Tapestry
 概要
概要
Tapestry[2,3] は PRR の論文[1]に基づいた Prefix ルーティングを行う分散ハッシュテーブルルゴリズム。RPP にノードの参加と離脱のアルゴリズムが追加されている。各ノードは SHA-1 を使用した ID (アドレス) が割り当てられ、アプリケーションにもエンドポイント GUID が割り当てられる。
Prefix ルーティングで使用する ID 設計の基数を \(\beta\)、最大レベル (ID の桁数) を \(n\) とすると ID の名前空間は \(\beta^n\) の大きさを持つ。ネットワークに参加しているノード数を \(N\) とすると 1 ノードが担当する ID は平均で \(\beta^n/N\) 個である。Tapestry (および PRR に基づく) Prefix ルーティングは平均で \(\log_\beta N\) ホップ、最悪ケースでも \(n\) ホップで目的のノードに到達することができる。ここで目的のノードとは該当する ID を担当するノードであって ID が完全一致するノードとは限らないことに注意。
Tapestry の Prefix ルーティングは ID のジオメトリー空間における「近さ」によって担当範囲のローカリティ特性を規定する。Prefix ルーティングのネットワークでは、ノードは ID 空間上で近いノードと負荷を分散する。したがってノードの ID が一様に分布していないと特定のノードに負荷が偏ることに注意しなければならない。
Table of Contents
ルーティングテーブルの作成
Prefix ルーティングに参加するノードは ID に対応するメッセージ転送先ノードを定義したルーティングテーブルを持っている。
このルーティングテーブルは、ノード ID の Prefix の桁に対応するレベル (深さ) と、各レベルの桁値の 2 次元で構成されている。ルーティングテーブルはそのノードが直接リンクしている (1 ホップで到達する) ノードのみが保存されているため、含まれるノードはネットワーク全体の一部のみであり、その内容もノードごとに異なる。
ルーティングテーブルのレベル \(i\)、インデックス \(j\) に位置するエントリ \(e_{i,j}\) は、ローカルノードの ID と先頭 \(i\) 桁が一致し、その次の桁が \(j\) であるノード ID が設定される。ただし \(j\) がローカルノードの値と一致する場合はローカルノードの ID が設定される。該当するノードが存在しない場合、エントリは null となる。
Table 1 は基数 \(\beta=16\)、最大レベル \(n=5\) 想定でのノード ID 325AE が構築する \(5\times 16\) ルーティングテーブルの例である。例えばエントリ \(e_{3,4}\) にはローカルノードの ID と先頭 3 桁が一致し 4 桁目が 4 である 3254C が設定されていることがわかる。また \(e_{3,6}\) は null であるため 3256* に該当するノードが存在しないことを意味している。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| L0 | 03806 | 1EFB9 | 2747E | 325AE | 47251 | 52327 | 682AF | 7C95A | 80881 | 94516 | A11F2 | B7131 | CC660 | D7717 | E8109 | F4024 |
| L1 | 30E91 | 31EB5 | 325AE | 335BE | 34EA5 | 35C13 | 3670C | 373AE | 38DD8 | 39208 | 3A4A2 | 3B2D2 | 3C681 | 3D5FE | 3EB21 | 3F289 |
| L2 | 320ED | 321E8 | 322B6 | 323A8 | 324A0 | 325AE | 32698 | 327F1 | 32884 | 329A5 | 32AA5 | 32BF1 | 32C7C | 32D50 | 32EBF | 32FB4 |
| L3 | 3250E | 3251F | 3254C | 32558 | 3258E | 32595 | 325AE | 325C8 | 325ED | 325FB | ||||||
| L4 | 325AB | 325AE |
転送先ノードの検索
ノードがメッセージを受信したとき、ノードはそのメッセージが自分宛てであるか、あるいは他のノードへ転送しなければならないかをルーティングテーブルを用いて判断する。
ルーティングテーブルの検索は宛先 ID の先頭から順に各レベルで一致するエントリを探す。このとき:
- 前方一致したエントリの ID が null の場合、同じレベルで右側に存在する非 null エントリを対象とする。null でない場合、対象エントリは前方一致したエントリである。
- 対象のエントリの ID がローカルのノード ID でなければそのノード ID にメッセージを転送する。
- 対象のエントリの ID がローカルのノード ID であれば次のレベルへ移動する。探索位置が最大レベルを超えたとき、メッセージの宛先はローカルノードである。
この手順は前述のサンプルコードの nextHop() メソッドが該当する。テーブルのエントリ数を \(N_e\) とすると、この手順での検索の複雑度は \(O(\log N_e)\)、最悪ケースは最大レベル \(n\) である。
Table 1 で示したルーティングテーブルは Fig 1 のような探索木で表すことができる。この例では、ノード 325AE は E9C11 宛のメッセージを E8189 に転送するだろう。また該当するノードが存在しない 3256* へのルーティングは、隣接する有効なノードである 3258E へ転送する (Tapestry ではより大きい側へ、最大値 16 を超えたら 0 へ循環するものとしている)。

