ランダムサンプリング
 概要
概要
ランダムサンプリング (RS; random sampling) は統計学やデータ分析において大規模な集合 (母集団) から無作為にデータを抽出する手法である。母集団の各要素が等しい確率で選ばれるサンプリングでは、得られたサンプルは母集団全体の特性を統計的に正しく反映していることが期待される。社会科学分野での実験的統計のために利用されることも多いが、このページではコンピュータ分野におけるランダムサンプリングのアルゴリズムに焦点を当てている。
Table of Contents
- 概要
- サンプリングの特徴
- 確率的サンプリング
- 選択サンプリング
- 累積和法
- Alias 法
- min-wise 独立なハッシュを使う方法
- Naive サンプリング
- Reservoir サンプリング法
- 重み付き非復元サンプリングの不公平性
- ウィンドウサンプリング
- 参考文献
サンプリングの特徴
一様/重み付きサンプリング
集合の各要素が「選ばれやすさ」に関連するパラメータを持っている場合は重み付きランダムサンプリング (WRS; weighted random sampling) あるいは非等価ランダムサンプリング (unequal random sampling) と呼ばれる。WRS に対して重みを持たないランダムサンプリングを一様ランダムサンプリング (uniformed random sampling) と呼ぶ。
分散システムにおいてマシンの相対的な性能でタスク分配の優先度を重み付けしたり、Web 広告での関連度や出稿料金でランダムに広告を選択する場合などでは WRS が利用される。
復元/非復元サンプリング
母集団から続けてサンプリングを行うとき、次の要素を選択する前に抽出した要素を元の母集団に戻す方法を復元サンプリング (sampling with replacement) と呼ぶ。復元サンプリングではそれぞれの抽選は事象として独立しており、\(n\) 個の母集団に対して \(m\) のサンプリングを試行したときに各要素が何回選ばれているかを確率変数とする離散確率分布を多項分布で表すことができる。同一の要素が複数回選択される可能性がある (したがって \(m\) 回の試行で選択される要素はかならず \(m\) 個以下となる)。一般的に復元サンプリングは母集団が非常に大きく重複選択の起きる可能性が無視できる場合や、後述するように選択機会の公平性が優先される場合に適用される。
次の要素を選択する前に抽出された要素を母集団には戻さずまだ選択されていない要素のみで抽選を続ける方法を非復元サンプリング (sampling without replacement) と呼ぶ (これらは壺問題![]() における復元と同じ意味)。これは数学の組み合わせ問題から一つの組み合わせをランダムに選択するのと本質的に同じである。非復元サンプリングではサンプリングの対象となる母集団は \(m\) 回のサンプリングまでに毎回変化することから、それぞれのサンプリングは事象として独立しておらず、サンプリングごとに選択確率が変化する。詳細は非復元サンプリングの公平性で説明している。
における復元と同じ意味)。これは数学の組み合わせ問題から一つの組み合わせをランダムに選択するのと本質的に同じである。非復元サンプリングではサンプリングの対象となる母集団は \(m\) 回のサンプリングまでに毎回変化することから、それぞれのサンプリングは事象として独立しておらず、サンプリングごとに選択確率が変化する。詳細は非復元サンプリングの公平性で説明している。
\(n\) 個の母集団に \(k\) 個の「当たり」が含まれているとき、\(m\) 回のサンプリングで引き当てる当たりの個数を確率変数とする離散確率分布を、復元サンプリングでは二項分布、非復元サンプリングでは超幾何分布で表すことができる。これは一定数の故障ノードが含まれる集合から WRS で合意のための委員会クラスタを選出するときに \(2f+1\) や \(3f+1\) の前提が破られる確率分布などに使用することができる。
効率化
母集団が巨大で全ての要素を検討するには非効率であったり、母集団の全ての要素を検討する必要がない場合は、サンプリングの前に部分母集団を作成する多段サンプリング (multi-stage sampling) や層化サンプリング![]() (stratified sampling) といった体系的サンプリング (systematic sampling) の手法が使われる。それらに対し、母集団に対して単純にサンプリングを行う手法を単純サンプリング (simple sampling) と呼ぶ。
(stratified sampling) といった体系的サンプリング (systematic sampling) の手法が使われる。それらに対し、母集団に対して単純にサンプリングを行う手法を単純サンプリング (simple sampling) と呼ぶ。
ランダムサンプリングは乱数を使用した非決定論的な標本抽出手法である。もし結果に非決定性が不要であれば (重み付き) ラウンドロビンも検討することができる。
確率的サンプリング
確率的サンプリング (probabilistic sampling) またはベルヌーイサンプリング (Bernoulli sampling) は母集団に含まれるすべての要素が等しい確率 \(p\) で選択されるサンプリング手法である。つまり母集団の各要素に対して独立したベルヌーイ試行を行い標本に含めるかを決定する。
各要素が独立してサンプリングされるため選択される標本数は固定されておらず、\(N\) 個の集合から平均標本数 \(n\) を得る確率 \(p=n/N\) の設定では標準偏差 \(\sigma=\sqrt{n(1-n/N)}\) の二項分布に従う [5]。
