関連している。もしノードが Infoset や PSVI からのマッピングによって構築されたなら、これらの特性間の関係は [XQuery/XPath データモデル (XDM)] 規則によって定義される。
読者への便宜として、さまざまな種類のノードに対する型に関連付けられた値と文字列値の関係を下記でまとめて例示する。
テキストやドキュメントノードに対して
xs:untypedAtomic型のインスタンスとしてノードの型に関連付けられた値はその文字列値と等しい。ドキュメントノードの文字列値はそのすべての子孫テキストノードの文字列値をドキュメントで結合して作り出される。コメント、名前空間および処理命令ノードの型に関連付けられた値はその文字列値と同じである。これは
xs:string型のインスタンスである。型注釈に
xs:anySimpleTypeまたはxs:untypedAtomicが付属する属性ノードの型に関連付けられた値はxs:untypedAtomicのインスタンスとしてその文字列値と同じである。それ以外の型注釈が付けられた属性ノードの型に関連付けられた値は、関連した型に対して [XML Schema] Part 2 で定義されている lexical-to-value-space マッピングを使用している文字列値と型注釈から派生している。例: A1 は文字列値
"3.14E-2"を持つ属性であり型注釈がxs:doubleである。A1 の型に関連付けられた値はその論理式が3.14E-2であるxs:double値となる。例: A2 は型注釈
xs:IDREFSの付けられた属性であり、それは原子データ型xs:IDREFのリストデータ型である。その文字列値が "bar baz faz" である。A2 の型に関連付けられた値はxs:IDREF型の 3 つの原子値のシーケンス ("bar", "baz", "faz") である。ノードの型に関連付けられた値が named リスト型のインスタンスと扱われることは決してないが、もしノードの型注釈がリスト型なら (xs:IDREFSのような)、その型に関連付けられた値は由来する原子型のシーケンスとして扱われる (xs:IDREFのような)。要素ノードに対して、型に関連付けられた値と文字列値との関係は以下のようにノードの型注釈に依存している:
型注釈が
xs:untyped、xs:anySimpleTypeまたは混合内容 (xs:anyTypeを含む) の複合型の場合、ノード型に関連付けられた値はその文字列値と等しいxs:untypedAtomicのインスタンスとなる。ただし、ノードのnilledプロパティがtrueならその型に関連付けられた値は空シーケンスである。例: E1 は型注釈
xs:untypedで文字列値 "1999-05-31" を持つ要素ノードである。E1 の型に関連付けられた値は "1999-05-31" となるxs:untypedAtomicのインスタンスである。例: E2 は型注釈
formulaを持つ要素ノードであり、混合内容の複合型である。E2 の内容は文字 "H"、内容に文字列値 "2" を持つsubscriptという名前の子要素、文字 "O" で構成されている。E2 の型に関連付けられた値は "H2O" というxs:untypedAtomicのインスタンスである。型注釈が単純型 (simple type)、あるいは単純内容 (simple content) を持つ複合型 (complex type) ならば、ノードの型に関連付けられた値はその文字列値とスキーマ検証と一致している型注釈に由来している。ただし
nilledプロパティにtrueが設定されているなら型に関連付けられた値は空シーケンスとなる。例: E3 は
cost型注釈を持つ要素ノードであり、いくつかの属性とxs:decimalの簡単な型を持つ複合型である。E3 の文字列値は74.95である。E3 の型に関連付けられた値はxs:decimalインスタンスの74.95である。例: E4 は原子型
hatsizeから単純に派生したhatsizelist型注釈を持つ要素ノードであり、さらにそれはxs:integerから派生している。E4 の文字列値は "7 8 9" である。E4 の型に関連付けられた値は 3 つの値 (7,8,9) のシーケンスであり、それぞれの型はhatsizeである。例: E5 は
xs:integerとxs:string型メンバを持つユニオン型のmy:integer-or-string型注釈要素ノードである。E5 の文字列値が "47" の時、xs:inegerが E5 の内容として有効なメンバ型のため、E5 の型に関連付けられた値はxs:integerの47である。一般に、ノードの型注釈がユニオン型の場合、ノードの型に関連付けられた値はユニオンメンバ型の一つのインスタンスとなるだろう。Note:
もし実装がノードの文字列値のみを保持し、ノードの型注釈がユニオン型であるなら、実装は適切なメンバ型のインスタンスとしてノードの型に関連付けられた値を変換できなければならない。
もし型注釈が空の内容を持つ複合型を示すなら、ノードの型に関連付けられた値は空のシーケンスであり、文字列値は長さ 0 の文字列である。
もし型注釈が要素のみの内容を持つ複合型を示している場合、ノードの型に関連付けられた値は未定義である。
fn:data関数がそのようなノードに適用された場合、型エラー [err:FOTY0012] が発生する。そのようなノードの文字列値は、そのすべての子孫テキストノードをドキュメント順序で連結した文字列値と等しい。例: E6 は
element-onlyと指定された内容型の複合型を持つ型注釈weatherの要素ノードである。E6 はtemprture(気温) とprecipitation(降水量) という名前の 2 つの要素を持っている。このとき E6 の型に関連付けられた値は未定義であり、E6 へのfn:data関数の適用はエラーとなる。
2.5.3 SequenceType 構文
XPath 式では、型を参照する必要があるときはいつでも SequenceType 構文が使用される。
特別な型 empty-sequence() を除いて、シーケンス型はシーケンスの項目それぞれの型を制約する項目方 (Item Type) と、シーケンス内での項目の数を制約する要素数 (Cardinality) で構成されている。どのような種類の項目でも許可する item() 型項目は別として、項目型は (element() のような) ノード型 (Node Type)、または (xs:integer のような) 原子型 (Atomic Type) に分けられる。
要素と属性ノードを表している項目型は、スキーマ型の形式でこれらのノードの必須型注釈を指定することができる。従って、項目型 element(*, us:address) は型注釈 us:address という名前のスキーマ型である (あるいはそれから派生した) どの要素ノードも表している。
ここで XPath 式で使用される可能性のあるシーケンス型のいくつかの例を挙げる:
xs:dateはxs:dateという名前のビルトイン原子スキーマ型を参照するattribute()?は省略可能な属性ノードを参照するelement()任意数の要素ノードを参照するelement(po:shipto, po:address)はpo:shiptoという名前でpo:addressという型注釈 (またはpo:addressから派生したスキーマ型) を持つ一つの要素ノードを参照するelement(*, po:address)は任意の名前でpo:addressという型注釈 (またはpo:addressから派生したスキーマ型) を持つ一つの要素ノードを参照するelement(customer)はcustomerという名前で任意の型注釈を持つ一つの要素ノードを参照するschema-element(customer)は、customerという名前 (またはcustomerから始まる置換 (代理? Substitution) グループ) で、スコープ内要素宣言のcustomer要素に対して宣言されているスキーマ型と一致する型注釈を持つ要素ノードを参照するnode()*は任意の種類で 0 個以上のノードのシーケンスを参照するitem()+は 1 つ以上の原子値のシーケンスを参照する
2.5.4 SequenceType マッチング
[定義: 式を評価している時、しばしば既知の動的型を持つ値が期待するシーケンス型と "一致" しているかどうかを評価する必要性が出てくる。この処理はSequeceType マッチング (SequenceType Matching) と言う。] 例えば instance of 式は、与えられた値の動的型が与えられたシーケンス型と一致する場合 true を返すし、そうでなければ false を返す。
シーケンス型に出現する QName は、静的で既知の名前空間と (該当するなら) デフォルトの要素/型名前空間によって、名前空間 URI に展開される接頭辞を持っている。接頭辞の付けられていない属性 QName は特定の名前空間には所属しない。QName の等価性は eq 演算子によって定義される。
SequenceType マッチングの規則は、値の動的型と、それから期待するシーケンス型とを比較する。これらの規則は、Formal Semantics が値に対して SequenceType 構文を使用して式できない型と比較できなければいけないため、[XQuery 1.0 and XPath 2.0 Formal Semantics] で定義されている予期した型の値に一致する公式規則のサブセットである。
SequenceType マッチングに対する規則のいくつかは、与えられたスキーマ型が同じであるか、期待したスキーマ型から派生したものかを決定する必要がある。与えられたスキーマ型は (スコープ内スキーマ定義で定義されている) "既知" (known)、または (スコープ内スキーマ定義で定義されていない) "未知" (unknown) であろう。例えばソース文章が静的コンテキストにインポートされなかったスキーマを使って検証されているなら、未知のスキーマ型を検出することもありうる。この場合、実装は未知のスキーマ型が期待したスキーマ型から派生したものかどうかを決定するために実装依存メカニズムを提供することができる (必須ではない)。例えば、型階層に関する情報のデータディクショナリを実装で保持するかもしれない。
[定義: 期待した型から派生した動的型の値の使用はサブタイプ代入 (Subtype Substitution) と言う。] サブタイプ代入は値の実際の型を変更しない。例えば、xs:decimal 値を期待している部分で xs:integer 値が使用された場合、その値は xs:integer 型で保持される。
SequenceType マッチングは擬似関数 derives-from(AT, ET) を使用している。これは実際の単純スキーマ型または複合スキーマ型 AT と、期待する単純または複合スキーマ型 ET を取り、boolean 値か型エラー [err:XPTY0004] を発生させる。擬似関数 derives-from は下記で定義し、公式には [XQuery 1.0 and XPath 2.0 Formal Semantics] で定義する。
ET が既知の型で以下の条件の一つでも真となるなら
derives-from(AT, ET)はtrueを返す:AT がスコープ内スキーマ定義に存在するスキーマであり、ET と同じか ET からの制約 (restriction) か拡張 (extension) として派生している
AT がスコープ内スキーマ定義に存在しないスキーマであり、実装依存のメカニズムが AT が ET からの制約 (restriction) から派生していると確定できる
derives-from(IT, ET)とderives-from(AT, IT)が共に真となるようなスキーマ型 IT が存在する
もし ET が既知の型であり、下記の 1 と 3、または 2 と 3 が真となるなら、
derives-from(AT, ET)はfalseを返す:AT がスコープ内スキーマ定義に存在するスキーマ定義であり、ET と異なり、かつ ET から制約 (restriction) あるいは拡張 (extension) で派生した型でもない
AT はスコープ内スキーマ定義に存在しないスキーマ型であり、実装依存メカニズムが AT が ET の制約 (restriction) から派生していないと確定できる
derives-from(IT, ET)とderives-from(AT, IT)が真となるようなスキーマ型 IT が存在しない
以下の状況で
derives-from(AT, ET)は型エラー [err:XPTY0004] を発生する:ET の型が不明、または
AT の型が不明であり、AT が ET から制約 (restriction) 二よって派生しているかどうかを実装が決定できない
SequenceType マッチングに対する規則および例を下記に記述する (例は説明を目的としており、考えうるすべてのケースをカバーしているわけではない)。
2.5.4.1 SequenceType と値のマッチング
シーケンス型
empty-sequence()は空シーケンスの値と一致する。OccurrenceIndicator (繰り返し指示) の付属しない ItemType (項目型) は、その ItemType と一致する項目に対して (2.5.4.2 Matching an ItemType and an Item 参照)、その項目一つだけを含むどのような値とも一致する。
OccurrenceIndicator (繰り返し指示) を持つ ItemType (項目型) は、項目の数が OccurrenceIndicator と一致し ItemType がそれぞれの項目の値と一致するなら、一致する。
OccurrenceIndicator (繰り返し指示) はシーケンスにおける項目の数を以下のように指定する:
?は 0 か 1 つの項目に一致する*は 0 かそれ以上の項目に一致する+は 1 かそれ以上の項目に一致する
これらの規則の結果として、* や ? の OccurrenceIndicator を持つあらゆるシーケンス型は空シーケンスの値と一致する。
2.5.4.2 ItemType と項目のマッチング
単純な QName で構成されている ItemType (項目型) は AtomicType (原子型) と解釈される。原子型 AtomicType は
derives-from(AT, AtomicType)がtrueならば、実際の型が AT となる原子値と一致する。もし AtomicType で使用されている QName がスコープ内スキーマ型の原子型として定義されているなら、静的エラー [err:XPST0051] が発生するだろう。例: AtomicType
xs:decimalは値12.34(10進数リテラル) と一致する。もしshoesizeがxs:decimalから制約 (restriction) によって派生した原子型であるなら、xs:decimalはshoesize型の値とも一致する。Note:
xs:IDREFSのような非原子型の名前はこのコンテキストでは受け付けられないが、しばしばxs:IDREF+のような繰り返し指示を伴う原子型によって置き換えることができる。item()はあらゆる単一の項目と一致する。例:
item()は原子値1や要素<a/>と一致する。node()はあらゆるノードと一致する。text()はあらゆるテキストノードと一致するprocessing-instruction()はあらゆる処理命令 (Processing Instruction) ノードと一致する。processing-instruction(N)はその名前 (XML では "PITarget" と呼ばれる) が N と等しいあらゆる処理命令ノードと一致する。ここで N は NCName である。例:
processing-instruction(xml-stylesheet)は PITarget がxml-stylesheetであるあらゆる処理命令と一致する。XPath 1.0 との後方互換のため、例えば
processing-instruction("xml-stylesheet")のように処理命令の PITarget を文字列リテラルとして示すこともできる。comment()はあらゆるコメントノードと一致する。document-node()はあらゆる文章ノードと一致する。document-node(E)は、もし E が要素ノードと一致 (2.5.4.3 Element Test と 2.5.4.4 Schema Element Test 参照) する ElementTest または SchemaElementTest ならば、正確に 1 つの要素ノードと、任意だが一つ以上のコメントと処理命令ノードが付随するあらゆる文章ノードと一致する。例:
document-node(element(book))は ElementTestelement(book)と一致する正確に 1 つのノードを含むドキュメントノードと一致する。ElementTest、SchemaElementTest、AttributeTest、SchemaAttributeTest の ItemType は下記のセクションで記述しているような要素または属性ノードと一致する。
2.5.4.3 要素判定
ElementTest (要素判定) は要素ノードの名前と型注釈による一致判定で使用される。ElementTest は下記の形式のどれでもとることができる。これらの形式では、ElementName はスコープ内要素宣言に存在する必要はないが、TypeName はスコープ内スキーマ型で存在しなければならない [err:XPST0008]。substitution groups が ElementTest のセマンティクスに影響を与えないことに注意。
element()とelement(*)は名前や型注釈に関係なく、あらゆる単一の要素ノードと一致する。element(ElementName)はその型注釈やnilledプロパティに関係なく名前が ElementName のあらゆる要素ノードと一致する。例:
element(person)は名前にpersonを持つあらゆる要素ノードと一致する。element(ElementName,TypeName)はderives-from(AT, TypeName)がtrueとなる ElementName という名前の要素ノードと一致する。ここで AT は要素ノードの型注釈であり、ノードのnilledプロパティはfalseである。例:
element(person, surgeon)は名前がpersonであり型注釈がsurgeon(またはsurgeonから派生した) と非 nilled 要素ノードと一致する。element(ElementName, TypeName?)はderives-from(AT, TypeName)がtrueとなるような ElementName という名前の要素ノードと一致する。ここで AT は要素ノードの型注釈である。ノードのnilledプロパティはtrueまたはfalseである。例:
element(person, surgeon?)は名前がperson、型注釈がsurgeon(あるいはsurgeonから派生した) である nilled または非 nilled 要素ノードと一致する。element(*,TypeName)は名前に関係なくderives-from(AT, TypeName)がtrueとなる要素ノードと一致する。ここで AT は要素ノードの型注釈であり、ノードのnilledプロパティはfalseである。例:
element(*, surgeon)は要素の名前に関係なくsurgeon(またはsurgeonから派生した) という型注釈を持つあらゆる非 nilled 要素ノードと一致する。element(*,TypeName?)は名前に関係なくderives-from(AT, TypeName)がtrueとなる要素ノードと一致する。ここで AT は要素ノードの型注釈であり、ノードのnilledプロパティはtrueまたはfalseである。例:
element(*, surgeon?)は要素の名前に関係なくsurgeon(またはsurgeonから派生した) という型注釈を持つあらゆる nilled または非 nilled 要素ノードと一致する。
2.5.4.4 スキーマ要素判定
SchemaElementTest (スキーマ要素判定) はスコープ内要素宣言の対応する要素宣言と要素ノードを比較する。これは以下の形式となる
schema-element(ElementName)
もし SchemaElementTest で示されている ElementName がスコープ内要素宣言に存在しなければ、静的エラー [err:XPST0008] が発生する。
以下の 3 つの条件すべてが満たされた場合、SchemaElementTest は候補の要素ノードと一致する:
候補のノード名が ElementName と一致するか、ElementName と名づけられている要素で率いられている (headed by) substitution group の中の要素の名前と一致する。
derives-from(AT, ET)がtrueである。ここで AT は候補ノードの型注釈であり、ET は要素 ElementName に対してスコープ内変数宣言で宣言されたスキーマ型である。もしスコープ内要素宣言の ElementName に対する要素宣言が
nillableでないなら、候補ノードのnilledプロパティがfalseである。
例: SchemaElementTest schema-element(customer) は、customer がスコープ内要素宣言のトップレベル要素宣言であり、候補ノードの名前が customer または customer によって率いられている substitution group の中に存在し、候補ノードの型注釈が customer 要素に対して宣言されたスキーマ型と同じか派生したものであり、候補ノードが nilled でないか customer が nillable と宣言されているなら一致する。
2.5.4.5 属性判定
AttributeTest (属性判定) は属性ノードの名前と型注釈による判定で使用される。AttributeTest は以下の形式のどれでもとりうる。これらの形式では AttributeName はスコープ内属性宣言に存在する必要はないが、TypeName はスコープ内スキーマ型に存在しなければならない。[err:XPST0008]
attribute()とattribute(*)は属性の名前や型注釈に関係なくすべての単一の属性ノードと一致する。attribute(AttributeName)は属性の型注釈に関係なく名前が AttributeName のあらゆる属性ノードと一致する。例:
attribute(price)は名前がpriceであるどのような属性ノードにも一致する。attribute(AttributeName, TypeName)は名前が AttributeName でderives-from(AT, TypeName)がtrueとなる属性ノードと一致する。ここで AT は属性ノードの型注釈である。例:
attribute(price, currency)は名前がpriceで型注釈がcurrency(あるいはcurrencyの派生型) の属性ノードと一致する。attribute(*,TypeName)は名前に関係なくderives-from(AT, TypeName)がtrueとなる。ここで AT は属性ノードの型注釈である。例:
attribute(*, currency)は名前に関係なく型注釈がcurrency(あるいはcurrencyの派生型) である属性ノードと一致する。
2.5.4.6 スキーマ属性判定
SchemaAttributeTest (スキーマ属性判定) は属性ノードとスコープ内属性宣言に存在する対応する属性宣言とを評価する。これは以下の形式をとる:
schema-attribute(AttributeName)
SchemaAttributeTest で指定された AttributeName がスコープ内属性宣言に存在しないなら、静的エラー [err:XPST0008] が発生する。
SchemaAttributeTest は下記の条件が両方とも満たされるなら候補の属性ノードと一致する:
候補ノードの名前が指定された AttributeName と一致する。
derives-from(AT, ET)がtrueである。ここで AT は候補ノードの型注釈であり、ET はスコープ内属性宣言で属性 AttributeName に対して宣言されたスキーマ型である。
例: color がスコープ内属性宣言におけるトップレベル属性宣言であり、候補のノードが color という名前を持ち、候補ノードの型注釈が color 属性に対して宣言されたスキーマ型と同じかその派生型であるなら、SchemaAttributeTest schema-attribute(color) はその属性と一致する。
2.6 コメント
| [77] | Comment |
::= | "(:" (CommentContents | Comment)* ":)" |
| [82] | CommentContents |
::= | (Char+ - (Char* ('(:' | ':)') Char*)) |
コメントは式に対する追加情報的な注釈を提供するために使うことができる。コメントは構文上でのみの構成概念であり、式処理には影響を与えない。
コメントは記号 (: と :) で区切られた文字列である。
コメントは無視可能な空白文字が使用できる場所であればどこでも使用することができる (see A.2.4.1 デフォルトの空白処理参照)。
以下はコメントの例である:
(: Houston, we have a problem :)
3 式 (Expressions)
このセクションはそれぞれの基本的な式種別を議論する。それぞれの式種別は PathExpr のような名前を持ち、そしてそれらは式を定義する文法提示の左側 (?on the left side of) で導入されている。XPath は組み立て可能な言語であるため、それぞれの式種別はより高い優先順位を持つ演算子の他の式に特有の式で定義されている。このように、演算子の優先順位は文法によってはっきりと表されている。
この文章で論議される式の説明順序は演算子の優先順位の順序を反映しない。一般に、この文章では最初に簡単な式種別から入り、後により複雑な式を説明する。完全な文法については [A XPath 文法] を参照。
XPath 文法における最高位のシンボルは XPath である。
| [1] | XPath |
::= | Expr |
| [2] | Expr |
::= | ExprSingle ("," ExprSingle)* |
| [3] | ExprSingle |
::= | ForExpr |
最も低い優先順位を持つ演算子はコンマ演算子であり、これはシーケンスを形成するために 2 つのオペランドを結合するのに使用される。文法で示しているように、一般的な式 (Expr) はコンマで区切られた複数の ExprSingle オペランドで構成されている。ExprSingle という名前はトップレベルのコンマ演算子を含まない式を意味している (しかし ExprSingle は複数の項目を含むシーケンスを評価できる)。
シンボル ExprSingle は、トップレベルコンマを含むことが許されていない式に対する文法のさまざまな箇所で使用される。例えば、関数呼び出しの引数は、それぞれの引数を分割するのにコンマが使用されているため ExprSingle でなければならない。
コンマの次に優先順位の低い式は ForExpr、 QuantifiedExpr、IfExpr、OrExpr である。これらの式はこの文章の個別のセクションで説明している。
3.1 一次式
[定義: 一次式 (Primary expressions) は言語の基本プリミティブである。これらはリテラル、変数参照、コンテキスト項目式、関数呼び出しを含んでいる。どのような式も括弧で括ることによって一次式となりうる。これはしばしば演算子の優先順位を制御するのに有用である。]
| [41] | PrimaryExpr |
::= | Literal | VarRef | ParenthesizedExpr | ContextItemExpr | FunctionCall |
3.1.1 リテラル
[定義: リテラル (literal) は原子値の直接的な統語式である。] XPath では 2 種類のリテラルをサポートしている。
| [42] | Literal |
::= | NumericLiteral | StringLiteral |
| [43] | NumericLiteral |
