タグ抽出
 特徴
特徴
タグ抽出 (tag extraction) またはキーワード抽出の目的は文書の内容を代表していると思われる単語を選択する処理。他に自然文の構文構造を素性として重み付けする方法などいくつか過去の研究ある。
アルゴリズム
TF-IDF
TF-IDF は文書を特徴づける単語の抽出としてよく知られている方法である。文書の集合の中で相対的に文書を特徴づけている単語をスコアリングすることから、文書内で大きな TF-IDF 値を持つ単語をその文書のタグ (キーワード) とみなすことができる。アルゴリズムの詳細は TF-IDF 参照。
TextRank アルゴリズム
TextRank (2004) は文中の単語がその近傍に位置する要素と関係している (共起) という分布仮説に基づく関係グラフから PageRank (固有ベクトル中心性) を使用して各単語の重要度を算出する。一見すると頻出単語の重要度が高くなるだけのように思えるが、PageRank の特性によってグラフ構造上の中心性による調整が行われるため単純な出現頻度や TF-IDF による重み付けとは異なる結果が得られる。
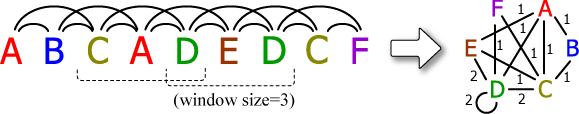
以下 TextRank 論文より。
- ウィンドウサイズ \(k\) はどこまでの隣接範囲を関係グラフとして接続するかを示す。\(k\) は 2 以上で多くても 10 程度。論文の実験では 2 で最も良好な結果が得られている。
- 前処理として文書を構文解析し、構文フィルタでノイズとなる形態素を除去する。論文では名詞と形容詞のみで最良の結果が得られている。
- 有向グラフ/無向グラフのどちらでも利用できるが有向グラフの方が収束が速い。論文では単語の出現順に前方から後方に有向グラフを形成したが精度が有意に向上することはなかった。
- 接続数をエッジの重みとするのは有効。
論文で得られた結果は DUC 2004 のテストデータに対する評価である事に注意。日本語では句点で区切った上で関連を作成した方が良い精度を示す印象がある。
PositionRank アルゴリズム
PositionRank (2017) は TextRank と同じ \(k\)-近傍の単語共起による関連グラフに加えて、文書の先頭に近い位置に現れる単語は代表性が高いと考え、文書内の出現位置でバイアスを加えた PageRank アルゴリズムを使用する。文書の前方に代表性を見出すのはリード法の考え方である。つまりリード法に沿った文章記述を行っている科学論文、ニュース、Wikipedia 記事のような文書に対して TextRank よりも有効性が期待できる。
PositionRank ではまず文書中の (品詞フィルタリングを行う前の) 出現位置の逆数の和で単語の重みを算出する。例えばある単語 \(v_i\) が文書中の 2 番目、5番目、10番目に存在している場合、その重み \(p_i\) は: \[ p_i = \frac{1}{2} + \frac{1}{5} + \frac{1}{10} = 0.8 \] と表すことができる。さらに、全ての単語の重みで正規化し \(\widetilde{p}_i\) とする。\[ \begin{equation} \widetilde{p}_i = \frac{p_i}{\sum_{j=1} p_j} \label{position_weight} \end{equation} \]
重み付き有向グラフに対するバイアスありの PageRank は、頂点 \(v_i\) から \(v_j\) へ向かうエッジの重みを \(w_{ij}\)、減衰係数 \(\alpha\) としたとき、\(\widetilde{p}\) を導入して以下のように表される。\[ \begin{equation} S(v_i) = (1 - \alpha) \widetilde{p}_i + \alpha \sum_{v_j \in {\it Adj}(v_i)} \frac{w_{ji} S(v_j)}{\sum_{v_k \in {\it Adj}(v_j)} w_{kj}} \label{positionrank} \end{equation} \] ここで \({\it Adj}(v_i)\) は頂点 \(v_i\) に隣接している \(v_i\) 以外の頂点の集合を示している。
またこの論文では形態素に分解した単語からフレーズを再構築するために、正規表現風に (形容詞)*(名詞)+ の並びとなる単語を最大 3 つまでまとめフレーズとしている。このとき、フレーズの重みは連結した単語それぞれの重みの合計となる。
タグ/キーワード抽出実験
※名詞 (代名詞、非自立を除く) + 形容詞。PositionRank の冒頭優先が強すぎる場合は \(k\) を少し大きめに調整。このデモの PositionRank は論文と同じではなく、位置による重み (\(\ref{position_weight}\)) をノードの重みとして PageRank を適用している (式 (\(\ref{positionrank}\)) 対応版の PageRank を実装するのが面倒だったため)。
参照
- PageRank

- Rada Mihalcea, Paul Tarau (2004), "TextRank: Bringing Order into Texts" (日本語訳)
- Corina Florescu, Cornelia Caragea (2017), "PositionRank: An Unsupervised Approach to Keyphrase Extraction from Scholarly Documents" (日本語訳)
