論文翻訳: Generating Representative Web Workloads for Network and Server Performance Evaluation
Paul Barford and Mark Crovella
Computer Science Department
Boston University
111 Cummington St, Boston, MA 02215
{barford,crovella}@cs.bu.edu
 ABSTRACT
ABSTRACT
ワークロード生成における一つの重要な役割は、サーバーとネットワークが負荷変動に対してどのように応答するかを理解するための手段を提供することである。これにより、現在および将来の使用状況に基づいた管理とキャパシティプランニングが可能となる。本論文では、Web サーバーの利用状況に関する複数の観測結果を統合し、実際のユーザーがサーバーにアクセスする状況を忠実に再現する現実的な Web ワークロード生成ツールを開発した。本ツール SURGE (Scalable URL Reference Generator) は、1) サーバー上のファイルサイズ分布、2) リクエストサイズ分布、3) ファイルの相対的な人気度、4) 埋め込みファイル参照、5) 参照の時間的局所性、および 6) 個々のユーザーのアイドル期間という 6 つの要素について実証的な測定値と一致する参照パターンを生成する。本論文では、代表的な Web ワークロードを生成する際に必要となる重要な要素について考察する。さらに、参照ストリームの特性に対するこの大規模な同時制約条件 (large set of simultaneous constraints) を満たすための技術的課題、我々が採用した解決策、およびそれらの精度についても論じる。最後に、SURGE が他の Web サーバーベンチマークと比較して、サーバーに対して著しく異なる負荷パターンを生成することを実証する結果を提示する。
Table of Contents
- ABSTRACT
- 1 導入
- 2 Web ワークロード特性
- 3 代表的な Web ワークロード生成における技術的課題
- 4 SURGEに採用された4つのソリューション
- 5 SURGE ワークロードの 5 つの性能特性
- 6 結論
- Acknowledgements
- References
- 翻訳抄
1 導入
インターネットにおける主要なアプリケーションとしての Web の重要性が高まるにつれ、典型的な Web ワークロードを正確にモデル化し再現する必要性が増大している。特に、実際のユーザー集団を模倣した HTTP リクエストストリームを生成する能力は、サーバー、プロキシ、ネットワークの性能評価やキャパシティプランニングにおいて極めて重要である。
Web ワークロードにはいくつか特異な特徴があるため、代表的な Web 参照トレースを生成することは困難である。第一に、稼働中の Web サーバーに関する実証研究によれば、これらのシステムは極めて変動性の高い要求負荷を経験することが明らかになっている。これは CPU 負荷やオープン接続数の変動として観測される (例: [15] 参照)。このことは特に、リクエスト間隔 [9, 11] やファイルサイズ [6, 21] など、高い変動性を示すことが確認されている Web 参照ストリームの特性に注意を払うことが重要であることを示している。
Web ワークロードの第二の特異な特徴は、Web リクエストに起因するネットワークトラフィックが自己相似性 (self-similar) を示す点である。つまり、トラフィックは広範囲にわたるスケールにわたって顕著な変動性を示すことがある。トラフィックにおける自己相似性は、ネットワーク性能に重大な負の影響を及ぼすことが示されている [10, 17] ため、合成ワークロードにおいて正確に捉えるべき重要な特性である。
これらの特性をワークロードジェネレータに組み込むためには、主にトレースベースアプローチと解析的アプローチの 2 つのアプローチが考えられる。トレースベースのワークロード生成では、過去のワークロードを記録した事前記録データを使用し、サンプル抽出またはトレースの再生によってワークロードを生成する。これに対し、解析的ワークロード生成では、まず様々なワークロード特性に対する数学的モデルを構築し、それらのモデルに準拠した出力を生成する。
これら 2 つのアプローチにはそれぞれ長所と短所が存在する。トレースベースのアプローチの利点は、実装が容易であり、既知のシステムの動作を忠実に模倣できる点にある。しかしながら、この手法ではワークロードを「ブラックボックス」として扱うため、システム動作の根本原因を解明することが困難である。さらに、将来の条件変化や変動する要求負荷に合わせてワークロードを調整することが難しいという課題もある。一方、解析的ワークロードはこれらの欠点を持たないものの、少なくとも 3 つの理由から構築が困難である。第一に、モデル化すべきワークロードの重要な特性を特定する必要がある。第二に、選択した特性は実証的に測定されなければならない。第三に、多数の異なる特性を正確に表現する単一の出力ワークロードを作成することが難しい場合がある。
本論文では、我々が開発してきた解析的手法に基づく Web 参照ストリーム生成手法について述べる。本手法の目的は、固定された Web ユーザー集団から生成される HTTP リクエストストリームを高精度に模倣することにある。これらの手法は SURGE (Scalable URL Reference Generator) というツールに実装されている。SURGE で採用されている手法は、解析的アプローチの利点をすべて備えている。特に、SURGE で使用されるモデルは明示的であるため、ユーザーが直接検証可能である。さらに、SURGE のモデルは調整可能であり、将来の予想需要や他の代替条件を探索するために活用することができる。
解析的 Web ワークロードを構築するには、前述の 3 つの課題に対処する必要がある。本論文では、各課題に対する具体的な解決策を提示する。第一に、我々がモデル化対象として選択した Web 参照ストリームの特性セットについて説明し、このセットが重要であると考える根拠を明らかにする。第二に、SURGE モデルの構築に必要な新たな Web 計測の結果について報告する。第三に、これらのモデルを単一の出力参照ストリームに統合する際に生じる技術的課題と、それらをどのように解決したかについて詳細に記述する。
最終的な結果である SURGE は、一般的な Web ワークロード生成ツール [5] である SPECweb96 とは大きく異なる特性を示している。SURGE と SPECweb96 は、1 秒あたり転送されるバイト数という指標で同等の負荷がかかるように設定した。これらの条件下では、SURGE はサーバーの CPU に対してはるかに高い負荷をかけるとともに、サーバー上で同時にオープンされている接続数も大幅に増加する。
さらに重要な点として、SURGE が生成するワークロードは、典型的な Web ワークロード生成ツールとは大きく異なる性質を持つことが明らかになった。特に、SURGE が生成するトラフィックには自己相似性という特性が見られる。これは、高負荷状態で動作させた場合、一般的な代替 Web ワークロード生成ツール (SPECweb96) では一般的に見られない特性である。SURGE の解析的アプローチによりモデルが明示的に定義されているため、我々は SURGE のトラフィックにおける自己相似性の原因を詳細に分析することが可能である。この知見に基づき、これまでに提案されてきたほとんどの Web ワークロード生成ツールは、高負荷状態において自己相似性を持つトラフィックを生成していない可能性が高いと結論づけられる。