::= | IntegerLiteral | DecimalLiteral | DoubleLiteral |
| [71] | IntegerLiteral |
::= | Digits |
| [72] | DecimalLiteral |
::= | ("." Digits) | (Digits "." [0-9]*) |
| [73] | DoubleLiteral |
::= | (("." Digits) | (Digits ("." [0-9]*)?)) [eE] [+-]? Digits |
| [74] | StringLiteral |
::= | ('"' (EscapeQuot | [^"])* '"') | ("'" (EscapeApos | [^'])* "'") |
| [75] | EscapeQuot |
::= | '""' |
| [76] | EscapeApos |
::= | "''" |
| [81] | Digits |
::= | [0-9]+ |
"." や e、E の文字を含んでいない数値リテラル (Numeric Literal) の値は xs:integer 型の原子値である。"." を含むが e や E は含まない数値リテラルの値は xs:decimal 型の原子値である。e や E の文字を含む数値リテラルは xs:double 型の原子値である。数値リテラルの値は、xs:untypedAtmic からセクション 17.1.1 xs:string および xs:untypedAtmic からのキャストFO で詳述しているような数値型へのト規則に従った適切な型へのキャストによって決定される。
文字列リテラル (String Literal) の値は xs:string の型を持ち、アポストロフィまたはダブルクォートで囲まれることで意味付けされる文字列の原子値である。リテラルがアポストロフィによって区切られるなら、リテラル内の 2 つの連続したアポストロフィは単一のアポストロフィ文字として解釈される。同様にダブルクォートで区切られているなら 2 つの連続したダブルクォートは単一のダブルクォート文字として解釈される。
リテラル式の例をいくつか示す:
"12.5"は '1'、'2'、'.'、'5' で構成される文字列を意味する。12はxs:integer値の 12 を意味する。12.5はxs:decimal値の 12.5 を意味する。125E2はxs:double値の 125×102 (12,500) を意味する。"He said, ""I don't like it."""は 2 つのダブルクォートと 1 つのアポストロフィを含む文字列を意味する。Note:
XML 属性のような、これらの引用記号に特別な意味を持たせているコンテキストに XPath 式を埋め込む場合、更なるエスケープが必要となるだろう。
xs:boolean 値 true と false はそれぞれビルトイン関数 fn:true() と fn:false() を呼ぶことで表すことができる。
その他の原子型は所定の型のコンストラクタ関数を呼ぶことで構築することができる。XML Schema ビルトイン型に対するコンストラクタ関数は [XQuery 1.0 と XPath 2.0 関数および演算子] で定義されている。一般に、所定の型のコンストラクタ関数の名前は (その名前空間も含めて) 型の名前と同じである。例えば:
xs:integer("12")は整数値 12 を返す。xs:date("2001-08-25")はxs:date型で値が 2001 年 8 月 25 日を表す項目を返す。xs:dayTimeDuration("PT5H")は型がxs:dayTimeDurationで値が 5 時間を表す項目を返す。
コンストラクタ関数は、以下の例のようにリテラル式でない特別な値を作り出すために使うこともできる:
xs:float("NaN")は浮動小数点の特別な値 "Not a Number" を返す。xs:double("INF")は倍精度浮動小数点の特別な値 "正の無限" を返す。
cast 式を使用することによってさまざまな型の値を構築することもできる。例えば:
9 cast as hatsizeはhatsize型の原子値9を返す。
3.1.2 変数参照
| [44] | VarRef |
::= | "$" VarName |
| [45] | VarName |
::= | QName |
[定義: 変数参照 (Variable Reference) は $ 記号に続く QName である。] ローカル名が同じで、双方の名前空間接頭辞が同じ静的に既知の名前空間 URI に関連付けられているなら、それら 2 つの変数参照は同じである。接頭辞の付けられていない変数参照は名前空間に属さない。
あらゆる変数参照はスコープ内変数の名前と一致しなければならない。スコープ内変数は以下のソースからの変数を含んでいる:
あらゆる変数バインディングは静的スコープを持つ。スコープは変数への参照が正しく見出される範囲を定義する。スコープに存在しない変数参照は静的エラー [err:XPST0008] である。変数が式に対す静的コンテキストに結び付けられているなら、その変数は式の全体をスコープとして持っている。
もし変数参照がスコープ内の複数の変数バインディングと一致するなら、より小さいスコープを持つ、内々のバインディングの参照が選択される。変数バインディングのスコープは変数を結び付けられる式種別の各々で別に定義される。
3.1.3 括弧付けされた式
| [46] | ParenthesizedExpr |
::= | "(" Expr? ")" |
括弧は複数の演算子を持つ式において特定の優先順位を強いるのに使用することができる。例えば (2 + 4) * 5 は、先に括弧式 (2 + 4) が評価されてから 5 がかかるため 30 という結果になる。括弧がなければ加算演算子より乗算演算子が優先されるため、式 2 + 4 * 5 は 22 という結果になる。
中身のない括弧は 3.3.1 Constructing Sequences で詳述されている空シーケンスを意味する。
3.1.4 コンテキスト項目式
| [47] | ContextItemExpr |
::= | "." |
コンテキスト項目式 (Context Item Expression) はコンテキスト項目を評価し、それは (fn:doc("bib.xml")/books/book[fn:count(./author)>1] のような) ノード、または ((1 to 100)[. mod 5 eq 0] のような) 原子値である。
もしコンテキスト項目が定義されていないなら、コンテキスト項目式は動的エラー [err:XPDY0002] が発生する。
3.1.5 関数呼び出し
[定義: XPath がサポートしているビルトイン関数は [XQuery 1.0 と XPath 2.0 関数および演算子] で定義している。] 追加の関数が静的コンテキスト追加の関数が functions may be provided in the 静的コンテキストで提供されるかもしれない。当然 XPath では関数を宣言する方法は提供しないが、ホスト言語でそのメカニズムを提供することができる。
| [48] | FunctionCall |
::= | QName "(" (ExprSingle ("," ExprSingle)*)? ")" |
関数呼び出し (Function Call) は、QName とそれに続く引数 (Argument) と呼ばれる 0 以上の式を連ねた括弧で構成されている。もし関数呼び出しの QName が名前空間接頭辞を持たないならデフォルトの関数名前空間であると見なされる。
関数呼び出しにおける展開 QName と引数の数が静的コンテキスト内のどの関数シグネチャの名前および引数の数とも一致しない場合は静的エラー [err:XPST0017] が発生する。
関数呼び出しは以下のように評価される:
引数の値を得るために引数式が評価される。引数の評価順序は実装依存であり、引数の評価を行うことなしに内部を実行する事ができるなら、関数は引数を評価する必要がない。
それぞれの引数値は後述の関数変換規則を適用することで変換される。
関数は変換された引数値を使用して評価される。結果は関数で宣言されているリターン型か、もしくは動的エラーである。実行結果の動的型は宣言されたリターン型から派生した型とすることができる。関数で発生するエラーは [XQuery 1.0 と XPath 2.0 関数お呼び演算子] で定義している。
関数変換規則 (Fnction Conversion Rule) は引数値を関数が期待する型-つまり関数パラメータで宣言した型に変換するために使用される。期待する型はシーケンス型として表される。関数変換規則は以下の所定の値に適用される:
もし XPath 1.0 互換モードが
trueかつ引数が期待した型でないなら、引数値 V に対して以下の変換が順に適用される:期待した型が単一項目または省略可能な単一項目を必要とする場合 (例:
xs:string,xs:string?,xs:untypedAtomic,xs:untypedAtomic?,node(),node()?,item(),item()?)、値 V は V[1] として有効に置き換えられる。もし期待する型が
xs:stringやxs:string?の場合、値Vはfn:string(V)によって有効に置き換えられる。期待する型が
xs:doubleやxs:double?の場合、値Vはfn:number(V)によって有効に置き換えられる。
期待した型が原子型のシーケンス (繰り返し指示
*、+、?かもしれない) の場合、以下の変換が適用される:与えられた値に原子化が適用され、原子値のシーケンスをもたらす。
xs:untypedAtomic型の原子シーケンスのそれぞれの項目を期待した原子型にキャストする。数値として指定された型を期待しているビルトイン関数に対してはxs:untypedAtomic型の引数はxs:doubleにキャストされる。B.1 型昇格で詳述されるような数値昇格を使用する、期待する原子型に昇格可能な原子シーケンスの数値項目それぞれに対しては昇格が行われる。
B.1 型昇格で詳述されているような URI 昇格を使用する、期待する原子型に昇格可能な原子シーケンスの
xs:anyURI型項目それぞれに対しては昇格が行われる。
上記の変換後、結果として生じる値が SequenceType マッチングの規則に従って期待する型と一致しなければ、型エラー [err:XPTY0004] が発生する。SequenceType マッチングに対する規則では、派生型の値を基本型の値に代入できることに注意すること。
関数呼び出しの引数がコンマで区切られているため、トップレベルにコンマ演算子を持つ引数式を括弧内に含むことはできない。ここで関数呼び出しの実例をいくつか挙げる:
my:three-argument-function(1, 2, 3)は 3 つの引数を持つ関数呼び出しを意味している。my:two-argument-function((1, 2), 3)は 2 つの引数を持つ関数呼び出しを意味しており、その最初のものは 2 つの値のシーケンスである。my:two-argument-function(1, ())は 2 つの引数を持つ関数呼び出しを意味しており、その 2 つ目は空シーケンスである。my:one-argument-function((1, 2, 3))は 3 つの値を持つシーケンスの引数 1 つの関数呼び出しを意味している。my:one-argument-function(( ))は空シーケンスを 1 つ持つ関数呼び出しを意味している。my:zero-argument-function( )は引数を持たない関数呼び出しを意味している。
3.2 パス式
| [25] | PathExpr |
::= | ("/" RelativePathExpr?) |
| [26] | RelativePathExpr |
::= | StepExpr (("/" | "//") StepExpr)* |
[定義: パス式 (Path Expression) はツリーの中でノードを位置づけるために使用することができる。パス式は "/" または "//" で区切られた一つ以上のステップで構成され、任意 (Optionally) で "/" か "//" から始まる。] 最初の "/" や "//" は、後述するようにパス式の開始に暗黙的に加えられる一つ以上の初期ステップの省略形である。
単一ステップで構成されるパス式は 3.2.1 ステップで詳述されているように評価される。
パス式の開始 "/" は初期ステップ fn:root(self::node()) treat as document-node()/ の省略形である (ただし、もしパス式全体が "/" しかないなら、拡張形式の最後の "/" は省略される)。この初期ステップの目的は、コンテキストノードを含んでいるツリーのルートノードからパスを開始することである。もしコンテキストがノードでないなら型エラー [err:XPTY0020] が発生する。評価時に、もしコンテキストノードの上のルートノードがドキュメントノードでなければ、動的エラー [err:XPDY0050] が発生する。
パス式の開始 "//" は初期ステップ fn:root(self::node()) treat as document-node()/descendant-or-self::node()/ の省略形である (ただし、"//" は単独で存在しうるパス式ではない [err:XPST0003])。これらの初期ステップの目的は、コンテキストノードが存在するツリーのルート、それにこのルートにぶら下がる全てのノードを含む初期ノードシーケンスを作り上げることである。このノードシーケンスはパス式での以降のステップへの入力として使用される。もしコンテキスト項目がノードでなければ型エラー [err:XPTY0020] が発生する。評価時には、コンテキストノードの上のルートノードがドキュメントノードでなければ動的エラー [err:XPDY0050] が発生する。
Note:
ノードの子孫は属性ノードや名前空間ノードを含まない。
パス式における "//" のそれぞれの非初期繰り返しは 3.2.4 Abbreviated Syntax で詳述されるように展開され、"/" で区切られたステップのシーケンスが残る。この時、ステップのシーケンスは左から右へ評価される。E1/E2 のオペレーションはそれぞれ以下のように評価される: 式 E1 が評価され、ノードのシーケンスではない (ありがちなのは空) 場合、型エラー [err:XPTY0019] が発生する。E1 の評価でもたらされたノードのそれぞれは、2.1.2 動的コンテキストで詳述されるように、順番に E2 の評価に対する内部的フォーカスを提供するのに利用される。E2 の評価全てからもたらされるシーケンスは以下のように連結される:
もし
E2の評価それぞれがノードのシーケンス (空の可能性もある) を返すなら、それらのシーケンスは連結され、そして重複したノードはノード識別子に基づいて除外される。結果としてもたらされるノードのシーケンスはドキュメント順序で返される。もし
E2の評価それぞれが原子値のシーケンス (空の可能性もある) なら、これらのシーケンスはその順序で連結されて返される。もし
E2の評価の複数が少なくとも一つのノードと一つの原子値を返したなら、型エラー [err:XPTY0018] が発生する。
Note:
パスにおけるそれぞれのステップが下層のステップにコンテキストノードを提供するため、実質的にパス内の最後のステップのみが原子値のシーケンスを返すことを許される。
パス式の例として、child::div1/child::para はコンテキストノードの子供である div1 要素の子供の param 要素、言い換えれば、コンテキストノードの孫であり親に div1 を持つ para 要素を選択する。
Note:
文字 "/" は完全なパス式か、あるいは "/*" のようなより長い (longer) パス式の開始として使用することができる。さらに "*" は乗算演算子かパス式のワイルドカードでもある。これは "/" が "*" の左側に現れる時に解析の困難性を引き起こすことがある。これは leading-lone-slash 制約を使うことで解決することができる。例えば、"/*" と "/ *" はワイルドカードを含む有効なパス式であるが、"/*5" や "/ * 5" は構文エラーを発生する。演算子の左側に "/" が使用される場合は "(/) * 5" のようにカッコを使用しなければならない。同様に、"4 + / * 5" は構文エラーを発生するが "4 + (/) * 5" は有効な式である。式 "4 + /" も / が演算子の左側ではないため有効である。
3.2.1 ステップ
| [27] | StepExpr |
::= | FilterExpr | AxisStep |
| [28] | AxisStep |
::= | (ReverseStep | ForwardStep) PredicateList |
| [29] | ForwardStep |
::= | (ForwardAxis NodeTest) | AbbrevForwardStep |
| [32] | ReverseStep |
::= | (ReverseAxis NodeTest) | AbbrevReverseStep |
| [39] | PredicateList |
::= | Predicate* |
[定義: ステップ (Step) は項目のシーケンスを生成し、0 個以上の述部 (Predicate) によってシーケンスをフィルタするパス式の一部である。ステップの値は述部の条件を満たす項目で構成されており、左から右に機能する。ステップは軸ステップかフィルタ式のどちらかとなりうる。] フィルタ式は 3.3.2 フィルタ式で詳述する。
[定義: 軸ステップ (Axis Step) は指定された軸を経由してコンテキストノードから到達可能なノードのシーケンスを返す。このようなステップは 2 つの部分を持っている: ステップの "展開方向" を定義する軸 (Axis)、そしてノードの種類、名前、型注釈に基づいてノードを選択するノード判定である。] もしコンテキスト項目がノードなら、軸ステップは 0 個以上のノードのシー消すを返す; そうでなければ型エラー [err:XPTY0020] が発生する。結果として生じるノードシーケンスはドキュメント順序で返される。軸ステップは 0 個以上の述部が続く順方向ステップ (Forward Step) あるいは逆方向ステップ (Reverse Step) のどちらかとなりうる。
ステップに対する省略構文 (Abbreviated Syntax) において軸は省略することができ、また3.2.4 Abbreviated Syntax で詳述するように他の略称表記を使用することができる。
軸ステップの省略されていない構文はchild::para はコンテキストノードの子の para 要素を選択する: child は軸の名前であり、para はこの軸で選択される要素ノードの名前である。利用可能な軸は 3.2.1.1 軸で、ノード判定は 3.2.1.2 ノード判定で詳述する。またステップの例は 3.2.3 省略されていない構文と 3.2.4 省略構文で示す。
3.2.1.1 軸 (Axis)
| [30] | ForwardAxis |
::= | ("child" "::") |
| [33] | ReverseAxis |
::= | ("parent" "::") |
XPath は文章を横断する軸 (Axis) の完全セットを定義するが、ホスト言語 (Host Language) がこれらの軸のサブセットを定義することができる。以下の軸が定義されている:
child軸はコンテキストノードの子を含んでおり、その子は[XQuery/XPath データモデル (XDM)] におけるdm:childrenアクセサによって返されるノードである。Note:
文章ノードと要素ノードのみが子を持つ。もしコンテキストノードがその他のノードか、空の文章ノードあるいは空の要素ノードであるなら、child 軸は空シーケンスである。文章ノードや要素ノードの子は要素、処理命令、コメント、テキストノードが許される。属性、名前空間、そして文章ノードが子として出現することは決してない。
descendant(子孫) 軸は child 軸の推移閉包 (Transitive Closure) として定義される; これはコンテキストノードの子孫 (子、子の子、… など) を含んでいる。parent軸は [XQuery/XPath データモデル (XDM)] におけるdm:parentアクセサによって返されるシーケンスを含んでおり、コンテキストノードの親か、あるいはコンテキストノードが親を持たないなら空のシーケンスを返す。Note:
たとえ属性ノードが要素ノードの子でないとしても、属性ノードはその親として要素ノードを持つことができる。
ancestor(祖先) 軸は parent 軸の推移閉包 (Transitive Closure) として定義される; これはコンテキストノードの祖先 (親、親の親、…など) を含んでいる。Note:
コンテキストノードがルートノードでない限り、ancestor 軸はコンテキストノードが存在するツリーのルートノードを含む。
following-sibling(後の兄弟) 軸はコンテキストノードの後方の兄弟で構成されており、コンテキストノードの親から見てコンテキストノードの後ろにドキュメント順序で並んでいる; もしコンテキストノードが属性や名前空間ノードであるならfollowing-sibling軸は空である。preceding-sibling(前の兄弟) 軸はコンテキストノードの前方の兄弟で構成されており、コンテキストノードの親から見てコンテキストノードの前にドキュメント順序で並んでいる; もしコンテキストノードが属性や名前空間ノードであるならpreceding-sibling軸は空である。following軸はコンテキストノードが存在するツリーのルートの子孫であり、コンテキストノードの子孫でなく、ドキュメント順序でコンテキストノードの後ろに存在する全てのノードで構成される。preceding軸はコンテキストノードが損じするツリーのルートの子孫であり、コンテキストノードの祖先でなく、ドキュメント順序でコンテキストノードの前に存在する全てのノードで構成される。attribute軸はコンテキストノードの属性で構成されている。その属性は [XQuery/XPath データモデル (XDM)] におけるdm:attributesアクセサによって返されるノードである; コンテキストノードが要素でなければこの字句は空になるだろう。self軸はコンテキストノードそのものを示す。descendant-or-self軸はコンテキストノードとその子孫で構成される。ancestor-or-self軸はコンテキストノードとその祖先で構成される; 従って、ancestor-or-self 軸には常にルートノードが含まれるだろう。namespace軸はコンテキストノードの名前空間ノードで構成される。この名前空間ノードは [XQuery/XPath データモデル (XDM)] でのdm:namespace-nodesアクセサによって返されるノードである; この軸はコンテキストノードが要素ノードでなければ空となる。namespace軸は XPath 2.0 で推奨されなくなっている。もし XPath 1.0 互換モードがtrueならnamespace軸はサポートされなければならない。XPath 1.0 互換モードがfalseならnamespace軸のサポートは実装定義である。XPath 1.0 互換モードがfalseの状態でnamespace軸をサポートしない実装は、もしそれが使われているなら静的エラー [err:XPST0010] を発生させなければならない。スコープ内名前空間に関する情報を必要とするアプリケーションは [XQuery 1.0 と XPath 2.0 関数および演算子] で定義されているfn:in-scope-prefixesとfn:namespace-uri-for-prefix関数を使用すべきである。
軸は前方軸 (Forward Axis) と後方軸 (Reverse Axis) に分類することができる。コンテキストノードやドキュメント順序でコンテキストノードの後ろに存在するノードのみで構成される軸は前方軸である。またコンテキストノードやドキュメント順序でコンテキストノードの前方に存在するノードのみで構成される軸は後方軸である。
parent、ancestor、ancestor-or-self、preceding、preceding-sibling は後方軸であり、それ以外は前方軸である。ancestor、descendant、following、preceding、self 軸は文章を区分する (属性と名前空間は考慮しない): これらは重ならないで文章内の全てのノードを含んでいる。
[定義: 全ての軸は主ノード種別 (Principal Node Kind) を持っている。もし軸が属性を含んでいるなら、主ノード種別は要素である; そうでなければ軸が含むことのできるノードの種類である。] 従って:
属性軸に対して、種ノード種別は属性である。
名前空間軸に対して、種ノード種別は名前空間である。
それ以外の全ての軸に対して、主ノード種別は要素である。
3.2.1.2 ノード判定
[定義: ノード判定 (Node Test) はステップが選択するそれぞれのノードに対して真とならなければならない条件である。] 条件はノードの種類 (要素、属性、テキスト、文章、コメント、処理命令)、ノードの名前 (要素、属性、文章ノードの場合)、あるいはノードの型注釈に基づくことができる。
| [35] | NodeTest |
::= | KindTest | NameTest |
| [36] | NameTest |
::= | QName | Wildcard |
| [37] | Wildcard |
::= | "*" |
[定義: QName またはワイルドカードのみで構成されているノード判定は名前判定 (Name Test) と呼ばれる。] ノードの種類 (Kind) が軸の主ノード種別であり、ノードの展開された QName が名前判定で指定された展開された QName と等しい (eq 演算子によって定義される) 場合に限り、名前判定は真となる。例えば child::para はコンテキストノードの子である para 要素を選択する; もしコンテキストノードが子に para を持たなければ、ノードの空セットを選択する。attribute::abc:href はコンテキストノードの QName abc:href を持つ属性を選択する; もしコンテキストノードが該当する属性を持たなければノードの空セットを選択する。
名前判定の QName は式コンテキストにおける静的に既知の名前空間を使用して展開された QName で解決される。QName が静的に既知の名前空間のどれとも一致しない接頭辞を持つ場合は静的エラー [err:XPST0081] が発生する。接頭辞の付けられていない QName は、主ノード種別が要素である軸上の名前判定で使用されている場合、式コンテキストにおけるデフォルト要素/型名前空間の名前空間 URI を持つ; そうでなければ名前空間 URI は持たない。
名前判定は、たとえ先頭が名前付き要素の代理グループにあるとしても、名前判定の展開された QName が一致しない名前の要素ノードでは満たされない。
ノード判定 * はステップ軸の主ノード種別のあらゆるノードに対して真となる。例えば child::* はコンテキストノードの全ての子要素を選択し、attribute::* はコンテキストノードの全ての属性を選択する。
ノード判定は NCName:* の形式をとることができる。この場合、接頭辞は静的コンテキスト内の静的に既知の名前空間を使用して QName と同じ方法で展開される。接頭辞が静的に既知の名前空間に存在しない場合、静的エラー [err:XPST0081] が発生する。名前のローカル部分に関係なく、展開された QName が接頭辞に関連付けられた名前空間 URI を持っているようなステップ軸の主ノード種別のあらゆるノードに対してノード判定は真となる。
ノード判定は *:NCName の形式をとることもできる。この場合、ノードの名前空間や名前空間の欠落に関係なく、ローカル名が NCName と一致するような、ステップ軸の主ノード種別のあらゆるノードに対してノード判定は真となる。
[定義: 種別テスト (Kind Test) と呼ばれるノード判定の振り替え形式はノードの種類、名前、型注釈に基づいて選択を行うことができる。] 種別判定の構文とセマンティクスは 2.5.3 SequenceType 構文と 2.5.4 SequenceType マッチングで詳述している。ノード判定で種別判定を使用した場合、種別判定に一致する指定された軸のノードのみが選択される。パス式で使用される種別判定のいくつかの例は下記に示す:
