論文翻訳: TextRank: Bringing Order into Texts
Rada Mihalcea and Paul Tarau
Department of Computer Science
University of North Texas
{rada,tarau}@cs.unt.edu
 Abstract
Abstract
この論文ではテキスト処理において graph-based ランキングモデルである TextRank を導入し、このモデルが自然言語アプリケーションにおいて有効に機能するかを示す。特に、キーワード抽出と文抽出の 2 つの革新的な教師なし学習の方法を提案し、得られた結果が既存のベンチマークで過去に公表された結果と適合することを示す。
Table of Contents
- Abstract
- 1 Introduction
- 2 The TextRank Model
- 3 Keyword Extraction
- 4 Sentence Extraction
- 5 Why TextRank Works
- 6 Conclusions
- References
- 翻訳抄
1 Introduction
Kleinberg の HITS アルゴリズム (Kleinberg, 1999)、Google の PageRank (Brin and Page, 1998) のような graph-based ランキングアルゴリズムは既に引用分析やソーシャルネットワーク、World-Wide Web のリンク構造の分析に有効に利用されている。おそらくこれらのアルゴリズムは、個々の Web ページのコンテンツ分析のみならず、Web アーキテクチャの集合知に依存する Web ページランキングメカニズムを提供することによって、Web 検索技術の分野で引き起こされるパラダイムシフトの重要な要素として認識されうるだろう。要約すると、graph-based ランキングアルゴリズムは局所的な頂点固有情報のみに頼るのではなく、グラフ全体から再帰的に計算された大域的な情報考慮してグラフ内の頂点の重要度を決定する方法である。
自然言語の文書から抽出された語彙または意味論グラフに対しても同様の考え方を適用することで、テキスト全体から抽出された知識を局所的なランキング/選択の決定として使用する様々な自然言語処理アプリケーションに適用できる graph-based ランキングモデルを得ることができる。このようなテキスト志向のランキング方法はキーフレーズの自動抽出から要約抽出、曖昧な単語の除去まで幾つかのタスクに適用することができる (Mihalcea et al., 2004)。
本稿では自然言語文章から抽出したグラフに対する TextRank graph-based ランキングモデルを導入する。教師なし学習においてキーワードと文章抽出からなる 2 つの言語処理タスクに対して TextRank 適用結果を評価し、TextRank で得られた結果がそれらの分野で開発された最新のシステムと適合することを示す。
2 The TextRank Model
基本的に graph-based ランキングアルゴリズムはグラフ全体から再帰的に導き出した大域情報に基づいてグラフ内の頂点の重要度を決定する方法である。graph-based ランキングモデルによって実装される基本的な考え方は「投票」または「レコメンド」の概念である。基本的に、ある頂点が別の頂点とリンクすると、別に頂点に対して投票が行われたとみなす。そして頂点に向けられた投票の数が多いほどその頂点の重要度は高くなる。さらに、投票を行う頂点の重要度も投票全体がどれほど重要であるかを決定し、その情報もランク付けのモデルに加味される。従って、頂点に関連付けられるスコアは、それに対して向けられた票とそれらの票を投じた頂点のスコアに基づいて決定される。
より正確に表すと \(G=(E,V)\) を頂点集合 \(V\) とエッジ集合 (辺集合) \(E\) を持つ有向グラフとする。ここで \(E\) は \(V\times V\) の部分集合である。与えられた頂点 \(V_i\) に対して (V_i\) へ向かう頂点の集合を \({\rm In}(V_i)\) (predecessors)、\(V_i\) が指す頂点の集合を \({\rm Out}(V_i)\) (successors) とする。このとき頂点 \(V_i\) のスコアは以下のように定義される (Brin and Page, 1998)。\[ S(V_i) = (1 - d) + d * \sum_{j \in {\rm In}(V_i)} \frac{1}{|{\rm Out}(V_j)|} S(V_j) \] ここで \(d\) は 0 から 1 までの値を取る減衰係数であり、与えられた頂点からグラフ上のランダムに選んだ別の頂点にジャンプする確率をモデルに統合する役割を持っている。例えば Web サーフィンの文脈では graph-based ランキングアルゴリズムは "random surfer model" を実装しており、ユーザは確率 \(d\) でランダムにリンクをクリックし、確率 \(1-d\) で完全に新しいページへジャンプする。係数 \(d\) は通常 0.85 (Brin and Page, 1998) に設定され、我々の実装でもこの値を使用する。
グラフの各ノードに割り当てられている任意の値から開始し、所定のしきい値を下回る収束[1]が確認されるまで計算を繰り返す。このアルゴリズムを適用した後、各頂点に関連付けられたスコアはその頂点のグラフ内での「重要度」を表している。TextRank が収束するまで実行された後に取得される最終的な値は、初期値の影響を受けず、収束までのイテレーション回数のみによって異なることに注意。
この論文で説明する TextRank アプリケーションは Google の PageRank (Prin and Page, 1998) から派生したアルゴリズムに依存しているが、他の graph-based ランキングアルゴリズム HITS (Kleinberg, 1999) や Positional Function (Herings et al., 2001) は TextRank モデルと容易に統合することができる (Mihalcea, 2004)。
[1] Convergence is achieved when the error rate for any vertex in the graph falls below a given threshold. The error rate of a vertex \(V_i\) is defined as the difference between the "real" score of the vertex \(S(V_i)\) and the score computed at iteration \(k\), \(S^k(V_i)\). Since the real score is not known apriori, this error rate is approximated with the difference between the scores computed at two successive iterations: \(S^{k+1}(V_i) - S^k(V_i)\).