データストリーム化された母集団からベルヌーイサンプリングを行う場合はギャップサンプリングを導入すると計算効率が良い。ギャップサンプリングは、データストリーム上のそれぞれの要素で選択確率を評価する代わりに、選択間隔の分布に従う乱数を使用してサンプルを選択する手法である。
ベルヌーイサンプリングをギャップサンプリングで表現する場合、各要素の間に発生するギャップ (選択されない要素の数) は幾何分布に従うため、幾何分布に従う乱数を構築すれば良い (幾何分布は確率 \(p\) で表が出るコインフリップで \(k\) 回目の試行で初めて表が出る確率分布)。この累積分布関数 \[ 1 - (1 - p)^k \le P \lt 1 - (1 - p)^{k+1} \] の逆関数 \(k = \left\lfloor \frac{\log(1-P)}{\log(1-p)} \right\rfloor\) から逆関数法を適用することができる。\(1-P\) は \(0 \lt u \lt 1\) の一様乱数 \(u\) と置き換えることができるため \[ k = \left\lfloor \frac{\log u}{\log (1-p)} \right\rfloor \] でサンプリングする要素のギャップ \(k\) を得ることができる。
use rand::Rng;
fn bernoulli_gap_sampling<T>(data: &[T], p: f64) -> Vec<&T> {
let mut rng = rand::thread_rng();
let mut sampled = Vec::new();
let mut i = gap(rng.gen(), p);
while i < data.len() {
sampled.push(&data[i]);
let k = gap(rng.gen(), p);
i += k + 1; // move to the next element after the gap
}
sampled
}
fn gap(u: f64, p: f64) -> usize {
(u.ln() / (1.0 - p).ln()).floor() as usize
}ポアソンサンプリング (Poisson sampling) は選択確率 \(p\) が一定ではなく、要素ごとに異なる選択確率 \(p_i\) が設定されている重み付きサンプリングである。ポアソンサンプリングではギャップサンプリングを適用することができないため、要素ごとにベルヌーイ試行を行う必要がある。
選択サンプリング
選択サンプリング (selection sampling) または Algorithm S は \(N\) 個の集合から \(n\) 個の要素を選択する非復元サンプリング手法である。\(p=n/N\) のベルヌーイサンプリングでは結果として得られる標本数が \(n\) 個となることを保証できない問題を、確率を補正することで解決している。
すでに集合内の \(t\) 個の要素が評価され \(m\) 個が選択されている状態で、残りの \(N-t\) 個の中から \(n-m\) を選択する組み合わせは \(\binom{N-t}{n-m}\) 通りあり、その中で \(t+1\) 番目の要素が選択されている組み合わせは \(\binom{N-t-1}{n-m-1}\) である。したがって次の \(t+1\) 個目の要素が選択される確率は式 (\(\ref{selsmp}\)) のように表すことができる [5]。\[ \begin{equation} p_{t+1} \frac{\binom{N-t-1}{n-m-1}}{\binom{N-t}{n-m}} = \frac{n-m}{N-t} \label{selsmp} \end{equation} \] それぞれの試行が独立しておらず、サンプリングの進行によって確率が変動することは公平ではないという直感があるかもしれないが、その問題はモンティホール問題で扱っている直感との乖離と同じである。
累積和法
累積和法 (cumulative sum) は Algorithm D [1] とも呼ばれるシンプルな WRS アルゴリズムである。母集団に含まれている要素を直列に並べ、一様乱数が重み累積のどの要素の区間に含まれるかで判定する (これは累積離散確率分布から逆変換サンプリングで乱数を生成する方法と同じである)。個人的に重みの円グラフを高速回転させ矢を放つ Fig 1 で示すような回転ダーツを用いて説明することが多い。

以下は累積和法による重み付き非復元サンプリングで選択された要素のインデックスを参照するサンプルコードである。
use rand;
use crate::wrs::Weighted;
pub fn sampling<T: Weighted>(population: &[&T]) -> usize {
let total_weight = population.iter().map(|e| e.weight()).sum::<f64>();
let threshold = total_weight * rand::random::<f64>();
let mut cumsum = 0.0;
for (i, e) in population.iter().enumerate() {
if cumsum <= threshold && threshold < cumsum + e.weight() {
return i;
}
cumsum += e.weight();
}
panic!()
}単純な累積和法は線形探索となることから \(O(n)\) とあまり効率的ではないが、母集団に変化がないのであれば平衡二分探索木 (AVL 木) や B-Tree のような \(O(\log n)\) の構造を持つ探索木を実装してインデックスとして使用することで、繰り返しのサンプリングを高速化することができる。