node()はあらゆるノードの一致する。text()はあらゆるテキストノードに一致する。comment()はあらゆるコメントノードに一致する。element()はあらゆる要素ノードに一致する。schema-element(person)は名前にperson(またはpersonが先頭の代理グループ) を持ち、型注釈がスコープ内要素宣言においてperson要素の宣言された型と同じ (もしくは派生) であるあらゆる要素ノードと一致する。element(person)は型注釈に関係なく名前がpersonのあらゆる要素ノードに一致する。element(person, surgeon)は名前がpersonで型注釈がsurgeonと等しいあるいはその派生型であるようなあらゆる非 nilled 要素ノードと一致する。element(*, surgeon)は要素の名前に関係なく型注釈がsurgeonと等しいかその派生型のあらゆる非 nilled 要素ノードと一致する。attribute()はあらゆる属性ノードと一致する。attribute(price)はノードの型注釈に関係なく名前がpriceのあらゆる属性と一致する。attribute(*, xs:decimal)は名前に関係なく型注釈がxs:decimalかその派生型であるあらゆる属性と一致する。document-node()はあらゆるドキュメントノードと一致する。document-node(element(book))は内容が種別判定element(book)を満たす単一の要素ノード (ただし 0 個以上のコメントと処理命令にはさまれていても良い) で構成されているあらゆるドキュメント要素と一致する。
3.2.2 述部
| [40] | Predicate |
::= | "[" Expr "]" |
[定義: 述部 (Predicate) は述部式 (Predicate Expression) と呼ばれる式で構成されており、角括弧で囲まれる。述部はシーケンス中のいくつかの項目を保持し他を捨てるフィルタとして使用される。複数の述部が隣接している場合、述部は左から右に適用され、個々の述部を適用した結果は後の述部への入力シーケンスとして使用される。
入力シーケンス中のそれぞれの項目に対して、述部は以下に定義するように内部フォーカス (Inner Focus) を使用して評価される: コンテキスト項目は述部によって現在評価されている項目である。コンテキストサイズは入力シーケンスの項目数である。コンテキストポジションは入力シーケンス内でのコンテキスト項目の位置である。述部内のコンテキストポジションを評価する目的で、入力シーケンスは以下のようにソートされると考えられる: 述部が前方軸ステップにあるならドキュメント順序、述部が後方軸ステップにあるなら逆ドキュメント順序、述部がステップにないなら元々の順序。
入力シーケンスのそれぞれの項目に対して、述部式の結果は後述するように述部真理値 (Predicate Truth Value) と呼ばれる xs:boolean 値を強制する。述部真理値が true となる項目のみが残され、false となるものは捨てられる。
述部真理値は以下の規則を順に適用することでもたらされる:
もし述部式の値が数値型かその派生型の単体原子値であり、述部式の値が評価項目のコンテキストポジション (Context Position) と演算子
eqで等しいなら、述部真理値はtrueである。そうでなければfalseである。[定義: 数値型を返す述部式の述部は数値述部 (Numeric Predicte) と呼ばれる。]数値型でないなら述部真理値は述部式の有効ブール値である。
以下は述部を含んでいる軸ステップの例である:
コンテキストノードの子であり
chapter要素の 2 番目を選択する例:child::chapter[2]
コンテキストノードの子孫で名前が
"toy"でcolor属性が"red"の全ての要素を選択する例:descendant::toy[attribute::color = "red"]
コンテキストノードの子で、子に
secretary要素とassistant要素の両方を持つemployeeという名前の全ての要素を選択する例:child::employee[secretary][assistant]
Note:
ノードシーケンスの述部を後方軸を使って選択した場合、そのようなシーケンスに対するコンテキストポジションは逆ドキュメント順序で割り当てられることを覚えておかなければならない。例えば、述部が後方軸を使っている軸ステップ一部であるため、preceding::foo[1] は逆ドキュメント順序において最初に適した foo 要素を返す。対照的に、括弧 (preceding::foo) はコンテキストの位置がドキュメント順序で割り当てられる一次式として解析されるため、(preceding::foo)[1] はドキュメント順序で最初に適した foo 要素を返す。同様に、ancestor 軸が後方軸であるため ancestor::*[1] は最も近い祖先要素を返すが、(ancestor::*)[1] はルート要素 (ドキュメント順序での最初の祖先) を返す。
述部を評価する目的で後方軸ステップが逆ドキュメント順序でコンテキストポジションを割り当てるという事実は、最終的な結果が常にドキュメント順序になるという事実と変らない。
3.2.3 省略されていない構文
このセクションではそれぞれのステップで軸を明示的に指定するパス式のいくつかの例を示す。これらの例で使用する構文は省略されていない構文 (Unabbreviated Syntax) と呼ばれる。よく使われる例の多くは3.2.4 省略構文で説明する省略構文 (Abbreviated Syntax) を使ったより簡潔なパス式で書くことが可能である。
child::paraはコンテキストノードの子でparaという名の要素を選択する。child::*はコンテキストノードの全ての子要素を選択する。child::text()はコンテキストノードの子テキストノードを選択する。child::node()はコンテキストノードの全ての子を選択する。属性は子ではないため属性ノードは選択対象ではないことに注意。attribute::nameはコンテキストノードのnameという名の属性を選択する。attribute::*はコンテキストノードの全ての属性を選択する。parent::node()はコンテキストノードの親を選択する。もしコンテキストノードが属性の場合、この構文はその属性ノードが付属する要素ノード (あるなら) を返す。descendant::paraは名前がparaであるコンテキストノードの子孫要素を選択する。ancestor::divはコンテキストノードの全てのdiv祖先を選択する。ancestor-or-self::divはコンテキストノードに対するdivという名前の祖先と、もしコンテキストノードがdiv要素ならコンテキストノードも選択する。descendant-or-self::paraはコンテキストノードに対するparaという名前の子孫と、もしコンテキストオードがpara要素ならコンテキストノードも選択する。self::paraはコンテキストノードがpara要素ならそれを選択するが、そうでなければ空のシーケンスを返す。child::chapter/descendant::paraはコンテキストノードの子要素chapterの子孫であるparaを選択する。child::*/child::paraはコンテキストノードの孫となる全てのpara要素を選択する。/はコンテキストノードが所属しているツリーのルートを選択するが、ルートが文章ノードでないなら動的エラーが発生する。/descendant::paraはコンテキストノードと同じ文章に所属する全てのpara要素を選択する。/descendant::list/child::memberはコンテキストノードと同じ文章に所属し、親にlistを持つ全てのmember要素を選択する。child::para[fn:position() = 1]はコンテキストノードで最初の子para要素を選択する。child::para[fn:position() = fn:last()]はコンテキストノードで最後の子para要素を選択する。child::para[fn:position() = fn:last()-1]はコンテキストノードで最後から 2 番目の子para要素を選択する。child::para[fn:position() > 1]はコンテキストノードの子で最初のpara要素以外のpara要素を選択する。following-sibling::chapter[fn:position() = 1]はコンテキストノードの兄弟で後ろに存在する最初のchapter要素を選択する。preceding-sibling::chapter[fn:position() = 1]はコンテキストノードの兄弟で前に存在する最初のchapter要素を選択する。/descendant::figure[fn:position() = 42]はコンテキスト要素が所属する文章内で 42 番目のfigure要素を選択する。/child::book/child::chapter[fn:position() = 5]/child::section[fn:position() = 2]はコンテキストノードが所属する文章のルートであるbook要素の 5 番目のchapter要素の 2 番目のsection要素を選択する。child::para[attribute::type eq "warning"]はコンテキストノードの子でparaという名前を持ち、そのtype属性がwarningの全ての要素を選択する。child::para[attribute::type eq 'warning'][fn:position() = 5]はコンテキスト属性の子para要素で、type属性にwarningを持つものの 5 番目を選択する。child::para[fn:position() = 5][attribute::type eq "warning"]はコンテキストノードの 5 番目の子para要素で、もしそのtype属性がwarningならそれを選択する。child::chapter[child::title = 'Introduction']はコンテキストノードの子で、型に関連付けられた値が文字列Introductionと等しい一つ以上のtitle子要素を持つchapter要素を選択する。child::chapter[child::title]はコンテキストの子で一つ以上のtitle要素を持つchapter要素を選択する。child::*[self::chapter or self::appendix]はコンテキストノードの子でchapterとappendix要素の全てを選択する。child::*[self::chapter or self::appendix][fn:position() = fn:last()]はコンテキストノードの子でchapterまたはappendix要素の最後の 1 つを選択する。
3.2.4 省略構文
| [31] | AbbrevForwardStep |
::= | "@"? NodeTest |
| [34] | AbbrevReverseStep |
::= | ".." |
省略構文 (Abbreviated Syntax) は以下の省略形を許可する
属性軸
attribute::は@と省略される。例えば、パス式para[@type="warning"]はchild::para[attribute::type="warning"]の短縮であり、type属性がwarningである子要素paraを選択する。軸名ステップから軸名が省略されている場合のデフォルトの軸は
childである; ただし軸ステップが AttributeTest や SchemaAttributeTest を含んでる場合はattributeである。例えば、パス式section/paraはchild::section/child::paraの省略形であり、同様にsection/attribute(id)はchild::section/attribute::attribute(id)の省略形である。後者の式が軸指定とノード判定の両方を含んでいることに注意。先頭ではない位置に出現する
//のそれぞれは、パス式の処理中は/descendant-or-self::node()/と置き換えられる。例えば、div1//paraはchild::div1/descendant-or-self::node()/child::paraの短縮形であり、div1の子の子孫である全てのparaを選択する。Note:
パス式
//para[1]はパス式/descendant::para[1]と同じ意味ではない。後者は最初の子孫para要素のみを選択するが、前者は子孫para要素のうち、自分の親に対して最初の子para要素である全ての最初の子para要素を選択する。..で構成されるステップはparent::nodeの短縮形である。例えば、../titleはpara::node()/child::titleの短縮形であり、コンテキストノードの親に対して子のtitle要素を選択する。Note:
コンテキスト項目式 (Context Item Expression) として知られる式
.は第一式であり、3.1.4 Context Item Expression で詳述している。
以下は省略構文を用いたパス式の例である:
paraはコンテキストノードの子para要素を選択する。*はコンテキストノードの全ての子要素を選択するtext()はコンテキストノードの全てのテキストノードを選択する。@nameはコンテキストノードのname属性を選択する。@*はコンテキストノードの全ての属性値選択する。para[1]はコンテキストノードの最初のpara要素を選択する。para[fn:last()]はコンテキストノードの最後のpara要素を選択する*/paraはコンテキストノードの全ての孫para要素を選択する。/book/chapter[5]/section[2]はコンテキストノードの所属する文章ノードを親に持つbookの 5 番目のchapterの 2 番目のsectionを選択する。chapter//paraはコンテキストノードの子chapter要素の子孫para要素を選択する。//paraは文章ノードの全ての子孫para要素、つまりコンテキストノードが所属する文章の全てのpara要素を選択する。//@versionはこのコンテキストノードが所属するドキュメント内の全てのversion属性を選択する。//list/memberはコンテキストノードが所属する文章内でlistを親に持つ全てのmember要素を選択する。.//paraはコンテキストノードの子孫para要素を選択する。..はコンテキストノードの親を選択する。../@langはコンテキストノードの親のlang属性を選択する。para[@type="warning"]はコンテキストノードの子で属性typeに値warningを持つ全てのpara要素を選択する。para[@type="warning"][5]はコンテキストノードの子で属性typeに値warningを持つ 5 番目のpara要素を選択する。para[5][@type="warning"]はコンテキストノードの 5 番目の子para要素が属性typeに値warningを持つならそれを選択する。chapter[title="Introduction"]はコンテキストノードの子で、型に関連付けられた値が文字列Introductionと等しい一つ以上の子title要素を持っているchapter要素を選択する。chapter[title]はコンテキストノードの子で一つ以上の子title要素を持っているchapter要素を選択する。employee[@secretary and @assistant]はコンテキストノードの子でsecretary属性とassistant属性の両方を持つemployee要素を選択する。book/(chapter|appendix)/sectionはコンテキストノードの子book要素の子でchapterまたはappendix要素の子section要素を選択する。もし
Eがノードのシーケンスを返す式なら、式E/.はドキュメント順序で同じノードを返す。
3.3 シーケンス式
XPath は項目シーケンスの構築、フィルタ、連結演算子をサポートしている。シーケンスがネストすることはない - 例えば 1、(2, 3)、( ) を一つのシーケンスに連結するとシーケンス (1, 2, 3) となる。
3.3.1 シーケンスの構築
| [2] | Expr |
::= | ExprSingle ("," ExprSingle)* |
| [11] | RangeExpr |
::= | AdditiveExpr ( "to" AdditiveExpr )? |
[Definition: One way to construct a sequence is by using the comma operator, which evaluates each of its operands and concatenates the resulting sequences, in order, into a single result sequence.] Empty parentheses can be used to denote an empty sequence.
A sequence may contain duplicate atomic values or nodes, but a sequence is never an item in another sequence. When a new sequence is created by concatenating two or more input sequences, the new sequence contains all the items of the input sequences and its length is the sum of the lengths of the input sequences.
Note:
In places where the grammar calls for ExprSingle, such as the arguments of a function call, any expression that contains a top-level comma operator must be enclosed in parentheses.
Here are some examples of expressions that construct sequences:
The result of this expression is a sequence of five integers:
(10, 1, 2, 3, 4)
This expression combines four sequences of length one, two, zero, and two, respectively, into a single sequence of length five. The result of this expression is the sequence
10, 1, 2, 3, 4.(10, (1, 2), (), (3, 4))
The result of this expression is a sequence containing all
salarychildren of the context node followed by allbonuschildren.(salary, bonus)
Assuming that
$priceis bound to the value10.50, the result of this expression is the sequence10.50, 10.50.($price, $price)
A range expression can be used to construct a sequence of consecutive integers. Each of the operands of the to operator is converted as though it was an argument of a function with the expected parameter type xs:integer?. If either operand is an empty sequence, or if the integer derived from the first operand is greater than the integer derived from the second operand, the result of the range expression is an empty sequence. If the two operands convert to the same integer, the result of the range expression is that integer. Otherwise, the result is a sequence containing the two integer operands and every integer between the two operands, in increasing order.
This example uses a range expression as one operand in constructing a sequence. It evaluates to the sequence
10, 1, 2, 3, 4.(10, 1 to 4)
This example constructs a sequence of length one containing the single integer
10.10 to 10
The result of this example is a sequence of length zero.
15 to 10
This example uses the
fn:reversefunction to construct a sequence of six integers in decreasing order. It evaluates to the sequence15, 14, 13, 12, 11, 10.fn:reverse(10 to 15)
3.3.2 フィルタ式
| [38] | FilterExpr |
::= | PrimaryExpr PredicateList |
| [39] | PredicateList |
::= | Predicate* |
[Definition: A filter expression consists simply of a primary expression followed by zero or more predicates. The result of the filter expression consists of the items returned by the primary expression, filtered by applying each predicate in turn, working from left to right.] If no predicates are specified, the result is simply the result of the primary expression. The ordering of the items returned by a filter expression is the same as their order in the result of the primary expression. Context positions are assigned to items based on their ordinal position in the result sequence. The first context position is 1.
Here are some examples of filter expressions:
Given a sequence of products in a variable, return only those products whose price is greater than 100.
$products[price gt 100]
List all the integers from 1 to 100 that are divisible by 5. (See 3.3.1 Constructing Sequences for an explanation of the
tooperator.)(1 to 100)[. mod 5 eq 0]
The result of the following expression is the integer 25:
(21 to 29)[5]
The following example returns the fifth through ninth items in the sequence bound to variable
$orders.$orders[fn:position() = (5 to 9)]
The following example illustrates the use of a filter expression as a step in a path expression. It returns the last chapter or appendix within the book bound to variable
$book:$book/(chapter | appendix)[fn:last()]
The following example also illustrates the use of a filter expression as a step in a path expression. It returns the element node within the specified document whose ID value is
tiger:fn:doc("zoo.xml")/fn:id('tiger')
3.3.3 Combining Node Sequences
| [14] | UnionExpr |
::= | IntersectExceptExpr ( ("union" | "|") IntersectExceptExpr )* |
| [15] | IntersectExceptExpr |
::= | InstanceofExpr ( ("intersect" | "except") InstanceofExpr )* |
XPath provides the following operators for combining sequences of nodes:
The
unionand|operators are equivalent. They take two node sequences as operands and return a sequence containing all the nodes that occur in either of the operands.The
intersectoperator takes two node sequences as operands and returns a sequence containing all the nodes that occur in both operands.The
exceptoperator takes two node sequences as operands and returns a sequence containing all the nodes that occur in the first operand but not in the second operand.
All these operators eliminate duplicate nodes from their result sequences based on node identity. The resulting sequence is returned in document order.
If an operand of union, intersect, or except contains an item that is not a node, a type error is raised [err:XPTY0004].