2.1 Undirected Graphs
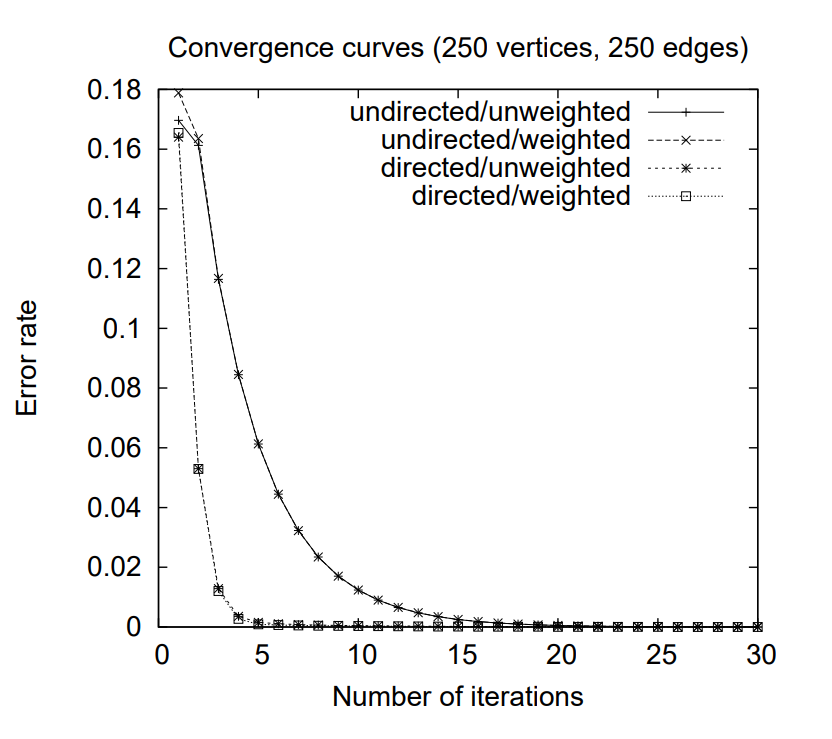
Figure 1: graph-based ランキングにおける収束曲線: 有向/無向, 重み付き/重みなし, 250頂点, 250エッジ。
再帰 graph-based ランキングアルゴリズムは伝統的に有向グラフに適用されてきたが無向グラフにも適用することができる。この場合、頂点の出次数 (out-degree) と入次数 (in-degree) は等しくなる。頂点の数にエッジの数が比例するような疎結合グラフの場合、無向グラフはより緩やかな収束曲線を描く傾向がある。
Figure 1 は収束のしきい値を 0.0001 としたとき、250 の頂点と 250 のエッジを持つランダムに生成されたグラフの収束曲線をプロットしている。グラフの接続性が増加するにつれて (つまりエッジ数が増加するにつれて) 少ないイテレーション数でも収束するようになり、有向グラフと無向グラフの収束曲線が実質的に重なっている。
2.2 Weighted Graphs
Web サーフィンの文脈では、あるページから別のあるページへ複数リンクを設置したり部分的なリンクを設置することがまれであることから、元々の graph-based ランキングである PageRank 定義は重み付けされていないグラフを想定している。
しかし、我々のモデルでは、グラフは自然言語テキストから構築され、テキストから抽出された単位 (頂点) 間に複数のリンクまたは部分的なリンクを含むことができる。従って、2 つの頂点 \(V_i\) と \(V_j\) との間の接続の「強度」を 2つの頂点の接続に対応するエッジが持つ重み \(w_{ij}\) としてモデルに表示し組み込むことは有用である。
従って、グラフの頂点に関連づけられたスコアを計算する際にエッジの重みを考慮した graph-based ランキングの新しい式を導入する。同様の公式は頂点の重みを積分するために定義されることに注意。\[ WS(V_i) = (1-d) + d*\sum_{V_j \in {\rm In}(V_i)} \frac{w_{ji}}{\sum_{V_k\in {\rm Out}(V_j)} w_jk} WS(V_j) \]
Figure 1 は 2.1 章と同じサンプルグラフに 0-10 の範囲のランダムな重みをエッジに追加してプロットしている。最終的な頂点のスコア (つまりランク) は重み付けされていない方と比較して大幅に異なるが、収束までのイテレーション回数と収束曲線の形状は重み付けされたグラフと重み付けされていないグラフとでほぼ同じである。
2.3 Text as a Graph
graph-based ランキングアルゴリズムを自然言語テキストに適用するには、テキストを表すグラフを作成し、単語や他のテキストエンティティを意味のある関係に結びつける必要がある。取り扱う用途に応じて、例えば単語、連語 (collocation)、文全体など、様々なサイズのテキスト単位または特徴をグラフの頂点として追加することが出来る。同様にそれらの頂点を接続する関係タイプも例えば語彙的関係、意味論的関係、文脈上の重複など、用途による。
グラフに追加された要素の種類と特徴にかかわらず、graph-based ランキングアルゴリズムを自然言語テキストに適用するには次の主要なステップが存在する:
- 取り扱うタスクを最もよく定義するテキスト単位を特定し、それらをグラフの頂点として追加する。
- それらのテキスト単位を結ぶ関係を特定し、それらの関係を使用してグラフの頂点間にエッジを作成する。エッジは有向/無向、重みあり/なしを選択できる。
- 収束するまで graph-based ランキングアルゴリズムをイテレーションする。
- 最終的なスコアに基づいて頂点をソートする。ランキング/選択の決定には各頂点に付けられた価を使用する。
テキスト単位のランク付けを含む自然言語処理タスクに対する TextRank の適用を以下の 2 点で調査および評価する: (1) 特定のテキストを表すキーフレーズの選択からなるキーワード抽出タスク; および (2) 文中の最も重要な文の識別からなる文抽出タスク。概要抽出の構築にも利用できる。
3 Keyword Extraction
キーワード抽出用途のタスクは文書を最も的確に記述する用語のセットをテキスト内から自動的に識別することである。そのようなキーワードは文書コレクションの自動索引を構築するための有用なエントリを構成することができ、テキストを分類するために使用することができ、また与えられた文書の簡潔な要約として利用することができる。さらに、用語抽出の問題やドメイン特有の辞書の作成のために、重要な用語をテキスト内で自動的に識別するシステムとして使用することができる。