Alias 法
Alias 法 (Walker's alias method) は離散確率分布からランダムサンプリングを行うための効率的なアルゴリズム。正方ヒストグラム (square histogram, エイリアス) [2] を作成し、横方向と縦方向のたかだか 2 回の一様ランダムサンプリングで WRS を行うことができる。正方ヒストグラムの作成に \(O(n)\) を要するが、サンプリングは \(O(1)\) と非常に効率的であるため、要素やそれらの重み付けに変化がない母集団に対してサンプリングを繰り返して行うケースに向いている。
ロビンフッド法
正方ヒストグラムはロビンフッド法 (Robin Hood method) で作成することができる。これは平均より高いものから低いものへ、低いほうが平均と一致する量の富を移動する操作を、貧富の差がなくなるまで (全てが平均と等しい富を持つまで) 繰り返す方法である (Fig 2 参照)。
各要素 \(i \in \{1,2,\ldots,n\}\) に対応する重みを \(w_i\) としたとき、最終的に全ての \(w_i\) はそれらの平均 (\(\ref{sqhg_average}\)) と等しくなる。\[ \begin{equation} a = \frac{\sum_i w_i}{n} \label{sqhg_average} \end{equation} \] 富の移動 1 回の操作で必ず富の低いほうが平均と等しくなり、また最後の 1 回は必ず両者が平均と等しくなる。したがってロビンフッド法は最大でも \(n-1\) の操作で完了する。富の移動によって富者が貧者となる可能性がある点に注意 (例えば Fig 2 の 2)。

正方ヒストグラムの生成
Alias 法ではロビンフッド法に基づいて以下の手順で \(K\) と \(U\) を生成する。
- \(K_i=i\) で初期化する。
- \(w_j \lt a\) となるような \(j\) が存在するかぎり以下の 3 ステップを繰り返す。
- \(w_i \gt a\) となるような \(i\) を適当に選択する (\(j\) が存在するなら \(i\) も必ず存在する)。以下の 2 ステップは \(i\) から \(j\) へ \(a - w_j\) の量を移動する意味の操作である。
- \(K_j=i\) を設定する。
- \(w_i \to w_i - (a - w_j) = w_i + w_j - a\) へ再設定する。
- すべての区分 \(d_i\) に対してしきい値 \(U_i = \frac{w_i}{a}\) を計算する。
この操作によって 1 つまたは 2 つの領域を持つ等しい高さ \(a\) の区分 \(d_i\) で構成されるヒストグラムができあがる (Fig 3)。区分 \(d_i\) の下の領域は要素 \(i\) の確率域、上の領域は要素 \(K_i\) の確率域を表している。そして \(U_i\) は区分 \(d_i\) における \(i\) と \(K_i\) の確率域の境界を表している。

\(a=1\) となるように (つまり \(\sum_i w_i = n\) となるように) 各重み \(w_i\) を設計すると \(w_i=U_i\) となるため操作 3. は不要になる。また誤差がなく \(U_i = 1\) と正確に一致させることができる場合はその区分の \(K_i\) が参照されることもないため操作 1. も省略可能である。
操作 2.1. の判断があるため正方ヒストグラムの作成は浮動小数点の誤差に非常に敏感である。\(a\) の算出に除算が用いられることから、多くのケースでは浮動小数点の加算と比較が多用されることに注意しなければならない。特に、極端に大きな重みを持つ要素が存在するケースでは操作 2.3. の繰り返しで桁落ち、情報落ちの誤差の累積が大きくなる。これは、\(w_j \lt a\) となるような \(j\) が存在しなくなったにも拘らず、\(w_i \gt a\) となるような \(i\) が存在する (ように見える) といった現象で顕在化する。
ラフな対処としては、\(w_j \lt a\) となるような \(j\) が存在しなくなった時点で \(w_i \gt a\) に見えている全ての \(i\) を \(w_i = a\) とする方法が考えられる。あるいはより正確に、計算機イプシロン \(\epsilon \simeq 10^{-15}\) (倍精度浮動小数点の場合)、ループカウンタ \(m\in\{1,\ldots\}\) として、操作 2.1. の判断を \(w_i/a-1 \gt m\epsilon\)、\(a/w_j-1 \gt m\epsilon\) のように累積分の機械イプシロンの幅を想定して許容範囲を設けることで対処することもできる。
サンプリングの実行
サンプリング操作は、ランダムに選んだ区分 \(d_i\) に対して一様乱数が上部と下部のどちらの確率域を指しているかでサンプルを決定する。以下の手順では 1 回の一様乱数生成でその 2 つを行っている。
- \(0 \le x \lt 1\) となるような一様乱数 \(x\) を生成する。
- \(i = \lfloor n x \rfloor + 1\), \(y = n x + 1 - i\) とする (つまり \(i \in \{1,2,\ldots,n\}、0 \le y \lt 1\))。
- 区分 \(d_i\) において \(y \lt U_i\) であれば下の確率域の \(i\)、そうでなければ上の確率域の \(K_i\) をサンプルとする。
Alias 法サンプリングの実装
以下は Alias 法に基づく WRS の実装例である。ここでは \(w_i \gt a\) となるものを overfull, \(w_i \lt a\) となるものを underfull となるように分類している。
