
HyperLogLog
 概要
概要
HyperLogLog は多重集合 (multiset) における異なりの数問題 (distinct-count problem) を概算するための確率的アルゴリズム。つまり同じ値が複数存在するデータセットから値の種類の数を概算する。異なりの数 (distinct count) とは SQL で COUNT(DISTINCT item) に相当する数であり、例えば集合 \(\{T,\) \(A,\) \(A,\) \(C,\) \(G,\) \(C,\) \(T,\) \(A\}\) の異なりの数は 4 である。
元の Flajolet らの論文 [2] では、多重集合における異なりの数を指してカーディナリティ (cardinality) と言葉を使用しているが、集合論の文脈でのカーディナリティ (濃度) とは重複分を含む要素数を意味している。例えば多重集合 {a,a,b,c,c,c} の濃度は 6 だが異なりの数は 3 である。混乱を避けるためこの記事ではカーディナリティという言葉は使用しない。
重複値を持つデータセットから正確な異なりの数 \(n\) を集計するには重複を排除するために \(O(n)\) のメモリ空間が必要となる。しかし追加や削除が頻繁に行われている大規模なデータセットにおいては概算値が得られれば良いことも多く、そのような状況では HyperLogLog を使うことでメモリ量と処理時間を大幅に削減することができる。
HyperLogLog は特に大規模データセットでの集計や分散ストリーミング分析に適していることから、Redis, Spark, Redshift といった分散システムで利用することができる。例えば Redshift では SELECT APPROXIMATE COUNT(item) ... とすることで HyperLogLog を使った集計処理を実行する。
Table of Contents
アルゴリズム
HyperLogLog の考え方の基礎となる確率カウント法、確率的平均化、LogLog について順番に説明する。
確率的カウント法
確率的カウント法 (probabilistic counting) または Flajolet-Martine アルゴリズム (1985) [1] は大規模データセットにおいて異なりの数を効率的に推定するためのアルゴリズムである。データセット (多重集合, データストリーム) に含まれている各要素をハッシュ化し、そのハッシュ値のビット列で最初に 1 が出現する位置の最も大きなものから、データセットに含まれている異なりの数を推定する。この考え方は HyperLogLog の基礎となっている。
入力 \(x\) に対して長さ \(m\) のビット列 \(\{0,1\}^m\) を生成するハッシュ関数 \(h(x)\) を想定する。このハッシュ値は \([0,2^m-1]\) の範囲に均一に分散される。また \(\rho(y)\) を \(y\) の最下位ビットから 0 が連続している数を返す関数とする。例えば \(\rho(20)=\rho(10100_2)=2\) であり、\(\rho(11)=\rho(01011_2)=0\) である。ここでデータセットに含まれる
データセット \(\mathcal{M}\) に含まれるすべての要素 \(x\) のハッシュ値に \(\rho(x)\) を適用した最大値を \[ r = \max_{\forall x \in \mathcal{M}} \rho(h(x)) \] とする。この \(r\) はデータセット \(\mathcal{M}\) の要素で逐次更新してゆけば 1 度の読み込みだけで構築できる、確率的カウント法におけるレジスタ (記憶領域) である。
さて、ハッシュ値が均一に分散しているということは、ハッシュ値の各ビットは 0 と 1 が等しい確率で出現するということと等価である。つまり、ハッシュ値の最下位ビットパターンが 1 となる確率は \(p=1/2\)、10 となる確率は \(p=1/4\)、100 となる確率は \(p=1/8\)、… と言う具合続く。
前出の \(\rho(y)\) はビット列 \(y=h(x)\) において右から 1 が最初に現われる位置 (=右端で連続する 0 の個数 + 1) であるため、そのようなパターンの出現確率は \[ p_x = 2^{-\rho(h(x))} \] と表すことができる。またデータセット \(\mathcal{M}\) に \(\rho(x)=r\) となるような要素 \(x\) が含まれる確率は \[ p=2^{-r} \] である。
単純に考えると「確率 \(p=2^{-r}\) の現象が起きた」ということは、データセットの中に異なりの数が \(1/2^{-r}=2^r\) 個含まれていたということになる。つまりデータセット \(\mathcal{M}\) に含まれる異なりの数の推定値は \[ E = 2^r \] と表すことができる。
ただし現実的には \(E=2^r\) だけでは大雑把すぎで大きな誤差を含むこととなるため、確率的カウント法では異なる方法で推定値 \(E\) を算出している。そのアプローチは HyperLogLog の由来とは異なるためここでは省略する。
確率的カウント法のアプローチ (省略された説明)
確率カウント法に基づいて推定アルゴリズムを組み立てると以下のようになる。
長さ \(m\) のビット列 \(z\) を用意する。初期状態はすべてのビットが 0 である。