最も簡単な方法はおそらく頻度基準を使用して文書内の「重要な」キーワードを選択することだろう。しかしながら、この方法は一般的に貧弱な結果になることが判明しており、その結果として別の方法が検討された。現在、この分野の最先端技術は教師あり学習方法によって表されている。このシステムは語彙や文法上の特徴に基づいてテキスト内のキーワードを認識するように訓練される。このアプローチは (Turney, 1999) で最初に提案された。ここでパラメータ化されたヒューリスティックルールが遺伝的アルゴリズムと組み合わされ、文中のキーワードを自動的に識別するキーフレーズ抽出システム GenEx に組み入れられた。また異なる学習アルゴリズムが (Frank et al., 1999) で使用された。Naive Bayes 学習スキームが文書コレクションに適用され (Turney, 1999) で使用されているのと同じデータセットで改善された結果が観測された。Turney も Frank もシステムの再現率について報告していないが精度についてのみ述べている: GenEx (Turney, 1999) では文書ごとに抽出された 5 つのフレーズについて 29.0% の精度が達成された。Kea (Frank et al., 1999) では文書ごとに 15 のキーフレーズで 18.3% の精度が達成された。
最近では (Hulth, 2003) が語彙と構文的特徴の組み合わせを用いて概要文 (abstract) からのキーワード抽出に教師あり学習システムを適用し、以前に公表された結果よりも有意に改善することを証明した。Hulth が示唆しているように、インターネット上の多くの文書が全文として利用可能ではなく概要文としてのみ利用可能であることから、概要文からのキーワード抽出は全文よりも広く適用可能である。彼女の研究では、Hulth は (Turney, 1999) で提案された手法を用いて実験を行い、品詞情報を学習プロセスに統合する新しいアプローチを示し、用語表現に言語知識を追加することでシステムの精度がほぼ倍増することを示している。
この章では TextRank を使用したキーワード抽出の実験について報告し、graph-based ランキングモデルがこの問題で公開された結果の中で最も良く上回る事を示す。(Hulth, 2003) と同様に、主にキーフレーズ抽出システムで報告した結果と直接比較できるように、概要文からのキーワード抽出アルゴリズムを評価する。テキストのサイズはシステムによって課される制限ではなく、全文に TextRank を適用したのと同等の結果が期待される点に注意。
3.1 TextRank for Keyword Extraction
この適用で期待される結果は特定の自然原簿テキストを表す単語またはフレーズのセットである。従って、ランク付けされる単位はテキストから抽出された 1 つ以上の字句単位のシーケンスであり、それらはテキストグラフに追加される頂点を表している。2 つの語彙単位の間に定義できる関連はその2つの頂点の間に追加できる潜在的に有用な接続 (エッジ) である。我々は単語が出現する距離によって制御される共起関係を使用している: 2 つの頂点は、それぞれの語彙単位が 2 から 10 の任意の単語数をとる最大単語数のウィンドウ内で共起する場合に接続される。共起リンクは構文要素間の関連を表現し、語義の曖昧さを除去するタスクに有用な意味リンクと同様であり (Mihalcea et al., 2004)、それらは与えられたテキストの結束指数 (cohesion indicator) を示す。
グラフに追加された頂点は特定の品詞の語彙単位のみを選択する構文フィルタによって制限することができる。例えばグラフに追加する語彙を名詞と動詞のみを考慮することができ、結果的に名詞と動詞の間に確立されている関係のみに基づいて潜在的なエッジを構築することができる。3.2 章で記述しているように、我々は全てのオープンクラス[訳注1]の単語や、名詞と動詞のみ、その他の組み合わせで実験し、名詞と形容詞のみの状況で最良の結果を観測している。
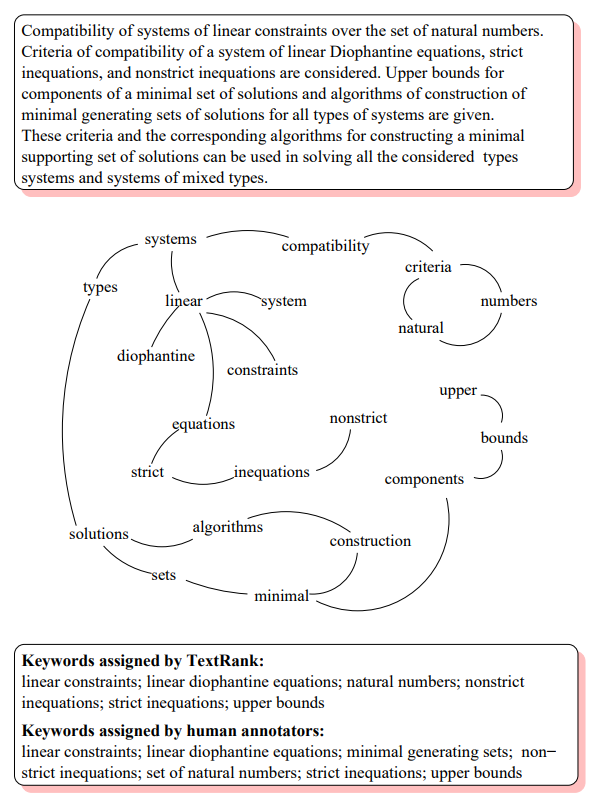
Figure 2: Inspec abstract からのキーフレーズ抽出に対して構築されたサンプルグラフ
TextRank キーワード抽出アルゴリズムは完全な教師なし学習であり以下の手順で進行する。最初に、テキストはトークン化され品詞のタグが付けられる (形態素解析)。これは構文フィルタの適用を可能にするために必要な前処理ステップである。一つ以上の語彙単位 (n-gram) からなるシーケンスの全組み合わせを追加することでグラフサイズが過剰に大きくなることを避けるため、我々はグラフに追加する候補として単一の単語のみを考慮する。複数語で構成されるキーワードは最終的に後処理段階で再構成される。