min-wise 独立なハッシュを使う方法
入力に対して出力値のランダム性さが保証されているハッシュ関数を \(\pi\) とする。集合 \(X\) から min-wise 独立置換族 [4] を使う。
Naive サンプリング
ある母集団から複数の標本を選択する最も単純な方法は、1 つの標本を選択するランダムサンプリング (抽選) を既定の個数が選択されるまで繰り返すことである。
この方法での復元サンプリングは各要素ごとに何回選択されたかの回数が生成される。これは選択回数を確率変数とした離散確率分布 (多項分布) と等価である。
一方で、少数の母集団に対する復元サンプリングは重複選択の発生する頻度が高く、それによって規定数からの差異が無視できないなくなることがある。シミュレーションなどで WRS を扱う場合は重複選択なく正確に \(m\) 個が選択されることが重要であるケースが多いことから非復元サンプリングが利用される。非復元サンプリングは \(m\) 回の抽選に対して必ず \(m\) 個の標本を生成するが、それぞれの抽選は独立しておらず、要素数の減少により抽選が進むにつれて当選の期待値が高くなる。
Reservoir サンプリング法
Reservoir (リザーバー) サンプリングは母集団のサイズが未知のデータストリームから非復元サンプリングで特定の個数のサンプルを抽出するときに利用できるアルゴリズムである。
Algorithm R
Algorithm R と呼ばれるサンプリング手法は未知の大きさのデータセットから等しい確率で \(n\) 個の要素をサンプリングする Reservoir サンプリングアルゴリズムである [5]。Reservoir サンプリングの代表例として紹介されることも多いが、同じ Reservoir サンプリングでギャップサンプリングを行う Algorithm Z や Algorithm L の方が効率は良い。
データセットの先頭の要素を \(i=1\) としたとき、アルゴリズムは次のように実行される。
データセットの先頭に現われる \(i \le n\) の要素を無条件で候補 (リザーバー) に入れる。
- \(i \gt n\) の評価では、要素 \(i\) に対して \(u = [0,i)\) の乱数を生成し、\(u \lt n\) であれば候補内の位置 \(u\) の要素と置き換える。データセットの最後に到達するまでこの操作を繰り返す。
🎲サンプルコード
use rand::Rng;
struct AlgorithmR<T> {
n: usize,
reservoir: Vec<T>,
i: u64, // 最初の要素を i=0 とする
}
impl<T: Clone> AlgorithmR<T> {
fn new(n: usize) -> Self {
AlgorithmR { n, reservoir: Vec::with_capacity(n), i: 0 }
}
fn add(&mut self, element: T) {
if self.i < self.n as u64 {
// 最初の n 個の要素はそのままリザーバに入れる
self.reservoir.push(element.clone());
} else {
// n+1 個目以降の要素はランダムにリザーバ内の要素と入れ替える
let mut rng = rand::thread_rng();
let j: u64 = rng.gen_range(0..=self.i);
if j < self.n as u64 {
self.reservoir[j as usize] = element.clone();
}
}
self.i += 1;
}
fn get_samples(&self) -> &Vec<T> {
&self.reservoir
}
}証明
帰納法を使う。アルゴリズムの目標は \(N\) 個の要素を含む集合からサンプリングした \(n\) 個の要素すべてが等しい確率 \(p=\frac{n}{N}\) で選択されていることである。まずデータセットの先頭に現われる \(n\) 個の要素は無条件で候補に入る。これは要素 \(i=n\) を評価した時点で候補内のすべての要素が \[ p_{n} = \frac{n}{i} = \frac{n}{n} = 1 \] の確率で選択されたという意味である。
要素 \(i\) を評価した時点で候補に含まれているすべての要素の選択確率が \(\frac{n}{i}\) だったとする。その次の要素 \(i+1\) は \(\frac{n}{i+1}\) の確率で候補となって既に候補に入っている要素のいずれかと置き換えられる (\(i+1\) が候補となると既存の要素は \(\frac{1}{n}\) の確率で候補から外れる)。したがって、\(i\) の評価までに候補に入り、\(i+1\) の評価でも候補に残り続ける (置き換えられない) 確率は \[ p_{i+1} = \frac{n}{i} \left( 1 - \frac{n}{i+1} \frac{1}{n} \right) = \frac{n}{i + 1} \] となる。つまり \(i+1\) 評価後のすべての候補は (要素 \(i+1\) も置き換えを免れた要素も) すべて確率 \(\frac{n}{i+1}\) で候補に残っていることになる。結果的に、最後の要素 \(i=N\) を評価し終えたとき、候補に含まれている要素はそれぞれ \[ p_{N} = \frac{n}{N} \] の確率で選択されている。∎
バイアス付き Reservoir サンプリング
