Chord
 概要
概要
Chord はコンシステントハッシュ法 (consistent hashing) に基づく分散ハッシュテーブルである。対数メッシュのリンクを内包する論理リングで表される。
Chord Network Simulation Console
Routing
Join / Leave
Table of Contents
構造化アルゴリズム
Chord リング
Chord はリング状に閉じた数直線 (剰余環) 上にノードを配置する。このリングの大きさは 2 のべき乗 \(N=2^m\) で表され、ノード ID の名前空間もこの大きさとなる。
Chord に参加するノードはリング上での位置を決めるための 0 から \(2^m-1\) までの一意な ID が割り当てられているものとする。ノードの位置の偏りは負荷の偏りを引き起こすことから、ID は名前空間上でなるべく一様になる方法で決定する必要がある。例えば IP アドレスのハッシュ値やノードの公開鍵から取り出した \(m\) ビットなどを使用することができる。
ルーティングテーブル
あるノードより前 (ID の小さい方向) に存在するもっとも近いノードをそのノードの Predecessor と呼ぶ。Chord ネットワークに参加している各ノードは自身の Predecessor へのリンク (IP アドレスなど) を保持している。
ノード \(i\) の Predecessor の ID を \(p\) としたとき、そのノード \(i\) は \(p+1\) から \(i\) までのキーを担当している。つまりノード \(i\) の受け取ったメッセージの宛先が \(k \in [p+1,i]\) の範囲であればそれはノード \(i\) 自身が受け取るべきメッセージであると認識できる。
あるノードの受信したメッセージが自分宛てでない場合、その宛先である \(k\) により近いが \(k\) を超えないノードにそのメッセージを転送 (またはリダイレクト) しなければならない。Chord の各ノードはそのためのルーティングテーブルを維持している (Chord では finger テーブルと呼ばれている)。ルーティングテーブルには \(m\) 個のエントリがあり、そのエントリ \(j\) には \(k \in [i + 2^j, i + 2^{j+1} - 1]\) 宛のメッセージの転送先ノードへのリンクが格納されている。この転送先のノードは ID が \(i + 2^j\) と一致するかそれより後 (ID の大きい方向) に実在するもっとも近いノードである。
ルーティングテーブルの先頭のエントリは自身より後に存在するもっとも近いノードを示しているため Predecessor の対比として特別に Successor とも呼ぶ。
Fig 1 は ID 0, 2, 4, 5, 7 のノードが存在する \(m=3\), \(N=8\) の Chord リングにおいてノード 2 が維持しているリンクを示している。また Table 1 はこのような状況でノード 2 が持つルーティングテーブルである。
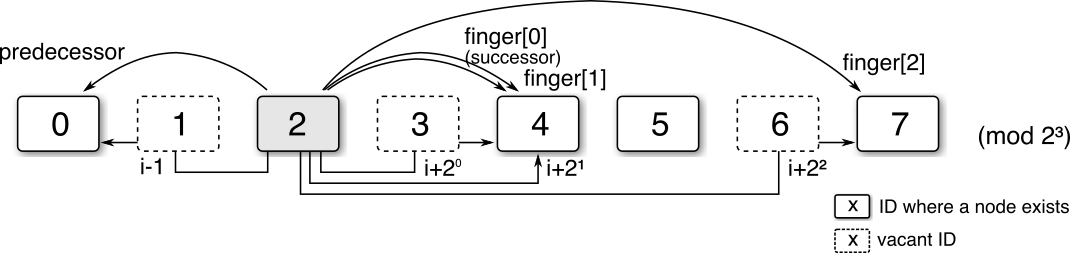
| # | Key Range | Destination |
|---|---|---|
| 0 | 3 | 4 |
| 1 | 4〜5 | 4 |
| 2 | 6〜1 | 7 |
メッセージルーティング
メッセージは Chord リングに参加している任意のノードを始点にすることができる。それぞれのノードは宛先 (キー) が \(k\) のメッセージを以下のようにルーティングする。
- メッセージを受信したノード ID を \(i\)、その Predecessor の ID を \(p\) とするとき、メッセージの宛先が \(k \in [p + 1, i] \pmod{N}\) であればノード \(i\) が受信しルーティングを終了する。
- 受信したメッセージが \(k \in [f, i-1] \pmod{N}\) となるようなノード \(f\) から転送されているとき、\(f\) のルーティング実装は不正である。論文では特に言及はなかったが、このようなノードが Chord リングに存在するとメッセージを無限にループさせる可能性があるため (\(f=i\) の自己ループも含めて) このような状況を検知した場合は \(f\) の障害としてルーティングを中止すべきだろう。