次に、構文フィルタを通った全ての語彙単位がグラフに追加され、\(N\) の単語ウィンドウ内で共起している語彙単位の間にエッジが追加される。グラフが構築された後 (無向で重み付けされていないグラフ)、各頂点に対するスコアは初期値 1 に設定され、2章で説明したランキングアルゴリズムでしきい値 0.0001 に収束するまで 30 回イテレーションを行った (通常は20秒間)。
グラフの各頂点に対する最終スコアが決定すると、頂点はスコアの降順ソートされ、ランキング上位 \(T\) 個の頂点が後処理のために保持される。\(T\) は任意の固定値で通常は 5 から 20 キーワードにせていできるが (例えば (Turney, 1999) は GenEx システムで抽出されるキーワード数を 5 に制限している)、我々はテキストサイズに基づいてキーワード数を決定するより柔軟なアプローチを使用している。我々が使用した比較的短い概要文で構成されるデータに対して、\(T\) はグラフの頂点数の 1/3 に設定されている。
後処理では TextRank アルゴリズムによって潜在的なキーワードとして抽出された全ての語彙単位がテキストにマークされ、隣接するキーワード並びが複数語で構成されるキーワードとして折りたたまれる。例えば、テキスト "Matlab code for plotting ambiguity functions" において TextRank によって Matlab と code の両方が潜在的なキーワードとして抽出された場合、それらが隣接していることから一つのキーワード Matlab code に折りたたまれる。
Figure 2 は我々のテストコレクションの要約用に作成されたサンプルグラフを示している。使用した概要文のサイズは 50 語から 350 語までで平均 120 語だが、我々は目的を表現するためにあえて小さな概要文を選択している。この例で、TextRank アルゴリズムに寄って高い重要度を持つ事が判明した語彙単位は (カッコ内は TextRank スコアを示す): numbers (1.46)、inequations (1.45)、linear (1.29)、diophantine (1.28)、upper (0.99), bounds (0.99)、strict (0.77) であった。このランク付けは単純な単語の出現頻度で算出されたものとは異なることに注意。同じテキストに対して出現頻度でのアプローチは: system (4)、types (3)、solution (3)、minimal (3)、linear (2)、inequations (2)、algorithms (2) が上位ランクの語彙単位となる。他のすべての語彙単位の頻度は 1 であるためランク付けはできないがリストにのみ表示される。
[訳注1] open class=名詞、動詞、形容詞など、closed class=代名詞、接続詞など新しい語彙が増えることはめったにない
3.2 Evaluation
この実験で使用したデータセットは Inspec データベースからの 500 の概要と、対応する手動で割り当てられたキーワードの集まりである。これは (Hulth, 2003) で報告されたキーワード抽出実験で使用されているのと同じデータセットである。Inspec の概要はコンピュータサイエンスと情報技術のジャーナル論文からのものである。我々は (Hulth, 2003) の評価手法に従い制御されていないキーワードセットを使用する。
彼女の実験では Hulth は学習に 1000、開発に 500、テスト[2]に 500 と合計で 2000 概要文を使用している。我々のアプローチは教師なし学習であるため学習/開発のデータは不要で、評価目的でのみテスト文書を使用している。
結果は精度、再現率、F値を使用して評価する。(我々のシステムでは) 索引作成者がキーワード抽出に限定されず、明示的にテキストに現れないキーワードをもたらすようなキーワード生成も可能であったため、このコレクションで達成できる再現率の最大は 100% に満たないことに注意。
比較に (Hulth, 2003) で報告された最先端のキーワード抽出システムの結果を使用する。手短に、彼女のシステムは文書からキーワードを最もよく抽出する方法を学習しようとする教師あり学習スキームからなる。これは各「候補」キーワードについて決定される 4 つの特徴セット: (1) 文書内出現頻度、(2) 収集頻度、(3) 最初に出現する相対位置、(4) 品詞タグのシーケンス、を調べることによる。これらの機能は、N-gram (概要文から抽出された unigram, bigram または trigram)、NP-chunk (名詞フレーズ)、パターン (学習用概要文に添付されたキーワードから検出した品詞パターンのセット) などを候補キーワードとする、全ての「候補」キーワードのトレーニングデータとテストデータの両方から抽出されるこの学習システムは bagging を伴う規則帰納 (rule induction) システムである。