Algorithm R の Reservoir サンプリングはデータストリームから偏りのないサンプルを抽出するが、サンプルは時間の経過により関連や関心が薄くなることがある。特に長期間にわたる計測でストリームの長さが大きくなるとサンプル間の期間は広がり、新しい要素がサンプルへ挿入される機会が著しく減少する。このような理由でサンプリングされる確率が逆指数的に減少するアルゴリズムが提案されている [6]。
新しく到着した要素は確率 \(p_{\rm in}\) でリザーバーに挿入される。挿入時、リザーバーサイズに対して一様にランダムな数値を生成し、既に存在している要素のインデックスであればそれと置き換え、そうでなければ追加する。このアルゴリズムはデータストリームから \(t\) 番目の要素が到着したとき、\(r\) 番目の要素のバイアス関数 \(f(r;t)\) は次のように表すことができる。\[ f(r;t) = e^{-\lambda(t-r)} \] \(\lambda\) は \([0,1]\) 範囲で、データストリームの要素の総数の逆数に基づいて通常は非常に小さい値を取る。サンプル内に \(r\) 番目の要素が存在する確率は、バイアス関数に定数を掛けた \(p(r;t)=c f(r;t)\) で表される。
🎲サンプルコード [7] と実行例
到着した最新の要素が必ず一度リザーバーに入る \(p_{\rm in}=1\) のケース。
use rand::Rng;
struct BiasedReservoir<T> {
n: usize,
reservoir: Vec<Option<T>>,
occupied: usize,
}
impl<T: Clone> BiasedReservoir<T> {
fn new(lambda: f64) -> Self {
let n = (1.0 / lambda).floor() as usize;
let reservoir = vec![None; n];
BiasedReservoir { n, reservoir, occupied: 0 }
}
fn add(&mut self, element: T) {
let mut rng = rand::thread_rng();
let u = rng.gen_range(0..self.n);
if u < self.occupied {
let j = rng.gen_range(0..self.occupied);
self.reservoir[j] = Some(element);
} else {
let j = self.occupied;
self.reservoir[j] = Some(element);
self.occupied += 1;
}
}
fn get_samples(&self) -> &Vec<Option<T>> {
&self.reservoir
}
}
Algorithm A
Algorithm A と呼ばれている非復元 WRS アルゴリズム [1] は母集団から式 (\(\ref{reservoir_key}\)) で示すキーが最も大きい \(m\) 個の要素を選択する。\[ \begin{equation} k_i = u_i^{\frac{1}{w_i}} \label{reservoir_key} \end{equation} \] ここで \(u_i\) は要素ごとに割り振られた 0 以上 1 未満の一様乱数を表している。具体的な実装は以下のようになる。
val samples = population
.sortBy { e => - math.pow(math.random, 1 / e.weight()) }
.take(m)A アルゴリズムは非常に単純で見通しが良く簡易実装に向いているが、母集団のサイズと同じ回数 \(O(n)\) の乱数生成とべき乗演算を行わなければならないため、結果的に累積和法より遅くなることも多い。
しかし \(k_i\) の計算は要素ごとに独立しており、重みの総和も必要ないことから、ランダムサンプリングの分散実行や、母集団全体をメモリ上に置くことが現実的ではない巨大なデータ集合に対して 1 パスで WRS を行うことができるという利点を持つ (このときに使用する一時保存領域を Reservoir (貯水池の意味) と呼ぶ)。近年では Apache Spark の RDD のような抽象化ストリームに基づいたデータ処理プラットフォームと親和性の高い WRS アルゴリズムとして注目を集めている。
Reservoir サンプリングでは「Reservoir 内の最小の \(k_{\rm min}\) より大きな \(k\) を持つ要素を見つけたら、\(k_{\rm min}\) を持つ要素と置き換える」という操作が頻繁に行われるため、しばしば最小の要素が常に先頭に配置されるヒープ、優先キュー、ソートキューといったデータ構造を使用する。
Algorithm A-Res
Algorithm A-Res (A-Reservoir) はサイズ \(m\) の Reservoir 領域を使用し、母集団の中で \(k_i\) の大きい \(m\) 個のみを保持する Algorithm A の改良バージョンである。以下のアルゴリズムで処理を行う。
- 先頭の \(m\) 個の要素に対して \(k\) を計算し Reservoir に挿入する。
- \(m+1\) 個目以降の要素に対して \(k\) を計算し、Reservoir に含まれる要素で最も小さい \(k\) より大きければ、その最も小さい \(k\) を持つ要素と置き換える。
- 最終的に Reservoir に残った要素が非復元 WRS によって得られた標本である。
use rand;
use std::collections::BinaryHeap;
use crate::wrs::a::Sample;
use crate::wrs::Weighted;
pub fn sampling<'s, T: Weighted>(population: &[&'s T], m: usize) -> Vec<&'s T> {