Here are some examples of expressions that combine sequences. Assume the existence of three element nodes that we will refer to by symbolic names A, B, and C. Assume that the variables $seq1, $seq2 and $seq3 are bound to the following sequences of these nodes:
$seq1is bound to (A, B)$seq2is bound to (A, B)$seq3is bound to (B, C)
Then:
$seq1 union $seq2evaluates to the sequence (A, B).$seq2 union $seq3evaluates to the sequence (A, B, C).$seq1 intersect $seq2evaluates to the sequence (A, B).$seq2 intersect $seq3evaluates to the sequence containing B only.$seq1 except $seq2evaluates to the empty sequence.$seq2 except $seq3evaluates to the sequence containing A only.
In addition to the sequence operators described here, [XQuery 1.0 and XPath 2.0 Functions and Operators] includes functions for indexed access to items or sub-sequences of a sequence, for indexed insertion or removal of items in a sequence, and for removing duplicate items from a sequence.
3.4 Arithmetic Expressions
XPath provides arithmetic operators for addition, subtraction, multiplication, division, and modulus, in their usual binary and unary forms.
| [12] | AdditiveExpr |
::= | MultiplicativeExpr ( ("+" | "-") MultiplicativeExpr )* |
| [13] | MultiplicativeExpr |
::= | UnionExpr ( ("*" | "div" | "idiv" | "mod") UnionExpr )* |
| [20] | UnaryExpr |
::= | ("-" | "+")* ValueExpr |
| [21] | ValueExpr |
::= | PathExpr |
A subtraction operator must be preceded by whitespace if it could otherwise be interpreted as part of the previous token. For example, a-b will be interpreted as a name, but a - b and a -b will be interpreted as arithmetic expressions. (See A.2.4 Whitespace Rules for further details on whitespace handling.)
The first step in evaluating an arithmetic expression is to evaluate its operands. The order in which the operands are evaluated is implementation-dependent.
If XPath 1.0 compatibility mode is true, each operand is evaluated by applying the following steps, in order:
Atomization is applied to the operand. The result of this operation is called the atomized operand.
If the atomized operand is an empty sequence, the result of the arithmetic expression is the
xs:doublevalueNaN, and the implementation need not evaluate the other operand or apply the operator. However, an implementation may choose to evaluate the other operand in order to determine whether it raises an error.If the atomized operand is a sequence of length greater than one, any items after the first item in the sequence are discarded.
If the atomized operand is now an instance of type
xs:boolean,xs:string,xs:decimal(includingxs:integer),xs:float, orxs:untypedAtomic, then it is converted to the typexs:doubleby applying thefn:numberfunction. (Note thatfn:numberreturns the valueNaNif its operand cannot be converted to a number.)
If XPath 1.0 compatibility mode is false, each operand is evaluated by applying the following steps, in order:
Atomization is applied to the operand. The result of this operation is called the atomized operand.
If the atomized operand is an empty sequence, the result of the arithmetic expression is an empty sequence, and the implementation need not evaluate the other operand or apply the operator. However, an implementation may choose to evaluate the other operand in order to determine whether it raises an error.
If the atomized operand is a sequence of length greater than one, a type error is raised [err:XPTY0004].
If the atomized operand is of type
xs:untypedAtomic, it is cast toxs:double. If the cast fails, a dynamic error is raised. [err:FORG0001]
After evaluation of the operands, if the types of the operands are a valid combination for the given arithmetic operator, the operator is applied to the operands, resulting in an atomic value or a dynamic error (for example, an error might result from dividing by zero.) The combinations of atomic types that are accepted by the various arithmetic operators, and their respective result types, are listed in B.2 Operator Mapping together with the operator functions that define the semantics of the operator for each type combination, including the dynamic errors that can be raised by the operator. The definitions of the operator functions are found in [XQuery 1.0 and XPath 2.0 Functions and Operators].
If the types of the operands, after evaluation, are not a valid combination for the given operator, according to the rules in B.2 Operator Mapping, a type error is raised [err:XPTY0004].
XPath supports two division operators named div and idiv. Each of these operators accepts two operands of any numeric type. As described in [XQuery 1.0 and XPath 2.0 Functions and Operators], $arg1 idiv $arg2 is equivalent to ($arg1 div $arg2) cast as xs:integer? except for error cases.
Here are some examples of arithmetic expressions:
The first expression below returns the
xs:decimalvalue-1.5, and the second expression returns thexs:integervalue-1:-3 div 2 -3 idiv 2
Subtraction of two date values results in a value of type
xs:dayTimeDuration:$emp/hiredate - $emp/birthdate
This example illustrates the difference between a subtraction operator and a hyphen:
$unit-price - $unit-discount
Unary operators have higher precedence than binary operators, subject of course to the use of parentheses. Therefore, the following two examples have different meanings:
-$bellcost + $whistlecost -($bellcost + $whistlecost)
Note:
Multiple consecutive unary arithmetic operators are permitted by XPath for compatibility with [XPath 1.0].
3.5 Comparison Expressions
Comparison expressions allow two values to be compared. XPath provides three kinds of comparison expressions, called value comparisons, general comparisons, and node comparisons.
| [10] | ComparisonExpr |
::= | RangeExpr ( (ValueComp |
| [23] | ValueComp |
::= | "eq" | "ne" | "lt" | "le" | "gt" | "ge" |
| [22] | GeneralComp |
::= | "=" | "!=" | "<" | "<=" | ">" | ">=" |
| [24] | NodeComp |
::= | "is" | "<<" | ">>" |
Note:
When an XPath expression is written within an XML document, the XML escaping rules for special characters must be followed; thus "<" must be written as "<".
3.5.1 Value Comparisons
The value comparison operators are eq, ne, lt, le, gt, and ge. Value comparisons are used for comparing single values.
The first step in evaluating a value comparison is to evaluate its operands. The order in which the operands are evaluated is implementation-dependent. Each operand is evaluated by applying the following steps, in order:
Atomization is applied to the operand. The result of this operation is called the atomized operand.
If the atomized operand is an empty sequence, the result of the value comparison is an empty sequence, and the implementation need not evaluate the other operand or apply the operator. However, an implementation may choose to evaluate the other operand in order to determine whether it raises an error.
If the atomized operand is a sequence of length greater than one, a type error is raised [err:XPTY0004].
If the atomized operand is of type
xs:untypedAtomic, it is cast toxs:string.Note:
The purpose of this rule is to make value comparisons transitive. Users should be aware that the general comparison operators have a different rule for casting of
xs:untypedAtomicoperands. Users should also be aware that transitivity of value comparisons may be compromised by loss of precision during type conversion (for example, twoxs:integervalues that differ slightly may both be considered equal to the samexs:floatvalue becausexs:floathas less precision thanxs:integer).
Next, if possible, the two operands are converted to their least common type by a combination of type promotion and subtype substitution. For example, if the operands are of type hatsize (derived from xs:integer) and shoesize (derived from xs:float), their least common type is xs:float.
Finally, if the types of the operands are a valid combination for the given operator, the operator is applied to the operands. The combinations of atomic types that are accepted by the various value comparison operators, and their respective result types, are listed in B.2 Operator Mapping together with the operator functions that define the semantics of the operator for each type combination. The definitions of the operator functions are found in [XQuery 1.0 and XPath 2.0 Functions and Operators].
Informally, if both atomized operands consist of exactly one atomic value, then the result of the comparison is true if the value of the first operand is (equal, not equal, less than, less than or equal, greater than, greater than or equal) to the value of the second operand; otherwise the result of the comparison is false.
If the types of the operands, after evaluation, are not a valid combination for the given operator, according to the rules in B.2 Operator Mapping, a type error is raised [err:XPTY0004].
Here are some examples of value comparisons:
The following comparison atomizes the node(s) that are returned by the expression
$book/author. The comparison is true only if the result of atomization is the value "Kennedy" as an instance ofxs:stringorxs:untypedAtomic. If the result of atomization is an empty sequence, the result of the comparison is an empty sequence. If the result of atomization is a sequence containing more than one value, a type error is raised [err:XPTY0004].$book1/author eq "Kennedy"
The following path expression contains a predicate that selects products whose weight is greater than 100. For any product that does not have a
weightsubelement, the value of the predicate is the empty sequence, and the product is not selected. This example assumes thatweightis a validated element with a numeric type.//product[weight gt 100]
The following comparison is true if
my:hatsizeandmy:shoesizeare both user-defined types that are derived by restriction from a primitive numeric type:my:hatsize(5) eq my:shoesize(5)
The following comparison is true. The
eqoperator compares two QNames by performing codepoint-comparisons of their namespace URIs and their local names, ignoring their namespace prefixes.fn:QName("http://example.com/ns1", "this:color") eq fn:QName("http://example.com/ns1", "that:color")
3.5.2 General Comparisons
The general comparison operators are =, !=, <, <=, >, and >=. General comparisons are existentially quantified comparisons that may be applied to operand sequences of any length. The result of a general comparison that does not raise an error is always true or false.
If XPath 1.0 compatibility mode is true, a general comparison is evaluated by applying the following rules, in order:
If either operand is a single atomic value that is an instance of
xs:boolean, then the other operand is converted toxs:booleanby taking its 有効ブール値.Atomization is applied to each operand. After atomization, each operand is a sequence of atomic values.
If the comparison operator is
<,<=,>, or>=, then each item in both of the operand sequences is converted to the typexs:doubleby applying thefn:numberfunction. (Note thatfn:numberreturns the valueNaNif its operand cannot be converted to a number.)The result of the comparison is
trueif and only if there is a pair of atomic values, one in the first operand sequence and the other in the second operand sequence, that have the required magnitude relationship. Otherwise the result of the comparison isfalse. The magnitude relationship between two atomic values is determined by applying the following rules. If acastoperation called for by these rules is not successful, a dynamic error is raised. [err:FORG0001]If at least one of the two atomic values is an instance of a numeric type, then both atomic values are converted to the type
xs:doubleby applying thefn:numberfunction.If at least one of the two atomic values is an instance of
xs:string, or if both atomic values are instances ofxs:untypedAtomic, then both atomic values are cast to the typexs:string.If one of the atomic values is an instance of
xs:untypedAtomicand the other is not an instance ofxs:string,xs:untypedAtomic, or any numeric type, then thexs:untypedAtomicvalue is cast to the dynamic type of the other value.After performing the conversions described above, the atomic values are compared using one of the value comparison operators
eq,ne,lt,le,gt, orge, depending on whether the general comparison operator was=,!=,<,<=,>, or>=. The values have the required magnitude relationship if and only if the result of this value comparison istrue.
If XPath 1.0 compatibility mode is false, a general comparison is evaluated by applying the following rules, in order:
Atomization is applied to each operand. After atomization, each operand is a sequence of atomic values.
The result of the comparison is
trueif and only if there is a pair of atomic values, one in the first operand sequence and the other in the second operand sequence, that have the required magnitude relationship. Otherwise the result of the comparison isfalse. The magnitude relationship between two atomic values is determined by applying the following rules. If acastoperation called for by these rules is not successful, a dynamic error is raised. [err:FORG0001]If one of the atomic values is an instance of
xs:untypedAtomicand the other is an instance of a numeric type, then thexs:untypedAtomicvalue is cast to the typexs:double.If one of the atomic values is an instance of
xs:untypedAtomicand the other is an instance ofxs:untypedAtomicorxs:string, then thexs:untypedAtomicvalue (or values) is (are) cast to the typexs:string.If one of the atomic values is an instance of
xs:untypedAtomicand the other is not an instance ofxs:string,xs:untypedAtomic, or any numeric type, then thexs:untypedAtomicvalue is cast to the dynamic type of the other value.After performing the conversions described above, the atomic values are compared using one of the value comparison operators
eq,ne,lt,le,gt, orge, depending on whether the general comparison operator was=,!=,<,<=,>, or>=. The values have the required magnitude relationship if and only if the result of this value comparison istrue.
When evaluating a general comparison in which either operand is a sequence of items, an implementation may return true as soon as it finds an item in the first operand and an item in the second operand that have the required magnitude relationship. Similarly, a general comparison may raise a dynamic error as soon as it encounters an error in evaluating either operand, or in comparing a pair of items from the two operands. As a result of these rules, the result of a general comparison is not deterministic in the presence of errors.
Here are some examples of general comparisons:
The following comparison is true if the typed value of any
authorsubelement of$book1is "Kennedy" as an instance ofxs:stringorxs:untypedAtomic:$book1/author = "Kennedy"
The following example contains three general comparisons. The value of the first two comparisons is
true, and the value of the third comparison isfalse. This example illustrates the fact that general comparisons are not transitive.(1, 2) = (2, 3) (2, 3) = (3, 4) (1, 2) = (3, 4)
The following example contains two general comparisons, both of which are
true. This example illustrates the fact that the=and!=operators are not inverses of each other.(1, 2) = (2, 3) (1, 2) != (2, 3)
Suppose that
$a,$b, and$care bound to element nodes with type annotationxs:untypedAtomic, with string values "1", "2", and "2.0" respectively. Then($a, $b) = ($c, 3.0)returnsfalse, because$band$care compared as strings. However,($a, $b) = ($c, 2.0)returnstrue, because$band2.0are compared as numbers.
3.5.3 Node Comparisons
Node comparisons are used to compare two nodes, by their identity or by their document order. The result of a node comparison is defined by the following rules:
The operands of a node comparison are evaluated in implementation-dependent order.
If either operand is an empty sequence, the result of the comparison is an empty sequence, and the implementation need not evaluate the other operand or apply the operator. However, an implementation may choose to evaluate the other operand in order to determine whether it raises an error.
Each operand must be either a single node or an empty sequence; otherwise a type error is raised [err:XPTY0004].
A comparison with the
isoperator istrueif the two operand nodes have the same identity, and are thus the same node; otherwise it isfalse. See [XQuery/XPath Data Model (XDM)] for a definition of node identity.A comparison with the
<<operator returnstrueif the left operand node precedes the right operand node in document order; otherwise it returnsfalse.A comparison with the
>>operator returnstrueif the left operand node follows the right operand node in document order; otherwise it returnsfalse.
Here are some examples of node comparisons:
The following comparison is true only if the left and right sides each evaluate to exactly the same single node:
/books/book[isbn="1558604820"] is /books/book[call="QA76.9 C3845"]
The following comparison is true only if the node identified by the left side occurs before the node identified by the right side in document order:
/transactions/purchase[parcel="28-451"] << /transactions/sale[parcel="33-870"]
3.6 論理式
A logical expression is either an and-expression or an or-expression. If a logical expression does not raise an error, its value is always one of the boolean values true or false.
| [8] | OrExpr |
::= | AndExpr ( "or" AndExpr )* |
| [9] | AndExpr |
::= | ComparisonExpr ( "and" ComparisonExpr )* |
The first step in evaluating a logical expression is to find the 有効ブール値 of each of its operands (see 2.4.3 有効ブール値).
The value of an and-expression is determined by the effective boolean values (EBV's) of its operands, as shown in the following table:
| AND: | EBV2 = true |
EBV2 = false |
error in EBV2 |
EBV1 = true |
true |
false |
error |
EBV1 = false |
false |
false |
if XPath 1.0 compatibility mode is true, then false; otherwise either false or error. |
| error in EBV1 | error | if XPath 1.0 compatibility mode is true, then error; otherwise either false or error. |
error |
The value of an or-expression is determined by the effective boolean values (EBV's) of its operands, as shown in the following table:
| OR: | EBV2 = true |
EBV2 = false |
error in EBV2 |
EBV1 = true |
true |
true |
if XPath 1.0 compatibility mode is true, then true; otherwise either true or error. |
EBV1 = false |
true |
false |
error |
| error in EBV1 | if XPath 1.0 compatibility mode is true, then error; otherwise either true or error. |
error | error |
If XPath 1.0 compatibility mode is true, the order in which the operands of a logical expression are evaluated is effectively prescribed. Specifically, it is defined that when there is no need to evaluate the second operand in order to determine the result, then no error can occur as a result of evaluating the second operand.
If XPath 1.0 compatibility mode is false, the order in which the operands of a logical expression are evaluated is implementation-dependent. In this case, an or-expression can return true if the first expression evaluated is true, and it can raise an error if evaluation of the first expression raises an error. Similarly, an and-expression can return false if the first expression evaluated is false, and it can raise an error if evaluation of the first expression raises an error. As a result of these rules, a logical expression is not deterministic in the presence of errors, as illustrated in the examples below.
Here are some examples of logical expressions:
The following expressions return
true:1 eq 1 and 2 eq 2
1 eq 1 or 2 eq 3
The following expression may return either
falseor raise a dynamic error(in XPath 1.0 compatibility mode, the result must befalse):1 eq 2 and 3 idiv 0 = 1
The following expression may return either
trueor raise a dynamic error(in XPath 1.0 compatibility mode, the result must betrue):1 eq 1 or 3 idiv 0 = 1
The following expression must raise a dynamic error:
1 eq 1 and 3 idiv 0 = 1
In addition to and- and or-expressions, XPath provides a function named fn:not that takes a general sequence as parameter and returns a boolean value. The fn:not function is defined in [XQuery 1.0 and XPath 2.0 Functions and Operators]. The fn:not function reduces its parameter to an 有効ブール値. It then returns true if the effective boolean value of its parameter is false, and false if the effective boolean value of its parameter is true. If an error is encountered in finding the effective boolean value of its operand, fn:not raises the same error.
3.7 for 式
XPath provides an iteration facility called a for expression.
| [4] | ForExpr |
::= | SimpleForClause "return" ExprSingle |
| [5] | SimpleForClause |
::= | "for" "$" VarName "in" ExprSingle ("," "$" VarName "in" ExprSingle)* |
A for expression is evaluated as follows:
If the
forexpression uses multiple variables, it is first expanded to a set of nestedforexpressions, each of which uses only one variable. For example, the expressionfor $x in X, $y in Y return $x + $yis expanded tofor $x in X return for $y in Y return $x + $y.In a single-variable
forexpression, the variable is called the range variable, the value of the expression that follows theinkeyword is called the binding sequence, and the expression that follows thereturnkeyword is called the return expression. The result of theforexpression is obtained by evaluating thereturnexpression once for each item in the binding sequence, with the range variable bound to that item. The resulting sequences are concatenated (as if by the comma operator) in the order of the items in the binding sequence from which they were derived.
The following example illustrates the use of a for expression in restructuring an input document. The example is based on the following input:
<bib>
<book>
<title>TCP/IP Illustrated</title>
<author>Stevens</author>
<publisher>Addison-Wesley</publisher>
</book>
<book>
<title>Advanced Programming in the Unix Environment</title>
<author>Stevens</author>
<publisher>Addison-Wesley</publisher>
</book>
<book>
<title>Data on the Web</title>
<author>Abiteboul</author>
<author>Buneman</author>
<author>Suciu</author>
</book>
</bib>
The following example transforms the input document into a list in which each author's name appears only once, followed by a list of titles of books written by that author. This example assumes that the context item is the bib element in the input document.
for $a in fn:distinct-values(book/author)
return (book/author[. = $a][1], book[author = $a]/title)
The result of the above expression consists of the following sequence of elements. The titles of books written by a given author are listed after the name of the author. The ordering of author elements in the result is implementation-dependent due to the semantics of the fn:distinct-values function.
<author>Stevens</author> <title>TCP/IP Illustrated</title> <title>Advanced Programming in the Unix environment</title> <author>Abiteboul</author> <title>Data on the Web</title> <author>Buneman</author> <title>Data on the Web</title> <author>Suciu</author> <title>Data on the Web</title>
The following example illustrates a for expression containing more than one variable:
for $i in (10, 20),
$j in (1, 2)
return ($i + $j)
The result of the above expression, expressed as a sequence of numbers, is as follows: 11, 12, 21, 22
The scope of a variable bound in a for expression comprises all subexpressions of the for expression that appear after the variable binding. The scope does not include the expression to which the variable is bound. The following example illustrates how a variable binding may reference another variable bound earlier in the same for expression:
for $x in $z, $y in f($x)
return g($x, $y)
Note:
The focus for evaluation of the return clause of a for expression is the same as the focus for evaluation of the for expression itself. The following example, which attempts to find the total value of a set of order-items, is therefore incorrect:
fn:sum(for $i in order-item return @price * @qty)
Instead, the expression must be written to use the variable bound in the for clause:
fn:sum(for $i in order-item
return $i/@price * $i/@qty)
3.8 条件式
XPath supports a conditional expression based on the keywords if, then, and else.
| [7] | IfExpr |
::= | "if" "(" Expr ")" "then" ExprSingle "else" ExprSingle |
The expression following the if keyword is called the test expression, and the expressions following the then and else keywords are called the then-expression and else-expression, respectively.
The first step in processing a conditional expression is to find the 有効ブール値 of the test expression, as defined in 2.4.3 有効ブール値.
The value of a conditional expression is defined as follows: If the effective boolean value of the test expression is true, the value of the then-expression is returned. If the effective boolean value of the test expression is false, the value of the else-expression is returned.