2 Web ワークロード特性
SURGE 開発における我々の目標は、Web 環境を忠実に再現した形でサーバーとネットワークをテスト可能な環境を構築することにある。特にサーバーに関しては、ネットワークスタックとファイルシステムの動作特性、およびそれらに関連するバッファリングサブシステムの挙動を詳細に分析することを目的としている。ネットワークとサーバーの双方において、ワークロードの変動性がシステム性能に及ぼす影響についても重点的に調査する。
これらの研究目的に基づき、SURGE で採用する Web ワークロード特性を慎重に選定した。これらの特性は大きく2つのカテゴリに分類される。第一のカテゴリはユーザ相当物 (user equivalents) と呼ぶ概念に関連する特性群である。第二のカテゴリは、分布モデル (distributional models) の集合体である。
ユーザー相当物. ユーザー相当物の概念は、SURGE が生成するワークロードが、既知の人数のユーザー集団が生成するワークロードとほぼ同等の特性を示すべきであるという考え方に基づいている。したがって、SURGE が生成するサービス要求の強度は、ユーザー相当数 (UE) 単位で測定可能である。
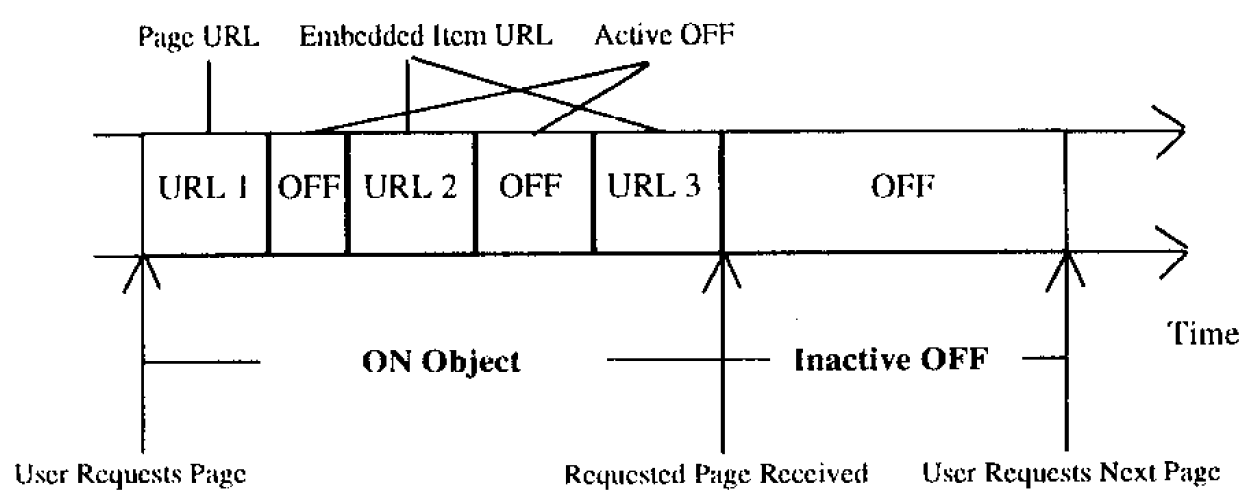
ユーザー相当物とは、Web ファイルのリクエスト送信と待機状態を交互に繰り返す単一プロセスとして定義される。Web ファイルリクエストと待機時間の双方が、実際の Web ユーザーの特性を示す分布特性と相関特性を備えている必要がある。各 UE は本質的に ON/OFF プロセスであり、ファイル転送が行われている期間を ON 時間 (ON time)、待機期間を OFF 時間 (OFF time) と呼称する。UE は独立したスレッドまたはプロセスとして容易に実装可能である。
ユーザー相当物をワークロードモデルとして採用することは、システム性能に重大な影響を及ぼす。各 UE は有意な待機期間を有するため、非常にバースト性の高いプロセスとなる。各 UE は長時間の活動期間とその後に続く長時間の非活動期間という特徴的な動作パターンを示す。
UE モデルは、[13] で提案されたアプローチといくつかの点で類似しているものの、他の Web ワークロードジェネレータで一般的に採用されている手法とは大きく異なる特徴を持っている。ほとんどの他のワークロードジェネレータは、OFF 時間の一貫した特性を保持せずにリクエストを送信する [5, 16, 20]。これらのワークロードジェネレータで採用されている一般的なアプローチは、単にサーバーからファイルを可能な限り迅速に要求することである。セクション 5 で示すように、OFF 時間を無視すると、高負荷時の生成トラフィックにおける自己相似性が損なわれることが明らかとなる。
ON 期間における UE の動作を規定するには、Web システムの構成に関する詳細な理解が必要である。特に、Web ファイルには参照によって他のファイルが含まれる場合があり、これらのファイルは正しく表示されるために必ず転送されなければならない (通常、これらの参照ファイルは画像やグラフィックデータを提供するものである)。したがって、ユーザーが単一の Web ファイルを要求した場合でも、実際には Web サーバーから複数のファイルが転送されることがよくよくある。我々は、このような Web ファイルと、それを正しく表示するために同時に転送が必要なすべてのファイルを総称して Web オブジェクト (web object) と呼んでいる。
Web オブジェクトの構成要素がどのように転送されるかの具体的な詳細は、使用されるブラウザの種類と採用されている HTTP プロトコルのバージョンによって異なる。HTTP 0.9/1.0 では各ファイルごとに別々の TCP 接続が使用されるが、HTTP 1.1 では複数のファイルに対して単一の TCP 接続を使用することが可能である。さらに、一部の HTTP 0.9/1.0 対応ブラウザでは、Web オブジェクトの構成要素を転送する際に複数の TCP 接続を同時に開く場合がある。本論文で報告する実験では、SURGE は HTTP 0.9 を使用するように設定され、複数の TCP 接続は使用されなかったが、SURGE を他の方式に変更することは容易に実現可能です。
この Web オブジェクト転送方式では、Figure 1 に示すように 2 種類の OFF 時間が存在する。非アクティブ OFF (inactive OFF) 時間は、Web オブジェクトの転送間隔に対応する。これはユーザーの「思考時間」に相当する。一方、アクティブ OFF (active OFF) 時間は、単一の Web オブジェクトを構成する各コンポーネントの転送間隔を指し、ブラウザが Web ファイルを解析し、新たな TCP 接続を開始する準備に要する処理時間に対応する。
分布モデル. SURGE の設計における UE 基底 (UE basis) について説明した後、各 UE が必要とする確率分布の集合について述べる。
本論文で検討する分布の重要な特徴の一つは、重い裾 (heavy tails) を持つ分布が存在することである。ここで「重い裾を持つ分布」とは、分布の上位部分がべき乗則に従って減少する分布を指し、具体的には以下の条件を満たす分布を意味する: \[ P[X \gt x ] \sim x^{-\alpha} \quad 0 \lt \alpha \le 2 \] ここで、\(a(x) \sim b(x)\) とは、ある定数 \(c\) に対して \(\lim_{x\to\infty} a(x)/b(x)=c\) が成立することを意味する。このような重い裾を持つ分布に従う確率変数は、極めて高い変動性を示す。実際、その分散は無限大であり、さらに \(\alpha \le 1\) の場合、平均も無限大となる。
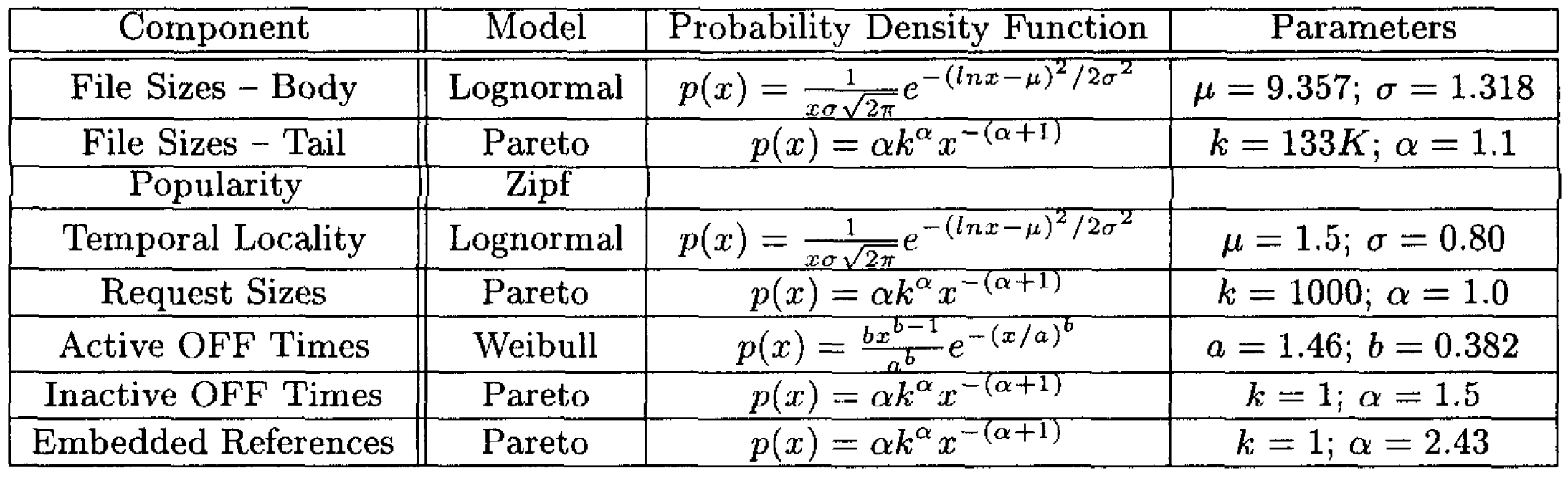
SURGE の設計目標を達成するためには、その出力は以下の 6 つの Web 参照ストリームに関する統計的特性を満たさなければならない:
1) ファイルサイズ (file size). サーバのファイルシステムを適切にテストするためには、サーバ上に保存されるファイル群のサイズ分布が実際の測定値と一致していることが重要である。[6, 2] で指摘されているように、これらの分布は重い裾を持つ可能性があり、つまりサーバのファイルシステムは高度に変動するファイルサイズに対応できなければならない。
2) リクエストサイズ (request size). ネットワークを適切にテストするためには、転送されるファイル群のサイズ分布が実際の測定値と一致している必要がある。この集合をリクエスト (request) と呼ぶ。リクエストの分布は、個々のファイルが複数回転送されたり、全く転送されなかったりする可能性があるため、ファイルの分布とは大きく異なる場合がある。ここでも、実際の測定結果から、リクエストサイズの集合が重い裾を示す可能性があることが示唆されている [6]。
ここで注意すべきは、ファイルサイズとリクエストサイズという 2 つの集合の違いは、サーバのファイルシステムに保存されているデータと、サーバからネットワーク経由で転送されるデータの分布の違いに対応しているという点である。
3) 人気度 (popularity). ワークロードの第三の特性として、前二者に関連するのが、サーバー上の個々のファイルに対するリクエストの相対的な数である。人気度とは、ファイル単位でのリクエストの分布状況を測定する指標である。注意すべきは、前二者の特性 (ファイルサイズ分布とリクエストサイズ分布) が固定されている場合でも、個々のファイルへのリクエスト配分には依然として大きな柔軟性が存在する点である。人気度の分布は、キャッシュの動作特性 (例えばファイルシステムのバッファキャッシュなど) に重大な影響を及ぼす。なぜなら、人気の高いファイルは通常、キャッシュ内に長期間保持される傾向があるためである。