メッセージルーティング
ノードは受信したメッセージが自分の担当する ID ではなかった場合に自身のルーティングテーブルから転送先のノードを検索してメッセージを転送する。Prefix ルーティングでは転送が進むにつれて転送先ノードのルーティングテーブルでの先頭一致部分が大きくなり、目的となるノードが絞り込まれてゆく性質を持つ。
Table 1 に示したルーティングテーブルでは基数 16、最大レベル 5 の ID 設計であることから名前空間のサイズは \(16^5\) である。これに対してノード数は約 \(65536 \simeq 16^4\) であることから 1 ノードが担当する平均の ID 数は \(16^5/16^4=16\) 程度と考えられる。また平均的なホップ数は \(\log_{16} 16^4 = 4\) である。これは \(16^4\) というノード数によって Table 1 のおおむね上位 4 レベルが満たされることからも直感的に理解できるだろう。Fig 2 は ID 1C71D 宛のメッセージが 4 ホップしてその ID を担当するノード 1C712 に到達するルーティングの例である。
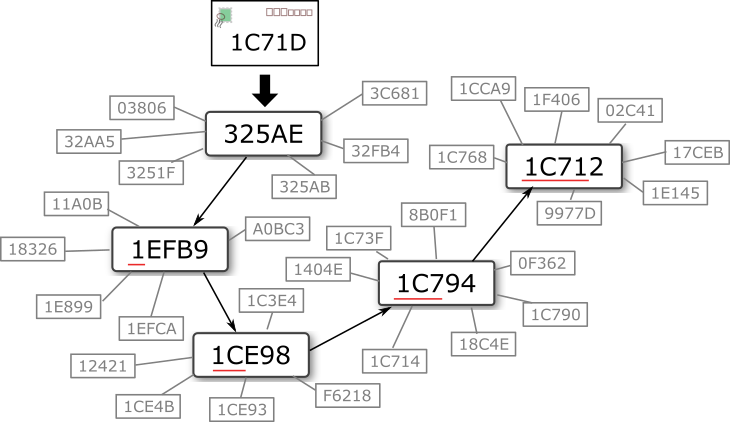
325AE から始まる 1C71D 宛のメッセージルーティングのイメージ。このイラストではノード 1C712 が 1C71D を担当してるため 4 ホップで到達する。オブジェクトの公開と位置情報
Tapestry ではメッセージのルーティングに加えてネットワーク上でオブジェクト (画像のようなファイルやサービスの API など) を公開する方法を提案している。
あるノードが自身のローカルに存在するオブジェクトを公開したいとき、Prefix ルーティングを使用してオブジェクトの ID と自身のアドレスのマッピングを Publish する (オブジェクト自身のコピーが転送されるわけではない点に注意)。このロケーション情報は宛先のノードだけではなく中継するノードにも保存される。結果的に各ノードにはオブジェクトの ID とそのオブジェクトが保存されているノードのマッピングが生成される。オブジェクトのロケーション情報を持つノードは Publish されたオブジェクトが有効であることを確認するために定期的に Publish 元のノードに問い合わせを行う。
オブジェクトの ID に対するロケーションの問い合わせも同様に Prefix ルーティングで行われる。ここで担当ノードに到達する前に中継経路のノードがロケーション情報を持っていることを期待することができる。
アプリケーションインターフェース
Tapestry の API は以下の 4 つで構成される。メッセージに含まれる識別子 \(A_{\rm id}\) は宛先のプロセスやアプリを識別するための情報である (TCP や UDP でのポート番号と同じ目的)。
- \({\rm PublishObject}({\rm ID}_{\rm obj},A_{\rm id})\): ローカルノードのオブジェクトを \({\rm ID}_{\rm obj}\) として公開し有効化する。
- \({\rm UnpublishObject}({\rm ID}_{\rm obj},A_{\rm id})\): オブジェクト\({\rm ID}_{\rm obj}\) に対するロケーションマッピングを削除する。
- \({\rm RouteToObject}({\rm ID}_{\rm obj},A_{\rm id})\): \({\rm ID}_{\rm obj}\) のオブジェクトが存在するノードにメッセージを送信する。
- \({\rm RouteToNode}({\rm ID}_{\rm node},A_{\rm id},{\rm Exact})\): ノード \({\rm ID}_{\rm node}\) のアプリケーション \(A_{\rm id}\) にメッセージを送信する。\({\rm Exact}\) が true の場合、\({\rm ID}_{\rm node}\) は担当ノードの ID と完全に一致しなければならない。
参考文献
- Plaxton CG, Rajaraman R, Richa A. Accessing nearby copies of replicated objects in a distributed environment. In Anon, editor, Annual ACM Symposium on Parallel Algorithms and Architectures. New York, NY, United States: ACM. 1997. p. 311-320
- Ben Y. Zhao, John Kubiatowicz, Anthony. D. Joseph. Tapestry: An infrastructure for fault-tolerant wide-area location and routing. Univ. California, Berkeley, CA, Tech. Rep. CSD-01-1141, Apr. 2001.
- Ben Y. Zhao, Ling Huang, Jeremy Stribling, Sean C. Rhea, Anthony D. Joseph, John D. Kubiatowicz. Tapestry: A Resilient Global-Scale Overlay for Service Deployment. IEEE Journal on Selected Areas in Communications. 22 (1): 41–53.