| Assigned | Correct | ||||||
|---|---|---|---|---|---|---|---|
| Method | Total | Mean | Total | Mean | 精度 | 再現率 | F値 |
| TextRank | |||||||
| 無向, 共起ウィンドウ=2 | 6,784 | 13.7 | 2,116 | 4.2 | 31.2 | 43.1 | 36.2 |
| 無向, 共起ウィンドウ=3 | 6,715 | 13.4 | 1,897 | 3.8 | 28.2 | 38.6 | 32.6 |
| 無向, 共起ウィンドウ=5 | 6,558 | 13.1 | 1,851 | 3.7 | 28.2 | 37.7 | 32.2 |
| 無向, 共起ウィンドウ=10 | 6,570 | 13.1 | 1,846 | 3.7 | 28.1 | 37.6 | 32.2 |
| 有向, forward, 共起ウィンドウ=2 | 6,662 | 13.3 | 2,081 | 4.1 | 31.2 | 42.3 | 35.9 |
| 有向, backward, 共起ウィンドウ=2 | 6,636 | 13.3 | 2,082 | 4.1 | 31.2 | 42.3 | 35.9 |
| TextRank (Hulth, 2003) | |||||||
| Ngram with tag | 7,815 | 15.6 | 1,973 | 3.9 | 25.2 | 51.7 | 33.9 |
| NP-chunks with tag | 4,788 | 9.6 | 1,421 | 2.8 | 29.7 | 37.2 | 33.0 |
| Pattern with tag | 7,012 | 14.0 | 1,523 | 3.1 | 21.7 | 39.9 | 28.1 |
我々のシステムは 3.1 節で説明した TextRank のアプローチと 2, 3, 5 または 10 単語に設定された共起ウィンドウサイズで構成されている。Table 1 に TextRank で得られた結果を示す。最良の結果は (Hulth, 2003) で報告されたものである。この表では、それぞれの方法について、割り当てられたキーワードの総数、概要文あたりの平均キーワード数、プロの索引作成者によって割り当てられたキーワードセットに対して評価された正しいキーワードの総数、正しいキーワードの平均値が一覧表示されている。
論議. TextRank は全てのシステムで最高の精度とF値を達成するが、再現率は教師ありの方法ほど高くはない。これは、おそらく教師ありシステム[3]では作成されていない、選択されたキーワード数に対する我々のアプローチによって課せられた制限のためである。より大きなウィンドウは助けにならないと思われる -- 逆にウィンドウが大きくなるほど精度は低下する。これは、離れた単語の関係がテキストグラフの接続を定義するのに十分でないという事実によって説明できるだろう。
実験はすべてのオープンクラスの単語、名詞と形容詞、名詞のみ、を含む様々な構文フィルタを使用して実行された。そして名詞と形容詞のみを抽出するフィルタで最高のパフォーマンスが達成された。また、テキストに品詞情報が追加されず、定義済みのストップワードのみを除外したすべての単語がグラフに追加される設定も試みた。この設定の結果は、言語情報がキーワード抽出処理の助けになるという過去の研究 (Hulth, 2003) と一致するように、品詞を考慮するシステムよりも大幅に低かった。
また、テキストの自然な流れに従って方向が設定された有向グラフを用いて実験を行った。例えばある候補キーワードは、共起関係によって課せられた束縛を維持しながら、テキスト内で後ろに続く候補キーワードを「レコメンド」する (つまりその方向へ有向の弧を持つ)。また我々は語彙単位がテキストの前のトークンを示す逆方向も試みた。Table 1 は共起ウィンドウ 2 の有向グラフで得られた結果を含んでいる。
有向グラフで得られた結果は、弧に対して選択した方向にかかわらず無向グラフで得られた結果よりも悪かった。対象とするテキストに自然な流れがあるにもかかわらず、共起する単語間に確立できる自然な「方向」はないことを示唆している。
全体として我々の TextRank システムは以前に提案されたどのシステムより高い評価をもたらしている。他の学習ありシステムこと異なり TextRank は教師なし学習である。テキスト自体から引き出された情報にのみ依存していることから、他の文書コレクションやドメイン、言語に容易に移植することができる。