データセット \(\mathcal{M}\) に含まれるすべての要素 \(x\) に対して、\(z\) の \(\rho(h(x))\) 番目のビットを 1 に設定する; つまり \(z[\rho(h(x_i))] \leftarrow 1\) とする。
\(s\) を \(z[i]=0\) となる最も小さい \(i\) とする (例えば \(z=101111111_2\) であれば \(s=7\))。このとき \(\mathcal{M}\) の異なりの数はおおよそ \(2^s/\phi\) である。ここで \(\phi \simeq 0.77351\) とする。
データセット \(\mathcal{M}\) に含まれる要素の異なりの数を \(n\) 種とすると、先述の通りハッシュ値の均一性によって \(z\) の最下位ビット \(z[0]\) に 1 を設定するような値は集合内におよそ \(n/2\) 種程度存在する。同様に \(z[1]\) には \(n/4\) 種、\(z[2]\) には \(n/8\) 種、…。つまり \(z[i]\) に 1 を設定する値の数は \(n/2^i\) 種程度と推測される。したがって \(n \ll 2^i\)、すなはち \(\log_2 n \ll i\) であれば \(z[i]\) はほぼ確実に 0 であり、また \(\log_2 n \gg i\) であればほぼ確実に 1 である。
たまたま \(\rho(h(x))\) が大きくなるような外れ値が含まれると \(z\) の「大きすぎる位置」のビットに 1 が設定される可能性がある。しかし、すべての値のハッシュ値が \(z\) の「小さすぎる位置」のビットを回避するような値を取ることは考えにくいことから確率的カウント法では \(z[i]=0\) となる最も小さい \(i\) から異なりの数から概算を行う方針をとっている。
しかしそれでも確率的カウント法は外れ値の影響を受けやすく、実際には結果の分散が大きくなることが問題となる。例えば以下の実装で N を様々な値に変えてみると、誤差 5% 程度となることもあれば 60% や 80% を超えることもある。
import scala.util.hashing.MurmurHash3
// y の k ビット目を返す
def bit(y: Long, k: Int): Int = ((y >> k) & 1).toInt
// 最下位ビットから連続する 0 ビットの数を返す
def ρ(y: Long): Int = (0 to 31).find(i => bit(y, i) == 1).getOrElse(31)
// 31 ビット幅のハッシュ関数
def h(x: Int): Int = MurmurHash3.bytesHash(BigInt(x).toByteArray) & 0x7FFFFFFF
val N = 100000 // 異なりの数
val M = 0 until N // 重複集合 (実際には重複していないが)
val z = M.foldLeft(0L) { case (z, x) => z | (1 << ρ(h(x))) }
val r = (0 to 31).find(i => bit(z, i) == 0).getOrElse(-1)
val n = math.pow(2, r) / 0.77351
val err = math.abs(n - N) / N
System.out.printf("z=%s, r=%d, n=%f, err=%f\n", z.toBinaryString, r, n, err)
z=1111111111111111, r=16, n=84725.472198, err=0.152745このような外れ値の影響を軽減するために LogLog や HyperLogLog では部分集合に分けて独立して算出した値の調和平均を取る方法などが検討される。
LogLog
確率的カウント法は \(2^r\) で異なりの数の大まかな指標を得るだけである。そして 1 つの変数を 1 つの観測で推定することは外れ値の影響による変動がかなり大きいことから十分ではない。LogLog アルゴリズムでは外れ値が推定に及ぼす影響を低減するために、データセットを複数の部分集合に分割してそれぞれの平均から推定値 \(E\) を算出する確率的平均化 (stochastic averaging) を行う。
まずデータセット \(\mathcal{M}\) を \(m=2^b\) 個の部分集合 \(\mathcal{M}_i\) に分割する。これはハッシュ値の先頭 \(b\) ビットに基づいて各要素を部分集合へ振り分ける。次に、\(m\) 個の部分集合それぞれで前述の確率的カウント法に基づいてビットの並びの最大値 \(r_i\) を算出する。
次に各部分集合の \(r_i\) から幾何平均 \(A=\frac{\sum_{i=1}^m r_i}{m}\) を算出し、2 をべき乗して各部分集合の異なりの数の推定値 \(E_{\rm ss}\) を得る。\[ E_{\rm ss} = 2^A = 2^{\frac{\sum_{i=1}^m r_i}{m}} \] これは \(m\) 個の部分集合のそれぞれに対する確率的カウントの幾何平均を表しているため、全体の推定値 \(E\) を得るために \(m\) を乗算する。またランダムな変数 \(r_i\) をそのまま使うと結果が大きくなりすぎることから、正規化定数 \(\tilde{a}_m\) を乗算して推定値 \(E\) を得る。\[ E = \tilde{a}_m m E_{\rm ss} = \tilde{a}_m m 2^{\frac{\sum_{i=1}^m r_i}{m}} \] ここで \(\tilde{a}_m\) は \(m\) をパラメータとした \[ \tilde{a}_m \simeq 0.39701 - \frac{2 \pi^2 + (\log_e 2)^2}{48m} \] である。ほとんどの実用的な利用 (特に \(m \ge 64\)) では \(\tilde{a}_m=0.39701\) を使用することができる。