Conditional expressions have a special rule for propagating dynamic errors. If the effective value of the test expression is true, the conditional expression ignores (does not raise) any dynamic errors encountered in the else-expression. In this case, since the else-expression can have no observable effect, it need not be evaluated. Similarly, if the effective value of the test expression is false, the conditional expression ignores any dynamic errors encountered in the then-expression, and the then-expression need not be evaluated.
Here are some examples of conditional expressions:
In this example, the test expression is a comparison expression:
if ($widget1/unit-cost < $widget2/unit-cost) then $widget1 else $widget2
In this example, the test expression tests for the existence of an attribute named
discounted, independently of its value:if ($part/@discounted) then $part/wholesale else $part/retail
3.9 定量式 (Quantified Expression)
Quantified expressions support existential and universal quantification. The value of a quantified expression is always true or false.
| [6] | QuantifiedExpr |
::= | ("some" | "every") "$" VarName "in" ExprSingle ("," "$" VarName "in" ExprSingle)* "satisfies" ExprSingle |
A quantified expression begins with a quantifier, which is the keyword some or every, followed by one or more in-clauses that are used to bind variables, followed by the keyword satisfies and a test expression. Each in-clause associates a variable with an expression that returns a sequence of items, called the binding sequence for that variable. The in-clauses generate tuples of variable bindings, including a tuple for each combination of items in the binding sequences of the respective variables. Conceptually, the test expression is evaluated for each tuple of variable bindings. Results depend on the 有効ブール値 of the test expressions, as defined in 2.4.3 有効ブール値. The value of the quantified expression is defined by the following rules:
If the quantifier is
some, the quantified expression istrueif at least one evaluation of the test expression has the 有効ブール値true; otherwise the quantified expression isfalse. This rule implies that, if the in-clauses generate zero binding tuples, the value of the quantified expression isfalse.If the quantifier is
every, the quantified expression istrueif every evaluation of the test expression has the 有効ブール値true; otherwise the quantified expression isfalse. This rule implies that, if the in-clauses generate zero binding tuples, the value of the quantified expression istrue.
The scope of a variable bound in a quantified expression comprises all subexpressions of the quantified expression that appear after the variable binding. The scope does not include the expression to which the variable is bound.
The order in which test expressions are evaluated for the various binding tuples is implementation-dependent. If the quantifier is some, an implementation may return true as soon as it finds one binding tuple for which the test expression has an 有効ブール値 of true, and it may raise a dynamic error as soon as it finds one binding tuple for which the test expression raises an error. Similarly, if the quantifier is every, an implementation may return false as soon as it finds one binding tuple for which the test expression has an 有効ブール値 of false, and it may raise a dynamic error as soon as it finds one binding tuple for which the test expression raises an error. As a result of these rules, the value of a quantified expression is not deterministic in the presence of errors, as illustrated in the examples below.
Here are some examples of quantified expressions:
This expression is
trueif everypartelement has adiscountedattribute (regardless of the values of these attributes):every $part in /parts/part satisfies $part/@discounted
This expression is
trueif at least oneemployeeelement satisfies the given comparison expression:some $emp in /emps/employee satisfies ($emp/bonus > 0.25 * $emp/salary)In the following examples, each quantified expression evaluates its test expression over nine tuples of variable bindings, formed from the Cartesian product of the sequences
(1, 2, 3)and(2, 3, 4). The expression beginning withsomeevaluates totrue, and the expression beginning witheveryevaluates tofalse.some $x in (1, 2, 3), $y in (2, 3, 4) satisfies $x + $y = 4every $x in (1, 2, 3), $y in (2, 3, 4) satisfies $x + $y = 4This quantified expression may either return
trueor raise a type error, since its test expression returnstruefor one variable binding and raises a type error for another:some $x in (1, 2, "cat") satisfies $x * 2 = 4
This quantified expression may either return
falseor raise a type error, since its test expression returnsfalsefor one variable binding and raises a type error for another:every $x in (1, 2, "cat") satisfies $x * 2 = 4
3.10 SequenceTypes 上の式
シーケンス型は instance of、cast、castable、treat 式で使用される。
3.10.1 Instance Of
| [16] | InstanceofExpr |
::= | TreatExpr ( "instance" "of" SequenceType )? |
The boolean operator instance of returns true if the value of its first operand matches the SequenceType in its second operand, according to the rules for SequenceType matching; otherwise it returns false. For example:
5 instance of xs:integerThis example returns
truebecause the given value is an instance of the given type.5 instance of xs:decimalThis example returns
truebecause the given value is an integer literal, andxs:integeris derived by restriction fromxs:decimal.(5, 6) instance of xs:integer+This example returns
truebecause the given sequence contains two integers, and is a valid instance of the specified type.. instance of element()This example returns
trueif the context item is an element node orfalseif the context item is defined but is not an element node. If the context item is undefined, a dynamic error is raised [err:XPDY0002].
3.10.2 Cast
| [19] | CastExpr |
::= | UnaryExpr ( "cast" "as" SingleType )? |
| [49] | SingleType |
::= | AtomicType "?"? |
Occasionally it is necessary to convert a value to a specific datatype. For this purpose, XPath provides a cast expression that creates a new value of a specific type based on an existing value. A cast expression takes two operands: an input expression and a target type. The type of the input expression is called the input type. The target type must be an atomic type that is in the in-scope schema types [err:XPST0051]. In addition, the target type cannot be xs:NOTATION or xs:anyAtomicType [err:XPST0080]. The optional occurrence indicator "?" denotes that an empty sequence is permitted. If the target type has no namespace prefix, it is considered to be in the default element/type namespace. The semantics of the cast expression are as follows:
Atomization is performed on the input expression.
If the result of atomization is a sequence of more than one atomic value, a type error is raised [err:XPTY0004].
If the result of atomization is an empty sequence:
If
?is specified after the target type, the result of thecastexpression is an empty sequence.If
?is not specified after the target type, a type error is raised [err:XPTY0004].
If the result of atomization is a single atomic value, the result of the cast expression depends on the input type and the target type. In general, the cast expression attempts to create a new value of the target type based on the input value. Only certain combinations of input type and target type are supported. A summary of the rules are listed below— the normative definition of these rules is given in [XQuery 1.0 and XPath 2.0 Functions and Operators]. For the purpose of these rules, an implementation may determine that one type is derived by restriction from another type either by examining the in-scope schema definitions or by using an alternative, implementation-dependent mechanism such as a data dictionary.
castis supported for the combinations of input type and target type listed in Section 17.1 Casting from primitive types to primitive typesFO. For each of these combinations, both the input type and the target type are primitive schema types. For example, a value of typexs:stringcan be cast into the schema typexs:decimal. For each of these built-in combinations, the semantics of casting are specified in [XQuery 1.0 and XPath 2.0 Functions and Operators].If the target type of a
castexpression isxs:QName, or is a type that is derived fromxs:QNameorxs:NOTATION, and if the base type of the input is not the same as the base type of the target type, then the input expression must be a string literal [err:XPTY0004].Note:
The reason for this rule is that construction of an instance of one of these target types from a string requires knowledge about namespace bindings. If the input expression is a non-literal string, it might be derived from an input document whose namespace bindings are different from the statically known namespaces.
castis supported if the input type is a non-primitive atomic type that is derived by restriction from the target type. In this case, the input value is mapped into the value space of the target type, unchanged except for its type. For example, ifshoesizeis derived by restriction fromxs:integer, a value of typeshoesizecan be cast into the schema typexs:integer.castis supported if the target type is a non-primitive atomic type and the input type isxs:stringorxs:untypedAtomic. The input value is first converted to a value in the lexical space of the target type by applying the whitespace normalization rules for the target type (as defined in [XML Schema]); a dynamic error [err:FORG0001] is raised if the resulting lexical value does not satisfy the pattern facet of the target type. The lexical value is then converted to the value space of the target type using the schema-defined rules for the target type; a dynamic error [err:FORG0001] is raised if the resulting value does not satisfy all the facets of the target type.castis supported if the target type is a non-primitive atomic type that is derived by restriction from the input type. The input value must satisfy all the facets of the target type (in the case of the pattern facet, this is checked by generating a string representation of the input value, using the rules for casting toxs:string). The resulting value is the same as the input value, but with a different dynamic type.If a primitive type P1 can be cast into a primitive type P2, then any type derived by restriction from P1 can be cast into any type derived by restriction from P2, provided that the facets of the target type are satisfied. First the input value is cast to P1 using rule (b) above. Next, the value of type P1 is cast to the type P2, using rule (a) above. Finally, the value of type P2 is cast to the target type, using rule (d) above.
For any combination of input type and target type that is not in the above list, a
castexpression raises a type error [err:XPTY0004].
If casting from the input type to the target type is supported but nevertheless it is not possible to cast the input value into the value space of the target type, a dynamic error is raised. [err:FORG0001] This includes the case when any facet of the target type is not satisfied. For example, the expression "2003-02-31" cast as xs:date would raise a dynamic error.
3.10.3 Castable
| [18] | CastableExpr |
::= | CastExpr ( "castable" "as" SingleType )? |
| [49] | SingleType |
::= | AtomicType "?"? |
XPath provides an expression that tests whether a given value is castable into a given target type. The target type must be an atomic type that is in the in-scope schema types [err:XPST0051]. In addition, the target type cannot be xs:NOTATION or xs:anyAtomicType [err:XPST0080]. The optional occurrence indicator "?" denotes that an empty sequence is permitted.
The expression V castable as T returns true if the value V can be successfully cast into the target type T by using a cast expression; otherwise it returns false. The castable expression can be used as a predicate to avoid errors at evaluation time. It can also be used to select an appropriate type for processing of a given value, as illustrated in the following example:
if ($x castable as hatsize) then $x cast as hatsize else if ($x castable as IQ) then $x cast as IQ else $x cast as xs:string
Note:
If the target type of a castable expression is xs:QName, or is a type that is derived from xs:QName or xs:NOTATION, and the input argument of the expression is of type xs:string but it is not a literal string, the result of the castable expression is false.
3.10.4 Constructor Functions
For every atomic type in the in-scope schema types (except xs:NOTATION and xs:anyAtomicType, which are not instantiable), a constructor function is implicitly defined. In each case, the name of the constructor function is the same as the name of its target type (including namespace). The signature of the constructor function for type T is as follows:
T($arg as xs:anyAtomicType?) as T?
[Definition: The constructor function for a given type is used to convert instances of other atomic types into the given type. The semantics of the constructor function call T($arg) are defined to be equivalent to the expression (($arg) cast as T?).]
The constructor functions for xs:QName and for types derived from xs:QName and xs:NOTATION require their arguments to be string literals or to have a base type that is the same as the base type of the target type; otherwise a type error [err:XPTY0004] is raised. This rule is consistent with the semantics of cast expressions for these types, as defined in 3.10.2 Cast.
The following examples illustrate the use of constructor functions:
This example is equivalent to
("2000-01-01" cast as xs:date?).xs:date("2000-01-01")This example is equivalent to
(($floatvalue * 0.2E-5) cast as xs:decimal?).xs:decimal($floatvalue * 0.2E-5)
This example returns a
xs:dayTimeDurationvalue equal to 21 days. It is equivalent to("P21D" cast as xs:dayTimeDuration?).xs:dayTimeDuration("P21D")If
usa:zipcodeis a user-defined atomic type in the in-scope schema types, then the following expression is equivalent to the expression("12345" cast as usa:zipcode?).usa:zipcode("12345")
Note:
An instance of an atomic type that is not in a namespace can be constructed in either of the following ways:
By using a
castexpression, if the default element/type namespace is "none".17 cast as apple
By using a constructor function, if the default function namespace is "none".
apple(17)
3.10.5 Treat
| [17] | TreatExpr |
::= | CastableExpr ( "treat" "as" SequenceType )? |
XPath provides an expression called treat that can be used to modify the static type of its operand.
Like cast, the treat expression takes two operands: an expression and a SequenceType. Unlike cast, however, treat does not change the dynamic type or value of its operand. Instead, the purpose of treat is to ensure that an expression has an expected dynamic type at evaluation time.
The semantics of expr1 treat as type1 are as follows:
During static analysis:
The static type of the
treatexpression istype1. This enables the expression to be used as an argument of a function that requires a parameter oftype1.During expression evaluation:
If
expr1matchestype1, using the rules for SequenceType matching, thetreatexpression returns the value ofexpr1; otherwise, it raises a dynamic error [err:XPDY0050]. If the value ofexpr1is returned, its identity is preserved. Thetreatexpression ensures that the value of its expression operand conforms to the expected type at run-time.Example:
$myaddress treat as element(*, USAddress)
The static type of
$myaddressmay beelement(*, Address), a less specific type thanelement(*, USAddress). However, at run-time, the value of$myaddressmust match the typeelement(*, USAddress)using rules for SequenceType matching; otherwise a dynamic error is raised [err:XPDY0050].
A XPath 文法
A.1 EBNF
XPath の文法は [XML 1.0] での単純な Extended Backus-Naur Form (EBNF) と同じ表記を使用している。ただし以下の些細な違いを含む。
All named symbols have a name that begins with an uppercase letter.
It adds a notation for referring to productions in external specs.
Comments or extra-grammatical constraints on grammar productions are between '/*' and '*/' symbols.
A 'xgc:' prefix is an extra-grammatical constraint, the details of which are explained in A.1.2 Extra-grammatical Constraints
A 'ws:' prefix explains the whitespace rules for the production, the details of which are explained in A.2.4 Whitespace Rules
A 'gn:' prefix means a 'Grammar Note', and is meant as a clarification for parsing rules, and is explained in A.1.3 Grammar Notes. These notes are not normative.
The terminal symbols for this grammar include the quoted strings used in the production rules below, and the terminal symbols defined in section A.2.1 Terminal Symbols.
The EBNF notation is described in more detail in A.1.1 Notation.
To increase readability, the EBNF in the main body of this document omits some of these notational features. This appendix is the normative version of the EBNF.
A.1.1 Notation
The following definitions will be helpful in defining precisely this exposition.
[Definition: Each rule in the grammar defines one symbol, using the following format:
symbol ::= expression
]
[Definition: A terminal is a symbol or string or pattern that can appear in the right-hand side of a rule, but never appears on the left hand side in the main grammar, although it may appear on the left-hand side of a rule in the grammar for terminals.] The following constructs are used to match strings of one or more characters in a terminal:
- [a-zA-Z]
-
matches any Char with a value in the range(s) indicated (inclusive).
- [abc]
-
matches any Char with a value among the characters enumerated.
- [^abc]
-
matches any Char with a value not among the characters given.
- "string"
-
matches the sequence of characters that appear inside the double quotes.
- 'string'
-
matches the sequence of characters that appear inside the single quotes.
- [http://www.w3.org/TR/REC-example/#NT-Example]
-
matches any string matched by the production defined in the external specification as per the provided reference.
Patterns (including the above constructs) can be combined with grammatical operators to form more complex patterns, matching more complex sets of character strings. In the examples that follow, A and B represent (sub-)patterns.
- (A)
-
Ais treated as a unit and may be combined as described in this list. - A?
-
matches
Aor nothing; optionalA. - A B
-
matches
Afollowed byB. This operator has higher precedence than alternation; thusA B | C Dis identical to(A B) | (C D). - A | B
-
matches
AorBbut not both. - A - B
-
matches any string that matches
Abut does not matchB. - A+
-
matches one or more occurrences of
A. Concatenation has higher precedence than alternation; thusA+ | B+is identical to(A+) | (B+).
- A*
-
matches zero or more occurrences of
A. Concatenation has higher precedence than alternation; thusA* | B*is identical to(A*) | (B*)
A.1.2 Extra-grammatical Constraints
This section contains constraints on the EBNF productions, which are required to parse legal sentences. The notes below are referenced from the right side of the production, with the notation: /* xgc: <id> */.
Constraint: leading-lone-slash
A single slash may appear either as a complete path expression or as the first part of a path expression in which it is followed by a RelativePathExpr, which can take the form of a NameTest ("*" or a QName). In contexts where operators like "*", "union", etc., can occur, parsers may have difficulty distinguishing operators from NameTests. For example, without lookahead the first part of the expression "/ * 5", for example is easily taken to be a complete expression, "/ *", which has a very different interpretation (the child nodes of "/").
To reduce the need for lookahead, therefore, if the token immediately following a slash is "*" or a keyword, then the slash must be the beginning, but not the entirety, of a PathExpr (and the following token must be a NameTest, not an operator).
A single slash may be used as the left-hand argument of an operator by parenthesizing it: (/) * 5. The expression 5 * /, on the other hand, is legal without parentheses.
An implementation's choice to support the [XML 1.0] and [XML Names], or [XML 1.1] and [XML Names 1.1] lexical specification determines the external document from which to obtain the definition for this production. The EBNF only has references to the 1.0 versions. In some cases, the XML 1.0 and XML 1.1 definitions may be exactly the same. Also please note that these external productions follow the whitespace rules of their respective specifications, and not the rules of this specification, in particular A.2.4.1 Default Whitespace Handling. Thus prefix : localname is not a valid QName for purposes of this specification, just as it is not permitted in a XML document. Also, comments are not permissible on either side of the colon. Also extra-grammatical constraints such as well-formedness constraints must be taken into account.
Constraint: reserved-function-names
Unprefixed function names spelled the same way as language keywords could make the language harder to recognize. For instance, if(foo) could be taken either as a FunctionCall or as the beginning of an IfExpr. Therefore it is not legal syntax for a user to invoke functions with unprefixed names which match any of the names in A.3 Reserved Function Names.
A function named "if" can be called by binding its namespace to a prefix and using the prefixed form: "library:if(foo)" instead of "if(foo)".
Constraint: occurrence-indicators
As written, the grammar in A XPath Grammar is ambiguous for some forms using the '+' and '*' Kleene operators. The ambiguity is resolved as follows: these operators are tightly bound to the SequenceType expression, and have higher precedence than other uses of these symbols. Any occurrence of '+' and '*', as well as '?', following a sequence type is assumed to be an occurrence indicator. That is, a "+", "*", or "?" immediately following an ItemType must be an OccurrenceIndicator. Thus, 4 treat as item() + - 5 must be interpreted as (4 treat as item()+) - 5, taking the '+' as an OccurrenceIndicator and the '-' as a subtraction operator. To force the interpretation of "+" as an addition operator (and the corresponding interpretation of the "-" as a unary minus), parentheses may be used: the form (4 treat as item()) + -5 surrounds the SequenceType expression with parentheses and leads to the desired interpretation.
This rule has as a consequence that certain forms which would otherwise be legal and unambiguous are not recognized: in "4 treat as item() + 5", the "+" is taken as an OccurrenceIndicator, and not as an operator, which means this is not a legal expression.
A.1.3 Grammar Notes
This section contains general notes on the EBNF productions, which may be helpful in understanding how to interpret and implement the EBNF. These notes are not normative. The notes below are referenced from the right side of the production, with the notation: /* gn: <id> */.
Note:
- grammar-note: parens
-
Look-ahead is required to distinguish FunctionCall from a QName or keyword followed by a Comment. For example:
address (: this may be empty :)may be mistaken for a call to a function named "address" unless this lookahead is employed. Another example isfor (: whom the bell :) $tolls in 3 return $tolls, where the keyword "for" must not be mistaken for a function name. - grammar-note: comments
-
Comments are allowed everywhere that ignorable whitespace is allowed, and the Comment symbol does not explicity appear on the right-hand side of the grammar (except in its own production). See A.2.4.1 Default Whitespace Handling.
A comment can contain nested comments, as long as all "(:" and ":)" patterns are balanced, no matter where they occur within the outer comment.
Note:
Lexical analysis may typically handle nested comments by incrementing a counter for each "(:" pattern, and decrementing the counter for each ":)" pattern. The comment does not terminate until the counter is back to zero.
Some illustrative examples:
(: commenting out a (: comment :) may be confusing, but often helpful :)is a legal Comment, since balanced nesting of comments is allowed."this is just a string :)"is a legal expression. However,(: "this is just a string :)" :)will cause a syntax error. Likewise,"this is another string (:"is a legal expression, but(: "this is another string (:" :)will cause a syntax error. It is a limitation of nested comments that literal content can cause unbalanced nesting of comments.for (: set up loop :) $i in $x return $iis syntactically legal, ignoring the comment.5 instance (: strange place for a comment :) of xs:integeris also syntactically legal.
A.2 構文構造
The terminal symbols assumed by the grammar above are described in this section.
Quoted strings appearing in production rules are terminal symbols.
Other terminal symbols are defined in A.2.1 Terminal Symbols.
A host language may choose whether the lexical rules of [XML 1.0] and [XML Names] are followed, or alternatively, the lexical rules of [XML 1.1] and [XML Names 1.1] are followed.
When tokenizing, the longest possible match that is valid in the current context is used.
All keywords are case sensitive. Keywords are not reserved—that is, any QName may duplicate a keyword except as noted in A.3 Reserved Function Names.