[2] Many thanks to Anette Hulth for allowing us to run our algorithm on the data set used in her keyword extraction experiments, and for making available the training/test/development data split.
[3] The fact that the supervised system does not have the capability to set a cutoff threshold on the number of keywords, but it only makes a binary decision on each candidate word, has the downside of not allowing for a precision-recall curve, which prohibits a comparison of such curves for the two methods.
4 Sentence Extraction
これ以外で我々が調査の対象としている TextRank の適用は自動要約のための文抽出である。ある意味、文抽出はキーワード抽出と同様にみなすことができる。これは、両方の適用が特定のテキストから「代表的な」シーケンスを識別することを目的としているためだ。キーワード抽出では候補のテキスト単位が単語またはフレーズで構成され、文抽出では文全体を処理の対象とする。テキスト全体から抽出された情報に基づいて再帰的に計算されるテキスト単位のランク付けが可能であることから、TextRank はこのタイプの適用に適していることが判明した。
4.1 TextRank for Sentence Extraction

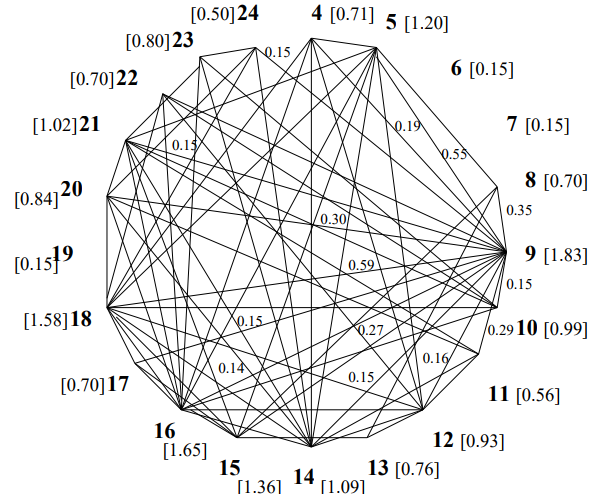

Figure 3: 新聞記事から抽出した文で構築したグラフ。手動で割り当てた要約と TextRank 抽出の要約も表示している。
TextRank を適用するには最初にテキストに関連付けられたグラフを作成する必要がある。ここでグラフの頂点はランク付けされる単位を表している。文抽出の処理での目的は文全体をランク付けすることであり、従って文章中の各文に対する頂点がグラフに追加される。
ここで考慮するテキスト単位は 1 語または数語よりはるかに大きく、そのような大きな文脈では「共起」は意味のある関係ではないことから、キーワード抽出で使用した共起関係はここでは適用できない。その代わりに、2 つの文に「類似性」関係が存在する場合に 2つの文の接続を決定する関係を定義する。ここで「類似性」は内容の重なりの関数として測定されるものである。このような 2 つの文の関係は「レコメンド」のプロセスと見ることができる: テキスト内の特定の概念に対する文章は、同じ概念を扱うテキスト内の他の文章を参照するための「レコメンド」を提供し、従ってそのような共通の内容を共有する 2 文の間にリンクを作成することができる。
2 文の重なりは単純に 2 文の字句表現で共通のトークン数として決定することができる。あるい、例えば全てのオープンクラスの単語、名詞と動詞のみ、といったような文法フィルターを通して実行しても良い。また長文を避けるために正規化係数を用いて 2 文の内容の重なりを各文章の長さで割ることも可能だ。数式で表すと、文を文中に現れる \(N_i\) 語の集合: \(S_i=w_1^i, w_2^i, \ldots, w_{N_i}^i\) として表すとき、与えられた 2 文 \(S_i\) と \(S_j\) の類似度は以下のように定義される: \[ {\it Similarity}(S_i, S_j) = \frac{|\{w_k|w_k \in S_i \ \& \ w_k \in S_j\}|}{\log(|S_i|)+\log(|S_j|)} \]
文字列カーネル、コサイン類似度、最長共通部分列など、他の文類似指標も可能であるが、我々は現在のところ集計パフォーマンスへの影響を評価している。
得られたグラフはそれぞれのエッジに関連付けられた重みによって高度に接続され、テキスト内の様々な文の対の間に確立された接続の強さを示している。従ってテキストは重み付きグラフとして表されるため、2.2節で紹介した重み付きグラフに基づくランキングの式を使用する。
グラフ上でランキングアルゴリズムが実行された後、文はスコアの逆順にソートされ、要約に含める上位の文を選択する。