- そうでなければ、ルーティングテーブルから \(k \in [i + 2^j, i + 2^{j+1}-1] \pmod{N}\) に一致するエントリ \(j \in [0, M-1]\) の指すノードにメッセージを転送する。
Chord を俯瞰すると、Predecessor と Successor による双方向の循環リンクリストに対数メッシュのリンク (スキップリスト) を追加した構造であることがわかる。対数メッシュリンクは循環リンクリスト上の探索コスト、およびルーティングのための各ノードが維持しなければならない内部状態のサイズを \(O(N)\) から \(O(\log N)\) へスケールさせる効果を持っている。これは、言い換えると Predecessor と Successor の 2 つのリンクさえ正しく構成されていれば (効率は落ちるものの) 対数メッシュリンクは必ずしも必要ではないことを意味している。つまり、あるノードのルーティングテーブルの Successor 以外のエントリに何らかの不具合があったとしても、最悪ケースとして Successor に転送するようにフォールバックすれば最終的にメッセージは正しい宛先に転送される。
Plaxton ルーティングでは ID の近さはグラフ上の距離の近さ (少ないホップ数で到達可能) を意味していたが、Chord は数直線上を片方向にしかルーティングしないことから自分の直前に位置する ID への距離はむしろもっとも遠くなる。最悪ケースは \(n=N=2^m\) において \(i\) から \(i-1\) へのルーティングであり \(m\) ホップを要する。
ノードの参加と離脱
新しいノードが Chord ネットワークに参加したり、既存のノードが離脱するには、そのノードの位置へのリンクを持っている可能性のあるノードのルーティングテーブルを書き換えなければならない。位置 \(i\) のリンクを持っている (または持っている可能性のある) ノードは以下の 2 種類となる。
- 位置 \(i\) の Predecessor および Successor にあたるノード。つまり \(i\) より前に実在するノードと \(i\) より後に実在するノード。
- \(j \in [0, m-1]\) に対して \(i - 2^j\) に位置するノード、またはその位置にノードが存在しなければ \(i - 2^j\) から見て Predecessor にあたるノード。さらに、そこから \(i\) を参照している Predecessor を再帰的にたどる。該当するノードはルーティングテーブルの \(j\) 番目のエントリを修正する。後述するサンプルコードの
update_finger_table(),leaving()を参照。
特にノード \(i\) とその Predecessor が大きく離れているケース、つまり \(i\) の手前に大きな空間があるとき、\(i\) は多くのノードから参照されている可能性がある。
ある Chord リングに参加しようとしているノードはその Chord リングにすでに参加しているいずれかのノード (ブートストラップノード) に問い合わせて自身が挿入される位置の前後を知ることができる。
サンプル実装
以下の chord.py は Chord リングの動作をシミュレーションすることのできる説明用のサンプル実装である。この実装は Chord 論文 [1] の 4. The Base Chord Protocol に基づいている。非同期システムでの参加/離脱を想定するのであればセクション 5 の Stabilization を実装する必要があるだろう。
このサンプル実装を使用して、例えば偶数 ID のノードのみで構成される Chord ネットワークを以下のように作成することができる。
from chord import Node, N
node = Node(0)
node.join(None)
for i in range(2, N, 2):
Node(i).join(node)
for i in range(N):
print("%d -> %d" % (i, node.lookup(i).id))0 -> 0
1 -> 2
2 -> 2
3 -> 4
...