A.2.1 Terminal Symbols
| [71] | IntegerLiteral |
::= | Digits |
|
| [72] | DecimalLiteral |
::= | ("." Digits) | (Digits "." [0-9]*) |
/* ws: explicit */ |
| [73] | DoubleLiteral |
::= | (("." Digits) | (Digits ("." [0-9]*)?)) [eE] [+-]? Digits |
/* ws: explicit */ |
| [74] | StringLiteral |
::= | ('"' (EscapeQuot | [^"])* '"') | ("'" (EscapeApos | [^'])* "'") |
/* ws: explicit */ |
| [75] | EscapeQuot |
::= | '""' |
|
| [76] | EscapeApos |
::= | "''" |
|
| [77] | Comment |
::= | "(:" (CommentContents | Comment)* ":)" |
/* ws: explicit */ |
| /* gn: comments */ | ||||
| [78] | QName |
::= | [http://www.w3.org/TR/REC-xml-names/#NT-QName] Names |
/* xgs: xml-version */ |
| [79] | NCName |
::= | [http://www.w3.org/TR/REC-xml-names/#NT-NCName] Names |
/* xgs: xml-version */ |
| [80] | Char |
::= | [http://www.w3.org/TR/REC-xml#NT-Char] XML |
/* xgs: xml-version */ |
The following symbols are used only in the definition of terminal symbols; they are not terminal symbols in the grammar of A.1 EBNF.
| [81] | Digits |
::= | [0-9]+ |
| [82] | CommentContents |
::= | (Char+ - (Char* ('(:' | ':)') Char*)) |
A.2.2 Terminal Delimitation
XPath 2.0 expressions consist of terminal symbols and symbol separators.
Terminal symbols that are not used exclusively in /* ws: explicit */ productions are of two kinds: delimiting and non-delimiting.
[Definition: The delimiting terminal symbols are: "-", (comma), (colon), "::", "!=", "?", "/", "//", (dot), "..", StringLiteral, "(", ")", "[", "]", "@", "$", "*", "+", "<", "<<", "<=", "=", ">", ">=", ">>", "|"]
[Definition: The non-delimiting terminal symbols are: IntegerLiteral, NCName, QName, DecimalLiteral, DoubleLiteral, "ancestor", "ancestor-or-self", "and", "as", "attribute", "cast", "castable", "child", "comment", "descendant", "descendant-or-self", "div", "document-node", "element", "else", "empty-sequence", "eq", "every", "except", "external", "following", "following-sibling", "for", "ge", "gt", "idiv", "if", "in", "instance", "intersect", "is", "item", "le", "lt", "mod", "namespace", "ne", "node", "of", "or", "parent", "preceding", "preceding-sibling", "processing-instruction", "return", "satisfies", "schema-attribute", "schema-element", "self", "some", "text", "then", "to", "treat", "union"]
[Definition: Whitespace and Comments function as symbol separators. For the most part, they are not mentioned in the grammar, and may occur between any two terminal symbols mentioned in the grammar, except where that is forbidden by the /* ws: explicit */ annotation in the EBNF, or by the /* xgs: xml-version */ annotation. ]
It is customary to separate consecutive terminal symbols by whitespace and Comments, but this is required only when otherwise two non-delimiting symbols would be adjacent to each other. There are two exceptions to this, that of "." and "-", which do require a symbol separator if they follow a QName or NCName. Also, "." requires a separator if it precedes or follows a numeric literal.
A.2.3 End-of-Line Handling
The XPath processor must behave as if it normalized all line breaks on input, before parsing. The normalization should be done according to the choice to support either [XML 1.0] or [XML 1.1] lexical processing.
A.2.3.1 XML 1.0 End-of-Line Handling
For [XML 1.0] processing, all of the following must be translated to a single #xA character:
the two-character sequence #xD #xA
any #xD character that is not immediately followed by #xA.
A.2.3.2 XML 1.1 End-of-Line Handling
For [XML 1.1] processing, all of the following must be translated to a single #xA character:
the two-character sequence #xD #xA
the two-character sequence #xD #x85
the single character #x85
the single character #x2028
any #xD character that is not immediately followed by #xA or #x85.
A.2.4 Whitespace Rules
A.2.4.1 Default Whitespace Handling
[Definition: A whitespace character is any of the characters defined by [http://www.w3.org/TR/REC-xml#NT-S].]
[Definition: Ignorable whitespace consists of any whitespace characters that may occur between terminals, unless these characters occur in the context of a production marked with a ws:explicit annotation, in which case they can occur only where explicitly specified (see A.2.4.2 Explicit Whitespace Handling).] Ignorable whitespace characters are not significant to the semantics of an expression. Whitespace is allowed before the first terminal and after the last terminal of a module. Whitespace is allowed between any two terminals. Comments may also act as "whitespace" to prevent two adjacent terminals from being recognized as one. Some illustrative examples are as follows:
foo- fooresults in a syntax error. "foo-" would be recognized as a QName.foo -foois syntactically equivalent tofoo - foo, two QNames separated by a subtraction operator.foo(: This is a comment :)- foois syntactically equivalent tofoo - foo. This is because the comment prevents the two adjacent terminals from being recognized as one.foo-foois syntactically equivalent to single QName. This is because "-" is a valid character in a QName. When used as an operator after the characters of a name, the "-" must be separated from the name, e.g. by using whitespace or parentheses.10div 3results in a syntax error.10 div3also results in a syntax error.10div3also results in a syntax error.
A.2.4.2 Explicit Whitespace Handling
Explicit whitespace notation is specified with the EBNF productions, when it is different from the default rules, using the notation shown below. This notation is not inherited. In other words, if an EBNF rule is marked as /* ws: explicit */, the notation does not automatically apply to all the 'child' EBNF productions of that rule.
- ws: explicit
-
/* ws: explicit */ means that the EBNF notation explicitly notates, with
Sor otherwise, where whitespace characters are allowed. In productions with the /* ws: explicit */ annotation, A.2.4.1 Default Whitespace Handling does not apply. Comments are also not allowed in these productions.
A.3 予約関数名
以下の名前は式構文が優先的に処理するため、接頭辞の付かない形式で使用することはできない。
attributecommentdocument-nodeelementempty-sequenceifitemnodeprocessing-instructionschema-attributeschema-elementtexttypeswitchNote:
キーワード
typeswitchは XPath では使用されていないが、XQuery との互換性に対する予約関数名として考慮している。
A.4 優先順位
A.1 EBNF の文法は XPath の演算子間のビルトイン優先順位を規範的に定義している。これらの演算子は優先順位の低いものから高いものの順でここで明示しておく。優先順位の低い演算子は高い優先順位の演算子に含まれることができない。結合方向の列は式の中で適応される等しい優先順位の演算子であることを示している。
| # | 演算子 | 結合方向 |
|---|---|---|
| 1 | , (コンマ) | left-to-right |
| 3 | for, some, every, if | left-to-right |
| 4 | or | left-to-right |
| 5 | and | left-to-right |
| 6 | eq, ne, lt, le, gt, ge, =, !=, <, <=, >, >=, is, <<, >> | left-to-right |
| 7 | to | left-to-right |
| 8 | +, - | left-to-right |
| 9 | *, div, idiv, mod | left-to-right |
| 10 | union, | | left-to-right |
| 11 | intersect, except | left-to-right |
| 12 | instance of | left-to-right |
| 13 | treat | left-to-right |
| 14 | castable | left-to-right |
| 15 | cast | left-to-right |
| 16 | -(単項), +(単項) | right-to-left |
| 17 | ?, *(繰り返し指示), +(繰り返し指示) | left-to-right |
| 18 | /, // | left-to-right |
| 19 | [ ], ( ), {} | left-to-right |
B 型昇格と演算子マッピング
B.1 型昇格
[Definition: Under certain circumstances, an atomic value can be promoted from one type to another. Type promotion is used in evaluating function calls (see 3.1.5 Function Calls) and operators that accept numeric or string operands (see B.2 Operator Mapping).] The following type promotions are permitted:
Numeric type promotion:
A value of type
xs:float(or any type derived by restriction fromxs:float) can be promoted to the typexs:double. The result is thexs:doublevalue that is the same as the original value.A value of type
xs:decimal(or any type derived by restriction fromxs:decimal) can be promoted to either of the typesxs:floatorxs:double. The result of this promotion is created by casting the original value to the required type. This kind of promotion may cause loss of precision.
URI type promotion: A value of type
xs:anyURI(or any type derived by restriction fromxs:anyURI) can be promoted to the typexs:string. The result of this promotion is created by casting the original value to the typexs:string.Note:
Since
xs:anyURIvalues can be promoted toxs:string, functions and operators that compare strings using the default collation also comparexs:anyURIvalues using the default collation. This ensures that orderings that include strings,xs:anyURIvalues, or any combination of the two types are consistent and well-defined.
Note that type promotion is different from subtype substitution. For example:
A function that expects a parameter
$pof typexs:floatcan be invoked with a value of typexs:decimal. This is an example of type promotion. The value is actually converted to the expected type. Within the body of the function,$p instance of xs:decimalreturnsfalse.A function that expects a parameter
$pof typexs:decimalcan be invoked with a value of typexs:integer. This is an example of subtype substitution. The value retains its original type. Within the body of the function,$p instance of xs:integerreturnstrue.
B.2 演算子マッピング
The operator mapping tables in this section list the combinations of types for which the various operators of XPath are defined. [Definition: For each operator and valid combination of operand types, the operator mapping tables specify a result type and an operator function that implements the semantics of the operator for the given types.] The definitions of the operator functions are given in [XQuery 1.0 and XPath 2.0 Functions and Operators]. The result of an operator may be the raising of an error by its operator function, as defined in [XQuery 1.0 and XPath 2.0 Functions and Operators]. In some cases, the operator function does not implement the full semantics of a given operator. For the definition of each operator (including its behavior for empty sequences or sequences of length greater than one), see the descriptive material in the main part of this document.
The and and or operators are defined directly in the main body of this document, and do not occur in the operator mapping tables.
If an operator in the operator mapping tables expects an operand of type ET, that operator can be applied to an operand of type AT if type AT can be converted to type ET by a combination of type promotion and subtype substitution. For example, a table entry indicates that the gt operator may be applied to two xs:date operands, returning xs:boolean. Therefore, the gt operator may also be applied to two (possibly different) subtypes of xs:date, also returning xs:boolean.
[Definition: When referring to a type, the term numeric denotes the types xs:integer, xs:decimal, xs:float, and xs:double.] An operator whose operands and result are designated as numeric might be thought of as representing four operators, one for each of the numeric types. For example, the numeric + operator might be thought of as representing the following four operators:
| Operator | First operand type | Second operand type | Result type |
+ |
xs:integer |
xs:integer |
xs:integer |
+ |
xs:decimal |
xs:decimal |
xs:decimal |
+ |
xs:float |
xs:float |
xs:float |
+ |
xs:double |
xs:double |
xs:double |
A numeric operator may be validly applied to an operand of type AT if type AT can be converted to any of the four numeric types by a combination of type promotion and subtype substitution. If the result type of an operator is listed as numeric, it means "the first type in the ordered list (xs:integer, xs:decimal, xs:float, xs:double) into which all operands can be converted by subtype substitution and type promotion." As an example, suppose that the type hatsize is derived from xs:integer and the type shoesize is derived from xs:float. Then if the + operator is invoked with operands of type hatsize and shoesize, it returns a result of type xs:float. Similarly, if + is invoked with two operands of type hatsize it returns a result of type xs:integer.
[Definition: In the operator mapping tables, the term Gregorian refers to the types xs:gYearMonth, xs:gYear, xs:gMonthDay, xs:gDay, and xs:gMonth.] For binary operators that accept two Gregorian-type operands, both operands must have the same type (for example, if one operand is of type xs:gDay, the other operand must be of type xs:gDay.)
| Operator | Type(A) | Type(B) | Function | Result type |
|---|---|---|---|---|
| A + B | numeric | numeric | op:numeric-add(A, B) | numeric |
| A + B | xs:date | xs:yearMonthDuration | op:add-yearMonthDuration-to-date(A, B) | xs:date |
| A + B | xs:yearMonthDuration | xs:date | op:add-yearMonthDuration-to-date(B, A) | xs:date |
| A + B | xs:date | xs:dayTimeDuration | op:add-dayTimeDuration-to-date(A, B) | xs:date |
| A + B | xs:dayTimeDuration | xs:date | op:add-dayTimeDuration-to-date(B, A) | xs:date |
| A + B | xs:time | xs:dayTimeDuration | op:add-dayTimeDuration-to-time(A, B) | xs:time |
| A + B | xs:dayTimeDuration | xs:time | op:add-dayTimeDuration-to-time(B, A) | xs:time |
| A + B | xs:dateTime | xs:yearMonthDuration | op:add-yearMonthDuration-to-dateTime(A, B) | xs:dateTime |
| A + B | xs:yearMonthDuration | xs:dateTime | op:add-yearMonthDuration-to-dateTime(B, A) | xs:dateTime |
| A + B | xs:dateTime | xs:dayTimeDuration | op:add-dayTimeDuration-to-dateTime(A, B) | xs:dateTime |
| A + B | xs:dayTimeDuration | xs:dateTime | op:add-dayTimeDuration-to-dateTime(B, A) | xs:dateTime |
| A + B | xs:yearMonthDuration | xs:yearMonthDuration | op:add-yearMonthDurations(A, B) | xs:yearMonthDuration |
| A + B | xs:dayTimeDuration | xs:dayTimeDuration | op:add-dayTimeDurations(A, B) | xs:dayTimeDuration |
| A - B | numeric | numeric | op:numeric-subtract(A, B) | numeric |
| A - B | xs:date | xs:date | op:subtract-dates(A, B) | xs:dayTimeDuration |
| A - B | xs:date | xs:yearMonthDuration | op:subtract-yearMonthDuration-from-date(A, B) | xs:date |
| A - B | xs:date | xs:dayTimeDuration | op:subtract-dayTimeDuration-from-date(A, B) | xs:date |
| A - B | xs:time | xs:time | op:subtract-times(A, B) | xs:dayTimeDuration |
| A - B | xs:time | xs:dayTimeDuration | op:subtract-dayTimeDuration-from-time(A, B) | xs:time |
| A - B | xs:dateTime | xs:dateTime | op:subtract-dateTimes(A, B) | xs:dayTimeDuration |
| A - B | xs:dateTime | xs:yearMonthDuration | op:subtract-yearMonthDuration-from-dateTime(A, B) | xs:dateTime |
| A - B | xs:dateTime | xs:dayTimeDuration | op:subtract-dayTimeDuration-from-dateTime(A, B) | xs:dateTime |
| A - B | xs:yearMonthDuration | xs:yearMonthDuration | op:subtract-yearMonthDurations(A, B) | xs:yearMonthDuration |
| A - B | xs:dayTimeDuration | xs:dayTimeDuration | op:subtract-dayTimeDurations(A, B) | xs:dayTimeDuration |
| A * B | numeric | numeric | op:numeric-multiply(A, B) | numeric |
| A * B | xs:yearMonthDuration | numeric | op:multiply-yearMonthDuration(A, B) | xs:yearMonthDuration |
| A * B | numeric | xs:yearMonthDuration | op:multiply-yearMonthDuration(B, A) | xs:yearMonthDuration |
| A * B | xs:dayTimeDuration | numeric | op:multiply-dayTimeDuration(A, B) | xs:dayTimeDuration |
| A * B | numeric | xs:dayTimeDuration | op:multiply-dayTimeDuration(B, A) | xs:dayTimeDuration |
| A idiv B | numeric | numeric | op:numeric-integer-divide(A, B) | xs:integer |
| A div B | numeric | numeric | op:numeric-divide(A, B) | numeric; but xs:decimal if both operands are xs:integer |
| A div B | xs:yearMonthDuration | numeric | op:divide-yearMonthDuration(A, B) | xs:yearMonthDuration |
| A div B | xs:dayTimeDuration | numeric | op:divide-dayTimeDuration(A, B) | xs:dayTimeDuration |
| A div B | xs:yearMonthDuration | xs:yearMonthDuration | op:divide-yearMonthDuration-by-yearMonthDuration (A, B) | xs:decimal |
| A div B | xs:dayTimeDuration | xs:dayTimeDuration | op:divide-dayTimeDuration-by-dayTimeDuration (A, B) | xs:decimal |
| A mod B | numeric | numeric | op:numeric-mod(A, B) | numeric |
| A eq B | numeric | numeric | op:numeric-equal(A, B) | xs:boolean |
| A eq B | xs:boolean | xs:boolean | op:boolean-equal(A, B) | xs:boolean |
| A eq B | xs:string | xs:string | op:numeric-equal(fn:compare(A, B), 0) | xs:boolean |
| A eq B | xs:date | xs:date | op:date-equal(A, B) | xs:boolean |
| A eq B | xs:time | xs:time | op:time-equal(A, B) | xs:boolean |
| A eq B | xs:dateTime | xs:dateTime | op:dateTime-equal(A, B) | xs:boolean |
| A eq B | xs:duration | xs:duration | op:duration-equal(A, B) | xs:boolean |
| A eq B | Gregorian | Gregorian | op:gYear-equal(A, B) etc. | xs:boolean |
| A eq B | xs:hexBinary | xs:hexBinary | op:hex-binary-equal(A, B) | xs:boolean |
| A eq B | xs:base64Binary | xs:base64Binary | op:base64-binary-equal(A, B) | xs:boolean |
| A eq B | xs:anyURI | xs:anyURI | op:numeric-equal(fn:compare(A, B), 0) | xs:boolean |
| A eq B | xs:QName | xs:QName | op:QName-equal(A, B) | xs:boolean |
| A eq B | xs:NOTATION | xs:NOTATION | op:NOTATION-equal(A, B) | xs:boolean |
| A ne B | numeric | numeric | fn:not(op:numeric-equal(A, B)) | xs:boolean |
| A ne B | xs:boolean | xs:boolean | fn:not(op:boolean-equal(A, B)) | xs:boolean |
| A ne B | xs:string | xs:string | fn:not(op:numeric-equal(fn:compare(A, B), 0)) | xs:boolean |
| A ne B | xs:date | xs:date | fn:not(op:date-equal(A, B)) | xs:boolean |
| A ne B | xs:time | xs:time | fn:not(op:time-equal(A, B)) | xs:boolean |
| A ne B | xs:dateTime | xs:dateTime | fn:not(op:dateTime-equal(A, B)) | xs:boolean |
| A ne B | xs:duration | xs:duration | fn:not(op:duration-equal(A, B)) | xs:boolean |
| A ne B | Gregorian | Gregorian | fn:not(op:gYear-equal(A, B)) etc. | xs:boolean |
| A ne B | xs:hexBinary | xs:hexBinary | fn:not(op:hex-binary-equal(A, B)) | xs:boolean |
| A ne B | xs:base64Binary | xs:base64Binary | fn:not(op:base64-binary-equal(A, B)) | xs:boolean |
| A ne B | xs:anyURI | xs:anyURI | fn:not(op:numeric-equal(fn:compare(A, B), 0)) | xs:boolean |
| A ne B | xs:QName | xs:QName | fn:not(op:QName-equal(A, B)) | xs:boolean |
| A ne B | xs:NOTATION | xs:NOTATION | fn:not(op:NOTATION-equal(A, B)) | xs:boolean |
| A gt B | numeric | numeric | op:numeric-greater-than(A, B) | xs:boolean |
| A gt B | xs:boolean | xs:boolean | op:boolean-greater-than(A, B) | xs:boolean |
| A gt B | xs:string | xs:string | op:numeric-greater-than(fn:compare(A, B), 0) | xs:boolean |
| A gt B | xs:date | xs:date | op:date-greater-than(A, B) | xs:boolean |
| A gt B | xs:time | xs:time | op:time-greater-than(A, B) | xs:boolean |
| A gt B | xs:dateTime | xs:dateTime | op:dateTime-greater-than(A, B) | xs:boolean |
| A gt B | xs:yearMonthDuration | xs:yearMonthDuration | op:yearMonthDuration-greater-than(A, B) | xs:boolean |
| A gt B | xs:dayTimeDuration | xs:dayTimeDuration | op:dayTimeDuration-greater-than(A, B) | xs:boolean |
| A gt B | xs:anyURI | xs:anyURI | op:numeric-greater-than(fn:compare(A, B), 0) | xs:boolean |
| A lt B | numeric | numeric | op:numeric-less-than(A, B) | xs:boolean |
| A lt B | xs:boolean | xs:boolean | op:boolean-less-than(A, B) | xs:boolean |
| A lt B | xs:string | xs:string | op:numeric-less-than(fn:compare(A, B), 0) | xs:boolean |
| A lt B | xs:date | xs:date | op:date-less-than(A, B) | xs:boolean |
| A lt B | xs:time | xs:time | op:time-less-than(A, B) | xs:boolean |
| A lt B | xs:dateTime | xs:dateTime | op:dateTime-less-than(A, B) | xs:boolean |
| A lt B | xs:yearMonthDuration | xs:yearMonthDuration | op:yearMonthDuration-less-than(A, B) | xs:boolean |
| A lt B | xs:dayTimeDuration | xs:dayTimeDuration | op:dayTimeDuration-less-than(A, B) | xs:boolean |
| A lt B | xs:anyURI | xs:anyURI | op:numeric-less-than(fn:compare(A, B), 0) | xs:boolean |
| A ge B | numeric | numeric | op:numeric-greater-than(A, B) or op:numeric-equal(A, B) | xs:boolean |
| A ge B | xs:boolean | xs:boolean | fn:not(op:boolean-less-than(A, B)) | xs:boolean |
| A ge B | xs:string | xs:string | op:numeric-greater-than(fn:compare(A, B), -1) | xs:boolean |
| A ge B | xs:date | xs:date | fn:not(op:date-less-than(A, B)) | xs:boolean |
| A ge B | xs:time | xs:time | fn:not(op:time-less-than(A, B)) | xs:boolean |
| A ge B | xs:dateTime | xs:dateTime | fn:not(op:dateTime-less-than(A, B)) | xs:boolean |
| A ge B | xs:yearMonthDuration | xs:yearMonthDuration | fn:not(op:yearMonthDuration-less-than(A, B)) | xs:boolean |
| A ge B | xs:dayTimeDuration | xs:dayTimeDuration | fn:not(op:dayTimeDuration-less-than(A, B)) | xs:boolean |
| A ge B | xs:anyURI | xs:anyURI | op:numeric-greater-than(fn:compare(A, B), -1) | xs:boolean |
| A le B | numeric | numeric | op:numeric-less-than(A, B) or op:numeric-equal(A, B) | xs:boolean |
| A le B | xs:boolean | xs:boolean | fn:not(op:boolean-greater-than(A, B)) | xs:boolean |
| A le B | xs:string | xs:string | op:numeric-less-than(fn:compare(A, B), 1) | xs:boolean |
| A le B | xs:date | xs:date | fn:not(op:date-greater-than(A, B)) | xs:boolean |
| A le B | xs:time | xs:time | fn:not(op:time-greater-than(A, B)) | xs:boolean |
| A le B | xs:dateTime | xs:dateTime | fn:not(op:dateTime-greater-than(A, B)) | xs:boolean |
| A le B | xs:yearMonthDuration | xs:yearMonthDuration | fn:not(op:yearMonthDuration-greater-than(A, B)) | xs:boolean |
| A le B | xs:dayTimeDuration | xs:dayTimeDuration | fn:not(op:dayTimeDuration-greater-than(A, B)) | xs:boolean |
| A le B | xs:anyURI | xs:anyURI | op:numeric-less-than(fn:compare(A, B), 1) | xs:boolean |
| A is B | node() | node() | op:is-same-node(A, B) | xs:boolean |
| A << B | node() | node() | op:node-before(A, B) | xs:boolean |
| A >> B | node() | node() | op:node-after(A, B) | xs:boolean |
| A union B | node()* | node()* | op:union(A, B) | node()* |
| A | B | node()* | node()* | op:union(A, B) | node()* |
| A intersect B | node()* | node()* | op:intersect(A, B) | node()* |
| A except B | node()* | node()* | op:except(A, B) | node()* |
| A to B | xs:integer | xs:integer | op:to(A, B) | xs:integer* |
| A , B | item()* | item()* | op:concatenate(A, B) | item()* |
| Operator | Operand type | Function | Result type |
|---|---|---|---|
| + A | numeric | op:numeric-unary-plus(A) | numeric |
| - A | numeric | op:numeric-unary-minus(A) | numeric |
C コンテキストコンポーネント
このセクションの表は静的コンテキストおよび動的コンテキストのさまざまなコンポーネントのスコープ (適用範囲) を記述している。
C.1 静的コンテキストコンポーネント
The following table describes the components of the static context. For each component, "global" indicates that the value of the component applies throughout an XPath expression, whereas "lexical" indicates that the value of the component applies only within the subexpression in which it is defined.