Figure 3 はサンプルのテキストとそのテキストに対して構築された重み付き関連グラフを示している。この図には頂点 9[4] に接続されたエッジに添付されているサンプルの重みと、各文ごとに計算された最終的な TextRank スコアを記載している。最高ランクの文章が要約に含めるために選択される。このサンプル記事では id-s 9, 15, 16, 18 の文が抽出されて約 100 語の要約が得られている。自動評価指標によれば他の 15 のシステムによって生成されたようやくのうち 2 番目にランク付けされている (自動評価指標 (automatic evaluation measures) については 4.2 節参照)。
[4] Weights are listed to the right or above the edge they correspond to. Similar weights are computed for each edge in the graph, but are not displayed due to space restrictions.
4.2 Evaluation
我々は評価に対して Ngram の統計に基づく方法である ROUGE 評価ツールキットを使用している。これは人の評価と非常に相関していることが判明している (Lin and Hovy, 2003)。手動で作成された 2 つのリファレンス概要が提要され、評価プロセス[5]で使用される。
15 の異なるシステムがこのタスクに参加している。DUC 評価者によって提案されたベースライン (各記事の最初の文章から 100 単語を取り出して作成した要約) とともに、我々は TextRank のパフォーマンスと上位 5 の能力をもつシステムとを比較する。Table 2 は DUC 2002 単一文書要約タスク (DUC, 2002) において、TextRank (太字で示す)、ベースライン、上位 5 つの実行システムの結果を含む 567 の新しい記事のデータセットから得られた結果を示す。
| ROUGE score - Ngram(1,1) | |||
|---|---|---|---|
| System | basic (a) |
stemmed (b) |
stemmed no-stopwords (c) |
| S27 | 0.4814 | 0.5011 | 0.4405 |
| S31 | 0.4715 | 0.4914 | 0.4160 |
| TextRank | 0.4708 | 0.4904 | 0.4229 |
| S28 | 0.4703 | 0.4890 | 0.4346 |
| S21 | 0.4683 | 0.4869 | 0.4222 |
| Baseline | 0.4599 | 0.4779 | 0.4162 |
| S29 | 0.4502 | 0.4681 | 0.4019 |
論議. TextRank はテキストそのものから引き出された情報に基づいてテキスト中のもっとも重要な文を特定することに成功している。別の記事で構築した要約のコレクションを使って訓練することで、何が良い要約となるかの学習を試みる他の教師ありシステムと違い、TextRank は完全な教師なしシステムであり与えられたテキストのみに依存して要約抽出を導き出す。これは、人間が特定の文書の要約を作成するときに行っていることと近い要約モデルを表している。
TextRank はテキスト内の文の「接続性」以上のものであることに注意。例えば Figure 3 に示す例の文 15 は、グラフ内の他の頂点との接続数から見れば「重要」ではないが、TextRank (および人間 -- 同じ図内で示されるリファレンス要約を参照) では「重要」と識別される。
TextRank のもう一つの重要な側面は、テキスト内のすべての文のランク付けを行うことだ。これは、非常に短い要約 (1文からなる見出し) を抽出することにも、100 語を超えるより長い説明的要約を抽出することにも容易に適合できることを意味する。我々はまた、短い/長い要約を作成する方法として、キーフレーズと文抽出の技法を組み合わせた方法を調査している。
最後に、抽出型要約の構築に関して過去に提案された方法より TextRank が優れている点は、訓練コーパスを必要とせず、別の言語やドメインに容易に適用できるという事実である。
[5] 5ROUGE is available at http://www.isi.edu/˜cyl/ROUGE/. The evaluation is done using the Ngram(1,1) setting of ROUGE, which was found to have the highest correlation with human judgments, at a confidence level of 95%. Only the first 100 words in each summary are considered.