Web サーバー上のファイルにおける人気度分布は、Zipf の法則に従うことが確認されている [22, 1, 7]。この法則によれば、ファイルが最も人気のあるものから最も人気のないものへと順に並べられた場合、あるファイルへの参照回数 (\(P\)) はその順位 (\(r\)) に対して反比例する傾向がある。具体的には: \[ P = kr^{-1} \] という関係式が成り立ち、ここで \(k\) は正の定数である。この特性は驚くほど普遍的に観察され、指数値の経験的測定値はしばしば \(-1\) に極めて近い値を示すものの、Web ワークロードにおけるこの現象の根本的な原因は依然として解明されていない。ファイル間の参照分布は、一部のファイルが極めて高い人気を持つ一方で、大多数のファイルは比較的少ない参照しか受けないという状況を生み出している。
4) 埋め込み参照 (embedded references). Web オブジェクトの構造を正確に捉えるためには、Web オブジェクト内に含まれる埋め込み参照の数を特性化することが重要である。これは、Web ファイル内の埋め込み参照数の分布を分析することによって行われる。本論文で採用した SURGE の構成においては、埋め込み参照間の OFF 時間 (アクティブ OFF 時間) は通常短いのに対し、Web オブジェクト自体間の OFF 時間 (非アクティブ OFF 時間) は通常はるかに長いという特徴がある。これまでの研究 [4] などでは、Web オブジェクトに典型的に含まれる埋め込み参照数の分布モデルを構築する試みは行われてこなかった。
5) 時間的局所性 (temporal locality). Web ワークロードにおける時間的局所性とは、一度ファイルが要求された場合、近い将来に再び要求される可能性が高いという特性を指す。時間的局所性を正確に把握することは重要である。なぜなら、この特性が存在する場合、キャッシュの有効性を大幅に向上させることが可能だからである。
時間的局所性を測定する一つの方法として、スタック距離 (stack distance) の概念を用いることができる。要求シーケンスが与えられた場合、それに対応するスタック距離シーケンスは次のように生成される。ファイルをプッシュダウンスタックに格納していると仮定する。各要求を順番に処理する際、要求されたファイルをスタックの最上部に移動させ、他のファイルを下に押し下げる。各要求されたファイルがスタック内で見つかる深さが、その要求のスタック距離となる [1, 14]。
スタック距離は時間的局所性を捉える上で有効である。なぜなら、小さなスタック距離は、参照ストリーム内で時間的に近接して発生する同一ファイルへの要求に対応するからである。なお、スタックの初期内容が既知であると仮定すれば、スタック距離シーケンスは要求シーケンスと同等の情報を含んでおり、相互に取得可能である。
したがって、Web リクエストシーケンスにおけるスタック距離の分布は、そのシーケンスに存在する時間的局所性の尺度として機能する。Web サーバに到来するリクエストシーケンスの典型的な分布については [1] で研究が行われており、その結果から、これらの分布は対数正規分布を用いて適切にモデル化できることが明らかになっている。対数正規分布はその質量の大部分が小さな値に集中する特性を持つため、これは Web リクエストシーケンスにおいて顕著な時間的局所性が頻繁に存在することを示唆している。
6) OFF 時間. 前節で述べたように、個々の Web ユーザーのリクエストがバースト的に発生する性質を正確にモデル化するためには、非アクティブ状態の OFF 時間を正確にモデル化することが不可欠である。また、Web オブジェクトの転送を再現するためには、アクティブ状態から非アクティブ状態への移行時間を適切に特徴付けることが必要である。従来研究では、OFF 時間 [6] およびサーバーにおける HTTP リクエストの到着間隔という関連課題 [9] について測定が行われている。
3 代表的な Web ワークロード生成における技術的課題
前節で述べた要件を満たすワークロード生成器を構築するにあたり、主に 2 つの根本的な課題が生じる。第一に、6 種類の分布モデルをすべて実装する必要があること、第二に、これらの分布を単一の出力ストリームに統合するための手法を確立する必要があることである。
3.1 分布モデルに関する技術的課題
分布モデルの完全なセットを構築するには、新たに 3 種類の分布モデルが必要であった。
セクション 2 で述べたように、Web ワークロードの重要な特性の一つとして、サーバ上のファイルサイズが挙げられる。サーバ上のファイルサイズについては [6] で研究が行われているものの、その研究は分布のテール部分 (極端な値の領域) に限定されていた。SURGE プロジェクトでは、分布のテール部分だけでなく、分布の本体部分についても正確なモデルが求められる。
アクティブ OFF 時間については、他の研究では特に取り上げられていない。クライアントの OFF 時間については一般に [6] で記述されているが、アクティブ OFF 時間を独立した分布として記述しようとする試みは行われていなかった。このため、アクティブ OFF 時間に特化したモデルの開発が必要となった。
最後に、文書内の埋め込み参照数に関するモデルも必要であった。この数値は、クライアントのトレースデータから直接抽出することが困難である。なぜなら、通常のデータ記録には、どの文書が他の文書に埋め込まれているかを示す情報が含まれていないからである。ただし、この特性はアクティブ OFF 時間を用いて推論することが可能である (セクション 4 で説明する通りである)。
これらの Web 特性ごとに分布モデルを開発するという課題に取り組むためには、実際に測定された Web ワークロードのトレースデータを分析する必要があった。データセットに対する統計モデルを定義する最も一般的な手法としては、quantile-quantile プロットや累積分布関数 (CDF) プロットといった視覚的 (visual) 手法が用いられる。しかし、これらの手法では、互いに非常によく適合する 2 つの分布を区別することができない上に、モデルの適合度に対する信頼性の度合いも示されない。この欠点を克服するためには、適合度検定 [8, 18] を適用することが可能である。ただし、これらの検定手法にもいくつかの問題点が存在する。例えばカイ二乗検定のようなデータビン分割に基づく手法では、ビンサイズの選択によって精度に問題が生じることがある。また、Anderson-Darling 検定のような経験的分布関数に基づく手法は、大規模データセットに適用した場合に失敗する確率が高くなる傾向がある。ほとんどの Web 測定データは大規模データセットを構成するため、我々が分布モデルを選択するために用いた手法では、これらの適合度検定の限界点を克服する必要があった。
3.2 分布の統合における課題
SURGE モデルを構成する 6 つの特性をすべて備えた単一の出力ワークロードを生成することは困難である。本研究では、この問題に対処するため、リクエストとファイルのマッチング手法と、代表的な出力シーケンスを生成する手法を開発した。
3.2.1 マッチング問題
マッチング問題は、Web ワークロードの 3 つの主要な特性 ― ファイルサイズ分布、リクエストサイズ分布、および人気度 ― を出発点とする。これら 3 つの分布が与えられた場合、サーバー上の各ファイルに対する総リクエスト数を算出することがマッチング問題となる。この問題が生じるのは、これら3つの分布が固定されている場合でも、実際のリクエストが個々のファイルにどのように割り当てられるかについては依然として大きな自由度が存在するためである。