| Component | Scope |
|---|---|
| XPath 1.0 Compatibility Mode | global |
| Statically known namespaces | global |
| Default element/type namespace | global |
| Default function namespace | global |
| In-scope schema types | global |
| In-scope element declarations | global |
| In-scope attribute declarations | global |
| In-scope variables | lexical; for-expressions and quantified expressions can bind new variables |
| Context item static type | lexical |
| Function signatures | global |
| Statically known collations | global |
| Default collation | global |
| Base URI | global |
| Statically known documents | global |
| Statically known collections | global |
| Statically known default collection type | global |
C.2 動的コンテキストコンポーネント
The following table describes how values are assigned to the various components of the dynamic context. All these components are initialized by mechanisms defined by the host language. For each component, "global" indicates that the value of the component remains constant throughout evaluation of the XPath expression, whereas "dynamic" indicates that the value of the component can be modified by the evaluation of subexpressions.
| Component | Scope |
|---|---|
| Context item | dynamic; changes during evaluation of path expressions and predicates |
| Context position | dynamic; changes during evaluation of path expressions and predicates |
| Context size | dynamic; changes during evaluation of path expressions and predicates |
| Variable values | dynamic; for-expressions and quantified expressions can bind new variables |
| Current date and time | global; must be initialized by implementation |
| Implicit timezone | global; must be initialized by implementation |
| Available documents | global; must be initialized by implementation |
| Available collections | global; must be initialized by implementation |
| Default collection | global; overwriteable by implementation |
D 実装定義項目
この仕様における以下の項目は実装定義である:
表記を構成する Unicode のバージョン。
The implicit timezone.
The circumstances in which warnings are raised, and the ways in which warnings are handled.
The method by which errors are reported to the external processing environment.
Whether the implementation is based on the rules of [XML 1.0] and [XML Names] or the rules of [XML 1.1] and [XML Names 1.1]. One of these sets of rules must be applied consistently by all aspects of the implementation.
Whether the implementation supports the namespace axis.
Any static typing extensions supported by the implementation, if the Static Typing Feature is supported.
Note:
Additional implementation-defined items are listed in [XQuery/XPath Data Model (XDM)] and [XQuery 1.0 and XPath 2.0 Functions and Operators].
E リファレンス
E.1 規範リファレンス
- RFC 2119
- S. Bradner. Key Words for use in RFCs to Indicate Requirement Levels. IETF RFC 2119. See http://www.ietf.org/rfc/rfc2119.txt .
- RFC2396
- T. Berners-Lee, R. Fielding, and L. Masinter. Uniform Resource Identifiers (URI): Generic Syntax . IETF RFC 2396. See http://www.ietf.org/rfc/rfc2396.txt .
- RFC3986
- T. Berners-Lee, R. Fielding, and L. Masinter. Uniform Resource Identifiers (URI): Generic Syntax . IETF RFC 3986. See http://www.ietf.org/rfc/rfc3986.txt .
- RFC3987
- M. Duerst and M. Suignard. Internationalized Resource Identifiers (IRIs) . IETF RFC 3987. See http://www.ietf.org/rfc/rfc3987.txt .
- ISO/IEC 10646
- ISO (International Organization for Standardization). ISO/IEC 10646:2003. Information technology—Universal Multiple-Octet Coded Character Set (UCS) , as, from time to time, amended, replaced by a new edition, or expanded by the addition of new parts. [Geneva]: International Organization for Standardization. (See http://www.iso.org for the latest version.)
- Unicode
- The Unicode Consortium. The Unicode Standard Reading, Mass.: Addison-Wesley, 2003, as updated from time to time by the publication of new versions. See http://www.unicode.org/unicode/standard/versions for the latest version and additional information on versions of the standard and of the Unicode Character Database. The version of Unicode to be used is implementation-defined , but implementations are recommended to use the latest Unicode version.
- XML 1.0
- World Wide Web Consortium. Extensible Markup Language (XML) 1.0. (Third Edition) W3C Recommendation. See http://www.w3.org/TR/REC-xml
- XML 1.1
- World Wide Web Consortium. Extensible Markup Language (XML) 1.1. W3C Recommendation. See http://www.w3.org/TR/xml11/
- XML Base
- World Wide Web Consortium. XML Base. W3C Recommendation. See http://www.w3.org/TR/xmlbase/
- XML Names
- World Wide Web Consortium. Namespaces in XML. W3C Recommendation. See http://www.w3.org/TR/REC-xml-names/
- XML Names 1.1
- World Wide Web Consortium. Namespaces in XML 1.1. W3C Recommendation. See http://www.w3.org/TR/xml-names11/
- XML ID
- World Wide Web Consortium. xml:id Version 1.0. W3C Recommendation. See http://www.w3.org/TR/xml-id/
- XML Schema
- World Wide Web Consortium. XML Schema, Parts 0, 1, and 2 (Second Edition) . W3C Recommendation, 28 October 2004. See http://www.w3.org/TR/xmlschema-0/ , http://www.w3.org/TR/xmlschema-1/ , and http://www.w3.org/TR/xmlschema-2/ .
- XQuery/XPath Data Model (XDM)
- World Wide Web Consortium. XQuery 1.0 and XPath 2.0 Data Model (XDM) . W3C Recommendation, 23 Jan. 2007. See http://www.w3.org/TR/xpath-datamodel/ .
- XQuery 1.0 and XPath 2.0 Formal Semantics
- World Wide Web Consortium. XQuery 1.0 and XPath 2.0 Formal Semantics . W3C Recommendation, 23 Jan. 2007. See http://www.w3.org/TR/xquery-semantics/ .
- XQuery 1.0 and XPath 2.0 Functions and Operators
- World Wide Web Consortium. XQuery 1.0 and XPath 2.0 Functions and Operators W3C Recommendation, 23 Jan. 2007. See http://www.w3.org/TR/xpath-functions/ .
- XSLT 2.0 and XQuery 1.0 Serialization
- World Wide Web Consortium. XSLT 2.0 and XQuery 1.0 Serialization . W3C Recommendation, 23 Jan. 2007. See http://www.w3.org/TR/xslt-xquery-serialization/ .
E.2 非規範リファレンス
- XPath 2.0 Requirements
- World Wide Web Consortium. XPath Requirements Version 2.0 . W3C Working Draft 22 August 2003. See http://www.w3.org/TR/xpath20req .
- XQuery
- World Wide Web Consortium. XQuery 1.0: An XML Query Language . W3C Recommendation, 23 Jan. 2007. See http://www.w3.org/TR/xquery/ .
- XSLT 2.0
- World Wide Web Consortium. XSL Transformations (XSLT) 2.0. W3C Recommendation, 23 Jan. 2007. See http://www.w3.org/TR/xslt20/
- Document Object Model
- World Wide Web Consortium. Document Object Model (DOM) Level 3 Core Specification. W3C Recommendation, April 7, 2004. See http://www.w3.org/TR/DOM-Level-3-Core/ .
- XML Infoset
- World Wide Web Consortium. XML Information Set. W3C Recommendation 24 October 2001. See http://www.w3.org/TR/xml-infoset/
- XPath 1.0
- World Wide Web Consortium. XML Path Language (XPath) Version 1.0 . W3C Recommendation, Nov. 16, 1999. See http://www.w3.org/TR/xpath.html
- XPointer
- World Wide Web Consortium. XML Pointer Language (XPointer). W3C Last Call Working Draft 8 January 2001. See http://www.w3.org/TR/WD-xptr
E.3 背景資料
- Character Model
- World Wide Web Consortium. Character Model for the World Wide Web. W3C Working Draft. See http://www.w3.org/TR/charmod/ .
- XSLT 1.0
- World Wide Web Consortium. XSL Transformations (XSLT) 1.0. W3C Recommendation. See http://www.w3.org/TR/xslt
F Conformance
XPath is intended primarily as a component that can be used by other specifications. Therefore, XPath relies on specifications that use it (such as [XPointer] and [XSLT 2.0]) to specify conformance criteria for XPath in their respective environments. Specifications that set conformance criteria for their use of XPath must not change the syntactic or semantic definitions of XPath as given in this specification, except by subsetting and/or compatible extensions.
F.1 Static Typing Feature
[Definition: The Static Typing Feature is an optional feature of XPath that provides support for the static semantics defined in [XQuery 1.0 and XPath 2.0 Formal Semantics], and requires implementations to detect and report type errors during the static analysis phase.] Specifications that use XPath may specify conformance criteria for use of the Static Typing Feature.
If an implementation does not support the Static Typing Feature, but can nevertheless determine during the static analysis phase that an expression will necessarily raise a type error if evaluated at run time, the implementation may raise that error during the static analysis phase. The choice of whether to raise such an error at analysis time is implementation dependent.
F.1.1 Static Typing Extensions
In some cases, the static typing rules defined in [XQuery 1.0 and XPath 2.0 Formal Semantics] are not very precise (see, for example, the type inference rules for the ancestor axes—parent, ancestor, and ancestor-or-self—and for the function fn:root). Some implementations may wish to support more precise static typing rules.
A conforming implementation that implements the Static Typing Feature may also provide one or more static typing extensions. [Definition: A static typing extension is an implementation-defined type inference rule that infers a more precise static type than that inferred by the type inference rules in [XQuery 1.0 and XPath 2.0 Formal Semantics].] See Section 6.1.1 Static Typing ExtensionsFS for a formal definition of the constraints on static typing extensions.
G エラー状況
- err:XPST0001
-
It is a static error if analysis of an expression relies on some component of the static context that has not been assigned a value.
- err:XPDY0002
-
It is a dynamic error if evaluation of an expression relies on some part of the dynamic context that has not been assigned a value.
- err:XPST0003
-
It is a static error if an expression is not a valid instance of the grammar defined in A.1 EBNF.
- err:XPTY0004
-
It is a type error if, during the static analysis phase, an expression is found to have a static type that is not appropriate for the context in which the expression occurs, or during the dynamic evaluation phase, the dynamic type of a value does not match a required type as specified by the matching rules in 2.5.4 SequenceType Matching.
- err:XPST0005
-
During the analysis phase, it is a static error if the static type assigned to an expression other than the expression
()ordata(())isempty-sequence(). - err:XPTY0006
-
(Not currently used.)
- err:XPTY0007
-
(Not currently used.)
- err:XPST0008
-
It is a static error if an expression refers to an element name, attribute name, schema type name, namespace prefix, or variable name that is not defined in the static context, except for an ElementName in an ElementTest or an AttributeName in an AttributeTest.
- err:XPST0010
-
An implementation must raise a static error if it encounters a reference to an axis that it does not support.
- err:XPST0017
-
It is a static error if the expanded QName and number of arguments in a function call do not match the name and arity of a function signature in the static context.
- err:XPTY0018
-
It is a type error if the result of the last step in a path expression contains both nodes and atomic values.
- err:XPTY0019
-
It is a type error if the result of a step (other than the last step) in a path expression contains an atomic value.
- err:XPTY0020
-
It is a type error if, in an axis step, the context item is not a node.
- err:XPDY0021
-
(Not currently used.)
- err:XPDY0050
-
It is a dynamic error if the dynamic type of the operand of a
treatexpression does not match the sequence type specified by thetreatexpression. This error might also be raised by a path expression beginning with "/" or "//" if the context node is not in a tree that is rooted at a document node. This is because a leading "/" or "//" in a path expression is an abbreviation for an initial step that includes the clausetreat as document-node(). - err:XPST0051
-
It is a static error if a QName that is used as an AtomicType in a SequenceType is not defined in the in-scope schema types as an atomic type.
- err:XPST0080
-
It is a static error if the target type of a
castorcastableexpression isxs:NOTATIONorxs:anyAtomicType. - err:XPST0081
-
It is a static error if a QName used in an expression contains a namespace prefix that cannot be expanded into a namespace URI by using the statically known namespaces.
- err:XPST0083
-
(Not currently used.)
H 用語集 (Non-Normative)
- atomic value
-
An atomic value is a value in the value space of an atomic type, as defined in [XML Schema].
- atomization
-
Atomization of a sequence is defined as the result of invoking the
fn:datafunction on the sequence, as defined in [XQuery 1.0 and XPath 2.0 Functions and Operators]. - available collections
-
Available collections. This is a mapping of strings onto sequences of nodes. The string represents the absolute URI of a resource. The sequence of nodes represents the result of the
fn:collectionfunction when that URI is supplied as the argument. - available documents
-
Available documents. This is a mapping of strings onto document nodes. The string represents the absolute URI of a resource. The document node is the root of a tree that represents that resource using the data model. The document node is returned by the
fn:docfunction when applied to that URI. - axis step
-
An axis step returns a sequence of nodes that are reachable from the context node via a specified axis. Such a step has two parts: an axis, which defines the "direction of movement" for the step, and a node test, which selects nodes based on their kind, name, and/or type annotation.
- base URI
-
Base URI. This is an absolute URI, used when necessary in the resolution of relative URIs (for example, by the
fn:resolve-urifunction.) - built-in function
-
The built-in functions supported by XPath are defined in [XQuery 1.0 and XPath 2.0 Functions and Operators].
- collation
-
A collation is a specification of the manner in which strings and URIs are compared and, by extension, ordered. For a more complete definition of collation, see [XQuery 1.0 and XPath 2.0 Functions and Operators].
- comma operator
-
One way to construct a sequence is by using the comma operator, which evaluates each of its operands and concatenates the resulting sequences, in order, into a single result sequence.
- constructor function
-
The constructor function for a given type is used to convert instances of other atomic types into the given type. The semantics of the constructor function call
T($arg)are defined to be equivalent to the expression(($arg) cast as T?). - context item
-
The context item is the item currently being processed. An item is either an atomic value or a node.
- context item static type
-
Context item static type. This component defines the static type of the context item within the scope of a given expression.
- context node
-
When the context item is a node, it can also be referred to as the context node.
- context position
-
The context position is the position of the context item within the sequence of items currently being processed.
- context size
-
The context size is the number of items in the sequence of items currently being processed.
- current dateTime
-
Current dateTime. This information represents an implementation-dependent point in time during the processing of an expression, and includes an explicit timezone. It can be retrieved by the
fn:current-dateTimefunction. If invoked multiple times during the execution of an expression, this function always returns the same result. - data model
-
XPath operates on the abstract, logical structure of an XML document, rather than its surface syntax. This logical structure, known as the data model, is defined in [XQuery/XPath Data Model (XDM)].
- data model schema
-
For a given node in an XDM instance, the data model schema is defined as the schema from which the type annotation of that node was derived.
- default collation
-
Default collation. This identifies one of the collations in statically known collations as the collation to be used by functions and operators for comparing and ordering values of type
xs:stringandxs:anyURI(and types derived from them) when no explicit collation is specified. - default collection
-
Default collection. This is the sequence of nodes that would result from calling the
fn:collectionfunction with no arguments. - default element/type namespace
-
Default element/type namespace. This is a namespace URI or "none". The namespace URI, if present, is used for any unprefixed QName appearing in a position where an element or type name is expected.
- default function namespace
-
Default function namespace. This is a namespace URI or "none". The namespace URI, if present, is used for any unprefixed QName appearing in a position where a function name is expected.
- delimiting terminal symbol
-
The delimiting terminal symbols are: "-", (comma), (colon), "::", "!=", "?", "/", "//", (dot), "..", StringLiteral, "(", ")", "[", "]", "@", "$", "*", "+", "<", "<<", "<=", "=", ">", ">=", ">>", "|"
- document order
-
Informally, document order is the order in which nodes appear in the XML serialization of a document.
- dynamic context
-
The dynamic context of an expression is defined as information that is available at the time the expression is evaluated.
- dynamic error
-
A dynamic error is an error that must be detected during the dynamic evaluation phase and may be detected during the static analysis phase. Numeric overflow is an example of a dynamic error.
- dynamic evaluation phase
-
The dynamic evaluation phase is the phase during which the value of an expression is computed.
- dynamic type
-
A dynamic type is associated with each value as it is computed. The dynamic type of a value may be more specific than the static type of the expression that computed it (for example, the static type of an expression might be
xs:integer*, denoting a sequence of zero or more integers, but at evaluation time its value may have the dynamic typexs:integer, denoting exactly one integer.) - 有効ブール値
-
The 有効ブール値 of a value is defined as the result of applying the
fn:booleanfunction to the value, as defined in [XQuery 1.0 and XPath 2.0 Functions and Operators]. - empty sequence
-
A sequence containing zero items is called an empty sequence.
- error value
-
In addition to its identifying QName, a dynamic error may also carry a descriptive string and one or more additional values called error values.
- expanded QName
-
An expanded QName consists of an optional namespace URI and a local name. An expanded QName also retains its original namespace prefix (if any), to facilitate casting the expanded QName into a string.
- expression context
-
The expression context for a given expression consists of all the information that can affect the result of the expression.
- filter expression
-
A filter expression consists simply of a primary expression followed by zero or more predicates. The result of the filter expression consists of the items returned by the primary expression, filtered by applying each predicate in turn, working from left to right.
- focus
-
The first three components of the dynamic context (context item, context position, and context size) are called the focus of the expression.
- function implementation
-
Function implementations. Each function in function signatures has a function implementation that enables the function to map instances of its parameter types into an instance of its result type.
- function signature
-
Function signatures. This component defines the set of functions that are available to be called from within an expression. Each function is uniquely identified by its expanded QName and its arity (number of parameters).
- Gregorian
-
In the operator mapping tables, the term Gregorian refers to the types
xs:gYearMonth,xs:gYear,xs:gMonthDay,xs:gDay, andxs:gMonth. - ignorable whitespace
-
Ignorable whitespace consists of any whitespace characters that may occur between terminals, unless these characters occur in the context of a production marked with a ws:explicit annotation, in which case they can occur only where explicitly specified (see A.2.4.2 Explicit Whitespace Handling).