5 Why TextRank Works
直感的に、TextRank はテキスト単位 (頂点) の局所コンテキストに依存するのではなく、テキスト全体 (グラフ) から再帰的に引き出された情報を考慮に入れているためうまく機能する。
TextRank はテキスト上に構築されたグラフを通じてテキスト内の様々なエンティティ間の接続を識別し、レコメンドの概念を実装する。テキスト単位は他の関連するテキスト単位をレコメンドし、レコメンドの強さはレコメンドを行う単位の重要性に基づいて再帰的に計算される。例えば、キーフレーズ抽出への適用では、共起する単語は互いに重要なものとしてレコメンドしており、テキスト内での単語間の接続の識別を可能にする共通のコンテキストとなる。テキスト内の重要な文章を識別する過程で、ある文章はテキスト全体の理解に有用な同類の概念を示す別の文章をレコメンドする。テキスト内で他の文章に強くレコメンドされる文章は、与えられたテキストにおいてより有用である可能性が高く、従って高いスコアが与えられる。
またユーザが任意の Web ページからリンクをたどって Web を閲覧する PageRank の「ランダムサーファーモデル」でも類推することもできる。テキストモデリングの文脈では TextRank はテキストの結束 (cohesion) (Halliday and Hasan, 1976) という概念に関連する「テキストファーフィン」と呼ばれるもの実装している: テキスト内の特定の概念から、我々は、現在の概念と関係を持つ概念である、接続された概念 (つまり語彙的または意味論的な関係) へのリンクを「追跡」しているようだ。これは「編み込み」現象 (Hobbs, 1974) にも関係している: 言葉に関連している出来事は談話中の様々な部分で共有され、そのような関係は「一緒に談話を編み込む」ために役に立つ。
TextRank はその反復的なメカニズムにより単なるグラフの接続性を超え、リンク先の他のテキスト単位の「重要性」にも基づいてテキスト単位をスコアリングすることができる。特定の適用に対して TextRank によって抽出されたテキスト単位は、テキスト内で関連しているテキスト単位によって最もレコメンドされたものであり、例えば他の関連する単位によって強くレコメンドされているように、最も影響力のあるレコメンドが優先される。根底にある仮説は、密接なテキスト断片において関連をもつテキスト単位が、談話理解の過程において人間が構築したモデルを近似する接続の「Web」を形成する傾向にあることである。
6 Conclusions
この論文で我々はテキスト処理のための graph-based ランキングモデルである TextRank を導入し、自然言語アプリケーションでどのように利用できるかを示した。特にキーワード抽出と文抽出に対して 2 つの革新的な教師なし学習のアプローチを提案、評価し、これらの適用で TextRank が達成した精度は過去に提案された最先端のアルゴリズムの精度を競合することを示した。TextRank の重要な側面は、深い言語知識やドメイン、言語に特化した注釈付きコーパスを必要とせず、他のドメイン、ジャンル、言語への移植性が高いことだ。
References
- S. Brin and L. Page. 1998. The anatomy of a large-scale hypertextual Web search engine. Computer Networks and ISDN Systems, 30(1–7).
- DUC. 2002. Document understanding conference 2002. http://www-nlpir.nist.gov/projects/duc/.
- E. Frank, G. W. Paynter, I. H. Witten, C. Gutwin, and C. G. Nevill-Manning. 1999. Domain-specific keyphrase extraction. In Proceedings of the 16th International Joint Conference on Artificial Intelligence.
- M. Halliday and R. Hasan. 1976. Cohesion in English. Longman.
- P.J. Herings, G. van der Laan, and D. Talman. 2001. Measuring the power of nodes in digraphs. Technical report, Tinbergen Institute.
- J. Hobbs. 1974. A model for natural language semantics. Part I: The model. Technical report, Yale University.
- A. Hulth. 2003. Improved automatic keyword extraction given more linguistic knowledge. In Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, Japan, August.
- J.M. Kleinberg. 1999. Authoritative sources in a hyperlinked environment. Journal of the ACM, 46(5):604–632.
- C.Y. Lin and E.H. Hovy. 2003. Automatic evaluation of summaries using n-gram co-occurrence statistics. In Proceedings of Human Language Technology Conference (HLT-NAACL 2003), Edmonton, Canada, May.
- R. Mihalcea, P. Tarau, and E. Figa. 2004. PageRank on semantic networks, with application to word sense disambiguation. In Proceedings of the 20st International Conference on Computational Linguistics (COLING 2004), Geneva, Switzerland.
- R. Mihalcea. 2004. Graph-based ranking algorithms for sentence extraction, applied to text summarization. In Proceedings of the 42nd Annual Meeting of the Association for Computational Lingusitics (ACL 2004) (companion volume), Barcelona, Spain.
- P. Turney. 1999. Learning to extract keyphrases from text. Technical report, Nationa
翻訳抄
文書要約、自動要約アルゴリズム TextRank に関する 2004 年の論文。