第一に、いかなるサーバーにも、それぞれ固有の名前を持ち、特定のサイズを有するファイル群が存在している。ここで \(X\) をサーバー上のファイルサイズの集合とし、\(x_i\) をファイル \(i\) のサイズとする。第二に、Zipf の法則を用いることで、サーバー上の各ファイルに対する参照回数からなる集合 \(Y\) (人気度分布) を算出することが可能である。しかしながら、Zipf の法則では集合 \(Y\) の各要素に対応する具体的なファイルを決定することはできない。最後に、リクエストサイズ分布も経験的分布 \(F(x)\) によって記述される。
これらを入力として、マッチング問題は以下の条件を満たす集合 \(Y\) の置換 (permutation) を求めることである:
\(X\) と \(Y\) の要素間に 1 対 1 の対応関係が存在すること。\(Y\) の置換は、整数 \(1,\ldots,n\) の置換であるインデックス集合 \(Z\) によって記述される。すなわち、各 \(y_{z_i}\) はファイル \(i\) に対するリクエスト数を表す。
\(X\) と \(Y\) の間の対応関係により、ファイルリクエストの集合が生成される。この集合は、以下のように定義される CDF \(G(x)\) によって記述可能である: \[ G(x_j) = 1 - \left( \sum_{i=1}^j y_{z_i} / \sum_{i=1}^n y_{z_i} \right) \] これにより、各 \(y_j\) に対して所望の値 \(\hat{y}_j\) を決定することができる。この値 \(\hat{y}_j\) は、\(G(x)\) と \(F(x)\) を等置し、\(\hat{y}_i\) について解くことで求められる: \[ \hat{y}_j = F(x) \sum_{i=1}^n y_{z_i} - \sum_{i=1}^{j-1} y_{y_i} \]
すべての \(i\) について \(\hat{y}_i\) が \(y_{z_i}\) に可能な限り近づくような置換 \(Z\) を作成する。
3.2.2 時間的局所性
マッチング処理の結果として、各固有のファイルに対して総リクエスト値が割り当てられる。しかしながら、これは時間的局所性を示すリクエストストリームを生成するには不十分である。時間的局所性は、スタック距離の分布を用いて分析可能である。この分布は時間的局所性の指標となる。なぜなら、スタック距離は同じ文書への参照間に存在する中間参照の数を測定するものだからである [1]。時間的局所性を満たすためには、文書リクエストの順序を、プッシュダウンスタックに展開した際に得られるスタック距離の分布が、実際に測定された分布と一致するように配置しなければならない。
スタック距離の分布に加え、リクエスト順序生成手法においては、各ファイルへの参照をシーケンス全体にわたって可能な限り均等に分散させる必要がある。
4 SURGEに採用された4つのソリューション
4.1 新たな分布モデル
[7] で議論された BU クライアントのトレースデータセットを用いて、SURGE を完成させるために必要な 3 つのモデルを開発した。これらのトレースデータは、2 ヶ月間にわたる Web アクセス時のユーザー行動を記録したものである。一般的に、異なる環境から収集した多数のデータセットを分析し、代表的な分布特性を明らかにすることが望ましい。しかしながら、これまでの研究では作業負荷特性の定義に主眼を置いていたため、分析対象とするデータセットの範囲は限定的なものとなっていた。今後の研究ではより多くのデータセットを検討する予定であり、その前提から、SURGE のアルゴリズムと基本構造は、他の分布特性にも容易に適応できるよう設計されている。このため、SURGE は極めてパラメータ設定が容易なツールとして開発されている。
これらのモデルを開発するにあたり、我々は [18] で用いられたものと同様の標準的な統計手法を採用した。適合度検定には Anderson-Darling 検定 (\(A^2\) 検定) [8, 18] と、[19] で説明されている \(\lambda^2\) 検定を使用し、解析モデルが経験的データセットをどの程度適切に記述しているかを比較評価した。
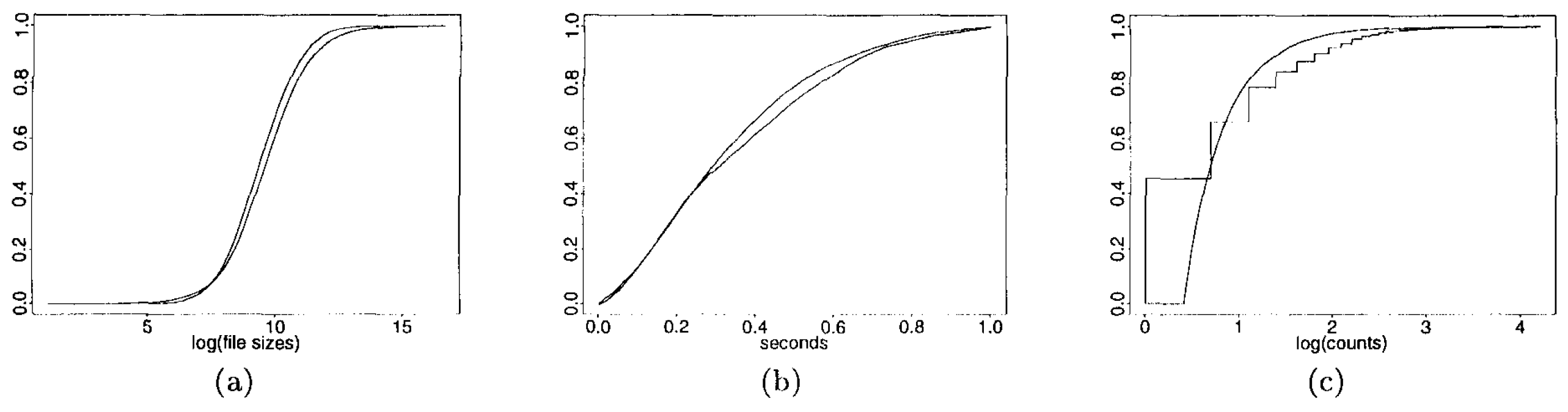
ファイルサイズ. ファイルサイズモデルの開発においては、[6, 2] で記述されているように、分布の重尾特性が正確であるという前提から着手した。その後、ボディ部分に新たな分布モデルを採用し、上位テール部分にはパレート分布 (Pareto distribution) を組み合わせたハイブリッドモデルを構築した。データ本体部分 (11,188 ポイント) に対して、複数の分布モデル (対数正規分布、ワイブル分布、パレート分布、指数分布、対数極値分布) を用いた \(\lambda^2\) 検定を実施した結果、最も \(\lambda^2\) 適合度が高い (値が最も小さい)のは対数正規分布であることが判明した。対数変換を施したデータの累積分布関数 (CDF) と正規分布との比較結果を Figure 2(a) に示す。
しかしながら、\(A^2\) 検定は適合度の観点では有意性を示さなかった。この検定が有意性を欠いた主な原因は、比較的大規模なデータセットを検定に用いたことにある。このような問題は EDF 検定においてよく見られる現象である [8, 18]。このため、ランダムな部分標本を用いた適合度検定手法 [18, 3] を採用したところ、ファイルサイズの EDF と対数正規分布との間に良好な適合関係が確認された。
検閲手法を適用することで、体部 (メイン部分) と尾部 (重尾部分) の境界を決定するための適切な分割点を特定した。ある値を超える観測値がすべて欠損している場合、そのサンプルは右打ち切りサンプルとみなされる。本サンプルの体部は、ヘビーテール成分によって汚染されていると仮定しているため、右打ち切り (right censored) サンプルとして扱うことが妥当である。我々は \(A^2\) 統計量を用いて、体部と尾部を分ける閾値点を決定した。経験的データにおける右打ち切りの度合いを段階的に増加させながら適合度検定を実施した結果、これらの分布間の境界は約 133KB に位置することが確認された (ファイルの 93% がこの閾値以下に分布している)。閾値値とハイブリッド分布モデルを組み合わせることで、サーバー上のファイルサイズ分布を適切に生成することが可能となる。
アクティブ OFF 時間. 本研究では、閾値時間未満の OFF 時間を「アクティブ」と定義する。この閾値はデータの分析結果に基づき 1 秒に設定した。\(\lambda^2\) 検定の結果、検討してモデルの中で最も適合度が高かったのはワイブル分布であることが明らかになった。アクティブ OFF 時間の集合と適合させたワイブル分布の累積分布関数 (CDF) プロットを Figure 2(b) に示す。\(A^2\) 検定においてはいかなる有意水準においても有意性が認められなかったが、これはやはり比較的大規模なサンプルサイズ (40,037 要素) に起因するものと考えられる。ただし、ランダムな部分標本を用いた場合、\(A^2\) 検定ではワイブルモデルへの良好な適合が示された。