- implementation defined
-
Implementation-defined indicates an aspect that may differ between implementations, but must be specified by the implementor for each particular implementation.
- implementation dependent
-
Implementation-dependent indicates an aspect that may differ between implementations, is not specified by this or any W3C specification, and is not required to be specified by the implementor for any particular implementation.
- implicit timezone
-
Implicit timezone. This is the timezone to be used when a date, time, or dateTime value that does not have a timezone is used in a comparison or arithmetic operation. The implicit timezone is an implementation-defined value of type
xs:dayTimeDuration. See [XML Schema] for the range of legal values of a timezone. - in-scope attribute declarations
-
In-scope attribute declarations. Each attribute declaration is identified either by an expanded QName (for a top-level attribute declaration) or by an implementation-dependent attribute identifier (for a local attribute declaration).
- in-scope element declarations
-
In-scope element declarations. Each element declaration is identified either by an expanded QName (for a top-level element declaration) or by an implementation-dependent element identifier (for a local element declaration).
- in-scope namespaces
-
The in-scope namespaces property of an element node is a set of namespace bindings, each of which associates a namespace prefix with a URI, thus defining the set of namespace prefixes that are available for interpreting QNames within the scope of the element. For a given element, one namespace binding may have an empty prefix; the URI of this namespace binding is the default namespace within the scope of the element.
- in-scope schema definitions
-
In-scope schema definitions. This is a generic term for all the element declarations, attribute declarations, and schema type definitions that are in scope during processing of an expression.
- in-scope schema type
-
In-scope schema types. Each schema type definition is identified either by an expanded QName (for a named type) or by an implementation-dependent type identifier (for an anonymous type). The in-scope schema types include the predefined schema types described in 2.5.1 Predefined Schema Types.
- in-scope variables
-
In-scope variables. This is a set of (expanded QName, type) pairs. It defines the set of variables that are available for reference within an expression. The expanded QName is the name of the variable, and the type is the static type of the variable.
- item
-
An item is either an atomic value or a node.
- kind test
-
An alternative form of a node test called a kind test can select nodes based on their kind, name, and type annotation.
- literal
-
A literal is a direct syntactic representation of an atomic value.
- name test
-
A node test that consists only of a QName or a Wildcard is called a name test.
- node
-
A node is an instance of one of the node kinds defined in [XQuery/XPath Data Model (XDM)].
- node test
-
A node test is a condition that must be true for each node selected by a step.
- non-delimiting terminal symbol
-
The non-delimiting terminal symbols are: IntegerLiteral, NCName, QName, DecimalLiteral, DoubleLiteral, "ancestor", "ancestor-or-self", "and", "as", "attribute", "cast", "castable", "child", "comment", "descendant", "descendant-or-self", "div", "document-node", "element", "else", "empty-sequence", "eq", "every", "except", "external", "following", "following-sibling", "for", "ge", "gt", "idiv", "if", "in", "instance", "intersect", "is", "item", "le", "lt", "mod", "namespace", "ne", "node", "of", "or", "parent", "preceding", "preceding-sibling", "processing-instruction", "return", "satisfies", "schema-attribute", "schema-element", "self", "some", "text", "then", "to", "treat", "union"
- numeric
-
When referring to a type, the term numeric denotes the types
xs:integer,xs:decimal,xs:float, andxs:double. - numeric predicate
-
A predicate whose predicate expression returns a numeric type is called a numeric predicate.
- operator function
-
For each operator and valid combination of operand types, the operator mapping tables specify a result type and an operator function that implements the semantics of the operator for the given types.
- path expression
-
A path expression can be used to locate nodes within trees. A path expression consists of a series of one or more steps, separated by "
/" or "//", and optionally beginning with "/" or "//". - predicate
-
A predicate consists of an expression, called a predicate expression, enclosed in square brackets. A predicate serves to filter a sequence, retaining some items and discarding others.
- primary expression
-
Primary expressions are the basic primitives of the language. They include literals, variable references, context item expressions, and function calls. A primary expression may also be created by enclosing any expression in parentheses, which is sometimes helpful in controlling the precedence of operators.
- principal node kind
-
Every axis has a principal node kind. If an axis can contain elements, then the principal node kind is element; otherwise, it is the kind of nodes that the axis can contain.
- QName
-
Lexically, a QName consists of an optional namespace prefix and a local name. If the namespace prefix is present, it is separated from the local name by a colon.
- reverse document order
-
The node ordering that is the reverse of document order is called reverse document order.
- schema type
-
A schema type is a type that is (or could be) defined using the facilities of [XML Schema] (including the built-in types of [XML Schema]).
- sequence
-
A sequence is an ordered collection of zero or more items.
- sequence type
-
A sequence type is a type that can be expressed using the SequenceType syntax. Sequence types are used whenever it is necessary to refer to a type in an XPath expression. The term sequence type suggests that this syntax is used to describe the type of an XPath value, which is always a sequence.
- SequenceType matching
-
During evaluation of an expression, it is sometimes necessary to determine whether a value with a known dynamic type "matches" an expected sequence type. This process is known as SequenceType matching.
- serialization
-
Serialization is the process of converting an XDM instance into a sequence of octets (step DM4 in Figure 1.)
- singleton
-
A sequence containing exactly one item is called a singleton.
- stable
-
Document order is stable, which means that the relative order of two nodes will not change during the processing of a given expression, even if this order is implementation-dependent.
- statically known collations
-
Statically known collations. This is an implementation-defined set of (URI, collation) pairs. It defines the names of the collations that are available for use in processing expressions.
- statically known collections
-
Statically known collections. This is a mapping from strings onto types. The string represents the absolute URI of a resource that is potentially available using the
fn:collectionfunction. The type is the type of the sequence of nodes that would result from calling thefn:collectionfunction with this URI as its argument. - statically known default collection type
-
Statically known default collection type. This is the type of the sequence of nodes that would result from calling the
fn:collectionfunction with no arguments. - statically known documents
-
Statically known documents. This is a mapping from strings onto types. The string represents the absolute URI of a resource that is potentially available using the
fn:docfunction. The type is the static type of a call tofn:docwith the given URI as its literal argument. - statically known namespaces
-
Statically known namespaces. This is a set of (prefix, URI) pairs that define all the namespaces that are known during static processing of a given expression.
- static analysis phase
-
The static analysis phase depends on the expression itself and on the static context. The static analysis phase does not depend on input data (other than schemas).
- static context
-
The static context of an expression is the information that is available during static analysis of the expression, prior to its evaluation.
- static error
-
A static error is an error that must be detected during the static analysis phase. A syntax error is an example of a static error.
- static type
-
The static type of an expression is a type such that, when the expression is evaluated, the resulting value will always conform to the static type.
- static typing extension
-
A static typing extension is an implementation-defined type inference rule that infers a more precise static type than that inferred by the type inference rules in [XQuery 1.0 and XPath 2.0 Formal Semantics].
- static typing feature
-
The Static Typing Feature is an optional feature of XPath that provides support for the static semantics defined in [XQuery 1.0 and XPath 2.0 Formal Semantics], and requires implementations to detect and report type errors during the static analysis phase.
- step
-
A step is a part of a path expression that generates a sequence of items and then filters the sequence by zero or more predicates. The value of the step consists of those items that satisfy the predicates, working from left to right. A step may be either an axis step or a filter expression.
- string value
-
The string value of a node is a string and can be extracted by applying the
fn:stringfunction to the node. - substitution group
-
代理グループ (Substitution Groups) は [XML Schema] Part 1, Section 2.2.2.2 で定義されている。端的に説明すると (先頭要素 (Head Element) と呼ばれる) 与えられた要素を先頭に持つ代理グループはスキーマ検証の結果に影響を及ぼすことなく先頭要素の代用にすることができる要素のセットで構成される。
- subtype substitution
-
The use of a value whose dynamic type is derived from an expected type is known as subtype substitution.
- symbol
-
Each rule in the grammar defines one symbol, using the following format:
symbol ::= expression
- symbol separators
-
Whitespace and Comments function as symbol separators. For the most part, they are not mentioned in the grammar, and may occur between any two terminal symbols mentioned in the grammar, except where that is forbidden by the /* ws: explicit */ annotation in the EBNF, or by the /* xgs: xml-version */ annotation.
- terminal
-
A terminal is a symbol or string or pattern that can appear in the right-hand side of a rule, but never appears on the left hand side in the main grammar, although it may appear on the left-hand side of a rule in the grammar for terminals.
- type annotation
-
Each element node and attribute node in an XDM instance has a type annotation (referred to in [XQuery/XPath Data Model (XDM)] as its
type-nameproperty.) The type annotation of a node is a schema type that describes the relationship between the string value of the node and its typed value. - typed value
-
The typed value of a node is a sequence of atomic values and can be extracted by applying the
fn:datafunction to the node. - type error
-
A type error may be raised during the static analysis phase or the dynamic evaluation phase. During the static analysis phase, a type error occurs when the static type of an expression does not match the expected type of the context in which the expression occurs. During the dynamic evaluation phase, a type error occurs when the dynamic type of a value does not match the expected type of the context in which the value occurs.
- type promotion
-
Under certain circumstances, an atomic value can be promoted from one type to another. Type promotion is used in evaluating function calls (see 3.1.5 Function Calls) and operators that accept numeric or string operands (see B.2 Operator Mapping).
- URI
-
Within this specification, the term URI refers to a Universal Resource Identifier as defined in [RFC3986] and extended in [RFC3987] with the new name IRI.
- value
-
In the data model, a value is always a sequence.
- variable reference
-
A variable reference is a QName preceded by a $-sign.
- variable values
-
Variable values. This is a set of (expanded QName, value) pairs. It contains the same expanded QNames as the in-scope variables in the static context for the expression. The expanded QName is the name of the variable and the value is the dynamic value of the variable, which includes its dynamic type.
- warning
-
In addition to static errors, dynamic errors, and type errors, an XPath implementation may raise warnings, either during the static analysis phase or the dynamic evaluation phase. The circumstances in which warnings are raised, and the ways in which warnings are handled, are implementation-defined.
- whitespace
-
A whitespace character is any of the characters defined by [http://www.w3.org/TR/REC-xml#NT-S].
- XDM instance
-
The term XDM instance is used, synonymously with the term value, to denote an unconstrained sequence of nodes and/or atomic values in the data model.
- XPath 1.0 compatibility mode
-
XPath 1.0 compatibility mode. This value is
trueif rules for backward compatibility with XPath Version 1.0 are in effect; otherwise it isfalse. - xs:anyAtomicType
-
xs:anyAtomicTypeis an atomic type that includes all atomic values (and no values that are not atomic). Its base type isxs:anySimpleTypefrom which all simple types, including atomic, list, and union types, are derived. All primitive atomic types, such asxs:integer,xs:string, andxs:untypedAtomic, havexs:anyAtomicTypeas their base type. - xs:dayTimeDuration
-
xs:dayTimeDurationis derived by restriction fromxs:duration. The lexical representation ofxs:dayTimeDurationis restricted to contain only day, hour, minute, and second components. - xs:untyped
-
xs:untypedis used as the type annotation of an element node that has not been validated, or has been validated inskipmode. - xs:untypedAtomic
-
xs:untypedAtomicis an atomic type that is used to denote untyped atomic data, such as text that has not been assigned a more specific type. - xs:yearMonthDuration
-
xs:yearMonthDurationis derived by restriction fromxs:duration. The lexical representation ofxs:yearMonthDurationis restricted to contain only year and month components.
I XPath 1.0 との下位互換性 (Non-Normative)
This appendix provides a summary of the areas of incompatibility between XPath 2.0 and [XPath 1.0].
Three separate cases are considered:
Incompatibilities that exist when source documents have no schema, and when running with XPath 1.0 compatibility mode set to true. This specification has been designed to reduce the number of incompatibilities in this situation to an absolute minumum, but some differences remain and are listed individually.
Incompatibilities that arise when XPath 1.0 compatibility mode is set to false. In this case, the number of expressions where compatibility is lost is rather greater.
Incompatibilities that arise when the source document is processed using a schema (whether or not XPath 1.0 compatibility mode is set to true). Processing the document with a schema changes the way that the values of nodes are interpreted, and this can cause an XPath expression to return different results.
I.1 互換モード true 時の非互換性
The list below contains all known areas, within the scope of this specification, where an XPath 2.0 processor running with compatibility mode set to true will produce different results from an XPath 1.0 processor evaluating the same expression, assuming that the expression was valid in XPath 1.0, and that the nodes in the source document have no type annotations other than xs:untyped and xs:untypedAtomic.
Incompatibilities in the behavior of individual functions are not listed here, but are included in an appendix of [XQuery 1.0 and XPath 2.0 Functions and Operators].
Since both XPath 1.0 and XPath 2.0 leave some aspects of the specification implementation-defined, there may be incompatiblities in the behavior of a particular implementation that are outside the scope of this specification. Equally, some aspects of the behavior of XPath are defined by the host language.
Consecutive comparison operators such as
A < B < Cwere supported in XPath 1.0, but are not permitted by the XPath 2.0 grammar. In most cases such comparisons in XPath 1.0 did not have the intuitive meaning, so it is unlikely that they have been widely used in practice. If such a construct is found, an XPath 2.0 processor will report a syntax error, and the construct can be rewritten as(A < B) < CWhen converting strings to numbers (either explicitly when using the
numberfunction, or implicitly say on a function call), certain strings that converted to the special valueNaNunder XPath 1.0 will convert to values other thanNaNunder XPath 2.0. These include any number written with a leading+sign, any number in exponential floating point notation (for example1.0e+9), and the stringsINFand-INF.XPath 2.0 does not allow a token starting with a letter to follow immediately after a numeric literal, without intervening whitespace. For example,
10div 3was permitted in XPath 1.0, but in XPath 2.0 must be written as10 div 3.The namespace axis is deprecated in XPath 2.0. Implementations may support the namespace axis for backward compatibility with XPath 1.0, but they are not required to do so. (XSLT 2.0 requires that if XPath backwards compatibility mode is supported, then the namespace axis must also be supported; but other host languages may define the conformance rules differently.)
I.2 互換モード false 時の非互換性
Even when the setting of the XPath 1.0 compatibility mode is false, many XPath expressions will still produce the same results under XPath 2.0 as under XPath 1.0. The exceptions are described in this section.
In all cases it is assumed that the expression in question was valid under XPath 1.0, that XPath 1.0 compatibility mode is false, and that all elements and attributes are annotated with the types xs:untyped and xs:untypedAtomic respectively.
In the description below, the terms node-set and number are used with their XPath 1.0 meanings, that is, to describe expressions which according to the rules of XPath 1.0 would have generated a node-set or a number respectively.
When a node-set containing more than one node is supplied as an argument to a function or operator that expects a single node or value, the XPath 1.0 rule was that all nodes after the first were discarded. Under XPath 2.0, a type error occurs if there is more than one node. The XPath 1.0 behavior can always be restored by using the predicate
[1]to explicitly select the first node in the node-set.In XPath 1.0, the
<and>operators, when applied to two strings, attempted to convert both the strings to numbers and then made a numeric comparison between the results. In XPath 2.0, these operators perform a string comparison using the default collating sequence. (If either value is numeric, however, the results are compatible with XPath 1.0)When an empty node-set is supplied as an argument to a function or operator that expects a number, the value is no longer converted implicitly to NaN. The XPath 1.0 behavior can always be restored by using the
numberfunction to perform an explicit conversion.More generally, the supplied arguments to a function or operator are no longer implicitly converted to the required type, except in the case where the supplied argument is of type
xs:untypedAtomic(which will commonly be the case when a node in a schemaless document is supplied as the argument). For example, the function callsubstring-before(10 div 3, ".")raises a type error under XPath 2.0, because the arguments to thesubstring-beforefunction must be strings rather than numbers. The XPath 1.0 behavior can be restored by performing an explicit conversion to the required type using a constructor function or cast.The rules for comparing a node-set to a boolean have changed. In XPath 1.0, an expression such as
$node-set = true()was evaluated by converting the node-set to a boolean and then performing a boolean comparison: so this expression would returntrueif$node-setwas non-empty. In XPath 2.0, this expression is handled in the same way as other comparisons between a sequence and a singleton: it istrueif$node-setcontains at least one node whose value, after atomization and conversion to a boolean using the casting rules, istrue.This means that if
$node-setis empty, the result under XPath 2.0 will befalseregardless of the value of the boolean operand, and regardless of which operator is used. If$node-setis non-empty, then in most cases the comparison with a boolean is likely to fail, giving a dynamic error. But if a node has the value "0", "1", "true", or "false", evaluation of the expression may succeed.Comparisons of a number to a boolean, a number to a string, or a string to a boolean are not allowed in XPath 2.0: they result in a type error. In XPath 1.0 such comparisons were allowed, and were handled by converting one of the operands to the type of the other. So for example in XPath 1.0
4 = true()was true;4 = "+4"was false (because the string+4converts toNaN), andfalse = "false"was false (because the string"false"converts to the booleantrue). In XPath 2.0 all these comparisons are type errors.Additional numeric types have been introduced, with the effect that arithmetic may now be done as an integer, decimal, or single- or double-precision floating point calculation where previously it was always performed as double-precision floating point. The result of the
divoperator when dividing two integers is now a value of type decimal rather than double. The expression10 div 0raises an error rather than returning positive infinity.The rules for converting numbers to strings have changed. These may affect the way numbers are displayed in the output of a stylesheet. For numbers whose absolute value is in the range 1E-6 to 1E+6, the result should be the same, but outside this range, scientific format is used for non-integral
xs:floatandxs:doublevalues.The rules for converting strings to numbers have changed. In addition to the changes that apply when XPath 1.0 compatibility mode is true, when compatibility mode is false the strings
Infinityand-Infinityare no longer recognized as representations of positive and negative infinity. Note also that while thenumberfunction continues to convert all unrecognized strings toNaN, operations that cast a string to a number react to such strings with a dynamic error.Many operations in XPath 2.0 produce an empty sequence as their result when one of the arguments or operands is an empty sequence. Where the operation expects a string, an empty sequence is usually considered equivalent to a zero-length string, which is compatible with the XPath 1.0 behavior. Where the operation expects a number, however, the result is not the same. For example, if
@widthreturns an empty sequence, then in XPath 1.0 the result of@width+1wasNaN, while with XPath 2.0 it is(). This has the effect that a filter expression such asitem[@width+1 != 2]will select items having nowidthattribute under XPath 1.0, and will not select them under XPath 2.0.The typed value of a comment node, processing instruction node, or namespace node under XPath 2.0 is of type
xs:string, notxs:untypedAtomic. This means that no implicit conversions are applied if the value is used in a context where a number is expected. If a processing-instruction node is used as an operand of an arithmetic operator, for example, XPath 1.0 would attempt to convert the string value of the node to a number (and deliverNaNif unsuccessful), while XPath 2.0 will report a type error.In XPath 1.0, it was defined that with an expression of the form
A and B, B would not be evaluated if A was false. Similarly in the case ofA or B, B would not be evaluated if A was true. This is no longer guaranteed with XPath 2.0: the implementation is free to evaluate the two operands in either order or in parallel. This change has been made to give more scope for optimization in situations where XPath expressions are evaluated against large data collections supported by indexes. Implementations may choose to retain backwards compatibility in this area, but they are not obliged to do so.
I.3 Schema 使用時の非互換性
An XPath expression applied to a document that has been processed against a schema will not always give the same results as the same expression applied to the same document in the absence of a schema. Since schema processing had no effect on the result of an XPath 1.0 expression, this may give rise to further incompatibilities. This section gives a few examples of the differences that can arise.
Suppose that the context node is an element node derived from the following markup: <background color="red green blue"/>. In XPath 1.0, the predicate [@color="blue"] would return false. In XPath 2.0, if the color attribute is defined in a schema to be of type xs:NMTOKENS, the same predicate will return true.
Similarly, consider the expression @birth < @death applied to the element <person birth="1901-06-06" death="1991-05-09"/>. With XPath 1.0, this expression would return false, because both attributes are converted to numbers, which returns NaN in each case. With XPath 2.0, in the presence of a schema that annotates these attributes as dates, the expression returns true.
Once schema validation is applied, elements and attributes cannot be used as operands and arguments of expressions that expect a different data type. For example, it is no longer possible to apply the substring function to a date to extract the year component, or to a number to extract the integer part. Similarly, if an attribute is annotated as a boolean then it is not possible to compare it with the strings "true" or "false". All such operations lead to type errors. The remedy when such errors occur is to introduce an explicit conversion, or to do the computation in a different way. For example, substring-after(@temperature, "-") might be rewritten as abs(@temperature).
In the case of an XPath 2.0 implementation that provides the static typing feature, many further type errors will be reported in respect of expressions that worked under XPath 1.0. For example, an expression such as round(../@price) might lead to a static type error because the processor cannot infer statically that ../@price is guaranteed to be numeric.
Schema validation will in many cases perform whitespace normalization on the contents of elements (depending on their type). This will change the result of operations such as the string-length function.
Schema validation augments the data model by adding default values for omitted attributes and empty elements.