59 -> 60
60 -> 60
61 -> 62
62 -> 62
63 -> 0Chord を拡張した分散ハッシュテーブル
DKS(N,k,f)
\(\mathcal{DKS}(N,k,f)\) [3] (distributed \(k\)-ary search) は独立した 3 つのパラメータで特徴づけられた分散ハッシュテーブルを構築できるアルゴリズムである。
- \(N\) … 分散ハッシュテーブルが扱う識別子空間の大きさ。またはネットワークに参加する最大ノード数。
- \(k\) … Consistent Hashing リングの多段分割数。
- \(f\) … レプリケーション係数。つまり同じデータを複数のノードに配置する数であり障害耐性の程度を示している。
Chord と同様に Consistent Hashing に基づくリング構造を持つが、各ノードの次数 (リンク密度) を \(k\) で調整できる点が Chord と異なっている。Chord が再帰的な 2 分割で探索区間を絞り込むのに対して DKS は \(k\) 分割で絞り込んでゆく。このため \(k=2\) のケースでは Chord とよく似たルーティング特性となる。
Fig 2 は \(N=64\), \(k=4\) の DKS リングにおいてあるノードのルーティングテーブルが参照するノードを示している。
.png)
DKS のルーティングは次のように行われる: 最初のステップは識別子空間全体が探索空間となる。Level 1 のルーティングテーブルは全空間を \(k\) 分割した位置を示しており、その中から目的のノードを含む区間にホップする。次のステップでは、全空間を \(k\) 分割した探索空間がさらに \(k\) 分割され、同様に Level 2 のルーティングテーブルから目的のノードを含む区間にホップする。このような探索空間の分割は目的のノードを特定するまで繰り返される。結果的に、目的のノードへのルーティングは最大でも \(\log_k N\) ホップで到達することができる。
エントリテーブルは Level ごとに \(k-1\) 個のエントリ (ホップ先のノード) を維持している。Chord と同様に識別子に対応する参照先ノードが存在しない場合はその Successor を参照する。Level はホップの深さを表していることから \(\log_k N\) 個の Level が存在する。したがって各ノードが維持するルーティングテーブルのサイズは \((k-1) \log_k N\) である。
Chord#
Chord# [4] はルーティングテーブルの更新コストを \(O(\log N)\) から \(O(1)\) へ削減し、検索パフォーマンスを向上させた Chord の修正バージョン。
Chord# はレンジクエリー (キーの範囲指定のクエリー) をサポートしている [5]。Chord ではキーの順序を維持しない consistent hashing を使用するためオブジェクトがランダムに配置されるが、Chord# は consistent hashing の代わりに元のキーの辞書順を維持する関数 (key-order preserving function) を使用して識別子を生成するため隣接したキーをネットワーク上の近い位置に配置する。ただしその対価としてオブジェクトが不均一に分散されやすく負荷の不均衡が起きやすい。
Koorde
Koorde [6] は Chord と同じ閉じた数直線リングに、対数メッシュの代わりに de Bruijn グラフを追加した分散ハッシュテーブル。各ノードが 2 つの隣接ノードを持つ構造でのクエリーのホップ数は \(O(\log N)\) となり、また \(O(\log N)\) の隣接ノードを持つ構造では \(O(\frac{\log N}{\log \log N})\) となる。
参考文献
- I. Stoica, R. Morris, D. Karger, M. F. Kaashoek, and H. Balakrishnan. Chord: A Scalable Peer-to-peer Lookup Service for Internet Applications. In Proc. ACM SIGCOMM’01, San Diego, CA, Aug. 2001. (日本語訳)
- I. Stoica, R. Morris, D. Liben-Nowell, D.R. Karger, M.F. Kaashoek, F. Dabek, H. Balakrishnan. Chord: a scalable peer-to-peer lookup protocol for internet applications. Feb. 2003 IEEE/ACM Trans. Netw17-32 11, 1
- L. O. Alimal, S. El-Ansary, P. Brand and S. Haridi. DKS(N,k,f): a family of low communication, scalable and fault-tolerant infrastructures for P2P applications. CCGrid 2003. 3rd IEEE/ACM International Symposium on Cluster Computing and the Grid, 2003. Proceedings., Tokyo, Japan, 2003, pp. 344-350, doi: 10.1109/CCGRID.2003.1199386.
- T. Schütt, F. Schintke, A. Reinefeld. Structured Overlay without Consistent Hashing: Empirical Results. Proceedings of the Sixth IEEE International Symposium on Cluster Computing and the Grid (Ccgrid'06) May 16–19, 2006 CCGRID, IEEE Computer Society Washington, DC8- Vol. 00
- T. Schütt, F. Schintke, A. Reinefeld. Range queries on structured overlay networks. in Computer Communications Vol. 31 Feb. 2008280-291 No. 2
- Kaashoek M.F., Karger D.R. Koorde: A simple degree-optimal hash table. In: Kaashoek M.F., Stoica I. (eds) Peer-to-Peer Systems II. IPTPS 2003. Lecture Notes in Computer Science, vol 2735. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-45172-3_9