埋め込み参照. 各ファイルに含まれる埋め込み参照の数は、ファイル転送のトレースデータから抽出した。具体的には、特定のユーザーが取得したファイルの転送シーケンスを分析し、ファイル転送間の OFF 時間が常に 1 秒未満であったケースを識別した (これにより 26,142 のデータポイントが得られた)。初期のデータセット調査では、この分布が右裾の長い特性を示すことが明らかになった。分布プロットを生成した結果、パレート分布がデータに最も適した視覚的適合性を示すことが判明した。対数-対数補完分布プロットにおける尾部勾配の最小二乗推定を行ったところ、\(\alpha\) という推定値が得られた。この値は Figure 2(c) に示すように、視覚的にも良好な適合性を示している。
\(A^2\) 検定を再度実施したが、適合度に関する有意な結果は得られなかった。ランダム部分サンプル法を用いた場合でも、良好な適合性は確認されなかった。これは、経験的データの尾部に含まれる値がわずかであり、したがって部分サンプルの尾部に含まれる値も非常に少なかったためと考えられる。
SURGE で使用したモデル分布とパラメータの概要を Table 1 に示す。
4.2 マッチング問題の解法
セクション 3.2.1 で説明したマッチング問題の解法は、要求をファイルに割り当てる際に、所望のファイルサイズ分布、要求サイズ分布、および人気度特性をすべて満たすようにマッピングを行うものである。マッチングの成功度合いは、\(\hat{y}_i\) で表される所望のファイルサイズ \(x_i\) に対する参照回数と、\(y_z\) で表される実際のファイルサイズ \(x_i\) に対する参照回数の差として表現される。これらの差異を統合して最適化問題を構築する方法は複数存在する。第一に、二つの分布間の最大差異を上限値で制約する方法: \(\max | \hat{y}_i - y_{z_i}|\)。第二に、二つの分布間の総誤差を上限値で制約する方法: \(\sum_{i=1}^n|\hat{y}_i-y_{z_i}|\)。最後に、分布の重要な部分における誤差を上限値で制約する方法: \(|\hat{y}_i-y_{z_i}|\)。ただし \(z_1 \ldots z_{i-1}\) の値はあらかじめ決定されているものとする。
最初の二つのケースに対しては、単一のアルゴリズムが最適解となる。このアルゴリズムは、\(\hat{y}\) の中で最も大きい値を \(y\) の中で最も大きい値に、次に大きい \(\hat{y}\) の値を \(y\) の次に大きい値に、というように対応付けるような置換インデックス \(Z\) を生成する。上記の最初の二つのケースにおけるこの手法の最適性の証明は、極めて明快である。
しかしながら、この最適手法では、二つの分布間で誤差を望ましくない形で配分する可能性がある (例えば、分布の裾部分に誤差が集中する場合がある)。大きなファイルはネットワーク性能とサーバー性能に最も大きな影響を与えるため、分布の裾部分において可能な限り正確にマッチングを行うことが重要である。そこで本研究では、分布の裾部分または頭部のいずれかにおいて最適なマッチングを可能にする別の手法を開発した。この手法では、集合 \(Y\) の値を、\(X\) の最小値または最大値のいずれかから生成される \(F(x)\) の値と対応付ける。この方法により、分布の裾部分において非常に精度の高いマッチングが可能となり、分布の本体部分に大規模な誤差が生じることもない。
4.3 シーケンス生成問題の解決策
適切な時間的局所性を持つ参照シーケンスを生成するため、SURGE はまず個々のファイル名をスタックに格納する (初期の順序付けは重要ではない)。次に、適切な対数正規分布 (Table 1 参照) から値のシーケンスを生成する。このシーケンスを反転させることで、ファイル名のシーケンスを得る。この処理では、シーケンスの次の値に相当する間隔でスタックからファイルを順次選択し、選択のたびにスタックの順序を再構築する。
残念ながら、この単純な方法を厳密に適用すると、リクエストシーケンス全体にわたってファイル名が不均一に分布する結果となる。そこでこの手法を改良するため、対数正規シーケンスで指定された位置の前後に小さなウィンドウを定義した。このウィンドウ内の各ファイルには、その文書に対して必要な残りのリクエスト数に比例する重み値が割り当てられる。スタックの最上位に移動させるファイルの選択は、ウィンドウ内の各ファイルの重み値に基づいて確率的に決定される。
このファイルシーケンス生成手法を採用した結果、シーケンス全体にわたってファイル名が非常に良好に分布し、生成されるスタック距離の値も所望の対数正規分布に従うことが確認できた。
最終的に、複数のクライアントホストを使用する場合、時間的局所性に関する問題が生じる。UE スレッドが同じホスト上で動作している場合、共通のファイル名シーケンスを共有でき、各スレッドは必要に応じてシーケンス中の次のファイル名を使用できる。しかし、UE スレッドが複数のホスト上で動作している場合、重大な同期オーバーヘッドなしに共通のコンモンリストを共有することはできない。このケースに対応するため、我々は関連性のあるスタック距離特性を持つ独立したファイル名シーケンスを生成する。これは、ログ正規分布から出力される値を、シミュレーションで使用する予定のクライアント数でスケーリングすることで実現する。別々のホストからのリクエストがサーバ上で規則的に交互に発生する場合、この手法によって適切な時間的局所性特性が確保される。我々の実験結果によれば、この単純なスケーリング手法は、単一クライアントの場合とほぼ同等のスタック距離分布を維持するのに十分であることが示されている。
5 SURGE ワークロードの 5 つの性能特性
本節では、現在の SURGE の実装方法と、SURGE を用いて実施した初期実験の結果について述べる。比較対象として、SPECweb96 を使用した場合の結果も併せて提示する。
5.1 SURGE の実装と検証
SURGE は 2 つの主要な部分から構成されている。1 つ目は C 言語で記述された一連のプログラム群であり、これらは事前に 4 種類のデータセットを計算する。2 つ目は Java で記述されたマルチスレッドプログラムで、これらの 4 つのデータセットを使用して Web リクエストを実行する。事前計算されるデータセットには、実行すべきリクエストのシーケンス、各 Web オブジェクトに埋め込まれたファイル数、およびリクエスト間に挿入するアクティブ状態と非アクティブ状態の OFF 時間のシーケンスが含まれる。実装においては、幅広いクライアントマシンへの移植性を考慮して Java を採用した。
検証作業では、SURGE の出力結果が 6 種類の分布モデル (ファイルサイズ、リクエストサイズ、人気度、埋め込まれた参照リンク、時間的局所性、および OFF 時間) に適合していることを確認した。その結果、Java 実装の効率性が OFF 時間の生成精度に影響を与えることが判明した。特に、インタプリタ型の Java 実装では過剰なオーバーヘッドが生じ、理想的な OFF 時間パターンとの一致が得られないという問題があった。これを解決するため、コンパイル型の実装に切り替えることで問題は解消された。さらに、短時間の実行 (15 分未満) では、一部の分布特性について十分なサンプル数が得られず、理想的なケースとの一致が得られない場合があることが分かった。ただし、30 分間の実行時間を確保すれば、理想的な分布パターンと測定結果との間に良好な一致を得ることが一般的に可能であった。
すべての分布モデルの中で、SURGE を拡張した場合 (より多くのホストマシンで実行した場合) に影響を受けるのは時間的局所性のみであった。SURGE で使用するホスト数を増加させると、生成されるスタック距離分布は常に対数正規分布を示したが、その特性には若干の変化が見られた。これは、全てのクライアント間で厳密な同期が確保されていない限り、時間的局所性の特性に完全に一致させることは保証できないためである。このような同期を強制した場合、許容できないほど低い最大リクエストレートが生じることになる。
5.2 実験環境設定