assert!(m <= population.len());
let mut reservoir = BinaryHeap::new(); // in general, priority queue
for i in 0..m {
let k = rand::random::<f64>().powf(1.0 / population[i].weight());
reservoir.push(Sample { value: population[i], key: k });
}
for i in m..population.len() {
let k = rand::random::<f64>().powf(1.0 / population[i].weight());
if k > reservoir.peek().unwrap().key {
reservoir.pop(); // remove a sample with the smallest key
reservoir.push(Sample { value: population[i], key: k });
}
}
assert!(reservoir.len() == m);
reservoir.iter().map(|s| s.value).collect()
}A-Res は A と同様に \(k\) を計算するために比較的コストの高い乱数生成と指数演算が母集団のサイズ \(n\) と同じ回数必要である。
Algorithm A-ExpJ
Algorithm A-ExpJ (A-Exponential Jump) は A-Res の計算量を大幅に削減した改良バージョンである。A-Res において新しい要素が Reservoir に入るまでスキップされる要素の重みの合計を \(w_s\) とすると、\(w_s\) は指数分布に従う乱数とみなすことができる。したがって、要素ごとに乱数や \(k\) を計算する代わりに、指数分布に従う乱数 \(w_s\) を生成し、該当する要素までジャンプすることで代用可能という理論に基づいている。
use rand;
use std::collections::BinaryHeap;
use crate::wrs::a::Sample;
use crate::wrs::Weighted;
pub fn sampling<'s, T: Weighted>(population: &[&'s T], m: usize) -> Vec<&'s T> {
assert!(m <= population.len());
let mut reservoir = BinaryHeap::new(); // in general, priority queue
for i in 0..m {
let k = rand::random::<f64>().powf(1.0 / population[i].weight());
reservoir.push(Sample { value: population[i], key: k });
}
let mut x = rand::random::<f64>().ln() / reservoir.peek().unwrap().key.ln();
for i in 0..m {
x -= population[i].weight();
if x <= 0.0 {
let t = reservoir.peek().unwrap().key.powf(population[i].weight());
let r = (t + (1.0 - t) * rand::random::<f64>()).powf(1.0 / population[i].weight());
reservoir.pop();
reservoir.push(Sample { value: population[i], key: r });
x += rand::random::<f64>().ln() / reservoir.peek().unwrap().key.ln();
}
}
assert!(reservoir.len() == m);
reservoir.iter().map(|s| s.value).collect()
}A-ExpJ も A-Res と同様に母集団全体をメモリ上に保持する必要がなくデータストリームとして扱うことができる。
アルゴリズム比較
以下はそれぞれの非復元 WRS アルゴリズムのコスト理論値と、上記のサンプル Rust コードを実際に Core i7 2.7GHz macOS 10.14 で実行した結果である。
| 累積和法 | A-Res | A-ExpJ | |
|---|---|---|---|
| 最悪計算量 | \(O(m n)\) | \(O(n)\) | \(O(n)\) |
| 乱数生成 | \(O(m)\) | \(O(n)\) | \(O(m \log \frac{n}{m})\) |
| べき乗演算 | \(0\) | \(O(n)\) | \(O(m \log \frac{n}{m})\) |
| \(m=5,n=100\) | 524 [nsec] | 4,277 [nsec] | 723 [nsec] |
| \(m=25,n=100\) | 1,769 [nsec] | 4,991 [nsec] | 2,331 [nsec] |
| \(m=25,n=1000\) | 9,090 [nsec] | 40,357 [nsec] | 2,138 [nsec] |
| \(m=25,n=10000\) | 96,336 [nsec] | 374,878 [nsec] | 2,146 [nsec] |
| \(m=250,n=1000\) | 76,089 [nsec] | 43,913 [nsec] | 16,592 [nsec] |