この LogLog の標準誤差 (相対誤差) は \(\sigma=1.3/\sqrt{m}\) 程度に近似される。
HyperLogLog
HyperLogLog アルゴリズムでは幾何平均ではなく調和平均 (harmonic mean) を使用することで LogLog から外れ値の問題をさらに改善している。各部分集合の推定値は調和平均を用いて次のように表される。\[ E_{\rm ss} = \frac{m}{\sum_{i=1}^m 2^{-r_i}} \] さらにバイアス補正係数 \(\alpha_m\) を使用して各部分集合の推定値を合算して推定値 \(E\) を算出する。\[ E = \alpha_m m E_{\rm ss} = \frac{\alpha_m m^2}{\sum_{i=1}^m 2^{-r_i}} \] ここで \[ \alpha_m = \left( m \int_0^\infty \left( log_2 \left( \frac{2+u}{1+u} \right) \right)^m du \right)^{-1} \] である。
直感的には、各部分集合に \(n/m\) 種類の異なる要素が含まれているとき、それぞれの \(r_i\) は \(\log_2 \frac{n}{m}\) に近いはずである。\(2^{r_i}\) の調和平均 \(E_{\rm ss}\) は \(\frac{n}{m}\) のオーダーであり、したがって \(mE_{\rm ss}\) は \(n\) オーダーとなる。\(mE_{\rm ss}\) の体系的な乗法バイアスを補正するために \(\alpha_m\) を掛けている。
HyperLogLog の現実の適用ではさらに補正が必要である。例えばクーポンコレクター問題![]() から \(n \ll m \log m\) のとき \(E=0\) となるためアルゴリズムは小さな異なりの数に対して大きな誤差を伴う。部分集合の数 \(m\) に対してデータセットの要素数が非常に小さい場合、多くの部分集合は要素数 0 となる。このような状況で HyperLogLog は線形カウント法 (linear counting) という方法にフォールバックする。これは \(m\) 個のビンに一様にランダムに \(n\) 個のボールを投げ入れたとき、空になるビンの数の期待値からボールの数 \(n\) を逆算する手法である。このように、非常に大きな異なりの数から非常に小さな異なりの数までを扱えるようにするために、論文 [2] では \(E\) を算出した後に適切な補正を行っている。
から \(n \ll m \log m\) のとき \(E=0\) となるためアルゴリズムは小さな異なりの数に対して大きな誤差を伴う。部分集合の数 \(m\) に対してデータセットの要素数が非常に小さい場合、多くの部分集合は要素数 0 となる。このような状況で HyperLogLog は線形カウント法 (linear counting) という方法にフォールバックする。これは \(m\) 個のビンに一様にランダムに \(n\) 個のボールを投げ入れたとき、空になるビンの数の期待値からボールの数 \(n\) を逆算する手法である。このように、非常に大きな異なりの数から非常に小さな異なりの数までを扱えるようにするために、論文 [2] では \(E\) を算出した後に適切な補正を行っている。
誤差と容量の見積もり
HyperLogLog の標準誤差は \(\sigma=1.04/\sqrt{m}\) 程度に近似される。現在の多くの実装では \(m=2^{14}\) を設定しており [3]、この場合、データセットに含まれる要素数や異なりの数に関係なく \(1.04/\sqrt{2^{14}}=0.81\%\) となることが見込める。
異なりの数の最大値を \(n_{\rm max}\) と想定したとき、それらをすべて区別するにはハッシュ値に \(O(\log_2 n_{\rm max})\) ビットの長さが必要となる。したがって、各部分集合が \(r_i\) を保持するには \(O(\log_2 \log_2 n_{\rm max})\) ビットのレジスタが必要であり、レジスタは全体で \(O(m \log_2 \log_2 n_{\rm max})\) ビットの空間となる (これが LogLog という名の由来である)。
例えば非常に大きな異なりの数の最大値として \(n_{\rm max}=2^{64}\) と想定したとき、各データセットのレジスタには \(\log_2 \log_2 2^{64}=6\) ビットが必要である。よく使われる \(m=2^{14}\) の設定では \(2^{14}\times 6=98,304\) ビット (12kB) となる。つまり HyperLogLog は 12kB の記憶領域があれば \(\sigma=0.81\%\) の標準誤差で \(10^{19}\) の異なりの数を概算することができる。