本実験で使用した環境は、100 Mbps のネットワークに接続された 6 台の PC から構成されており、他のネットワークから隔離可能な構成となっていた。各 PC の仕様は以下の通りである: 200MHz Pentium Pro CPU と 32MB の RAM を搭載。SURGE クライアント (1 台から 5 台のホストで動作) は Windows NT 4.0 上で動作し、サーバシステム (単一ホスト) は Linux 2.0 上で Apache 1.2.4 を実行していた。リソース制限を回避するため、いかなる SURGE ホストにおいても同時に 50 個以上の UE スレッドを実行することはなかった。
Web サーバ側では、CPU 使用率とアクティブな TCP 接続数を計測した。ネットワーク側では、実験期間中に転送されたファイル数とパケット数の総計を測定した。サーバ上のオープン接続数は 100 ミリ秒ごとにサンプリングし、CPU 使用率は 1 秒ごとにサンプリングした。これらの値はいずれも Linux の /proc ファイルシステムから取得した。ネットワークトラフィックの測定には tcpdump を使用した。
本節で述べる各実験において、UE の数は実験期間中一貫して一定に保たれた。したがって、本研究ではこの時点でのワークロードの定常的な挙動のみを調査している。このワークロードの定常性という仮定は、実際の Web サーバにおいては、Web サーバのユーザ数がほぼ一定に保たれる短時間の期間にのみ適用されると考えられる。このため、実験時間は最長 30 分までに制限した。なお、このような短時間の計測期間であっても、Web サーバでは多くのシステム指標において高い変動性が観測される場合がある [15]。
SPECweb96 によって生成されるワークロードは、2 つのユーザ定義パラメータに依存する: 1 秒あたりの目標 HTTP 操作数と、リクエスト送信に使用するスレッド数である。SPECweb96 が採用する一般的な手法では、各スレッドが一定のレートで HTTP リクエストを生成する。各スレッドのリクエストレートは、目標レートをスレッド数で割ることによって決定される。本研究で実施したすべての実験では、16 個のスレッドを使用したが、これは要求された値に近い操作数/秒を常に達成するのに十分な数であった。
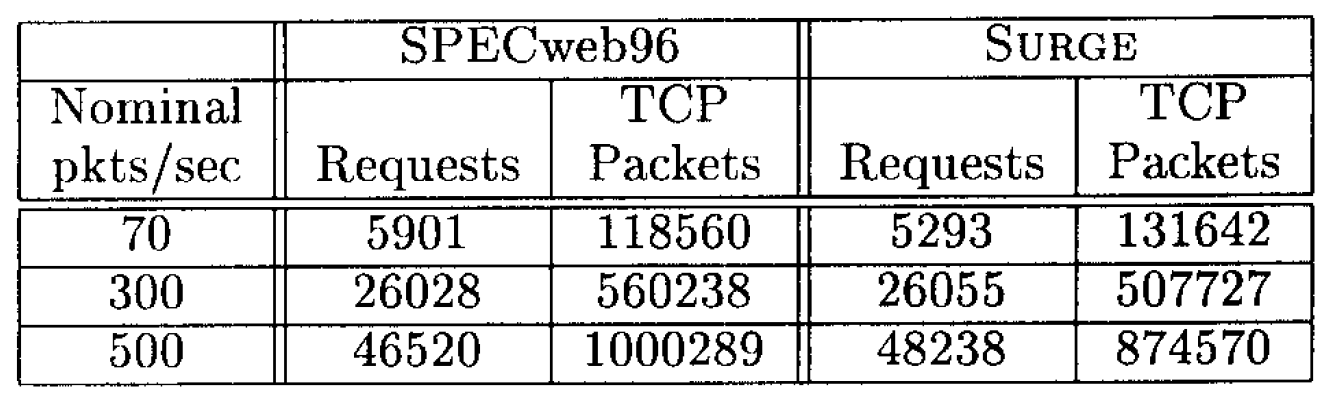
SPECweb96 ワークロードの負荷強度は、1 秒あたりの HTTP 操作の期待回数で定義されているのに対し、SURGE ワークロードの負荷強度は (セクション 2 で論じたように) ユーザ相当数で表現される。SURGE と SPECweb96 の影響を比較するため、我々は 30 分間の実行期間中に転送されるデータ量がほぼ等しくなるよう、各ワークロードの構成を経験的に決定した。各ワークロード生成器について、このような構成レベルを 3 種類特定した。各レベルにおいて、2 つの構成間の転送データ量の差は 20% 未満である。これらの構成レベル (Table 2 に示す) は、2 つのワークロード間の一般的な比較にのみ使用される。Table 3 は、使用した SURGE および SPECweb96 ワークロードの概要を示しており、各 30 分間の実行期間中に満たされたリクエスト数と、転送された TCP パケット数を記載している。

5.3 実験結果
まず第一に、SURGE と SPECweb96 のワークロードがサーバに与える影響の違いについて考察する。続いて、ネットワークに対するそれぞれの影響について分析する。
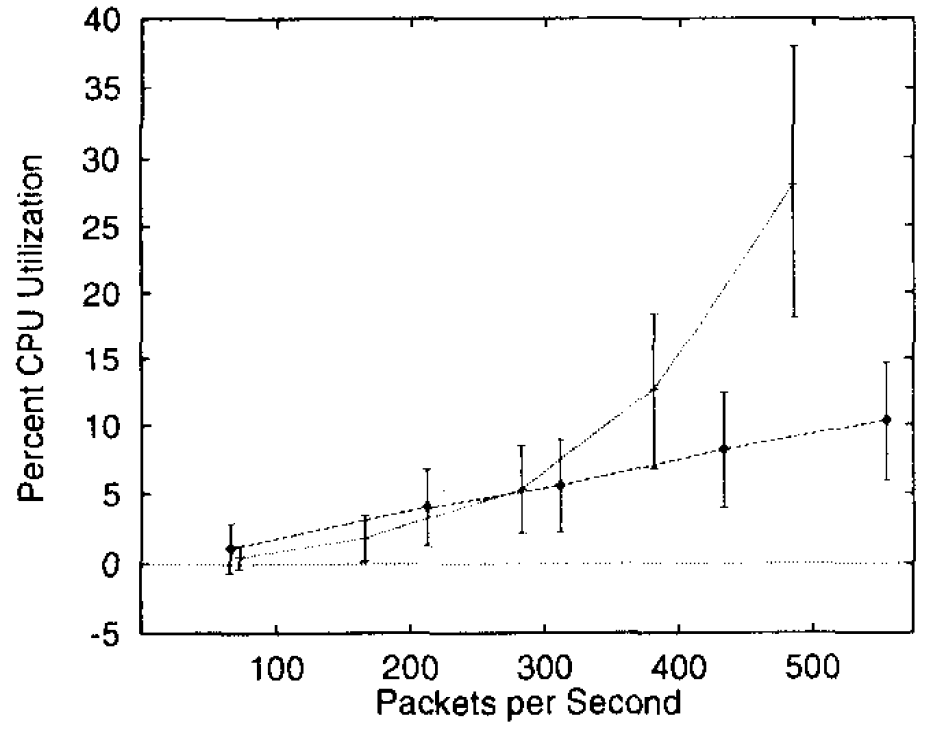
サーバへの影響. 両ワークロードがサーバに与える影響で最も顕著に表れるのは、CPU 使用率の差異である。Figure 3 に、両ワークロードにおける平均 CPU 使用率を、1 秒間に転送される平均パケット数の関数としてプロットした結果を示す。エラーバーは平均値からの標準偏差 1 個分の範囲を示している。平均使用率と標準偏差は、各実験の定常状態において測定しており、起動時の過渡現象は除外している。
Figure 3 から明らかなように、平均転送速度が 1 秒あたり 500 パケットに近づくと、SURGE ワークロードではサーバの CPU 負荷が急激に上昇するのに対し、SPECweb96 ワークロード下では CPU 負荷が比較的低く抑えられることがわかる。
時間経過に伴う CPU 負荷の差異を Figure 4 に示す。この図では、両ワークロードについて 3 回の実験全体を通じた瞬間的な CPU 負荷をプロットしている。この図は、実際の運用環境において両ワークロードがいかに異なる挙動を示すかを如実に示している。図が示すように、SURGE ワークロードでは転送速度が約 500pps の場合に CPU 使用率が最大 76% に達するなど、負荷が非常に変動しやすい。一方、SPECweb96 ワークロードでは CPU 負荷が比較的安定しており、使用率が 37% を超えることは一切ない。
両ワークロードの CPU 負荷に差異が生じる要因の一つとして、各ケースにおけるアクティブなTCP接続数の違いが挙げられる。Table 4 に、サーバ上で開かれている接続数の平均値と標準偏差を 100 ミリ秒間隔で測定した結果を示す。この表から、SURGE ワークロード実行時には多数の接続が通常開かれているのに対し、SPECweb96 ワークロードでは開かれている接続数が通常極めて少ないことがわかる。さらに、接続数の変動幅についても、SURGE ワークロードの方が SPECweb96 ワークロードよりもはるかに大きいことが確認される。
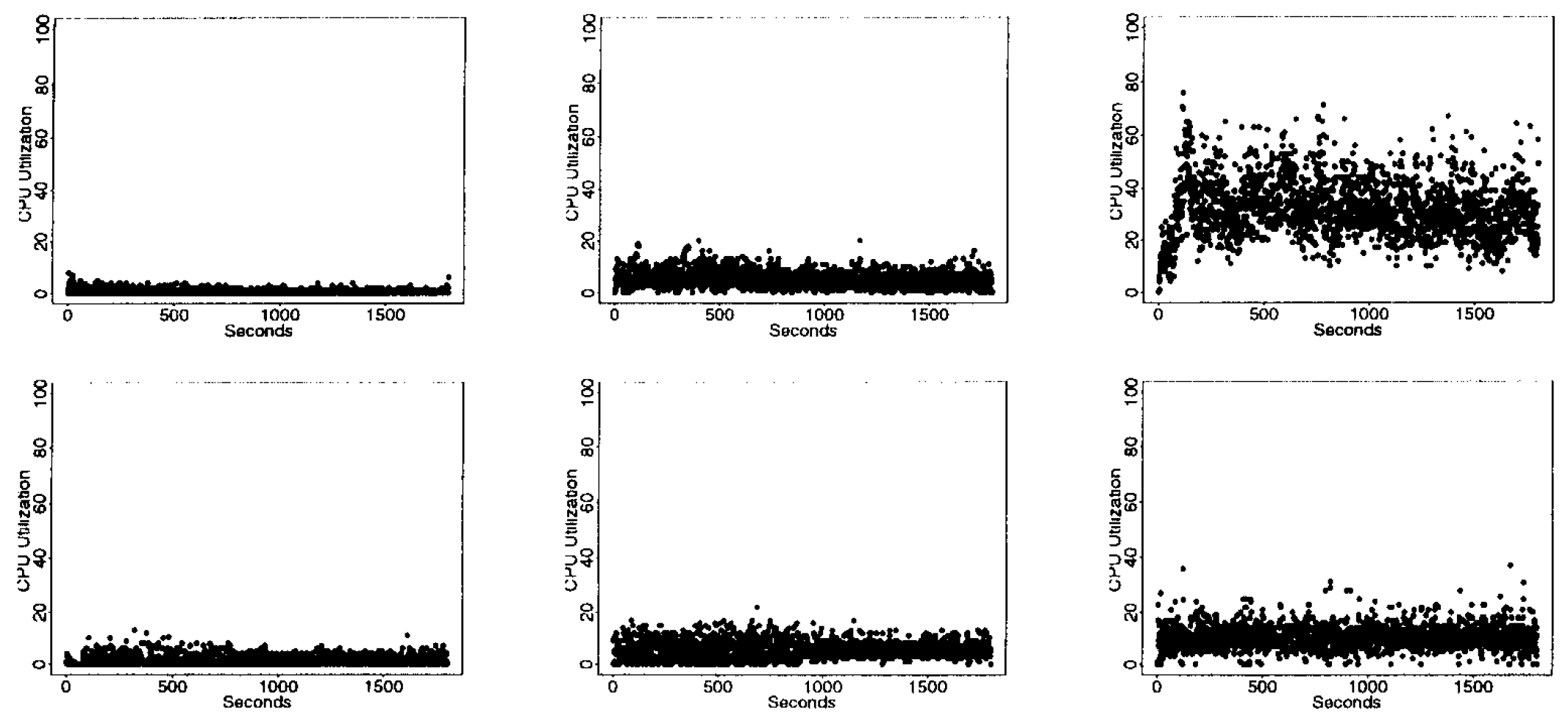
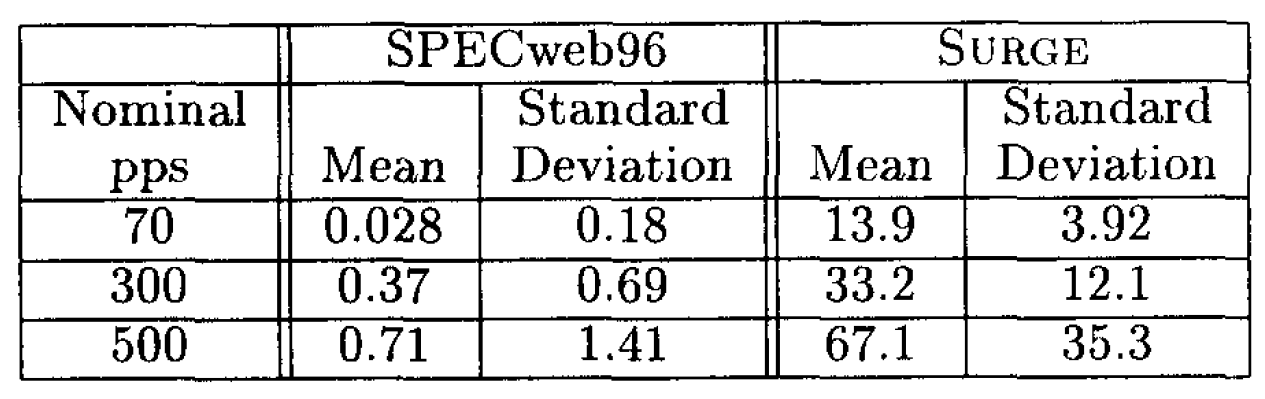
Figure 5 は、3 種類の実験におけるオープン接続数を 100 ミリ秒間隔で示したものである。なお、2 つの行のグラフでは \(y\) 軸のスケールが異なる点に注意されたい。この図は、SURGE ワークロードにおけるオープン接続数の大きな変動を示している。
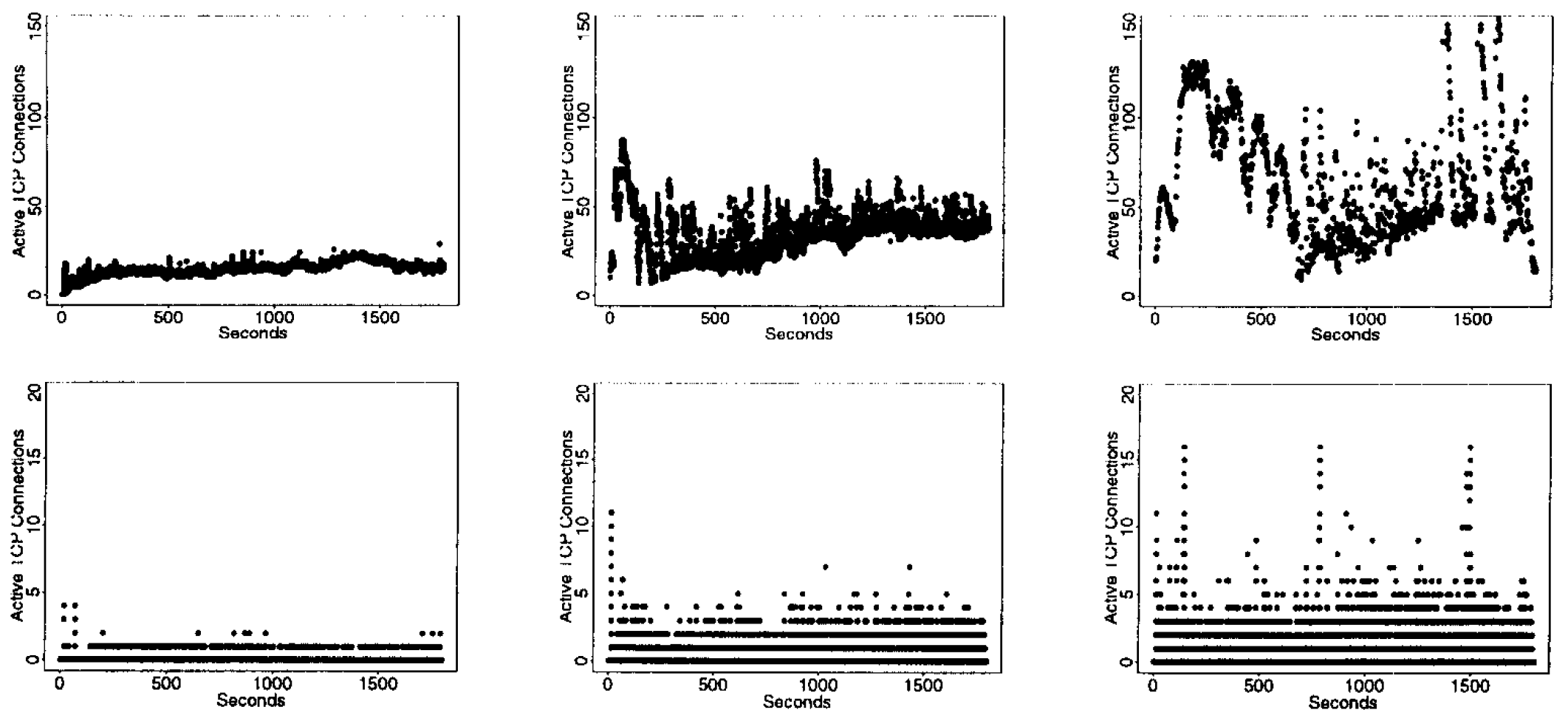
多数のオープン接続を維持・管理することは、[15] で指摘されている通り計算資源的に多大な負荷を伴う。特に、アクティブな接続数の差異は、2 種類のワークロード間で観測される CPU 使用率の違い (Figure 3) の主要な要因となっていることが明らかである。
SURGE が平均的にはるかに多くのオープンサーバー接続を維持する理由は、SURGE におけるリクエスト生成プロセスと SPECweb96 で採用されている手法を比較することで理解できる。SPECweb96 では、インターリクエスト時間は時間間隔あたりのリクエスト数を一定に保つという目標によって決定される。このため、SPECweb96 の場合、1 秒あたりのリクエスト数が増加すると、各スレッドのリクエスト間のアイドル時間は減少する。一方、SURGE では、1 秒あたりのリクエスト数が増加しても個々のスレッドのアイドル時間は減少せず、むしろ使用するスレッド数が増加する。
この結果、SPECweb96 では接続が比較的少数のスレッドに多重化されるため、同時に確立される接続数は少なくなる。これに対し、SURGE ではスレッド数はワークロードの負荷強度に比例して増加し、それに伴って同時に確立可能な接続数も比例的に増加する。接続が大量に重複する場合、接続あたりの処理速度が低下するため、SURGE では平均的に接続がオープン状態を維持する時間が SPECweb96 よりもはるかに長くなる。