累積和法は標本数 \(m\) や母集団 \(n\) が小さいケースでは速いがそれらの増加に伴って実行時間も大きく増加する傾向にある。A-ExpJ は \(m\) や \(n\) の増加に対する影響が小さく、結果からはスケーラビリティが高い傾向が見られる。全体的な傾向として、A-Res は \(n\) の影響が大きく、A-ExpJ は \(m\) の影響が大きく、累積和法はその両方の影響が大きく出ている。
使用したベンチマーク
extern crate test;
use test::Bencher;
use super::*;
const N: usize = 100;
const M: usize = 25;
struct Element(f64);
impl Weighted for Element {
fn weight(&self) -> f64 { self.0 }
}
#[bench]
fn bench_cumulative_sum(b: &mut Bencher) {
let set = generate_population(N, dist_inverse);
let population = set.iter().map(|e| e).collect::<Vec<&Element>>();
b.iter(|| {
cumsum::without_replacement::sampling(&population[..], M);
});
}
#[bench]
fn bench_algorithm_a_res(b: &mut Bencher) {
let set = generate_population(N, dist_inverse);
let population = set.iter().map(|e| e).collect::<Vec<&Element>>();
b.iter(|| {
a::res::sampling(&population[..], M);
});
}
#[bench]
fn bench_algorithm_a_expj(b: &mut Bencher) {
let set = generate_population(N, dist_inverse);
let population = set.iter().map(|e| e).collect::<Vec<&Element>>();
b.iter(|| {
a::expj::sampling(&population[..], M);
});
}
fn dist_inverse(_: usize, x: f64) -> f64 { 1.0 / (x + 0.2).powf(2.0) }
fn generate_population(n: usize, dist: fn(usize, f64) -> f64) -> Vec<Element> {
let mut population = Vec::<Element>::with_capacity(n);
for i in 0..n {
population.push(Element(dist(i, i as f64 / n as f64)));
}
population
}重み付き非復元サンプリングの不公平性
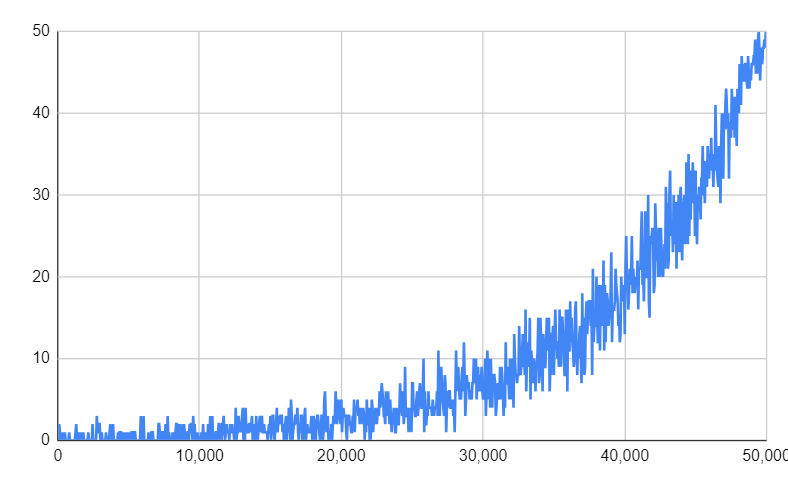
重み付き非復元ランダムサンプリングには要素の重みと実際の選択頻度が一致しないという特徴的な挙動がある。以下のシミュレーションは非復元ランダムサンプリングを行って各要素の選択された回数と勝率を示しているが、重みが均一でない場合に重みと勝率が一致しない傾向が見て取れる。
ウィンドウサンプリング
大規模データセットに対して最新のデータのみに興味があるアプリケーションでは、直近の \(n\) 件のデータや過去 \(t\) 時間以内のデータなど、固定長のウィンドウを最新状態でスライドさせてその中からランダムにサンプリングすることが考えられる。
チェーンサンプリング
データストリーム上に 1 から \(n-1\) の一様にランダムな間隔でサンプルが配置されていると仮定する。チェーンサンプリング (chain sampling) [8] はそのようなストリームにおいてサイズ \(n\) のスライディングウィンドウを想定して一つのサンプルを選択するアルゴリズムである (\(k\) 個のサンプルを選択するにはサンプラーのインスタンスを \(k\) 個並列に実行する)。
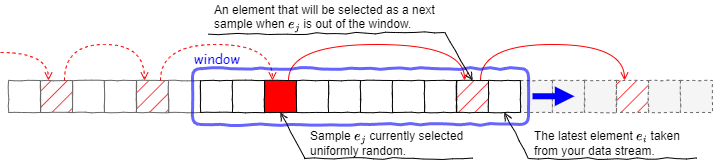
Fig 5 はチェーンサンプリングのサンプラーを表している。現在サンプルとして選択されている 1 つの要素 \(e_j\) と、その後に続く 1 つ以上の後継者要素 (要素がまだウィンドウに入っていない場合は将来のインデックス) がチェーン状に保持される。現在のサンプル \(e_j\) がウィンドウから外れたとき、その次に選択されているサンプルが「現在のサンプル」となる。
🎲 サンプルコード
以下は [7] に基づく。オリジナルの [8] から、\(\frac{1}{\min(i,n)}\) の確率でチェーンをクリアする処理が追加されているが根拠は不明。
use rand::Rng;
use std::collections::VecDeque;
use std::cmp::min;
struct ChainSampling<T> {
n: usize, // ウィンドウサイズ
i: usize, // 次に到着するデータのインデックス (最初の要素が 1)
k: usize, // 選択されているがまだ到達していないデータのインデックス
chain: VecDeque<(T, usize)>,
}
impl<T: Clone> ChainSampling<T> {
fn new(n: usize) -> Self {