実験的洞察から LogLog や HyperLogLog の分布は正規分布に似た形になっていることが分っている [3]。これらは標準誤差 \(\sigma\) が分かっていることから、推定値からの \(\pm\sigma\) (65%), \(\pm2\sigma\) (95%), \(\pm3\sigma\) (99%) 範囲を得ることができる。
和集合の推定
HyperLogLog を使用して集合 \(A\) と集合 \(B\) の異なりの数を個別に推定したとき、算出に使用したレジスタを再利用して和集合 \(A \cup B\) の異なりの数を推定することができる。これは、集合 \(A\) と \(B\) でハッシュ関数 \(h\) と部分集合数 \(m\) を共有していれば、各部分集合のレジスタの大きい方を採用することで和集合のレジスタを構築できるためである。\[ \forall i \in [1,m]: \ r_i \leftarrow \max(r_{A,i}, r_{B,i}) \]
例えばある駅の改札を IC 乗車券で通過したユニーク旅客数を 1 日ごとに HyperLogLog で推定していたとする。このとき、推定に使用した各レジスタ \(r_{{\rm day},i}\) が保存されていれば、週ごと、月ごとの訪問ユニーク旅客数はデータセットを再読み込みしなくても簡単に算出することができる。
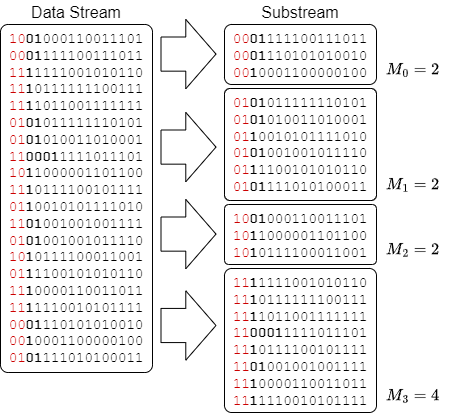
例1. \(n=20\) での HyperLogLog での推定値の算出
アルゴリズムを図で説明する。Fig 1 は異なりの数 20 を持つ集合 \(\mathcal{M}\) から HyperLogLog を使用してその推定値 \(E\) を算出する例である。各要素はハッシュ値の先頭 \(b=2\) ビットに基づいて \(m=4\) 個の部分集合に分けられ \(\rho\) の最大値 \(M_j\) を更新し、指標 \(Z\) から結果を算出している。
例2. \(n=10000\) での HyperLogLog での推定値の算出
HyperLogLog のアルゴリズムをプログラムにすると以下のようになる (論文にあるような最後の補正は行っていない)。このコードでは異なりの数 \(n=100000\) に対して誤差 0.13% の推定値 \(E=100129.57\) を算出している。
import scala.util.hashing.MurmurHash3
object HyperLogLogExample extends App {
val b = 14
val m = 1 << b
val alpha14 = 0.721
val M = Array.fill(m)(0) // 各サブストリームの ρ の最大値を保持するレジスタ
def hash(value: String): Int = MurmurHash3.stringHash(value)
def leadingZeros(x: Int): Int = {
val binary = x.toBinaryString.reverse.padTo(32, '0').reverse
val i = binary.indexOf('1')
return if (i >= 0) i else binary.length
}
// データストリームの例 (実際の異なりの数は 100000)
val n = 100000
val dataStream = (0 until n).map(_.toString)
// 各要素を HyperLogLog に追加
for (v <- dataStream) {
val h = hash(v)
val j = (h >> (32 - b)) & (m - 1) // 上位 b ビットを取得
val r = leadingZeros(h << b) + 1
M(j) = math.max(M(j), r)
}
// 異なりの数を推定
val Z = 1.0 / M.map(count => 1.0 / (1 << count)).sum
val E = alpha14 * m * m * Z
println(s"Estimated number of distinct elements: $E")
}
Estimated number of distinct elements: 100129.57268650533参考文献
- Philippe Flajolet, G. Nigel Martine. Probabilistic Counting Algorithms for Data Base Applications. Journal of Computer and System Sciences. 31 (2): 182–209. 1985.
- Philippe Flajolet, Éric Fusy, Olivier Gandouet, Frédéric Meunier. HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm. AofA: Analysis of Algorithms, Jun 2007, Juan les Pins, France. pp.137-156, ⟨10.46298/dmtcs.3545⟩. ⟨hal-00406166v2⟩
- Dzejla Medjedovic, Emin Tahirovic, Ines Dedovic. 大規模データセットのためのアルゴリズムとデータ構造. マイナビ出版 (2024)