SPECweb96 の場合、この差異は要求される操作率に比例して接続数を調整することで対処可能である。ただし、Web サーバーのベンチマークテストではこの手法が一般的ではないことに留意する必要がある。しかし、この現象は Web ワークロードジェネレーターで広く用いられている、少数または固定数のスレッドを用いてリクエストを送信するという手法の欠点を浮き彫りにしている。
ネットワークへの影響. 最後に、2 種類のワークロードが生成するネットワークトラフィックの差異について検討する。セクション 1 で述べたように、特に注目すべきは、これら 2 つのワークロードが自己相似的なトラフィックを生成するかどうかである [12]。この特性は Web トラフィックにおいて既に確認されており [6]、ネットワーク性能に重大な影響を及ぼすことが知られている [10, 17]。
ネットワークトラフィックにおける自己相似性とは、変動性 (バースト性) のスケーリング特性を指す。時系列データ \(X_t\), \(t=1,2,\ldots\) が厳密に二次の自己相似性 (exactly second-order self-similar) を持つとは、次の条件を満たす場合をいう: \[ X_t \stackrel{\mathrm{d}}{=} m^{-H} \sum_{i=m(t-1)+1}^{mt} X_i \quad (1/2 \lt H \lt 1 \text{ and all } m \gt 0) \] ここで \(\stackrel{\mathrm{d}}{=}\) は分布上の等価性を意味する。この定義に基づき、ネットワークトラフィックの自己相似性を判定する簡便なテストとして「分散-時間プロット」が提案されている。このテストでは、\(\sum_{i=m(t-1)+1}^{mt}X_i\) の分散を単位時間あたりのバイト数またはパケット数として測定した \(X_i\) 値に対して、対数-対数座標軸上にプロットする。これにより、トラフィック量の変動特性を視覚的に分析することが可能となる。傾きが \(-1/2\) より大きい直線的な傾向が見られる場合、それは非自明な自己相似性の存在を示唆する。
SURGE と SPECweb96 のトラフィックに対する分散-時間プロットを Figure 6 に示す。図中左から右へデータ転送量が増加するにつれ、SURGE が生成するトラフィックは約線形的な挙動を示し、その傾きは \(-1/2\) とは異なる値となる。つまり、すべての時間スケールにおいてバースト性が持続していることが確認できる。一方、SPECweb96 が生成するトラフィックは、トラフィック強度が低い場合には自己相似性の兆候を示すものの、転送量が増加するにつれてこの特性が失われ、分散-時間プロットの傾きは \(-1/2\) に近似するようになる。
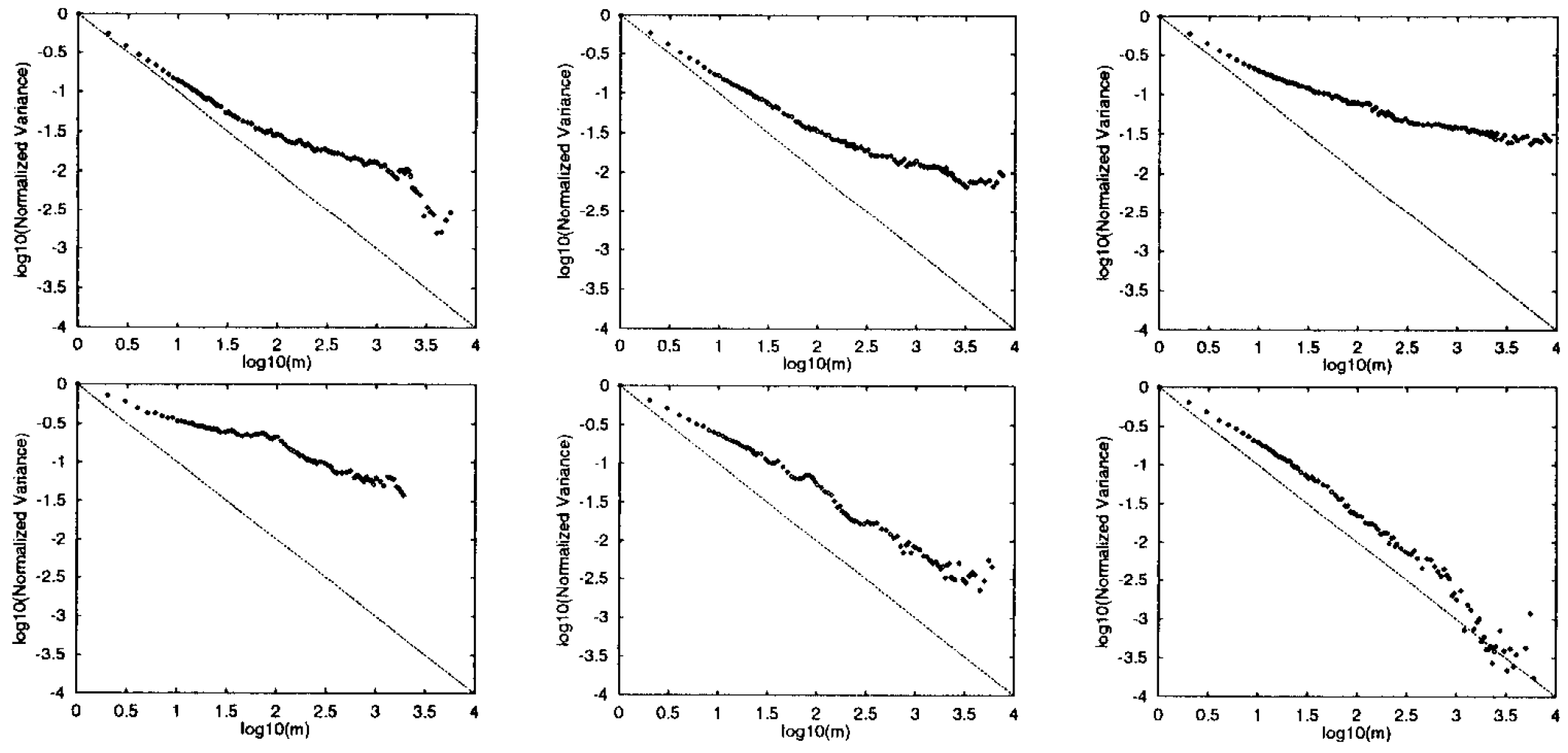
この現象は、2 つのケースをそれぞれ個別のソースの集合として分析することで理解できる。スレッドを ON/OFF 型のソースと見なすと、その周辺分布はベルヌーイ確率変数の分布となる。この場合、分散は 2 つの状態が等確率であるときに最大化される。一方の状態が他方を支配し始めると、スレッドの需要変動性は減少していく。
処理負荷強度が増大するにつれ、SPECweb96 における各スレッドの OFF 時間は短縮され、結果として個々のスレッドの需要変動幅は小さくなる。スレッドは常に稼働状態に近い状態へと近づいていく。したがって、SPECweb96 によって生成されるトラフィックは、変動幅が減少し続ける一定の数のソースから発生する。このため、最終的な集約トラフィックにおける変動幅も低減されることになる。
これに対し、SURGE によって生成されるトラフィックは、変動幅が一定のソースから発生するものである。この場合、変動幅が一定であるソースの数が、処理負荷強度の増大に伴って増加していく。理論的研究 [21] によれば、転送時間がヘビーテール分布を示す場合 (SURGE システムのように)、この条件が自己相似性を持つトラフィック生成の十分条件となる。この結果から、SURGE は処理負荷強度が高い場合も低い場合も、一般的に自己相似性を持つネットワークトラフィックを生成すると予想される。
この点において、SPECweb96 のソース動作特性は、サーバーからのリクエストを可能な限り迅速に処理することを目的としている他の Web ワークロード生成ツールと類似している [16, 20]。ただし、これらのワークロード生成ツールは個々のスレッド要求における顕著なバースト性を保持しないため、高負荷条件下では実際に自己相似性を持つトラフィックを生成する可能性は低いと考えられる。
6 結論
本論文では、Web 利用の分析モデルに基づく代表的な Web リクエストを生成するツールについて論じた。Web ワークロードにおいて把握すべき重要な特性とその意義について詳細に説明している。これらの要件をすべて満たすことが困難な課題を伴う一方で、その解決策も提示している。最終的に開発したツール SURGE は、ワークロードの強度指標としてユーザ相当数の概念を取り入れ、さらに 6 つの分布特性を考慮することで、代表的な Web ワークロードを生成する機能を備えている。
本研究は、Web 利用パターンを特徴づけた既存の広範な研究基盤に基づいている。加えて、SURGE モデルを完成させるために必要な新たな Web 利用測定手法を提案している。
これらの特性をすべて満たすワークロードは、最も一般的に使用されている Web ワークロード生成ツールである SPECweb96 とは全く異なる方法でサーバに負荷をかける。特に、SURGE が生成するワークロードは SPECweb96 と比較してはるかに多くのオープンコネクションを維持するため、CPU 負荷が大幅に増大する。さらに、SURGE は SPECweb96 とは異なる方法でネットワークに負荷をかける。高負荷時において、SURGE が生成するネットワークトラフィックは自己相似性を示すが、SPECweb96 ではこのような特性は確認されない。したがって、SURGE のワークロードはネットワークに対しても SPECweb96 よりも厳しい負荷をかけることになる。これらの結果は、現実的なワークロードとの比較から、SPECweb96 のような従来のワークロード生成ツールがシステム性能評価において楽観的な結果を示す可能性があることを示唆している。このことは、正確な Web ワークロード生成が重要であることを強く示している。
Acknowledgements
The authors would like to thank Vern Paxson, Ralph D’Agostino, Steve Homer and Randy Pruim for their help in various parts of this work.
References
- Virgilio Almeida, Azer Bestavros, Mark Crovella, and Adriana de Oliveira. Characterizing reference locality in the www. In Proceedings of 1996 International Conference on Parallel and Distributed Information Systems (PDIS '96), pages 92-103, December 1996.
- M.F. Arlitt and C.L. Williamson. Web server workload characterization: The search for invariants. In Proceeding of the ACM SIGMETRICS '96 Conference, Philadelphia, PA, April 1996.