Self { n, i: 1, k: 0, chain: VecDeque::new() }
}
// 新しい要素の到着を逐次的に通知する
fn add(&mut self, element: T) {
if let Some((_, j)) = self.chain.front() {
if self.i == j + self.n {
self.chain.pop_front();
}
}
let mut rng = rand::thread_rng();
let u = rng.gen_range(0.0..1.0);
if u < 1.0 / min(self.i, self.n) as f64 {
self.chain.clear(); // サンプルをクリアして新たに追加
self.chain.push_back((element.clone(), self.i));
let u = rng.gen_range(0.0..1.0);
self.k = self.i + (self.n as f64 * u).floor() as usize + 1;
} else if self.i == self.k {
self.chain.push_back((element.clone(), self.i));
let u = rng.gen_range(0.0..1.0);
self.k = self.i + (self.n as f64 * u).floor() as usize + 1;
}
self.i += 1;
}
// 現在のウィンドウ内でランダムに選択されたサンプルを取得
fn get_sample(&self) -> Option<&T> {
self.chain.front().map(|(value,_)| value)
}
}優先度サンプリング
優先度サンプリング (priority sampling) [7, 8] はある固定の時間ウィンドウの中でランダムサンプリングを行う。この基本的な考え方は、データストリームから到着した要素ごとに一様乱数の優先度 \(0 \le p \lt 1\) を割り当て、時間ウィンドウ内でもっとも大きい優先度を持つ要素をサンプルとして選択する。
時間ウィンドウの幅 \(T\) で時刻 \(t\) の要素 \(e_t\) とその優先度 \(p_t\) を格納するリスト \(L\) を想定する。ある時刻 \(t\) に要素 \(e_t\) が到着したとき:
- 最初に \(e_t\) の優先度 \(p_t \in [0,1)\) を一様にランダムに割り当てる。
- 次に \(L\) の先頭から順に時刻が \(t-T\) より前のエントリ (時間ウィンドウから外れたエントリ) を削除する。
- 次に \(L\) の末尾から順に優先度が \(p_t\) より小さいエントリ (時間ウィンドウ内でもう選択されることがないエントリ) を削除する。
- 最後に \(L\) の末尾にタプル \((t,e_t,p_t)\) を格納する。
この動作により \(L\) は優先度が降順に、時刻が昇順に並んでいるリストとなる。したがって \(L\) の先頭は時刻 \(t\) の時点で時間ウィンドウ \(T\) 内で選択されているサンプルを表している (サンプルのクエリー時刻 \(t_q\) を考慮する場合は \(L\) の先頭から \(t \lt t_q-T\) となるエントリをスキップする)。
参考文献
- Efraimidis P, Spirakis P. Weighted Random Sampling. In: Kao MY. (eds) Encyclopedia of Algorithms. Springer, New York, NY (日本語訳)
- G. Marsaglia, W. W. Tsang, and J. Wang. Fast Generation of Discrete Random Variables, Journal of Statistical Software, 11(3):1-11, 2004. (日本語訳)
- 汪 金芳, 標本調査法入門, 平成 17 年5 月 16 日
- BRODER, Andrei Z., et al. Min-wise independent permutations. In: Proceedings of the thirtieth annual ACM symposium on Theory of computing. 1998. p. 327-336.
- KNUTH, Donald E. The Art of Computer Programming: Seminumerical Algorithms, Volume 2. Addison-Wesley Professional, 2014.
- Charu C. Aggarwal. 2006. On biased reservoir sampling in the presence of stream evolution. In Proceedings of the 32nd international conference on Very large data bases (VLDB '06). VLDB Endowment, 607–618.
- Dzejla Medjedovic, Emin Tahirovic, Ines Dedovic. 大規模データセットのためのアルゴリズムとデータ構造. マイナビ出版 (2024)
- B. Babcock, M. Datar, and M. Rajeev, Sampling from a Moving Window Over Streaming Data. Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 633-634, 2002