- Henry Braun. A simple method for testing goodness of fit in the presence of nuisance parameters. Journal of the Royal Statistical Society, 1980.
- Tim Bray. Measuring the web. In Fifth International World Wide Web Conference, Paris, France, May 1996.
- The Standard Performance Evaluation Corporation. SPECweb96. http://www.specbench.org/osg/web96/.
- M.E. Crovella and A. Bestavros. Self-similarity in world wide web traffic: Evidence and possible causes. In Proceedings of the 1996 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems, May 1996.
- C.A. Cunha, A. Bestavros, and M.E. Crovella. Characteristics of www client-based traces. Technical Report TR-95-010, Boston University Department of Computer Science, April 1995.
- R. B. D'Agostino and M. A. Stephens, editors. Goodness-of-Fit Techniques. Marcel Dekker, Inc., 1986.
- S. Deng. Empirical model of WWW document arrivals at access link. In Proceedings of the 1996 IEEE International Conference on Communication, June 1996.
- A. Erramilli, O. Narayan, and W. Willinger. Experimental queueing analysis with long-range dependent packet traffic. IEEE/ACM Transactions on Networking, 4(2):209-223, April 1996.
- A. Feldmann. Modelling characteristics of tcp connections. Technical report, AT&T Laboratories, 1996.
- W.E. Leland, M.S. Taqqu, W. Willinger, and D.V. Wilson. On the self-similar nature of ethernet traffic (extended version). IEEE/ACM Transactions on Networking, pages 2:1-15, 1994.
- Bruce Mah. An empirical model of HTTP network traffic. In Proceedings of INFOCOM '97, Kobe, Japan, April 1997.
- R. Mattson, J. Gecsei, D. Slutz, and I. Traiger. Evaluation techniques and storage hierarchies. IBM Systems Journal, 9:78-117, 1970.
- J.C. Mogul. Network behavior of a busy web server and its clients. Technical Report WRL 95/5, DEC Western Research Laboratory, Palo Alto, CA, 1995.
- University of Minnesota. Gstone version 1. http://www8.cs.umn.edu/gstone/info.html.
- Kihong Park, Gitae Kim, and Mark E. Crovella. On the relationship between file sizes, transport protocols, and self-similar network traffic. In Proceedings of the Fourth International Conference on Network Protocols (ICNP'96), pages 171-180, October 1996.
- Vern Paxson. Empirically-derived analytic models of wide-area tcp connections. IEEE/ACM Transactions on Networking, 1994.
- S. Pederson and M. Johnson. Estimating model discrepancy. Technometrics, 1990.
- Gene Trent and Mark Sake. Webstone: The first generation in http server benchmarking, February 1995. Silicon Graphics White Paper.
- Walter Willinger, Murad S. Taqqu, Robert Sherman, and Daniel V. Wilson. Self-similarity through high-variability: Statistical analysis of Ethernet LAN traffic at the source level. IEEE/ACM Transactions on Networking, 5(1):71-86, February 1997.
- G. K. Zipf. Human Behavior and the Principle of Least-Effort. Addison-Wesley, Cambridge, MA, 1949.
翻訳抄
Web トラフィックの重裾分布特性に基づいて自己相似的なワークロードを生成し、従来のベンチマークが見落としていた現実的なサーバー・ネットワーク負荷を再現する分析的ワークロード生成ツール SURGE を提案した 1998 年の論文。6 つの統計的特性 (ファイルサイズ分布、リクエストサイズ分布、人気度、埋め込み参照、時間的局所性、アイドル期間) を同時に満たす参照ストリームを生成し、SPECweb96 などの従来手法と比較してサーバー CPU 負荷と同時接続数が大幅に高く、高負荷時にも自己相似性を維持することを実証した。
- BARFORD, Paul; CROVELLA, Mark. Generating representative web workloads for network and server performance evaluation. In: Proceedings of the 1998 ACM SIGMETRICS joint international conference on Measurement and modeling of computer systems. 1998. p. 151-160.
